1. Introduction
As one of the fundamental topics in computer vision and related fields, visual tracking has been playing a key role in many applications, such as video surveillance, motion recognition, traffic monitoring, and so on. Although many tracking methods have been proposed in recent years [
1,
2,
3,
4,
5,
6,
7,
8], it is still a challenging problem due to numerous factors, including illumination variations, pose changes, partial occlusions and background clutter, just to name a few.
Recently, sparse representation [
9] has been successfully applied to image restoration [
10], target detection [
8], face recognition [
11], and so on. Xue
et al. [
12] firstly introduced sparse representation into visual tracking, in which the tracked objects could be sparsely represented via a linear combination of the target templates (accounting for the object) and the trivial ones (accounting for the background noise). Thus, combined with the particle filter framework, the tracking task is formulated as solving a
norm optimization problem (named as L1 tracker) of one under-determined linear system, and the likelihood of particle belonging to the true object is calculated according to its error from being reconstructed in the target templates. For L1 tracker, the number of particles equals the number of the
norm minimizations for particles’ sparse representation. Hence, the number of particles dominates the total calculation cost of L1 tracker, and the resulting computational burden hinders its real-time applications. On the other hand, a small number of particles could not account for the dynamic changes of a moving object. Therefore, how to balance the efficiency and robustness is a difficult issue for sparse representation-based trackers.
For the efficiency aspect, in [
13], a minimum error bounded particle resampling method is advocated for removing the candidate samples, which have large reconstruction errors in the target templates, thereby reducing the amount of
norm minimizations. Bao
et al. [
14] also exploited a fast accelerated approach to boost the tracking efficiency of L1 tracker. However, these adopted strategies only take into account the foregone target observations, and the corresponding discriminative capability is not enough for complex environments. Therefore, some potential candidate samples may be abandoned, which results in a loss of tracking accuracy. Moreover, owing to that the information from backgrounds being ignored, there exist some surplus particle samples similar to the backgrounds, and the tracking speed is still restricted.
From the robustness point of view, several methods have also extended the L1 tracker, such as mining the interdependencies between candidates [
15], using orthogonal basis vectors instead of raw pixel templates [
16], and so on. These trackers have obtained some improvements in terms of tracking accuracy, but they do not take surrounding visual context into account as well as [
13,
14] and discard useful information that can be exploited to better separate the target object from the backgrounds.
In order to improve the robustness of sparse representation-based trackers, some scholars introduced the background information into the tracking framework. In [
17], the trivial templates are replaced with the background templates, and the object candidate should have the highest comparison between the foreground and backgrounds. However, the appearance changes of the backgrounds are very unstable. Therefore, the sparse constraints upon the background samples may not have a good performance. Motivated by [
17], Zhuang
et al. [
18] reversely find the sparse representation of the target and backgrounds in the candidate samples space and achieve some good results. However, numerous candidates are required for ensuring the over-complete property of the candidate sample space, thereby tending to be inefficient. Besides, to further boost the tracking robustness, the manifold learning constraint is introduced in [
18,
19]. For manifold learning, the correlation matrix between the samples for sparse representation is calculated in advance by the K-nearest neighbor (KNN) technique [
20]. However, computing from KNN is also a time-consuming task, which is not suitable for real-time tracking.
Through the above analysis, the existing sparse representation-based trackers often suffer from low efficiency and poor robustness, which can be attributed to the following two aspects: (1) most of the candidate samples participating in the sparse representation are from backgrounds, which dominate the total computational burden of the sparsity model; (2) the useful comparison information between the foreground and its surroundings is not utilized, which causes the tracker to not be robust in complicated backgrounds. To address these issues, we attempt to propose a new coarse-to-fine visual tracking framework, and the incipient motivations are shown in the following
Section 1.1.
1.1. Motivations
In this subsection, we present the detailed motivations in terms of the computational burden, the robustness aspect, the selection of the classifier and the further combination for the extreme learning machine (ELM) and sparse representation.
