1. Introduction
During the last decade, bandwidth demand for the limited spectrum has been greatly increasing due to the explosive growth of wireless services. The current static frequency allocation schemes, with a severe underutilization of the licensed spectrum over vast temporal and geographic expanses [
1], cannot support numerous emerging wireless services. This motivates the concept of cognitive radio (CR) [
2,
3,
4], which has been envisioned as an intelligent and promising approach to alleviate the problem of spectrum utilization inefficiency. In CR networks (CRNs), unlicensed secondary users (SUs) opportunistically access the spectrum dedicated to some licensed primary users (PUs) without interfering with the PU operation [
5]. Through enabling the CR users to dynamically access the available bands in the licensed spectrum, spectrum efficiency can be improved significantly.
The wireless sensor network (WSN), which is capable of performing event monitoring and data gathering, has been applied to various fields, including environment monitoring, military surveillance, smart homes and other industrial applications [
6,
7]. Currently, most WSNs work in the license-free band and are expected to suffer from heavy interference caused by other applications sharing the same spectrum. It is therefore imperative to employ CR in WSNs to exploit the dynamic spectrum access techniques, hence giving birth to the CR sensor networks (CRSNs) [
8,
9]. In CRSNs, in order to guarantee the quality-of-service (QoS) of primary users, it is indispensable for CR sensor nodes to sense the licensed spectrum to ensure that the spectrum is free of primary activities before data transmission. The exclusive operation of spectrum sensing along with subsequent data transmission results in high energy consumption in CRSNs, which traditionally operate powered by batteries. Consequently, one of the looming challenges that threatens the successful deployment of CRSNs is the energy efficiency [
6,
10].
Energy harvesting (EH) technology, which is used to replenish energy from various energy sources, such as solar, wind and thermal, has been flagged as one of the effective approaches for improving the energy efficiency with more eco-friendliness [
11]. Compared with traditional communication devices powered by batteries, EH-enabled devices could scavenge unlimited energy from the ambient environment energy sources, which enable them to operate continuously without battery replacement [
6]. This self-sustainable feature is very important because in many situations, periodically replacing or recharging batteries may be inconvenient or even impossible due to various physical restrictions [
12]. Besides, powering wireless networks with renewable energy source could also significantly reduce the harmful effects to the environment caused by fossil-based energy. Furthermore, energy harvesting systems can be built inexpensively in small dimensions, which could be a significant advantage in the manufacturing of small communication devices, such as sensor nodes [
13]. Recently, apart from traditional energy sources (e.g., solar, wind, thermal), the ambient radio signal is also regarded as a helpful optional source, which can be consistently available regardless of the time and location in urban areas [
14]. In light of the above advanced features, applying EH in CRSNs to improve energy efficiency has become increasingly eye-catching recently [
10,
15,
16,
17].
In this paper, we consider a time-slotted EH CR sensor network, where the secondary sensor node (also called SU) with a finite-capacity battery has no fixed energy supply and is powered exclusively by energy harvested from the ambient environment. There are multiple tradeoffs involved in the design of the parameters to achieve the optimal system performance of the SU. First, due to the existence of sensing errors, with a longer time allocated for channel sensing, the SU can acquire the status of a licensed spectrum with higher accuracy, such that the performance of the SU may be improved. However, in the slotted operating mode, with more time allocated for channel sensing, less time remains for data transmission, leading to possible performance reduction. Besides, as the amount of transmitting power used upon transmission will affect both the performance and energy consumption, a crucial challenge lies in adaptively tuning the transmission power levels according to the energy replenishment process, as well as channel variation. An overly conservative power allocation may limit the performance by failing to take full advantage of harvested energy, while an overly aggressive allocation of power may cause the energy in the battery to run out and affect the performance of the future time slots. Additionally, different from traditional CR systems with a fixed power supply, the energy consumption on the channel sensing is non-negligible in EH CRSNs; therefore, the problem of designing parameters, which should jointly consider the energy consumption of channel sensing and data transmission, as well as the dynamic battery replenishment process, becomes even more complicated than the traditional CR systems.
The objective of this paper is to minimize the long-term outage probability of the secondary sensor node by adapting the sensing time and the transmit power to the system states, including the battery energy, channel fading and the arrival energy by harvesting. The main contributions of this work are summarized as follows:
Considering the status of primary channels, the diversity of channel conditions, the energy replenishment process, as well as the imperfection of spectrum sensing, we investigate the joint optimization of channel sensing and adaptive transmit power allocation to minimize the SU’s long-term outage probability. The above design problem is formulated as a discounted Markov decision process (MDP).
We theoretically prove the existence of an optimal stationary deterministic policy and obtain the ϵ-optimal sensing-transmission (ST) policy, which specifies the allocation of sensing time and transmission power through using the value iteration in the MDP. Moreover, an interesting structural property regarding the optimal transmission policy is obtained. It is proven that the optimal long-term outage probability is non-increasing with the amount of the available energy in the battery.
For a special case where the signal-to-noise (SNR) power ratio is sufficiently high, we propose an efficient transmission (ET) policy with reduced computational complexity. It is theoretically proven that the efficient transmission policy achieves the same performance as the proposed sensing-transmission policy when the SNR is sufficiently high, which has also been validated through computer simulations.
We provide extensive simulation results to compare the performance of the sensing-transmission policy and the efficient transmission policy with that of a benchmark policy. It is shown that the proposed sensing-transmission policy achieves significant gains with respect to the benchmark policy, and both the sensing-transmission and the efficient transmission policies converge to the same value in high SNR regions. In addition, the impacts of various system parameters on the performance of proposed policies are also investigated.
The rest of the paper is organized as follows. The related work is reviewed in
Section 2. The network model and the related assumptions are presented in
Section 3. We formulate the outage probability minimization problem as an MDP in
Section 4. The proposed policies and the related theorems are illustrated in
Section 5. The performance and characteristics of the proposed policies are evaluated through numerical results in
Section 6. Finally, we conclude this paper in
Section 7.
2. Related Work
In the literature, the topic of energy harvesting and cognitive radio receive increasing attention. Three groups of existing works are most related. First, the CR technique has received significant attention during the past few years [
18,
19,
20,
21,
22]. In [
18], the authors focus on designing a database access strategy that allows the SUs to jointly consider the requirements of the existing rules, as well as the maximization of the expected communication opportunities through on-demand database access. The optimal strategy introduced in [
18], which is computationally unfeasible with the brute-force approach, can be solved by the efficient algorithm proposed in [
19]. In [
19], by proving that the optimal strategy has a threshold structure, an efficient algorithm is introduced by exploiting the threshold property. In [
20], the authors investigate the achievable throughput of an unlicensed sensor network operating over the TV white space spectrum. The achievable throughput is analytically derived as a function of the channel ordering. Additionally, the closed-form expression of the maximum expected throughput is illustrated. The work in [
21] studies the problem of coexistence interference among multiple secondary networks without the secondary cooperation. Under a reasonable assumption, a computationally-efficient algorithm for finding the optimal strategy is presented. The work in [
22] develops robust power control strategies for cognitive radios in the case of sensing delay and model parameter uncertainty. A robust power control framework that optimizes the worst-case system performance is proposed. All of the problems considered in the above works are formulated as Markov decision process problems, and the technical contributions are very important and valuable. However, due to the unique features of the EH CRSNs, such as the dynamic energy replenishment process, which stipulates a new design constraint on energy usage in the time axis, there is a need to revisit resource allocation policies so that the energy expenditure can efficiently adapt to the dynamics of energy arrivals.
