Genome Sequencing and Carbohydrate-Active Enzyme (CAZyme) Repertoire of the White Rot Fungus Flammulina elastica


Abstract
:1. Introduction
2. Results and Discussion
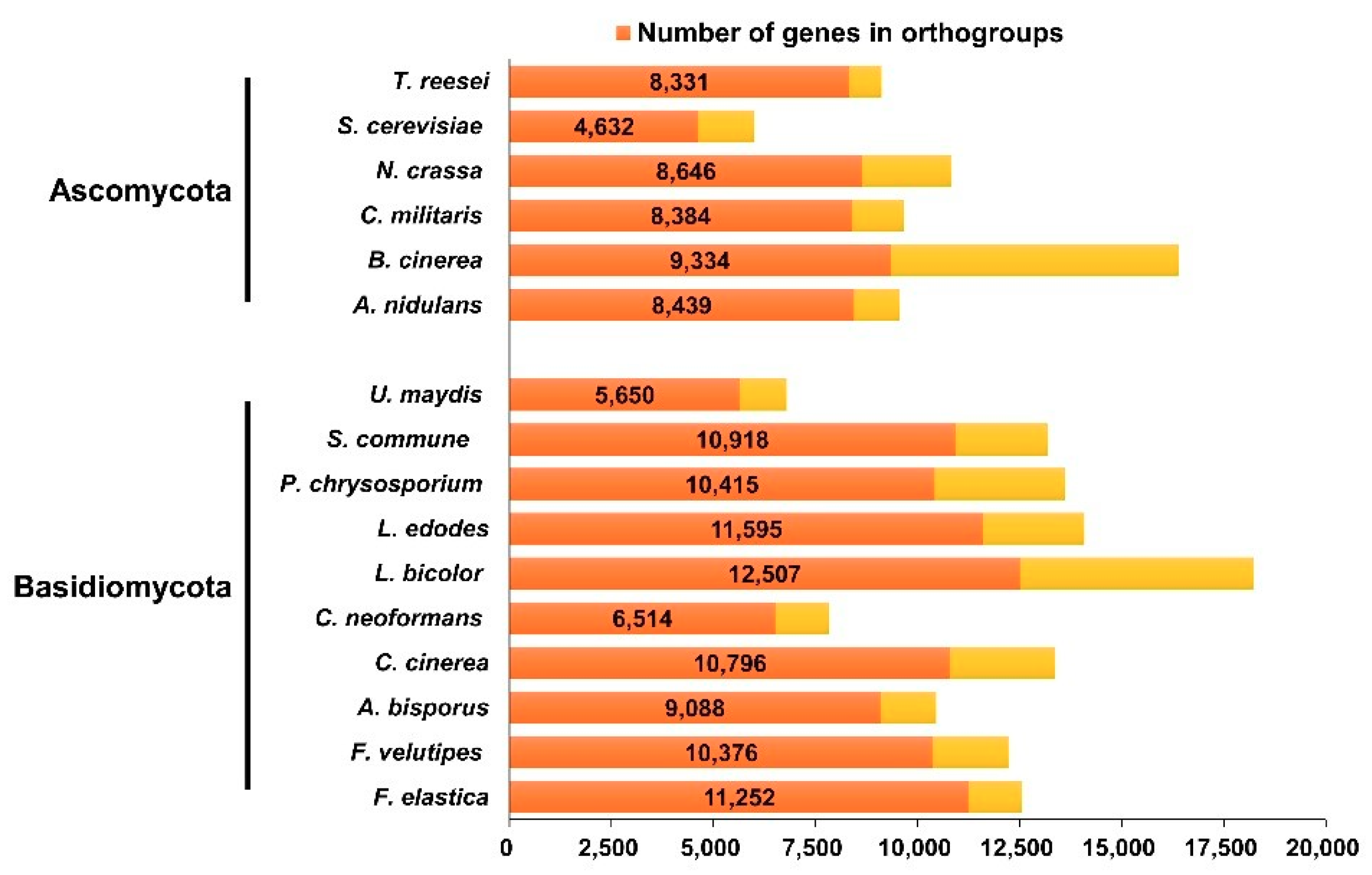
2.1. Genome Sequence Assembly, Gene Modeling, and Genome Comparisons
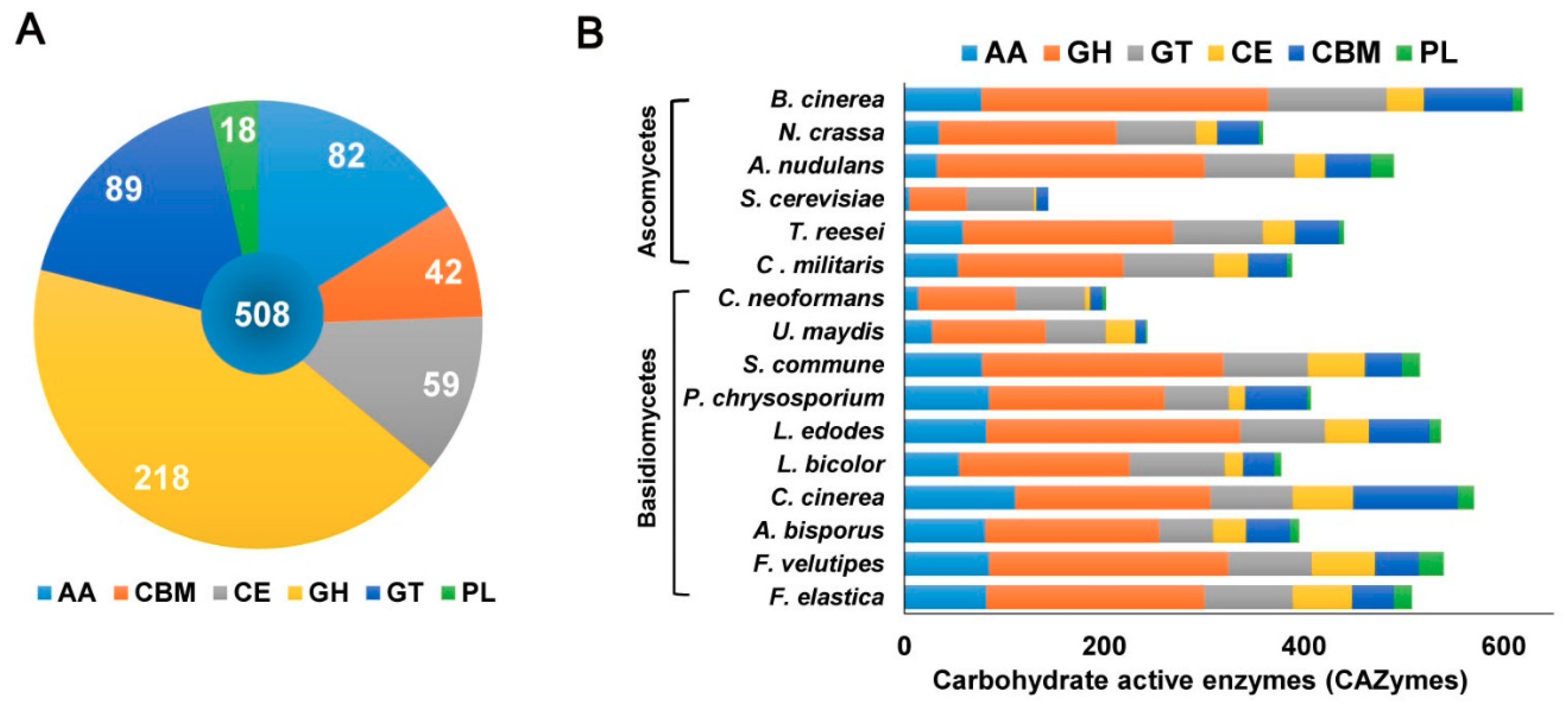
2.2. F. elastica CAZymes and Genome-Wide Comparisons with other Fungal Species
2.2.1. Glycosyltransferases (GTs)
2.2.2. Glycoside Hydrolases (GHs)
2.2.3. Polysaccharide Lyases (PLs)
2.2.4. Carbohydrate-Binding Modules (CBMs)
2.2.5. Carbohydrate Esterases (CEs)
2.2.6. Auxiliary Activities (AAs)
3. Materials and Methods
3.1. Fungal Strain Culture and Genomic DNA Isolation
3.2. Genome Sequencing and De Novo Assembly
3.3. Gene Prediction and Annotation
3.4. Ortholog Identification and Clustering
3.5. CAZyme Gene Identification and Signal Peptide Prediction
3.6. Data Access
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Redhead, S.A.; Petersen, R.H. New species, varieties and combinations in the genus Flammulina. Mycotaxon 1999, 71, 285–294. [Google Scholar]
- Petersen, R.H.; Hughes, K.W.; Redhead, S.A. The genus Flammulina, a Tennessee tutorial. Available online: https://www.bioinfo.org.uk/html/Flammulina.htm (accessed on 21 October 2009).
