1. Introduction
In recent years Power-Line Communications (PLC) have emerged as a consolidated broadband standard for data transmission [
1], taking advantage of the mains already installed in most indoor environments (public buildings, homes, industrial factories,
etc.). Apart from facilitating the deployment of devices since there is no need for additional cabling, this approach provides feasible solutions to different kinds of applications, such as sensory and automation systems [
2,
3,
4], distributed systems [
4,
5], smart spaces [
6,
7], or even industrial networks [
8,
9], where it is necessary to have available a broadband communication among the elements that integrate the system.
Nevertheless, PLC-based systems still have some details that can be improved in order to achieve a better performance. One of them is the implemented medium access technique, where most of the previous works have been focused on Multi-Carrier Modulation (MCM) [
10,
11], not only in PLC but also in other standards [
12] like Long Term Evolution (LTE) [
13]. MCM allows the performance and the spectrum efficiency to be enhanced by dividing the available bandwidth into subchannels, which data are transmitted through. Different MCM techniques have been successfully proposed for PLC, depending on how the subchannel division is carried out. Some of the most relevant are those based on Discrete Trigonometric Transform (DTT) [
14], or those based on filter banks (Filter-Bank Multi-Carrier, FBMC) [
10,
15]. In any case, no matter the considered medium access technique, all the approaches require a suitable and reliable synchronization method between transmitters and receivers, in order to be capable of achieving the expected performance, thus avoiding inter-symbol interference (ISI) and inter-carrier interference (ICI).
The synchronization issue has been widely considered in previous works for multi-carrier techniques, as Discrete Modulation Tone (DMT) [
16], FBMC [
17], or Orthogonal Frequency Division Multiplexing (OFDM) [
18,
19] for wireless communications.
Nevertheless, for broadband PLC there is a reduced number of works that deal with synchronization in such a scenario, where some features from the PLC channel, such as selective frequency fading, channel length, and noise models should be considered [
20]. Most of the research done for PLC is focused on the OFDM implementation proposed in the IEEE 1901–2010 standard [
21], but not on the FBMC physical layer approach. In those works, the auto-correlation metric is typically used, which consists on transmitting several repeated symbols and correlating the consecutive symbols in the receiver [
18,
22]. This metric is useful for wireless communications as it increases the robustness to Doppler shifts, but it suffers from the specific conditions of PLC channel. Furthermore, previous PLC synchronization works consider the maximum peak of the auto-correlation metric as the beginning of a symbol [
23,
24]. This cannot be assumed in practice due to multipath and therefore the first arriving path can be of lower magnitude than a multipath component [
25]. This is the reason why extra research efforts should be focused on the proposal and development of suitable synchronization algorithms for MCM in PLC communications.
Generally speaking, it is relevant to note that many previous proposals, not only for synchronization but also for multi-carrier medium access techniques, imply a challenge from a real-time implementation and sensory point of view [
26,
27]. They often handle high data rates, requiring intensive and parallel signal processing and a certain connection to digital converters and sensors. Accordingly, the possibility of providing a feasible real-time architecture for the implementation of the proposed synchronization algorithm actually becomes significant. Recent Field-Programmable Gate Array (FPGA) devices already play a key role in the implementation of this kind of systems [
28]. They allow the design of highly parallel and flexible architectures for signal processing at high frequencies (in the range of MHz).
This work presents a novel algorithm to estimate the synchronization delay, suitable for a FBMC transmultiplexer used in PLC communications. The proposed synchronization is based on cross correlation, where the received signal is correlated with the transmitted one. Unlike the common approaches based on auto-correlation techniques, the proposal makes possible to improve performance and robustness of communications in the PLC channel. Furthermore, a FPGA-based architecture is also described for the real-time implementation of the proposed algorithm, optimizing terms as resource consumption and operation frequencies, and increasing resource reutilization. The rest of the manuscript is organized as follows:
Section 2 reviews the medium access technique considered for PLC synchronization, whereas
Section 3 explains the proposed synchronization algorithm;
Section 4 describes the hardware architecture proposed for the implementation of the synchronization algorithm;
Section 5 shows some experimental results that validate the design; and, finally, conclusions are discussed in
Section 5.
2. Wavelet-OFDM Approach
Wavelet-OFDM is a medium access technique that can be efficiently implemented by means of the Discrete Cosine Transform (DCT), also known as a technique based on Cosine-Modulated Filter Bank (CMFB). According to the IEEE 1901–2010 standard [
21], in narrowband communications through mains, Wavelet-OFDM modulation is considered robust against selective frequency fading and narrowband noise, thus providing a better use of the available bandwidth since no guard intervals are required, unlike OFDM. Furthermore, the IEEE 1901–2010 standard defines frequencies at which PLC systems can transmit. For that purpose,
M = 512 carriers are distributed in the baseband version, for the range from 0 to 31.25 MHz, although only those in the range 1.8–28 MHz can be actually used. Even in this range, a mask has to be applied to filter frequencies related to amateur radio, so, finally, a set of 360 carriers is available for information transmission.
