
Building an Enhanced Vocabulary of the Robot Environment with a Ceiling Pointing Camera

 , and
, and
Abstract
:1. Introduction
- We leverage the visual vocabulary for a more meaningful representation of a given working environment;
- We propose a novel way to include spatio-temporal information in the vocabulary construction process: thanks to feature tracking, our approach automatically groups the different appearances of scene elements;
- Additionally, we propose including each key-point altitude value in the key-point descriptors to encode the different viewpoints for the scene elements.
2. Related Work
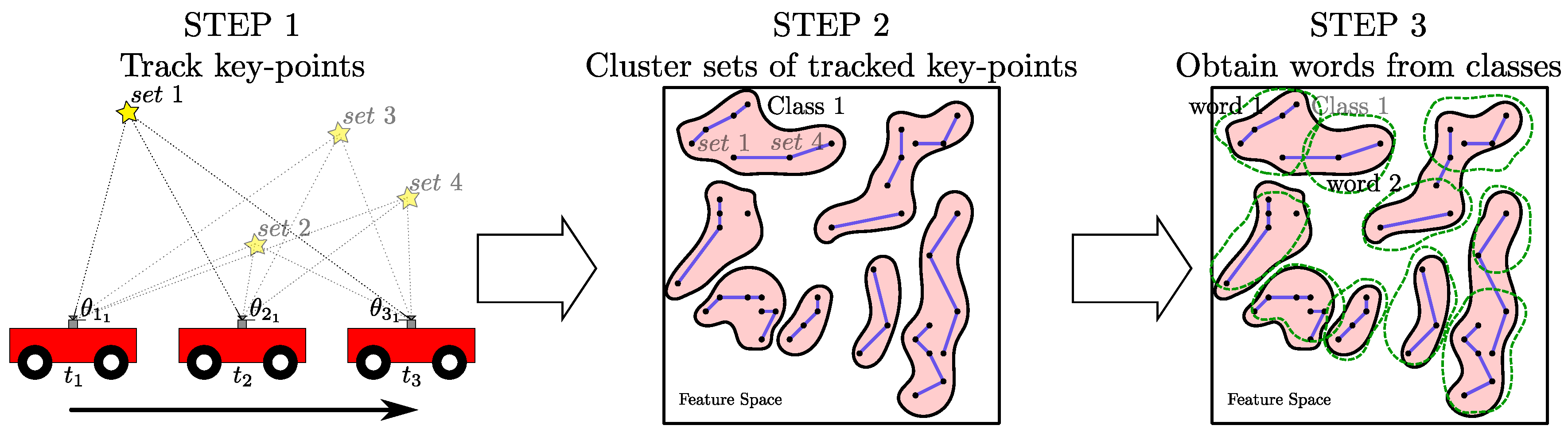
3. Enhanced Vocabulary Construction
3.1. Key-Point Detection and Tracking
3.2. Clustering Sets of Tracked Key-Points
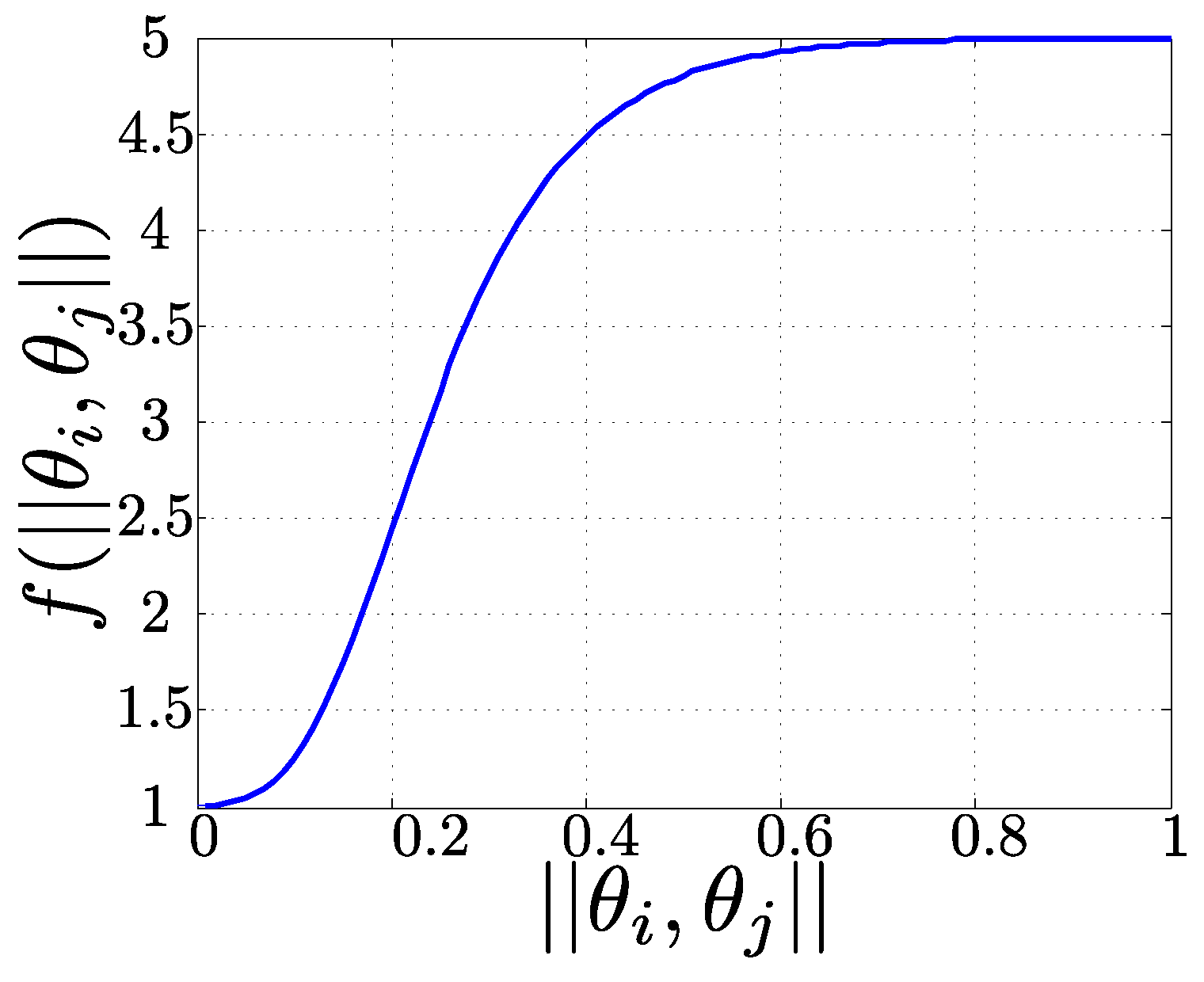
3.2.1. Similarity Measure
3.2.2. Clustering Approaches
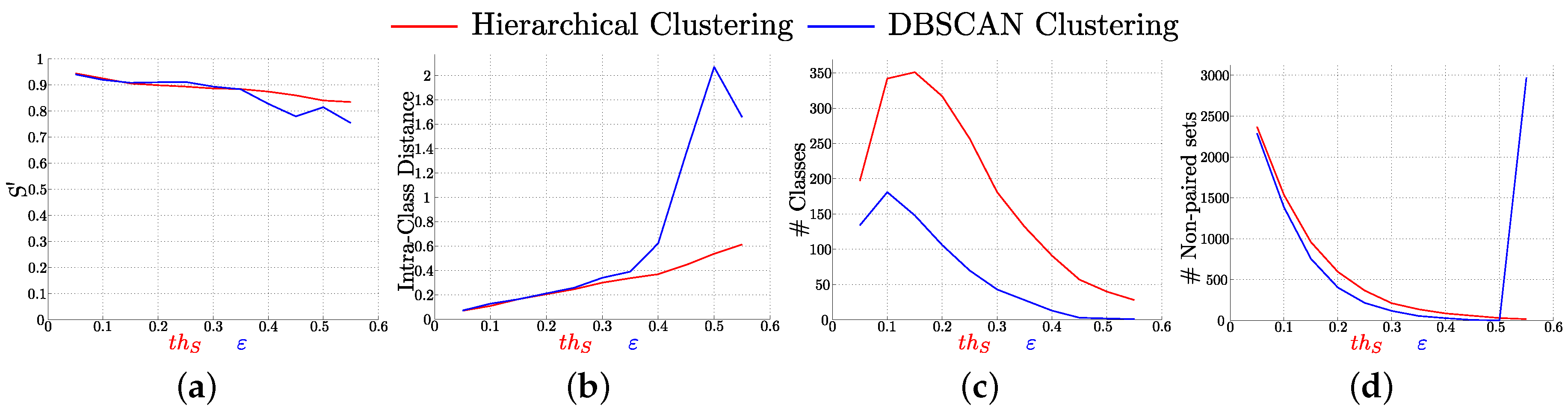
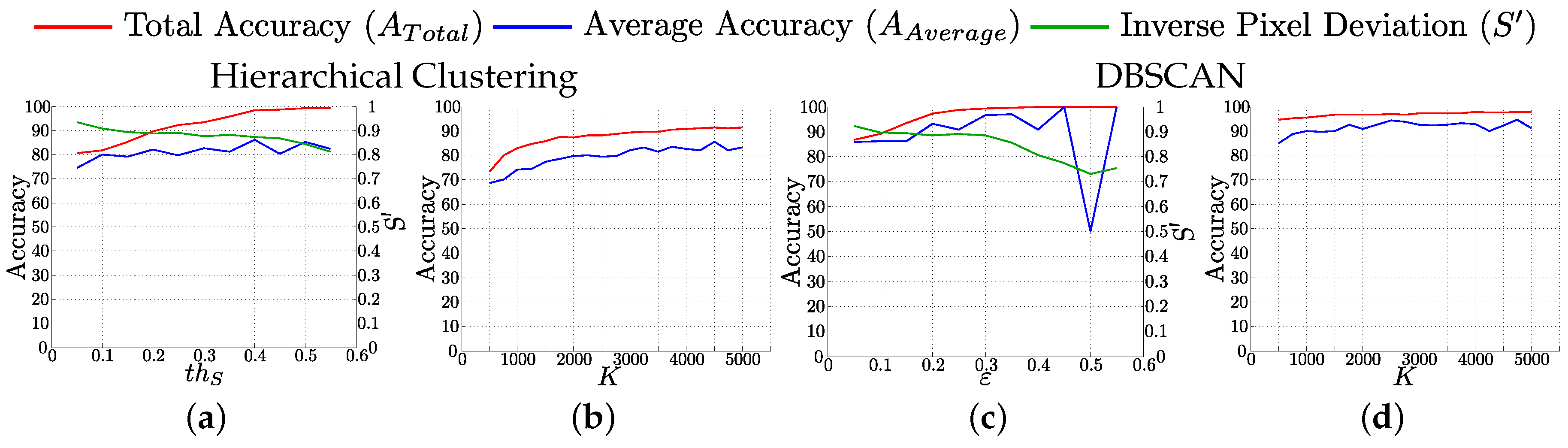
- Hierarchical Clustering.We have implemented a clustering method based on the agglomerative Hierarchical Clustering [47], where each element starts as a cluster and each cluster is paired with its most similar cluster as we move up in the hierarchy. Our hypothesis is that elements in the same cluster are probably observations originated from the same object or scene point. We modify the standard Hierarchical Clustering by defining threshold to avoid merging too dissimilar clusters (clusters are not paired if their distance is above this threshold). As a result of this modification of the standard Hierarchical Clustering, key-points sets far from any other set are not paired and compose a singleton cluster. In this method, new clusters are created on every iteration, so new distances have to be computed. We adopt the Unweighted Pair Group Method with Arithmetic Mean [48] approach, where the distance between two clusters is the mean of the distances between the sets of tracked key-points included in each cluster.Hierarchical Clustering is conceptually simple, that means it is easy to implement and modify. Additionally, it outputs a hierarchy of clusters, a structure more informative than flat clustering technique results. The drawback is its complexity, in the general case, what makes it too slow for big data-sets.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise).DBSCAN [49] is a density-based clustering algorithm that uses a estimated density distribution of corresponding nodes to find clusters in the data. This algorithm is based in the notion of density reachability: Two elements, q and p, are directly density reachable if their distance is not bigger than ε. q is called density-reachable from p if there is a sequence of elements, with and , where each is directly density-reachable from . With these definitions, a cluster is a subset of elements mutually density-connected. To handle the noise, this method defines the parameter , the minimum number of elements required to create a cluster. Subsets of density-connected elements with less than elements are considered as noise.DBSCAN is a widely used clustering technique. We use the DBSCAN implementation included in ELKI open source data mining software [50]. The complexity of this method is lower than for Hierarchical Clustering, for the basic form of the algorithm, so it is faster and more appropriate for big data-sets.
