
A Real-Time Marker-Based Visual Sensor Based on a FPGA and a Soft Core Processor



Abstract
:1. Introduction
2. Related Works
3. Architecture of the Proposed System
4. Detailed Architecture of the Proposed System
4.1. Grayscale
4.2. Segmentation
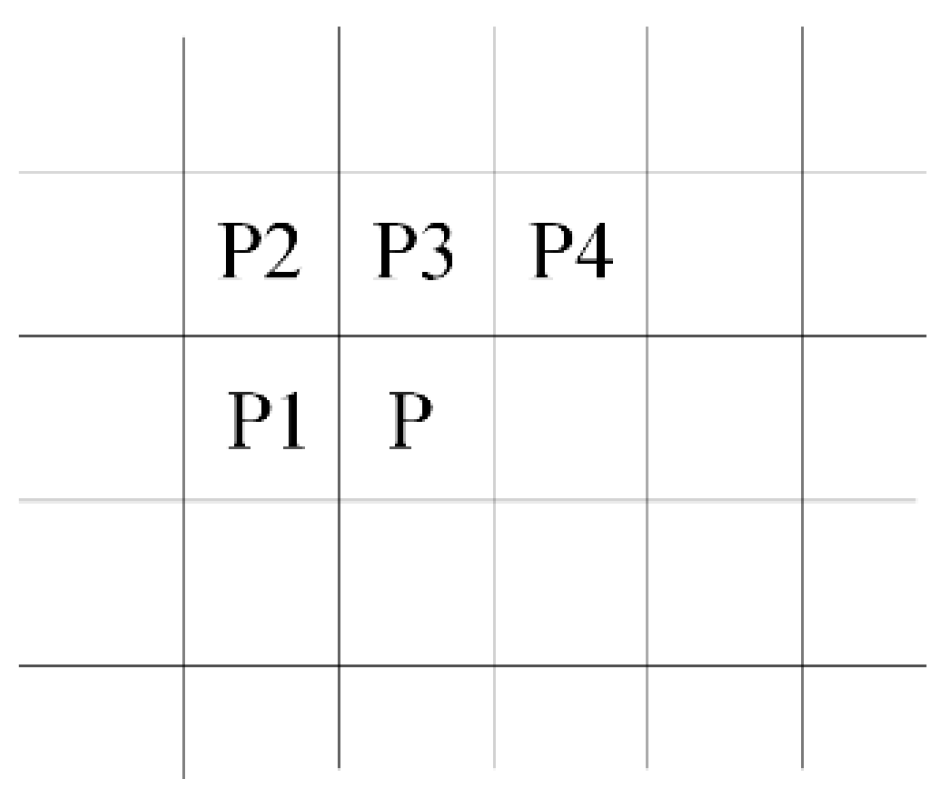
4.2.1. Neighborhood Block
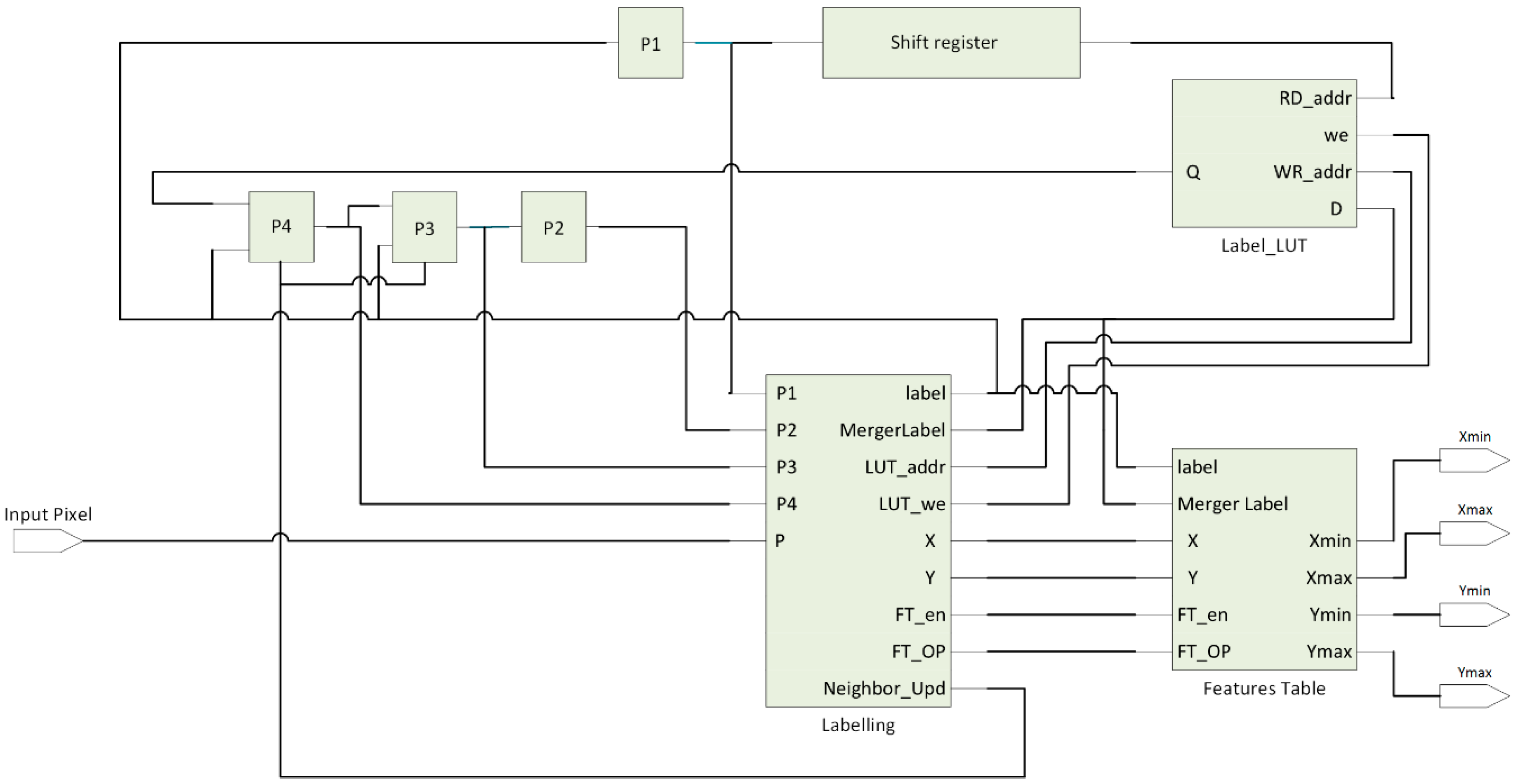
4.2.2. Label_LUT
4.2.3. Labeling Block
- Assign zero when the input pixel is background.
- Assign new label when all neighbors are backgrounds.
- In case of only one label is used in the labeled neighbors, this label will be assigned to the current pixel.
- A merger condition occurs when there are two different labels used among the neighbors.
- New Label: in this case, a new label is created and assigned to the input pixel P. A new entry will be created in “Label_LUT”. A new entry in “Features Table” for the newly created label will be added. The number of blobs will be incremented by one.
- Copy P1: in this case, the label of P1 will be assigned to P. The corresponding features values in “Features Table” at P1 address will be updated. “Label_LUT” will not be updated. A similar process will occur for Copy P2, Copy P3 and Copy P4.
- Compare P1 and P4: If P1 equals P4, P1 will be copied to the pixel P and features values at P1 address will be updated. “Label_LUT” will not be updated. If P1 < P4, a merger condition occurs. In this case, P1 will be copied to the pixel P, features values in the “Features Table” at P1 and P4 will be merged and stored at P1 address and “Label_LUT” will be updated by replacing the value at P4 with the value at P1. In addition, multiplexers will be set to read the newly updated label. When P4 < P1, a merger condition takes place. In this case, P4 will be copied to the pixel P, features values in the “Features Table” at P1 and P4 will be merged and stored at P4 and “Label_LUT” will be updated by replacing the value at P1 with the value of P4. Multiplexers will be set to read the newly updated label. The number of blobs will be decremented by one when there is a merger case. A similar process will occur for “Compare P2 and P4”.
- Leave Blob: Labeling block has a lookup table called “Last_x“ which is used for storing the x-coordinate of the pixel P. This “Last_x” LUT is used for deciding the “finish blob” case.
- Finish Blob: If the value of Last_x[P2] equals to the current x-coordinate of the input pixel, the current blob is finished, bounding box coordinates of the current region can be sent to next processing step and the label can be reused again.
- NOP: No operation.
