An Acoustic Signal Enhancement Method Based on Independent Vector Analysis for Moving Target Classification in the Wild

 ,
,  and
and 
Abstract
:1. Introduction
- Introducing the IVA algorithm to acoustic signal enhancement based on a microphone array in the wild environments.
- Presenting an improved IVA method, DCT-G-IVA, which adopts a special multivariate generalized Gaussian distribution as the source prior, an adaptive variable step strategy for learning algorithm. Besides, we employ DCT instead of DFT to convert the time domain observations to the frequency domain.
- Designing a moving target classification system with the aforementioned DCT-G-IVA enhancement method in UGS and achieving a satisfactory classification accuracy.
2. Signal Model and Problem Formulation
- The superscript ∗ denotes the conjugate of the complex number.
- The superscript H denotes the Hermitian transpose of the matrix, and the superscript T denotes the transpose of the matrix.
- The italic denotes the statistical expectation.
- The operator denotes the matrix determinant.
- Plain characters denote scalar variables; boldfaced lowercase characters denote vector variables; and boldfaced uppercase characters denote matrix variables.
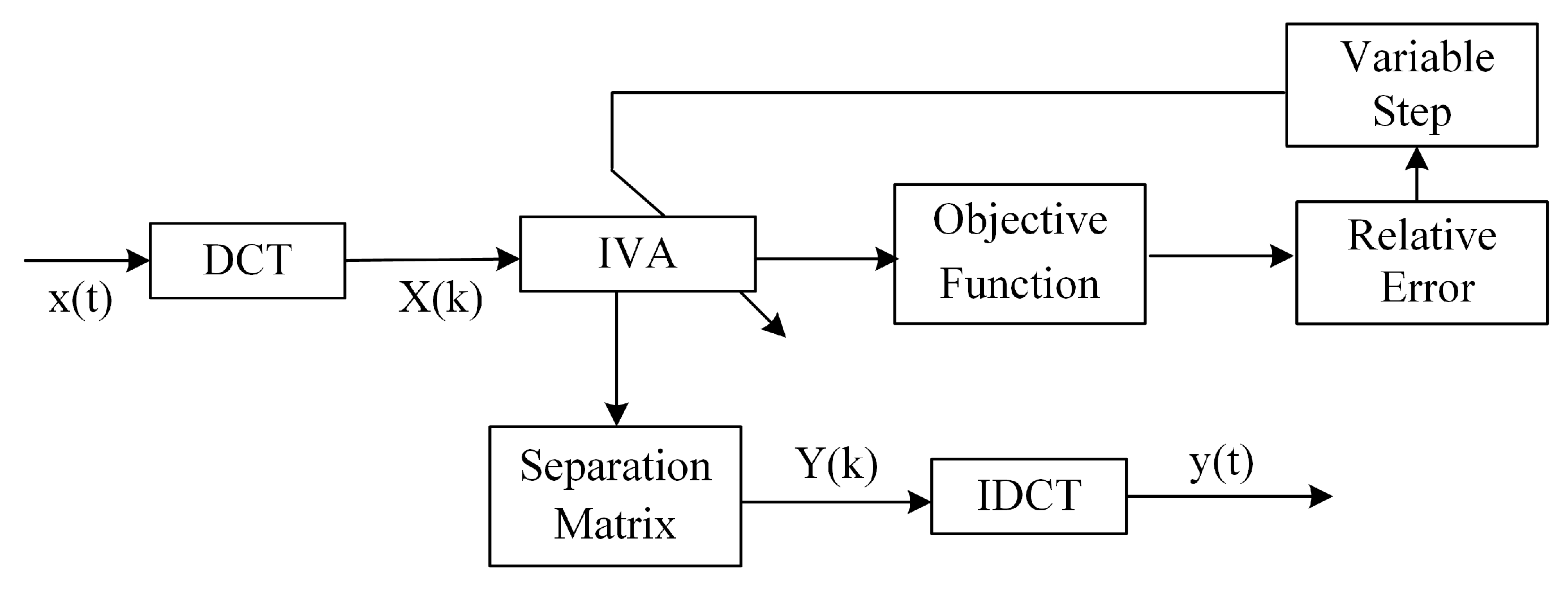
3. The IVA Methods of Signal Enhancement
3.1. Independent Vector Analysis
3.2. The Multivariate Generalized Gaussian Source Prior
3.3. Adaptive Variable Step for IVA
Parameters’ Selection
3.4. DCT versus DFT
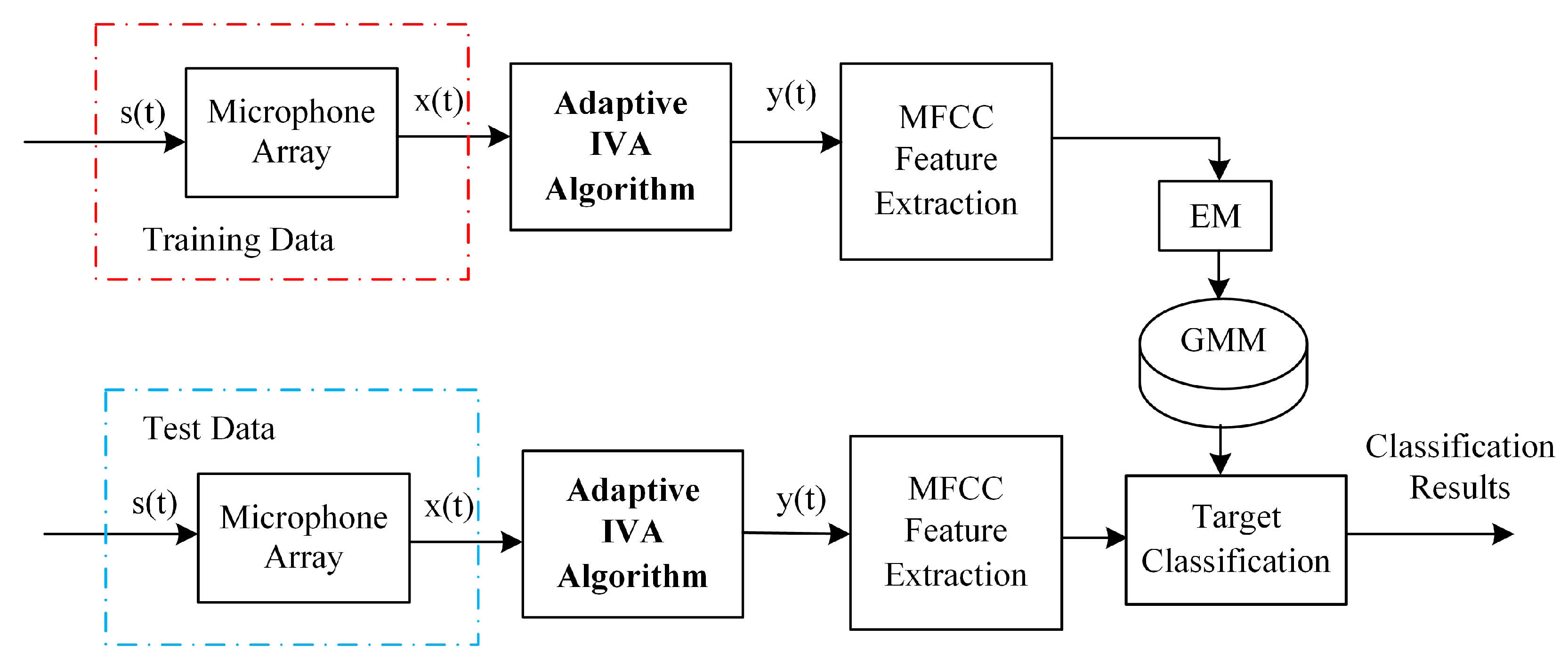
4. The System of Moving Target Classification
5. Experiments and Results
5.1. Experimental Description
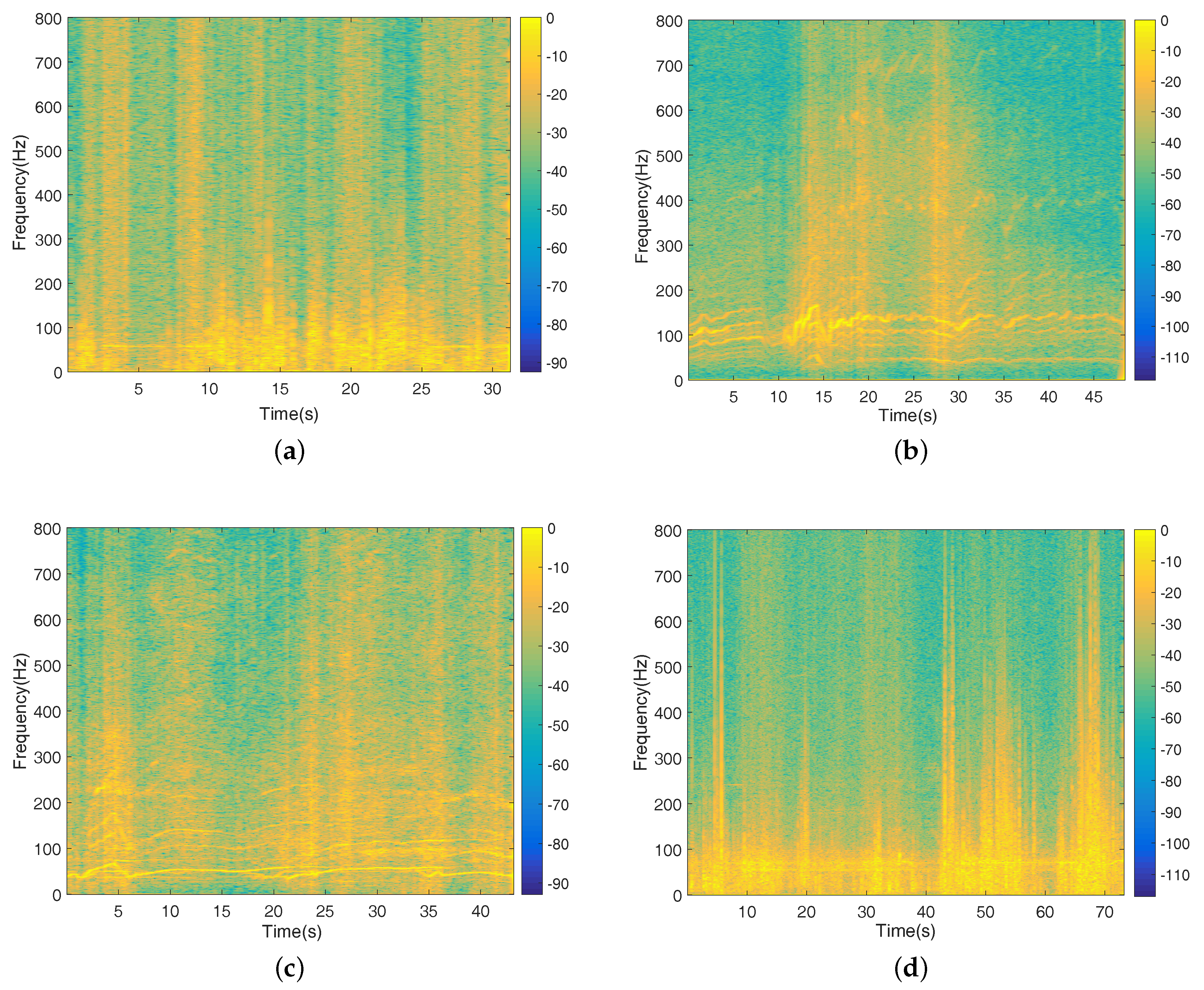
5.2. Datasets
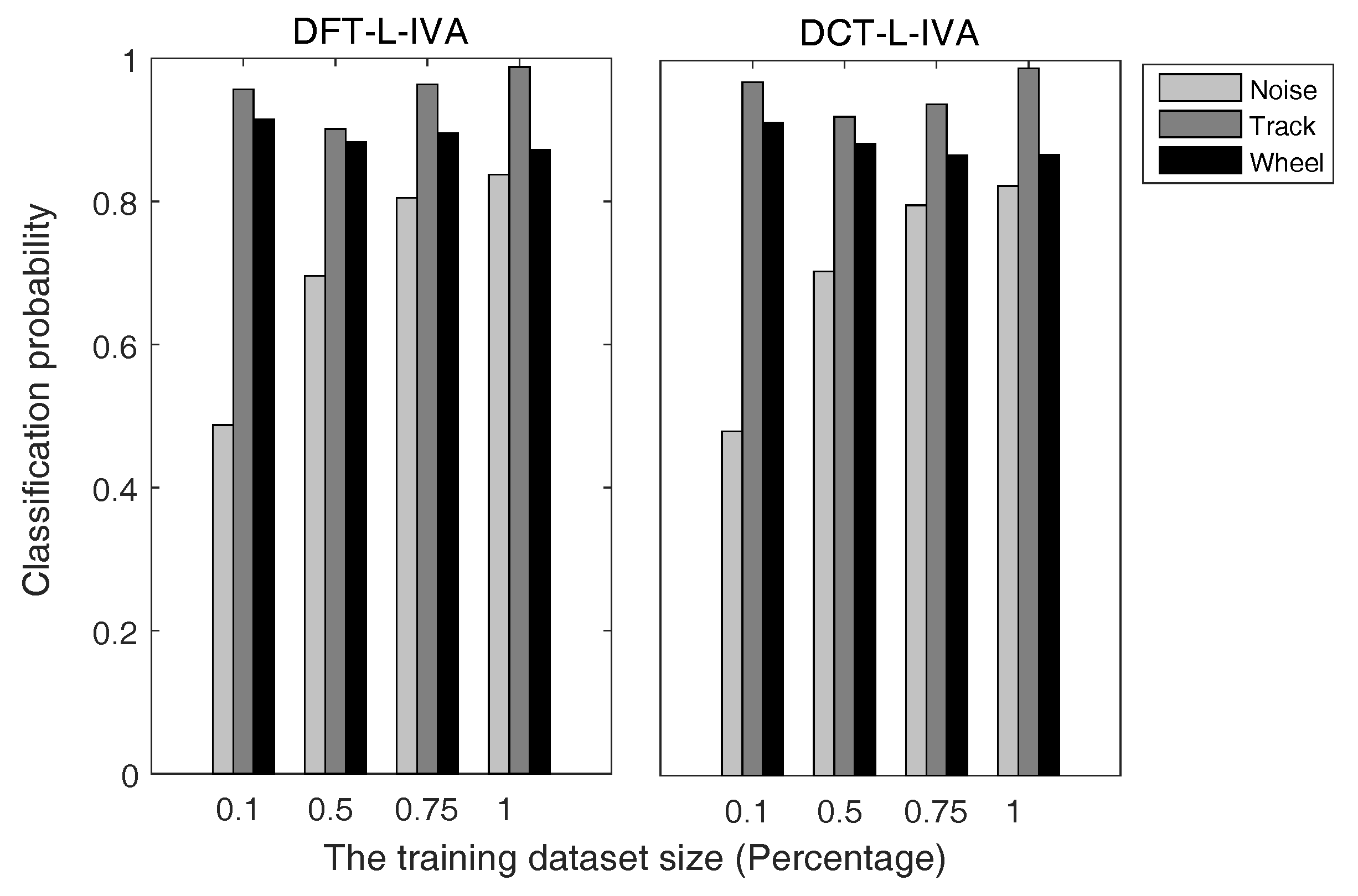
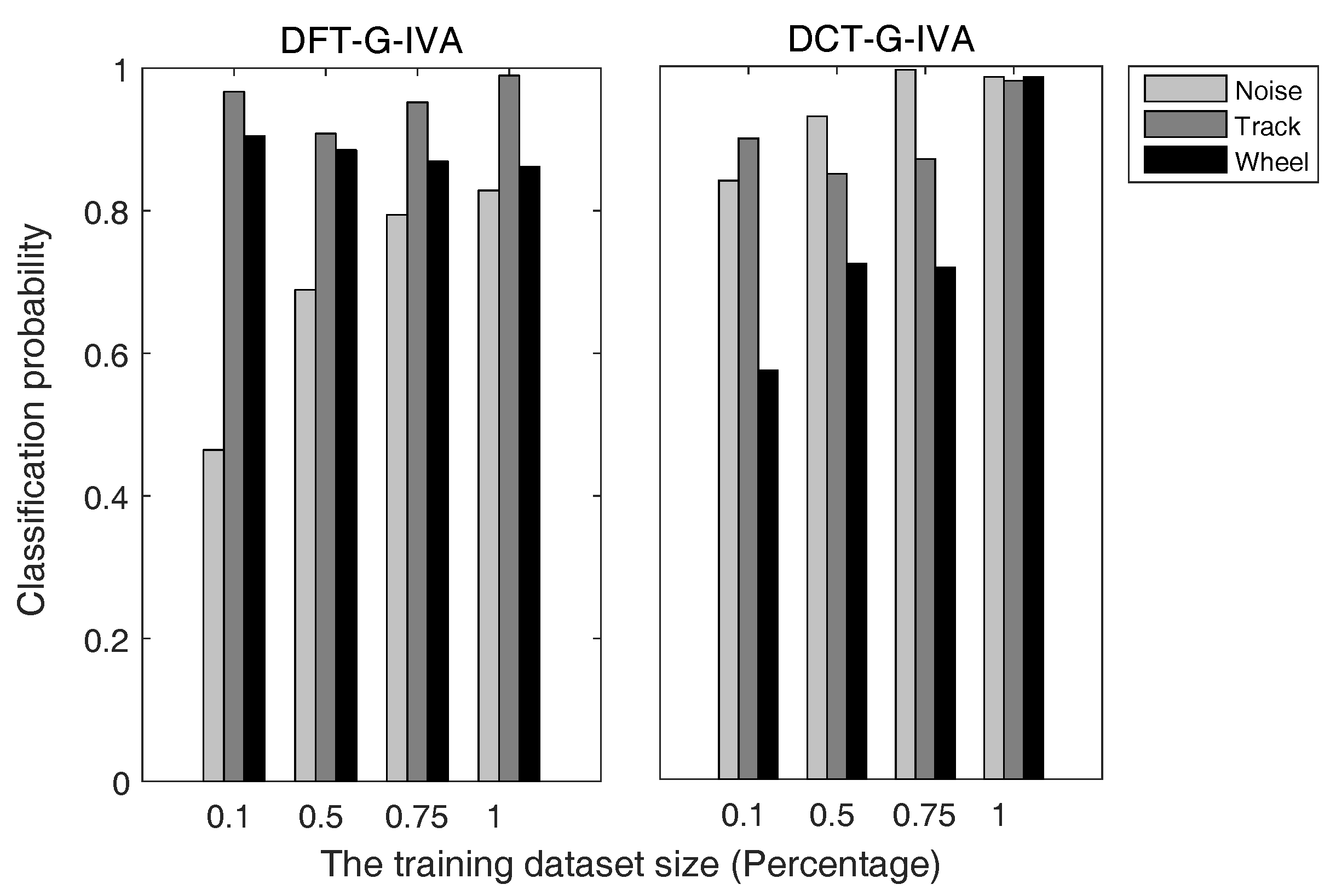
