In the simulation, the sensors’ geometry is arbitrary. The sensors are randomly located around the reference point. The distances between sensors and the reference point randomly vary from to , where λ is the wavelength of signals impinging on the array.
4.1. Discussion about the Best Values of μ, m and w
To get the best values of μ, m and w, first of all we have to know the meaning of each parameter. μ controls the size of the initialization space, m is the number of particles and w is the inertia factor. All these parameters are related to the computational complexity. Our purpose is to get the best combination of them which leads to the least computational complexity. Since there are so many parameters, we adopt qualitative analysis combined with quantitative experiment method.
To simplify this problem, firstly we discuss the inertia factor
w by fixing
μ and
m. From
Section 3.2.2, we have known that when
w is relatively large between 0.4 to 0.9, the particles move dramatically, while when
w is small between 0.4 to 0.9, the particles move smoothly. Therefore, a large value of
w between 0.4 to 0.9 is beneficial for the PSO algorithm search the “best” in a larger area, and a small value of
w between 0.4 to 0.9 is beneficial for fine search in a small area. For our proposed Joint-PSO algorithm, since the initialization space is already very close to the solution of SML, it is better for us to choose a small value of w between 0.4 and 0.9. To verify this conclusion, we do simulations with different value of
w (
w = 0.4, 0.5, 0.6, ..., 0.9) for fixed
μ and
m. Then we select some data as shown in
Table 1,
Table 2 and
Table 3. From
Table 1,
Table 2 and
Table 3, we can find that for fixed
μ and
m, when
w = 0.4, the computational complexity (Cal. time) of the proposed algorithm is much lower than that of other tables. Therefore, for our proposed algorithm, it is better to choose
w = 0.4.
Next we have to determine the best value of
μ and
m.
μ controls the size of initialization space. If
, the initialization space is the whole search space. In other words, it is the same to the conventional PSO algorithm. From the characteristics of the PSO algorithm (concluded at the beginning of
Section 3.2), we know that for conventional PSO algorithm, to guarantee that there are particles close to the optimal value,
m should be large enough (usually not fewer than 25). For our proposed Joint-PSO algorithm, since the solution of ESPRIT is already close to the solution of SML, to guarantee that all the particles are close to the solution of SML, it is better to choose a proper value of
μ (not too large or too small) which can control that the initialization space is not very large and can include the solution of SML. Considering that the stochastic CRB is a small value which is uniquely determined by the number of sensor, snapshots and SNR, the value of
μ should be not large. Then a small number of particles, i.e., small value of
m, is necessary. As a result, all the particles can quickly converge to the solution of SML. With these analysis, we select some representative value of
μ (1, 3, 10, 50 and 500 which mean that the initialization space gradually expands) and
m (5, 10 and 25) as shown in
Table 1,
Table 2 and
Table 3.
In
Table 1,
Table 2 and
Table 3, the scenario is that
,
, N = 100,
dB, RMSE = 0.26. Two sources are independently located in 30° and −15°. All the cases are done through 30 independent trials. “Cal. time” represents the average calculating time of the algorithm with that value of
μ,
m and
w to find the “best” (solution of SML). The Unit is second. Here the calculating time is the total computational complexity to get the estimation of DOA including the cost of ESPRIT and Stochastic CRB. Note that when
(infinity), it means the conventional PSO algorithm is used. We also have to note that for conventional PSO algorithm and the proposed algorithm, the convergence condition is the same, i.e., when the moving speed of all the particles converges to 0 (less than 10
−6) or the maximum iteration number is attained. The maximum iteration number is 300. Since in the simulation we found that both algorithms can find the global solution of SML successfully and the maximum iteration number is not attained, the RMSE of them are the same as shown in the caption of each Table.
From these Tables, we can find the following two facts. First, our proposed algorithm is much more efficient than the conventional PSO algorithm (). Second, for our proposed algorithm, when w = 0.4, μ = 3, and m = 5, the computational complexity is the lowest. Note that, these simulations are just for the case that p = 8, q = 2 (two independent signals), N = 100, = 5 dB. We have also done simulations for other cases with different SNRs. We find that the best values of μ and m are not constant. From a large number of simulations, we find that for different cases it is better to choose the value of μ between 1 and 10, and m between 3 and 10. This is because when μ is between 1 and 10, the initialization space is not so large and close enough to the “best” of SML. Since the initialization space is not so large, it is not necessary to set many particles.
