
An Efficient Method of Sharing Mass Spatio-Temporal Trajectory Data Based on Cloudera Impala for Traffic Distribution Mapping in an Urban City


Abstract
:1. Introduction
2. Impala-Enabled Spatio-Temporal Mass Data Sharing Methodology
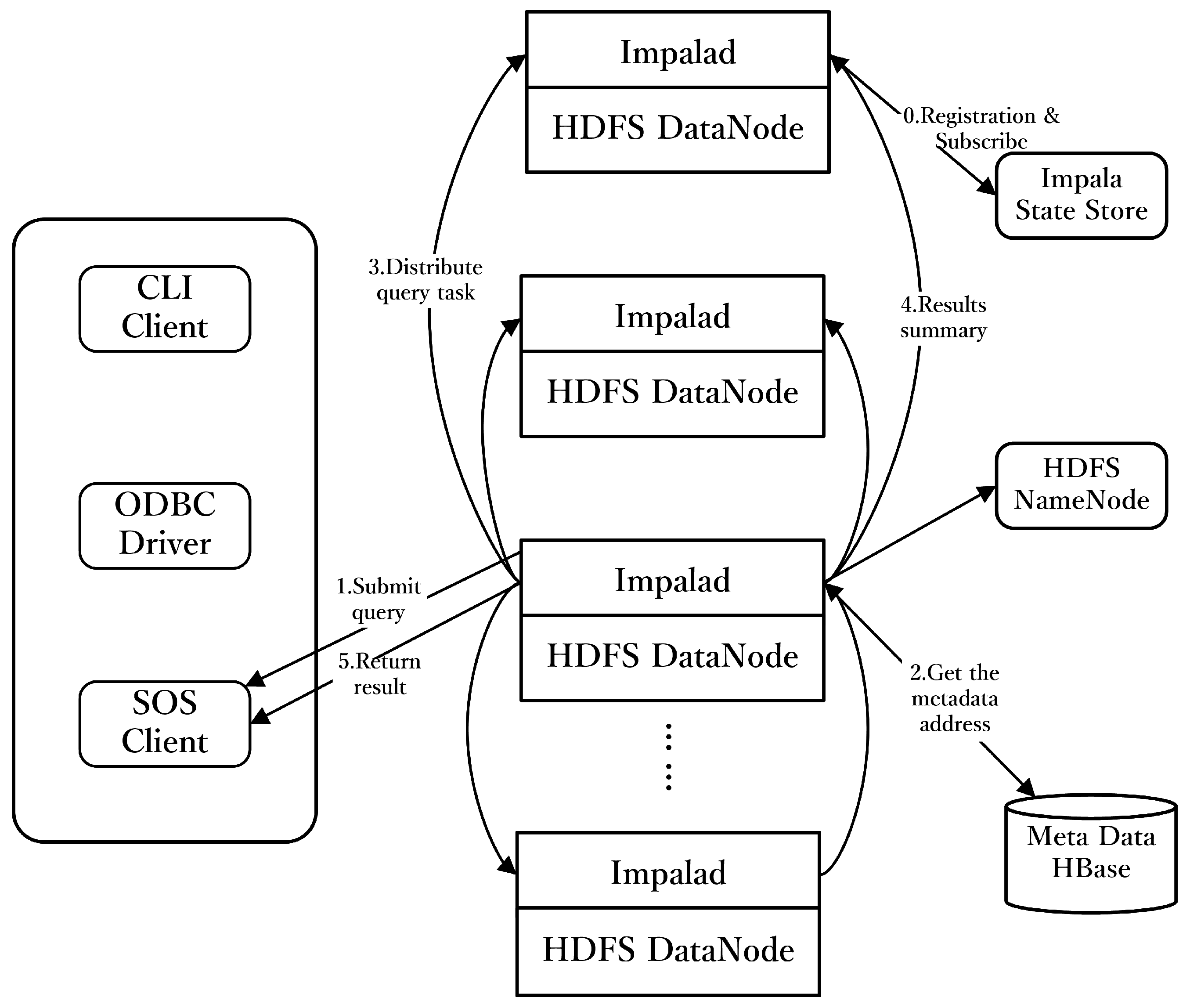
2.1. Mechanism of Impala and Core Parts
2.2. Spatio-Temporal Trajectory Data Sharing Algorithm Enabled by Impala
| Algorithm 1. Algorithm of spatio-temporal trajectory data retrieval |
| Input: current spatio-temporal data retrieval range ST-Box(PlongitudeRange, PlatitudeRange, Pbegin, Pend) |
| Output: query results ObservationCollection |
| Use: SensorObservationService(DatatnInput, AlgorithmIDIMPALA, ResponseFormat) inherits the data access object of SOS implementation |
| doConfiguration(PathHDFS, Numberport, URLSOS) configures PathHDFS, Numberport and URLSOS |
| SpatialQueryBlock(PlongitudeRange, PlatitudeRange) positions the spatial block according to the spatial range |
| TemporalQueryBlock(Pbegin, Pend) positions the spatial block according to the spatial constraint |
| SpatialPointInOrNot(Plongitude, Platitude, Pointtn_m) judges whether the point is in the spatial block |
| TemporalBlockInOrNot(Pbegin, Pend, Pointtn_m) judges whether the point is in the spatial block |
| STEP 1: Inherit the mandatory interface in SOS implementation through the SensorObservationService(DatatnInput, AlgorithmIDIMPALA, ResponseFormat) function in SOS implementation. |
