Causal Discovery Combining K2 with Brain Storm Optimization Algorithm



Abstract
:1. Introduction
2. Definitions
- (1)
- L either contains a chain, xi ← xk ← xj, and xk ∈ Z,
- (2)
- or a fork, xi ← xk → xj, and xk ∈ Z,
- (3)
- or a collider, xi → xk ← xj, and xk ∉ Z, and no descendent of xk is contained in Z.
3. The K2 and Brain Storm Optimization
3.1. The K2 Algorithm
3.2. Brain Storm Optimization
3.2.1. Brainstorming Algorithm Principle
- (A)
- Assemble as many parliamentarians with different backgrounds as possible;
- (B)
- Get the solutions based on the brainstorming rules in Table 1;
- (C)
- Choose a scheme as the best solution for the current problem from each of the problem-solving owners;
- (D)
- Generate new schemes from the schemes selected in C according to the rules in Table 1
- (E)
- Choose a solution from the idea of each problem-solving owner in D as the best solution for the current problem
- (F)
- Randomly select a scheme as a clue to generate new schemes in the case of meeting the Rules in Table 1;
- (G)
- Each problem-solving owner chooses a scheme from F to be the best solution for the current problem;
- (H)
- Get the best solution that is desired by considering merging these programs.
3.2.2. BSO Algorithm Steps
- (1)
- Obtain the solution of n potential problems, then divide n individuals into M class by K-means method, the individual in each class is sorted by evaluating these n individuals, and the optimal individual is selected as the central point of the class;
- (2)
- Randomly select the central individual of a class and determine whether it is replaced by a randomly generated individual according to the probability;
- (3)
- to update the individual, the way is updated by the following four ways: (a) randomly select a class (the probability of selection is proportional to the number of individuals within the class), the random perturbation is added to the class center to produce a new individual; (b) randomly select a class (the probability of selection is proportional to the number of individuals within the class) and randomly select an individual in the selected class, plus a random perturbation to produce a new individual; (c) randomly selected two classes, the fusion of the class center and the random perturbation to produce a new individual; (d) randomly select two classes, randomly select an individual in each class, and then add a random perturbation to create a new individual. By adjusting the parameters to control the proportion of the above four ways to produce new individuals. After the new individual generation, compared with the original individual, the final selection of the best one to retain to a new generation of individuals, repeat the above operation, the n individual to update each one, produced a new generation of n individuals.
4. The K2-BSO Method
4.1. Skeleton Learning Phase Based on K2-BSO
- (1)
- What needs to be optimized is the causal order that will highly affect the accuracy of K2. Generally, an input order approaching the actual topological order of the underling causal network will return the highest score and most similar causal structure.
- (2)
- The fitness function is easy to be chosen, that is the score return by K2.
- (2)
- The clustering method of BSO should be redesigned; all the distance function likes [46] cannot be directly applied to this case, as what we consider is the topological order. We design a new distance function like this:
4.2. Direction Learning Phase
| Algorithm 1. Skeleton learning based on K2-BSO. |
| Input: dataset X, population size . Output: the skeleton w.r.t. X. 1: Randomly generate n potential causal order ; 2: Cluster R into m clusters ; 3: For each Scorei = K2(); 4: End For 5: Score = Score1 ~ Scoren; 6: Roptimal = BSO (X, R, Score, C); 7: Goptimal = K2(Roptimal); 8: X = Goptimal; 9: return the causal skeleton X. |
| Algorithm 2. Learning causal direction from a sub-skeleton. |
| Input: sub-skeleton and the corresponding target node with all its neighbors . Output: the direction between and (partial) . 1: For each candidate parent set ; 2: fit and to ANM; 3: if is independent of then 4: accept ; 5: end if 6: end for |
4.3. K2-BSO Framework (Algorithm 3)
- Step 1. Learning the causal skeleton S by algorithm 1.
- Step 2. Split S into n sub-skeleton according to each node Xi contained in S.