5.3. Result Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Winston, M.; Mcquiddy, J.; Jones, B. Affordable Next-generation UGS Development and Testing. In Proceedings of the SPIE—The International Society for Optical Engineering, Orlando, FL, USA, 5–8 April 2010. [Google Scholar]
- Chattopadhyay, P.; Ray, A.; Damarla, T. Simultaneous tracking and counting of targets in a sensor network. J. Acoust. Soc. Am. 2016, 139, 2108. [Google Scholar] [CrossRef]
- William, P.E.; Hoffman, M.W. Classification of Military Ground Vehicles Using Time Domain Harmonics’ Amplitudes. IEEE Trans. Instrum. Meas. 2011, 60, 3720–3731. [Google Scholar] [CrossRef]
- Zu, X.; Guo, F.; Huang, J.; Zhao, Q.; Liu, H.; Li, B.; Yuan, X. Design of an Acoustic Target Intrusion Detection System Based on Small-Aperture Microphone Array. Sensors 2017, 17, 514. [Google Scholar] [CrossRef] [PubMed]
- Zu, X.; Zhang, S.; Guo, F.; Zhao, Q.; Zhang, X.; You, X.; Liu, H.; Li, B.; Yuan, X. Vehicle Counting and Moving Direction Identification Based on Small-Aperture Microphone Array. Sensors 2017, 17, 1089. [Google Scholar] [CrossRef] [PubMed]
- Guo, F.; Liu, H.; Huang, J.; Zhang, X.; Zu, X.; Li, B.; Yuan, X. Design of a Direction-of-Arrival Estimation Method Used for an Automatic Bearing Tracking System. Sensors 2016, 16, 1145. [Google Scholar] [CrossRef] [PubMed]
- Sahidullah, M.; Saha, G. A Novel Windowing Technique for Efficient Computation of MFCC for Speaker Recognition. IEEE Signal Process. Lett. 2013, 20, 149–152. [Google Scholar] [CrossRef]
- Nakagawa, S.; Wang, L.; Ohtsuka, S. Speaker Identification and Verification by Combining MFCC and Phase Information. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1085–1095. [Google Scholar] [CrossRef]
- Alsina-Pagés, R.M.; Navarro, J.; Alías, F.; Hervás, M. HomeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring. Sensors 2017, 17, 854. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Xiao, S.; Zhou, Q.; Guo, F.; You, X.; Li, H.; Li, B. A Robust Feature Extraction Algorithm for the Classification of Acoustic Targets in Wild Environments. Circuits Syst. Signal Process. 2015, 34, 2395–2406. [Google Scholar] [CrossRef]
