1. Introduction
At present time, Micro Air Vehicles (MAVs) are becoming very popular in various applications. They are affordable and flexible in terms of location due to their size and weight. Equipping them with additional sensors, MAVs are able to carry out autonomous flights. Thus, MAVs are able to explore areas autonomously that are difficult to access by pedestrians or ground vehicles. This can be for instance disaster areas, where the MAV provides rescue teams with mission-specific information. In order to execute such missions, a very accurate navigation solution at all times is required. Typically, MAVs are equipped with Global Navigation Satellite System (GNSS) receivers, which provide absolute position and aid the Inertial Navigation System (INS). However, this kind of navigation system is not sufficient because the MAV should be able to operate also in GNSS-denied areas, such as indoor environments. Moreover, urban canyons, multipath propagation and jamming are reasons for low GNSS positioning accuracy. Therefore, other sensors, like a camera and a laser rangefinder, are required. Those sensors do not provide absolute position information, but they increase the robustness and accuracy of the navigation system. The camera detects features easily, which are tracked so that ego-motion can be observed. Nevertheless, the scale factor with respect to metric dimensions is unknown due to the absence of depth information. The extensively-used visual odometry technique provides approaches to solve this problem. For example, either an Inertial Measurement Unit (IMU) [
1] or stereo camera [
2] can be used. Both methods are limited. The IMU filter approach needs variation in camera perspective in order to decrease the uncertainty of 3D points. The depth accuracy of the stereo camera approach is limited by its baseline [
3]. By contrast, laser rangefinders provide accurate depth information without triangulation. However, the drawback is that corresponding features between subsequent laser scans are in general hardly detectable. In addition, it is even more difficult as the MAV has six degrees of freedom. There are several laser-scan-matching approaches, but they mostly expect structured environments, such as indoor scenes (e.g., [
4]). In order to become more flexible in terms of the MAV’s surroundings, this article deals with fusing both complementary sensors at the early stage so that their advantages are combined. This requires good knowledge about the pose between both sensors. Thus, an extrinsic calibration is needed.
The literature on laser-camera calibration shows a variety of approaches. They differ in the kind of correspondences established between both sensors. An overview is given in [
5]. First, many publications are based on the approach of Zhang and Pless [
6], where plane-point correspondences are found. The idea is that the plane of a checkerboard is described in camera coordinates. Knowing that the plane contains also the laser points, the constraints per pose are obtained. At least five poses are needed to calibrate the laser-camera system. Second, line-point correspondences are used, for instance in [
7], where the calibration object has a triangular shape. The constraint is that the laser points on the edges correspond to extracted edges in the image. Third, in [
8], the calibration method of Zhang and Pless [
6] is enhanced. The approach finds plane-line correspondences in dual space. Besides the aforementioned kind of correspondences, Hoang et al. [
9] presents a calibration object that establishes point-point correspondences. Due to the geometry of the calibration object, 3D feature points of the laser rangefinder are recovered in image coordinates. The pose between both sensors is obtained by solving the Perspective-3-Point (P3P) problem [
10]. According to Li et al. [
7], who compared different feature points, point features lead to the most accurate results. Because of this finding, the approach of Hoang et al. was chosen. Moreover, the P3P problem describes the minimal problem, where a finite number of solutions exist. This is advantageous when implementing a robust model estimation optimally by using the smallest possible subset. The chosen approach is further improved in order to obtain very accurate calibration results.
After knowing the pose between both sensors, the relative motion of the MAV is estimated. The authors of [
11] propose an approach that estimates the depth information of image features, which do not necessarily lie on the projected laser line. This is possible by assuming ground vehicle motion and a structured environment, such as indoors. In [
12], the pixels with depth information are used in addition to the image features. The features are tracked by optical flow, and the relative motion is obtained by bundle adjustment. On the other hand, the authors of [
13] solve the P3P problem in order to gain relative motion. In this work, they equipped a ground vehicle with a vertical laser in the lateral direction and a camera system of six cameras. The estimated relative motion between adjacent frames is only accumulated and not integrated in a navigation system. The positioning is then refined by using manually-detected loop closures. This is not suitable for online navigation processing. In one of our previous papers, pixels with depth information are also used [
14]. However, this is focused on SLAM (Simultaneous Localization and Mapping) and the total navigation system of the MAV. To the authors’ best knowledge, in previous studies, deeply-integrated laser-camera systems have been scarcely investigated from the point of view of integrated navigation systems.
In this article, a hybrid laser-camera sensor for navigation aiding is presented. The objective is to obtain an accurate navigation solution and become more flexible in terms of the MAV’s surroundings compared to the existing laser-scan-matching approach [
4]. This includes many aspects from the deep integration of two complementary sensors, to ego-motion estimation, to the final integrated navigation system. Both deep integration, namely the laser-camera calibration and ego-motion estimation use 3D-to-2D correspondences. Hence, applying the algorithm proposed by Kneip et al. [
15] in a RANSAC (Random Sample and Consensus [
10]) scheme, the P3P problem is solved. The solution is further refined by nonlinear optimization. The calibration results obtained by simulation and experiments show that a precise knowledge about the pose between both sensors is gathered. Similarly, the ego-motion estimation is very accurate. Moreover, this article deals with the covariance estimation of the estimated relative motion. It is shown that the estimated uncertainty correlates with the actual errors. This results in a more accurate and robust navigation solution.
4. Calibration
In order to use both complementary sensors, namely a monocular camera and a 2D laser rangefinder, as a hybrid sensor, it is essential to have accurate knowledge about the pose to each other. Due to this pose information, and , accurate laser rangefinder readings can be assigned to image pixels of the calibrated camera.
4.1. Calibration Object
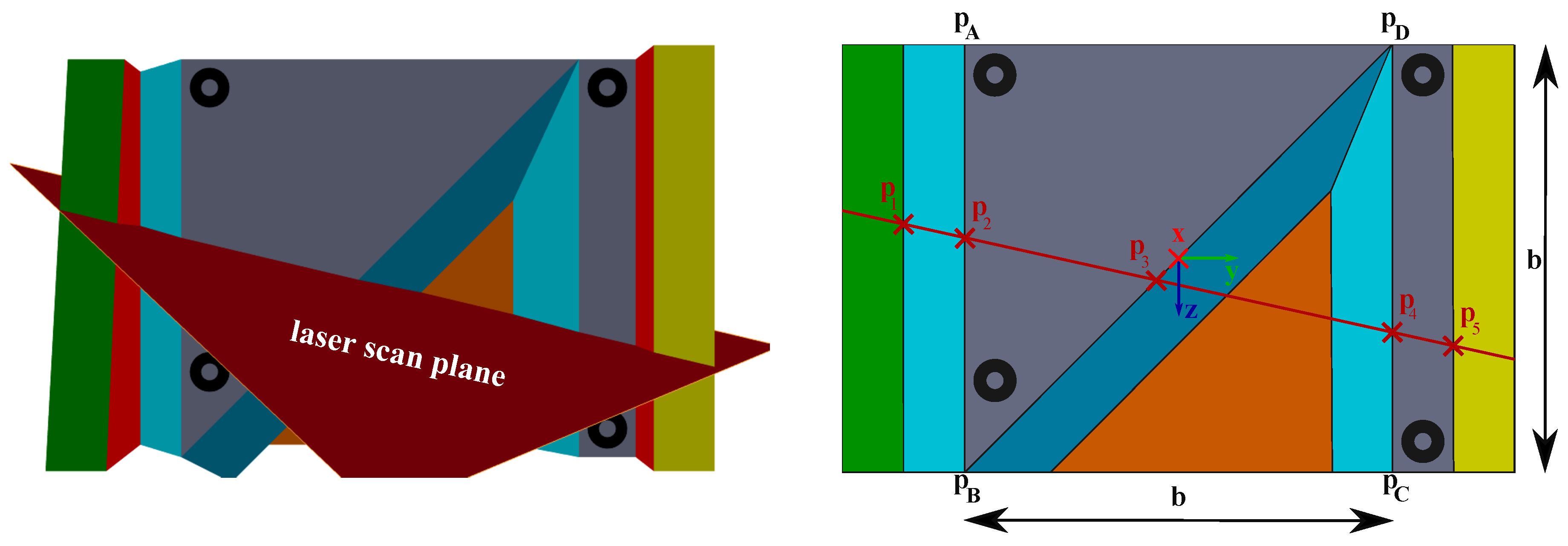
First of all, the calibration object and a possible sensor configuration are presented in
Figure 2. The calibration object consists of two main parallel planes (grey and orange), whereas the back plane (orange) is visible as a right-angled triangle. Similarly, Hoang et al. [
9] proposed this kind of calibration object. Apart from that, two more modifications were realized. First, four circular rings were attached to the front plane. Second, ramps connecting the front (grey) and back plane were established. The motivation of those modifications will be described later on.
