1. Introduction
Self-localization is widely recognized as one of the most basic problems for an autonomous robot with respect to navigation. This task can be performed pretty well when the environment is known a priori, but when a map of the environment is not available beforehand, robot localization becomes very difficult. This may be due to a lack of information of the environment that the robot moves in or to the excessive cost of manually building a map on purpose. In these cases, the robot must simultaneously build a map of the environment and localize itself within it. This problem, known as simultaneous localization and map building (SLAM), has been extensively studied over the last two decades. The solutions to the SLAM problem presented so far differ mainly for the environment description adopted and for the estimation technique employed. There are two main estimation forms: filter-based SLAM and graph-based SLAM.
Filter-based SLAM involves estimating the posterior by means of Bayes’ rule [
1]:
where
is the pose of the robot at time
t,
m is the map,
is the observation sequence and
is the odometry information (or motion control input). Filter-based SLAM is also called online SLAM, since it is incremental; past measurements and controls are discarded once they have been processed. According to different ways of addressing the posterior probability, there are many filter-based methods like the extended Kalman filter (EKF) method [
2], the extended information filter (EIF) method [
3], the particle filter (PF) method [
4],
etc.
Instead of estimating only current pose
in filter-based SLAM, the graph-based SLAM estimates a complete trajectory
and map
m by all observed information. The method is considered time-consuming and cannot satisfy real-time requirements. However, by means of efficient solving methods, the graph-based SLAM has received more attention [
5,
6,
7].
The initial studies on the SLAM problem focused on two-dimensional environments, so they were usually applied to mobile robots. Recently, a variety of 3D SLAM algorithms have supported 6-DOF (degree-of-freedom) pose optimization [
8]; therefore, the SLAM technique is employed in various platforms, such as quadrotors [
9], underwater robots [
10],
etc. In the early 3D SLAM studies, expensive sensors, like 2D and 3D-LRFs (laser range finders), were mainly used. However, recently, with the advent of inexpensive Kinect-style sensors [
11], which are called RGB-D (red-green-blue depth) cameras, since they give the color image and the depth data concurrently, the robotics and computer vision communities have focused on 3D SLAM techniques using the RGB-D camera data; we call these techniques RGB-D SLAM.
The current RGB-D SLAM techniques, which are reviewed in detail in the following section, are mostly based on graph-based SLAM. They need loop detection and loop correction to refine the graph, and sometimes, they are not real time. For most RGB-D SLAM systems, there are three major problems. (1) The hyper-high dimensional problem: In two-dimensional space, the pose is represented as , and the environmental map is denoted as , which contains N characteristics, where . The dimension of the state vector is . For the three-dimensional space, the pose is represented as , and the dimension of the state vector is . Since the number of features in the actual environment may reach tens of thousands, the SLAM problem is a hyper-high dimensional problem; (2) The data association problem: This problem means that the extracted feature is judged as to whether it is a new or pre-existing feature. Assume at time step t, m extracted features match n features in the map with computation complexity irrespective of the independence between features. The time complexity is very high for a real-time environment; (3) The selection and design of visual odometry: Frame-to-frame alignment based on feature matching should not be selected to avoid over-estimation. It is caused by re-applying the feature measurements that are used both as motion information and as measurement information in the SLAM process.
In this paper, we propose a new RGB-D SLAM method based on visual odometry (VO) and the extended information filter (EIF), referred to as VO-EIF RGB-D SLAM. As with current graph-based RGB-D SLAM algorithms, our filter-based RGB-D SLAM in this paper does not depend on other sensors (such as gyroscope, encoder,
etc.). Our contribution consists of providing an appropriate observation model and motion model for the SLAM for a robot. More concretely, this paper has the following contributions: (1) we adopt the method based on the extended information filter to decrease the dimensions for a high-dimensional state space; (2) inspired by the related works [
12,
13,
14], we employ the binary feature descriptor for feature matching to reduce the complexity effectively; (3) we build an RGB-D feature observation model that combines the 3D positions and the binary descriptors of the landmarks and that avoids explicit data association between the observations and map; and (4) we devise a visual dead reckoning algorithm based on visual residuals, which is used to estimate motion control input, to avoid over-estimation. Moreover, this is more robust and accurate than feature-based visual odometry methods.
The rest of the paper is organized as follows:
Section 2 refers to the related work.
Section 3 provides the principle of the extended information filter SLAM.
Section 4 describes the binary robust appearance and normals descriptor (BRAND) descriptor. The RGB-D feature observation model and the motion model in this work are introduced in
Section 5 and
Section 6, respectively.
Section 7 shows the experimental results, and
Section 8 sets out the conclusions and presents lines for future work.
2. Related Research
Currently, most robot SLAM is carried out with the sensor, which provides a 2D scene. The main reason is that acquiring high-quality 3D data is very expensive. However, with the advent of the low-cost Microsoft Kinect sensor, there has been great interest in capturing and reconstructing 3D environments using a movable RGB-D sensor [
7,
15,
16]. It provides dense, high-resolution depth information at a low price and small size.
Fioraio
et al. [
17] developed a SLAM application using Kinect. They used the bundle-adjustment framework to ingrate ICP (iterative closest point) [
18] with visual feature matches. In their research, the graph is optimized using a
(general graph optimization) framework [
5] to obtain global alignment. They adopted the ICP algorithm [
18] for pairwise alignment between sequential frames and recovering the rigid transformation between point clouds. The alignment accuracy of ICP significantly depends on the scene content.Po-Chang
et al. [
19] use color feature descriptors to improve depth data correspondences. Lee
et al. [
20] proposed an RGB-D SLAM method that handles low dynamic situations using a pose-graph structure, in which nodes are grouped based on their covariance values. Any false constraints are pruned based on an error metric related to the node groups.
Henry
et al. [
15,
16] studied highly efficient pose graph optimization, such as TORO (tree-based network optimizer) in 2010. In 2012, Henry
et al. [
16] improved this algorithm. They combined FAST (features from accelerated segment test) and Calonder descriptors [
21] to estimate pose, utilized the RE-RANSAC (re-projection error random sample consensus) method for frame-to-frame alignment and incorporated ICP constraints into SBA [
22] (sparse bundle adjustment) for global optimization. The core of their algorithm is RGB-D ICP, a novel ICP variant that makes use of the rich information included in RGB-D data. In 2013, Henry
et al. [
23] presented patch volumes to create globally-consistent maps. The approach combines GPU-accelerated volumetric representations with global consistency, which shows the great effect for indoor map building.
Audras
et al. [
24] presented ab RGB-D SLAM methodology that is very efficient for a complex indoor environment. In the algorithm, the trajectory estimation is integrated into a single global process, which does not rely on intermediate-level features. Moreover, using the accurate pose measurement with the localization techniques, a compact photometric model of the environment is acquired. In [
25], the rigid body motion of a handheld RGB-D camera is estimated by an energy-based approach. They combined visual odometry technology with an RGB-D sensor for autonomous flight experimental analysis. The experimental system is able to plan a complex 3D path in a cluttered environment. The work in [
24,
25] do not extract sparse features and warp the pixel for one frame to another using a depth map and a photometric error minimization method for frame-to-frame alignment. The work in [
26] presents a new dense visual odometry system, in which the geometric error is parameterized by the inverse depth instead of the depth, as used in most VO systems.
The work in [
27] puts forward a novel GPU implementation based on an RGB-D visual odometry algorithm. They used a 6-DOF camera odometry estimation methods to track and integrate RGB color information into the KinectFusion [
28] reconstruction process to allow a high-quality map. The experiment shows that there is no need for the use of keyframes, and the method results in real-time colored volumetric surface reconstructions. Many RGB-D SLAM techniques are limited to office-type and geometrically-structured environments. Hu
et al. [
29] proposed a switching-based algorithm that heuristically choose between RGB-D bundle adjustment and RGB-D bundle adjustment-based local map building. RGB-D SLAM maps are created by applying sparse bundle adjustment on an included two-step re-projection RANSAC and ICP approach. By a heuristic switching algorithm, they dealt with various failure modes associated with RGB-D-BA (RGB-D bundle adjustment). The map connection strategy significantly reduces the computational cost, and the algorithm has great potential to be applied in a larger scale environment.
Similar to [
15,
16], Endres
et al. [
30] used the ICP algorithm only when there were few or no matching keypoints in order to reduce the time complexity. They used the
framework [
5] to optimize the 3D pose graph and created a stereo 3D map for robot localization, navigation and path planning. The work in [
31] uses RGB-D data to provide a complete benchmark for evaluating visual SLAM and odometry systems and proposes two evaluation metrics and automatic evaluation tools.
Kerl
et al. [
32] proposed a dense visual SLAM method for RGB-D cameras and an entropy-based similarity measure for keyframe selection and loop closure detection. In contrast to sparse, feature-based methods [
15,
30], the approach significantly decreases the drift and is real time. Compared to the work by Tykkala
et al. [
33], the keyframe and pose graph optimization are obtained simultaneously without manual intervention. Since traditional loop closures have a high time complexity, the work in [
34] presents a novel SLAM system that takes advantage of non-rigid map deformations for map correction during loop closures.
Felix Endres
et al. [
35] extracted keypoints from the color images and used the depth images to localize them in 3D. RANSAC is used to estimate the transformations between associated keypoints and to optimize the pose graph using nonlinear optimization. In contrast to other RGB-D SLAM system, they performed a detailed experimental evaluation on benchmark dataset [
31] and discussed many parameters, such as the choice of the feature descriptor, the number of visual features,
etc. The system is robust for scenarios such as fast camera motions and feature-poor environments.