- Guo, F.; Huang, J.; Zhang, X.; You, X.; Zu, X.; Zhao, Q.; Ding, Y.; Liu, H.; Li, B. A Classification Method for Moving Targets in the Wild Based on Microphone Array and Linear Sparse Auto-Encoder. Neurocomputing 2017, 241, 28–37. [Google Scholar] [CrossRef]
- Wang, J.C.; Lee, H.P.; Wang, J.F.; Lin, C.B. Robust Environmental Sound Recognition for Home Automation. IEEE Trans. Autom. Sci. Eng. 2008, 5, 25–31. [Google Scholar] [CrossRef]
- Choi, J.H.; Chang, J.H. On using acoustic environment classification for statistical model-based speech enhancement. Speech Commun. 2012, 54, 477–490. [Google Scholar] [CrossRef]
- Li, Y.; Ho, K.C.; Popescu, M. A microphone array system for automatic fall detection. IEEE Trans. Biomed. Eng. 2012, 59, 1291–1301. [Google Scholar] [PubMed]
- Chen, J.; Benesty, J.; Huang, Y.; Doclo, S. New insights into the noise reduction Wiener filter. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1218–1234. [Google Scholar] [CrossRef]
- Yang, F.; Wu, M.; Yang, J. Stereophonic Acoustic Echo Suppression Based on Wiener Filter in the Short-Time Fourier Transform Domain. IEEE Signal Process. Lett. 2012, 19, 227–230. [Google Scholar] [CrossRef]
- Flanagan, J.L.; Johnston, J.D.; Zahn, R.; Elko, G.W. Computer-steered microphone arrays for sound transduction in large rooms. J. Acoust. Soc. Am. 1985, 78, S52. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y. Conventional Beamforming Techniques; Springer: Berlin/Heidelberg, Germany, 2008; pp. 39–65. [Google Scholar]
- Zeng, Y.; Hendriks, R.C. Distributed Delay and Sum Beamformer for Speech Enhancement via Randomized Gossip. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 260–273. [Google Scholar] [CrossRef]
