
Outlier Detection in GNSS Pseudo-Range/Doppler Measurements for Robust Localization


Abstract
:1. Introduction
2. Problem Formulation
2.1. Observation Model
2.2. Localization Problem
2.3. Dynamic Model
3. Proposed Approach
- For the localization problem, are Doppler measurements less subject to outliers than PR measurements?
- Does the presence of outliers also impact robust localization algorithms, such as PF or the Rao–Blackwell Particle Filter?
- In the affirmative case, is it worth detecting and discarding these outliers?
- If Doppler measurements are assumed reliable like in [1], they are directly used to derive , and the outlier detection is performed only within the PR set.
- Otherwise, we assume like [7] that, even if the Doppler measurements are less distorted by NLOS reception than PR measurements (and thus, more reliable), both Doppler and PR observations are contaminated by multipaths. Then, the outlier detection is applied for (PR,Dp), so that only Dp inliers are used to derive (and only PR inliers are considered for the estimation step further).
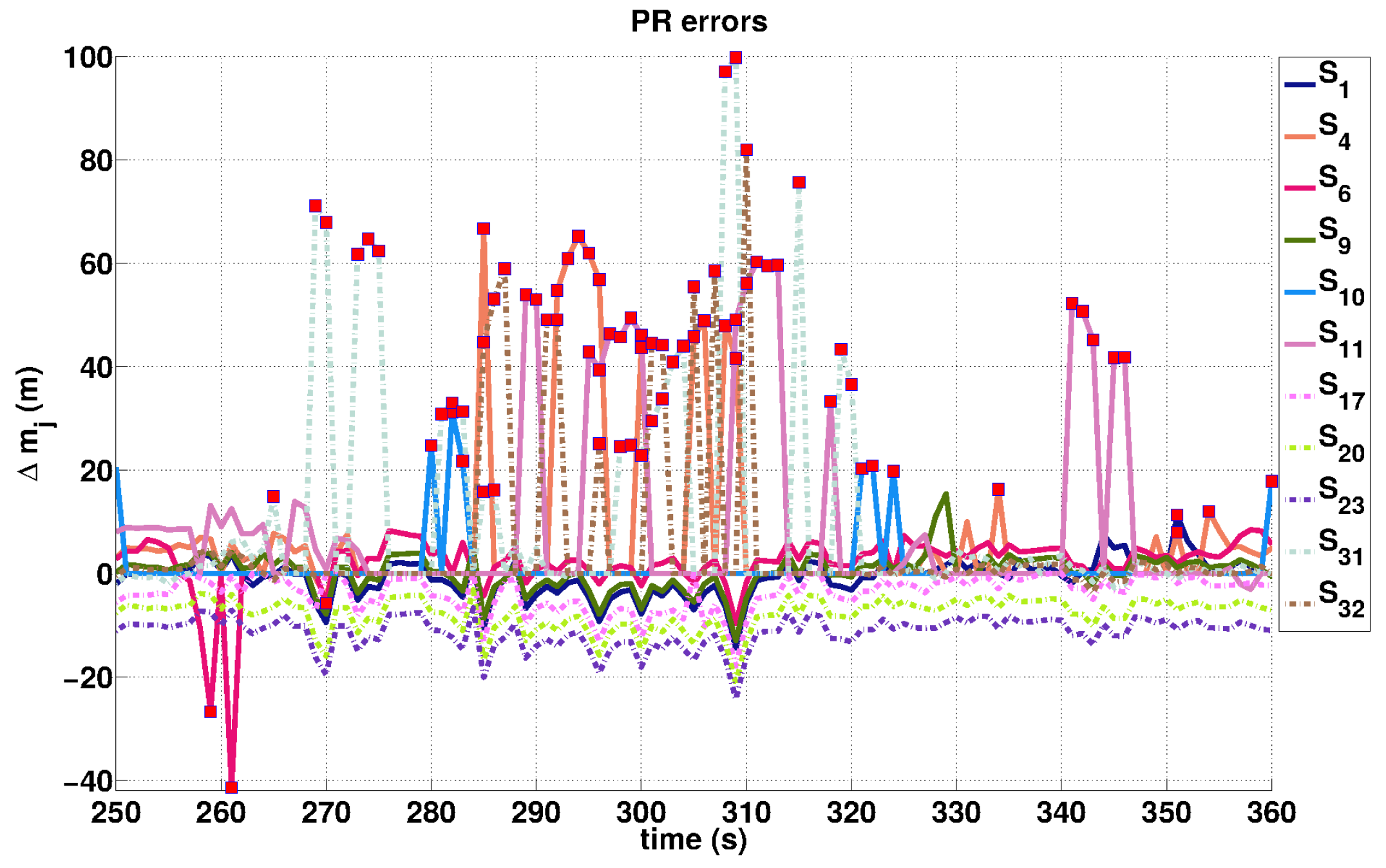
3.1. Outlier Detection
 |
3.2. Localization Algorithm
3.2.1. SIR-PF
Prediction Step
Estimation Step
Resampling
3.2.2. Rao-Blackwellised PF
Prediction Step
Estimation Step
4. Experiment and Results
4.1. Platform and Parameters
- In Algorithm 1, , and ;
- In EKF, SIR-PF and RBPF, the PR precision is m, and the Dp precision is Hz;
- In SIR-PF and RBPF, the number of particles is set to 3000.