Most RGB-D SLAM algorithms [
15,
24,
25,
27,
36,
37,
38] combine texture with geometric features to deal with the problem and regard the scene as a set of points. The work in [
39] exploits the structure of the scene and incorporates both point and plane features to implement the SLAM algorithm. The algorithm explains how to find point and plane correspondences using camera motion prediction and uses both points and planes to relocate and bundle adjustment, aiming at refining camera pose estimates.
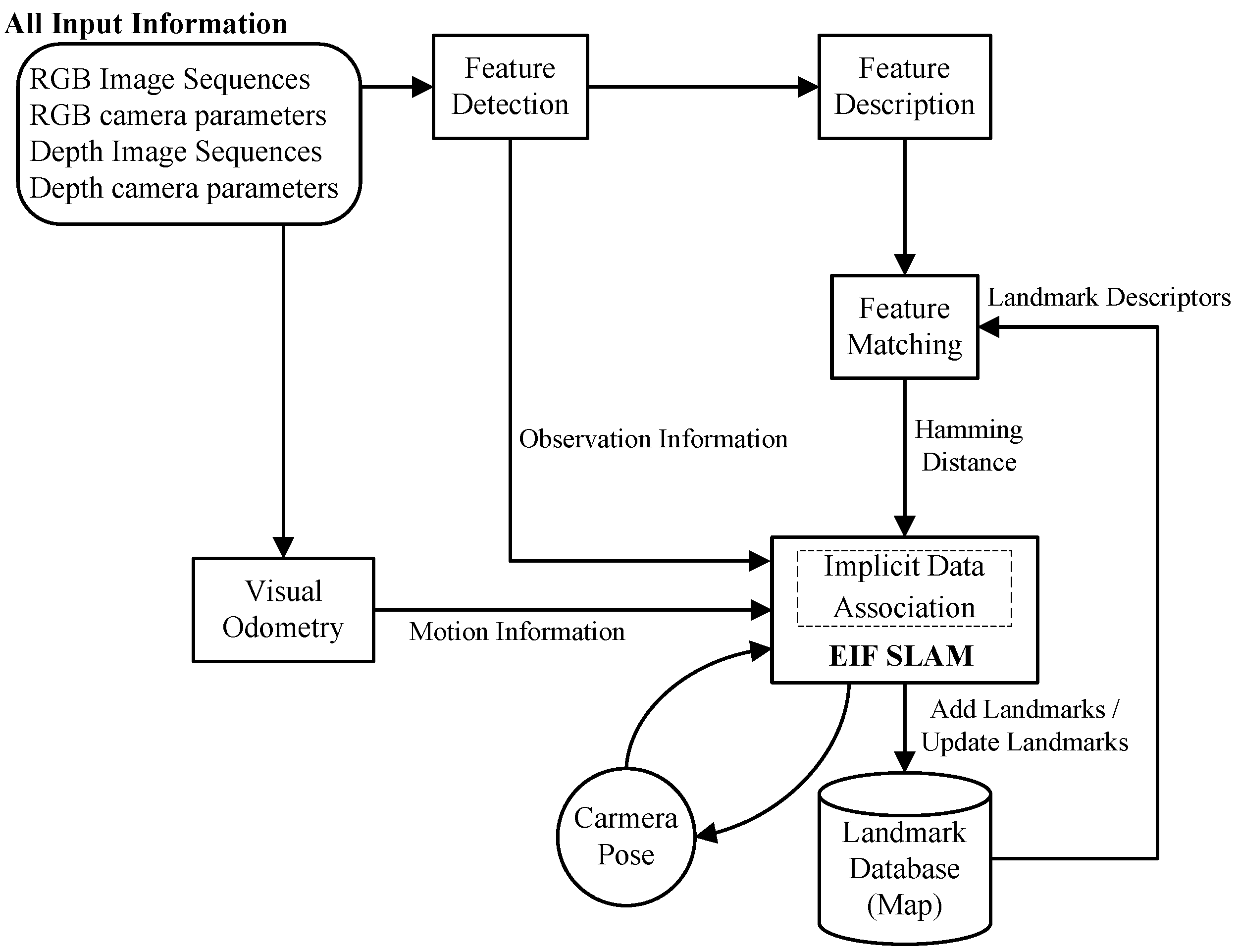
Figure 1.
Flow diagram of the visual odometry-extended information filter (VO-EIF) RGB-D SLAM system. Through the data association test, the landmark is added to the landmark descriptor database for the feature matching. The core of the system is the EIF SLAM.
Section 3 introduces the extended information filter approach. The binary descriptor is demonstrated in
Section 4. The observation model and the motion model are presented in
Section 5 and
Section 6, respectively.
Figure 1.
Flow diagram of the visual odometry-extended information filter (VO-EIF) RGB-D SLAM system. Through the data association test, the landmark is added to the landmark descriptor database for the feature matching. The core of the system is the EIF SLAM.
Section 3 introduces the extended information filter approach. The binary descriptor is demonstrated in
Section 4. The observation model and the motion model are presented in
Section 5 and
Section 6, respectively.
We put forward the RGB-D SLAM algorithm based on the traditional filter-based SLAM algorithm in the paper. Firstly, we apply the unsupervised learning algorithm without human intervention [
40] to correct depth distortion. Then, the BRISK (Binary Robust Invariant Scalable Keypoints) keypoint detector [
13] is adopted to extract feature points, and next, we use the BRAND [
12] descriptor to increase the credibility of data association in SLAM. Finally, We develop the RGB-D SLAM system integrating EIF SLAM with dense visual odometry (DVO). The flow diagram of the algorithm is illustrated in
Figure 1. The descriptor and the VO-EIF RGB-D SLAM algorithm will be described in detail in the following sections.
3. Extended Information Filter Approach to SLAM
In the SLAM algorithm, the state vector consists of RGB-D camera pose and the set of n map landmarks, i.e., , where is the 3D position coordinate of the j-th landmark in the world coordinate system at time step t. We use a first-order linearization of the motion and measurement models. Assume posterior obeys a Gaussian probability distribution, traditionally parameterized by the mean and the covariance matrix .
where
denotes the history of observational data,
denotes the observational data of the RGB-D camera and
denotes the observational data of the i-th landmark at time step
t.
is the history of motion control inputs;
is the motion control inputs of the RGB-D camera at time step
t. Gaussian probability distribution Equation (
2) is parameterized by the information vector
and the information matrix
.
Extended information filtering is similar to the extended Kalman filter. The algorithm is divided into two phases: measurement update and state prediction [
3].
Measurement update: The key of landmark observation is to reduce the uncertainty in the estimates for the camera pose and the map. The general measurement model Equation (
5) is a nonlinear state function with added white Gaussian noise,
. Equation (
6) is the first-order linearization related to the mean of the robot pose and observed features with the Jacobian.
Use
to update the current distribution and applying Bayes’ rule to infer a new observation.
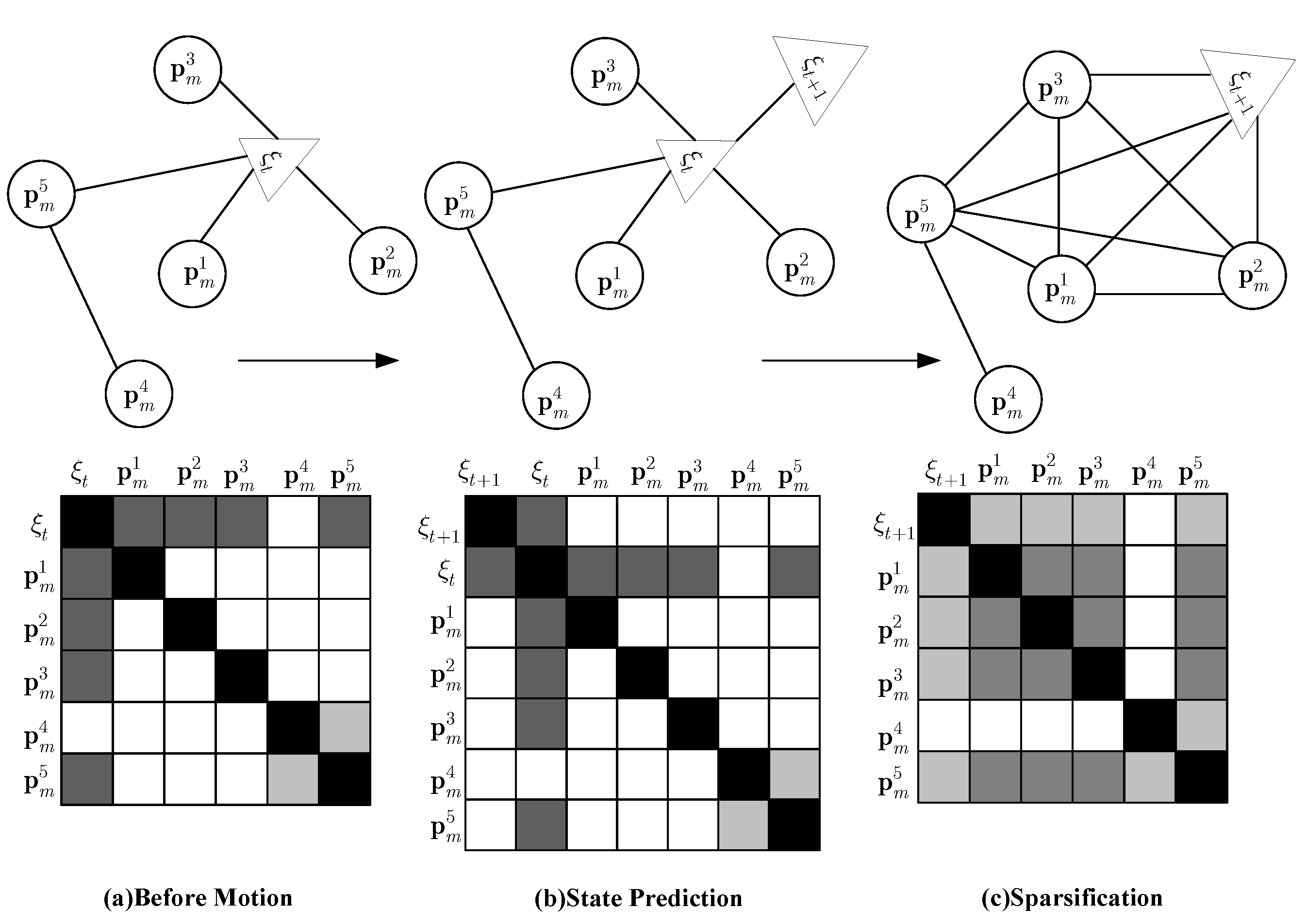
State prediction: The prediction stage predicts the distribution over the new camera pose as two steps. First, we predict robot pose
and get the state vector that includes the new camera pose,
. Second, we marginalizing
from the posterior to achieve the desired distribution
. This is exemplified in
Figure 2.