| STEP 2: Start configuring the parameters of the input path of the HDFS’ IP address and port number of entry of the Impala cluster. Create a JDBC using the parameters configured above and the function doConfiguration(PathHDFS, Numberport, URLSOS) to connect the Impala and HDFS layer. |
| STEP 3: Obtain the objects STtn information from ST-Box using the get4(ST-Box) function, which is developed based on the Observation & Measurement encoding model. The spatio-temporal metadata are used to construct a spatio-temporal query statement and obtain the retrieved data from the HDFS. |
| STEP 4: Implement the function SpatialQueryBlock(PlongitudeRange, PlatitudeRange) to achieve the specified blocktn_spatial acquisition. Via the function, the location of blocktn_spatial in the HDFS can be obtained. The data located in the acquired blocktn_spatial can be obtained from step 5 in detail. |
| STEP 5: Implement the function SpatialPointInOrNot(Plongitude, Platitude, Pointtn_m) to judge whether Pointspatial_m is in the range between Plongitude and Platitude or not. By traversing all the points in blocktn_spatial, the points meeting the judgement criteria are discovered. The function judges whether the point in blocktn_spatial is in the specified spatial range. |
| STEP 6: Implement the function TemporalQueryBlock(Pbegin, Pend), achieving the specified blocktn_temporal discovery. Via the function, the id of the blocktn can be discovered. The function judges whether the point in blocktn_spatial is in the specified temporal range. The data located in the acquired blocktn_temporal can be obtained from step 7 in detail. |
