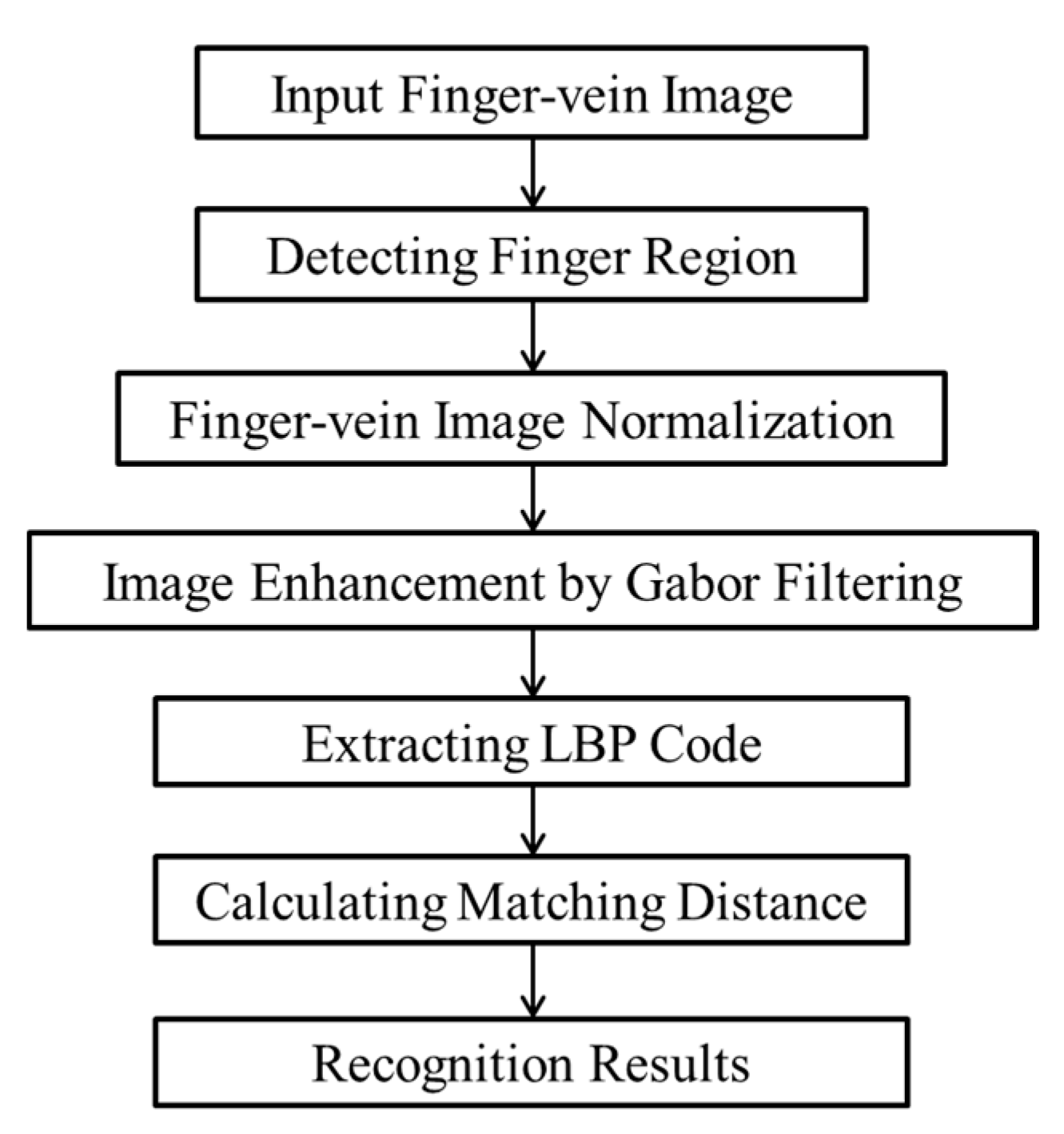
3.2. Performance Evaluation on Three Databases
For this research, we used three different finger-vein databases to evaluate the factors that affect the matching accuracy. The first database was created by collecting finger-vein data from 20 people using the device proposed in
Section 3.1. [
27]. For each person, the vein images of the index, middle, and ring fingers on both the left and right hands were captured 10 times with an image resolution of 640 × 480 pixels. The total number of images in our database was 1200 (20 people × 2 hands × 3 fingers × 10 images). Because the finger alignment and image quality of the images in this database were strictly assured, it was considered a good-quality database.
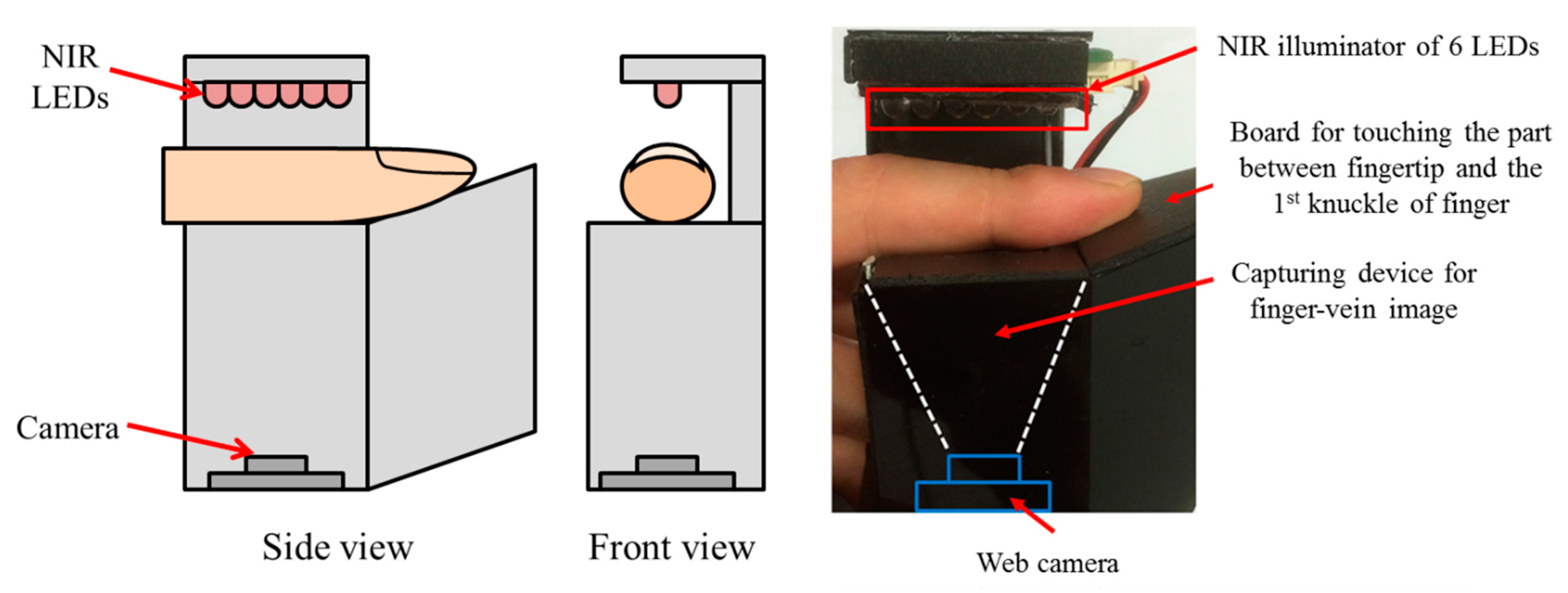
In addition, we used two other databases, the first of which was constructed by selecting the vein images of six fingers among the images of 10 fingers in the database I (which were collected by the finger-vein capturing device without the guiding bar in previous research [
7]). The device, which was used for collecting the database I [
7], is shown in
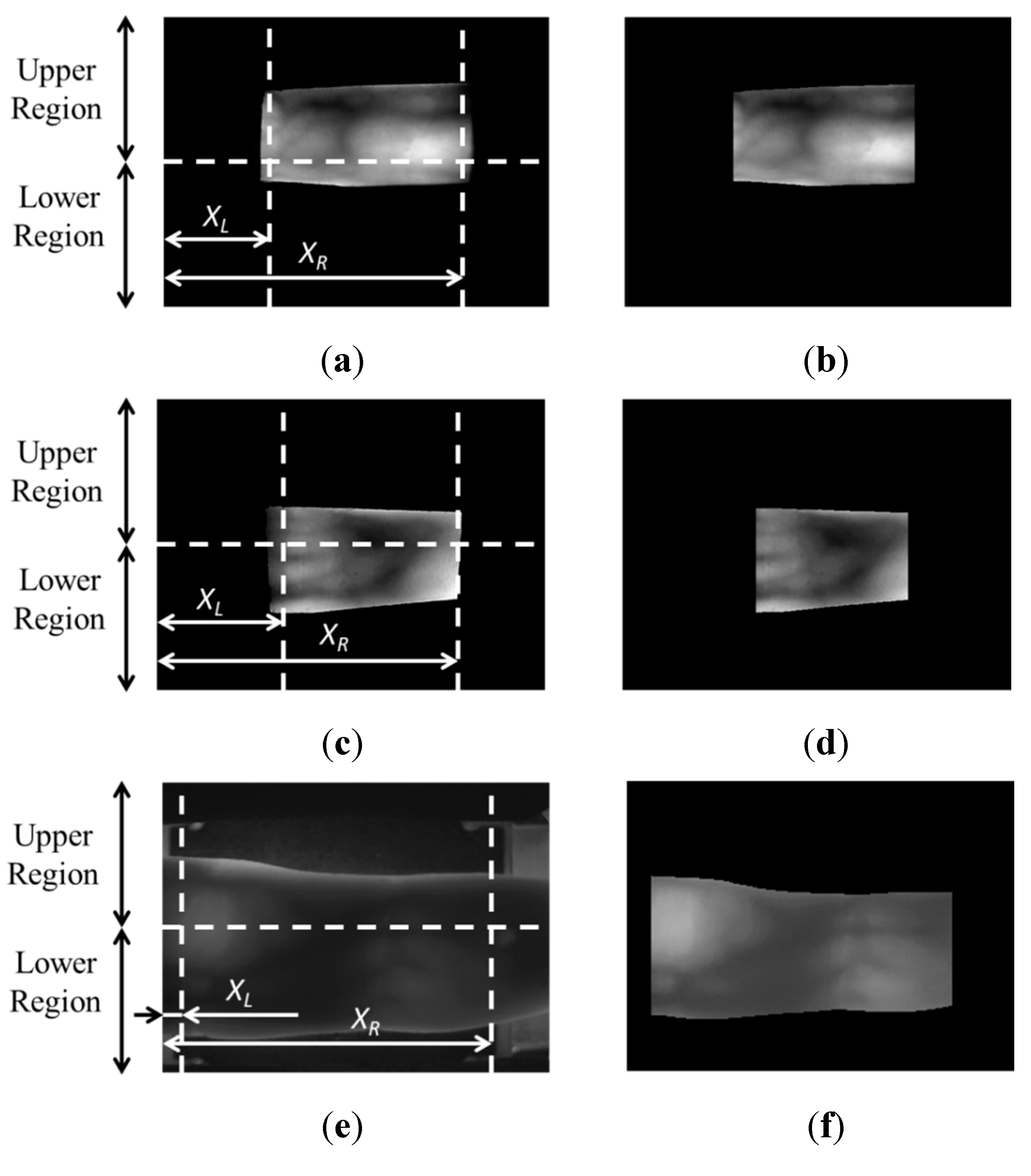
Figure 8. Because the guiding bar was absent, the misalignment among trial images of each finger in this database is relatively high; therefore, this was considered mid-quality database. In detail, each people puts his or her finger on the hole of the upper-part of device, and the size of the hole in the device for capturing the finger-vein image is fixed and limited in order to remove the effect by the environmental light into the captured image. Therefore, the part of finger area can be acquired in the image as shown in
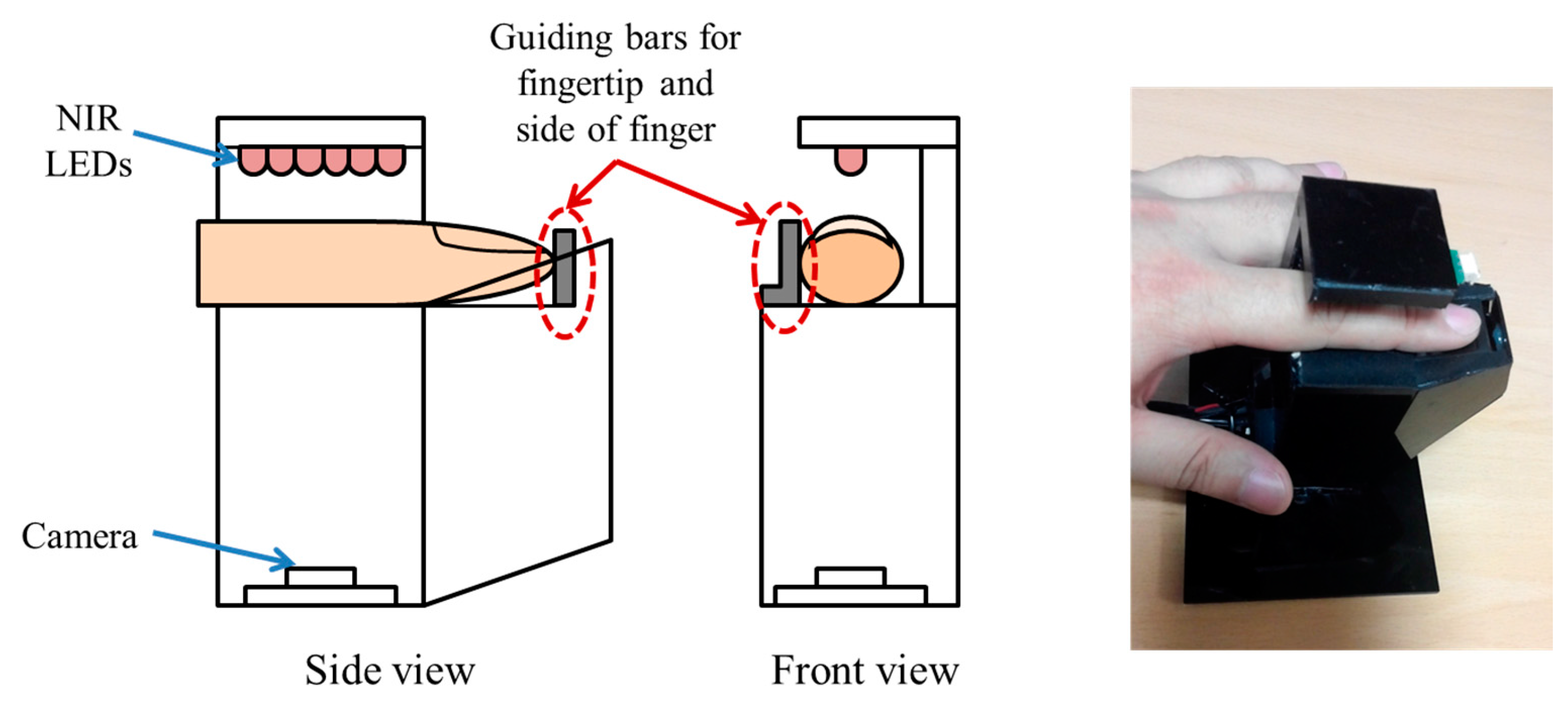
Figure 9a,b. Consequently, it is often the case that some part of the finger area (which is seen in the enrolled image) is not seen in the recognized image, which cannot be compensated by preprocessing step and can reduce the accuracy of recognition. In order to solve this problem, we propose a new device including two guiding bars for fingertip and side of finger as shown in
Figure 7, which can make the consistent finger area be acquired by our device with reduced misalignment. However, no guiding bar is used in the other device of
Figure 8, which is used for collecting the 2nd database. Therefore, we call the 1st and 2nd databases collected by the devices of
Figure 7 and
Figure 8 as good-quality and mid-quality databases, respectively.
The number of images in the mid-quality database is 1980 (33 people × 2 hands × 3 fingers × 10 trials), and each image has the same size as that of the images in the good-quality database,
i.e., 640 × 480 pixels [
27].
Figure 8.
Device for capturing finger-vein images for the second (mid-quality) database.
Figure 8.
Device for capturing finger-vein images for the second (mid-quality) database.
The last database used in this study is an open finger-vein database (SDUMLA-HMT Finger-vein database) [