From the computational burden point of view, as mentioned above, the majority of the input candidate samples belong to the background, which leads to low tracking speed for the traditional sparsity trackers. In [
13], the minimum error bounded strategy has been applied for removing the useless background candidates, which have large reconstruction errors in the target template space. However, as we empirically observed, some potential target samples may also have poor representation in the target template space and then be discarded. On the other hand, the reserved candidate samples still contain the background contents. Thus, only by using the target template space for reducing candidates, the resultant tracking may not be robust and efficient. How to effectively cut down the number of background samples is important for the tracker in practical applications. Recently, there has been much progress in the classifier model, and researchers found that the classifier could perform robustly in distinguishing one object from other ones [
21,
22]. Therefore, the classification technique can be used to find the optimal separate hyperplane between the target and its backgrounds. Utilizing the differences between the target and its surroundings, the tracker can effectively remove the background samples and select the potential object ones for the following sparse representation. Compared to the minimum error bounded strategy, the classification model would be superior and can be treated as the prior process before the sparse representation.
As for the robustness aspect, the sparsity-based trackers can be effective when dealing with the background noise and illumination changes. However, the traditional sparsity tracking framework only considers the foregone target observations and then does not performs well in some challenging environments (e.g., motion blur, low object-background contrast). In these cases, by using the classification technique, the resulting tracker could find the potential candidate regions and alleviate the disturbances from different background contents. Furthermore, the used classifier can handle the pose variations of object well, which further contributes to robust tracking.
For real-time and robust visual tracking, the adopted classification technique should have a low computational burden and quickly adapt to dynamic visual changes. However, most of the existing classifiers cannot achieve optimal performances in terms of learning accuracy and training speed. For instance, the support vector machine (SVM)-based models [
21,
22] often have good performances, but suffer from high computational burden owing to the heavy quadratic programming. On the other hand, the naive Bayes-based ones [
23,
24] have a fast implementation, while not being able to achieve satisfactory performance, because of the weakness of simple classifiers. In this work, we attempt to use an emergent learning technique,
i.e., ELM. The ELM proposed by Huang
et al. [
25,
26] was originally developed for training single hidden layer feed-forward neural networks (SLFNs). Compared to traditional methods (neural networks or SVM), ELM not only has a faster learning speed, but also obtains a better generalization in many applications, such as face recognition [
27], object localization [
28], data fusion [
29], and so on.
Via using the simple cascading combination of ELM and sparse representation, some good tracking results can be obtained. However, we hope to find the further interaction between the above two different models. As mentioned before, the manifold learning constraint (MLC) could boost the sparsity tracking performances [
18,
19]. Unfortunately, the calculation of the correlation matrix in MLC generally depends on the time-consuming KNN method. From the technique point of view, both ELM and KNN belong to the same machine learning category. Thus, we can also apply the ELM model for computing the correlation matrix in MLC. It is noted that the learning results of samples on the ELM classification can be directly exploited to construct the MLC, which is preferred for real-time visual tracking.
1.2. Contributions
Motivated by the above analysis and discussion, we attempt to apply the novel ELM technique into the sparse tracking model and achieve better tracking performances in terms of efficiency and robustness. To our knowledge, this is the first time that the extreme learning machine is combined into the sparsity tracking framework. Our contributions can be summed up in the following three aspects:
(1) To make full use of the comparison information between the foreground and its backgrounds, ELM is used to find the decision boundary between the target observations and background ones. Then, the trained ELM classification function is applied for removing most of the candidate samples similar to the background contents. The ELM method is discriminative enough for distinguishing the target and backgrounds with a fast learning speed [
30]. Thus, the few best potential candidate samples related to the object views can be quickly selected for the following sparse representation, which can decrease the total computational cost of the tracking algorithm.
(2) For further developing the combination of ELM and sparse representation, a novel constrained sparse tracking model is built. Specifically, the output values of candidate samples on the ELM classification function are to construct a new manifold learning constraint term for the sparse representation framework, thereby leading to more robust tracking results.
(3) Through the accelerated proximal gradient (APG) method [
31], the optimal solution (in matrix form) of the above constrained sparse tracking model is derived and can be quickly obtained within several iterations. Moreover, the matrix-form solution allows the candidate samples to be processed in parallel, which can further improve the calculation efficiency of the tracker.
The rest of this paper is organized as follows. In
Section 2, the related background contents of the proposed tracker are reviewed. The detailed tracking implementations are presented in
Section 3, and the insights of the proposed method are discussed in
Section 4. In
Section 5, experimental results and related analyses are demonstrated. Finally, the conclusion is given in
Section 6.
