1. Introduction
In modern industry, systems are becoming more and more complex, especially for the machine system. For example, an aircraft consists of several subsystems and millions of parts [
1]. To enhance its reliability, the condition of the main subsystems should be monitored. As the aircraft’s heart, the condition of the engine directly affects its operation and safety. The engine works in a very harsh environment (e.g., high pressure, high temperature, high rotation speed,
etc.). Therefore, its condition should be monitored thoroughly. The situation in other complex engineering systems is similar [
2]. One effective strategy to enhance the reliability of the system is to utilize Condition Monitoring (CM).
For improving the availability of equipment, many mathematical models and methodologies have been developed to realize and enhance the performance of CM. For example, dynamic fault tree is proposed to filter false warnings of the helicopter. The methodology is based on operational data analysis and can help identify the abnormal events of the helicopter [
3,
4]. For power conversion system CM, it is important to construct the measurement of damage indicators to estimate the current aging status of the power device, which include threshold voltage, gate leak current,
etc. [
5]. The optimum type, number, and location of sensors for improving fault diagnosis is realized in [
6]. Gamma process has been successfully applied to describe a certain type of degradation process [
7,
8]. CM can also be utilized to monitor the system’s sudden failure, which is carried out by forming an appropriate evolution progress [
9,
10].
In addition, CM can help provide the scheduled maintenance, reduce life-cycle costs,
etc. [
11]. Hence, it is important to sense the condition of the engine. Many existing research works have been carried out to realize CM. Among the available methods, one of the most promising technologies is Prognostics and Health Management (PHM). PHM has been applied in industrial systems [
12,
13] and avionics systems [
14,
15]. For the aircraft engine, PHM can provide failure warnings, extend the system life,
etc. [
16].
In summary, PHM methods can be classified into three major categories: model-based method, experience-based method, and data-driven method [
17]. If the system can be represented by an exact model, the model-based method is applicable [
18]. However, it is difficult for the accurate model to be identified in many practical applications. Hence, the model-based method is difficult to be put into use for complex systems [
19]. For the experience-based approach, the stochastic model is necessary, which is often not accurate for complex systems [
20]. Compared with the model-based method and the experience-based method, the data-driven method utilizes the direct data collected by instruments (most are based on sensors) and has become the primary selection for complex systems [
21,
22]. Many sensors are deployed on or inside the engine to sense various physical parameters (e.g., operation temperature, oil temperature, vibration, pressure,
etc.) [
23]. The operational, environmental and working conditions of the aircraft engine can be monitored by utilizing these sensors.
The aim of CM is to identify the unexpected anomalies, faults, and failures of the system [
24]. In theory, more sensor data are more helpful for CM. However, too many sensors will bring a large amount of data processing, system costs,
etc. [
11]. Therefore, one typical strategy is to select some sensors which can provide better CM results. One common method is to observe the degradation trend of sensor data [
25,
26]. Then, the appropriate sensors will be selected for CM. In our previous work [
27], one metric based on information theory for sensor selection has been proposed. This article is the extension of our previous work [
27] and aims at discovering the correlation between sensor selection strategy and data anomaly detection. Reasonable sensor selection can be considered as how to choose data for CM. The correctness of sensed data is significant for the system CM. The influence of sensor selection strategy on data anomaly detection is studied in this article. In this way, the correctness of condition data can help enhance the result of fault diagnosis and failure prognosis. Much work has been carried out for data anomaly detection [
28,
29,
30]. However, to the best of our knowledge, there is no work that considers the influence of sensor selection strategy on data anomaly detection.
To prove the correlation between sensor selection strategy and data anomaly detection, we first select the sensors that are more suitable for system CM. The methodology is based on information theory and the details can be found in our previous work [
27]. Then, mutual information is utilized to weight the dependency among sensors. In the domain of probability theory, mutual information is one type of method for correlation analysis and is an effective tool to measure dependency between random variables [
31]. It complies with the motivation of our study. To prove the influence of sensor selection strategy on data anomaly detection, mutual information is utilized to find the target sensor and the training sensor.