- Step 3. Perform Algorithm 2 for each sub-skeleton Si.
- Step 4. Merge all the partial results and output the final causal structure.
| Algorithm 3. K2-BSO framework. |
| Input: Dataset X, threshold k Output: Causal structure G. 1. Set Dimension X to n; 2. if (n < k) then 3. ; 4. else 5. Split S into n sub-skeleton according to each node contained in S; 6. For each in S 7. ; ; 8. Merge all to G; 9. End for 10. end if 11. return the final causal structure G. |
5. The Correctness and Performance of the Algorithms
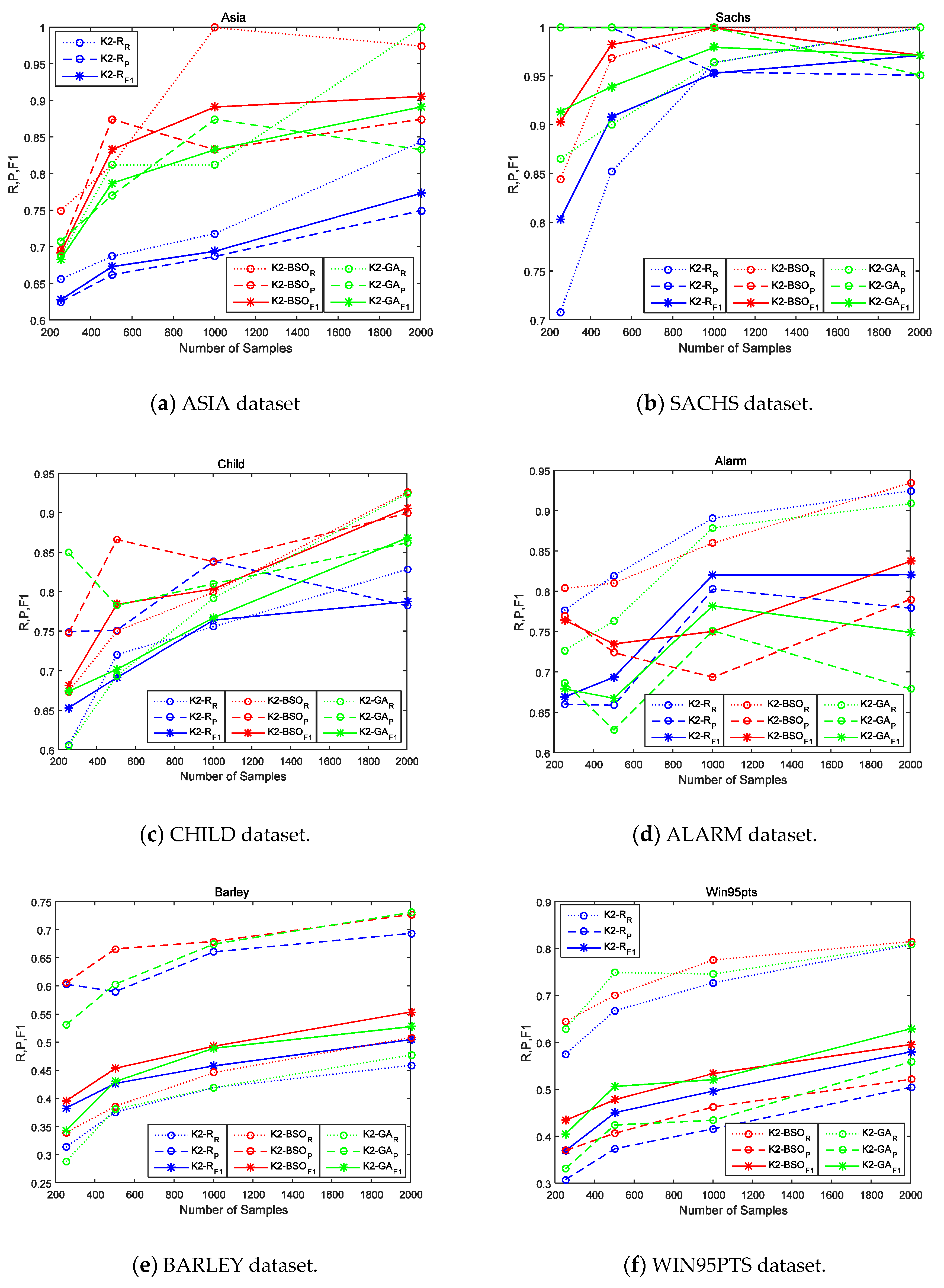
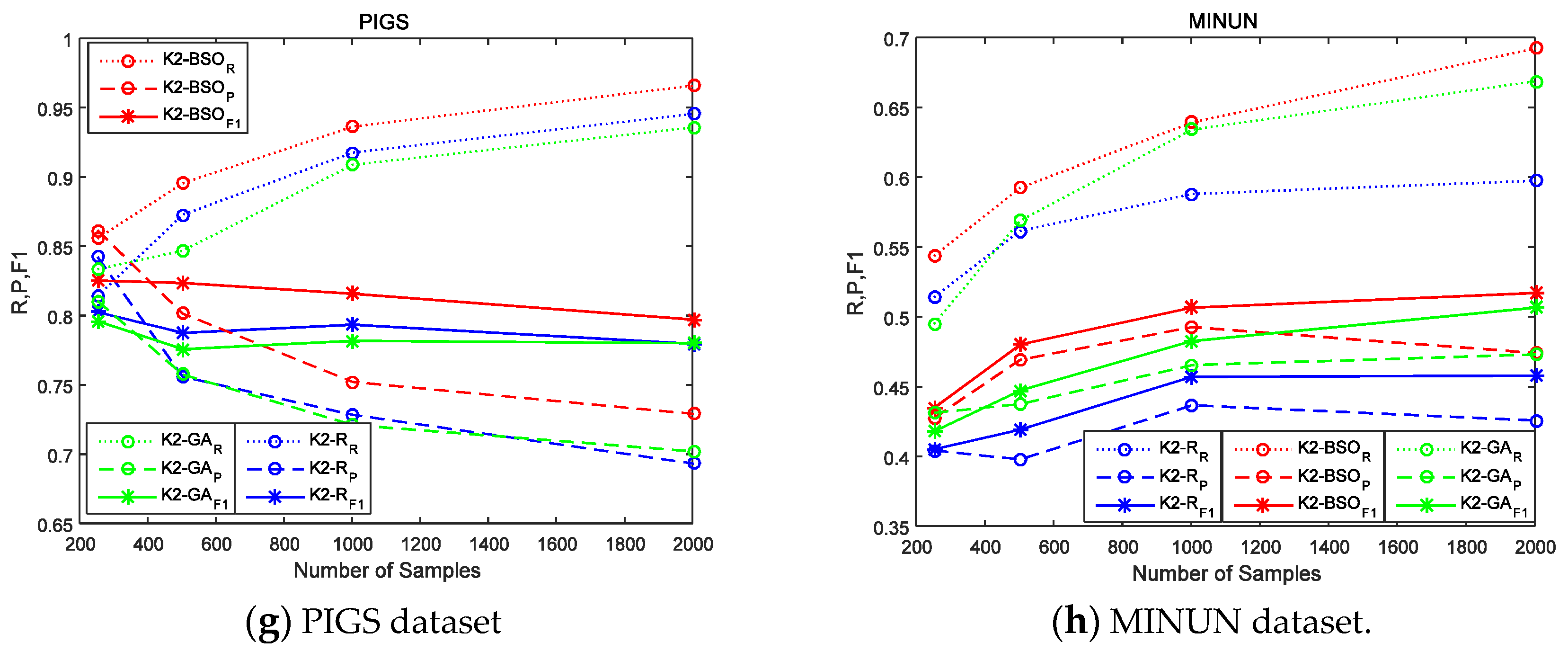
6. Experiments
- (1)
- CPU of the physical host: CPU E5-2640 v3, 2.60 GHz (2-way 8-core);
- (2)
- Platform belongs to the cloud platform version from Bingo Cloud: v6.2.4.161205143;
- (3)
- Memory is 24 G.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hao, Z.; Huang, J.; Cai, R.; Wen, W. A hybrid approach for large scale causality discovery. In Emerging Intelligent Computing Technology and Applications, Proceedings of the 8th International Conference, ICIC 2012, Huangshan, China, 25–29 July 2012; Springer: Berlin, Germany, 2013; Volume 375, pp. 1–6. [Google Scholar]
- Li, X.J.; Mishra, S.K.; Wu, M.; Zhang, F.; Zheng, J. Syn-lethality: An integrative knowledge base of synthetic lethality towards discovery of selective anticancer therapies. BioMed Res. Int. 2014, 2014, 196034. [Google Scholar] [CrossRef] [PubMed]
- Wu, M.; Li, X.; Zhang, F.; Li, X.; Kwoh, C.K.; Zheng, J. In silico prediction of synthetic lethality by meta-analysis of genetic interactions, functions, and pathways in yeast and human cancer. Cancer Inform. 2014, 13, 71–80. [Google Scholar] [CrossRef] [PubMed]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Spirtes, P.; Glymour, C.N.; Scheines, R.; Heckerman, D.; Meek, C.; Cooper, G.; Richardson, T. Causation, Prediction, and Search; Springer: New York, NY, USA, 1993; pp. 272–273. [Google Scholar]
- Chickering, D.M. Learning equivalence classes of bayesian-network structures. J. Mach. Learn. Res. 2002, 2, 150–157. [Google Scholar]
- Shimizu, S.; Hoyer, P.O.; Hyvärinen, A.; Kerminen, A. A linear non-gaussian acyclic model for causal discovery. J. Mach. Learn. Res. 2006, 7, 2003–2030. [Google Scholar]