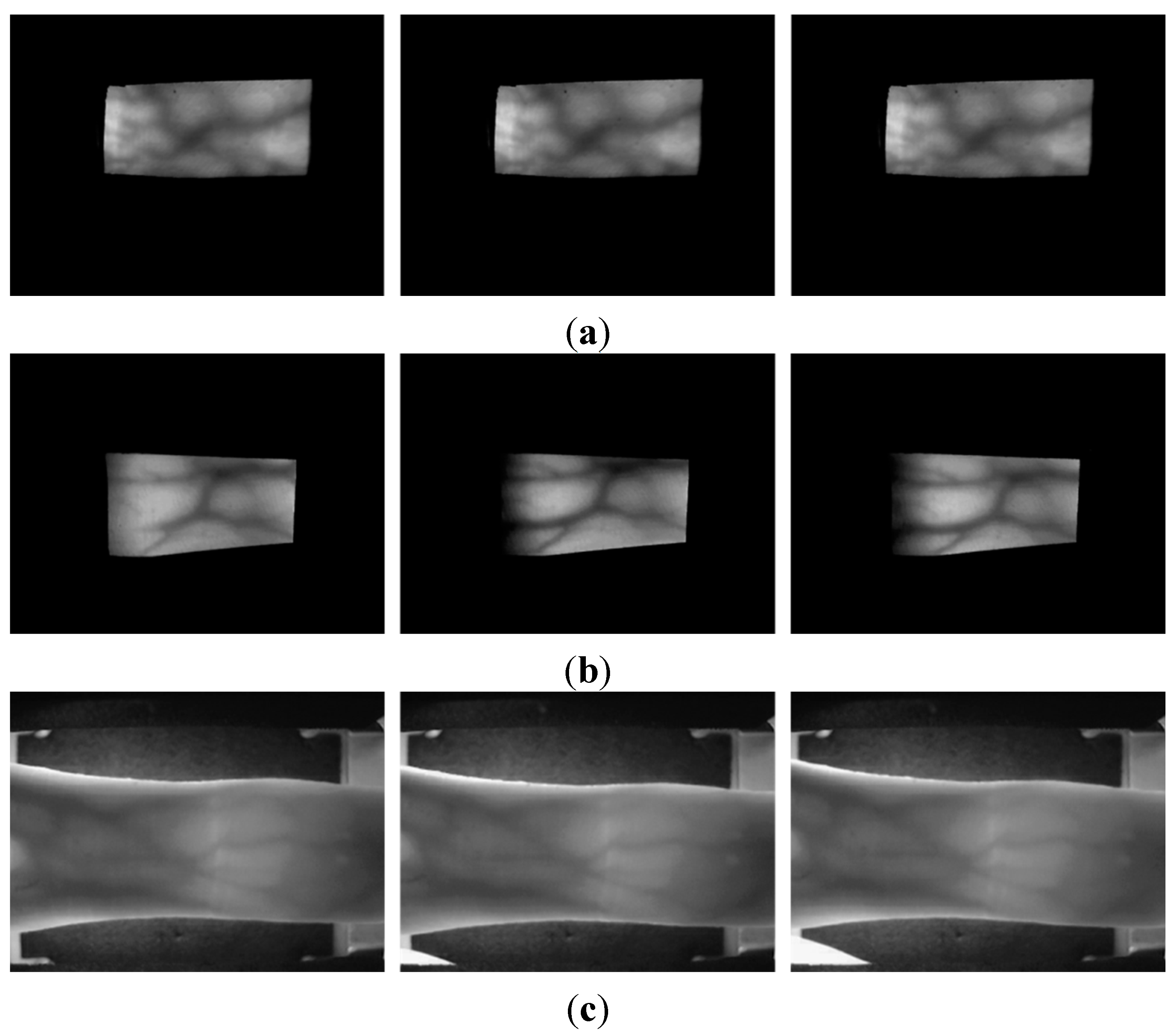
28], which comprises 3816 images, with a size of 320 × 240 pixels, from 106 people, including six fingers from each person and six trials for each finger. Example images of different trials of one individual (same finger) from each database are given in
Figure 9. It can be seen in
Figure 9 that the degree of misalignment among the trials of each finger from the mid-quality and open databases is larger than that from the good-quality database.
Figure 9.
Input images of different trials from the same finger of one individual from each database: (a) good-quality; (b) mid-quality; and (c) open database.
Figure 9.
Input images of different trials from the same finger of one individual from each database: (a) good-quality; (b) mid-quality; and (c) open database.
The accuracies of the finger-vein recognition method were evaluated by performing authentic and imposter matching tests. In our experiments, the images in each finger-vein database could be classified in various ways to allow the discrimination factors to be evaluated. In each experiment, authentic matching tests were used to calculate the pairwise matching distances between the images selected from the same class, whereas for the imposter matching tests, the distances between the pairs of images from different classes were calculated. Assuming that for a particular database, we classify finger-vein images into
M classes and each class has
N images, then the number of authentic and imposter matching tests denoted by
A and
I are determined by the following Equations (5) and (6), respectively.
where
NC2 =
N(
N − 1)/2 is the number of two-combinations from a set of
N elements.
By applying and adjusting the threshold on the matching Hamming distance, we calculated the false acceptance rates (FARs), false rejection rates (FRRs), and the EER. FAR refers to the error rates of imposter matching cases, which are misclassified into authentic classes, whereas FRR refers to the error rates of misclassified authentic testing cases into imposter classes. EER is the error rate when the difference between FAR and FRR is minimized. In addition, we measured the d-prime (
d') value, which represents the classifying ability between authentic and imposter matching distributions as the following Equation (7) [
3].
where µ
A and µ
I represent the mean values of the authentic and imposter matching distributions, respectively, and σ
A and σ
I denote the standard deviations of authentic and imposter matching distributions, respectively. A higher d-prime value indicates a larger separation between the authentic and imposter matching distributions, which corresponds to a lower error of recognition, in case that the distributions of authentic and imposter matching scores are similar to Gaussian shape, respectively.
We conducted the following experiments to evaluate the various factors that affect the results of the finger-vein recognition system.