Then, the classical Gaussian Process Regression (GPR) is adopted to detect the target sensor data anomalies [
32]. The parameters of GPR are calculated by the training sensor data. The target sensor data is detected by the trained GPR. For evaluation, the sensor data sets that are provided by the National Aeronautics and Space Administration (NASA) Ames Research Center for aircraft engine CM are utilized. The experimental results show the effectiveness of reasonable sensor selection on data anomaly detection. The claimed correlation between sensor selection strategy and data anomaly detection is one typical problem in the engineering system. The insights founded by the proposed method are expected to help provide more reasonable CM for the system.
The rest of this article is organized as follows.
Section 2 introduces the aircraft engine which is utilized as the CM target.
Section 3 presents the related theories, including information theory, GPR, and anomaly detection metrics.
Section 4 illustrates the detailed evaluation results and analysis.
Section 5 concludes this article and points out the future works.
2. Aircraft Engine for Condition Monitoring
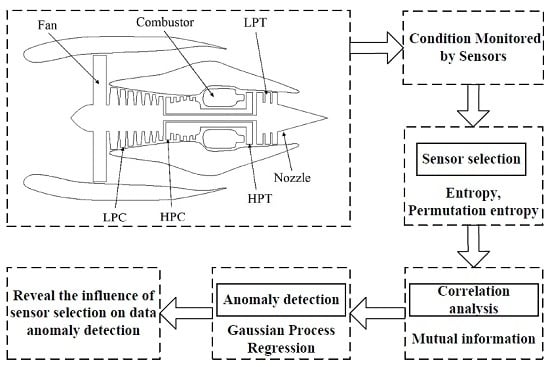
The turbofan aircraft engine is utilized as the objective system in this study. An important requirement for an aircraft engine is that its working condition can be sensed correctly. Then, some classical methodologies can be adopted to predict the upcoming anomalies, faults or failures. The typical architecture of the engine is shown in
Figure 1 [
33]. The engine consists of Fan, Low-Pressure Compressor (LPC), High-Pressure Compressor (HPC), Combustor, High-Pressure Turbine (HPT), Low-Pressure Turbine (LPT), Nozzle,
etc.
The engine illustrated in
Figure 1 is simulated by C-MAPSS (Commercial Modular Aero-Propulsion System Simulation). C-MAPSS is a simulating tool and has successfully been utilized to imitate the realistic work process of a commercial turbofan engine. Regarding operational profiles, a number of input parameters can be edited to realize expected functions.
Figure 2 shows the routine assembled in the engine.
The engine has a built-in control system, which includes a fan-speed controller, several regulators and limiters. The limiters include three high-limit regulators that are used to prevent the engine from exceeding the operating limits. These limits mainly include core speed, engine-pressure ratio, and HPT exit temperature. The function of regulators is to prevent the pressure going too low. These situations in C-MAPSS are the same as the real engine.
The aircraft engine directly influences the reliability and the safety of the aircraft. Therefore, the unexpected conditions of the engine should be monitored. The reliability can be understood from three factors. First, the failure of the main components (LPC, HPC, Combustor, etc.) can lead to the failure of the aircraft engine. Secondly, if the information transmitted to actuators is faulty, it will cause the failure of the aircraft engine. Finally, the external interferences (e.g., birds striking) can result in the failure of the aircraft engine.
In this article, the condition data of the aircraft engine are the concern and the anomaly detection of the condition data is the focus. To monitor the condition of the engine, several types of physical parameters can be utilized, such as temperature, pressure, fan speed, core speed, air ratio,
etc. A total of 21 sensors are installed on or inside different components of the aircraft engine to collect its working conditions, as illustrated in
Table 1. The deterioration and faults of the engine can be detected by analyzing these sensors data [
34].
