
Preprocessing NIR Spectra for Aquaphotomics




Abstract
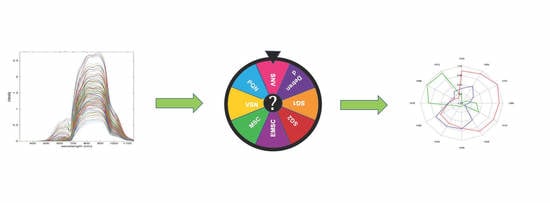
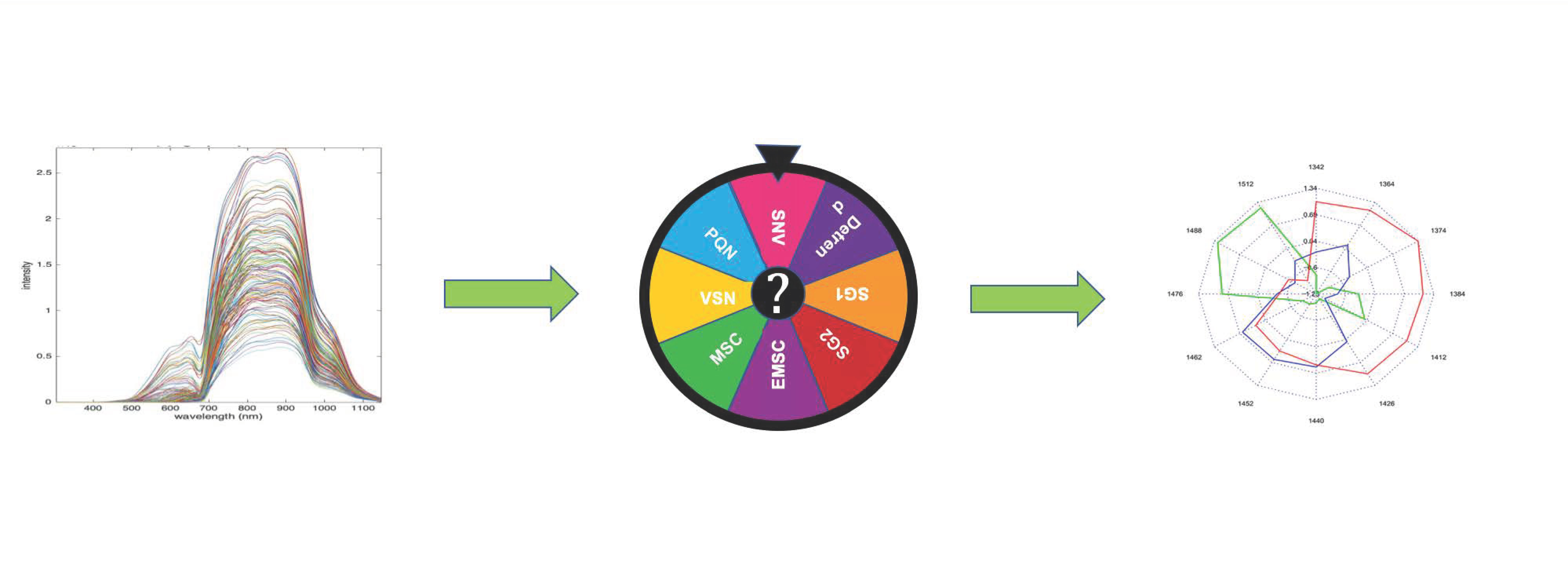
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
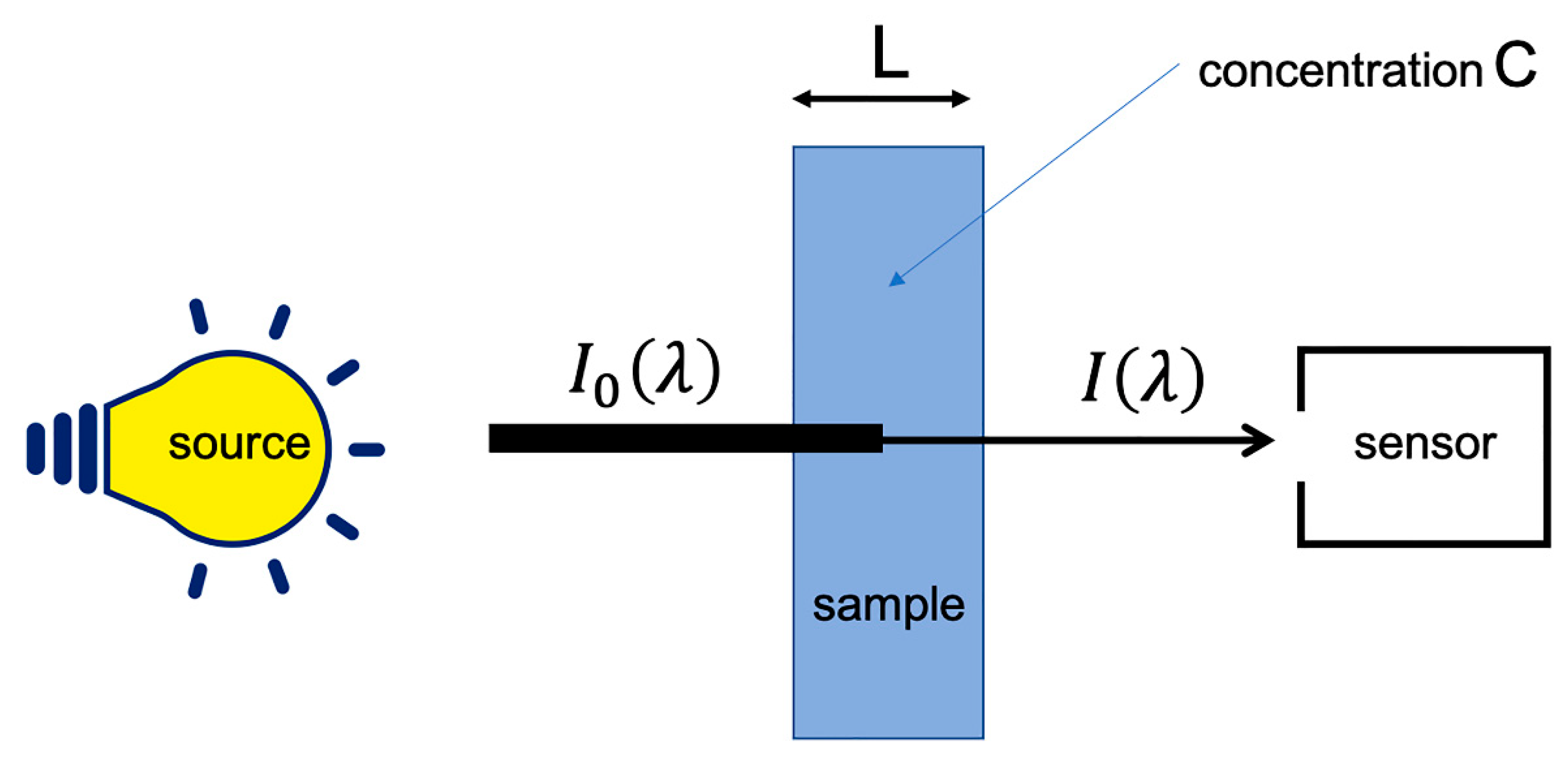
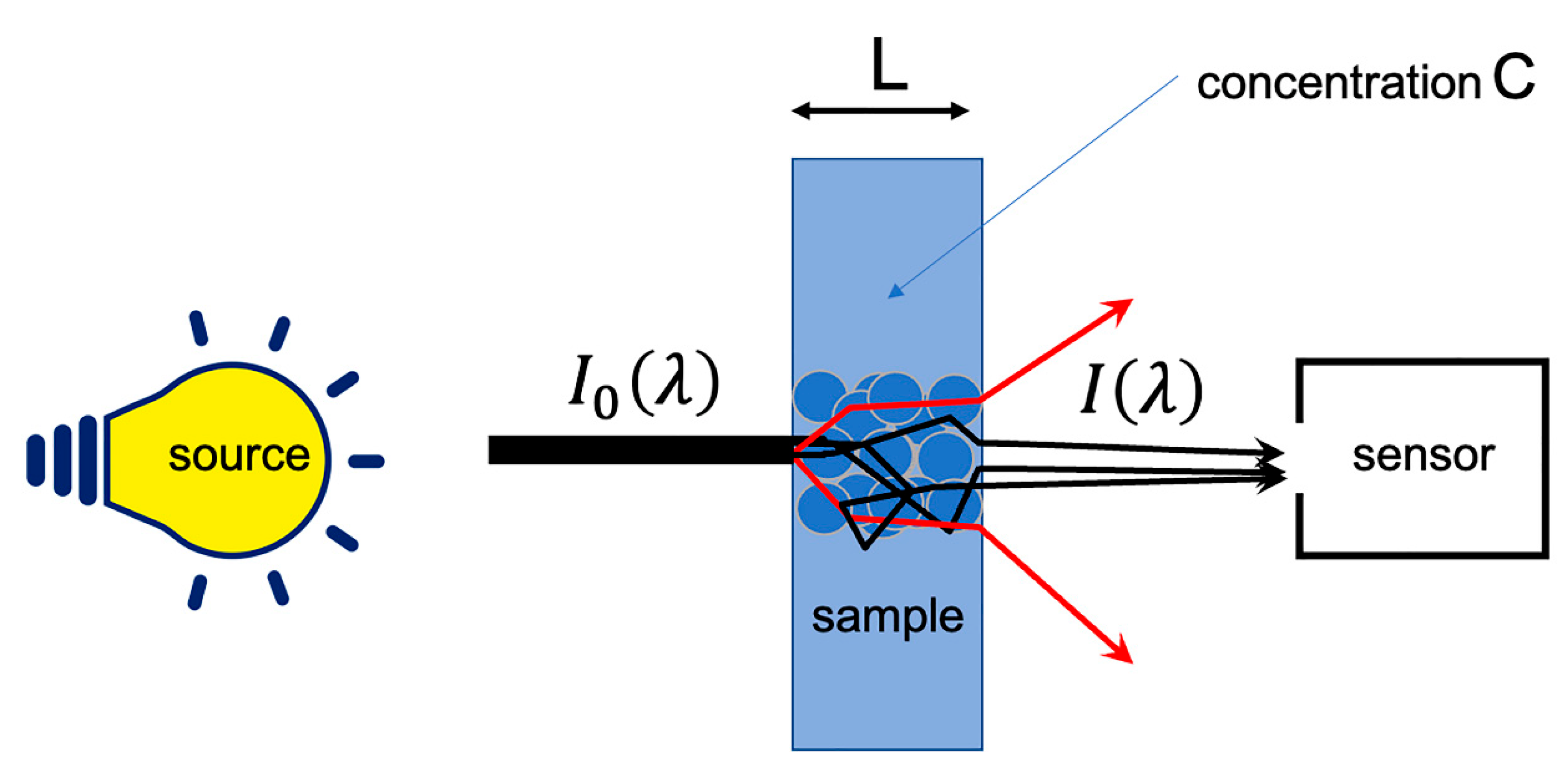
2. Why to Preprocess NIR Spectra?
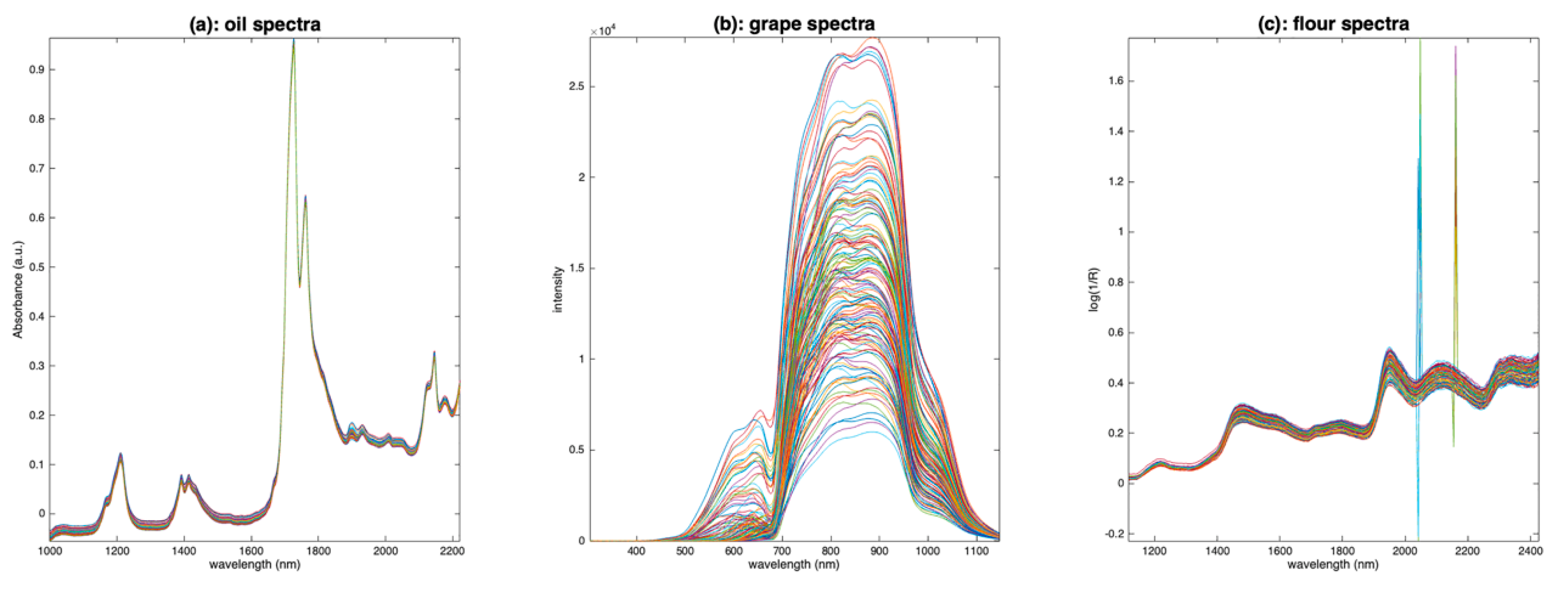