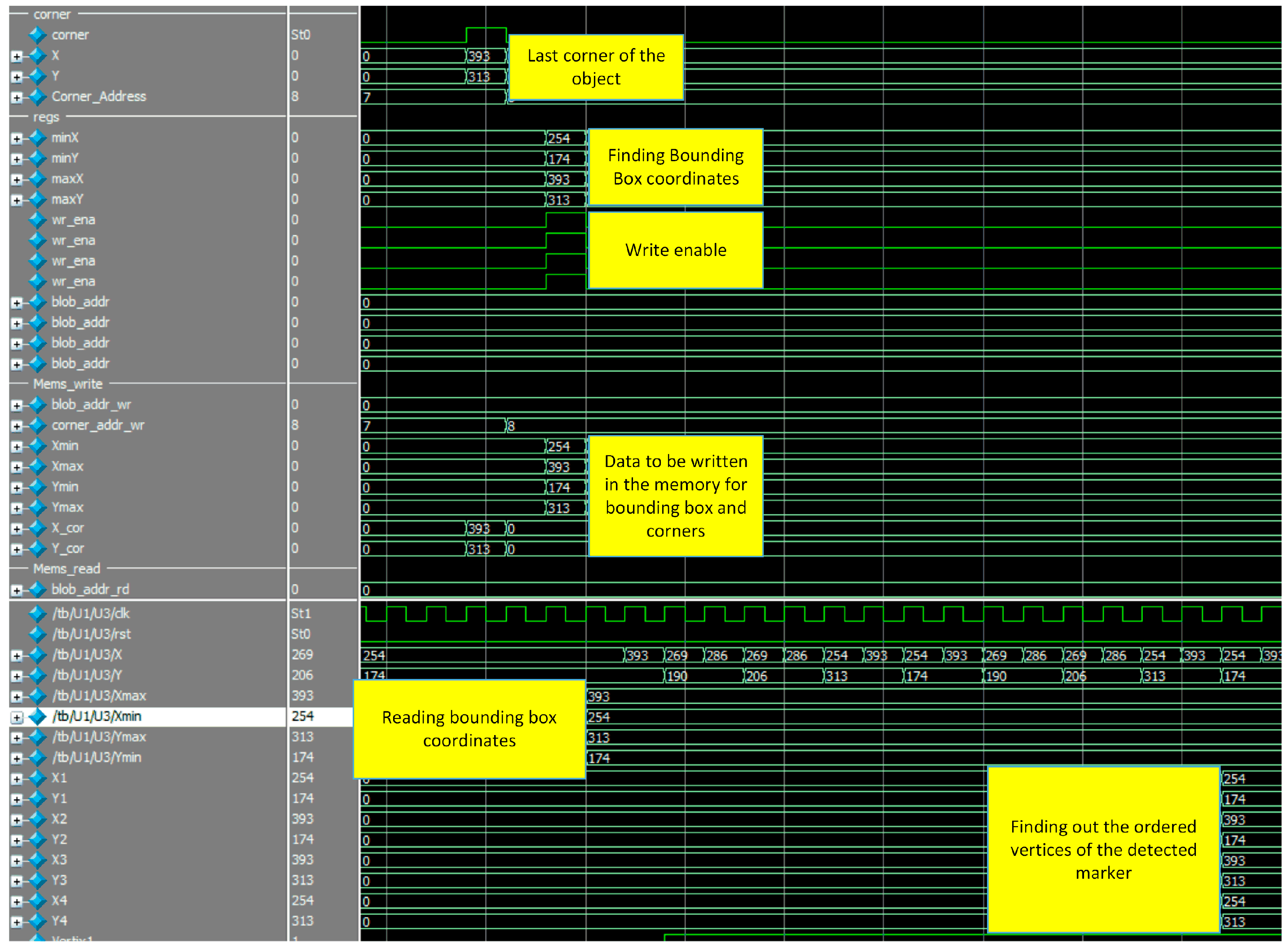
4.2.4. Features Table
- State0: In this state, the feature values at the addresses “Label” and “Merger Label” will be read out. After that, according to the “opcode” from the labeling block the value that will be written back in DPR’s will be figured out. A two-bit op code is used for representing four possible cases as follows: op = 00, new blob is recognized, the value of x and y coordinates of this blob will be prepared to be stored in the DPR’s in the next clock cycle of the features table’s frequency. When op = 01, the bounding box information of the blob defined by “label” will be updated. When op = 10, a merger case occurred, the data read out from port A and port B will be compared and the minimum one will be selected as xmin/ymin and the maximum one will be selected as xmax/ymax. When op = 11, the current blob completes and the data read out from DPR’s will be sent to the next processing step.
- State1: the data prepared from the state0 will be written in the DPR’s. Algorithm 1 shows the pseudo code for updating xmin/ymin feature.
| Algorithm 1. Pseudo code for updating xmin/ymin feature. |
| Always @(posedge clk) begin |
| If state==0 then |
| //Read feature values at label and merger_label |
| rd1 = portA[label]; |
| rd2 = portB[merger_label]; |
| case (op) |
| 00: wd1 = x; // new block recognized |
| 01: if x < rd1 then //update the current blob |
| wd1 = x; |
| 10: wd1 = (rd1 < rd2)? rd1:rd2; // merger case occurred |
| 11: send rd1 to next processing stage; // end of the current blob |
| endcase |
| state = 1 |
| else |
| portA[label] = wd1; // writing the prepared data in the state0 in the DPR. |
| State = 0; |
| end |
| end |
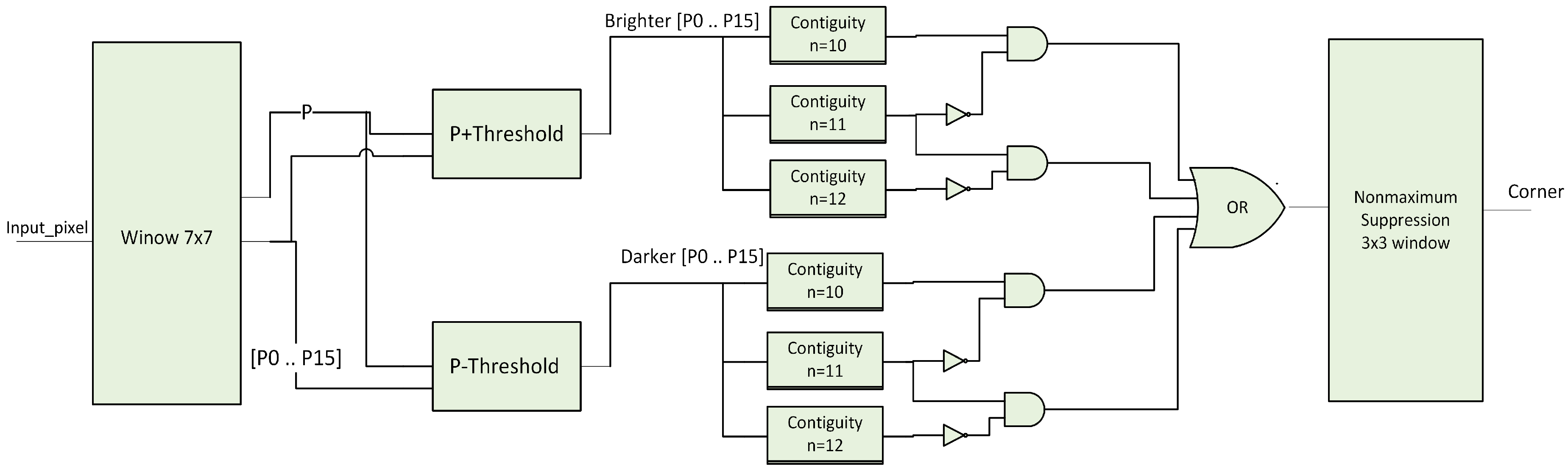
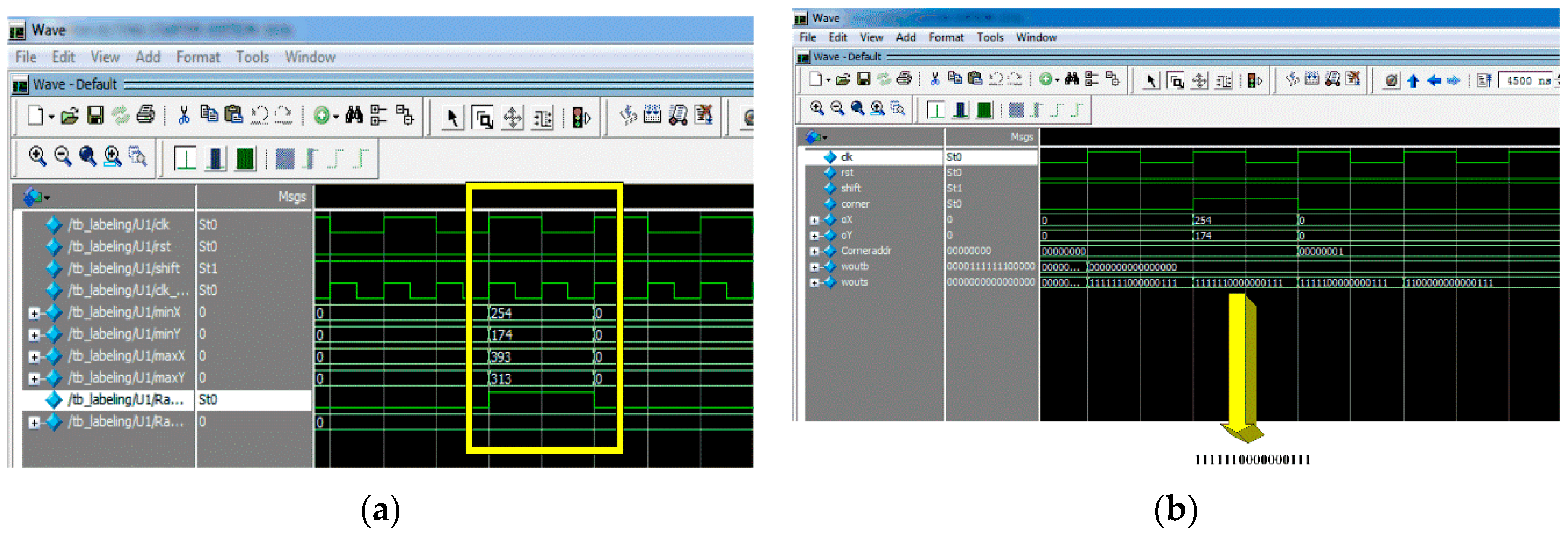
4.3. FAST Corner Detection
- Select a pixel P with intensity Ip.
