Obstacle Detection as a Safety Alert in Augmented Reality Models by the Use of Deep Learning Techniques



Abstract
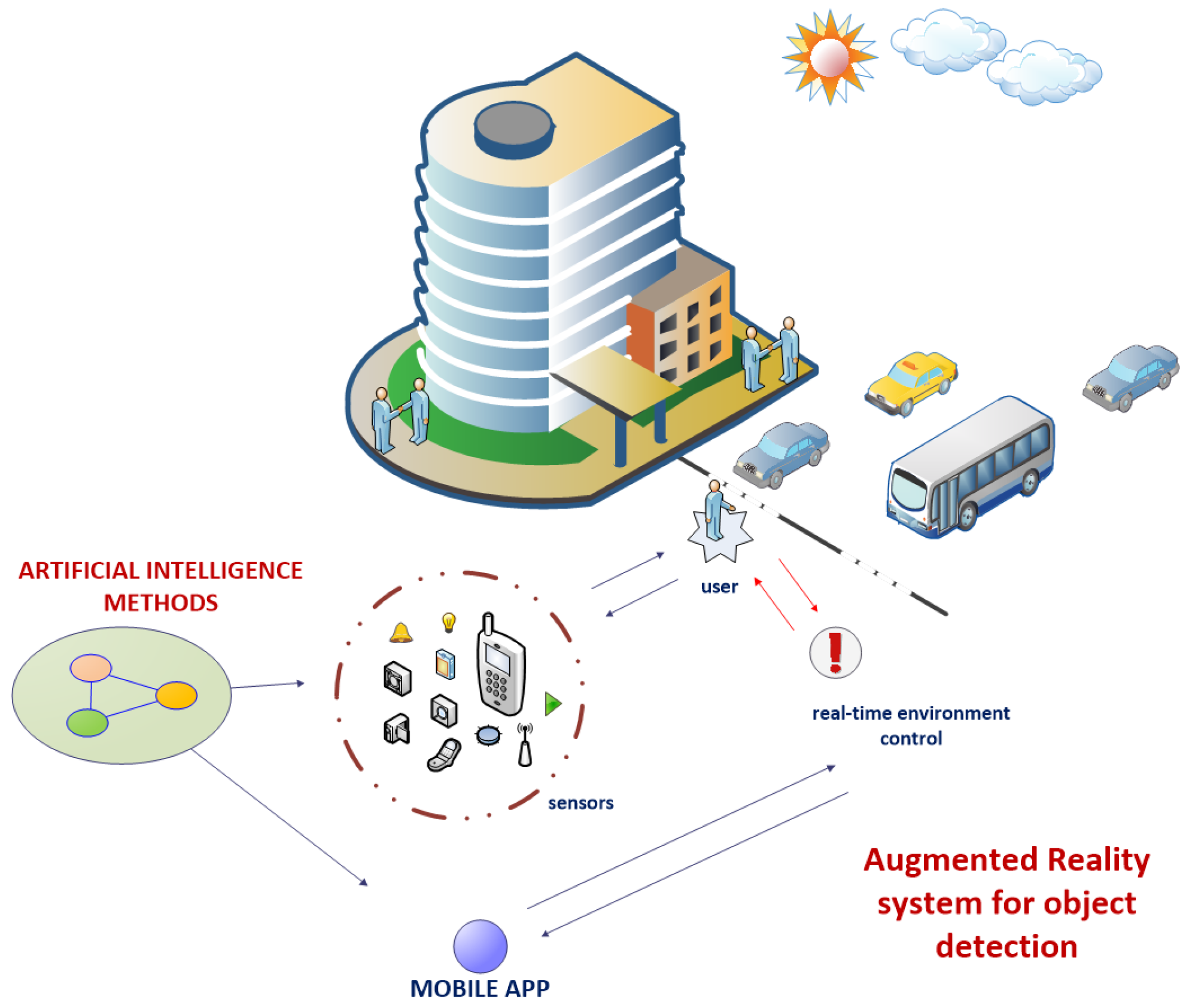
:1. Introduction
Related Works
2. Capturing Data in Environment
2.1. Data Extraction from the Camera Registry
2.2. Data Extraction from the Sound Registry
2.3. Data Extraction from Other Sensors
3. Neural Techniques
3.1. Spiking Neural Network
Training
3.2. Convolutional Neural Network
Training
4. Hybrid Architecture for Object Detection
Hybrid Architecture
5. Data Collection
6. Experiments
Conclusions
7. Final Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tateno, M.; Skokauskas, N.; Kato, T.A.; Teo, A.R.; Guerrero, A.P. New game software (Pokémon Go) may help youth with severe social withdrawal, hikikomori. Psychiatry Res. 2016, 246, 848–849. [Google Scholar] [CrossRef] [PubMed]
- LeBlanc, A.G.; Chaput, J.P. Pokémon Go: A game changer for the physical inactivity crisis? Prev. Med. 2017, 101, 235–237. [Google Scholar] [CrossRef] [PubMed]
- Rauschnabel, P.A.; Rossmann, A.; Dieck, M.C.T. An adoption framework for mobile augmented reality games: The case of Pokémon Go. Comput. Hum. Behav. 2017, 76, 276–286. [Google Scholar] [CrossRef]
- Juan, C.; Beatrice, F.; Cano, J. An augmented reality system for learning the interior of the human body. In Proceedings of the Eighth IEEE International Conference on Advanced Learning Technologies (ICALT’08), Santander, Cantabria, Spain, 1–5 July 2008; pp. 186–188. [Google Scholar]
- Koutromanos, G.; Styliaras, G. “The buildings speak about our city”: A location based augmented reality game. In Proceedings of the 2015 6th International Conference on Information, Intelligence, Systems and Applications (IISA), Corfu, Greece, 6–8 July 2015; pp. 1–6. [Google Scholar]
- Kumar, C.P.; Poovaiah, R.; Sen, A.; Ganadas, P. Single access point based indoor localization technique for augmented reality gaming for children. In Proceedings of the 2014 IEEE Students’ Technology Symposium (TechSym), Kharagpur, India, 28 February–2 March 2014; pp. 229–232. [Google Scholar]
- Bernhardt, S.; Nicolau, S.A.; Agnus, V.; Soler, L.; Doignon, C.; Marescaux, J. Automatic localization of endoscope in intraoperative CT image: A simple approach to augmented reality guidance in laparoscopic surgery. Med. Image Anal. 2016, 30, 130–143. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.L.; Suk, H.J.; Kang, J.H.; Jung, J.M.; Laine, T.H.; Westlin, J. Using Unity 3D to facilitate mobile augmented reality game development. In Proceedings of the 2014 IEEE World Forum on Internet of Things (WF-IoT), Seoul, Korea, 6–8 March 2014; pp. 21–26. [Google Scholar]
- Dieck, M.C.T.; Jung, T. A theoretical model of mobile augmented reality acceptance in urban heritage tourism. Curr. Issues Tour. 2015, 1–21. [Google Scholar] [CrossRef]
- Katz, B.F.; Kammoun, S.; Parseihian, G.; Gutierrez, O.; Brilhault, A.; Auvray, M.; Truillet, P.; Denis, M.; Thorpe, S.; Jouffrais, C. NAVIG: Augmented reality guidance system for the visually impaired. Virtual Real. 2012, 16, 253–269. [Google Scholar] [CrossRef]
