
Multi-Target Tracking Using an Improved Gaussian Mixture CPHD Filter

Abstract
:1. Introduction
2. Background
2.1. Random Finite Set Model
2.2. CPHD Filter and Its GM Implementation
3. Improved GM-CPHD Filter
3.1. The Proposed GM-CPHD Filter
| Algorithm 1. Pseudo-code for updating the confirmed Gaussian components (at time ) |
| Given , , the threshold and the attenuation function . |
| Step 0. Set , and . |
| Step 1. Update computation for detected components and undetected components. |
| for |
| for |
| Compute using (31). |
| end |
| Compute using (40). |
| if |
| Compute and using (32)–(33). |
| . |
| Set . |
| Assign for . |
| . |
| . |
| else |
| . |
| ; ; . |
| . |
| end |
| end |
| Step 2. Modify the updated weights of the Gaussian components in . |
|
for
|
| end |
| Output: . |
3.2. Implementation Issues
| Algorithm 2. Pseudo-code for the pruning and merging method |
| Given , a truncation threshold , a merging threshold and a maximum allowable number of Gaussian terms . |
| Step 0. Set and . |
| Step 1. repeat |
| . |
| . |
| . |
| , . |
| , . |
| . |
| . |
| Until ∅. |
|
| Output: . |
3.3. Gating Strategy
4. Simulation
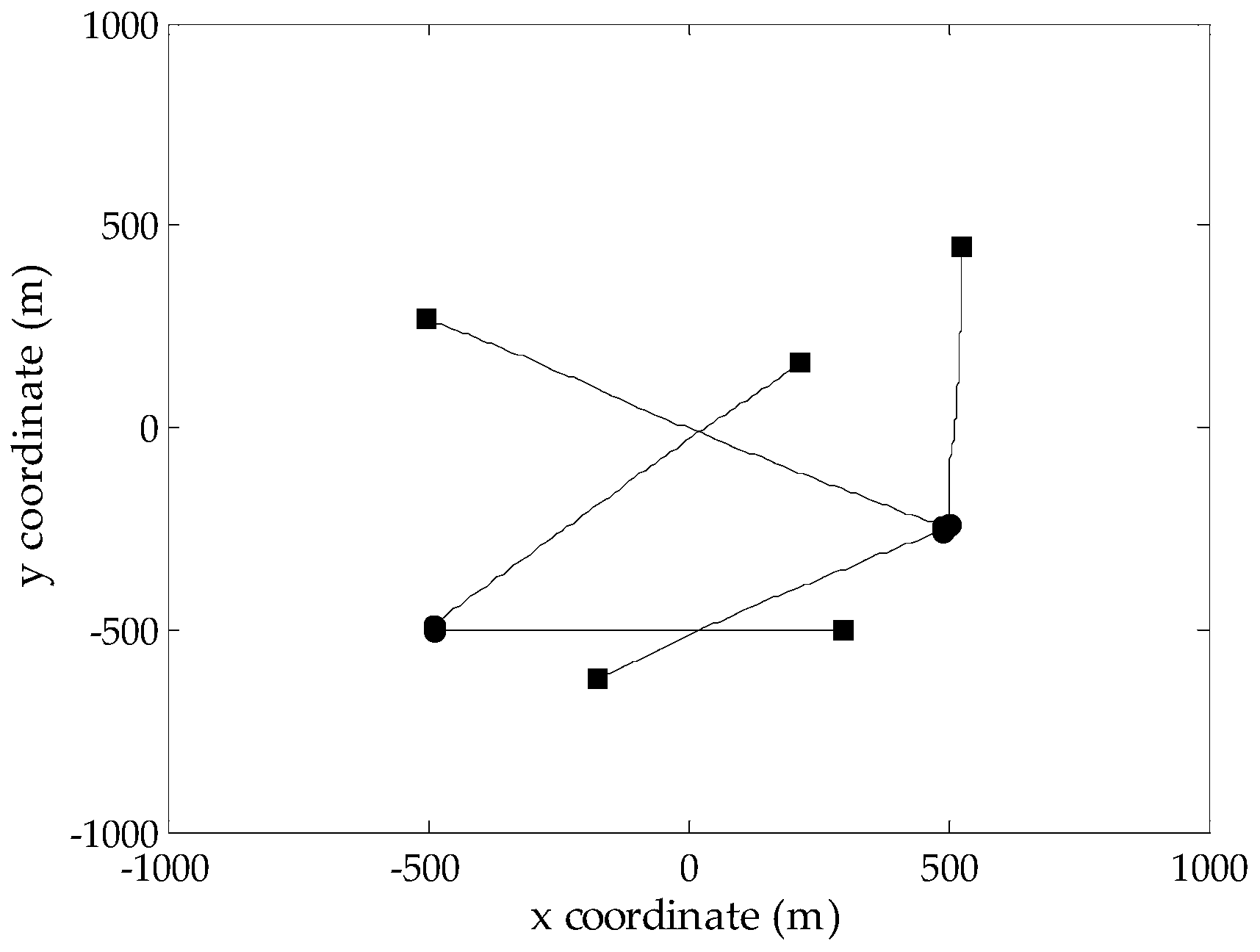
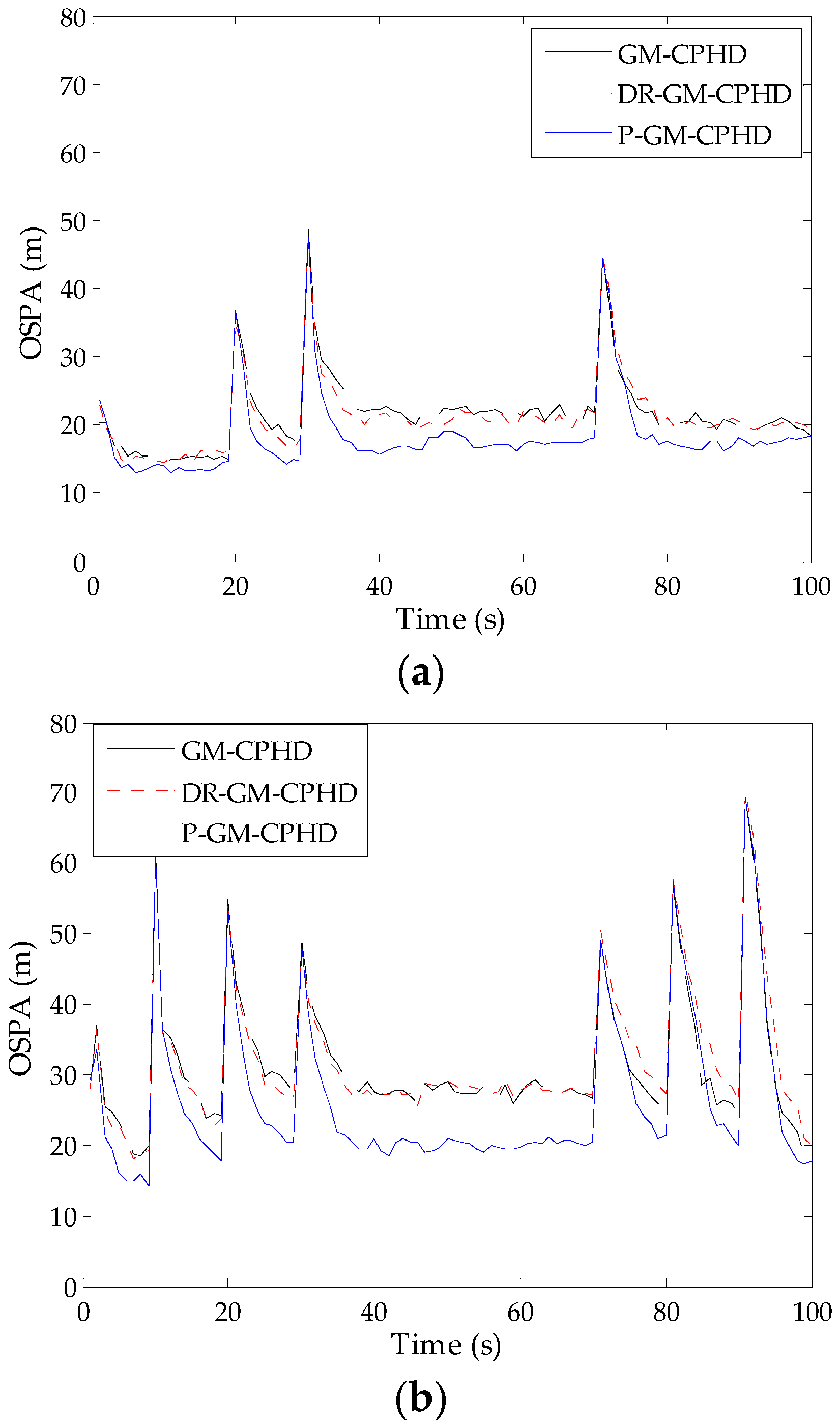
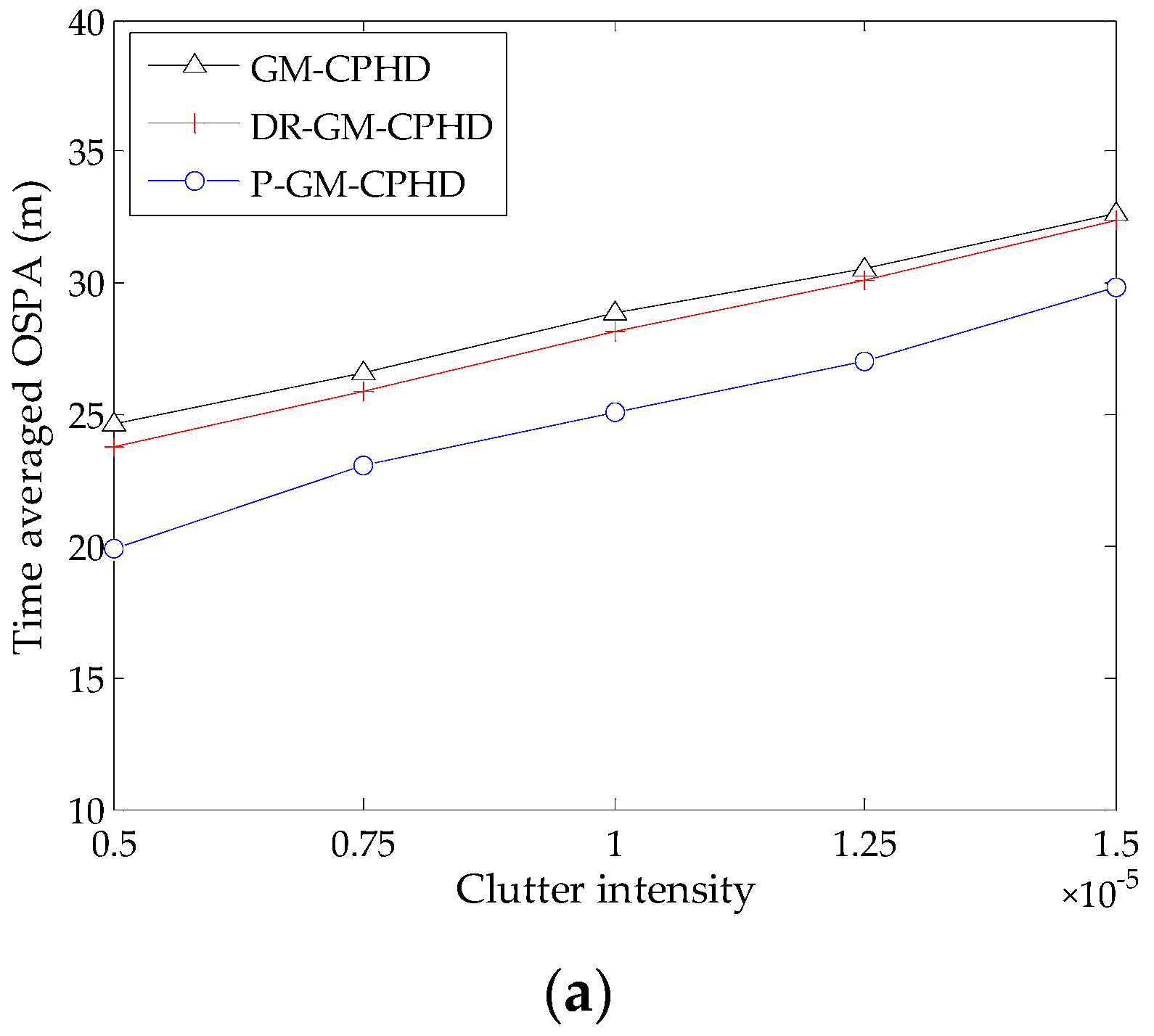
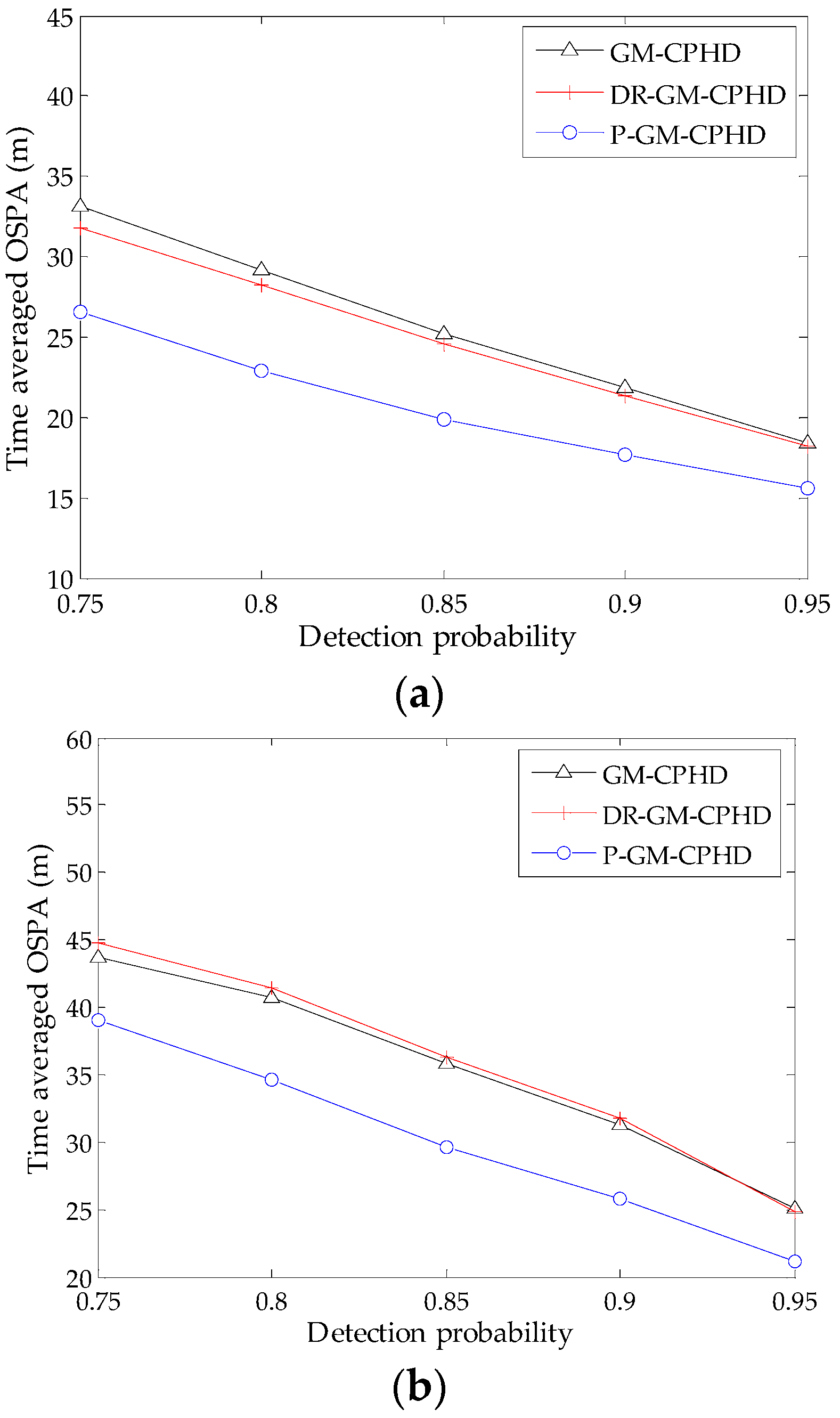
4.1. Evaluation of Different CPHD Filters
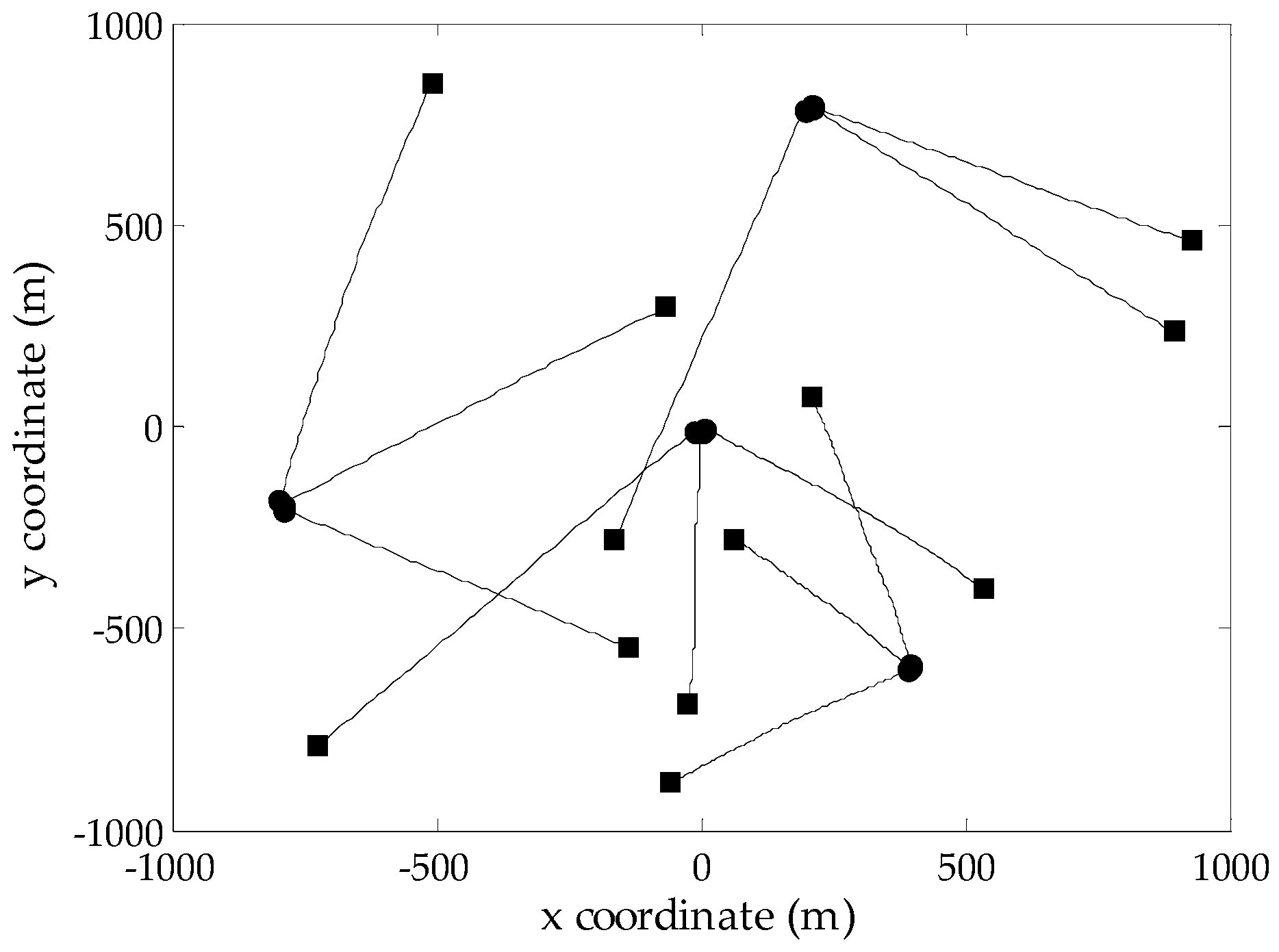
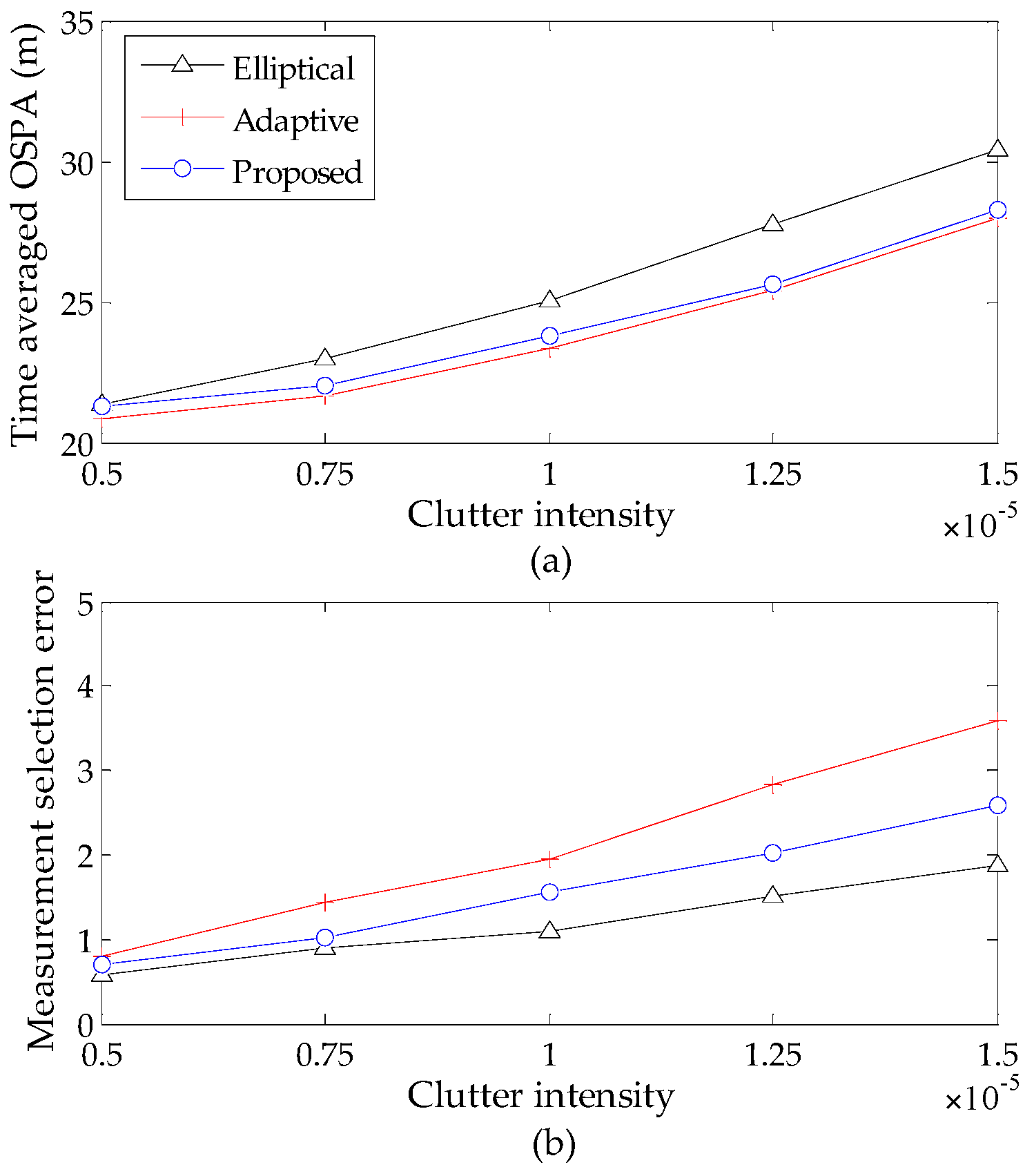
4.2. Evaluation of Different Gating Methods
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mallick, M.; Vo, B.N.; Kirubarajan, T.; Arulampalam, S. Introduction to the issue on multitarget tracking. IEEE J. Sel. Top. Signal Process. 2013, 7, 373–375. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation: Theory Algorithms and Software; John Wiley & Sons: New York, NY, USA, 2004; pp. 341–492. [Google Scholar]
