1. Introduction
The world population is aging rapidly. As time goes on, the proportion of the elderly relative to the total population has increased, and continues to increase, especially in developed countries [
1]. Thus, helping seniors live a better life is crucial and has great societal benefits. Although the elders have the option of going to nursing homes or hospice care, most of them would prefer to stay in their own houses where they feel more familiar and comfortable. Limited funding for public healthcare services and the shortage of registered nurses are also driving factors for the adoption of a home-based assisted living paradigm. Therefore, healthy aging at home has become one of the most active research areas [
1], especially the problem of abnormal activity detection [
2,
3,
4,
5]. The elderly living alone in isolated areas have been in need of emergency attention, and in the worst cases, some were found dead in their homes [
6].
Traditionally, abnormal activity detection approaches use cameras to obtain the data of full human body movements [
7]. However, there are challenging issues in vision-based methods, such as computational complexity in image processing, data consistency under different illumination conditions, and privacy infringement of the human target [
8]. These problems make the practical deployment of vision-based systems difficult. An alternative method is to collect sensing data from wearable motion sensors and detect abnormal activities based on the collected sensing data [
2]. Although motion sensors worn on the human body or integrated into human clothing can collect motion data with much less volume of data compared to those from vision-based systems, such wearable devices may make the human subject feel obtrusive. In addition, the elders are prone to forget wearing the devices after they change clothes. In addition, having to recharge the wearable devices regularly, even after deliberate design of power management units, is inconvenient for the user [
2]. In order to serve as a reliable and robust abnormal activity detection system for the elderly living alone, the following factors should be considered:
robust to the change of environment, especially the light illumination;
protective to the residents’ privacy;
convenient to use, especially for the elderly.
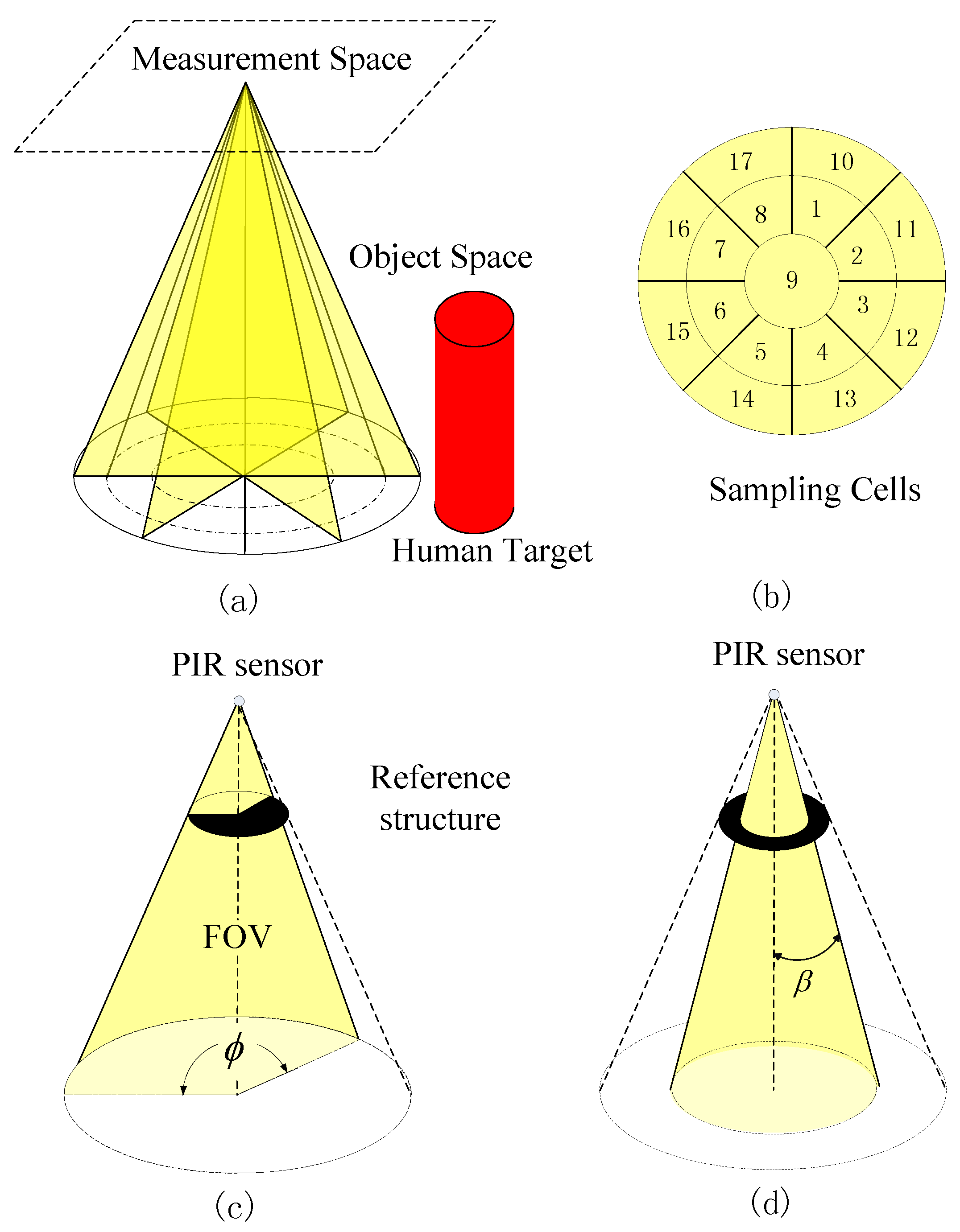
Bearing those factors in mind, a Pyroelectric Infrared (PIR) sensing paradigm offers a promising alternative to the optical and wearable counterparts [
3]. PIR sensors are non-intrusive sensors and only sensitive to the infrared radiation changes induced by human motion, which makes them robust to interference caused by clustered background and illumination variance. In addition, as PIR sensors are relatively cheap and can be embedded within home environments, such as ceiling-mounted deployment, they are suitable to be used for home-based assisted living.
