1. Introduction
Neurons are the basic elements that underlie the function of the nervous system, which contains the brain, spinal cord and peripheral ganglia. Neurons process and transmit information mainly by electrical signaling through the generation of action potentials. These action potentials can be recorded
in vivo by placing electrodes in the vicinity of the neurons. The spikes recorded by the electrodes represent spike events generated by an unknown number of neurons. The role of spike sorting [
1,
2] is to assign each spike to the neuron that produced it. A typical automatic spike sorting involves complicated operations, such as spike detection, feature extraction and classification. As the technology progresses, multi-channel arrays are increasingly being employed. Increasing the number of recording electrodes raises the computation time for automatic spike sorting, as detection and feature extraction become tedious tasks. However, for many spike sorting applications [
3], real-time operations are desired. Hardware systems offering dedicated circuits can substantially outperform their software counterparts in terms of computational performance and power dissipation. Hardware solutions are therefore necessary for neurophysiological signal recordings and analysis, where these factors are crucial.
One effective technique for spike sorting is based on principal component analysis (PCA) [
4,
5] for feature extraction. Implementation of PCA-based hardware systems [
6,
7] involves the computations for covariance matrix and eigenvalue decomposition. Therefore, direct realization of PCA requires substantial hardware costs, such as power consumption and hardware area. Alternatives to PCA, such as discrete derivatives [
8], integral transform [
9] and zero-cross features [
10], have been proposed to reduce the computational complexities for feature extraction. However, their effectiveness remains to be validated through real data experiments.
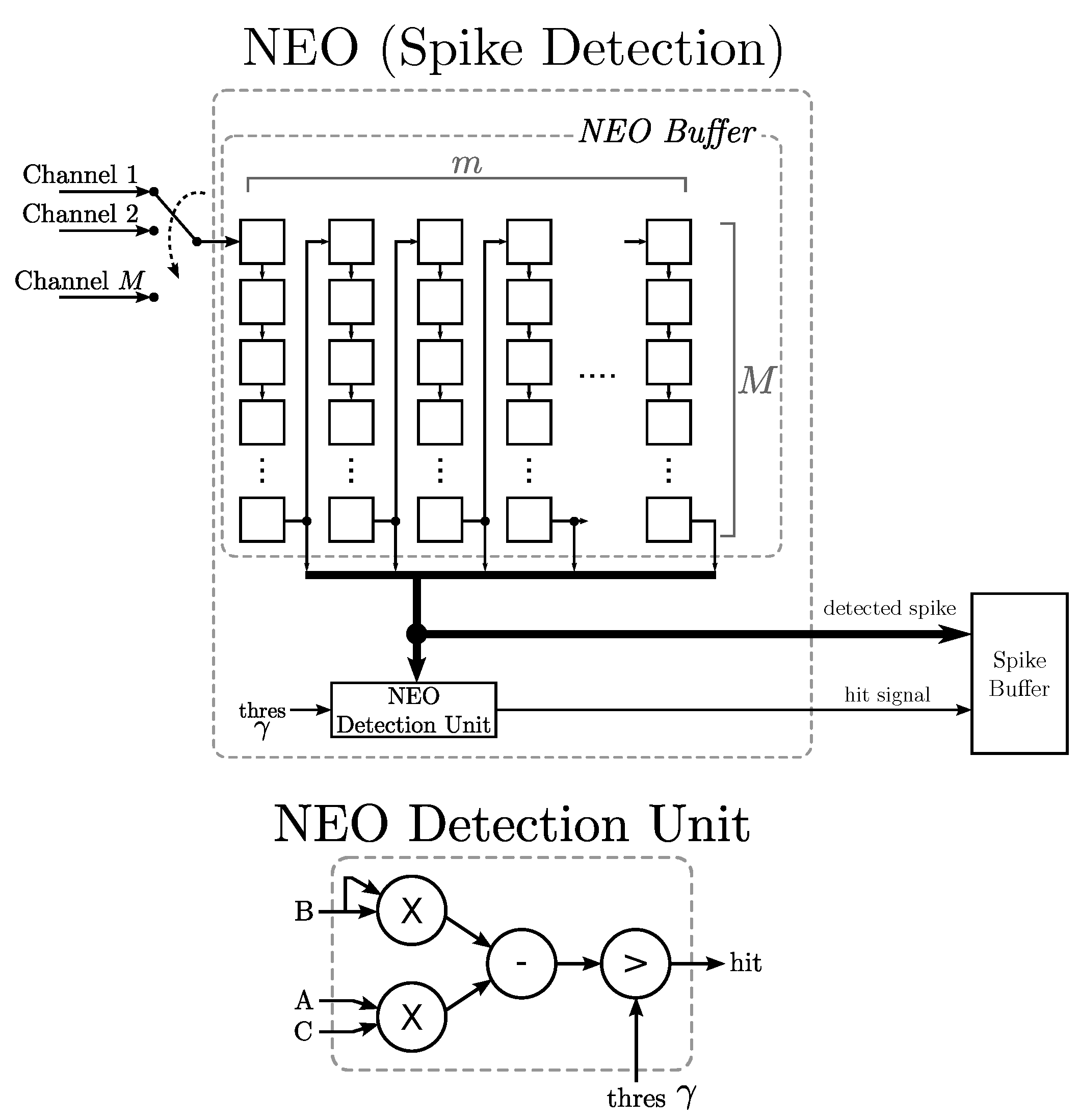
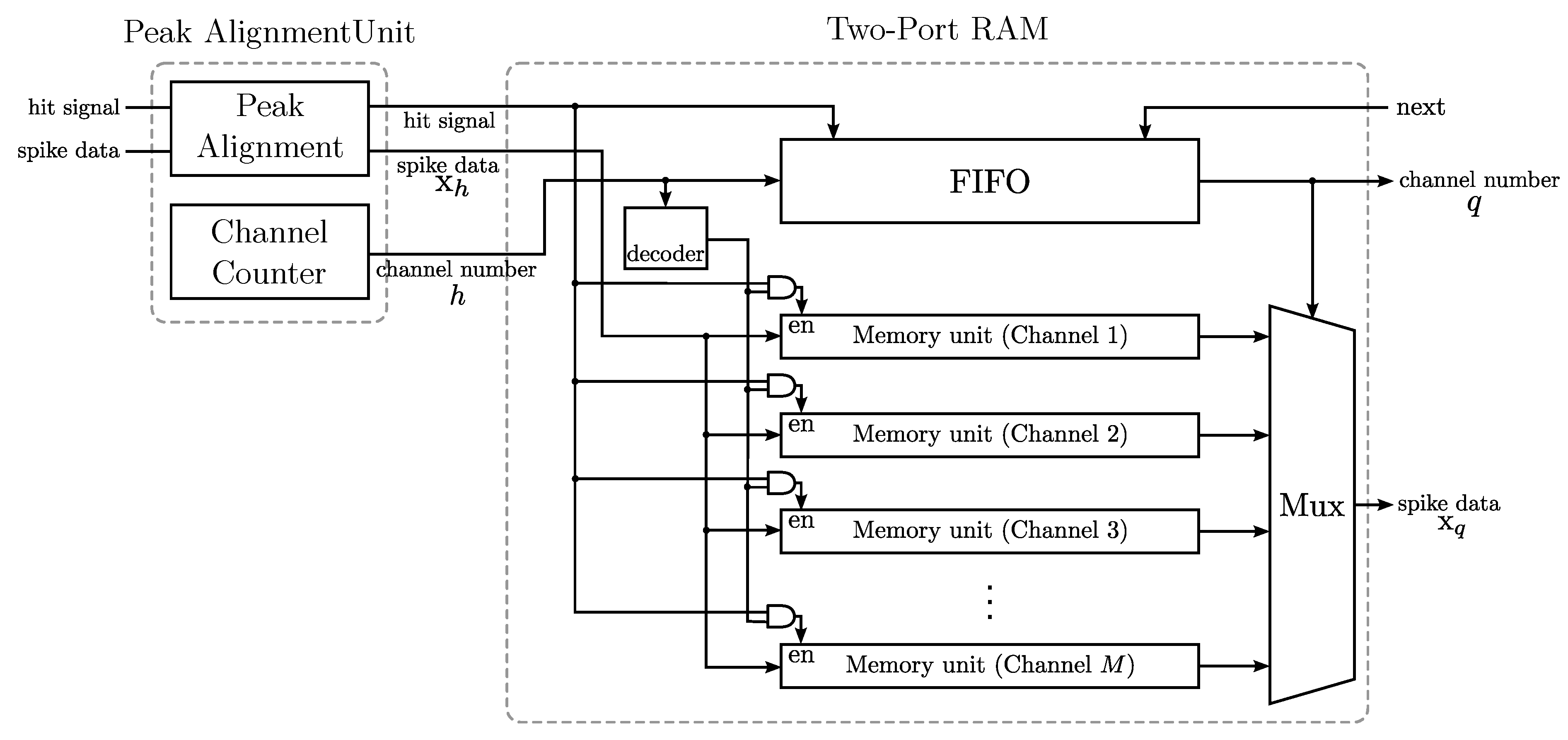
Besides feature extraction, spike sorting requires a set of prepossessing steps, including spike detection and spike alignment. Spike detection distinguishes neuronal spikes from background noises. A commonly-used detection method is to compare the absolute voltage of the recorded signal with a threshold [
11,
12]. However, the method may not performs well for spike trains corrupted by large noises. The nonlinear energy operator (NEO)-based [
13] spike detection method detects the peak of a spike by simple arithmetic operations. It provides a hardware-efficient alternative and also achieves high detection accuracy by considering both spike amplitude and frequency. Spike alignment can be carried out by the positions of the peak or maximum slope of the detected spikes [
