1. Introduction
An electronic nose (E-nose) is a device composed of an array of gas sensors combined with a corresponding artificial intelligence algorithm. It is able to imitate the olfactory system of humans and mammals and is used for the recognition of gases and odors. Nowadays it plays a more and more important role in many fields, including odor analysis [
1,
2], product quality testing (such as food [
3,
4], tobacco [
5], fermentation products [
6], flavorings [
7],
etc.), disease diagnosis [
8,
9,
10], environmental control [
11,
12], explosives detection [
13],
etc.Previous work has confirmed that it is feasible to use an E-nose to detect bacteria, including the investigation of volatile organic compounds (VOCs) from cultures and swabs taken from patients with infected wounds [
14,
15,
16]. However, it is still a great challenge for us to extract features from the original signals of sensors to further improve the accuracy of the pattern recognition. Firstly, we can extract features from the original response curves of sensors, such as peak values, integrals, differences, primary derivatives, secondary derivatives, adsorption slopes, and maximum adsorption slope at a specific interval from the response curves [
17]. Independent component analysis (ICA) [
18,
19,
20] is a statistical method for transforming an observed multidimensional vector into components that are statistically as independent from each other as possible. In this way, it removes the redundancies of the original data. Orthogonal signal correction (OSC) [
21,
22,
23] is a new and popular data processing technique, and its basic idea is to remove information in the input matrix which is orthogonal to the target matrix. Principal component analysis (PCA) [
24,
25] extracts the important information from the observations which are inter-correlated and expresses this information as a set of new orthogonal variables called principal components. Secondly, we can also extract features based on some transformations, such as Fourier transformation and wavelet transformation, and then the transformation coefficients are used as features. The fast Fourier transformation (FFT) [
26] gives useful information for rotating components since well-defined frequency components are associated with them. Wavelet transformation [
27] is an extension of FFT. It maps the signals into new space with basis functions quite localizable in time and frequency space. The wavelet transform decomposes the original response into the approximation (low frequencies) and details (high frequencies). It bears a good anti-interference ability for the following pattern recognition to use the wavelet coefficients of certain sub-bands as features.
For E-nose pattern recognition, a number of classifier algorithms have been widely used such as back propagation neural network (BPNN) [
28], radical basis function neural network (RBFNN) [