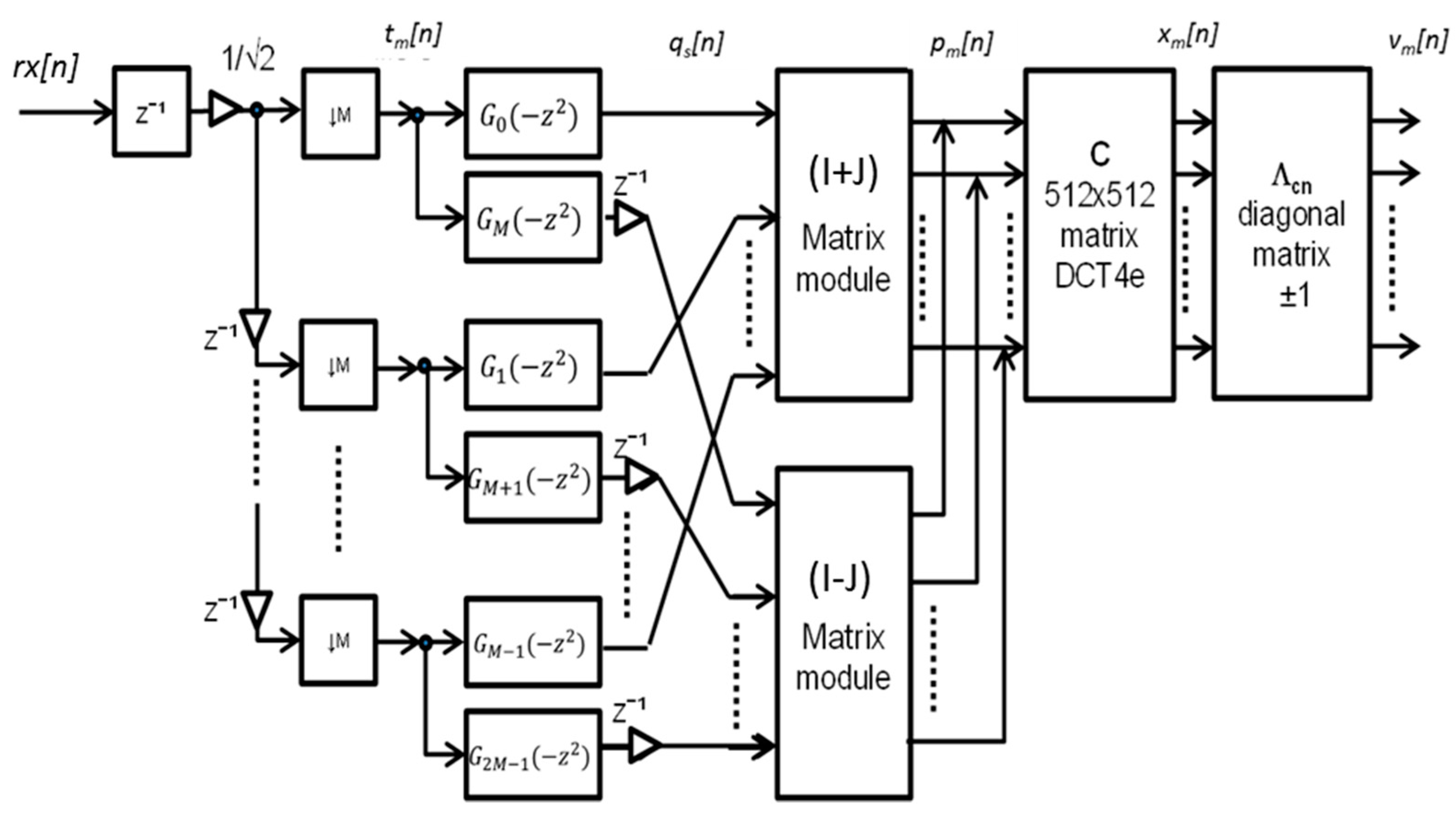
Figure 1.
General block diagram of the used Wavelet-OFDM receiver.
Figure 1.
General block diagram of the used Wavelet-OFDM receiver.
Figure 1 shows the block diagram of a possible efficient implementation of the filter bank at the Wavelet-OFDM receiver [
28], based on the DCT-4e. Basically, the processing consists of a first deserialization of the received signal
rx[n] to obtain the
M different subchannels
tm[n]. These
M subchannels are processed by pairs of filters
Gs(
z−1), where
s = 0, 1, …,
S−1 with
S = 2·
M, to obtain the intermediate signals
qs[n]. Afterwards, these signals
qs[n] are linearly operated by matrices (
I +
J) and (
I −
J) and added, so the DCT-input signals
pm[n] are obtained. The DCT module processes the
M subchannels to provide the signals
xm[n], which, after multiplied by the diagonal matrix
Λcn, provide the output subchannels
vm[n].
This efficient implementation can be expressed in a matricial way for the synthesis bank
f(
z) as Equation (2):
And for the analysis bank
h(
z) =
f(
z−1) as Equation (3):
where
g0(
z) is a diagonal matrix, whose diagonal elements are [
G0(–
z),
G1(–
z),…,
GM–1(–
z)] and
g1(
z) is also a diagonal matrix whose diagonal elements are [
GM(–
z),
GM+1(–
z),…,
G2M–1(–
z)], where
GM(–
z), 0 ≤
m ≤ 2·
M – 1, is the prototype filter in the discrete domain;
C4e is the DCT-4e matrix, whose elements are:
Λcn is a
M ×
M diagonal matrix, whose
i-th element is:
and
I denotes a
M ×
M identity matrix, whereas
J denotes the counter-identity matrix.
In the case of a bank with perfect reconstruction, then R(z)·f(z) = h(z)·R(z), where R(z) is the input to the synthesis bank. Nonetheless, ideal synchronization estimation is assumed to achieve a perfect reconstruction filter bank, otherwise the reconstructed signal is affected by ISI and ICI, making unfeasible to recover the transmitted data at the receiver side. For that reason it is significant to obtain the design and implementation of an efficient synchronization algorithm, able to accurately estimate the symbol timing.
4. Proposed Architecture
Some previous works have already dealt with the implementation of the Wavelet-OFDM emitter and receiver [
28], even describing in detail the efficient architecture proposed for the filter banks. Because of that, this section is focused on the definition and design of an efficient architecture for the implementation of the proposed synchronization algorithm. Furthermore, it is important to remark that the proposal has been developed on a Xilinx XC7K325T FPGA, whose internal architecture, datawidth and resource availability determine certain design decisions, especially those related to the fixed-point representation of the involved signals. This fixed-point representation has been defined hereinafter by a format Q(α·β), where α is the global number of bits and β is the number of fractional bits.