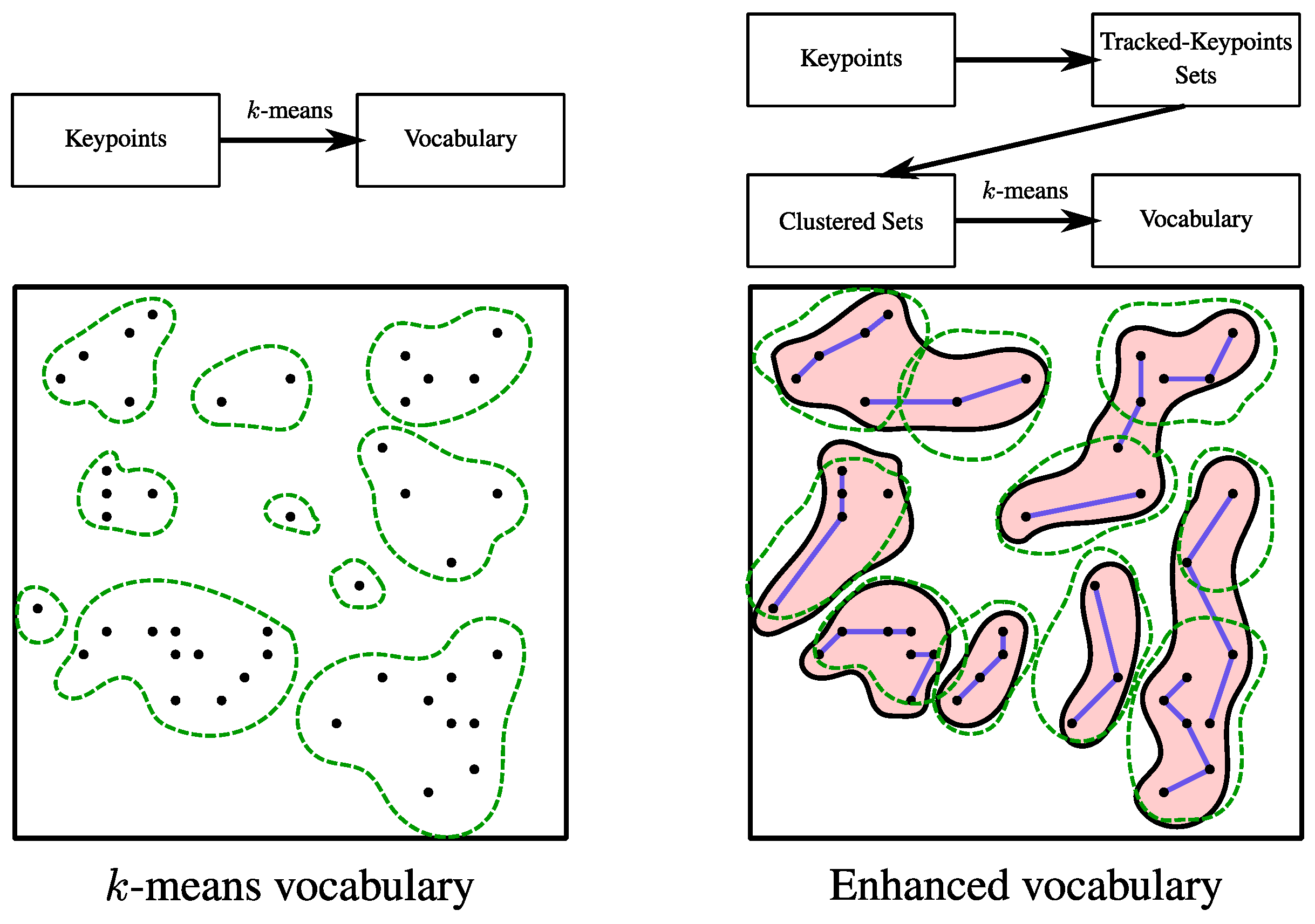
- The obtained clusters represent common scene points and include their possible appearances according to the different viewpoints under which the scene elements were observed.
- Non paired or noisy sets are unique scene points. These sets are dissimilar to the rest of sets but may be highly representative of the locations where they appear. These unique sets are clustered together after running the clustering step. The created cluster does not represent any common scene points, but includes unique key-points representative of a location. Unique sets are clusters with just one set of tracked key-points when using Hierarchical Clustering. When running DBSCAN with , these unique sets are considered as noise.
