
Joint Prior Learning for Visual Sensor Network Noisy Image Super-Resolution

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose a JPISR method based on the expectation maximization (EM) algorithm for image quality improvement in a visual sensor network, which can effectively reconstruct finer details and simultaneously suppress noises for smart sensing.
- In the M-step procedure, the novel adaptive non-local group-sparsity explicit prior serves as the likelihood estimation, and the geometric duality implicit prior is regard as the Bayesian prior estimation. They are effectively integrated into one framework by maximum a posteriori (MAP). Since there is no need for the external training data, this joint prior learning is very suitable for a VSN.
- When a pattern with a high frequency signal is simple, but rarely repeated in the image, we introduce a rotation invariance into non-local self-exemplars to increase the number of repeated image patches for explicit prior learning.
2. Related Works
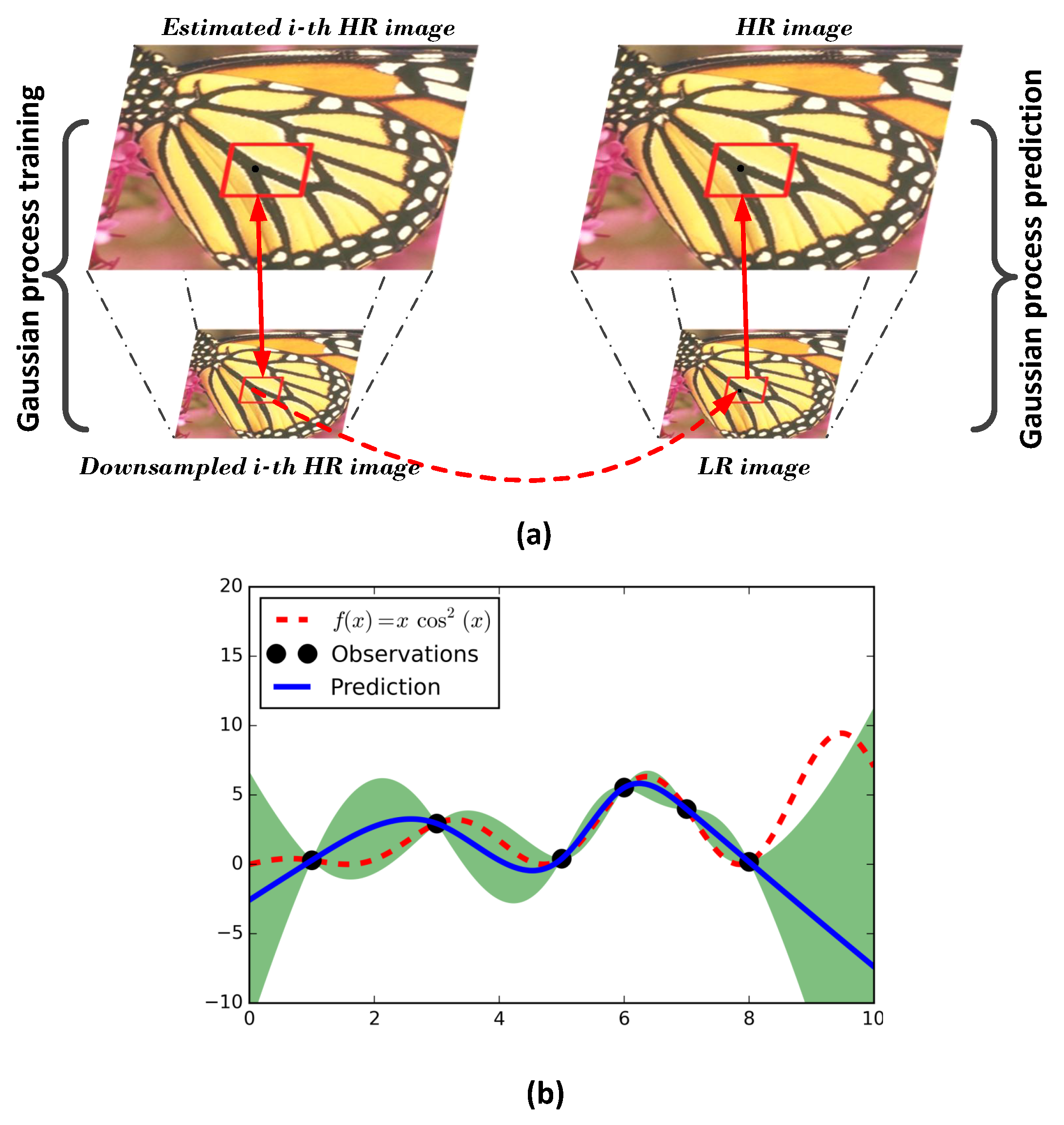
3. EM Scheme of Image Super-Resolution in a VSN
3.1. Problem Formulation
3.2. EM Scheme
3.2.1. E-Step: The Likelihood of the Super-Resolution Model Approach Procedure
3.2.2. M-Step: Image Denoising Procedure
- Likelihood of the super-resolution model approach (E-step):
