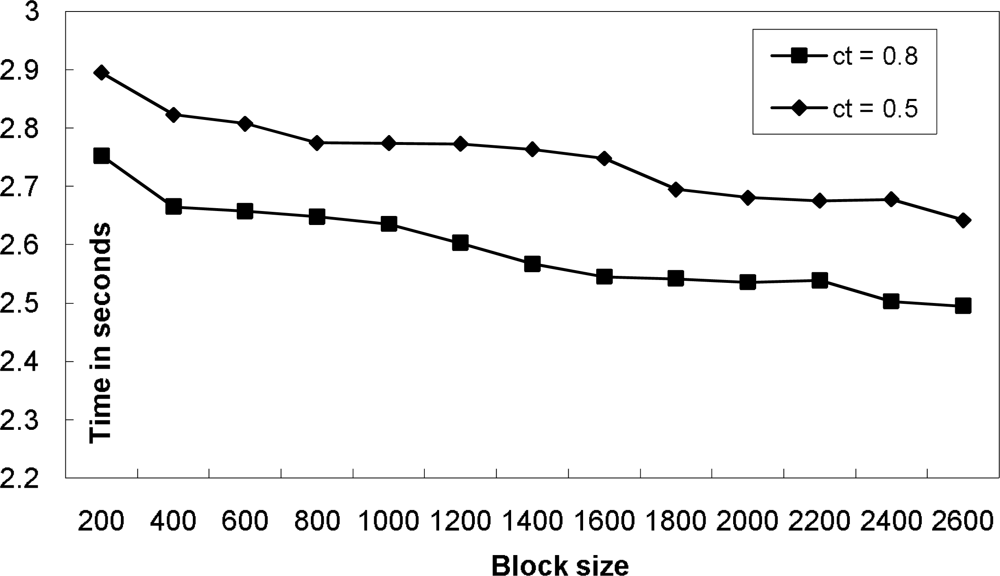
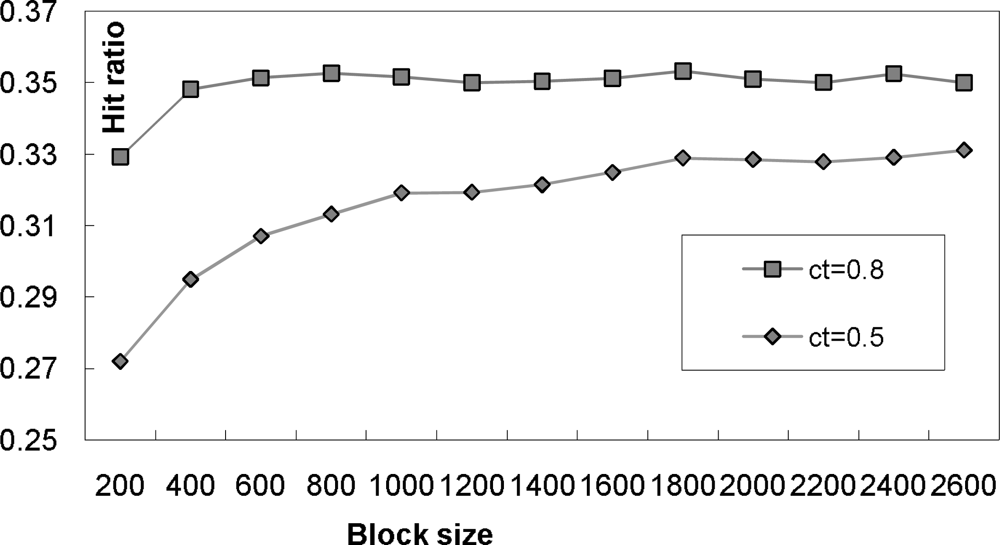
4.1. Efficient Timing Correlation
Throughout this section, we assume that there is an interval timing correlation such that it has a mutual deadline for two events such as |@S1 − @S2| ≤ d and a confidence threshold ct. In other words, we want to extract a pair of (e1, e2) satisfying the mutual deadline d and their satisfaction probability should be at least ct.
