
Distributed Density Estimation Based on a Mixture of Factor Analyzers in a Sensor Network



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
| Acronym list: | |
| GMM | Gaussian mixture model |
| EM | expectation maximization |
| E-step | expectation step |
| M-step | maximization step |
| MFA | mixture of factor analyzers |
| MtFA | mixture of Student’s t-factor analyzers |
| D-MFA | distributed density estimation algorithm for the MFA |
| D-MtFA | distributed density estimation algorithm for the MtFA |
| CSS | combined sufficient statistics |
| LSS | local sufficient statistics |
| S-MFA | standard EM algorithm for the MFA |
| S-MtFA | standard EM algorithm for the MtFA |
| NC-MFA | non-cooperation MFA |
| NC-MtFA | non-cooperation MtFA |
| D-GMM | distributed density estimation algorithm for the GMM |
| D-tMM | distributed density estimation algorithm for the Student’st-mixture model |
2. Preliminaries: MFA and MtFA
2.1. Mixture of Factor Analyzers
2.2. Mixture of Student’s t-Factor Analyzers
3. Distributed Estimation Algorithms for the MFA and MtFA
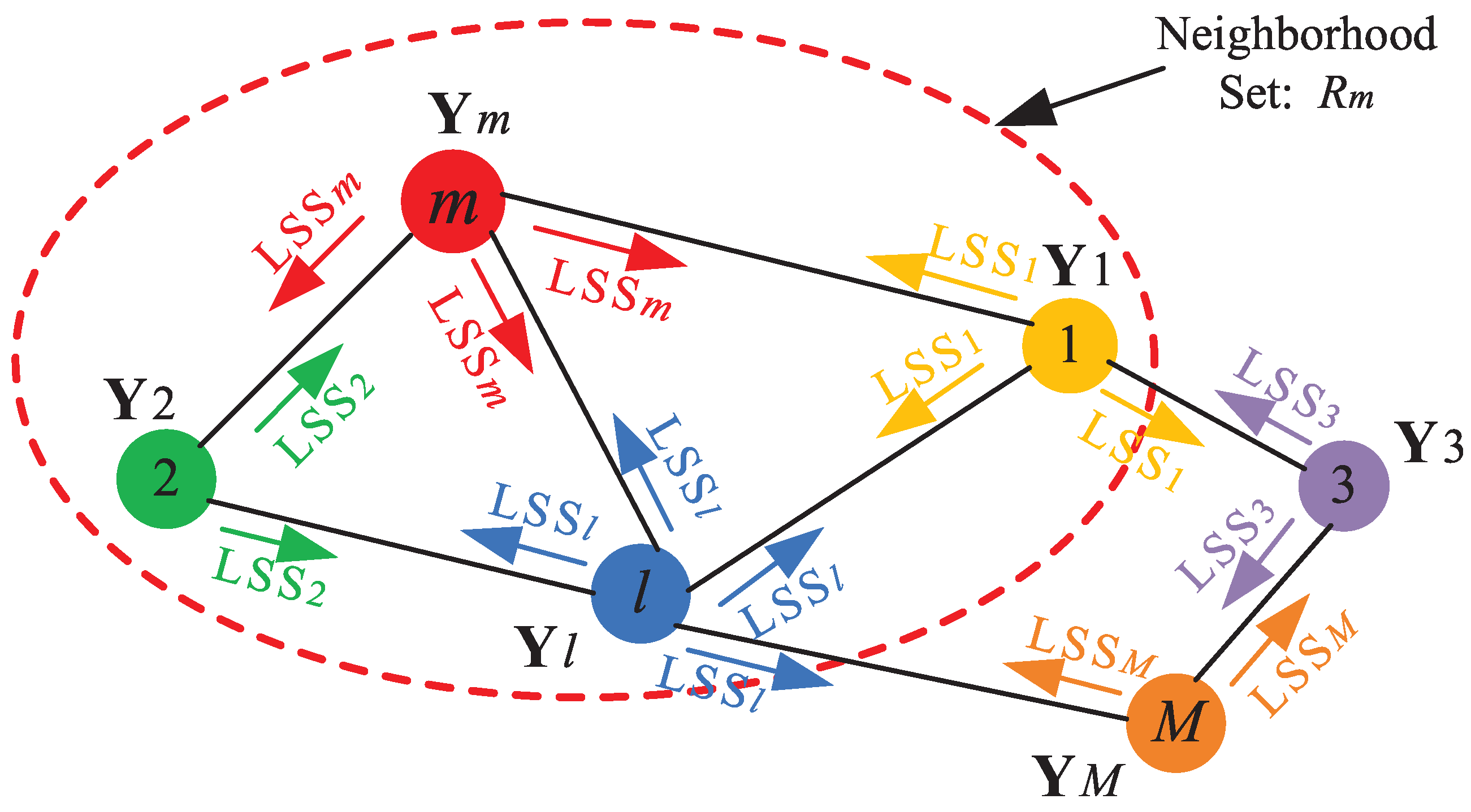
3.1. Network Model and Objective Function