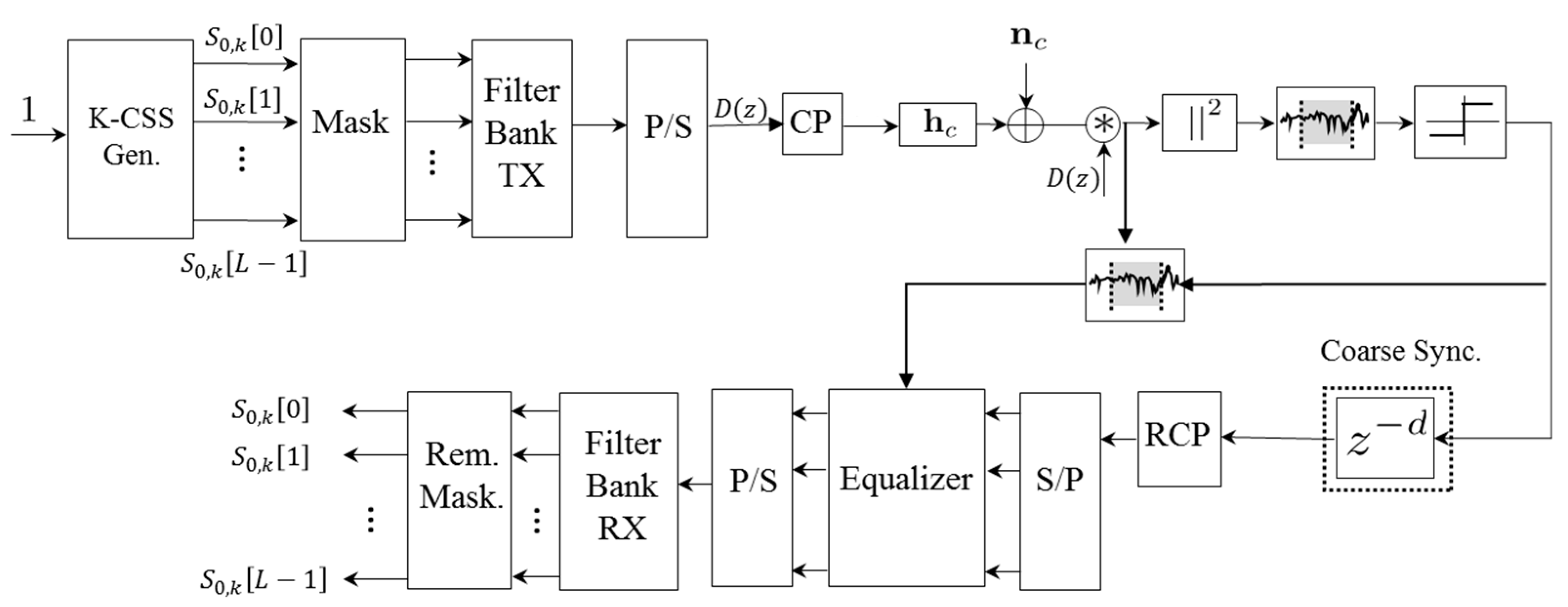
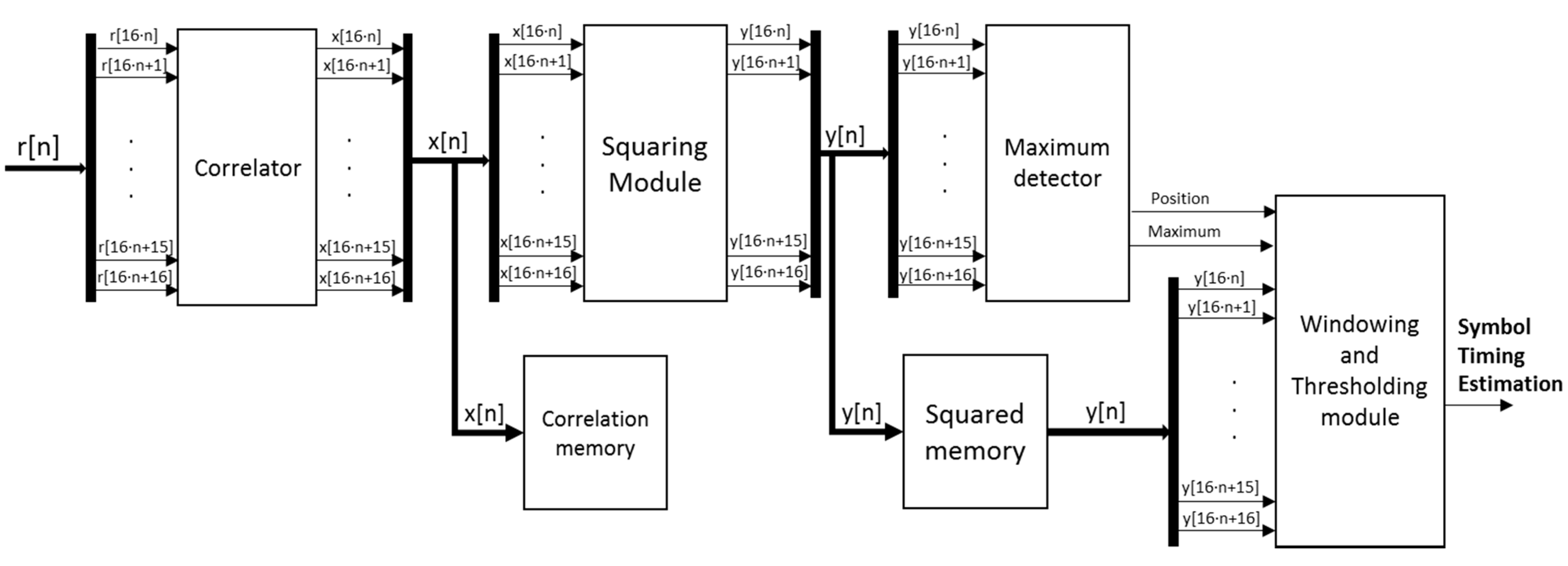
Figure 5 shows the block diagram of the synchronization proposal, according to the algorithm description carried out before. This diagram can be divided into four main modules: a correlator, a squaring module, a maximum detector, and a windowing and thresholding module. The global input for the synchronization architecture are the 2·
M received samples
r[n], obtained after discarding the cyclic prefix CP, whereas the final output is the estimated synchronization delay. Note that the input at the correlator has been parallelized in sets of 16 samples. This parallelism degree has been fixed in order not to significantly increase the resource consumption (especially multipliers), and, although it implies a latency in the global system operation, it is still possible to achieve real-time performance.
Figure 5.
General block diagram of the architecture proposed for the implementation of the synchronization algorithm.
Figure 5.
General block diagram of the architecture proposed for the implementation of the synchronization algorithm.
The critical issue about the design is to achieve real-time operation without discarding data at the reception, so the system should estimate the synchronization delay as fast as possible. Keeping this in mind, the most significant bottleneck is the correlation module, where a larger number of clock cycles are required to compute the corresponding correlation value
x[n]. The approach based on computing the correlation function
x[n] by means of sliding windows over the input data
r[n] has been rejected [
27], since the computational load becomes unfeasible for a real-time implementation. On the other hand, an approach based on non-overlapped windows over the input data
r[n] has been considered here. At this moment, it is important to recall the importance of the cyclic prefix to perform this kind of correlation, in order not to discard a part of the information and degrade the correlation maximum value
x[n], so only one block of 2·
M samples,
i.e., two symbols of
r[n], is processed to estimate the symbol timing.