3.3. Vocabulary Construction
3.4. Assigning Words to a New Feature Using the Created BoW
4. Analysis of the Performance of the Hierarchical Vocabulary
4.1. Experimental Settings
4.1.1. Data-Sets
4.1.2. Performance Measurements
- Accuracy: it evaluates the accuracy of the vocabulary to classify new features into the discovered classes. Total, , and average class accuracy, , of the classification are respectively computed as:where the i index represents the classes.
- Normalized inverse pixel deviation: it evaluates the similarity of the key-points patches included in each class. This quality measurement is based on the standard deviation of the image patches of features that have been clustered together. Given class i, we define the class pixel deviation, , as the mean of the standard deviation of the gray level of every pixel of the features patches included in class i:where represents all the patches of the features included in the class i, is the gray level of pixel from the patch of feature j, values are limited to the size of the patches ( pixels in our case) and is the standard deviation.We define the normalized inverse pixel deviation for each class, :where is the maximum pixel deviation. More meaningful classes will have higher values.
- Intra-class distance: it evaluates the similarity between all the sets of key-points included in each class. Distance between all the sets of key-points is computed using Equation (4). The intra-class distance is the mean of these distances. Lower values of this distance mean more compact clusters, where the sets grouped are more similar.
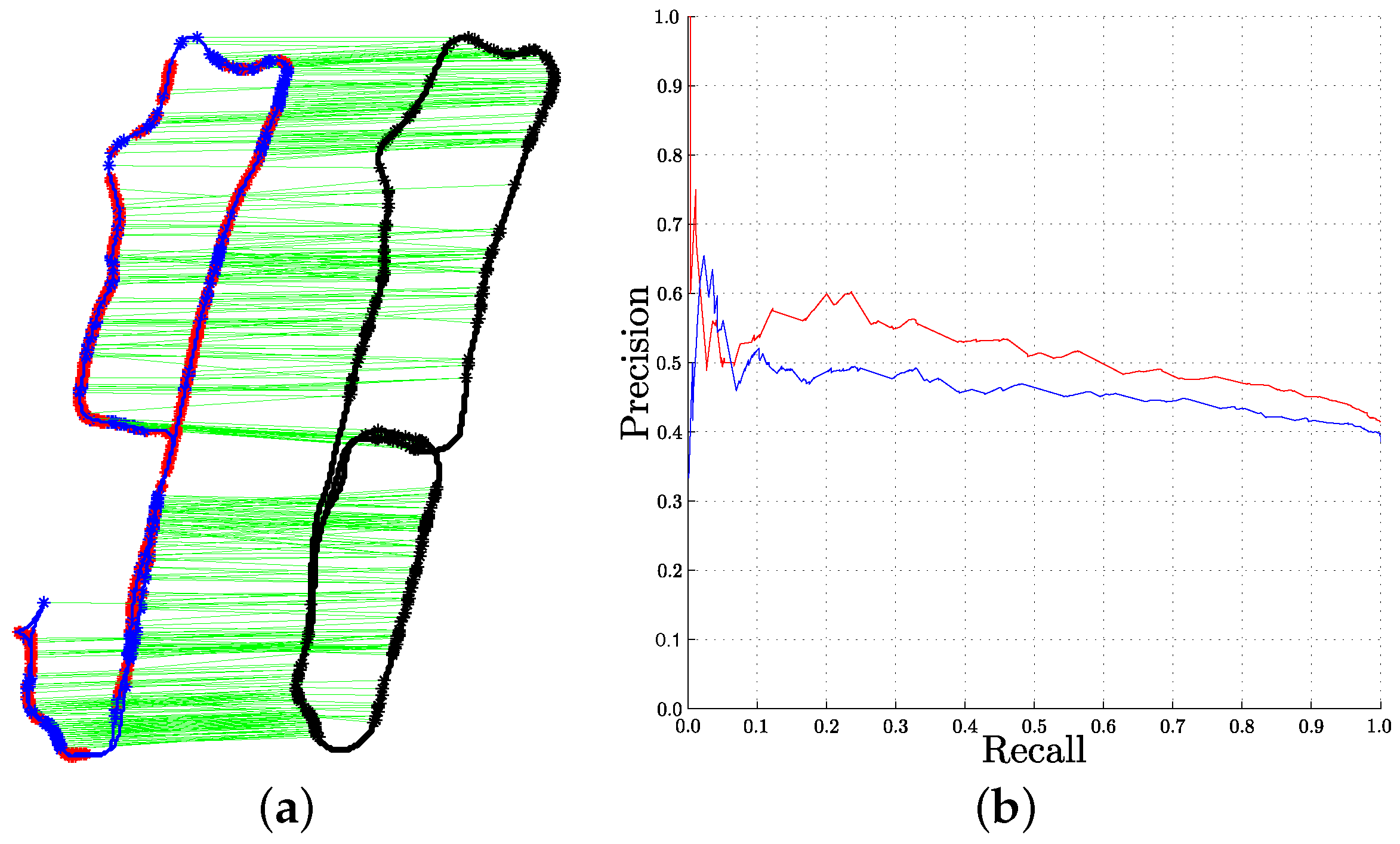