However, there are some challenges facing the PIR based sensing system for abnormal behavior detection. The first one is the design of sensor nodes, which are required to capture the spatio-temporal characteristic of the human motion. Furthermore, as the data generated continuously by ambient PIR sensors, there is an increasing demand to analyze those ever-growing sensing data automatically, with little human intervention. Most importantly, the problem of abnormal activity detection is computationally challenging [
4]. Here, we define abnormal activities as events that they have not been expected in advance. Unlike normal activities, the abnormal samples are extremely scarce, or even non-existent. It is impossible to acquire or simulate all kinds of abnormal samples to train the system beforehand.
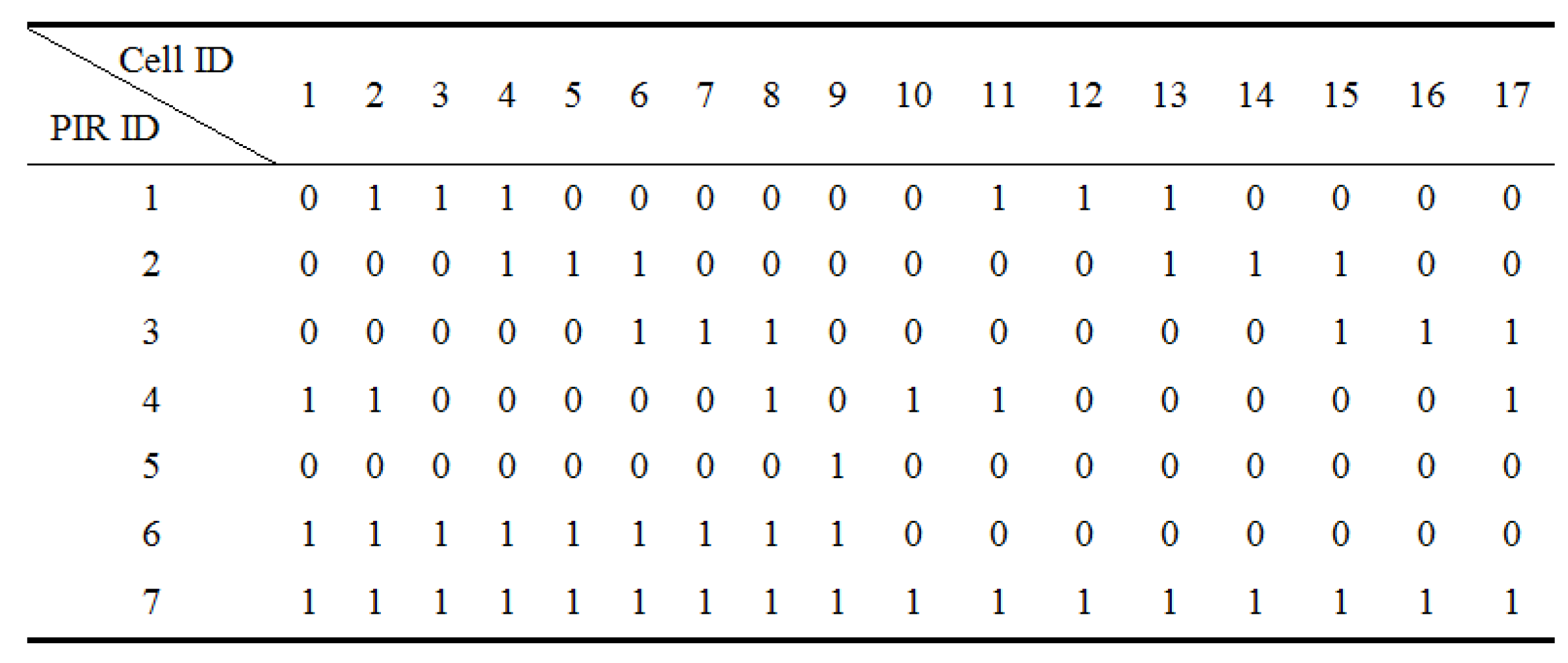
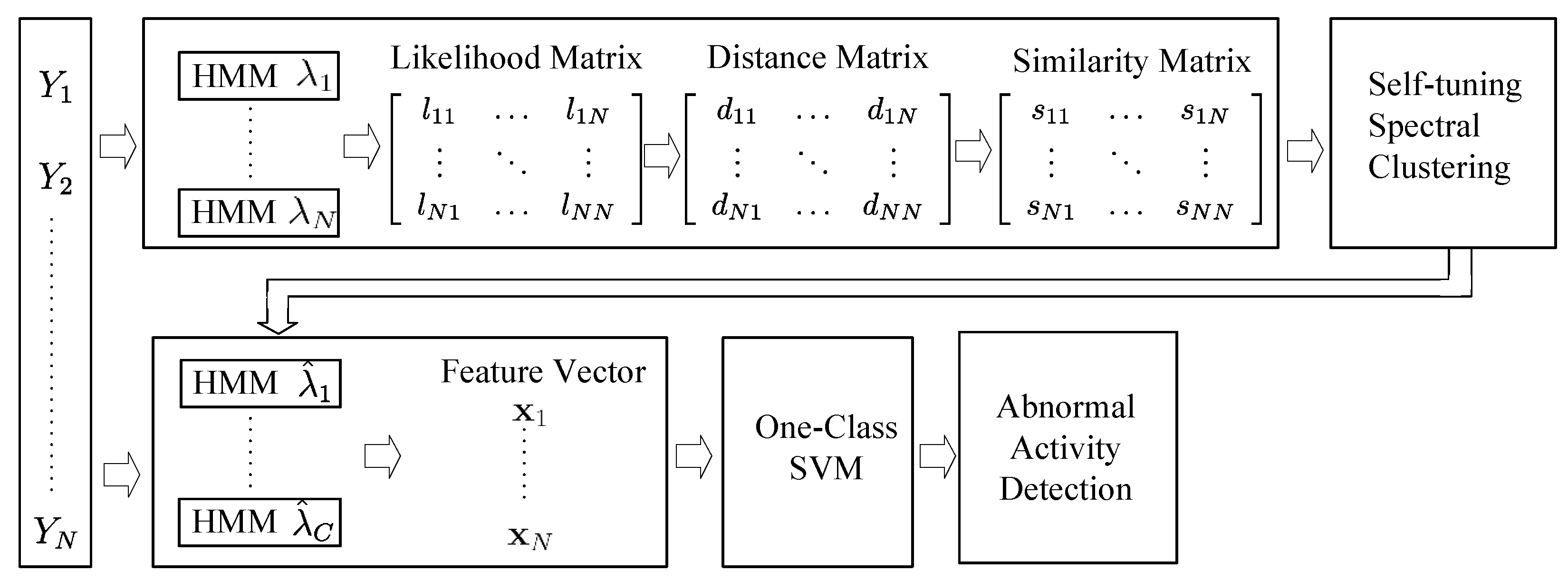
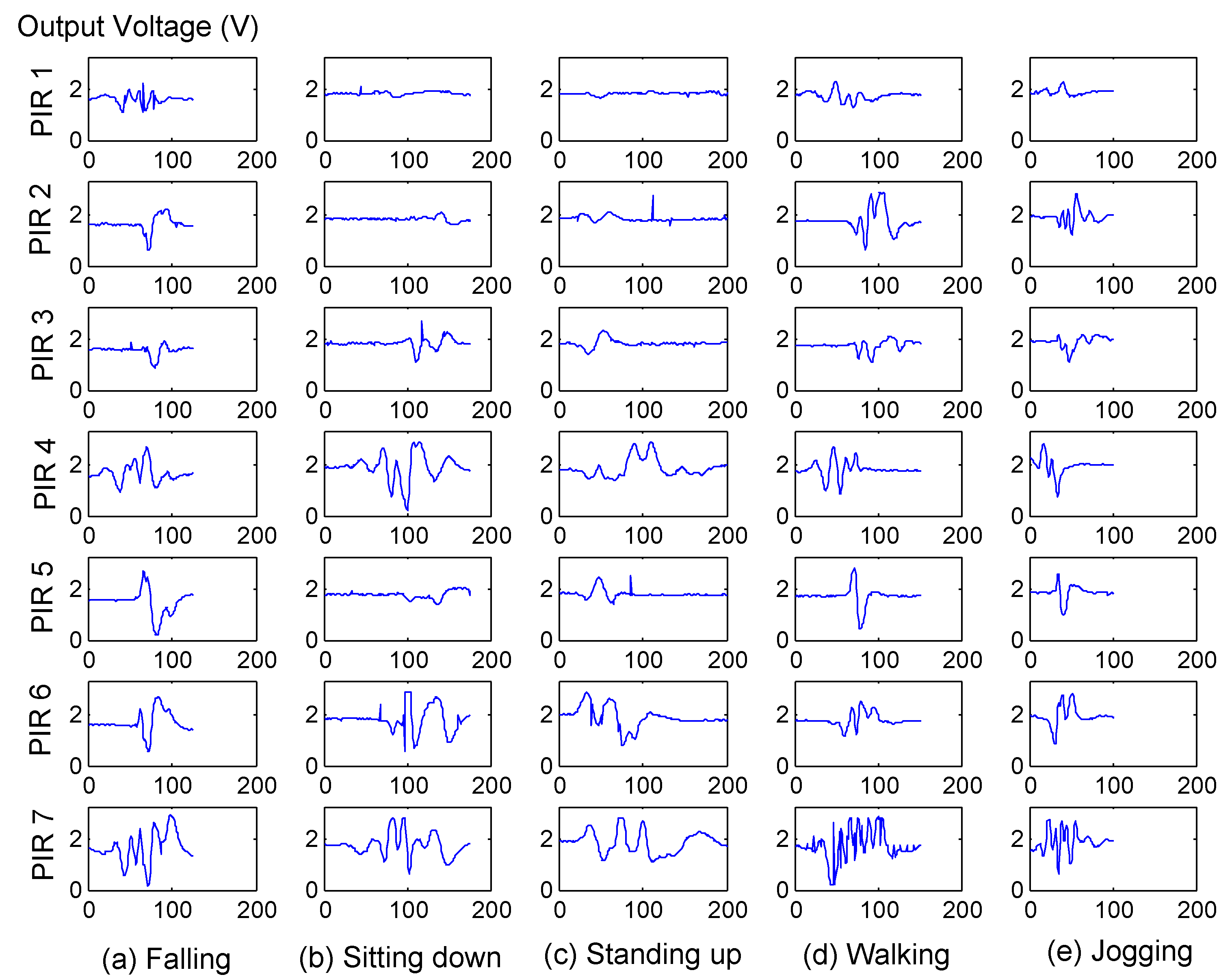
In this paper, we propose a PIR-based sensing system for anomaly detection. We design a PIR sensor node that can capture the spatio-temporal feature of human motion effectively. The key to achieve this target is by leveraging the visibility modulation of each sensor to enhance spatial resolution. We employ the reference structure tomography (RST) paradigm [
9] to segment the Field of View (FOV) of each PIR sensor into sampling cells. Thus, different human activities will generate discriminative spatio-temporal signals under the monitor region. Next, we use the Hidden Markov Models (HMMs) [
10], one kind of generative models, to profile normal activities. Each training sample is modeled by an HMM, and their dissimilarity is calculated based on the Kullback–Leibler (KL) divergence [
11]. A self-tuning spectral clustering algorithm is used to cluster similar training samples, without the need to specify the number of cluster and the distance kernel width manually [