3.2. Distributed Density Estimation Algorithm for the MFA
3.3. Distributed Density Estimation Algorithm for the MtFA
4. Experimental Results
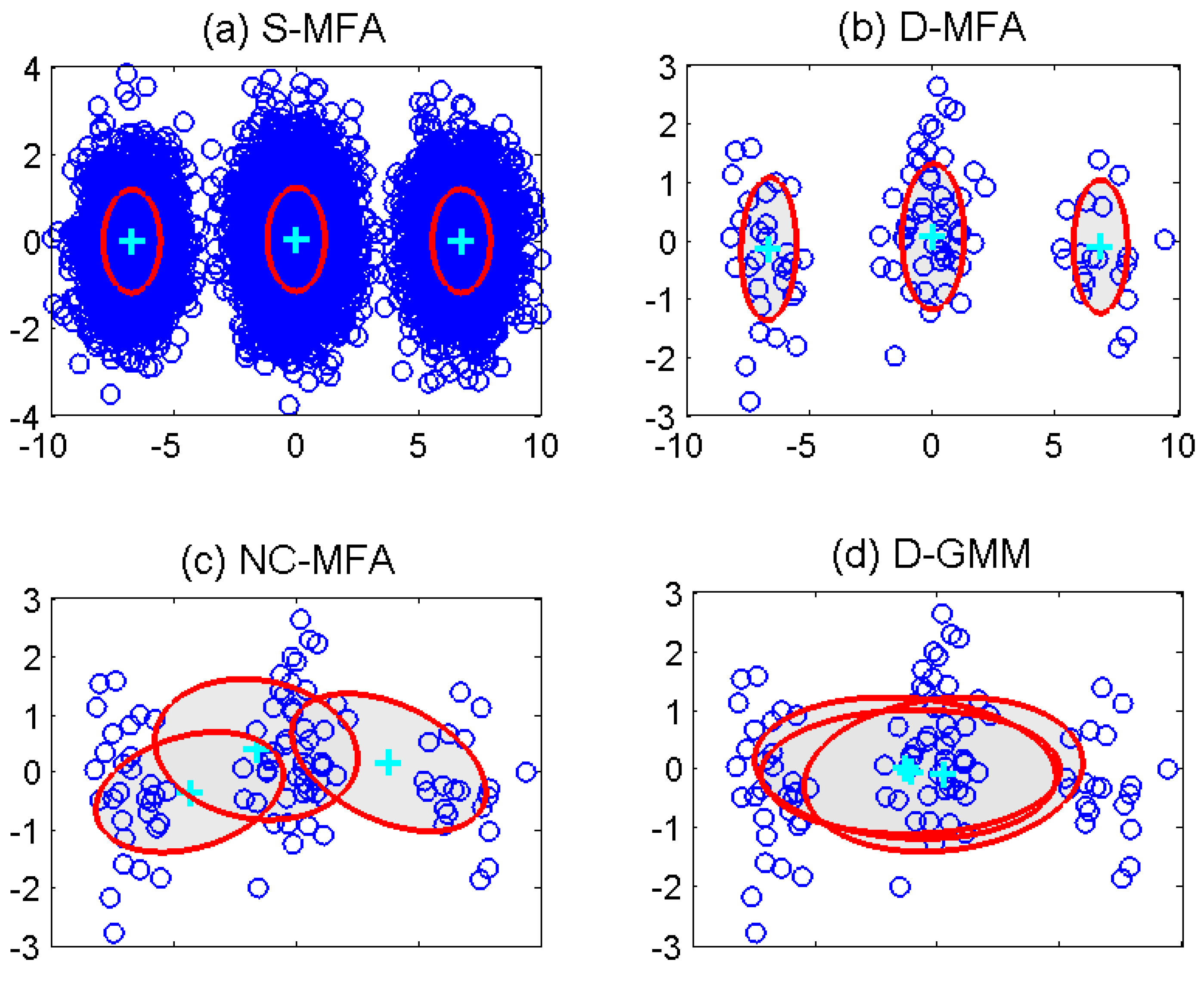
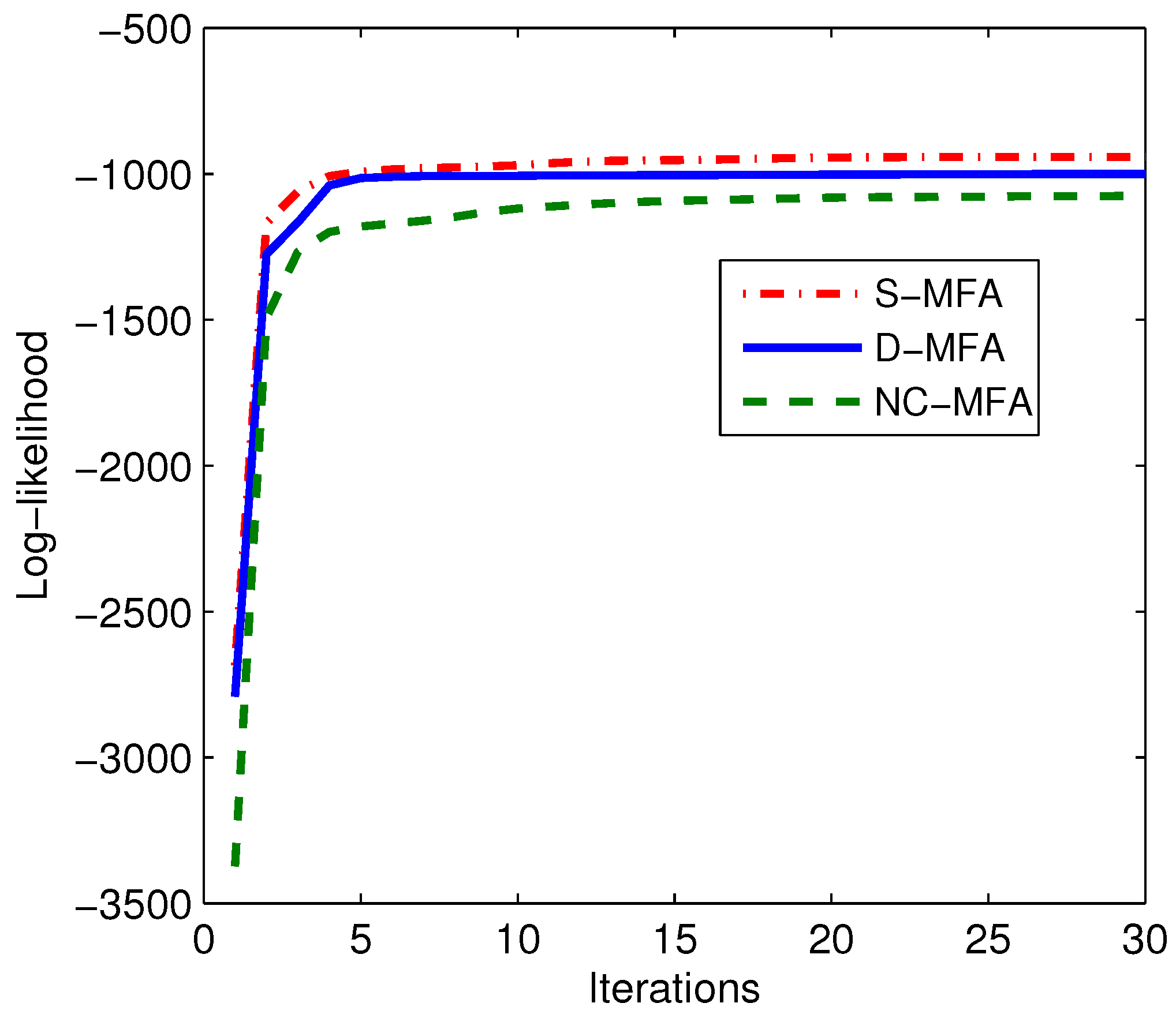
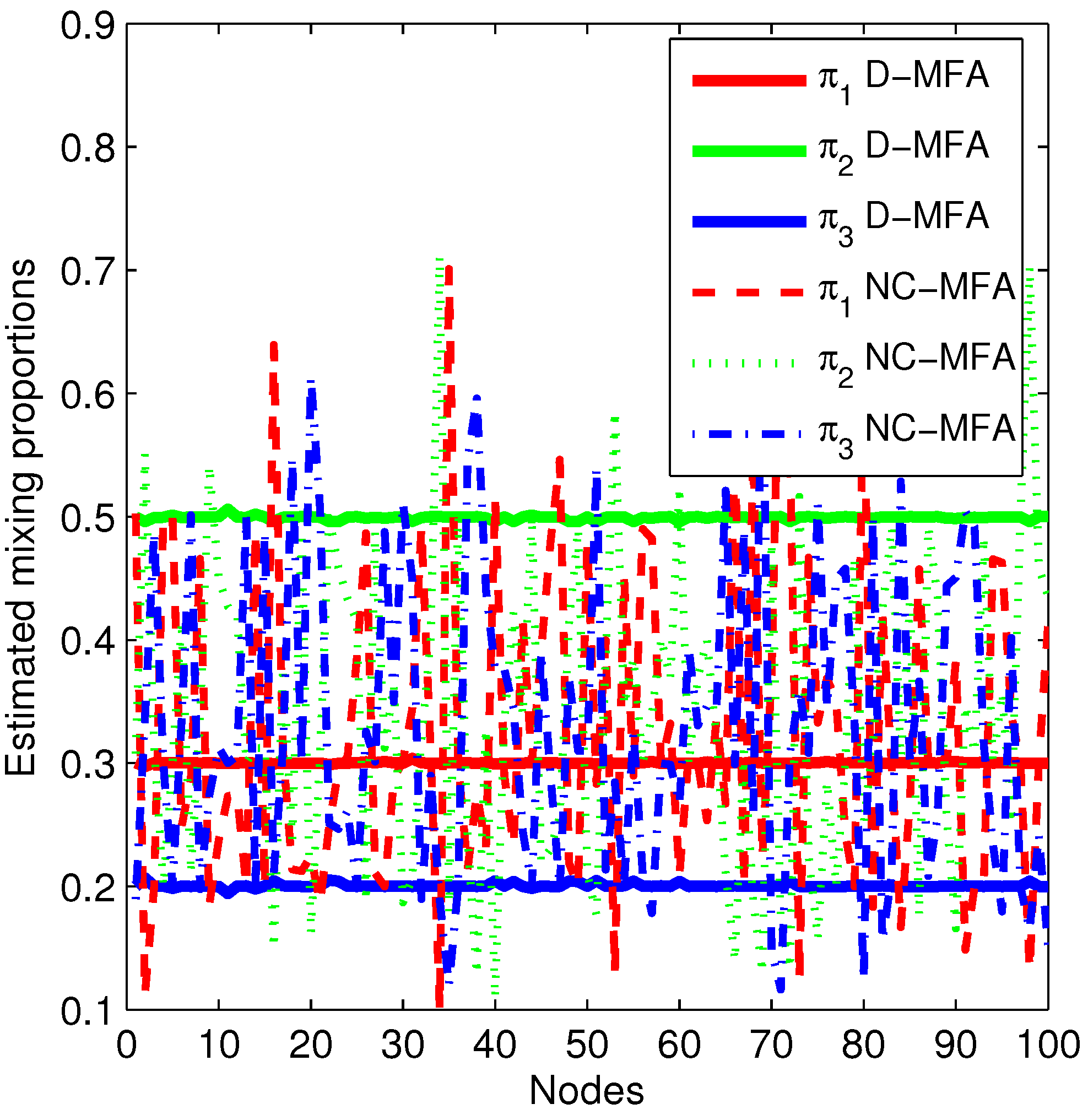
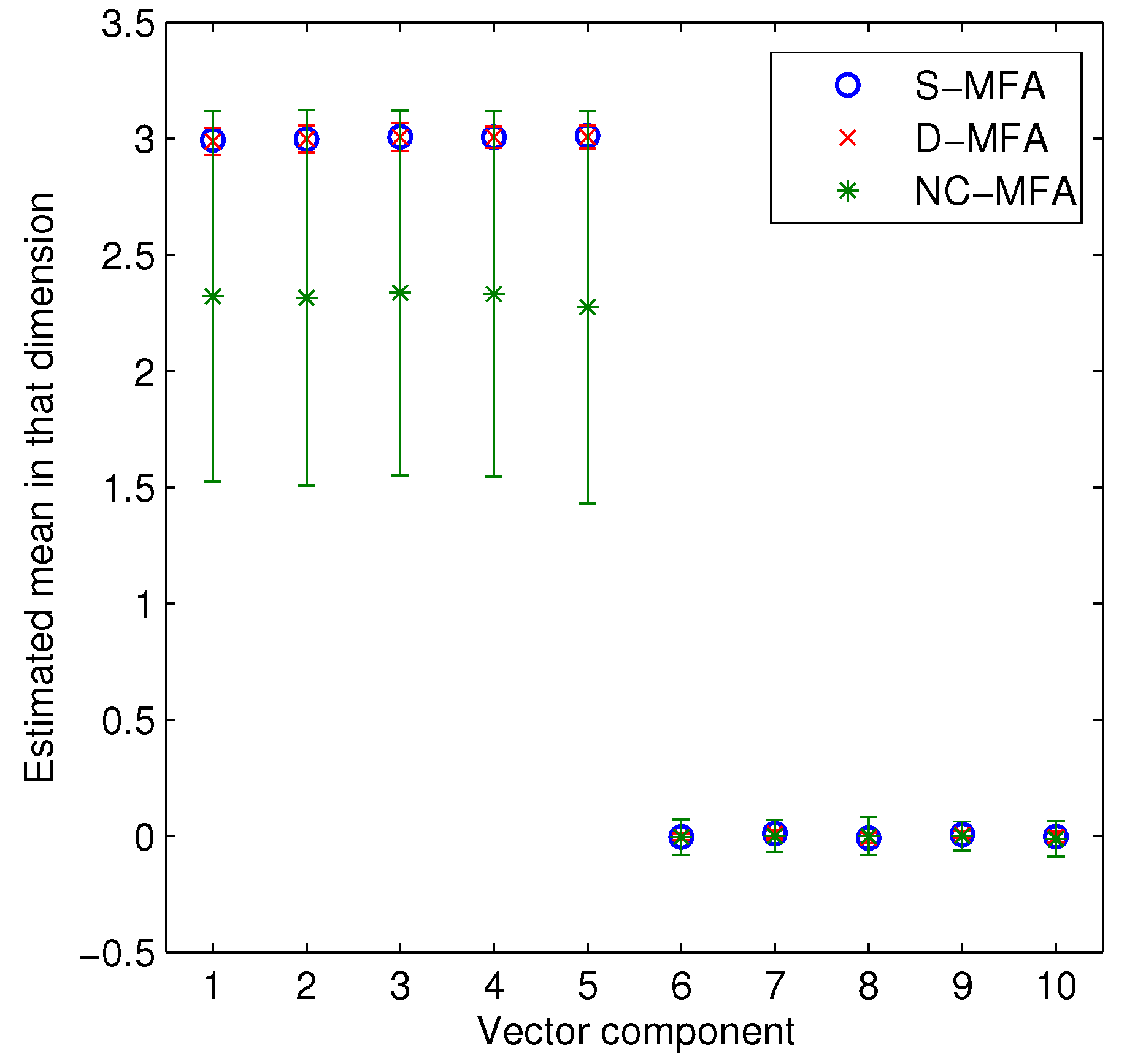
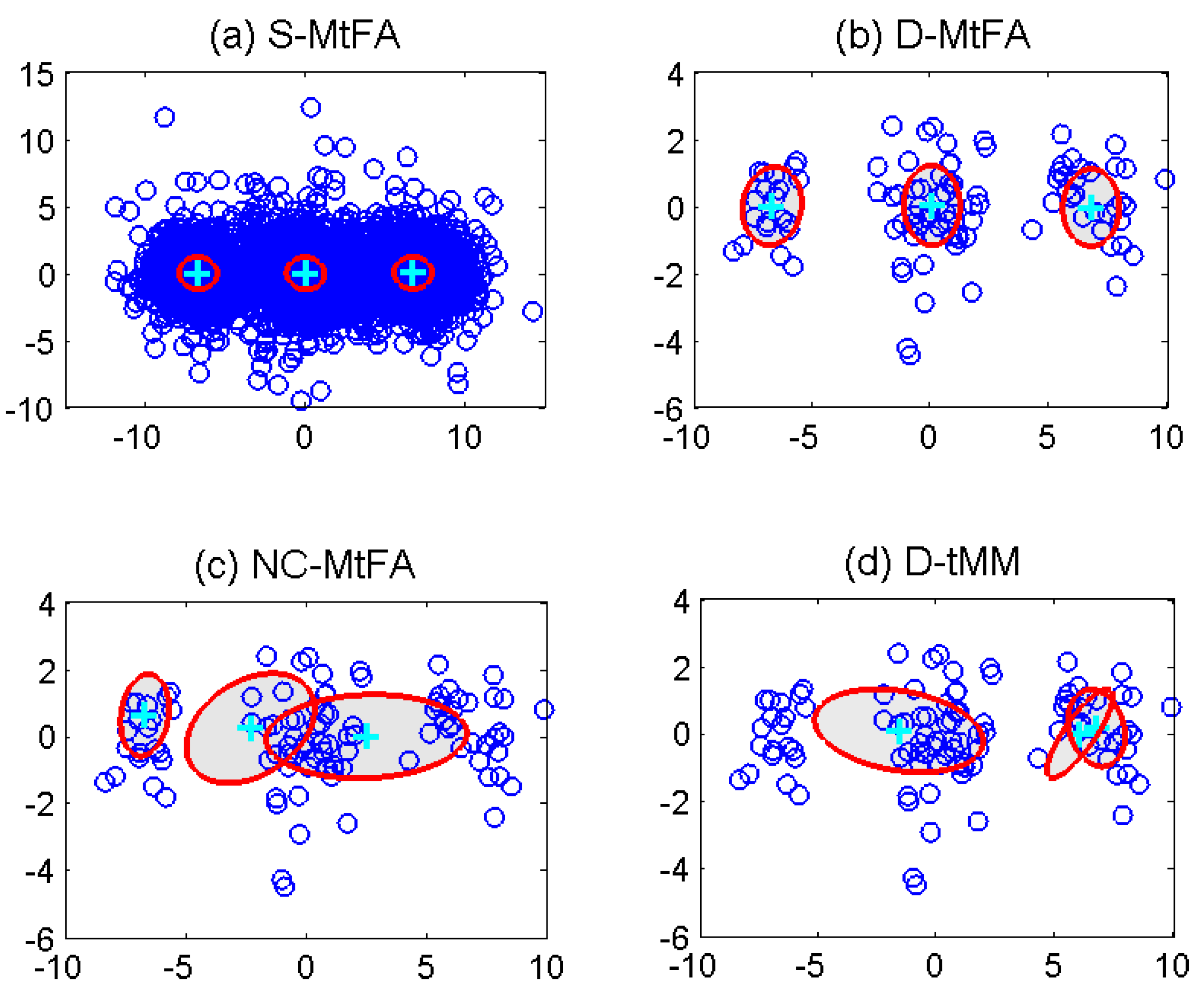
4.1. Synthetic Data






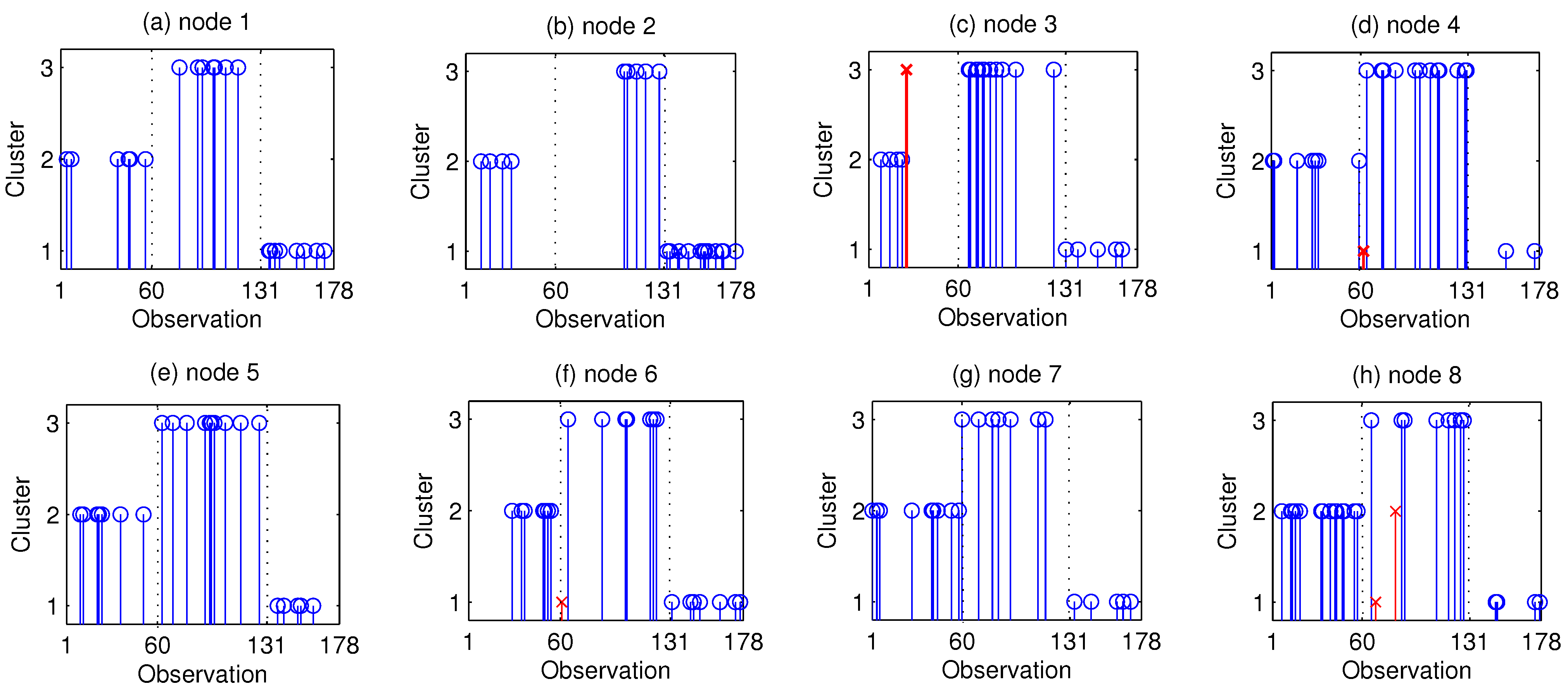
4.2. Real Data

5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix
A. Derivation of the D-MtFA Algorithm
References
- Akyildiz, I.; Su, W.; Sankarasubramniam, Y. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar] [CrossRef]
- Sayed, A.H.; Tu, S.Y.; Chen, J.; Zhao, X.; Towfic, Z. Diffusion strategies for adaptation and learning over networks: An examination of distributed strategies and network behavior. IEEE Signal Process. Mag. 2013, 30, 155–171. [Google Scholar] [CrossRef]
- Poza-Lujan, J.; Posadas-Yagüe, J.; Simó-Ten, J.; Simarro, R.; Benet, G. Distributed sensor architecture for intelligent control that supports quality of control and quality of service. Sensors 2015, 15, 4700–4733. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Sayed, A.H. Diffusion adaptation strategies for distributed optimization and learning over networks. IEEE Trans. Signal Process. 2012, 60, 4289–4305. [Google Scholar] [CrossRef]