- Ripková, S.; Hughes, K.; Adamčík, S.; Kučera, V.; Adamčíková, K. The delimitation of Flammulina fennae. Mycol. Prog. 2010, 9, 469–484. [Google Scholar] [CrossRef]
- Pérez-Butrón, J.L.; Ferdnández-Vicente, J. Una nueva especie de Flammulina P. Karsten, F. cephalariae (Agaricales) encontrada en España. Rev. Catalana Micol. 2007, 29, 81–91. [Google Scholar]
- Eriksson, K.; Blanchette, R.A.; Ander, P. Morphological aspects of wood degradation by fungi and bacteria. In Microbial and Ezymatic Degradation of Wood and Wood Components; Springer: Berlin/Heidelberg, Germany, 1990; pp. 1–87. ISBN 978-3-642-46687-8. [Google Scholar]
- Sista Kameshwar, A.K.; Qin, W. Comparative study of genome-wide plant biomass-degrading CAZymes in white rot, brown rot and soft rot fungi. Mycology 2018, 9, 93–105. [Google Scholar] [CrossRef]
- Rytioja, J.; Hildén, K.; Yuzon, J.; Hatakka, A.; de Vries, R.P.; Mäkelä, M.R. Plant-polysaccharide-degrading enzymes from basidiomycetes. Microbiol. Mol. Biol. Rev. 2014, 78, 614–649. [Google Scholar] [CrossRef] [PubMed]
- Lombard, V.; Golaconda Ramulu, H.; Drula, E.; Coutinho, P.M.; Henrissat, B. The carbohydrate-active enzymes database (CAZy) in 2013. Nucleic Acids Res. 2014, 42, D490–D495. [Google Scholar] [CrossRef] [PubMed]
- Martinez, D.; Larrondo, L.F.; Putnam, N.; Sollewijn Gelpke, M.D.; Huang, K.; Chapman, J.; Helfenbein, K.G.; Ramaiya, P.; Detter, J.C.; Larimer, F.; et al. Genome sequence of the lignocellulose degrading fungus Phanerochaete chrysosporium strain RP78. Nat. Biotechnol. 2004, 22, 695–700. [Google Scholar] [CrossRef] [PubMed]
- Kämper, J.; Kahmann, R.; Bölker, M.; Ma, L.-J.; Brefort, T.; Saville, B.J.; Banuett, F.; Kronstad, J.W.; Gold, S.E.; Müller, O.; et al. Insights from the genome of the biotrophic fungal plant pathogen Ustilago maydis. Nature 2006, 444, 97–101. [Google Scholar] [CrossRef] [PubMed]
- Park, Y.J.; Baek, J.H.; Lee, S.; Kim, C.; Rhee, H.; Kim, H.; Seo, J.S.; Park, H.R.; Yoon, D.E.; Nam, J.Y.; et al. Whole genome and global gene expression analyses of the model mushroom Flammulina velutipes reveal a high capacity for lignocellulose degradation. PLoS ONE 2014, 9, e93560. [Google Scholar] [CrossRef] [PubMed]
- Lowe, T.M.; Eddy, S.R. tRNAscan-SE: A program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 1997, 25, 955–964. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Mao, X.; Yang, J.C.; Chen, X.; Mao, F.; Xu, Y. dbCAN: A web resource for automated carbohydrate-active enzyme annotation. Nucleic Acids Res. 2012, 40, W445–W451. [Google Scholar] [CrossRef] [PubMed]
- Breton, C.; Šnajdrová, L.; Jeanneau, C.; Koča, J.; Imberty, A. Structures and mechanisms of glycosyltransferases. Glycobiology 2006, 16, 29R–37R. [Google Scholar] [CrossRef] [PubMed]
- Lairson, L.L.; Henrissat, B.; Davies, G.J.; Withers, S.G. Glycosyltransferases: Structures, functions, and mechanisms. Annu. Rev. Biochem. 2008, 77, 521–555. [Google Scholar] [CrossRef] [PubMed]
- Coutinho, P.M.; Deleury, E.; Davies, G.J.; Henrissat, B. An evolving hierarchical family classification for glycosyltransferases. J. Mol. Biol. 2003, 328, 307–317. [Google Scholar] [CrossRef]
- Campbell, J.A.; Davies, G.J.; Bulone, V.; Henrissat, B. A classification of nucleotide-diphospho-sugar glycosyltransferases based on amino acid sequence similarities. Biochem. J. 1997, 326, 929–939. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paulson, J.C.; Weinstein, J.; Ujita, E.L.; Riggs, K.J.; Lai, H. The membrane-binding domain of a rat liver Golgi sialyltransferase. Biochem. Soc. Trans. 1987, 15, 618–620. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wickner, W.T.; Lodish, H.F. Multiple mechanisms of protein insertion into and across membranes. Science 1985, 230, 400–407. [Google Scholar] [CrossRef] [PubMed]