3. Proposed Tracking Algorithm
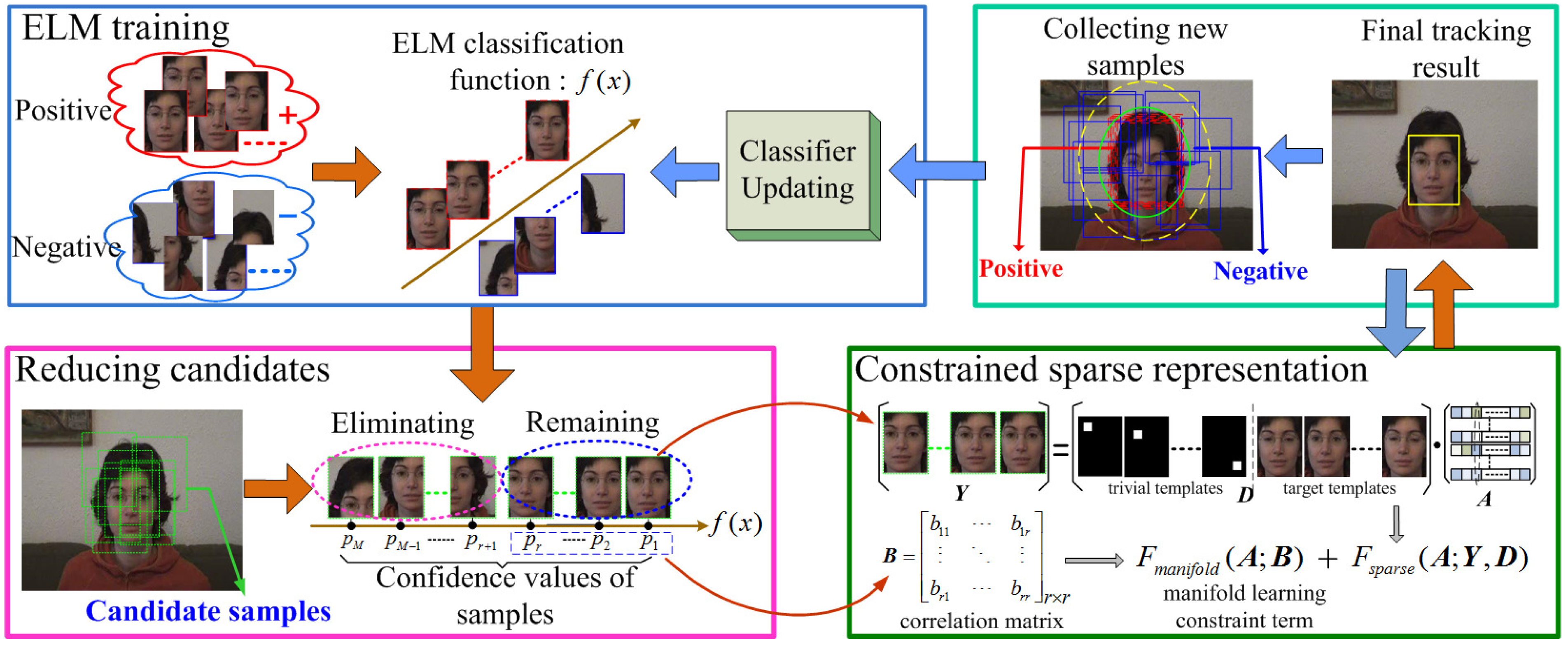
To achieve a better sparsity tracker in terms of efficiency and robustness, we plan to exploit the ELM technique in the sparse visual tracking framework. The flowchart of the proposed method is shown in
Figure 1. One can see that the ELM method firstly finds the optimal separated hyperplane between the target (positive) samples and background (negative) ones. Within the particle filter framework, a great deal of candidate particles are sampled for estimating the object state. To reduce the calculated amount of particle sparse representation, the trained ELM classification function is utilized for removing most of the particle samples related to the background. Then, the resultant confidence values of particle samples on the ELM classification function are viewed as the probabilities belonging to the target and used for establishing the manifold learning constraint term of the following sparse representation, which tends to improve the robustness of the tracker. Finally, the estimated tracking result is to update the target templates of the sparse representation, and some new positive and negative samples are collected for updating the ELM classifier online. Thus, the proposed tracker could adaptively handle the visual changes of the foreground and backgrounds during tracking, thereby leading to more robust tracking results.
