1. Introduction
Over the past few decades, hyperspectral imagery has been widely used in different remote sensing applications owing to its high-resolution spectral information of the materials in the scene [
1,
2,
3]. Various hyperspectral image classification techniques have been presented for a lot of real applications including material recognition, urban mapping and so on [
4,
5,
6,
7,
8].
To date, a lot of hyperspectral image classification methods have been presented. Among them, the most representative method is the support vector machine (SVM) [
9], which has shown desirable hyperspectral image classification performance. Recently, the sparse representation based classification methods have received a lot of attention in the area of image analysis [
10,
11,
12,
13,
14], particularly in the classification of hyperspectral image. Chen et al. introduced a dictionary-based sparse representation framework for hyperspectral classification [
15]. To be specific, a test pixel is sparsely represented by a few labeled training samples, and the class is determined as the one with the minimal class-specific representation error. In addition, Chen et al. also proposed the simultaneous orthogonal match pursuit (SOMP) to utilize the spatial information of hyperspectral data [
15]. To take the additional structured sparsity priors into consideration, Sun et al. reviewed and compared several structured priors for sparse representation based hyperspectral image classification [
16], which can exploit both the spatial dependences between the neighboring pixels and the inherent structure of the dictionary. In [
17], Chen et al. extended the joint sparse representation to the kernel version for hyperspectral image classification, which can provide a higher classification accuracy than the conventional linear sparse representation algorithms. In addition, Liu et al. proposed a class-specific sparse multiple kernel learning framework for hyperspectral image classification [
18], which determined the associated weights of optimal base kernels for any two classes and led to better classification performances. To take other spectral properties and higher order context information into consideration, Wang et al. proposed the spatial-spectral derivative-aided kernel joint sparse representation for hyperspectral image classification [
19], and the derivative-aided spectral information can complement traditional spectral features without inducing the curse of dimensionality and ignoring discriminating features. Moreover, Li et al. proposed the joint robust sparse representation classification (JRSRC) method to take the sparse representation residuals into consideration, which can deal with outliers in hyperspectral classification [
20]. To integrate the sophisticated prior knowledge about the spatial nature of the image, Roscher et al. proposed constructing a novel dictionary for sparse-representation-based classification [
21], which can combine the characteristic spatial patterns and spectral information to improve the classification performance. In order to adaptively explore the spatial information for different types of spatial structures, Fu et al. proposed a new shape-adaptive joint sparse representation method for hyperspectral image classification [
22], which can construct a shape-adaptive local smooth region for each test pixel. In order to capture the class-discriminative information, He et al. proposed a group-based sparse and low-rank representation to improve the dictionary for hyperspectral image classification [
23]. To take different types of features into consideration, Zhang et al. proposed an alternative joint sparse representation by the multitask joint sparse representation model [
24]. To overcome the high coherence of the training samples, Bian et al. proposed a novel multi-layer spatial-spectral sparse representation framework for hyperspectral image classification [
25]. In addition, to take the class structure of hyperspectral image data into consideration, Shao et al. proposed a probabilistic class structure regularized sparse representation method to incorporate the class structure information into the sparse representation model [
26].
It had been argued in [
27] that the collaborative representation classification can obtain very competitive classification performance, while the time consumption was much lower than that of sparse representation. Thus, various collaborative representation methods had been proposed for hyperspectral image classification. Li et al. proposed the nearest regularized subspace (NRS) classifier by using the distance-weighted Tikhonov regularization [
28]. Then, the Gabor filtering based nearest regularized subspace classifier had been proposed to exploit the benefits of using spatial features [
29]. Collaborative representation with Tikhonov regularization (CRT) had also been proposed for hyperspectral classification [
30]. The main difference between NRS and CRT was that the NRS only used within-class training data for collaborative representation while the latter adopted all the training data simultaneously [
30]. In [
31], the kernel version of a collaborative representation was proposed and denoted as kernel collaborative representation classifier (KCRC). In addition, Li et al. proposed proposed combining the sparse representation and collaborative representation for hyperspectral image classification to make a balance between sparse representation and collaborative representation in the residual domain [
32]. Moreover, Sun et al. combined the active learning and semi-supervised learning to improve the classification performance when given a few initial labeled samples, and proposed the extended random walker [
33] algorithm for the classification of hyperspectral image.