The correlation module between the signal
r[n] and the transmitted preamble
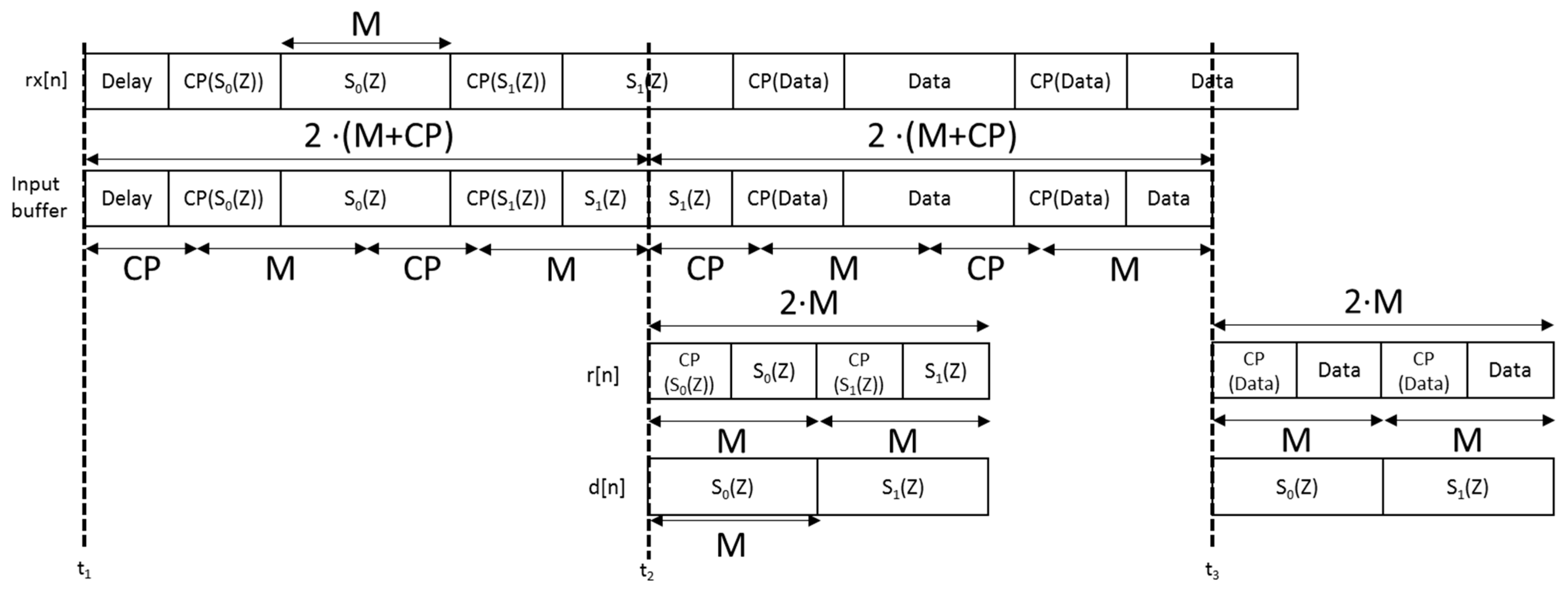
d[n] involves the FFT and IFFT modules, which require most of the multipliers available in the FPGA. The proposed correlation module is based on the continuous acquisition at the receiver, signal
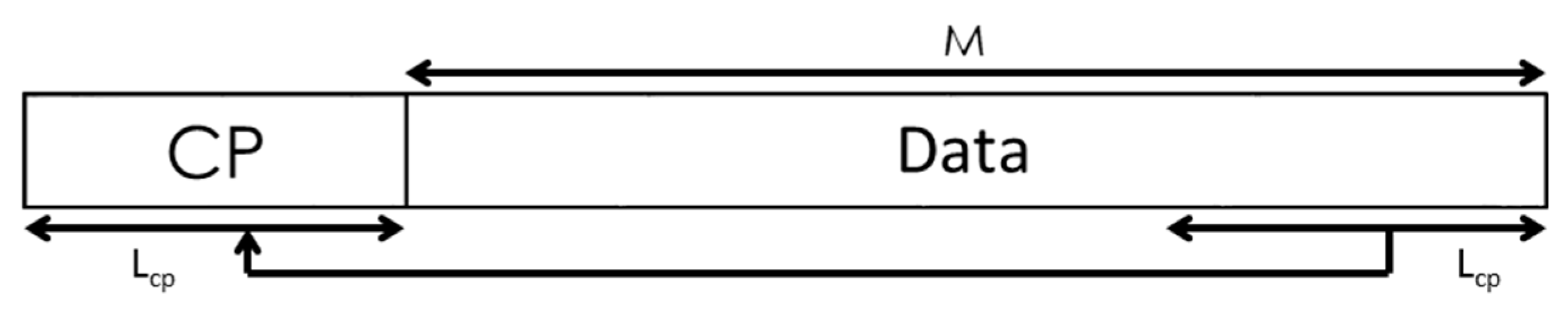
rx[n], and the storing in an input buffer with a length of 2(
M +
Lcp), where
M is the length of every packet and
Lcp the cyclic prefix length (see
Figure 6). Afterwards, it is possible to discard the cyclic prefix and obtain the input of the correlation module
r[n] with length 2·
M samples. Note that the transmitted preamble
d[n] consists of, either a pair of multi-level CSS, each one allocated in a different packet, or a Zadoff-Chu sequence. In this last case, the real and the imaginary parts are transmitted separately, so two data packets are still required for the preamble
d[n].
Figure 6.
Scheme of the CP removal process, and the corresponding input for the correlation module.
Figure 6.
Scheme of the CP removal process, and the corresponding input for the correlation module.
After removing the CP, the obtained signal
r[
n] should be correlated with the preamble
d[
n] modulated by the synthesis bank. It is assumed a constant preamble, and it only changes whether a different sequence is transmitted. This correlation can be expressed in the frequency domain as Equation (13):
where
x[
n] is the correlation output; DTF and IDFT mean the direct and inverse Discrete Fourier Transform, respectively;
r[
n] is the input buffer after CP removal; and
d[
n] is the transmitted preamble, both with a length of 2
M.