Figure 2.
A graphical explanation of EIF’s methodology in the information matrix. A circle indicates the position of a feature; a triangle indicates the camera pose. Darker shades in the matrix imply stronger relevance; white indicates no relevance. (a) represents features associated with the camera pose; represents features irrelevant to the camera pose; (b) new camera pose is added to the state vector ; (c) marginalized distribution with the old pose . The constraints between and each map element in are eliminated. New constraints between and are created. We see from the shading that many constraints between features are weakened.
Figure 2.
A graphical explanation of EIF’s methodology in the information matrix. A circle indicates the position of a feature; a triangle indicates the camera pose. Darker shades in the matrix imply stronger relevance; white indicates no relevance. (a) represents features associated with the camera pose; represents features irrelevant to the camera pose; (b) new camera pose is added to the state vector ; (c) marginalized distribution with the old pose . The constraints between and each map element in are eliminated. New constraints between and are created. We see from the shading that many constraints between features are weakened.
In this work we estimate the camera motion between RGB-D images through the visual odometry algorithm, explained in detail in
Section 6. The observation model, based on 3D landmarks with binary descriptors, will be shown in
Section 5.
4. RGB-D Image Feature Descriptor
There are many feature descriptor methods, which are divided into two categories: gradient histogram-based feature descriptors, like SIFT [
41] and SURF [
42], and binary feature descriptors, like BRISK [
13], ORB (Oriented Fast and Rotated BRIEF) [
43], BRIEF (Binary Robust Independent Elementary Features) [
14]. The evaluation criteria of the descriptor include invariance to image noise, scale, translation and rotation transformations. The traditional SIFT and SURF methods are very robust, but the computation time is not practicable for real-time scenes. Binary feature descriptors are described with a binary string. These descriptors are computed by pairwise intensity comparison tests, using simple intensity difference tests, which have the characteristics of less memory consumption, faster processing in creation and a matching process. The distance between two binary strings can be measured using the Hamming distance. The Hamming distance equation is given in equation:
where
represents bit inequality and
and
are the
i-th bits in the descriptors
x and
y, respectively.
In this work, we adopt BRAND [
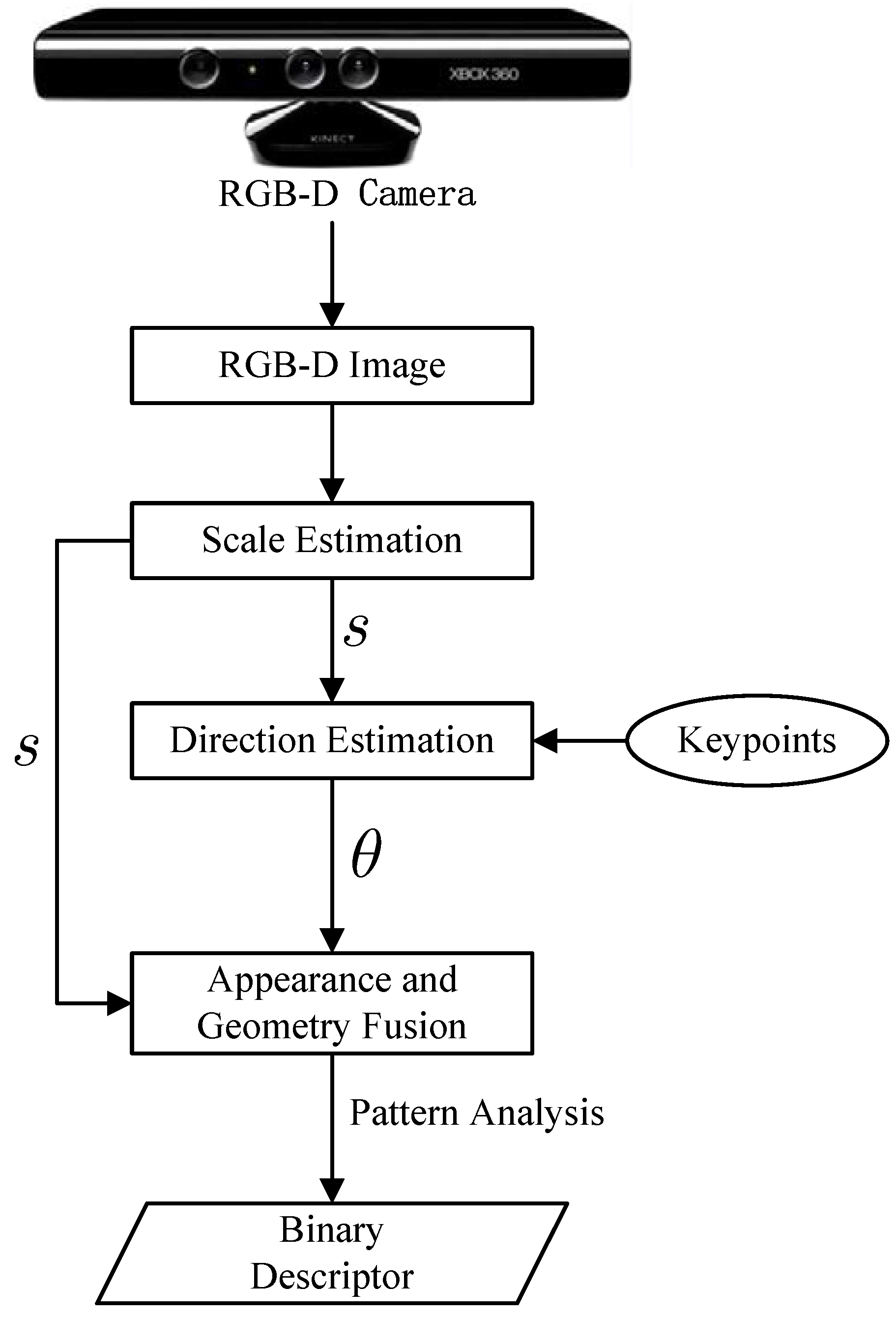
12], which combines appearance and geometric shape information from RGB-D images. Compared to other descriptors based on texture, geometry and a combination of both pieces of information, BRAND has advantages in accuracy, processing time and memory consumption, since it combines intensity and geometric information to improve the ability of fast and accurate matching. It is invariant to rotation and scale transform and suitable for applications with low memory consumption and high speed. The algorithm is composed of three main steps:
- Step 1.
We use the depth information from the RGB-D image to compute the scale factor, which is used in Step 2, and analysis the feature in the keypoint’s neighborhood.
- Step 2.
We extract a patch in the RGB domain to estimate the feature angular direction of the keypoint’s vicinity.
- Step 3.
We combine both appearance and geometric information to bring forth keypoint descriptors with a binary string.
The steps performed to build the binary string are illustrated in
Figure 3. The pair
represents the output of an RGB-D system, where
and
denote color and depth information of a pixel
x. In the BRAND algorithm, each pair
is evaluated:
where
denotes the pixel intensity of a pixel
x and
represents the characteristic gradient changes in the keypoint neighborhood.
evaluates the geometric pattern on its surface. The analysis of the geometric pattern using
is based on two invariant geometric measurements: the normal displacement and the surface’s convexity.
Figure 4 shows the construction process of the bit string.
Figure 3.
Flow diagram of binary robust appearance and normals descriptor (BRAND) descriptor. s is the scale factor, and θ is the dominant direction of the keypoint.
Figure 3.
Flow diagram of binary robust appearance and normals descriptor (BRAND) descriptor. s is the scale factor, and θ is the dominant direction of the keypoint.
