Spoof Detection for Finger-Vein Recognition System Using NIR Camera


Abstract
:1. Introduction
- To the best of our knowledge, this is the first approach for presentation attack detection using the deep learning framework for finger-vein biometric system. For this purpose, we apply the deep learning framework based on the CNN method for the PAD problem to overcome the limitation of previous methods that used the handcrafted methods for image feature extraction. By using a training procedure, we can learn a more suitable feature extractor for finger-vein PAD than the traditional handcrafted methods.
- Since the CNN method has a drawback of over-fitting problem caused by the huge amount of network parameters, we apply the transfer learning method instead of traditional training method for the network training procedure to minimize the over-fitting problem. By using the transfer learning method, we can utilize the optimal parameters of the existing network that were obtained using another problem. In our experiments, we used two successful CNNs, the Alex network and Visual Geometry Group (VGG) network, which were trained using ImageNet database as our preferred models for applying the transfer learning method.
- We extract image features using pre-trained CNN models to represent the input images. To reduce the effect of noise and the problem of high-dimensional features, we apply the principal component analysis (PCA) method on the extracted image features. Finally, the classification of real and presentation attack finger-vein image is done by using support vector machine (SVM).
- We collected our database of real and presentation attack finger-vein images, namely ISPR database, in which the number of images and kinds of presentation attacks are larger than those in open database. We made our database and algorithm including trained CNN model available to other researchers to compare the performance with our database and algorithm including CNN model.
2. Proposed Method for PAD Based on CNN with Transfer Learning, PCA and SVM
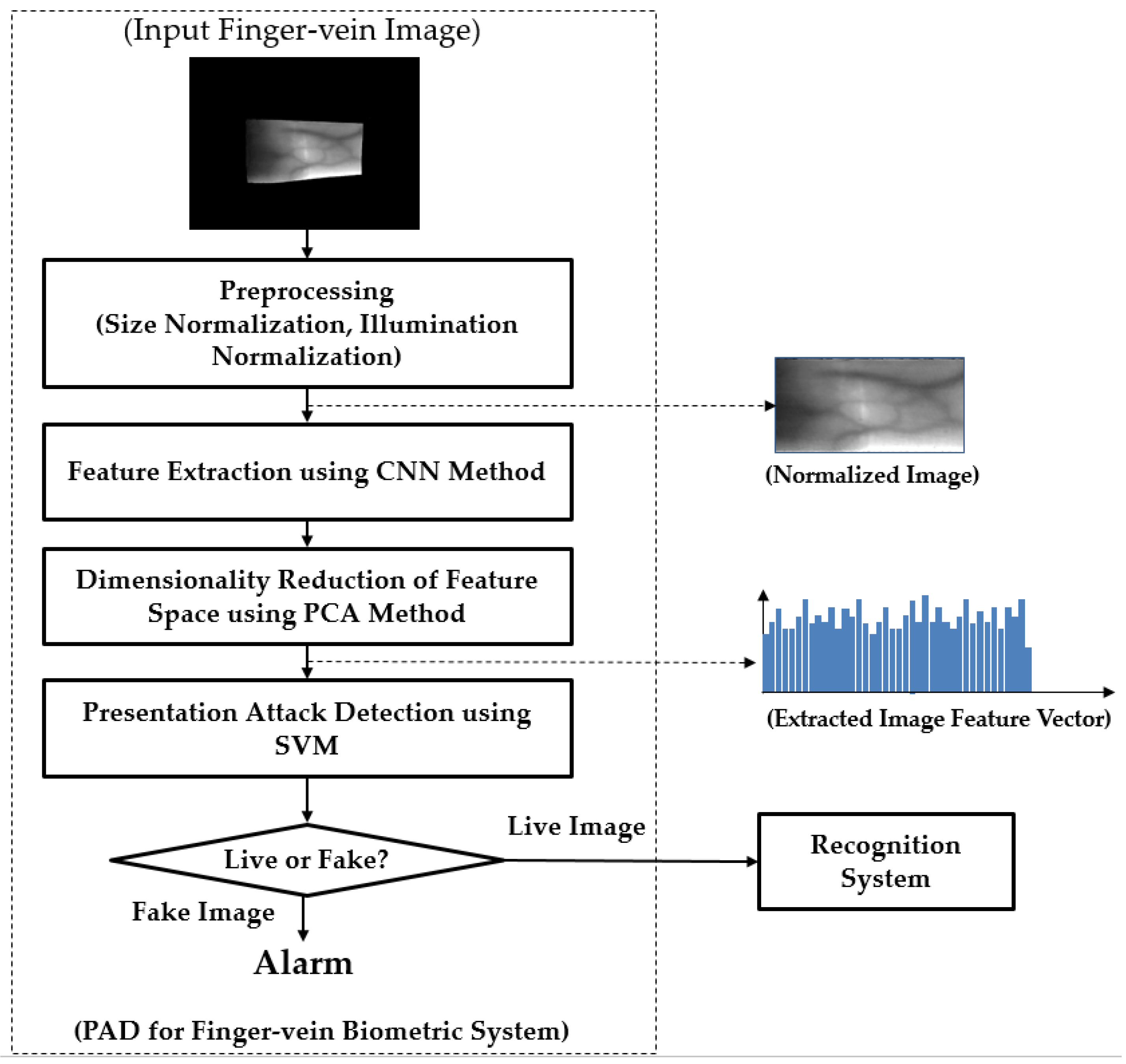
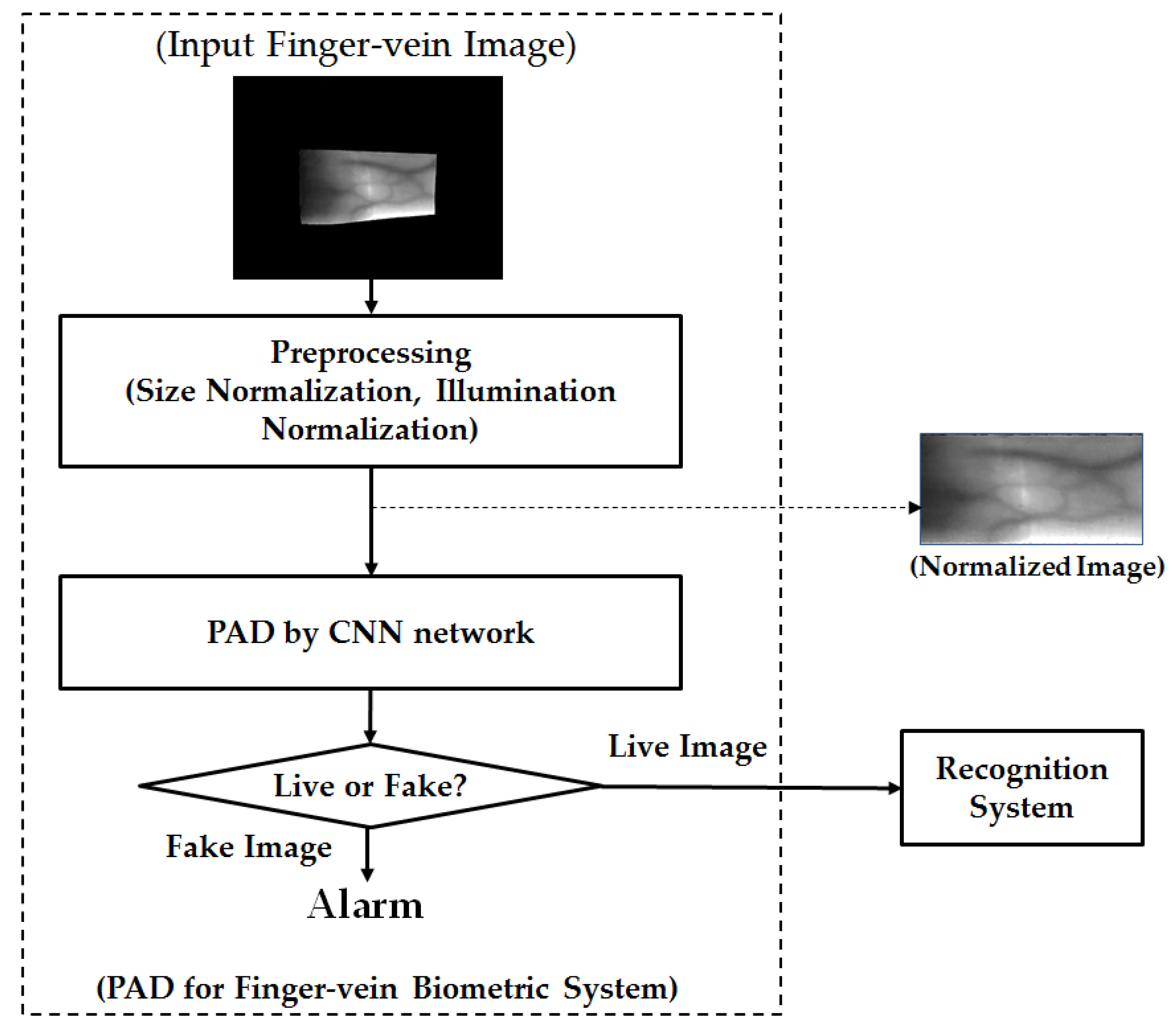
2.1. Overview of the Proposed Method
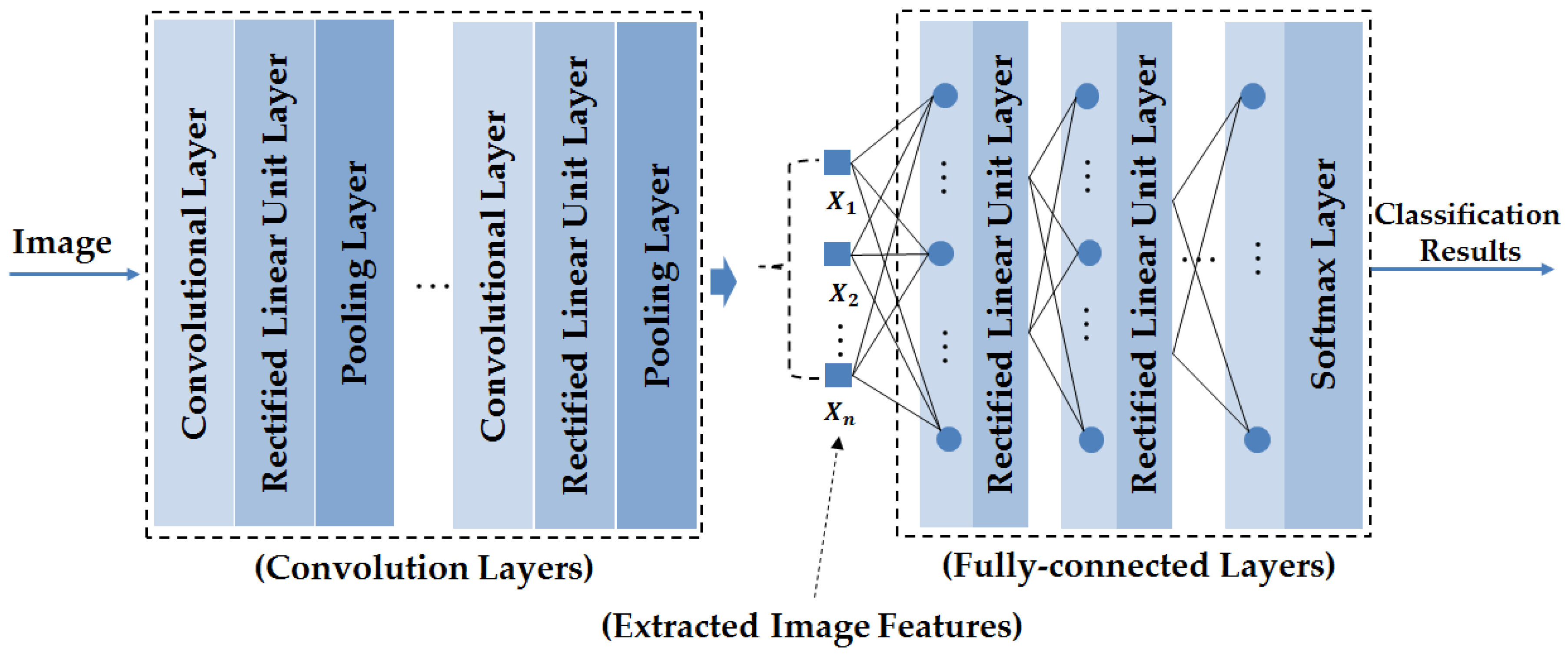
2.2. Convolutional Neural Network and Its Applications
2.2.1. CNN Architecture Based on Alex Network for PAD
2.2.2. Customized CNN Architecture Based on Alex Network for PAD
2.2.3. CNN Architecture Based on VGG Network for PAD
2.2.4. Customized CNN Architecture Based on VGG Network for PAD
2.3. Image Feature Extraction and Presentation Attack Image Detection Using PCA and SVM
3. Experimental Results
3.1. Experimental Setup
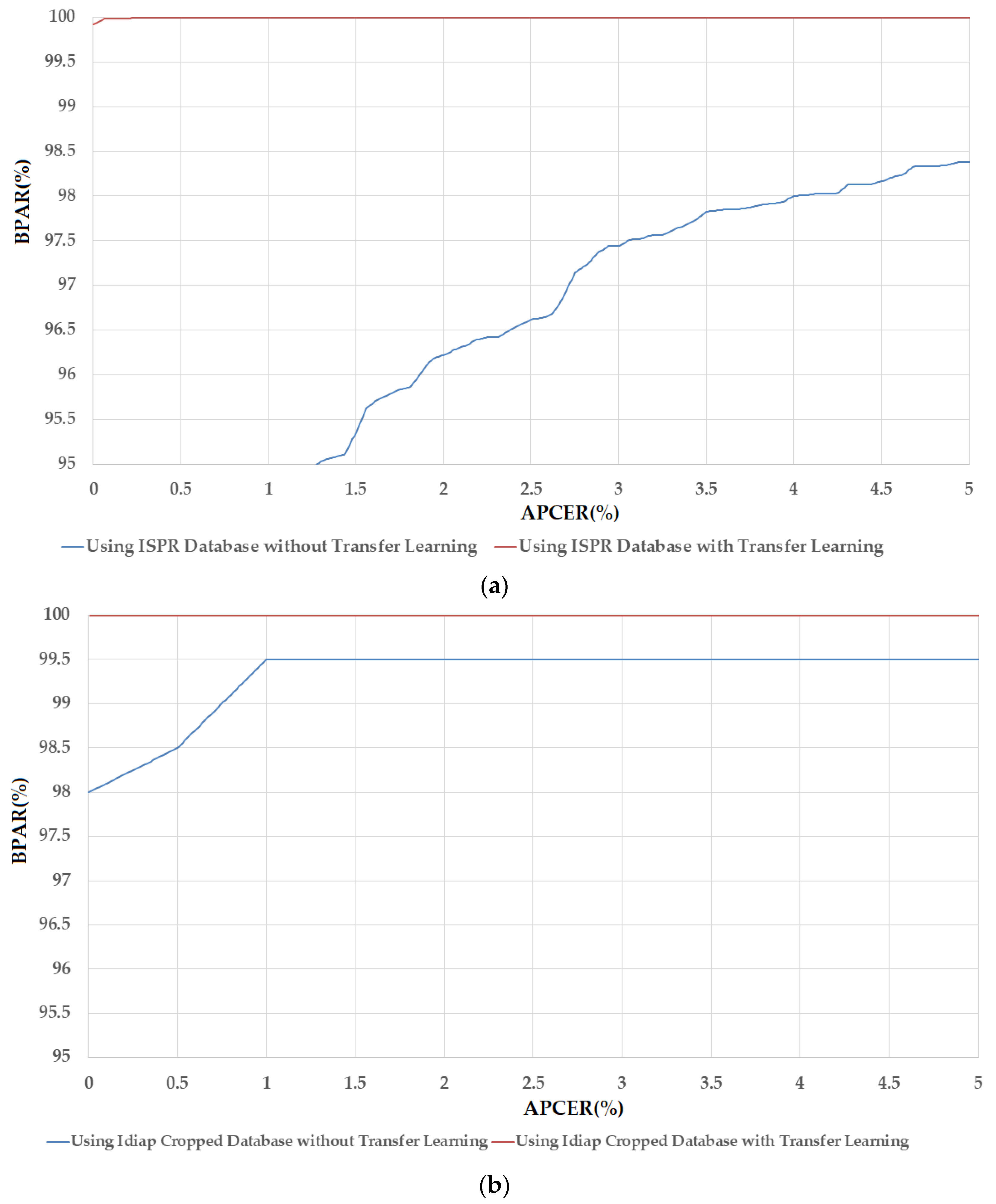
3.2. Experiment Results
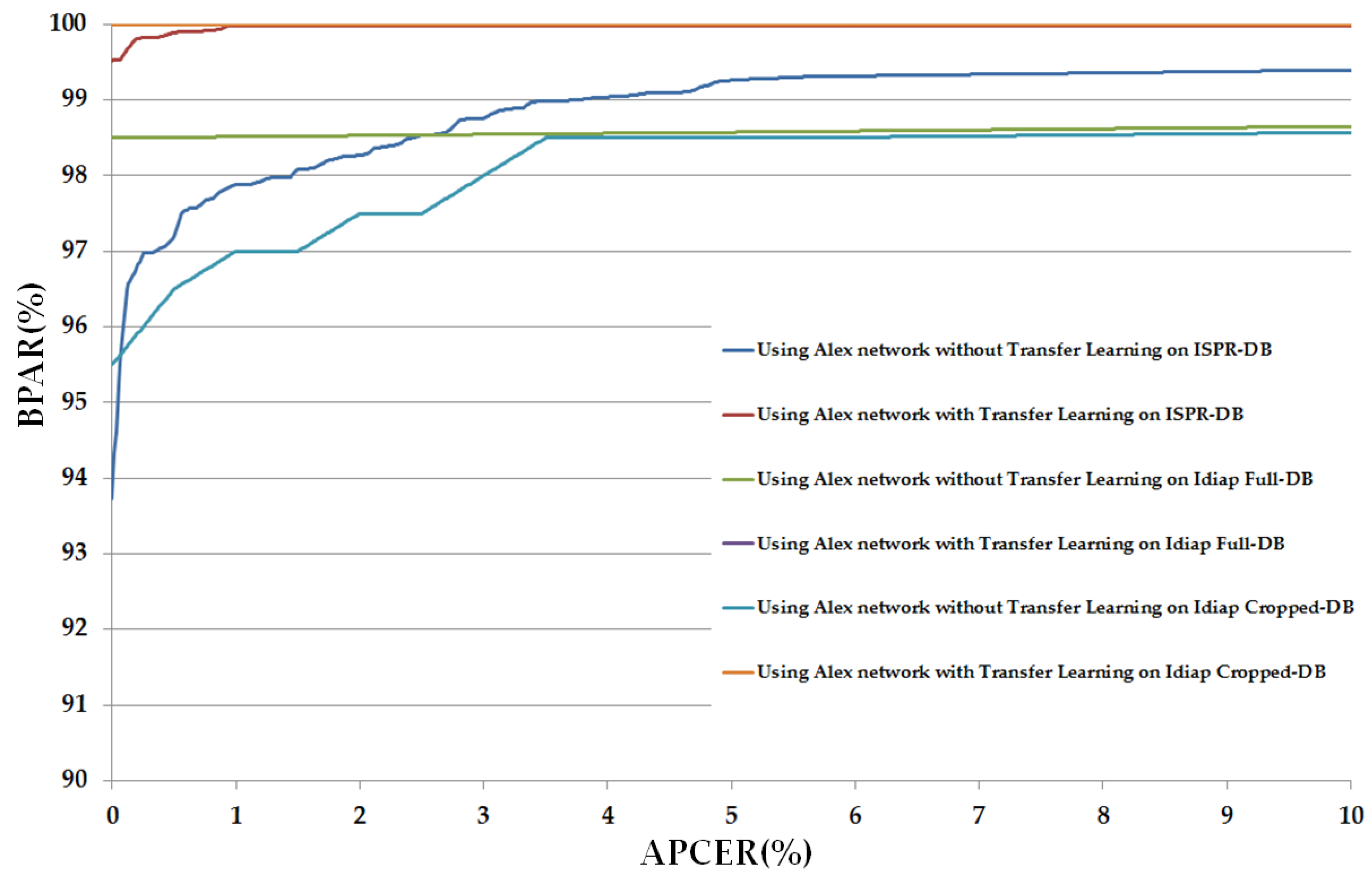
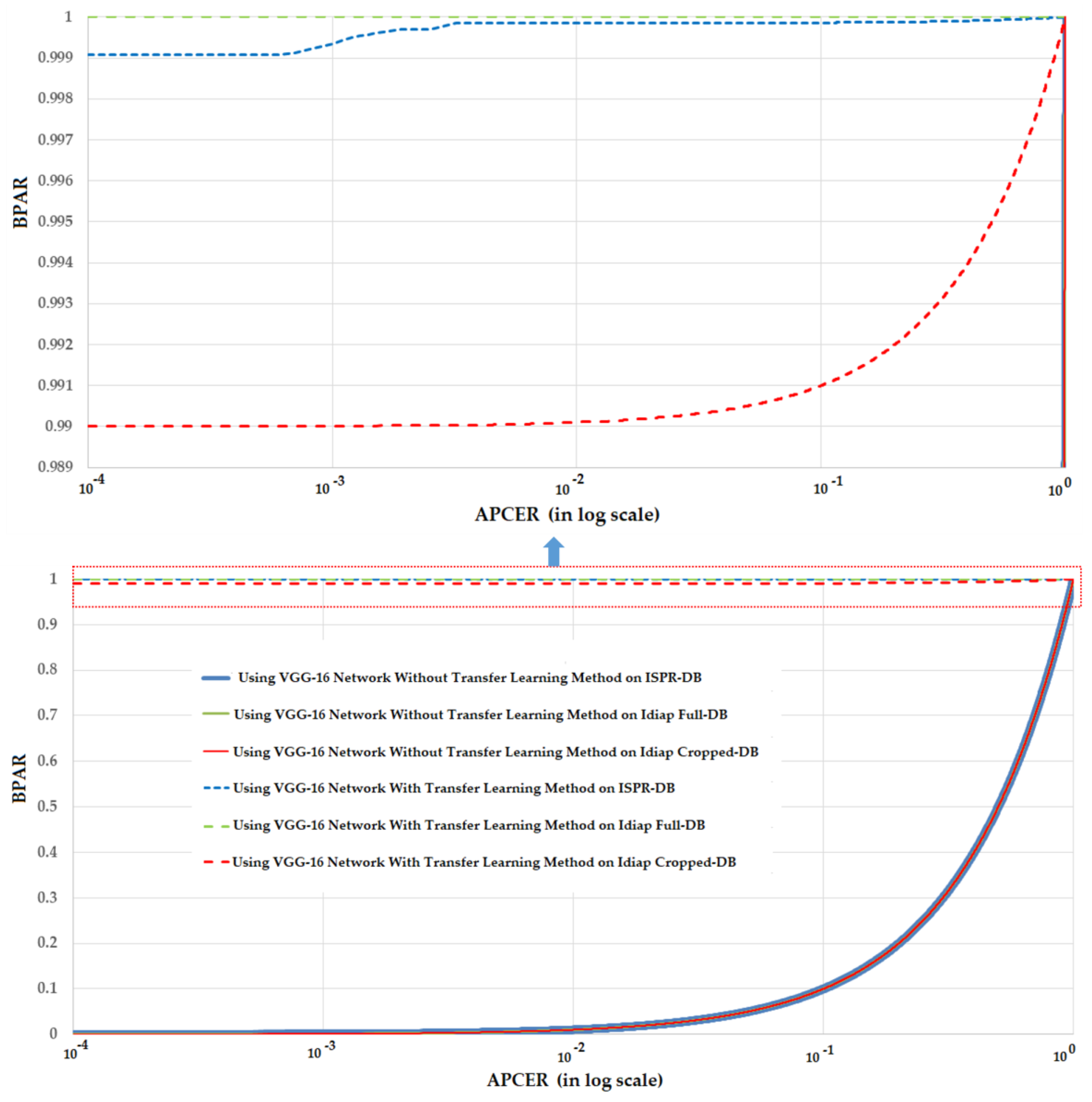
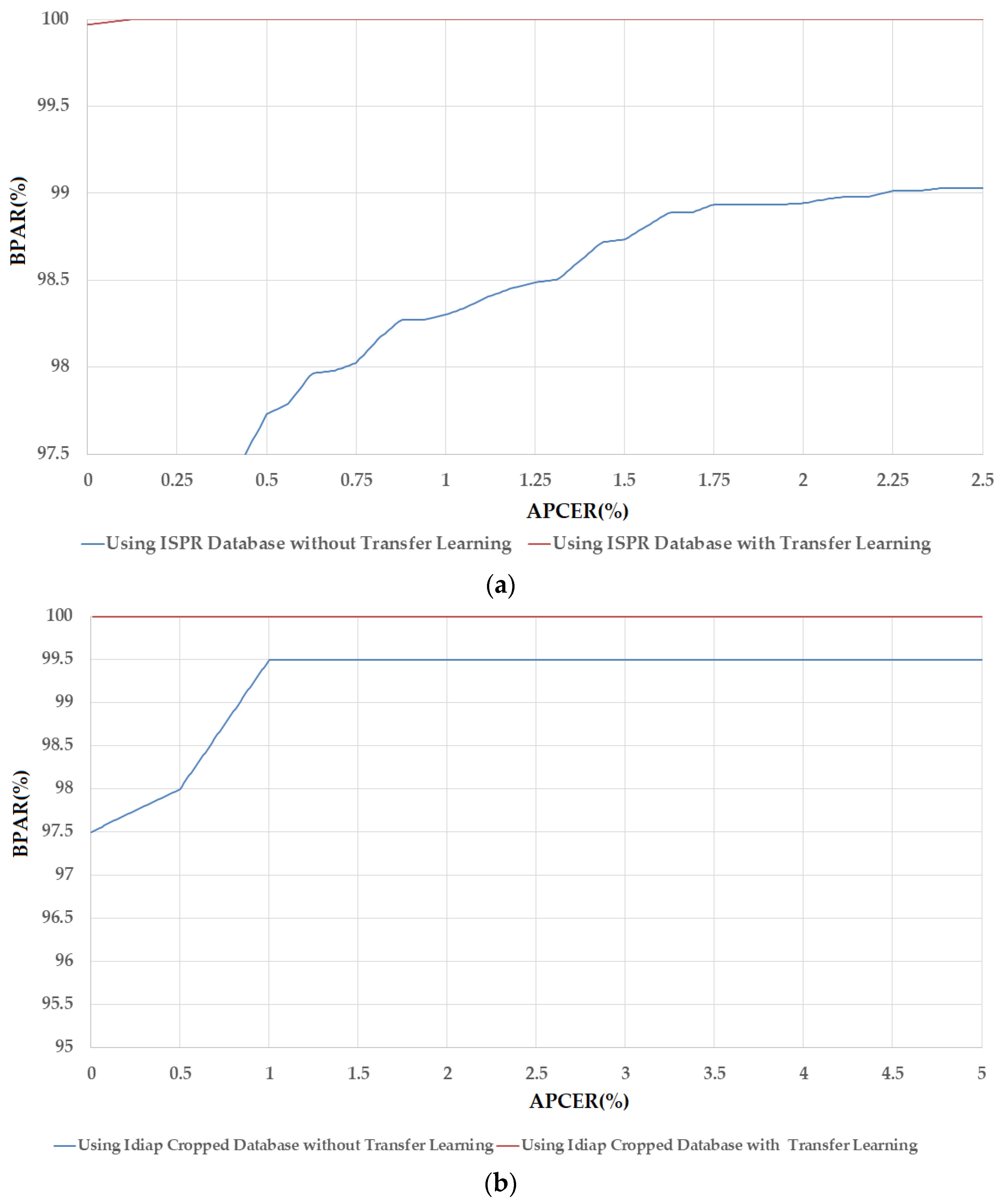
3.2.1. PAD Accuracy Assessment Using CNN-Based Method
3.2.2. PAD Accuracy Assessment Using Our Proposed Method Based on Alex and VGG-16 Network CNN Architectures
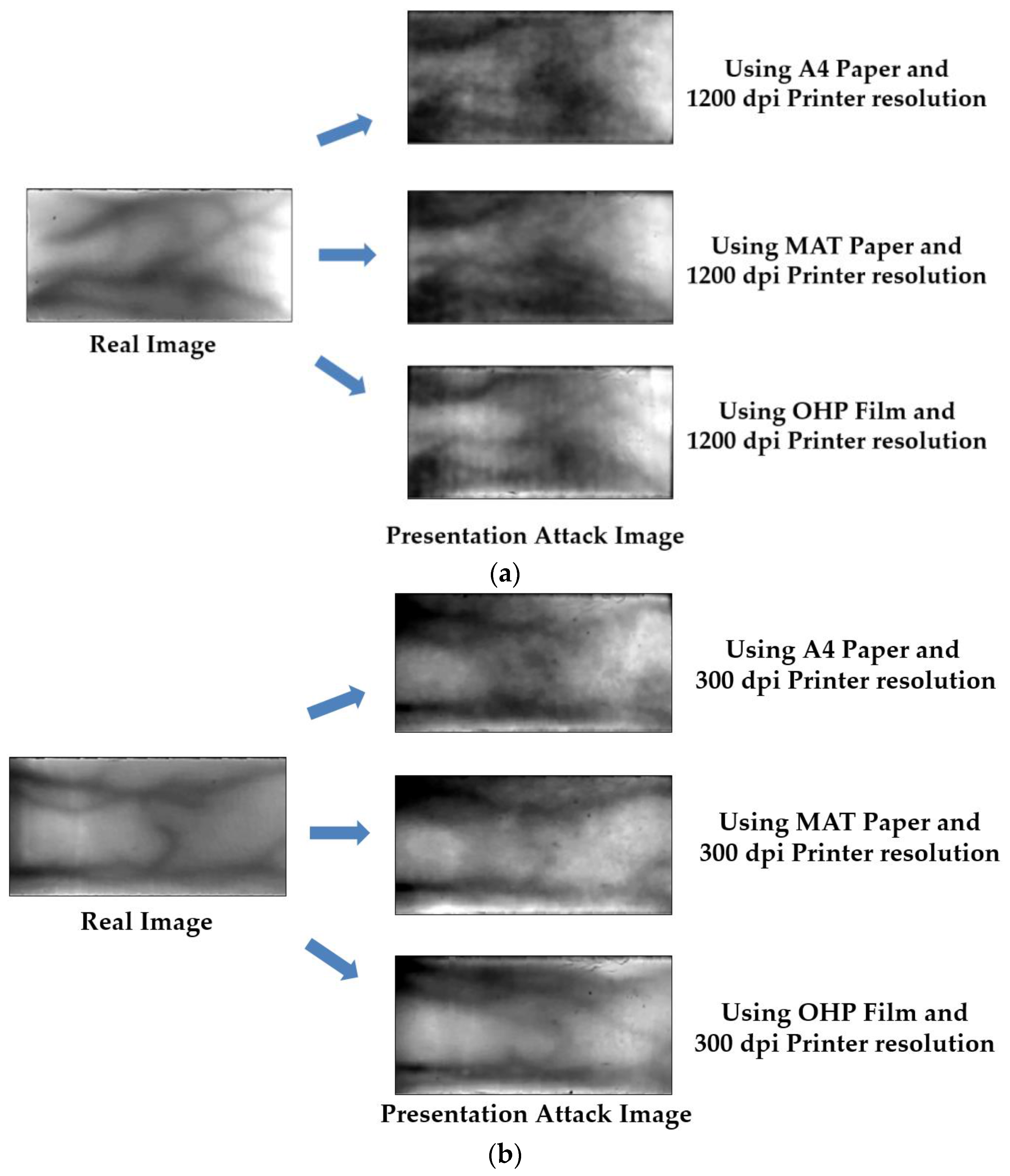
3.2.3. PAD Accuracy Assessment Using Our Proposed Method on ISPR Database Based on Printing Resolution and Printing Materials
3.2.4. PAD Accuracy Assessment Using Our Proposed Method Based on Customized Alex and VGG-16 Networks
3.2.5. Comparison with Various Methods
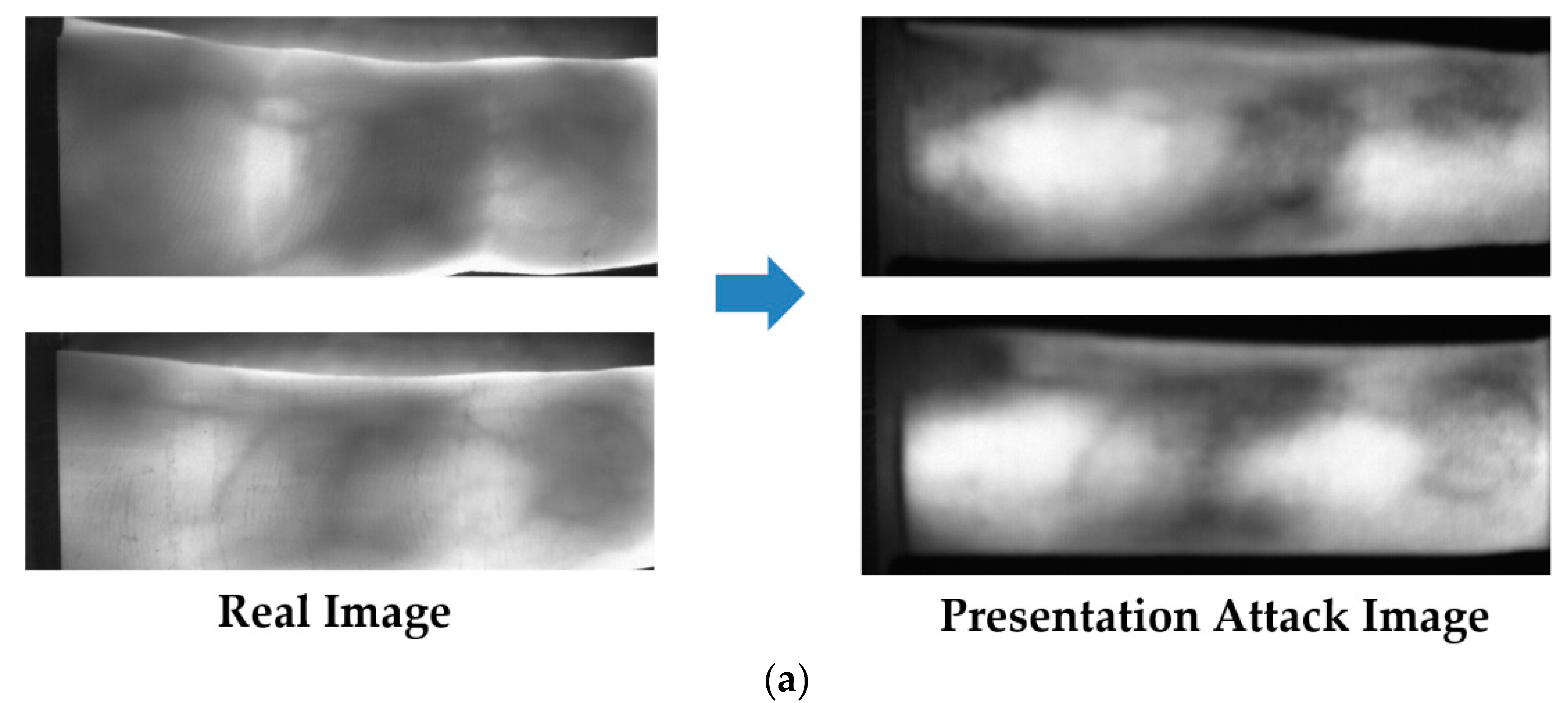
3.2.6. Application of our Proposed Method on PAD for Palm-Vein Recognition Systems
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jain, A.K.; Ross, A.; Prabhakar, S. An introduction to biometric recognition. IEEE Trans. Circuits Syst. Video Technol. 2014, 14, 4–20. [Google Scholar] [CrossRef]
- Eastwood, S.C.; Shmerko, V.P.; Yanushkevich, S.N.; Drahansky, M.; Gorodnichy, D.O. Biometric-enabled authentication machines: A survey of open-set real-world applications. IEEE T. Hum. Mach. Syst. 2016, 46, 231–242. [Google Scholar] [CrossRef]
- Sequeira, A.F.; Cardoso, J.S. Fingerprint liveness detection in the presence of capable intruders. Sensors 2015, 15, 14615–14638. [Google Scholar] [CrossRef] [PubMed]
- Soudedik, C.; Busch, C. Presentation attack detection method for fingerprint recognition systems: A survey. IET Biom. 2014, 3, 219–233. [Google Scholar] [CrossRef]
- Abhishek, K.; Yogi, A. A minutiae count based method for fake fingerprint detection. Procedia Comput. Sci. 2015, 58, 447–452. [Google Scholar] [CrossRef]
- Lee, W.O.; Kim, Y.G.; Hong, H.G.; Park, K.R. Face recognition system for set-top box-based intelligent TV. Sensors 2014, 14, 21726–21749. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Yu, S.; Kim, I.-J.; Lee, S. 3D multi-spectrum sensor system with face recognition. Sensors 2013, 13, 12804–12829. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.J.; Lu, Y.; Yoon, S.; Yang, J.; Park, D.S. Intensity variation normalization for finger vein recognition using guided filter based on single scale retinex. Sensors 2015, 15, 17089–17105. [Google Scholar] [CrossRef] [PubMed]