- Joseph, S.L.; Zhang, X.; Dryanovski, I.; Xiao, J.; Yi, C.; Tian, Y. Semantic indoor navigation with a blind-user oriented augmented reality. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Manchester, UK, 13–16 October 2013; pp. 3585–3591. [Google Scholar]
- Maule, L.; Fornaser, A.; Tomasin, P.; Tavernini, M.; Minotto, G.; Da Lio, M.; De Cecco, M. Augmented Robotics for Electronic Wheelchair to Enhance Mobility in Domestic Environment. In Proceedings of the International Conference on Augmented Reality, Virtual Reality and Computer Graphics, Ugento, Italy, 12–15 June 2017; Springer: Cham, Switzerland, 2017; pp. 22–32. [Google Scholar]
- Gelenbe, E.; Hussain, K.; Kaptan, V. Simulating autonomous agents in augmented reality. J. Syst. Softw. 2005, 74, 255–268. [Google Scholar] [CrossRef]
- Mesarosova, A.; Hernandez, M.F. ARecycle NOID ARt Game: The Augmented Reality Game in Public Space. In Proceedings of the 2014 International Conference on Cyberworlds (CW), Santander, Spain, 6–8 October 2014; pp. 421–424. [Google Scholar]
- Cordeiro, D.; Correia, N.; Jesus, R. ARZombie: A mobile augmented reality game with multimodal interaction. In Proceedings of the 2015 7th International Conference on Intelligent Technologies for Interactive Entertainment (INTETAIN), Turin, Italy, 10–12 June 2015; pp. 22–31. [Google Scholar]
- Lv, Z.; Halawani, A.; Feng, S.; Ur Réhman, S.; Li, H. Touch-less interactive augmented reality game on vision-based wearable device. Pers. Ubiquitous Comput. 2015, 19, 551–567. [Google Scholar] [CrossRef]
- Estevez, D.; Victores, J.G.; Morante, S.; Balaguer, C. Robot devastation: Using DIY low-cost platforms for multiplayer interaction in an augmented reality game. In Proceedings of the 2015 7th International Conference on Intelligent Technologies for Interactive Entertainment (INTETAIN), Turin, Italy, 10–12 June 2015; pp. 32–36. [Google Scholar]
- Shin, J.; Kim, J.; Woo, W. Narrative design for Rediscovering Daereungwon: A location-based augmented reality game. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 8–10 January 2017; pp. 384–387. [Google Scholar]
- Garay-Cortes, J.; Uribe-Quevedo, A. Location-based augmented reality game to engage students in discovering institutional landmarks. In Proceedings of the 2016 7th International Conference on Information, Intelligence, Systems & Applications (IISA), Chalkidiki, Greece, 13–15 July 2016; pp. 1–4. [Google Scholar]
- Nguyen, M.; Yeap, W.; Hooper, S. Design of a new trading card for table-top augmented reality game environment. In Proceedings of the 2016 International Conference on Image and Vision Computing New Zealand (IVCNZ), Palmerston North, New Zealand, 21–22 November 2016; pp. 1–6. [Google Scholar]
