
Vehicle Detection Based on Probability Hypothesis Density Filter

Abstract
:1. Introduction
2. Hypothesis Generation
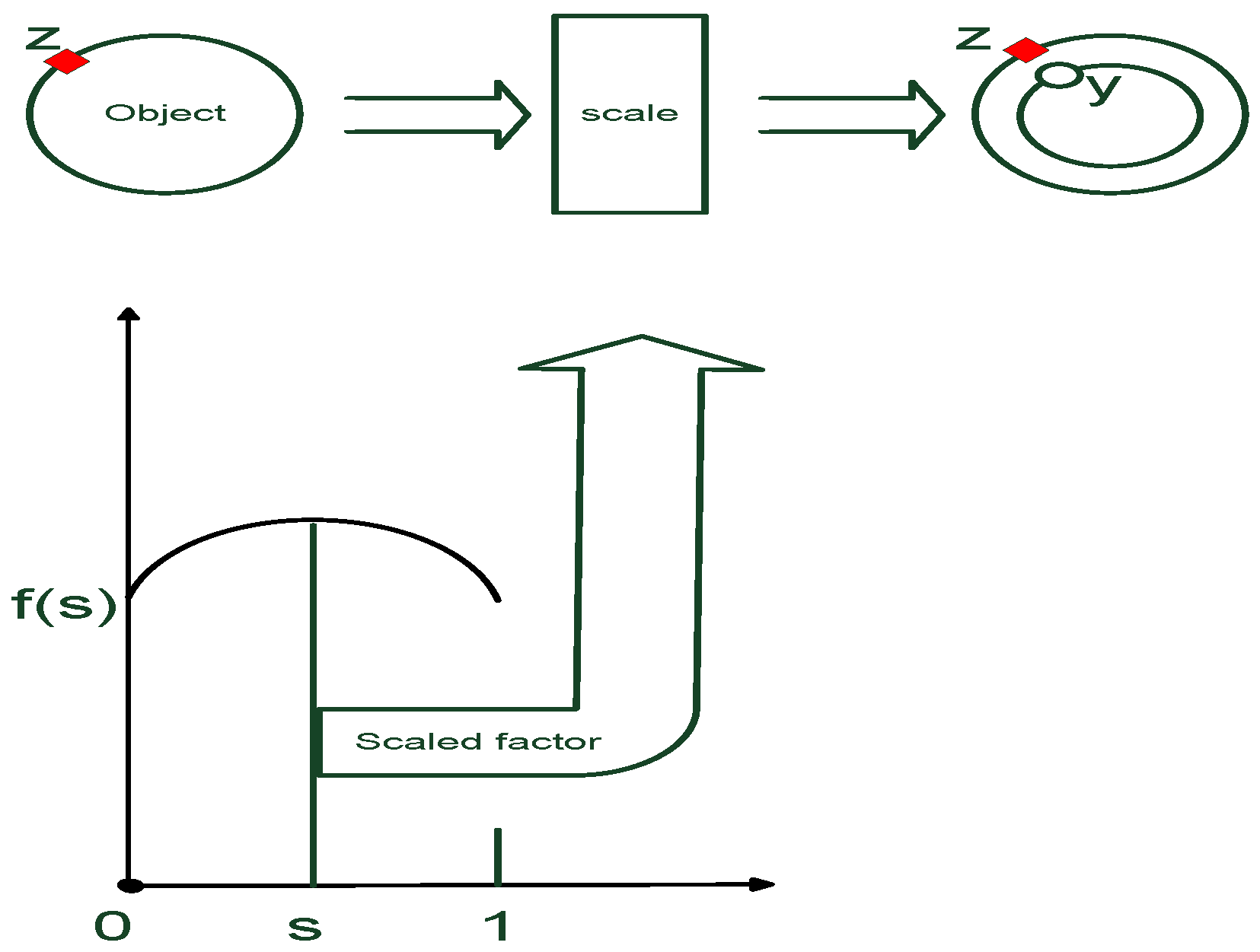
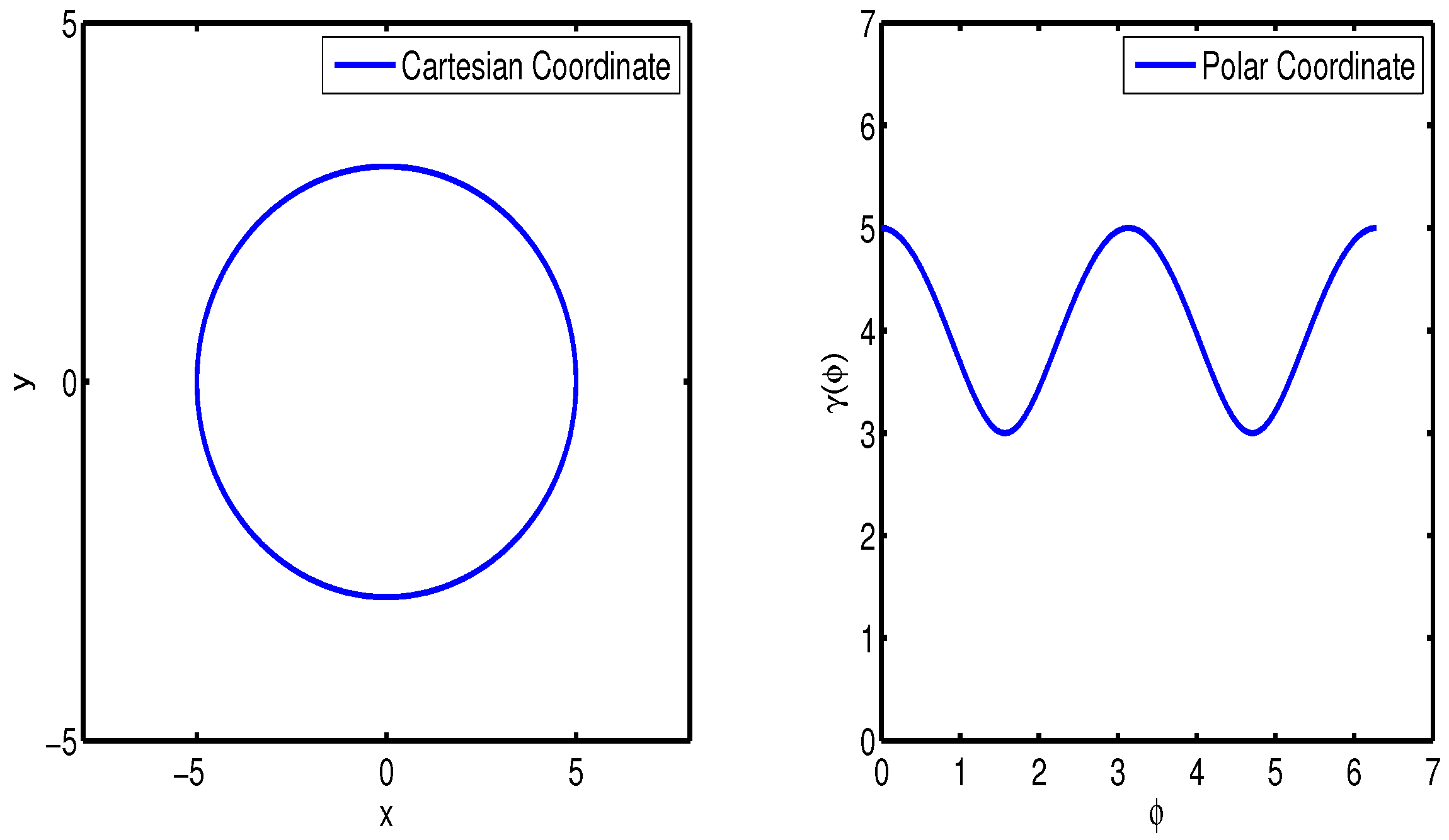
2.1. Random Hypersurface Model (RHM)
Bayes Filter
- Process model
- Measurement model
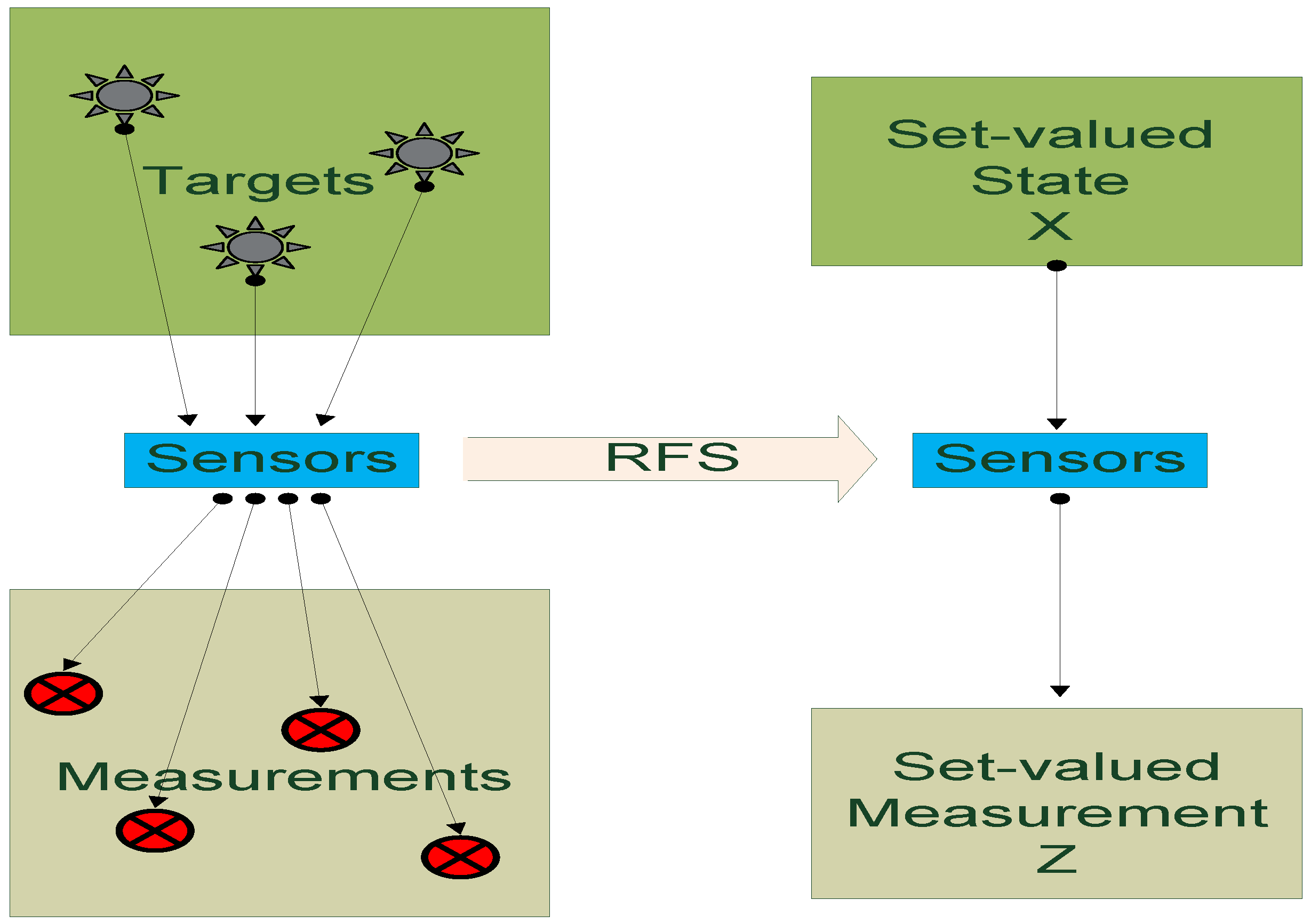
2.2. Probability Hypothesis Density (PHD) Filter
2.2.1. Overview
2.2.2. Mathematic Background
2.3. RHM–GM–PHD Filter
3. Hypothesis Verification
3.1. Support Vector Machine (SVM)
3.2. Implementation Detail