- Pham, D.T.; Park, Y.H.; Nguyen, D.T.; Kwon, S.Y.; Park, K.R. Nonintrusive finger-vein recognition system using NIR image sensor and accuracy analyses according to various factors. Sensors 2015, 15, 16866–16894. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yin, Y.; Wang, H.; Song, S.; Li, Q. Finger vein recognition with manifold learning. J. Netw. Comput. Appl. 2010, 33, 275–282. [Google Scholar] [CrossRef]
- Lin, C.-L.; Wang, S.-H.; Cheng, H.-Y.; Fan, K.-H.; Hsu, W.-L.; Lai, C.-R. Bimodal biometric verification using the fusion of palmprint and infrared palm-dorsum vein images. Sensors 2015, 15, 31339–31361. [Google Scholar] [CrossRef] [PubMed]
- Han, W.-Y.; Lee, J.-C. Palm vein recognition using adaptive Gabor filter. Expert Syst. Appl. 2012, 39, 13225–13234. [Google Scholar] [CrossRef]
- Nalla, P.R.; Kumar, A. Toward more accurate iris recognition using cross-spectral matching. IEEE Trans. Image Process. 2017, 26, 208–221. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Sirlantzis, K.; Howells, G. Optimal generation of iris codes for iris recognition. IEEE Trans. Inf. Forensics Secur. 2017, 12, 157–171. [Google Scholar] [CrossRef]
- Marsico, M.D.; Petrosino, A.; Ricciardi, S. Iris recognition through machine learning techniques: A survey. Pattern Recognit. Lett. 2016, 82, 106–115. [Google Scholar] [CrossRef]
- Nam, G.P.; Park, K.R. New fuzzy-based retinex method for illumination normalization of face recognition. Int. J. Adv. Robot. Syst. 2012, 9, 1–9. [Google Scholar] [CrossRef]
- Bartunek, J.S.; Nilsson, M.; Sallberg, B.; Claesson, I. Adaptive fingerprint image enhancement with emphasis on preprocessing of data. IEEE Trans. Image Process. 2013, 22, 644–656. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.T.; Park, Y.H.; Lee, H.C.; Shin, K.Y.; Kang, B.J.; Park, K.R. Combining touched fingerprint and finger-vein of a finger, and its usability evaluation. Adv. Sci. Lett. 2012, 5, 85–95. [Google Scholar] [CrossRef]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face spoofing detection using colour texture analysis. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1818–1830. [Google Scholar] [CrossRef]
- Galbally, J.; Marcel, S.; Fierrez, J. Biometric anti-spoofing methods: A survey in face recognition. IEEE Access 2014, 2, 1530–1552. [Google Scholar] [CrossRef]
- Lee, E.C.; Ko, Y.J.; Park, K.R. Fake iris detection method using Purkinje images based on gaze position. Opt. Eng. 2009, 47. [Google Scholar] [CrossRef]
- Galbally, J.; Marcel, S.; Fierrez, J. Image quality assessment for fake biometric detection: Application to iris, fingerprint and face recognition. IEEE Trans. Image Process. 2014, 23, 710–724. [Google Scholar] [CrossRef] [PubMed]
- Tome, P.; Raghavendra, R.; Busch, C.; Tirunagari, S.; Poh, N.; Shekar, B.H.; Gragnaniello, D.; Sansone, C.; Verdoliva, L.; Marcel, S. The 1st competition on counter measures to finger vein spoofing attacks. In Proceedings of the International Conference on Biometrics, Phuket, Thailand, 19–22 May 2015; pp. 513–518. [Google Scholar]
- Nguyen, D.T.; Park, Y.H.; Shin, K.Y.; Kwon, S.Y.; Lee, H.C.; Park, K.R. Fake finger-vein image detection based on fourier and wavelet transforms. Digit. Signal Process. 2013, 23, 1401–1413. [Google Scholar] [CrossRef]
- Kocher, D.; Schwarz, S.; Uhl, A. Empirical evaluation of LBP-extension features for finger vein spoofing detection. In Proceedings of the International Conference of the Biometrics Special Interest Group, Darmstadt, Germany, 21–23 September 2016; pp. 1–5. [Google Scholar]
- Tirunagari, S.; Poh, N.; Bober, M.; Windridge, D. Windowed DMD as a micro-texture descriptor for finger vein counter-spoofing in biometrics. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Rome, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar]
- Raghavendra, R.; Busch, C. Presentation attack detection algorithms for finger vein biometrics: A comprehensive study. In Proceedings of the 11th International Conference on Signal-Image Technology and Internet-based Systems, Bangkok, Thailand, 23–27 November 2015; pp. 628–632. [Google Scholar]
- Qin, B.; Pan, J.F.; Cao, G.Z.; Du, G.G. The anti-spoofing study of vein identification system. In Proceedings of the International Conference on Computational Intelligence and Security, Beijing, China, 11–14 December 2009; pp. 357–360. [Google Scholar]
- Kang, B.J.; Park, K.R. Multi-model biometric method based on vein and geometry of a single finger. IET Comput. Vis. 2010, 4, 209–217. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional neural networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, Kunming, China, 25–27 September 2013. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar]