First, we considered each finger of each person to form a different class. This method is used by conventional finger-vein recognition systems to evaluate the recognition accuracy [
7,
8,
9,
11,
16,
17,
18,
19,
20,
21,
22,
23,
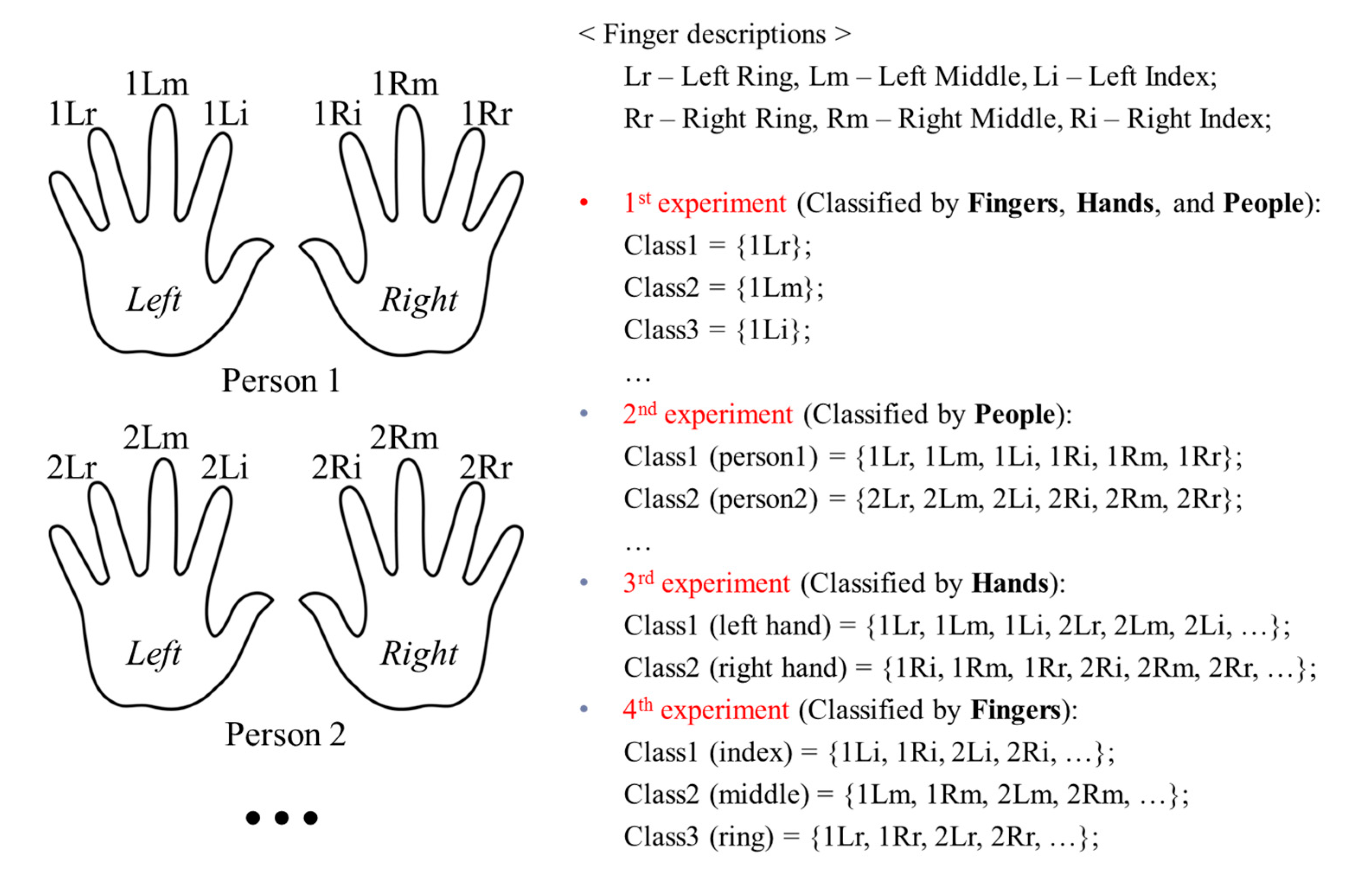
25]. Consequently, for the good-quality, mid-quality, and open databases, the number of classes were 120 (20 people × 6 fingers), 198 (33 people × 6 fingers), and 636 (106 people × 6 fingers), respectively. As this class definition method includes the dissimilarity information of fingers, hands, and people in the finger-vein database, we considered this as the 1st experiment (classified by fingers, hands, and people).
In the 2nd experiment, we classified the finger-vein images based on people (classified by people), by assuming that the images of all the fingers on both hands from the same person formed the same class. As a result, in the 2nd experiment, the number of classes in each database equaled the number of users, which was 20, 33, and 106 for the good-quality, mid-quality, and open databases, respectively.
In the 3rd experiment, we assumed that the finger-vein images of all the fingers on the left hands of all the people belong to the same class, and those on the right hands of all the people form another class. Thus, there were two classes based on different hand sides in this experiment (classified by hands).
In the 4th experiment, we evaluated the dissimilarities of finger types by assuming that the images from the index fingers, middle fingers, and ring fingers on both hands of all the people belong to three different classes. This assumption is referred to as (classified by fingers). The organization of these experiments is summarized in
Figure 10. The numbers of authentic and imposter matching tests in the experiments on the three databases are determined by Equations (5) and (6), and are shown in
Table 2.
Table 2.
Number of matching tests (authentic and imposter) for the experiments on the three finger-vein databases (M is the number of classes in each experiment and N is the number of images belonging to one class. Authentic and Imposter refer to the numbers of authentic and imposter matching tests, respectively).
Table 2.
Number of matching tests (authentic and imposter) for the experiments on the three finger-vein databases (M is the number of classes in each experiment and N is the number of images belonging to one class. Authentic and Imposter refer to the numbers of authentic and imposter matching tests, respectively).
| Experiments Databases | 1st Experiment | 2nd Experiment | 3rd Experiment | 4th Experiment |
|---|
| Classified by Fingers, Hands and People | Classified by People | Classified by Hands | Classified by Fingers |
|---|
| Good-quality Database | N/M | 10/120 | 60/20 | 600/2 | 400/3 |
| Authentic | 5400 | 35,400 | 359,400 | 239,400 |
| Imposter | 714,000 | 684,000 | 360,000 | 480,000 |
| Mid-quality Database | N/M | 10/198 | 60/33 | 990/2 | 660/3 |
| Authentic | 8910 | 58,410 | 979,110 | 652,410 |
| Imposter | 1,950,300 | 1,900,800 | 980,100 | 1,306,800 |
| Open Database | N/M | 6/636 | 36/106 | 1908/2 | 1272/3 |
| Authentic | 9540 | 66,780 | 3,638,556 | 2,425,068 |
| Imposter | 7,269,480 | 7,212,240 | 3,640,464 | 4,853,952 |
Table 3 shows the comparative results of the four experiments defined in
Table 2 and
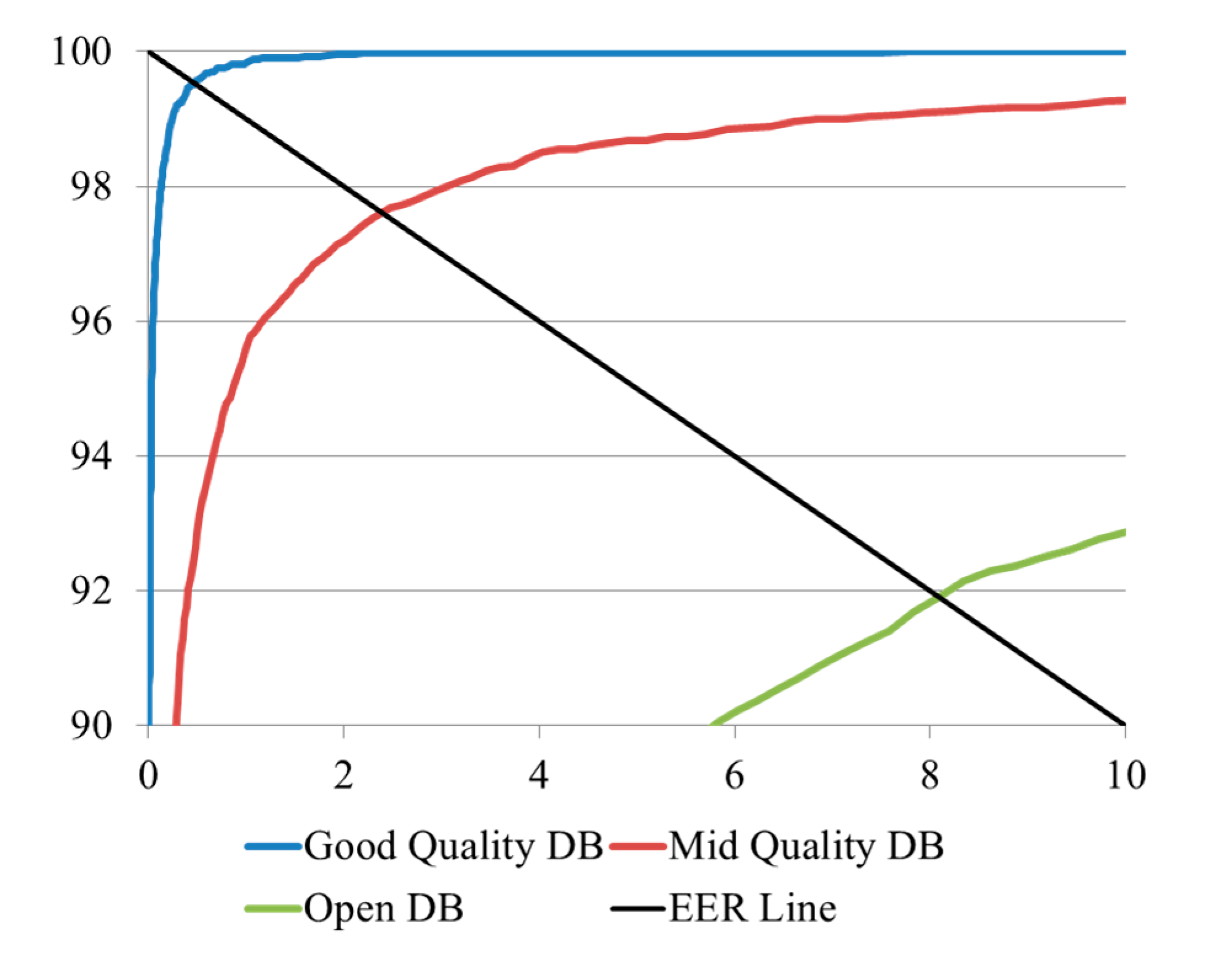
Figure 10 for the three databases. In the 1st experiment, in which finger-vein images were classified by fingers, hands, and people, the lowest EER (0.474%) was obtained for the good-quality database. This is due to the fact that this database was captured by the proposed capturing device, which uses a guiding bar to reduce the misalignment among input finger-vein images. In the case of the open database, the authors did not apply any guiding bar for alignment in the image-capturing device [
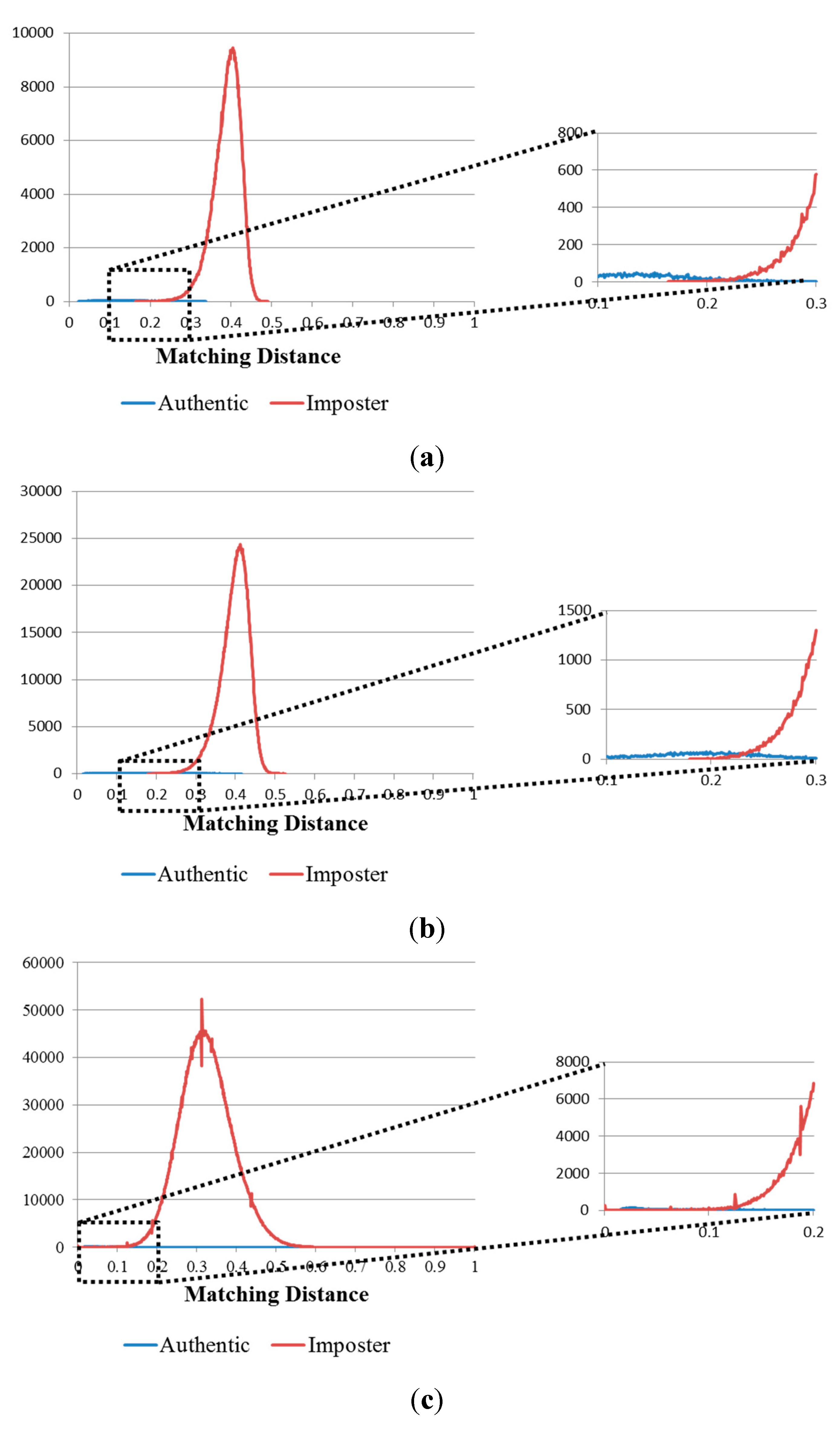
29]. As a result, the EER obtained from this database was the highest (8.096%) because of the misalignment of captured fingers. The results of the first experiment also indicate that the matching accuracies from images in the good-quality database were the highest, followed by those in the mid-quality database, whereas the worst matching accuracies were obtained for the open database, in terms of EERs (0.474%, 2.393%, and 8.096%, respectively). These results correspond to the level of misalignment in each finger-vein database. The resulting plots of the ROC curves and matching distance distributions obtained from the experiments classified by fingers, hands, and people for the three databases are shown in
Figure 11 and
Figure 12.