4.1.3. Comparison with k-Means Vocabulary
4.2. Analysis of the Clustering of Tracked Key-Points Sets
4.3. Influence of , ε and K Parameters in the Performance of the Resulting Vocabulary
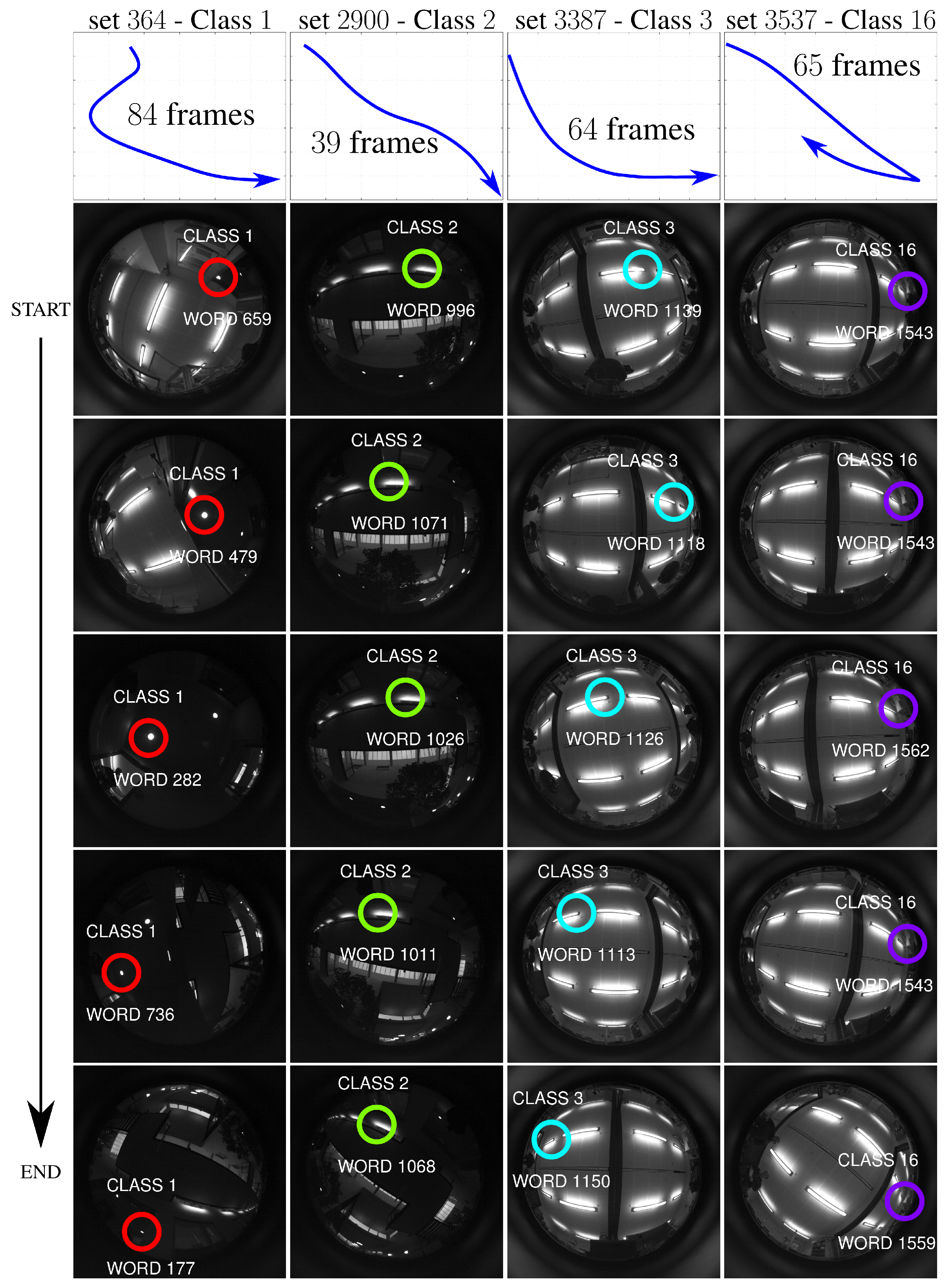
4.4. Influence of the Robot Motion in the Detection of Key-Point Classes
4.5. Analysis of the Object Information Included in the Vocabulary
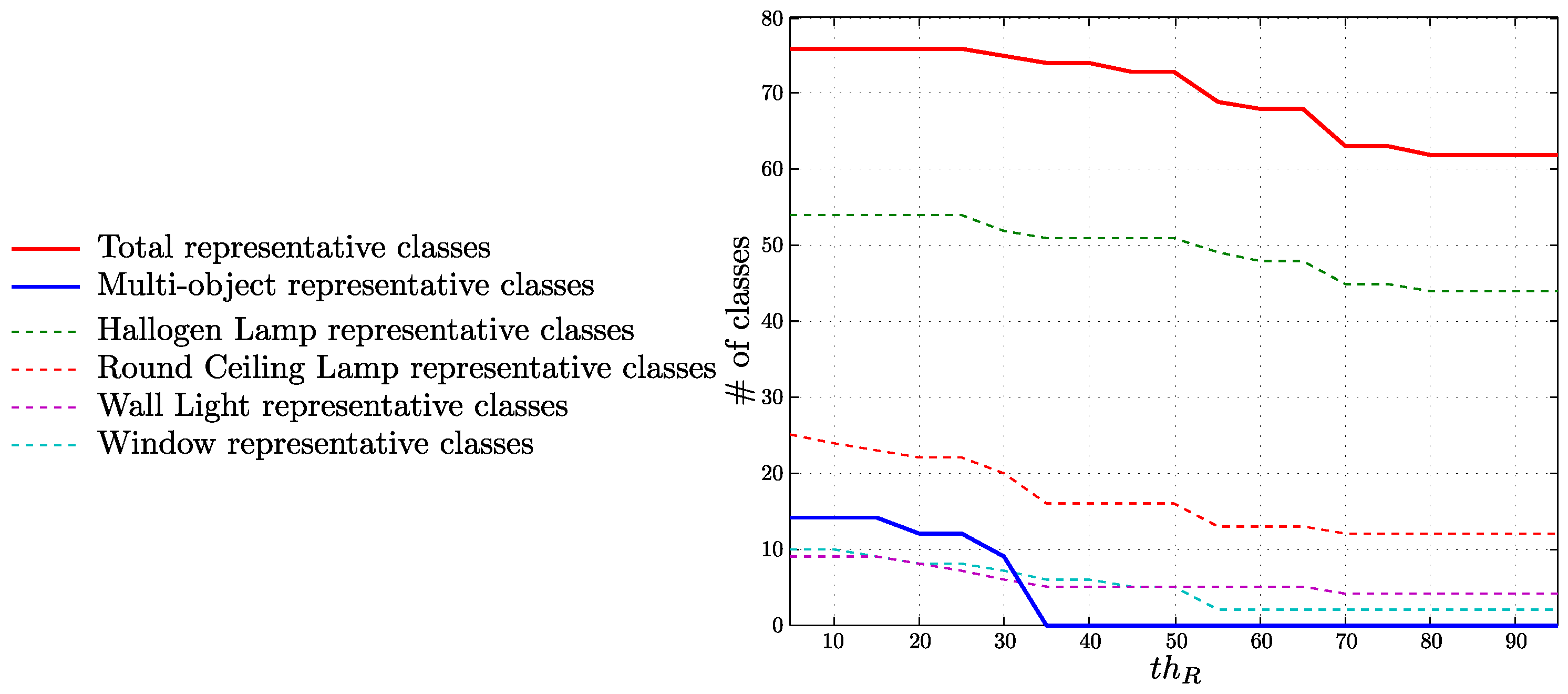
4.5.1. Relationship between Words and Classes with the Environment Objects
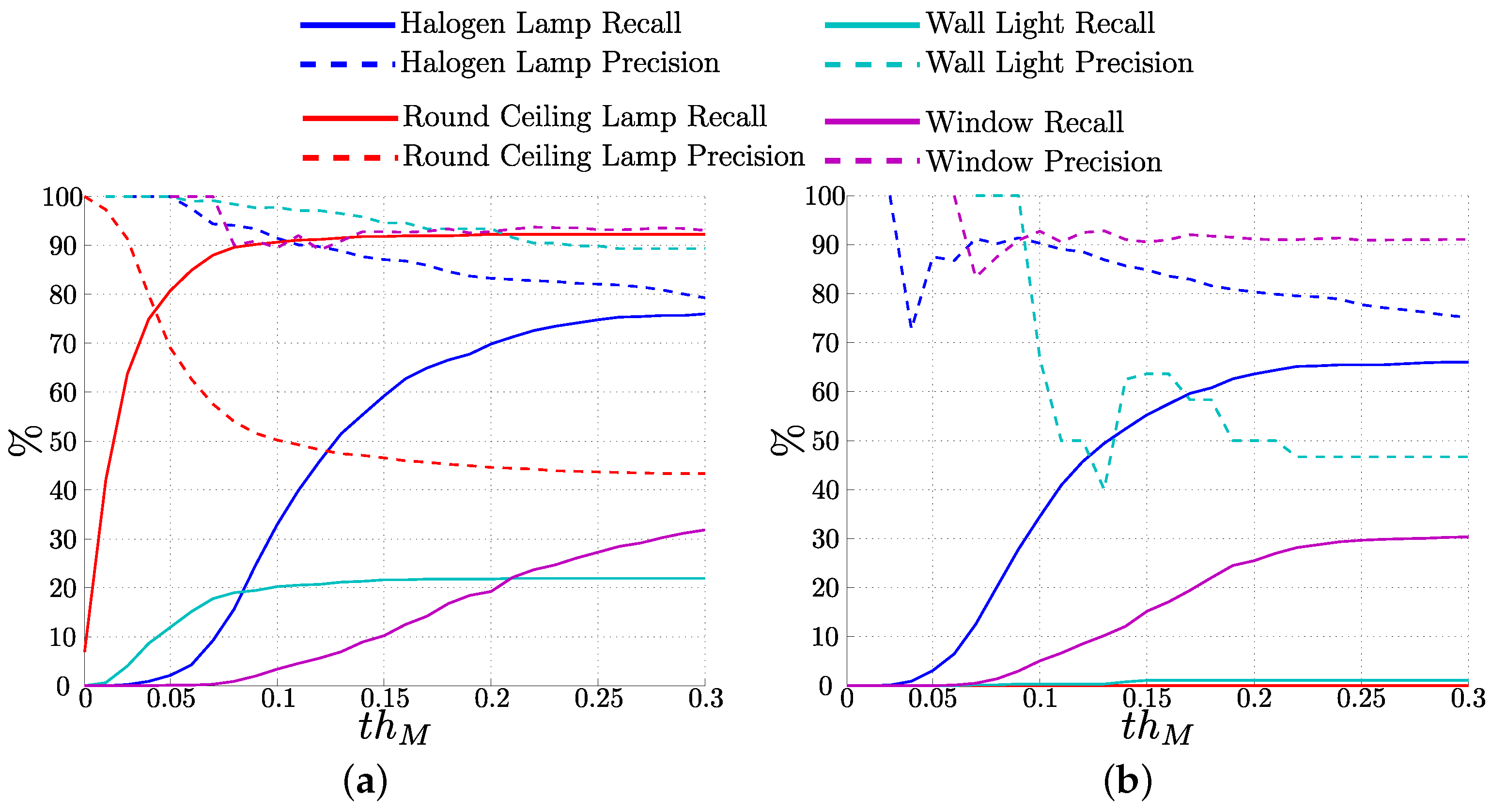
4.5.2. Classes Representing Objects
Inclusion of the Altitude Values
4.5.3. Qualitative Object-Class Correspondence
5. Applications Using the Proposed Vocabulary
5.1. Place Recognition
5.2. Object Detection
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; pp. 1470–1477.