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. DeepLanes: End-to-end lane position estimation using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 38–45. [Google Scholar]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye tracking for everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2176–2184. [Google Scholar]
- Qin, H.; Yan, J.; Li, X.; Hu, X. Joint training of cascaded CNN for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3456–3465. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- George, D.; Shen, H.; Huerta, E.A. Deep transfer learning: A new deep learning glitch classification method for advanced LIGO. 2017. arXiv.org e-print archive. Available online: http:// arXiv.org/abs/1706.07446 (accessed on 27 September 2017).
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Nanni, L.; Ghidoni, S. How could a subcellular image, or a painting by Van Gogh, be similar to a great white shark or to a pizza? Pattern Recognit. Lett. 2017, 85, 1–7. [Google Scholar] [CrossRef]
- Ravishankar, H.; Sudhakar, P.; Venkataramani, R.; Thiruvenkadam, S.; Annangi, P.; Babu, N.; Vaidya, V. Understanding the mechanisms of deep transfer learning for medical images. 2017. arXiv.org e-print archive. Available online: https://arxiv.org/abs/1704.06040 (accessed on 27 September 2017).
- ISPR Database (Real and Presentation Attack Finger-Vein Images) and Algorithm Including CNN Model. Available online: http://dm.dgu.edu/link.html (accessed on 30 April 2017).
- Nguyen, D.T.; Kim, K.W.; Hong, H.G.; Koo, J.H.; Kim, M.C.; Park, K.R. Gender recognition from human-body images using visible-light and thermal camera videos based on a convolutional neural network for image feature extraction. Sensors 2017, 17, 637. [Google Scholar] [CrossRef] [PubMed]
- MATLAB Convolutional Neural Networks (CNN) Toolbox. Available online: https://www.mathworks.com/help/nnet/convolutional-neural-networks.html?s_tid=gn_loc_drop (accessed on 30 April 2017).
- ISO/IEC JTC1 SC37 Biometrics. ISO/IEC WD 30107–3: 2014 Information Technology—Presentation Attack Detection-Part 3: Testing and Reporting and Classification of Attacks; International Organization for Standardization: Geneva, Switzerland, 2014.
- Tome, P.; Marcel, S. On the vulnerability of palm vein recognition to spoofing attacks. In Proceedings of the International Conference on Biometrics, Phuket, Thailand, 19–22 May 2015; pp. 319–325. [Google Scholar]
- Ma, X.; Jing, X.; Huang, H.; Cui, Y.; Mu, J. Palm-vein recognition scheme based on an adaptive Gabor filter. IET Biom. 2017, 6, 325–333. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Methods | Strength | Weakness | Accuracy (Database) |
|---|---|---|---|---|
| PAD methods using handcrafted methods | Uses a series of images to check the variation of vein patterns based on heart rate [28] | Easy to implement | Requires high processing time for capturing and processing successive images | Not available |
| Uses the combination of features in both spatial and frequency domain through Fourier and wavelet transform [24] | Uses information from both spatial and frequency domain for fake image detection. Fair detection accuracy | More complex than the method in [28]. Detection accuracy is limited due to the uses of handcrafted image feature extractor. | Equal error rate (EER) = 2.874% (Using ISPR Database) | |
| Uses average vertical energy of the Fourier spectrum; BSIF feature; monogenic scale space based global descriptor; and local binary pattern on residual image [23]. | Fair detection accuracy | Detection accuracy is limited due to the use of handcrafted image feature extractor. | Half total error rate (HTER) = 0.00% (Using Idiap Database) | |
| Uses the windowed DMD as micro-texture descriptor for fake finger-vein image detection [26] | Results comparable to previous methods | EER = 1.59% (Idiap Cropped Database) EER = 0.08% (Using Idiap Full Database) | ||
| Uses steerable pyramids decomposition for image feature extraction [27] | Improved detection accuracy compared to some other previous proposed methods. | Average classification error rate (ACER) = about 3.0% (A collected database consists of 300 unique finger-vein instance) | ||
| PAD method using learning-based method (Proposed Method) | Uses CNN to learn the suitable image feature extractor Post-processing by PCA and SVM to enhance the detection performance | Suitable image feature extractor is obtained using CNN-based method. Produces very high detection accuracy compared to previous methods. | Requires a large amount of computation operations and is more complex than previous methods. | HTER = 0.00% (Using Idiap database) HTER = 0.031% (Using ISPR database) |