As mentioned before,
Figure 2 shows a possible sensor configuration seen from the camera perspective. The camera detects the circular rings easily, and the laser scan plane intersects with the calibration object. Since depth discontinuities will occur, particularly points
to
can be extracted from the laser depth readings. A detailed description of feature extraction follows in the next sections.
As laser points are not in general visible to the camera, the coplanar circular rings make it possible to recover them in the image. Thus, 3D-to-2D correspondences can be obtained for the P3P-algorithm, which calculates the pose between both sensors.
To sum up, a successful calibration can be achieved, when the camera’s field of view includes all four circular rings and the laser scan plane includes at least the relevant points to .
4.2. 3D Laser Feature Extraction
Because of the local depth discontinuity intersection, points to are suitable to choose as 3D laser feature points. Once extracted, those points can be directly described in laser coordinates.
This approach is also described by Hoang et al. [
9]. However, the actual implementation is scarcely mentioned. For our calibration method, the Adaptive Line Extraction (ALE) [
16] was chosen. In the presence of noise, this method shows robust performance regarding the problem that true line segments are falsely broken [
17]. Thus, laser points on the calibration object can be described as line segments, and their endpoints include
to
. Consequently, the relevant points are determined with all laser points that correspond to the individual line segments. On the contrary, depth gradient approaches would only depend on the points on the edges, where laser artifacts or ambiguous solutions can be expected.
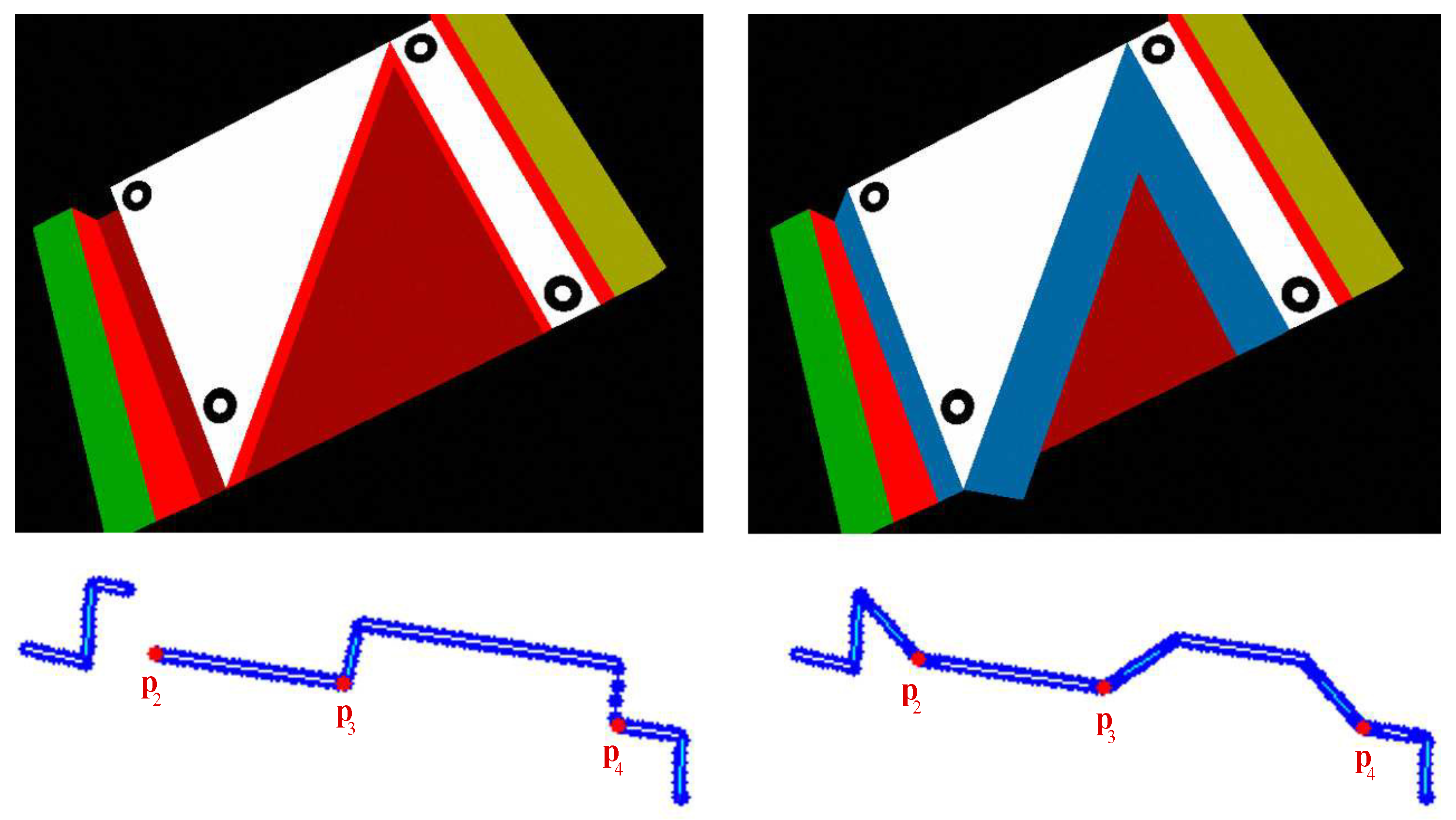
However, an accurate extraction of points located on edges cannot be assured, since the horizontal discretization of laser range measurements is not negligible. Attaching the ramps to the calibration object, this problem can be solved. In order to get edge points, the intersection of line segments, found by the ALE algorithm, is calculated. For this purpose the line segments are recalculated by using only the inner points in order to obtain a better parametrization of lines.
A comparison between two laser range readings caused by the original and the modified calibration object is depicted in
Figure 3.
This indicates that due to the ramps, all relevant line segments are visible from various view points, so that an accurate point estimation can be achieved.
4.3. 2D Corresponding Camera Feature Point
After finding the relevant points
to
in laser coordinates, it is now necessary to recover the corresponding points, especially
, in the image. This is possible because of the geometry and the circular markers of the calibration object. First, the points are described in object coordinates by simple geometrical calculations. Second, the points will be found in image coordinates by using the circular rings (see
Section 4.3.2).