- ET–GM–PHD Implementation
- SVM Implementation
- Key Parameters and Open Issues
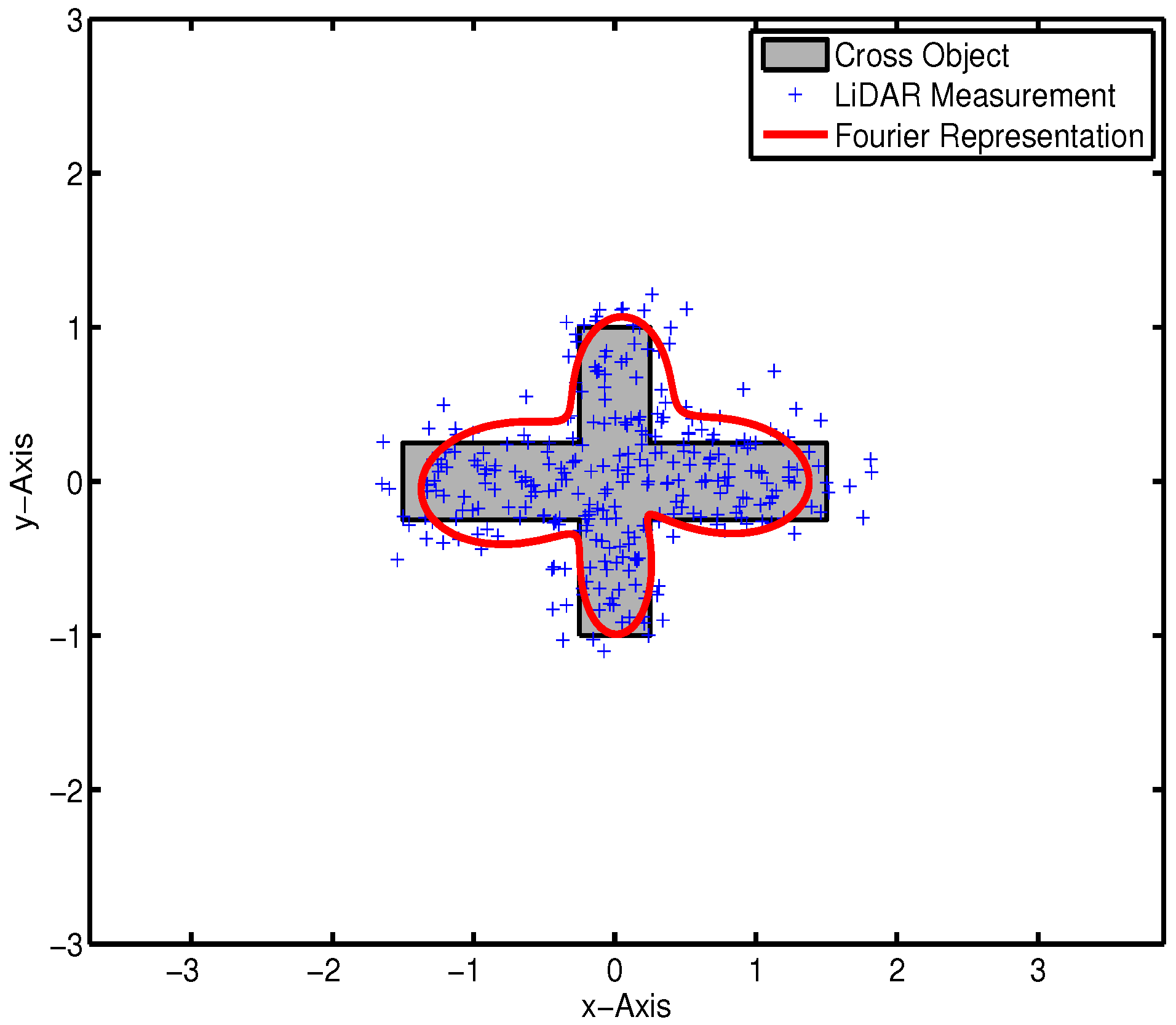
4. Experiment Evaluation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Global Status Report on Road Safety 2013. Available online: http://www.who.int/violence_injury_prevention/road_safety_status/2013/en/ (accessed on 1 October 2013).
- Leon, L.; Hirata, R. Vehicle detection using mixture of deformable parts models: Static and dynamic camera. In Proceedings of the 25th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Ouro Preto, Brazil, 22–25 August 2012; pp. 237–244.
- Khammari, A.; Nashashibi, F.; Abramson, Y.; Laurgeau, C. Vehicle detection combining gradient analysis and AdaBoost classification. In Proceedings of the 2005 IEEE Intelligent Transportation Systems, Vienna, Austria, 13–15 September 2005; pp. 66–71.
- Sun, Z.; Bebis, G.; Miller, R. On-road vehicle detection using evolutionary Gabor filter optimization. IEEE Trans. Intell. Transp. Sys. 2005, 6, 125–137. [Google Scholar] [CrossRef]
- Paragios, N.; Deriche, R. Geodesic active contours and level sets for the detection and tracking of moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 266–280. [Google Scholar] [CrossRef]
- Sun, Z.; Bebis, G.; Miller, R. Monocular precrash vehicle detection: Features and classifiers. IEEE Trans. Image Process. 2006, 15, 2019–2034. [Google Scholar] [PubMed]
- Huang, L.; Barth, M. Tightly-coupled LIDAR and computer vision integration for vehicle detection. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 604–609.