- Blackman, S.S. Multiple hypothesis tracking for multiple target tracking. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 5–18. [Google Scholar] [CrossRef]
- Fortmann, T.E.; Bar-shalom, Y.; Scheffe, M. Sonar tracking of multiple targets using joint probabilistic data association. IEEE J. Oceanic Eng. 1983, 8, 173–184. [Google Scholar] [CrossRef]
- Oh, S.; Russell, S.; Sastry, S. Markov chain Monte Carlo data association for multi-target tracking. IEEE Trans. Autom. Control 2009, 54, 481–497. [Google Scholar]
- Mahler, R. Statistical Multisource-Multitarget Information Fusion; Artech House Publishers: Boston, MA, USA, 2007. [Google Scholar]
- Mahler, R. Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Mahler, R. PHD filters of higher order in target number. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1523–1543. [Google Scholar] [CrossRef]
- Reuter, S.; Vo, B.T.; Vo, B.N.; Dietmayer, K. The labeled multi-Bernoulli filter. IEEE Trans. Signal Process. 2014, 62, 3246–3260. [Google Scholar]
- Vo, B.N.; Singh, S.; Doucet, A. Sequential Monte Carlo methods for multi-target filtering with random finite sets. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1224–1245. [Google Scholar]
- Vo, B.N.; Ma, W.K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Cantoni, A. Analytic implementations of the cardinalized probability hypothesis density filter. IEEE Trans. Signal Process. 2007, 55, 3553–3567. [Google Scholar] [CrossRef]
- Mahler, R. “Statistics 102” for Multisource-Multitarget detection and tracking. IEEE J. Sel. Top. Signal Process. 2013, 7, 376–389. [Google Scholar] [CrossRef]
- Ulmke, M.; Erdinc, O.; Willett, P. GMTI tracking via the Gaussian mixture cardinalized probability hypothesis density filter. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 1821–1833. [Google Scholar] [CrossRef]
- Saucan, A.A.; Chonavel, T.; Sintes, C. CPHD-DOA tracking of multiple extended sonar targets in impulsive environments. IEEE Trans. Signal Process. 2016, 64, 1147–1160. [Google Scholar] [CrossRef]