- Set an appropriate threshold T.
- Get a circle of sixteen pixels around the pixel under test as shown in Figure 5.
- Decide that the central pixel P is a corner if there exists a set of n contiguous pixels in the surrounding circle which are all brighter than Ip + T, or darker than Ip − T where Ip is the intensity of the central pixel and T is the selected threshold.
- Window 7 × 7: this block is used for getting the 16 surrounding pixels of the circle and the central pixel. In order to achieve this, six FIFO delay buffers were used, the width of every FIFO equals to the image width. In addition, 42 8-bit registers were used to store pixel intensity values in the investigated window. The 16 pixels and the central pixel will pass to the thresholder stage.
- Thresholder: this block decides if the pixels in the circle are brighter or darker than the central pixel. If the intensity of the pixel Pi-Pi is a pixel in the circle- is greater than the intensity of the central pixel P added to threshold then the pixel Pi is brighter than the pixel P. In this case, it will be assigned 1 in the output vector in the corresponding position of the pixel Pi. On the other hand, if the intensity of the pixel Pi is smaller than the intensity of the central pixel P subtracted by threshold then the pixel Pi is darker than the pixel P. It will be assigned 1 in the output vector in the same position of the pixel Pi. As a result, two 16-bit vectors will be the result of this stage. One is for the brighter pixels and the other one is for the darker pixels.