- Behley, J.; Kersting, K.; Schulz, D.; Steinhage, V.; Cremers, A. Learning to hash logistic regression for fast 3D scan point classification. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 5960–5965.
- Li, Y.; Ruichek, Y.; Cappelle, C. Extrinsic calibration between a stereoscopic system and a LIDAR with sensor noise models. In Proceedings of the 2012 IEEE Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Hamburg, Germany, 13–15 September 2012; pp. 484–489.
- Xiong, X.; Munoz, D.; Bagnell, J.; Hebert, M. 3-D scene analysis via sequenced predictions over points and regions. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 2609–2616.
- Li, Y.; Ruichek, Y.; Cappelle, C. Optimal Extrinsic Calibration Between a Stereoscopic System and a LIDAR. IEEE Trans. Instrum. Meas. 2013, 62, 2258–2269. [Google Scholar] [CrossRef]
- Dominguez, R.; Onieva, E.; Alonso, J.; Villagra, J.; Gonzalez, C. LIDAR based perception solution for autonomous vehicles. In Proceedings of the 11th International Conference on Intelligent Systems Design and Applications (ISDA), Cordoba, Spain, 22–24 November 2011; pp. 790–795.
- Zhang, F.; Clarke, D.; Knoll, A. LiDAR based vehicle detection in urban environment. In Proceedings of the 2014 International Conference on Multisensor Fusion and Information Integration for Intelligent Systems (MFI), Beijing, China, 28–29 September 2014; pp. 1–5.
- Ioannou, Y.; Taati, B.; Harrap, R.; Greenspan, M. Difference of normals as a multi-scale operator in unorganized point clouds. In Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission (3DIMPVT), Zurich, Switzerland, 13–15 October 2012; pp. 501–508.
- Baum, M.; Hanebeck, U. Shape tracking of extended objects and group targets with star-convex RHMs. In Proceedings of the 14th International Conference on Information Fusion (FUSION), Chicago, IL, USA, 5–8 July 2011; pp. 1–8.
- Mahler, R. Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Mahler, R. Approximate multisensor CPHD and PHD filters. In Proceedings of the 13th Conference on Information Fusion (FUSION), Edinburgh, UK, 26–29 July 2010; pp. 1–8.
- Vo, B.T.; Vo, B.N.; Hoseinnezhad, R.; Mahler, R. Robust multi-Bernoulli filtering. IEEE J. Sel. Top. Signal Process. 2013, 7, 399–409. [Google Scholar] [CrossRef]
- Mahler, R. Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Vo, B.N.; Ma, W.K. The Gaussian Mixture Probability Hypothesis Density Filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Mahler, R. PHD filters for nonstandard targets, I: Extended targets. In Proceedings of the 12th International Conference on Information Fusion, FUSION ’09, Seattle, WA, USA, 6–9 July 2009; pp. 915–921.
- Han, Y.; Zhu, H.; Han, C. A Gaussian-mixture PHD filter based on random hypersurface model for multiple extended targets. In Proceedings of the 16th International Conference on Information Fusion (FUSION), Istanbul, Turkey, 9–12 July 2013; pp. 1752–1759.
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361.
- Wang, D.Z.; Posner, I. Voting for voting in online point cloud object detection. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015.
- Plotkin, L. PyDriver: Entwicklung Eines Frameworks für Räumliche Detektion und Klassifikation von Objekten in Fahrzeugumgebung. Bachelor’s Thesis, Karlsruhe Institute of Technology, Karlsruhe, Germany, March 2015. [Google Scholar]
- Behley, J.; Steinhage, V.; Cremers, A. Laser-based segment classification using a mixture of bag-of-words. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 4195–4200.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Knoll, A. Vehicle Detection Based on Probability Hypothesis Density Filter. Sensors 2016, 16, 510. https://doi.org/10.3390/s16040510
Zhang F, Knoll A. Vehicle Detection Based on Probability Hypothesis Density Filter. Sensors. 2016; 16(4):510. https://doi.org/10.3390/s16040510
Chicago/Turabian StyleZhang, Feihu, and Alois Knoll. 2016. "Vehicle Detection Based on Probability Hypothesis Density Filter" Sensors 16, no. 4: 510. https://doi.org/10.3390/s16040510
APA StyleZhang, F., & Knoll, A. (2016). Vehicle Detection Based on Probability Hypothesis Density Filter. Sensors, 16(4), 510. https://doi.org/10.3390/s16040510