Second, the energy harvesting technique has been widely studied in wireless communication systems [
23,
24,
25,
26,
27,
28,
29,
30]. The works in [
23,
24,
25,
26] consider the point-to-point wireless communications. In [
23], through optimizing the time sequence of transmit powers, the authors focus on maximizing the throughput by a deadline and minimizing the transmission completion time. For the offline policy, a directional water-filling algorithm is introduced to find the optimal power allocation. For the online policy, dynamic programming is applied to solve the optimal power allocation. In [
24], the authors consider the problem of energy allocation over a finite horizon to maximize the throughput. A water-filling energy allocation where the water-level follows a staircase function is introduced. The work in [
25] studies the problem of energy allocation for sensing and transmission to maximize the throughput in an energy harvesting wireless sensor network. The problem studied in [
25] considers the finite horizon case, which is extended in [
26] to an infinite-horizon case. In [
26], the authors study the energy allocation for sensing and transmission for an energy harvesting sensor node. An optimal energy allocation algorithm and an optimal transmission energy allocation algorithm are introduced. The works in [
27,
28] consider the problem of hybrid energy supply. In [
27], the authors investigate the minimization of the power consumption stemming from the constant energy source for transmitting a given number of data packets. In [
28], for a hybrid energy supply system employing a save-then-transmit protocol, the authors explore the transmission scheduling problem. In [
29], the authors study the transmission power allocation strategy to achieve the energy-efficient transmission. The harvest-use technique is adopted, which means that the harvested energy cannot be stored and must be used immediately. In [
30], for a solar-powered wireless sensor network, the authors present an optimal transmission policy based on a data-driven approach. However, due to the distinctive operation of cognitive radio, such as spectrum sensing, spectrum management, etc., directly applying the strategies mentioned above to EH CRSNs can be ineffective or inefficient.
Third, much recent research has been tightly focused on CR systems powered by energy harvesting. The work in [
11] focuses on an energy harvesting cognitive radio network with the save-then-transmit protocol; the authors mainly investigate the joint optimization of saving factor, sensing duration, sensing threshold and fusion rules to maximize the achievable throughput. In [
31], for a single-user multi-channel setting, jointly considering probabilistic arrival energy, channel conditions and the probability of PU’s occupation, the authors propose a channel selection criterion. In [
32], jointly considering the battery replenish process and the secondary belief regarding the primary activities, the authors introduce an energy allocation for sensing and transmission to maximize the long-term throughput. Different from [
32], a suboptimal energy allocation algorithm that allocates energy in an online approach is introduced in [
33]. In [
34], in order to maximize the throughput, the authors derive an optimal sensing strategy through optimizing the access probabilities of idle channels and busy channels. In [
35], a joint design of the spectrum sensing and detection threshold to maximize the long-term throughput is studied. Furthermore, the upper bound of the achievable throughput is derived as a function of the energy arrival rate, the statistical behavior of the primary network traffic and the detection threshold in [
36]. In [
10], the authors propose a spectrum and energy-efficient heterogeneous cognitive radio sensor network (HCRSNs), where EH-enabled spectrum sensors cooperatively detect the status of the licensed channels, while the data sensors transmit data to the sink. Compared with these works, the salient feature of this paper is that, according to the current knowledge of the battery state, channel fading, as well as the arrival energy based on EH, we jointly optimize the action of channel sensing and transmission power allocation for an energy harvesting cognitive sensor node, to minimize the long-term outage probability.
4. Problem Formulation
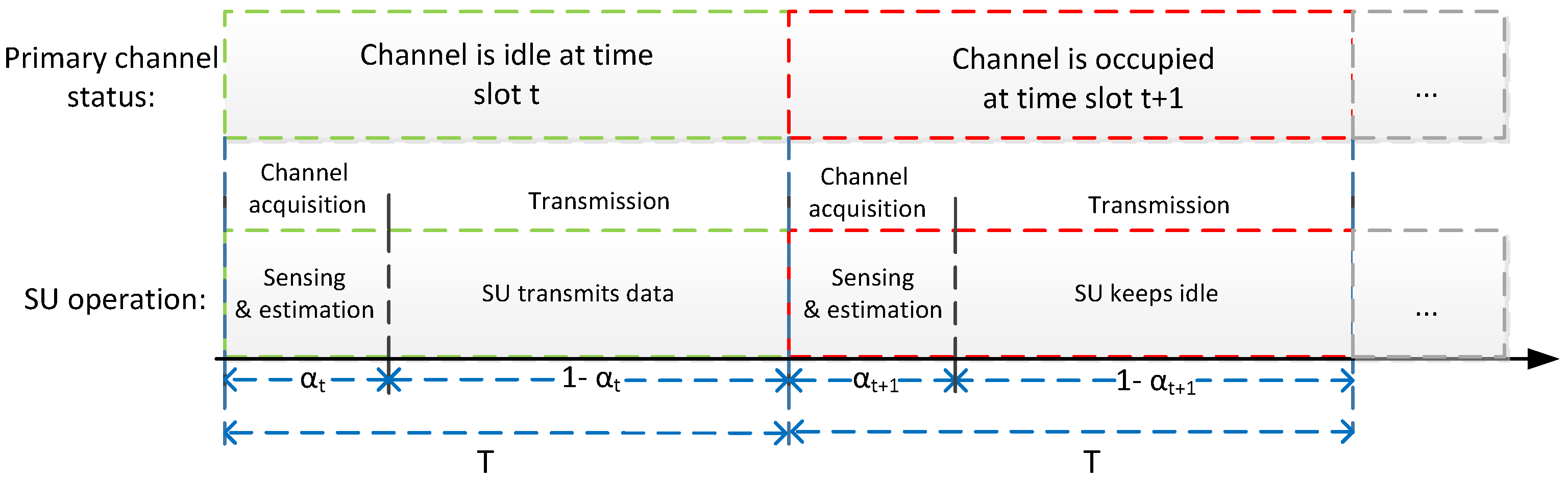
In this section, we formulate the problem of long-term outage probability minimization as an MDP. The MDP model is mainly composed of decision epochs, states, actions, state transition probabilities and rewards. The decision epoch is time slot
. The state of the system is denoted as
, where
b indicates the battery energy state,
g indicates the channel state and
h indicates the state of arrival energy based on EH. We assume that
b,
g and
h take discrete values from discrete finite set
,
and
, respectively. Thus, the state space can be expressed as
, where × denotes the Cartesian product. We assume the battery is quantized in units of
, which can be referred to as one unit of energy quantum . Additionally, we denote the battery energy State 0 corresponds to the energy
, which is the energy consumption when the SU stays in the idle state within the entire time slot, and for battery state
, the total energy in the battery is
. As for the arrival energy, if the arrival energy state is
, then the actually arrival energy is
, where
. It should be noted that as the channel state and arrival energy state can only be acquired casually, at the beginning of time slot
t, the SU only attains the exact channel state and the arrival energy state of the previous time slot. Therefore, the system state for time slot
t can be represented as
, where
is the energy state for the current time slot, whereas
and
are the states of channel and arrival energy of the previous time slot. The evolvement of the arrival energy
is assumed to be a first-order discrete-time Markovian model introduced in
Section 3.2; hence, in the following, we will first introduce the update process of the battery energy state
along with the SU’s channel capacity. Then, the evolvement of the channel state
is presented.