4.2. Localization Results
- Among the implemented algorithms, the Particle Filter (PF) provides rather disappointing results with an error lower than 6 m in only of cases. This relatively bad performance of PF, against EKF for instance, is probably due to the fact that the velocity is not part of the state vector; it is not at all filtered, conversely to the case of the EKF.
- The ORKF has better performance than the simplest version of PF and the classical EKF, and similar performance to EKF + NFA (PR) and EKF + NFA (PR + Dp) when the errors are less than 6 m.
- By removing the PR outliers at the entry of the filters, EKF + NFA (PR) and PF + NFA (PR) allow for much better localization than the ‘all-data’ EKF, PF or even ORKF for errors lower than 6 m. Besides, if EKF + NFA (PR) still performs better than PF + NFA (PR) for errors lower than 6 m, the gap has narrowed, and in terms of errors lower than 3 m, PF + NFA (PR) outperforms EKF + NFA (PR).
- By removing also the Dp outliers, PF + NFA (PR,Dp) provides better results than the previous methods. For instance, its 95th percentile corresponds to an error lower than 9 m, whereas PF + NFA (PR) percentile error is 11.5 m. This clearly illustrates the interest of removing also the Doppler outliers, especially as they are not filtered (by the estimation step of PF). Conversely, in the case of the EKF where velocities are filtered, the effect of removing Dp outliers is less clear: it appears just for errors lower than 9 m.
- By removing the PR outliers, RBPF + NFA (PR) has the same performance in localization as the PF + NFA (PR,Dp) version (see Table 1). This can be explained by the fact that, by filtering the velocity estimation, RBPF is rather robust to outliers in Doppler measurements. It also outperforms EKF + NFA (PR).
- Finally, removing also the Dp outliers, RBPF + NFA(PR,Dp) outperforms all of the other results. According to Table 1, if the performance for PR + NFA (PR,Dp) and the two RBPFs is close under 3 m, a higher level of confidence is achieved by RBPF + NFA (PR,Dp) for errors lower than 6 m and 9 m.
4.3. Validation of the Outlier Estimation
4.3.1. Bias Estimation for Qualitative Analysis
4.3.2. Bias Classification for Quantitative Analysis
4.3.3. Correlation between PR and Doppler Outliers
5. Conclusions
Appendix
 |
Author Contributions
Conflicts of Interest
References
- Kaplan, E.; Hegarty, C. Understanding GPS: Principles and Applications; Artech House: Norwood, MA, USA, 2005. [Google Scholar]
- Skog, I.; Handel, P. In-car positioning and navigation technologies: A survey. IEEE Trans. Intell. Transp. Syst. 2009, 10, 4–21. [Google Scholar] [CrossRef]
- Chiang, K.W.; Duong, T.T.; Liao, J.K. The Performance Analysis of a Real-Time Integrated INS/GPS Vehicle Navigation System with Abnormal GPS Measurement Elimination. Sensors 2013, 13, 10599–10622. [Google Scholar] [CrossRef] [PubMed]
- Peyraud, S.; Bataille, D.; Renault, S.; Ortiz, M.; Mougel, F.; Meizel, D.; Peyret, F. About non-Line-of-Sight Satellite Detection and Exclusion in a 3D Map-Aided Localization Algorithm. Sensors 2013, 13, 829–847. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Seignez, E.; Rodriguez, F.A.; Reynaud, R. Lane marking based vehicle localization using particle filter and multi-kernel estimation. In Proceedings of the 13th International Conference on Control Automation Robotics Vision (ICARCV), Singapore, 10–12 December 2014; pp. 601–606.