| Layer Name | Number of Filters | Filter Size | Stride Size | Padding Size | Dropout Value | Output Size |
|---|---|---|---|---|---|---|
| Input Layer | n/a | n/a | n/a | n/a | n/a | 227 × 227 × 3 |
| Convolution Layer 1 (conv1) | 96 | 11 × 11 × 3 | 4 × 4 | 0 | n/a | 55 × 55 × 96 |
| Rectified Linear Unit (relu1) | n/a | n/a | n/a | n/a | n/a | 55 × 55 × 96 |
| Normalization Layer (norm1) | n/a | n/a | n/a | n/a | n/a | 55 × 55 × 96 |
| MAX Pooling Layer 1 (pool1) | 1 | 3 × 3 | 2 × 2 | 0 | n/a | 27 × 27 × 96 |
| Convolution Layer 2 (conv2) | 256 | 5 × 5 × 48 | 1 × 1 | 2 × 2 | n/a | 27 × 27 × 256 |
| Rectified Linear Unit (relu2) | n/a | n/a | n/a | n/a | n/a | 27 × 27 × 256 |
| Normalization Layer (norm2) | n/a | n/a | n/a | n/a | n/a | 27 × 27 × 256 |
| MAX Pooling Layer 2 (pool2) | 1 | 3 × 3 | 2 × 2 | 0 | n/a | 13 × 13 × 256 |
| Convolution Layer 3 (conv3) | 384 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 13 × 13× 384 |
| Rectified Linear Unit (relu3) | n/a | n/a | n/a | n/a | n/a | 13 × 13 × 384 |
| Convolution Layer 4 (conv4) | 384 | 3 × 3 × 192 | 1 × 1 | 1 × 1 | n/a | 13 × 13 × 384 |
| Rectified Linear Unit (relu4) | n/a | n/a | n/a | n/a | n/a | 13 × 13 × 384 |
| Convolution Layer 5 (conv5) | 256 | 3 × 3 × 192 | 1 × 1 | 1 × 1 | n/a | 13 × 13 × 256 |
| Rectified Linear Unit (relu5) | n/a | n/a | n/a | n/a | n/a | 13 × 13 × 256 |
| MAX Pooling Layer 5 (pool5) | 1 | 3 × 3 | 2 × 2 | 0 | n/a | 6 × 6 × 256 |
| Fully Connected Layer 1 (fc6) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Dropout Layer (drop6) | n/a | n/a | n/a | n/a | 0.50 | 4096 |
| Rectified Linear Unit (relu6) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Fully Connected Layer 2 (fc7) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Rectified Linear Unit (relu7) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Dropout Layer (drop7) | n/a | n/a | n/a | n/a | 0.50 | 4096 |
| Output Layer (fc8) | n/a | n/a | n/a | n/a | n/a | 2 |
| Softmax Layer (prob) | n/a | n/a | n/a | n/a | n/a | 2 |
| Classification Layer (output) | n/a | n/a | n/a | n/a | n/a | 2 |
| Layer Name | Number of Filters | Filter Size | Stride Size | Padding Size | Dropout Value | Output Size |
|---|---|---|---|---|---|---|
| Input Layer | n/a | n/a | n/a | n/a | n/a | 87 × 151 × 3 |
| Convolution Layer 1 (conv1) | 96 | 11 × 11 × 3 | 2 × 2 | 0 | n/a | 39 × 71 × 96 |
| Rectified Linear Unit (relu1) | n/a | n/a | n/a | n/a | n/a | 39 × 71 × 96 |
| Normalization Layer (norm1) | n/a | n/a | n/a | n/a | n/a | 39 × 71 × 96 |
| MAX Pooling Layer 1 (pool1) | 1 | 3 × 3 | 2 × 2 | 0 | n/a | 19 × 35 × 96 |
| Convolution Layer 2 (conv2) | 128 | 5 × 5 × 96 | 1 × 1 | 2 × 2 | n/a | 19 × 35 × 128 |
| Rectified Linear Unit (relu2) | n/a | n/a | n/a | n/a | n/a | 19 × 35 × 128 |
| Normalization Layer (norm2) | n/a | n/a | n/a | n/a | n/a | 19 × 35 × 128 |
| MAX Pooling Layer 2 (pool2) | 1 | 3 × 3 | 2 × 2 | 0 | n/a | 9 × 17 × 128 |
| Convolution Layer 3 (conv3) | 192 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | n/a | 9 × 17 × 192 |
| Rectified Linear Unit (relu3) | n/a | n/a | n/a | n/a | n/a | 9 × 17 × 192 |
| Convolution Layer 4 (conv4) | 192 | 3 × 3 × 192 | 1 × 1 | 1 × 1 | n/a | 9 × 17 × 192 |
| Rectified Linear Unit (relu4) | n/a | n/a | n/a | n/a | n/a | 9 × 17 × 192 |
| Convolution Layer 5 (conv5) | 128 | 3 × 3 × 192 | 1 × 1 | 1 × 1 | n/a | 9 × 17 × 128 |
| Rectified Linear Unit (relu5) | n/a | n/a | n/a | n/a | n/a | 9 × 17 × 128 |
| MAX Pooling Layer 5 (pool5) | 1 | 3 × 3 | 2 × 2 | 0 | n/a | 4 × 8 × 128 |
| Fully Connected Layer 1 (fc6) | n/a | n/a | n/a | n/a | n/a | 2048 |
| Dropout Layer (drop6) | n/a | n/a | n/a | n/a | 0.50 | 2048 |
| Rectified Linear Unit (relu6) | n/a | n/a | n/a | n/a | n/a | 2048 |
| Fully Connected Layer 2 (fc7) | n/a | n/a | n/a | n/a | n/a | 1024 |
| Rectified Linear Unit (relu7) | n/a | n/a | n/a | n/a | n/a | 1024 |
| Dropout Layer (drop7) | n/a | n/a | n/a | n/a | 0.50 | 1024 |
| Output Layer (fc8) | n/a | n/a | n/a | n/a | n/a | 2 |
| Softmax Layer (prob) | n/a | n/a | n/a | n/a | n/a | 2 |
| Classification Layer (output) | n/a | n/a | n/a | n/a | n/a | 2 |
| Layer Name | Number of Filters | Filter Size | Stride Size | Padding Size | Dropout Value | Output Size |
|---|---|---|---|---|---|---|
| Input Layer | n/a | n/a | n/a | n/a | n/a | 224 × 224 × 3 |
| Convolution Layer (conv1_1) | 64 | 3 × 3 × 3 | 1 × 1 | 1 × 1 | n/a | 224 × 224 × 64 |
| Rectified Linear Unit 1 (relu1_1) | n/a | n/a | n/a | n/a | n/a | 224 × 224 × 64 |
| Convolution Layer (conv1_2) | 64 | 3 × 3 × 64 | 1 × 1 | 1 × 1 | n/a | 224 × 224 × 64 |
| Rectified Linear Unit (relu1_2) | n/a | n/a | n/a | n/a | n/a | 224 × 224 × 64 |
| MAX Pooling Layer (pool1) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 112 × 112 × 64 |