Figure 10.
Organization of experiments for finger-vein database.
Figure 10.
Organization of experiments for finger-vein database.
Table 3.
Comparative results of the four experiments for the three databases.
Table 3.
Comparative results of the four experiments for the three databases.
| Experiments | Good-Quality Database | Mid-Quality Database | Open Database |
|---|
| EER (%) | d-Prime | EER (%) | d-Prime | EER (%) | d-Prime |
|---|
| 1st Experiment | Classified by Fingers, Hands, and People | 0.474 | 5.805 | 2.393 | 4.022 | 8.096 | 2.727 |
| 2nd Experiment | Classified by People | 40.223 | 0.695 | 39.280 | 0.759 | 36.095 | 0.791 |
| 3rd Experiment | Classified by Hands | 48.427 | 0.136 | 49.320 | 0.072 | 49.137 | 0.039 |
| 4th Experiment | Classified by Fingers | 45.434 | 0.277 | 45.506 | 0.267 | 47.299 | 0.147 |
Figure 11.
ROC curves of the 1st experiment on the three databases (DBs).
Figure 11.
ROC curves of the 1st experiment on the three databases (DBs).
In the 2nd experiment, we classified the finger-vein images from the three databases based on people. In this way, the finger-vein images from the same person were considered as belonging to the same class; hence, the finger-vein images in different classes indicated the dissimilarities between different people. Likewise, the 3rd and 4th experiments on the three databases, considered images from the same hand side (i.e., either the left or the right hand), and images from the same finger type (i.e., the index, middle, or ring fingers) of all the people to be from the same classes, respectively. A comparison of the results of the three experiments (2nd, 3rd and 4th) on each database by considering the finger-vein dissimilarity between people, hands, and fingers, enabled us to evaluate the effect of each of these factors on the accuracy of the finger-vein recognition system.