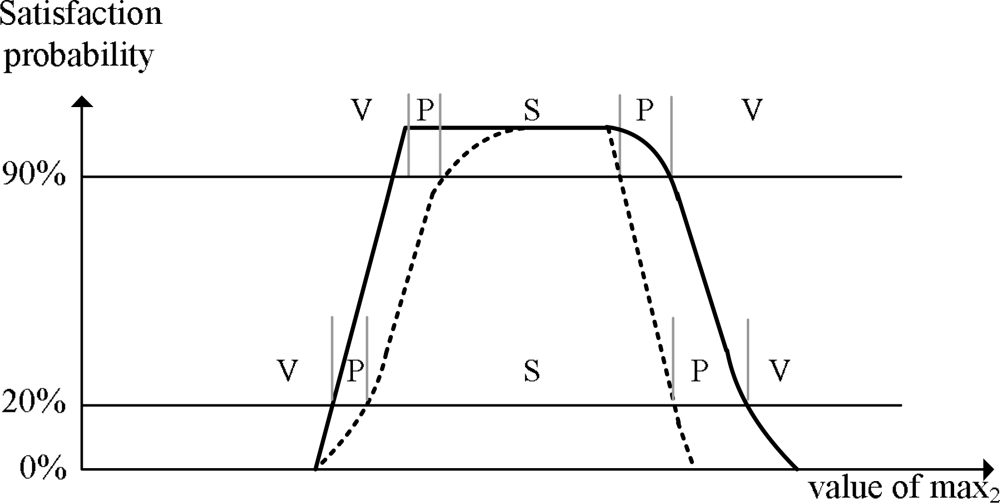
Figure 1 illustrates the core results studied in [
11]. In the figure, we assume that a base tuple with the timestamp
I1 = (
min1,
max1) has arrived from stream
S1. The graph presents the upper-bounds (solid lines) and the lower-bounds (dotted lines) of satisfaction probabilities for each possible
x =
max(
I2) where
I2 is the timestamp of a tuple in the targets stream (
S2 in this specific example).
A timing correlation process starts upon receiving a tuple from a stream. The tuple and the stream is referred to as base tuple and base stream respectively. The other stream is called as target stream.
By using the information shown in the
Figure 1(a), we can efficiently partition the target tuples in order to extract the results satisfying the timing correlation as listed in the following:
Any target tuple with the timestamp I where max(I) ∈ [LL, RL] is guaranteed to satisfy the given timing condition.
Any target tuple with the timestamp I where max(I) < LH is guaranteed to violate the given timing condition.
Any target tuple with the timestamp I where max(I) > RH is guaranteed to violate the given timing condition.
Any target tuple with the timestamp I where max(I) ∈ [LH, LL) needs an evaluation of the satisfaction probability.
Any target tuple with the timestamp I where max(I) ∈ (RL, RH] needs an evaluation of the satisfaction probability.
where
LL,
RL,
LH,
RH are the X-axis values of the points crossing with a horizontal line of which Y-axis value is
ct as shown in
Figure 1(b).
ct is the confidence threshold requirement of the timing condition.
From the figure, the above observations are intuitively derived. For example, any target tuple with the max(timestamp) ∈ [
LL,
RL] is guaranteed to satisfy the given correlation condition; its minimum satisfaction probability must be greater than or equal to the requested confidence threshold. In our previous work [
11], we presented efficient algorithms for performing interval timing correlations by using the above result. In the next subsection, we extend the previous findings and present two new algorithms for interval timing correlations.
4.2. Algorithms for Interval Timing Correlation
In this section, we review the algorithms for the interval timing correlation proposed in [
11] and introduce novel algorithms.