| Convolution Layer (conv2-1) | 128 | 3 × 3 × 64 | 1 × 1 | 1 × 1 | n/a | 112 × 112 × 128 |
| Rectified Linear Unit (relu2_1) | n/a | n/a | n/a | n/a | n/a | 112 × 112 × 128 |
| Convolution Layer (conv2_2) | 128 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | n/a | 112 × 112 × 128 |
| Rectified Linear Unit (relu2_2) | n/a | n/a | n/a | n/a | n/a | 112 × 112 × 128 |
| MAX Pooling Layer (pool2) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 56 × 56 × 128 |
| Convolution Layer (conv3_1) | 256 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | n/a | 56 × 56 × 256 |
| Rectified Linear Unit (relu3_1) | n/a | n/a | n/a | n/a | n/a | 56 × 56 × 256 |
| Convolution Layer (conv3_2) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 56 × 56 × 256 |
| Rectified Linear Unit (relu3_2) | n/a | n/a | n/a | n/a | n/a | 56 × 56 × 256 |
| Convolution Layer (conv3_3) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 56 × 56 × 256 |
| Rectified Linear Unit (relu3_3) | n/a | n/a | n/a | n/a | n/a | 56 × 56 × 256 |
| MAX Pooling Layer (pool3) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 28 × 28 × 256 |
| Convolution Layer (conv4_1) | 512 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 28 × 28 × 512 |
| Rectified Linear Unit (relu4_1) | n/a | n/a | n/a | n/a | n/a | 28 × 28 × 512 |
| Convolution Layer (conv4_2) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | n/a | 28 × 28 × 512 |
| Rectified Linear Unit (relu4_2) | n/a | n/a | n/a | n/a | n/a | 28 × 28 × 512 |
| Convolution Layer (conv4_3) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | n/a | 28 × 28 × 512 |
| Rectified Linear Unit (relu4_3) | n/a | n/a | n/a | n/a | n/a | 28 × 28 × 512 |
| MAX Pooling Layer (pool4) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 14 × 14 × 512 |
| Convolution Layer (conv5_1) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | n/a | 14 × 14 × 512 |
| Rectified Linear Unit (relu5_1) | n/a | n/a | n/a | n/a | n/a | 14 × 14 × 512 |
| Convolution Layer (conv5_2) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | n/a | 14 × 14 × 512 |
| Rectified Linear Unit (relu5_2) | n/a | n/a | n/a | n/a | n/a | 14 × 14 × 512 |
| Convolution Layer (conv5_3) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | n/a | 14 × 14 × 512 |
| Rectified Linear Unit (relu5_3) | n/a | n/a | n/a | n/a | n/a | 14 × 14 × 512 |
| MAX Pooling Layer (pool5) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 7 × 7 × 512 |
| Fully Connected Layer (fc6) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Rectified Linear Unit (relu6) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Dropout Layer (drop6) | n/a | n/a | n/a | n/a | 0.50 | 4096 |
| Fully Connected Layer (fc7) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Rectified Linear Unit (relu7) | n/a | n/a | n/a | n/a | n/a | 4096 |
| Dropout Layer (drop7) | n/a | n/a | n/a | n/a | 0.50 | 4096 |
| Output Layer (fc8) | n/a | n/a | n/a | n/a | n/a | 2 |
| Softmax Layer (prob) | n/a | n/a | n/a | n/a | n/a | 2 |
| Classification Layer (output) | n/a | n/a | n/a | n/a | n/a | 2 |
| Layer Name | Number of Filters | Filter Size | Stride Size | Padding Size | Dropout Value | Output Size |
|---|---|---|---|---|---|---|
| Input Layer | n/a | n/a | n/a | n/a | n/a | 128 × 256 × 3 |
| Convolution Layer (conv1_1) | 32 | 3 × 3 × 3 | 1 × 1 | 1 × 1 | n/a | 128 × 256 × 32 |
| Rectified Linear Unit 1 (relu1_1) | n/a | n/a | n/a | n/a | n/a | 128 × 256 × 32 |
| Convolution Layer (conv1_2) | 32 | 3 × 3 × 32 | 1 × 1 | 1 × 1 | n/a | 128 × 256 × 32 |
| Rectified Linear Unit (relu1_2) | n/a | n/a | n/a | n/a | n/a | 128 × 256 × 32 |
| MAX Pooling Layer (pool1) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 64 × 128 × 32 |
| Convolution Layer (conv2-1) | 64 | 3 × 3 × 32 | 1 × 1 | 1 × 1 | n/a | 64 × 128 × 64 |
| Rectified Linear Unit (relu2_1) | n/a | n/a | n/a | n/a | n/a | 64 × 128 × 64 |
| Convolution Layer (conv2_2) | 64 | 3 × 3 × 64 | 1 × 1 | 1 × 1 | n/a | 64 × 128 × 64 |
| Rectified Linear Unit (relu2_2) | n/a | n/a | n/a | n/a | n/a | 64 × 128 × 64 |
| MAX Pooling Layer (pool2) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 32 × 64 × 64 |
| Convolution Layer (conv3_1) | 128 | 3 × 3 × 64 | 1 × 1 | 1 × 1 | n/a | 32 × 64 × 128 |
| Rectified Linear Unit (relu3_1) | n/a | n/a | n/a | n/a | n/a | 32 × 64 × 128 |
| Convolution Layer (conv3_2) | 128 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | n/a | 32 × 64 × 128 |
| Rectified Linear Unit (relu3_2) | n/a | n/a | n/a | n/a | n/a | 32 × 64 × 128 |
| Convolution Layer (conv3_3) | 128 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | n/a | 32 × 64 × 128 |
| Rectified Linear Unit (relu3_3) | n/a | n/a | n/a | n/a | n/a | 32 × 64 × 128 |
| MAX Pooling Layer (pool3) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 16 × 32 × 128 |