First, as to the battery energy state update process, a combination of sensing overhead
and transmit power
leads to one of the following four possible consequences:
Idle detection with probability
: the primary channel is idle while the sensing result is correct. Then, channel capacity:
is gained, and the battery energy state updates as:
False alarm with probability
: the primary channel is idle while the sensing result is wrong. The SU abstains from the transmission, and the channel capacity
R is zero. The battery energy state is:
Occupied detection with probability
: the primary channel is occupied while the sensing result is correct. SU abstains from the transmission, and channel capacity
R is zero; the battery energy state is the same as (
10).
Misdetection with probability
: the primary channel is occupied while the sensing result is wrong. Channel capacity
R is zero due to the collision with PU and the battery energy state updates the same as (
9).
Second, we formulate the evolvement of channel states. The channel fading process can be modeled as a time-homogeneous finite-state Markov chain (FSMC), which has been widely used to model the block fading channel [
44,
45,
46,
47]. Specifically, the channel power is quantized using a finite number of thresholds
, where
when
. The channel is considered to be in state
i,
, if the instantaneous channel power gain belongs to the interval
. We consider that the wireless channel fluctuates slowly over time slots and remains constant within a time slot, as assumed in [
48,
49]. Hence, the channel state transition occurs only from the current state to its neighboring states at the beginning of each time slot [
30]. Considering the Rayleigh fading channel, the channel state transition probability is determined by [
50]:
where
is the stationary probability that the channel state is
i, and
;
is the average channel power gain.
is the level crossing rate, where
is the maximum Doppler frequency, normalized by
. The boundary transition probabilities for channel states are:
According to the current system state
, we introduce the action set of the SU. The sensing overhead
is quantized in units of
, and the the action set of sensing overhead can be expressed as follows:
where
is the floor function.
indicates that the energy level in the battery is so low (the energy stored in the battery is
) that the available energy is merely enough to compensate the energy expenditure when the SU stays in the idle state within the entire time slot. In this case, the SU stops the sensing, as well as transmission and keeps on harvesting energy. Respecting the constraint
, the first constraint indicates that the sensing duration should be less than the time slot
T; the second constraint indicates that the energy consumption for sensing should be less than the available energy
. When an action
is taken, the sensing overhead is
, the sensing time is
and the energy consumption for sensing is
. According to the action of sensing overhead, the action set of transmission power is quantized in units of
, and the action set can be expressed as:
For an action
, SU will consume
energy for data transmission.
Therefore, given a system state
, the action set can be represented as:
We use
to denote the system state transition probability, which indicates the probability that the system will go into state
in the case that the current system state is
and SU takes an action
. The state transition probability can be derived as follows:
where:
since
is a certain value, which is determined by
b,
and action
,
.
denotes the indicator function which takes the value of one if
x is true, otherwise zero.
The reward function is defined as the outage probability regarding the system state
and the corresponding action
, which is given by [
51]:
where
. If
, then
; if
, then
; otherwise,
.
In the following section, we first mainly study the existence of the optimal transmission policy. Then, the ϵ-optimal sensing-transmission policy that specifies the actions concerning the sensing overhead and the transmit power to minimize the long-term outage probability is introduced. Last, for a special case where the signal-to-noise power ratio is sufficiently high, we introduce an efficient transmission policy, which achieves the same performance as the ϵ-optimal sensing-transmission policy.
5. Proposed Transmission Policies
In this section, we focus on deriving policies that specify the actions regarding the sensing overhead and transmit power, with the goal of minimizing the long-term outage probability. First, we introduce the concept of the stationary deterministic policy. Second, we prove the convergence and the existence of the stationary deterministic policy. Then, based on the Bellman equation, we propose an ϵ-optimal stationary deterministic policy named the sensing-transmission policy through the value iteration approach. Last, for the special case where the signal-to-noise (SNR) is sufficiently high, we introduce an efficient transmission policy.
Denote
as the decision policy that specifies the decision rules to be used at each time slot, and
is the decision rule that prescribes a procedure for action selection in time slot
t. A policy is stationary deterministic if
is deterministic Markovian and
for all
[
26]; therefore, the stationary deterministic policy can be represented as
. For an infinite-horizon MDP, our primary focus will be on the stationary deterministic policy because the decision rules do not change over time, and they are easiest to implement and evaluate [
52]. We denote the feasible set of stationary deterministic policies as
. Given the initial state
and the policy
, the expected discounted infinite-horizon reward that represents the long-term outage probability is defined to be [
52]:
where
is the long-term expected reward with respect to the initial state
,
is the discount factor,
is the reward function defined by (
19) and
a is the action determined by the policy
π. The alteration of
λ brings a wide range of performance characteristics, which can be altered according to the actual needs.
The objective of the SU is to find the optimal stationary deterministic policy
that minimize the long-term expected reward defined in (
20), that is:
First, we prove that the long-term expected reward , where , is finite.
Lemma 1. is finite, namely , where and .
Proof of Lemma 1. In order to prove that the value of
is limited, according to [
52], we only need to prove that
. As
,
and
is discrete and finite, we can deduce that
is finite. Since
,
, it can be derived that
is limited. Thus, we can conclude that
, and therefore,
is finite. ☐
Lemma 1 indicates that for any initial system state, the value of converges to a certain value. Next, we explain the existence of the optimal stationary deterministic policy .
Theorem 1. There exists an optimal stationary deterministic policy to minimize the long-term expected reward displayed in Equation (20). Proof of Theorem 1. Since the system state
is discrete and finite and for an arbitrary
, the corresponding action space
is also discrete and finite, thus there exists an optimal stationary deterministic policy [
52]. ☐
Given an arbitrary system system
s, the optimal long-term expected reward
should satisfy the following Bellman optimality equation:
The first term on the right-hand side of Equation (
22) is the immediate reward for the current time slot, and the second term is the expected total discount future reward if SU chooses action
a. The well-known value iteration approach is then applied to find the
ϵ-optimal stationary deterministic policy, as shown in Algorithm 1.
| Algorithm 1 Sensing-transmission (ST) policy. |
- 1:
Set for all , set , specify . - 2:
For each , calculate the according to , , . - 3:
If , go to Step 4. Otherwise, increase i by 1 and go back to Step 2. - 4:
For each , choose - 5:
Obtain the ϵ-optimal transmission policy
|
In Algorithm 1, the SU iteratively finds the optimal policy. Specifically, in Step 1, is initialized to zero for all ; the error bound ϵ is specified; and set the iteration sequence i to be zero. In Step 2, we compute the for each according to the knowledge of . Then, in Step 3, the SU first estimates whether holds, where , and . If the inequality holds, which means that the value iteration algorithm has converged, then we proceed to Step 4 to obtain the decision rule and then formulate the sensing-transmission policy. Otherwise, we need to go back to Step 2 and continue to perform the iteration. According to Algorithm 1, the SU can pre-compute the policy and records it in a look-up table. Then, based on the specific system state, the SU can check the look-up table to find out the corresponding action.