- Habets, E.A.P.; Benesty, J.; Cohen, I.; Gannot, S.; Dmochowski, J. New Insights Into the MVDR Beamformer in Room Acoustics. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 158–170. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Q.; Wang, X.Q.; Yuan, C.M. Simulation of high-speed train pass-by noise source identification based on MVDR beamforming. In Proceedings of the IEEE International Conference on Control and Automation, Hangzhou, China, 12–14 June 2013; pp. 254–258. [Google Scholar]
- Pan, C.; Chen, J.; Benesty, J. Performance Study of the MVDR Beamformer as a Function of the Source Incidence Angle. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 67–79. [Google Scholar] [CrossRef]
- Haykin, S. Unsupervised Adaptive Filtering Volume I: Blind Source Separation; Wiley-Interscience: Hoboken, NJ, USA, 2000. [Google Scholar]
- Visser, E.; Otsuka, M.; Lee, T.W. A spatio-temporal speech enhancement scheme for robust speech recognition in noisy environments. Speech Commun. 2003, 41, 393–407. [Google Scholar] [CrossRef]
- Souden, M.; Araki, S.; Kinoshita, K.; Nakatani, T.; Sawada, H. A Multichannel MMSE-Based Framework for Speech Source Separation and Noise Reduction. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1913–1928. [Google Scholar] [CrossRef]
- Zoulikha, M.; Djendi, M. A new regularized forward blind source separation algorithm for automatic speech quality enhancement. Appl. Acoust. 2016, 112, 192–200. [Google Scholar] [CrossRef]
- Hyvärinen, A. Fast and robust fixed-point algorithms for independent component analysis. IEEE Trans. Neural Netw. 1999, 10, 626–634. [Google Scholar] [CrossRef] [PubMed]
- Comon, P.; Jutten, C. Handbook of Blind Source Separation: Independent Component Analysis and Separation; Academic Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Hyvärinen, A. Independent component analysis: Recent advances. Philos. Trans. R. Soc. A 2012, 371. [Google Scholar] [CrossRef] [PubMed]