Figure 1.
Flowchart of the proposed tracking algorithm.
Figure 1.
Flowchart of the proposed tracking algorithm.
3.1. ELM Training
To promote the tracking efficiency of the sparse representation-based tracker, the number of particles in the sparse representation should be reduced. In [
13], a portion of candidate particles is removed via computing the reconstruction error in the target space. However, there still exist some particles relevant to the backgrounds, and the tracking speed is thus restricted to some extent. In this subsection, to make full use of the comparison information between the target and its backgrounds, a binary classifier is firstly trained for discarding most of the particle samples related to the background contents. The adopted classifier should have a low computational burden and a good discriminative capability. Compared to other techniques, the ELM model has a faster implementation and tends to achieve better generalization [
30]. Thus, the ELM technique is preferred in visual tracking, and the detailed procedure is as follows.
3.1.1. Generating Initial Training Samples
The object state in the first frame is often manually or automatically located. Supposing the initial center of the object is , the initial positive (target) samples are randomly generated within a circular area defined by , where is the center of the i-th sampled patch. Meanwhile, the initial negative (background) samples are collected from an annular region defined by (φ and ϖ are inner and outer radii, respectively). Let denote the sampled training dataset and be the corresponding class labels. Here, and are the number of positive and negative samples, respectively.
3.1.2. Classifier Training
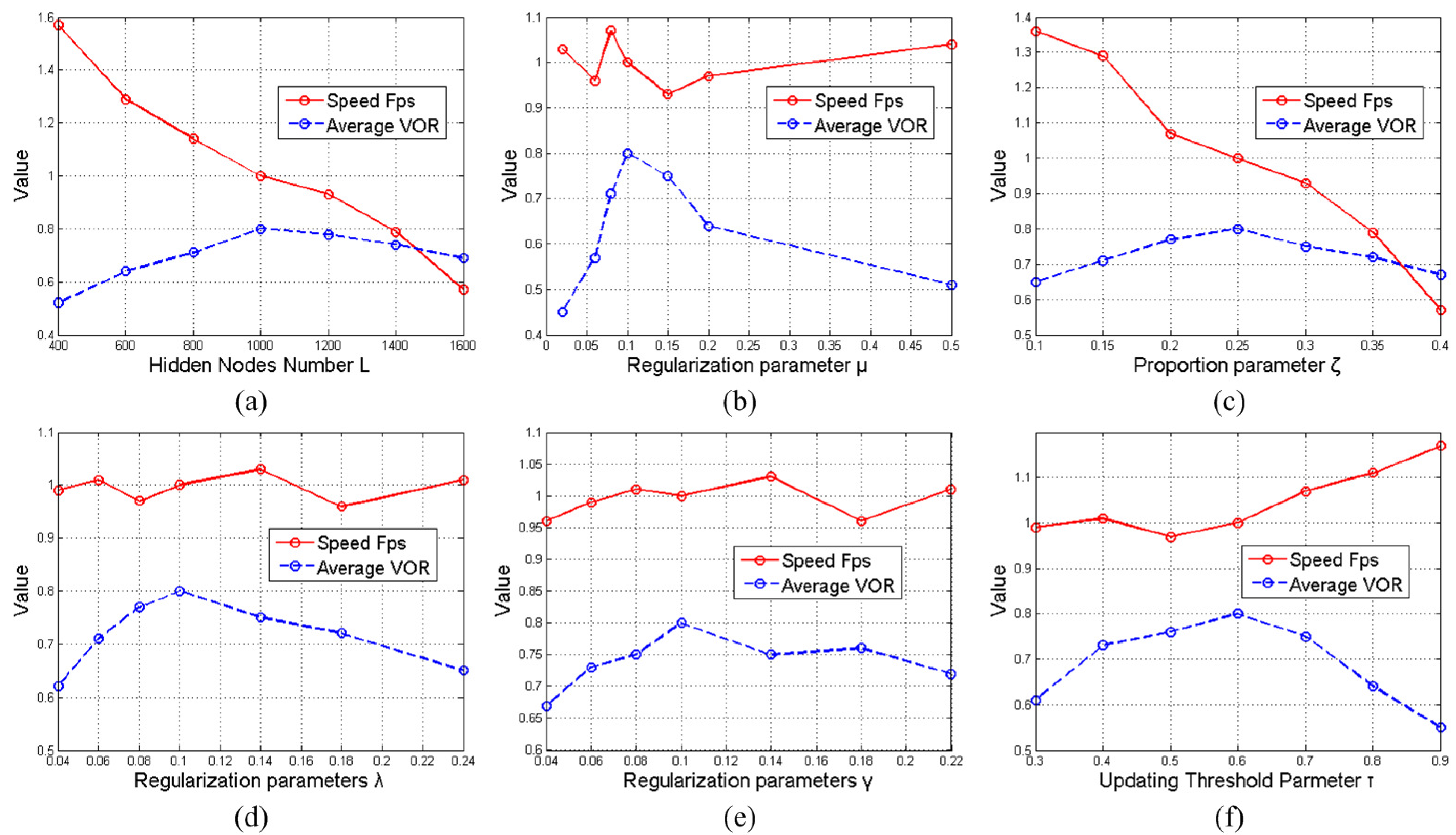
Let the hidden node number of the ELM classifier be
L. The input hidden parameters
and
(
) are randomly assigned based on a Gaussian distribution. Then, the hidden layer output matrix is computed via
, where
is the
j-th hidden node output. For visual tracking, we only have the object state in the first frame and no other information in a video. Thus, the number of collected training samples is not sufficient. Meanwhile, for a good generalization, the hidden node number
L is generally larger than the number of initial training data from the first frame. In this case, the output weights
β of the ELM classifier are calculated by:
The corresponding ELM classification function is:
Considering the truth that the number of initial training samples in the first frame is not sufficient, the trained classifier may not have good adaptability. To expand the training sample set, we uniformly collect