As for the effect of different values of , we also do some simulations and we find that it has little impact on the final computational complexity. That is because the PSO algorithm is an iterative technique and is just the moving speed of the first step.
For the conventional PSO algorithm, it is obvious that it is much better to choose the number of particles to be 25 since the whole search space (when
) is very large. Furthermore, we have discussed the improvement of the value of
w in [
25]. In [
25] we proposed to change the value of
w in a parabolic curve according to (26). The reason is as we have discussed in the
Section 3.2.2. For our proposed Joint-PSO algorithm, it is not necessary to make
w change with iteration times since the number of iteration is usually very small and they are already very close to the solution of SML. In simulations, we find that for our proposed Joint-PSO algorithm, the iteration times are almost the same when
and when
w changes according to Equation (26).
In the simulations below for our proposed Joint-PSO algorithm, we set , , and for the conventional PSO algorithm, , w changing according to Equation (26) if there is no special explanation.
4.2. Initialization Space and Convergence of Conventional PSO and Proposed Algorithm
In this subsection, we do simulations to show the initialization space and convergence process of the proposed algorithm. In Figures, “Joint-PSO” represents our proposed algorithm since we jointly use the solution of ESPRIT and CRBs.
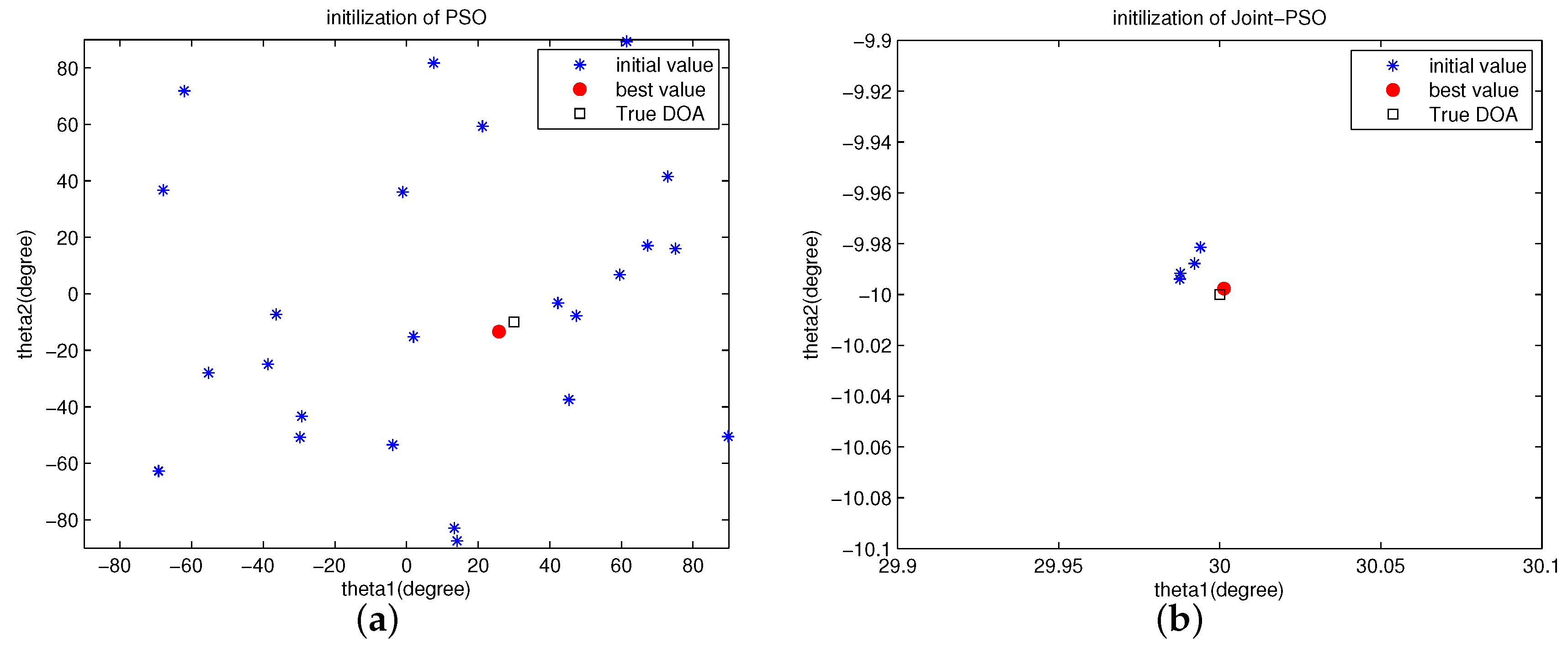
Figure 1 shows the initialization of PSO and Joint-PSO algorithms. The scenario is the same to
Table 1,
Table 2 and
Table 3. “best value” represents the solution of SML. “Ture DOA” is 30° and −15°. The values of
m,
μ and
w are set as above.