- HR image estimation from a hidden image (M-step):
4. HR Image Estimation via Maximum A Posterior
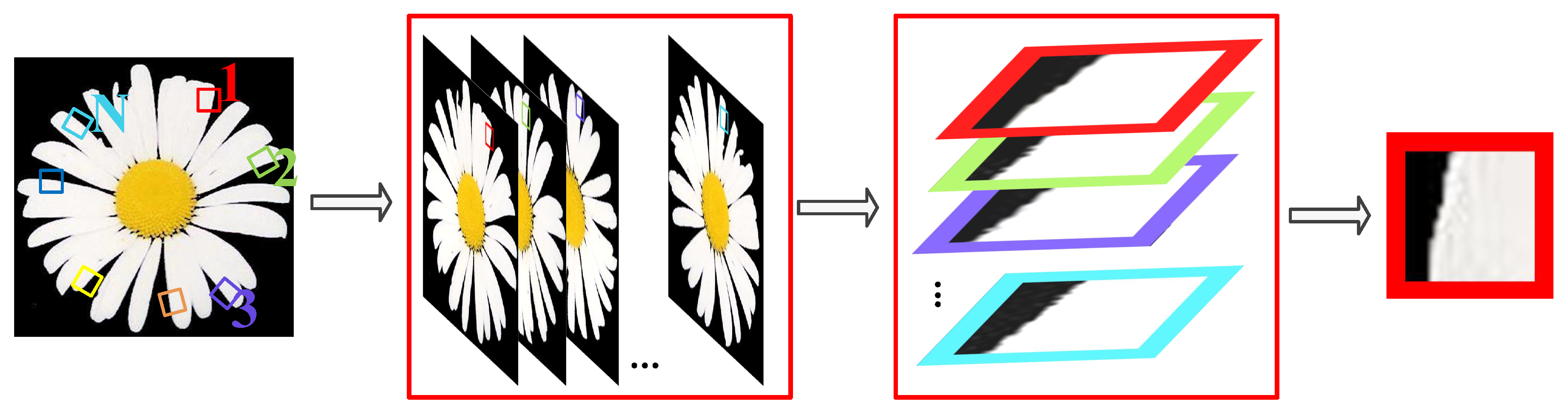
4.1. Non-Local Group-Sparsity Explicit Prior Learning
4.2. Geometric Duality Implicit Prior Learning
4.3. Improving Similar Patches Match by Introducing Rotation Invariance
5. Experiment Results and Discussion
5.1. Experimental Configuration
5.2. Comparison with Six Super-Resolution Algorithms
5.3. Comparison on Noisy Images
5.4. Comparison of Data Size with PSNR
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Babacan, S.D.; Molina, R.; Katsaggelos, A.K. Variational Bayesian super resolution. IEEE Trans. Image Process. 2011, 20, 984–999. [Google Scholar] [CrossRef] [PubMed]
- Unger, M.; Pock, T.; Werlberger, M.; Bischof, H. A convex approach for variational super-resolution. Patt. Recogn. 2010, 313–322. [Google Scholar]
- Zhao, N.; Wei, Q.; Basarab, A.; Kouame, D.; Tourneret, J.-Y. Fast Single Image Super-Resolution. Available online: http://arxiv.org/abs/1510.00143 (accessed on 15 February 2016).
- Efrat, N.; Glasner, D.; Apartsin, A.; Nadler, B.; Levin, A. Accurate blur models vs. image priors in single image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Austria, 10–13 December 2013; pp. 2832–2839.