- Bell, A.J.; Lambert, R.H. Blind Separation of Delayed and Convolved Sources. In Proceedings of the Conference on Neural Information Processing Systems (NIPS 1996), Denver, CO, USA, 2–5 December 1996; pp. 758–764. [Google Scholar]
- Smaragdis, P. Blind separation of convolved mixtures in the frequency domain. Neurocomputing 1998, 22, 21–34. [Google Scholar] [CrossRef]
- Lee, I.; Kim, T.; Lee, T.W. Fast fixed-point independent vector analysis algorithms for convolutive blind source separation. Signal Process. 2007, 87, 1859–1871. [Google Scholar] [CrossRef]
- Anderson, M.; Fu, G.S.; Phlypo, R.; Adali, T. Independent Vector Analysis: Identification Conditions and Performance Bounds. IEEE Trans. Signal Process. 2014, 62, 4399–4410. [Google Scholar] [CrossRef]
- Sawada, H.; Mukai, R.; Araki, S.; Makino, S. Frequency-Domain Blind Source Separation; Springer: Berlin/Heidelberg, Germany, 2005; pp. 299–327. [Google Scholar]
- Hiroe, A. Solution of Permutation Problem in Frequency Domain ICA, Using Multivariate Probability Density Functions. Lect. Notes Comput. Sci. 2006, 3889, 601–608. [Google Scholar]
- Kim, T.; Attias, H.T.; Lee, S.Y.; Lee, T.W. Blind Source Separation Exploiting Higher-Order Frequency Dependencies. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 70–79. [Google Scholar] [CrossRef]
- Harris, J.; Rivet, B.; Naqvi, S.M.; Chambers, J.A.; Jutten, C. Real-time independent vector analysis with Student’s t source prior for convolutive speech mixtures. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Australia, 19–24 April 2015; pp. 1856–1860. [Google Scholar]
- Anderson, M.; Adali, T.; Li, X.L. Joint Blind Source Separation With Multivariate Gaussian Model: Algorithms and Performance Analysis. IEEE Trans. Signal Process. 2012, 60, 1672–1683. [Google Scholar] [CrossRef]
- Giri, R.; Rao, B.D.; Garudadri, H. Reweighted Algorithms for Independent Vector Analysis. IEEE Signal Process. Lett. 2017, 24, 362–366. [Google Scholar] [CrossRef]
