
Interaction of Proteins with Inverted Repeats and Cruciform Structures in Nucleic Acids




Abstract
:1. Introduction
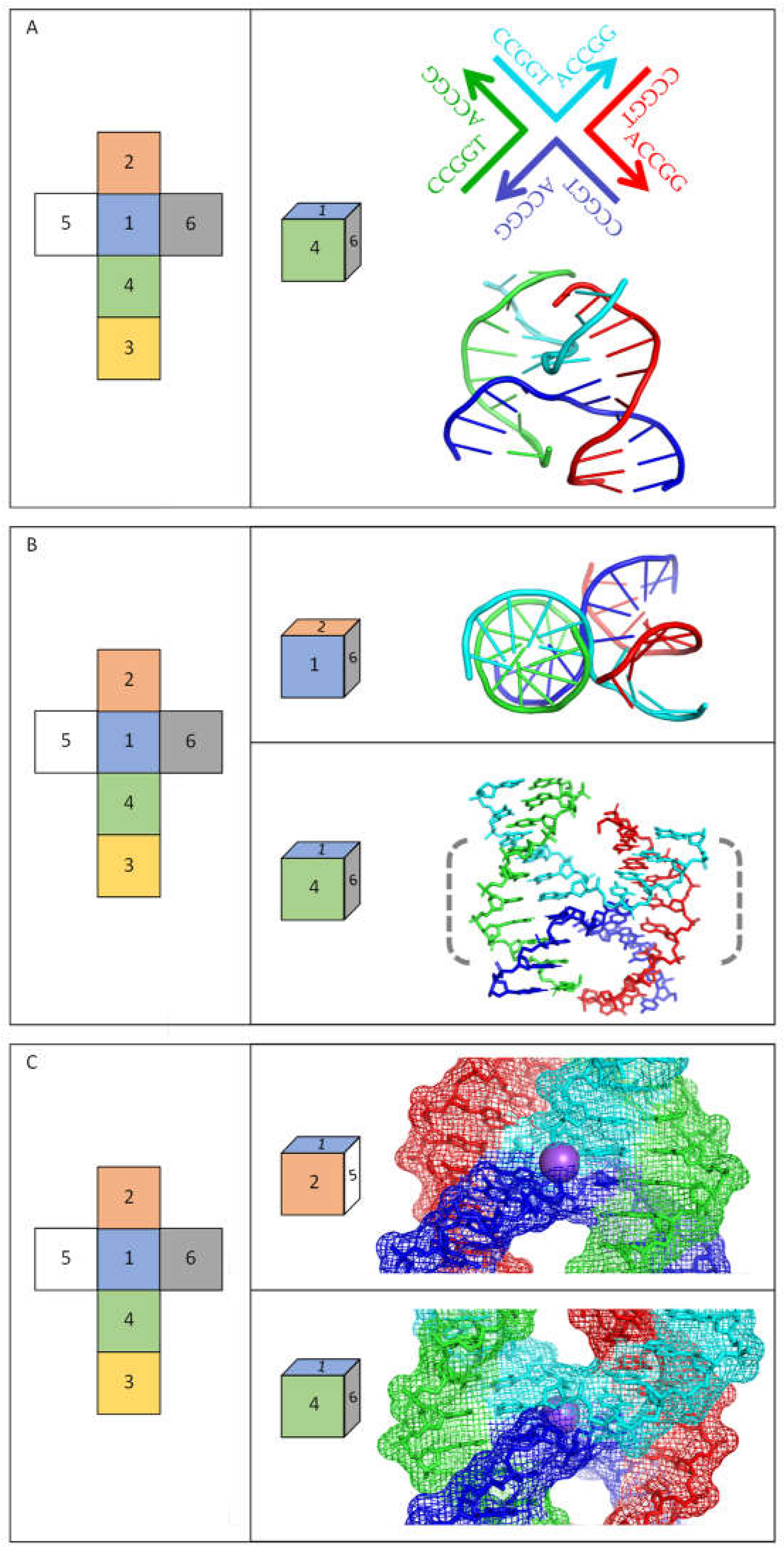
2. Biophysical and Molecular Characterization of Cruciforms
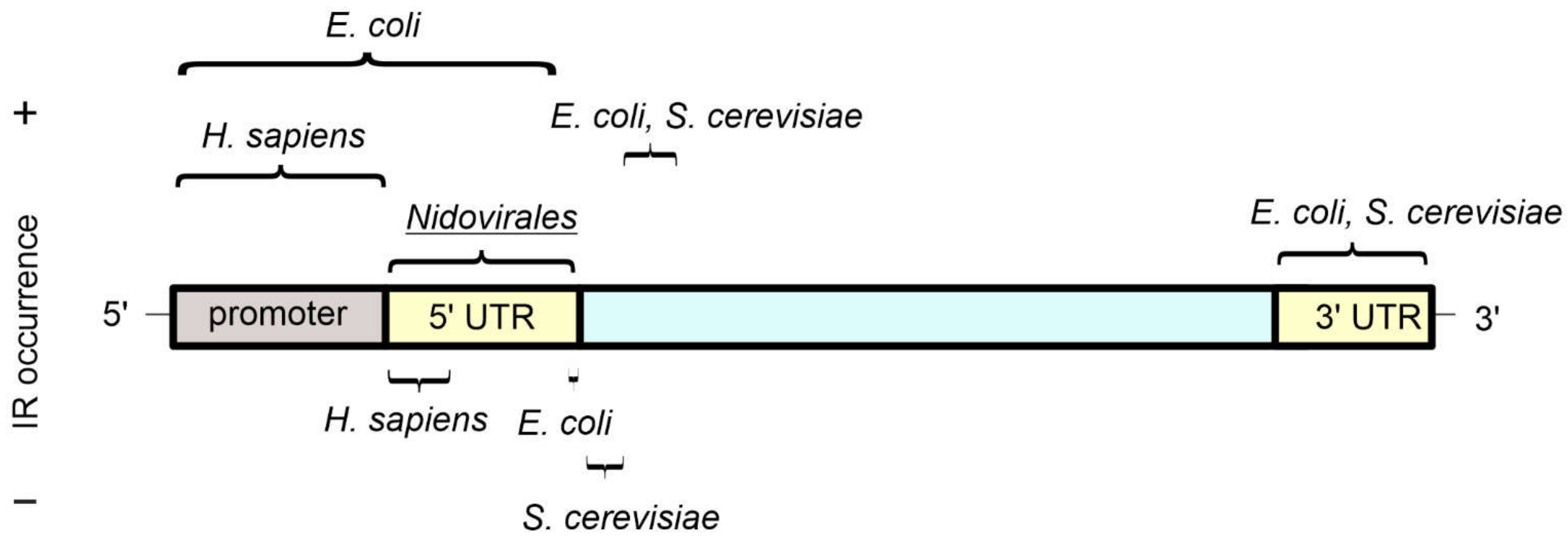
3. Presence of Inverted Repeats in Genomes
3.1. Viruses
3.2. Prokaryotes
3.3. Eukaryotes
4. A Range of Proteins Interact with Cruciforms
5. Inverted Repeats and Cruciforms as Potential Therapeutics in Human Disease
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Sato, M.P.; Ogura, Y.; Nakamura, K.; Nishida, R.; Gotoh, Y.; Hayashi, M.; Hisatsune, J.; Sugai, M.; Takehiko, I.; Hayashi, T. Comparison of the Sequencing Bias of Currently Available Library Preparation Kits for Illumina Sequencing of Bacterial Genomes and Metagenomes. DNA Res. 2019, 26, 391–398. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oprzeska-Zingrebe, E.A.; Meyer, S.; Roloff, A.; Kunte, H.-J.; Smiatek, J. Influence of Compatible Solute Ectoine on Distinct DNA Structures: Thermodynamic Insights into Molecular Binding Mechanisms and Destabilization Effects. Phys. Chem. Chem. Phys. 2018, 20, 25861–25874. [Google Scholar] [CrossRef] [PubMed]
- Brazda, V.; Fojta, M.; Bowater, R.P. Structures and Stability of Simple DNA Repeats from Bacteria. Biochem. J. 2020, 477, 325–339. [Google Scholar] [CrossRef] [PubMed]
- Summers, P.A.; Lewis, B.W.; Gonzalez-Garcia, J.; Porreca, R.M.; Lim, A.H.M.; Cadinu, P.; Martin-Pintado, N.; Mann, D.J.; Edel, J.B.; Vannier, J.B.; et al. Visualising G-Quadruplex DNA Dynamics in Live Cells by Fluorescence Lifetime Imaging Microscopy. Nat. Commun. 2021, 12, 162. [Google Scholar] [CrossRef]
- Di Antonio, M.; Ponjavic, A.; Radzevičius, A.; Ranasinghe, R.T.; Catalano, M.; Zhang, X.; Shen, J.; Needham, L.-M.; Lee, S.F.; Klenerman, D.; et al. Single-Molecule Visualization of DNA G-Quadruplex Formation in Live Cells. Nat. Chem. 2020, 12, 832–837. [Google Scholar] [CrossRef]
- Poggi, L.; Richard, G.-F. Alternative DNA Structures In Vivo: Molecular Evidence and Remaining Questions. Microbiol. Mol. Biol. Rev. 2021, 85, e00110-20. [Google Scholar] [CrossRef]
- Brown, J.A. Unraveling the Structure and Biological Functions of RNA Triple Helices. Wiley Interdiscip. Rev. RNA 2020, 11, e1598. [Google Scholar] [CrossRef]
- Neil, A.J.; Liang, M.U.; Khristich, A.N.; Shah, K.A.; Mirkin, S.M. RNA–DNA Hybrids Promote the Expansion of Friedreich’s Ataxia (GAA)n Repeats via Break-Induced Replication. Nucleic Acids Res. 2018, 46, 3487–3497. [Google Scholar] [CrossRef]
- Kosiol, N.; Juranek, S.; Brossart, P.; Heine, A.; Paeschke, K. G-Quadruplexes: A Promising Target for Cancer Therapy. Mol. Cancer 2021, 20, 40. [Google Scholar] [CrossRef]
- Martella, M.; Pichiorri, F.; Chikhale, R.V.; Abdelhamid, M.A.S.; Waller, Z.A.E.; Smith, S.S. I-Motif Formation and Spontaneous Deletions in Human Cells. Nucleic Acids Res. 2022, 50, gkac158. [Google Scholar] [CrossRef]
- Niehrs, C.; Luke, B. Regulatory R-Loops as Facilitators of Gene Expression and Genome Stability. Nat. Rev. Mol. Cell Biol. 2020, 21, 167–178. [Google Scholar] [CrossRef]
- Tye, S.; Ronson, G.E.; Morris, J.R. A Fork in the Road: Where Homologous Recombination and Stalled Replication Fork Protection Part Ways. Semin. Cell Dev. Biol. 2021, 113, 14–26. [Google Scholar] [CrossRef] [PubMed]
- Palecek, E. Local Supercoil-Stabilized DNA Structures. Crit. Rev. Biochem. Mol. Biol. 1991, 26, 151–226. [Google Scholar] [CrossRef]
- Brázda, V.; Fojta, M. The Rich World of P53 DNA Binding Targets: The Role of DNA Structure. Int. J. Mol. Sci. 2019, 20, 5605. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brázda, V.; Laister, R.C.; Jagelská, E.B.; Arrowsmith, C. Cruciform Structures Are a Common DNA Feature Important for Regulating Biological Processes. BMC Mol. Biol. 2011, 12, 33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benham, C.J.; Savitt, A.G.; Bauer, W.R. Extrusion of an Imperfect Palindrome to a Cruciform in Superhelical DNA: Complete Determination of Energetics Using a Statistical Mechanical Model. J. Mol. Biol. 2002, 316, 563–581. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Čutová, M.; Manta, J.; Porubiaková, O.; Kaura, P.; Šťastný, J.; Jagelská, E.B.; Goswami, P.; Bartas, M.; Brázda, V. Divergent Distributions of Inverted Repeats and G-Quadruplex Forming Sequences in Saccharomyces Cerevisiae. Genomics 2020, 112, 1897–1901. [Google Scholar] [CrossRef]