- Contiguity blocks: these blocks are used to study if there is n contiguous bright or dark pixels in the circle. In this system, three blocks were used for studying the contiguity n = 10, n = 11 and n = 12. The architecture for each block contains 16 n-input logical AND gates. The output of these contiguity blocks will be set to 1 if there is a ‘10’ or ‘11’ contiguous bright or dark pixels in the circle.
- OR gate: this gate is used for deciding whether the pixel is a corner or not from brighter or darker contiguities blocks.
- Non-maximum suppression: the 3 × 3 window was used with two FIFOs and six 1-bit registers. The architecture of this block is similar to the window 7 × 7 block.
4.4. Memory Blocks
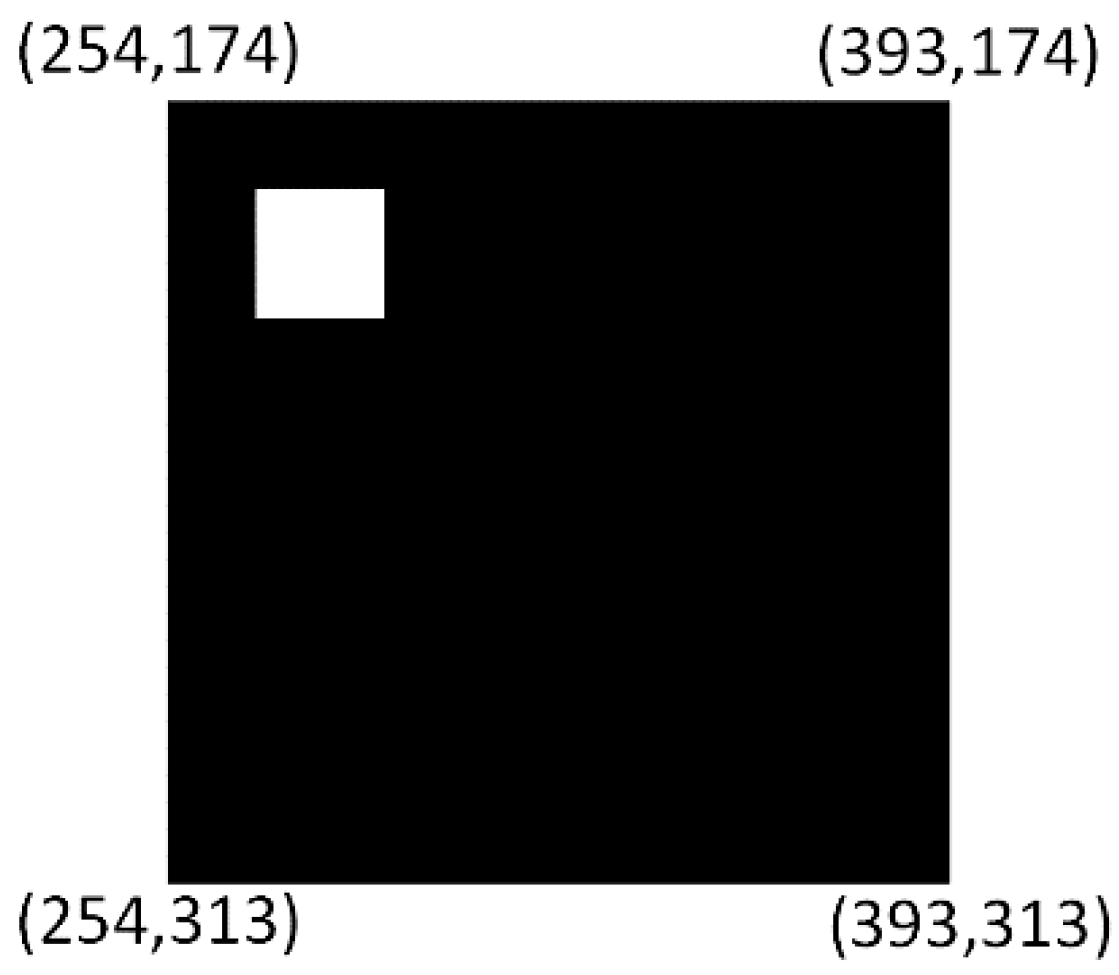
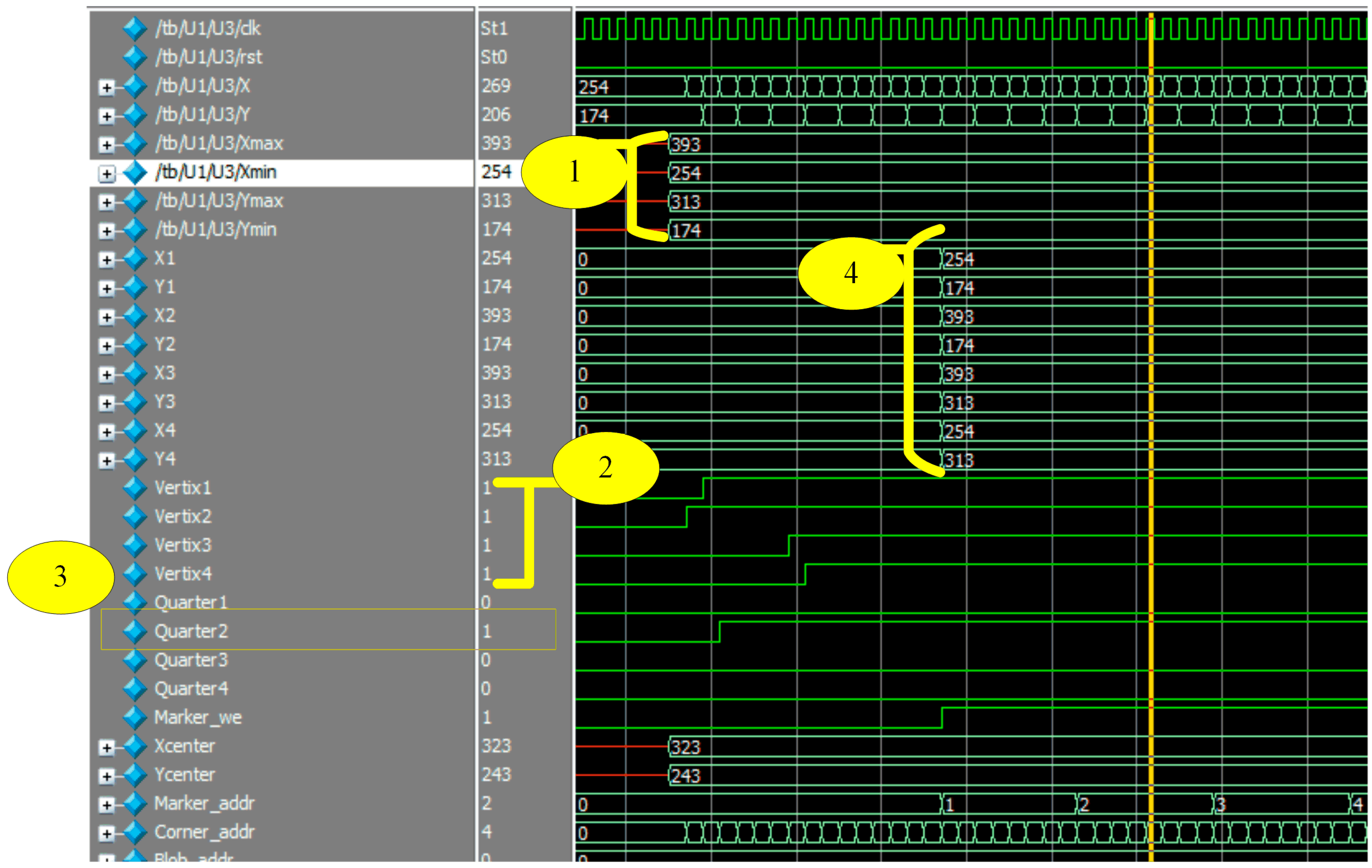
4.5. Pattern Matching
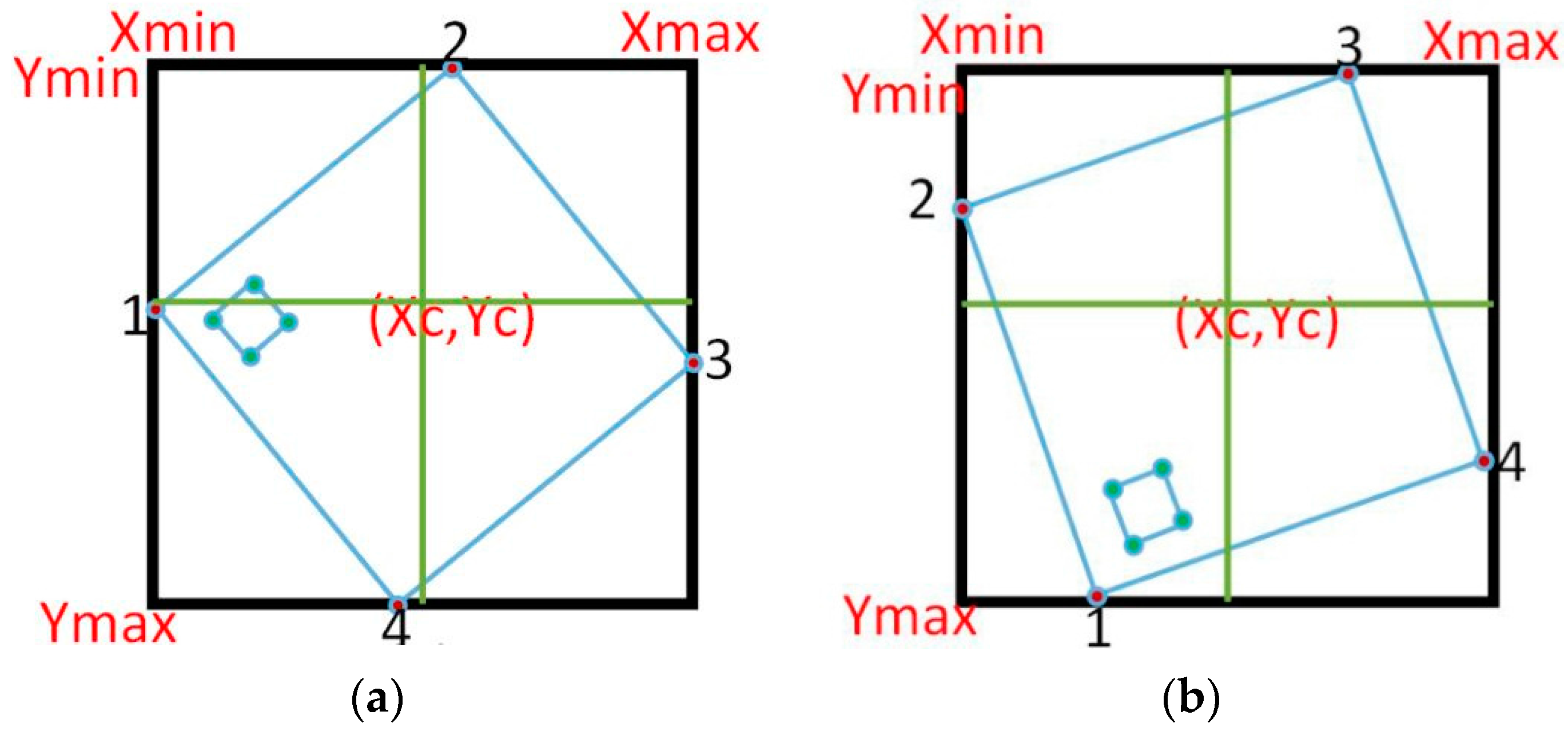
- Divide the bounding box into four quarters by calculating the center coordinates of the bounding box.
- Every quarter should have one corner, located only on the edge of the bounding box.
- It is assumed that all corners of the inner square are located in one quarter or in two adjacent quarters.
- Based on the location of the inner square, the first vertex of the marker will be decided.
- The remaining vertices are a clockwise direction to the first one.