| STEP 7: Implement the function TemporalBlockInOrNot(Pbegin, Pend, Pointtn_m) to judge whether Pointtn_m is in the range between Plongitude and Platitude. By traversing all the points in blocktn_temporal, the points meeting the judgement criteria are discovered. Package the data in Pointspatial_m and Pointtemporal_m to assemble the obsevationCollection and return it to the SOS or CLI. |
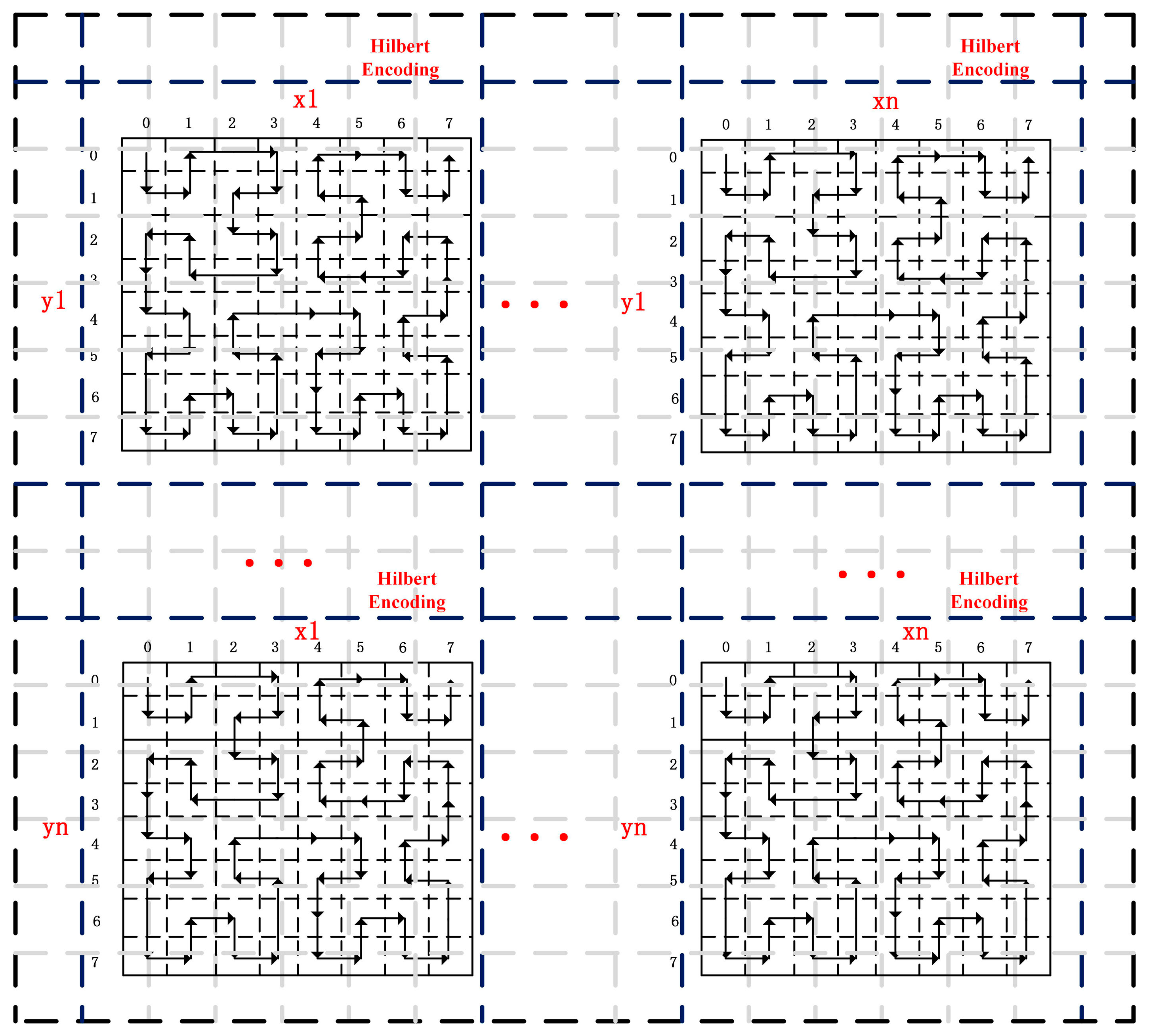
2.3. Block Division for Indexing the Spatio-Temporal Trajectory Data
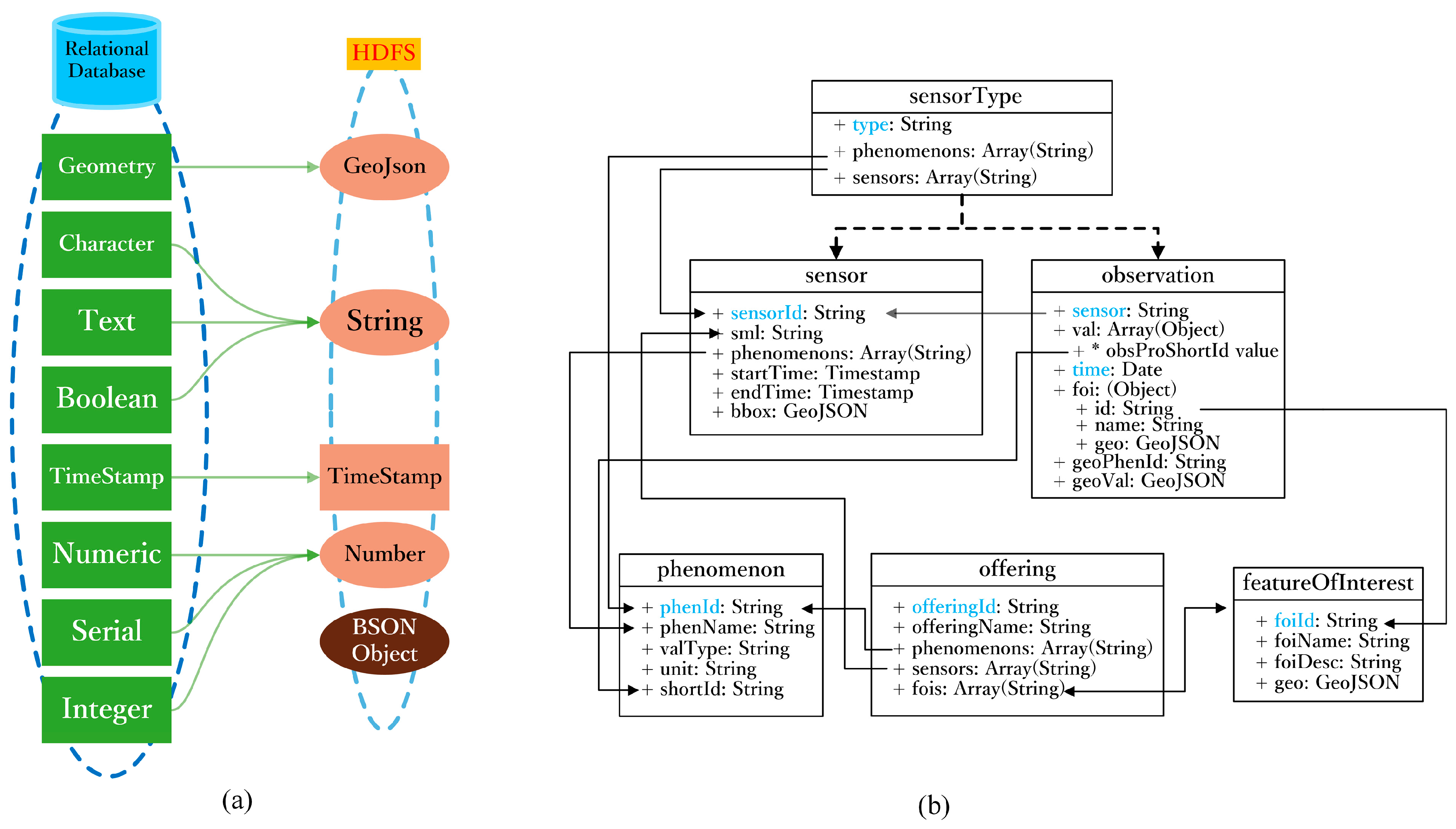
2.4. Approach for Integrating Impala and SOS
- (1)
- sensorType table: Stores the sensor type information of the sensors and phenomenon.
- (2)
- sensor table: Stores the sensor information, including the sensor metadata, the time when the sensor begins observation and the time when the sensor ends observation.
- (3)
- observation table: Stores the observation information when the sensors finishes observation, including the observation time, spatial range of the observation and the observation result.
- (4)
- phenomenon table: Stores the phenomenon information, including the phenomenon name, observation value type and unit information.
- (5)
- offering table: Stores the organization information, including the organization name, phenomenon name and sensor information.
- (6)
- featureOfInterest table: Stores the spatial arrangement of observations, including the name and coordinate encoded within the GeoJson data type.