29] and support vector machine (SVM) [
30]-based methods. Heuristic and bio-inspired methods [
31], in particular, such as genetic algorithms (GA) [
32], simulated annealing algorithm (SAA) [
33], particle swarm optimization (PSO) [
34] and recently the quantum-behaved particle swarm algorithm (QPSO) [
35] have been applied for feature selection, sensor array optimization, and classifier parameter selection. The QPSO algorithm has been investigated in detail and it has been proved that the QPSO algorithm is a form of contraction mapping that can converge to the global optimum [
36,
37]. Ordinary optimization methods, which we mention in this paper, can easily to fall into a local minimum point and the QPSO outperforms them in the rate of convergence and convergence ability for many applications. SVM is a new machine learning method introduced by Vapnik [
38,
39] based on the small sample statistical learning theory. It adopts the structural risk minimization (SRM) principle, and finds the best compromise between the learning ability and the complexity of the model to get the best generalization ability according to the limited sample information. Because of its excellent learning, classification ability, high generalization capability and good ability of dealing with high dimensionality space, SVM has already been widely used with excellent performance in pattern recognition, function regression and density estimation problems in recent years. Ordinary classifiers based on empirical risk minimization principle, such as artificial neural networks, usually have the problem of over-fitting and are liable to fall into local minima. SVM can solve small-sample, non-linear and high dimension problems which use the structural risk minimization principle instead of empirical risk minimization.
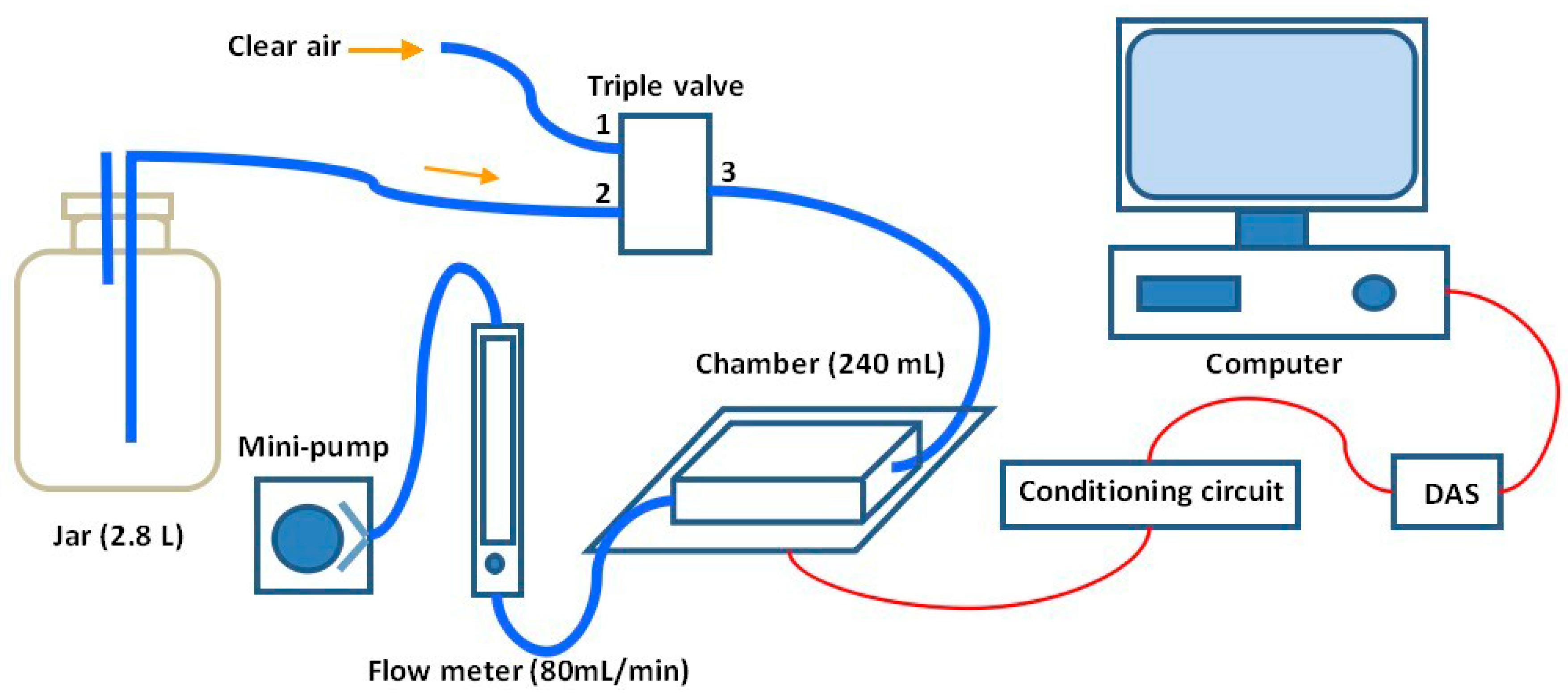
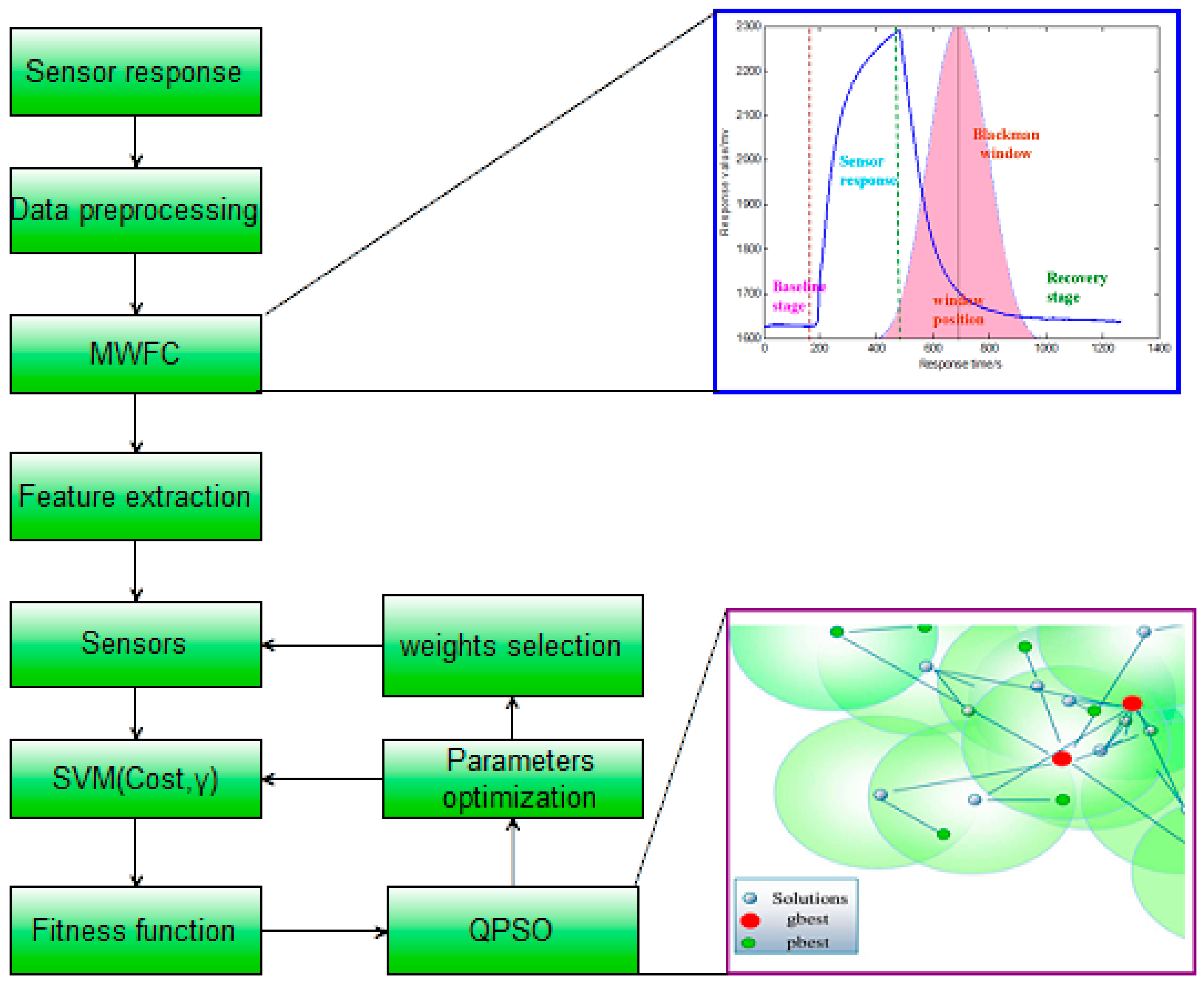
Previous methods for feature extraction do not include the steady-state and transient information of the entire response curve. Moreover, a features-based transform domain will miss the time domain information and cannot completely reflect the characteristics of the entire response process. Extraction of features only using the response signal itself of an electronic nose cannot reflect the interaction between the array signal and other specific functions, which can provide more interesting information. In this paper, a novel feature extraction approach which can be referred to as moving window function capturing (MWFC) is introduced to enhance the performance of E-noses. In the rest of this paper, we will firstly introduce the sampling experiments in
Section 2; then the whole methodology of MWFC with the QPSO based synchronization optimization of sensor array and SVM model parameters will be described in
Section 3; the results and discussion will be shown in
Section 4; finally we will draw our conclusions in
Section 5.