Very recently, some deep models had been proposed for hyperspectral image classification [
34]. To the best of our knowledge, Chen et al. proposed a deep learning method named stacked autoencoder for hyperspectral image classification in 2014 [
35]. Recently, convolutional neural networks have been very popular in pattern recognition, computer vision and remote sensing. Convolutional neural networks usually contained a number of convolutional layers and a classification layer, which can learn deep features from the training data and exploit spatial dependence among them. Krizhevsky et al. trained a large convolutional neural networks to classify the 1.2 million high-resolution images in the ImageNet, which had obtained superior image classification accuracy [
36]. Since then, convolutional neural networks had been applied for hyperspectral image classification [
37,
38], which had achieved desirable classification performance. To take the spatial information into consideration, a novel convolutional neural networks framework for hyperspectral image classification using both spectral and spatial features was presented [
39]. In addition, Aptoula et al. proposed a combined strategy of both attribute profiles and convolutional neural networks for hyperspectral image classification [
40]. To overcome the imbalance between dimensionality and the number of available training samples, Ghamisi et al. proposed a self-improving band selection based convolutional neural networks method for hyperspectral image classification [
41]. In addition, some patch based convolutional neural networks hyperspectral image classification methods had also been proposed, such as the method in [
42,
43]. In order to achieve low computational cost and good generalization performance, Li et al. proposed combining convolutional neural networks with extreme learning machines for hyperspectral image classification [
44]. Furthermore, Shi et al. proposed a 3D convolutional neural networks (3D-CNN) method for hyperspectral image classification that can take both the spectral and spatial information into consideration [
45].
However, all of the above mentioned methods, whether they are based on sparse representation, collaborative representation or deep models, adopt the pixel-wise classification strategy, i.e., they do not consider all the pixels simultaneously. In [
46], theoretical work has demonstrated that multichannel joint sparse recovery is superior to applying standard sparse reconstruction methods to each single channel individually, and the probability of recovery failure decays exponentially with the increase in the number of channels. In addition, the probability bounds still hold true even for a small number of signals. For the classification of hyperspectral images, the multichannel means recovering multi hyperspectral pixels simultaneously. Therefore, inspired by the theoretical work in [
46], in this paper, we propose a hyperspectral classification method with spatial filtering and
norm (SFL) to deal with all the test samples simultaneously, which can not only take much less time but also obtain comparable good or better classification performance. First, the
norm regularization is adopted to select correlated training samples among the whole training data set. Meanwhile, the
norm loss function which is robust for outliers is also implemented. Second, we adopt the simple strategy in [
47] to exploit the local continuity, and all the training and testing samples are spatially averaged with their nearest neighbors to take the spatial information into consideration, which can be seen as spatial filtering. Third, the non-negative constraint is added in the sparse representation coefficient matrix motivated by hyperspectral unmixing. Finally, to solve SFL, we use the alternating direction method of multipliers [
48], a simple but powerful algorithm that is well suited to distributed convex optimization.
