
Market Model for Resource Allocation in Emerging Sensor Networks with Reinforcement Learning




Abstract
:1. Introduction
2. Market Model for Resource Allocation
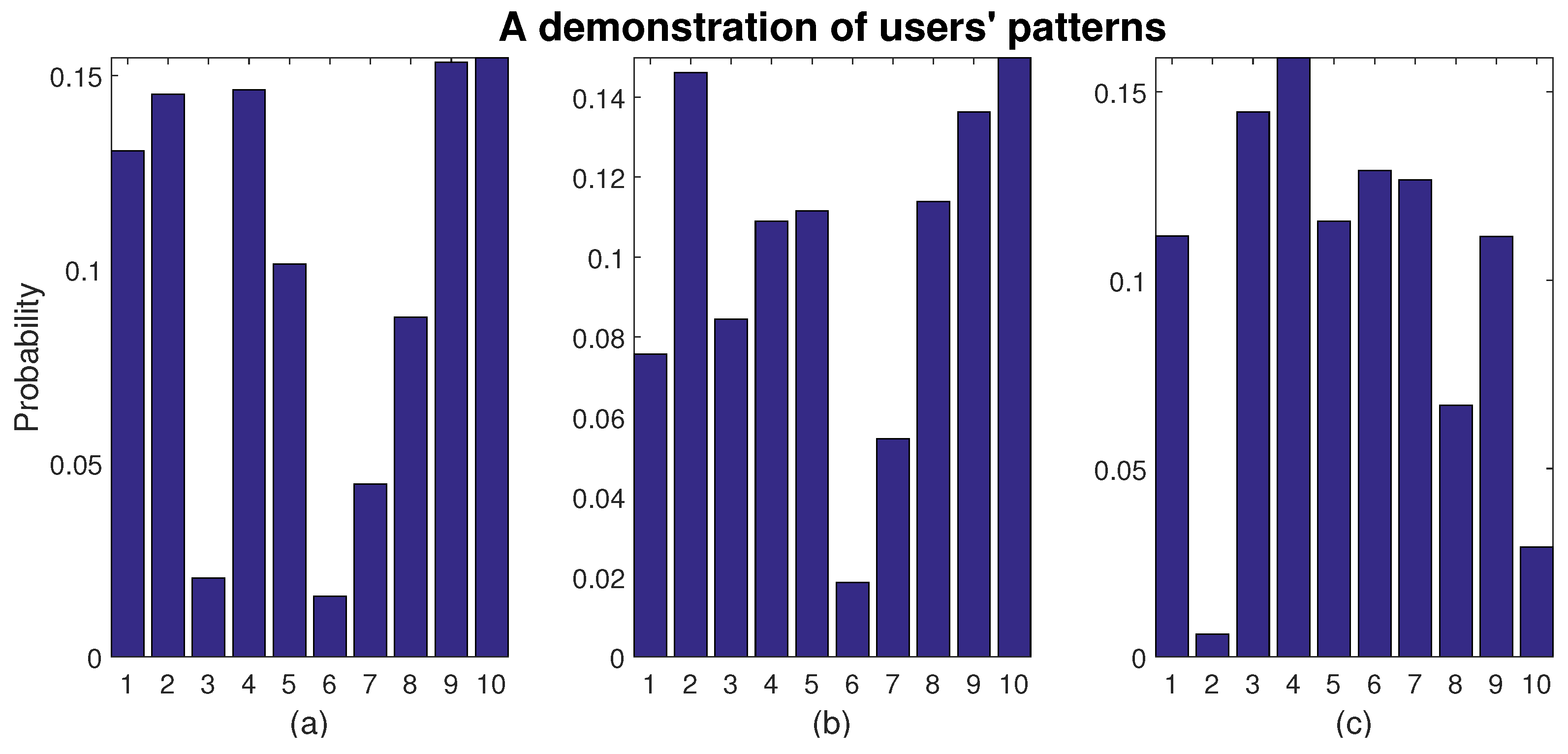
2.1. Users’ Patterns
2.2. Market Model and Price Scheme
3. Agent-Based Modelling and Reinforcement Learning
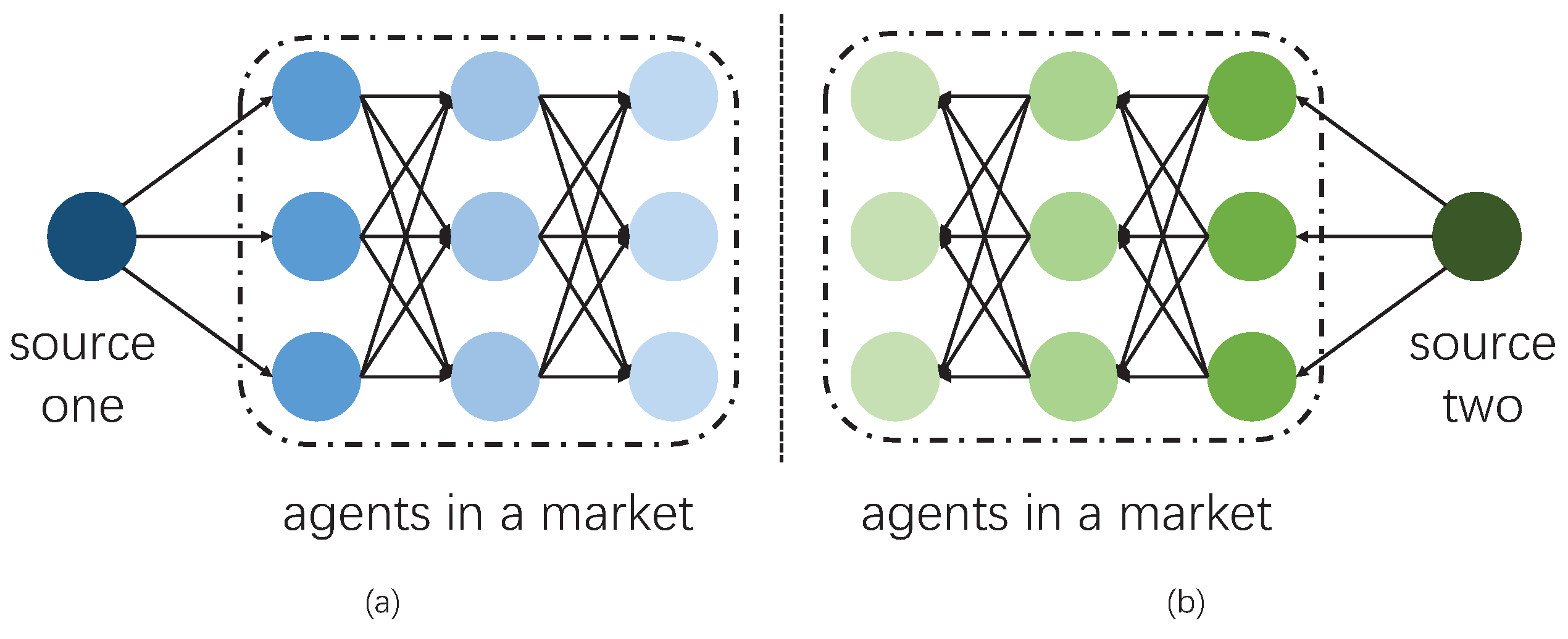
3.1. Multi-Agent Environments and Agent-Based Modelling
3.2. Game Theory and Reinforcement Learning
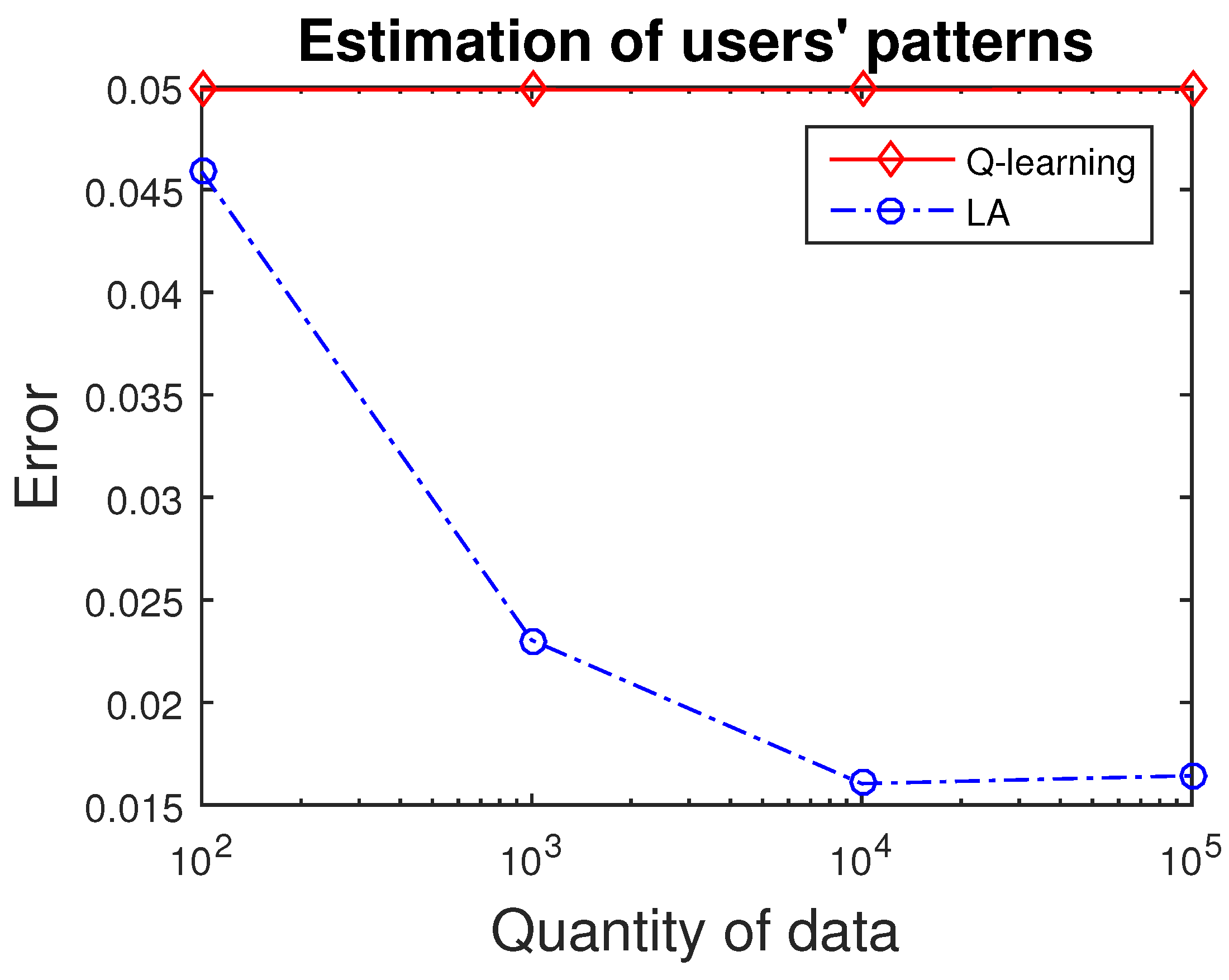
3.3. Applying Reinforcement Learning to Estimate Users’ Patterns
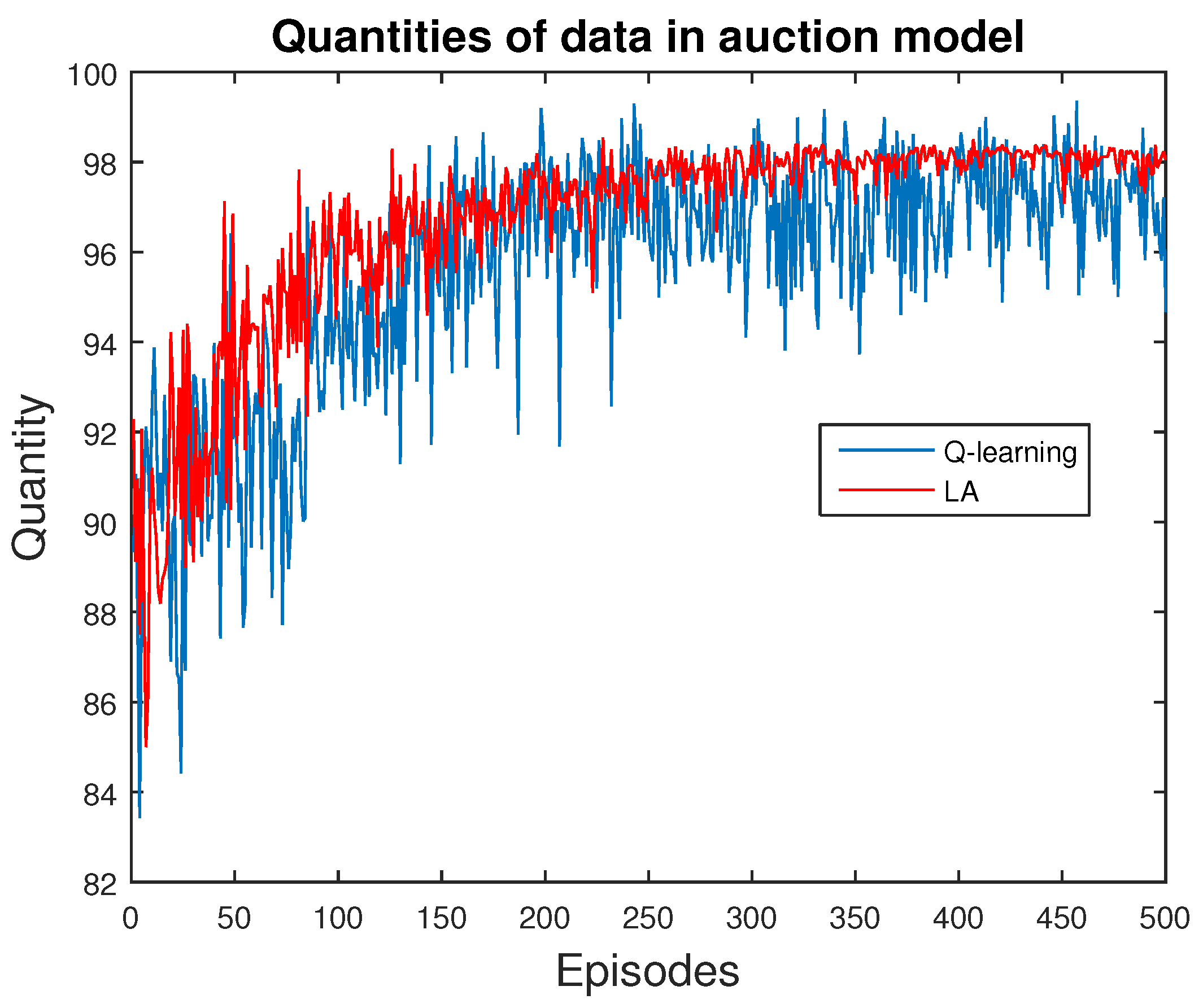
3.4. Applying Reinforcement Learning in a Market Model
4. Results and Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hu, H.; Wen, Y.; Chua, T.S.; Li, X. Toward scalable systems for big data analytics: A technology tutorial. IEEE Access 2014, 2, 652–687. [Google Scholar]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar] [CrossRef]
- Maglaras, L.A.; Al-Bayatti, A.H.; He, Y.; Wagner, I.; Janicke, H. Social internet of vehicles for smart cities. J. Sens. Actuator Netw. 2016, 5, 3. [Google Scholar] [CrossRef]
- Riazul Islam, S.M.; Kwak, D.; Kabir, H.; Hossain, M.; Kwak, K.-S. The internet of things for health care: A comprehensive survey. IEEE Access 2015, 3, 678–708. [Google Scholar] [CrossRef]