- Brázda, V.; Bartas, M.; Lýsek, J.; Coufal, J.; Fojta, M. Global Analysis of Inverted Repeat Sequences in Human Gene Promoters Reveals Their Non-Random Distribution and Association with Specific Biological Pathways. Genomics 2020, 112, 2772–2777. [Google Scholar] [CrossRef]
- Lavi, B.; Karin, E.L.; Pupko, T.; Hazkani-Covo, E. The Prevalence and Evolutionary Conservation of Inverted Repeats in Proteobacteria. Genome Biol. Evol. 2018, 10, 918–927. [Google Scholar] [CrossRef] [Green Version]
- Brázda, V.; Lýsek, J.; Bartas, M.; Fojta, M. Complex Analyses of Short Inverted Repeats in All Sequenced Chloroplast DNAs. BioMed Res. Int. 2018, 2018, 1097018. [Google Scholar] [CrossRef]
- Čechová, J.; Lýsek, J.; Bartas, M.; Brázda, V. Complex Analyses of Inverted Repeats in Mitochondrial Genomes Revealed Their Importance and Variability. Bioinformatics 2018, 34, 1081–1085. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gierer, A. Model for DNA and Protein Interactions and the Function of the Operator. Nature 1966, 212, 1480–1481. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murchie, A.I.; Bowater, R.; Aboul-ela, F.; Lilley, D.M. Helix Opening Transitions in Supercoiled DNA. Biochim. Biophys. Acta BBA Gene Struct. Expr. 1992, 1131, 1–15. [Google Scholar] [CrossRef]
- Zhabinskaya, D.; Benham, C.J. Competitive Superhelical Transitions Involving Cruciform Extrusion. Nucleic Acids Res. 2013, 41, 9610–9621. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neelsen, K.J.; Chaudhuri, A.R.; Follonier, C.; Herrador, R.; Lopes, M. Visualization and Interpretation of Eukaryotic DNA Replication Intermediates In Vivo by Electron Microscopy. In Functional Analysis of DNA and Chromatin; Methods in Molecular Biology; Stockert, J.C., Espada, J., Blázquez-Castro, A., Eds.; Humana Press: Totowa, NJ, USA, 2014; pp. 177–208. ISBN 978-1-62703-706-8. [Google Scholar]
- Torregrosa-Muñumer, R.; Goffart, S.; Haikonen, J.A.; Pohjoismäki, J.L.O. Low Doses of Ultraviolet Radiation and Oxidative Damage Induce Dramatic Accumulation of Mitochondrial DNA Replication Intermediates, Fork Regression, and Replication Initiation Shift. Mol. Biol. Cell 2015, 26, 4197–4208. [Google Scholar] [CrossRef] [PubMed]
- Correll-Tash, S.; Lilley, B.; Iv, H.S.; Mlynarski, E.; Franconi, C.P.; McNamara, M.; Woodbury, C.; Easley, C.A.; Emanuel, B.S. Double Strand Breaks (DSBs) as Indicators of Genomic Instability in PATRR-Mediated Translocations. Hum. Mol. Genet. 2021, 29, 3872–3881. [Google Scholar] [CrossRef]
- Rekvig, O.P. The Anti-DNA Antibodies: Their Specificities for Unique DNA Structures and Their Unresolved Clinical Impact—A System Criticism and a Hypothesis. Front. Immunol. 2022, 12, 808008. [Google Scholar] [CrossRef]
- Brázda, V.; Kolomazník, J.; Lýsek, J.; Hároníková, L.; Coufal, J.; Št’astný, J. Palindrome Analyser-A New Web-Based Server for Predicting and Evaluating Inverted Repeats in Nucleotide Sequences. Biochem. Biophys. Res. Commun. 2016, 478, 1739–1745. [Google Scholar] [CrossRef]
- Gibbs, D.R.; Dhakal, S. Homologous Recombination under the Single-Molecule Fluorescence Microscope. Int. J. Mol. Sci. 2019, 20, 6102. [Google Scholar] [CrossRef] [Green Version]
- Stefanovsky, V.Y.; Moss, T. The Cruciform DNA Mobility Shift Assay: A Tool to Study Proteins That Recognize Bent DNA. Methods Mol. Biol. Clifton NJ 2015, 1334, 195–203. [Google Scholar] [CrossRef]
- Ramreddy, T.; Sachidanandam, R.; Strick, T.R. Real-Time Detection of Cruciform Extrusion by Single-Molecule DNA Nanomanipulation. Nucleic Acids Res. 2011, 39, 4275–4283. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shaheen, C.; Hastie, C.; Metera, K.; Scott, S.; Zhang, Z.; Chen, S.; Gu, G.; Weber, L.; Munsky, B.; Kouzine, F.; et al. Non-Equilibrium Structural Dynamics of Supercoiled DNA Plasmids Exhibits Asymmetrical Relaxation. Nucleic Acids Res. 2022, 50, 2754–2764. [Google Scholar] [CrossRef] [PubMed]
- Mandal, S.; Selvam, S.; Cui, Y.; Hoque, M.E.; Mao, H. Mechanical Cooperativity in DNA Cruciform Structures. ChemPhysChem 2018, 19, 2627–2634. [Google Scholar] [CrossRef] [PubMed]