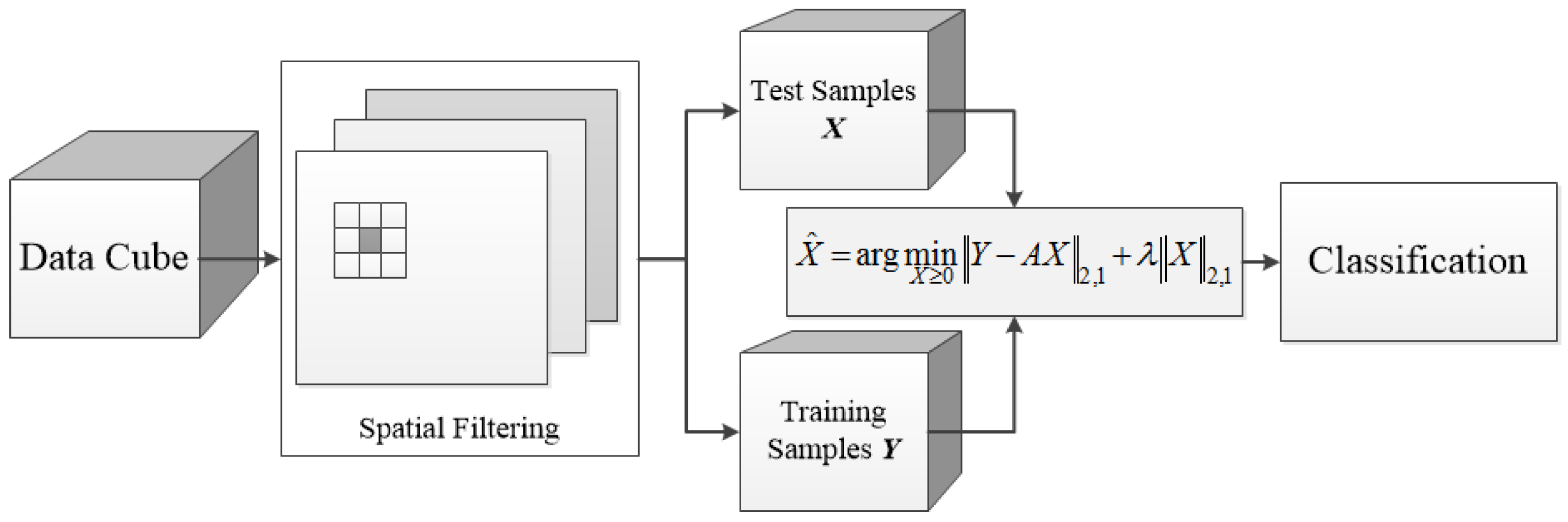
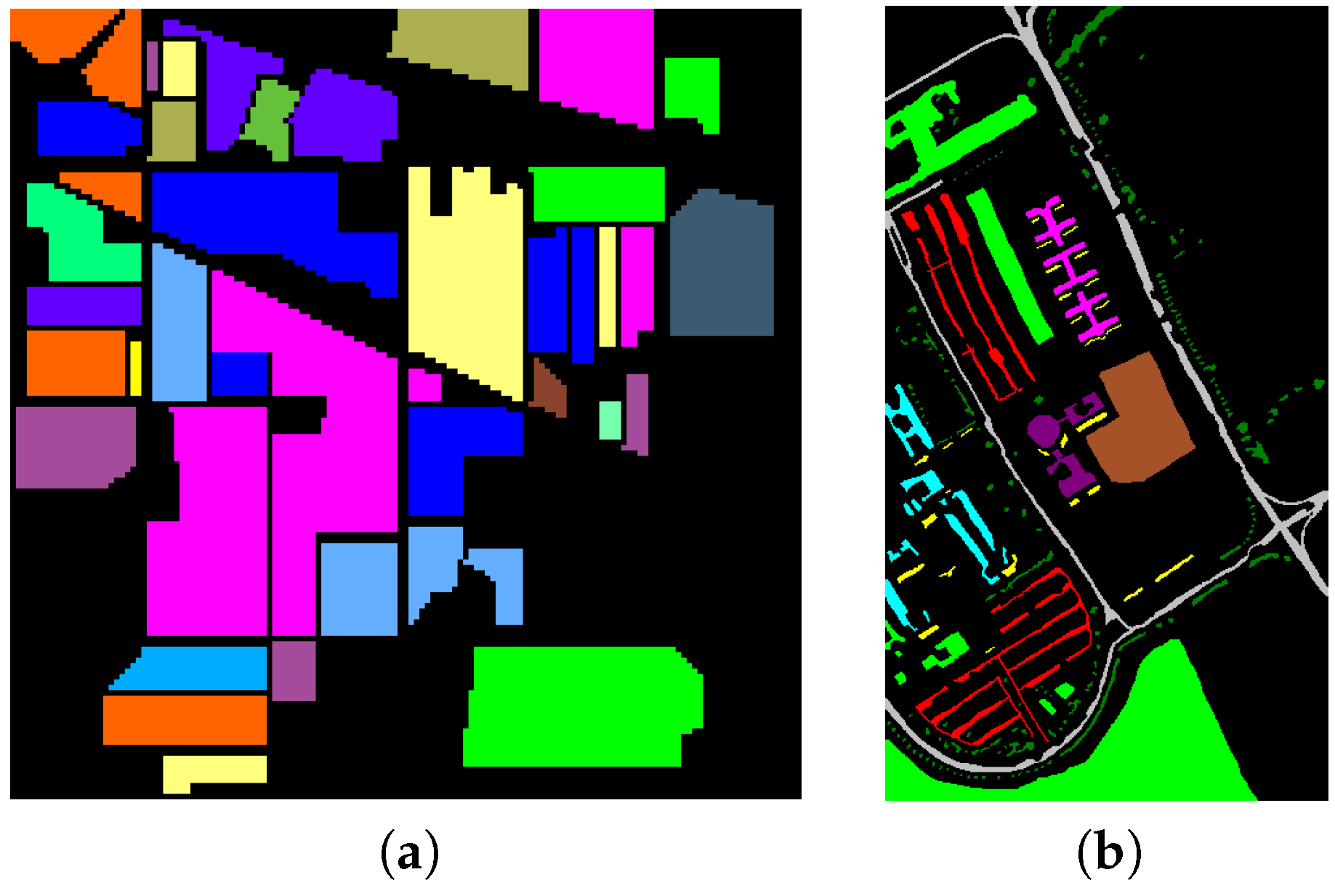
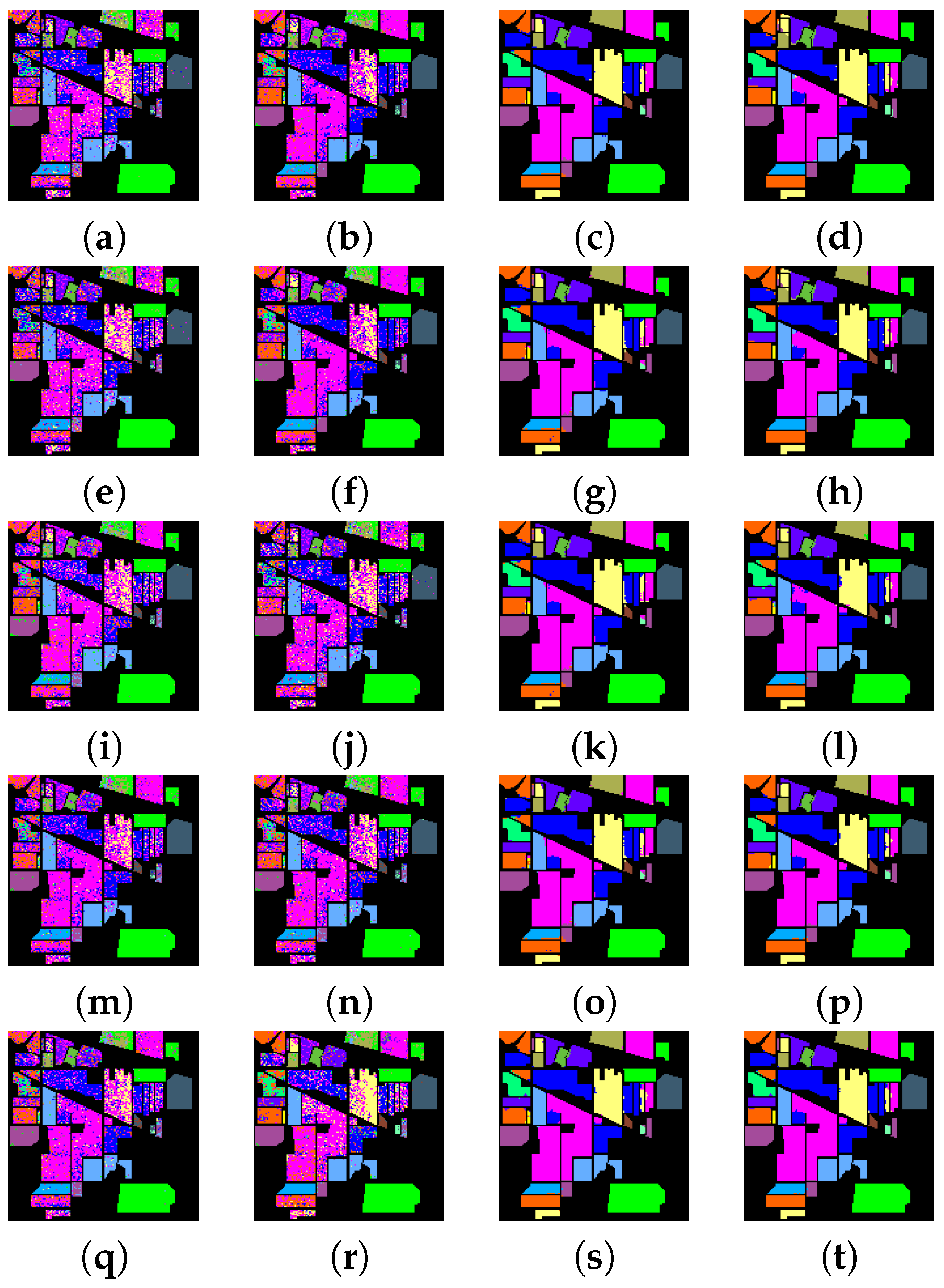
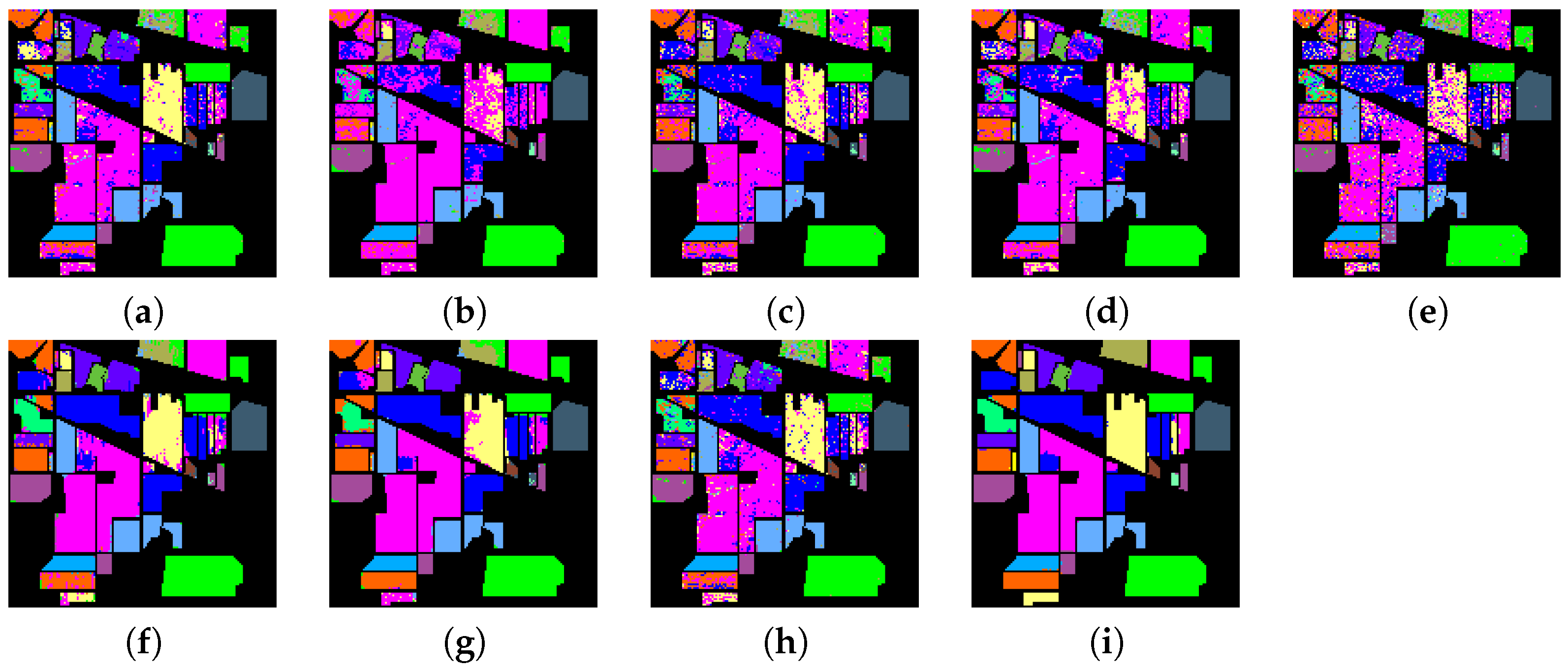
The main contribution of this work lies in proposing an SFL for hyperspectral classification that can deal with all the test pixels simultaneously. Experiments on real hyperspectral images demonstrate that the proposed SFL method can obtain better classification performance than some other popular classifiers.
3. Proposed Classifiers
In [
46], it has been proved that, with the increase in the number of channels, the failure probability of sparse reconstruction decreases exponentially. Thus, multichannel sparse reconstruction is superior to single channel sparse reconstruction. In addition, the probability bounds are valid even for a small number of signals. Based on this theory, we deal with all the test samples simultaneously, and the proposed SFL classification method will be briefly described.