- Boukouvalas, Z.; Fu, G.S.; Adali, T. An efficient multivariate generalized Gaussian distribution estimator: Application to IVA. In Proceedings of the 2015 49th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 18–20 March 2015; pp. 1–4. [Google Scholar]
- Ahmed, N.N.; Natarajan, T.; Rao, K.R. Discrete Cosine Transform. IEEE Trans. Comput. 1974, C-23, 90–93. [Google Scholar] [CrossRef]
- Strang, G. The Discrete Cosine Transform. Siam Rev. 1999, 41, 135–147. [Google Scholar] [CrossRef]
- Rhabi, M.E.; Fenniri, H.; Keziou, A.; Moreau, E. A robust algorithm for convolutive blind source separation in presence of noise. Signal Process. 2013, 93, 818–827. [Google Scholar] [CrossRef]
- Yang, Y. Elements of Information Theory. J. Am. Stat. Assoc. 2012, 103, 429. [Google Scholar] [CrossRef]
- Amari, S.I.; Cichocki, A.; Yang, H.H. A New Learning Algorithm for Blind Signal Separation. In Proceedings of the 8th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 27 November–2 December 1995; pp. 757–763. [Google Scholar]
- Liang, Y.; Harris, J.; Naqvi, S.M.; Chen, G.; Chambers, J.A. Independent vector analysis with a generalized multivariate Gaussian source prior for frequency domain blind source separation. Signal Process. 2014, 105, 175–184. [Google Scholar] [CrossRef]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L.; Zue, V. TIMIT Acoustic-Phonetic Continuous Speech Corpus; Linguistic Data Consortium: Philadelphia, PA, USA, 1993. [Google Scholar]
- Proakis, J.G.; Manolakis, D.G. Digital Signal Processing: Principles, Algorithms and Applications; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Grimaldi, M.; Cummins, F. Speaker Identification Using Instantaneous Frequencies. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 1097–1111. [Google Scholar] [CrossRef]