- Chou, M.M.; Kendall, D.A. Polymeric sequences reveal a functional interrelationship between hydrophobicity and length of signal peptides. J. Biol. Chem. 1990, 265, 2873–2880. [Google Scholar] [PubMed]
- IngMarie, N.; Whitley, P.; von Heijne, G. The COOH-terminal ends of internal signal and signal-anchor sequences are positioned differently in the ER translocase. J. Cell. Biol. 1994, 126, 1127–1132. [Google Scholar] [CrossRef] [Green Version]
- Mukai, Y.; Hirokawa, T.; Tomii, K.; Asai, K.; Akiyama, Y.; Suwa, M. Identification of glycosyltransferases focusing on Golgi transmembrane region. Trends Glycosci. Glycotechnol. 2008, 19, 41–47. [Google Scholar] [CrossRef]
- Berlemont, R.; Martiny, A.C. Glycoside hydrolases across environmental microbial communities. PLoS Comput. Biol. 2016, 12, e1005300. [Google Scholar] [CrossRef] [PubMed]
- Henrissat, B. A classification of glycosyl hydrolases based on amino acid sequence similarities. Biochem. J. 1991, 280, 309–316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Galagan, J.E.; Calvo, S.E.; Cuomo, C.; Ma, L.J.; Wortman, J.R.; Batzoglou, S.; Lee, S.I.; Baştürkmen, M.; Spevak, C.C.; Clutterbuck, J.; et al. Sequencing of Aspergillus nidulans and comparative analysis with A. fumigatus and A. oryzae. Nature 2005, 438, 1105–1115. [Google Scholar] [CrossRef] [PubMed]
- Zheng, P.; Xia, Y.; Xiao, G.; Xiong, C.; Hu, X.; Zhang, S.; Zheng, H.; Huang, Y.; Zhou, Y.; Wang, S.; et al. Genome sequence of the insect pathogenic fungus Cordyceps militaris, a valued traditional Chinese medicine. Genome Biol. 2011, 12, R116. [Google Scholar] [CrossRef] [PubMed]
- Fisk, D.G.; Ball, C.A.; Dolinski, K.; Engel, S.R.; Hong, E.L.; Issel-Tarver, L.; Schwartz, K.; Sethuraman, A.; Botstein, D.; Cherry, J.M. Saccharomyces cerevisiae S288C genome annotation: A working hypothesis. Yeast 2006, 23, 857–865. [Google Scholar] [CrossRef] [PubMed]
- Li, W.C.; Huang, C.H.; Chen, C.L.; Chuang, Y.C.; Tung, S.Y.; Wang, T.F. Trichoderma reesei complete genome sequence, repeat-induced point mutation, and partitioning of CAZyme gene clusters. Biotechnol. Biofuels 2017, 10, 170. [Google Scholar] [CrossRef] [PubMed]
- Hahn, M.; Olsen, O.; Politz, O.; Borriss, R.; Heinemann, U. Crystal structure and site-directed mutagenesis of Bacillus macerans endo-1,3-1,4-β-glucanase. J. Biol. Chem. 1995, 270, 3081–3088. [Google Scholar] [CrossRef] [PubMed]
- Masuda, S.; Endo, K.; Koizumi, N.; Hayami, T.; Fukazawa, T.; Yatsunami, R.; Fukui, T.; Nakamura, S. Molecular identification of a novel β-1,3-glucanase from alkaliphilic Nocardiopsis sp. strain F96. Extremophiles 2006, 10, 251–255. [Google Scholar] [CrossRef] [PubMed]
- Kotake, T.; Hirata, N.; Degi, Y.; Ishiguro, M.; Kitazawa, K.; Takata, R.; Ichinose, H.; Kaneko, S.; Igarashi, K.; Samejima, M.; et al. Endo-β-1,3-galactanase from winter mushroom Flammulina velutipes. J. Biol. Chem. 2011, 286, 27848–27854. [Google Scholar] [CrossRef] [PubMed]
- Horton, P.; Park, K.J.; Obayashi, T.; Fujita, N.; Harada, H.; Adams-Collier, C.J.; Nakai, K. WoLF PSORT: Protein localization predictor. Nucleic Acids Res. 2007, 35, W585–W587. [Google Scholar] [CrossRef] [PubMed]
- Berlemont, R. Distribution and diversity of enzymes for polysaccharide degradation in fungi. Sci. Rep. 2017, 7, 222. [Google Scholar] [CrossRef] [PubMed]
- Wilson, D.B. Microbial diversity of cellulose hydrolysis. Curr. Opin. Microbiol. 2011, 14, 259–263. [Google Scholar] [CrossRef] [PubMed]
- Berlemont, R.; Martiny, A.C. Phylogenetic distribution of potential cellulases in bacteria. Appl. Environ. Microbiol. 2013, 79, 1545–1554. [Google Scholar] [CrossRef] [PubMed]
- Berlemont, R.; Martiny, A.C. Genomic potential for polysaccharides deconstruction in bacteria. Appl. Environ. Microbiol. 2015, 81, 1513–1519. [Google Scholar] [CrossRef] [PubMed]