3. Experiments and Discussion
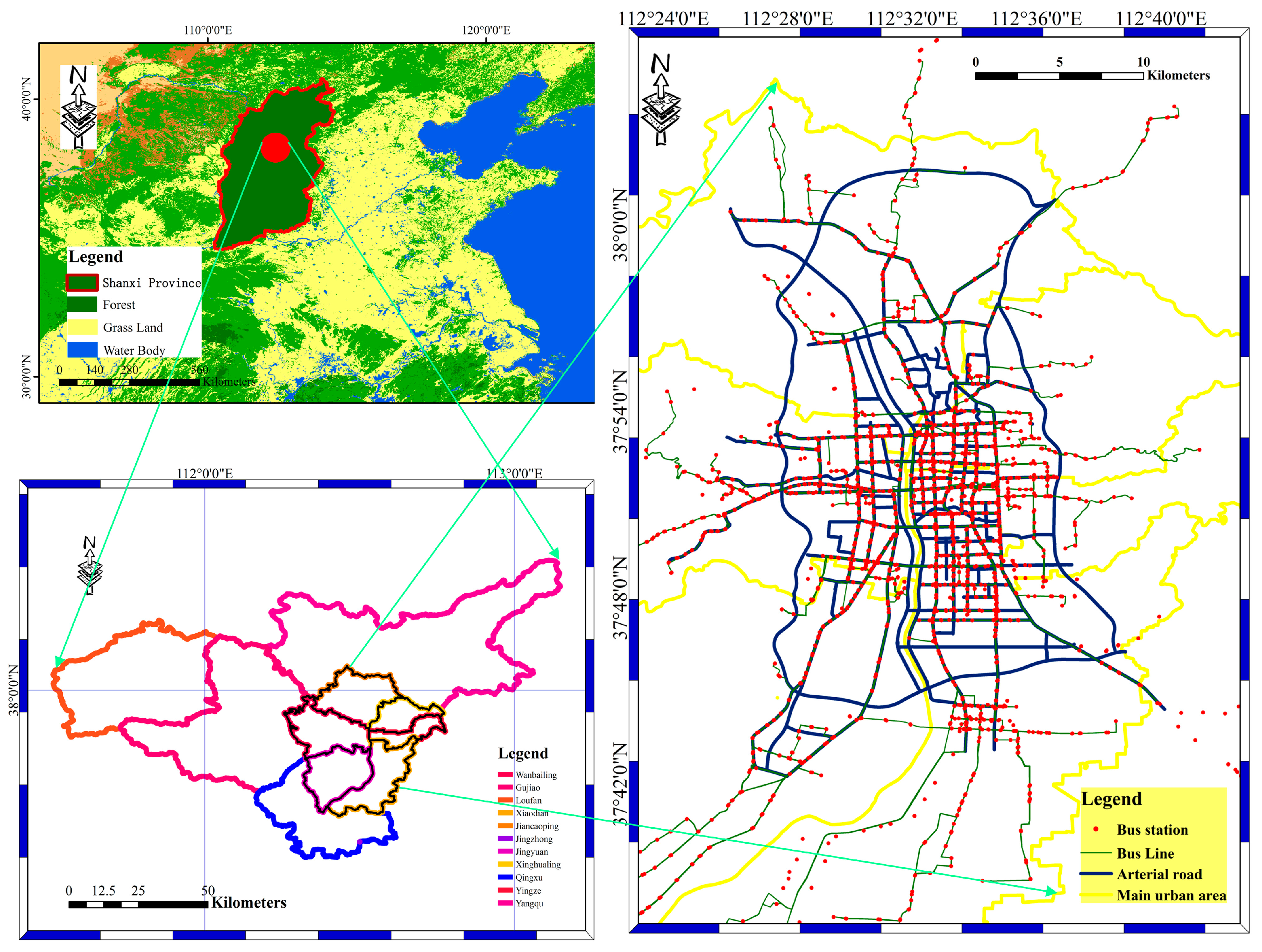
3.1. BD Bus Network and Experimental Environment
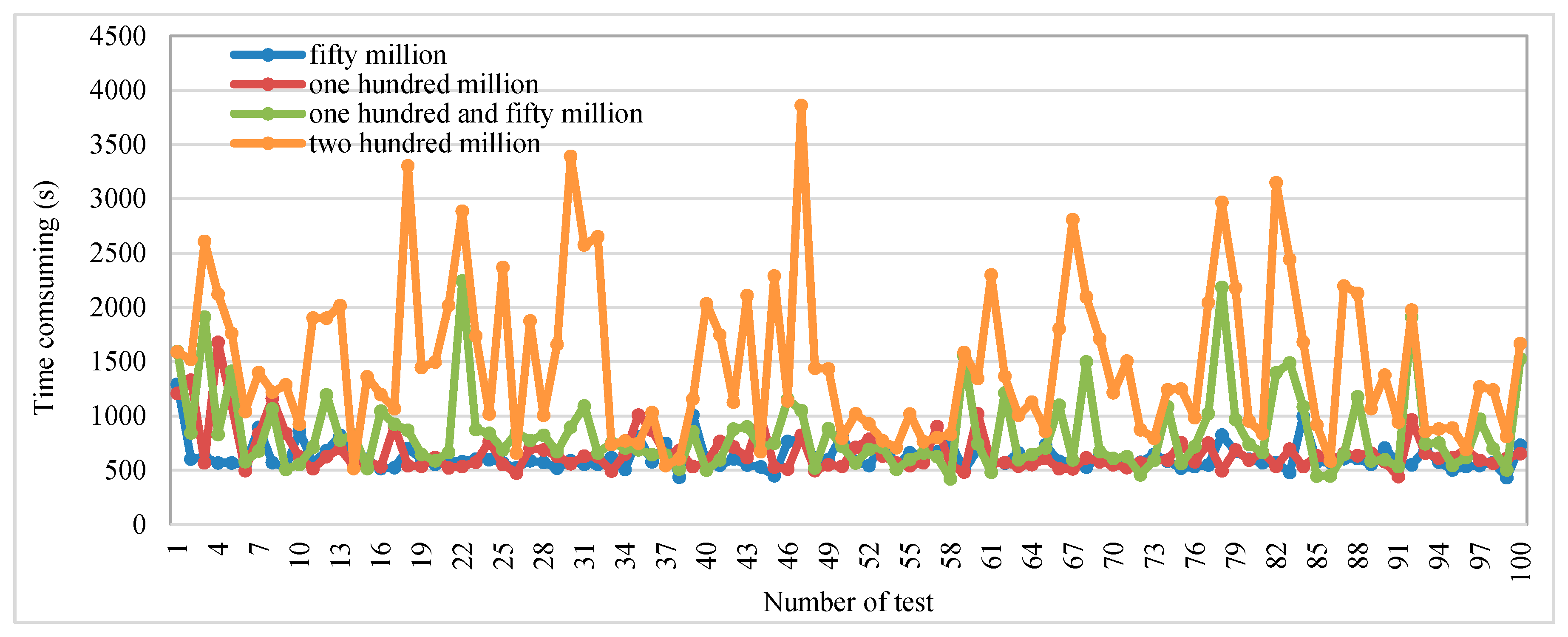
3.2. Data Partitions and Data Encoding
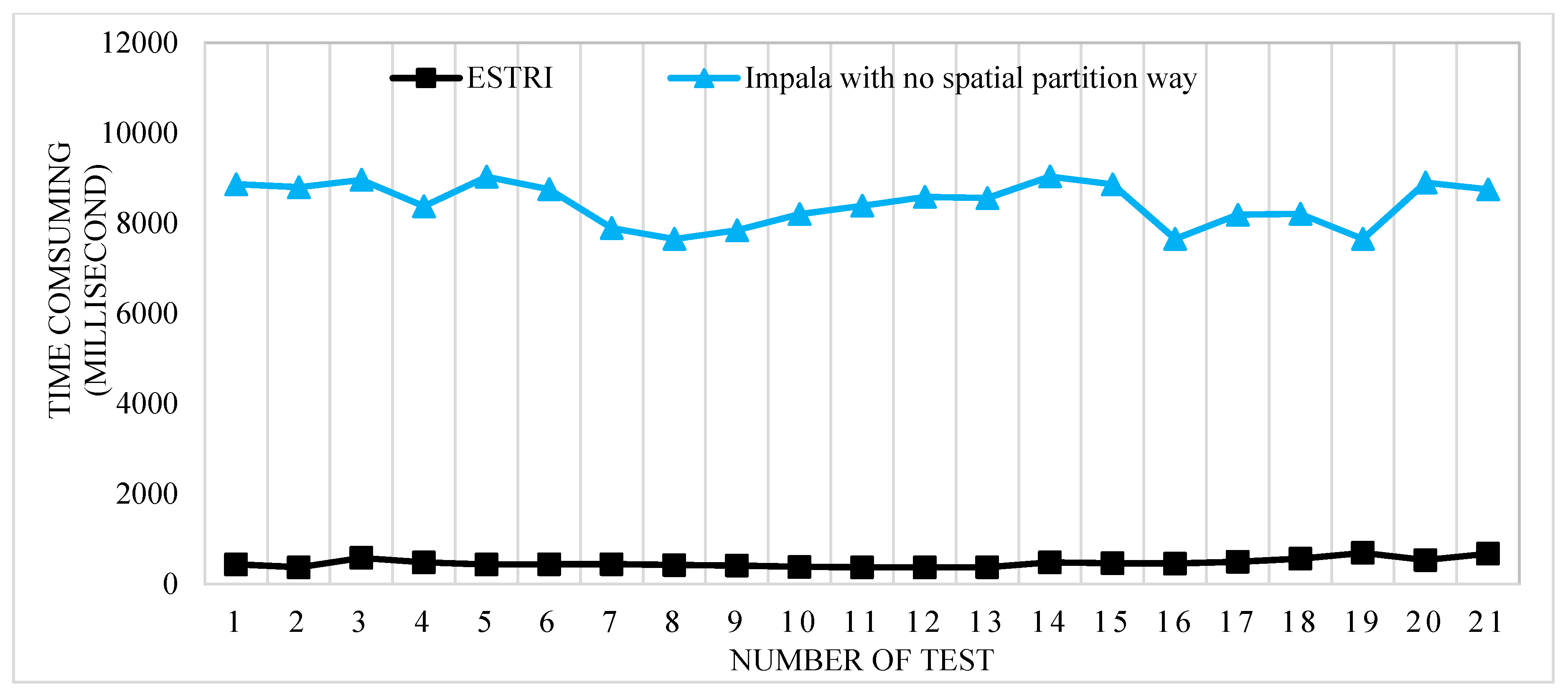
3.3. Data Retrieval at Different Times
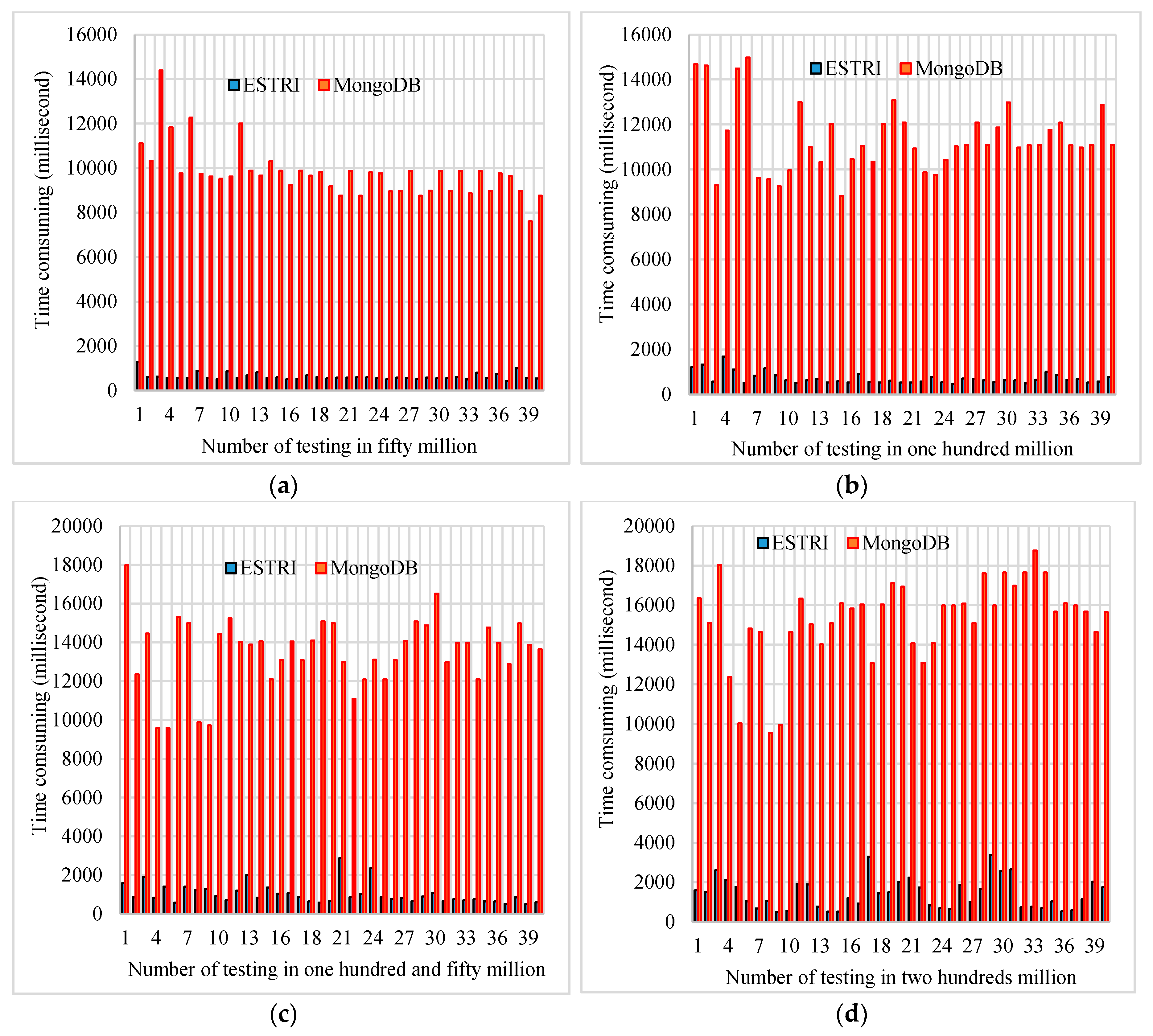
3.4. Performance Evaluation
4. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ESTRI | Efficient spatio-temporal data retrieval method based on Impala |
| RAM | Random Access Memory |
| NoSQL | Not Only SQL |
| CLI | Command-line interface |
| ODBC | Open Database Connectivity |
| SQL | Structured Query Language |
| HDFS | Hadoop Distributed File System |
| SOS | Sensor Observation Service |