- Jayanna, H.S.; Prasanna, S.R.M. An experimental comparison of modelling techniques for speaker recognition under limited data condition. Sadhana 2009, 34, 717. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, J.; Song, E.; Liu, H.; Li, B.; Yuan, X. Design of Small MEMS Microphone Array Systems for Direction Finding of Outdoors Moving Vehicles. Sensors 2014, 14, 4384–4398. [Google Scholar] [CrossRef] [PubMed]
- Guo, F.; Huang, J.; Zhang, X.; Cheng, Y.; Liu, H.; Li, B. A Two-Stage Detection Method for Moving Targets in the Wild Based on Microphone Array. IEEE Sens. J. 2015, 15, 5795–5803. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Guo, F.; Zhou, Q.; Liu, H.; Li, B. Design of an Acoustic Target Classification System Based on Small-Aperture Microphone Array. IEEE Trans. Instrum. Meas. 2015, 64, 2035–2043. [Google Scholar] [CrossRef]
- Cevher, V.; Chellappa, R.; Mcclellan, J.H. Vehicle Speed Estimation Using Acoustic Wave Patterns. IEEE Trans. Signal Process. 2009, 57, 30–47. [Google Scholar] [CrossRef]
- Raina, R.; Battle, A.; Lee, H.; Packer, B.; Ng, A.Y. Self-taught learning: Transfer learning from unlabeled data. In Proceedings of the International Conference on Machine Learning, Cincinnati, OH, USA, 13–15 December 2007; pp. 759–766. [Google Scholar]
- Li, J.; Zhang, X.; Cao, R.; Zhou, M. Reduced-Dimension MUSIC for Angle and Array Gain-Phase Error Estimation in Bistatic MIMO Radar. IEEE Commun. Lett. 2013, 17, 443–446. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| c2 | 0.01 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | 1.2 | 1.4 | 1.6 | 1.8 | 2.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Iterations | 17 | 37 | 37 | 35 | 34 | 31 | 25 | 24 | 24 | 24 | 24 |
| ISI | 0.129 | 0.125 | 0.124 | 0.121 | 0.117 | 0.112 | 0.091 | 0.103 | 0.105 | 0.114 | 0.126 |
| c1 | 0.1 | 0.3 | 0.5 | 0.8 | 1.0 | 1.2 | 1.4 | 1.8 | 2.0 | 2.5 | 3.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Iterations | 29 | 31 | 33 | 31 | 27 | 26 | 22 | 21 | 19 | 18 | 18 |