- Cattivelli, F.S.; Sayed, A.H. Diffusion LMS strategies for distributed estimation. IEEE Trans. Signal Process. 2010, 58, 1035–1048. [Google Scholar] [CrossRef]
- Meteos, G.; Giannakis, G.B. Distributed recursive least-squares: Stability and performance analysis. IEEE Trans. Signal Process. 2012, 60, 3740–3754. [Google Scholar] [CrossRef]
- Cao, M.; Meng, Q.; Zeng, M.; Sun, B.; Li, W.; Ding, C. Distributed least-squares estimation of a remote chemical source via convex combination in wireless sensor networks. Sensors 2014, 14, 11444–11466. [Google Scholar] [CrossRef] [PubMed]
- Cao, L.; Xu, C.; Shao, W.; Zhang, G.; Zhou, H.; Sun, Q.; Guo, Y. Distributed power allocation for sink-centric clusters in multiple sink wireless sensor networks. Sensors 2010, 10, 2003–2026. [Google Scholar] [CrossRef] [PubMed]
- Lorenzo, P.D.; Sayed, A.H. Sparse distributed learning based on diffusion adaption. IEEE Trans. Signal Process. 2013, 61, 1419–1433. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Y.; Li, C. Distributed sparse recursive least-squares over networks. IEEE Trans. Signal Process. 2014, 62, 1385–1395. [Google Scholar] [CrossRef]