| BD | BeiDou |
| GPS | Global Position System |
| OSGeo | Open Source Geospatial Foundation |
| OGC | Open GIS Consortium |
| WKT | Well-Known Text |
| GML | Geography Markup Language |
References
- Nellore, K.; Hancke, G.P. A Survey on Urban Traffic Management System Using Wireless Sensor Networks. Sensors 2016, 16, 157. [Google Scholar] [CrossRef] [PubMed]
- Own, C.M.; Lee, D.S.; Wang, T.H.; Wang, D.J.; Ting, Y.L. Performance Evaluation of UHF RFID Technologies for Real-Time Bus Recognition in the Taipei Bus Station. Sensors 2013, 13, 7797–7812. [Google Scholar] [CrossRef] [PubMed]
- Fernández-Lozano, J.; Martín-Guzmán, M.; Martín-Ávila, J.; García-Cerezo, A. A Wireless Sensor Network for Urban Traffic Characterization and Trend Monitoring. Sensors 2015, 15, 26143–26169. [Google Scholar] [CrossRef] [PubMed]
- Suranthiran, S.; Jayasuriya, S. Optimal fusion of multiple nonlinear sensor data. IEEE Sens. J. 2004, 4, 651–663. [Google Scholar] [CrossRef]
- Vitolo, C.; Elkhatib, Y.; Reusser, D.; Macleod, C.J.A.; Buytaert, W. Web technologies for environmental big data. Environ. Model. Softw. 2015, 63, 185–198. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, S.F.; Furlinger, K.; Kranzlmuller, D. Trends in computation, communication and storage and the consequences for data intensive science. In Proceedings of the IEEE 14th International Conference on High Performance Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 572–579.