4. Experimental Results and Analysis
In this section, we first present the overview of the sensor data for CM of the aircraft engine. The suitable sensors for CM are first selected. Then, the most related sensors are carried out the following data anomaly detection. The framework of sensor selection and data anomaly detection is shown in
Figure 4.
After the system condition collected by pre-deployed sensors, the sensor data sets can be utilized for the following analysis. The sensor selection strategy for CM is based on our previous work. Then, mutual information among sensors is calculated to weight the correlation. The target sensor that will be used for data anomaly detection should be same for the following comparison of detection performance analysis. The sensor that has the largest value of mutual information to the target sensor is used to train GPR. By analyzing the anomaly detection results of the target sensor, the influence of sensor selection strategy on data anomaly detection is proved.
4.1. Sensor Data Description
As introduced in
Section 2, there are 21 sensors that are utilized to sense the engine condition. The experiments are carried out under four different combinations of operational conditions and failure modes [
34]. The sensor data sets of the overall experiments are illustrated in
Table 2.
Each data set is divided into the training and testing subsets. The training set contains run-to-failure information, while the testing set has up-to-date data. In order to evaluate the effectiveness of our method, the data set 1 which has one fault mode (HPC degradation) and one operation condition (Sea Level) is picked first, as shown in
Table 3.
4.2. Sensor Selection Procedure
The sensor selection procedure method is based on our previous work [
27], which is based on the quantitative sensor selection strategy. The procedure includes two steps. First, the information contained in the sensor data is weighted by entropy, as introduced in
Section 3.1.1. Then, the modified permutation entropy is calculated, which only considers the 2! permutation entropy value. The 2! permutation entropy value can be utilized to describe the increasing or decreasing trend of the sensor data. In this way, the sensors which are more suitable for CM will be selected.
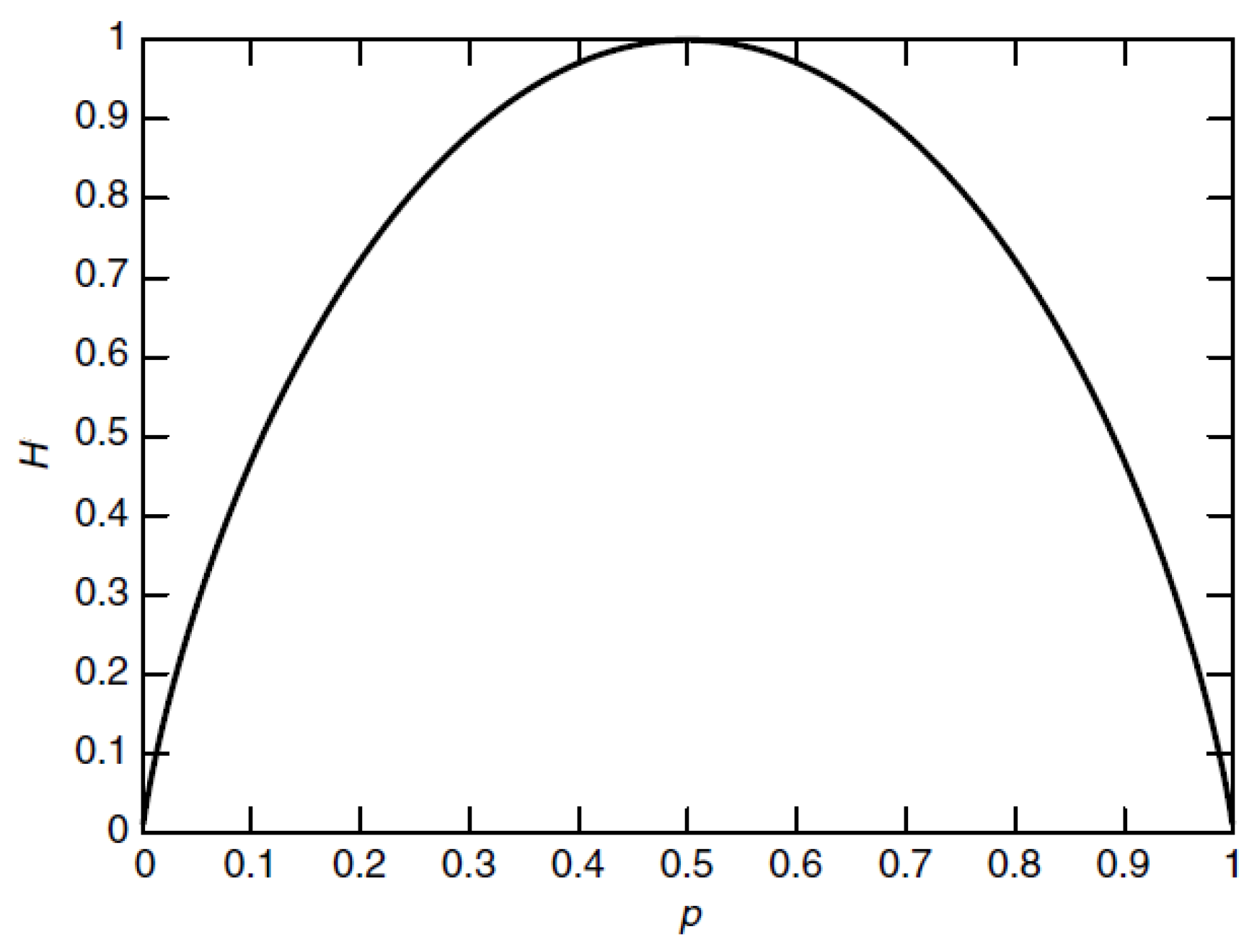