4.3.1. Geometric Calculation
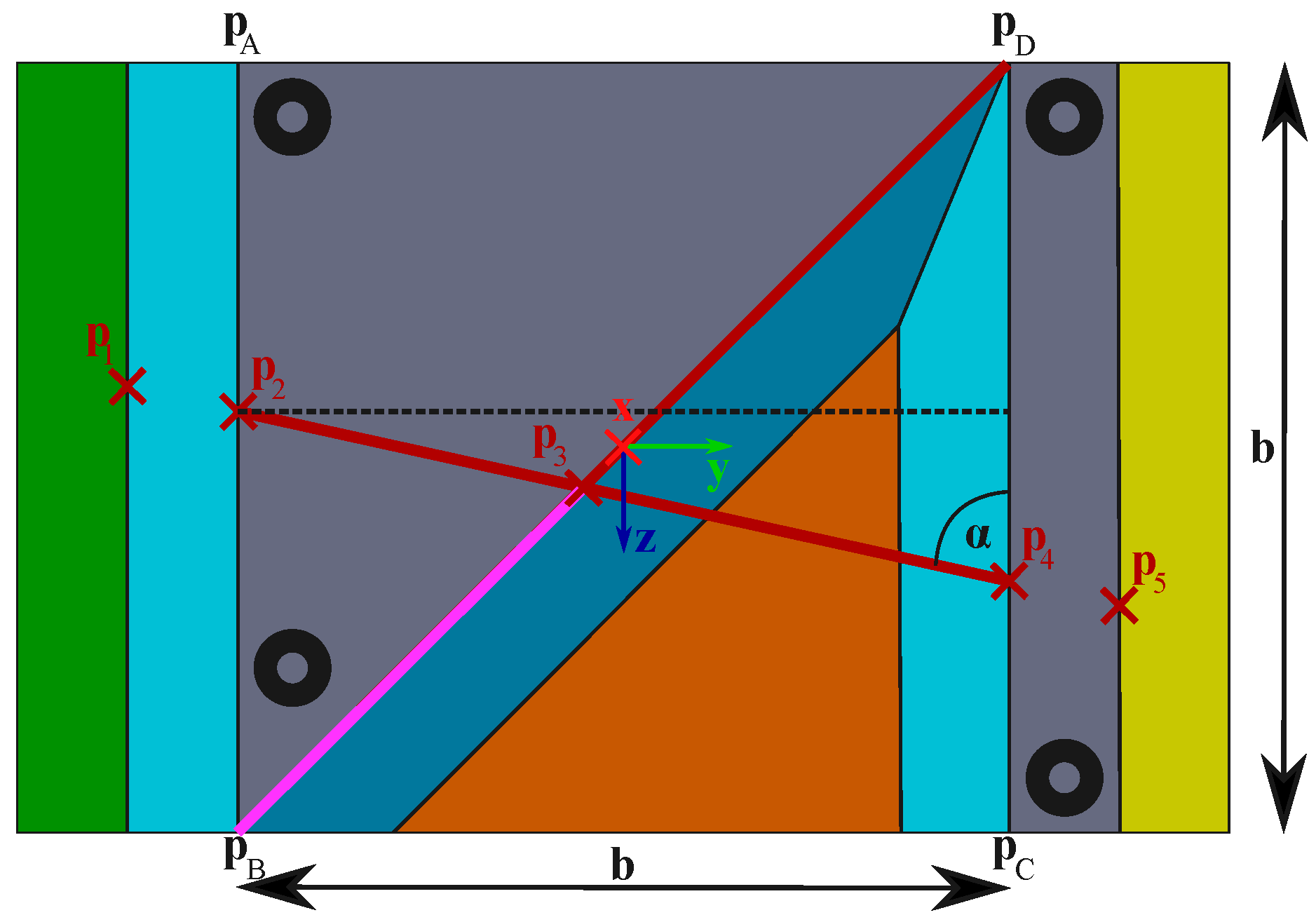
Point
can be simply calculated by the intercept theorem. The intersection point
is caused by lines through
,
and
,
, respectively. The distances
,
are given by the extracted laser feature points, where the distances are defined by:
In addition, the length of the diagonal is also known by
. Thus, the marked distance in
Figure 4 can be calculated by:
It is clear that from Equation (
2),
in object coordinates can be obtained by:
Beyond that, Hoang et al. [
9] suppose the calculation of
and
in object coordinates. Using the law of cosines, the distances:
can be calculated.
Since the determination of angle:
illustrated in
Figure 4, is ambiguous, two possible solutions for
and
respectively exist. As the P3P algorithm is embedded in a RANSAC scheme, outliers are detected, so that the incorrect hypothesis can also be used as the input. Eventually, the hypotheses from Equation (
4) can be computed by:
and:
Nevertheless, only the 3D-to-2D correspondences of
per pose are used for our calibration. Small errors in determining the 3D feature points could cause non-acceptable position errors of
and
in object coordinates. Concerning this issue, those randomly-generated small errors were simulated to show the effect on the estimation error of angle
α from Equation (
5) and the distances
and
from Equation (
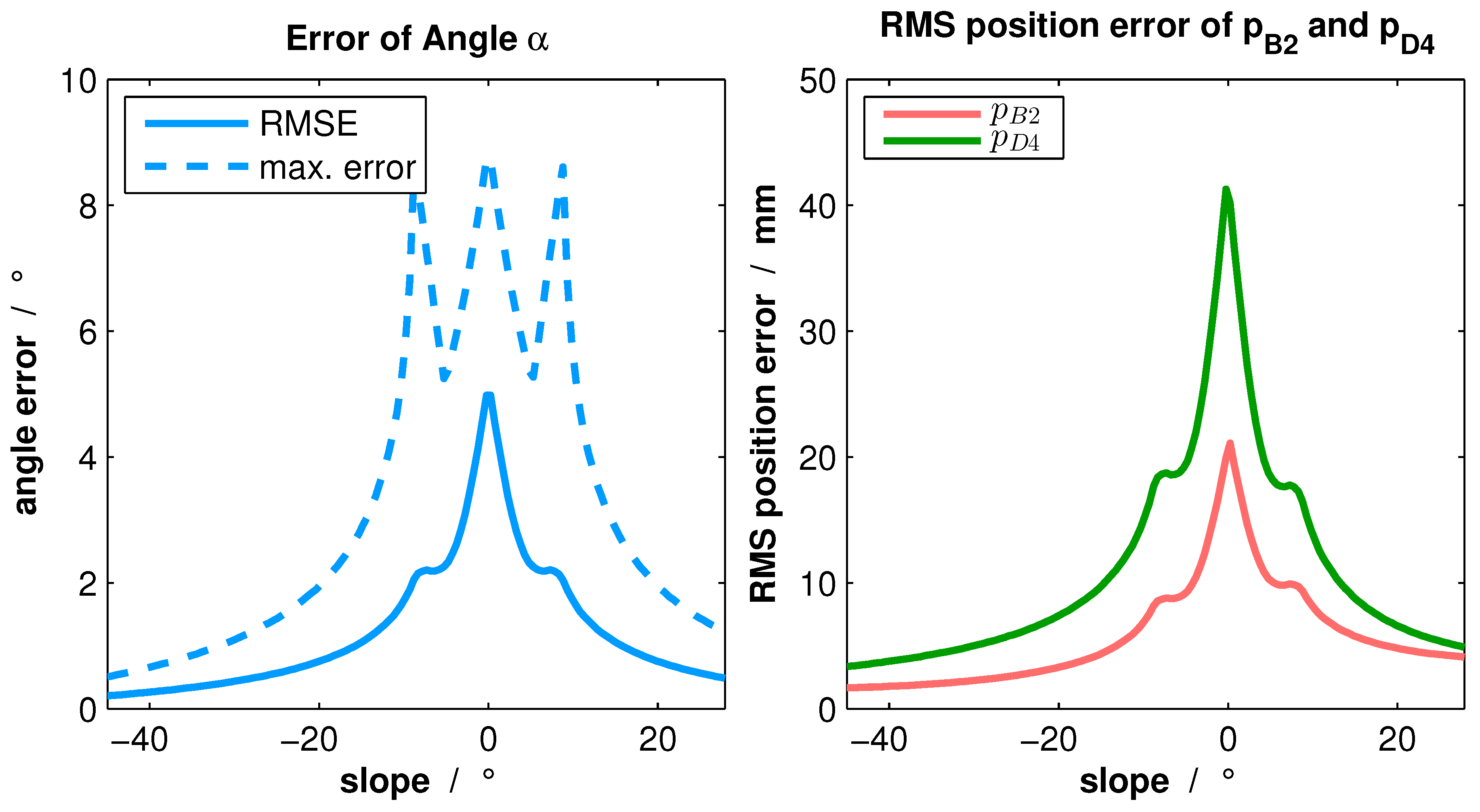
4). Various constellations of line position and slope
were simulated.