4. Results
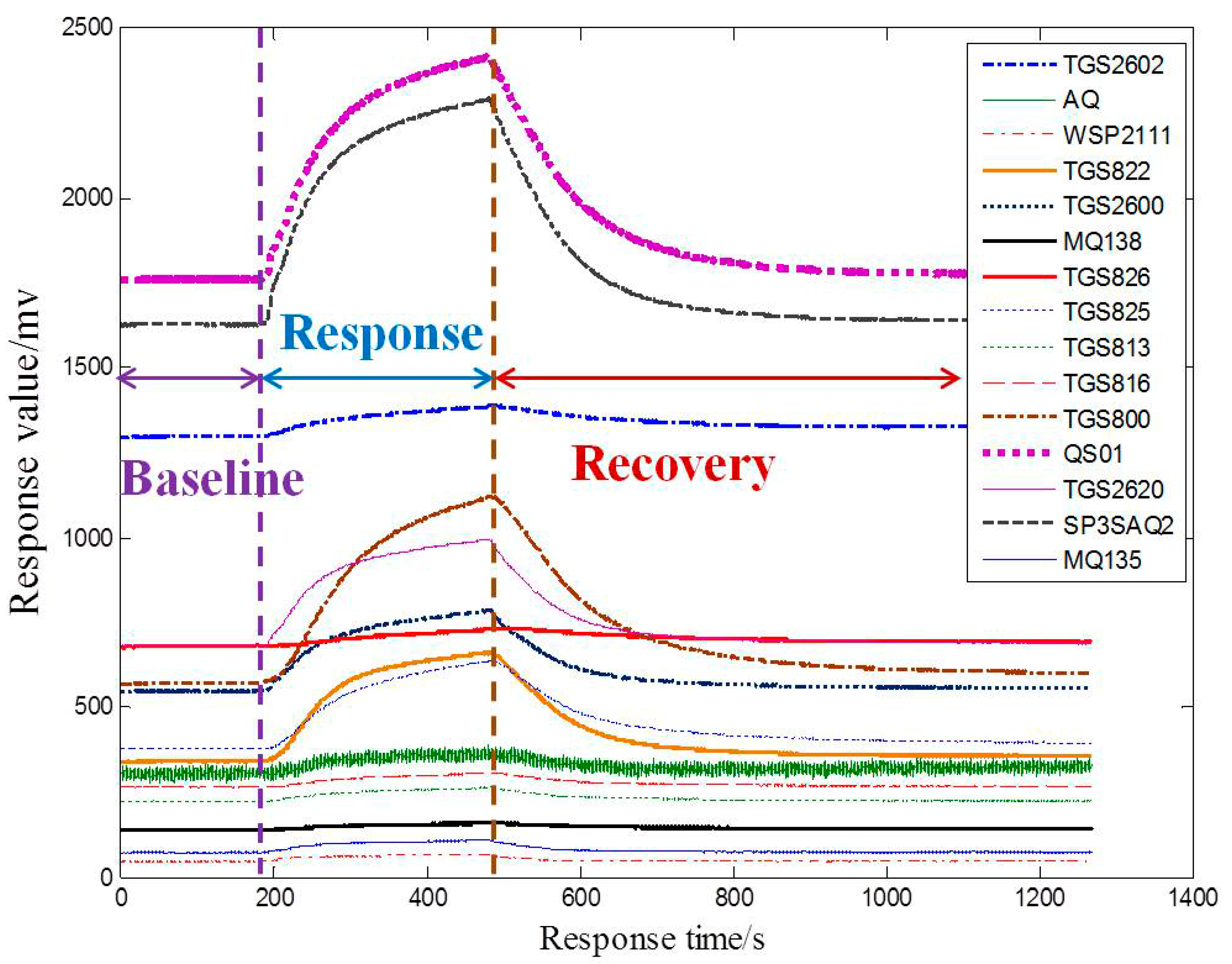
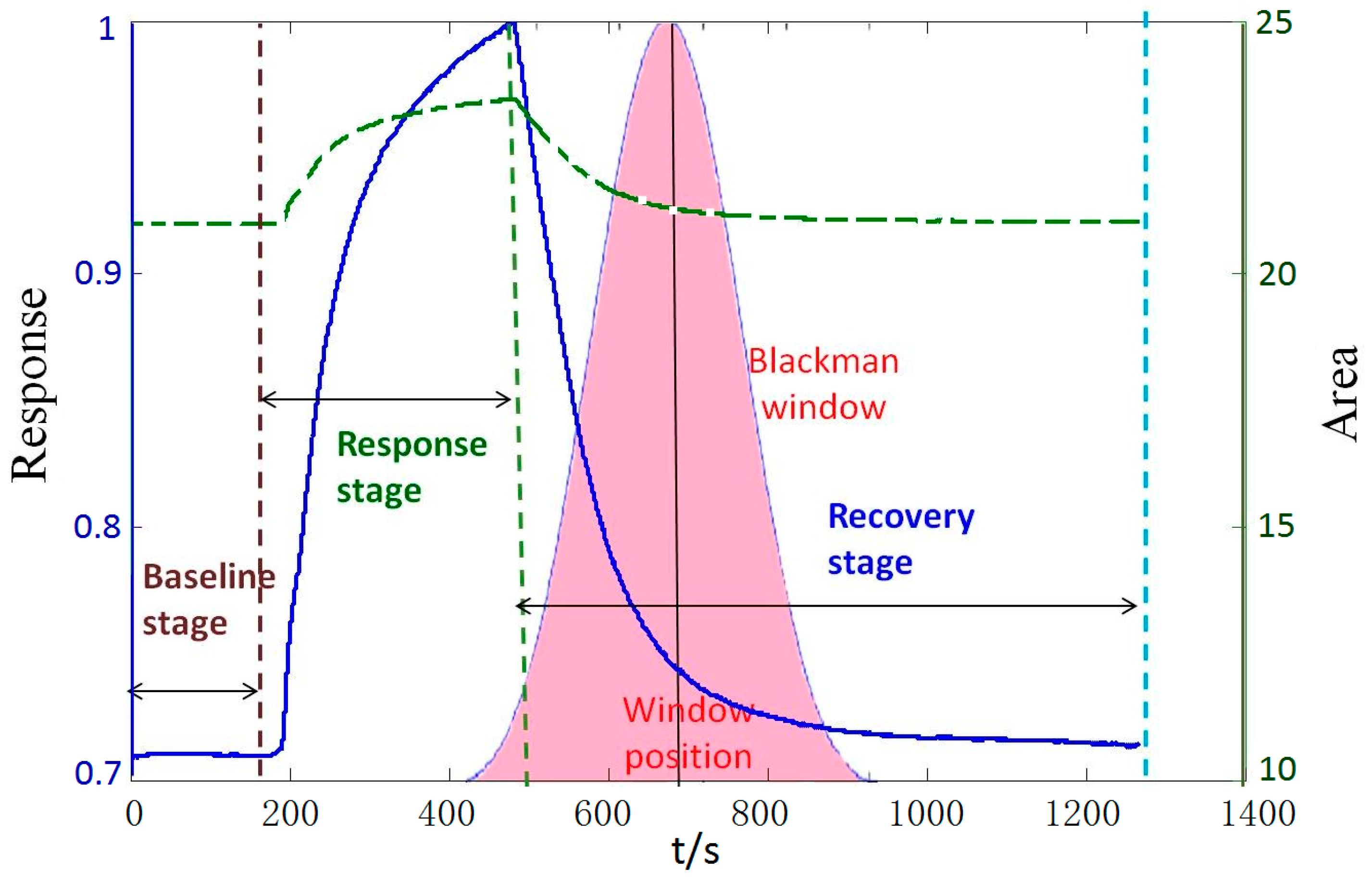
The window function of 64 time-points is placed at four different positions which response time are 180 s (the end of baseline stage), 330 s (the middle of response stage), 480 s (the end of response stage) and 930 s (the middle of the recovery stage), respectively, and four area values are extracted as different features.
Table 5 shows the classification accuracy rate of six different windows placed at four different positions, respectively. It is observed that the type and position of the window function will both influence the classification. Compared with other positions, 480 s is a more suitable position relatively, where the Triang window, Blackman window, Hamming window, Hanning window, Boxcar window and Gaussian window can achieve classification accuracies of 95.0%, 92.5%, 92.5%, 92.5%, 90.0% and 95.0% , which are higher than the other positions.
Table 5.
Classification accuracy (%) of four positions based on different windows.
Table 5.
Classification accuracy (%) of four positions based on different windows.