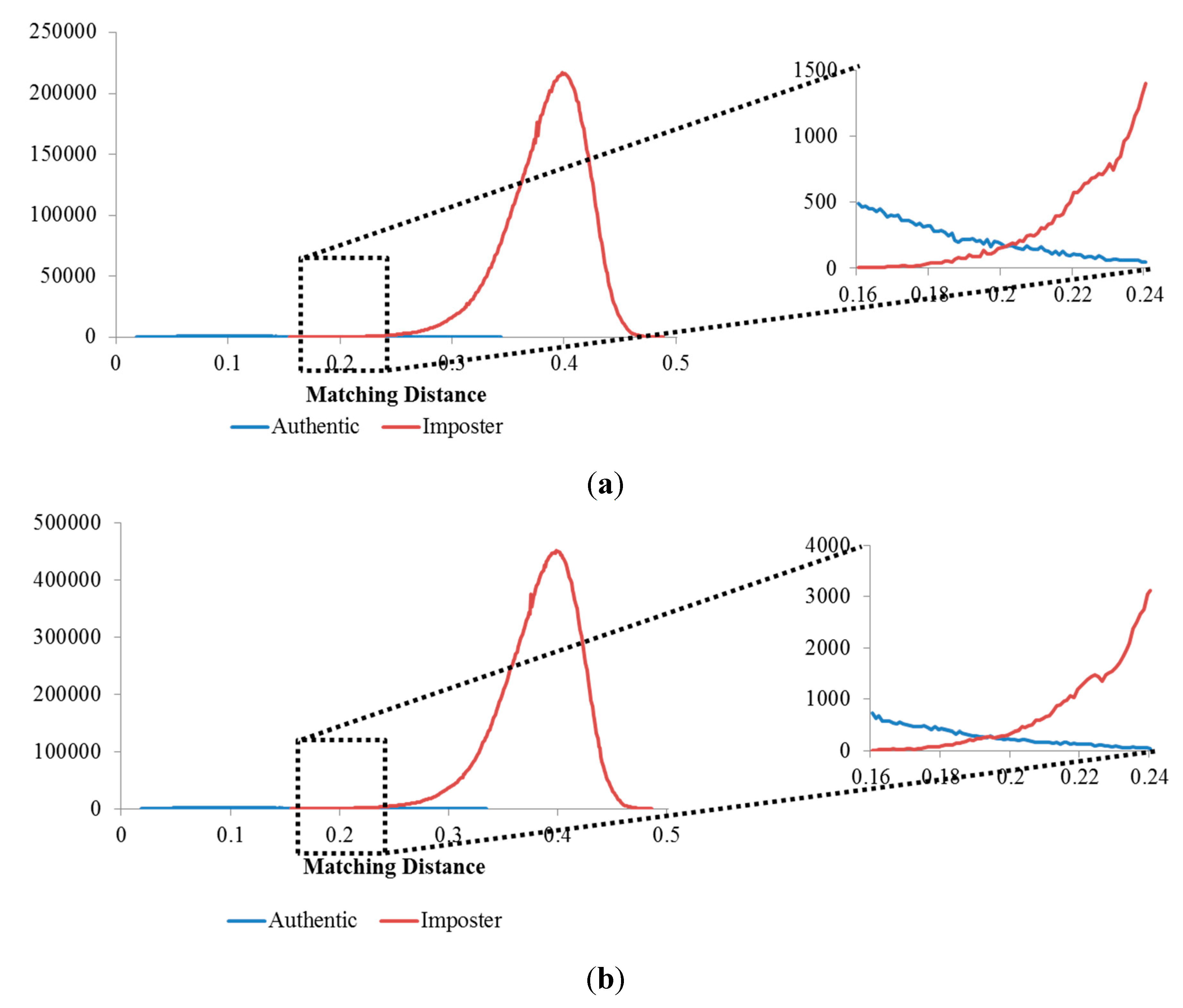
Figure 12.
Matching distance distribution of authentic and imposter matching tests in the 1st experiment on the three databases: (a) good-quality; (b) mid-quality; and (c) open database.
Figure 12.
Matching distance distribution of authentic and imposter matching tests in the 1st experiment on the three databases: (a) good-quality; (b) mid-quality; and (c) open database.
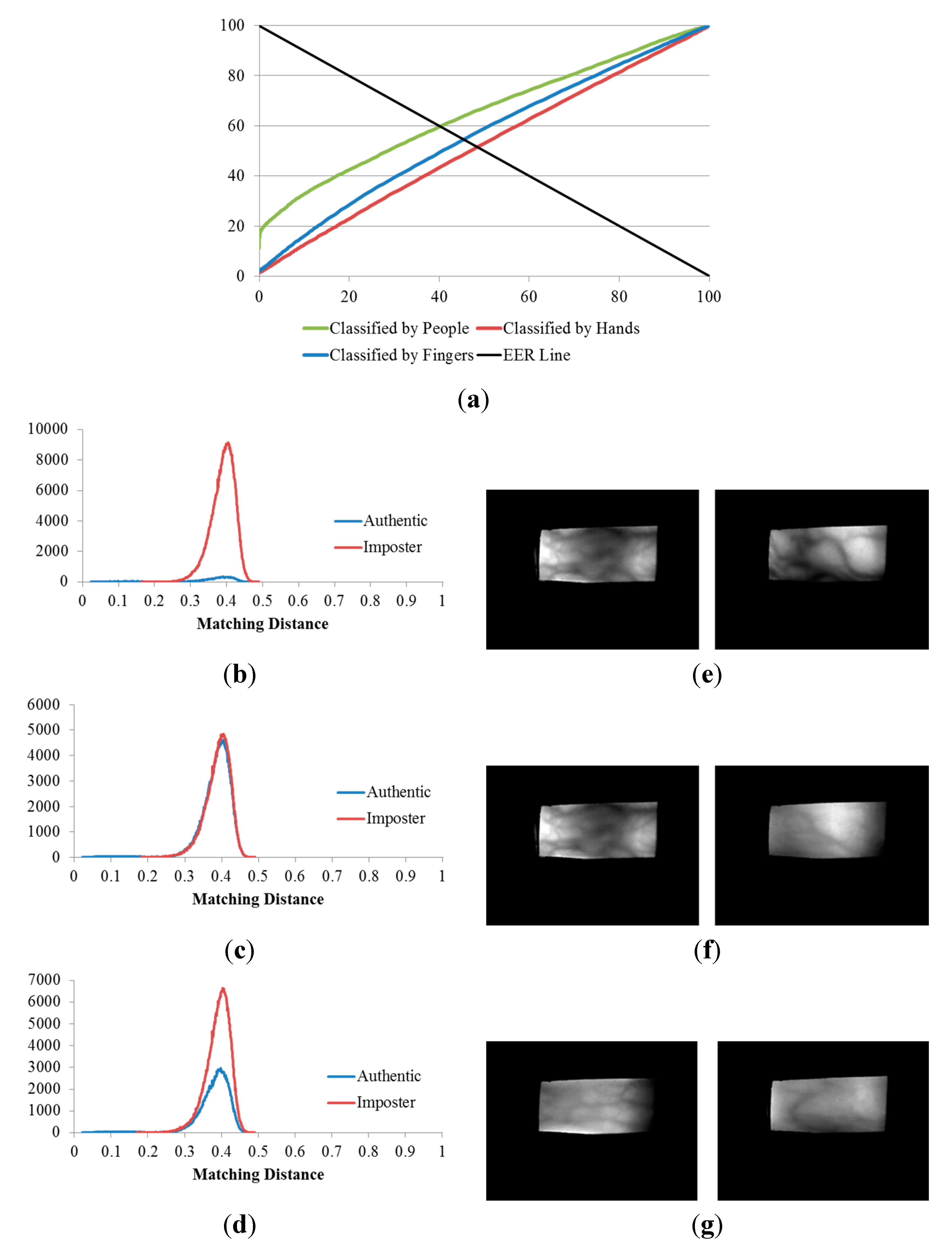
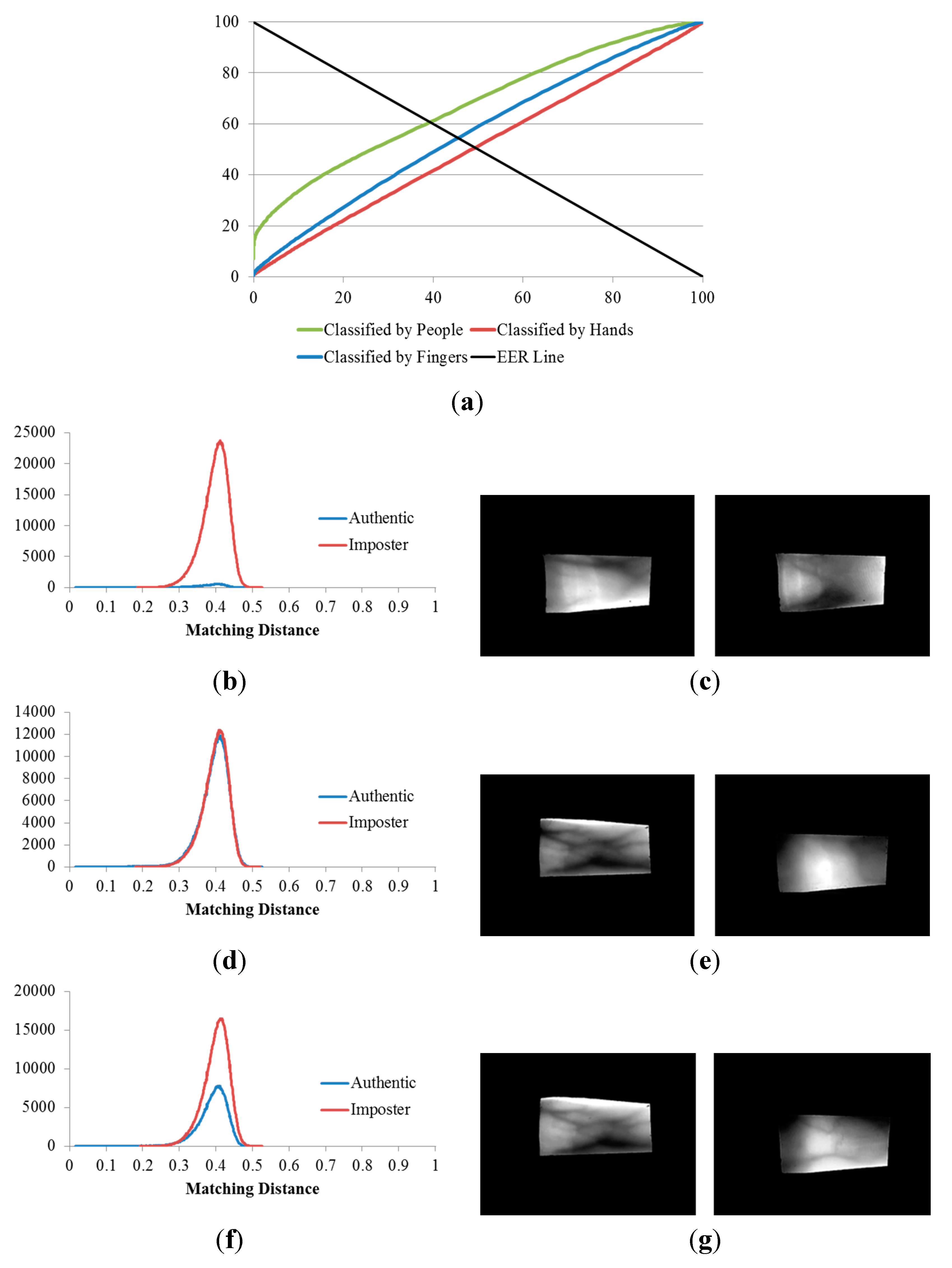
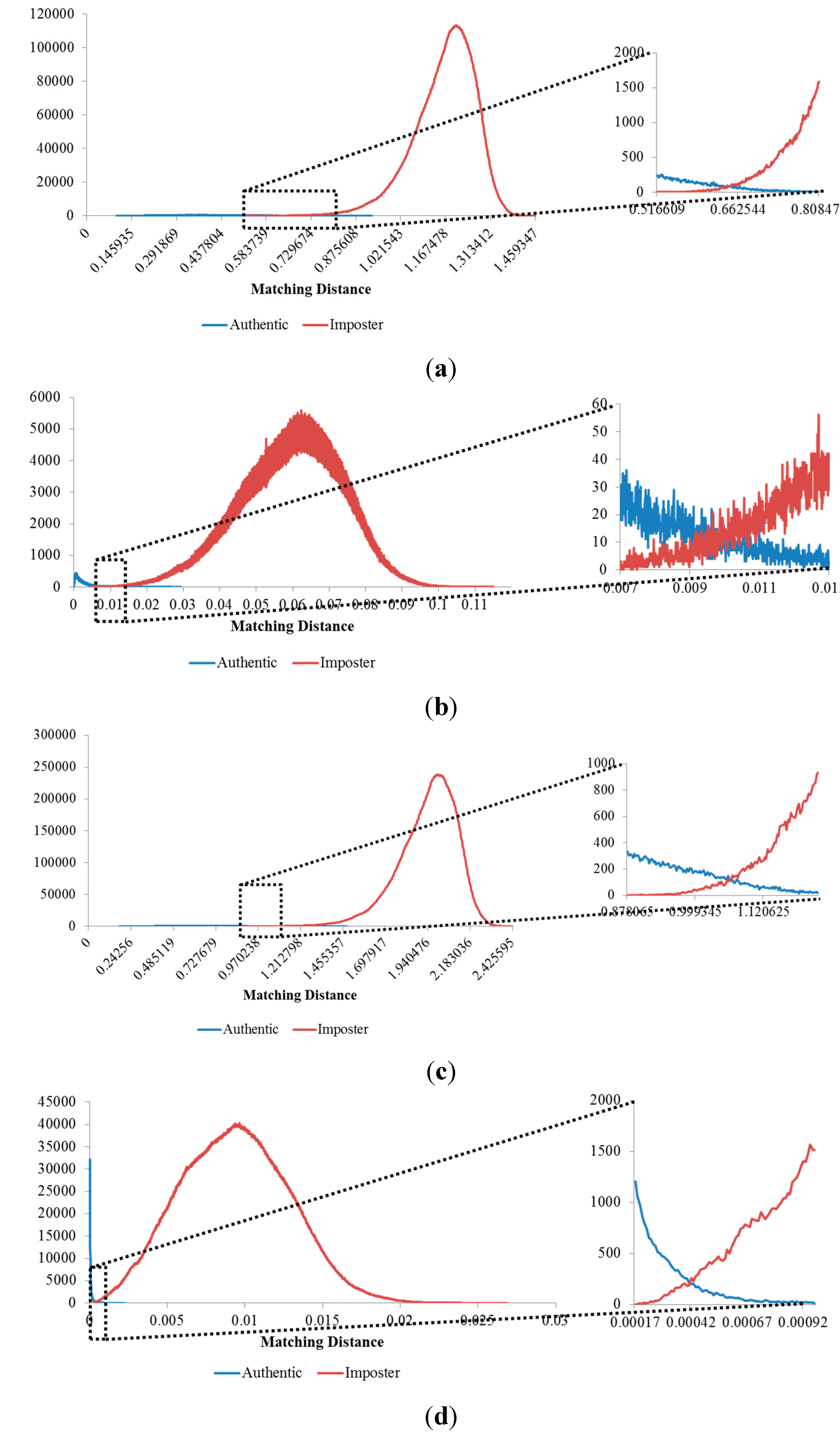
Figure 13.
Results of the 2nd, 3rd and 4th experiments on the good-quality database: (a) ROC curves of the results of the three experiments; matching distribution of (b) the experiment classified by people (2nd experiment); (c) the experiment classified by hands (3rd experiment); and (d) the experiment classified by fingers (4th experiment), each shown with its corresponding false rejection error case: (e) images of the ring and index fingers on left hand of the same person; (f) images of the ring and index fingers on left hands of two different people; and (g) images of the middle fingers on left and right hands of two different people.
Figure 13.
Results of the 2nd, 3rd and 4th experiments on the good-quality database: (a) ROC curves of the results of the three experiments; matching distribution of (b) the experiment classified by people (2nd experiment); (c) the experiment classified by hands (3rd experiment); and (d) the experiment classified by fingers (4th experiment), each shown with its corresponding false rejection error case: (e) images of the ring and index fingers on left hand of the same person; (f) images of the ring and index fingers on left hands of two different people; and (g) images of the middle fingers on left and right hands of two different people.
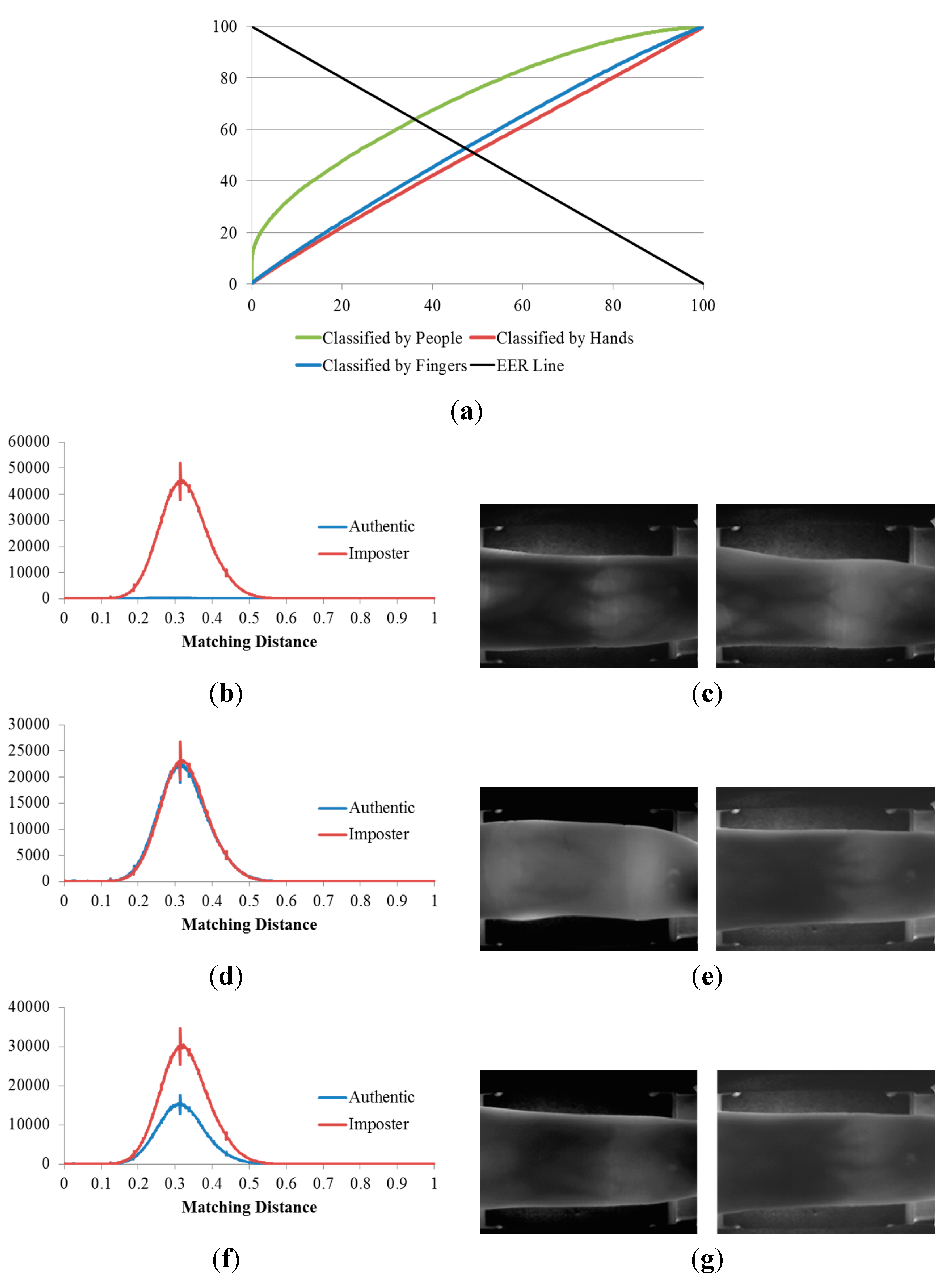
Figure 14.