The quantitative sensor selection strategy aims at finding out the information contained in the sensor data sets. The output of every sensor can be considered as one random variable. To measure the information contained in the sensor data, the entropy which calculates the probability of every data is utilized. The larger value of entropy means that the data contains more information, as introduced in
Section 3.1. Then, the suitable sensors for system CM are selected by utilizing the improved permutation entropy that considers the probability of the increasing or decreasing of the two adjacent sensor data. This feature can be utilized to describe the increasing or decreasing trend of the sensor data and is preferred for system CM.
The work in [
25] utilizes the observing sensor selection strategy and selects seven sensors for the aircraft engine CM. The observing method is based on subjective judgement. To improve the effectiveness of the quantitative sensor selection strategy, the number of sensors selected in [
27] is the same as [
25]. In this study, we also adopt the same data set and the same seven sensors as in our previous work [
27] which are #3, #4, #8, #9, #14, #15, and #17. The sensors selected in [
25] are #2, #4, #7, #8, #11, #12, and #15. In the following evaluation, the experiments are carried out between these two groups of sensors to prove the merit of the quantitative sensor selection strategy.
4.3. Data Anomaly Detection and Analysis
In order to evaluate the effectiveness of sensor selection strategy on data anomaly detection, we first calculate the mutual information among the sensors in the two groups, respectively. Mutual information can be utilized to weight the correlation among sensors.
Mutual information values among the sensors selected by the quantitative sensor selection strategy for data set 1 are shown in
Table 4.
Mutual information values among the sensors selected by the observing sensor selection strategy for data set 1 are shown in
Table 5.
To compare the effectiveness of the quantitative sensor selection method with the observing sensor selection method, the testing sensor data should be same and the training sensor data should be different. By analyzing illustrated sensors in
Table 4 and
Table 5, sensor #15 is selected as the target testing sensor. For the quantitative sensor selection, sensor #3 is chosen to be the training sensor. For the observing sensor selection, sensor #2 is chosen to be the training sensor.