12]. Finally, One-Class Support Vector Machines (OSVM) [
13] are setup to profile the normal activities, and any unexpected activities will be classified as anomaly. It is worth pointing out that our system is trained in an unsupervised manner, which aims to avoid the laborious and inconsistent manual data labeling process.
The rest of the paper is structured as follows:
Section 2 introduces the related work.
Section 3 provides the design and implement of the PIR sensors.
Section 4 offers the overview of our proposed method.
Section 5 presents the framework of human activity representation, dissimilarity calculation and clustering.
Section 6 depicts the usage of the OSVM algorithm for abnormal activity detection. The experimental results are provided in
Section 7. Conclusions and future work are given in
Section 8.
2. Related Works
Traditionally, cameras have been used for human activity classification and abnormal activity detection [
14]. The processing of video includes background subtraction, human motion extraction and activity modeling [
15]. The video data streams usually contain tens of thousands of pixels in each frame, and their intensity is easily effected by the change of illumination [
5]. The excessive computational burden and the feeling of privacy intrusion make it difficult to be employed massively in real home environment.
Wearable sensors is another paradigm for anomaly detection. Yin
et al. [
4] propose a two-stage approach for detecting abnormal activities. The first stage is to train an OSVM to model the commonly normal activities, and the second stage is to derive abnormal activity models from the suspicious activities filtered by the first stage. Zhu
et al. [