As to the convergence,
computed by Step 2 converges to
for all
. Once the inequality condition in Step 3 is satisfied, then the obtained optimal policy ensures that
, where
is the long-term expected reward achieved by the
ϵ-optimal policy obtained in Step 5 of the Algorithm 1. In practice, according to the actual needs, SU can predefine the value of
ϵ to control the accuracy of convergence. Choosing
ϵ small enough ensures that the algorithm stops with a policy that is very close to optimal. Next, we introduce the complexity of Algorithm 1. The complexity of each iteration in the value iteration algorithm is
[
53], where
represents the total number of states in the state space,
indicates the total number of states that the system can possibly transmit to and
represents the total number of actions in the action space. For our MDP problem, the total number of states in state space
is
. As the battery state of the next time slot is deterministic and the channel can only transmit to the neighbor state or remains in its current state, therefore the total possible states the current system state can transmit to is
. The maximum number of actions regarding the sensing overhead, as well as the transmit power is
. Hence, the complexity of each iteration in Algorithm 1 is
.
Next, we study the structural property of the proposed sensing-transmission policy. Regarding the reward function, we have the following lemma:
Lemma 2. Given a system s, for an arbitrary certain action of , the immediate reward is non-increasing with , namely , where and .
Proof of Lemma 2. First, we prove that for a certain action of
,
defined in Equation (
19) is non-increasing with transmit action
, namely
, where
. As
is decreasing with
, we have
. If
, we can derive that
. If
, we can derive that
. Otherwise, it can be derived that
. Therefore, we can conclude that
is non-increasing with transmit action
.
Next, we calculate the difference between
and
:
since
is non-increasing with
, we can derive that
, that is
. ☐
Lemma 3. For any given channel state and arrival energy state , the minimum immediate reward is non-increasing in battery state . That is, , where , , , .
Proof of Lemma 3. The action set for
can be expressed as
, and the action set for
s can be expressed as
. When
, we can derive that the unit of transmit power
, and
; according to Lemma 2, we have
, and
. Since:
therefore, we have
.
As
, thus
; therefore, we have:
namely
. ☐
Based on Lemma 3, we have following lemma:
Lemma 4. For any given channel state and arrival energy state , we have that is non-increasing in the battery state , that is .
Proof of Lemma 4. We prove this lemma by the induction. When
, as the initial condition
for all
, thus
. According to Lemma 3, we have
. Assume when
, for any given
,
and
,
holds. When
, we use
to indicate system state
and use
s to indicate system state
. The action sets for
and
s are
and
, respectively. When
, for arbitrary
, we have
. Since
, for any
, we have that:
Since
, we can deduce that:
As
, we have:
☐
According to Lemma 4, we have the following theorem:
Theorem 2. For any given channel state and arrival energy state , the long-term expected reward achieved by the proposed sensing-transmission policy is non-increasing in the battery state b, that is , .
Proof of Theorem 2. Assume when , the inequality holds. According to Step 4 in Algorithm 1, is actually . Based on Lemma 3, we can conclude that , namely , . ☐
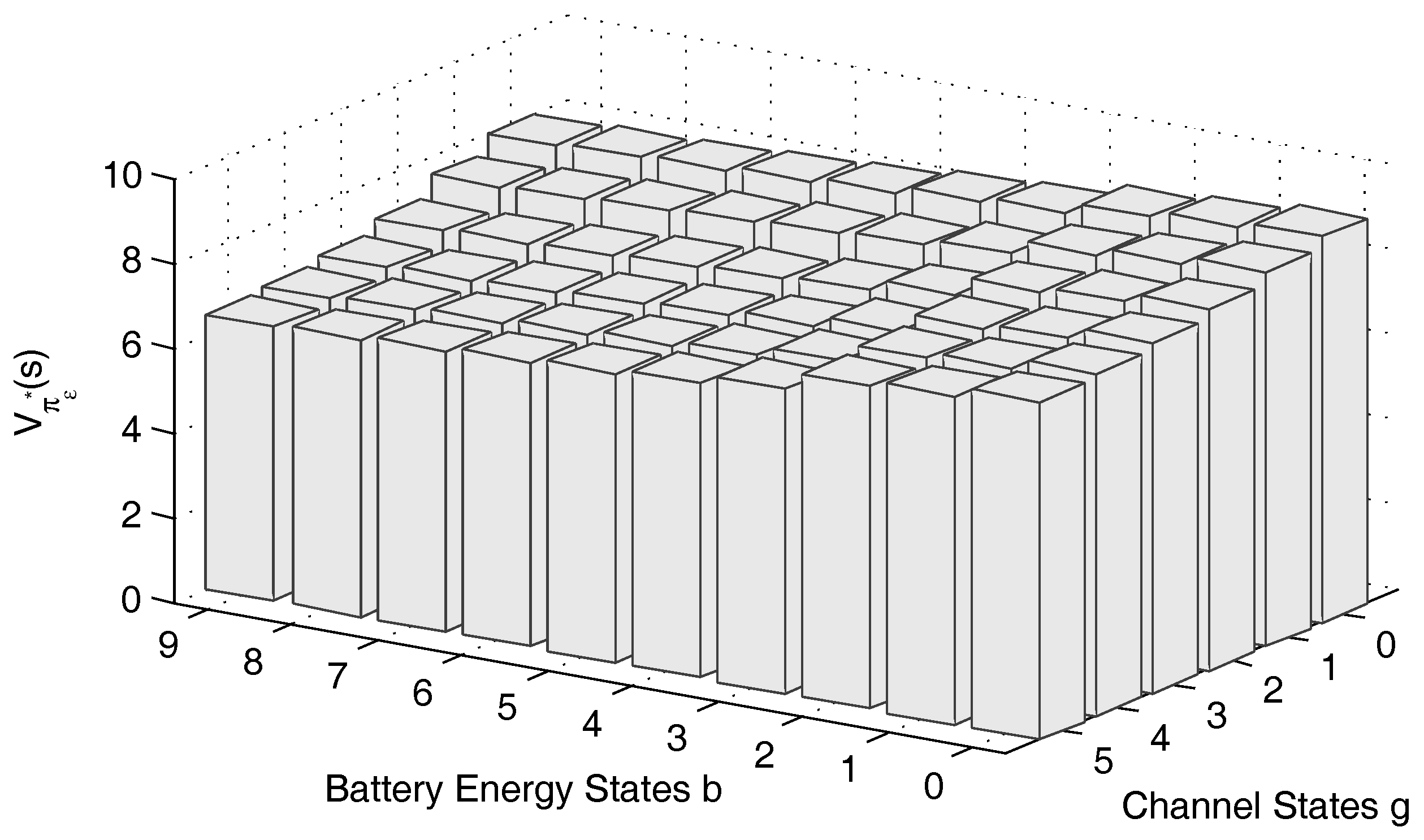
From Theorem 2, we perceive that the long-term reward
is non-increasing in the battery state
b. By taking the parameters in
Section 6 except as otherwise stated, the reward of the proposed
ϵ-optimal sensing-access policy is depicted in
Figure 2. From
Figure 2, we can see that
is non-increasing in the direction along the battery state, which validates Theorem 2.
Theorem 3. For any given channel state and arrival energy state , the optimal long-term expected reward achieved by optimal policy is non-increasing in battery state b, that is , .
Proof of Theorem 3. According to Theorem 2, we acquire that the ϵ-optimal policy is non-increasing in battery state b; therefore, the optimal long-term expected reward is non-increasing in b for any given g and h. ☐
In the following, we consider a special case where the signal-to-noise ratio (
) is sufficiently high. When
is sufficiently high, namely
, the reward function for the system state
and the corresponding action
are degenerated to:
For the i-th iteration, denote the long-term expected reward function with respect to action as . Then, we have the following theorem.
Theorem 4. When the SNR is sufficiently high, for any iteration i, the expected reward with action is no greater than the expected reward with action , where . That is, , where .