- Lilley, D.M.J. Holliday Junction-Resolving Enzymes-Structures and Mechanisms. FEBS Lett. 2017, 591, 1073–1082. [Google Scholar] [CrossRef] [Green Version]
- Ho, P.S. Structure of the Holliday Junction: Applications beyond Recombination. Biochem. Soc. Trans. 2017, 45, 1149–1158. [Google Scholar] [CrossRef]
- Eichman, B.F.; Vargason, J.M.; Mooers, B.H.M.; Ho, P.S. The Holliday Junction in an Inverted Repeat DNA Sequence: Sequence Effects on the Structure of Four-Way Junctions. Proc. Natl. Acad. Sci. USA 2000, 97, 3971–3976. [Google Scholar] [CrossRef] [Green Version]
- Yadav, R.K.; Yadava, U. Molecular Dynamics Simulation of Hydrated d(CGGGTACCCG)4 as a Four-Way DNA Holliday Junction and Comparison with the Crystallographic Structure. Mol. Simul. 2016, 42, 25–30. [Google Scholar] [CrossRef]
- Kulkarni, D.S.; Owens, S.N.; Honda, M.; Ito, M.; Yang, Y.; Corrigan, M.W.; Chen, L.; Quan, A.L.; Hunter, N. PCNA Activates the MutLγ Endonuclease to Promote Meiotic Crossing Over. Nature 2020, 586, 623–627. [Google Scholar] [CrossRef]
- Yan, J.; Hong, S.; Guan, Z.; He, W.; Zhang, D.; Yin, P. Structural Insights into Sequence-Dependent Holliday Junction Resolution by the Chloroplast Resolvase MOC1. Nat. Commun. 2020, 11, 1417. [Google Scholar] [CrossRef]
- Wendorff, T.J.; Berger, J.M. Topoisomerase VI Senses and Exploits Both DNA Crossings and Bends to Facilitate Strand Passage. eLife 2018, 7, e31724. [Google Scholar] [CrossRef]
- Bartas, M.; Brázda, V.; Bohálová, N.; Cantara, A.; Volná, A.; Stachurová, T.; Malachová, K.; Jagelská, E.B.; Porubiaková, O.; Červeň, J.; et al. In-Depth Bioinformatic Analyses of Nidovirales Including Human SARS-CoV-2, SARS-CoV, MERS-CoV Viruses Suggest Important Roles of Non-Canonical Nucleic Acid Structures in Their Lifecycles. Front. Microbiol. 2020, 11, 1583. [Google Scholar] [CrossRef] [PubMed]
- Treangen, T.J.; Salzberg, S.L. Repetitive DNA and Next-Generation Sequencing: Computational Challenges and Solutions. Nat. Rev. Genet. 2012, 13, 36–46. [Google Scholar] [CrossRef]
- Altemose, N.; Logsdon, G.A.; Bzikadze, A.V.; Sidhwani, P.; Langley, S.A.; Caldas, G.V.; Hoyt, S.J.; Uralsky, L.; Ryabov, F.D.; Shew, C.J.; et al. Complete Genomic and Epigenetic Maps of Human Centromeres. Science 2022, 376, eabl4178. [Google Scholar] [CrossRef] [PubMed]
- Hoyt, S.J.; Storer, J.M.; Hartley, G.A.; Grady, P.G.S.; Gershman, A.; de Lima, L.G.; Limouse, C.; Halabian, R.; Wojenski, L.; Rodriguez, M.; et al. From Telomere to Telomere: The Transcriptional and Epigenetic State of Human Repeat Elements. Science 2022, 376, eabk3112. [Google Scholar] [CrossRef]
- Spanò, M.; Lillo, F.; Miccichè, S.; Mantegna, R.N. Inverted Repeats in Viral Genomes. Fluct. Noise Lett. 2005, 5, L193–L200. [Google Scholar] [CrossRef] [Green Version]
- Bartas, M.; Goswami, P.; Lexa, M.; Červeň, J.; Volná, A.; Fojta, M.; Brázda, V.; Pečinka, P. Letter to the Editor: Significant Mutation Enrichment in Inverted Repeat Sites of New SARS-CoV-2 Strains. Brief. Bioinform. 2021, 22, bbab129. [Google Scholar] [CrossRef]
- Goswami, P.; Bartas, M.; Lexa, M.; Bohálová, N.; Volná, A.; Červeň, J.; Červeňová, V.; Pečinka, P.; Špunda, V.; Fojta, M.; et al. SARS-CoV-2 Hot-Spot Mutations Are Significantly Enriched within Inverted Repeats and CpG Island Loci. Brief. Bioinform. 2021, 22, 1338–1345. [Google Scholar] [CrossRef]
- Berns, K.I. The Unusual Properties of the AAV Inverted Terminal Repeat. Hum. Gene Ther. 2020, 31, 518–523. [Google Scholar] [CrossRef] [Green Version]
- Miura, O.; Ogake, T.; Ohyama, T. Requirement or Exclusion of Inverted Repeat Sequences with Cruciform-Forming Potential in Escherichia Coli Revealed by Genome-Wide Analyses. Curr. Genet. 2018, 64, 945–958. [Google Scholar] [CrossRef] [Green Version]
- Miura, O.; Ogake, T.; Yoneyama, H.; Kikuchi, Y.; Ohyama, T. A Strong Structural Correlation between Short Inverted Repeat Sequences and the Polyadenylation Signal in Yeast and Nucleosome Exclusion by These Inverted Repeats. Curr. Genet. 2019, 65, 575–590. [Google Scholar] [CrossRef] [Green Version]