The fact of implementing both the DFT and the IDFT significantly increases the multiplier consumption in the design. Taking into account the DFT properties, it can be concluded that it is not necessary to implement an IDFT, since it is possible to reutilize the DFT to obtain the time-domain correlation. Simplifying Equation (13):
Since the IDFT is similar to DFT, with different sign in the exponential factor and different scaling constant, the correlation process can be rewritten as Equation (15):
where
N is the length of the signal to be correlated; and
X[
k]* is the complex conjugate of
X[
k]. If it is assumed that the signals
r[
n] and
d[
n] are real-valued, it is possible to discard the imaginary part at the correlation output
x[
n], so:
Taking into account Equation (14), it can be obtained Equation (17):
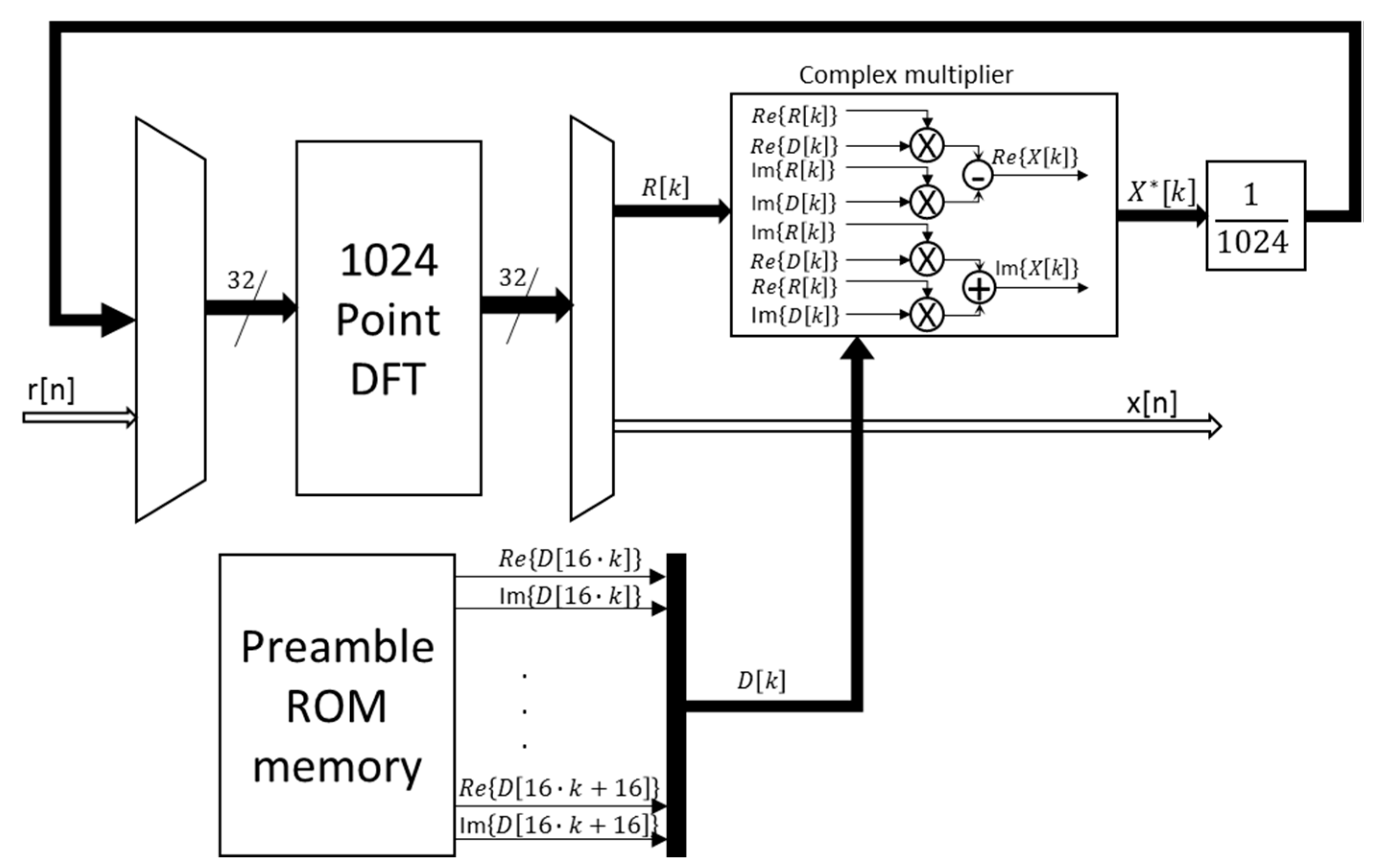
Figure 7 shows the block diagram proposed for the implementation of the correlation module, according to the optimizations described previously. It can be observed how the 1024-point FFT is reutilized to compute the time-domain correlation.
Figure 7.
General block diagram of the architecture proposed for the implementation of the correlation module.
Figure 7.
General block diagram of the architecture proposed for the implementation of the correlation module.
At the first stage, the system carries out the DFT for the input signal r[n] with a length of 2·M samples. The DFT block has 32 parallel inputs, half for the real part of the input samples and the other half for the imaginary part. Since the received signal r[n] is real, the imaginary inputs are null at this first stage. Not only the input data but also the outputs are represented in fixed point, with a format Q(18.8).
At the second stage, the complex multiplication between the output data from the DFT of the input signal
r[
n] and the output data from the DFT of the preamble
d[
n] is carried out. As has been already mentioned before, since the preamble is constant, its DFT can be computed off-line and stored in the corresponding Preamble ROM memory shown in
Figure 7. The available multiplication cells, DSP48E1, are 25 × 18 bits, so, in order to use all the available data span, the stored DFT data for the preamble
d[
n] have a format Q(25.15). The output of the multipliers is divided by a scaling factor 1/
N and truncated to the DFT format Q(18.8). Finally, in the last stage, the DFT block is involved again to compute the time-domain correlation, thus providing the output signal
x[
n] in the format Q(18.8) as well.
The correlation memory block in
Figure 5 has been included to store the resulting correlation
x[
n], so it can be used later in the channel estimation and the computation of the equalizer coefficients. When the correlation module starts to provide valid output data after an initial latency, it is capable of generating 16 18-bit samples
x[
n] every clock cycle until the final length of 1024 samples. The squaring module consists of 16 multipliers that compute in parallel the squaring of signal
x[
n] in a format Q(36.16). This squared signal
y[
n] is truncated to the most significant 18 bits, Q(18.0), since the higher a correlation maximum is, the easier its detection becomes. The squared correlation function
y[
n] is also stored in a squared memory block to be used in the windowing and thresholding module, whereas the squared values
y[
n] are also processed by the maximum detector to determine the exact position of the correlation peak. Both the correlation and the squared memory blocks have a size of 64 × 288 bits, corresponding to a set of 16 samples with 18 bits each. This makes possible to read/write a whole set of 16 samples in a single memory access.