Proof of Theorem 4. The value difference of the two long-term expected rewards with actions
and
can be calculated as:
where
. As
, according to Lemma 4, we have
; thus, we can derive
. ☐
Based on Theorem 4, we can deduce the following theorem:
Theorem 5. When the SNR is sufficiently high, for any iteration i with a certain action of sensing overhead , the action set of transmit power to minimize the expected reward is , where , .
Proof of Theorem 5. When
, the available transmit power set is
. When
, if
, the available transmit power set is
; otherwise
; the available transmit power set is
. When
, we have two cases:
Case 1: , then if , the action set is ; otherwise, for arbitrary , according to Theorem 4, we have where ; therefore, the transmit power set to minimize the long-term value is .
Case 2: , for arbitrary , according to Theorem 4, we have where ; therefore, the action set to minimize the long-term value is .
Thus, we can derive that the action set to minimize the long-term reward is . ☐
Based on Theorem (5), we present an efficient transmission policy with reduced computational complexity, which is suitable for the case that the
is sufficiently high, as shown in Algorithm 2.
| Algorithm 2 Efficient transmission (ET) policy. |
- 1:
Set for all , set , specify . - 2:
For each , formulate the new action space: , , Calculate the according to , , . - 3:
If , go to Step 4. Otherwise, increase i by 1 and go back to step 2. - 4:
For each , choose - 5:
Obtain the efficient transmission policy
|
In Algorithm 2, since illustrated in Theorem 4, we can ignore the actions that and formulate the new action space with a lesser number of candidate actions, which reduces the computational complexity significantly. The total number of states in the state space is . Similar to the analysis of Algorithm 1, the total possible states the current system state can transmit to is . The maximum number of actions regarding the sensing overhead is , and the maximum number of actions regarding the transmit power is two. Therefore, the complexity of each iteration in Algorithm 2 is .
6. Numerical Results and Discussion
In this section, we evaluate the performance and characteristics of the proposed policies by extensive simulations on MatlabR2012a. Unless otherwise stated, the system parameters employed in the simulation are summarized in
Table 1, which draws mainly from [
26,
30,
31,
42]. The unit of the energy quantum is
mJ, and
. The quantization levels of the channel power are
. The arrival energy takes values from the finite set
mJ per time slot, namely
,
,
,
, and evolves according to the four-state Markov chain with the state transition probability given by:
A normalized SNR (i.e., ) is defined with respect to the transmit power of 1 mW throughout the simulation. We choose ϵ to be . The initial energy state is ; the initial channel state is ; and the initial arrival energy state is . The total simulation duration is 500 time slots. All of the numerical results are averaged over 500 independent runs.
We compare the proposed sensing-transmission (ST) and efficient transmission (ET) policies with a benchmark named shortsighted policy [
32,
54] in terms of the performance in
Figure 3,
Figure 4,
Figure 5 and
Figure 6. The primary concern of the shortsighted policy is to minimize the immediate reward of the current time slot, without considering the impact of the current action on the future reward, i.e.,
. However, the policies proposed in this paper take into account not only the current immediate reward, but also the future expected reward. Therefore, by comparing with the shortsighted policy, we can evaluate the benefit and advantage of proposed policies.
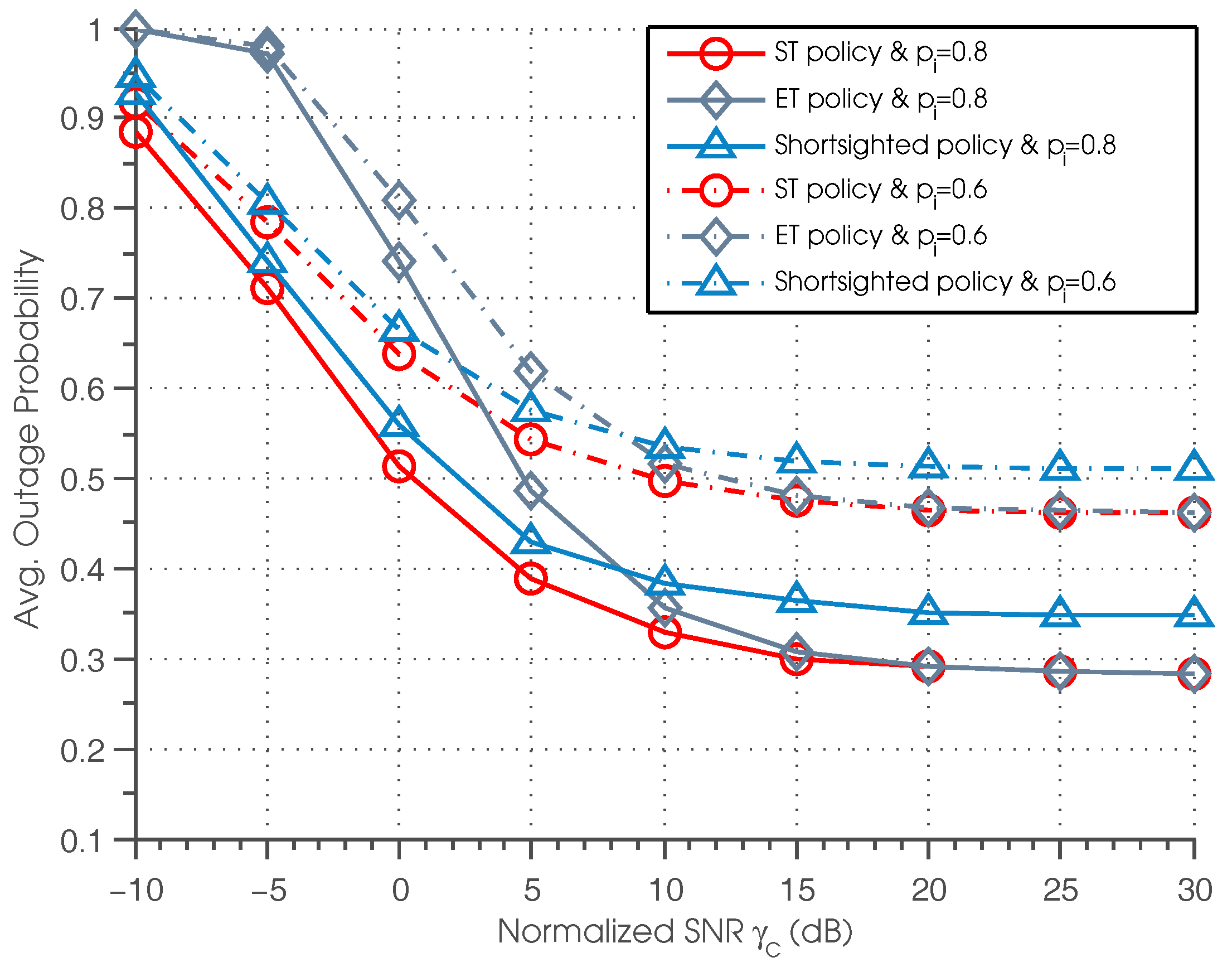
Figure 3 depicts the outage probability of ST, ET and the shortsighted policies under different normalized SNRs and channel idle probabilities. First, it can be seen that the ST policy outperforms the shortsighted policy for all settings of normalized SNR. This can be explained by the fact that the ST policy considers a tradeoff between the current immediate reward and the future achievable reward; while the shortsighted policy only focuses on maximizing the current immediate reward, ignoring the impact of the current action on the future reward. It should be noted that despite the better performance of the ST policy, it is much more computationally extensive than the shortsighted policy. Second, we can see that for ST and ET policies, when
is sufficiently high, the curves of ST and ET policies almost overlap, and a saturation effect is observed, namely the outage probability gradually converges to the same value. This phenomenon coincides with Theorem 5, that is when
is sufficiently high, the transmit action set that SU needs to consider is
, and that ET policy is equivalent to the ST policy in high
regions. Third, we also observe that the saturation outage probability of the three policies in high SNR regions becomes smaller when
gets larger. This is because larger
indicates more probability of employing the licensed channel for data transmission, resulting in lower outage probability.
