5.3.1. Basic Query Processing
In this subsection, we present how QET exploits a TQ-index for the efficient processing of a basic query.
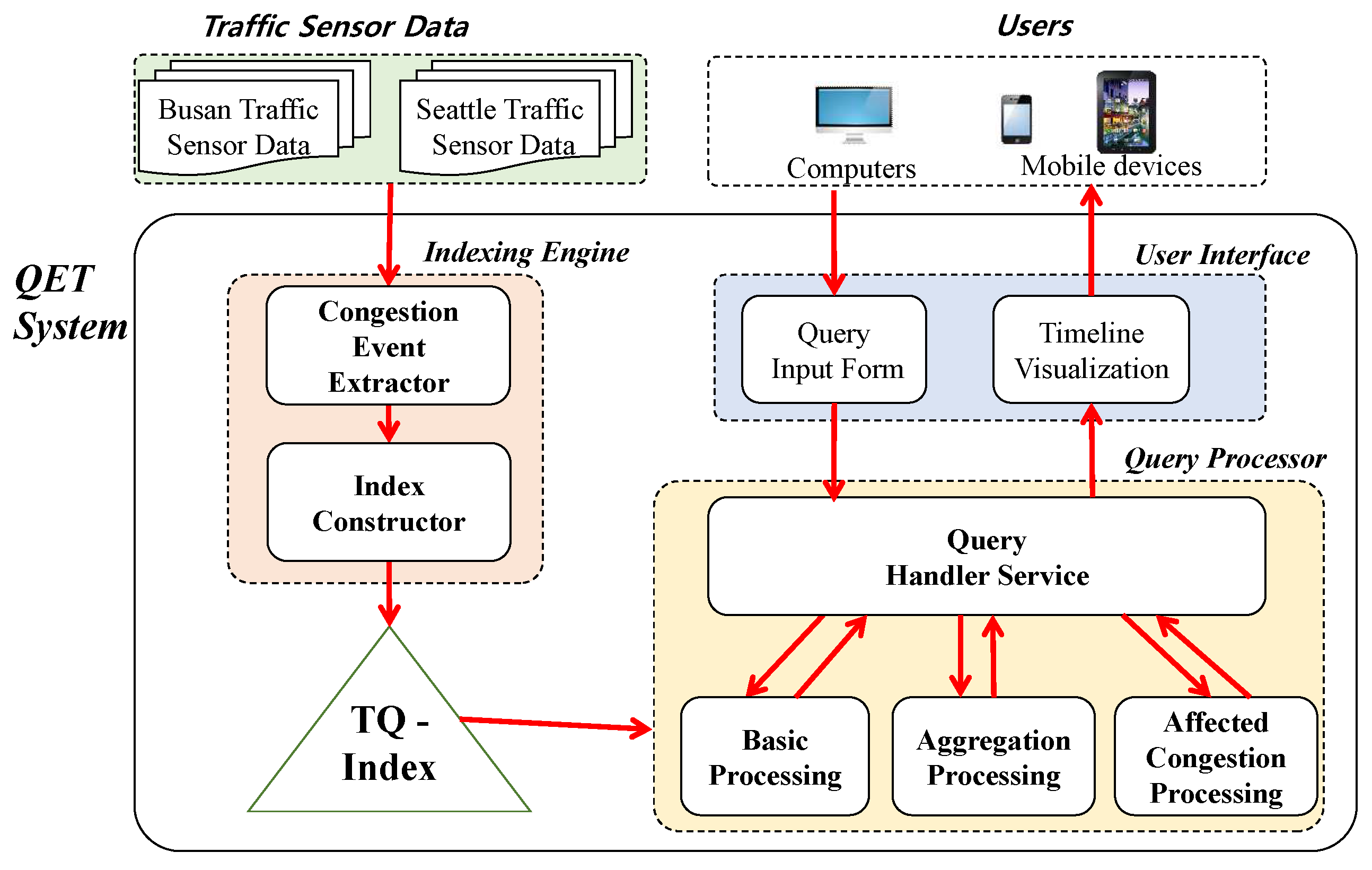
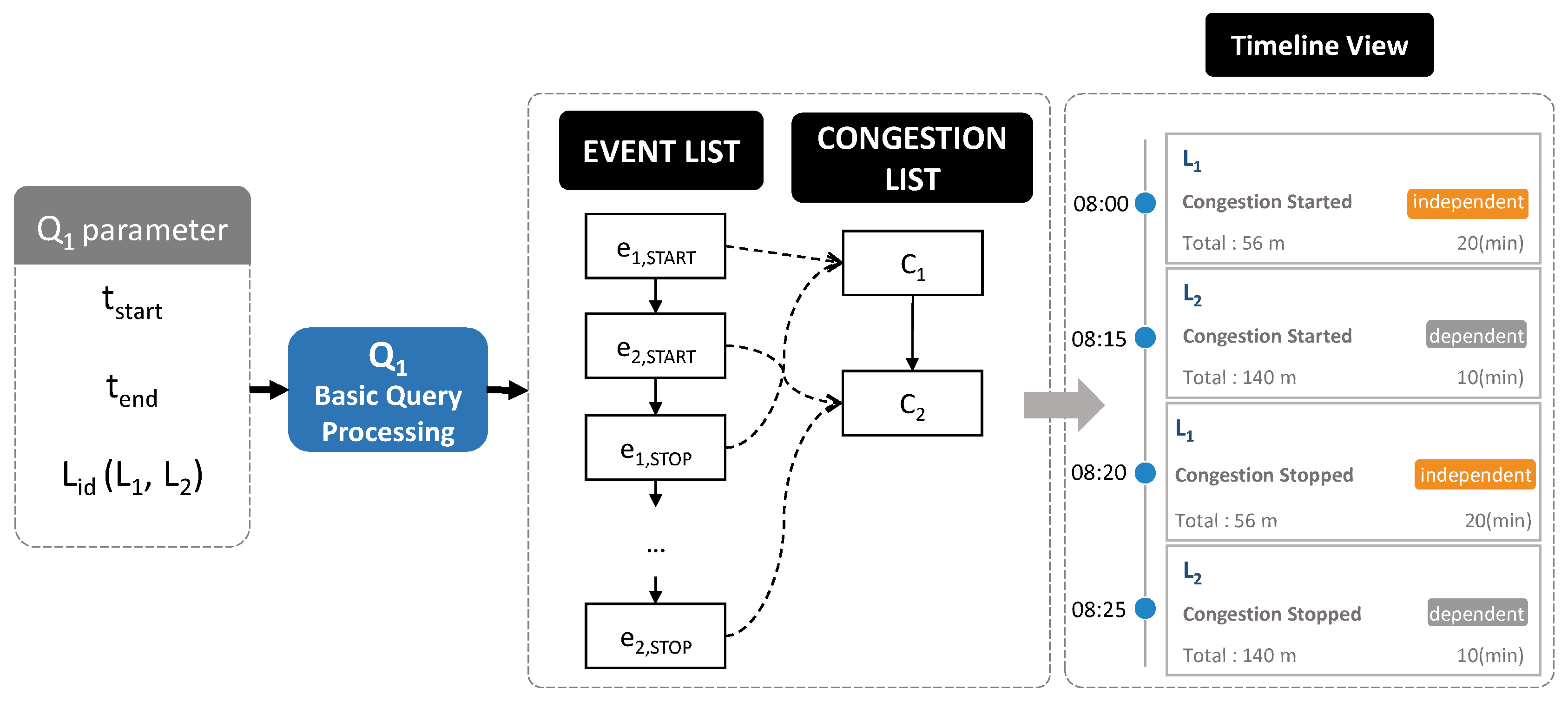
Figure 13 depicts the overview of basic query processing. A user specifies parameters of a query
and returns the timeline model including information about traffic congestion in chronological order. This result is visualized as a timeline view in a web browser.