1]. Because the peak location of the detected spikes can be obtained from the NEO, the peak-based spike alignment operating in conjunction with the NEO may be more hardware friendly as compared to its counterparts using maximum slope techniques.
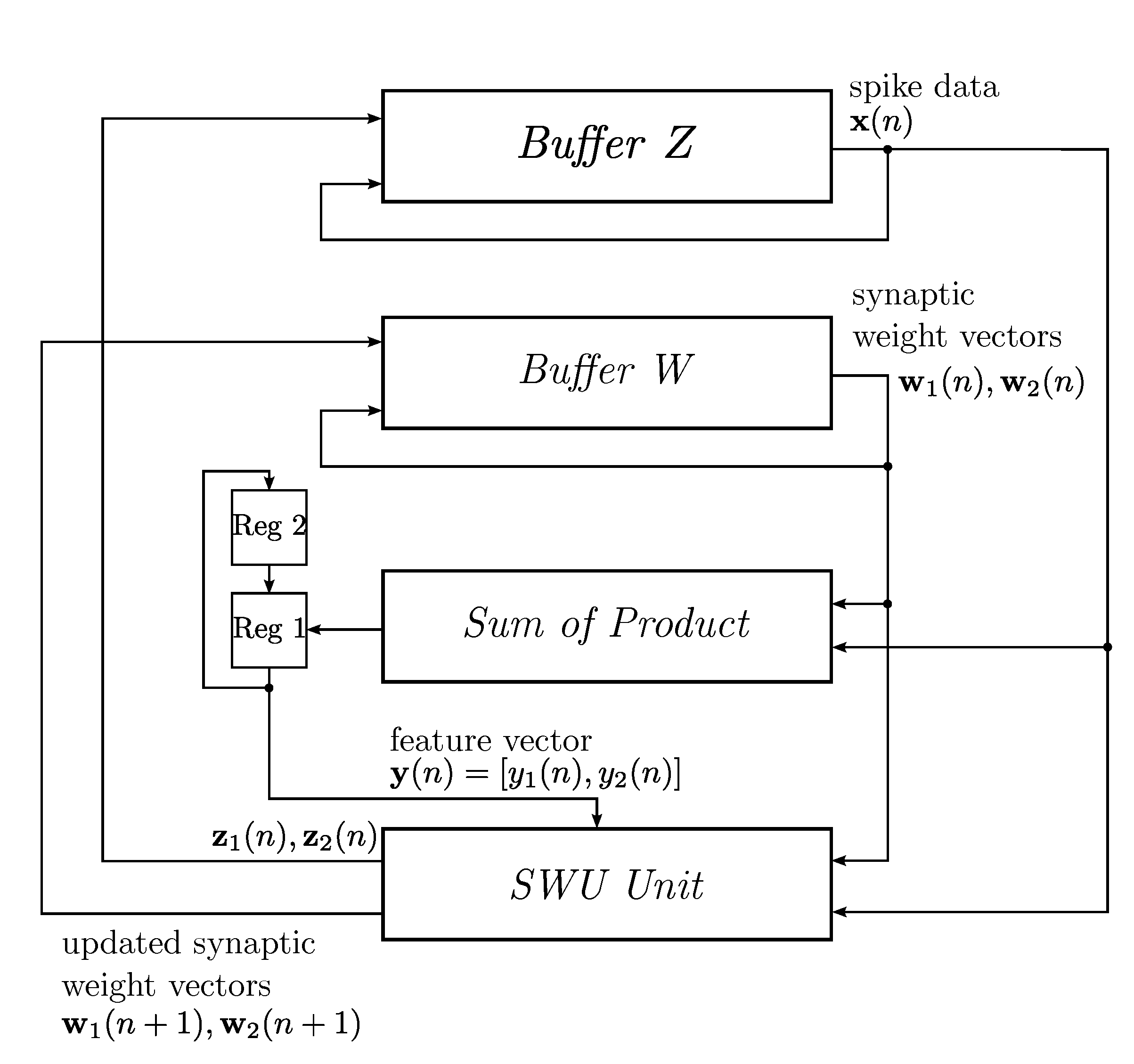
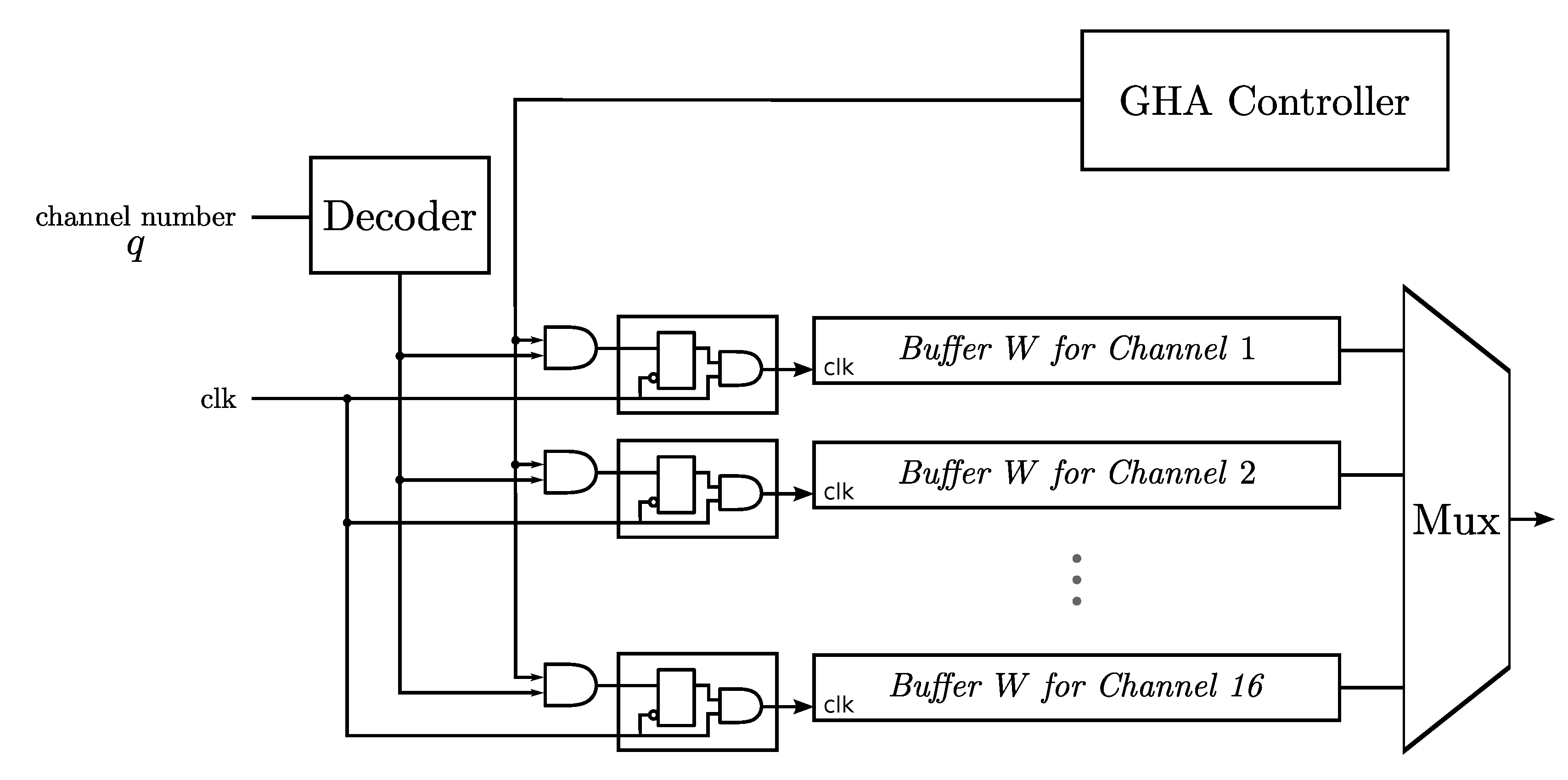
The objective of this paper is to present a novel VLSI architecture capable of performing
in vivo multi-channel spike sorting. In the architecture, the spike detection and alignment are based on NEO with peak-based alignment, and the feature extraction is carried out by the generalized Hebbian algorithm (GHA) [
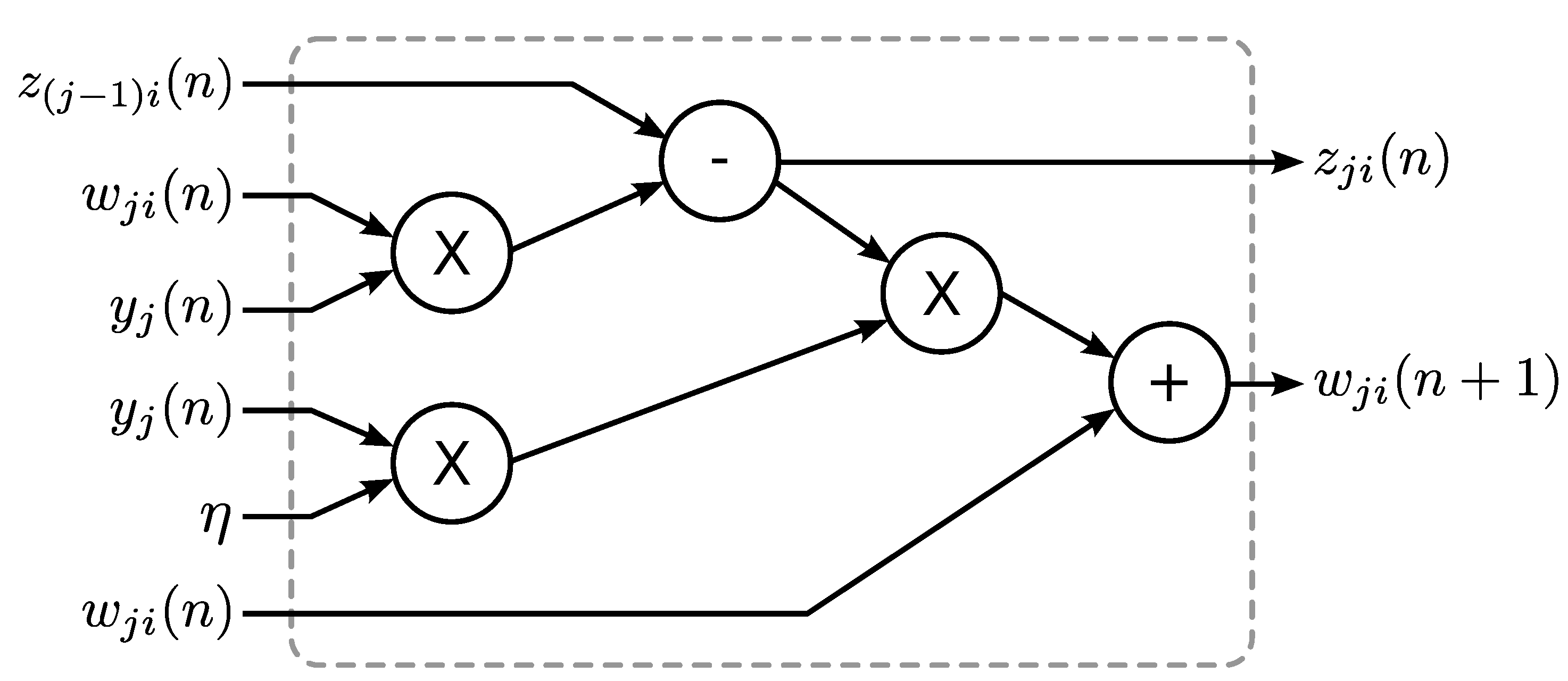
14]. The GHA can be viewed as an incremental PCA, which computes the principal components without the involvement of the covariance matrix. In the GHA, the principal components are updated incrementally based on a set of training data. For the spike sorting applications, the training set is formed by the detected spikes. In the hardware implementation for GHA, only the buffers storing the principal components and the arithmetic operation circuits for updating principal components are required. No memory for storing the covariance matrix of the training set is necessary. Power consumption and hardware area can then be reduced substantially, as compared to its counterparts based on the batch PCA algorithm.