- Lal, A.; Dhar, A.; Trostel, A.; Kouzine, F.; Seshasayee, A.S.N.; Adhya, S. Genome Scale Patterns of Supercoiling in a Bacterial Chromosome. Nat. Commun. 2016, 7, 11055. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lillo, F.; Basile, S.; Mantegna, R.N. Comparative Genomics Study of Inverted Repeats in Bacteria. Bioinformatics 2002, 18, 971–979. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pourcel, C.; Touchon, M.; Villeriot, N.; Vernadet, J.-P.; Couvin, D.; Toffano-Nioche, C.; Vergnaud, G. CRISPRCasdb a Successor of CRISPRdb Containing CRISPR Arrays and Cas Genes from Complete Genome Sequences, and Tools to Download and Query Lists of Repeats and Spacers. Nucleic Acids Res. 2020, 48, D535–D544. [Google Scholar] [CrossRef] [PubMed]
- Makarova, K.S.; Grishin, N.V.; Shabalina, S.A.; Wolf, Y.I.; Koonin, E.V. A Putative RNA-Interference-Based Immune System in Prokaryotes: Computational Analysis of the Predicted Enzymatic Machinery, Functional Analogies with Eukaryotic RNAi, and Hypothetical Mechanisms of Action. Biol. Direct 2006, 1, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nuñez, J.K.; Lee, A.S.Y.; Engelman, A.; Doudna, J.A. Integrase-Mediated Spacer Acquisition during CRISPR-Cas Adaptive Immunity. Nature 2015, 519, 193–198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moch, C.; Fromant, M.; Blanquet, S.; Plateau, P. DNA Binding Specificities of Escherichia Coli Cas1-Cas2 Integrase Drive Its Recruitment at the CRISPR Locus. Nucleic Acids Res. 2017, 45, 2714–2723. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Ge, F.; Li, H.; Chen, Y.; Zhao, Y.; Gao, Y.; Liu, Z.; Yang, L. PCIR: A Database of Plant Chloroplast Inverted Repeats. Database J. Biol. Databases Curation 2019, 2019, baz127. [Google Scholar] [CrossRef]
- Liu, X.; Wu, X.; Tan, H.; Xie, B.; Deng, Y. Large Inverted Repeats Identified by Intra-Specific Comparison of Mitochondrial Genomes Provide Insights into the Evolution of Agrocybe Aegerita. Comput. Struct. Biotechnol. J. 2020, 18, 2424–2437. [Google Scholar] [CrossRef]
- Damas, J.; Carneiro, J.; Gonçalves, J.; Stewart, J.B.; Samuels, D.C.; Amorim, A.; Pereira, F. Mitochondrial DNA Deletions Are Associated with Non-B DNA Conformations. Nucleic Acids Res. 2012, 40, 7606–7621. [Google Scholar] [CrossRef] [Green Version]
- Nurk, S.; Koren, S.; Rhie, A.; Rautiainen, M.; Bzikadze, A.V.; Mikheenko, A.; Vollger, M.R.; Altemose, N.; Uralsky, L.; Gershman, A.; et al. The Complete Sequence of a Human Genome. Science 2022, 376, 44–53. [Google Scholar] [CrossRef]
- Miga, K.H.; Koren, S.; Rhie, A.; Vollger, M.R.; Gershman, A.; Bzikadze, A.; Brooks, S.; Howe, E.; Porubsky, D.; Logsdon, G.A.; et al. Telomere-to-Telomere Assembly of a Complete Human X Chromosome. Nature 2020, 585, 79–84. [Google Scholar] [CrossRef] [PubMed]
- Logsdon, G.A.; Vollger, M.R.; Hsieh, P.; Mao, Y.; Liskovykh, M.A.; Koren, S.; Nurk, S.; Mercuri, L.; Dishuck, P.C.; Rhie, A.; et al. The Structure, Function and Evolution of a Complete Human Chromosome 8. Nature 2021, 593, 101–107. [Google Scholar] [CrossRef] [PubMed]
- Brazda, V.; Bohalova, N.; Bowater, R.P. New Telomere to Telomere Assembly of Human Chromosome 8 Reveals a Previous Underestimation of G-Quadruplex Forming Sequences and Inverted Repeats. Gene 2021, 810, 146058. [Google Scholar] [CrossRef] [PubMed]
- Bohálová, N.; Mergny, J.-L.; Brázda, V. Novel G-Quadruplex Prone Sequences Emerge in the Complete Assembly of the Human X Chromosome. Biochimie 2021, 191, 87–90. [Google Scholar] [CrossRef]
- Forth, S.; Sheinin, M.Y.; Inman, J.; Wang, M.D. Torque Measurement at the Single Molecule Level. Annu. Rev. Biophys. 2013, 42, 583–604. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Wang, M.D. DNA Supercoiling during Transcription. Biophys. Rev. 2016, 8, 75–87. [Google Scholar] [CrossRef]
- Yamamoto, Y.; Miura, O.; Ohyama, T. Cruciform Formable Sequences within Pou5f1 Enhancer Are Indispensable for Mouse ES Cell Integrity. Int. J. Mol. Sci. 2021, 22, 3399. [Google Scholar] [CrossRef]
- Brázda, V.; Cechová, J.; Coufal, J.; Rumpel, S.; Jagelská, E.B. Superhelical DNA as a Preferential Binding Target of 14-3-3γ Protein. J. Biomol. Struct. Dyn. 2012, 30, 371–378. [Google Scholar] [CrossRef]
- Brázda, V.; Hároníková, L.; Liao, J.C.C.; Fridrichová, H.; Jagelská, E.B. Strong Preference of BRCA1 Protein to Topologically Constrained Non-B DNA Structures. BMC Mol. Biol. 2016, 17, 14. [Google Scholar] [CrossRef] [Green Version]
- Samoilova, E.O.; Krasheninnikov, I.A.; Levitskii, S.A. Interaction between Saccharomyces Cerevisiae Mitochondrial DNA-Binding Protein Abf2p and Cce1p Resolvase. Biochemistry 2016, 81, 1111–1117. [Google Scholar] [CrossRef]