- Alvi, S.A.; Afzal, B.; Shah, G.A.; Atzori, L.; Mahmood, W. Internet of multimedia things: Vision and challenges. Ad Hoc Netw. 2015, 33, 87–111. [Google Scholar] [CrossRef]
- Iera, A.; Morabito, G.; Nitti, M. The social internet of things (siot)—When social networks meet the internet of things: Concept, architecture and network characterization. Comput. Netw. 2012, 56, 3594–3608. [Google Scholar]
- Alam, K.M.; Saini, M.; El Saddik, A. Toward social internet of vehicles: Concept, architecture, and applications. IEEE Access 2015, 3, 343–357. [Google Scholar] [CrossRef]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of things for smart cities. IEEE Int. Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Zhou, Z.; Dong, M.; Ota, K.; Wang, G.; Yang, L.T. Energy-Efficient Resource Allocation for D2D Communications Underlaying Cloud-RAN-Based LTE-A Networks. IEEE Int. Things J. 2016, 3, 428–438. [Google Scholar] [CrossRef]
- Bello, O.; Zeadally, S. Intelligent device-to-device communication in the internet of things. IEEE Syst. J. 2014, 10, 1172–1182. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, E.; Song, L.; Saad, W.; Dawy, Z.; Han, Z. Social network aware device-to-device communication in wireless networks. IEEE Trans. Wirel. Commun. 2015, 14, 177–190. [Google Scholar] [CrossRef]