The simple timing correlation is the most simplest one among the algorithms discussed here. When a tuple e arrives at the base stream, every tuple in the target stream buffer is examined and the satisfaction probability is calculated. While the system is visiting the tuples in the target stream buffer, it marks the obsolete tuples. Finally the marked tuples are removed from the target stream buffer and e is inserted into the base stream buffer.
Algorithm 1.
SimpleTimingCorrelation(enew, BaseStream)
Algorithm 1.
SimpleTimingCorrelation(enew, BaseStream)
| 1: | for all tuple e in the target buffer do |
| 2: | if (ct ≤ prob(|@enew − @e| ≤ d)) then |
| 3: | Add (enew, e) to the result |
| 4: | end if |
| 5: | Mark e if it is obsolete. |
| 6: | end for |
| 7: | Remove the marked obsolete tuples in the target buffer. |
| 8: | Insert enew into the end of base buffer. |
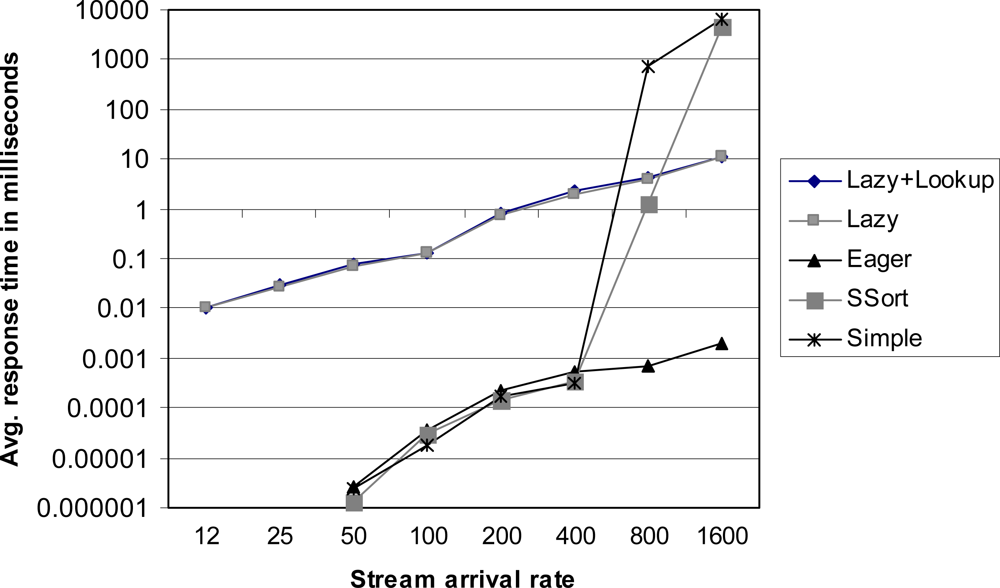
The Simple-Sort (SSort in short) timing correlation slightly modifies the simple timing correlation such that it keeps the tuples in order with respect to the max timestamps. Hence, the algorithm expects longer blocks of obsolete tuples consecutively located than those in the simple timing correlation.
The eager timing correlation uses the upper-bounds and lower-bounds of the satisfaction probability presented in the previous section. Every time a tuple e arrives, the system computes LH, LL, RL and RH based on e. As illustrated in the previous section, all tuples belonging to [LL, RL] in the target stream buffer are guaranteed to be in the correlation result. The tuples belonging to [LH, LL) or (RL, RH] in the target stream buffer should be probed further. To determine the block of invalid tuples, we first set @einv to (CurrentTime − delaybase − π, CurrentTime − delaybase) where delaybase is the maximum delay in the base stream. Then, we compute LH based on einv. The target tuples having the timestamp I such that max(I) < max(LH(einv)) in the target buffer are guaranteed not to be in the result with any future incoming base tuples. Hence, they can be removed from the target buffer.
Algorithm 2.
EagerTimingCorrelation(enew, BaseStream)
Algorithm 2.