- Talamantes, D.; Biabini, N.; Dang, H.; Abdoun, K.; Berlemont, R. Natural diversity of cellulases, xylanases, and chitinases in bacteria. Biotechnol. Biofuels 2016, 9, 133. [Google Scholar] [CrossRef] [PubMed]
- Eichlerová, I.; Homolka, L.; Žifčáková, L.; Lisá, L.; Dobiášová, P.; Baldrian, P. Enzymatic systems involved in decomposition reflects the ecology and taxonomy of saprotrophic fungi. Fungal Ecol. 2015, 13, 10–22. [Google Scholar] [CrossRef]
- Treseder, K.K.; Lennon, J.T. Fungal traits that drive ecosystem dynamics on land. Microbiol. Mol. Biol. Rev. 2015, 79, 243–262. [Google Scholar] [CrossRef] [PubMed]
- Sutherland, I.W. Polysaccharide lyases. FEMS Microbiol. Rev. 1995, 16, 323–347. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yip, V.L.; Withers, S.G. Breakdown of oligosaccharides by the process of elimination. Curr. Opin. Chem. Biol. 2006, 10, 147–155. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Liu, H.; Wang, C.; Xu, J.R. Correction: Comparative analysis of fungal genomes reveals different plant cell wall degrading capacity in fungi. BMC Genom. 2013, 14, 274. [Google Scholar] [CrossRef] [PubMed]
- Stajich, J.E.; Wilke, S.K.; Ahrén, D.; Au, C.H.; Birren, B.W.; Borodovsky, M.; Burns, C.; Canbäck, B.; Casselton, L.A.; Cheng, C.K.; et al. Insights into evolution of multicellular fungi from the assembled chromosomes of the mushroom Coprinopsis cinerea (Coprinus cinereus). Proc. Natl. Acad. Sci. USA 2010, 107, 11889–11894. [Google Scholar] [CrossRef] [PubMed]
- Van den Brink, J.; de Vries, R.P. Fungal enzyme sets for plant polysaccharide degradation. Appl. Microbiol. Biotechnol. 2011, 91, 1477–1492. [Google Scholar] [CrossRef] [PubMed]
- Garron, M.L.; Cygler, M. Structural and mechanistic classification of uronic acid-containing polysaccharide lyases. Glycobiology 2010, 20, 1547–1573. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Linhardt, R.J.; Galliher, P.M.; Cooney, C.L. Polysaccharide lyases. Appl. Biochem. Biotechnol. 1987, 12, 135–176. [Google Scholar] [CrossRef]
- Ohm, R.A.; De Jong, J.F.; Lugones, L.G.; Aerts, A.; Kothe, E.; Stajich, J.E.; de Vries, R.P.; Record, E.; Levasseur, A.; Baker, S.E.; et al. Genome sequence of the model mushroom Schizophyllum commune. Nat. Biotechnol. 2010, 28, 957–963. [Google Scholar] [CrossRef] [PubMed]
- Staats, M.; van Kan, J.A. Genome update of Botrytis cinerea strains B05. 10 and T4. Eukaryot. Cell 2012, 11, 1413–1414. [Google Scholar] [CrossRef] [PubMed]
- Xavier-Santos, S.; Carvalho, C.C.; Bonfá, M.; Silva, R.; Capelari, M.; Gomes, E. Screening for pectinolytic activity of wood-rotting basidiomycetes and characterization of the enzymes. Folia Microbiol. 2004, 49, 46–52. [Google Scholar] [CrossRef]
- Boraston, A.B.; Bolam, D.N.; Gilbert, H.J.; Davies, G.J. Carbohydrate-binding modules: Fine-tuning polysaccharide recognition. Biochem. J. 2004, 382, 769–781. [Google Scholar] [CrossRef] [PubMed]
- Shoseyov, O.; Shani, Z.; Levy, I. Carbohydrate binding modules: Biochemical properties and novel applications. Microbiol. Mol. Biol. Rev. 2006, 70, 283–295. [Google Scholar] [CrossRef] [PubMed]
- The CAZypedia Consortium. Ten years of CAZypedia: A living encyclopedia of carbohydrate-active enzymes. Glycobiology 2018, 28, 3–8. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Fueyo, E.; Ruiz-Dueñas, F.J.; Ferreira, P.; Floudas, D.; Hibbett, D.S.; Canessa, P.; Larrondo, L.F.; James, T.Y.; Seelenfreund, D.; Lobos, S.; et al. Comparative genomics of Ceriporiopsis subvermispora and Phanerochaete chrysosporium provide insight into selective ligninolysis. Proc. Natl. Acad. Sci. USA 2012, 109, 5458–5463. [Google Scholar] [CrossRef] [PubMed]
- Várnai, A.; Mäkelä, M.R.; Djajadi, D.T.; Rahikainen, J.; Hatakka, A.; Viikari, L. Carbohydrate-binding modules of fungal cellulases: Occurrence in nature, function, and relevance in industrial biomass conversion. Adv. Appl. Microbiol. 2014, 88, 103–165. [Google Scholar] [CrossRef] [PubMed]
