Adapting Local Features for Face Detection in Thermal Image

Abstract
:1. Introduction
- We create new feature types by considering the properties of facial regions in thermal images. We realize our new feature types by extending Multi-Block LBP. We consider 2 aspects: (1) A margin around the reference; (2) The generally constant distribution of facial temperature. In this way we make the features more robust to image noise and more effective for face detection in thermal images.
- We propose an AdaBoost-based training method to build cascade classifiers containing different feature types with different advantages. Our algorithm can build cascade classifiers containing number-type and/or category-type features. In this way we can obtain an improved description power.
2. Related Work
2.1. Local Features
2.2. Fusion of Features
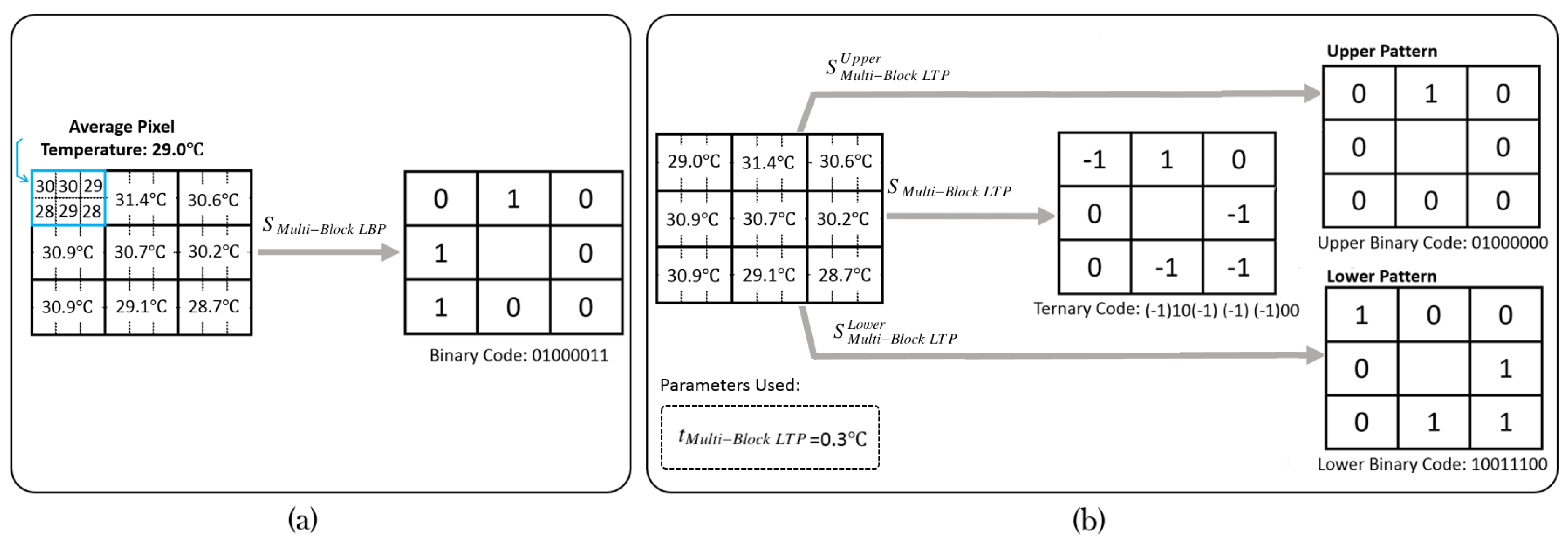
3. Extension of Multi-Block LBP Feature
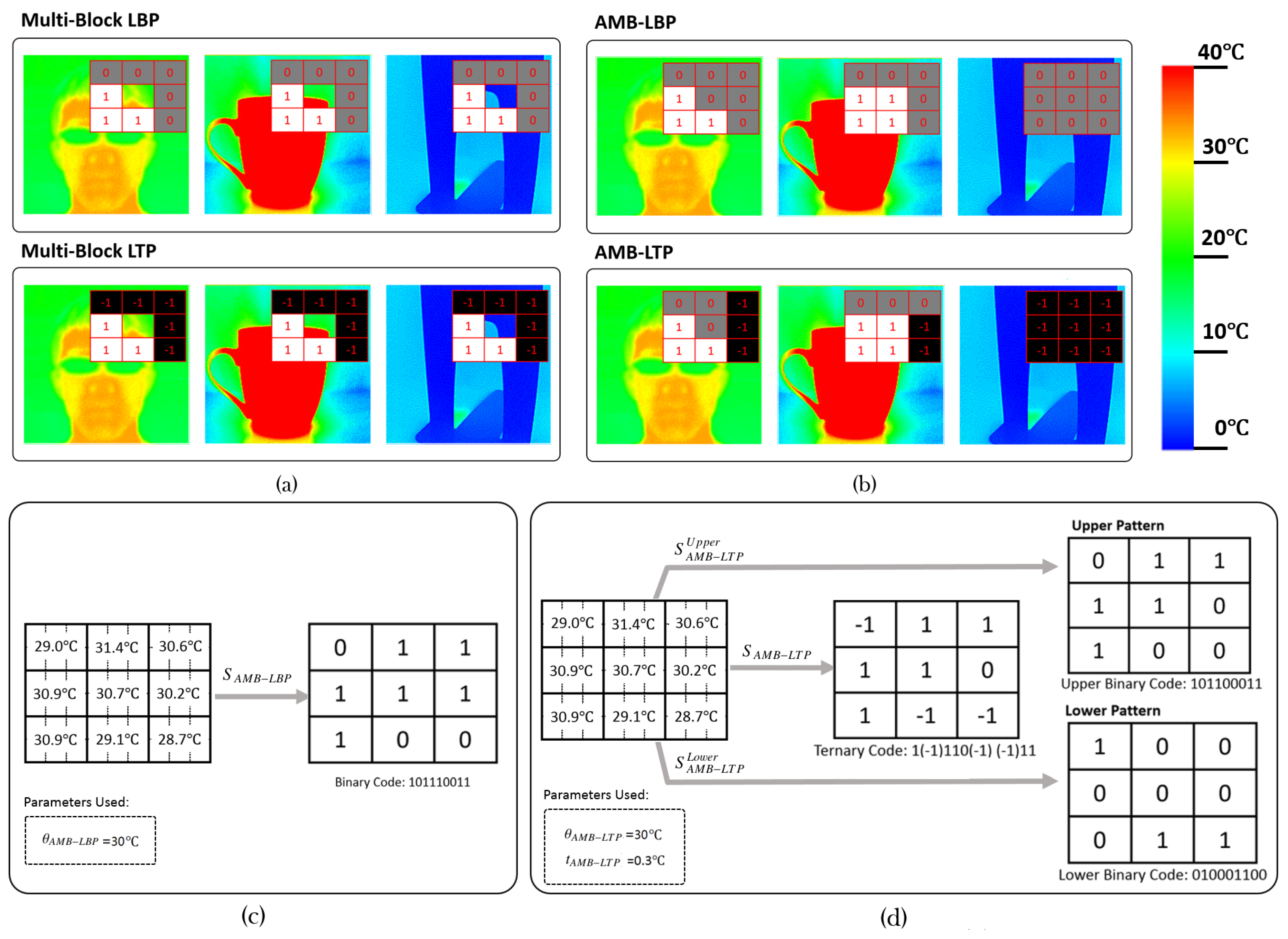
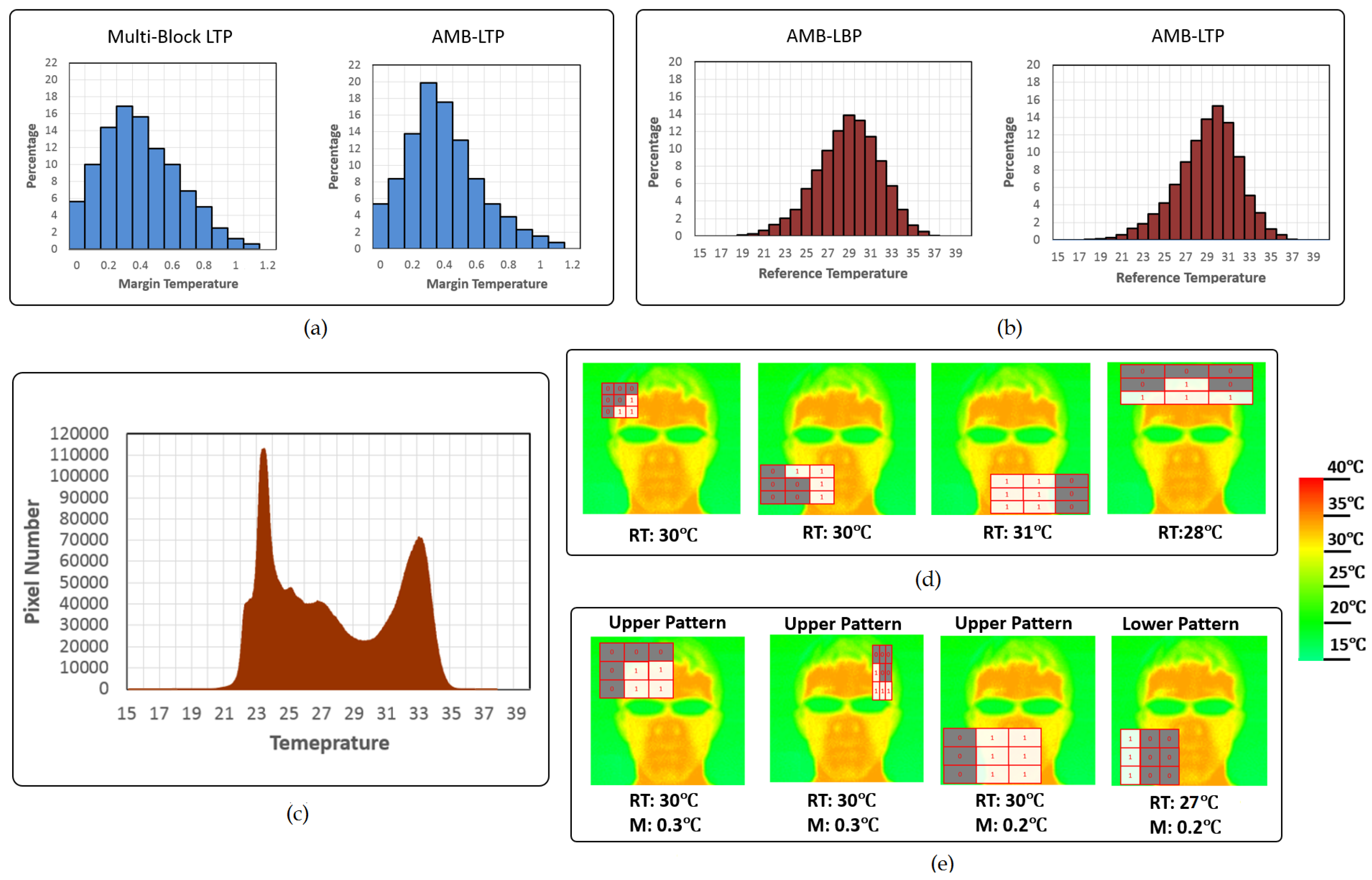
3.1. Multi-Block Local Ternary Patterns
3.2. Absolute Multi-Block LBP and Absolute Multi-Block LTP
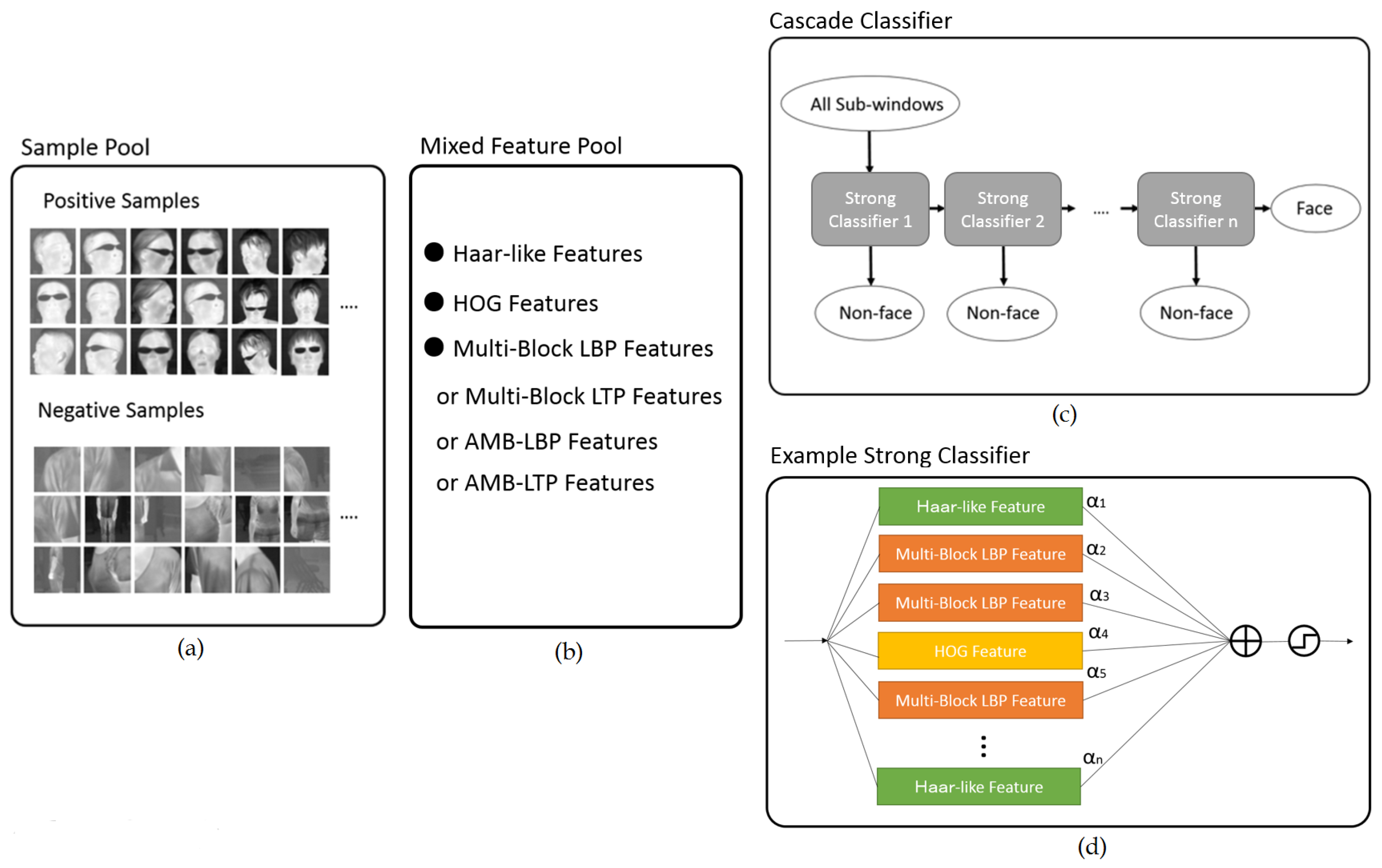
4. Learning Mixed Features
4.1. Overview
4.2. Building One Strong Classifier
- Input:
- r training samples where for the s negative samples and for the t positive samples.
- Mixed feature pool: .
- User defined training parameter: minimum detection rate (DR), and maximum false alarm rate (FAR) for one strong classifier.
- Output:
- Feature set , its associated voter set , where for number-type features, and for category-type features. and represent the weights of the weak classifiers with features m and n, respectively.