In
Figure 1, it shows clearly that our proposed Joint-PSO algorithm has a very good initialization space. Since the initialization space is not large and very close to the “best value” (solution of SML), only a small number of particles are necessary (set to be 5) and all the particles are close to the “best value”. As a result, all the particles will converge quickly to the “best value” as shown in
Figure 2.
Figure 2 shows samples of the convergence process (moving speed) of all the particles according to the iteration times for PSO and Joint-PSO algorithms. The vertical axis is the velocity of all the particles. The scenario is the same to
Figure 1.
Figure 2a,b are samples for conventional PSO algorithm with different values of
w.
Figure 2c is a sample for the proposed Joint-PSO algorithm with
.
The updating process for both algorithms will not be stopped until the moving speed of all the particles converges to 0 (less than 10−6) or the maximum iteration number is attained. The maximum iteration number is set to be 300 for conventional PSO algorithm.
From
Figure 2a,b, we can find that for conventional PSO algorithm, the number of iteration is reduced about one fifth when
w is set according to Equation (26). The reason is as we have discussed above.
Figure 2c shows that the number of iterations for the proposed Joint-PSO algorithm is much less than that of conventional PSO algorithm. Note that one iteration means an update of all the particles. Since the number of particles of the proposed Joint-PSO algorithm is also much less than that of conventional PSO algorithm, the computational complexity of the proposed algorithm is much lower.
In
Figure 2, we just show the moving speed of all the particles of
according to iteration times. The moving speed of the other source (
) is almost the same as that of
because the convergence condition is that the moving speed of all the particles converges to 0 (for both
and
), or the maximum iteration number is attained. Therefore, we omit the description of
.
4.3. Comparison of RMSE and Computational Complexity
In this subsection, we will show the efficiency of our proposed Joint-PSO algorithm with comparison to the conventional PSO algorithm, classic AM algorithm [
9] and Genetic algorithm (GA) [
17]. Note that the original ESPRIT algorithm [
3] is formulated based on assumptions that the array is ULA and there is no signal coherent. However, in our simulation, the sensors’ geometry is arbitrary and there are coherent signals. In this case, if we want to use the estimation result of ESPRIT to determine the initialization space, we have to take the following two steps. Firstly, it uses virtual array transformation technique [
26] to change the sensors’ geometry to be ULA. Secondly, we need to use the spatial smoothing technique [
6] such that it can deal with coherent signals.
In the simulation, for the GA algorithm [
17], it also has many parameters such as the population size, the crossover probability and the mutation probability. To have a fair comparison, we also need to choose the best values of them for SML estimation. As a result, we do simulation with different value of each parameter for SML estimation as shown in
Table 4. In
Table 4, “psize” represents the population size; “mu-prob” represents the mutation probability. “Cal. time” represents the average calculating time, i.e., the whole computational complexity.
From
Table 4, we find that with different values of population size and mutation probability, the whole computational complexity changes little. They are in the same order of magnitude. We also do simulations with different values of crossover probability. Similar simulation results are observed. As a result, for GA algorithm, we set that the population size is 60, the crossover probability is 0.6 and the mutation probability is 0.1.