2] propose using the wearable sensors together with location information provided by the camera to detect abnormal activities. A probabilistic framework is used to model different anomalies, including spatial anomalies, timing anomalies, duration anomalies and sequence anomalies. However, the biggest inconvenience of wearable sensing is that the sensors have to be recharged regularly even after deliberate design of power control units [
2].
PIR sensing is a promising choice besides camera-based and wearable-based sensing. In [
16], three PIR sensor models which are deployed in a hallway are used to detect the movement of eight human targets, including the two moving directions, three distance intervals and three speed levels. PIR sensor models can also be used to construct wireless sensor networks, which are intended to track and recognize multiple human targets [
17]. Using only the binary information obtained by infrared sensors attached to the ceiling of a room, the human positions can be estimated, and even the number of humans in the room changes dynamically [
18].
To capture the spatio-temporal feature of human movement, the monitored region is segmented into discrete sampling cells [
19]. By leveraging the idea of compressive infrared sampling, the FOV of each PIR sensor is modulated by reference structure [
9]. In [
20], PIR sensors were used to extract the spatio-temporal feature of the human motion from the infrared radiation domain. Ten aerobic exercises, 360 examples in total, which were performed in front of the PIR sensor node were recorded, and the nearest neighbor classifier was then used to classify different exercises. Furthermore, they presented a PIR-based compressive classification method for recognizing six typical physical activities [
21]. Similar to the experimental setup in [
16], three sensor models were located on the ceiling, with opposite tripods facing each other. SVM and HMMs were used to evaluate the performance of their system [
21].