Results of the 2nd, 3rd, and 4th experiments on the mid-quality database: (a) ROC curves of the results of the three experiments; matching distribution of (b) the experiment classified by people (2nd experiment); (d) the experiment classified by hands (3rd experiment); and (f) the experiment classified by fingers (4th experiment), each shown with its corresponding false rejection error case: (c) images of the right ring and left middle fingers of the same person; (e) images of the ring and index fingers on right hands of two different people; and (g) images of the ring fingers on right hands of two different people.
Figure 14.
Results of the 2nd, 3rd, and 4th experiments on the mid-quality database: (a) ROC curves of the results of the three experiments; matching distribution of (b) the experiment classified by people (2nd experiment); (d) the experiment classified by hands (3rd experiment); and (f) the experiment classified by fingers (4th experiment), each shown with its corresponding false rejection error case: (c) images of the right ring and left middle fingers of the same person; (e) images of the ring and index fingers on right hands of two different people; and (g) images of the ring fingers on right hands of two different people.
Figure 15.
Results of the 2nd, 3rd, and 4th experiments on the open database: (a) ROC curves of the results of the three experiments; matching distribution of (b) the experiment classified by people (2nd experiment); (d) the experiment classified by hands (3rd experiment); and (f) the experiment classified by fingers (4th experiment); each shown with its corresponding false rejection error case: (c) images of the right middle and right ring fingers of the same person; (e) images of the index and middle fingers on left hands of two different people; and (g) images of the middle fingers on two hands of two different people.
Figure 15.
Results of the 2nd, 3rd, and 4th experiments on the open database: (a) ROC curves of the results of the three experiments; matching distribution of (b) the experiment classified by people (2nd experiment); (d) the experiment classified by hands (3rd experiment); and (f) the experiment classified by fingers (4th experiment); each shown with its corresponding false rejection error case: (c) images of the right middle and right ring fingers of the same person; (e) images of the index and middle fingers on left hands of two different people; and (g) images of the middle fingers on two hands of two different people.
Table 3 indicates that, when the three databases are compared, the lowest EERs (the highest d-prime value) were obtained from the experiment classified by people (the 2nd experiment), the second lowest EERs (the second highest d-prime value) were obtained from the experiment classified by fingers (the 4th experiment), and that classified by hands (3rd experiment) produced the highest EERs (the lowest d-prime value). This sequence was consistent for all three of the databases.
Consequently, we are able to conclude that, finger-vein dissimilarity increases in the order people, fingers, and hands, respectively. In other words, the discrimination between finger-vein images from different people is larger than that between the different finger types (index, middle, and ring fingers) and that between hands from different sides (left or right hands).
The plots of the ROC curves and matching distributions of authentic and imposter tests obtained from the three experiments (the 2nd, 3rd, and 4th experiments) as well as the error cases for the good-quality, mid-quality, and open databases are shown in
Figure 13,
Figure 14 and
Figure 15, respectively. In the 2nd experiment (classified by people), the cases for which a false rejection was obtained were for different fingers from the same person. The false rejection cases of the 3rd experiment (classified by hands) were the matching pair of vein images of fingers from the same hand side, but belonging to different people or captured from different fingers. Similarly, the false rejections of the 4th experiment (classified by fingers) are cases in which images were captured from the same finger types (
i.e., index, middle, or ring fingers) but belonged to different people or hand sides.
3.3. Experimental Results Using Multiple Images for Enrollment
In this experiment, we used a number of input finger-vein images for enrollment instead of using only one image as was done previously [
7,
8,
9,
11,
16,
17,
18,
19,
20,
21,
22,
23,
25]. The method involving the enrollment of finger-vein data using the average of multiple finger-vein images is as follows. After the input images were captured for enrollment, they were processed and normalized by the methods described in
Section 2.2 and
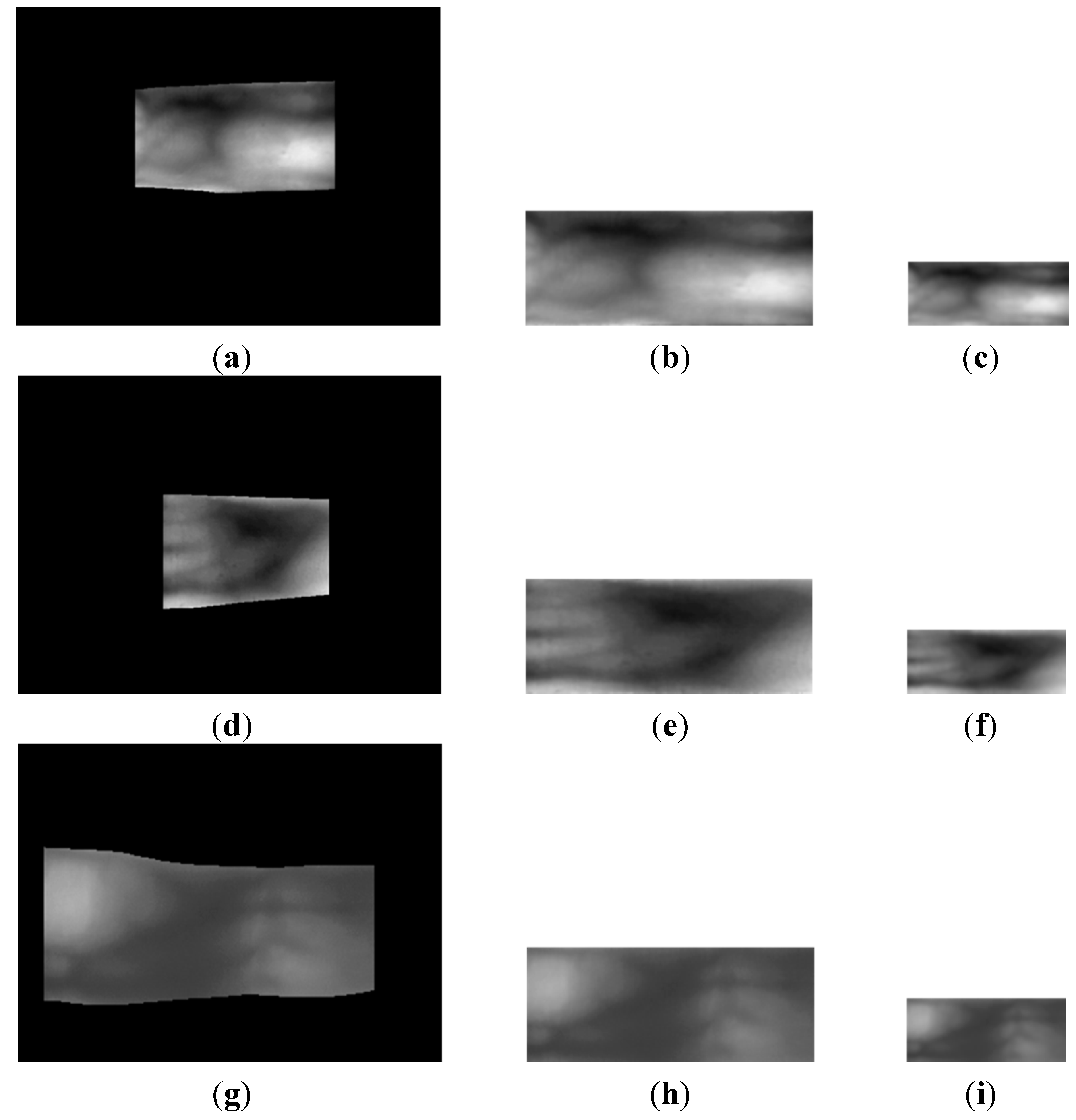
Section 2.3. From the image consisting of 50 × 20 pixels, obtained as a result of sub-sampling, we obtained the average image from which we extracted the LBP code which was then enrolled into the system. We applied this method by using either three or five enrollment finger-vein images to compare the matching accuracies with the conventional method, which only uses one image for enrollment. Examples of the average images generated from the 50 × 20 pixel images are shown in
Figure 16. The experiments were conducted on the good-quality database as demonstrated in
Figure 9a.
Figure 16.
Normalized finger-vein images and their average images when: (a) three images; and (b) five images were used for enrollment.
Figure 16.
Normalized finger-vein images and their average images when: (a) three images; and (b) five images were used for enrollment.
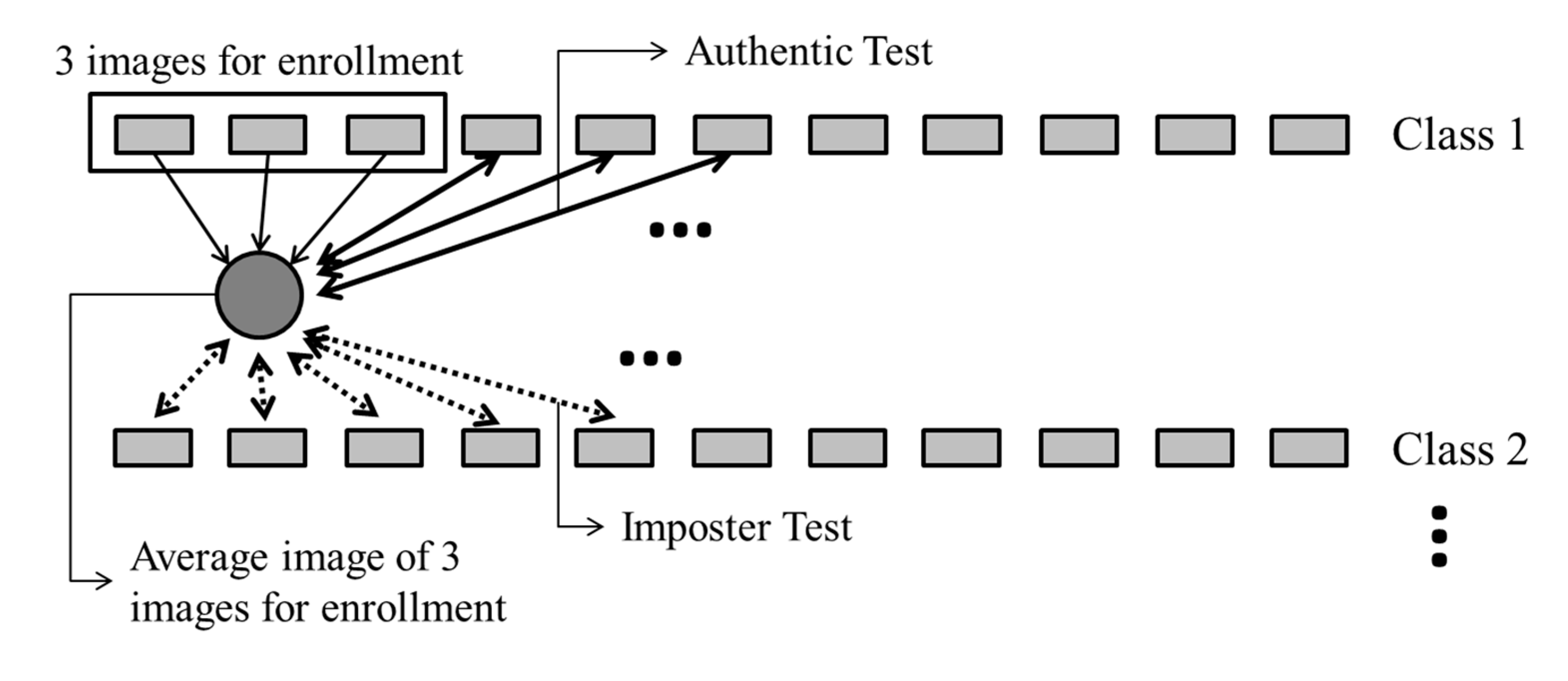
When three images were used for enrollment, these were selected from the 10 images of each finger of the same user. Then, we extracted the finger-vein code from the average of these three images, and used the data extracted from the remaining seven images of the same finger to perform authentic matching tests. For the imposter matching tests, we used the images of the other fingers to perform matching with the average image generated for the enrolled finger. This experimental method is illustrated in
Figure 17.