- Wei, W.; Qi, Y. Information potential fields navigation in wireless Ad-Hoc sensor networks. Sensors 2011, 11, 4794–4807. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.; Song, H.; Li, W.; Shen, P.; Vasilakos, A. Gradient-driven parking navigation using a continuous information potential field based on wireless sensor network. Inf. Sci. 2017, 408, 100–114. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. Computer Vision–ECCV 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Sejdić, E.; Djurović, I.; Jiang, J. Time–frequency feature representation using energy concentration: An overview of recent advances. Digit. Signal Process. 2009, 19, 153–183. [Google Scholar] [CrossRef]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Xin, J.; Embrechts, M.J. Supervised learning with spiking neural networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN’01), Washington, DC, USA, 15–19 July 2001; Volume 3, pp. 1772–1777. [Google Scholar]
- Bohte, S.M.; Kok, J.N.; La Poutre, H. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 2002, 48, 17–37. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Value | Average Correctness | ||
|---|---|---|---|
| CNN Frames | CNN for Audio | SNN | |
| 0.1 | 0.1 | 0.1 | 32% |
| 0.1 | 0.1 | 0.01 | 35% |
| 0.1 | 0.1 | 0.01 | 36.5% |
| 0.1 | 0.01 | 0.1 | 38% |
| 0.1 | 0.01 | 0.01 | 39% |
| 0.1 | 0.01 | 0.001 | 39.5% |
| 0.1 | 0.001 | 0.1 | 41% |
| 0.1 | 0.001 | 0.01 | 39% |
| 0.1 | 0.001 | 0.001 | 44% |
| Error Value | Average Correctness | ||
|---|---|---|---|
| CNN Frames | CNN for Audio | SNN | |
| 0.01 | 0.1 | 0.1 | 41% |
| 0.01 | 0.1 | 0.01 | 43.5% |
| 0.01 | 0.1 | 0.01 | 44% |
| 0.01 | 0.01 | 0.1 | 43% |
| 0.01 | 0.01 | 0.01 | 46% |
| 0.01 | 0.01 | 0.001 | 49% |
| 0.01 | 0.001 | 0.1 | 48.5% |
| 0.01 | 0.001 | 0.01 | 53% |
| 0.01 | 0.001 | 0.001 | 55% |
| Error Value | Average Correctness | ||
|---|---|---|---|
| CNN Frames | CNN for Audio | SNN | |
| 0.001 | 0.1 | 0.1 | 63% |
| 0.001 | 0.1 | 0.01 | 64.5% |
| 0.001 | 0.1 | 0.01 | 66% |
| 0.001 | 0.01 | 0.1 | 62% |
| 0.001 | 0.01 | 0.01 | 68% |
| 0.001 | 0.01 | 0.001 | 71% |
| 0.001 | 0.001 | 0.1 | 65% |
| 0.001 | 0.001 | 0.01 | 76% |
| 0.001 | 0.001 | 0.001 | 79% |
| User | TP | TN | FP | FN | |||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1912 | 614 | 265 | 402 | 0.79 | 0.85 | 0.74 | 0.82 | 0.7 |
| 2 | 1405 | 231 | 190 | 600 | 0.67 | 0.78 | 0.64 | 0.7 | 0.54 |
| 3 | 2512 | 401 | 111 | 174 | 0.91 | 0.95 | 0.9 | 0.94 | 0.78 |
| Average | 1943 | 415.33 | 188.67 | 392 | 0.79 | 0.86 | 0.76 | 0.82 | 0.68 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Połap, D.; Kęsik, K.; Książek, K.; Woźniak, M. Obstacle Detection as a Safety Alert in Augmented Reality Models by the Use of Deep Learning Techniques. Sensors 2017, 17, 2803. https://doi.org/10.3390/s17122803
Połap D, Kęsik K, Książek K, Woźniak M. Obstacle Detection as a Safety Alert in Augmented Reality Models by the Use of Deep Learning Techniques. Sensors. 2017; 17(12):2803. https://doi.org/10.3390/s17122803
Chicago/Turabian StylePołap, Dawid, Karolina Kęsik, Kamil Książek, and Marcin Woźniak. 2017. "Obstacle Detection as a Safety Alert in Augmented Reality Models by the Use of Deep Learning Techniques" Sensors 17, no. 12: 2803. https://doi.org/10.3390/s17122803
APA StylePołap, D., Kęsik, K., Książek, K., & Woźniak, M. (2017). Obstacle Detection as a Safety Alert in Augmented Reality Models by the Use of Deep Learning Techniques. Sensors, 17(12), 2803. https://doi.org/10.3390/s17122803