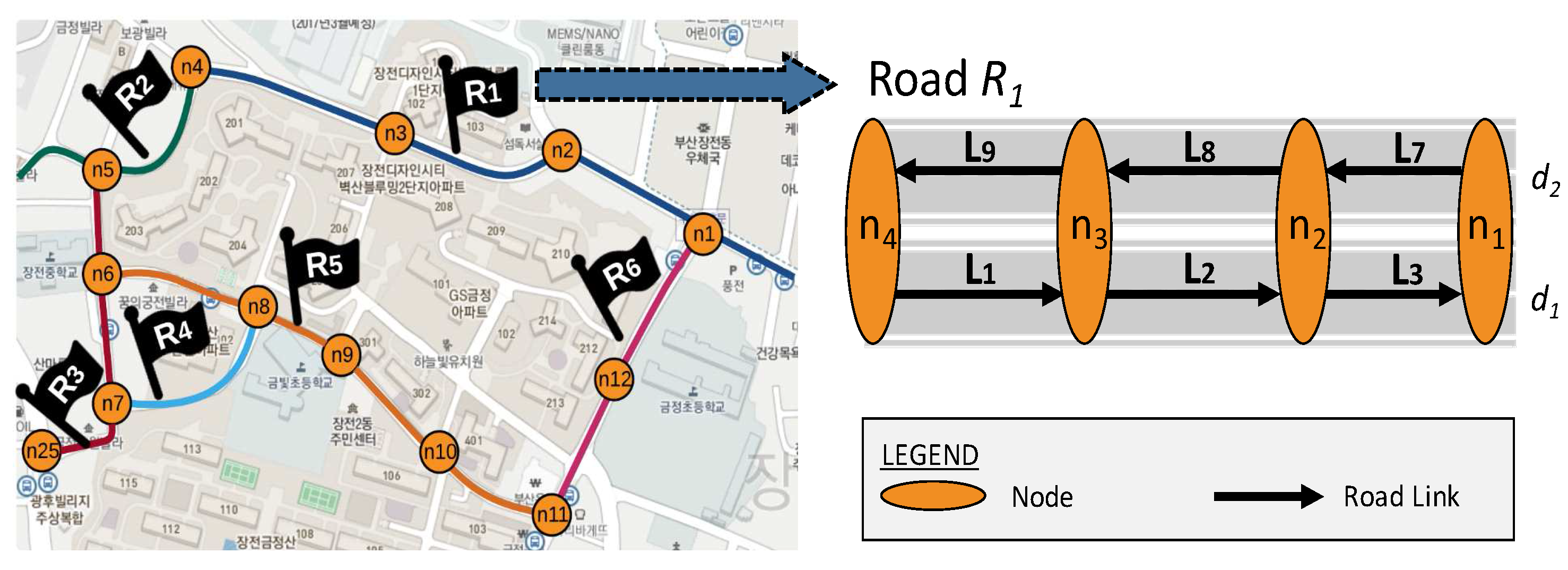
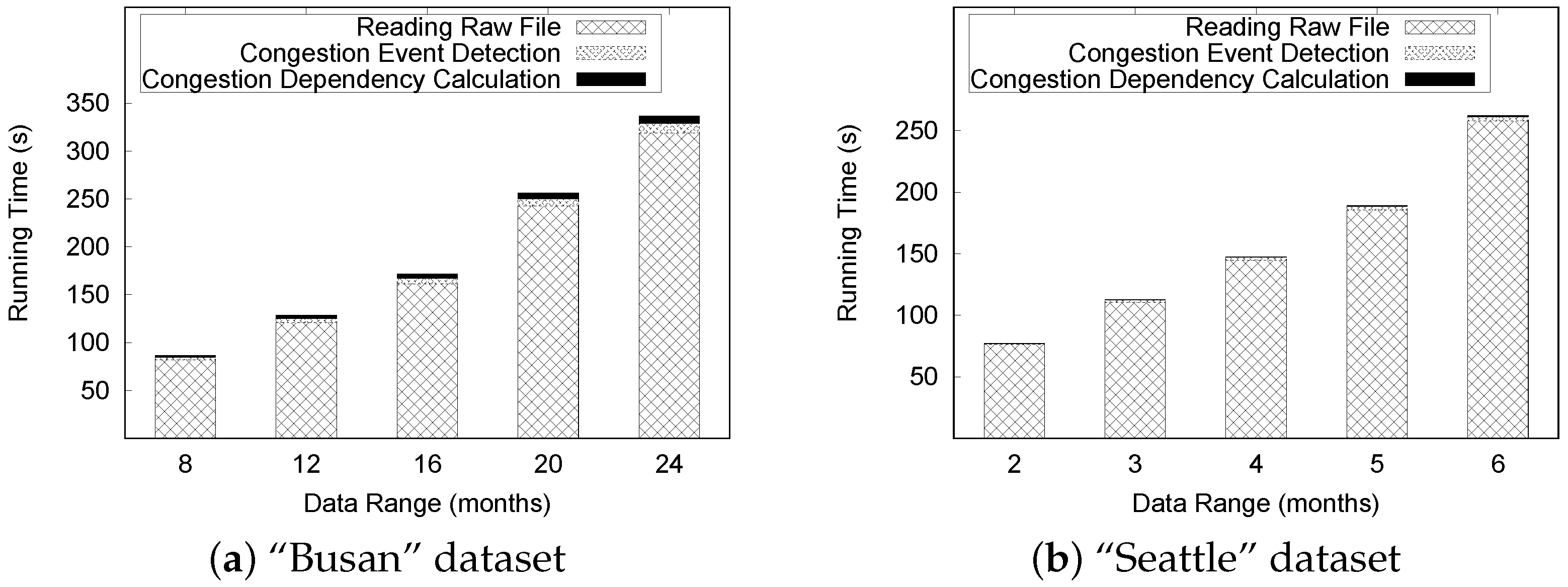
The basic query processing algorithm that identifies the congestion events in specified road links within the given time range is presented in Algorithm 6. A basic query utilizes the location index (
) of a TQ-index to find specified road links from road networks (line 4). Then, the query obtains a time index (
) of the location for locating the
at the given start date (line 5). Once we obtain the starting event (line 6) , we can linearly scan the
through lines 7 to 11. While scanning, we collect a set of related traffic congestion and events that appear within the given start time and end time of the timeline model (line 9).
