Conditional Random Field (CRF)-Boosting: Constructing a Robust Online Hybrid Boosting Multiple Object Tracker Facilitated by CRF Learning



Abstract
:1. Introduction
- A robust hybrid data association is proposed by cascading robust CRF-based pairwise similarity matching and online hybrid boosting.
- A hierarchical feature association framework is adopted to improve the accuracy.
- A fully automated online MOT method called CRF-boosting is established.
2. Related Work
3. Background
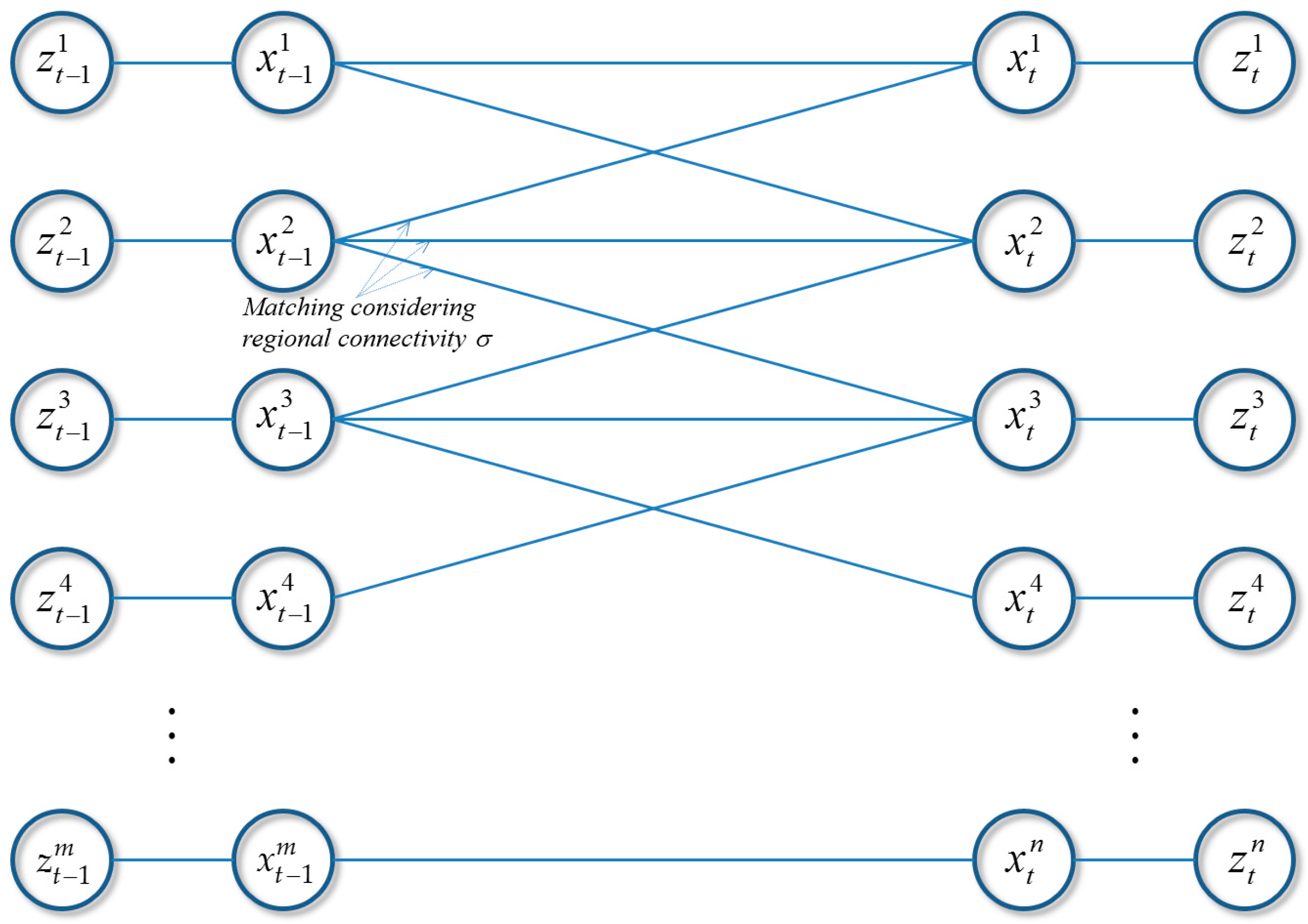
3.1. Conditional Random Fields
3.2. Hybrid Boosting
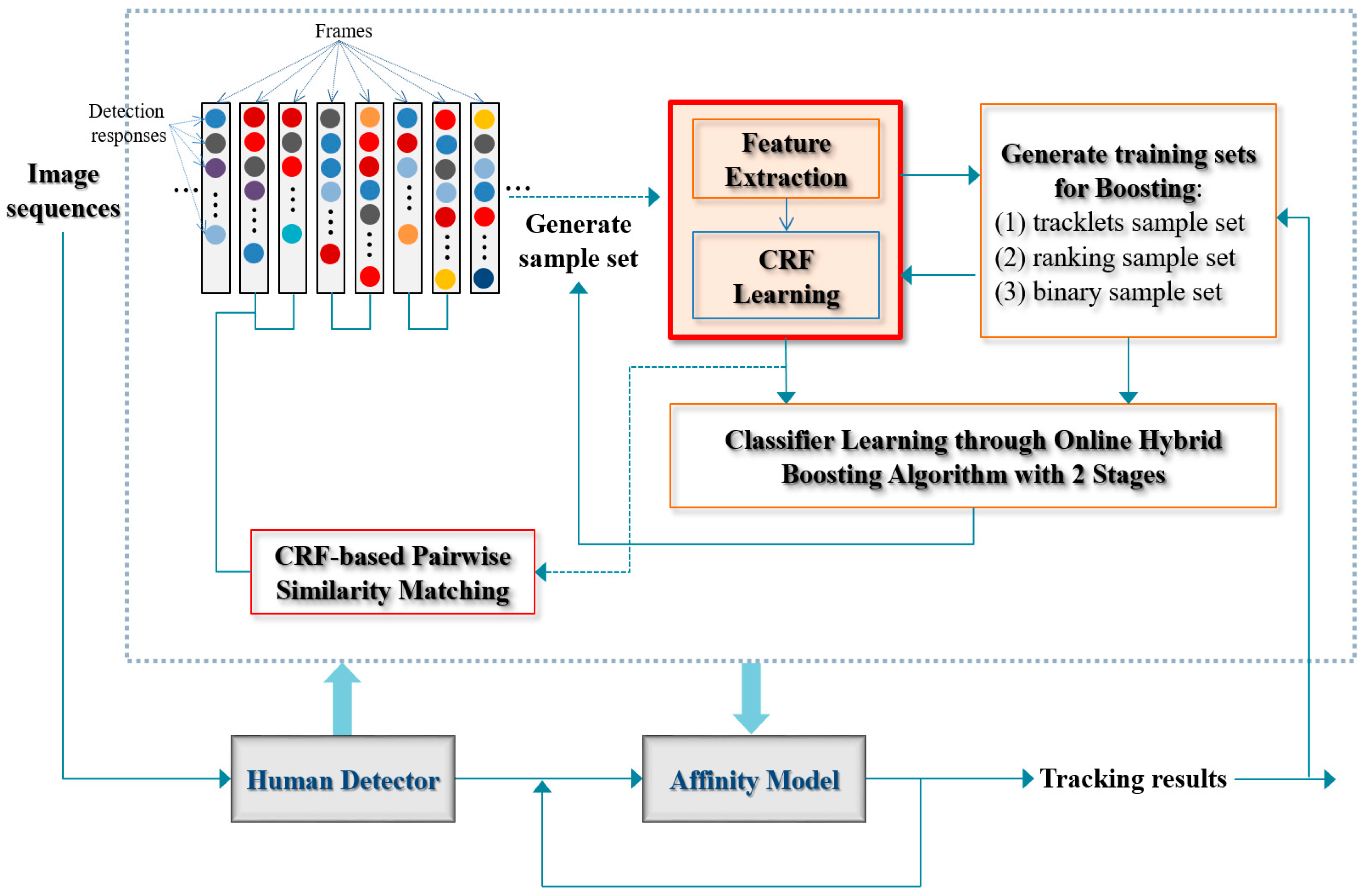
4. Proposed Approach: CRF-Boosting
4.1. Overall Procedure
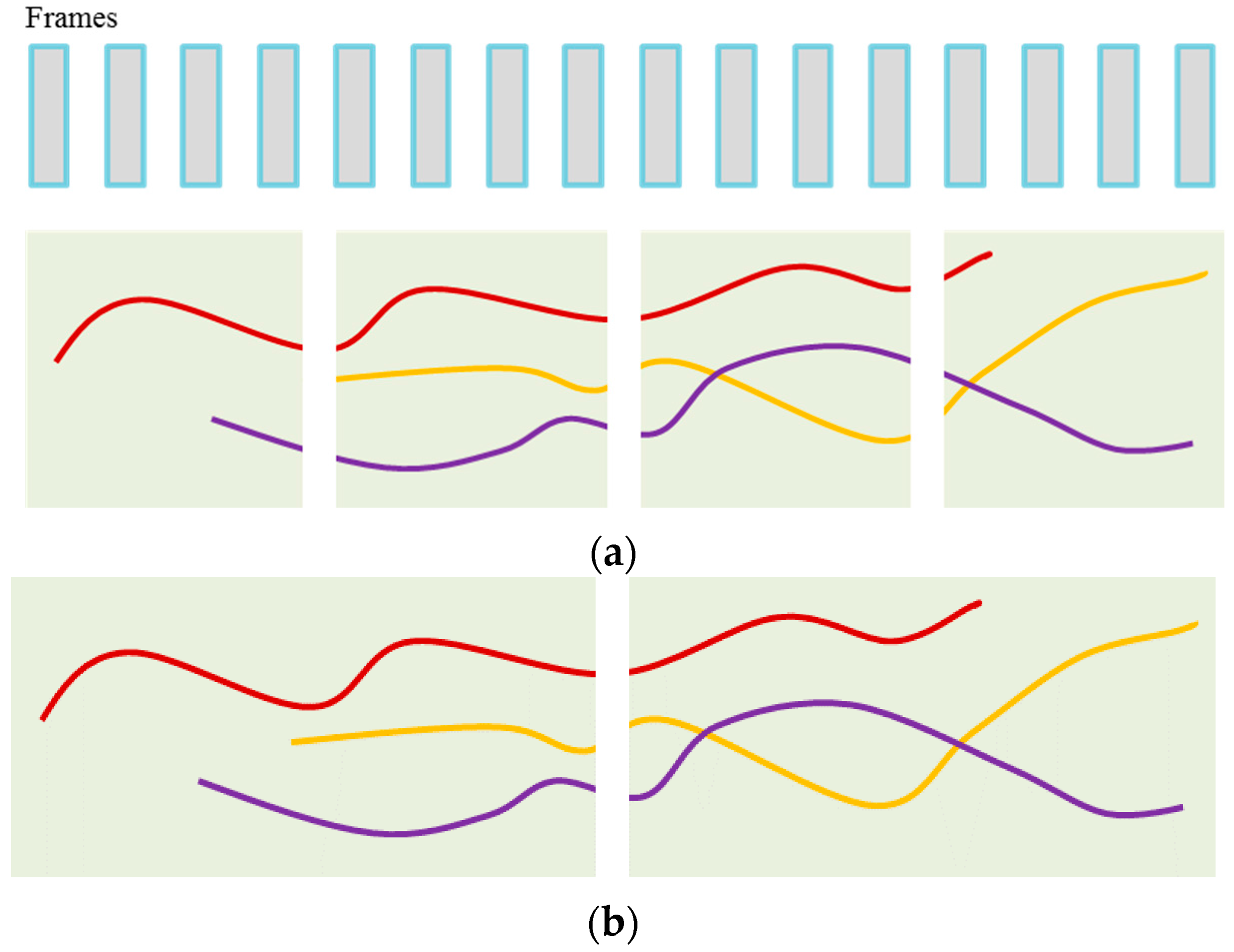
4.2. CRF Matching
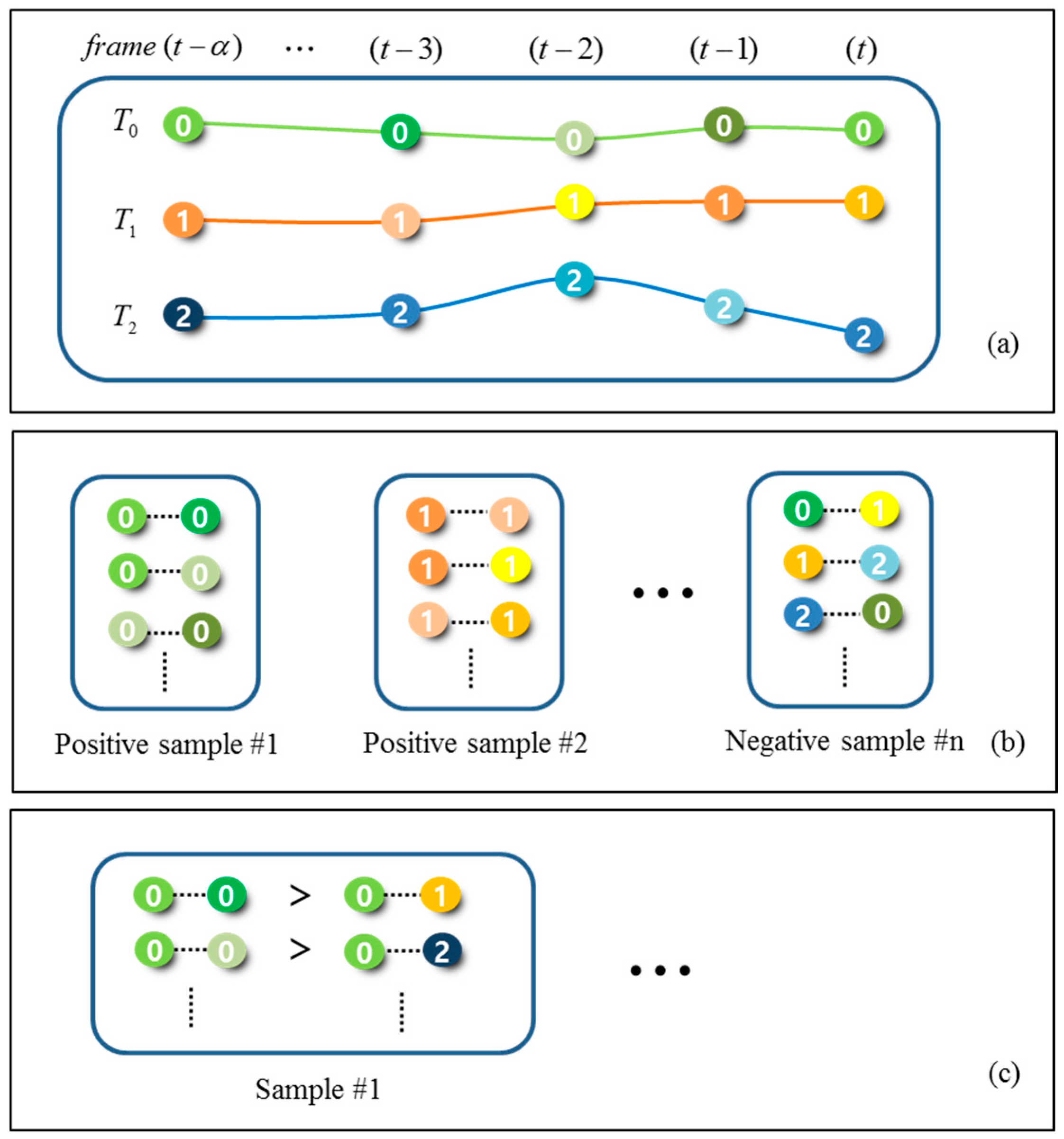
4.3. Composing Training Sets using CRF Matching Output
4.4. Hybrid Boosting
| Algorithm 1: Online Hybrid Boosting Algorithm |
 |
| Algorithm 2: CRF-Boosting Tracker with the Two-Stage Training Procedure |
 |
5. Experimental Results and Analysis
5.1. Evaulation Metrics
5.2. Experimental Results and Discussion
6. Conclusions and Future Research Agendas
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Fleuret, F.; Berclaz, J.; Lengagne, R.; Fua, P. Multicamera people tracking with a probabilistic occupancy map. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 267–282. [Google Scholar] [CrossRef] [PubMed]
- Berclaz, J.; Fleuret, F.; Turetken, E.; Fua, P. Multiple object tracking using k-shortest paths optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1806–1819. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005.