- Franken, D.; Schmidt, M.; Ulmke, M. “Spooky Action at a Distance” in the Cardinalized Probability Hypothesis Density Filter. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 1657–1664. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N. The para-normal Bayes multi-target filter and the spooky effect. In Proceedings of the 15th International Conference on Information Fusion, Singapore, 9–12 July 2012; pp. 173–180.
- Ouyang, C.; Ji, H.B.; Tian, Y. Improved Gaussian mixture CPHD tracker for multitarget tracking. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 1177–1191. [Google Scholar] [CrossRef]
- Beard, M.; Vo, B.T.; Vo, B.N.; Arulampalam, S. A partially uniform target birth model for Gaussian mixture PHD/CPHD filtering. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 2835–2844. [Google Scholar] [CrossRef]
- Li, B.; Pang, F.W. Improved cardinalized probability hypothesis density filtering algorithm. Appl. Soft Comput. 2014, 24, 692–703. [Google Scholar] [CrossRef]
- Ristic, B.; Clark, D.; Vo, B.N.; Vo, B.T. Adaptive target birth intensity in PHD and CPHD filters. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 1656–1668. [Google Scholar] [CrossRef]
- Zhang, H.J.; Jing, Z.L.; Hu, S.Q. Gaussian mixture CPHD filter with gating technique. Signal Process. 2009, 89, 1521–1530. [Google Scholar] [CrossRef]
- Macagnano, D.; De Abreu, G.T.F. Adaptive gating for multitarget tracking with Gaussian mixture filters. IEEE Trans. Signal Process. 2012, 60, 1533–1538. [Google Scholar] [CrossRef]
- Yazdian-Dehkordi, M.; Azimifar, Z. Refined GM-PHD tracker for tracking targets in possible subsequent missed detections. Signal Process. 2015, 116, 112–126. [Google Scholar] [CrossRef]
- Shalom, Y.B.; Daum, F.; Huang, J. The probabilistic data association filter estimation in the presence of measurement uncertainty. IEEE Control Syst. Mag. 2009, 6, 82–100. [Google Scholar] [CrossRef]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Clutter Intensity | Processing Time (Gating) | Processing Time (No Gating) |
|---|---|---|
| 2.30 | 3.18 | |
| 2.65 | 4.87 | |
| 3.22 | 8.35 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Si, W.; Wang, L.; Qu, Z. Multi-Target Tracking Using an Improved Gaussian Mixture CPHD Filter. Sensors 2016, 16, 1964. https://doi.org/10.3390/s16111964
Si W, Wang L, Qu Z. Multi-Target Tracking Using an Improved Gaussian Mixture CPHD Filter. Sensors. 2016; 16(11):1964. https://doi.org/10.3390/s16111964
Chicago/Turabian StyleSi, Weijian, Liwei Wang, and Zhiyu Qu. 2016. "Multi-Target Tracking Using an Improved Gaussian Mixture CPHD Filter" Sensors 16, no. 11: 1964. https://doi.org/10.3390/s16111964
APA StyleSi, W., Wang, L., & Qu, Z. (2016). Multi-Target Tracking Using an Improved Gaussian Mixture CPHD Filter. Sensors, 16(11), 1964. https://doi.org/10.3390/s16111964