- Shimizu, S.; Inazumi, T.; Sogawa, Y.; Hyvärinen, A.; Kawahara, Y.; Washio, T.; Hoyer, P.O.; Bollen, K. Directlingam: A direct method for learning a linear non-gaussian structural equation model. J. Mach. Learn. Res. 2011, 2, 1225–1248. [Google Scholar]
- Hoyer, P.O.; Janzing, D.; Mooij, J.M.; Peters, J.; Schölkopf, B. Nonlinear causal discovery with additive noise models. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 689–696. [Google Scholar]
- Peters, J.; Mooij, J.M.; Janzing, D.; Schölkopf, B. Causal discovery with continuous additive noise models. J. Mach. Learn. Res. 2013, 15, 2009–2053. [Google Scholar]
- Peters, J.; Janzing, D.; Scholkopf, B.; Teh, Y.W.; Titterington, M. Identifying cause and effect on discrete data using additive noise models. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 597–604. [Google Scholar]
- Peters, J.; Janzing, D.; Scholkopf, B. Causal inference on discrete data using additive noise models. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2436–2450. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Hyvärinen, A. Distinguishing causes from effects using nonlinear acyclic causal models. In Proceedings of the 2008th International Conference on Causality: Objectives and Assessment, Vancouver, BC, Canada, 8–10 December 2008; Volume 6, pp. 157–164. [Google Scholar]
- Daniusis, P.; Janzing, D.; Mooij, J.; Zscheischler, J.; Steudel, B.; Zhang, K.; Schölkopf, B. Inferring deterministic causal relations. In Proceedings of the Conference on UAI, Catalina Island, CA, USA, 8–11 July 2010; pp. 143–150. [Google Scholar]
- Janzing, D.; Mooij, J.; Zhang, K.; Lemeire, J.; Zscheischler, J.; Daniušis, P.; Steudel, B.; Scholkopf, B. Information-geometric approach to inferring causal directions. Artif. Intell. 2012, 182–183, 1–31. [Google Scholar] [CrossRef]
- Janzing, D.; Steudel, B.; Shajarisales, N.; Scholkopf, B. Justifying information-geometric causal inference. In Measures of Complexity; Springer: Cham, Switzerland, 2015; pp. 253–265. [Google Scholar]
- Chen, W.; Hao, Z.; Cai, R.; Zhang, X.; Hu, Y.; Liu, M. Multiple-cause discovery combined with structure learning for high-dimensional discrete data and application to stock prediction. Soft Comput. 2016, 20, 4575–4588. [Google Scholar] [CrossRef]