- Phung, H.T.T.; Tran, D.H.; Nguyen, T.X. The Cruciform DNA-Binding Protein Crp1 Stimulates the Endonuclease Activity of Mus81-Mms4 in Saccharomyces Cerevisiae. FEBS Lett. 2020, 594, 4320–4337. [Google Scholar] [CrossRef] [PubMed]
- Deutzmann, A.; Ganz, M.; Schönenberger, F.; Vervoorts, J.; Kappes, F.; Ferrando-May, E. The Human Oncoprotein and Chromatin Architectural Factor DEK Counteracts DNA Replication Stress. Oncogene 2015, 34, 4270–4277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martinez-Useros, J.; Rodriguez-Remirez, M.; Borrero-Palacios, A.; Moreno, I.; Cebrian, A.; del Pulgar, T.G.; del Puerto-Nevado, L.; Vega-Bravo, R.; Puime-Otin, A.; Perez, N.; et al. DEK Is a Potential Marker for Aggressive Phenotype and Irinotecan-Based Therapy Response in Metastatic Colorectal Cancer. BMC Cancer 2014, 14, 965. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Calhoun, L.N.; Kwon, Y.M. Structure, Function and Regulation of the DNA-Binding Protein Dps and Its Role in Acid and Oxidative Stress Resistance in Escherichia Coli: A Review. J. Appl. Microbiol. 2011, 110, 375–386. [Google Scholar] [CrossRef]
- Antipov, S.S.; Tutukina, M.N.; Preobrazhenskaya, E.V.; Kondrashov, F.A.; Patrushev, M.V.; Toshchakov, S.V.; Dominova, I.; Shvyreva, U.S.; Vrublevskaya, V.V.; Morenkov, O.S.; et al. The Nucleoid Protein Dps Binds Genomic DNA of Escherichia Coli in a Non-Random Manner. PLoS ONE 2017, 12, e0182800. [Google Scholar] [CrossRef]
- Melekhov, V.V.; Shvyreva, U.S.; Timchenko, A.A.; Tutukina, M.N.; Preobrazhenskaya, E.V.; Burkova, D.V.; Artiukhov, V.G.; Ozoline, O.N.; Antipov, S.S. Modes of Escherichia Coli Dps Interaction with DNA as Revealed by Atomic Force Microscopy. PLoS ONE 2015, 10, e0126504. [Google Scholar] [CrossRef] [Green Version]
- Freeman, A.D.J.; Déclais, A.-C.; Lilley, D.M.J. The Importance of the N-Terminus of T7 Endonuclease I in the Interaction with DNA Junctions. J. Mol. Biol. 2013, 425, 395–410. [Google Scholar] [CrossRef]
- Inagaki, H.; Ohye, T.; Kogo, H.; Tsutsumi, M.; Kato, T.; Tong, M.; Emanuel, B.S.; Kurahashi, H. Two Sequential Cleavage Reactions on Cruciform DNA Structures Cause Palindrome-Mediated Chromosomal Translocations. Nat. Commun. 2013, 4, 1592. [Google Scholar] [CrossRef]
- Li, D.; Lv, B.; Zhang, H.; Lee, J.Y.; Li, T. Disintegration of Cruciform and G-Quadruplex Structures during the Course of Helicase-Dependent Amplification (HDA). Bioorg. Med. Chem. Lett. 2015, 25, 1709–1714. [Google Scholar] [CrossRef]
- Boyer, A.-S.; Grgurevic, S.; Cazaux, C.; Hoffmann, J.-S. The Human Specialized DNA Polymerases and Non-B DNA: Vital Relationships to Preserve Genome Integrity. J. Mol. Biol. 2013, 425, 4767–4781. [Google Scholar] [CrossRef]
- Bettridge, K.; Verma, S.; Weng, X.; Adhya, S.; Xiao, J. Single-Molecule Tracking Reveals That the Nucleoid-Associated Protein HU Plays a Dual Role in Maintaining Proper Nucleoid Volume through Differential Interactions with Chromosomal DNA. Mol. Microbiol. 2021, 115, 12–27. [Google Scholar] [CrossRef] [PubMed]
- Brázda, V.; Coufal, J.; Liao, J.; Arrowsmith, C. Preferential Binding of IFI16 Protein to Cruciform Structure and Superhelical DNA. Biochem. Biophys. Res. Commun. 2012, 422, 716–720. [Google Scholar] [CrossRef] [PubMed]
- Hároníková, L.; Coufal, J.; Kejnovská, I.; Jagelská, E.B.; Fojta, M.; Dvořáková, P.; Muller, P.; Vojtesek, B.; Brázda, V. IFI16 Preferentially Binds to DNA with Quadruplex Structure and Enhances DNA Quadruplex Formation. PLoS ONE 2016, 11, e0157156. [Google Scholar] [CrossRef]
- Cannavo, E.; Sanchez, A.; Anand, R.; Ranjha, L.; Hugener, J.; Adam, C.; Acharya, A.; Weyland, N.; Aran-Guiu, X.; Charbonnier, J.-B.; et al. Regulation of the MLH1–MLH3 Endonuclease in Meiosis. Nature 2020, 586, 618–622. [Google Scholar] [CrossRef] [PubMed]
- Rogacheva, M.V.; Manhart, C.M.; Chen, C.; Guarne, A.; Surtees, J.; Alani, E. Mlh1-Mlh3, a Meiotic Crossover and DNA Mismatch Repair Factor, Is a Msh2-Msh3-Stimulated Endonuclease. J. Biol. Chem. 2014, 289, 5664–5673. [Google Scholar] [CrossRef] [Green Version]
- Saada, A.A.; Costa, A.B.; Sheng, Z.; Guo, W.; Haber, J.E.; Lobachev, K.S. Structural Parameters of Palindromic Repeats Determine the Specificity of Nuclease Attack of Secondary Structures. Nucleic Acids Res. 2021, 49, 3932–3947. [Google Scholar] [CrossRef]