PIR sensors are also used to detect abnormal activities, especially fall detection. In [
22], PIR sensors were deployed in a distributed sensing paradigm, which aimed at capturing the synergistic motion patterns of head, upper-limb and lower-limb. The experiment results of fall detection were encouraging. However, their system was side-view, which means it was easily occluded by other objects, and the falls had to occur perpendicular to the FOV of the PIR sensors. In other words, it was view-dependent. To overcome these limitations, Luo
et al. [
3] proposed using the ceiling-mounted PIR sensor array to implement a fall detection system,
SensFall. To achieve fall detection, the normal and abnormal training samples had to be collected beforehand. In other words, it was the supervised machine learning paradigm [
23]. However, the abnormal detection is clearly a cost sensitive problem [
4] because the samples of abnormal behavior were rare, or even non-existent. All types of the anomalies can not be elaborated on in advance. If we can only acquire the sensing data generated from normal activities, how can we train the system for abnormal activity detection automatically? This is the motivation of our study.
In this paper, we propose a PIR sensor based sensing paradigm for abnormal activity detection in an unsupervised fashion. To avoid the laborious and inconsistent manual data labeling process, we propose using the self-tuning spectral clustering algorithm to discover the number of normal activities automatically. The KL divergence is employed to measure the similarity between each pair of normal training samples and construct the similarity matrix. HMMs are then utilized to profile each cluster of training samples, and OSVM is trained to detect abnormal activities. The details of our method will be elaborated on in the following sections.
5. Spectral Clustering
To profile the normal activities in an unsupervised fashion, we employ the spectral clustering method to cluster similar sequences. However, because the lengths of these sequential data are different and vary greatly in value, it is a challenging issue to model these data for better similarity measures.
5.1. Likelihood Matrix Construction
Since the training sequences are generated by a hidden mechanism associated with human’s underlying activities, it is reasonable to model these sequences using a generative model [
27]. In this work, we adopt a set of HMMs to model the training sequences. HMMs are a type of non-deterministic stochastic finite state automata, which are widely employed in signal processing and pattern recognition [
28]. The parameters of a continuous HMM with Gaussian mixture emissions can be represented in the following compact form:
where
π is the initial state probability distribution,
A is the state transition probability distribution,
μ is the mean vector, and Σ is the covariance matrix.
The
ith training sequence
can be presented as the output of
M PIR sensors,
where
is the output of the
jth PIR sensor at time
t,
. By using the Baum–Welch algorithm [
10], we fit
N HMMs, one for each individual sequence
.
To calculate the distance between each pair of these sequences, a probabilistic model-based framework for sequence clustering is proposed in [
29]. The likelihood matrix
, whose
th element is defined as
where
is the
jth sequence,
is the model trained for the
ith sequence, and
is the likelihood of
generated by model
.
5.2. Sequence Distance Measures
After the likelihood matrix is constructed, the original variable-length sequence clustering problem is transformed to a typical similarity-based one. The jth column of represents the likelihood of sequence under each of the trained models. The next step is to define a meaningful distance measure for these sequences.
A popular paradigm is to obtain likelihood-based distances between each pair of sequences [
29]. Based on this work, several other distance measures have been proposed under a similar philosophy [
27,
30,
31]. However, the main limitation of these methods is that they only consider the distance between two sequences each time, not including the global information of the whole set of data. Hence, we propose using the definition of distance measurement from a probabilistic perspective [
32].
We regard the likelihood of each of the sequences under the trained models as samples from the conditional likelihoods of the models given the data, which embeds information from the whole data set [
32]. This gives rise to highly structured distance matrices to give a better performance in comparison with aforementioned distance-based methods [
27,
29,
30,
31].
According to the definition of likelihood matrix , the jth column of can be regarded as the likelihood of the sequence under each of the trained models . These N models can be regarded as a set of “sampled points” from the model space Λ surrounding the HMMs that actually span the data space. Thus, these N trained models become a good discrete approximation to the model space of interest.
If we normalize the likelihood matrix
, which means each column adds up to one, we get a new matrix
whose columns can be regarded as the probability density functions (pdfs) over the approximated model space conditioned on each of the individual sequences:
This interpretation leads to the Kullback–Leibler (KL) divergence, which is a natural choice for the measurement of the dissimilarity between two pdfs. The discrete case of the KL divergence formulation is as follows:
where
and
are two discrete pdfs. Obviously, the KL divergence is not a proper distance because of its asymmetry; a symmetrized version is used as:
Thus, the distance between the sequences
and
can be defined as:
Distances defined this way are obtained according to the patterns created by each sequence in the probability space spanned by different models, and the distance measured between two sequences and involves information related to the rest of the data sequences.
5.3. Similarity Matrix Construction
Before applying a spectral clustering algorithm, the distance matrix
should be transformed into a similarity matrix
. A commonly used procedure is to apply a Gaussian kernel,
where
σ is the scaling parameter controlling the kernel width.
The value of
σ is commonly specified manually, or numerous iteration has to be run for a range of
σ [
33]. However, when the input data includes clusters with different local statistics, a single value of
σ may not work well for all the data. Thus, instead of selecting a single scaling parameter, we propose calculating a local scaling
for each data point
[
12]. The similarity between
to
can be revised as
while the converse is
. Therefore,
is symmetry, and the Equation (10) can be generalized as:
where
,
is the K’th neighbor of
. The selection of
K is independent of scale and is a function of the data dimension of the embedding space.