- Li, C.; Shen, P.; Liu, Y.; Zhang, Z. Diffusion information theoretic learning for distributed estimation over network. IEEE Trans. Signal Process. 2013, 61, 4011–4024. [Google Scholar] [CrossRef]
- Gu, D.; Hu, H. Spatial Gausssian process regression with mobile sensor networks. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1279–1290. [Google Scholar] [PubMed]
- Dempster, A.P.; Laird, N.M.; Robin, D.B. Maximum likelihood estimation from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions, 2nd ed.; Wiley: New York, NY, USA, 2008. [Google Scholar]
- McLachlan, G.J.; Peel, D. Finite Mixture Models; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Ghahramani, Z.; Hinton, G.E. The EM Algorithm for Mixtures of Factor Analyzers; Tech. Rep. CRG-TR-96-1; Department of Computer Science, University of Toronto: Toronto, ON, USA, 1997. [Google Scholar]
- Zhao, J.; Yu, P.L.H. Fast ML estimation for the mixture of factor analyzers via an ECM algorithm. IEEE Trans. Neural Netw. 2008, 19, 1956–1961. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McLachlan, G.J.; Bean, R.W.; Jones, L.B. Extension of the mixture of factor analyzers model to incorporate the multivariated t-distribution. Comput. Stat. Data Anal. 2007, 51, 5327–5338. [Google Scholar] [CrossRef]
- Andrews, J.L.; McNicholas, P.D. Mixtures of modified t-factor analyzers for model-based clustering, classification, and discriminant analysis. J. Stat. Plan. Infer. 2011, 141, 1479–1486. [Google Scholar] [CrossRef]
- Carin, L.; Baraniuk, R.G.; Cevher, V.; Dunson, D.; Jordan, M.I.; Sapiro, G.; Wakin, M.B. Learning low-dimensional signal models. IEEE Signal Process. Mag. 2011, 28, 39–51. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Tian, T.P.; Sclaroff, S. 3D human motion tracking with a coordinated mixture of factor analyzers. Int. J. Comput. Vis. 2010, 87, 1–2. [Google Scholar] [CrossRef]
- Wu, Z.; Kinnunen, T.; Chng, E.S. Mixture of factor analyzers using priors from non-parallel speech for voice conversion. IEEE Signal Process. Lett. 2012, 19, 914–917. [Google Scholar] [CrossRef]