| Convolution Layer (conv4_1) | 256 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | n/a | 16 × 32 × 256 |
| Rectified Linear Unit (relu4_1) | n/a | n/a | n/a | n/a | n/a | 16 × 32 × 256 |
| Convolution Layer (conv4_2) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 16 × 32 × 256 |
| Rectified Linear Unit (relu4_2) | n/a | n/a | n/a | n/a | n/a | 16 × 32 × 256 |
| Convolution Layer (conv4_3) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 16 × 32 × 256 |
| Rectified Linear Unit (relu4_3) | n/a | n/a | n/a | n/a | n/a | 16 × 32 × 256 |
| MAX Pooling Layer (pool4) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 8 × 16 × 256 |
| Convolution Layer (conv5_1) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 8 × 16 × 256 |
| Rectified Linear Unit (relu5_1) | n/a | n/a | n/a | n/a | n/a | 8 × 16 × 256 |
| Convolution Layer (conv5_2) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 8 × 16 × 256 |
| Rectified Linear Unit (relu5_2) | n/a | n/a | n/a | n/a | n/a | 8 × 16 × 256 |
| Convolution Layer (conv5_3) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | n/a | 8 × 16 × 256 |
| Rectified Linear Unit (relu5_3) | n/a | n/a | n/a | n/a | n/a | 8 × 16 × 256 |
| MAX Pooling Layer (pool5) | 1 | 2 × 2 | 2 × 2 | 0 | n/a | 4 × 8 × 256 |
| Fully Connected Layer (fc6) | n/a | n/a | n/a | n/a | n/a | 2048 |
| Rectified Linear Unit (relu6) | n/a | n/a | n/a | n/a | n/a | 2048 |
| Dropout Layer (drop6) | n/a | n/a | n/a | n/a | 0.50 | 2048 |
| Fully Connected Layer (fc7) | n/a | n/a | n/a | n/a | n/a | 1024 |
| Rectified Linear Unit (relu7) | n/a | n/a | n/a | n/a | n/a | 1024 |
| Dropout Layer (drop7) | n/a | n/a | n/a | n/a | 0.50 | 1024 |
| Output Layer (fc8) | n/a | n/a | n/a | n/a | n/a | 2 |
| Softmax Layer (prob) | n/a | n/a | n/a | n/a | n/a | 2 |
| Classification Layer (output) | n/a | n/a | n/a | n/a | n/a | 2 |
| Image Making Protocol | Real Access | Presentation Attack Access | |||||
|---|---|---|---|---|---|---|---|
| Train Set | Test Set | Total | Train Set | Test Set | Total | ||
| Material | Printed on A4 Paper (ISPR-DB1) | 1700 | 1600 | 3300 | 1440 | 1080 | 2520 |
| Printed on MAT Paper (ISPR-DB2) | 1700 | 1600 | 3300 | 1440 | 1080 | 2520 | |
| Printed on OHP Film (ISPR-DB3) | 1700 | 1600 | 3300 | 1440 | 1080 | 2520 | |
| Printer Resolution | Printed Using 300 DPI Resolution Printer (ISPR-DB4) | 1700 | 1600 | 3300 | 1440 | 1080 | 2520 |
| Printed Using 1200 DPI Resolution Printer (ISPR-DB5) | 1700 | 1600 | 3300 | 1440 | 1080 | 2520 | |
| Printed Using 2400 DPI Resolution Printer (ISPR-DB6) | 1700 | 1600 | 3300 | 1440 | 1080 | 2520 | |
| Entire Database (ISPR-DB) | 1700 | 1600 | 3300 | 4320 | 3120 | 7560 | |
| Image Making Protocol | Real Access | Presentation Attack Access | ||||
|---|---|---|---|---|---|---|
| Train Set | Test Set | Validation Set | Train Set | Test Set | Validation Set | |
| Full Image Database (Idiap Full-DB) | 120 | 200 | 120 | 120 | 200 | 120 |
| Cropped Image Database (Idiap Cropped-DB) | 120 | 200 | 120 | 120 | 200 | 120 |
| Database | Real Access | Presentation Attack Access | ||||
|---|---|---|---|---|---|---|
| Train Set | Test Set | Validation Set | Train Set | Test Set | Validation Set | |
| Idiap Full-DB | 7440 (120 × 62) | 200 | 120 | 7440 (120 × 62) | 200 | 120 |
| Idiap Cropped-DB | 7440 (120 × 62) | 200 | 120 | 7440 (120 × 62) | 200 | 120 |
| Database | Real Access | Presentation Attack Access | |||
|---|---|---|---|---|---|
| Train Set | Test Set | Train Set | Test Set | ||
| Material | Printed on A4 Paper (ISPR-DB1) | 37,400 (1700 × 22) | 1600 | 37,440 (1440 × 26) | 1080 |
| Printed on MAT Paper (ISPR-DB2) | 37,400 (1700 × 22) | 1600 | 37,440 (1440 × 26) | 1080 | |
| Printed on OHP Film (ISPR-DB3) | 37,400 (1700 × 22) | 1600 | 37,440 (1440 × 26) | 1080 | |
| Printer Resolution | Printed Using 300 DPI Resolution Printer (ISPR-DB4) | 37,400 (1700 × 22) | 1600 | 37,440 (1440 × 26) | 1080 |
| Printed Using 1200 DPI Resolution Printer (ISPR-DB5) | 37,400 (1700 × 22) | 1600 | 37,440 (1440 × 26) | 1080 | |
| Printed Using 2400 DPI Resolution Printer (ISPR-DB6) | 37,400 (1700 × 22) | 1600 | 37,440 (1440 × 26) | 1080 | |
| Entire Database (ISPR-DB) | 56,100 (1700 × 33) | 1600 | 56,160 (4320 × 13) | 3240 | |
| Database | Without Transfer Learning | With Transfer Learning | ||||
|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | APCER | BPCER | ACER | |
| ISPR-DB | 2.5000 | 0.8073 | 1.6536 | 0.2018 | 0.1863 | 0.1940 |
| Idiap Full-DB | 0.000 | 1.5000 | 0.7500 | 0.0000 | 0.0000 | 0.0000 |
| Idiap Cropped-DB | 2.5000 | 2.5000 | 2.500 | 0.0000 | 0.0000 | 0.0000 |
| Database | Without Transfer Learning | With Transfer Learning | ||||
|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | APCER | BPCER | ACER | |
| ISPR-DB | 0.0000 | 100.00 | 50.00 | 0.0000 | 0.1240 | 0.0620 |