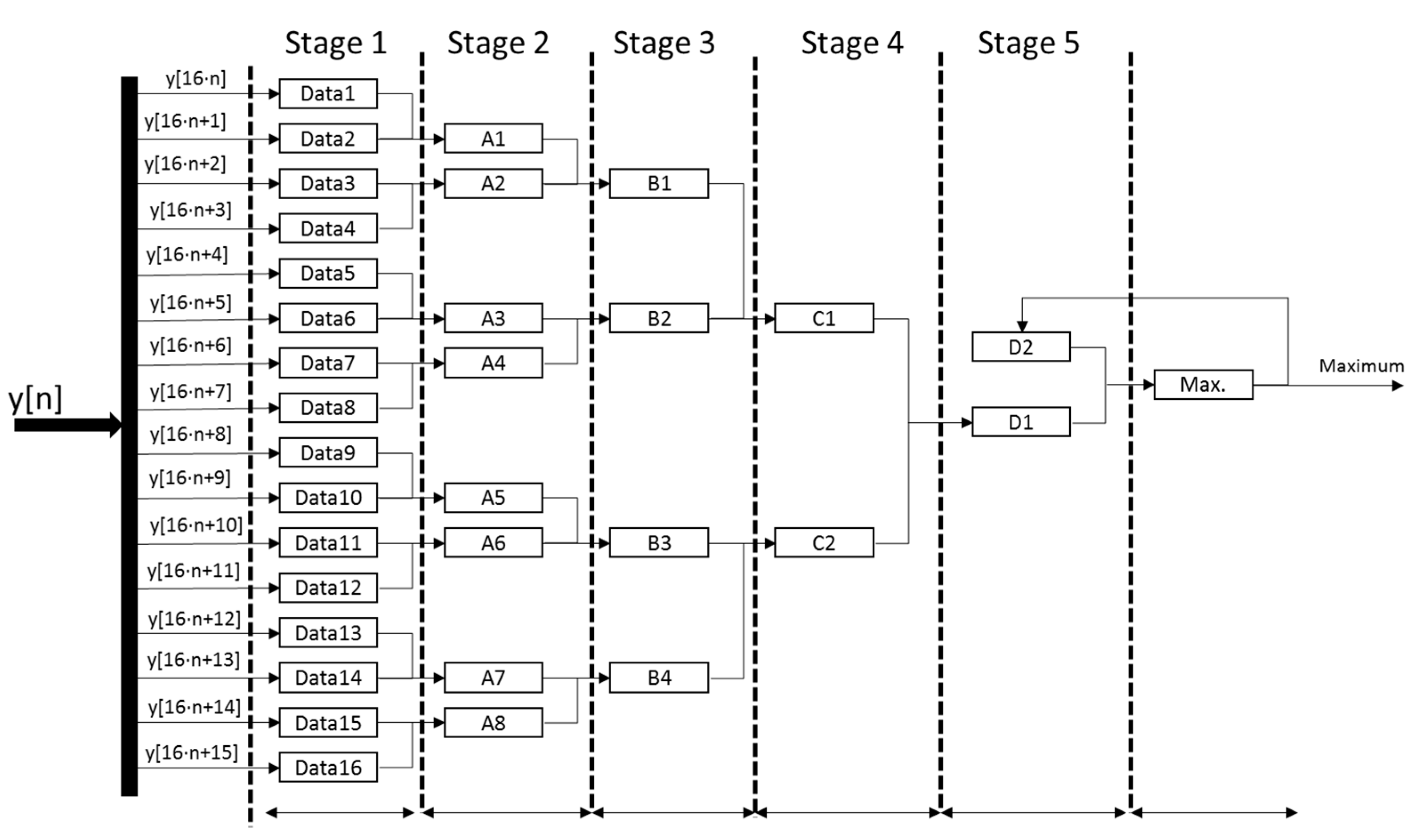
The detection of the maximum correlation value consists of a successive and pipelined comparison to determine the maximum value among every set of 16 samples
y[
n] coming from the squaring module. Every clock cycle, a new set of 16 samples
y[
n] is inserted, and, by comparing in pairs at every clock cycle, the local maximum is obtained after four clock cycles. A last clock cycle is dedicated to determine the global maximum for the global length of 1024 samples, by comparing the local maximum values from every set of 16 samples.
Figure 8 shows the scheme for the implementation of this maximum detector. Since the correlation length is 1024 samples and 16 new samples are inserted every clock cycle, 64 clock cycles plus a latency of five cycles are required to obtain the maximum correlation value and determine its position in the squared memory block.
Figure 8.
General scheme proposed for the implementation of the detector of the maximum correlation values.
Figure 8.
General scheme proposed for the implementation of the detector of the maximum correlation values.
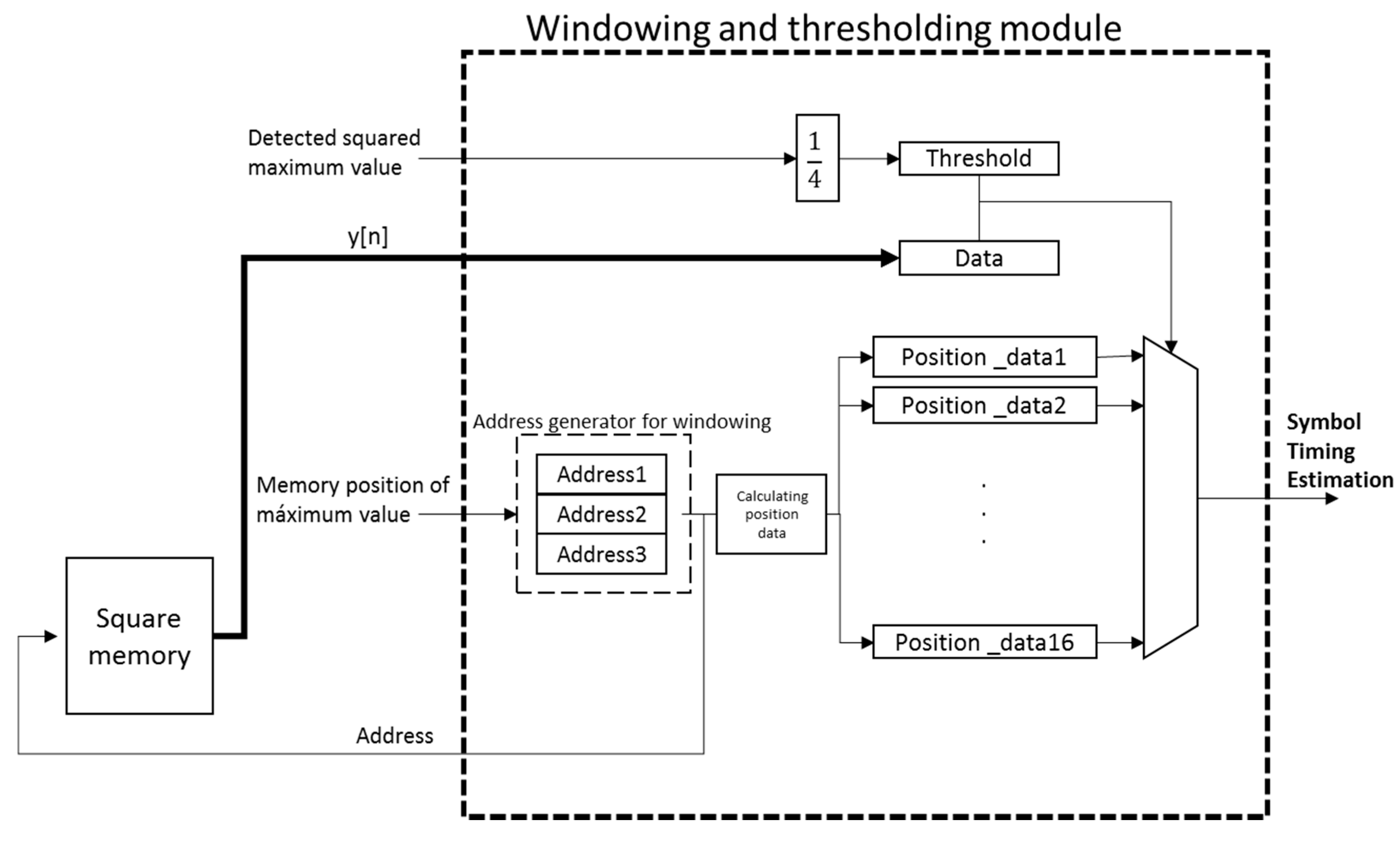
Finally, the windowing and thresholding module is in charge of searching the first sample y[n] over a certain threshold before the detected maximum value, since that sample y[n] is considered as the start of the PLC channel. The windowing is implemented by reading the squared memory block at the position where the detected correlation peak is stored. Since every memory access provides 16 samples y[n] and three reading accesses are carried out, the length of the final window varies from 32 to 47 samples, depending on the exact position of the detected maximum value in the set of 16 samples y[n].