- Laney, D. 3-D Data Management: Controlling Data Volume, Velocity and Variety. Application Delivery Strategies by META Group Inc. Available online: http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf (accessed on 7 April 2016).
- Chen, C.L.P.; Zhang, C.Y. Data-intensive applications, challenges, techniques and technologies: A survey on big data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Jin, X.; Sieber, R.E. A land use/land cover change geospatial cyberinfrastructure to integrate big data and temporal topology. Int. J. Geogr. Inf. Sci. 2016, 30, 573–593. [Google Scholar]
- Chen, J.; Sheng, H.; Li, C.; Xiong, Z. PSTG-based multi-label optimization for multi-target tracking. Comput. Vis. Image Underst. 2016, 144, 217–227. [Google Scholar] [CrossRef]
- Zhang, C. The Roles of Web Feature Service and Web Map Service in Real Time Geospatial Data Sharing for Time-Critical Applications. Geogr. Inf. Sci. 2005, 32, 269–283. [Google Scholar] [CrossRef]
- Zerger, A.; Smith, D.I. Impediments to using GIS for real-time disaster decision support. Comput. Environ. Urban Syst. 2003, 27, 123–141. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, T.; Li, W. Automatic search of geospatial features for disaster and emergency management. Int. J. Appl. Earth Obs. 2010, 6, 409–418. [Google Scholar] [CrossRef]
- Ting, R.H. An introduction to spatial database systems. VLDB J. 1994, 3, 357–399. [Google Scholar]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Boston, MA, USA, 1–4 September 1984.
- Sellis, T.; Roussopoulos, N.; Faloutsos, C. The R+ tree: A dynamic index for multidimensional objects. In Proceedings of the 13th International Conference on Very Large Databases, Brighton, UK, 7–9 August 1987.
- Beckmann, N.; Kriegel, H.-P.; Schneider, R.; Seeger, B. The R* tree: An efficient and robust access method for points and rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 23–25 May 1990.
- Kamel, I.; Faloutsos, C. Hilbert R-Tree: An improved R-Tree using fractals. In Proceedings of the 20th International Conference on Very Large Databases, Santiago de, Chile, 12–15 September 1993.
- Xia, J.; Yang, C.; Gui, Z.; Liu, K.; Li, Z. Optimizing an index with spatiotemporal patterns to support GEOSS Clearinghouse. Int. J. Geogr. Inf. Sci. 2014, 28, 1459–1481. [Google Scholar] [CrossRef]
- Kothuri, R.K.V.; Ravada, S.; Abugov, D. Quad-tree and R-tree indexes in oracle spatial: A comparison using GIS data. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 3–6 June 2002.
- Gkatzoflias, D.; Mellios, G.; Samaras, Z. Development of a web GIS application for emissions inventory spatial allocation based on open source software tools. Comput. Geosci. 2013, 52, 21–33. [Google Scholar] [CrossRef]
- Barbierato, E.; Gribaudo, M.; Iacono, M. Performance evaluation of NoSQL big-data applications using multi-formalism models. Future Gener. Comput. Syst. 2014, 7, 345–353. [Google Scholar] [CrossRef]
- Vora, M.N. Hadoop-Hbase for large-scale data. In Proceedings of the 2011 International Conference on Computer Science and Network Technology (ICCSNT), Harbin, China, 24–26 December 2011.
- Lakshman, A.; Malik, P. Cassandra: A decentralized structured storage system. ACM SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. 2008, 26, 205–218. [Google Scholar] [CrossRef]
- Calil, A.; Mello, R.D.S. SimpleSQL: A Relational Layer for SimpleDB. In Proceedings of the East European Conference on Advances in Databases and Information Systems, Poznań, Poland, 18–21 September 2012; pp. 99–110.
- Liakos, P.; Koltsida, P.; Kakaletris, G.; Baumann, P.; Ioannidis, Y.; Delis, A. A Distributed Infrastructure for Earth-Science Big Data Retrieval. Int. J. Coop. Inf. Syst. 2015, 2, 2–10. [Google Scholar] [CrossRef]
- Sun, S.; Gong, J.; He, J.; Peng, S. A spreading activation algorithm of spatial big data retrieval based on the spatial ontology model. Cluster Comput. 2015, 18, 563–575. [Google Scholar] [CrossRef]
- You, S.; Zhang, J.; Le, G. Large-scale spatial join query processing in Cloud. In Proceedings of the 31st IEEE International Conference on Data Engineering Workshops (ICDEW), Seoul, Korea, 13–17 April 2015.