- Brázda, V.; Čechová, J.; Battistin, M.; Coufal, J.; Jagelská, E.B.; Raimondi, I.; Inga, A. The Structure Formed by Inverted Repeats in P53 Response Elements Determines the Transactivation Activity of P53 Protein. Biochem. Biophys. Res. Commun. 2017, 483, 516–521. [Google Scholar] [CrossRef]
- Čechová, J.; Coufal, J.; Jagelská, E.B.; Fojta, M.; Brázda, V. P73, like Its P53 Homolog, Shows Preference for Inverted Repeats Forming Cruciforms. PLoS ONE 2018, 13, e0195835. [Google Scholar] [CrossRef] [Green Version]
- Feng, X.; Xie, F.-Y.; Ou, X.-H.; Ma, J.-Y. Cruciform DNA in Mouse Growing Oocytes: Its Dynamics and Its Relationship with DNA Transcription. PLoS ONE 2020, 15, e0240844. [Google Scholar] [CrossRef]
- Marie, L.; Symington, L.S. Mechanism for Inverted-Repeat Recombination Induced by a Replication Fork Barrier. Nat. Commun. 2022, 13, 32. [Google Scholar] [CrossRef]
- Pastrana, C.L.; Carrasco, C.; Akhtar, P.; Leuba, S.H.; Khan, S.A.; Moreno-Herrero, F. Force and Twist Dependence of RepC Nicking Activity on Torsionally-Constrained DNA Molecules. Nucleic Acids Res. 2016, 44, 8885–8896. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sukackaite, R.; Jensen, M.R.; Mas, P.J.; Blackledge, M.; Buonomo, S.B.; Hart, D.J. Structural and Biophysical Characterization of Murine Rif1 C Terminus Reveals High Specificity for DNA Cruciform Structures. J. Biol. Chem. 2014, 289, 13903–13911. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mukherjee, C.; Tripathi, V.; Manolika, E.M.; Heijink, A.M.; Ricci, G.; Merzouk, S.; de Boer, H.R.; Demmers, J.; van Vugt, M.A.T.M.; Chaudhuri, A.R. RIF1 Promotes Replication Fork Protection and Efficient Restart to Maintain Genome Stability. Nat. Commun. 2019, 10, 3287. [Google Scholar] [CrossRef] [PubMed]
- Eykelenboom, J.K.; Blackwood, J.K.; Okely, E.; Leach, D.R.F. SbcCD Causes a Double-Strand Break at a DNA Palindrome in the Escherichia Coli Chromosome. Mol. Cell 2008, 29, 644–651. [Google Scholar] [CrossRef]
- Achar, Y.J.; Adhil, M.; Choudhary, R.; Gilbert, N.; Foiani, M. Negative Supercoil at Gene Boundaries Modulates Gene Topology. Nature 2020, 577, 701–705. [Google Scholar] [CrossRef]
- Lu, S.; Wang, G.; Bacolla, A.; Zhao, J.; Spitser, S.; Vasquez, K.M. Short Inverted Repeats Are Hotspots for Genetic Instability: Relevance to Cancer Genomes. Cell Rep. 2015, 10, 1674–1680. [Google Scholar] [CrossRef] [Green Version]
- Carreira, R.; Aguado, F.J.; Hurtado-Nieves, V.; Blanco, M.G. Canonical and Novel Non-Canonical Activities of the Holliday Junction Resolvase Yen1. Nucleic Acids Res. 2021, 50, 259–280. [Google Scholar] [CrossRef]
- Vos, S.M.; Tretter, E.M.; Schmidt, B.H.; Berger, J.M. All Tangled up: How Cells Direct, Manage and Exploit Topoisomerase Function. Nat. Rev. Mol. Cell Biol. 2011, 12, 827–841. [Google Scholar] [CrossRef] [Green Version]
- Coufal, J.; Jagelská, E.B.; Liao, J.C.C.; Brázda, V. Preferential Binding of P53 Tumor Suppressor to P21 Promoter Sites That Contain Inverted Repeats Capable of Forming Cruciform Structure. Biochem. Biophys. Res. Commun. 2013, 441, 83–88. [Google Scholar] [CrossRef]
- Unterholzner, L.; Keating, S.E.; Baran, M.; Horan, K.A.; Jensen, S.B.; Sharma, S.; Sirois, C.M.; Jin, T.; Latz, E.; Xiao, T.S.; et al. IFI16 Is an Innate Immune Sensor for Intracellular DNA. Nat. Immunol. 2010, 11, 997–1004. [Google Scholar] [CrossRef] [Green Version]
- Johnson, K.E.; Bottero, V.; Flaherty, S.; Dutta, S.; Singh, V.V.; Chandran, B. IFI16 Restricts HSV-1 Replication by Accumulating on the HSV-1 Genome, Repressing HSV-1 Gene Expression, and Directly or Indirectly Modulating Histone Modifications. PLoS Pathog. 2014, 10, e1004503. [Google Scholar] [CrossRef] [PubMed]
- Toleikis, A.; Webb, M.R.; Molloy, J.E. OriD Structure Controls RepD Initiation during Rolling-Circle Replication. Sci. Rep. 2018, 8, 1206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Noirot, P.; Bargonetti, J.; Novick, R.P. Initiation of Rolling-Circle Replication in PT181 Plasmid: Initiator Protein Enhances Cruciform Extrusion at the Origin. Proc. Natl. Acad. Sci. USA 1990, 87, 8560–8564. [Google Scholar] [CrossRef] [Green Version]