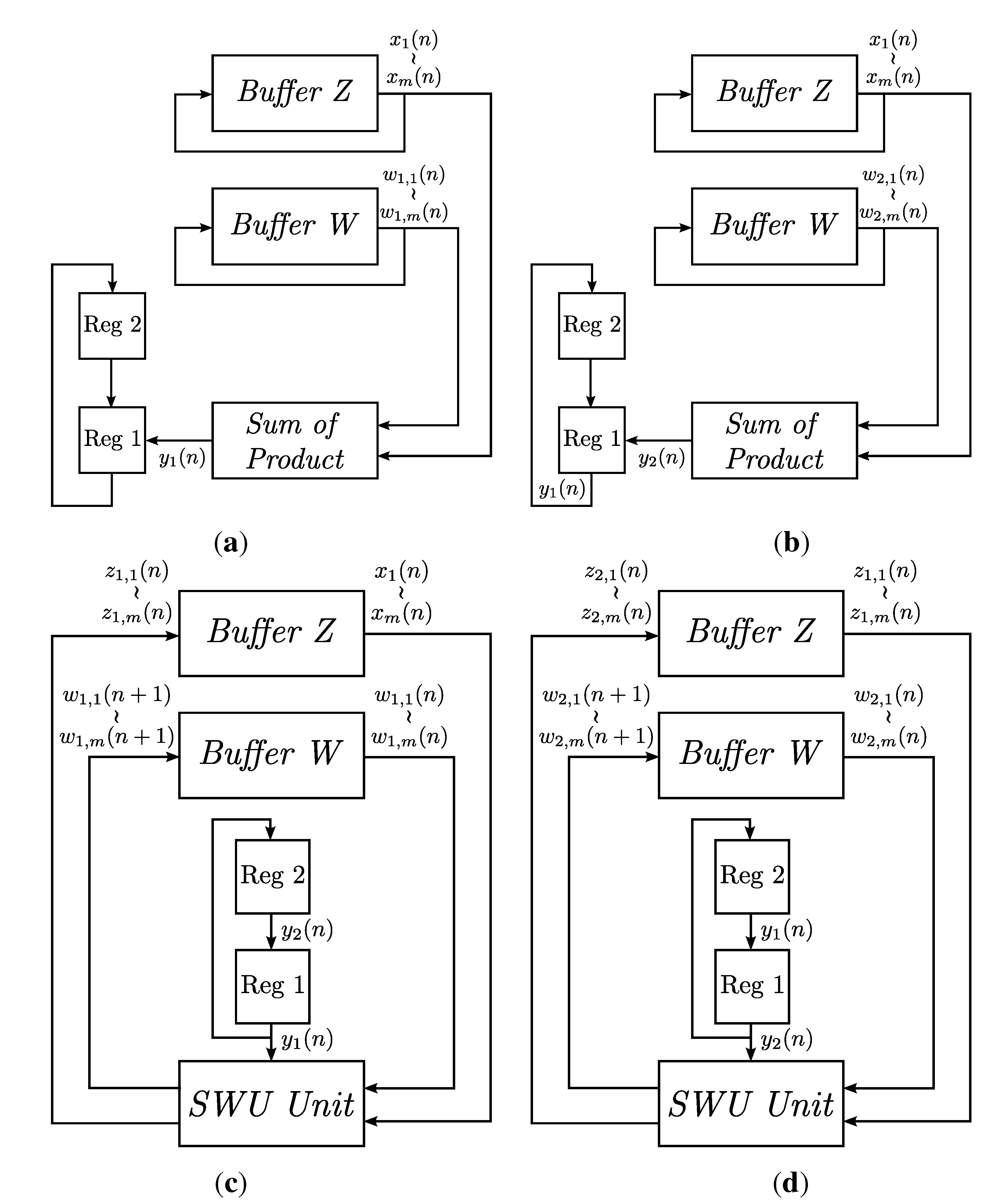
Although a number of GHA hardware architectures [
15,
16] have been proposed, the circuits are implemented for single channel spike sorting only. One simple way to extend the circuits to multi-channel cases is to replicate the circuits, one for each channel. Designs in this way may result in high power dissipation and large hardware area. In addition, the existing implementations are by field programmable gate array (FPGA) [
17], which may not be well suited for the realization of bio-implantable spike sorting systems due to the large power consumption inherited from FPGAs.
The proposed NEO and GHA circuits are implemented by an application-specific integrated circuit (ASIC) [
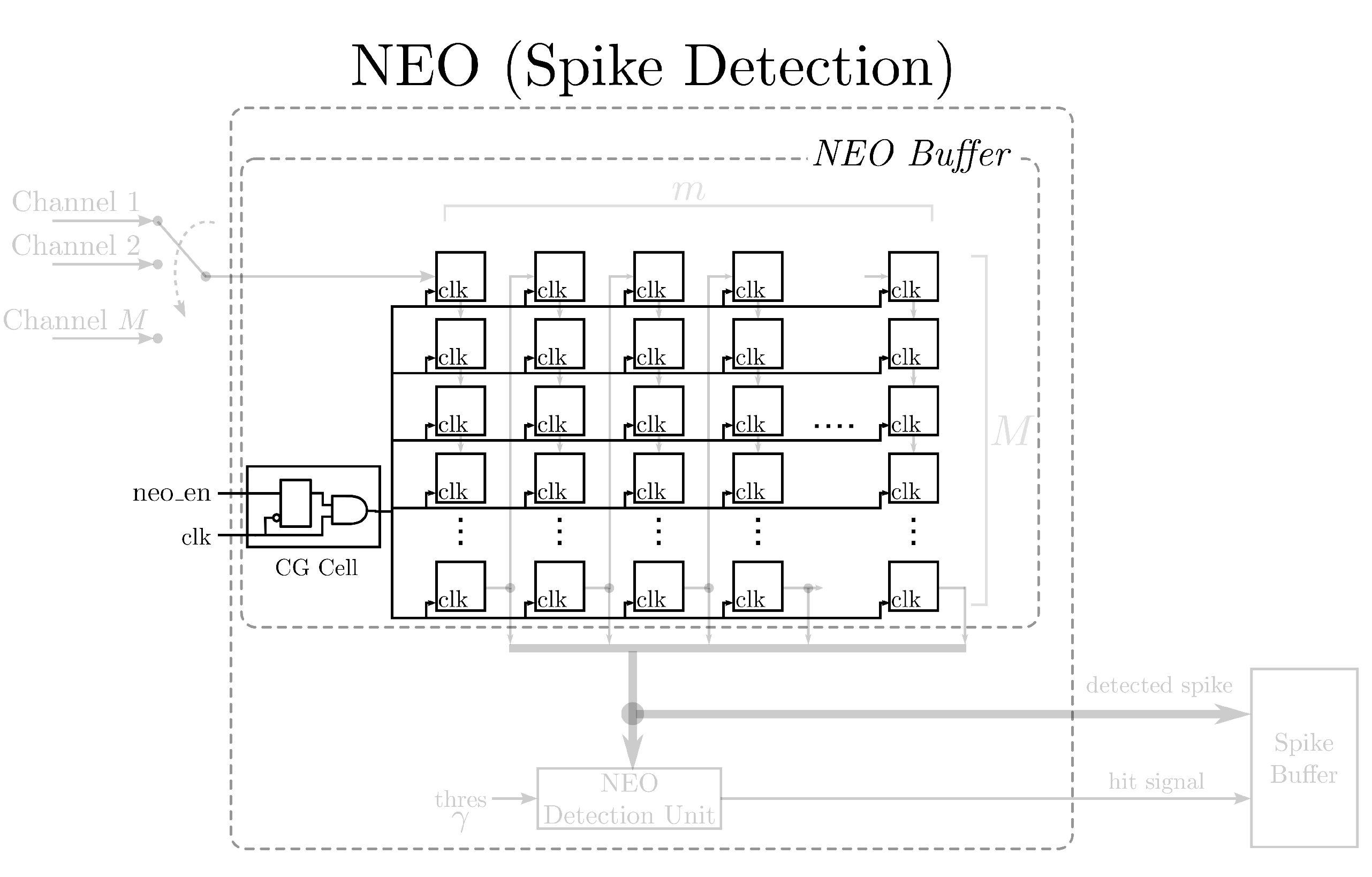
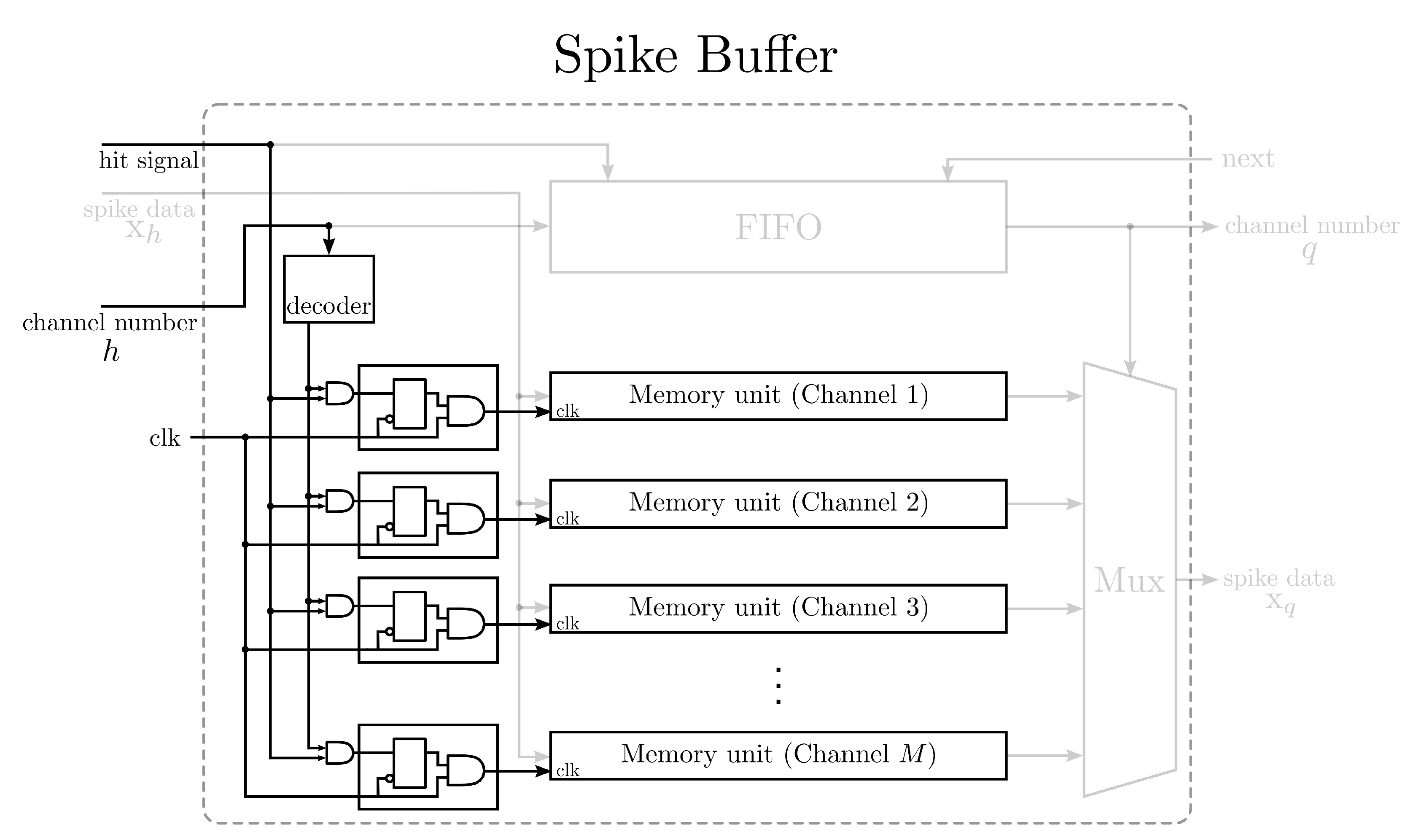
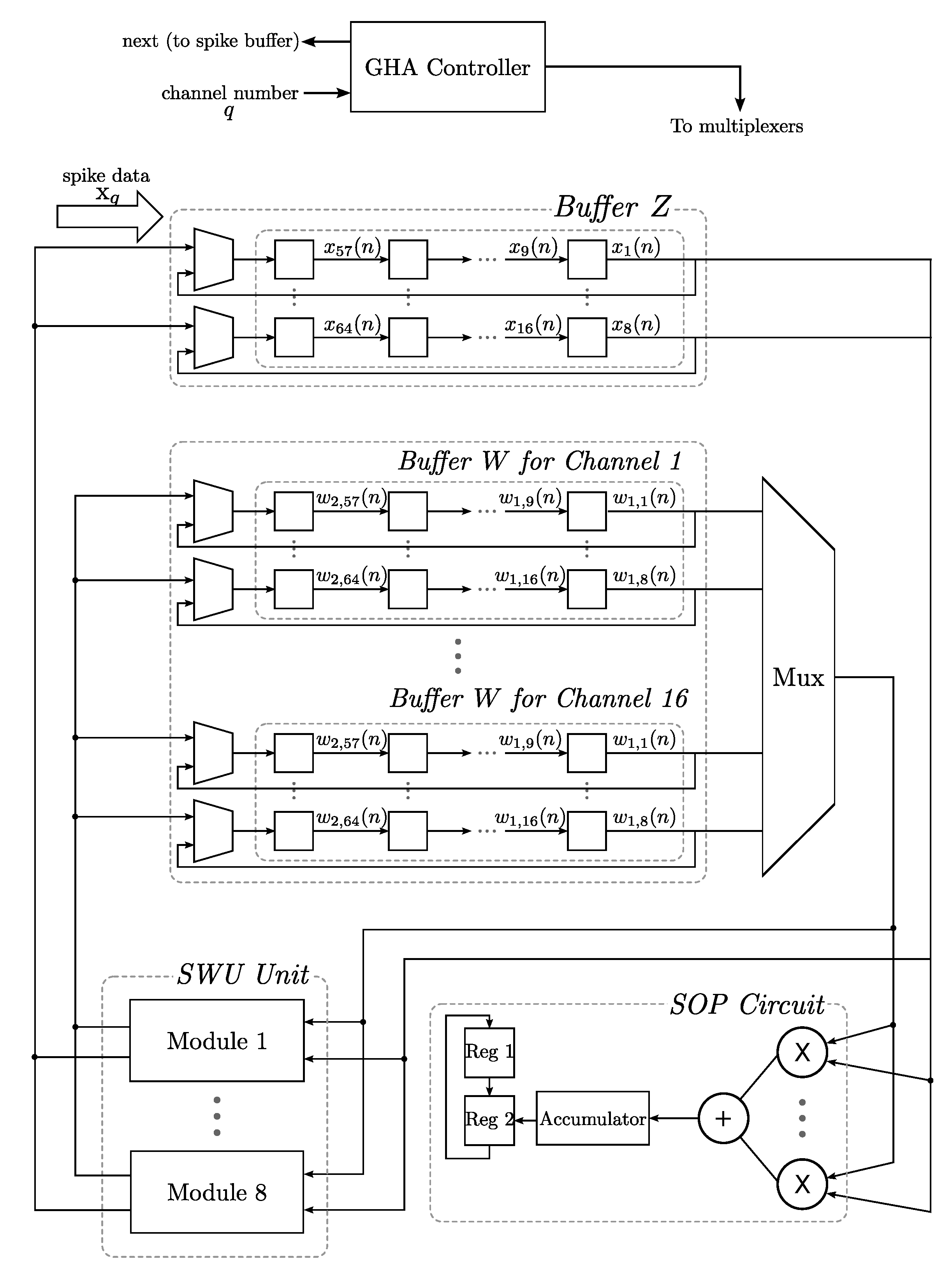
18] to lower the power consumption. In addition, they are designed specifically for multi-channel spike sorting. To minimize the power consumption and area costs of the circuits, all of the channels share the same core for spike detection and feature extraction operations. Each channel has dedicated buffers for storing the detected spikes and the principal components of that channel. A clock gating (CG) technique [
19,
20] is employed to supply the system clock only to the buffers of the channels currently using the computation core. The dynamic power dissipation of the inactive channels can then be further reduced. Furthermore, the relations among the sampling rate of spikes, the number of channels of the recording system and the latency of the GHA circuit are investigated in this study. A general guideline for optimizing the design is then derived. A number of design examples are provided to demonstrate the effectiveness of the proposed architecture. Experimental results reveal that the proposed architecture is an effective alternative for “
in vivo” multi-channel spike sorting with low power dissipation and low hardware area costs.