| Windows | Positions |
|---|
| 180 s | 330 s | 480 s | 930 s |
|---|
| Triang | 85.0 | 90.0 | 95.0 | 90.0 |
| Blackman | 82.5 | 90.0 | 92.5 | 87.5 |
| Hamming | 85.0 | 87.5 | 92.5 | 90.0 |
| Hanning | 85.0 | 90.0 | 92.5 | 90.0 |
| Boxcar | 80.0 | 90.0 | 90.0 | 87.5 |
| Gaussian | 85.0 | 92.5 | 95.0 | 87.5 |
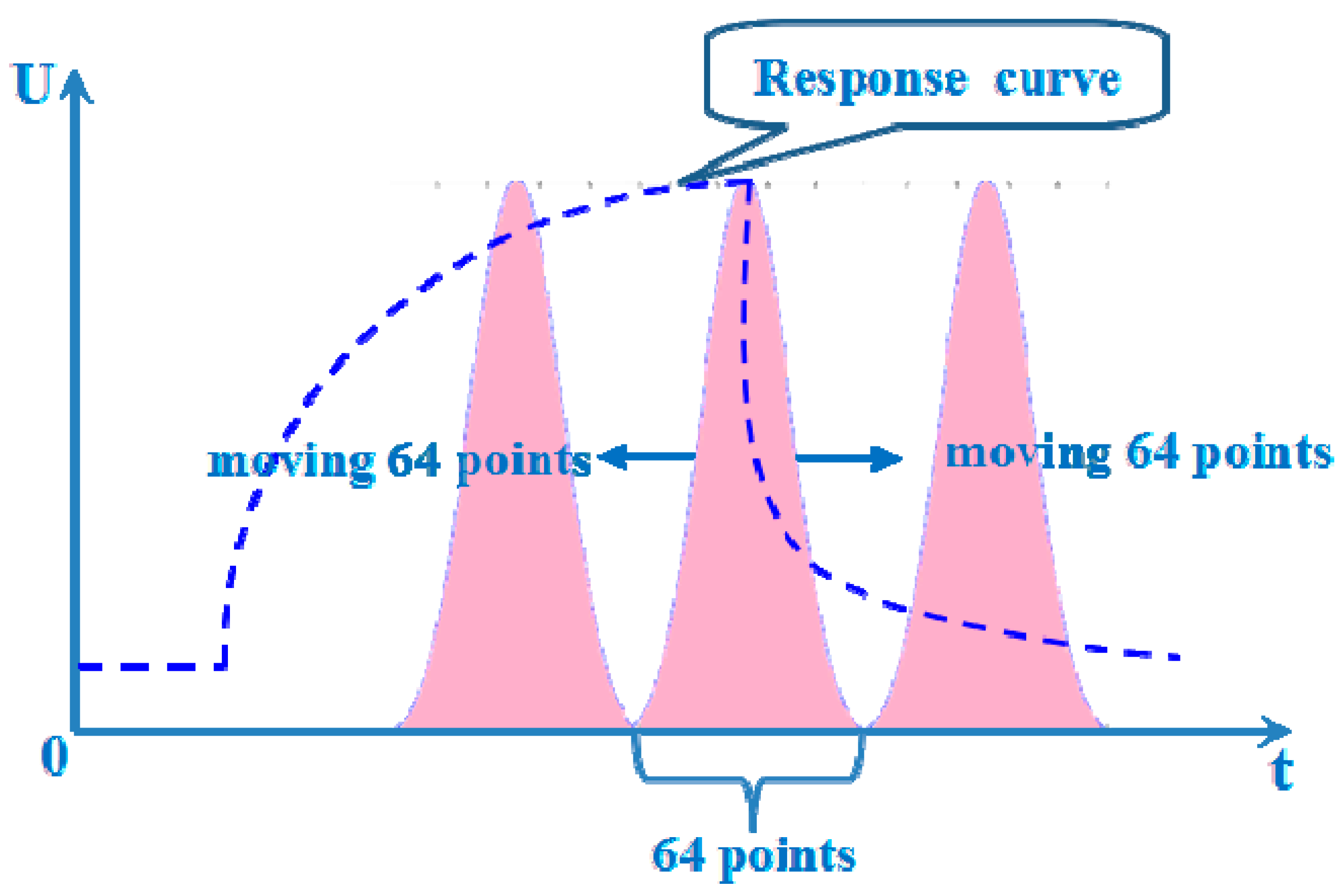
Table 6 shows the classification accuracy of different windows placed at the 480 s position with different widths. It is interesting to note that the classification accuracy rate will be different as the width of the window is changing. It is observed that the width of 64-points is a relatively more suitable width compared to the other widths, whereby the Boxcar window obtains a classification of 90.0%, the Blackman window, Hamming window and Hanning window obtain classification rates of 92.5%, and the Triang window and Gaussian window can obtain a classification rate of 95%.
Table 6.
Classification accuracy (%) of different windows shaped different widths.
Table 6.
Classification accuracy (%) of different windows shaped different widths.
| Windows | Widths |
|---|
| 32-points | 64-points | 128-points | 256-points | 512-points | 1024-points |
|---|
| Triang | 92.5 | 95.0 | 92.5 | 92.5 | 90.0 | 90.0 |
| Blackman | 87.5 | 92.5 | 92.5 | 90.0 | 90.0 | 87.5 |
| Hamming | 90.0 | 92.5 | 90.0 | 90.0 | 87.5 | 85.0 |
| Hanning | 90.0 | 92.5 | 92.5 | 90.0 | 90.0 | 87.5 |
| Boxcar | 87.5 | 90.0 | 90.0 | 87.5 | 87.5 | 85.0 |
| Gaussian | 90.0 | 95.0 | 92.5 | 92.5 | 92.5 | 90.0 |
From
Table 5, it can be observed that 480 s is relatively a more suitable position compared with other positions. This means that the surrounding range of peak values contains much more key information to improve the classification accuracy. The positions where each sensor obtains its peak value are different, which is shown in
Figure 7. Moreover, we take the width of window into consideration and find that the width of 64-points is relatively a more suitable width compared to the other widths shown in
Table 6.
Figure 7.
The positions where each sensor obtains the peak value.
Figure 7.
The positions where each sensor obtains the peak value.