- Tsiropoulos, G.I.; Dobre, O.A.; Ahmed, M.H.; Baddour, K.E. Radio resource allocation techniques for efficient spectrum access in cognitive radio networks. IEEE Commun. Surv. Tutor. 2014, 18, 824–847. [Google Scholar] [CrossRef]
- Al-Zahrani, A.; Yu, F.R. An Energy-Efficient Resource Allocation and Interference Management Scheme in Green Heterogeneous Networks Using Game Theory. IEEE Trans. Veh. Technol. 2016, 65, 5384–5396. [Google Scholar] [CrossRef]
- Bae, B.; Park, J.; Lee, S. A Free Market Economy Model for Resource Management in Wireless Sensor Networks. Wirel. Sens. Netw. 2015, 7, 76. [Google Scholar] [CrossRef]
- Mankiw, N. Chapter 1 Ten Principles of Economics. In Principles of Economics, 7th ed.; Cengage Learning: Stamford, CT, USA, 2011; pp. 3–18. [Google Scholar]
- Bouarfa, S.; Blom, H.A.P.; Curran, R. Agent-Based Modeling and Simulation of Coordination by Airline Operations Control. IEEE Trans. Emerg. Top. Comput. 2016, 4, 9–20. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, F.; Song, B.; Du, X. Social vehicle swarms: A novel perspective on socially aware vehicular communication architecture. IEEE Wirel. Commun. 2016, 23, 82–89. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Chapter 1 The Reinforcement Learning Problem. In Reinforcement Learning: An Introduction, 2nd ed.; in progress; The MIT Press: Cambridge, MA, USA, 2017; pp. 1–25. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Yan, Z.; Liu, J.; Vasilakos, A.V.; Yang, L.T. Trustworthy data fusion and mining in Internet of Things. Future Gener. Comput. Syst. 2015, 49, 45–46. [Google Scholar] [CrossRef]
- Xu, L.; Jiang, C.; Wang, J.; Yuan, J.; Ren, Y. Information security in big data: Privacy and data mining. IEEE Access 2014, 2, 1149–1176. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User 1 | User 2 | User 3 | User 4 | User 5 | User 6 | User 7 | User 8 | User 9 | |
|---|---|---|---|---|---|---|---|---|---|
| Red | 0.2866 | 0.4321 | 0.1990 | 0.1766 | 0.3227 | 0.2310 | 0.3659 | 0.3138 | 0.3223 |
| Green | 0.2920 | 0.1965 | 0.4026 | 0.4224 | 0.5192 | 0.0866 | 0.2718 | 0.3729 | 0.2335 |
| Blue | 0.4214 | 0.3714 | 0.3983 | 0.4010 | 0.1580 | 0.6825 | 0.3624 | 0.3133 | 0.4442 |
| User 1 | User 2 | User 3 | User 4 | User 5 | User 6 | User 7 | User 8 | User 9 | |
|---|---|---|---|---|---|---|---|---|---|
| Red | 0.2800 | 0.4300 | 0.1900 | 0.1700 | 0.3200 | 0.2300 | 0.3600 | 0.3100 | 0.3200 |
| Green | 0.2900 | 0.1900 | 0.4000 | 0.4200 | 0.5100 | 0.0800 | 0.2700 | 0.3700 | 0.2300 |
| Blue | 0.4200 | 0.3700 | 0.3900 | 0.4000 | 0.1500 | 0.6800 | 0.3600 | 0.3100 | 0.4400 |