The start of the PLC channel is searched in this window, and it is defined by the first value over a certain threshold. This threshold is experimentally fixed at the 25% of the detected maximum squared value
y[
n] and it should be updated for every PLC channel condition to effectively estimate the first arriving path.
Figure 9 shows the block diagram of the windowing and thresholding module, where the input signals are the detected maximum squared value
y[
n] and its corresponding location in the squared memory block. This module provides the symbol timing estimation.
Figure 9.
Block diagram of the proposed windowing and thresholding module.
Figure 9.
Block diagram of the proposed windowing and thresholding module.
5. Experimental Results
The synchronization algorithm proposed previously has been implemented in a KC705 platform [
37] by Xilinx Inc. (San Jose, CA, USA), which is based on a Kyntex XC7K325T FPGA [
38]. Regarding the resource consumption,
Table 1 shows the figures for the main logic elements available in the device. Generally speaking, the reduced utilization percentage can be observed. Furthermore,
Table 2 details this resource consumption for every module involved in the proposed design. In this case, the most of the required resources are dedicated to the correlation module, where it is necessary to implement a FFT block in charge of parallelizing the input data. This minimizes the latency cycles required to obtain every output sample.
Table 1.
Resource consumption of the synchronization algorithm implementation in a Xilinx XC7K325T FPGA.
Table 1.
Resource consumption of the synchronization algorithm implementation in a Xilinx XC7K325T FPGA.
| | Proposed Design | Utilization Percentage |
|---|
| Flip-Flops | 27,046 | 6% |
| RAMB | 68 | 7% |
| LUTs | 21,207 | 10% |
| DSP48E1 | 236 | 28% |
Table 2.
Detailed resource consumption for the main modules of the design in a Xilinx XC7K325T FPGA.
Table 2.
Detailed resource consumption for the main modules of the design in a Xilinx XC7K325T FPGA.
| | Flip-Flops | RAMB | LUTs | DSP48E1 |
|---|
| Global Design | 27,046 | 68 | 21,207 | 236 |
| Correlation Module | 26,388 (97.57%) | 64 (94.12%) | 20,587 (97.08%) | 220 (93.22%) |
| Squaring Module | 12 (0.04%) | 0 (0.00%) | 10 (0.05%) | 16 (6.78%) |
| Maximum Detection | 325 (1.20%) | 0 (0.00%) | 343 (1.62%) | 0 (0.00%) |
| Thresholding Module | 14 (0.05%) | 0 (0.00%) | 177 (0.65%) | 0 (0.00%) |
The proposed design works at a clock frequency of fCLK = 50 MHz, thus requiring 1024 input data every 64 clock cycles (16 18-bit samples every clock cycle), with a latency of 580 cycles. In this case, it is assumed that the sampling frequency at the receiver is fS = 50 Msps in order to fill up a buffer with a length 2(M + Lcp), for M = 512 subchannels and cyclic prefix length Lcp = 400. In a parallel way, the synchronization delay is estimated for the previous buffer, providing a final estimation after a latency of 580 cycles for a clock frequency of fCLK = 50 MHz. This implies a long enough interval in order to synchronize the receiver and not to discard input samples at the reception. Since the latency may still increase without any drawback for the system operation, the resource consumption in the correlation module could be minimized by parallelizing even more the data input.
Another aspect that has been analyzed is the quantization error due the fixed-point representation used in FPGA-based designs. This study has been focused on the two modules where the most intensive computation is carried out: the correlation and the squaring modules. Note that the maximum detection module and the thresholding module imply comparisons and assignments, but not arithmetical operations where quantization errors could have influence on them.
Table 3 shows the maximum relative error and the averaged relative error for the input signal
r[
n], for the correlation output
x[
n], and for the squared output
y[
n], obtained by performing 1000 simulations with different channel models according to [
25,
36], for a SNR = 10 dB. Due to the fact that all the fractional bits are discarded at the output
y[
n] of the squaring module, quantization errors become more relevant. Nevertheless, this signal
y[
n] is only used further to detect maximum values in correlation, so the global performance of the system is not degraded by this decision.
Table 3.
Relative quantization errors for the main signals in the proposed design.
Table 3.
Relative quantization errors for the main signals in the proposed design.
| | Maximum Relative Error | Averaged Relative Error |
|---|
| Input r[n], Q(18.8) | 0.055% | 0.052% |
| Correlation output x[n], Q(18.8) | 0.132% | 0.117% |
| Squared output y[n], Q(18.0) | 7.98% | 4.72% |
Finally, to validate the proposed synchronization algorithm and its FPGA-based implementation, some simulation results have been performed. The study has been carried out for two different PLC channel model parameters, where signal-noise ratios (SNR) from −5 dB to 30 dB, in steps of 5 dB, have been configured. For every configuration, 1000 simulations have been performed. Regarding the PLC channel model, it is based on the Tonello PLC channel model [
36], where two parameter configurations have been considered: the channel B with more favorable parameters [
36] and channel A, more complex and obtained from [
25].
Table 4 describes the main parameters for both models.
Table 4.
Parameters for the PLC channel model considered here [
25,
36].
Table 4.
Parameters for the PLC channel model considered here [25,36].
| | Channel B | Channel A |
|---|
| Maximum length | 300 m | 800 m |
| Attenuation dependent of the frequency
a0 | 10−5 | 0.3 × 10−2 |
| Attenuation dependent of the frequency
a1 | 10−9 | 4 × 10−2 |
| Poisson arrival time intensity | 0.667 m−1 | 0.2 m−1 |
| Channel length | 4 µs | 5.56 µs |
| Stop frequency | 31.25 MHz | 31.25 MHz |
Furthermore, four different types of noise have been evaluated: synchronous impulsive noise, asynchronous impulsive noise, background noise, and narrowband noise; whose power levels are defined in [
20].