Figure 5 presents the results for line position
.
The graph indicates that due to the nonlinearity of arcsin in Equation (
5), small errors of 3D feature point extraction result in greater angle errors at slopes within the range of ±20
. Consequently, the position errors of
and
in object coordinates, calculated via Equations (
6) and (
7), are no more suitable for calibration. By contrast, small errors do not influence the calculation of
significantly.
4.3.2. Recovering the Feature Point in the Image
After determining points
in object coordinates, the feature points are projected in the camera image. To project an arbitrary point of the calibration front plane (
) to the image plane, a homography matrix
is estimated. This homography matrix maps those points on image coordinates as follows:
In order to estimate the homography matrix, at least four corresponding points of the planes are needed [
18]. This is possible by using the circular rings, since the positions of their centers are known in object coordinates and are found in image coordinates. For this purpose, contours are detected in a binary image according to [
19], and elliptical shapes are extracted. As various camera perspectives are expected, it is more suitable to detect ellipses than circles. In addition, using rings makes it easier to filter filled circles that can occur because of inhomogeneous illumination and shading. Moreover, the limitation that the outer and inner contours of a ring have similar ratios of distance between the major and minor axis improves the robustness of the circular marker detection.
Finally, the corresponding 2D points can be written as unit vectors, i.e., feature vectors,
where the intrinsic camera matrix is represented by
.
5. Ego-Motion Estimation
After a successful calibration, it is possible to add 3D information of the laser rangefinder to certain pixels of the camera. The transformation of measured world points
at time
in laser coordinates to camera coordinates satisfies the following equation:
In order to get the corresponding 2D information at time
k, the world points of Equation (
10) are tracked. Since it is not guaranteed that feature points, like SURF [
20], lie along the laser-line, feature-based trackers are not suitable for this purpose. Therefore, the pixels with 3D information are tracked by the Kanade-Lucas-Tomasi feature tracker (KLT) [
21] and described as feature vectors by:
whereas
represents the intrinsic matrix.
Thus, 3D-to-2D correspondences, i.e.,
and
, are established, which provide the input for the P3P algorithm. The world points
provide the relative positioning at time
, whereas the feature vectors
, also called unit vectors, bearing vectors or directional vectors [
15], provide the two 2D information at time
k. Therefore, the metrical relationship at time
and the angular relationship at time
k between the observed control points is given in order to establish the P3P problem [
10].
Figure 6 visualizes this approach at time
and current time
k.
The left image shows the projection of laser data according to Equation (
10). On the other hand, the right image illustrates the tracking by KLT, whereas the P3P-RANSAC inliers are marked blue. Those inliers are used for the Levenberg–Marquardt algorithm [
22]. Moreover, the initial estimation for the optimization process is given by the best P3P model. Eventually, the resulting ego-motion,
and
, is integrated in the navigation system, which is described in the next section.
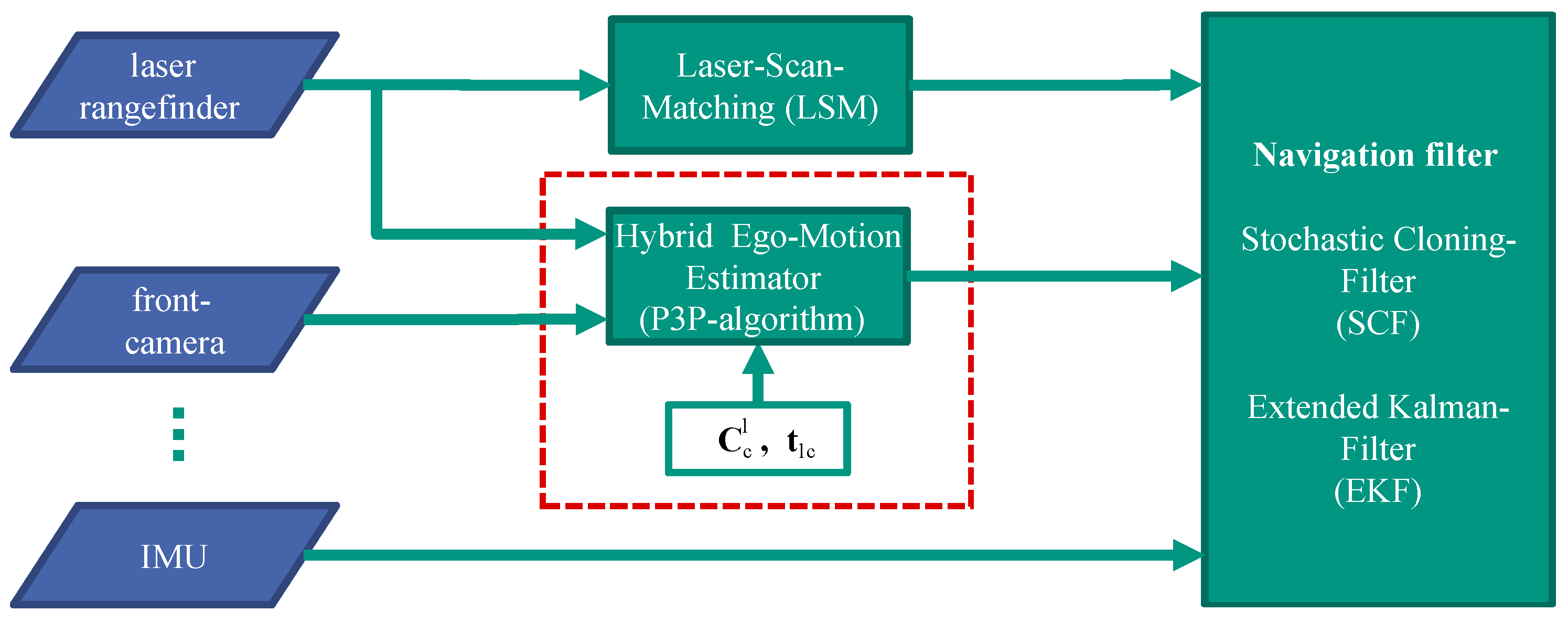
6. Integrated Navigation System
The objective of this section is to integrate the calibrated hybrid ego-motion estimator with the given navigation system; see
Figure 7. Typically, the navigation system is an Extended Kalman Filter (EKF). Thereby, the acceleration and angular rate information provided by the IMU is used by the strapdown algorithm at the prediction step. Additionally, the navigation system is updated by further sensor information. However, it is not possible to update the classical EKF with relative positioning and attitude measurements. In order to correctly integrate relative measurements, the navigation system is augmented with the Stochastic Cloning Filter (SCF) approach [
23].