- Bornscheuer, U.T. Microbial carboxyl esterases: Classification, properties and application in biocatalysis. FEMS Microbiol. Rev. 2002, 26, 73–81. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, K.E.; Eggert, T. Lipases for biotechnology. Curr. Opin. Biotechnol. 2002, 13, 390–397. [Google Scholar] [CrossRef]
- Cantarel, B.L.; Coutinho, P.M.; Rancurel, C.; Bernard, T.; Lombard, V.; Henrissat, B. The Carbohydrate-Active EnZymes database (CAZy): An expert resource for glycogenomics. Nucleic Acids Res. 2009, 37, D233–D238. [Google Scholar] [CrossRef] [PubMed]
- Biely, P. Microbial carbohydrate esterases deacetylating plant polysaccharides. Biotechnol. Adv. 2012, 30, 1575–1588. [Google Scholar] [CrossRef] [PubMed]
- Janbon, G.; Ormerod, K.L.; Paulet, D.; Byrnes, E.J., III; Yadav, V.; Chatterjee, G.; Mullapudi, N.; Hon, C.-C.; Billmyre, R.B.; Brunel, F.; et al. Analysis of the genome and transcriptome of Cryptococcus neoformans var. grubii reveals complex RNA expression and microevolution leading to virulence attenuation. PLOS Genet. 2014, 10, e1004261. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nakamura, A.M.; Nascimento, A.S.; Polikarpov, I. Structural diversity of carbohydrate esterases. Biotechnol. Res. Innov. 2017, 1, 35–51. [Google Scholar] [CrossRef]
- Adesioye, F.A.; Makhalanyane, T.P.; Biely, P.; Cowan, D.A. Phylogeny, classification and metagenomic bioprospecting of microbial acetyl xylan esterases. Enzyme. Microb. Technol. 2016, 93, 79–91. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, Y.; Schottel, J.L.; Derewenda, U.; Swenson, L.; Patkar, S.; Derewenda, Z.S. A novel variant of the catalytic triad in the Streptomyces scabies esterase. Nat. Struct. Biol. 1995, 2, 218–223. [Google Scholar] [CrossRef] [PubMed]
- Petersen, E.I.; Valinger, G.; Sölkner, B.; Stubenrauch, G.; Schwab, H. A novel esterase from Burkholderia gladioli shows high deacetylation activity on cephalosporins is related to β-lactamases and dd-peptidases. J. Biotechnol. 2001, 89, 11–25. [Google Scholar] [CrossRef]
- Christov, L.P.; Prior, B.A. Esterases of xylan-degrading microorganisms: Production, properties, and significance. Enzyme Microb. Tech. 1993, 15, 460–475. [Google Scholar] [CrossRef]
- Levasseur, A.; Drula, E.; Lombard, V.; Coutinho, P.M.; Henrissat, B. Expansion of the enzymatic repertoire of the CAZy database to integrate auxiliary redox enzymes. Biotechnol. Biofuels 2013, 6, 41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.; Gong, Y.; Cai, Y.; Liu, W.; Zhou, Y.; Xiao, Y.; Xu, Z.; Liu, Y.; Lei, X.; Wang, G.; et al. Genome sequence of the edible cultivated mushroom Lentinula edodes (Shiitake) reveals insights into lignocellulose degradation. PLoS ONE 2016, 11, e0160336. [Google Scholar] [CrossRef] [PubMed]
- Martin, F.; Aerts, A.; Ahrén, D.; Brun, A.; Danchin, E.G.J.; Duchaussoy, F.; Gibon, J.; Kohler, A.; Lindquist, E.; Pereda, V.; et al. The genome of Laccaria bicolor provides insights into mycorrhizal symbiosis. Nature 2008, 452, 88–92. [Google Scholar] [CrossRef] [PubMed]
- Reiss, R.; Ihssen, J.; Richter, M.; Eichhorn, E.; Schilling, B.; Thöny-Meyer, L. Laccase versus laccase-like multi-copper oxidase: A comparative study of similar enzymes with diverse substrate spectra. PLoS ONE 2013, 8, e65633. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.I.; Kwon, O.; Kong, W.S.; Lee, C.S.; Park, Y.J. Genome-wide identification and characterization of novel laccase genes in the white-rot fungus Flammulina velutipes. Mycobiology 2014, 42, 322–330. [Google Scholar] [CrossRef] [PubMed]
- Fernandez, I.S.; Ruiz-Duenas, F.J.; Santillana, E.; Ferreira, P.; Martinez, M.J.; Martinez, A.T.; Romero, A. Novel structural features in the GMC family of oxidoreductases revealed by the crystal structure of fungal aryl-alcohol oxidase. Acta Crystallogr. 2009, D65, 1196–1205. [Google Scholar] [CrossRef] [PubMed]