- Liao, H.; Ji, F.; Helleday, T.; Ying, S. Mechanisms for Stalled Replication Fork Stabilization: New Targets for Synthetic Lethality Strategies in Cancer Treatments. EMBO Rep. 2018, 19, e46263. [Google Scholar] [CrossRef]
- Rass, U.; Compton, S.A.; Matos, J.; Singleton, M.R.; Ip, S.C.Y.; Blanco, M.G.; Griffith, J.D.; West, S.C. Mechanism of Holliday Junction Resolution by the Human GEN1 Protein. Genes Dev. 2010, 24, 1559–1569. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, S.; Geng, X.; Syeda, M.Z.; Huang, Z.; Zhang, C.; Ying, S. Human MUS81: A Fence-Sitter in Cancer. Front. Cell Dev. Biol. 2021, 9, 657305. [Google Scholar] [CrossRef] [PubMed]
- Leach, D.R. Long DNA Palindromes, Cruciform Structures, Genetic Instability and Secondary Structure Repair. Bioessays 1994, 16, 893–900. [Google Scholar] [CrossRef] [PubMed]
- Lai, P.J.; Lim, C.T.; Le, H.P.; Katayama, T.; Leach, D.R.F.; Furukohri, A.; Maki, H. Long Inverted Repeat Transiently Stalls DNA Replication by Forming Hairpin Structures on Both Leading and Lagging Strands. Genes Cells 2016, 21, 136–145. [Google Scholar] [CrossRef] [Green Version]
- Ganapathiraju, M.K.; Subramanian, S.; Chaparala, S.; Karunakaran, K.B. A Reference Catalog of DNA Palindromes in the Human Genome and Their Variations in 1000 Genomes. Hum. Genome Var. 2020, 7, 40. [Google Scholar] [CrossRef]
- Guiblet, W.M.; Cremona, M.A.; Harris, R.S.; Chen, D.; Eckert, K.A.; Chiaromonte, F.; Huang, Y.-F.; Makova, K.D. Non-B DNA: A Major Contributor to Small- and Large-Scale Variation in Nucleotide Substitution Frequencies across the Genome. Nucleic Acids Res. 2021, 49, 1497–1516. [Google Scholar] [CrossRef]
- Tanaka, H.; Watanabe, T. Mechanisms Underlying Recurrent Genomic Amplification in Human Cancers. Trends Cancer 2020, 6, 462–477. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, H.; Tapscott, S.J.; Trask, B.J.; Yao, M.-C. Short Inverted Repeats Initiate Gene Amplification through the Formation of a Large DNA Palindrome in Mammalian Cells. Proc. Natl. Acad. Sci. USA 2002, 99, 8772–8777. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopes-Nunes, J.; Oliveira, P.A.; Cruz, C. G-Quadruplex-Based Drug Delivery Systems for Cancer Therapy. Pharmaceuticals 2021, 14, 671. [Google Scholar] [CrossRef] [PubMed]
- Miklenić, M.S.; Svetec, I.K. Palindromes in DNA—A Risk for Genome Stability and Implications in Cancer. Int. J. Mol. Sci. 2021, 22, 2840. [Google Scholar] [CrossRef]
- Inagaki, H.; Kato, T.; Tsutsumi, M.; Ouchi, Y.; Ohye, T.; Kurahashi, H. Palindrome-Mediated Translocations in Humans: A New Mechanistic Model for Gross Chromosomal Rearrangements. Front. Genet. 2016, 7, 125. [Google Scholar] [CrossRef] [Green Version]
- Kaushal, S.; Wollmuth, C.E.; Das, K.; Hile, S.E.; Regan, S.B.; Barnes, R.P.; Haouzi, A.; Lee, S.M.; House, N.C.M.; Guyumdzhyan, M.; et al. Sequence and Nuclease Requirements for Breakage and Healing of a Structure-Forming (AT)n Sequence within Fragile Site FRA16D. Cell Rep. 2019, 27, 1151–1164.e5. [Google Scholar] [CrossRef] [Green Version]
- Brosh, R.M., Jr.; Matson, S.W. History of DNA Helicases. Genes 2020, 11, 255. [Google Scholar] [CrossRef] [Green Version]
- Datta, A.; Brosh, R.M., Jr. New Insights into DNA Helicases as Druggable Targets for Cancer Therapy. Front. Mol. Biosci. 2018, 5, 59. [Google Scholar] [CrossRef]
- Savvateeva-Popova, E.V.; Zhuravlev, A.V.; Brázda, V.; Zakharov, G.A.; Kaminskaya, A.N.; Medvedeva, A.V.; Nikitina, E.A.; Tokmatcheva, E.V.; Dolgaya, J.F.; Kulikova, D.A.; et al. Drosophila Model for the Analysis of Genesis of LIM-Kinase 1-Dependent Williams-Beuren Syndrome Cognitive Phenotypes: INDELs, Transposable Elements of the Tc1/Mariner Superfamily and MicroRNAs. Front. Genet. 2017, 8, 123. [Google Scholar] [CrossRef]
- Abnous, K.; Danesh, N.M.; Ramezani, M.; Charbgoo, F.; Bahreyni, A.; Taghdisi, S.M. Targeted Delivery of Doxorubicin to Cancer Cells by a Cruciform DNA Nanostructure Composed of AS1411 and FOXM1 Aptamers. Expert Opin. Drug Deliv. 2018, 15, 1045–1052. [Google Scholar] [CrossRef]
- Yao, F.; An, Y.; Li, X.; Li, Z.; Duan, J.; Yang, X.-D. Targeted Therapy of Colon Cancer by Aptamer-Guided Holliday Junctions Loaded with Doxorubicin. Int. J. Nanomed. 2020, 15, 2119–2129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fleming, A.M.; Zhu, J.; Jara-Espejo, M.; Burrows, C.J. Cruciform DNA Sequences in Gene Promoters Can Impact Transcription upon Oxidative Modification of 2′-Deoxyguanosine. Biochemistry 2020, 59, 2616–2626. [Google Scholar] [CrossRef] [PubMed]