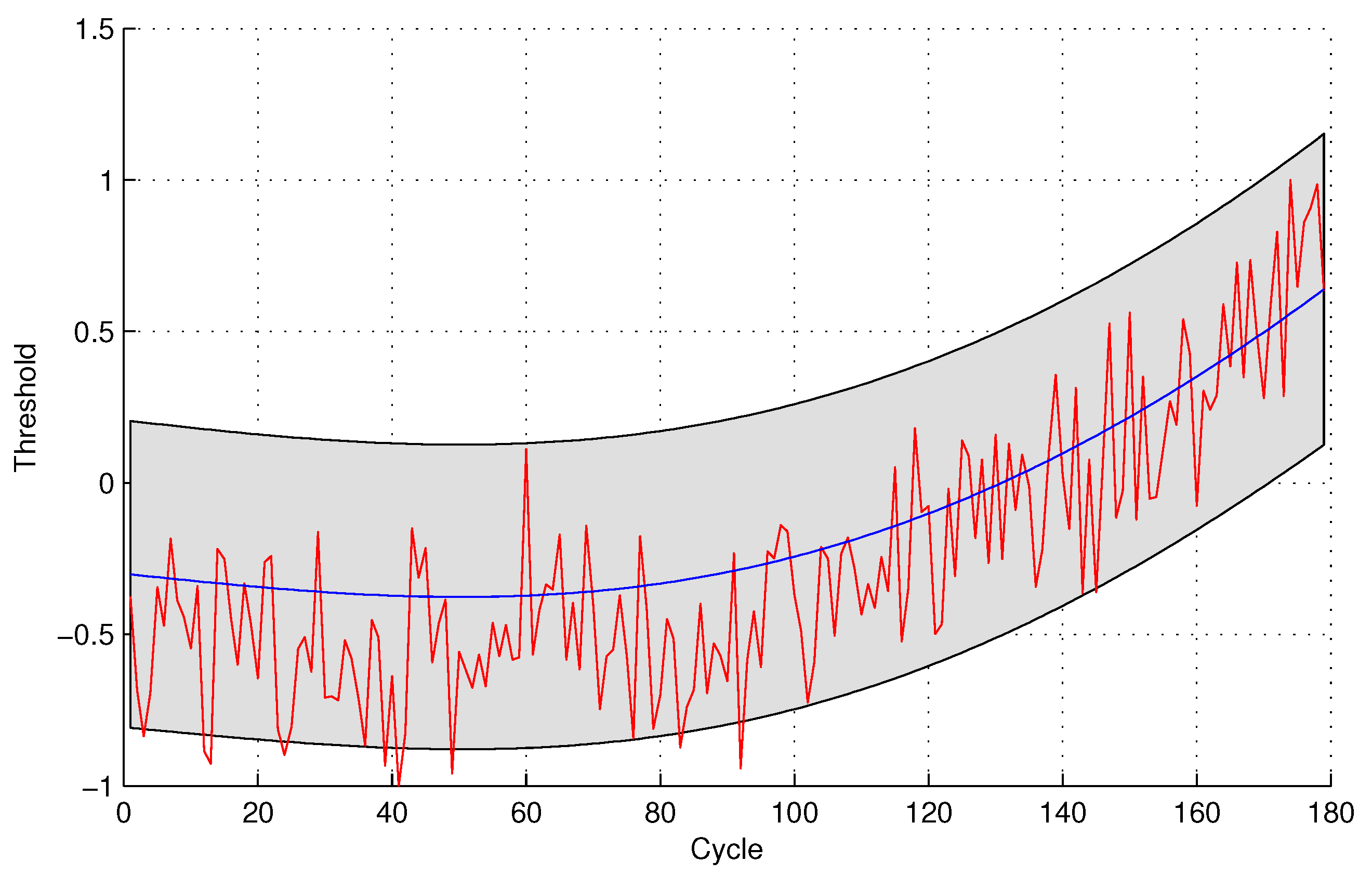
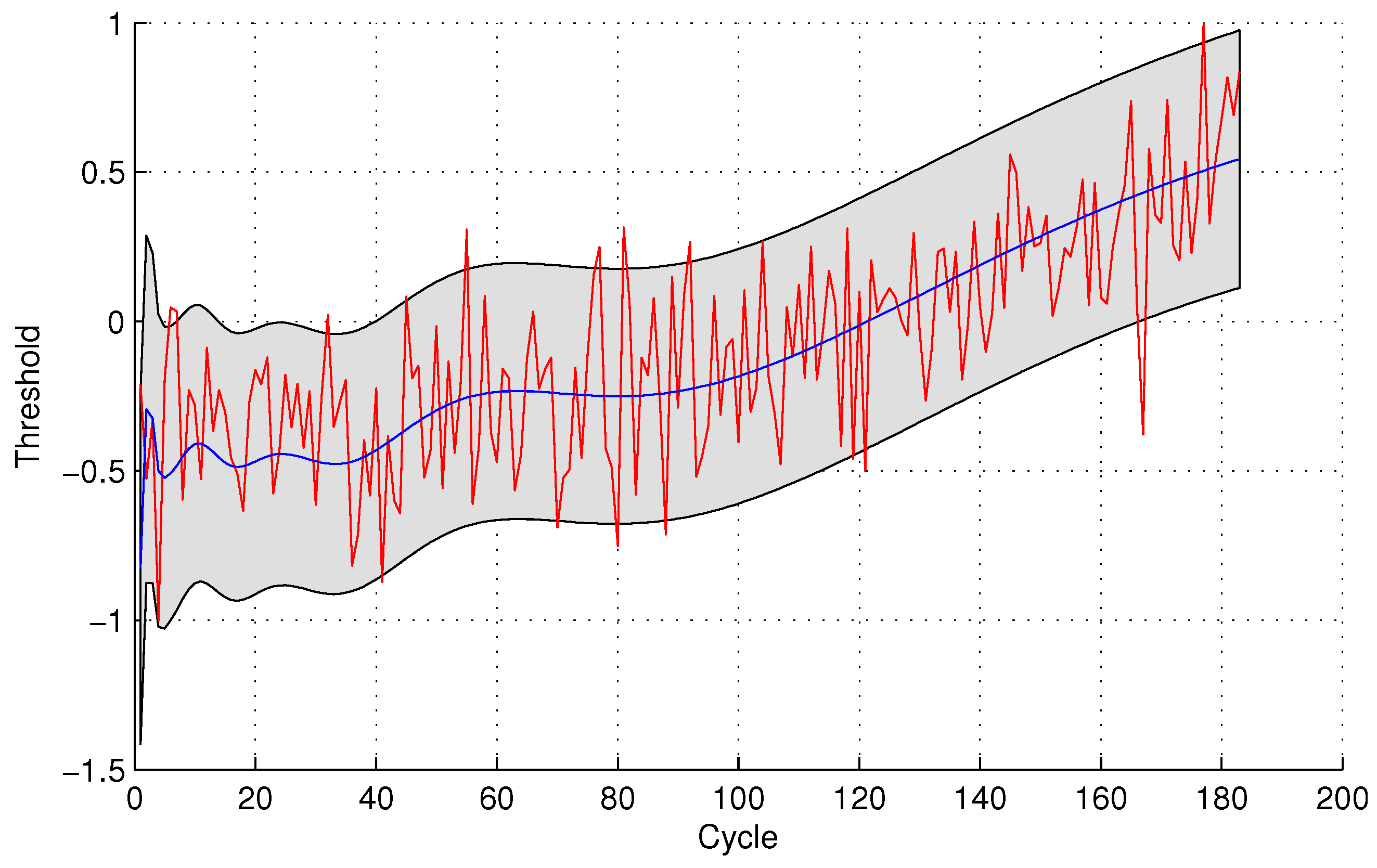
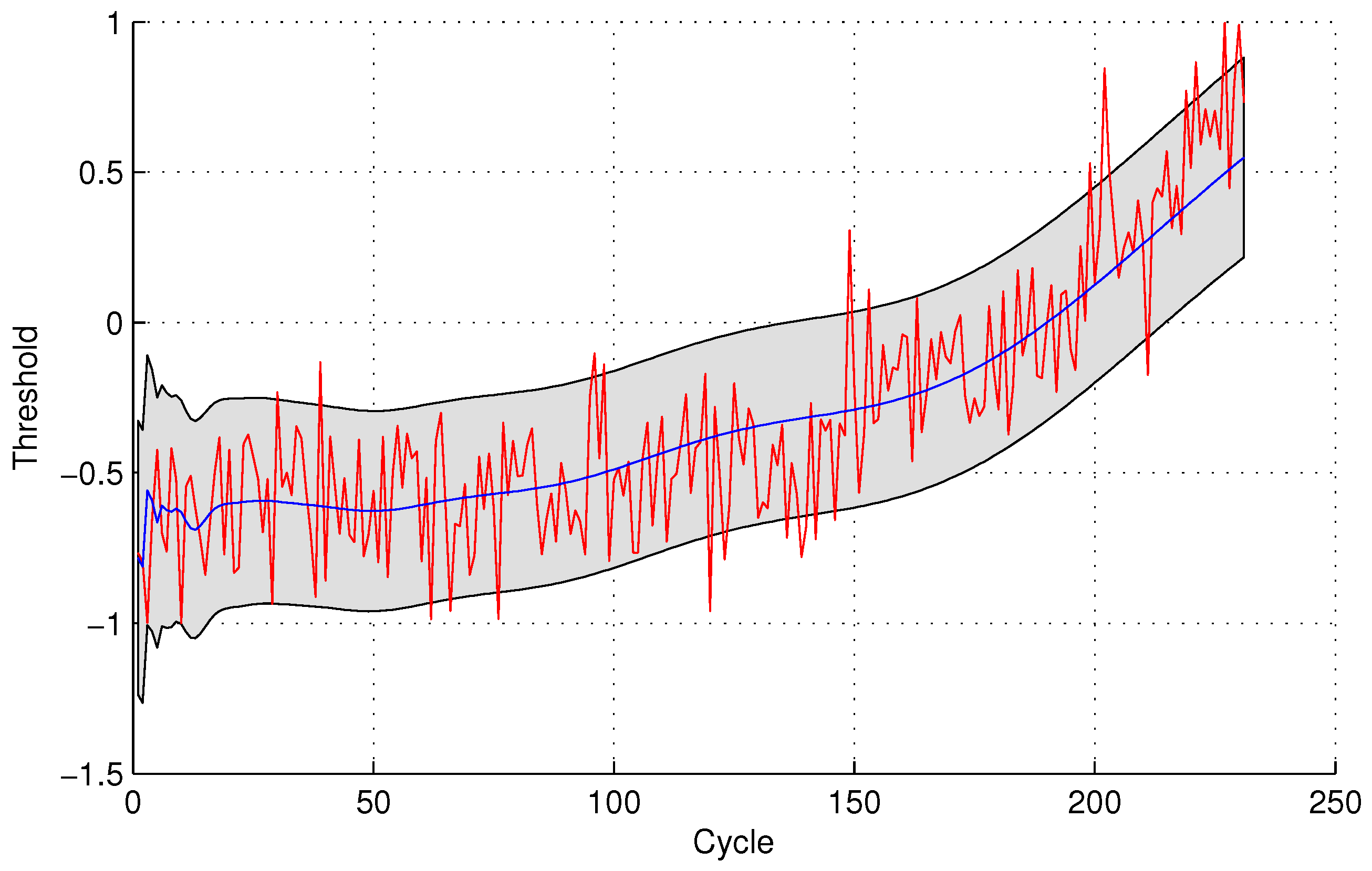
In the following evaluation step, GPR is utilized to detect the testing sensor data. The parameters of GPR are trained by sensor #4 and sensor #3 for the two sensor selection strategies, respectively, due to the maximal mutual information with the same sensor. The experimental results of data anomaly detection for data set 1 are shown in the following
Figure 5 and
Figure 6.