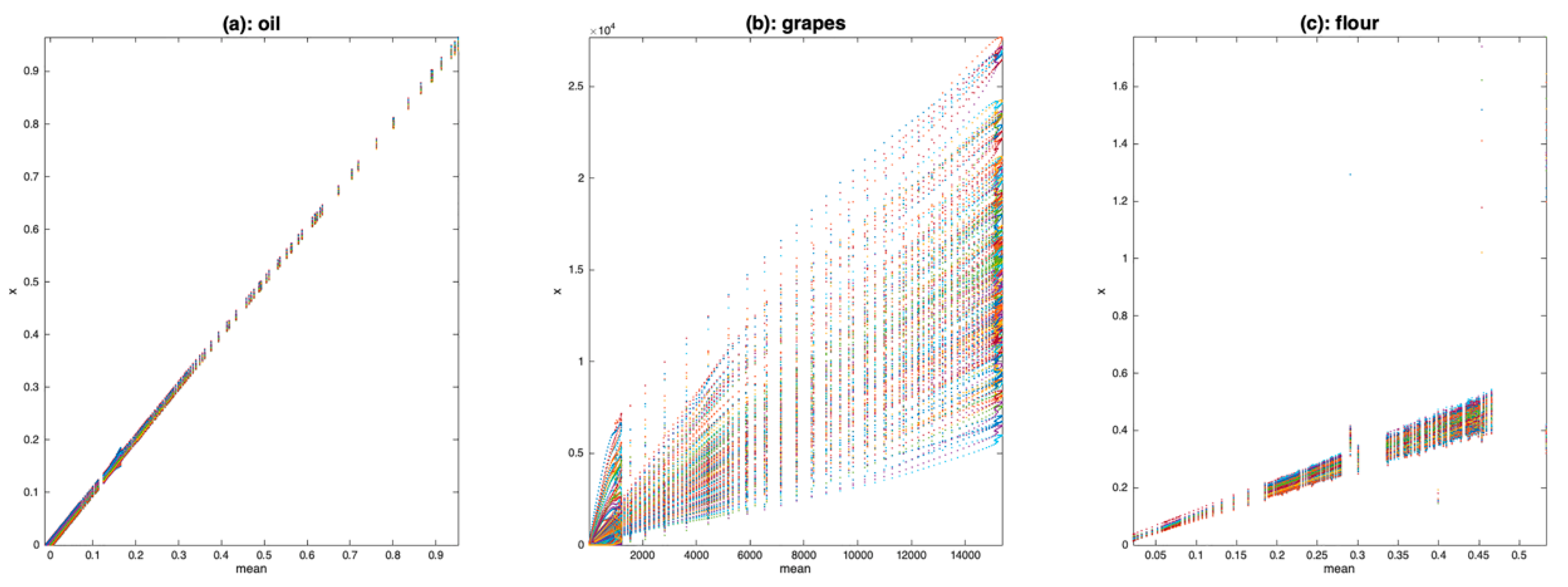
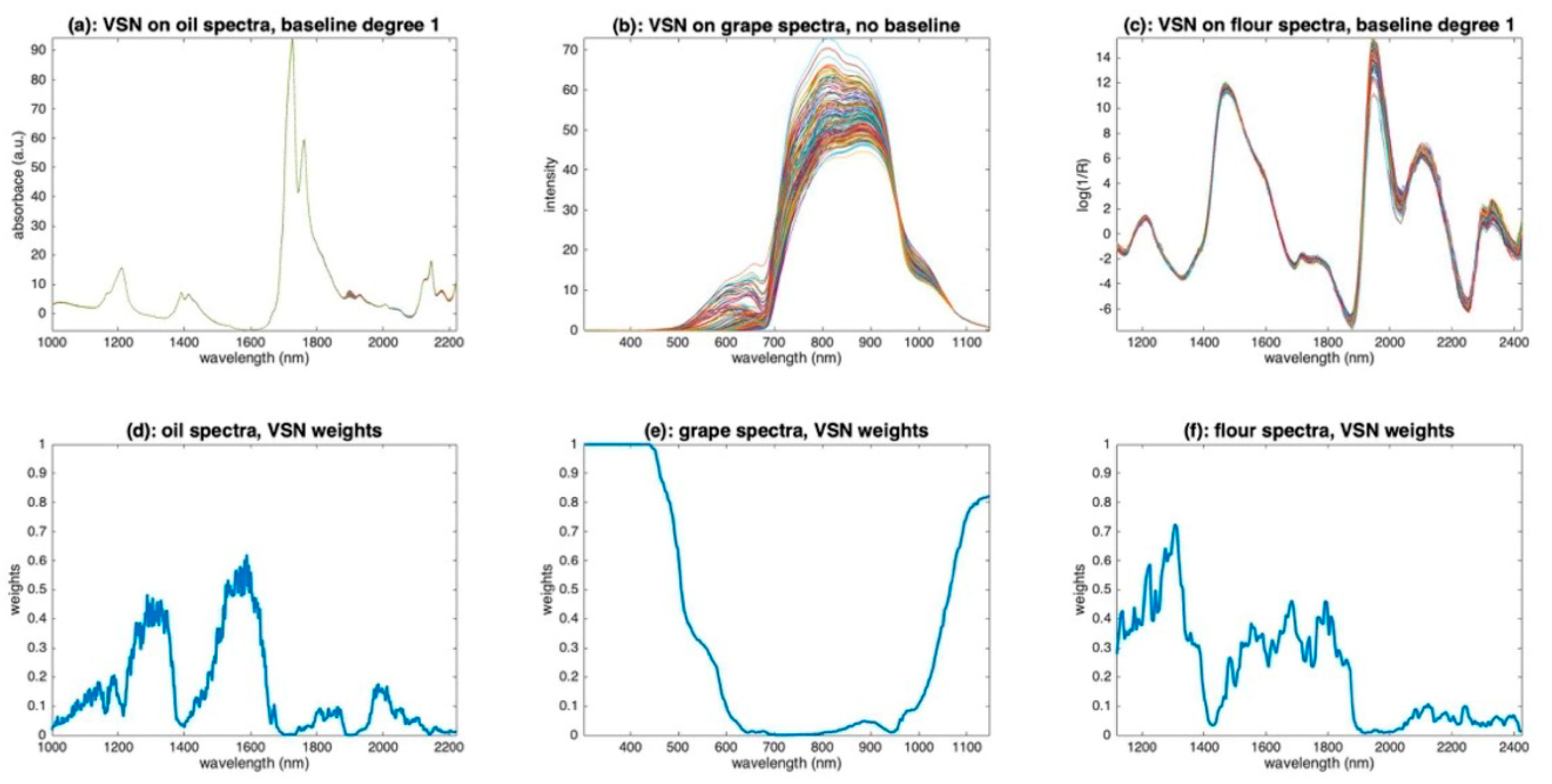
3. Data
- The first one contains 187 NIR spectra of virgin olive oils from Southern France measured in transmission [8]. The spectra were recorded at 612 wavelengths regularly spaced every 2 nm over the range 1000–2222 nm. The spectra were converted in absorbance.