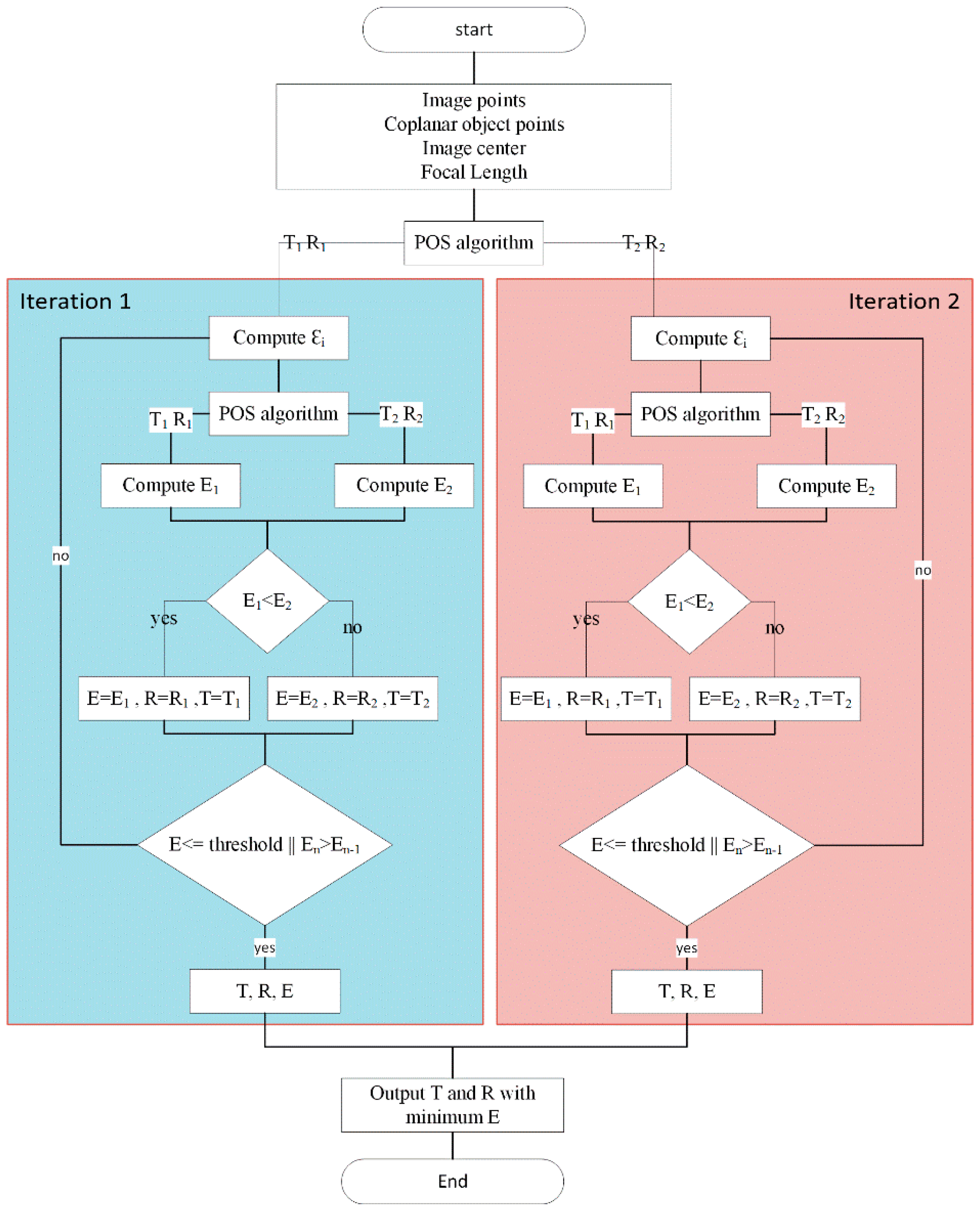
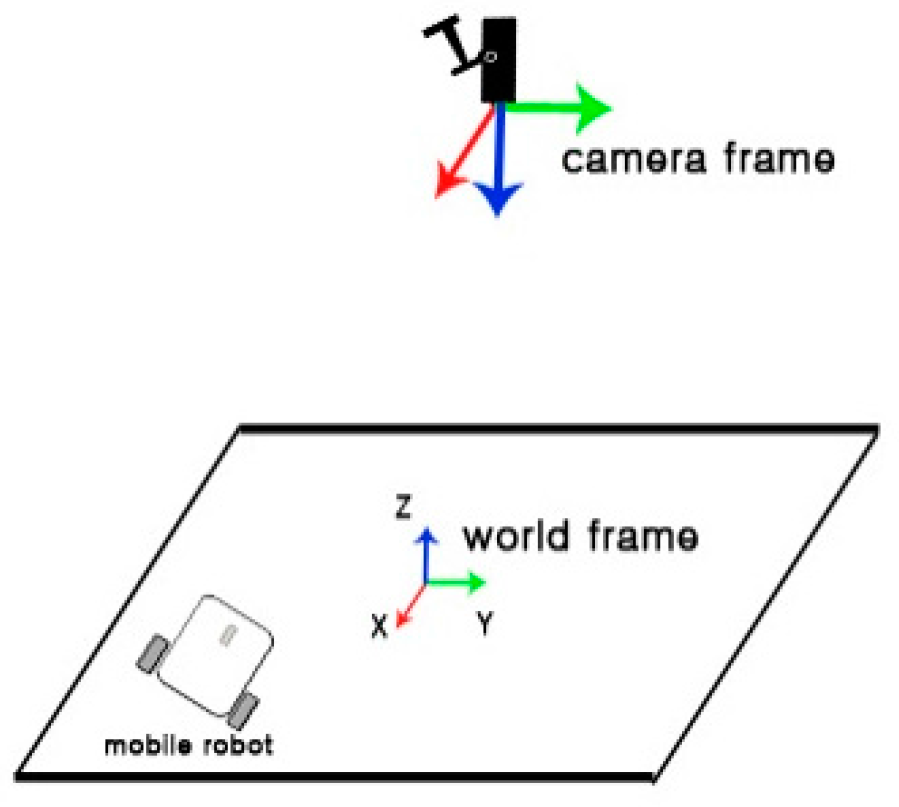
4.6. Pose Estimation
4.6.1. Coplanar PosIt Algorithm
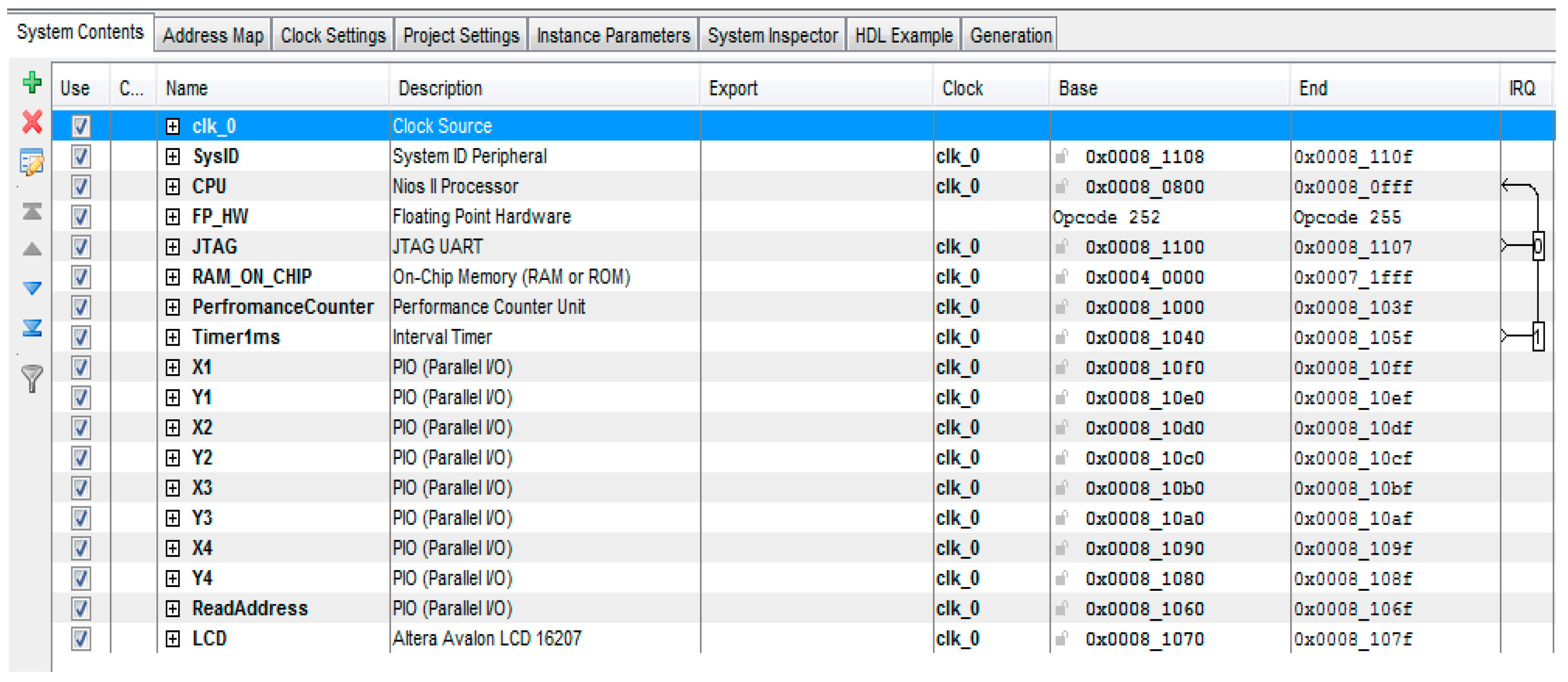
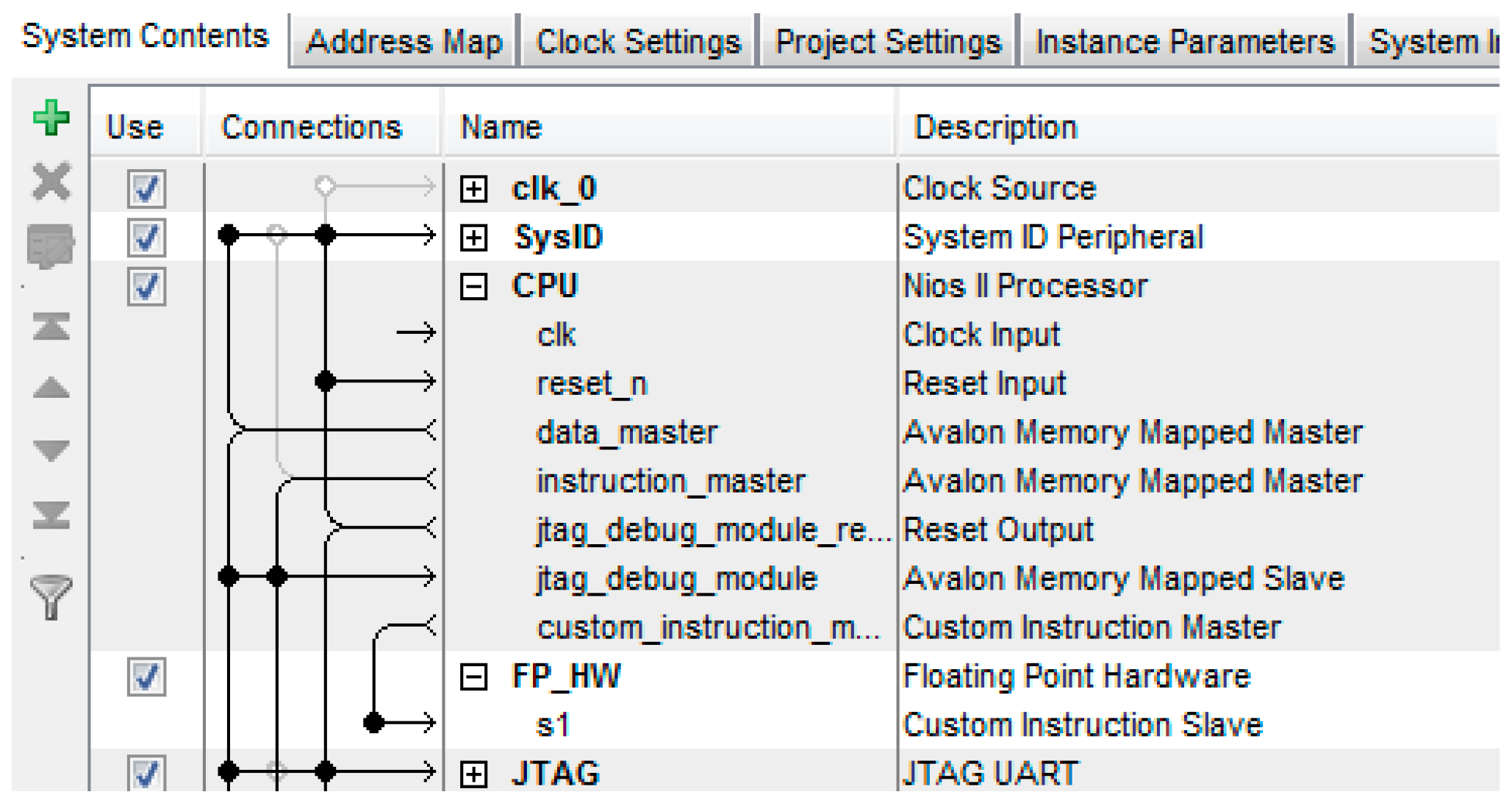
4.6.2. Soft-Core Processor
4.6.3. Floating-Point versus Fixed-Point
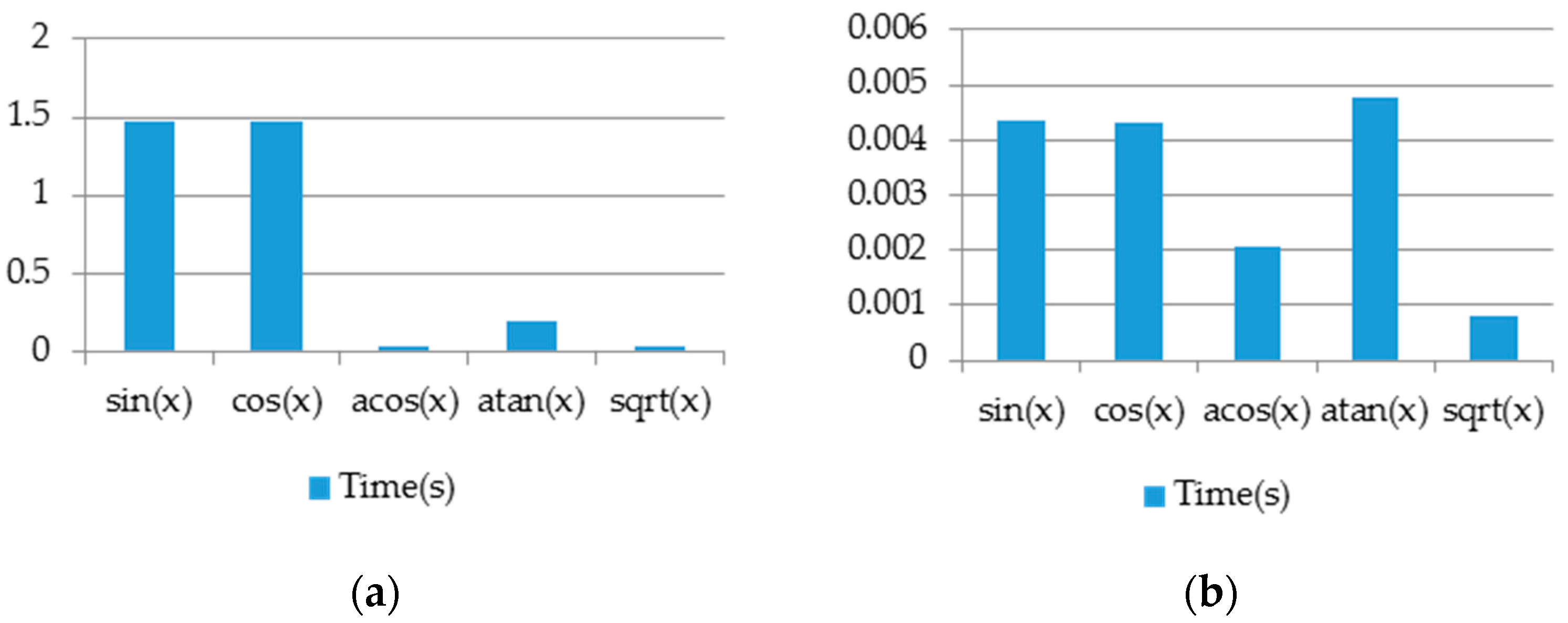
4.6.4. Mathematical Functions Approximation
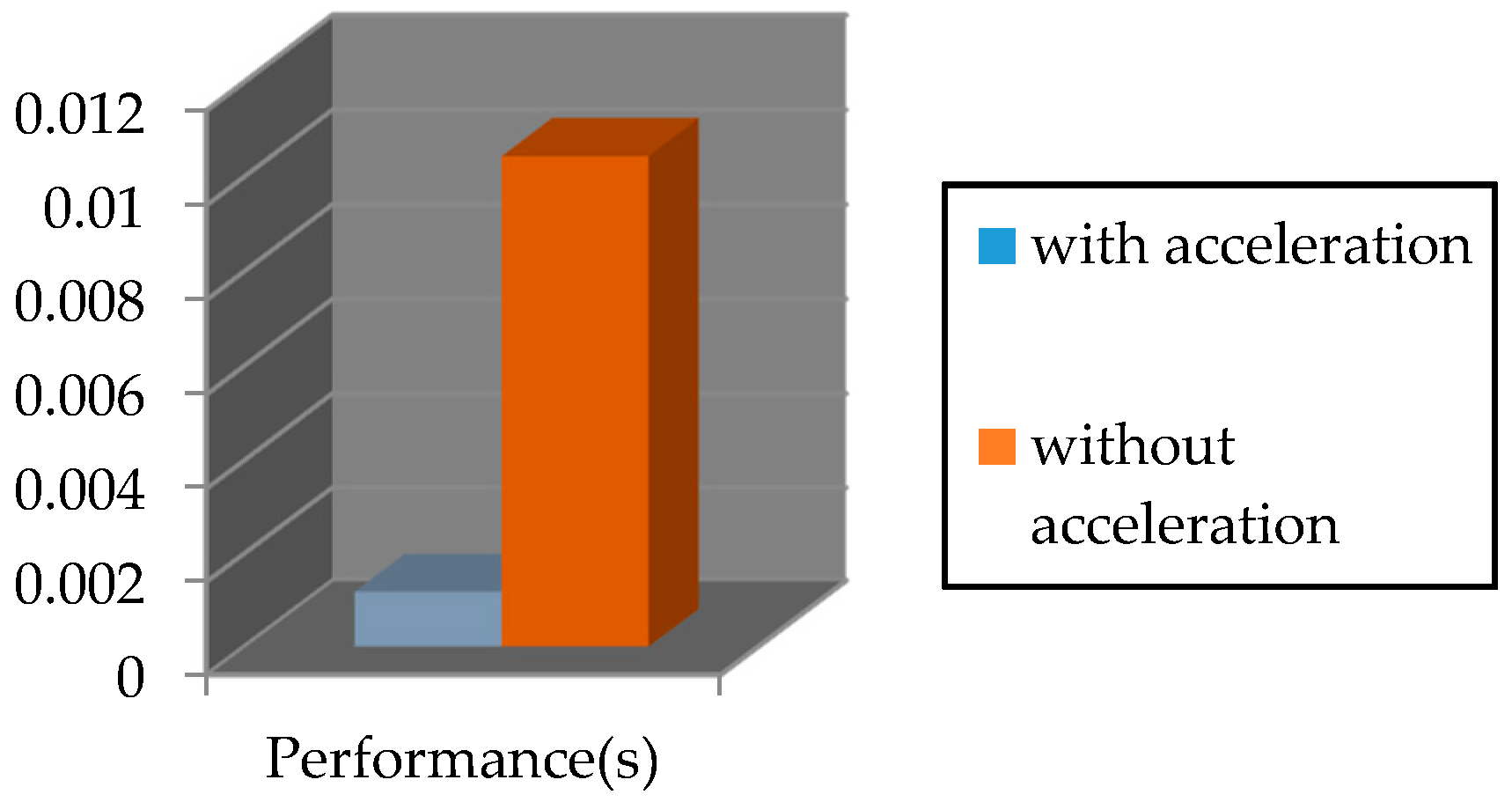
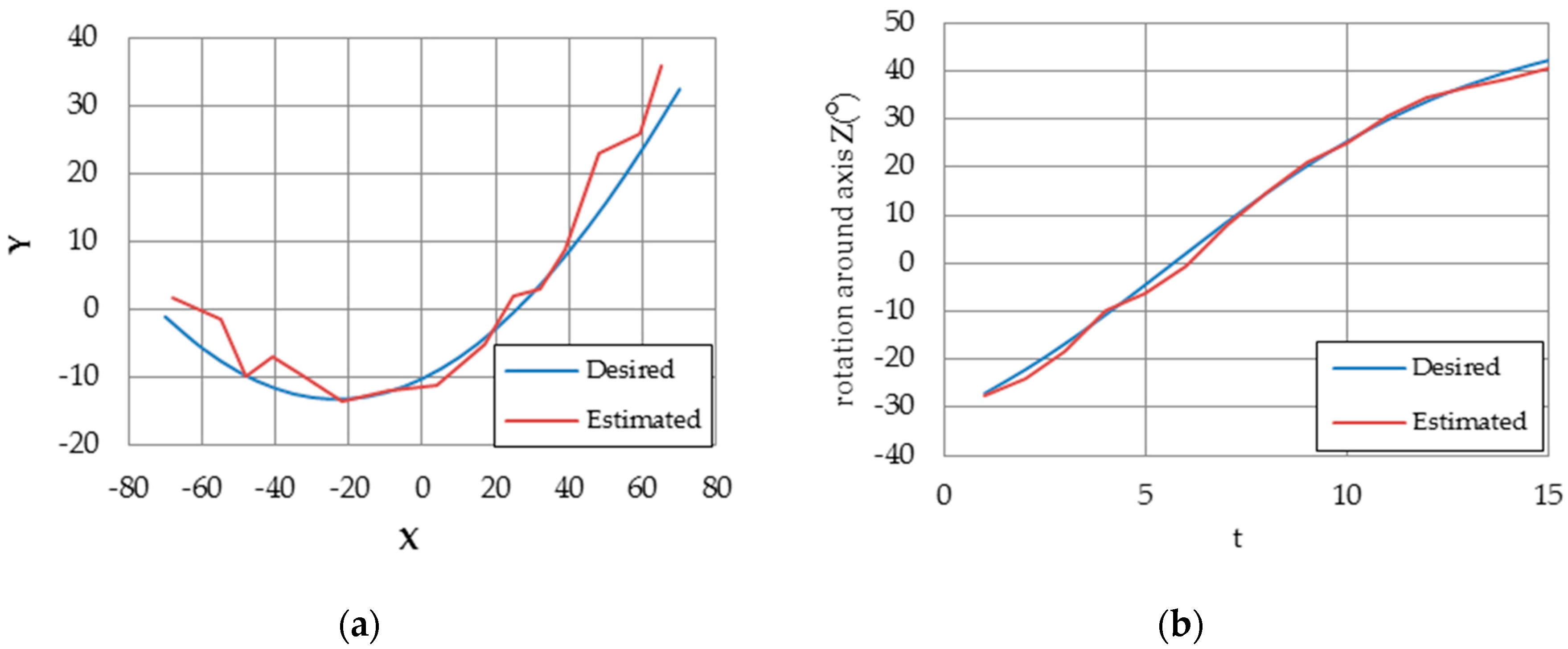
5. Experimental Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jang, D.M.; Turk, M. Car-rec: A real time car recognition system. In Proceedings of the 2011 IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 599–605.
- Liu, J.F.; Su, Y.F.; Ko, M.K.; Yu, P.N. Development of a vision-based driver assistance system with lane departure warning and forward collision warning functions. In Proceedings of the Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 1–3 December 2008; pp. 480–485.
- Henderson, S.J.; Feiner, S. Evaluating the benefits of augmented reality for task localization in maintenance of an armored personnel carrier turret. In Proceedings of the 2009 8th IEEE International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 135–144.
- Schwerdtfeger, B.; Reif, R.; Gunthner, W.A.; Klinker, G.; Hamacher, D.; Schega, L.; Bockelmann, I.; Doil, F.; Tumler, J. Pick-by-vision: A first stress test. In Proceedings of the 8th IEEE International Symposium on Mixed and Augmented Reality (ISMAR 2009), Orlando, FL, USA, 19–22 October 2009; pp. 115–124.