3. Experimental Results
In this section, the performance of the proposed architecture is evaluated. The area complexities of the proposed architecture are first analyzed. There are five types of area costs: the number of comparators, adders, multipliers, registers and multiplexers. All of the costs are expressed in terms of the asymptotic function (
i.e., the Big
O function) in the tables.
Table 1 shows the area complexities of the GHA circuit. It can be observed from
Table 1 that the numbers of adders and the multipliers of the GHA are independent of the number of channel
M. This is because all of the channels share the same computation core (
i.e., the SWU and SOP circuits) for the GHA training. The computation core of the GHA circuit is able to process the detected spikes one segment at a time. Therefore, the numbers of adders and multipliers grow with the dimension of the segments
L. On the other hand, because the circuit needs to store the synaptic weight vectors for each and every channels, the number of registers is dependent on the number of channels
M, the number of weight vectors for each channel
p and the dimension of each vector
m.
Based on the analytical results in
Table 1, the overall area complexities of the proposed spike sorting circuit are summarized in
Table 2. The area complexities of the NEO circuit and spike buffer are also included in the table for evaluation. We can observe from
Table 2 that the number of registers in both the NEO circuit and spike buffer are also dependent on the number of channels
M. This is because it is necessary to store spike trains from all of the
M channels for detection. Moreover, each channel needs to have its own memory unit to hold the detected spikes for the subsequent GHA training. Therefore, the number of registers in the NEO circuit, spike buffer and GHA circuit all increase with the number of channels
M. By contrast, because the NEO circuit has only a fixed number of adders and multipliers independent of
M, the overall area costs for the adders and multipliers in the spike sorting circuit are dependent only on
L.
Table 1.
The area complexities of the GHA circuit.
Table 1.
The area complexities of the GHA circuit.
| Comparators | Adders | Multipliers | Registers | Multiplexers |
|---|
| SWU Circuit | 0 | | | 0 | 0 |
| SOP Circuit | 0 | | | | 0 |
| Buffer Z | 0 | 0 | 0 | | |
| Buffer W | 0 | 0 | 0 | | |
| GHA Circuit | 0 | | | | |
Table 2.
The area complexities of the proposed spike sorting circuit.
Table 2.
The area complexities of the proposed spike sorting circuit.
| Comparators | Adders | Multipliers | Registers | Multiplexers |
|---|
| NEO Circuit | | | | | 0 |
| Spike Buffer | 0 | 0 | 0 | | |
| GHA Circuit | 0 | | | | |
| Total | | | | | |
We next evaluate the hardware resource consumption of the ASIC implementation of the proposed circuit with clock gating. The implementation is based on the TSMC90-nm technology. The gate level design platform is Synopsys Design Compiler.
Table 3 shows the area (μm
2) of the proposed circuit for different numbers of channels
M and segment lengths
L. For all of the experiments shown after
Table 3, the dimension of spikes and weight vectors is
. The number of principal components is
. From
Table 3, we see that the area of the proposed circuit grows with
M and
L, which is consistent with the results shown in
Table 2.
Table 4 shows the normalized area (μm
2 per channel) of the proposed architecture. The normalized area is defined as the area of the circuit divided by the number of channels
M. The normalized area can be viewed as the average area cost per channel. For a fixed
L, it can be observed from the table that the normalized area decreases as the number of channels
M increases. In particular, when
, the normalized area decreases from 162,255 μm
2/ch. for
to 80,503 μm
2/ch. for
. The reduction in normalized area for large
M is due to the fact that all of the channels share the same computation cores in the NEO circuit (
i.e., the NEO detection unit) and GHA circuit (
i.e., the SWU unit and the SOP circuit). The area of computation cores is independent of
M. Therefore, the average area per channel decreases as
M increases. Consequently, because of the hardware resource sharing scheme, the proposed architecture shows a higher efficiency in area costs for a larger number of channels.
Table 3.
The area (μm2) of the proposed circuit for different numbers of channels M and segment lengths L.
Table 3.
The area (μm2) of the proposed circuit for different numbers of channels M and segment lengths L.
| Segment | Number of Channels M |
|---|
| Length L | 2 | 4 | 8 | 16 | 32 | 64 |
|---|
| 2 | 241,090 | 395,565 | 701,479 | 1,318,032 | 2,548,962 | 5,010,148 |
| 4 | 268,776 | 423,957 | 731,167 | 1,350,163 | 2,586,267 | 5,057,620 |
| 8 | 324,509 | 480,852 | 790,654 | 1,414,494 | 2,661,096 | 5,152,185 |
| 16 | 435,478 | 594,419 | 909,403 | 1,543,228 | 2,810,642 | 5,341,566 |
| 32 | 658,196 | 822,560 | 1,148,565 | 1,802,752 | 3,114,285 | 5,728,802 |
Table 4.
The normalized area (μm2/ch.) of the proposed circuit for different numbers of channels M and segment lengths L.
Table 4.
The normalized area (μm2/ch.) of the proposed circuit for different numbers of channels M and segment lengths L.
| Segment | Number of Channels M |
|---|
| Length L | 2 | 4 | 8 | 16 | 32 | 64 |
|---|
| 2 | 120,545 | 98,891 | 87,685 | 82,377 | 79,655 | 78,284 |
| 4 | 134,388 | 105,989 | 91,396 | 84,385 | 80,821 | 79,025 |
| 8 | 162,255 | 120,213 | 98,832 | 88,406 | 83,159 | 80,503 |
| 16 | 217,739 | 148,604 | 113,675 | 96,452 | 87,833 | 83,462 |
| 32 | 329,098 | 205,640 | 143,571 | 112,672 | 97,321 | 89,513 |
Although a larger segment length
L increases the area of the proposed architecture, the latency
P of the GHA circuit is reduced. As a result, the maximum number of channels
is increased given fixed sampling period
and clock period
.
Table 5 shows the latency
P (in clock cycles) of the GHA circuit for various
L values. The maximum number of channels
for each
L value is also shown. The
is computed by Equation (
9). The sampling rate of spike trains is set to be
samples/s. There are three clock rates considered in the table:
= 0.5 MHz, 1 MHz and 2 MHz. The minimum number of samples between the peak of successive spikes detected by the NEO circuit from the same channel is
. We can observe from
Table 5 that the latency
P is lowered to 16 clock cycles when
L is 32. Because
Q is 16, from Equation (
9), it can be concluded that the maximum number of channels of the proposed architecture is identical to that limited by the NEO circuit (
i.e.,
) when
L is 32.
When a larger
Q is allowed, the maximum number of channels
supported by the proposed architecture may be increased.