- Mao, X.; Wada, M.; Hashimoto, H. Nonlinear filtering algorithms for GPS using pseudorange and Doppler shift measurements. In Proceedings of the IEEE 5th International Conference on Intelligent Transportation Systems, Singapore, 3–6 September 2002; pp. 914–919.
- Le Marchand, O.; Bonnifait, P.; Ibanez-Guzmán, J.; Betaille, D.; Peyret, F. Characterization of GPS multipath for passenger vehicles across urban environments. ATTI dell’Ist. Ital. Navig. 2009, 189, 77–88. [Google Scholar]
- Xie, P.; Petovello, M. Measuring GNSS Multipath Distributions in Urban Canyon Environments. IEEE Trans. Instrum. Meas. 2015, 64, 366–377. [Google Scholar]
- Obst, M.; Wanielik, G. Probabilistic non-line-of-sight detection in reliable urban GNSS vehicle localization based on an empirical sensor model. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Gold Coast, Australia, 23–26 June 2013; pp. 363–368.
- Brown, R.G. A baseline GPS RAIM scheme and a note on the equivalence of three RAIM methods. Navigation 1992, 39, 301–316. [Google Scholar] [CrossRef]
- Seignez, E.; Kieffer, M.; Lambert, A.; Walter, E.; Maurin, T. Real-time bounded-error state estimation for vehicle tracking. Int. J. Robot. Res. 2009, 28, 34–48. [Google Scholar] [CrossRef]
- Hewitson, S.; Wang, J. GNSS Receiver Autonomous Integrity Monitoring with a Dynamic Model. J. Navig. 2007, 60, 247–263. [Google Scholar] [CrossRef]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Marais, J.; Nahimana, D.F.; Viandier, N.; Duflos, E. GNSS accuracy enhancement based on pseudo range error estimation in an urban propagation environment. Expert Syst. Appl. 2013, 40, 5956–5964. [Google Scholar] [CrossRef]
- Giremus, A.; Tourneret, J.Y.; Calmettes, V. A particle filtering approach for joint detection/estimation of multipath effects on GPS measurements. IEEE Trans. Signal Process. 2007, 55, 1275–1285. [Google Scholar] [CrossRef] [Green Version]
- Desolneux, A.; Moisan, L.; Morel, J.M. Meaningful alignments. Int. J. Comput. Vis. 2000, 40, 7–23. [Google Scholar] [CrossRef]
- Desolneux, A.; Moisan, L.; Morel, J.M. From Gestalt Theory to Image Analysis: A Probabilistic Approach; Springer Science & Business Media: New York, NY, USA, 2007; Volume 34. [Google Scholar]
- Almansa, A.; Desolneux, A.; Vamech, S. Vanishing point detection without any a priori information. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 502–507. [Google Scholar] [CrossRef]
- Muse, P.; Sur, F.; Cao, F.; Gousseau, Y.; Morel, J.M. An a-contrario Decision Method for Shape Element Recognition. Int. J. Comput. Vis. 2006, 69, 295–315. [Google Scholar] [CrossRef]
- Burrus, N.; Bernard, T.M.; Jolion, J.M. Image segmentation by a-contrario simulation. Pattern Recognit. 2009, 42, 1520–1532. [Google Scholar] [CrossRef]
- Robin, A.; Moisan, L.; Le Hégarat-Mascle, S. An a-contrario approach for subpixel change detection in satellite imagery. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1977–1993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ammar, M.; Le Hégarat-Mascle, S.; Vasiliu, M.; Reynaud, R. An a-contrario approach for object detection in video sequence. Int. J. Pure Appl. Math. 2013, 89, 173–201. [Google Scholar] [CrossRef]
- Zair, S.; Le Hégarat-Mascle, S.; Seignez, E. A-contrario modeling for robust localization using raw GNSS data. IEEE Trans. Intell. Transp. Syst. 2016. [Google Scholar] [CrossRef]
- Zair, S.; Le Hégarat-Mascle, S.; Seignez, E. Coupling Outlier Detection with Particle Filter for GPS-Based Localization. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems (ITSC), Las Palmas de Gran Canaria, Spain, 15–18 September 2015; pp. 2518–2524.