EagerTimingCorrelation(enew, BaseStream)
| 1: | Compute LH, LL, RL, and RH based on enew |
| 2: | for all tuple e belongs to [LL, RL] in the target buffer do |
| 3: | Add (enew, e) to the result |
| 4: | end for |
| 5: | for all tuple e belongs to [LH, LL) or (RL, RH] in the target buffer do |
| 6: | Probe(enew, e, d, ct) |
| 7: | end for |
| 8: | Invalidate obsolete tuples in the target buffer by LH (einv). |
| 9: | Insert enew into the base buffer in a sorted order. |
Algorithm 3.
Probe(enew, e, d, ct)
Algorithm 3.
Probe(enew, e, d, ct)
| 1: | if ct ≤ prob(|@enew − @e| ≤ d) then |
| 2: | Add (enew, e) to the result |
| 3: | end if |
The
lazy timing correlation also uses the upper-bounds and the lower-bounds like the eager algorithm; however, it does not start correlation processing every time a new tuple arrives. Upon receiving a new tuple, the lazy timing correlation just inserts the tuple into the appropriate stream buffer and waits until its re-evaluation time [
12].
When to re-evaluate can be determined either by the number of unprocessed tuples or by a time frequency (or both). For example, a system can be designed to re-evaluate whenever there are more than 500 unprocessed tuples or every one second.
It is noted in [
12] that the lazy correlation is preferable over the eager correlation when the arrival rates of data streams are so high that it is hard to handle the incoming every tuple instantly.
However, the benefit of the lazy algorithm comes at the expense of the longer response time; until the re-evaluation condition is met, the already arrived but un-evaluated tuples should wait in the buffers. Therefore, the re-evaluation condition must be designed carefully not to violate the system performance requirements. The algorithm for the lazy timing correlation is presented in
Algorithms 4 and
5.
Algorithm 4.
LazyTimingCorrelation(enew, BaseStream)
Algorithm 4.
LazyTimingCorrelation(enew, BaseStream)
| 1: | Insert enew into the end of base buffer. |
| 2: | if there are “enough” tuples then |
| 3: | call BlockTimingCorrelation(BaseStream) |
| 4: | end if |
Algorithm 5.
BlockTimingCorrelation(BaseStream)
Algorithm 5.
BlockTimingCorrelation(BaseStream)
| 1: | Sort the target stream buffer |
| 2: | tpl ← the first tuple in the unprocessed block in the base stream buffer |
| 3: | tpr ← the last tuple in the unprocessed block in the base stream buffer |
| 4: | for enew = tpr to tpl in the base stream buffer do |
| 5: | Compute LH, LL, RL, and RH based on enew |
| 6: | for all tuple e in [LL, RL] in the sorted block of the target stream buffer do |
| 7: | AddResult(enew, e) |
| 8: | end for |
| 9: | for all tuple e in [LH, LL) or (RL, RH] in the sorted block of the target stream buffer do |
| 10: | Probe(enew, e, d, ct) |
| 11: | end for |
| 12: | end for |
| 13: | Sort the base stream buffer |
| 14: | Invalidate obsolete tuples in the base buffer by LH (einv). |
| 15: | Invalidate obsolete tuples in the target buffer by LH (einv). |
Now we extend the lazy timing correlation to use look-up tables in order to perform the probing process more efficiently. The following corollary presents properties used in the algorithm.
Corollary 2 Assume there are timestamps I1, Ii, and Ij where max(I1) ≤ max(Ii) ≤ max(Ij) and min(I1) ≤ min(Ii) ≤ min(Ij). If a timing condition (I1 + d ≥ Ij, ct) is satisfied then, so is the timing condition (I1 + d ≥ Ii, ct). Similarly if a timing condition (I1 + d ≥ Ii, ct) is violated, then so is (I1 + d ≥ Ij, ct).