Figure 10 plots the Root Mean Squared Error (RMSE) for the synchronization delay estimation with respect to the SNR level, taking into account both channel models A and B. It can be observed that the difference between the floating-point algorithm and the fixed-point version implemented in the FPGA device is negligible. Furthermore, it can be verified how the RMSE for the model A is higher than the one for the model B, due to the complexity of this type of PLC channel. In order to compare the proposal with other approaches,
Figure 10 also shows the RMSE obtained for the auto-correlation method [
22]. Note that its RMSE values are higher than those achieved by the proposed algorithm for both channel models A and B, so the proposed synchronization algorithm improves the performance provided by auto-correlation methods. For every configuration, the RMSE value presents a fluctuation below one sample, which is due to the statistical estimation carried out (1000 simulations for every SNR value). The figures have been obtained by means of multilevel complementary sequences with a length
L = 360 bits.
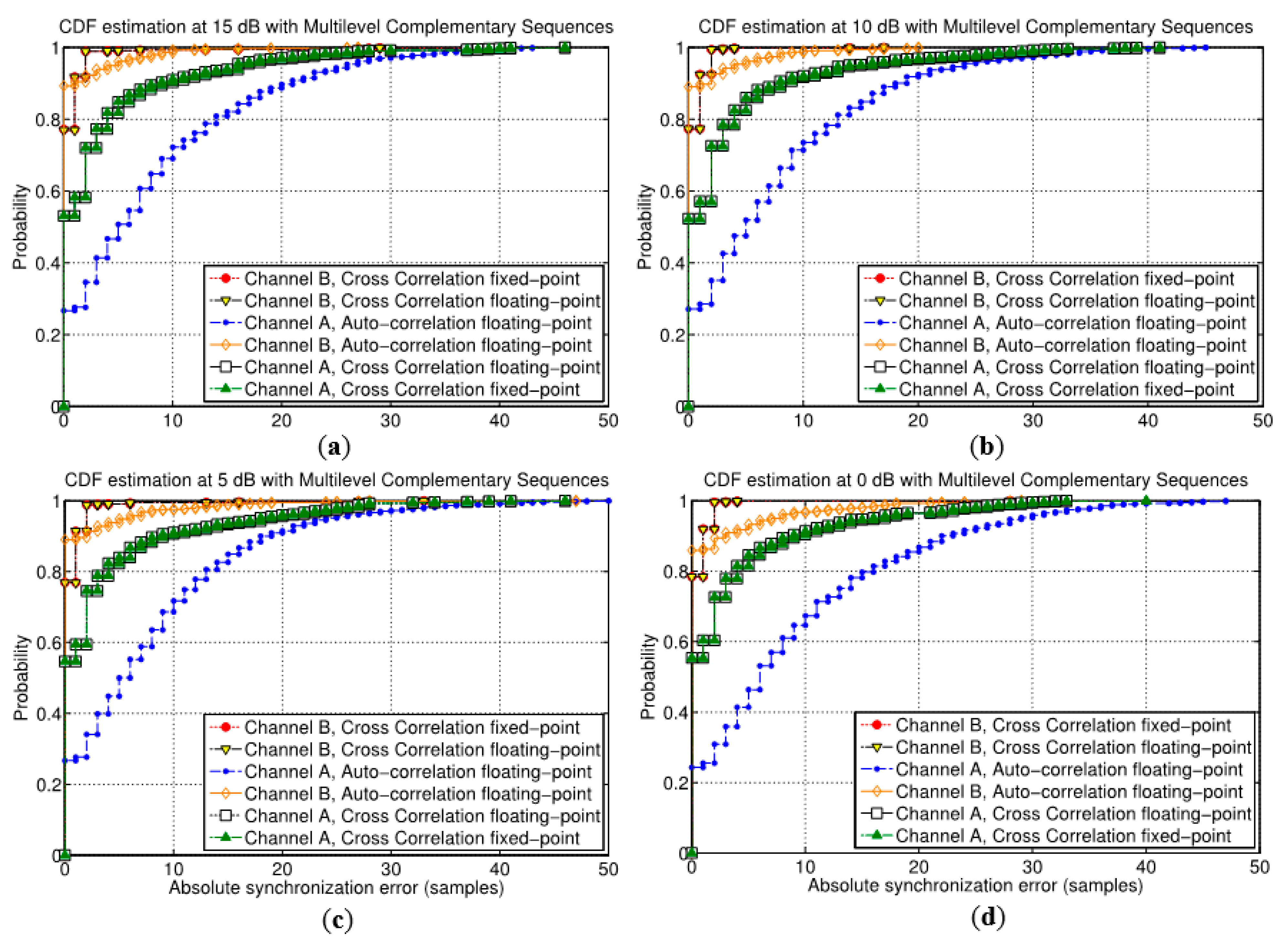
On the other hand,
Figure 11 shows the cumulative distribution function (CDF) of the absolute error in the synchronization delay estimation for different SNR values and using multilevel complementary sequences. Note that the absolute error is considered as the absolute difference in samples between the estimated synchronization delay and the real delay. The CDF is plotted for both channel models A and B, and not only for the proposed algorithm based on cross correlation but also for the auto-correlation approach. Furthermore, the proposed synchronization algorithm based on cross correlation is evaluated in its corresponding floating- and fixed-point representations. In general terms, the proposed algorithm achieves a better performance than the auto-correlation one, especially for the more complex channel model A regardless the SNR value. In the case of the simpler channel model B, the auto-correlation approach can provide a higher rate of ideal estimation of the synchronization delay, but in case of not achieving a perfect estimation, the errors in the delay estimation are greater than the proposed cross-correlation algorithm. Also, the FPGA-based architecture proposed for the fixed-point implementation provides negligible differences with the floating-point version (note that both plots are almost overlapped in
Figure 11). Taking into account the analyzed SNR values, it can be observed the immunity to noise of the proposal, since the performance is not degraded as the noise level increases.
Figure 10.
RMSE in the synchronization delay estimation for both channels, and for a floating- and a fixed-point representation and the auto-correlation method.
Figure 10.
RMSE in the synchronization delay estimation for both channels, and for a floating- and a fixed-point representation and the auto-correlation method.
Figure 11.
Cumulative distribution function (CDF) of the absolute error in the synchronization delay estimation with different SNR values, (a) 15 dB, (b) 10 dB, (c) 5 dB, (d) 0 dB, for both models A and B, for the auto-correlation method and for the floating- and fixed-point versions of the proposed algorithm.
Figure 11.
Cumulative distribution function (CDF) of the absolute error in the synchronization delay estimation with different SNR values, (a) 15 dB, (b) 10 dB, (c) 5 dB, (d) 0 dB, for both models A and B, for the auto-correlation method and for the floating- and fixed-point versions of the proposed algorithm.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