positive and
negative training samples from the initial five tracking frames and ensure that the total number of expanded training samples is larger than the hidden node number. Therefore, the new output weights
β of the retrained ELM classifier are computed by:
For the subsequent tracking frames, the likelihoods belonging to the true object of particle samples are calculated via the following function.
3.1.3. Classifier Updating
During the tracking process, to deal with the appearance changes of both targets and environments, the tracker should update the ELM classifier online. The input hidden parameters (
and
b) and hidden node number
L are fixed and never changed. Thus, the updating of ELM is equal to updating the output weights
β. Simply, the ELM model can be retrained with the total training data (including the old data). However, this kind of updating needs to store more and more training samples, and retraining with a large number of samples is a time-consuming task. Under this condition, the online sequential technique [
37] is exploited for updating the ELM model.
Suppose now that we already have some training samples
, and
is the number of initial training data. According to the above subsection, the output weights
are:
Here,
is the initial calculated hidden output matrix. Given
new training data
, we can update the output weights as follows.
In Equation (
18),
. With these equations, we can easily obtain the incremental updating expression of output weights
β.
From the above derivation, one can see that the updating of the ELM model only considers computing the new training data, and the resultant output weights can obtain the same learning accuracy as the retrained holistic training using the whole training data.
3.2. Reducing Candidate Samples
This work treats the tracking as a Bayesian inference task with hidden state variables, and the particle filter technique [
32] is utilized for providing the object
a posteriori estimation. With the assumption that the object state transition probability follows the Gaussian distribution,
M candidate particles are sampled to estimate the object state:
. For tracking accuracy, the number of candidate particles is often huge. In
Section 3.1, the ELM classifier is well trained with respect to the target and background samples. Generally, the potential target particles have high ELM functional output values, and
vice versa. Thus, with the trained ELM classification function
, those particles related to the background contents can be removed. Then, only a few potential particles are selected for the particle sparse representation. The detailed implementation is as follows.