Let
, where
denotes the columns of
, and
N denotes the number of test pixels. To deal with all the test pixels simultaneously, it is natural that the sparse representation coefficient matrix
for all the test pixels can be obtained by solving the optimization problem as follows:
which also can be solved by the alternating direction method of multipliers in [
49].
represents the matrix Frobenius norm, which is equal to the Euclidean norm of the vector of singular values, i.e.,
where
(
) denotes the singular value of
. After the optimized
is obtained, the classes of all test pixels can be obtained by the minimum class reconstruction error:
However, Equation (
4) adopts the pixel-wise independent regression, which ignores the correlation among the whole training data set. Recent research shows that the high-dimensional data space is smooth and locally linear, and it has been versified in image reconstruction and classification problems [
50,
51]. For joint consideration of the classification of neighborhoods, in this paper, we introduce the
norm regularization and adapt it to extract correlated training samples among the whole training data set with joint sparsity, which is defined as follows:
The
norm was first introduced by Ding et al. [
52], which makes the traditional principal component analysis more robust for outliers. The outliers are defined as data points that deviate significantly from the rest of data. Traditional principal component analysis optimizes the sum of squared errors, since the few data points that have large squared errors will dominate the sum. Therefore, the traditional principal component analysis is sensitive to outliers. It has been shown that minimizing the
norm is more robust and can resist a larger proportion of outliers compared with quadratic
norms [
53]. The
norm is identical to a rotational invariant
norm, and the solution of
norm based robust principal component analysis is the principal eigenvectors of a more robust re-weighted covariance matrix, which can alleviate the effects of outliers. In addition, the
norm has the advantage of being rotation invariant compared with the
norm [
52,
54,
55], i.e., applying the same rotation to all points has no effect on its performance. Due to the above-mentioned advantages, the
norm has been applied in feature selection [
56], multi-task learning [
57], multi-kernel learning [
58], and non-negative matrix factorization [
59]. Nie et al. [
56] introduced the
norm to feature selection, and they used
norm regularization to select features across all data points with joint sparsity. The
norm based loss function is used to remove outliers, and the feature selection process is proved to be effective and efficient.