- Baek, J.; McLachlan, G.J. Mixtures of common t-factor analyzers for clustering high-dimensional microarray data. Bioinformatics 2011, 21, 1269–1276. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Li, C. Bayesian mixtures of common factor analyzers: Model, variational inference, and applications. Signal Process. 2013, 93, 2894–2904. [Google Scholar] [CrossRef]
- Nowak, R.D. Distributed EM algorithms for density estimation and clustering in sensor neworks. IEEE Trans. Signal Process. 2003, 51, 2245–2253. [Google Scholar] [CrossRef]
- Safarinejadian, B.; Menhaj, M.B.; Karrari, M. Distributed variational Bayesian algorithms for Gaussian mixtures in sensor networks. Signal Process. 2010, 90, 1197–1208. [Google Scholar] [CrossRef]
- Gu, D. Distributed EM algorithm for Gaussian mixtures in sensor networks. IEEE Trans. Neural Netw. 2008, 19, 1154–1166. [Google Scholar] [CrossRef]
- Safarinejadian, B.; Menhaj, M.B.; Karrari, M. Distributed unsupervised Gaussian mixture learning for density estimation in sensor networks. IEEE Trans. Instrum. Meas. 2010, 59, 2250–2260. [Google Scholar] [CrossRef]
- Pereira, S.S.; Valcarce, R.L.; Zamora, A.P. A diffusion-based EM algorithm for distributed estimation in unreliable sensor networks. IEEE Signal Process. Lett. 2013, 20, 595–598. [Google Scholar] [CrossRef]