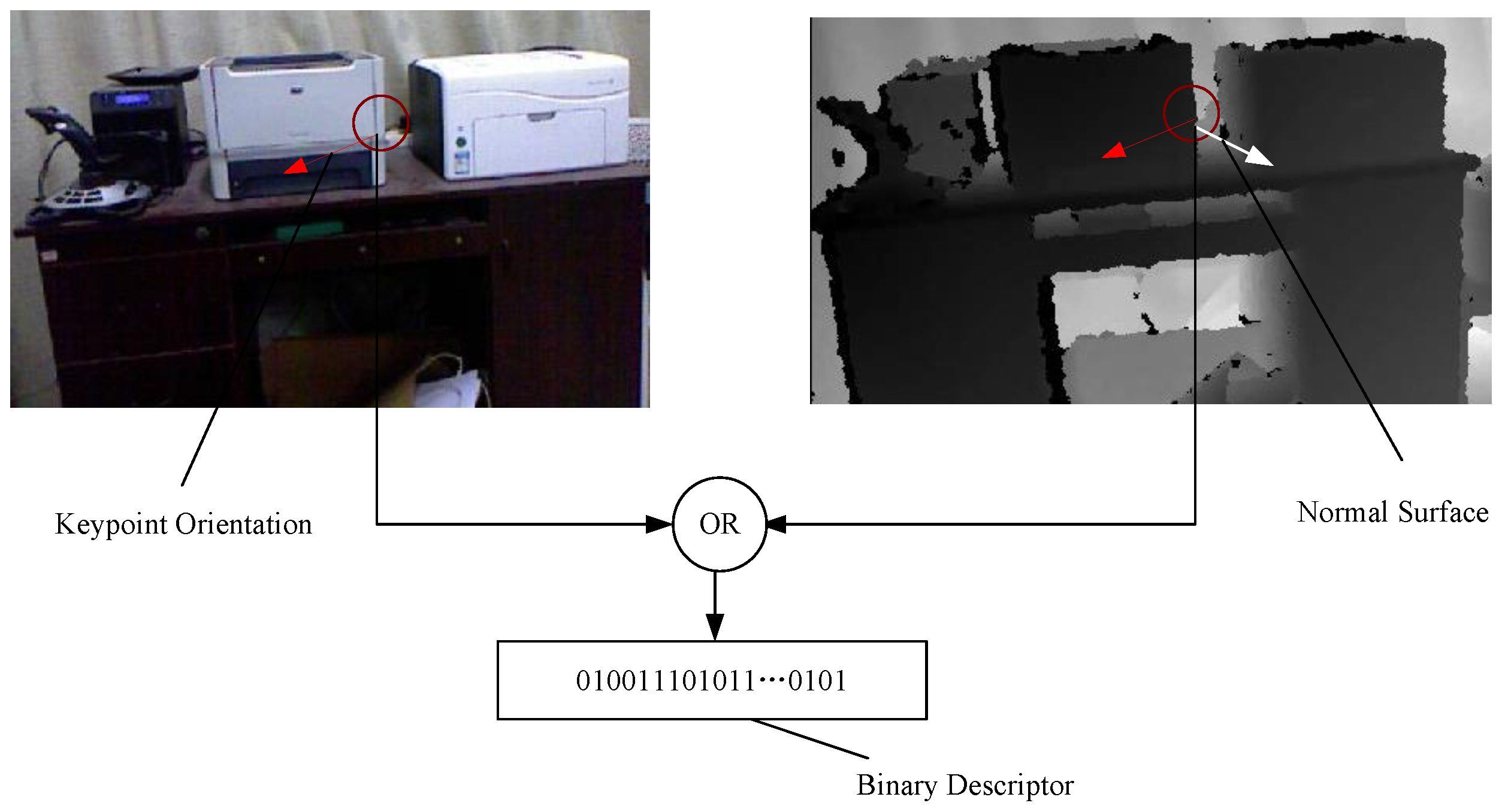
Figure 4.
The construction process of the bit string. The red circle represents the patch of size centered at the keypoint location. For sampled pair in a patch P , the changes in the intensity and geometry are evaluated.
Figure 4.
The construction process of the bit string. The red circle represents the patch of size centered at the keypoint location. For sampled pair in a patch P , the changes in the intensity and geometry are evaluated.
We evaluate changes in the intensity and geometry of the sampled pair
in a patch
p and encode the descriptor extracted from a patch
p associated with a keypoint
k. It is represented as a binary string:
The BRAND descriptor takes into account appearance and geometry from RGB-D images. Appearance is an object property invariant to any geometric transformation, and geometric measurements are invariant to rotation, translation and scaling. Different from descriptors that use either appearance information or geometric information, the BRAND descriptor spends little memory space and little processing time without losing accuracy, which presents invariance to rotation, translation, scale transform and robustness to different illumination conditions.
6. Motion Model: Dense Visual Odometry
Visual odometry [
37,
44] is an estimation process of the movement information of an intelligent body only using the input information of a single or multiple cameras. In this paper, we use the DVO proposed by Kerl
et al. [
37] to estimate the ego-motion of RGB-D sensor, which is used as the motion model of EIF. DVO estimates camera motion by aligning two consecutive RGB-D images.
A 3D point p in the scene observed by two cameras is assumed to yield the same brightness in both images, i.e., . This assumption is based on the photo-consistency theory. is the warping function; is the camera motion; maps a pixel coordinate in the first image ( to a coordinate in the second image(. In the following, we will give a detailed derivation of the warping function, calculate the error function based on all of the pixels and minimize the difference between the estimated and the real depth measurements.
6.1. Camera Model
We reconstruct a 3D point
p from its pixel coordinates
and a corresponding depth measurement
using the inverse projection function
,
i.e.,
where
α,
β are the focal length and
,
are the center coordinates of the pinhole camera model.
6.2. Warping Function
In the coordinate frame of the second camera, the point
p is rotated and translated according to the rigid body motion
g (
, which is the special Euclidean group). A rigid body motion comprises a rotation matrix
R (
, which is the rotation group) and a translation vector
t (
). The transformation matrix
T is given as:
The transformation of the 3D point p with g is . T has twelve parameters, while g has six degrees of freedom. Therefore, we use twist coordinates u; u is a six-vector, i.e., . are called the linear velocity and are the angular velocity of the motion. The transformation matrix T can be calculated from u using the matrix exponential relating Lie algebra to Lie group .
When the transformed point
is observed by the second camera, we calculate warped pixel coordinates as:
We summarize Equation (
21)–(
23); the full warping function is:
6.3. Probabilistic Estimation
The difference in brightness between the first and the warped second image is defined as:
By assuming that all
n pixels
(
) in the image are equal, the probability of whole residual image
is
. After applying Bayes’ rule, the posterior probability of a camera motion
u given a residual image
r is:
We seek for
by maximizing the posterior probability,
i.e.,
By integrating Equation (
26) with Equation (
27) and removing the term
, which does not depend on
u, we obtain:
Assuming all residuals
(
) are independent and identically distributed, by minimizing instead the negative log likelihood, we get:
The minimum is found when the derivative of the log likelihood is set to zero. To simplify Equation (
29), we drop the motion prior
and obtain:
We define
and get
. The photometric error follows a t-distribution [
45]
. In the distribution, mean
, and variance =
; degree of freedom =
v. In Equation (
29), we assume that all residuals are equal. It is very difficult to satisfy. Really, large errors covering the outliers get low weights. On the contrary, small errors with large variance get higher probability. The t-distribution is fit for this model. If
is defined as a t-distribution, the weighted least squares problem is:
The function
is called the weighting function and is defined as:
In this paper, the residual
follows a bivariate t-distribution. Based on the t-distribution
, the weights
are:
The weight termed by ∑ is automatically adapted.
6.4. Optimization of Motion Estimation
This optimization problem is a non-linear least squares problem. The residuals
are non-linear in
u; we use a first order Taylor expansion to linearize it. We obtain normal equations of this non-linear least squares problem:
where
is the Jacobian matrix, which contains the derivatives of
concerning
u. The normal equation for increments
is iteratively calculated. At each iteration, the scale matrix ∑ and the weights
are re-estimated. A is the Hessian matrix of nonlinear least squares problems. Assuming parameters
u are normally distributed,
is a lower bound for the variance of the estimated parameters
u,
i.e.,
.
7. Experimental Results
The experiments were implemented with the Robot Operating System (ROS) framework. All of the experiments were done using the same notebook computer, which has an Intel Core i7-4700HQ CPU and 8.0 GB RAM with Ubuntu 14.04 64-bit operation system. In the experiments, we compared three methods: the VO-EIF RGB-D SLAM, the DVO algorithm and a type of graph-based RGB-D SLAM implemented in the RTAB-Map system [
46]. In the graph-based RGB-D SLAM, the TORO (tree-based network optimizer) [
47] is selected to optimize the pose graph, and FAST/BRAND is selected as the detector/descriptor [
48]. The other parameter settings of the graph-based RGB-D SLAM are the same as in [
48], except that time limit
T is not set. In our VO-EIF RGB-D SLAM, we set two update thresholds
and
. When any of the following two conditions are satisfied, the filter update will execute: the accumulated changes of
x,
y or
z of the visual odometry are greater than
, or any of the accumulated changes of
,
or
of the visual odometry are greater than
. In the following experiments,
is set to 0.1 m and
is set to 0.1 rad.