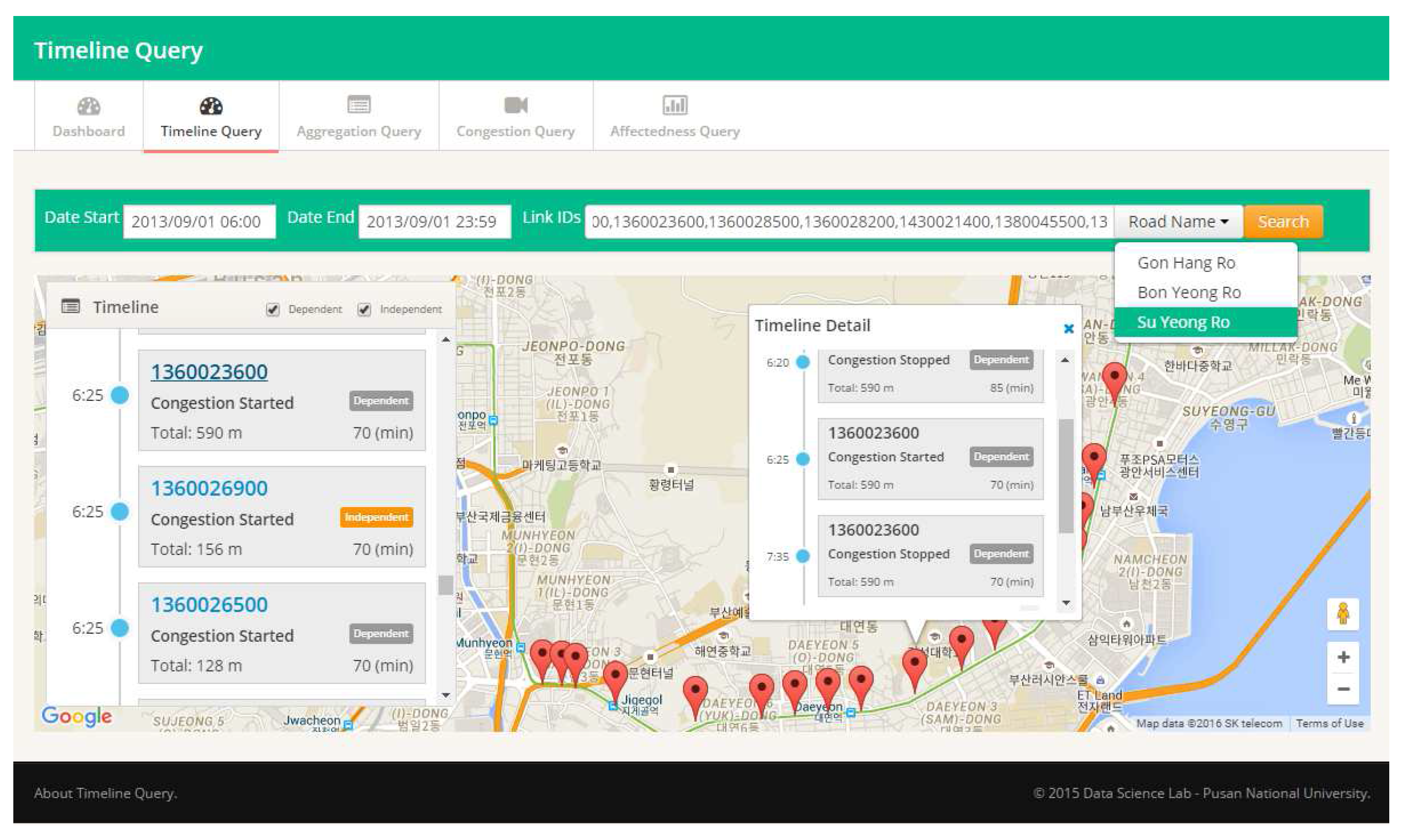
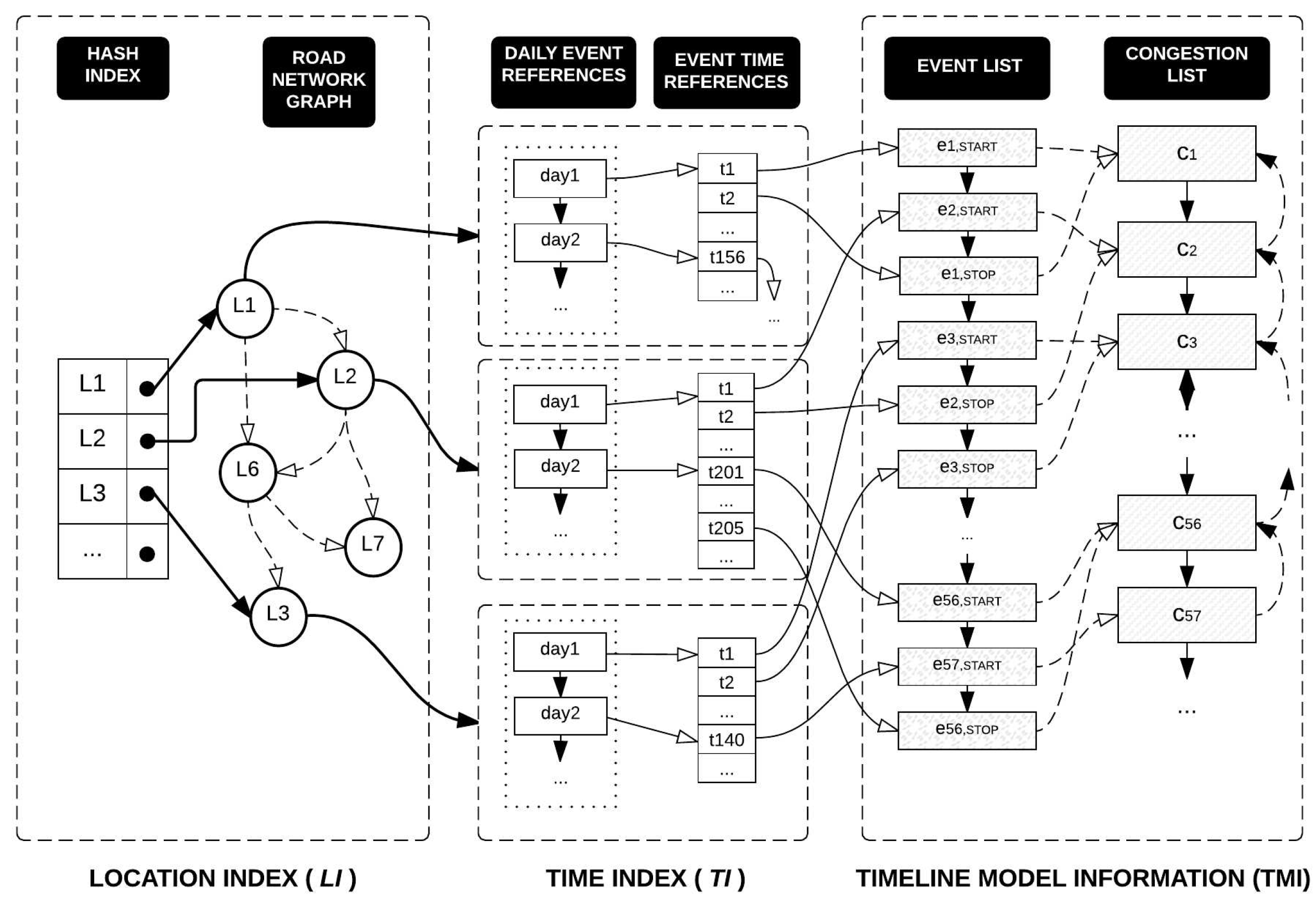
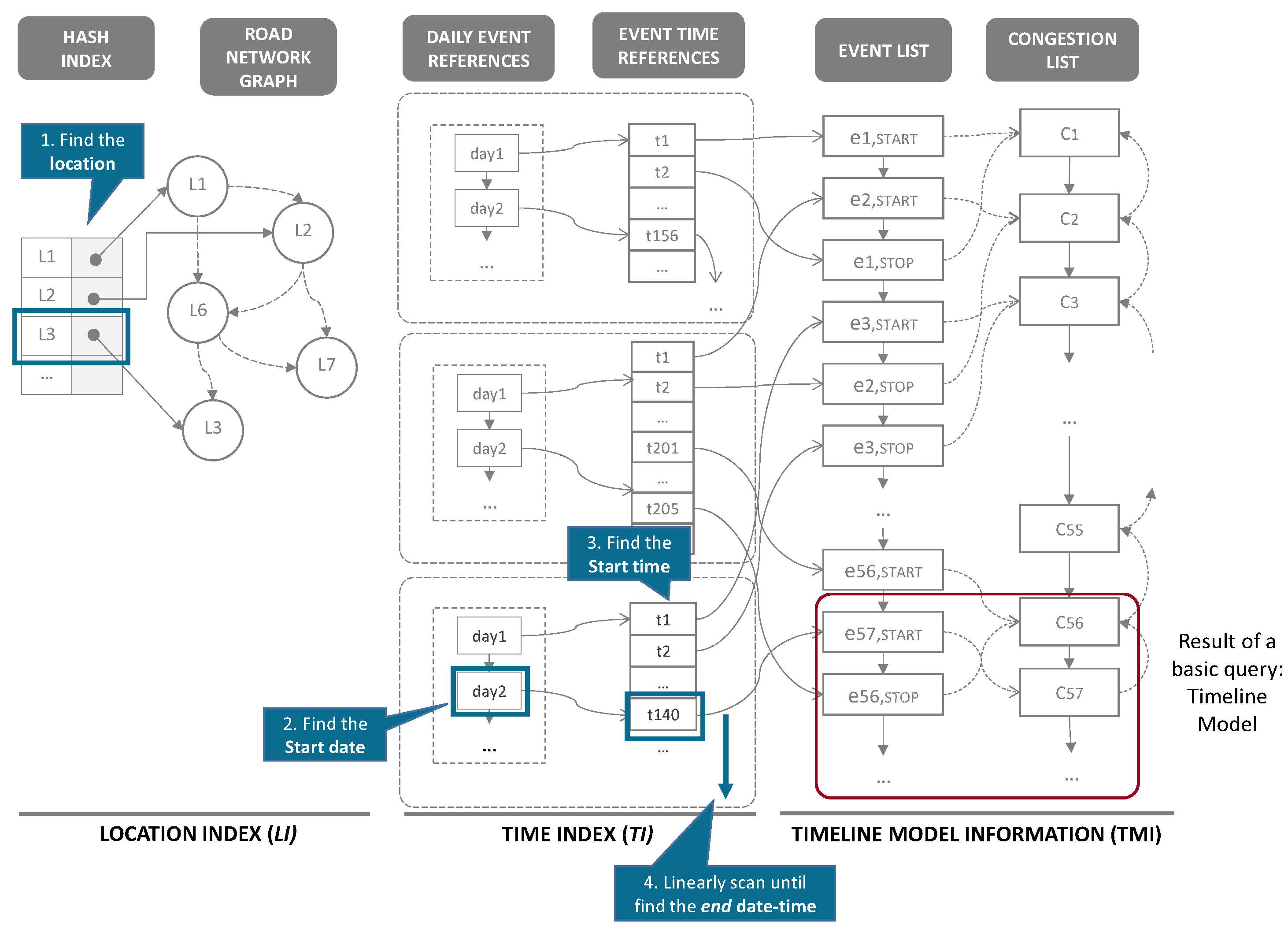
Example 7. Assume that a user specifies identifying congestion events that occur in road link from to . Figure 14 explains how a TQ-index is exploited during the basic query processing. First, we find the road link in (step 1). Then, following the pointer of , we access the to locate the (step 2). In this case, we obtain the starting date point from (step 3). From this list, we can start to scan linearly until we meet the time greater than . While scanning, we also collect a set of traffic congestion and events as a timeline model (step 4). To prove the correctness of Algorithm 6, we use the loop invariant technique [
47]. This approach examines the correctness of the algorithm in three loop stages: (1) initialization; (2) maintenance; and (3) termination.
Theorem 4. With a given start time and an end time as input parameters of a query and a as a pointer to trace EventTimeReferences, algorithm Basic Query Processing is correct with this loop invariant: for any step in the inner loop, this statement is applied: .t , otherwise, the value of the will be more than or it is .
Proof. Inner Loop: Before an iteration is started, a TQ-index is already constructed, and is the LocationIndex of the TQ-index . For each that is defined in the outer loop, the algorithm will find corresponding events that started between and .
Initialization: When the iteration begins by exploiting the time index of , is supposed to be the first node whose time value (denoted as ) is between the given date range and . Otherwise, is supposed to be .
Maintenance: Suppose that at the ith iteration, the cursor is at position j of LocalEventReferences and of is still between and . Then, because the long node at position exists and the , we can update the cursor to position .