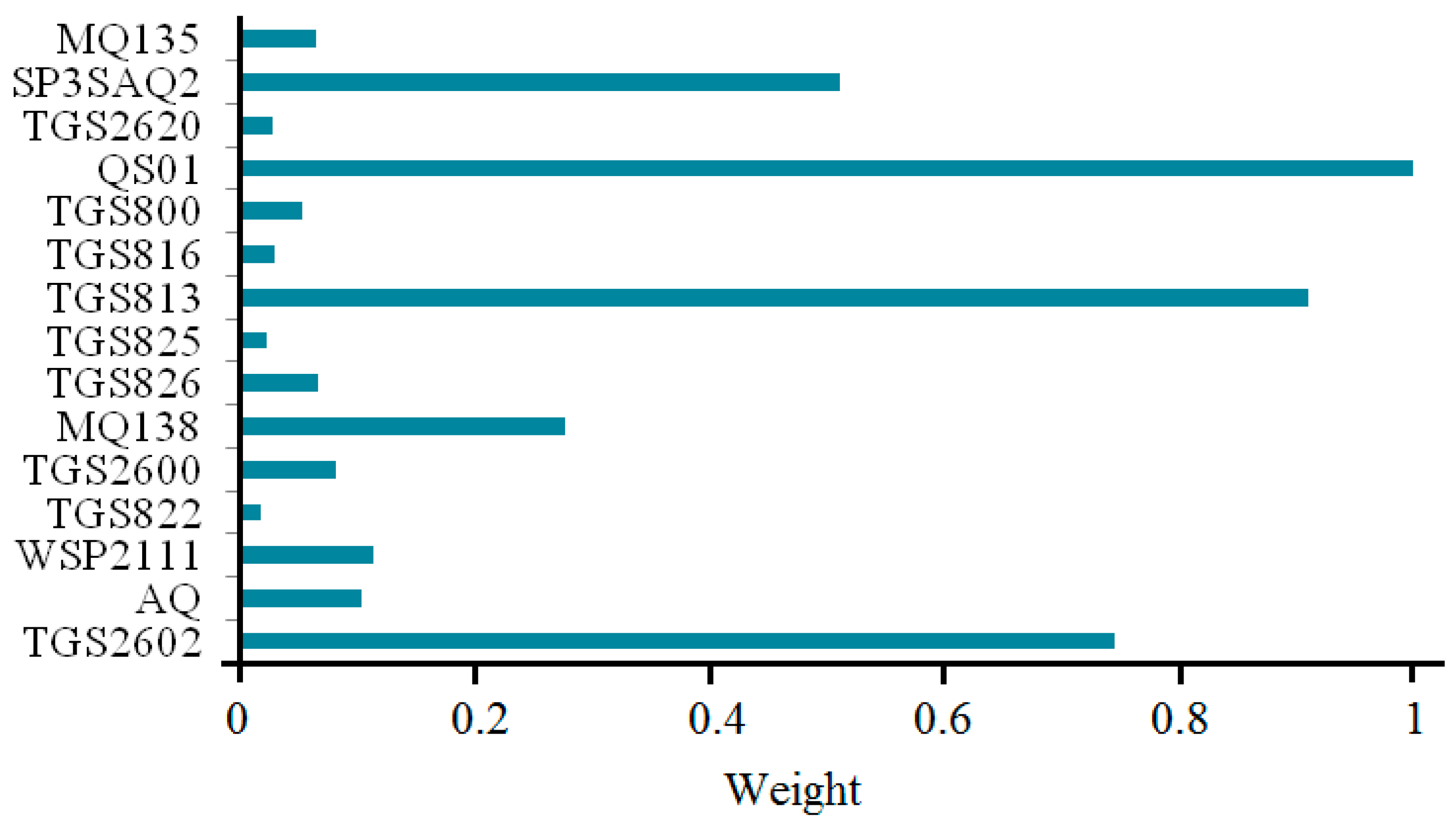
The importance of the 15 sensors is shown in
Figure 8, where the corresponding optimal normalizing importance factors, that is the weighting coefficients of sensors, are [0.7445, 0.1032, 0.1144, 0.0180, 0.0816, 0.2771, 0.0668, 0.0224, 0.9095, 0.0299, 0.0539, 1.0000, 0.0279, 0.5109, 0.0646].
Figure 8.
Optimal importance factors with QPSO for 15 sensors.
Figure 8.
Optimal importance factors with QPSO for 15 sensors.
Table 7 shows the classification accuracy of MWFC with SVM and RBFNN. It is observed that the classification accuracy with SVM is higher than RBFNN and the classification accuracy with sensor optimization is higher than without sensor optimization. From
Table 7 we can see that the QPSO-SVM method combined with weighting sensor array by importance factors obtains a 97.5% classification rate with the Triang window, 95.0% classification rate with the Blackman window, 95.0% classification rate with the Hamming window, 97.5% classification rate with the Hanning window, 95.0% classification rate with the Boxcar window, 97.5% classification rate with the Gaussian window.
Table 7.
Classification accuracy (%) of MWFC with SVM and RBF.
Table 7.