Thus, the scaling parameters for each pair of and are not fixed; they are determined automatically according to the local statistics of the neighborhoods.
5.4. Self-Tuning Spectral Clustering
After the similarity matrix is constructed, we apply spectral clustering methods to partition the training sequences into clusters. For an undirected graph G with vertices and edges , the matrix could be considered as an adjacent matrix for G, where each element can be viewed as the similarity between the vector and . The target of spectral clustering is to partition the G into a distinct sub-graph.
It is a tricky problem to specify the number of clusters
C. One method to discover the number of clusters is to analyze the eigenvalues of the normalized Laplacian matrix
, which is based on the similarity matrix
. The analysis given in [
33] shows the number of repeated eigenvalues of magnitude 0 with multiplicity equal to the number of clusters
C. However, eigenvalues depend on the structure of the individual clusters, and no assumptions can be placed on their values [
12]. Once noise is introduced, the eigenvalues deviate from the ideal case, and it is difficult to decide the number of clusters.
An alternative approach to discover the number of clusters
C automatically is to analyze the eigenvectors of Laplacian matrix
[
12]. Assume the matrix
is constructed by stacking the largest eigenvectors of
in columns. In the ideal case where the data points could be separated distinctly,
will be strictly block diagonal after sorting the eigenvectors of
. Nevertheless, in the general case, the
’s off-diagonal blocks are non-zero, and the eigensolver could just pick any other set of the orthogonal vectors;
could have been replaced by