- Cai, R.; Zhang, Z.; Hao, Z. Causal gene identification using combinatorial v-structure search. Neural Netw. 2013, 43, 63–71. [Google Scholar] [CrossRef] [PubMed]
- Cai, R.; Zhang, Z.; Hao, Z. SADA: A General Framework to Support Robust Causation Discovery. In Proceedings of the 30th International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 208–216. [Google Scholar]
- Cai, R.; Zhang, Z.; Hao, Z.; Winslett, M. Understanding Social Causalities Behind Human Action Sequences. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1801–1813. [Google Scholar] [CrossRef] [PubMed]
- Cai, R.; Zhang, Z.; Hao, Z. BASSUM: A Bayesian semi-supervised method for classification feature selection. Pattern Recognit. 2011, 44, 811–820. [Google Scholar] [CrossRef] [Green Version]
- Mooij, J.; Janzing, D.; Peters, J.; Scholkopf, B. Regression by dependence minimization and its application to causal inference in additive noise models. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 745–752. [Google Scholar]
- Zhang, K.; Peters, J.; Janzing, D.; Scholkopf, B. Kernel-based conditional independence test and application in causal discovery. Comput. Sci. 2012, 6, 895–907. [Google Scholar]
- Cheng, S.; Qin, Q.; Chen, J.; Shi, Y. Brain storm optimization algorithm: A review. Artif. Intell. Rev. 2016, 46, 445–458. [Google Scholar] [CrossRef]
- Hong, Y.H.; Liu, Z.S.; Mai, G.Z. An efficient algorithm for large-scale causal discovery. Soft Comput. 2016, 21, 7381–7391. [Google Scholar] [CrossRef]
- Hong, Y.H. Fast causal network skeleton learning algorithm. J. Nanjing Univ. Sci. Technol. 2016, 40, 315–321. [Google Scholar]
- Hong, Y.H.; Mai, G.Z.; Liu, Z.S. Learning tree network based on mutual information. Metall. Min. Ind. 2015, 12, 146–151. [Google Scholar]
- Duan, H.; Li, S.; Shi, Y. Predator–prey brain storm optimization for DC brushless motor. IEEE Trans. Mag. 2013, 49, 5336–5340. [Google Scholar] [CrossRef]
- Shi, Y. Brain storm optimization algorithm. In Proceedings of the International Conference in Swarm Intelligence, Chongqing, China, 12–15 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 303–309. [Google Scholar]