Classification accuracy (%) of MWFC with SVM and RBF.
| Methods | Types |
|---|
| Triang | Blackman | Hamming | Hanning | Boxcar | Gaussian |
|---|
| RBF-MWFC a | 87.5 | 85.0 | 90.0 | 85.0 | 85.0 | 90.0 |
| QPSO-RBF-MWFC b | 92.5 | 87.5 | 92.5 | 90.0 | 87.5 | 90.0 |
| SVM-MWFC a | 92.5 | 90.0 | 92.5 | 92.5 | 92.5 | 92.5 |
| QPSO-SVM-MWFC b | 97.5 | 95.0 | 95.0 | 97.5 | 95.0 | 97.5 |
Table 8 lists the results of accuracy comparison of various feature extraction techniques. It is observed that the peak value method obtains an accuracy rate of 87.5%, the same as that of the rising slope, and is better than that of descending slope, which is only 85.0%. FFT and DWT achieve classification accuracies of 90.0% and 92.5%, and the SVM-WFC method which uses QPSO to optimize SVM parameters and the weights of each gas sensor can achieve an accuracy rate of 95.0%. It is interesting to note that the performance of the E-nose can be improved further when choosing the method of SVM-MWFC, which can achieve an accuracy rate of 97.5%.
Table 8.
Accuracy comparison of various feature extraction techniques (%).
Table 8.
Accuracy comparison of various feature extraction techniques (%).
| Feature Extraction | Accuracy Rate |
|---|
| Peak value | 87.5 |
| Rising slope | 87.5 |
| Descending slope | 85 |
| FFT | 90.0 |
| DWT | 92.5 |
| WFC | 95.0 |
| MWFC | 97.5 |
To demonstrate the generalization to other datasets of the proposed approach, we use the feature extraction method of MWFC to deal with another two experimental E-nose datasets: (1) MWFC has been applied to deal with the data of an E-nose which detects five odors: nonane, 2-propyl alcohol, heptanal, 1-phenylethanone, and isopropyl myristate, and the classification results are shown in
Table 9. More details about the sample preparation experiments can be found in [
40]; (2) MWFC has also been applied to deal with the data of an E-nose which detects six indoor air contaminants including formaldehyde (HCHO), benzene (C
6H
6), toluene (C
7H
8), carbon monoxide (CO), ammonia (NH
3) and nitrogen dioxide (NO
2) and classification results are also shown in
Table 9. More details about the sample preparation experiments can be found in [
41].
Table 9.
Accuracy of various feature extraction techniques for other datasets (%).
Table 9.
Accuracy of various feature extraction techniques for other datasets (%).
| Feature Extraction | Accuracy Rate |
|---|
| Dataset in [40] | Dataset in [41] |
|---|
| Peak value | 85.33 | 82.11 |
| Rising slope | 88.00 | 80.49 |
| Descending slope | 82.67 | 81.30 |
| FFT | 89.33 | 83.74 |
| DWT | 90.67 | 86.17 |
| WFC | 92.00 | 89.43 |
| MWFC | 93.33 | 91.06 |
From
Table 9, MWFC also achieves better classification results of than the compared feature extraction methods. This shows the generalized performance of the feature extraction method of MWFC with other datasets. The efficacy of this approach does not depend on a particular dataset.
5. Discussion
We use one-way analysis of variance (ANOVA) to test whether the feature extraction methods have a significant influence on the classification accuracy rate and then the test results can be obtained by SPSS as shown as
Table 10. A one-sample Kolmogorov-Smirnov test confirms that the distributions of each feature extracted follow normal (or Gaussian) distributions. It can be found that the value of the
statistic is 553.976, which is significantly greater than 1 and the significance value is 0. Given the level of significance
, we can reject the null hypothesis and conclude that there is a significant difference of accuracy rates under different feature extraction methods.
Table 10.
ANOVA Results.
| | Sum of Squares | df | Mean Square | F | Significant |
|---|
| Between Groups | 4.1817 | 6 | 0.6969 | 553.976 | 0 |
| Within Groups | 0.3434 | 273 | 0.0013 | | |
| Total | 4.5251 | 279 | | | |
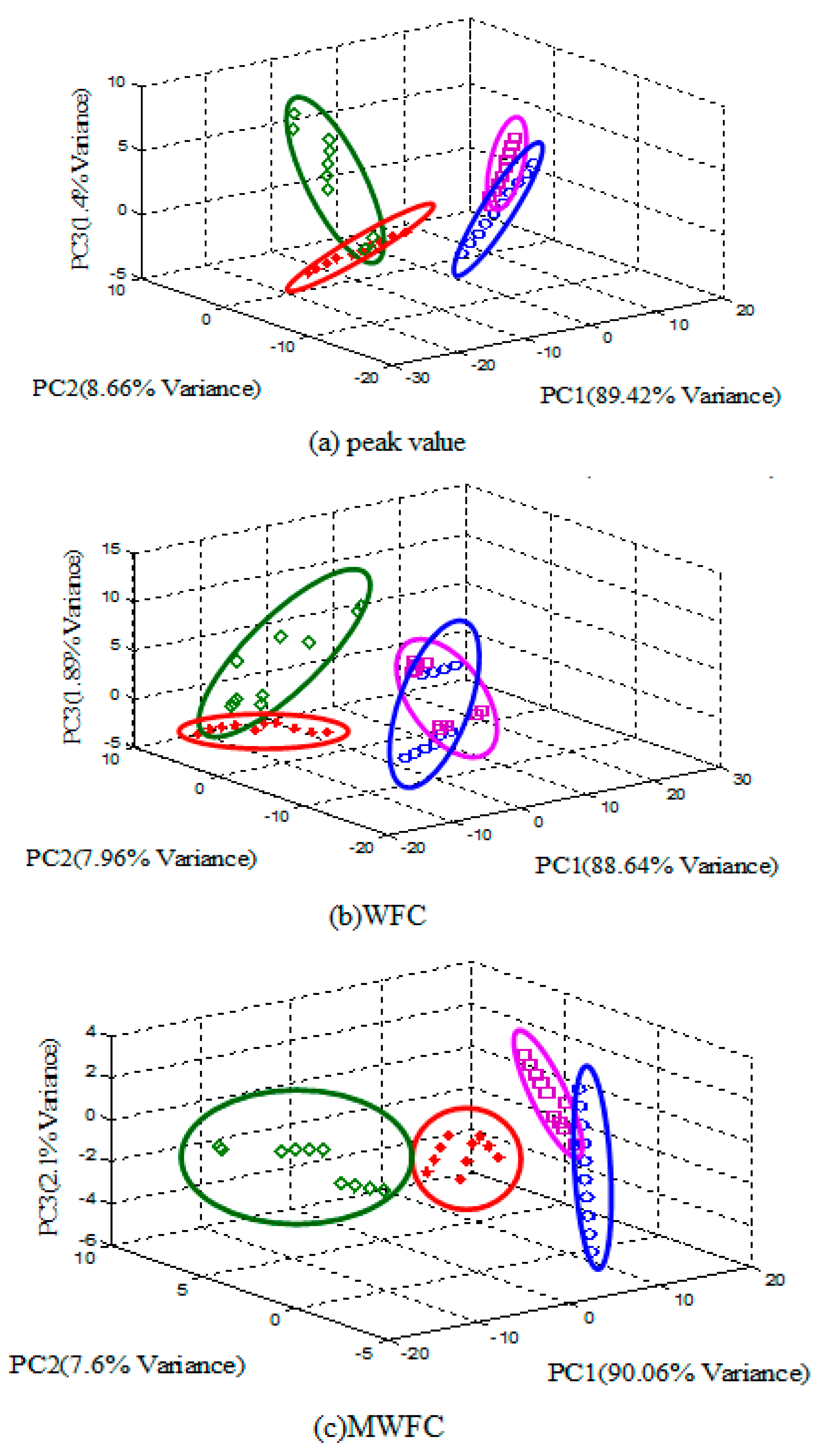
To visualize the efficacy of the proposed method, PCA is applied for the peak value, WFC and MWFC features and the PCA score plots are shown from
Figure 9, respectively. The higher degree of overlaps of four kinds of samples can be observed in
Figure 9a and the distribution of four kinds of samples is relatively dispersive in
Figure 9b, whereas, in
Figure 9c, the cluster of four kind of samples are overlapping little and can be more easily distinguished. In a word, the performance of classification with the MWFC method is better than the others.