The main idea of SCF is to augment the state and its corresponding covariance at time
as follows:
The absolute state is defined as:
whereas the position, velocity, attitude and inertial bias are estimated.
After the filter propagation step, the state and its corresponding covariance can be written as:
so that the correlation between state
and
is established. As a consequence, the state can be corrected by relative measurements.
Using frame-by-frame motion estimation, the clone would be renewed permanently. As a consequence, the relative measurements and their errors would be directly accumulated. In order to use the SCF optimally, it is desirable to retain the clone as long as possible. Due to the front-facing camera, feature points can be observed for a long period of time. Therefore, a keyframe-by-frame motion estimation is used. At reference time
, the keyframe is retained, and the state is cloned according to Equation (
12). To each subsequent image, the relative pose to the reference frame is derived. This procedure can mitigate the increasing of the uncertainty of the estimated state.
Covariance Estimation
Since the correction step of Kalman-based navigation filters requires not only measurement, but also information about its uncertainty, this section deals with the covariance estimation. In this case, the covariance of the parameter vector:
is estimated on the basis of backward propagation described in [
24]. Using this parameter vector, i.e., the relative motion estimation obtained by the P3P algorithm, the
n feature vectors
(compare
Section 5) can be estimated by the following mapping:
The covariance of the total feature vector
is approximated by:
where the Jacobian
is defined by
with
.
As the covariance of parameter vector
is required, the back propagation:
gives a good approximation of the desired covariance matrix [
24]. Assuming that particularly each of the estimation errors of
are uncorrelated with each other, the covariance matrix is simplified as
. In order to estimate
, the sample covariance of the reprojection errors
with
is calculated.
7. Results
The various aspects from calibration, to ego-motion estimation, to covariance estimation, to the final integrated navigation system are studied in the next sections.
7.1. Calibration
The proposed calibration method is validated by simulation. Then, the experimental results of calibrating two laser-camera systems confirm the simulation findings.
7.1.1. Simulation
In the first step, our calibration method was evaluated by simulation. As an exact ground truth pose between the laser and camera is given, accuracy information can be gained.
Table 1 shows the simulated laser-camera constellation.
The designed 3D model of the calibration object was rendered by the simulation framework. Hence, for each pose between the MAV and the calibration object, simulated sensor data were obtained. A visual representation of the generated poses is illustrated in
Figure 8.
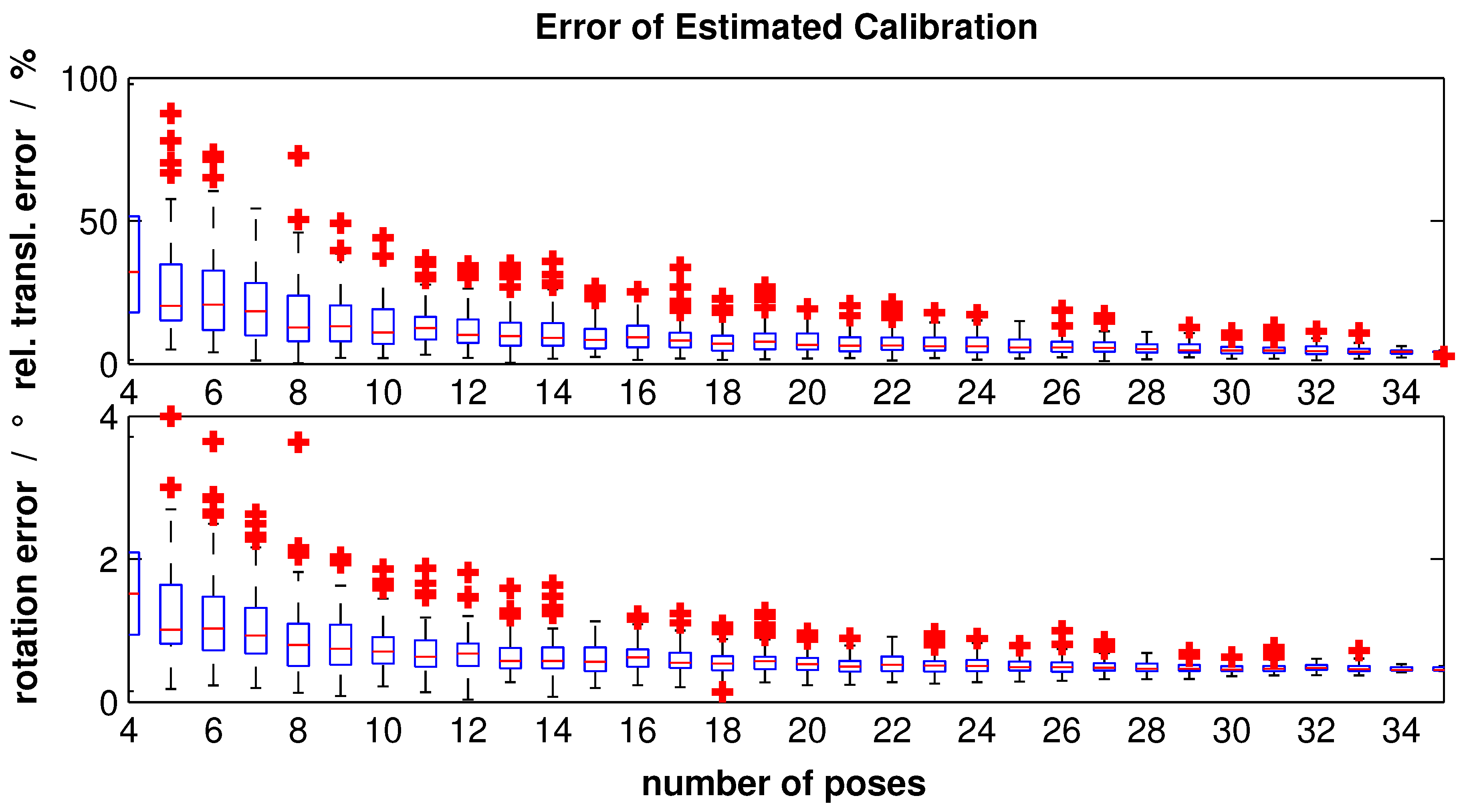
For each number of calibration poses, 100 calibration runs were performed. The error analysis of estimated translation
and rotation
can be seen as the boxplot in
Figure 9. The analysis is done similar to that in [
8].
The red horizontal lines represent the median; the borders of the boxes are the first and third quartiles, respectively. Furthermore, the red crosses can be seen as outliers that are outside the 2.7
σ range. The upper part of
Figure 9 shows the relative translation error described as follows:
The part below outlines the rotation error calculated by the metric:
whereas
and
are quaternions [
25]. This metric compares the estimated quaternion
with the reference quaternion
and gives values in the range
.