| Idiap (Full-DB) | 0.0000 | 100.00 | 50.00 | 0.0000 | 0.0000 | 0.0000 |
| Idiap (Cropped-DB) | 0.0000 | 100.00 | 50.00 | 0.0000 | 1.0000 | 0.5000 |
| Database | Without Transfer Learning | With Transfer Learning | ||||||
|---|---|---|---|---|---|---|---|---|
| SVM Kernel (No. PC) | APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| ISPR-DB | Polynomial Kernel (No. PC = 60) | 1.1875 | 1.1725 | 1.1800 | Linear Kernel (No. PC = 50) | 0.0313 | 0.0310 | 0.0311 |
| Idiap (Full-DB) | RBF Kernel (No. PC = 50) | 0.0000 | 0.0000 | 0.0000 | RBF Kernel (No. PC = 95) | 0.0000 | 0.0000 | 0.0000 |
| Idiap (Cropped-DB) | RBF Kernel (No. PC = 150) | 1.0000 | 1.0000 | 1.0000 | Linear Kernel (No. PC = 100) | 0.0000 | 0.0000 | 0.0000 |
| Database | Without Transfer Learning | With Transfer Learning | ||||||
|---|---|---|---|---|---|---|---|---|
| SVM Kernel (No. PC) | APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| ISPR-DB | RBF Kernel (No. PC = 200) | 2.8438 | 2.8550 | 2.8494 | Linear Kernel (No. PC = 70) | 0.0313 | 0.0310 | 0.0311 |
| Idiap (Full-DB) | RBF Kernel (No. PC = 70) | 0.0000 | 0.0000 | 0.0000 | Linear Kernel (No. PC = 60) | 0.0000 | 0.0000 | 0.0000 |
| Idiap (Cropped-DB) | RBF Kernel (No. PC = 105) | 1.0000 | 1.0000 | 1.0000 | RBF Kernel (No. PC = 95) | 0.0000 | 0.0000 | 0.0000 |
| Database | CNN-Based Method with Transfer Learning | Our Proposed Method | |||||
|---|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| Printed on A4 Paper (ISPR-DB1) | 0.1875 | 0.1855 | 0.1865 | Polynomial Kernel (No. PC = 110) | 0.0313 | 0.0465 | 0.0389 |
| Printed on MAT Paper (ISPR-DB2) | 0.0625 | 0.0930 | 0.0778 | Polynomial Kernel (No. PC = 105) | 0.0000 | 0.0000 | 0.0000 |
| Printed on OHP Film (ISPR-DB3) | 0.3750 | 0.3700 | 0.3725 | Polynomial Kernel (No. PC = 90) | 0.0938 | 0.0930 | 0.0934 |
| Database | CNN-Based Method with Transfer Learning | Our Proposed Method | |||||
|---|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| Printed Using 300 DPI Resolution Printer (ISPR-DB4) | 0.1250 | 0.1390 | 0.1320 | Linear Kernel (No. PC = 90) | 0.0313 | 0.0465 | 0.0389 |
| Printed Using 1200 DPI Resolution Printer (ISPR-DB5) | 0.0000 | 0.0000 | 0.0000 | Linear Kernel (No. PC = 60) | 0.0000 | 0.0000 | 0.0000 |
| Printed Using 2400 DPI Resolution Printer (ISPR-DB6) | 0.2813 | 0.2775 | 0.2794 | Polynomial Kernel (No. PC = 135) | 0.0625 | 0.0930 | 0.0778 |
| Database | CNN-Based Method with Transfer Learning | Our Proposed Method | |||||
|---|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| Printed on A4 Paper (ISPR-DB1) | 0.0313 | 0.0465 | 0.0389 | Polynomial Kernel (No. PC = 50) | 0.0313 | 0.0465 | 0.0389 |
| Printed on MAT Paper (ISPR-DB2) | 0.0000 | 0.0000 | 0.0000 | Polynomial Kernel (No. PC = 70) | 0.0000 | 0.0000 | 0.0000 |
| Printed on OHP Film (ISPR-DB3) | 0.1250 | 0.1390 | 0.1320 | Polynomial Kernel (No. PC = 90) | 0.0000 | 0.0000 | 0.0000 |
| Database | CNN-Based Method with Transfer Learning | Our Proposed Method | |||||
|---|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| Printed Using 300 DPI Resolution Printer (ISPR-DB4) | 0.0313 | 0.0465 | 0.0389 | RBF Kernel (No. PC = 145) | 0.0000 | 0.0000 | 0.0000 |
| Printed Using 1200 DPI Resolution Printer (ISPR-DB5) | 0.0000 | 0.0000 | 0.0000 | Linear Kernel (No. PC = 195) | 0.0000 | 0.0000 | 0.0000 |
| Printed Using 2400 DPI Resolution Printer (ISPR-DB6) | 0.0625 | 0.0465 | 0.0545 | RBF Kernel (No. PC = 140) | 0.0313 | 0.0465 | 0.0389 |
| Database | CNN-Based Method with Transfer Learning | Our Proposed Method | |||||
|---|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| ISPR-DB | 0.6563 | 0.6640 | 0.6601 | RBF Kernel (No. PC = 70) | 0.2500 | 0.2625 | 0.2563 |
| Idiap Full-DB | 0.0000 | 0.0000 | 0.0000 | Linear Kernel (No. PC = 75) | 0.0000 | 0.0000 | 0.0000 |
| Idiap Cropped-DB | 0.0000 | 0.0000 | 0.0000 | Linear Kernel (No. PC = 55) | 0.0000 | 0.0000 | 0.0000 |
| Database | CNN-Based Method with Transfer Learning | Our Proposed Method | |||||
|---|---|---|---|---|---|---|---|
| APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| ISPR-DB | 0.2500 | 0.2780 | 0.2640 | Linear Kernel (No. PC = 105) | 0.2188 | 0.2160 | 0.2174 |
| Idiap Full-DB | 0.0000 | 0.5000 | 0.2500 | Linear Kernel (No. PC = 90) | 0.0000 | 0.0000 | 0.0000 |
| Idiap Cropped-DB | 1.0000 | 1.0000 | 1.0000 | Linear Kernel (No. PC = 80) | 0.0000 | 0.0000 | 0.0000 |
| Database | Using Customized Alex Network | Using Customized VGG-16 Network | ||||||
|---|---|---|---|---|---|---|---|---|
| SVM Kernel | APCER | BPCER | ACER | SVM Kernel (No. PC) | APCER | BPCER | ACER | |
| Printed on A4 Paper (ISPR-DB1) | RBF Kernel (No. PC = 75) | 0.3438 | 0.3240 | 0.3339 | Polynomial Kernel (No. PC = 115) | 0.2188 | 0.2315 | 0.2251 |