- A strong classifier built from U, with a trained threshold T, its prediction function H on sample is:
- Step 1 Initialization:
- .
- Initialize the sample weights and for positive and negative samples, respectively.
- Initialize the feature set , and voter set .
- Step 2 Strong Classifier Building:
- Normalize sample weights so that their sum equals 1:
- Obtain the weak classifier with feature v by optimization. The feature v has the minimal error in the mixed feature pool:
- Determine the weight of the weak classifier with feature v using
- , add the voter to the voter set :
- Update the weight of all training samples for current strong classifier: , where if the sample is correctly classified by the classifier with feature v, otherwise , .
- .
- Step 3 Stop Condition Checking:
- Check currently built strong classifier to decide whether it is finished or not. The voting result of current strong classifier built from on sample is calculated by . Sort the voting results of all training samples from small to large, and find the minimum value T where the detection rate satisfies DR.
- Use the threshold T to check the false alarm rate of all the training samples. If it is larger than FAR, go to step 2 to continue adding a voter to the strong classifier, otherwise, T is the threshold for the strong classifier, , and building of the current strong classifier is finished.
5. Experiment by Hold-Out Validation
5.1. Dataset
5.2. Experiment Settings
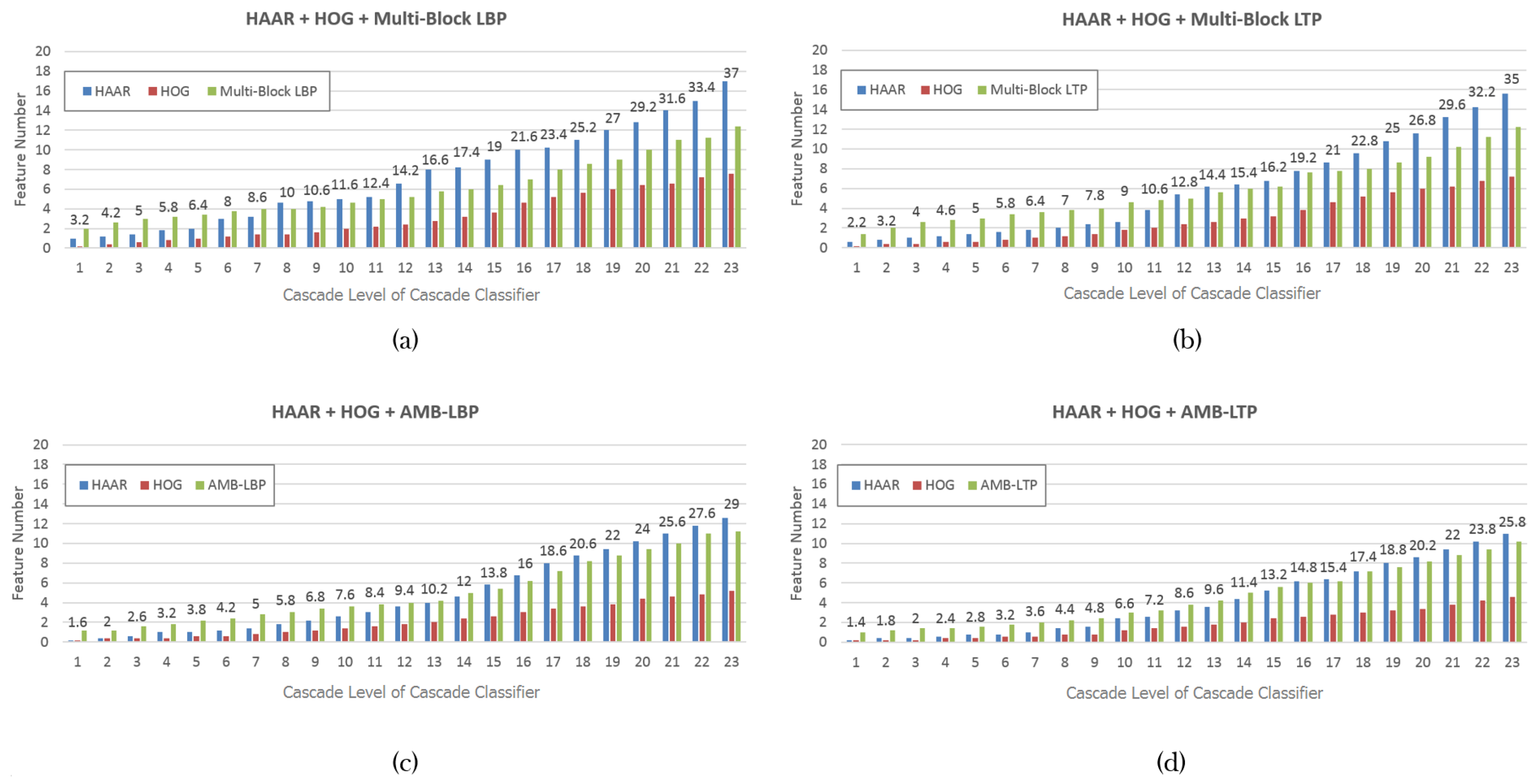
5.3. Training Results and Discussion
5.4. Testing Results and Discussion
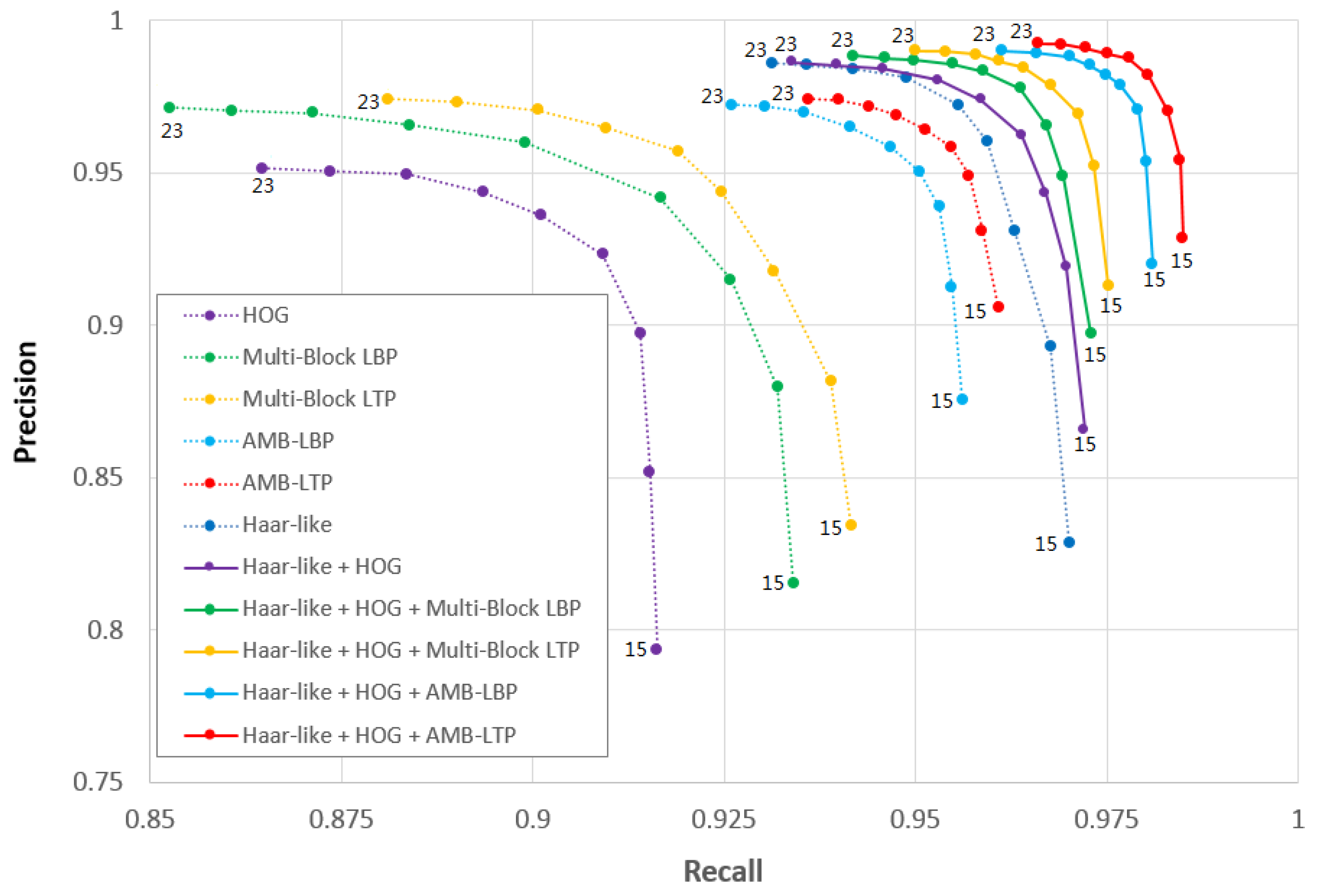
5.4.1. Discussion Based on Recall and Precision
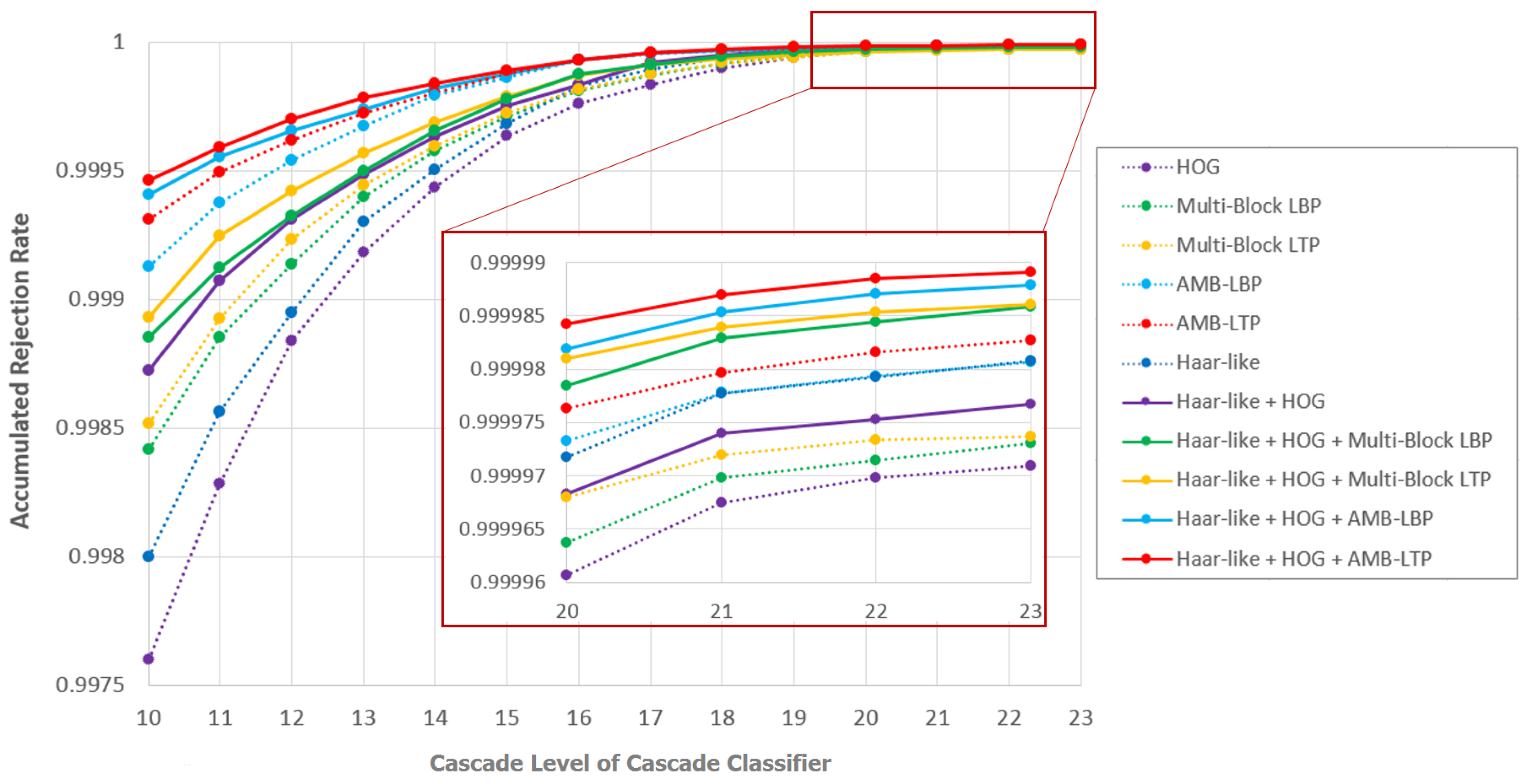
5.4.2. Discussion Based on Accumulated Rejection Rate