Assuming that the images from different fingers, hands, and people belong to different classes, the good-quality database contained 120 classes in total, as shown in
Table 2. When three images were used for enrollment, the number of authentic matching tests was 100,800 (
10C
3 × 7 (the number of remaining images in the same class) × 120 (the number of classes)), whereas the number of imposter matching tests was 17,136,000 (
10C
3 × 10 (the number of images in other classes) × 119 (the number of other classes) × 120 (the number of classes from which images for enrollment were selected)).
When five images were used for enrollment, the number of authentic matches was 151,200 (10C5 × 5 (the number of remaining images in the same class) × 120 (the number of classes)), whereas that of imposter matches was 35,985,600 (10C5 × 10 (the number of images in other classes) × 119 (the number of other classes) × 120 (the number of classes from which images for enrollment were selected)).
Figure 17.
Experimental method when three images were used for finger-vein enrollment.
Figure 17.
Experimental method when three images were used for finger-vein enrollment.
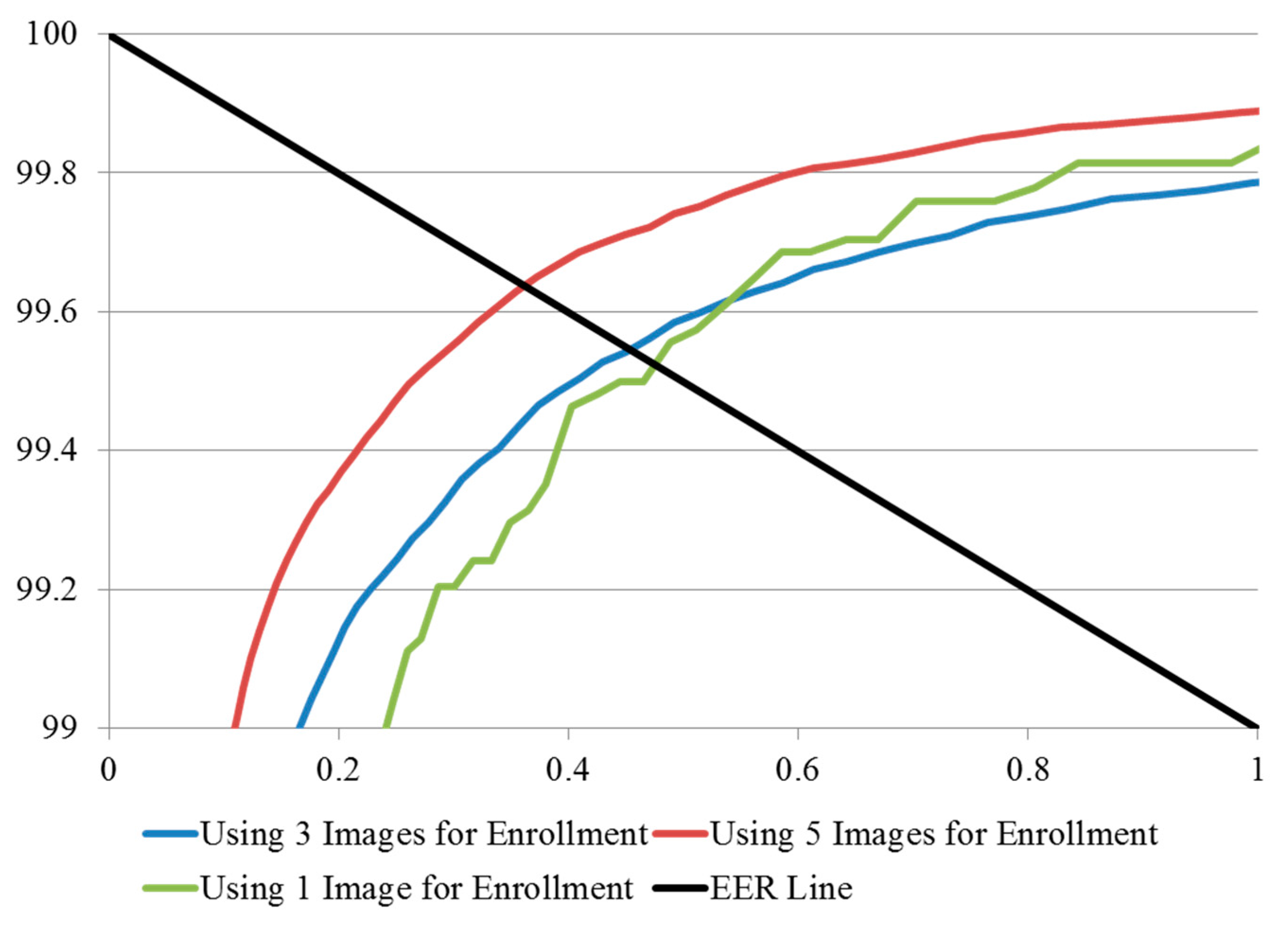
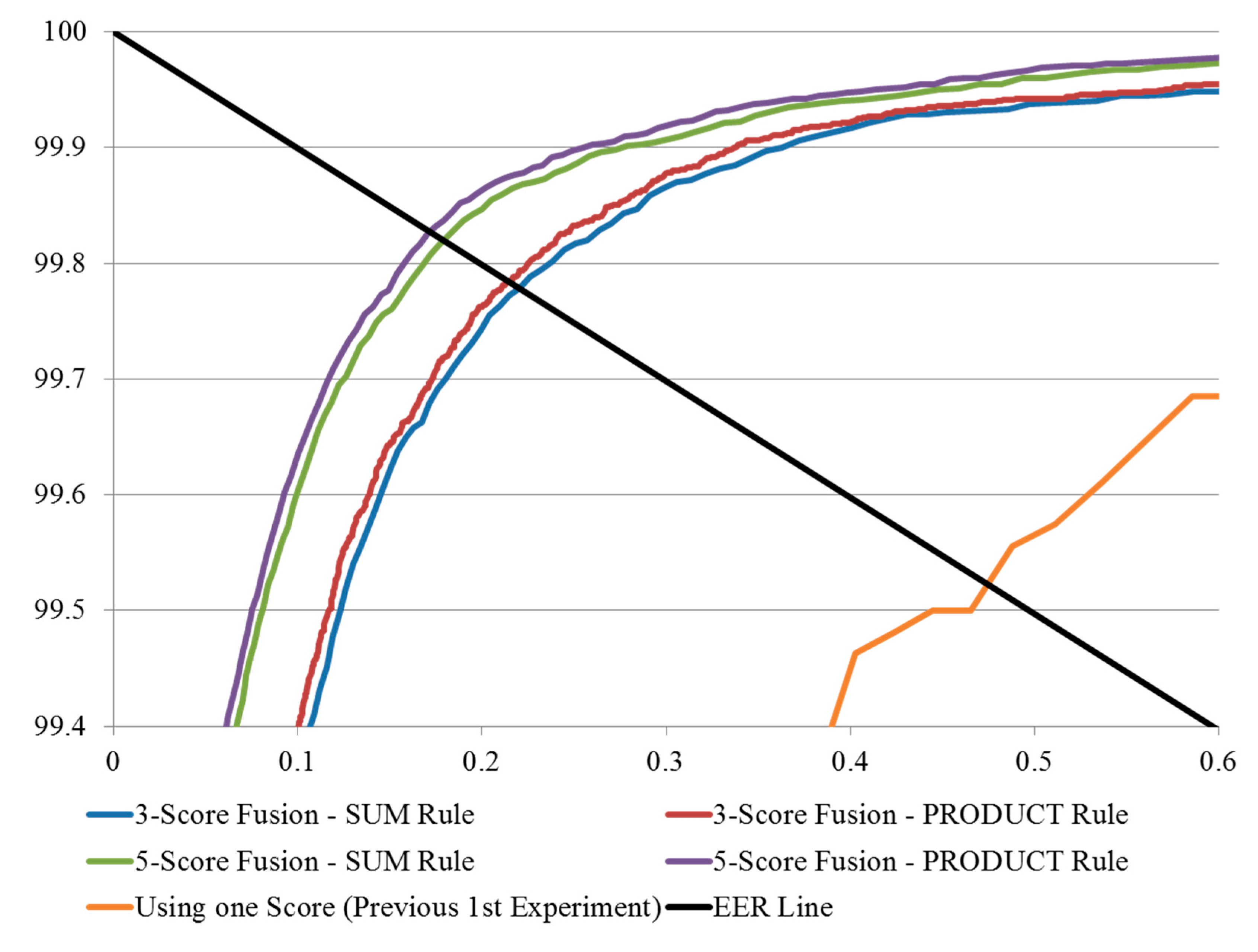
The experimental results of the methods in which three and five images were used for enrollment, are compared with those obtained by the conventional method (using one image for enrollment) in
Table 4, where it can be seen that the matching accuracy was enhanced by increasing the number of enrollment images, in terms of low EER and high d-prime values. The ROC curves and the distribution plots of authentic and imposter tests corresponding to the results in
Table 4 are shown in
Figure 18 and
Figure 19, respectively, and can be explained as follows. In the finger-vein database, matching errors were mostly caused by misalignment at the time when the input finger-vein images were initially recorded, which subsequently resulted in translation errors in the normalized images of 50 × 20 pixels. The use of image averaging reduced the translation errors within the normalized images and increased the similarities between the enrolled and the matched finger-vein data.
Table 5 shows examples of error cases resulting in false rejection when the enrolled images were compared with the test image in the same class, listed according to the number of images used for enrollment.
Table 4.
Comparative results when multiple images were used for enrollment.
Table 4.
Comparative results when multiple images were used for enrollment.
| Number of Images for Enrollment | EER (%) | d-Prime |
|---|
| 1 | 0.474 | 5.805 |
| 3 | 0.454 | 6.406 |
| 5 | 0.362 | 6.633 |
Figure 18.
ROC curves of using multiple images for enrollment methods.
Figure 18.
ROC curves of using multiple images for enrollment methods.
Figure 19.
Matching distance distributions of authentic and imposter tests using (a) three images; and (b) five images for enrollment methods.
Figure 19.
Matching distance distributions of authentic and imposter tests using (a) three images; and (b) five images for enrollment methods.
Table 5.
False rejection cases: Comparison of the detected input finger-vein images with the enrolled images.
From
Table 5, we can see that, when one image was used for finger-vein enrollment, false rejection was mostly caused by translational errors between images of the same finger. These errors can either occur during translations in the horizontal direction of the image (the first row of
Table 5) or in the vertical direction of the image (the second row of
Table 5).
The reason why false rejections occur when either three or five images are used for enrollment is as follows. The misalignment between finger-vein images selected for enrollment resulted in blurred vein lines and the appearance of artifacts in the average images that were generated. Consequently, this led to high matching distances between the enrolled finger-vein data and test data, and these cases were misclassified into the imposter matching class.
3.5. Discussions
Regarding the issue of using average images for feature extraction as shown in
Figure 16 and
Figure 17, the method of selecting one enrolled image (whose finger-vein code shows the minimum distances compared to the codes of other enrolled images) has been most widely used (1st method). However, the finger-vein code of one image among three or five enrolled images for enrollment is selected by this method, which cannot fully compensate for the differences among three or five enrolled images. Therefore, we adopt the method of using average image for enrollment as shown in
Figure 16 and
Figure 17 (2nd method). To prove this, we compared the accuracy of finger-vein recognition by this 1st method with that by the 2nd method. The EER (d-prime) by the 1st method with three and five images for enrollment are 0.468% (6.128) and 0.412% (6.597), respectively. By comparing the EER (d-prime) by the 2nd method as shown in the 3rd and 4th rows of
Table 4, we confirm that our 2nd method using average image for enrollment outperforms the 1st method.