- Wierenga, R.K.; Drenth, J.; Schulz, G.E. Comparison of the 3-dimensional protein and nucleotide structure of the FAD-binding domain of parahydroxybenzoate hydroxylase with the FAD-binding as well as NADPH-binding domains of glutathionereductase. J. Mol. Biol. 1983, 167, 725–739. [Google Scholar] [CrossRef]
- Varela, E.; Martinet, M.J.; Martinez, A.T. Arylalcohol oxidase protein sequence: A comparison with glucose oxidase and other FAD oxidoreductases. Biochem. Biophys. Acta Protein Struct. Mol. Enzymol. 2000, 1481, 202–208. [Google Scholar] [CrossRef]
- Lynd, L.R. Overview and evaluation of fuel ethanol production from cellulosic biomass: Technology, economics, the environment, and policy. Annu. Rev. Energ. Environ. 1996, 21, 403–465. [Google Scholar] [CrossRef]
- Lynd, L.R.; Weimer, P.J.; Van Zyl, W.H.; Pretorius, I.S. Microbial cellulose utilization: Fundamentals and biotechnology. Microbiol. Mol. Biol. Rev. 2002, 66, 506–577. [Google Scholar] [CrossRef] [PubMed]
- Ruiz-Dueñas, F.J.; Martínez, A.T. Microbial degradation of lignin: How a bulky recalcitrant polymer is efficiently recycled in nature and how we can take advantage of this. Microb. Biotechnol. 2009, 2, 164–177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martínez, A.T.; Ruiz-Dueñas, F.J.; Martínez, M.J.; Del Río, J.C.; Gutiérrez, A. Enzymatic delignification of plant cell wall: From nature to mill. Curr. Opin. Biotechnol. 2009, 20, 348–357. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leonowicz, A.; Matuszewska, A.; Luterek, J.; Ziegenhagen, D.; Wojtas-Wasilewska, M.; Cho, N.S.; Hofrichter, M.; Rogalski, J. Biodegradation of lignin by white rot fungi. Fungal Genet. Biol. 1999, 27, 175–185. [Google Scholar] [CrossRef] [PubMed]
- Guillén, F.; Martínez, M.J.; Gutiérrez, A.; Del Rio, J.C. Biodegradation of lignocellulosics: Microbial, chemical, and enzymatic aspects of the fungal attack of lignin. Int. Microbiol. 2005, 8, 195–204. [Google Scholar]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef] [PubMed]
- Zerbino, D.R.; Birney, E. Velvet: Algorithms for β short read assembly using de Bruijn graphs. Genome Res. 2008, 18, 821–829. [Google Scholar] [CrossRef] [PubMed]
- Stanke, M.; Morgenstern, B. AUGUSTUS: A web server for gene prediction in eukaryotes that allows user-defined constraints. Nucleic Acids Res. 2005, 33, W465–W467. [Google Scholar] [CrossRef] [PubMed]
- Buchfink, B.; Xie, C.; Huson, D. Fast and sensitive protein alignment using DIAMOND. Nat. Methods 2015, 12, 59–60. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Coggill, P.; Eberhardt, R.Y.; Eddy, S.R.; Mistry, J.; Mitchell, A.L.; Potter, S.C.; Punta, M.; Qureshi, M.; Sangrador-Vegas, A.; et al. The Pfam protein families database: Towards a more sustainable future. Nucleic Acids Res. 2016, 44, D279–D285. [Google Scholar] [CrossRef] [PubMed]
- Emms, D.; Kelly, S. OrthoFinder: Solving fundamental biases in whole genome comparisons dramatically improves orthogroup inference accuracy. Genome Biol. 2015, 16, 157. [Google Scholar] [CrossRef] [PubMed]
- Morin, E.; Kohler, A.; Baker, A.R.; Foulongne-Oriol, M.; Lombard, V.; Nagye, L.G.; Ohm, R.A.; Patyshakuliyeva, A.; Brun, A.; Aerts, A.L.; et al. Genome sequence of the button mushroom Agaricus bisporus reveals mechanisms governing adaptation to a humic-rich ecological niche. Proc. Natl. Acad. Sci. USA 2012, 109, 17501–17506. [Google Scholar] [CrossRef] [PubMed]
- Galagan, J.E.; Calvo, S.E.; Borkovich, K.A.; Selker, E.U.; Read, N.D.; Jaffe, D.; FitzHugh, W.; Ma, L.J.; Smirnov, S.; Purcell, S.; et al. The genome sequence of the filamentous fungus Neurospora crassa. Nature 2003, 422, 859–868. [Google Scholar] [CrossRef] [PubMed]
- Petersen, T.N.; Brunak, S.; von Heijne, G.; Nielsen, H. SignalP 4.0: Discriminating signal peptides from transmembrane regions. Nat. Methods 2011, 8, 785–786. [Google Scholar] [CrossRef] [PubMed]