Table 6 shows the
of the proposed algorithm for
. By comparing
Table 5 and
Table 6, it can be observed that
may increases two-fold for the circuits when
Q increases from 16 to 32. In particular, when
and
MHz, the
is 16 and 33 for
and 32, respectively. These facts can be further elaborated in
Table 7 for various combinations of
Q,
L and
. When
, we can see from
Table 7 that
grows linearly with
Q for all of the clock rates
. The
for
is larger than that for
given the same
Q and
. In addition, it also grows with
Q for small
Q values. Moreover, since the latency for
is
, the proposed architecture achieves the maximum number of channels limited by the NEO circuit when
Q is larger or equal to 40. By contrast, the proposed architecture with
supports the maximum channel capacity when
Q reaches 72. Therefore, when both smaller
Q values and a larger number of channels are desirable for GHA training, larger
L values may be preferred. Otherwise, a smaller
L value could be selected for the spike sorting due to lower area costs.
Table 5.
The latency P of the GHA circuit and the maximum number of channels for various segment lengths L and clock rates of the proposed spike sorting circuit with clock gating. The sampling rate of spike trains is 24,000 samples/s. The minimum number of samples between the peak of successive spikes from the same channel is assumed to be .
Table 5.
The latency P of the GHA circuit and the maximum number of channels for various segment lengths L and clock rates of the proposed spike sorting circuit with clock gating. The sampling rate of spike trains is 24,000 samples/s. The minimum number of samples between the peak of successive spikes from the same channel is assumed to be .
| Segment | Latency | Max. No. of Channels |
|---|
| Length L | P | = 0.5 MHz | = 1 MHz | = 2 MHz |
|---|
| | | | |
|---|
| 1 | 264 | 1 | 2 | 5 |
| 2 | 136 | 2 | 4 | 9 |
| 4 | 72 | 4 | 9 | 18 |
| 8 | 40 | 8 | 16 | 33 |
| 16 | 24 | 13 | 27 | 55 |
| 32 | 16 | 20 | 41 | 83 |
Table 6.
The latency P of the GHA circuit and the maximum number of channels for various segment lengths L and clock rates of the proposed spike sorting circuit. The sampling rate of spike trains is 24,000 samples/s. The minimum number of samples between the peak of successive spikes from the same channel is assumed to be .
Table 6.
The latency P of the GHA circuit and the maximum number of channels for various segment lengths L and clock rates of the proposed spike sorting circuit. The sampling rate of spike trains is 24,000 samples/s. The minimum number of samples between the peak of successive spikes from the same channel is assumed to be .
| Segment | Latency | Max. No. of Channels |
|---|
| Length L | P | = 0.5 MHz | = 1 MHz | = 2 MHz |
|---|
| | | | |
|---|
| 1 | 264 | 2 | 5 | 10 |
| 2 | 136 | 4 | 9 | 19 |
| 4 | 72 | 9 | 18 | 37 |
| 8 | 40 | 16 | 33 | 66 |
| 16 | 24 | 20 | 41 | 83 |
| 32 | 16 | 20 | 41 | 83 |
Table 7.
The maximum number of channels for various combinations of Q, L and .
Table 7.
The maximum number of channels for various combinations of Q, L and .
| | Max. No. of Channels |
|---|
| | = 0.5 MHz | = 1 MHz | = 2 MHz |
|---|
| | | | |
|---|
| | 4 | 9 | 18 |
| | 8 | 16 | 33 |
| | 9 | 18 | 37 |
| | 16 | 33 | 66 |
| | 13 | 27 | 55 |
| | 20 | 41 | 83 |
| | 18 | 37 | 74 |
| | 20 | 41 | 83 |
Table 8 shows the power dissipation of the proposed architecture for
with different clock rates
. When
MHz, the numbers of channels implemented are
, 16 and 32. The circuit with
is not implemented because the maximum number of channels
is only 41, even for large
Q, such as
, as shown in
Table 7. When
MHz, we have implemented the circuit for
, 16, 32 and 64. For each
M value considered in
Table 8, its normalized power consumptions with and without clock gating are measured. The percentage of power reduction from the circuit without clock gating to the circuit with clock gating for each
M is also included. The power consumption measurement is performed numerically by Synopsys Prime Time.
Table 8.
The performance of the proposed spike sorting circuit for .
Table 8.
The performance of the proposed spike sorting circuit for .
| Number of | Clock | Normalized Power | Power |
|---|
| Channels M | Rates | No Clock Gating | Clock Gating | Reduction |
|---|
| 8 | 1 MHz | 156.1 μW/ch. | 114.3 μW/ch. | 26.78 % |
| 16 | 1 MHz | 133.1 μW/ch. | 91.4 μW/ch. | 31.33 % |
| 32 | 1 MHz | 120.5 μW/ch. | 78.7 μW/ch. | 34.69 % |
| 8 | 2 MHz | 215.4 μW/ch. | 152.4 μW/ch. | 29.2 % |
| 16 | 2 MHz | 179.1 μW/ch. | 115.5 μW/ch. | 35.5 % |
| 32 | 2 MHz | 159.3 μW/ch. | 95.3 μW/ch. | 40.18 % |
| 64 | 2 MHz | 150.0 μW/ch. | 85.8 μW/ch. | 42.80 % |
It can be observed from
Table 8 that the clock gating technique is able to reduce the power consumption of the proposed circuit. The reduction is due to the lower dynamic power consumption by disabling clock supply to the buffers of the channels currently not engaged in GHA training. We can also see from
Table 8 that, as the number of channels and/or the clock rate increase, the reduction in power consumption increases. In particular, for
and
MHz, the power consumption is lowered from 150.0 μW/ch. without clock gating to 85.8
μW/ch. with clock gating. The reduction is therefore 42.80%. For a lower number of channels and/or lower clock rate, the power reduction is still above 26.78%. The clock gating technique is therefore beneficial for the low power design of the spike sorting system.
To further demonstrate the effectiveness of the proposed architecture,
Table 9 compares the proposed architecture with the existing ASIC implementations for spike sorting. Direct comparisons among these architectures may be difficult because these architectures are implemented by different technologies and are based on different spike detection and/or feature extraction algorithms. Moreover, their operation frequencies are different. Nevertheless, it can be observed from
Table 9 that, as compared with the existing architectures, the proposed architecture provides effective area-power performance while supporting both spike detection and feature extraction functions. In particular, subject to the same technology (
i.e., 90 nm), clock rate (1 MHz) and spike dimension (
i.e., 64), the proposed architecture has lower power dissipation (78.819 μW/ch.
vs. 521 μW/ch.) and lower area (83,159 μm
2/ch.
vs. 255,495 μm
2/ch.) as compared to the architecture in [
6]. The proposed architecture has superior performance because it adopts the GHA training operations for feature extraction. Therefore, there is no need to incorporate memory blocks for covariance matrices of the training data, which are required by [
6]. A variant of PCA, termed Streaming Pattern dIscoveRy in multIple Time-series (SPIRIT), has been implemented by ASIC in [
21] without the employment of memory blocks for covariance matrices. Although the SPIRIT circuit is able to consume lower average power, it has a higher area cost as compared to the proposed circuit. In addition, the SPIRIT circuit supports only one channel without spike detection and alignment capabilities. The proposed circuit therefore provides a superior solution when a low-cost implementation of multi-channel spike detection and feature extraction is desired.
Table 9.
Comparison between existing architectures and that proposed. SPIRIT, streaming pattern discovery in multiple time-series.
Table 9.