Obviously, the errors and their deviations decrease by increasing the number of poses. Using all poses, a median relative translation error of 2.49% and median rotation error of 0.16
can be achieved with our modified calibration object. In comparison to that, using the same poses with the original calibration object supposed by Hoang et al. [
9], relative translation error and rotation error are 4.28% and 0.46
, respectively. Likewise, the resulting deviation, namely the box width, for the modified calibration object is smaller than the original one.
In addition, the absolute pose errors between the laser rangefinder and camera presented in
Table 2 agree with the previous observation. Considering the rotation angles separately, the pitch angle
θ is reduced remarkably.
When distances
and
are estimated too short, the point
calculated via Equations (
2) and (
3) is estimated too low. This tends to happen very often for the original calibration object. Thus, a bigger pitch angle error for the given sensor constellation is caused. In this context, the distance errors
were calculated, and their influence on the distance errors
was observed.
Table 3 shows the median of the distance errors. It indicates that the modifications improve the calibration result by reducing
.
7.1.2. Experimental
After obtaining successful simulation results, the laser rangefinder and camera of the MAV (compare
Section 2) were calibrated. Since the position and orientation of the sensor coordinate systems cannot be accurately determined, ground truth pose information does not exist. However, the projection of laser scans with the given pose parameters found in
Figure 10 shows plausible calibration results. The endpoints of the laser lines are aligned to the edges of the objects.
Beyond that, the calibration method was performed with the Multi-Sensor Pedestrian Navigation System (MSPNS) consisting of a camera and laser rangefinder. This system is applied for pedestrian navigation [
26]. In this case, the imager detects also near-infrared (NIR) wavelengths, as described in [
27]. Hence, the reflecting laser points are visible in the image. This can be compared to the laser projection transformed by the given calibration result. Thus,
Figure 11 confirms the previous observations.
7.2. Ego-Motion Estimation
The ego-motion estimation was separately evaluated with a real indoor-flight along a corridor. The relative poses between the subsequent camera frames were estimated. In order to gain ground truth information, a Kalman filter smoother, based on [
28] and presented in [
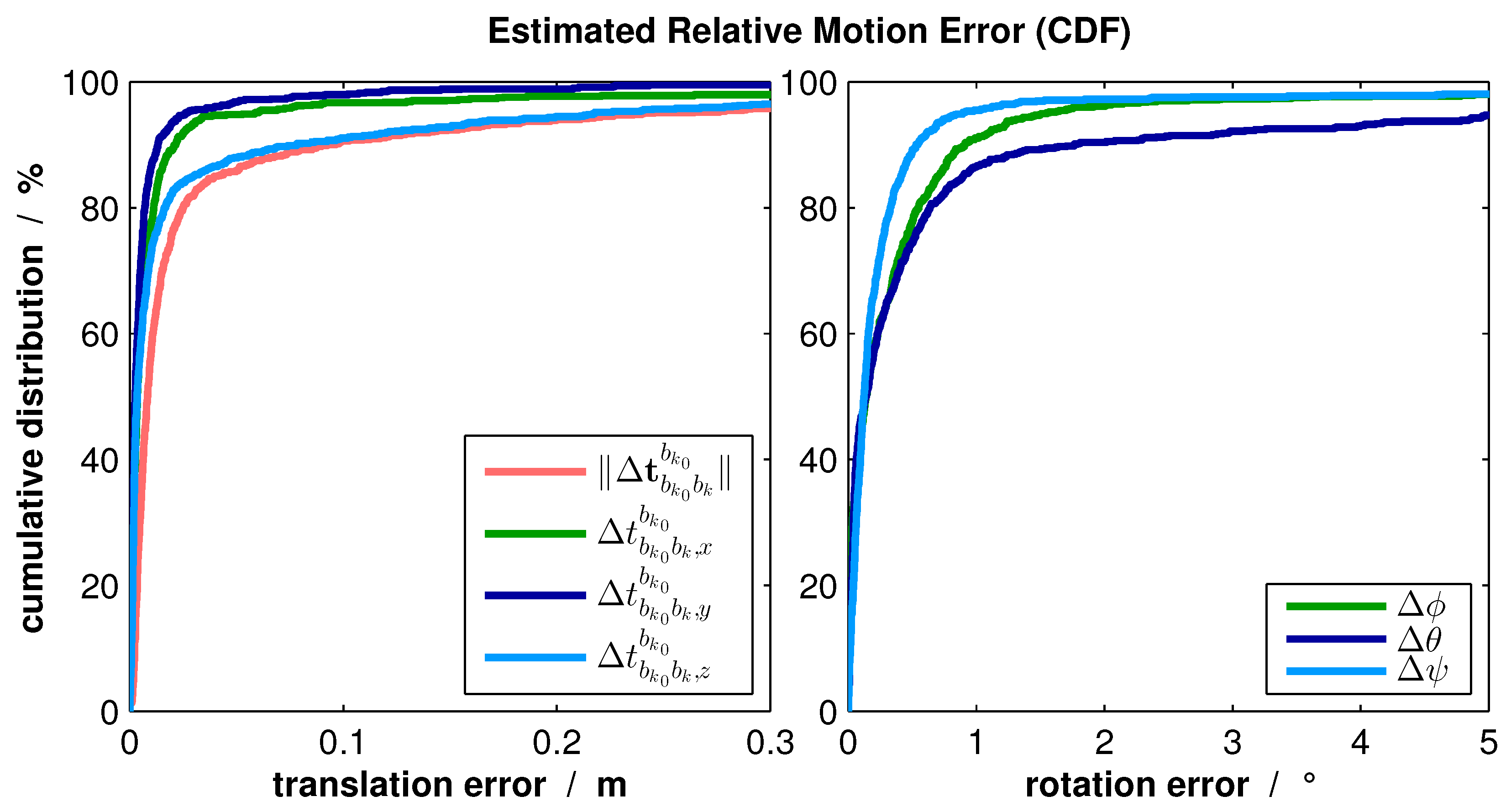
17], was used. This approach provides very accurate navigation solutions by reprocessing the flight in both the forward and backward direction. However, this method is not suitable for online processing due to high computational costs. The resulting estimation errors illustrated as a Cumulative Distribution Function (CDF) can be found in
Figure 12.
From this figure, it can be seen that 80% of translation errors are below 2 cm. Considering the translation components separately, the horizontal components and are significantly more accurate. This observation can be explained by the homogenous structure of walls in the vertical direction, which results in greater uncertainty of the KLT tracker. Despite being still accurate in the vertical direction, the total navigation system will be aided additionally by an altimeter and laser measurement directed to the floor.
The right part of
Figure 12 demonstrates that the rotation errors are also small. About 80% of those errors are below 0.65
. Due to the same reason as described before, the estimation of horizontal component
ψ is the most accurate.
7.3. Integrated Navigation System
This section deals with the evaluation of the proposed covariance estimation. Moreover, the performance of the integrated navigation system is studied and is compared to an existing laser-scan-matching approach.
The following
Table 4 shows the sampling rates of the sensors used.