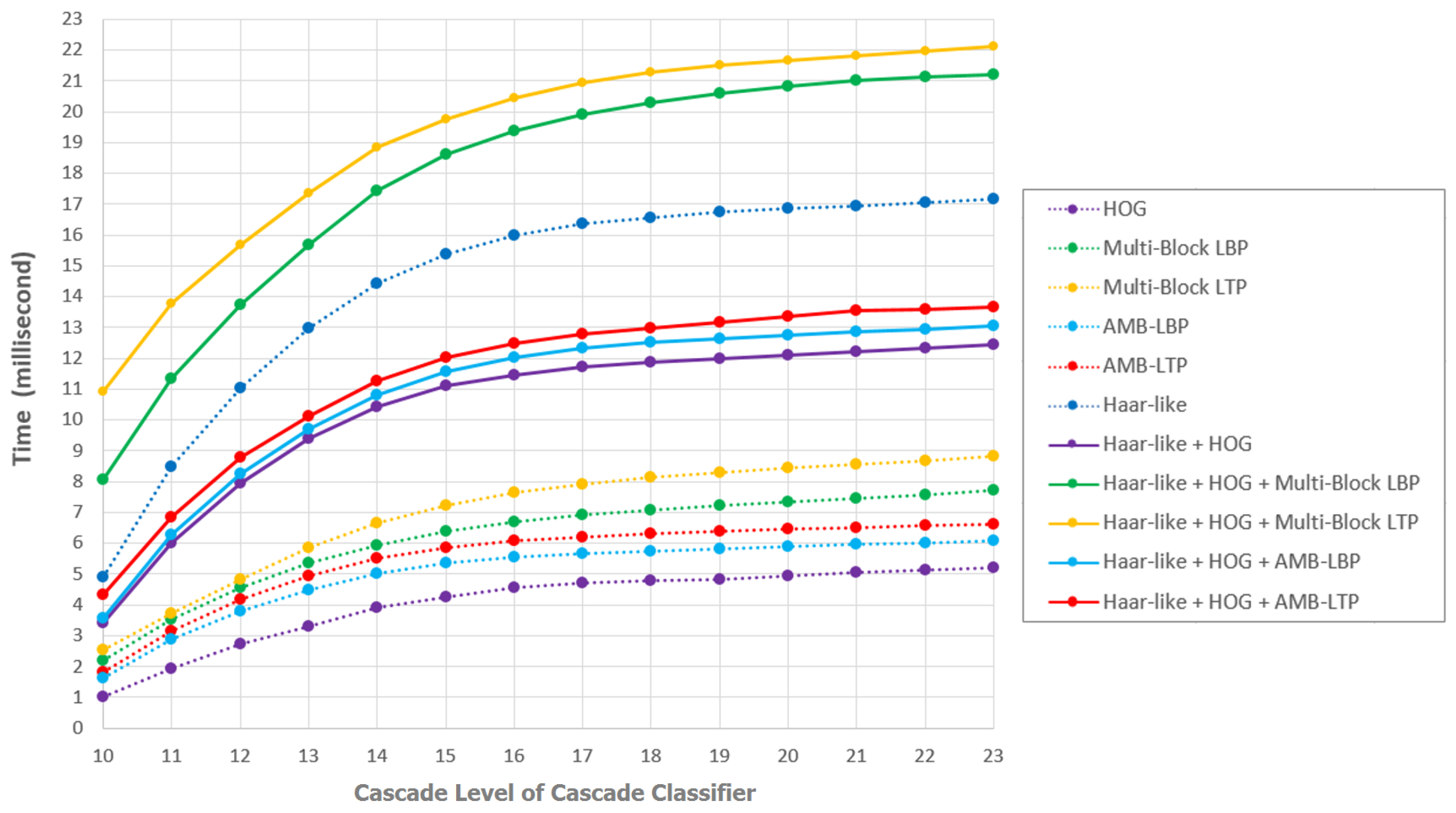
5.4.3. Detection Time Evaluation
6. Experiment in Real Scenes
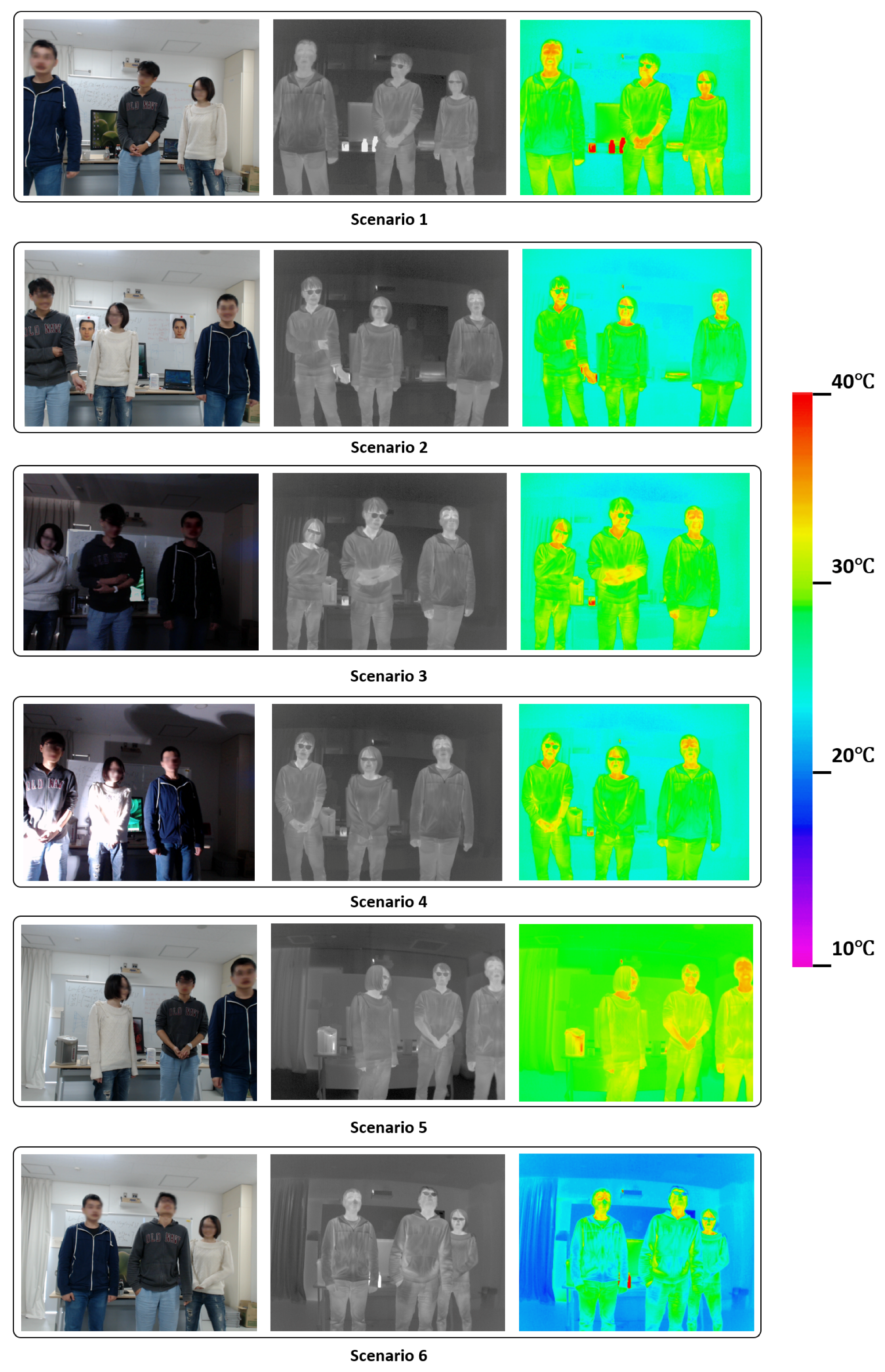
6.1. Capturing Environment Settings
6.2. Experiment Settings
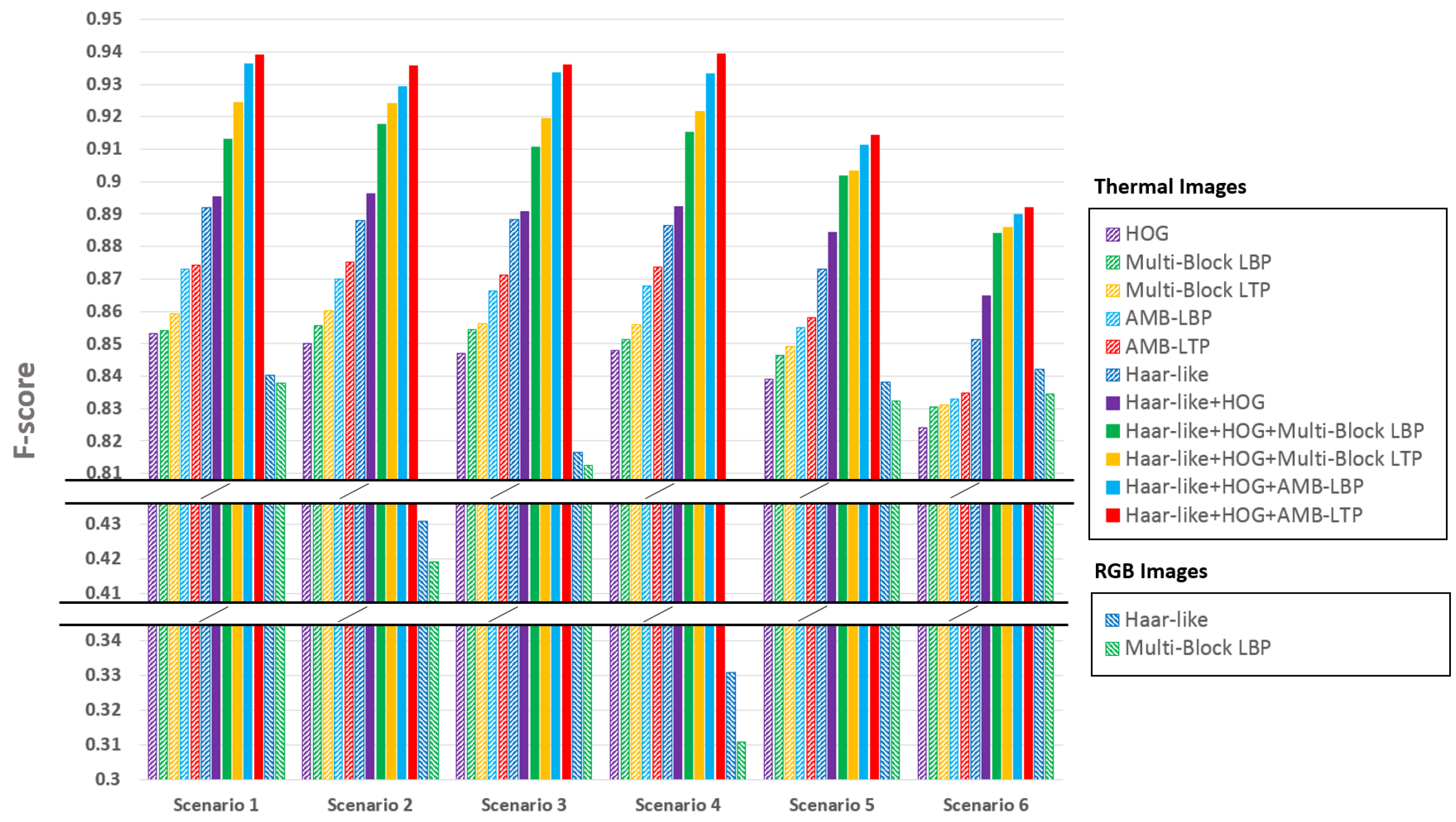
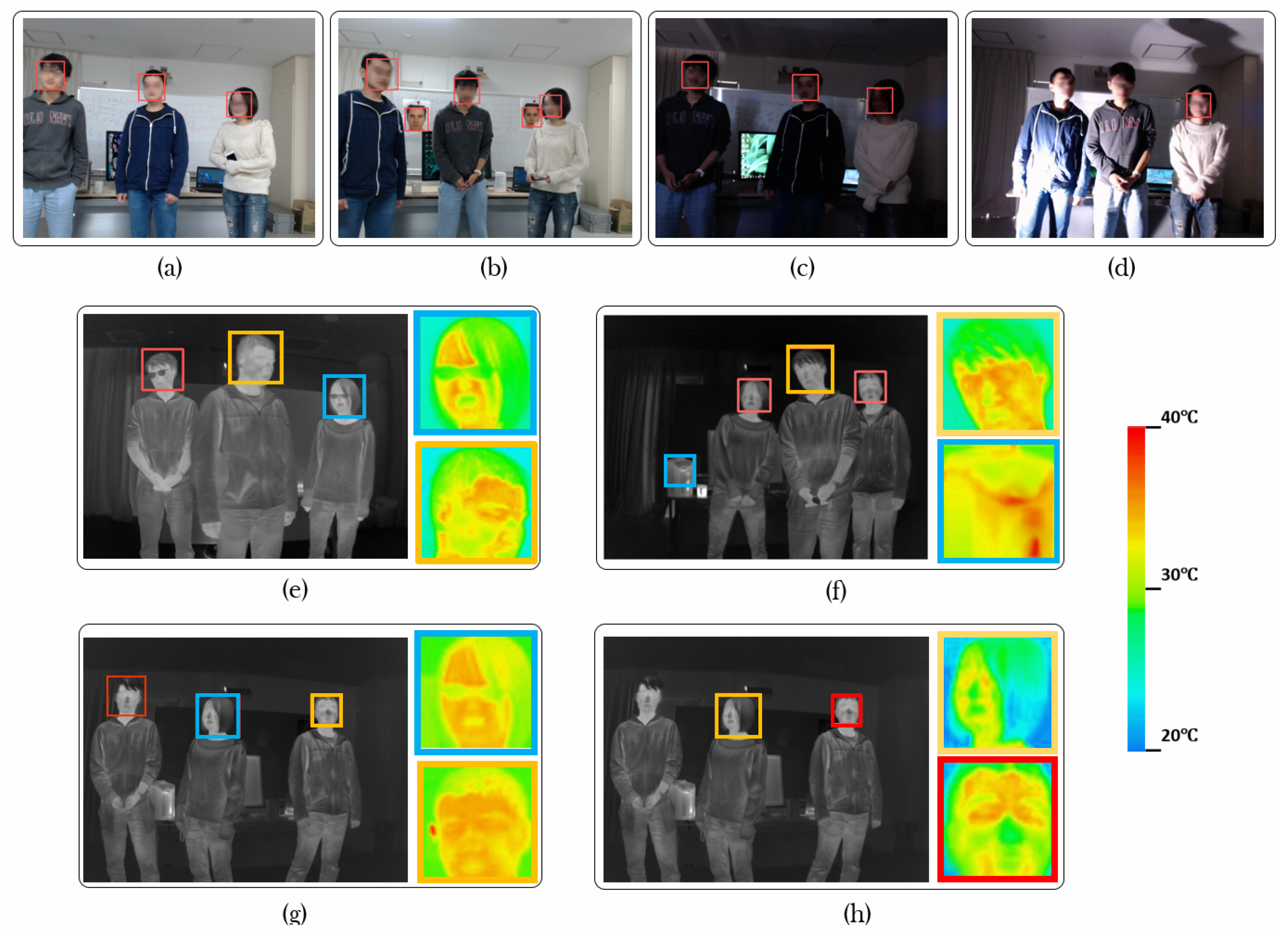
6.3. Results and Discussion
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zafeiriou, S.; Zhang, C.; Zhang, Z.A. Survey on face detection in the wild: Past, present and future. Comput. Vis. Image Underst. 2015, 138, 1–24. [Google Scholar] [CrossRef]
- Wilber, M.J.; Shmatikov, V.; Belongie, S. Can we still avoid automatic face detection? In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV 2016), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–9. [Google Scholar]