for any orthogonal matrix
. Now, we have to recover the rotation which best aligns
’s columns with the canonical system with the minimum cost.
Let
be the matrix obtained after rotating the eigenvector matrix
; that is,
. We wish to recover the rotation
for which, in every row in
, there will be at most one non-zero entry. We thus define the cost function:
where
. Minimizing this cost function over all possible rotations will provide the best alignment with the canonical coordinate system. The number of clusters,
C, is taken as the one providing the minimal cost.
The spectral clustering algorithm that we apply is similar to the one proposed in [
12]. The algorithm works as follows:
Define a diagonal degree matrix with , and then construct the normalized Laplacian matrix .
Find principal eigenvectors and form the matrix by stacking the eigenvectors in columns, where is the largest possible cluster number.
Recover the rotation
which best aligns
’s columns with the canonical coordinate system using the incremental gradient descent algorithm [
12].
According to Equation (
12), grade the cost of the alignment for each group number up to
. Set the final group number
to be the largest group number with minimal alignment cost.
Take the alignment result of the eigenvectors, and assign the original point to cluster c if and only if .
In our experiments, because the voulunteers will emulate five kinds of activities, is set to 10, and the self-tuning spectral clustering will determine automatically.
8. Conclusions
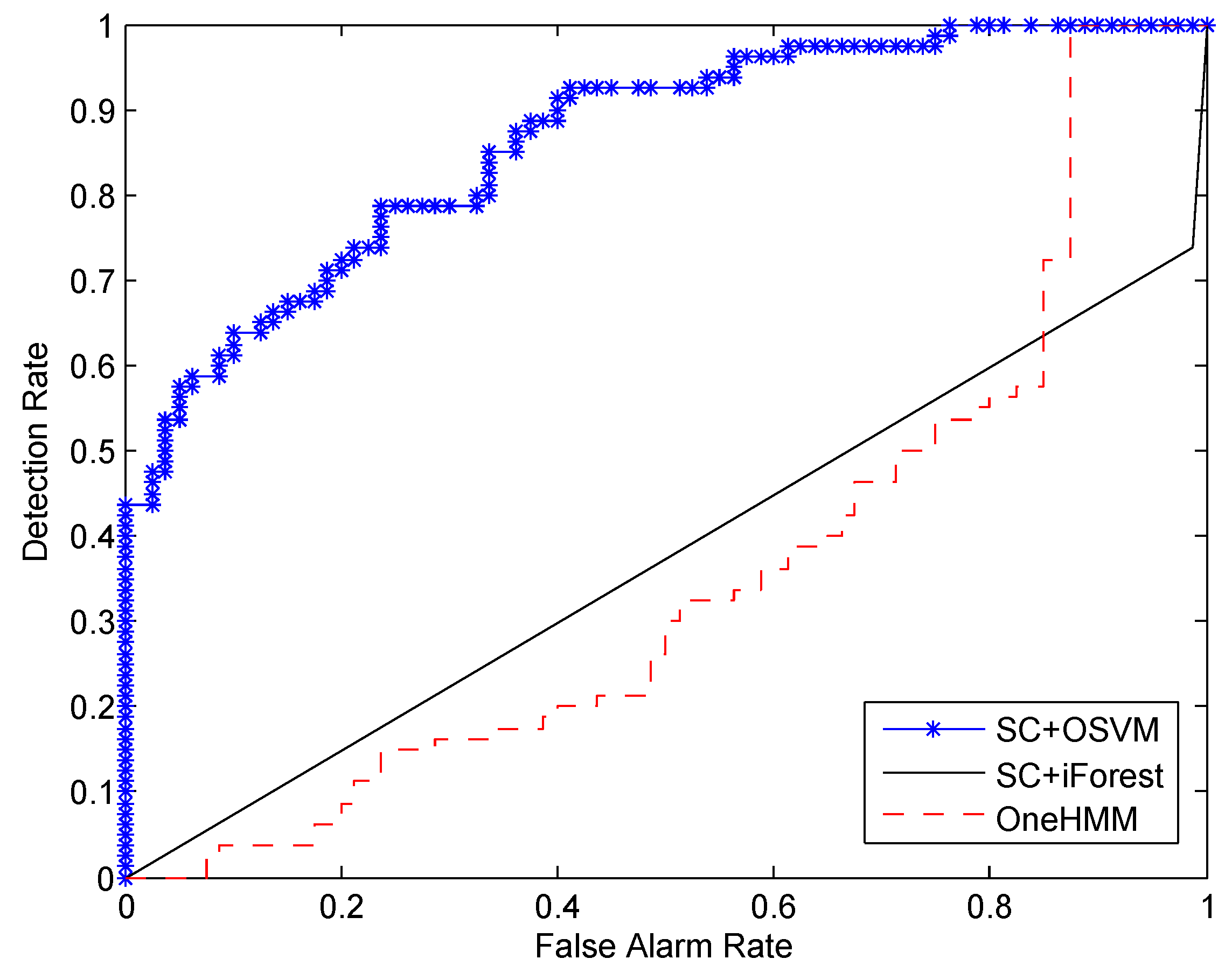
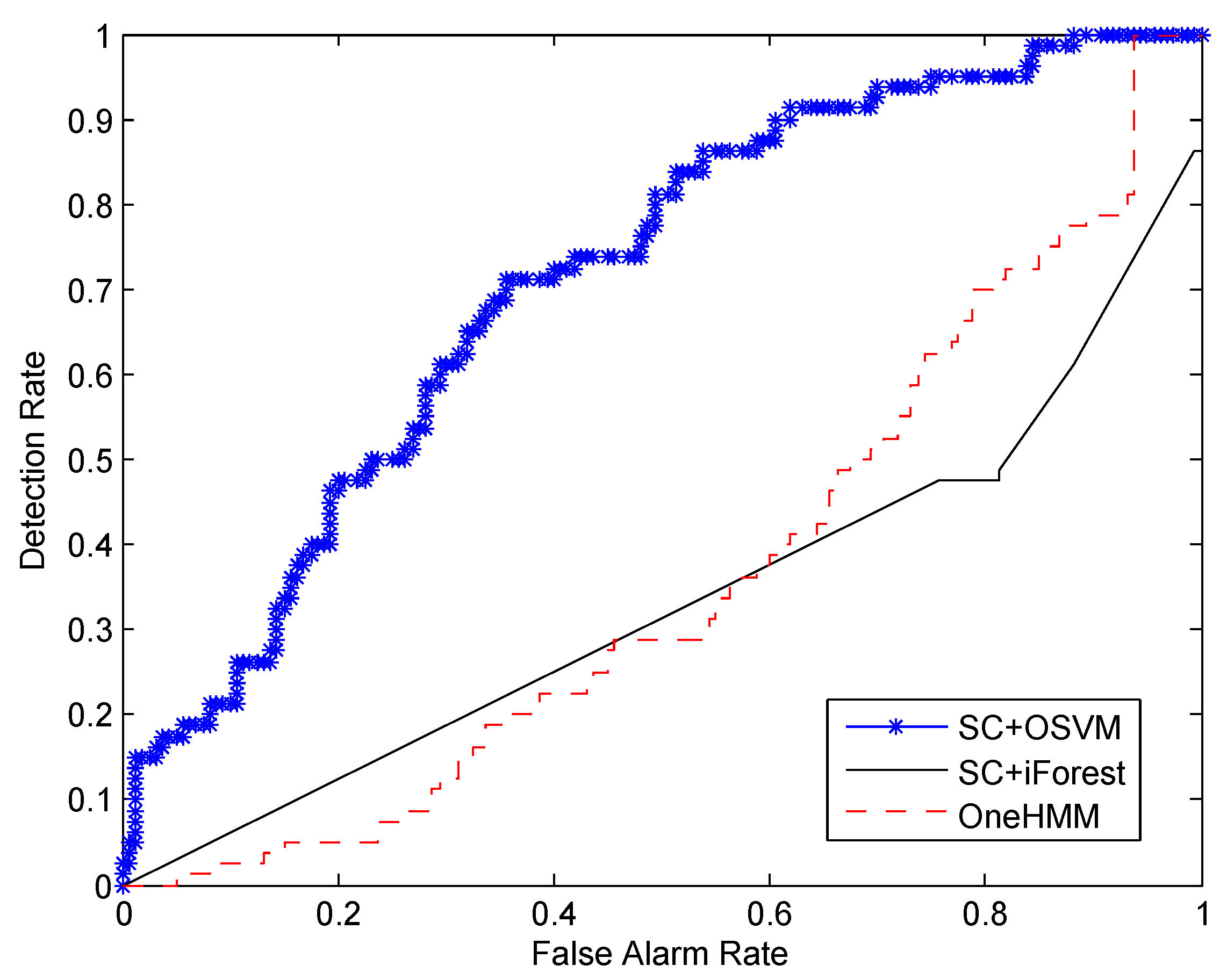
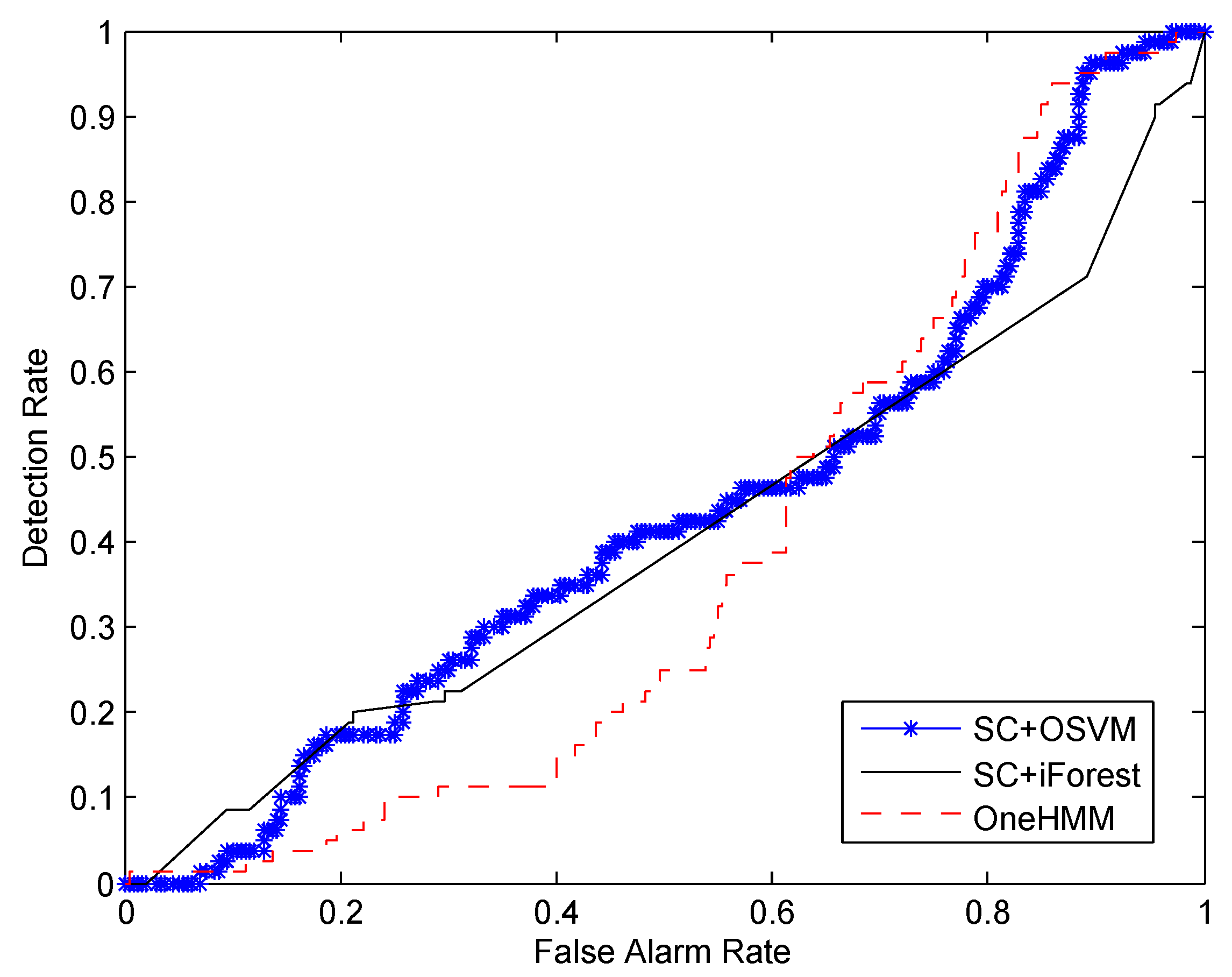