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Amato, G.; Falchi, F.; Bolettieri, P. Recognizing landmarks using automated classification techniques: Evaluation of various visual features. In Proceedings of the 2010 Second International Conferences on Advances in Multimedia, Athens, Greece, 13–19 June 2010; pp. 78–83.
- González, D.; Botella, G.; Meyer-Baese, U.; García, C.; Sanz, C.; Prieto-Matías, M.; Tirado, F. A low cost matching motion estimation sensor based on the nios ii microprocessor. Sensors 2012, 12, 13126–13149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- González, D.; Botella, G.; García, C.; Prieto, M.; Tirado, F. Acceleration of block-matching algorithms using a custom instruction-based paradigm on a nios II microprocessor. EURASIP J. Adv. Signal Process. 2013, 2013, 118. [Google Scholar] [CrossRef]
- González, D.; Botella, G.; García, C.; Meyer Bäse, A.; Meyer Bäse, U.; Prieto-Matías, M. Customized nios ii multi-cycle instructions to accelerate block-matching techniques. In Proceedings of the 2015 Real-Time Image and Video Processing, San Francisco, CA, USA, 8–12 February 2015; pp. 940002–940014.
- Trivedi, S.V.; Hasamnis, M.A. Development of platform using nios ii soft core processor for image encryption and decryption using aes algorithm. In Proceedings of the 2015 International Conference on Communications and Signal Processing (ICCSP), Melmaruvathur, India, 2–4 April 2015; pp. 1147–1151.