In order to test the validity of our algorithm, we implemented two different experiments. The first experiment was conducted online in our lab environment, which focused on the effectiveness and timeliness of all parts of our algorithm, as well as qualitatively verifying the accuracy. The second was accomplished off-line by utilizing the RGB-D benchmark provided by the Technical University of Munich [
31]. The advantage of using this benchmark is that each dataset of the benchmark accompanies an accurate ground truth trajectory obtained with an external motion capture system, and it can be used to quantitatively evaluate the accuracy of the algorithm. Benchmark data were taken with a Microsoft Kinect sensor, providing
RGB and depth frames at a 30-Hz rate; the ground truth data were taken with a highly accurate motion capture system, composed of eight 100-Hz cameras.
7.1. Lab Environment Results
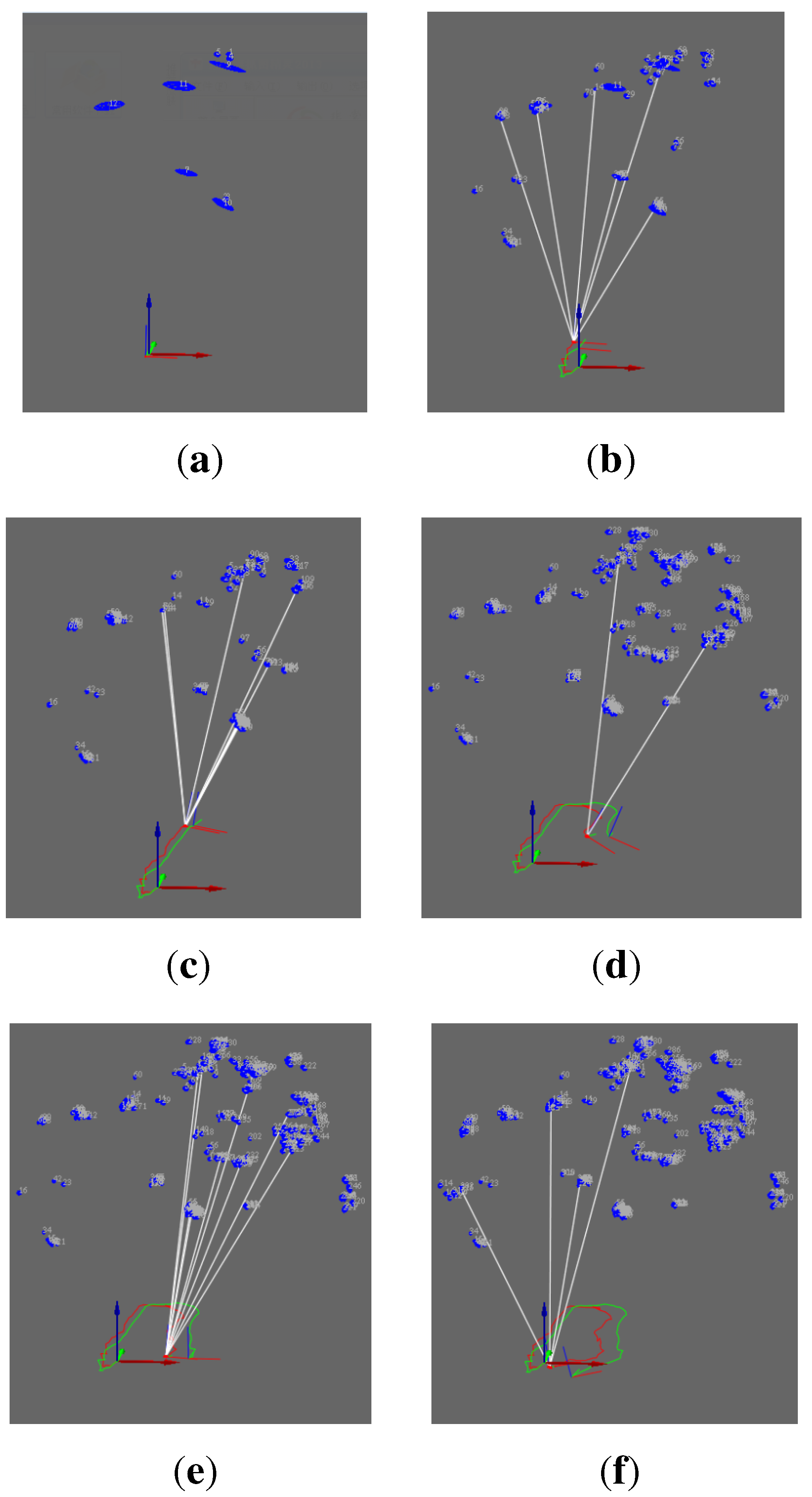
Figure 5 shows landmark observation in the process of the camera motion.
Figure 5a demonstrates the observation of the first frame. Seen from the view of
(the red arrow represents the
x-axis and the blue arrow represents the
z-axis), no landmark is observed in the first frame (the blue oval represents the landmark). In
Figure 5b–f, white lines represent landmark re-observation. The number of keypoints for observation is limited to 10 for the purpose of improving the speed of SLAM. From
Figure 5b–f, we can see that the landmarks number gradually increased and the uncertainties of re-observed landmarks gradually decreased.
Figure 5.
The map building process of VO-EIF RGB-D SLAM: (a) The first frame; (b) The eighth frame; (c) The thirty-first frame; (d) The fifty-second frame; (e) The sixty-first frame; (f) The seventy-third frame.
Figure 5.
The map building process of VO-EIF RGB-D SLAM: (a) The first frame; (b) The eighth frame; (c) The thirty-first frame; (d) The fifty-second frame; (e) The sixty-first frame; (f) The seventy-third frame.
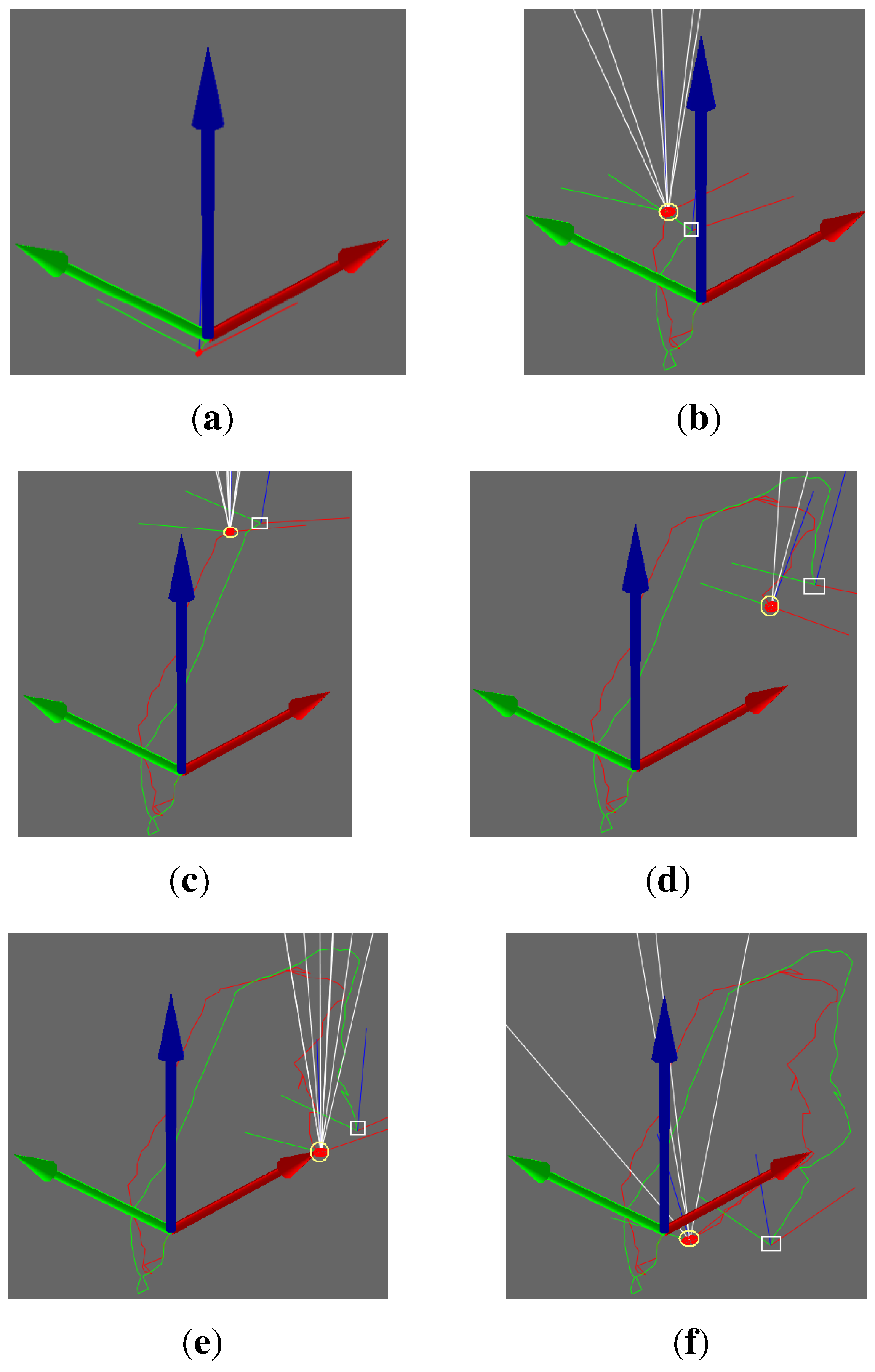
Figure 6 demonstrates a comparison between two trajectories of the two methods. The red curve stands for the motion trajectory with the VO-EIF RGB-D SLAM algorithm, and the green curve stands for the motion trajectory with traditional visual odometry. In
Figure 6b–f, the yellow circles represent the camera position estimated with the VO-EIF RGB-D SLAM method, and the white square represents the camera position estimated with the DVO method. Seen from
Figure 6, the difference between the two methods is not obvious in the first 30 frames of the motion. In the later stage of the motion, when the camera moves toward the original position, the red trajectory is close to the original position, but the green trajectory deviates from the original position. Without the observation model, accumulative error with the DVO method increased with time and affected proper trajectory estimation. In each step of the observation of the VO-EIF RGB-D SLAM method, the error is very small, and accumulative error can be corrected. Therefore, the algorithm of VO-EIF RGB-D SLAM can properly estimate camera motion.