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Jégou, H.; Douze, M.; Schmid, C. Improving bag-of-features for large scale image search. Int. J. Comput. Vis. 2010, 87, 316–336. [Google Scholar] [CrossRef] [Green Version]
- Tuytelaars, T.; Lampert, C.H.; Blaschko, M.B.; Buntine, W. Unsupervised object discovery: A comparison. Int. J. Comput. Vis. 2010, 88, 284–302. [Google Scholar] [CrossRef]
- Cummins, M.; Newman, P. Appearance-only SLAM at large scale with FAB-MAP 2.0. Int. J. Robot. Res. 2011, 30, 1100–1123. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Learning spatially semantic representations for cognitive robot navigation. Robot. Auton. Syst. 2013, 61, 1460–1475. [Google Scholar] [CrossRef]
- Everett, H.R.; Gage, D.W.; Gilbreath, G.A.; Laird, R.T.; Smurlo, R.P. Real-world issues in warehouse navigation. Photonics Ind. Appl. Int. Soc. Opt. Photonics 1995, 2352, 249–259. [Google Scholar]
- Burgard, W.; Cremers, A.B.; Fox, D.; Hähnel, D.; Lakemeyer, G.; Schulz, D.; Steiner, W.; Thrun, S. Experiences with an interactive museum tour-guide robot. Artif. Intell. 1999, 114, 3–55. [Google Scholar] [CrossRef]
- Fukuda, T.; Yokoyama, Y.; Arai, F.; Shimojima, K.; Ito, S.; Abe, Y.; Tanaka, K.; Tanaka, Y. Navigation system based on ceiling landmark recognition for autonomous mobile robot-position/orientation control by landmark recognition with plus and minus primitives. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Minneapolis, MN, USA, 22–28 April 1996; pp. 1720–1725.
- Wulf, O.; Lecking, D.; Wagner, B. Robust self-localization in industrial environments based on 3D ceiling structures. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Beijing, China, 9–15 October 2006; pp. 1530–1534.
- Konolige, K.; Bowman, J. Towards lifelong visual maps. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), St. Louis, MO, USA, 9–15 October 2009; pp. 1156–1163.
- Valgren, C.; Lilienthal, A.J. SIFT, SURF & seasons: Appearance-based long-term localization in outdoor environments. Robot. Auton. Syst. 2010, 58, 149–156. [Google Scholar]
- Bredeche, N.; Chevaleyre, Y.; Zucker, J.D.; Drogoul, A.; Sabah, G. A meta-learning approach to ground symbols from visual percepts. Robot. Auton. Syst. 2003, 43, 149–162. [Google Scholar] [CrossRef]
- Duygulu, P.; Baştan, M. Multimedia translation for linking visual data to semantics in videos. Mach. Vis. Appl. 2011, 22, 99–115. [Google Scholar] [CrossRef] [Green Version]
- Rituerto, A.; Murillo, A.; Guerrero, J. Semantic labeling for indoor topological mapping using a wearable catadioptric system. Robot. Auton. Syst. 2014, 62, 685–695. [Google Scholar] [CrossRef]
- Astua, C.; Barber, R.; Crespo, J.; Jardon, A. Object Detection Techniques Applied on Mobile Robot Semantic Navigation. Sensors 2014, 14, 6734–6757. [Google Scholar] [CrossRef] [PubMed]
- Arandjelović, R.; Zisserman, A. Visual Vocabulary with a Semantic Twist. In Asian Conference on Computer Vision (ACCV); Springer: Berlin, Germany, 2015; pp. 178–195. [Google Scholar]
- Xu, D.; Han, L.; Tan, M.; Li, Y.F. Ceiling-based visual positioning for an indoor mobile robot with monocular vision. IEEE Trans. Ind. Electron. 2009, 56, 1617–1628. [Google Scholar]
- Hwang, S.Y.; Song, J.B. Monocular vision-based SLAM in indoor environment using corner, lamp, and door features from upward-looking camera. IEEE Trans. Ind. Electron. 2011, 58, 4804–4812. [Google Scholar] [CrossRef]
- Vieira, M.; Faria, D.R.; Nunes, U. Real-Time Application for Monitoring Human Daily Activity and Risk Situations in Robot-Assisted Living. In Robot 2015: Second Iberian Robotics Conference; Springer International Publishing: Lisbon, Portugal, 2016; pp. 449–461. [Google Scholar]
- Kani, S.; Miura, J. Mobile monitoring of physical states of indoor environments for personal support. In Proceedings of the IEEE/SICE International Symposium on System Integration (SII), Nagoya, Japan, 11–13 December 2015; pp. 393–398.
- Mantha, B.R.; Feng, C.; Menassa, C.C.; Kamat, V.R. Real-time building energy and comfort parameter data collection using mobile indoor robots. In Proceedings of the International Symposium on Automation and Robotics in Construction (ISARC), Oulu, Finland, 15–18 June 2015; Volume 32, p. 1.
- Garcia-Fidalgo, E.; Ortiz, A. Vision-based topological mapping and localization methods: A survey. Robot. Auton. Syst. 2015, 64, 1–20. [Google Scholar] [CrossRef]
- Myers, G.K.; Nallapati, R.; van Hout, J.; Pancoast, S.; Nevatia, R.; Sun, C.; Habibian, A.; Koelma, D.C.; van de Sande, K.E.; Smeulders, A.W.; et al. Evaluating multimedia features and fusion for example-based event detection. Mach. Vis. Appl. 2014, 25, 17–32. [Google Scholar] [CrossRef]
- Irschara, A.; Zach, C.; Frahm, J.M.; Bischof, H. From structure-from-motion point clouds to fast location recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2599–2606.