- Cho, M.Y.; Jeong, Y.S. Face recognition performance comparison of fake faces with real faces in relation to lighting. J. Internet Serv. Inf. Secur. 2014, 4, 82–90. [Google Scholar]
- Vollmer, M.; Möllmann, K.P. Infrared Thermal Imaging: Fundamentals, Research and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2010; ISBN 9783527407170. [Google Scholar]
- Ariyaratnam, S.; Rood, J.P. Measurement of facial skin temperature. J. Dent. 1990, 18, 250–253. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, Y.; Nagahara, H.; Taniguchi, R. Anonymous camera for privacy protection. In Proceedings of the 2014 22nd International Conference on Pattern Recognition (ICPR 2014), Stockholm, Sweden, 24–28 August 2014; pp. 4170–4175. [Google Scholar]
- Reese, K.; Zheng, Y.; Elmaghraby, A. A comparison of face detection algorithms in visible and thermal spectrums. In Proceedings of the International Conference on Advances in Computer Science and Application, Amsterdam, The Netherlands, 7–8 June 2012. [Google Scholar]
- Zhang, L.; Chu, R.; Xiang, S.; Liao, S.; Li, S.Z. Face detection based on multi-block lbp representation. In Proceedings of the 2007 International Conference on Biometrics (ICB 2007), Crystal City, VA, USA, 27–29 September 2007; pp. 11–18. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wilson, P.I.; Fernandez, J. Facial feature detection using Haar classifiers. J. Comput. Sci. Coll. 2006, 21, 127–133. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV 2009), Kyoto, Japan, 27 September–4 October 2009; pp. 32–39. [Google Scholar]
- OpenCV Dev. Team. OpenCV 2.4.9.0 Documentation. Available online: https://docs.opencv.org/2.4.9/modules/objdetect/doc/cascade_classification.html#featureevaluator-calcord (accessed on 19 October 2017).