- Impala. Cloudera Impala 2.0.0. Available online: http://www.cloudera.com/products/apache-hadoop/impala.html (accessed on 14 January 2016).
- Hive. Apache Hive 2.0.0. Available online: http://hive.apache.org/ (accessed on 14 January 2016).
- Estevezrams, E.; Perezdavidenko, C.; Fernández, B.A.; Loraserrano, R. Visualizing long vectors of measurements by use of the Hilbert curve. Comput. Phys. Commun. 2015, 197, 118–127. [Google Scholar] [CrossRef]
- Steiniger, S.; Bocher, E. An overview on current free and open source desktop GIS developments. Int. J. Geogr. Inf. Sci. 2009, 23, 1345–1370. [Google Scholar] [CrossRef]
- Chen, Z.; Lin, H.; Chen, M.; Liu, D.; Bao, Y.; Ding, Y. A framework for sharing and integrating remote sensing and GIS models based on Web Service. Sci. World J. 2014, 1, 57–78. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Chen, N.; Di, L.; Gong, J. A flexible data and sensor planning service for virtual sensors based on web service. IEEE Sens. J. 2011, 6, 1429–1439. [Google Scholar] [CrossRef]
- Bröring, A.; Stasch, C.; Echterhoff, J. OGC Sensor Observation Service Interface Standard (Version 2.0); Open Geospatial Consortium: Wayland, MA, USA, 2012. [Google Scholar]
- Bröring, A.; Echterhoff, J.; Jirka, S.; Simonis, I.; Everding, T.; Stasch, C.; Liang, S.; Lemmens, R. New Generation Sensor Web Enablement. Sensors 2011, 11, 2652–2699. [Google Scholar] [CrossRef] [PubMed]
- Botts, M. OpenGIS Sensor Model Language (SensorML) Implementation Specification; Open Geospatial Consortium: Wayland, MA, USA, 2007. [Google Scholar]
- Cox, S. OGC Implementation Specification 07-022r1: Observations and Measurements—Part 17 1—Observation Schema; Open Geospatial Consortium: Wayland, MA, USA, 2007. [Google Scholar]
- Cox, S. OGC Implementation Specification 07-022r3: Observations and Measurements—Part 19 2—Sampling Features; Open Geospatial Consortium: Wayland, MA, USA, 2007. [Google Scholar]
- He, H.; Li, J.; Yang, Y.; Xu, J.; Guo, H.; Wang, A. Performance assessment of single- and dual-frequency Beidou/GPS single-epoch kinematic positioning. GPS Solut. 2014, 3, 393–403. [Google Scholar] [CrossRef]
- 52 North SOS, 2016. 52 North SOS Prototype 1.0.0. Available online: http://52north.org/communities/sensorweb/sos/index.html (accessed on 17 January 2016).
- Chen, Z.; Chen, N. Provenance information representation and tracking for remote sensing observations in a sensor web enabled environment. Remote Sens. 2015, 6, 7646–7670. [Google Scholar] [CrossRef]
- Lv, Q.; Xie, W. A real-time log analyzer based on MongoDB. Appl. Mech. Mater. 2014, 571–572, 497–501. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bus Network | Shenzhen taxi network | Wuhan taxi network | Taiyuan bus network | New York taxi network |
| Location | Shenzhen, China | Wuhan, China | Taiyuan, China | New York, America |
| Locating Device | Global Position System (GPS) | GPS | BeiDou (BD) Navigation Satellite System | GPS |
| Start Date | February 2011 | March 2012 | August 2013 | June 2009 |
| Vehicle Number | 25,000 | 12,137 | 2200 | 33,000 |
| Measurement Attribute | Speed, location, direction | Speed, location, direction | Speed, location, direction | Speed, location, direction |
| Observation Interval (Seconds) | 60 | 30 | 30 | 30 |
| Data Produced per Day | 800 million | 860 million | 12.67 million | 984 million |
| Data Storage | Oracle | MongoDB cluster | MySQL | Unknown |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Chen, N.; Yuan, S.; Chen, Z. An Efficient Method of Sharing Mass Spatio-Temporal Trajectory Data Based on Cloudera Impala for Traffic Distribution Mapping in an Urban City. Sensors 2016, 16, 1813. https://doi.org/10.3390/s16111813
Zhou L, Chen N, Yuan S, Chen Z. An Efficient Method of Sharing Mass Spatio-Temporal Trajectory Data Based on Cloudera Impala for Traffic Distribution Mapping in an Urban City. Sensors. 2016; 16(11):1813. https://doi.org/10.3390/s16111813
Chicago/Turabian StyleZhou, Lianjie, Nengcheng Chen, Sai Yuan, and Zeqiang Chen. 2016. "An Efficient Method of Sharing Mass Spatio-Temporal Trajectory Data Based on Cloudera Impala for Traffic Distribution Mapping in an Urban City" Sensors 16, no. 11: 1813. https://doi.org/10.3390/s16111813
APA StyleZhou, L., Chen, N., Yuan, S., & Chen, Z. (2016). An Efficient Method of Sharing Mass Spatio-Temporal Trajectory Data Based on Cloudera Impala for Traffic Distribution Mapping in an Urban City. Sensors, 16(11), 1813. https://doi.org/10.3390/s16111813