Figure 6.
Comparison of two trajectories: (a) The first frame; (b) The eighth frame; (c) The thirty-first frame; (d) The fifty-second frame; (e) The sixty-first frame; (f) The seventy-third frame.
Figure 6.
Comparison of two trajectories: (a) The first frame; (b) The eighth frame; (c) The thirty-first frame; (d) The fifty-second frame; (e) The sixty-first frame; (f) The seventy-third frame.
These results show that VO-EIF RGB-D SLAM has the advantage of smaller accumulative error. We acquire the trajectory closer to the real trajectory with the VO-EIF RGB-D SLAM. Especially, when the camera comes back to the original position, the trajectory with the traditional method deviates from the original position, but the trajectory with the VO-EIF RGB-D SLAM is very close to the original position (as can bee seen in
Figure 6f).
7.2. Benchmark Results
The results of the benchmark experiments were calculated using the absolute trajectory error (ATE) evaluation tool provided with the benchmark. This evaluation method directly compares the difference between poses in the ground truth and measured trajectory, and the end result of it is the root mean squared error (RMSE) of the per pose errors summed over the entire trajectory.
In this paper, we evaluated two datasets using our proposed algorithm, the DVO algorithm and the above graph-based RGB-D SLAM separately. The two datasets are sequences “freiburg1_room” and “freiburg3_long_office_household”. Their durations are 48.90 s and 87.09 s, respectively. The statistical results are shown in
Table 1 and
Table 2.
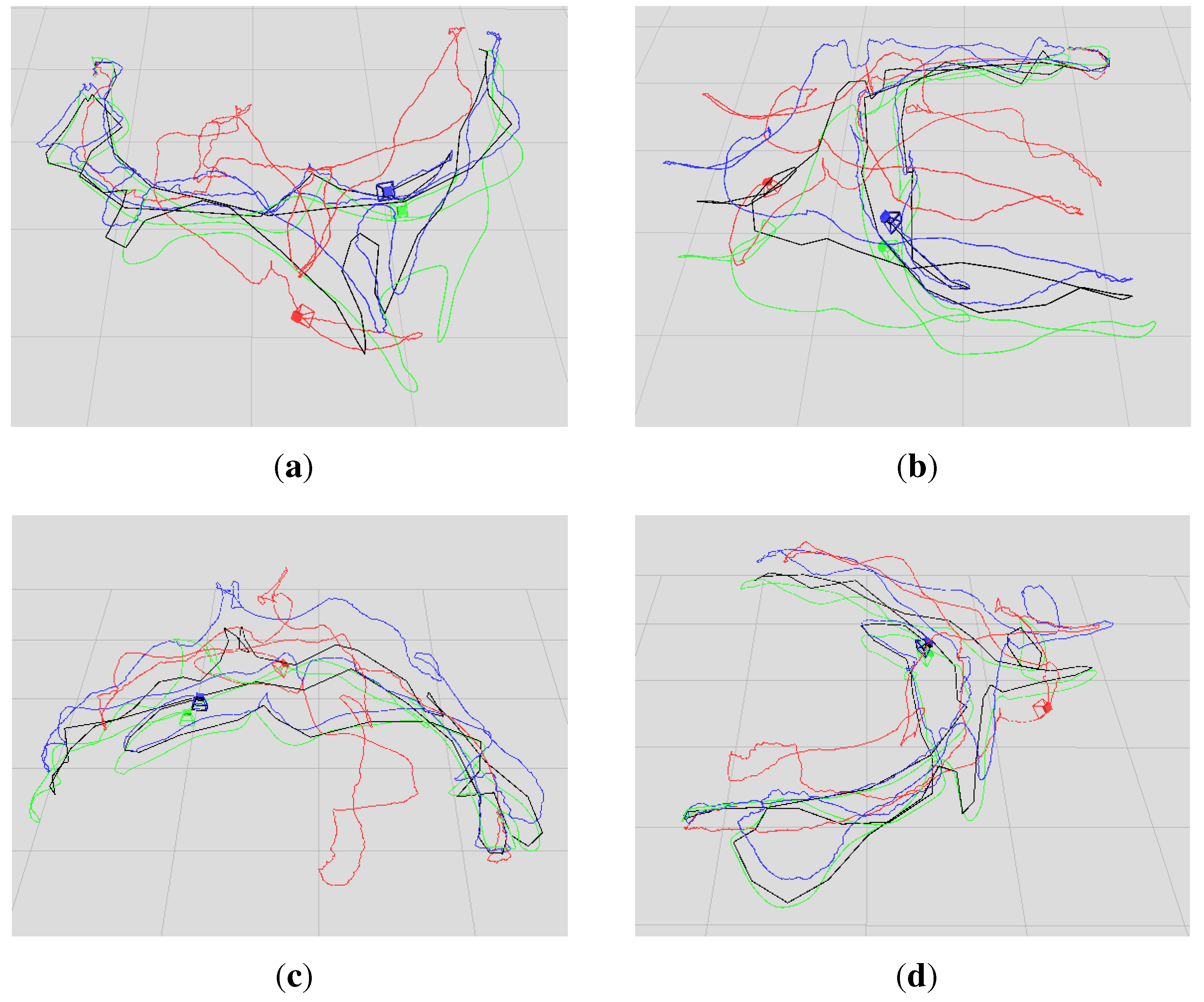
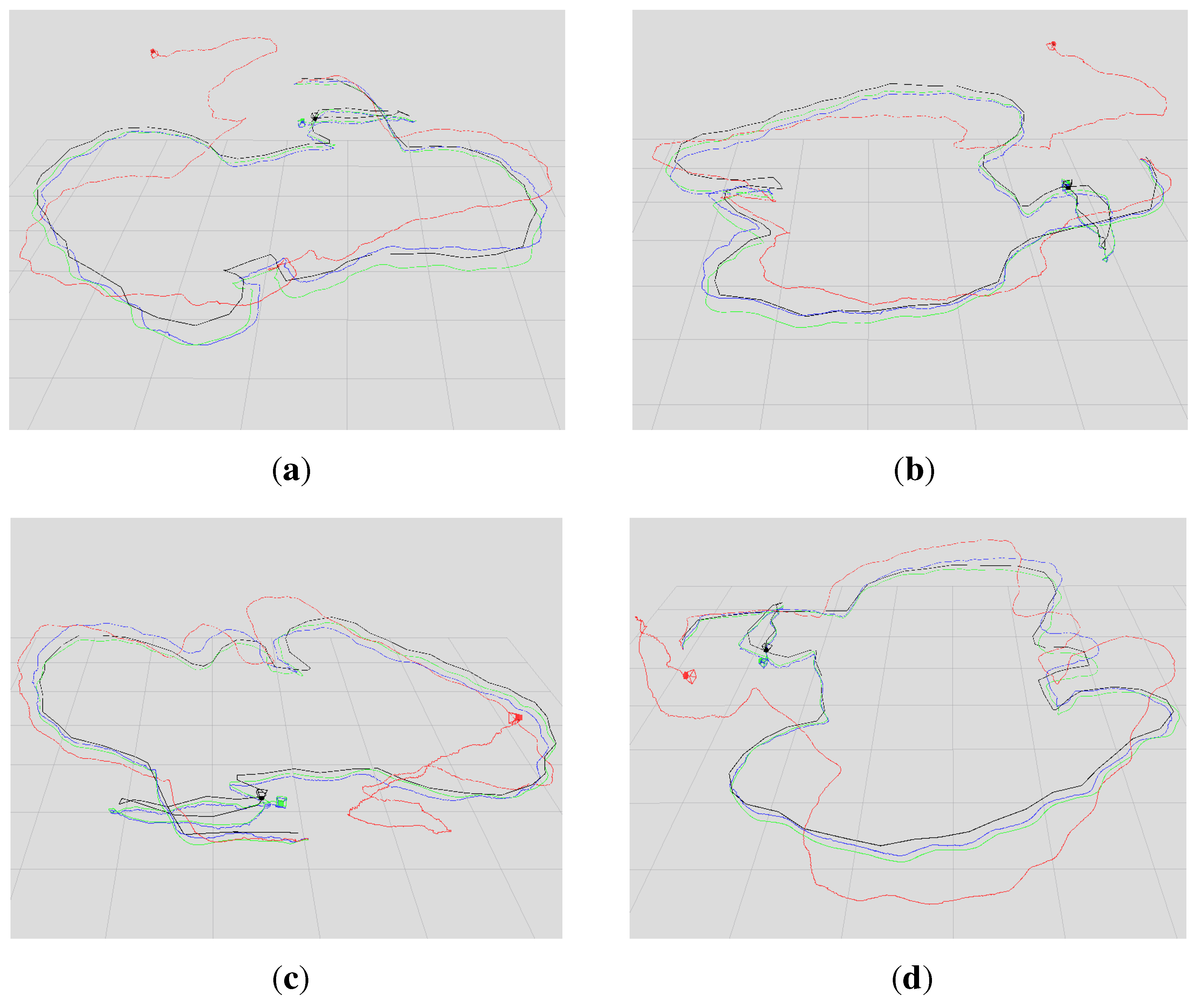
Figure 7 shows in four different perspectives the trajectory results of the sequence “freiburg1_room”: the ground truth trajectory and the three trajectories, which are respectively generated by the three algorithms. Similar to
Figure 7,
Figure 8 is the trajectory results of the sequence “freiburg3_long_office_household”. The measured trajectory errors are shown in
Figure 9 and
Figure 10. From these experimental results, we can see that the VO-EIF RGB-D SLAM can successfully complete the large loop closing, while the DVO cannot (as can be seen in
Figure 10a). This is because in VO-EIF RGB-D SLAM, the re-observed features can greatly improve the sensor localization accuracy. The localization precision of our algorithm is nearly the equivalent of the graph-based algorithm. It should be pointed out that the trajectory of the graph-based algorithm is nearly fully updated at every update time, but in our filter-based algorithm, only the current camera pose is updated, and the poses of the passed time are not saved and updated in the filter. In other words, in the filter-based algorithm, the estimation of the camera pose at time
t is only based on the information by time
t, which has no post updating.