- The second one contains 150 Vis-NIR spectra of grapes measured in transmission [9]. The spectra were recorded at 256 wavelengths regularly spaced every 3.30 nm over the range 303–1146 nm. No transformation was conducted on the spectra which are, thus, raw intensity spectra.
- The third one contains 126 NIR spectra of flour measured in reflectance mode [10]. The spectra were recorded at 209 wavelengths regularly spaced every 6.28 nm over the range 1118–2425 nm. A log transformation was conducted on the spectra which are, thus, expressed as pseudo absorbances (log(1/R)).
4. Looking at the Data
4.1. Spectra Plot
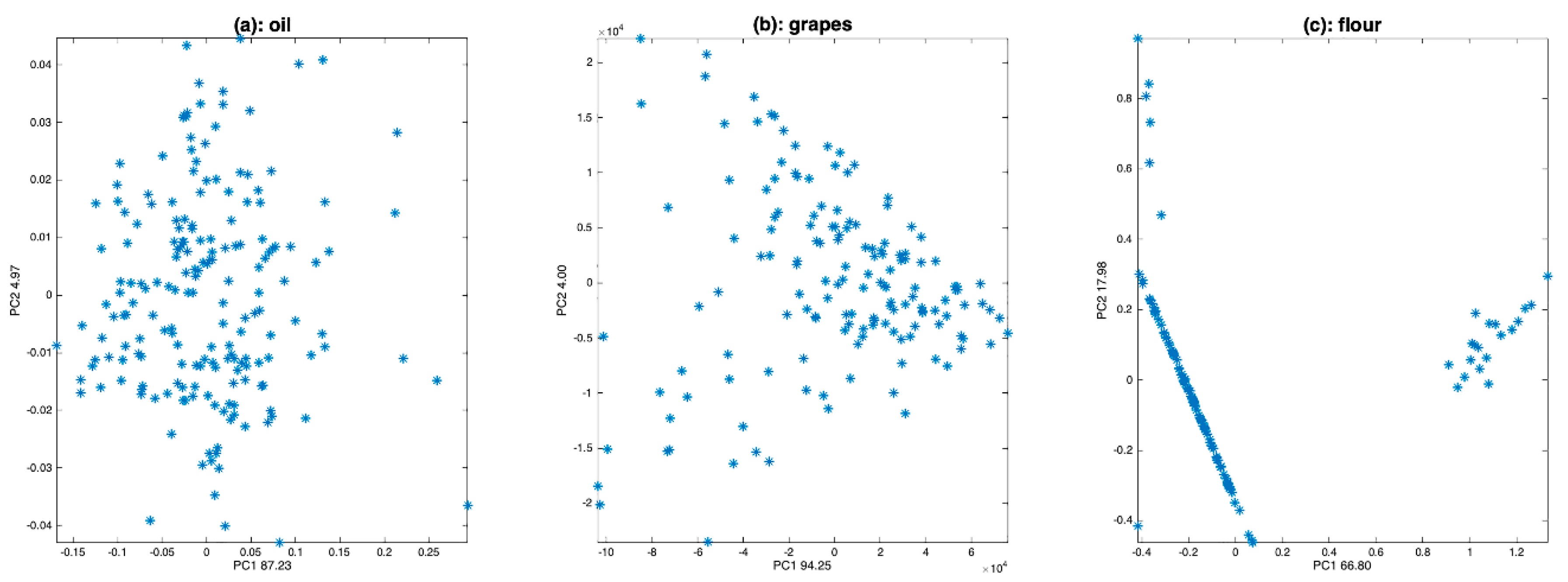
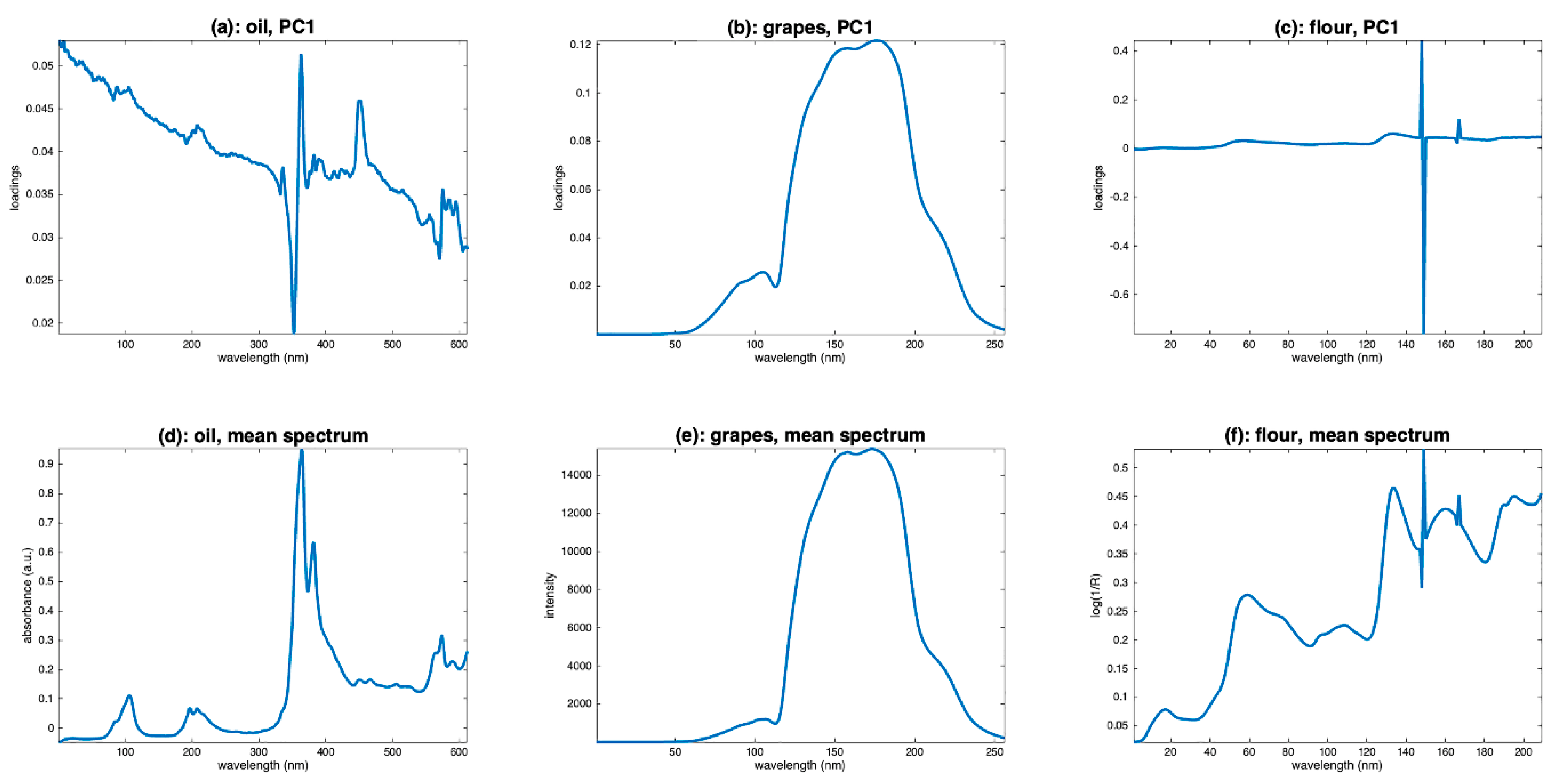
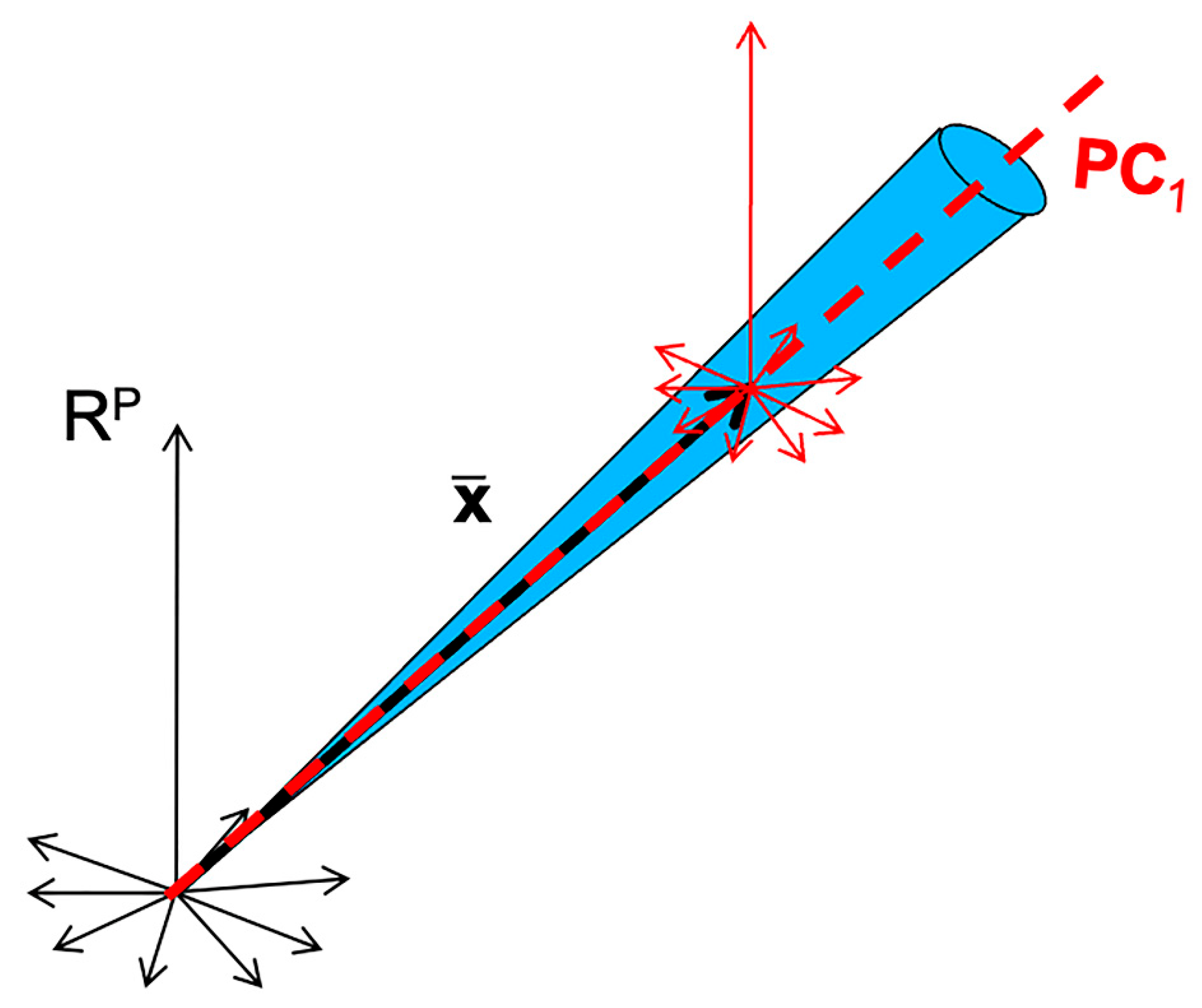
4.2. PCA
5. Most Usual Preprocessing
5.1. Noise Removal
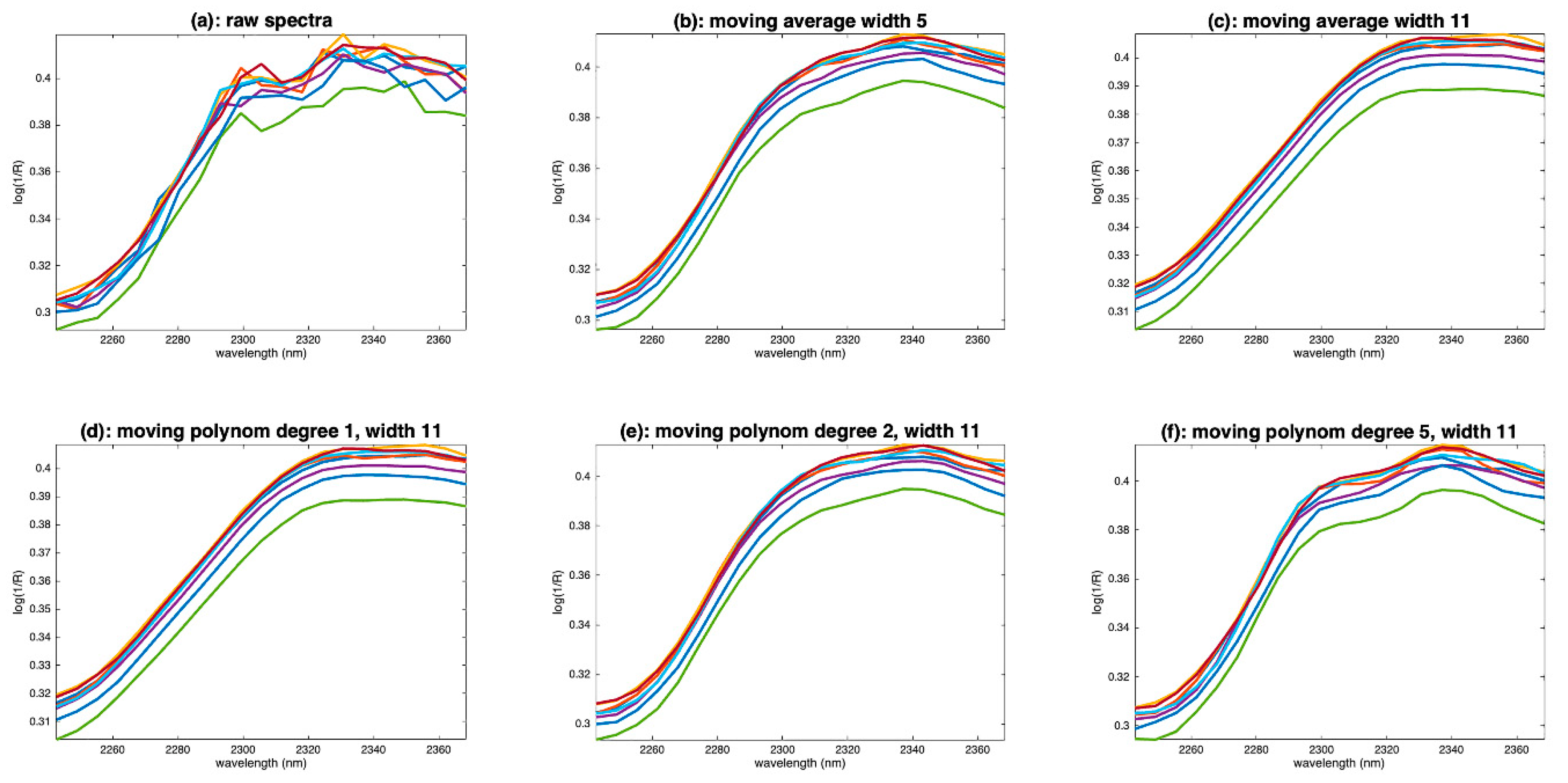
5.1.1. Moving Averaging
5.1.2. Moving Polynomial Fitting
5.1.3. Frequency Filtering
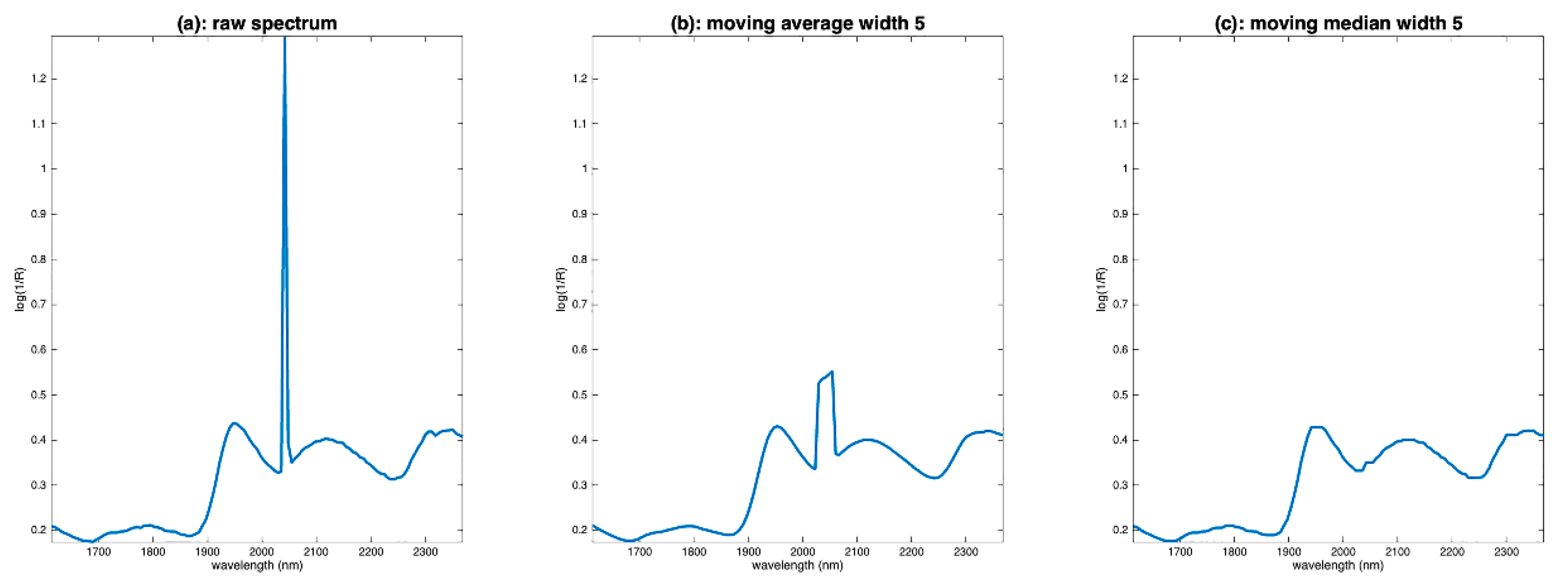