- Mizuno, R.; Ichinose, H.; Honda, M.; Takabatake, K.; Sotome, I.; Takai, T.; Maehara, T.; Okadome, H.; Isobe, S.; Gau, M.; et al. Use of whole crop sorghums as a raw material in consolidated bioprocessing bioethanol production Using Flammulina velutipes. Biosci. Biotechnol. Biochem. 2009, 73, 1671–1673. [Google Scholar] [CrossRef] [PubMed]
- Mizuno, R.; Ichinose, H.; Maehara, T.; Takabatake, K.; Kaneko, S. Properties of ethanol fermentation by Flammulina velutipes. Biosci. Biotechnol. Biochem. 2009, 73, 2240–2245. [Google Scholar] [CrossRef] [PubMed]
- Lynd, L.R.; Van Zyl, W.H.; McBride, J.E.; Laser, M. Consolidated bioprocessing of cellulosic biomass: An update. Curr. Opin. Biotechnol. 2005, 16, 577–583. [Google Scholar] [CrossRef] [PubMed]
- Van Zyl, W.H.; Lynd, L.R.; Den Haan, R.; McBride, J.E. Consolidated bioprocessing for bioethanol production using Saccharomyces cerevisiae. Adv. Biochem. Eng. Biotechnol. 2007, 108, 205–235. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Singh, A.; Himmel, M.E. Perspectives and new directions for the production of bioethanol using consolidated bioprocessing of lignocellulose. Curr. Opin. Biotechnol. 2009, 20, 364–371. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hiseq 2000 NGS Analysis | Total reads (100 bp) | 57,658,112 |
| Reads after trimming (%), >Q 30 | 53,555,252 (92.88) | |
| Velvet De Novo Assembly | Optimized Velvet hash value (kmer) | 31 |
| Total number of contigs | 13,877 | |
| Number of contigs (>1 kb) | 2055 | |
| Contig N50 (bp) | 42,684 | |
| Length of longest contig (bp) | 275,350 | |
| Total bases in contigs (bp) | 35,045,521 | |
| Total bases in contigs (>1 kb) | 33,024,561 | |
| GC content (%) | 49.85 | |
| Gene Prediction | Predicted gene | 12,536 |
| Average gene length (bp) | 1973 | |
| Average protein length (aa) | 524.34 | |
| Average exon per gene | 6.72 | |
| Average exon size (bp) | 233.91 | |
| Average intron size (bp) | 69.29 |
| Fungal Species | F. elastica | F. velutipes | L. bicolar | C. cinerea | P. chrysosporium | U. maydis | S. commune |
|---|---|---|---|---|---|---|---|
| Strain | KACC46182 | KACC42780 | S238N-H82 | Okayama7#130 | RP78 | 521 | H4-8 |
| Genome Assembly (Mb) | 35 | 35.6 | 64.9 | 37.5 | 35.1 | 19.7 | 38.5 |
| Number of Protein-Coding Genes | 12,536 | 12,218 | 20,614 | 13,544 | 10,048 | 6522 | 13,181 |
| GC Contents (%) | 49.7 | 48.99 | 46.6 | 51.6 | 53.2 | 54.0 | 56.6 |
| Average Gene Length (bp) | 1973 | 2294 | 1533.0 | 1679.0 | 1667.0 | 1935.0 | 1794.9 |
| Average Exon Size (bp) | 233.91 | 231.4 | 210.1 | 251.0 | 232.0 | 1051.0 | 249.3 |
| Average Intron Size (bp) | 69.29 | 190.3 | 92.7 | 75.0 | 117.0 | 127.0 | 79.0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.-J.; Jeong, Y.-U.; Kong, W.-S. Genome Sequencing and Carbohydrate-Active Enzyme (CAZyme) Repertoire of the White Rot Fungus Flammulina elastica. Int. J. Mol. Sci. 2018, 19, 2379. https://doi.org/10.3390/ijms19082379
Park Y-J, Jeong Y-U, Kong W-S. Genome Sequencing and Carbohydrate-Active Enzyme (CAZyme) Repertoire of the White Rot Fungus Flammulina elastica. International Journal of Molecular Sciences. 2018; 19(8):2379. https://doi.org/10.3390/ijms19082379
Chicago/Turabian StylePark, Young-Jin, Yong-Un Jeong, and Won-Sik Kong. 2018. "Genome Sequencing and Carbohydrate-Active Enzyme (CAZyme) Repertoire of the White Rot Fungus Flammulina elastica" International Journal of Molecular Sciences 19, no. 8: 2379. https://doi.org/10.3390/ijms19082379
APA StylePark, Y. -J., Jeong, Y. -U., & Kong, W. -S. (2018). Genome Sequencing and Carbohydrate-Active Enzyme (CAZyme) Repertoire of the White Rot Fungus Flammulina elastica. International Journal of Molecular Sciences, 19(8), 2379. https://doi.org/10.3390/ijms19082379