- Zhan, Z.H.; Zhang, J.; Shi, Y.H.; Liu, H.L. A modified brain storm optimization. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation, Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Xue, J.; Wu, Y.; Shi, Y.; Cheng, S. Brain storm optimization algorithm for multi-objective optimization problems. In Advances in Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 513–519. [Google Scholar]
- Cooper, G.F.; Herskovits, E. A bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef]
- Shi, Y. An optimization algorithm based on brainstorming process. In Emerging Research on Swarm Intelligence and Algorithm Optimization; Information Science Reference: Hershey, Pennsylvania, 2015; pp. 1–35. [Google Scholar]
- Zhou, D.; Shi, Y.; Cheng, S. Brain storm optimization algorithm with modified step-size and individual generation. Adv. Swarm Intell. 2012, 7331, 243–252. [Google Scholar]
- Sun, C.; Duan, H.; Shi, Y. Optimal satellite formation reconfiguration based on closed-loop brain storm optimization. IEEE Comput. Intell. Mag. 2013, 8, 39–51. [Google Scholar] [CrossRef]
- Jadhav, H.T.; Sharma, U.; Patel, J.; Roy, R. Brain storm optimization algorithm based economic dispatch considering wind power. In Proceedings of the 2012 IEEE International Conference on Power and Energy (PECon), Parit Raja, Malaysia, 2–5 December 2012; pp. 588–593. [Google Scholar]
- Qiu, H.; Duan, H. Receding horizon control for multiple UAV formation flight based on modified brain storm optimization. Nonlinear Dyn. 2014, 78, 1973–1988. [Google Scholar] [CrossRef]
- Shi, Y.; Xue, J.; Wu, Y. Multi-objective optimization based on brain storm optimization algorithm. Int. J. Swarm Intell. Res. 2013, 4, 1–21. [Google Scholar] [CrossRef]
- Shi, Y. Brain storm optimization algorithm in objective space. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 1227–1234. [Google Scholar]
- Yang, Z.; Shi, Y. Brain storm optimization with chaotic operation. In Proceedings of the 2015 Seventh International Conference on Advanced Computational Intelligence (ICACI), Wuyi, China, 27–29 March 2015; pp. 111–115. [Google Scholar]