- Kurahashi, H.; Inagaki, H.; Yamada, K.; Ohye, T.; Taniguchi, M.; Emanuel, B.S.; Toda, T. Cruciform DNA Structure Underlies the Etiology for Palindrome-Mediated Human Chromosomal Translocations. J. Biol. Chem. 2004, 279, 35377–35383. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Protein | Source | Function | Reference * |
|---|---|---|---|
| 14-3-3 | Eukaryotes | Replication, DNA repair, TF | [69] |
| A22 | Coccinia virus | Junction-resolving enzyme | |
| AF10 | H. sapiens | TF | |
| Bmh1, homolog of 14-3-3 | S. cerevisiae | Replication, DNA repair, TF | |
| BRCA1 | Mammals | Chromatin AP, DNA repair, TF | [70] |
| Cas1, Cas2 | Archaea, Bacteria | Endonuclease, defence response to virus | [56,57] |
| Cce1 | Yeast | Junction-resolving enzyme | [71] |
| Crp-1 | S. cerevisiae | DNA repair | [72] |
| DEK | Mammals | Chromatin AP, replication, DNA repair | [73,74] |
| DNA-PK | Eukaryotes | DNA repair | |
| Dps | E. coli | DNA repair, stress response | [75,76,77] |
| Endonuclease I | Phage T7 | Junction-resolving enzyme | [78] |
| Endonuclease VII | Phage T4 | Junction-resolving enzyme | |
| Estrogen receptor | Mammals | TF | |
| GEN1 | Vertebrates | Junction-resolving enzyme | [79] |
| GF14, homolog of 14-3-3 | Plants | Replication, stress response | |
| Helicases | all | Replication | [80,81] |
| Hjc, Hje | Archaea | Junction-resolving enzymes | |
| HMG protein family | all | Chromatin AP, DNA repair, TF | |
| Hop1 | S. cerevisiae | DNA Repair | |
| HU | E. coli | Replication | [82] |
| IFI16 | H. sapiens | Viral DNA recognition | [83,84] |
| Integrases | all | Junction-resolving enzyme | |
| MLH1-MLH3 | Vertebrates | Junction-resolving enzyme | [85] |
| MLL (leukaemia) | H. sapiens | Replication | |
| MSH2 | Mammals | Junction-resolving enzyme | [86] |
| Mus81-Eme1 | Eukaryotes | Junction-resolving enzyme | |
| Mus81-Mms4 | S. cerevisiae | Junction-resolving enzyme | [72,87] |
| MutH | Eukaryotes | Junction-resolving enzyme | |
| p53 | H. sapiens and others | DNA repair, TF | [88] |
| p73 | H. sapiens and others | DNA repair, TF | [89] |
| PARP-1 | H. sapiens and others | DNA repair, TF | [90] |
| Rad51 | Eukaryotes | Chromatin AP | [91] |
| Rad52-Rad59 | Eukaryotes | Chromatin AP | [91] |
| Rad54 | Eukaryotes | Chromatin AP | [91] |
| RecU | G+ bacteria | Junction-resolving enzyme | |
| RepC | Bacteria | Replication | [92] |
| Rif1 | Mammals | DNA repair, TF | [93,94] |
| Rmi-1 | Yeast | DNA repair, TF | |
| RusA | E. coli | Junction-resolving enzyme | |
| RuvC | E. coli | Junction-resolving enzyme | |
| S16 | E. coli | Replication | |
| SbcCD | E. coli | Junction-resolving enzyme | [95] |
| Smc | S. cerevisiae | DNA repair, TF | |
| Topoisomerase I | Eukaryotes | Chromatin AP | |
| Topoisomerase II | Eukaryotes | Chromatin AP | [96] |
| TRF2 | H. sapiens | Junction-resolving enzyme | |
| Vlf-1 | Baculoviruses | Replication | |
| WRN(Werner syndrome) | H. sapiens | Replication | |
| XPF, XPG protein families | Eukaryotes | Junction-resolving enzyme | [97] |
| Ydc2 | S. pombe | Junction-resolving enzyme | |
| Yen1, homolog of GEN1 | S. cerevisiae | Junction-resolving enzyme | [98] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bowater, R.P.; Bohálová, N.; Brázda, V. Interaction of Proteins with Inverted Repeats and Cruciform Structures in Nucleic Acids. Int. J. Mol. Sci. 2022, 23, 6171. https://doi.org/10.3390/ijms23116171
Bowater RP, Bohálová N, Brázda V. Interaction of Proteins with Inverted Repeats and Cruciform Structures in Nucleic Acids. International Journal of Molecular Sciences. 2022; 23(11):6171. https://doi.org/10.3390/ijms23116171
Chicago/Turabian StyleBowater, Richard P., Natália Bohálová, and Václav Brázda. 2022. "Interaction of Proteins with Inverted Repeats and Cruciform Structures in Nucleic Acids" International Journal of Molecular Sciences 23, no. 11: 6171. https://doi.org/10.3390/ijms23116171
APA StyleBowater, R. P., Bohálová, N., & Brázda, V. (2022). Interaction of Proteins with Inverted Repeats and Cruciform Structures in Nucleic Acids. International Journal of Molecular Sciences, 23(11), 6171. https://doi.org/10.3390/ijms23116171