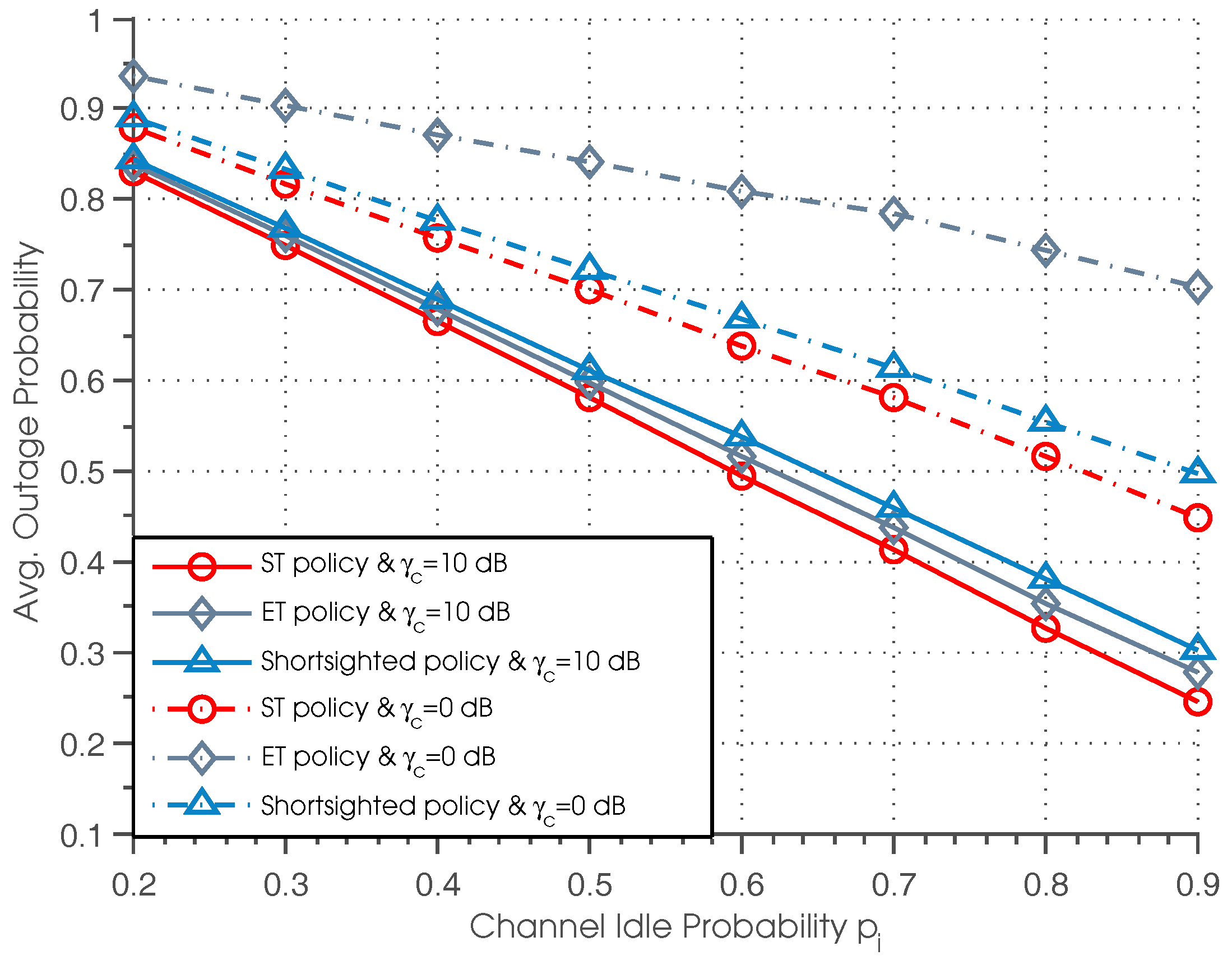
Figure 4 plots the outage probability of three policies versus the channel idle probability for different values of normalized SNR, where the performance curves plotted correspond to
dB and
dB, respectively. It can be seen that ST policy outperforms the other two policies for all settings of
. Besides, we can observe that the outage probability of all three policies decreases with the increase of channel idle probability, which can be easily understood since a higher value of
results in a higher possibility of successful data transmission and therefore reduces the outage probability. We can also observe that when
is small (
dB), the gap between the ST and ET policies becomes larger as
increases, and the shortsighted policy achieves better performance than the ET policy. While when
is large (
dB), there is only a tiny difference between the ST and ET policies, and the ET policy achieves better performance than the shortsighted policy.
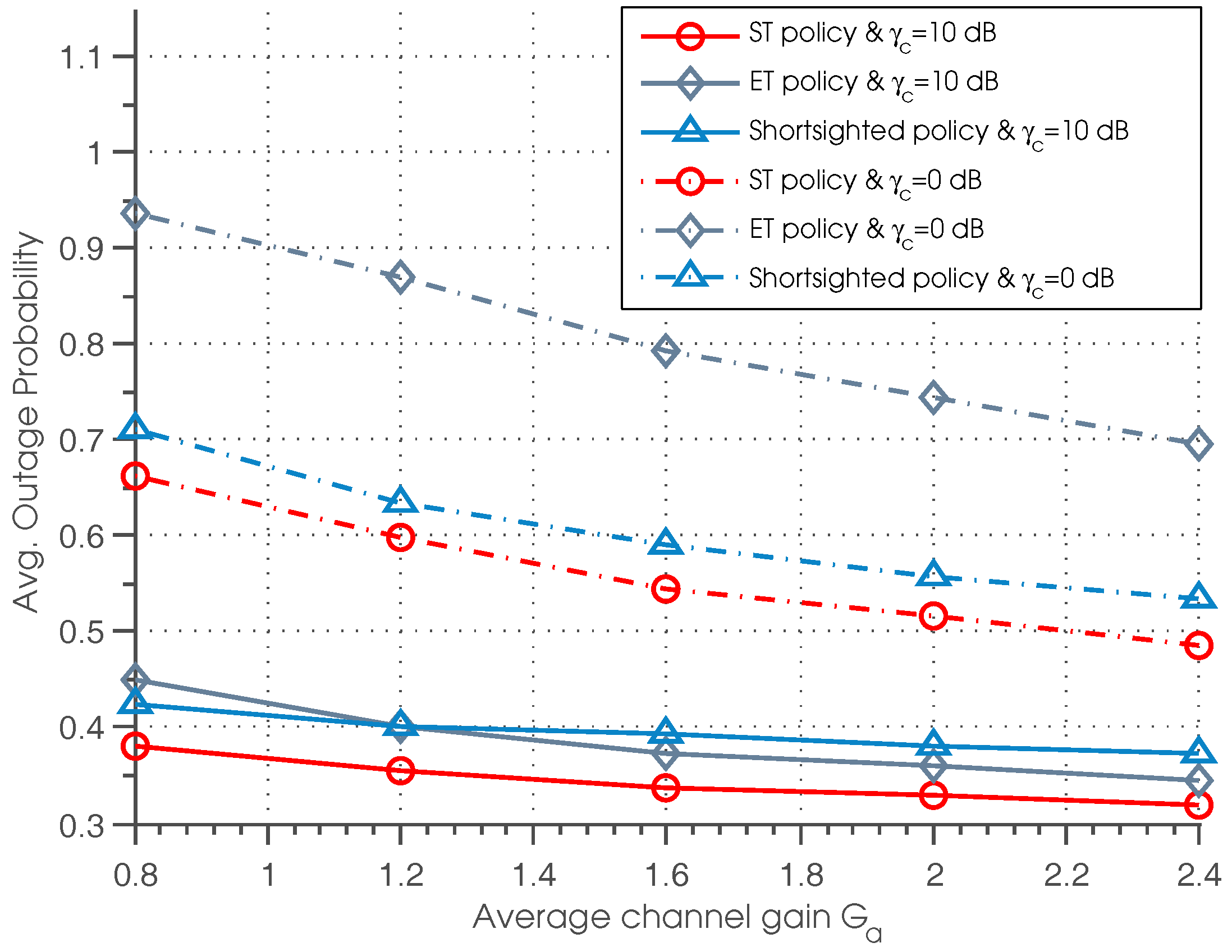
Figure 5 illustrates the outage probability of three policies as a function of average channel gain
for different
. It can be observed that the outage probability goes down with the increase of
. This is due to the fact that as
increases, the data transmission is more efficient when the primary channel is idle, resulting in lower outage probability. Besides, we can see that the ST policy outperforms the other two policies for all of the settings of
. It is also shown that when
is small (
dB), the shortsighted policy outperforms the ET policy, while when
is large (
dB), the ET policy achieve better performance than shortsighted performance in the case that
. Thus, we can conclude that in the case that the
is small or the channel quality is poor, the shortsighted policy outperforms the ET policy.