- Jaballah, M.A.; Mezghani, D.; Mami, A. Development of a mppt controller for hybrid wind/photovoltaic system based on sopc and nios II. In Proceedings of the 2015 16th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Sousse, Tunisia, 21–23 December 2015; pp. 700–706.
- Meyer-Bäse, U.; Botella, G.; Castillo, E.; García, A. Nios II hardware acceleration of the epsilon quadratic sieve algorithm. In Proceedings of the Independent Component Analyses, Wavelets, Neural Networks, Biosystems, and Nanoengineering VIII, Orlando, FL, USA, 5 April 2010. [CrossRef]
- Maidi, M.; Didier, J.-Y.; Ababsa, F.; Mallem, M. A performance study for camera pose estimation using visual marker based tracking. Mach. Vis. Appl. 2010, 21, 365–376. [Google Scholar] [CrossRef]
- Haralick, R.M.; Joo, H.; Lee, C.; Zhuang, X.; Vaidya, V.G.; Kim, M.B. Pose estimation from corresponding point data. IEEE Trans. Syst. Man Cybernet. 1989, 19, 1426–1446. [Google Scholar] [CrossRef]
- Schweighofer, G.; Pinz, A. Robust pose estimation from a planar target. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2024–2030. [Google Scholar] [CrossRef] [PubMed]
- Horaud, R.; Conio, B.; Leboulleux, O.; Lacolle, B. An analytic solution for the perspective 4-point problem. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’89), San Diego, CA, USA, 4–8 June 1989; pp. 500–507.