Similarly, we adopt the
norm regularization to select correlated training samples among the whole training data set with joint sparsity for hyperspectral image classification. Thus, the corresponding optimization problem is as follows:
which can be solved by the alternating direction method of multipliers in [
60]. This model can be seen as an instance of the methodology in [
61], which can impose sparsity across the pixels both at the group and individual levels. In addition, to make it more robust for outliers, the
norm loss function is adopted. Thus, the corresponding optimization problem is as follows:
Due to limited resolution of hyperspectral image sensors and the complexity of ground materials, mixed pixels can easily be found in hyperspectral images. Therefore, a hyperspectral unmixing step is needed [
62,
63]. Hyperspectral unmixing is a process to identify the pure constituent materials (endmembers) and estimate the proportion of each material (abundance) [
64]. The linear mixture model has been prevalently used in hyperspectral unmixing, and the abundance is considered to be non-negative in a linear mixture model [
65]. If we deem
as the spectral library consisting of endmembers, then
can be seen as the abundance matrix. Therefore,
is also non-negative. When adding the non-negative constraint into the sparse representation matrix, the corresponding optimization problem is as follows:
In addition, since the spectral signatures of neighboring pixels are highly correlated, which make them belong to the same material with high probability, we thus adopt the simple strategy in [
47] to exploit the local continuity, and all the training and testing samples are spatially averaged with their nearest neighbors to take the spatial information into consideration, which can be seen as spatial filtering. Moreover, when
N=1, it is easy to see that Equation (
8) reduces to Equation (
2), and Equation (
9) reduces to the optimization problem as follows:
To sum up, the detailed procedure of our proposed method can be seen from
Figure 1. Finally, to solve the optimization problem from Equation (
9) to Equation (
12), Equation (
10) can be solved by the alternating direction method of multipliers in [
60], and Equations (
9) and (
12) are special cases of Equation (
11). Thus, it comes down to solving Equation (
11). For simplification, Equation (
11) can be written as:
where
is the indicator function of nonnegative quadrant
, and
is the
i-th column of
. If
belongs to the nonnegative quadrant, then
is zero. If not, it is
.
In order to solve Equation (
11), the alternating direction method of multipliers [
48] method is implemented. By introducing auxiliary variables
,
and
, Equation (
11) could be rewritten as:
A compact version of it is:
where
,
,
,
,
, and
is the unit matrix. Thus, the augmented Lagrangian function could be expressed as:
where
,
stands for the Lagrange multipliers. In order to update
, we solve
and its solution is the famous vector soft threshold operator [
10], which updates each row independently
where
, and the vect-soft-threshold function
. To update
, we solve
and its solution is also the vector soft threshold operator [
10]:
where
.
The stopping criterion is
, where
ε is the error threshold, and
J and
K are the number of rows and columns of
.
μ is updated in the same way as [
48], which keeps the ratio between the alternating direction method of multiplier primal norms and dual residual norms within a given positive interval. Based on this, we can get Proposition 1, whose proof of convergence is given in [
48].