| ISI | 0.125 | 0.123 | 0.115 | 0.100 | 0.094 | 0.095 | 0.112 | 0.117 | 0.122 | 0.178 | 0.243 |
| Target | Car | Truck | TV | Noise | Sum |
|---|---|---|---|---|---|
| Sample number | 58 | 46 | 49 | 71 | 224 |
| Frame number | 6240 | 8551 | 12,185 | 11,237 | 38,213 |
| Training Set | Average | DS | DFT-L-IVA | DCT-L-IVA | DFT-G-IVA | DCT-G-IVA |
|---|---|---|---|---|---|---|
| 0.1 | 0.7937 | 0.8083 | 0.8901 | 0.8964 | 0.8912 | 0.8987 |
| 0.5 | 0.8476 | 0.8457 | 0.9373 | 0.9419 | 0.9482 | 0.9536 |
| 0.75 | 0.8572 | 0.8577 | 0.9354 | 0.9356 | 0.9421 | 0.9570 |
| 1 | 0.8636 | 0.8656 | 0.9482 | 0.9507 | 0.9589 | 0.9633 |
| Methods | DFT-L-IVA | DCT-L-IVA | DFT-G-IVA | DCT-G-IVA |
|---|---|---|---|---|
| Execution time | 344.013 s | 295.059 s | 325.680 s | 198.953 s |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Guo, F.; Zu, X.; Chang, Y.; Li, B.; Yuan, X. An Acoustic Signal Enhancement Method Based on Independent Vector Analysis for Moving Target Classification in the Wild. Sensors 2017, 17, 2224. https://doi.org/10.3390/s17102224
Zhao Q, Guo F, Zu X, Chang Y, Li B, Yuan X. An Acoustic Signal Enhancement Method Based on Independent Vector Analysis for Moving Target Classification in the Wild. Sensors. 2017; 17(10):2224. https://doi.org/10.3390/s17102224
Chicago/Turabian StyleZhao, Qin, Feng Guo, Xingshui Zu, Yuchao Chang, Baoqing Li, and Xiaobing Yuan. 2017. "An Acoustic Signal Enhancement Method Based on Independent Vector Analysis for Moving Target Classification in the Wild" Sensors 17, no. 10: 2224. https://doi.org/10.3390/s17102224
APA StyleZhao, Q., Guo, F., Zu, X., Chang, Y., Li, B., & Yuan, X. (2017). An Acoustic Signal Enhancement Method Based on Independent Vector Analysis for Moving Target Classification in the Wild. Sensors, 17(10), 2224. https://doi.org/10.3390/s17102224