5.1.4. Median Filter
5.2. Baseline Removal
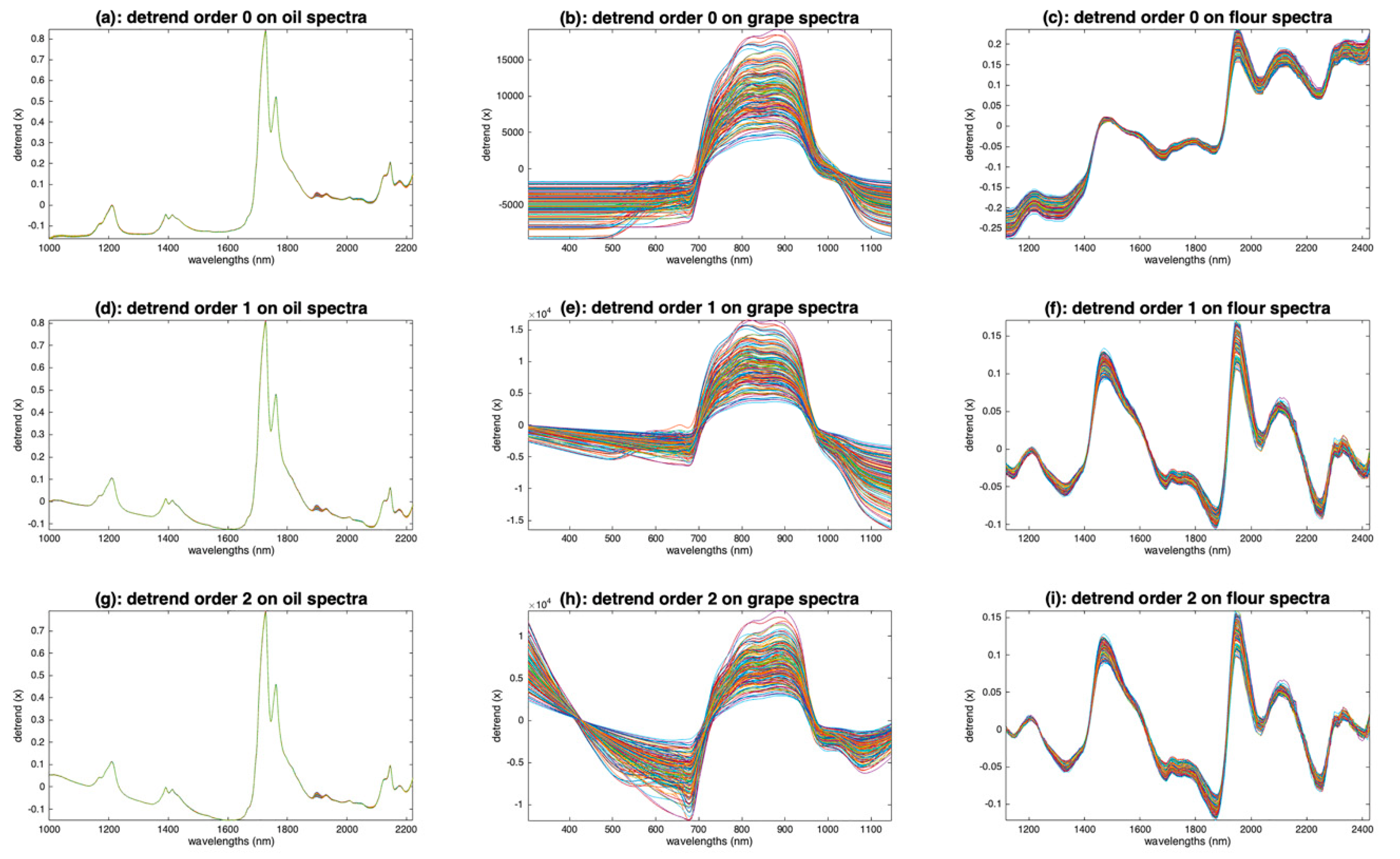
5.2.1. Detrending
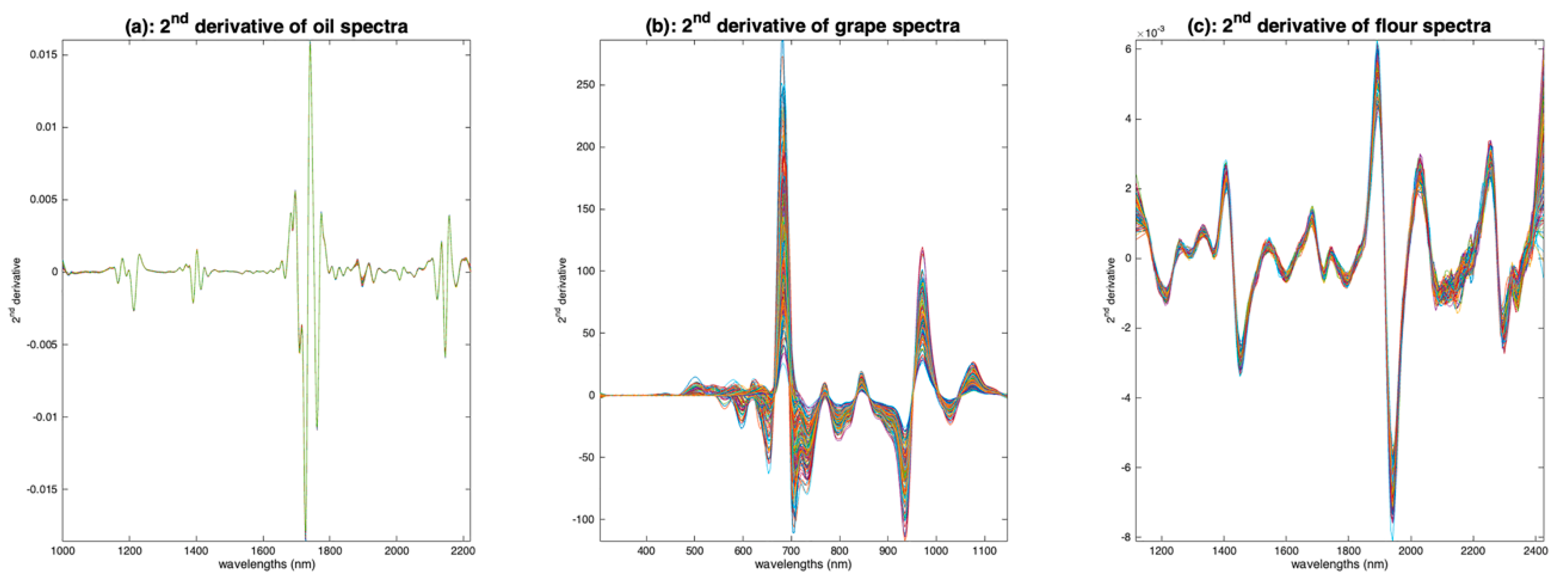
5.2.2. Derivatives
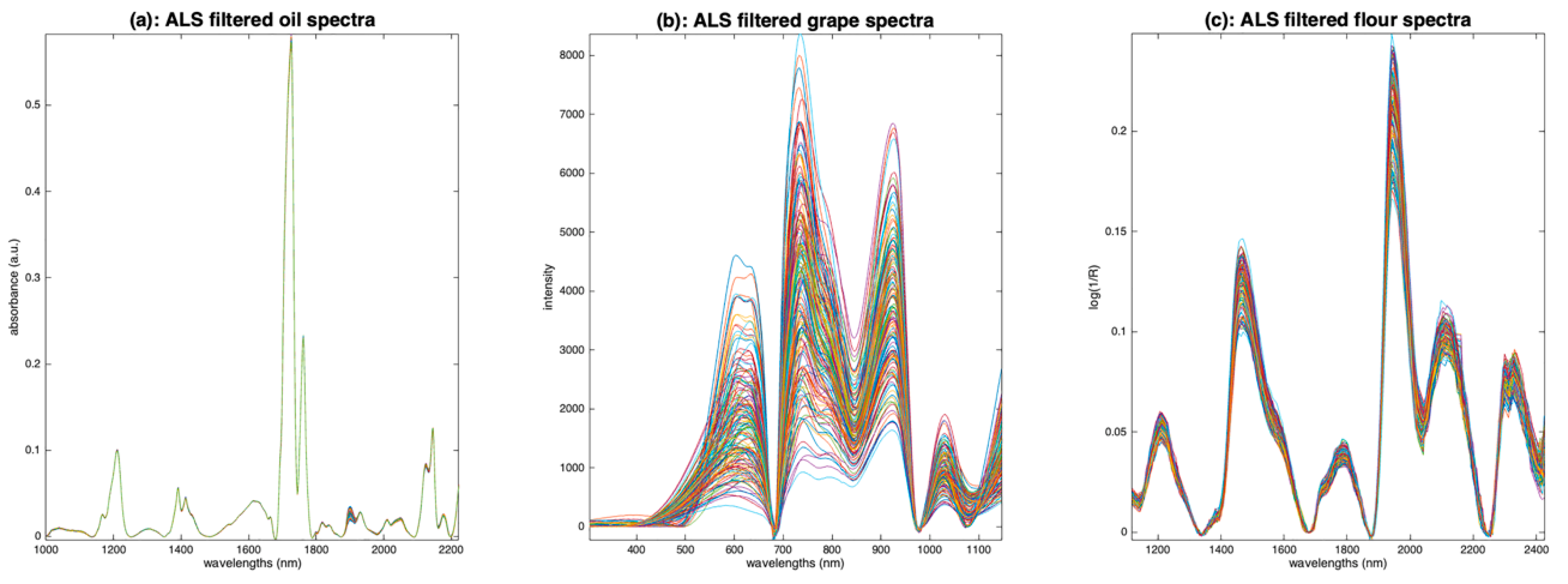
5.2.3. Asymmetric Least Squares
5.3. Multiplicative Effect Removal
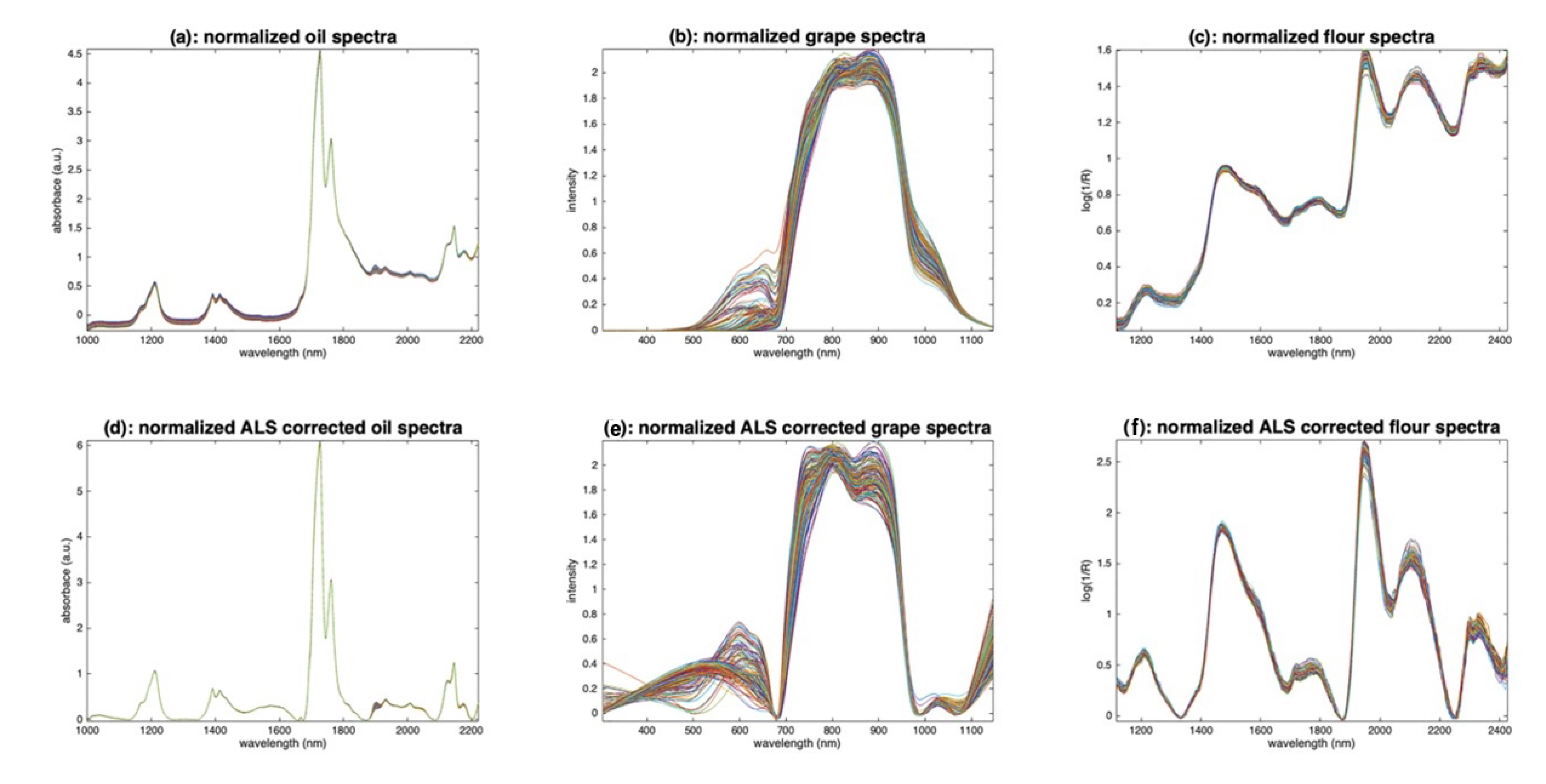
5.3.1. Normalization