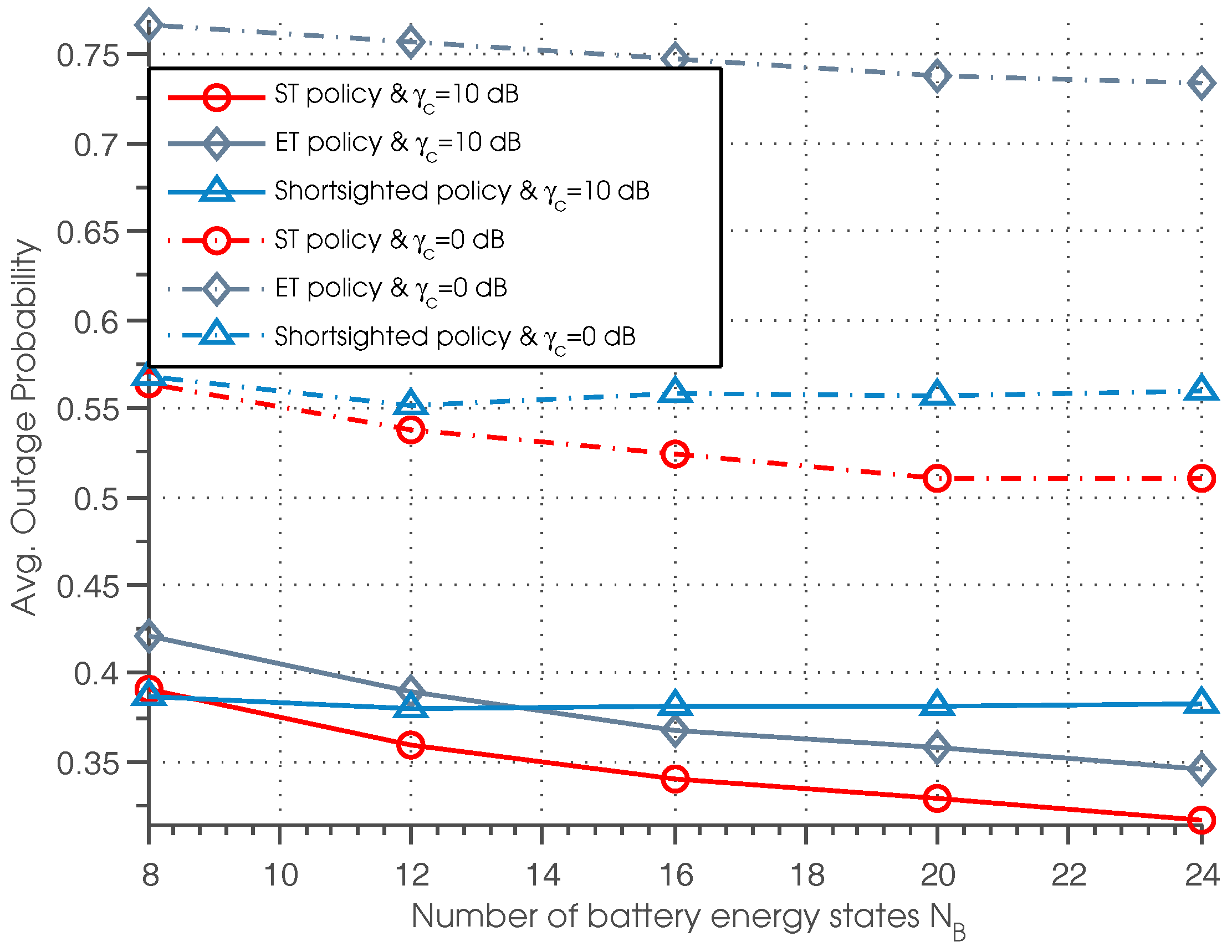
Figure 6 plots the outage probability of three policies with different settings of battery energy state and normalized SNR. It can be seen that the outage probability with respect to ST and ET policies decreases as
increases; while the outage probability regarding the shortsighted policy almost remains unchanged under different values of
. This phenomenon indicates that by increasing the capacity of the battery, we can efficiently decrease the outage probability, but the performance of the shortsighted policy is almost independent of the battery capacity. Besides, we can also observe that for lower
, the performance of shortsighted policy outperforms the ET policy. For higher
, the ET policy achieves better performance than the shortsighted policy when
.