- Yang, Y.; Shi, Y.; Xia, S. Advanced discussion mechanism-based brain storm optimization algorithm. Soft Comput. 2015, 19, 2997–3007. [Google Scholar] [CrossRef]
- Jia, Z.; Duan, H.; Shi, Y. Hybrid brain storm optimisation and simulated annealing algorithm for continuous optimisation problems. Int. J. Bio-Inspired Comput. 2016, 8, 109–121. [Google Scholar] [CrossRef]
- Cheng, S.; Shi, Y.; Qin, Q.; Gao, S. Solution clustering analysis in brain storm optimization algorithm. In Proceedings of the 2013 IEEE Symposium on Swarm Intelligence (SIS), Singapore, 16–19 April 2013; pp. 111–118. [Google Scholar]
- Cheng, S.; Shi, Y.; Qin, Q.; Zhang, Q.; Bai, R. Population diversity maintenance in brain storm optimization algorithm. J. Artif. Intell. Soft Comput. Res. 2014, 4, 83–97. [Google Scholar] [CrossRef]
- Cheng, S.; Shi, Y.; Qin, Q.; Ting, T.O.; Bai, R. Maintaining population diversity in brain storm optimization algorithm. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 3230–3237. [Google Scholar]
- Georgiou, D.N.; Karakasidis, T.E.; Nieto, J.J.; Torres, A. A study of entropy/clarity of genetic sequences using metric spaces and fuzzy sets. J. Theor. Biol. 2010, 267, 95–105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Sample Availability: Samples of the compounds are not available from the authors. |




{kind=link}
{kind=link}
{kind=link}
| Rule 1 No bad ideas, every thought is good |
| Rule 2 Every thought has to be shared and recorded |
| Rule 3 Most ideas are based on existing ideas, and some ideas can and should be raised to generate new ideas |
| Rule 4 Try to produce more ideas |
| Network | Nodes | Edges | Avg Degree | Maximum in-Degree |
|---|---|---|---|---|
| ASIA | 8 | 8 | 2 | 2 |
| SACHS | 11 | 17 | 3.09 | 3 |
| CHILD | 20 | 25 | 1.25 | 2 |
| ALARM | 37 | 46 | 2.49 | 4 |
| BARLEY | 48 | 84 | 3.5 | 4 |
| WIN95PTS | 76 | 112 | 2.95 | 7 |
| PIGS | 441 | 592 | 2.68 | 2 |
| MUMIN | 1041 | 1397 | 2.68 | 3 |
| Dataset | Sample | K2-Random | K2-BSO | K2-GA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Best | Mean | Worst | Best | Mean | Worst | Best | Mean | Worst | ||
| ASIA | 250 | 1.2555 | 1.749 | 2.6157 | 3.0185 | 4.5585 | 5.8543 | 2.8367 | 4.2504 | 5.5427 |
| ASIA | 500 | 1.085 | 1.4656 | 1.9224 | 3.2043 | 4.3753 | 6.3392 | 2.1125 | 4.8925 | 6.4698 |