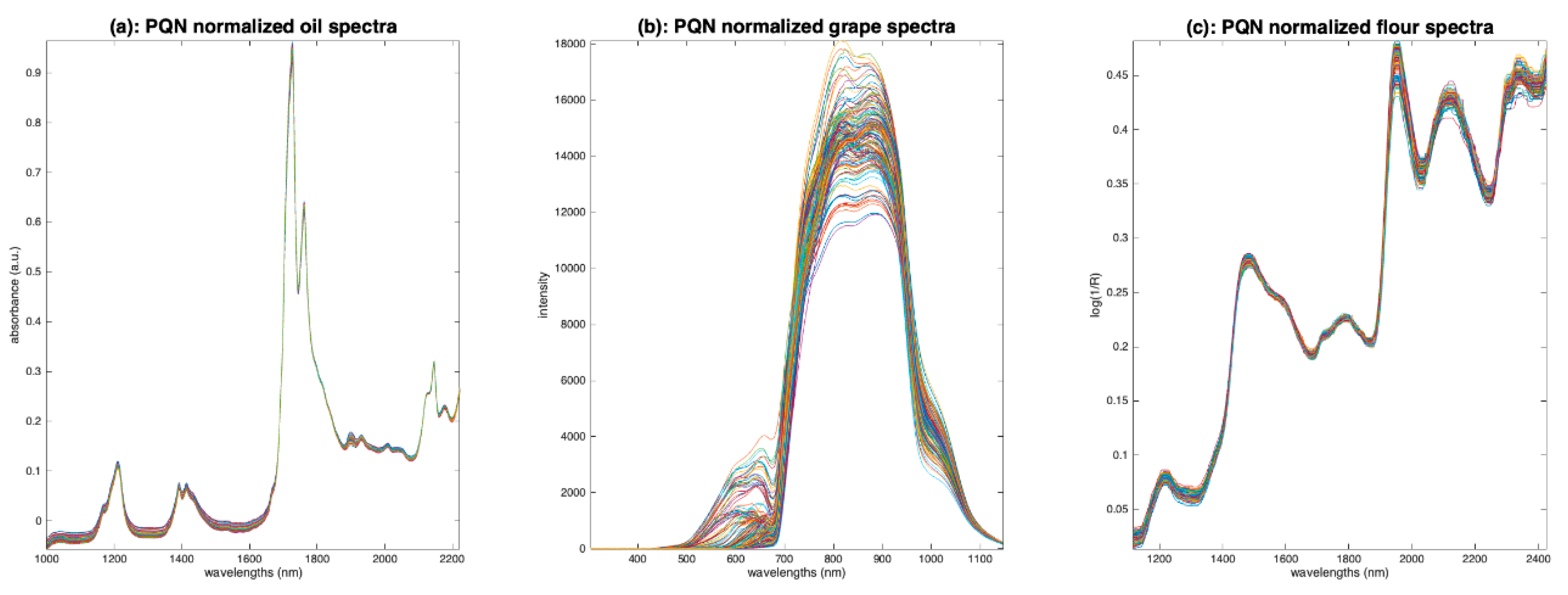
5.3.2. Probabilistic Quotient Normalization (PQN)
5.4. Combined Methods
6. A Focus on Log Transform
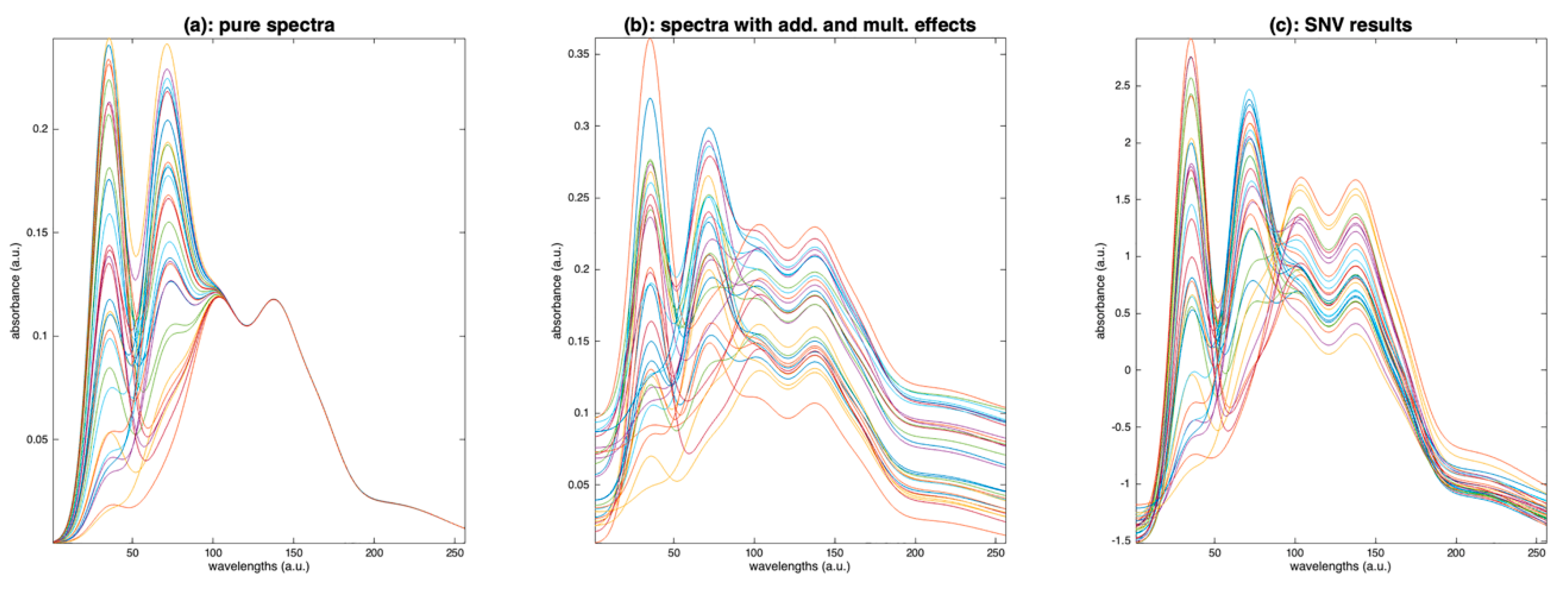
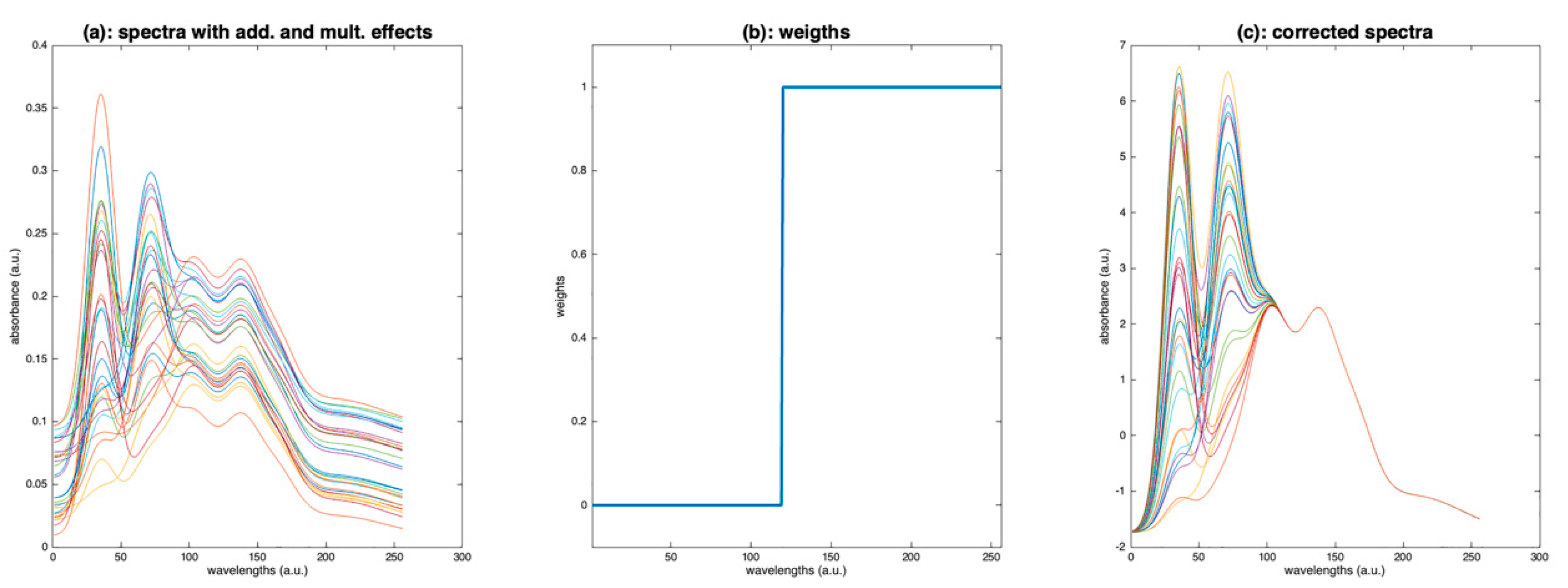
7. A Focus on SNV
- Compute the standard deviation of in place of ;
- Replace Equation (3) of detrending by: .