Termination: Because is a pointer that points the sorted elements of EventTimeReferences, there will always be the end of EventTimeReferences. At the end of the iteration, could be when it passes the end of EventTimeReferences, or the time of the cursor would satisfy the condition when it passed the matched elements of EventTimeReferences.
Correctness: At the end of the iteration (after termination), would be or the , which is greater than , trivially. ☐
5.3.2. Aggregation Query Processing
An aggregate function is a function that needs a grouping of the values of multiple rows together to provide a single value. Our QET system supports the common aggregate functions, such as SUM, MIN, MAX, COUNT, and AVG for the traffic analytical queries. For example, query
in
Section 1 needs to calculate COUNT values to find the amount of congestion on each road segment in a day and then apply MAX function to the count values. In this case, we use a road segment ID and date as the key for grouping. Another example is query
in
Section 1, which needs to keep the longest duration of congestion in a day by applying the MAX function.
Algorithm 7 describes the detailed steps for aggregation query processing. This algorithm begins by obtaining a timeline model from basic query processing (line 2). Then, we retrieve a list of traffic congestion from the timeline model (line 3). There are two iterations in the next steps. The first iteration groups congestion list
C based on the given key (lines 5 to 8). Then, the second iteration invokes AggregateFunction with a grouped set of congestion events as the parameter. The result of this function is aggregated values of the given set of congestion added into the aggregated value list (lines 10 to 13). Then, we sort the aggregated value list and return this list as the output of the algorithm.
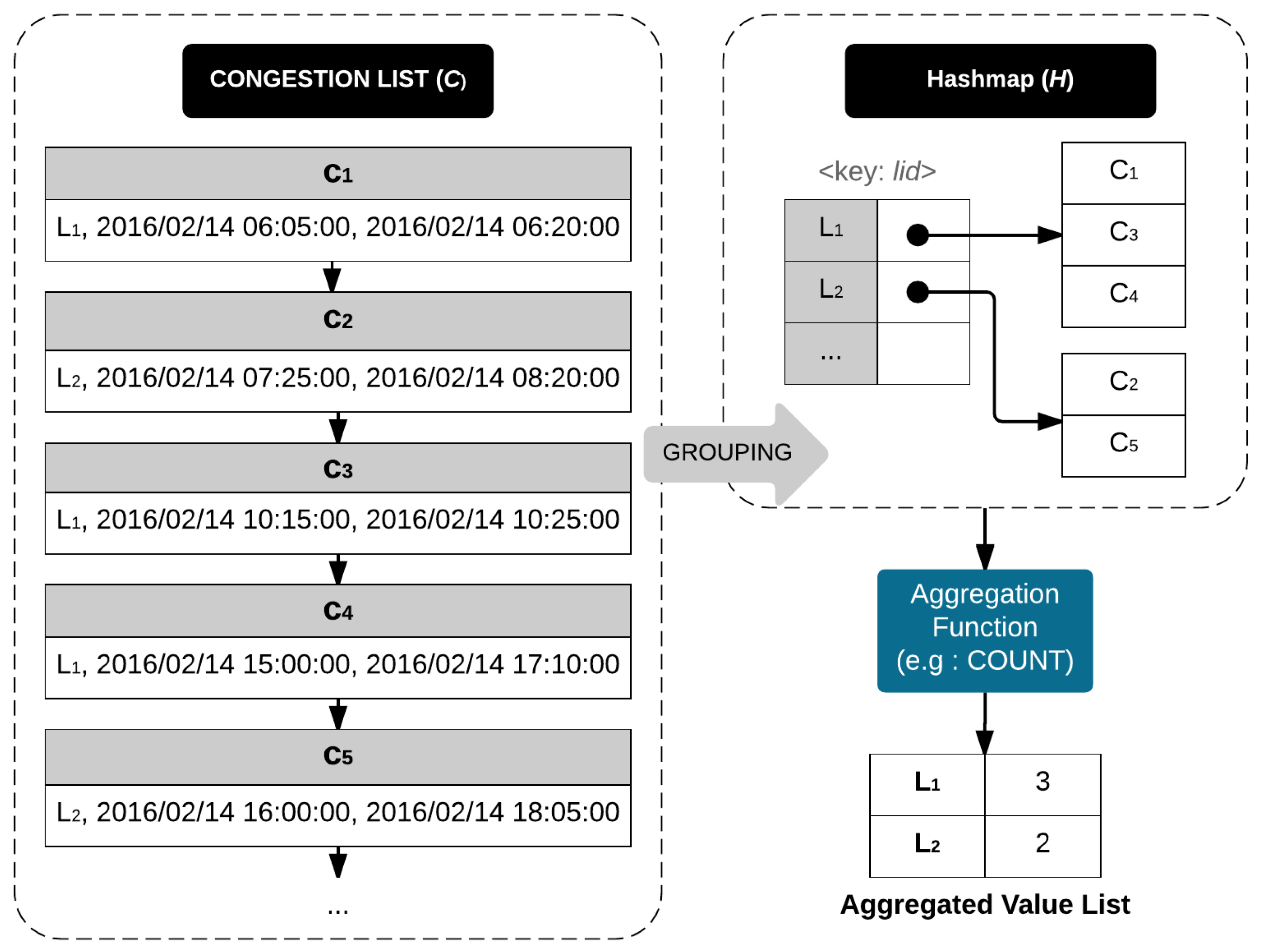
Example 8. Figure 15 describes aggregation query processing. We obtain a timeline model containing a list of traffic congestion events C by invoking BasicQueryProcessing. The elements of C are , , , , and . Next, we apply the grouping to C to obtain hashmap H as a result. The Hashmap H contains only two elements: and . Then, we pass H into a COUNT aggregation function. The result shows the number of congestion events for each group in H. In this example, has three and has two congestion events. The correctness of the aggregation query processing algorithm is proven by following a loop-invariant verification technique.