The number of normal sensor data detected as anomalous data is four and 24 for the two methods, respectively. For the quantitative sensor selection strategy, the
of data anomaly detection is
For the observing sensor selection strategy, the
of data anomaly detection is
Another sensor data set is also carried out to evaluate the proposed method. Mutual information values among the sensors selected by the quantitative sensor selection strategy for data set 2 are shown in
Table 6.
Mutual information values among the sensors selected by the observing sensor selection strategy for data set 2 are shown in
Table 7.
The experimental results of data anomaly detection for data set 2 are shown in the following
Figure 7 and
Figure 8.
For the quantitative sensor selection strategy, the
of data anomaly detection is
For the observing sensor selection strategy, the
of data anomaly detection is
To evaluate the effectiveness in further, two additional data sets of another working condition are utilized to carry out the following experiments. For the third data set, mutual information values among the sensors selected by the quantitative sensor selection strategy are shown in
Table 8.
Mutual information values among the sensors selected by the observing sensor selection strategy for data set 3 are shown in
Table 9.
The experimental results of data anomaly detection for data set 3 are shown in the following
Figure 9 and
Figure 10.
For the quantitative sensor selection strategy, the
of data anomaly detection is
For the observing sensor selection strategy, the
of data anomaly detection is
For the fourth data set, mutual information values among the sensors selected by the quantitative sensor selection strategy are shown in
Table 10.
Mutual information values among the sensors selected by the observing sensor selection strategy for data set 4 are shown in
Table 11.
The experimental results of data anomaly detection for data set 4 are shown in the following
Figure 11 and
Figure 12.
For the quantitative sensor selection strategy, the
of data anomaly detection is
For the observing sensor selection strategy, the
of data anomaly detection is
For the quantitative sensor selection strategy, the four values of
are 2.08%, 2.23%, 1.64%, and 7.79%, respectively. For the observing sensor selection strategy, the four values of
are 12.50%, 5.59%, 9.29%, and 10.82%, respectively. In the above mentioned data sets, four pairs of sensor data are selected randomly to implement the data anomaly detection. The values of
are 32.81%, 50.84%, 54.10%, and 25.97%, respectively. To compare the performance of three types of data anomaly detection, the mean and standard deviation of
are calculated, as illustrated in
Table 12.
From the evaluation experimental results, it can be seen that the quantitative sensor selection not only has better values but also the mean and the standard deviation. Therefore, compared with the observing sensor selection strategy and random sensor selection, the performance of the quantitative sensor selection strategy has better performance on data anomaly detection at a certain degree.
Compared with the observing sensor selection strategy and the random sensor selection, the quantitative sensor selection strategy achieves smaller numerical values of . The mean value and the standard deviation value of the quantitative sensor selection strategy are also smaller than the other two methods. The performance of the sensor selection strategy on data anomaly detection is validated at a certain degree. However, the effectiveness needs to be validated further with the involvement of more data, especially the anomalous data.
5. Conclusions
In this article, we present one typical problem in engineering, which is how to select sensors for CM. Compared with the observing sensor selection method, the quantitative sensor selection method is more suitable for system CM and data anomaly detection. The effectiveness is expected to enhance the reliability and performance of system CM. In this way, it can guarantee that the basic sensing information is correct. Therefore, the system reliability can be enhanced further. The method which can be utilized for selecting sensors to carry out anomaly detection is also illustrated. Experimental results with the sensor data sets that are obtained from aircraft engine CM show the correlation between sensor selection strategy and data anomaly detection.
In future work, we will focus on how to utilize multidimensional data sets to carry out anomaly detection. The anomaly detection accuracy is expected to be further improved. Then, the computing resource will be considered, especially for the online anomaly detection and the limited computing resource scenario. The uncertainty about anomaly detection results will also be taken into account. The influence of detection anomaly results for system CM will be evaluated. Finally, the recovery of anomalous data will be considered. The false-alarm produced by CM and the performance on the practical system will also be carried out. and will be utilized for the data sets that include anomalous data and validate the effectiveness of sensor selection on data anomaly detection.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}