- Schön, T.; Gustafsson, F.; Nordlund, P.J. Marginalized particle filters for mixed linear/nonlinear state-space models. IEEE Trans. Signal Process. 2005, 53, 2279–2289. [Google Scholar] [CrossRef]
- Rabaoui, A.; Viandier, N.; Duflos, E.; Marais, J.; Vanheeghe, P. Dirichlet process mixtures for density estimation in dynamic nonlinear modeling: Application to GPS positioning in urban canyons. IEEE Trans. Signal Process. 2012, 60, 1638–1655. [Google Scholar] [CrossRef] [Green Version]
- Gustafsson, F.; Gunnarsson, F.; Bergman, N.; Forssell, U.; Jansson, J.; Karlsson, R.; Nordlund, P.J. Particle filters for positioning, navigation, and tracking. IEEE Trans. Signal Process. 2002, 50, 425–437. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, K.; Grenfell, R.; Deakin, R. GPS satellite velocity and acceleration determination using the broadcast ephemeris. J. Navig. 2006, 59, 293–305. [Google Scholar] [CrossRef]
- Li, L.; Zhong, J.; Zhao, M. Doppler-Aided GNSS Position Estimation with Weighted Least Squares. IEEE Trans. Veh. Technol. 2011, 60, 3615–3624. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, B. GNSS windowing navigation with adaptively constructed dynamic model. GPS Solut. 2015, 19, 37–48. [Google Scholar] [CrossRef]
- Knight, N.L.; Wang, J. A comparison of outlier detection procedures and robust estimation methods in GPS positioning. J. Navig. 2009, 62, 699–709. [Google Scholar] [CrossRef]
- Le Marchand, O.; Bonnifait, P.; Bañez-Guzmán, J.; Peyret, F.; Betaille, D. Performance Evaluation of Fault Detection Algorithms as Applied to Automotive Localisation. In Proceedings of the European Navigation Conference-GNSS 2008, Toulouse, France, 22–25 April 2008.
- Cheng, C.; Tourneret, J.Y.; Pan, Q.; Calmettes, V. Detecting, estimating and correcting multipath biases affecting GNSS signals using a marginalized likelihood ratio-based method. Signal Process. 2016, 118, 221–234. [Google Scholar] [CrossRef] [Green Version]
- Hewitson, S.; Wang, J. GNSS receiver autonomous integrity monitoring (RAIM) performance analysis. GPS Solut. 2006, 10, 155–170. [Google Scholar] [CrossRef]
- Rabin, J.; Delon, J.; Gousseau, Y.; Moisan, L. MAC-RANSAC: A robust algorithm for the recognition of multiple objects. In Proceedings of the Fifth International Symposium on 3D Data Processing, Visualization and Transmission (3DPTV 2010), Paris, France, 25 March 2010.
- Doucet, A.; de Freitas, N.; Gordon, N. An Introduction to Sequential Monte Carlo Methods; Springer: New York, NY, USA, 2001. [Google Scholar]
- Casella, G.; Robert, C.P. Rao-Blackwellisation of sampling schemes. Biometrika 1996, 83, 81–94. [Google Scholar] [CrossRef]
- Doucet, A.; Godsill, S.; Andrieu, C. On sequential Monte Carlo sampling methods for Bayesian filtering. Stat. Comput. 2000, 10, 197–208. [Google Scholar] [CrossRef]
- Agamennoni, G.; Nieto, J.I.; Nebot, E.M. An outlier-robust Kalman filter. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011.