| Printed on MAT Paper (ISPR-DB2) | Linear Kernel (No. PC = 120) | 0.1563 | 0.1855 | 0.1709 | Linear Kernel (No. PC = 75) | 0.0313 | 0.0465 | 0.0389 |
| Printed on OHP Film (ISPR-DB3) | Polynomial Kernel (No. PC = 120) | 0.2188 | 0.2315 | 0.2251 | Linear Kernel (No. PC = 50) | 0.5625 | 0.5560 | 0.5593 |
| Printed Using 300 DPI Resolution Printer (ISPR-DB4) | Linear Kernel (No. PC = 55) | 0.3438 | 0.3705 | 0.3571 | Linear Kernel (No. PC = 75) | 0.2188 | 0.2315 | 0.2251 |
| Printed Using 1200 DPI Resolution Printer (ISPR-DB5) | Linear Kernel (No. PC = 120) | 0.0000 | 0.0000 | 0.0000 | Linear Kernel (No. PC = 200) | 0.0313 | 0.0465 | 0.0389 |
| Printed Using 2400 DPI Resolution Printer (ISPR-DB6) | Polynomial Kernel (No. PC = 120) | 0.5938 | 0.6015 | 0.5976 | Linear Kernel (No. PC = 60) | 0.0938 | 0.0925 | 0.0931 |
| Method | Printed Using 300 DPI Resolution Printer (ISPR-DB4) | Printed Using 300 DPI Resolution Printer (ISPR-DB5) | Printed Using 300 DPI Resolution Printer (ISPR-DB6) | Entire ISPR Database (ISPR-DB) |
|---|---|---|---|---|
| FFT + HW + DW [24] | 2.5460 | 1.4760 | 3.9310 | 2.8740 |
| CNN-based Method Using Alex network Architecture (Without PCA and SVM) | 0.1320 | 0.0000 | 0.2794 | 0.1940 |
| CNN-based Method using VGG-16 network Architecture (Without PCA and SVM) | 0.0389 | 0.0000 | 0.0545 | 0.0620 |
| Our Proposed Method (With PCA and SVM) | 0.0000 | 0.0000 | 0.0389 | 0.0311 |
| Database | Method | APCER | BPCER | ACER |
|---|---|---|---|---|
| Idiap Full-DB | Baseline [23] | 0.00 | 0.00 | 0.00 |
| GUC [23] | 0.00 | 8.00 | 4.00 | |
| B-Lab [23] | 0.00 | 0.00 | 0.00 | |
| GRIP-PRIAMUS [23] | 0.00 | 0.00 | 0.00 | |
| CNN-based Method Using Alex network Architecture (Without PCA and SVM) | 0.00 | 0.00 | 0.00 | |
| CNN-based Method using VGG-16 network Architecture (Without PCA and SVM) | 0.00 | 0.00 | 0.00 | |
| Our Proposed Method (With PCA and SVM) | 0.00 | 0.00 | 0.00 | |
| Idiap Cropped-DB | Baseline [23] | 11.00 | 30.00 | 20.50 |
| GUC [23] | 1.50 | 4.00 | 2.75 | |
| B-Lab [23] | 0.00 | 2.50 | 1.25 | |
| GRIP-PRIAMUS [23] | 0.00 | 0.00 | 0.00 | |
| CNN-based Method Using Alex network Architecture (Without PCA and SVM) | 0.00 | 0.00 | 0.00 | |
| CNN-based Method using VGG-16 network Architecture (Without PCA and SVM) | 0.00 | 0.00 | 0.00 | |
| Our Proposed Method (With PCA and SVM) | 0.00 | 0.00 | 0.00 |
| Idiap PVD Database | Training Database | Testing Database | ||
|---|---|---|---|---|
| Original Database | Augmented Database | |||
| Session 1 | Full Image Protocol | 500 | 24,500 (500 × 49) | 500 |
| Cropped Image Protocol | 500 | 24,500 (500 × 49) | 500 | |
| Session 2 | Full Image Protocol | 500 | 24,500 (500 × 49) | 500 |
| Cropped Image Protocol | 500 | 24,500 (500 × 49) | 500 | |
| Idiap PVD Database | Method | APCER | BPCER | ACER | |
|---|---|---|---|---|---|
| Session 1 | Full Protocol | FFT + HW + DW [24] | 2.6 | 3.6 | 3.1 |
| CNN-based Method Using Alex network (Without PCA and SVM) | 0.2 | 0.4 | 0.3 | ||
| CNN-based Method Using Alex network (Without PCA and SVM) | 0.0 | 0.0 | 0.0 | ||
| Our Proposed Method (With PCA and SVM) | 0.0 | 0.0 | 0.0 | ||
| Cropped Protocol | FFT + HW + DW [24] | 4.0 | 3.2 | 3.6 | |
| CNN-based Method Using Alex network (Without PCA and SVM) | 2.2 | 3.0 | 2.6 | ||
| CNN-based Method Using Alex network (Without PCA and SVM) | 0.2 | 0.4 | 0.3 | ||
| Our Proposed Method (With PCA and SVM) | 0.0 | 0.0 | 0.0 | ||
| Session 2 | Full Protocol | FFT + HW + DW [24] | 3.4 | 1.8 | 2.6 |
| CNN-based Method Using Alex network (Without PCA and SVM) | 0.2 | 2.0 | 1.1 | ||
| CNN-based Method Using Alex network (Without PCA and SVM) | 0.0 | 0.0 | 0.0 | ||
| Our Proposed Method (With PCA and SVM) | 0.0 | 0.0 | 0.0 | ||
| Cropped Protocol | FFT + HW + DW [24] | 5.8 | 4.4 | 5.1 | |
| CNN-based Method Using Alex network (Without PCA and SVM) | 2.2 | 2.2 | 2.2 | ||
| CNN-based Method Using Alex network (Without PCA and SVM) | 0.2 | 0.2 | 0.2 | ||
| Our Proposed Method (With PCA and SVM) | 0.0 | 0.0 | 0.0 | ||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.T.; Yoon, H.S.; Pham, T.D.; Park, K.R. Spoof Detection for Finger-Vein Recognition System Using NIR Camera. Sensors 2017, 17, 2261. https://doi.org/10.3390/s17102261
Nguyen DT, Yoon HS, Pham TD, Park KR. Spoof Detection for Finger-Vein Recognition System Using NIR Camera. Sensors. 2017; 17(10):2261. https://doi.org/10.3390/s17102261
Chicago/Turabian StyleNguyen, Dat Tien, Hyo Sik Yoon, Tuyen Danh Pham, and Kang Ryoung Park. 2017. "Spoof Detection for Finger-Vein Recognition System Using NIR Camera" Sensors 17, no. 10: 2261. https://doi.org/10.3390/s17102261
APA StyleNguyen, D. T., Yoon, H. S., Pham, T. D., & Park, K. R. (2017). Spoof Detection for Finger-Vein Recognition System Using NIR Camera. Sensors, 17(10), 2261. https://doi.org/10.3390/s17102261