7.3.1. Covariance Estimation
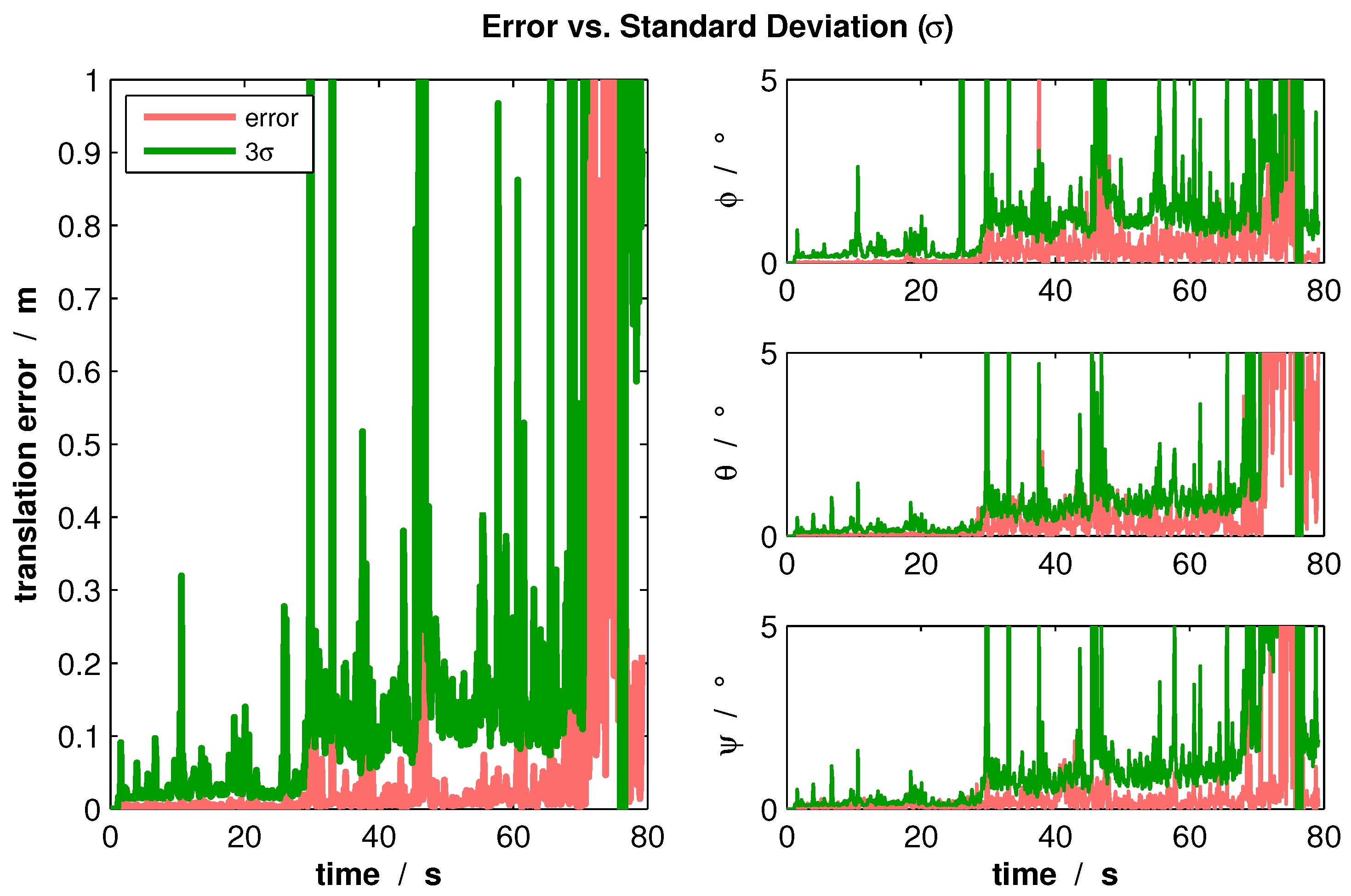
Two experiments were carried out to analyze the covariance estimation. The first experiment was a real indoor flight along a corridor (compare
Section 7.2). Using the Euclidean distance for translation components and considering the rotation components separately, the resulting
Figure 13 shows the comparison between the estimation errors and estimated uncertainties.
From this figure, it can be seen that the covariance estimation represents accurately the occurring errors. Furthermore, the graph shows that at the end of the flight, the estimation errors increase rapidly. This happens as the MAV is positioned in front of a wall, where only collinear control points exist. As soon as this degenerated situation occurs, the uncertainty increases accordingly so that the state is corrected by other sensors and methods.
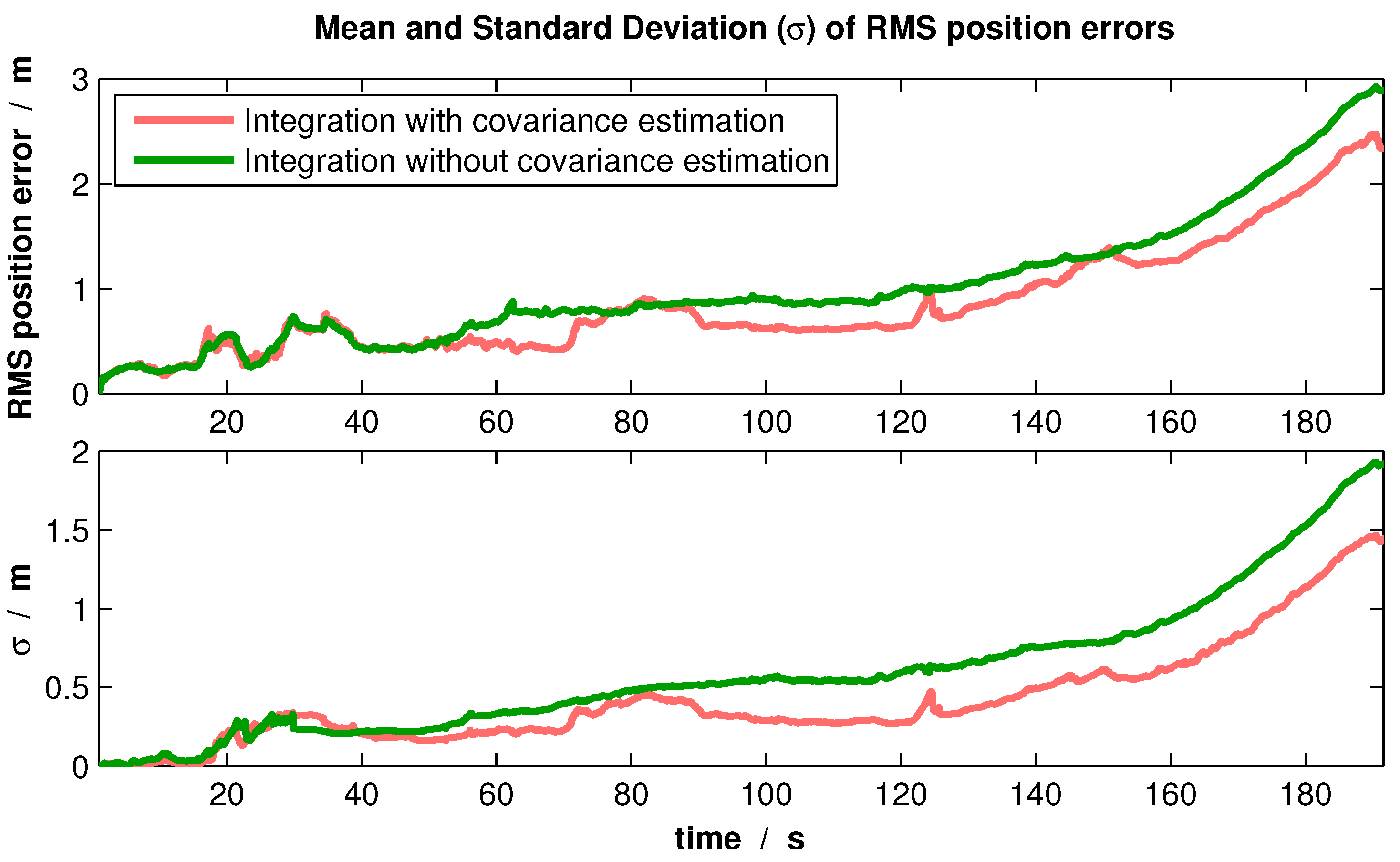
The second experiment was a real flight with an outdoor-indoor transition, which comprises different environments. In order to compare the variable covariance estimation with fixed values of uncertainty, this flight was reprocessed in each case 300 times. The root-mean-square errors (RMSE) of the position over time were logged. As a result, the comparison of the mean and standard deviation of those errors is presented in
Figure 14.