| ASIA | 1000 | 1.5104 | 1.7994 | 2.2099 | 4.7037 | 5.0472 | 5.3491 | 3.1055 | 5.1146 | 8.2191 |
| ASIA | 2000 | 2.2676 | 2.4993 | 2.6629 | 3.3815 | 3.9774 | 4.3823 | 4.1878 | 5.506 | 8.1496 |
| SACHS | 250 | 4.5248 | 5.025 | 5.3196 | 6.2266 | 6.4963 | 6.6793 | 3.02 | 4.6432 | 7.501 |
| SACHS | 500 | 2.4084 | 3.6746 | 5.2433 | 8.7819 | 11.2107 | 15.6879 | 5.5198 | 8.1696 | 8.6039 |
| SACHS | 1000 | 2.7062 | 3.5759 | 4.0197 | 8.3591 | 11.7962 | 15.3562 | 5.4356 | 8.6128 | 12.8977 |
| SACHS | 2000 | 3.4966 | 4.6789 | 6.4649 | 9.3677 | 10.7807 | 11.5173 | 6.1085 | 6.1516 | 6.1762 |
| CHILD | 250 | 7.7092 | 9.117 | 12.5631 | 28.0133 | 29.961 | 31.325 | 21.1455 | 25.986 | 30.974 |
| CHILD | 500 | 8.9414 | 11.8924 | 14.1062 | 17.7665 | 28.9292 | 41.265 | 30.2484 | 34.1696 | 38.9523 |
| CHILD | 1000 | 10.059 | 17.5069 | 28.2669 | 33.4957 | 38.4505 | 43.9597 | 23.6723 | 24.608 | 25.3404 |
| CHILD | 2000 | 10.709 | 13.8898 | 18.3508 | 30.1317 | 58.6901 | 78.3929 | 21.3343 | 38.465 | 47.0478 |
| ALARM | 250 | 46.647 | 71.9888 | 86.3291 | 217.3178 | 266.3269 | 355.1756 | 147.9969 | 283.8744 | 371.7365 |
| ALARM | 500 | 94.125 | 103.2041 | 119.5914 | 227.3739 | 293.7428 | 377.54 | 133.6973 | 388.0371 | 519.749 |
| ALARM | 1000 | 62.140 | 92.5241 | 125.1668 | 157.303 | 247.1288 | 294.8618 | 144.2063 | 316.8503 | 475.2459 |
| ALARM | 2000 | 95.002 | 159.3802 | 232.1197 | 323.0716 | 394.6686 | 496.8733 | 219.1187 | 275.1111 | 345.3221 |
| BARLEY | 250 | 66.378 | 91.2914 | 136.5331 | 198.4244 | 325.1975 | 400.4625 | 160.181 | 205.9434 | 233.3933 |
| BARLEY | 500 | 75.057 | 99.7028 | 138.1832 | 304.5911 | 364.1937 | 368.7941 | 194.9004 | 358.4717 | 567.8317 |
| BARLEY | 1000 | 86.012 | 100.4193 | 116.8377 | 326.8585 | 370.2588 | 404.4023 | 255.2328 | 396.0264 | 505.5334 |
| BARLEY | 2000 | 96.159 | 103.1696 | 116.3037 | 478.3594 | 525.7576 | 549.7203 | 368.8762 | 810.5905 | 1.48 × 103 |
| WIN95PTS | 250 | 649.75 | 1.10 × 103 | 1.52 × 103 | 1.81 × 103 | 4.44 × 103 | 7.16 × 103 | 1.60 × 104 | 2.06 × 104 | 2.31 × 104 |
| WIN95PTS | 500 | 555.26 | 727.4609 | 819.2716 | 2.33 × 103 | 4.76 × 103 | 6.67 × 103 | 6.23 × 103 | 1.83 × 104 | 2.48 × 104 |