Example 1 Assume there are timestamps as shown in Figure 2. Suppose that (I2 +
d ≥
I11,
ct) is violated. Then, by Corollary 2, we can claim that (I2 +
d ≥
I12,
ct) and (I2 +
d ≥
I14,
ct) are also violated without computing the satisfaction probabilities. Now suppose that (I2 +
d ≥
I12,
ct) is satisfied. Then, by Corollary 2, we can claim that (I2 +
d ≥
I11,
ct) is also satisfied. The main idea of the extended algorithm is to reuse the satisfaction probabilities calculated in the probe regions. As illustrated in the previous example, while performing an interval timing correlation for two blocks of tuples, there can be cases where we can reuse the previous calculation results and avoid expensive probability computations. By comparing
Algorithm 6 and the lazy timing correlation, we can notice that the main difference is the way of handling probe regions. To process the probe regions, the algorithm first initializes the look-up table after identifying the range of target tuples. There are two probing regions but their processes are symmetric; hence we shall explain only the part handling the left probe region.
Algorithm 6.
LazyWithLookup-newblock(BaseStream)
Algorithm 6.
LazyWithLookup-newblock(BaseStream)
| 1: | Sort the target stream buffer |
| 2: | tpl ← the first tuple in unprocessed block in the base stream |
| 3: | tpr ← the last tuple in unprocessed block in the base stream |
| 4: | for enew = tpr to tpl in the base stream buffer do |
| 5: | Compute LL, RL based on enew |
| 6: | for all tuple e belongs to [LL, RL] in the sorted block of the target buffer do |
| 7: | Add (enew, e) to the result |
| 8: | end for |
| 9: | end for |
| 10: | leftindex ← the index for LH(max(@tpl) – π, max(@tpl)) in the target stream buffer |
| 11: | rightindex ← the index for LL(max(@tpr) – ρ, max(@tpr)) in the target stream buffer |
| 12: | Initialize look-up table (leftindex, rightindex) |
| 13: | for enew = tpr downto tpl in the base stream buffer do |
| 14: | Compute LH, LL, based on enew |
| 15: | for all tuple e belongs to [LH, LL) in the target buffer do |
| 16: | EfficientProbe(enew, e, d, ct, BaseStream) |
| 17: | end for |
| 18: | end for |
| 19: | Initialize look-up table (leftindex, rightindex) |
| 20: | for enew = tpl to tpr in the base stream do |
| 21: | Compute RL, RH, based on enew |
| 22: | for all tuple e belongs to (RL, RH] in the target buffer do |
| 23: | EfficientProbe(enew, e, d, ct, BaseStream) |
| 24: | end for |
| 25: | end for |
| 26: | Invalidate obsolete tuples in the base buffer by LH (einv). |
| 27: | Invalidate obsolete tuples in the target buffer by LH (einv). |
The algorithm traverses the base tuples in the unprocessed block in reverse chronological order. Once we computed prob(|@eb – @et| ≤ d) where eb is a tuple in the base stream and et is a tuple in the target stream, we store the timestamp of eb as well as the computed satisfaction probability into the look-up table. When we compute prob(|@e′b – @et| ≤ d) where e′b is another tuple in the base stream, we first check whether e′b can use the result computed based on eb. This decision is made by comparing the min values of @eb and @e′b. If min(@e′b) ≤ min(@eb), then it means that @e′b is strictly less than @eb. (We define e′b is strictly less than eb iff min(@e′b) ≤ min(@eb) and max(@t′b) ≤ max(@tb).) The algorithm traverses the base stream buffer from the tail; hence, it is trivially true that max(@e′b) ≤ max(@eb). In case the @e′b is strictly less than eb, we can reuse this result; if the stored value is larger than ct (the confidence threshold for this timing condition), then it should be the case prob(|@e′b – @et| ≤ d) is no less than ct. Hence, the tuple pair (e′b, et) must be in the final result. Even if the stored value is less than ct, it is still possible that (e′b, et) can satisfy the interval timing condition. So, we compute the satisfaction probability for (e′b, et) and store the new result into the look-up table. If e′b is not strictly less than eb, then we cannot reuse the stored result; we compute the satisfaction probability and store it.