From the results shown above, the MWFC method can obtain a better accuracy rate for classification of different E-nose data than the compared methods. Peak value, which only represents the final steady-state feature of the entire dynamic response process in its final balance, reflects the maximum reaction degree change of sensors responding to odors. However, it misses all the transient response information of the reaction kinetics process and cannot describe the process well. Rising slope and descending slope also have specific physical meanings and represent the rate of the reaction of sensors responding to odors in the response and recovery stages, respectively. Although the rate of reaction of the sensors reflects the transient information in different stages, it only describes the reaction kinetics at one aspect. For the above features, it is difficult to distinguish tiny differences between response curves of different odors. They are not like the MWFC method which represents the cumulative total of the reaction degree change, accumulates these tiny differences in a specific way and makes these differences more significant. Moreover, these features only use the response signal itself and cannot reflect the interaction between the array signals to other specific functions, which can provide more interesting information. The widely used FFT, for which the basis functions are sine and cosine, maps the original data into a new space. It decomposes the original response into the superposition of the dc component and different harmonic components, and the feature characterized by amplitude of each component can be used for qualitative and quantitative analysis. However, FFT transforms the original signals from the time domain to the frequency domain and extracts features in the frequency domain. It misses the information in the time domain and cannot completely reflect the characteristics of the entire response process. Moreover, although extracting the coefficients of the dc component and first order harmonic component as features contains a large proportion of information of the original response curve, it misses the information in the higher harmonic components. Wavelet transform is an extension of the Fourier transform. It maps the signals into a new space with basis functions quite localizable in time and frequency space. DWT decomposes the original response into the approximation (low frequencies) and details (high frequencies). It bears good anti-interference ability for the followed pattern recognition to use the wavelet coefficients of certain sub-bands as features, so it obtains better result than the former features.
Figure 9.
PCA score plot of different features.
Figure 9.
PCA score plot of different features.
However, extracting the approximation coefficients as features, which reflects the low frequencies information, misses the details, which reflect the high frequencies information, though the low frequencies signal contain much more information. What is more, there are many parameters of DWT to set, which have an effect on the decomposition results, and it is difficult to determine an optimal parameters set. WFC chooses the area surrounded by a window function curve and the original response curve as an extracted feature. Because the WFC method only places the window at the position of the peak value and extracts one area value as feature, it only reflects the information around the steady-state response of the entire dynamic response process in its final balance, which is the most important information to distinguish different types and concentrations of gases. It does not take a great deal of transient information in the whole response and recover stages into consideration and obtains worse results as compared to MWFC.
MWFC is the extension of the WFC method, which can be employed as a filter to capture information from the time domain. It reflects the interaction between the response curve and different windows. If there are tiny differences between the response curves of different odors, the areas which are obtained by MWFC can accumulate these differences in a specific way, which is determined by different windows, and make these differences more significant. In this way, it can achieve a higher accuracy rate after selection of the proper window parameters.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