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | |
|---|---|---|---|---|---|---|---|---|---|
| Red | User 2 | User 7 | User 5 | User 9 | User 8 | User 1 | User 6 | User 3 | User 4 |
| Green | User 5 | User 4 | User 3 | User 8 | User 1 | User 7 | User 9 | User 2 | User 6 |
| Blue | User 6 | User 9 | User 1 | User 4 | User 3 | User 2 | User 7 | User 8 | User 5 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Song, B.; Zhang, Y.; Du, X.; Guizani, M. Market Model for Resource Allocation in Emerging Sensor Networks with Reinforcement Learning. Sensors 2016, 16, 2021. https://doi.org/10.3390/s16122021
Zhang Y, Song B, Zhang Y, Du X, Guizani M. Market Model for Resource Allocation in Emerging Sensor Networks with Reinforcement Learning. Sensors. 2016; 16(12):2021. https://doi.org/10.3390/s16122021
Chicago/Turabian StyleZhang, Yue, Bin Song, Ying Zhang, Xiaojiang Du, and Mohsen Guizani. 2016. "Market Model for Resource Allocation in Emerging Sensor Networks with Reinforcement Learning" Sensors 16, no. 12: 2021. https://doi.org/10.3390/s16122021
APA StyleZhang, Y., Song, B., Zhang, Y., Du, X., & Guizani, M. (2016). Market Model for Resource Allocation in Emerging Sensor Networks with Reinforcement Learning. Sensors, 16(12), 2021. https://doi.org/10.3390/s16122021