- Pereira, S.S.; Zamora, A.P.; Valcarce, R.L. A diffusion-based distributed EM algorithm for density estimation in wireless sensor networks. In Proceedings of the International Conference on Acoustics Speech, and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2003; pp. 4449–4453.
- Towfic, Z.J.; Chen, J.; Sayed, A.H. Collaborative learning of mixture models using diffusion adaptation. In Proceedings of the 2011 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Santander, Spain, 18–21 September 2011; pp. 1–6.
- Weng, Y.; Xiao, W.; Xie, L. Diffusion-based EM algorithm for distributed estimation of Gaussian mixtures in wireless sensor networks. Sensors 2011, 11, 6297–6316. [Google Scholar] [CrossRef] [PubMed]
- Pascal, B.; Gersende, F.; Walid, H. Performance of a distributed stochastic approximation algorithm. IEEE Trans. Inf. Theory 2013, 59, 7405–7418. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- UCI Machine Learning Repository, Irvine, CA: University of California, School of Information and Computer Science, 2013 [online]. Available online: http://archive.ics.uci.edu/ml (accessed on 16 April 2015).
- Katsuma, R.; Murata, Y.; Shibata, N.; Yasumoto, K.; Ito, M. Extending k-coverage lifetime of wireless sensor networks using mobile sensor nodes. In Proceedings of the 5th Annual IEEE International Conference on Wireless and Mobile Computing, Networking and Communications, Marrakech, Morocco, 12–14 October 2009; pp. 48–54.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, X.; Li, C.; Zhou, L.; Zhao, L. Distributed Density Estimation Based on a Mixture of Factor Analyzers in a Sensor Network. Sensors 2015, 15, 19047-19068. https://doi.org/10.3390/s150819047
Wei X, Li C, Zhou L, Zhao L. Distributed Density Estimation Based on a Mixture of Factor Analyzers in a Sensor Network. Sensors. 2015; 15(8):19047-19068. https://doi.org/10.3390/s150819047
Chicago/Turabian StyleWei, Xin, Chunguang Li, Liang Zhou, and Li Zhao. 2015. "Distributed Density Estimation Based on a Mixture of Factor Analyzers in a Sensor Network" Sensors 15, no. 8: 19047-19068. https://doi.org/10.3390/s150819047
APA StyleWei, X., Li, C., Zhou, L., & Zhao, L. (2015). Distributed Density Estimation Based on a Mixture of Factor Analyzers in a Sensor Network. Sensors, 15(8), 19047-19068. https://doi.org/10.3390/s150819047