The method of simply averaging the images for enrollment can be sensitive to image alignment and detailed features can be lost in the average image. In order to solve this problem, in our research, the misalignment among the images was firstly compensated by template matching before obtaining the average image. For example in
Table 5, in the case that the number of images for enrollment is 3, the horizontal and vertical movements of the second enrolled image based on the first one are measured by template matching with the first enrolled image. If the measured horizontal and vertical movements of the second enrolled image are −2 and −1 pixels, respectively, for example, the compensated image is obtained by moving the original second enrolled image by +2 and +1 pixels, respectively, in the horizontal and vertical directions. From this, we can obtain the (compensated) second enrolled image where the misalignment based on the first enrolled image is minimized. Same procedure is iterated with the third enrolled image. From this procedure, we can obtain three (compensated) enrolled images where the misalignment between each other is minimized, and these three images are averaged for obtaining one enrolled image. Therefore, we can solve the problem that the average image is sensitive to image alignment and detailed features can be lost in the average image.
The total number of images in the good-quality database was 1200 (20 people × 2 hands × 3 fingers × 10 images), and that in the mid-quality database is 1980 (33 people × 2 hands × 3 fingers × 10 images). In order to obtain the meaningful conclusions and prove our conclusion irrespective of kinds of database, we also include the third open database for experiments. The total number of images in the open database was 3816 (106 people × 2 hands × 3 fingers × 6 images). Consequently, a total of 6996 images were used for our experiments, and we obtained the conclusion through a great deal of authentic and imposter matching, as shown in
Table 2.
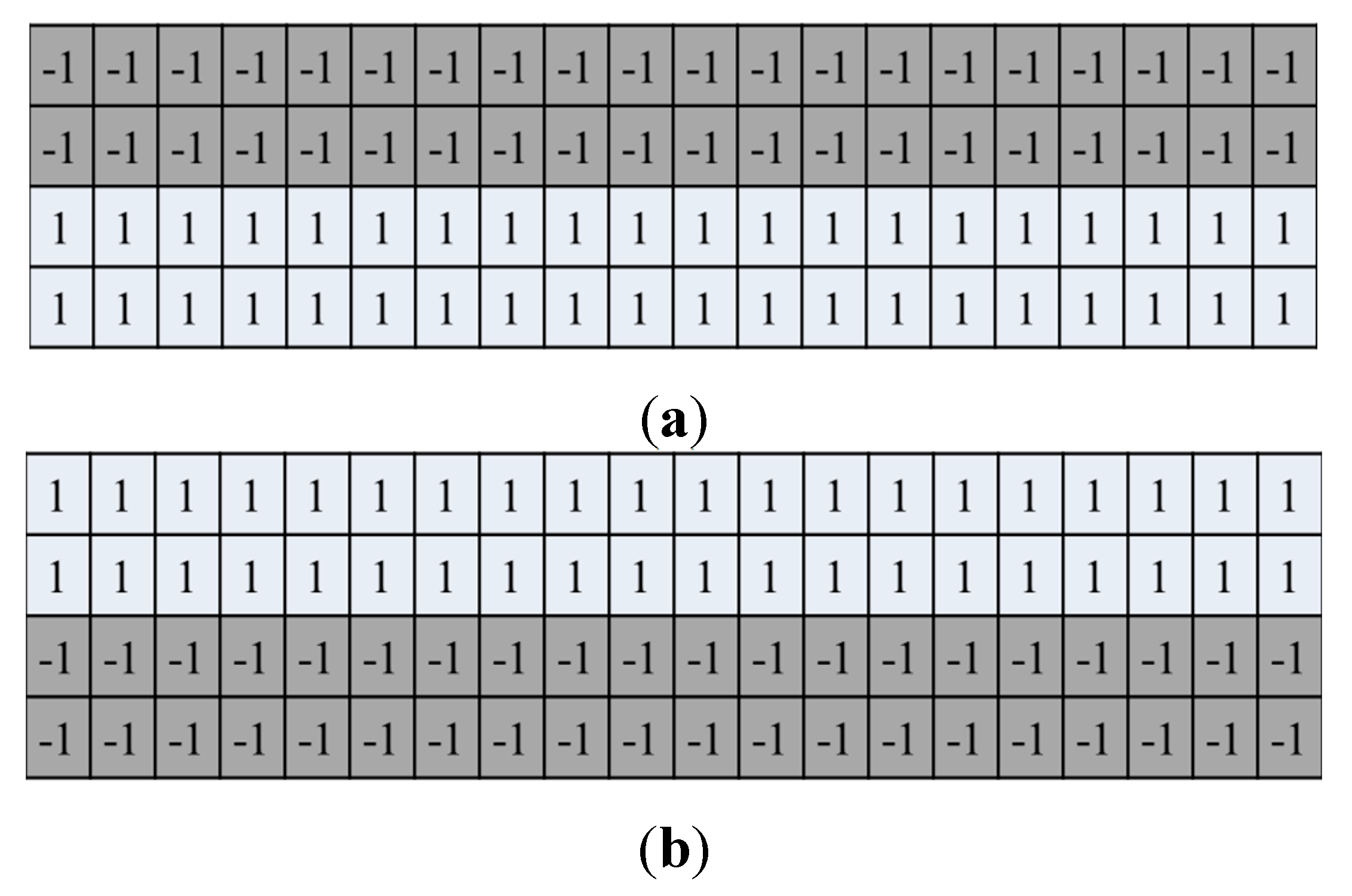
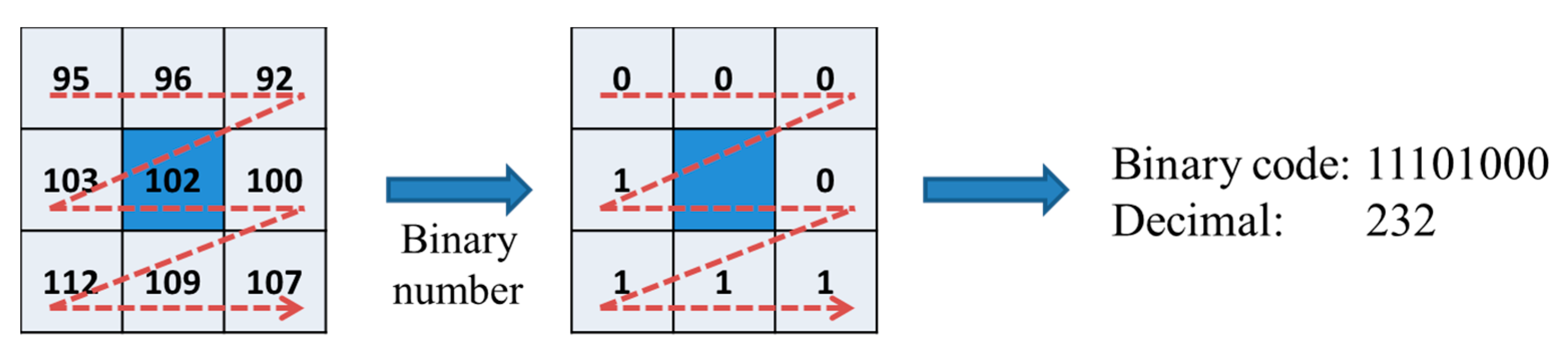
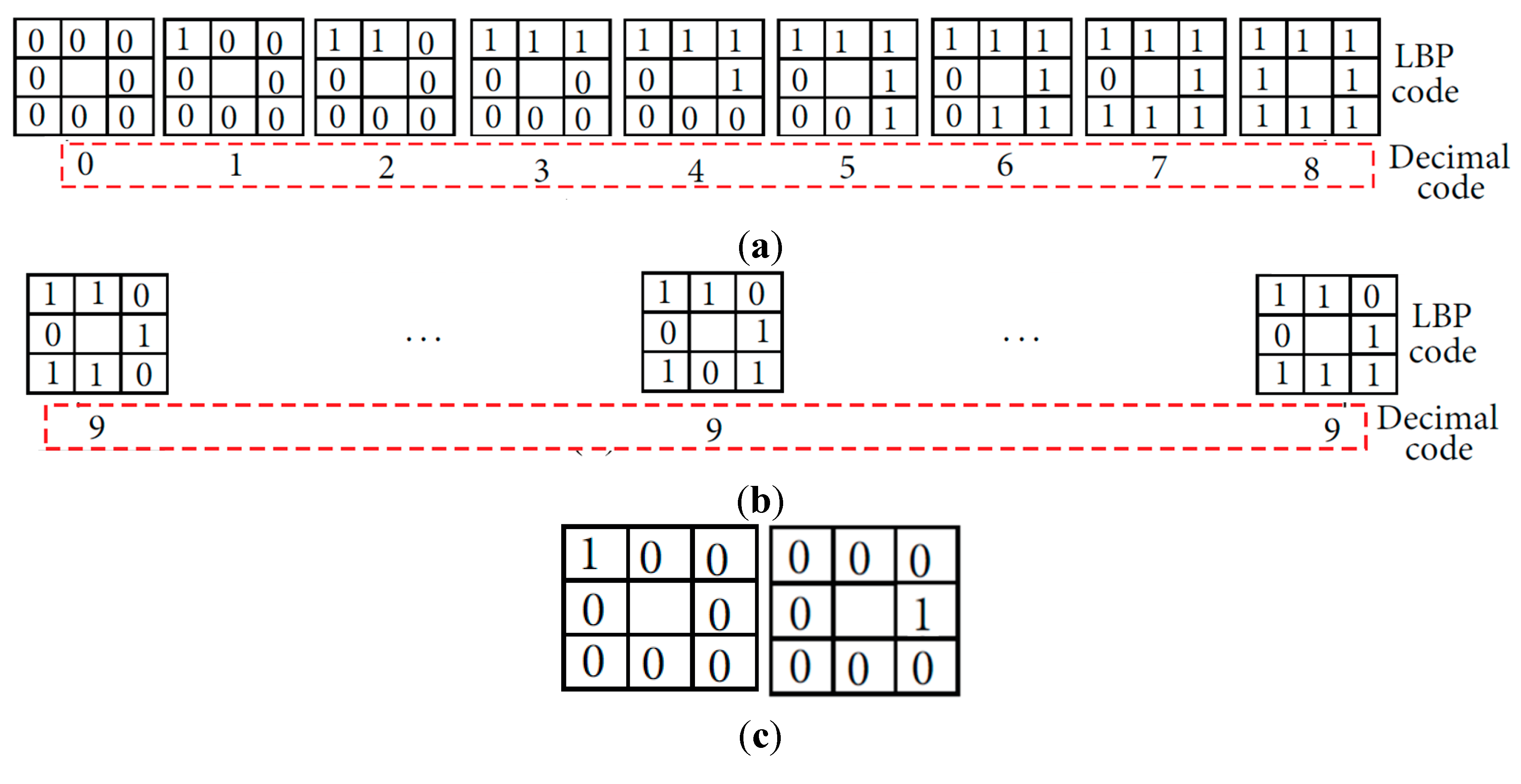
The original LBP used in our method can be more sensitive to noise than the uniform LBP. Therefore, in our method, the sub-sampled image of 50 × 20 pixel is used for feature extraction by LBP as shown in
Figure 4c,f,i, which can reduce the noise in the image for feature extraction. In addition, the two cases of LBP codes in
Figure 22c are assigned as same decimal code of 1 by the uniform LBP although they are actually different LBP code (00000001 (left case) and 00010000 (right case)), which can reduce the dissimilarity between two different patterns of finger-vein image. Therefore, we use the original LBP method in our research.
Figure 22.
Example of uniform and nonuniform patterns and their assigned decimal codes by uniform LBP, respectively: (a) uniform patterns; (b) nonuniform patterns; (c) two cases of decimal code of 1 by uniform LBP.
Figure 22.
Example of uniform and nonuniform patterns and their assigned decimal codes by uniform LBP, respectively: (a) uniform patterns; (b) nonuniform patterns; (c) two cases of decimal code of 1 by uniform LBP.
We compared the accuracies by our original LBP and those by uniform LBP. The EER (d-prime) by uniform LBP with 1st, 2nd, and 3rd databases are 0.925% (5.122), 4.513% (3.443), and 12.489% (2.114). The EERs by uniform LBP are larger than those by original LBP of the 1st row of
Table 3. In addition, the d-prime values by uniform LBP are smaller than those by original LBP of the 1st row of
Table 3. From that, we can confirm that the performance by our original LBP is better than that by uniform LBP.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}