For the AM algorithm [
9], in the one-dimensional global search of each updating process, we use different step-size for searching. At first, we have a relatively large step-size (0.1 degree) for rough search and then much smaller step-sizes (0.01, 0.0001 and 10
−6) for fine search. In this way we can have fewer computation times for one-dimensional global search to attend the convergence accuracy.
Note that since all these algorithms are used to find the global solution of SML criteria. i.e., to solve the multi-dimensional non-linear optimization problem of SML, the convergence accuracy of each algorithm is set to be the same (10−6) for identical simulation condition. Therefore, the RMSE of each algorithm for SML estimation is also the same as shown in the caption of each Table. Otherwise, it is meaningless to compare the computational complexity of them.
The scenario of
Figure 3 is that
,
and
. The ture DOA is 30° and −15°. The “RMSE” is defined as above and the unit is degree.
Figure 3 shows the RMSE of PSO and Joint-PSO algorithms for SML with comparison to ESPRIT. From
Figure 3a,b, we can find the following facts. First, for both coherent and non-coherent cases, the curve of Joint-PSO coincides with that of PSO and they converge well. It means that both algorithms find the DOA successfully. The RMSE of the other algorithms (AM, GA) also coincides with that of Joint-PSO and conventional PSO algorithms since the SML criteria is the same and their convergence accuracy is also set to be the same. Second, For coherent case, the RMSE of SML, i.e., estimation accuracy, is much better than that of ESPRIT just as we have introduced in the introduction. For non-coherent case, the RMSE of SML coincides with that of ESPRIT when SNR is larger than 10 dB. It means that when SNR is high and there are no coherent signals, it is not necessary to use the SML estimation because the ESPRIT is good enough and its computational complexity is much lower. Therefore, the proposed algorithm for SML estimation is suitable for the cases that when there are coherent signals or when SNR is relatively low.
Next, Let us see the computational complexity of our proposed Joint-PSO algorithm with comparison to the conventional PSO, AM and GA algorithms for different cases as shown in
Table 5,
Table 6,
Table 7 and
Table 8. The scenarios are described in the caption of each Table. The label “GA-SML” represents the Gentic algorithm for SML estimation. The other algorithms are labeled in the same manner. Obviously, the computational complexity of the iteration process of each algorithms is determined by “Times of calculation of
” which are the production of “Number of particles” and “Average iteration times”, while “Total calculating time” represents the whole computational complexity including the calculation of ESPRIT and CRB. Note that when there are coherent signals, the cost of the pre-processing techniques are also included.
Table 5 shows the non-coherent case;
Table 6 shows the coherent case;
Table 7 shows the case that two signals are very close, while
Table 8 shows the case that there are 4 independent signals. From all these tables, we can find that the proposed Joint-PSO algorithm is the most efficient. It is about one-tenth of the conventional PSO algorithm and almost one percent of GA and AM algorithms. Similar simulation results are observed in many other cases. These simulations prove the great efficiency of the proposed algorithm.
Note that, in
Table 5, the estimation of ESPRIT takes only 0.0015 s (in
Table 6 ESPRIT takes 0.0023 s; in
Table 7 ESPRIT takes 0.0021 s; in
Table 8 ESPRIT takes 0.0042 s) which is about one-tenth of the time our proposed algorithm takes. That is because the estimation of ESPRIT is not a multi-dimensional non-linear optimization problem and it can be calculated explicitly. The defect of ESPRIT is that its accuracy is much lower than that of SML as shown in
Figure 3. However, the ESPRIT is still one of the most commonly used algorithms in real systems because of its low computational complexity. On the other hand, from
Table 5,
Table 6,
Table 7 and
Table 8 we can find that for SML estimation our proposed algorithm is the most efficient one among all the solving techniques until now. Furthermore, we should note that the calculating time of the proposed Joint-PSO algorithm could even be greatly reduced if the parallel computing and distributed computing techniques are used. In these cases, the calculating time of our proposed algorithm for SML estimation could be comparable to that of ESPRIT. Therefore, our proposed Joint-PSO algorithm shows great potential for the application of SML in real systems.







{kind=link}
{kind=link}
{kind=link}