Proposition 1. Function g in Equation (
15)
is closed, proper, and convex. If there exist solutions and , then iterative sequence and converge to and , respectively. If not, at least one of and diverge [48]. 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
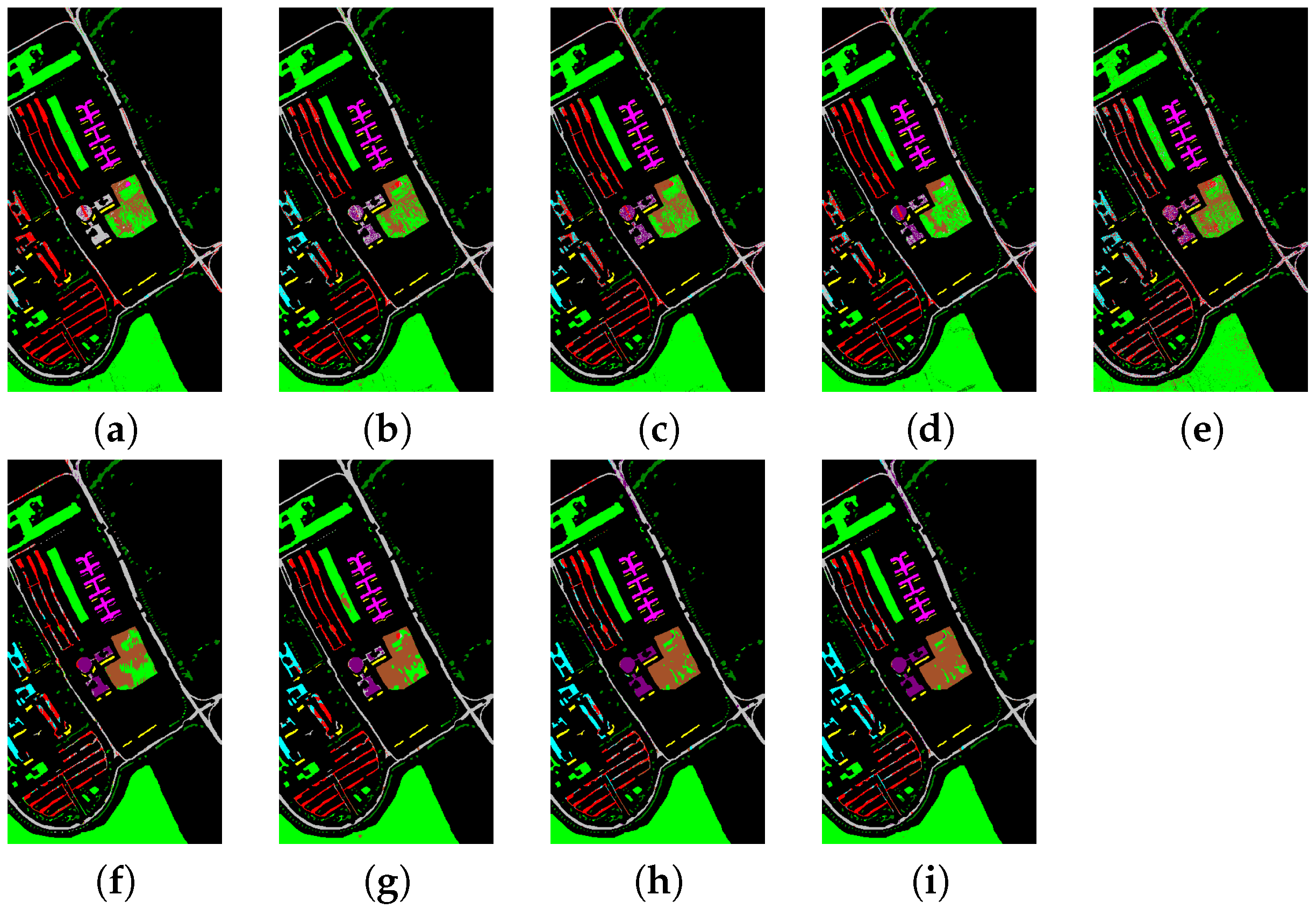{kind=link}