Comparison between existing architectures and that proposed. SPIRIT, streaming pattern discovery in multiple time-series.
| Architecture | [6] | [7] | [12] | [21] | Proposed | Proposed |
| Normalized | 255,495 | 1,770,000 | 116,000 | 268,000 | 83,159 | 80,503 |
| Area | μm2/ch. | μm2/ch. | μm2/ch. | μm2/ch. | μm2/ch. | μm2/ch. |
| Normalized | 521 | 256.875 | 95.6 | 8.589 | 78.719 | 85.828 |
| Power | μW/ch. | μW/ch. | μW/ch. | μW/ch. | μW/ch. | μW/ch. |
| Clock Rate | 1 MHz | N/A | 16 MHz | 281.25 KHz | 1 MHz | 2 MHz |
| # of Channels | 1 | 16 | 16 | 1 | 32 | 64 |
| Spike Dimension | 64 | N/A | 64 | 64 | 64 | 64 |
| Technology | 90 nm | 350 nm | 180 nm | 130 nm | 90 nm | 90 nm |
| Detection | No | NEO | Absolute | No | NEO | NEO |
| Feature Extraction | PCA | PCA | No | SPIRIT | GHA | GHA |
In addition to being effective for hardware implementation, the GHA architecture has comparable accuracy for feature extraction as compared to its software counterpart and the basic PCA algorithm. The software versions of GHA and PCA algorithms are implemented by MATLAB with double precision floating numbers. The GHA circuit is based on 17-bit fixed point numbers. The simulator developed in [
22] is adopted to generate extracellular recordings. The simulation gives access to ground truth about spiking activity in the recording and, thereby, facilitates a quantitative assessment, since the features of the spike trains are known
a priori.
Table 10 shows the classification success rates (CSRs) of the fuzzy C-means (FCM) algorithm [
23,
24] by clustering the feature vectors produced by the GHA and PCA hardware/software implementations for two and three neurons, respectively. The CSR is defined as the number of spikes that are correctly classified divided by the total number of spikes. Spike trains with different SNR levels are considered in the table. It can be observed in
Table 10 that the CSRs of the FCM algorithm for the data produced by GHA and PCA hardware/software implementations given the same SNR level are comparable. The GHA circuit has slight degradation in CSR, because the precision of its number representation is finite (
i.e., 17 bits). To further reveal the effectiveness of the GHA circuit,
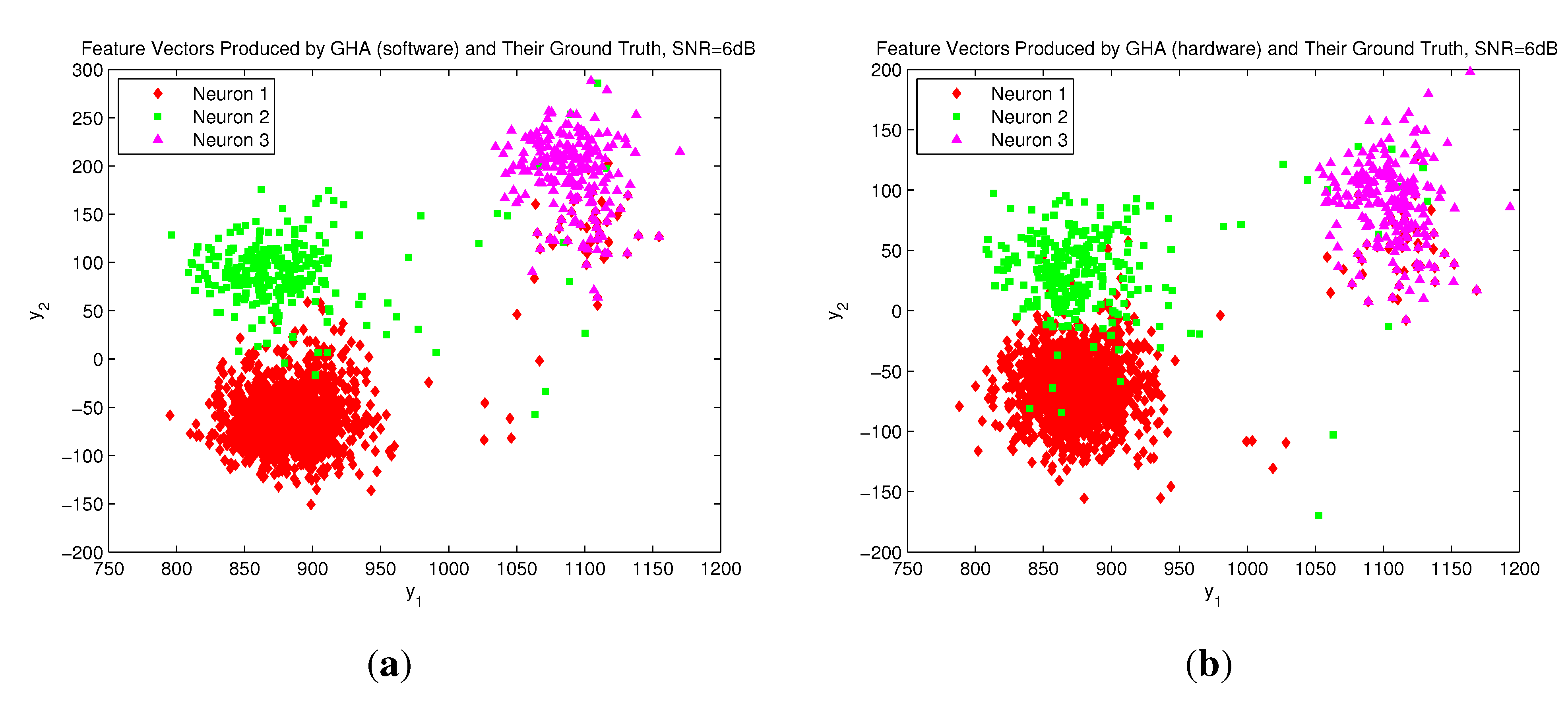
Figure 11 shows the distribution of the feature vectors extracted by the GHA circuit and the GHA software MATLAB codes for spike trains generated by three neurons with SNR = 6 dB. From
Figure 11, it can be observed that the GHA hardware and software implementations have a similar distribution of feature vectors. Therefore, they may produce comparable CSRs, as revealed in
Table 10. The GHA circuit therefore is an effective alternative for hardware implementation when the consumption of hardware resource and power and the classification performance are the important concerns. All of these facts show the effectiveness of the proposed architecture.
Figure 11.
The distribution of the feature vectors extracted by GHA hardware/software implementations for spike trains generated by three neurons with SNR = 6 dB: (a) feature vectors produced by the GHA software; (b) feature vectors produced by the GHA circuit.
Figure 11.
The distribution of the feature vectors extracted by GHA hardware/software implementations for spike trains generated by three neurons with SNR = 6 dB: (a) feature vectors produced by the GHA software; (b) feature vectors produced by the GHA circuit.
Table 10.
The classification success rates (CSRs) of the feature vectors produced by the GHA and PCA hardware/software implementations for two and three neurons.
Table 10.
The classification success rates (CSRs) of the feature vectors produced by the GHA and PCA hardware/software implementations for two and three neurons.
| Number of Neurons | 2 | 3 |
| SNR (dB) | 6 | 8 | 10 | 6 | 8 | 10 |
| PCA Software | 99.51% | 99.64% | 99.39% | 95.93% | 96.91% | 97.41% |
| GHA Software | 99.39% | 99.52% | 99.33% | 95.50% | 96.53% | 97.19% |
| GHA Hardware | 97.49% | 97.92% | 97.31% | 92.24% | 94.80% | 95.95% |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