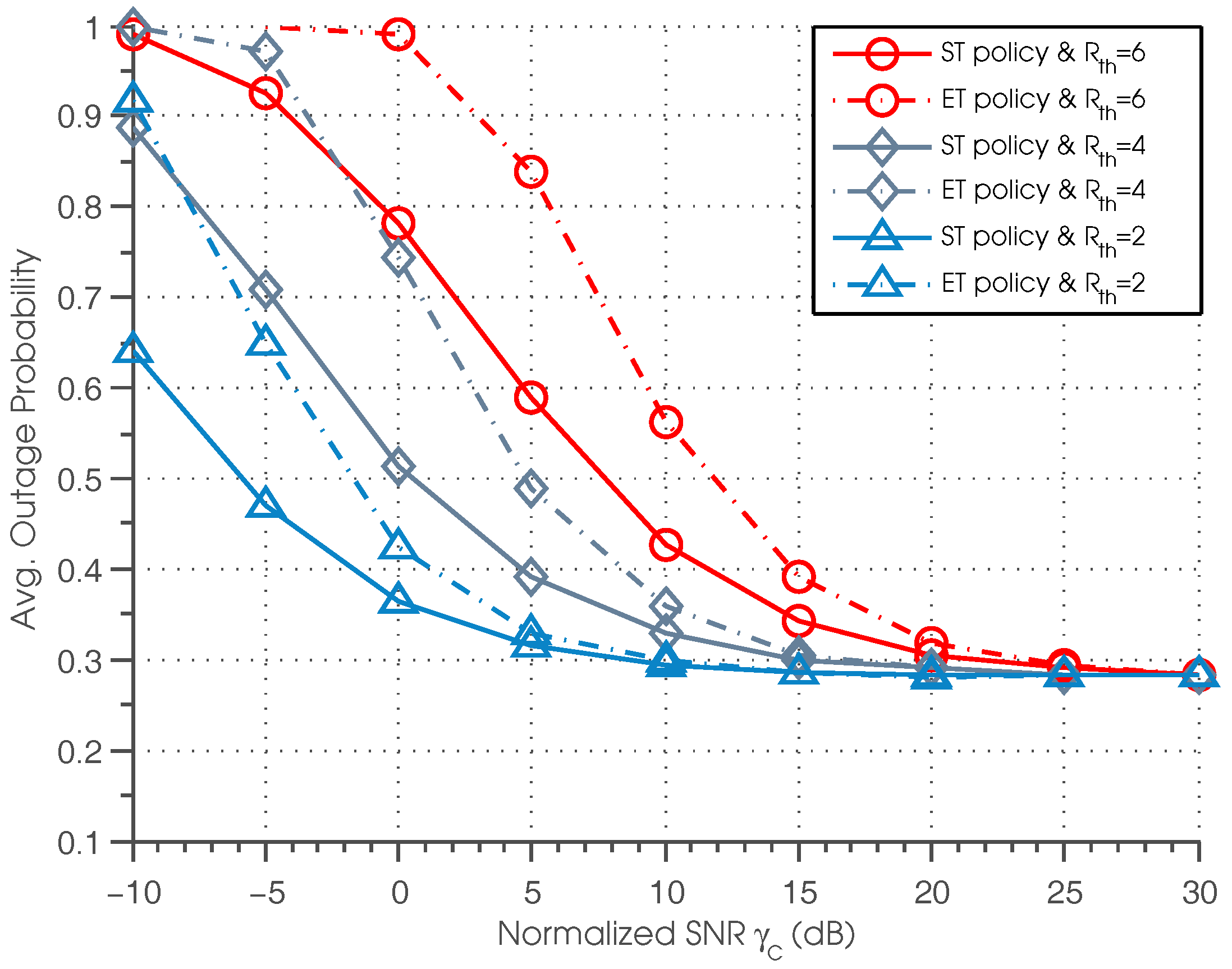
Figure 7 shows the outage probability of ST and ET policies as a function of
for different data rate threshold
. We can see that for lower
, a lower data rate threshold leads to a lower outage probability, and the curves with
outperform the curves with
and
. However, when
is sufficiently high, we observe that the curves correspond to
,
and
all converge to the same value. This is because when
is sufficiently high, according to Equation (
29), the reward functions have no relation to
; the curves with different
achieve the same outage probability.
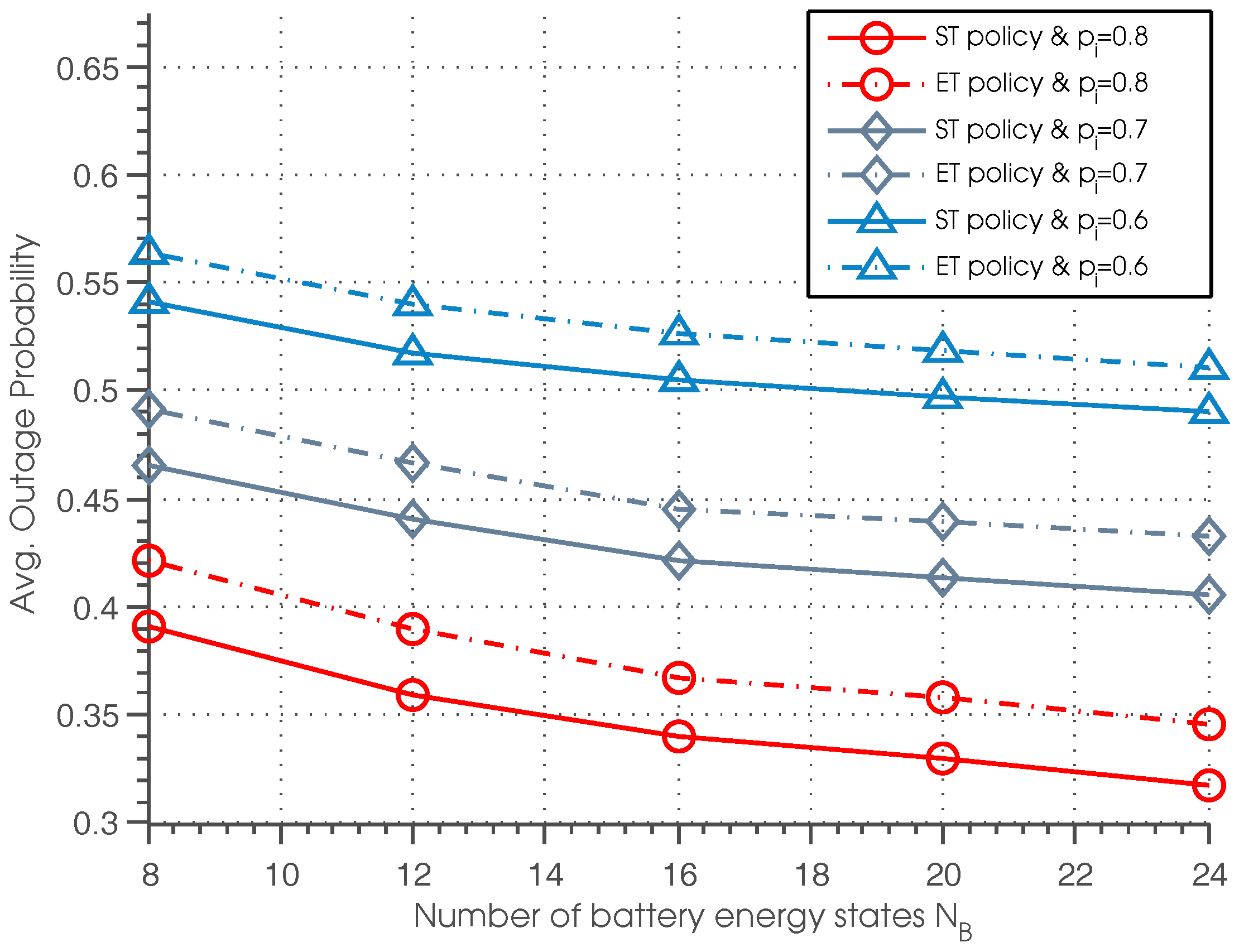
The outage probability of ST and ET policies with different settings of battery energy state
and idle probability
is shown in
Figure 8. It can be seen that outage probability of the ST and ET policies decreases as the battery storage capacity
increases. This is because with a higher
, SU can allocate the energy more efficiently: if the expected channel condition of the next time slot is good and the channel occupancy is estimated to be idle with high probability, the SU can allocate more energy for data transmission; otherwise, the SU can allocate less energy for data transmission and save more energy for future utilization.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}