In this paper, we propose a novel approach for detecting a human’s abnormal activities. By employing the FOV modulation for PIR sensors, the human activity is encoded into low-dimensional data streams, which can be used to extract the tempo-spatial feature of the human motion. A self-turning spectral clustering algorithm is used to cluster the training samples with modified KL distance. The HMMs are trained to profile each cluster of activity. One-class SVM is setup to classify whether the testing samples are abnormal or not. A major advantage of our approach is that it does not need abnormal samples for training in advance. This is critical in real deployment because it is unrealistic to train the system by providing all kinds of abnormal activities. Another advantage is that our training procedure is an unsupervised learning fashion, which does not need to specify the number of kinds of normal activities. In other words, it is not necessary to label the training samples. This advantage will facilitate the mass deployment in different locations, and it can greatly reduce the human labor spent on training sample preprocessing. We demonstrate the effectiveness of our approach using real data collected from PIR sensors attached to the ceiling of the monitoring region. It shows that, as the number of training samples increases, the performance of our system will improve accordingly.
In the future, we wish to continue in the direction of detecting abnormal activities from continuous data streams. We will investigate how to incorporate the location information with the motion information to improve the performance of our system. A robust and reliable abnormal activity detection system is the most important prerequisite of the home-based assisted living paradigm.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}