- Dhome, M.; Richetin, M.; Lapreste, J.-T. Determination of the attitude of 3D objects from a single perspective view. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 1265–1278. [Google Scholar] [CrossRef]
- Lu, C.P.; Hager, G.D.; Mjolsness, E. Fast and globally convergent pose estimation from video images. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 610–622. [Google Scholar] [CrossRef]
- Oberkampf, D.; DeMenthon, D.F.; Davis, L.S. Iterative pose estimation using coplanar feature points. Comput. Vis. Image Underst. 1996, 63, 495–511. [Google Scholar] [CrossRef]
- Dornaika, F.; Garcia, C. Pose estimation using point and line correspondences. Real-Time Imaging 1999, 5, 215–230. [Google Scholar] [CrossRef]
- Murphy, K.; Torralba, A.; Eaton, D.; Freeman, W. Object detection and localization using local and global features. In Toward Category-Level Object Recognition; Ponce, J., Hebert, M., Schmid, C., Zisserman, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 382–400. [Google Scholar]
- Romea, A.C.; Torres, M.M.; Srinivasa, S. The moped framework: Object recognition and pose estimation for manipulation. Int. J. Robot. Res. 2011, 30, 1284–1306. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-up robust features (surf). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Wu, X.; Shi, Z.; Zhong, Y. Detailed analysis and evaluation of keypoint extraction methods. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, China, 22–24 October 2010. [CrossRef]
- Cornelis, N.; Gool, L.V. Fast scale invariant feature detection and matching on programmable graphics hardware. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW’08), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Ma, X.; Najjar, W.A.; Roy-Chowdhury, A.K. Evaluation and acceleration of high-throughput fixed-point object detection on fpgas. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1051–1062. [Google Scholar]
- Xiaoyin, M.; Borbon, J.R.; Najjar, W.; Roy-Chowdhury, A.K. Optimizing hardware design for human action recognition. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–11.
- Botella, G.; Martín H., J.A.; Santos, M.; Meyer-Baese, U. Fpga-based multimodal embedded sensor system integrating low- and mid-level vision. Sensors 2011, 11, 8164–8179. [Google Scholar] [CrossRef] [PubMed]
- Botella, G.; Garcia, A.; Rodriguez-Alvarez, M.; Ros, E.; Meyer-Baese, U.; Molina, M.C. Robust bioinspired architecture for optical-flow computation. IEEE Trans. Very Large Scale Integr. Syst. 2010, 18, 616–629. [Google Scholar] [CrossRef]
- Dondo, J.; Villanueva, F.; Garcia, D.; Vallejo, D.; Glez-Morcillo, C.; Lopez, J.C. Distributed fpga-based architecture to support indoor localisation and orientation services. J. Netw. Comput. Appl. 2014, 45, 181–190. [Google Scholar] [CrossRef]
- Dinc, S.; Fahimi, F.; Aygun, R. Vision-based trajectory tracking for mobile robots using mirage pose estimation method. IET Comput. Vis. 2016, 10, 450–458. [Google Scholar] [CrossRef]
- He, M.; Ratanasawanya, C.; Mehrandezh, M.; Paranjape, R. Uav pose estimation using posit algorithm. Int. J. Digit. Content Technol. Appl. 2011, 5, 153–159. [Google Scholar]
- Schaeferling, M.; Hornung, U.; Kiefer, G. Object recognition and pose estimation on embedded hardware: Surf-based system designs accelerated by fpga logic. Int. J. Reconfig. Comput. 2012, 2012, 16. [Google Scholar] [CrossRef]
- Acevedo-Avila, R.; Gonzalez-Mendoza, M.; Garcia-Garcia, A. A linked list-based algorithm for blob detection on embedded vision-based sensors. Sensors 2016, 16, 782. [Google Scholar] [CrossRef] [PubMed]
- Rosenfeld, A.; Kak, A.C. Digital Picture Processing; Academic Press Inc.: Cambridge, MA, USA, 1982; p. 349. [Google Scholar]
- Rosenfeld, A.; Pfaltz, J.L. Sequential operations in digital picture processing. J. ACM 1966, 13, 471–494. [Google Scholar]
- Di Stefano, L.; Bulgarelli, A. A simple and efficient connected components labeling algorithm. In Proceedings of the 10th International Conference on Image Analysis and Processing, Venice, Italy, 27–29 September 1999; p. 322.
- Bailey, D.G.; Johnston, C.T. Single pass connected components analysis. In Proceedings of the Image and Vision Computing New Zealand 2007, Hamilton, New Zealand, 5–7 December 2007; pp. 282–287.
- Wu, K.; Otoo, E.; Suzuki, K. Optimizing two-pass connected-component labeling algorithms. Pattern Anal. Appl. 2009, 12, 117–135. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Fusing points and lines for high performance tracking. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 15–21 October 2005; Volume 1502, pp. 1508–1515.
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Computer Vision—ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Part I; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Altera. Nios II Processor. Available online: https://www.altera.com/products/processors/overview.html (accessed on 26 September 2016).
- Institute of Electrical and Electronics Engineers. IEEE Standard for Floating-Point Arithmetic; IEEE Std 754-2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–70. [Google Scholar]
- Lomont, C. Fast Inverse Square Root. Available online: http://www.lomont.org/ (accessed on 26 September 2016).
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P | P1 | P2 | P3 | P4 | Category |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | New blob |
| 1 | 1 | 0 | 0 | 0 | Copy P1 |
| 1 | 1 | 0 | 1 | 1 | |
| 1 | 1 | 1 | 0 | 0 | |
| 1 | 1 | 1 | 1 | 0 | |
| 1 | 1 | 1 | 1 | 1 | |
| 1 | 0 | 1 | 0 | 0 | Copy P2 |
| 1 | 0 | 1 | 1 | 0 | |
| 1 | 0 | 1 | 1 | 1 | |
| 1 | 1 | 0 | 1 | 0 | Copy P3 |
| 1 | 0 | 0 | 1 | 1 | |
| 1 | 0 | 0 | 0 | 1 | Copy P4 |
| 1 | 1 | 1 | 0 | 1 | Compare P1 and P4 |
| 1 | 1 | 0 | 0 | 1 | |
| 1 | 0 | 1 | 0 | 1 | Compare P2 and P4 |
| 0 | 0 | 1 | 0 | 0 | Finish Blob |
| 0 | 0 | 1 | 0 | 1 | |
| 0 | 0 | 0 | 0 | 0 | NOP |
| 0 | 0 | 0 | 0 | 1 | |
| 0 | 0 | 0 | 1 | 0 | |
| 0 | 0 | 0 | 1 | 1 | |
| 0 | 0 | 1 | 1 | 0 | |
| 0 | 0 | 1 | 1 | 1 | |
| The remaining cases | Leave Blob | ||||
| Parameters | X (cm) | Y (cm) | Z (cm) | Roll (°) | Yaw (°) | Pitch (°) |
|---|---|---|---|---|---|---|
| Maximum error | 5.57 | 4.5 | 3.4 | 1.2 | 4.7 | 4.7 |
| Minimum error | 1 | 0 | 0 | 0 | 0.1 | 0.1 |
| Mean error | 2.06 | 1.95 | 0.9 | 0.7 | 1.8 | 1.8 |
| Method | Translation Error on X-Axis | Translation Error on Y-Axis | Rotation Error |
|---|---|---|---|
| 4 target points | 3.249 | 8.7845 | 2.3101 |
| 20 target points | 3.3537 | 8.8294 | 2.1606 |
| 50 target points | 3.4167 | 8.7393 | 2.1728 |
| 100 target points | 3.1275 | 8.9024 | 2.2154 |
| Coplanar Posit (our implementation using 4 target points only) | 2.1924 | 2.3621 | 1.0951 |
| Hardware Architecture | Platform | Frame Size | Pixel Depth | Memory Usage | Frequency | FPS |
|---|---|---|---|---|---|---|
| Acevedo-Avila et al. (2016) [34] | Altera Cyclon III | 640 × 480 | 1 bit | 307,200 | 50 MHZ | 110 |
| Proposed in this paper | Altera Cyclon IVE | 640 × 480 | 1 bit | 307,200 | 50 MHZ | 162 |
| Resources | Used | Percentage |
|---|---|---|
| Total logic elements | 10,814 | 9% |
| Total combinational functions | 9.702 | 8% |
| Dedicated logic registers | 6.683 | 6% |
| Total registers | 6683 | - |
| Total memory bits | 1,703,417 | 43% |
| Embedded Multiplier 9-bit elements | 11 | 2% |
| Total PLLs | 1 | 25% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tayara, H.; Ham, W.; Chong, K.T. A Real-Time Marker-Based Visual Sensor Based on a FPGA and a Soft Core Processor. Sensors 2016, 16, 2139. https://doi.org/10.3390/s16122139
Tayara H, Ham W, Chong KT. A Real-Time Marker-Based Visual Sensor Based on a FPGA and a Soft Core Processor. Sensors. 2016; 16(12):2139. https://doi.org/10.3390/s16122139
Chicago/Turabian StyleTayara, Hilal, Woonchul Ham, and Kil To Chong. 2016. "A Real-Time Marker-Based Visual Sensor Based on a FPGA and a Soft Core Processor" Sensors 16, no. 12: 2139. https://doi.org/10.3390/s16122139
APA StyleTayara, H., Ham, W., & Chong, K. T. (2016). A Real-Time Marker-Based Visual Sensor Based on a FPGA and a Soft Core Processor. Sensors, 16(12), 2139. https://doi.org/10.3390/s16122139