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Siesler, H.W.; Kawata, S.; Heise, H.M.; Ozaki, Y. (Eds.) Near-Infrared Spectroscopy: Principles, Instruments, Applications; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Pasquini, C. Near infrared spectroscopy: A mature analytical technique with new perspectives–A review. Anal. Chim. Acta 2018, 1026, 8–36. [Google Scholar] [CrossRef]
- Tsenkova, R. Visible-near infrared perturbation spectroscopy: Water in action seen as a source of information. In Proceedings of the 12th International Conference on Near-Infrared Spectroscopy, Auckland, New Zealand, 1 September 2005; pp. 607–612. [Google Scholar]
- Muncan, J.; Tsenkova, R. Aquaphotomics—From innovative knowledge to integrative platform in science and technology. Molecules 2019, 24, 2742. [Google Scholar] [CrossRef] [Green Version]
- Martens, H.; Stark, E. Extended multiplicative signal correction and spectral interference subtraction: New preprocessing methods for near infrared spectroscopy. J. Pharm. Biomed. Anal. 1991, 9, 625–635. [Google Scholar] [CrossRef]
- Rinnan, Å. Pre-processing in vibrational spectroscopy–when, why and how. Anal. Methods 2014, 6, 7124–7129. [Google Scholar] [CrossRef]
- Roger, J.-M.; Boulet, J.-C.; Zeaiter, M.; Rutledge, D.N. Pre-processing Methods*. In Reference Module in Chemistry, Molecular Sciences and Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Dupuy, N.; Galtier, O.; Ollivier, D.; Vanloot, P.; Artaud, J. Comparison between NIR, MIR, concatenated NIR and MIR analysis and hierarchical PLS model. Application to virgin olive oil analysis. Anal. Chim. Acta 2010, 666, 23–31. [Google Scholar] [CrossRef]
- Chauchard, F.; Cogdill, R.; Roussel, S.; Roger, J.M.; Bellon-Maurel, V. Application of LS-SVM to non-linear phenomena in NIR spectroscopy: Development of a robust and portable sensor for acidity prediction in grapes. Chemom. Intell. Lab. Syst. 2004, 71, 141–150. [Google Scholar] [CrossRef] [Green Version]
- Data of a Challenge Proposed at 2022 Chimiométrie Conference, 7–8 June 2022, Brest, France. Available online: https://chimiobrest2022.sciencesconf.org/resource/page/id/5 (accessed on 15 December 2021).
- Mobley, P.R.; Kowalski, B.R.; Workman, J.J., Jr.; Bro, R. Review of chemometrics applied to spectroscopy: 1985-95, part 2. Appl. Spectrosc. Rev. 1996, 31, 347–368. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Maeda, H.; Ozaki, Y.; Tanaka, M.; Hayashi, N.; Kojima, T. Near infrared spectroscopy and chemometrics studies of temperature-dependent spectral variations of water: Relationship between spectral changes and hydrogen bonds. J. Near Infrared Spectrosc. 1995, 3, 191–201. [Google Scholar] [CrossRef]
- Renati, P.; Kovacs, Z.; De Ninno, A.; Tsenkova, R. Temperature dependence analysis of the NIR spectra of liquid water confirms the existence of two phases, one of which is in a coherent state. J. Mol. Liq. 2019, 292, 111449. [Google Scholar] [CrossRef]
- Eilers, P.H.; Boelens, H.F. Baseline correction with asymmetric least squares smoothing. Leiden Univ. Med. Cent. Rep. 2005, 1, 5. [Google Scholar]
- Rinnan, Å.; Van Den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Rabatel, G.; Marini, F.; Walczak, B.; Roger, J.M. VSN: Variable sorting for normalization. J. Chemom. 2020, 34, e3164. [Google Scholar] [CrossRef]
- Dieterle, F.; Ross, A.; Schlotterbeck, G.; Senn, H. Probabilistic quotient normalization as robust method to account for dilution of complex biological mixtures. Application in 1H NMR metabonomics. Anal. Chem. 2006, 78, 4281–4290. [Google Scholar] [CrossRef] [PubMed]
- Guo, Q.; Wu, W.; Massart, D.L. The robust normal variate transform for pattern recognition with near-infrared data Anal. Chim. Acta. 1999, 382, 87–103. [Google Scholar] [CrossRef]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard normal variate transformation and de-trending of near-infrared diffuse reflectance spectra. Appl. Spectrosc. 1989, 43, 772–777. [Google Scholar] [CrossRef]
- Isaksson, T.; Næs, T. The effect of multiplicative scatter correction (MSC) and linearity improvement in NIR spectroscopy. Appl. Spectrosc. 1988, 42, 1273–1284. [Google Scholar] [CrossRef]
- Dhanoa, M.S.; Lister, S.J.; Sanderson, R.; Barnes, R.J. The link between multiplicative scatter correction (MSC) and standard normal variate (SNV) transformations of NIR spectra. J. Near Infrared Spectrosc. 1994, 2, 43–47. [Google Scholar] [CrossRef]
- Gowen, A.A.; Marini, F.; Tsuchisaka, Y.; De Luca, S.; Bevilacqua, M.; Donnell, C.O.; Downey, G.; Tsenkova, R. On the feasibility of near infrared spectroscopy to detect contaminants in water using single salt solutions as model systems. Talanta 2015, 131, 609–618. [Google Scholar] [CrossRef]
- Gowen, A.A.; Stark, E.W.; Tsuchisaka, Y.; Tsenkova, R. Extended multiplicative signal correction as a tool for aquaphotomics. NIR News 2011, 22, 9–13. [Google Scholar] [CrossRef]
- Mallet, A.; Tsenkova, R.; Muncan, J.; Charnier, C.; Latrille, é.; Bendoula, R.; Steyer, J.P.; Roger, J.M. Relating Near-Infrared Light Path-Length Modifications to the Water Content of Scattering Media in Near-Infrared Spectroscopy: Toward a New Bouguer-Beer-Lambert Law. Anal. Chem. 2021, 93, 6817–6823. [Google Scholar] [CrossRef] [PubMed]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]

















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roger, J.-M.; Mallet, A.; Marini, F. Preprocessing NIR Spectra for Aquaphotomics. Molecules 2022, 27, 6795. https://doi.org/10.3390/molecules27206795
Roger J-M, Mallet A, Marini F. Preprocessing NIR Spectra for Aquaphotomics. Molecules. 2022; 27(20):6795. https://doi.org/10.3390/molecules27206795
Chicago/Turabian StyleRoger, Jean-Michel, Alexandre Mallet, and Federico Marini. 2022. "Preprocessing NIR Spectra for Aquaphotomics" Molecules 27, no. 20: 6795. https://doi.org/10.3390/molecules27206795
APA StyleRoger, J. -M., Mallet, A., & Marini, F. (2022). Preprocessing NIR Spectra for Aquaphotomics. Molecules, 27(20), 6795. https://doi.org/10.3390/molecules27206795