Theorem 5. [Correctness of aggregation query processing] The aggregation query processing algorithm is correct with two given loop invariants: In the first loop, H is empty or contains a critical ; for the second loop invariant, the number of A is the same as the number of iterations.
Proof. Before the iteration begins, assume that is the result of basic query processing, C is a finite set of traffic congestion from , and H is an empty hash map.
Initialization: (First Loop) At the beginning, H is empty, trivially.
Maintenance: (First Loop) For any steps in the iteration, if H does not contain a value of as keys, then a new list will be inserted to H with the value of as a key.
Termination: (First Loop) After the last iteration, we guarantee that H contains a value as a key, which is explained in the maintenance part.
Initialization: (Second Loop) At the beginning of the loop, a step number i is initialized to 0, and A is still empty.
Maintenance: (Second Loop) For each iteration, the new value from AGGREGATION-FUNCTION will be included as an element of A. Thus, at the ith iteration step, when , the number of A equals i. When we move to the next iteration step th, a new value for the group will be added to A again, which leads to an increase in the number of elements A to .
Termination: (Second Loop) At the end of the iteration, the value i is equal to the size of H, and the number of elements in A would be the same as H. Thus, the number of elements in A would be exactly the same as i.
Correctness: Both loop invariant methods are working with the finite sets. Thus, they are always terminated and produce the correct results. ☐
5.3.3. Affected Congestion Query Processing
An affected congestion query
requires the exploitation of the affectedness list, which is built during the CalculateDependency algorithm. For the affected congestion, we proceed with the results of the timeline model, as shown in
Figure 14.
Algorithm 8 explains the procedures. First, we invoke BasicQueryProcessing to obtain a timeline model. After obtaining a set of congestion events, we simply track the
pointers for each congestion’s node until we reach the last (lines 5 to 7).
| Algorithm 8: Affected Congestions Query Processing |
| Input: A TQ-index , a set of LinkIDs L, a start Time , an end time |
| Output: A set of congestions |
| 1: procedure AffectedCongestionsQueryProcessing(, , , ); |
| 2: A timeline model ← BasicQueryProcessing (, L, , ); |
| 3: GetCongestions(); |
| 4: A set of affected congestions ← NULL; |
| 5: foreach congestion c in C do |
| 6: | if is not NULL then .Add( c.); |
| 7: end foreach |
| 8: return ; |
The correctness of the affected congestions query processing algorithm is proved by following a loop invariant verification technique.
Theorem 6. [Correctness of affected congestion query processing] The affected congestion query processing algorithm is correct with a given loop invariant: At the start of the loop, the number of elements in is equal to or greater than the number of iteration steps.
Proof. Initialization: (Second Loop) At the beginning of the loop, a step number i is initialized to 0 and is still empty.
Maintenance: For each iteration, the newly affected congestion from congestion c will be included as an element of . Thus, at the ith iteration step, when , the number of equals i. When we move to the next iteration step th, the new affected congestion will be added to again, which leads to an increase in the number of elements to .
Termination: At the end of the iteration, the value i is equal to the size of C, and the number of elements in would be the same as i.
Correctness: This loop invariant method proves that the algorithm will be terminated and produce the correct results. ☐







































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}