- Xia, C.; Sun, S.F.; Chen, P.; Luo, H.; Dong, F.M. Haar-like and HOG fusion based object tracking. In Proceedings of the 2014 Pacific Rim Conference on Multimedia (PCM 2014), Kuching, Malaysia, 1–4 December 2014; pp. 173–182. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Ma, C.; Trung, N.T.; Uchiyama, H.; Nagahara, H.; Shimada, A.; Taniguchi, R. Mixed features for face detection in thermal image. In Proceedings of the 2017 Thirteenth International Conference on Quality Control by Artificial Vision (QCAV 2017), Tokyo, Japan, 14–16 May 2017; Volume 10338, p. 103380E. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 511–518. [Google Scholar]
- Jia, H.X.; Zhang, Y.J. Fast human detection by boosting histograms of oriented gradients. In Proceedings of the Fourth International Conference on Image and Graphics (ICIG 2007), Chengdu, China, 22–24 August 2007; pp. 683–688. [Google Scholar]
- Salas, Y.S.; Bermudez, D.V.; Peña, A.M.L.; Gomez, D.G.; Gevers, T. Improving hog with image segmentation: Application to human detection. In Proceedings of the 2012 14th International Conference on Advanced Concepts for Intelligent Vision Systems, Brno, Czech Republic, 4–7 September 2012; pp. 178–189. [Google Scholar]
- Liao, S.; Zhu, X.; Lei, Z.; Zhang, L.; Li, S.Z. Learning multi-scale block local binary patterns for face recognition. In Proceedings of the 2007 International Conference on Biometrics (ICB 2007), Crystal City, VA, USA, 27–29 September 2007; pp. 823–837. [Google Scholar]
- Jia, X.; Yang, X.; Zang, Y.; Zhang, N.; Dai, R.; Tian, J.; Zhao, J. Multi-scale block local ternary patterns for fingerprints vitality detection. In Proceedings of the 2013 International Conference on Biometrics (ICB 2013), Phuket, Thailand, 4–7 June 2013; pp. 1–6. [Google Scholar]
- Jiang, Y.; Ma, J. Combination features and models for human detection. In Proceedings of the 2015 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 8–10 June 2015; Volume 1, pp. 240–248. [Google Scholar]
- Mita, T.; Kaneko, T.; Hori, O. Joint haar-like features for face detection. In Proceedings of the 2005 IEEE 10th International Conference on Computer Vision (ICCV 2005), Beijing, China, 15–21 October 2005; Volume 2, pp. 1619–1626. [Google Scholar]
- Jin, H.; Liu, Q.; Lu, H.; Tong, X. Face detection using improved LBP under Bayesian framework. In Proceedings of the 2004 Third International Conference on Image and Graphics (ICIG 2004), Hong Kong, China, 18–20 December 2004; pp. 306–309. [Google Scholar]
- Hermosilla, G.; Ruiz-del, S.J.; Verschae, R.; Correa, M. A comparative study of thermal face recognition methods in unconstrained environments. Pattern Recognit. 2012, 45, 2445–2459. [Google Scholar] [CrossRef]
- Wang, S.; Liu, Z.; Lv, S.; Lv, Y.; Wu, G.; Peng, P.; Chen, F.; Wang, X. A natural visible and infrared facial expression database for expression recognition and emotion inference. IEEE Trans. Multimedia 2010, 12, 682–691. [Google Scholar] [CrossRef]
- Karlinsky, L.; Dinerstein, M.; Levi, D.; Ullman, S. Combined model for detecting, localizing, interpreting and recognizing faces. In Proceedings of the Workshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17–18 October 2008. [Google Scholar]
- Howse, J. Training detectors and recognizers in Python and OpenCV. In Proceedings of the 2014 IEEE International Symposium on Mixed and Augmented Reality (ISMAR 2014), Munich, Germany, 10–12 September 2014; pp. 1–2. [Google Scholar]
- Puttemans, S.; Can, E.; Goedemé, T. Improving Open Source Face Detection by Combining an Adapted Cascade Classification Pipeline and Active Learning. In Proceedings of the VISAPP 2017, Porto, Protugal, 27 February–1 March 2017. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temperature | Humidity | Lighting Condition | Other Factor | Function | |
|---|---|---|---|---|---|
| Scenario 1 | 24 C | 45% | Fluorescent Lighting | - | Control Group |
| Scenario 2 | 24 C | 45% | Fluorescent Lighting | Face Images | Experiment Group 1 |
| Scenario 3 | 24 C | 45% | No Lighting | - | Experiment Group 2 |
| Scenario 4 | 24 C | 45% | Spot Lighting | - | Experiment Group 3 |
| Scenario 5 | 28.5 C | 65% | Fluorescent Lighting | - | Experiment Group 4 |
| Scenario 6 | 20.5 C | 25% | Fluorescent Lighting | - | Experiment Group 5 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Trung, N.T.; Uchiyama, H.; Nagahara, H.; Shimada, A.; Taniguchi, R.-i. Adapting Local Features for Face Detection in Thermal Image. Sensors 2017, 17, 2741. https://doi.org/10.3390/s17122741
Ma C, Trung NT, Uchiyama H, Nagahara H, Shimada A, Taniguchi R-i. Adapting Local Features for Face Detection in Thermal Image. Sensors. 2017; 17(12):2741. https://doi.org/10.3390/s17122741
Chicago/Turabian StyleMa, Chao, Ngo Thanh Trung, Hideaki Uchiyama, Hajime Nagahara, Atsushi Shimada, and Rin-ichiro Taniguchi. 2017. "Adapting Local Features for Face Detection in Thermal Image" Sensors 17, no. 12: 2741. https://doi.org/10.3390/s17122741
APA StyleMa, C., Trung, N. T., Uchiyama, H., Nagahara, H., Shimada, A., & Taniguchi, R. -i. (2017). Adapting Local Features for Face Detection in Thermal Image. Sensors, 17(12), 2741. https://doi.org/10.3390/s17122741