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient Algorithms for Mining Outliers from Large Data Sets; ACM SIGMOD Record; ACM: New York, NY, USA, 2000; Volume 29, pp. 427–438. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Localization Method | % Error m | % Error m | % Error m |
|---|---|---|---|
| UBLOX | 20.9% | 47.15% | 64.92% |
| GARMIN | 28.6% | 72.97% | 90.72% |
| EKF | 37.26% | 71.66% | 80.75% |
| EKF + NFA (PR) | 40.94% | 81.82% | 91.73% |
| EKF + NFA (PR,Dp) | 37.13% | 74.88% | 96.49% |
| ORKF | 40.83% | 74.77% | 83.22% |
| PF | 21.1% | 55.02% | 75.12% |
| PF + NFA (PR) | 44.6% | 77.19% | 89.85% |
| PF + NFA (PR,Dp) | 59.95% | 87.05% | 94.61% |
| RBPF + NFA (PR) | 61% | 85.78% | 93.38% |
| RBPF + NFA (PR,Dp) | 61.96% | 90.11% | 98.28% |
| Error Measure | Localization Algorithm | Data | ||
|---|---|---|---|---|
| All-Data | NFA (PR) Inliers | NFA (PR,Dp) Inliers | ||
| UBLOX | (11.92,10.20) | - | - | |
| GARMIN | (3.35,2.76) | - | - | |
| EKF | (3.76,4.50) | (2.63,3.18) | (3.31,2.24) | |
| ORKF | (3.55,4.31) | - | - | |
| PF | (6.68,6.72) | (2.61,2.83) | (1.82,2.41) | |
| RBPF | - | (1.84,2.69) | (1.62,2.17) | |
| UBLOX | (20.44,18.60) | - | - | |
| GARMIN | (4.73,3.35) | - | - | |
| EKF | (5.77,7.47) | (3.43,5.00) | (3.92,3.09) | |
| ORKF | (5.55,7.79) | - | - | |
| PF | (9.09,9.49) | (3.48,3.86) | (2.95,3.51) | |
| RBPF | - | (3.37,3.53) | (2.51,3.20) | |
| () | UBLOX | (16.72,22.02) | - | - |
| GARMIN | (4.91,3.08) | - | - | |
| EKF | (6.40,6.96) | (4.59,3.96) | (4.37,2.42) | |
| ORKF | (6.13,7.36) | - | - | |
| PF | (10.43,7.99) | (4.25,3.41) | (3.37,3.11) | |
| RBPF | - | (3.53,3.56) | (2.96,2.25) | |
| Solution Quality | RBPF + NFA (PR) | RBPF + NFA (PR,Dp) | |
|---|---|---|---|
| RTK fixed | (1.44,2.08) | (1.27,1.74) | |
| RTK float | (2.21,3.03) | (1.91,2.55) | |
| Differential | (2.16,4.16) | (2.03,2.62) | |
| RTK fixed | (2.56,3.14) | (1.76,2.45) | |
| RTK float | (3.19,4.35) | (2.56,3.26) | |
| Differential | (3.70,6.02) | (2.75,3.85) | |
| () | RTK fixed | (2.74,2.99) | (2.38,1.85) |
| RTK float | (4.05,3.57) | (3.44,2.31) | |
| Differential | (5.08,4.96) | (3.68,3.00) |
| TP | FP | FN | TN | Accuracy | Precision | |
|---|---|---|---|---|---|---|
| NFA (PR) | 3131 | 39 | 49 | 279 | 97.5 | 98.7 |
| NFA (PR,Dp) | 3112 | 91 | 45 | 250 | 96.1 | 97.2 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zair, S.; Le Hégarat-Mascle, S.; Seignez, E. Outlier Detection in GNSS Pseudo-Range/Doppler Measurements for Robust Localization. Sensors 2016, 16, 580. https://doi.org/10.3390/s16040580
Zair S, Le Hégarat-Mascle S, Seignez E. Outlier Detection in GNSS Pseudo-Range/Doppler Measurements for Robust Localization. Sensors. 2016; 16(4):580. https://doi.org/10.3390/s16040580
Chicago/Turabian StyleZair, Salim, Sylvie Le Hégarat-Mascle, and Emmanuel Seignez. 2016. "Outlier Detection in GNSS Pseudo-Range/Doppler Measurements for Robust Localization" Sensors 16, no. 4: 580. https://doi.org/10.3390/s16040580
APA StyleZair, S., Le Hégarat-Mascle, S., & Seignez, E. (2016). Outlier Detection in GNSS Pseudo-Range/Doppler Measurements for Robust Localization. Sensors, 16(4), 580. https://doi.org/10.3390/s16040580