The confidence value of one candidate particle
is defined by
. With the same input hidden parameters (
and
b) as the ELM training stage, the corresponding hidden node output of
is calculated by
. Using the suitable output weights
β, we compute the confidence value
by:
According to the confidence score value, the candidate particles are ranked in descending order: . Here, . The value essentially indicates the probability of particle belongs to object. We only choose a small number of high-ranking samples: , and the other candidate samples are discarded, thereby alleviating the calculation amount for the particle sparse representation. Here, we define the proportion parameter ζ as , and the value of ζ controls the percentage number of the selected particles for the following sparse representation. The reducing candidate operation can lead to two advantages. One is to cut down the computational burden of the tracker. The other is that the ELM model is discriminative enough for separating the object from its backgrounds. Thus, it can be free from the background disturbance to some degree, which tends to achieve stabler solutions.
3.3. Constrained Sparse Representation
3.3.1. Model Formulation
According to the manifold learning framework, two similar candidate samples should have similar coefficients in sparse representation [
18]. To enforce this assumption on these particle samples, the following loss function is presented.
Here,
and
are the sparse coefficients of particle
and particle
, respectively.
is the correlation coefficient, which indicates the similarity relation of two particles. If the particle
is similar to particle
, the
is large; otherwise, the
is small. To further combine the ELM learning and sparse representation, we calculate the correlation coefficient with the resultant confidence values of particle samples on the ELM classification function.
With the calculated
, we define these expressions:
,
,
. Here,
denotes the diagonalizable matrix operator. The Equation (
21) can be transformed as:
where
is the trace of a matrix. As a new regularization item,
is introduced into the objective function of basic sparse representation Equation (
7).
Here, Equation (
24) is a problem of constrained sparse representation, in which ELM learning is further combined with the particle sparse representation via a regularization term. Thus, the solution of Equation (
24) can be robuster. In addition, the computing of the correlation matrix in the manifold learning term does not depend on the time-consuming KNN method, thereby contributing to the tracking efficiency.
3.3.2. Model Solution
In this subsection, we aim to solve the problem of Equation (
24). The indicated function
is defined by:
With the indicated function
, the minimization problem of Equation (
24) is equivalent to:
Obviously, the object function of Equation (
26) consists of two different parts: the first three terms are the differentiable smooth convex functions with a continuous gradient, and the last term is a non-smooth, but convex function. For solving this kind of optimization problem, the accelerated proximal gradient (APG) method could yield an
residual from the optimal solution after
k iterations [
31]. For clear representation, we rewrite the object function of Equation (
26) as:
With the APG method, we can calculate the sparse representation coefficients
via Algorithm 1. In Algorithm 1,
is a temporary variable, and the gradient function
is:
Here,
and
are the column vectors whose entries are all ones.
is the number of templates in sparse representation space, and
r is the number of selected particles for sparse representation. The key in the APG method is to solve the optimization problem of Step 2. Additionally, with the indicated function
, this optimization problem has the following closed form solution.
With the above closed form solution, the optimal solution of the constrained sparse tracking model can be achieved within several iterations. It should be noted that the optimal solution is derived in matrix form. Thus, it allows the particle samples to be calculated in parallel, which can further improve the tracking efficiency of the proposed tracker. After calculating the optimal sparse representation coefficients
, the probability of one candidate sample belongs to object is computed via Equation (
8), and the final tracking result can be estimated via the MAP estimation.
| Algorithm 1: Solving sparse representation coefficients . |
Input: The templates set , the candidate samples and the Lipschitz constant ξ. 1: The initial value of optimal solution: , iteration parameter: . 2: Calculating the following expressions, , not until convergence. Output: The calculated sparse representation coefficients .
|
3.4. Template Updating Scheme
To adapt to the visual changes of the foreground and its backgrounds during the tracking process, the tracker needs to update the target templates of the sparse representation space and select new training samples for updating the ELM classifier. Similar to [
18], we update the target templates with the tracking result. However, the confidence value of the updated template on the ELM classification function
should be larger than a threshold value
τ. Under this condition, we can prevent some inappropriate updating samples from degrading the tracker. In addition, the tracking result from sparse representation is treated as the new object center. The same strategy as adopted in the first frame is applied for selecting new positive and negative training samples. One can see that this template updating scheme considers two factors from the ELM learning and sparse representation. Therefore, from updating the tracker point of view, the effects of single classification error or sparse reconstruction error can be decreased via combining these two different models.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