| WIN95PTS | 1000 | 693.01 | 746.7864 | 827.4684 | 2.73 × 103 | 4.38 × 103 | 6.00 × 103 | 2.01 × 104 | 2.57 × 104 | 3.19 × 104 |
| WIN95PTS | 2000 | 715.72 | 1.43 × 103 | 1.85 × 103 | 2.25 × 103 | 7.04 × 103 | 1.50 × 104 | 2.13 × 104 | 3.44 × 104 | 4.98 × 104 |
| PIGS | 250 | 1.87 × 104 | 2.52× 104 | 3.96 × 104 | 2.60 × 105 | 3.89 × 105 | 4.85 × 105 | 1.45 × 105 | 2.48 × 105 | 3.77 × 105 |
| PIGS | 500 | 5.35 × 104 | 6.84 × 104 | 8.53 × 104 | 3.09 × 105 | 4.03 × 105 | 5.24 × 105 | 1.58 × 105 | 2.56 × 105 | 3.03 × 105 |
| PIGS | 1000 | 7.12 × 104 | 8.64 × 104 | 9.71 × 104 | 2.92 × 105 | 4.14 × 105 | 4.59 × 105 | 1.85 × 105 | 2.70 × 105 | 3.57 × 105 |
| PIGS | 2000 | 6.17 × 104 | 9.00 × 104 | 1.09 × 105 | 4.26 × 105 | 5.26 × 105 | 7.05 × 105 | 1.98 × 105 | 2.74 × 105 | 3.33 × 105 |
| MINUN | 250 | 1.98 × 105 | 2.70 × 105 | 4.33 × 105 | 1.71 × 106 | 2.70 × 106 | 3.46 × 106 | 4.54 × 105 | 7.74 × 105 | 1.09 × 106 |
| MINUN | 500 | 3.10 × 105 | 4.05 × 105 | 4.98 × 105 | 2.52 × 106 | 3.24 × 106 | 4.17 × 106 | 5.45 × 105 | 9.00 × 105 | 1.07 × 106 |
| MINUN | 1000 | 3.39 × 105 | 4.14 × 105 | 4.72 × 105 | 2.43 × 106 | 3.41 × 106 | 3.88 × 106 | 8.19 × 105 | 1.17 × 106 | 1.57 × 106 |
| MINUN | 2000 | 2.93 × 105 | 4.23 × 105 | 5.06 × 105 | 2.93 × 106 | 3.67 × 106 | 4.99 × 106 | 9.81 × 105 | 1.35 × 106 | 1.65 × 106 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, Y.; Hao, Z.; Mai, G.; Huang, H.; Kumar Sangaiah, A. Causal Discovery Combining K2 with Brain Storm Optimization Algorithm. Molecules 2018, 23, 1729. https://doi.org/10.3390/molecules23071729
Hong Y, Hao Z, Mai G, Huang H, Kumar Sangaiah A. Causal Discovery Combining K2 with Brain Storm Optimization Algorithm. Molecules. 2018; 23(7):1729. https://doi.org/10.3390/molecules23071729
Chicago/Turabian StyleHong, Yinghan, Zhifeng Hao, Guizhen Mai, Han Huang, and Arun Kumar Sangaiah. 2018. "Causal Discovery Combining K2 with Brain Storm Optimization Algorithm" Molecules 23, no. 7: 1729. https://doi.org/10.3390/molecules23071729
APA StyleHong, Y., Hao, Z., Mai, G., Huang, H., & Kumar Sangaiah, A. (2018). Causal Discovery Combining K2 with Brain Storm Optimization Algorithm. Molecules, 23(7), 1729. https://doi.org/10.3390/molecules23071729