From the resulting plot, it can be seen that integrating the relative measurements with the introduced covariance estimation improves the position error and, particularly, its variation.
7.3.2. Positioning
In order to evaluate the navigation system, the INS was aided by either the hybrid sensor measurements or by the Laser-Scan-Matching (LSM) approach [
4], so that a comparison can be done.
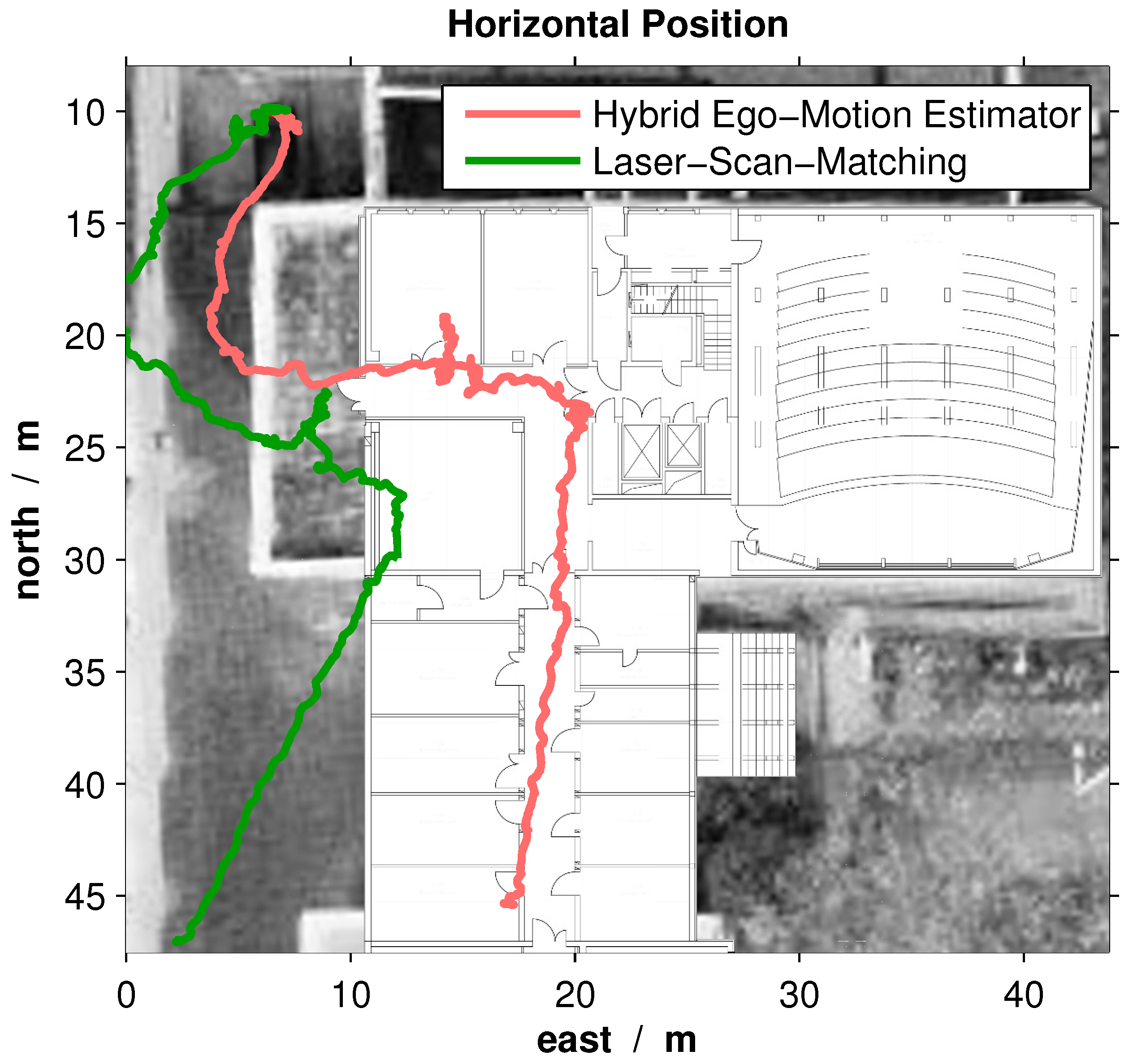
The experimental flight comprises an outdoor-indoor transition. It starts outdoors, enters the building and flies along the corridor. The start position and initial heading were measured so that absolute position information exists. This results in the trajectories, which are depicted in
Figure 15. Starting in the same position and with the same heading, the final position of the MAV using the LSM approach differs significantly from the one using the hybrid sensor-aided navigation system.
The transition of two doors and the corridor itself are good indicators of the estimation errors. Thus, both trajectories were transformed so that these constraints are fulfilled. Since it is known that the LSM approach yields good results in indoor environments, the transformation gives an idea of the performance in outdoor environments. The transformation shifts the starting point and rotates the initial heading so that the indoor constraints are fulfilled. The resulting translation of the starting point and rotation of the initial heading can be found in
Table 5.
The resulting trajectories indicate that both integrated navigation systems perform accurately in indoor environments. Thus, the greater heading error of the LSM approach occurs obviously outdoors. This observation shows that the hybrid ego-motion estimator circumvents the limitation of the orthogonal structure of the MAV’s surroundings.
8. Conclusions
This article presents a hybrid sensor combining a mono-camera and a 2D laser rangefinder for navigation aiding. This includes many aspects, such as an improved calibration method, ego-motion estimation and the MAV’s integrated navigation system. In this context, attention was focused on being more flexible in terms of environment compared to an existing laser-scan-matching approach. The improved calibration method results in very accurate pose information by both simulation and experiments. After successful calibration of the hybrid sensor system, the six degrees of freedom motion of the MAV have been estimated. Both calibration and ego-motion estimation use 3D-to-2D point correspondences, which are input for the P3P algorithm in the RANSAC scheme. The estimated relative motion of the MAV is integrated by using the stochastic cloning filter technique. In addition, the covariance estimation of the relative measurement is proposed. It shows that the navigation solution becomes more accurate and robust. Comparing the presented hybrid motion estimator with the existing laser-scan-matching approach, it can be concluded that a more flexible solution is found. The hybrid motion estimator can also be used in more unstructured areas, where GNSS is not available or applicable.
In order to optimize the system, it is desirable to study the influence of keyframe selection concerning the duration and other criteria. Beyond ego-motion estimation, the proposed system can also be used for environment perception purposes. Accumulating the laser scans, a metric map of the environment can be generated. In addition, interesting high-level objects from the camera perspective can be integrated so that a semantic map is obtained. The size of those object is estimated by the 3D pixels gained by calibration.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}