Table 1.
Comparison results of processing the sequence “freiburg1_room”. DVO, dense visual odometry.
Table 1.
Comparison results of processing the sequence “freiburg1_room”. DVO, dense visual odometry.
| Comparison Index Terms | Method |
|---|
| DVO | VO-EIF RGB-D SLAM | Graph RGB-D SLAM |
|---|
| | RMSE | 0.447535 | 0.114760 | 0.093479 |
| Trajectory | Mean | 0.418295 | 0.109373 | 0.083075 |
| error | Median | 0.412622 | 0.112226 | 0.072460 |
| indicators | STD | 0.159112 | 0.034747 | 0.042859 |
| (m) | Min | 0.092879 | 0.024764 | 0.025987 |
| | Max | 0.794312 | 0.309430 | 0.211681 |
| Total processing time (s) | 15.7327 | 24.6747 | 105.8131 |
Table 2.
Comparison results of processing the sequence “freiburg3_long_office_household”.
Table 2.
Comparison results of processing the sequence “freiburg3_long_office_household”.
| Comparison Index Terms | Method |
|---|
| DVO | VO-EIF RGB-D SLAM | Graph RGB-D SLAM |
|---|
| | RMSE | 0.535152 | 0.067632 | 0.053803 |
| Trajectory | Mean | 0.428854 | 0.061255 | 0.051310 |
| error | Median | 0.271139 | 0.053549 | 0.050743 |
| indicators | STD | 0.320113 | 0.028669 | 0.016189 |
| (m) | Min | 0.090521 | 0.010577 | 0.023585 |
| | Max | 1.124703 | 0.130501 | 0.124373 |
| Total processing time (s) | 29.9347 | 63.4500 | 184.4862 |
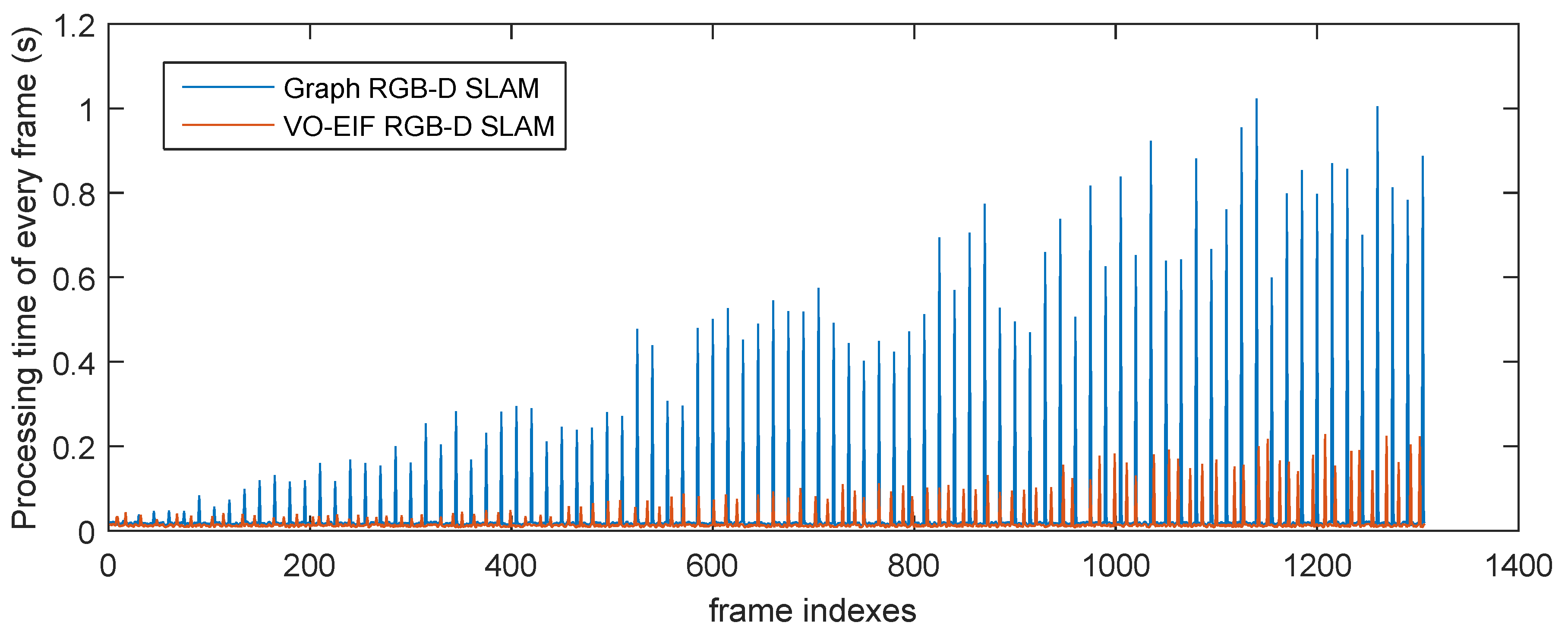
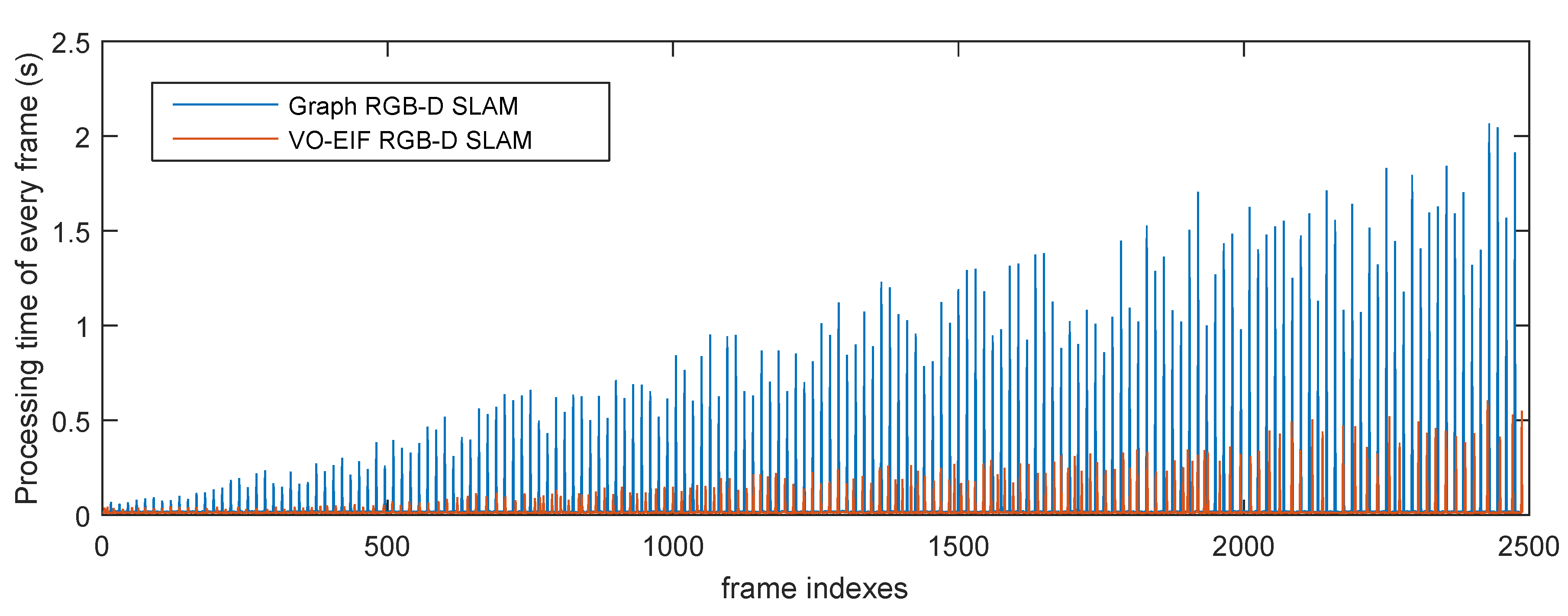
Figure 11 and
Figure 12 show the processing time for each frame of the two sequences by different algorithms. It can be seen that the update time of our algorithm is smaller than the processing time of the graph-based algorithm for the keyframe at a similar moment.