- Kang, W.; Yu, S.; Ko, S.; Paik, J. Multisensor Super Resolution Using Directionally-Adaptive Regularization for UAV Images. Sensors 2015, 15, 12053–12079. [Google Scholar] [CrossRef] [PubMed]
- Sajjad, M.; Mehmood, I.; Baik, S. Sparse representations-based super-resolution of key-frames extracted from frames-sequences generated by a visual sensor network. Sensors 2014, 14, 3652–3674. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Sun, J.; Xu, Z.; Shum, H.-Y. Image super-resolution using gradient profile prior. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Dong, W.; Zhang, D.; Shi, G.; Wu, X. Image Deblurring and Super-Resolution by Adaptive Sparse Domain Selection and Adaptive Regularization. IEEE Trans. Image Process. 2011, 20, 1838–1857. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Zhang, Y.; Li, H.; Huang, T.S. Generative Bayesian image super resolution with natural image prior. IEEE Trans. Image Process. 2012, 21, 4054–4067. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.-Y.; Huang, J.-B.; Yang, M.-H. Exploiting Self-Similarities for Single Frame Super-Resolution. In Computer Vision—ACCV; Springer Berlin Heidelberg: Berlin, Germany, 2010; pp. 497–510. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Yi, M. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 497–510. [Google Scholar]
- Yang, J.; Wang, Z.; Lin, Z.; Cohen, S.; Huang, T. Coupled dictionary training for image super-resolution. IEEE Trans. Image Process. 2012, 21, 3467–3478. [Google Scholar] [CrossRef] [PubMed]
- Roman, Z.; Michael, E.; Matan, P. On single Image Scale-Up Using Sparse-Representations. In Curves and Surfaces; Springer Berlin Heidelberg: Berlin, Germany, 2012; pp. 711–730. [Google Scholar]
- Zhang, K.; Tao, D.; Gao, X.; Li, X.; Xiong, Z. Learning Multiple Linear Mappings for Efficient Single Image Super-Resolution. IEEE Trans. Image Process. 2015, 24, 846–861. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Chang, H.; Shan, S.; Zhong, B.; Lin, X.; Chen, Z. Deep Network Cascade for Image Super-Resolution. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 49–64. [Google Scholar]
- Dong, C.; Chen, C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Li, X.; Orchard, M.T. New edge-directed interpolation. IEEE Trans. Image Process. 2001, 10, 1521–1527. [Google Scholar] [PubMed]
- Chang, H.; Yeung, D.-Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, WA, USA, 27 June–2 July 2004.
- Rasmussen, C.E. Regression. In Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; pp. 32–58. [Google Scholar]
- He, H.; Siu, W.-C. Single image super-resolution using Gaussian process regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 449–456.
- Zhu, J.; Javed, O.; Liu, J.; Yu, Q.; Cheng, H.; Sawhney, H. Pedestrian Detection in Low-Resolution Imagery by Learning Multi-scale Intrinsic Motion Structures (MIMS). In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2015; pp. 3510–3517.
- Jiang, N.; Liu, W.; Su, H.; Wu, Y. Tracking low resolution objects by metric preservation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 1329–1336.
- Li, J.; Wu, J.; Deng, H.; Liu, J. A Self-Learning Image Super-Resolution Method via Sparse Representation and Non-Local Similarity. Neurocomputing 2015. [Google Scholar] [CrossRef]
- Sajjad, M.; Mehmood, I.; Baik, S.W. Image super-resolution using sparse coding over redundant dictionary based on effective image representations. J. Vis. Commun. Image Represent. 2015, 26, 50–65. [Google Scholar] [CrossRef]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Figueiredo, M.; Nowak, R.D. An EM algorithm for wavelet-based image restoration. IEEE Trans. Image Process. 2003, 12, 906–916. [Google Scholar] [CrossRef] [PubMed]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2272–2279.
- Luo, E.; Chan, S.H.; Nguyen, T.Q. Adaptive Image Denoising by Targeted Databases. IEEE Trans. Image Process. 2015, 24, 2167–2181. [Google Scholar] [PubMed]
- Zhang, J.; Zhao, D.; Gao, W. Group-based sparse representation for image restoration. IEEE Trans. Image Process. 2014, 23, 3336–3351. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single Image Super-Resolution from Transformed Self-Exemplars. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5197–5206.
- Timofte, R.; Vincent, D.; GoolLuc, V. A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution. In Computer Vision—ACCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 111–126. [Google Scholar]












© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, B.; Wang, S.; Liang, X.; Jiao, L.; Xu, C. Joint Prior Learning for Visual Sensor Network Noisy Image Super-Resolution. Sensors 2016, 16, 288. https://doi.org/10.3390/s16030288
Yue B, Wang S, Liang X, Jiao L, Xu C. Joint Prior Learning for Visual Sensor Network Noisy Image Super-Resolution. Sensors. 2016; 16(3):288. https://doi.org/10.3390/s16030288
Chicago/Turabian StyleYue, Bo, Shuang Wang, Xuefeng Liang, Licheng Jiao, and Caijin Xu. 2016. "Joint Prior Learning for Visual Sensor Network Noisy Image Super-Resolution" Sensors 16, no. 3: 288. https://doi.org/10.3390/s16030288
APA StyleYue, B., Wang, S., Liang, X., Jiao, L., & Xu, C. (2016). Joint Prior Learning for Visual Sensor Network Noisy Image Super-Resolution. Sensors, 16(3), 288. https://doi.org/10.3390/s16030288