- Mikulik, A.; Perdoch, M.; Chum, O.; Matas, J. Learning vocabularies over a fine quantization. Int. J. Comput. Vis. 2013, 103, 163–175. [Google Scholar] [CrossRef]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Lost in quantization: Improving particular object retrieval in large scale image databases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Boiman, O.; Shechtman, E.; Irani, M. In defense of nearest-neighbor based image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Yang, L.; Jin, R.; Sukthankar, R.; Jurie, F. Unifying discriminative visual codebook generation with classifier training for object category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Wang, J.J.Y.; Bensmail, H.; Gao, X. Joint learning and weighting of visual vocabulary for bag-of-feature based tissue classification. Pattern Recognit. 2013, 46, 3249–3255. [Google Scholar] [CrossRef]
- Bai, S.; Matsumoto, T.; Takeuchi, Y.; Kudo, H.; Ohnishi, N. Informative patches sampling for image classification by utilizing bottom-up and top-down information. Mach. Vis. Appl. 2013, 24, 959–970. [Google Scholar] [CrossRef]
- Fernando, B.; Fromont, E.; Muselet, D.; Sebban, M. Supervised learning of Gaussian mixture models for visual vocabulary generation. Pattern Recognit. 2012, 45, 897–907. [Google Scholar] [CrossRef] [Green Version]
- Cao, Y.; Wang, C.; Li, Z.; Zhang, L.; Zhang, L. Spatial-bag-of-features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3352–3359.
- Ji, R.; Yao, H.; Sun, X.; Zhong, B.; Gao, W. Towards semantic embedding in visual vocabulary. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 918–925.
- Chum, O.; Perdoch, M.; Matas, J. Geometric min-hashing: Finding a (thick) needle in a haystack. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 17–24.
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1465–1472.
- Bolovinou, A.; Pratikakis, I.; Perantonis, S. Bag of spatio-visual words for context inference in scene classification. Pattern Recognit. 2013, 46, 1039–1053. [Google Scholar] [CrossRef]
- Penatti, O.; Silva, F.B.; Valle, E.; Gouet-Brunet, V.; Torres, R.D.S. Visual word spatial arrangement for image retrieval and classification. Pattern Recognit. 2014, 47, 705–720. [Google Scholar] [CrossRef]
- Jegou, H.; Douze, M.; Schmid, C. Hamming embedding and weak geometric consistency for large scale image search. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 304–317.
- Doersch, C.; Singh, S.; Gupta, A.; Sivic, J.; Efros, A.A. What makes Paris look like Paris? ACM Trans. Graph. 2012, 31, 101. [Google Scholar] [CrossRef]
- Berg, T.L.; Berg, A.C. Finding iconic images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Miami, FL, USA, 20–25 June 2009; pp. 1–8.
- Fergus, R.; Perona, P.; Zisserman, A. Object class recognition by unsupervised scale-invariant learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Madison, WI, USA, 18–20 June 2003; Volume 2, pp. II-264–II-271.
- Russell, B.C.; Freeman, W.T.; Efros, A.A.; Sivic, J.; Zisserman, A. Using multiple segmentations to discover objects and their extent in image collections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 1605–1614.
- Singh, S.; Gupta, A.; Efros, A.A. Unsupervised discovery of mid-level discriminative patches. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 73–86.
- Liu, J.; Yang, Y.; Shah, M. Learning semantic visual vocabularies using diffusion distance. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 461–468.
- Bay, H.; Ess, A.; Tuytelaars, T.; van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Ward, J.; Joe, H. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Sokal, R.; Michener, C. A statistical method for evaluating systematic relationships. Univ. Kansas Sci. Bull. 1958, 6, 1409–1438. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (KDD), Portland, OR, USA, 2–4 August 1996; pp. 226–231.
- Achtert, E.; Kriegel, H.P.; Schubert, E.; Zimek, A. Interactive data mining with 3D-parallel-coordinate-trees. In Proceedings of the ACM Conference on Special Interest Group on Management of Data (SIGMOD), New York, NY, USA, 22–27 June 2013; pp. 1009–1012.
- Rituerto, A.; Andreasson, H.; Murillo, A.C.; Lilienthal, A.; Guerrero, J.J. Hierarchical Vocabulary—Evaluation Data. Available online: http://aass.oru.se/Research/Learning/datasets.html (accessed on 4 April 2016).
- Kuemmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. g2o: A General Framework for Graph Optimization. Available online: http://openslam.org/g2o.html (accessed on 4 April 2016).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Words | |||
| Object | Our Approach DBSCAN | Our Approach Hierarchical Clustering | Standard k-Means |
| Halogen Lamp | |||
| Round Ceiling Lamp | |||
| Wall Light | |||
| Window | |||
| Mean | |||
| Classes | |||
| Object | Our Approach DBSCAN | Our Approach Hierarchical Clustering | Standard k-Means |
| Halogen Lamp | − | ||
| Round Ceiling Lamp | − | ||
| Wall Light | − | ||
| Window | − | ||
| Mean | − | ||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rituerto, A.; Andreasson, H.; Murillo, A.C.; Lilienthal, A.; Guerrero, J.J. Building an Enhanced Vocabulary of the Robot Environment with a Ceiling Pointing Camera. Sensors 2016, 16, 493. https://doi.org/10.3390/s16040493
Rituerto A, Andreasson H, Murillo AC, Lilienthal A, Guerrero JJ. Building an Enhanced Vocabulary of the Robot Environment with a Ceiling Pointing Camera. Sensors. 2016; 16(4):493. https://doi.org/10.3390/s16040493
Chicago/Turabian StyleRituerto, Alejandro, Henrik Andreasson, Ana C. Murillo, Achim Lilienthal, and José Jesús Guerrero. 2016. "Building an Enhanced Vocabulary of the Robot Environment with a Ceiling Pointing Camera" Sensors 16, no. 4: 493. https://doi.org/10.3390/s16040493
APA StyleRituerto, A., Andreasson, H., Murillo, A. C., Lilienthal, A., & Guerrero, J. J. (2016). Building an Enhanced Vocabulary of the Robot Environment with a Ceiling Pointing Camera. Sensors, 16(4), 493. https://doi.org/10.3390/s16040493