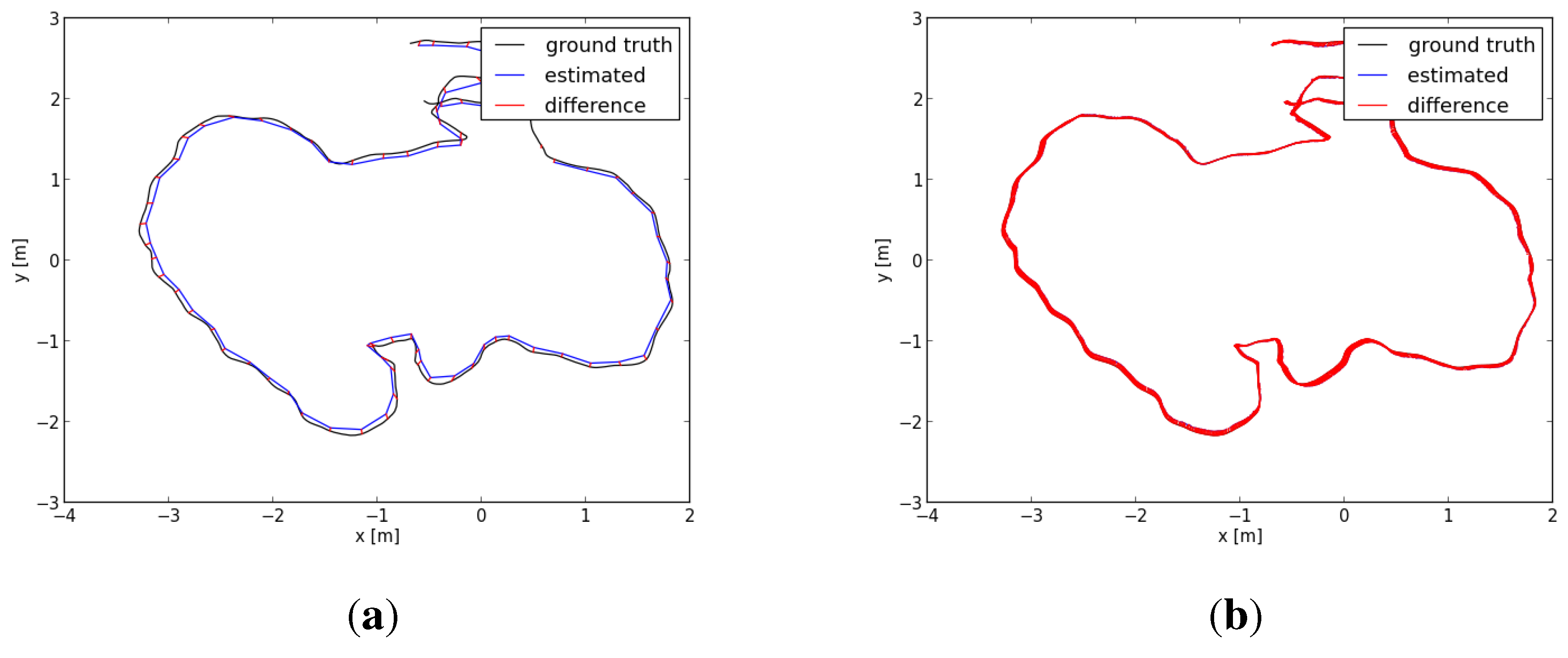
Figure 7.
Comparison of the four trajectories for the sequence “freiburg1_room”. The blue, red and black trajectories are generated by our algorithm, the DVO algorithm and the graph-based algorithm, respectively. The green trajectory is the ground truth. (a–d) The views in four different perspectives.
Figure 7.
Comparison of the four trajectories for the sequence “freiburg1_room”. The blue, red and black trajectories are generated by our algorithm, the DVO algorithm and the graph-based algorithm, respectively. The green trajectory is the ground truth. (a–d) The views in four different perspectives.
Figure 8.
Comparison of the four trajectories for the sequence “freiburg3_long_office_household”. The blue, red and black trajectories are generated by our algorithm, the DVO algorithm and the graph-based algorithm, respectively. The green trajectory is the ground truth. (a–d) The views in four different perspectives.
Figure 8.
Comparison of the four trajectories for the sequence “freiburg3_long_office_household”. The blue, red and black trajectories are generated by our algorithm, the DVO algorithm and the graph-based algorithm, respectively. The green trajectory is the ground truth. (a–d) The views in four different perspectives.
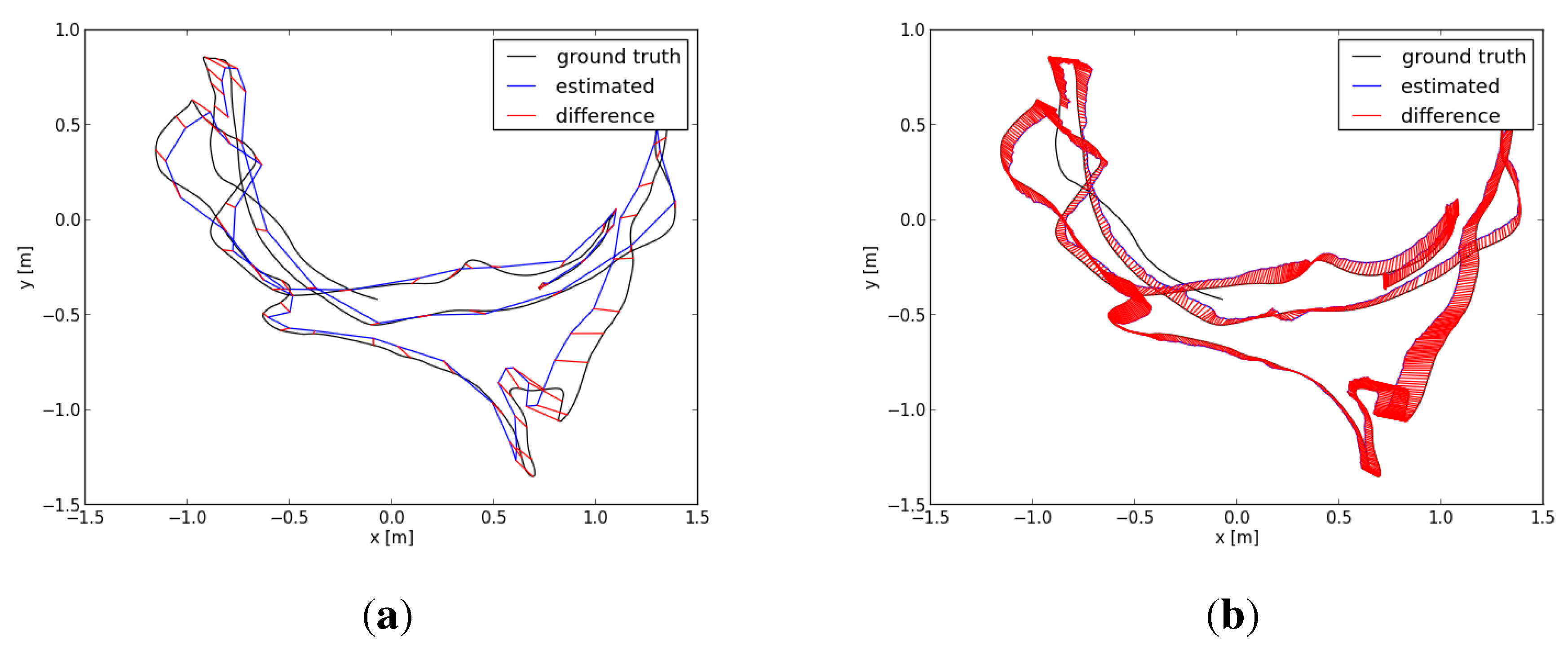
Figure 9.
Comparing absolute trajectory errors (ATEs) for the sequence “freiburg_1room”: (a) ATE using the graph-based RGB-D SLAM; (b) ATE using the VO-EIF RGB-D SLAM.
Figure 9.
Comparing absolute trajectory errors (ATEs) for the sequence “freiburg_1room”: (a) ATE using the graph-based RGB-D SLAM; (b) ATE using the VO-EIF RGB-D SLAM.
Figure 10.
Comparing ATEs for the sequence “freiburg3_long_office_household”: (a) ATE using the graph-based RGB-D SLAM; (b) ATE using the VO-EIF RGB-D SLAM.
Figure 10.
Comparing ATEs for the sequence “freiburg3_long_office_household”: (a) ATE using the graph-based RGB-D SLAM; (b) ATE using the VO-EIF RGB-D SLAM.
Figure 11.
Total processing time of every frame of the sequence “freiburg1_room” by different algorithms.
Figure 11.
Total processing time of every frame of the sequence “freiburg1_room” by different algorithms.
Figure 12.
Total processing time of every frame of the sequence “freiburg3_long_office_household” by different algorithms.
Figure 12.
Total processing time of every frame of the sequence “freiburg3_long_office_household” by different algorithms.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