Recall that the primary purpose of using the look-up table is to avoid the “relatively” expensive operation—the satisfaction probability calculation incurring floating-point operations. To minimize the overhead for accessing to the look-up tables, we used array data structure to implement the look-up table. Hence every access to the look-up table was done via the index to an element in the array.
Algorithm 7.
EfficientProbe(enew, e, d, ct, BaseStream)
Algorithm 7.
EfficientProbe(enew, e, d, ct, BaseStream)
| 1: | if the result in the look-up table is usable then |
| 2: | c ← lookup(e) |
| 3: | if c = notInit then |
| 4: | Probe(enew, e, d, ct) |
| 5: | SetLookup(prob(|@enew – @e| ≤ d), e) |
| 6: | else |
| 7: | if c ≥ ct then |
| 8: | Add (enew, e) to the result |
| 9: | else |
| 10: | Probe(enew, e, d, ct) |
| 11: | end if |
| 12: | end if |
| 13: | else |
| 14: | Probe(enew, e, d, ct) |
| 15: | SetLookup(prob(|@enew – @e| ≤ d), e) |
| 16: | end if |
Now let us prove the correctness of the look-up technique in the algorithm.
Corollary 3 Suppose there are two timestamps I1 and I2. Assume that min(I1) ≤ min(I2) and max(I1) ≥ max(I2), i.e., I1 covers entire I2. Then prob(|I1 − I2| ≤ d) = 1.
Proof:
Since d ≥ π, min(I1) + d ≥ max(I1). By the assumption, max(I1) ≥ max(I2). Therefore, min(I1) + d ≥ max(I2); hence prob(I1 + d ≥ I2) = 1. By the assumption, min(I2) ≥ min(I1). Hence, min(I2) + d ≥ min(I1) + d ≥ max(I1). Therefore, prob(I2 + d ≥ I1) = 1. Therefore, prob(|I1 – I2| ≤ d) = 1.
Theorem 2 Algorithm 6,
the lazy timing correlation with a look-up table, is correct. Proof:
Let us first prove that the code block handling the left probe region is correct. The main idea of the look-up technique is that we can reuse the result of the timing condition (|@e – @elookup| ≤ d, ct) in determining (|@e – @enew| ≤ d, ct). enew is the base tuple currently examined in the code and elookup is the base tuple which was used for calculating prob(|@e – @elookup| ≤ d) and stored in the look-up table where e is a tuple in the target stream buffer. The first line of the EfficientProbe function checks whether the tuple enew in the source stream buffer satisfies the condition min(@enew) ≤ min(@elookup).
First, let us prove that it is always the case that max(@e) ≤ max(@enew) ≤ max(@elookup). LL(max(@enew)) ≤ max(@enew) always holds. e is going to be used in processing enew only when @e belongs to [LH(@enew), LL(@enew)), i.e., LH(@enew) ≤ max(@e) < LL(@enew). Since the algorithm traverses the source stream buffer from the end of the unprocessed tuples, it should be always the case that max(@enew) ≤ max(@elookup); hence max(@e) ≤ max(@enew) ≤ max(@elookup). There can be two cases as shown in the following:
Case min(@e) ≤ min(@enew): In this case it is evident that prob(|@e – @enew| ≤ d) = prob(@e + d ≥ @enew) by Corollary 1. Similarly, prob(|@e – @elookup| ≤ d) = prob(@e + d ≥ @elookup). By Corollary 2 if (@e + d ≥ @elookup, ct) is satisfied then so is (@e + d ≥ @enew, ct).
Case min(@e) > min(@enew): In this case @enew covers entire @e. Hence, prob(|@e – @enew| ≤ d) = 1 ≥ prob(|@e – @elookup| ≤ d) by Corollary 3.
In both cases, it was shown that if (@e + d ≥ @elookup, ct) is satisfied then so is (@e + d ≥ @enew, ct). The proof for the codes handling the right probe region is similar to this, hence is omitted.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