- Bourdev, L.; Maji, S.; Brox, T.; Malik, J. Detecting people using mutually consistent poselet activations. In Proceedings of the 11th European Conference on Computer vision, Crete, Greece, 5–11 September 2010.
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Fels, S.; Little, J.J. A linear programming approach for multiple object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007.
- Zhang, L.; Li, Y.; Nevatia, R. Global data association for multi object tracking using network flows. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008.
- Perera, A.G.A.; Srinivas, C.; Hoogs, A.; Brooksby, G.; Hu, W. Multi-object tracking through simultaneous long occlusions and spilt-merge condition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006.
- Yang, E.; Gwak, J.; Jeon, M. Multi-human tracking using part-based appearance modelling and grouping-based tracklet association for visual surveillance applications. Multimedia Tools Appl. 2016. [Google Scholar] [CrossRef]
- Milan, A.; Schindler, K.; Roth, S. Multi-target tracking by discrete-continuous energy minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2016. [Google Scholar] [CrossRef] [PubMed]
- Dehghan, A.; Assari, S.M.; Shah, M. GMMCP Tracker: Globally Optimal Generalized Maximum Multi Clique Problem for Multiple Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015.
- Milan, A.; Leal-Taixe, L.; Schindler, K.; Reid, I. Joint Tracking and Segmentation of Multiple Targets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015.
- Chari, V.; Lacoste-Julien, S.; Laptev, I.; Sivic, J. On Pairwise Costs for Network Flow Multi-Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015.
- Tang, S.; Andres, B.; Andriluka, M.; Schiele, B. Subgraph Decomposition for Multi-Target Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015.
- Dehghan, A.; Tian, Y.; Torr, P.H.S.; Shah, M. Target Identity-aware Network Flow for Online Multiple Target Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015.
- Xu, Y.; Liu, X.; Liu, Y.; Zhu, S. Multi-view People Tracking via Hierarchical Trajectory Composition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lasvegas, NV, USA, 27–30 June 2016.
- Yu, S.; Meng, D.; Zuo, W.; Hauptmann, A. The Solution Path Algorithm for Identity-Aware Multi-Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lasvegas, NV, USA, 27–30 June 2016.
- Milan, A.; Rezatofighi, S.H.; Dick, A.; Schindler, K.; Reid, I. Online Multi-target Tracking using Recurrent Neural Networks. IEEE Conf. Comput. Vis. Pattern Recognit. 2016. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to Track: Online Multi-Object Tracking by Decision Making. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 10–18 December 2015.
- Wen, L.; Lei, Z.; Lyu, S.; Li, S.Z.; Yang, M. Exploiting Hierarchical Dense Structures on Hypergraphs for Multi-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1983–1996. [Google Scholar] [CrossRef] [PubMed]
- Lafferty, J.; McCallum, A.; Pereira, F.C.N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001.
- Kuo, C.H.; Nevatia, R. How does person identity recognition help multi-person tracking? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011.
- Freund, Y.; Iyer, R.; Schapire, R.E.; Singer, Y. An efficient boosting algorithm for combining preferences. J. Mach. Learn. Res. 2003, 4, 933. [Google Scholar]
- Li, Y.; Huang, C.; Nevatia, R. Learning to Associate: Hybrid Boosted Multi-Target Tracker for Crowded Scene. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009.
- Milan, A.; Schindler, K.; Roth, S. Detection- and trajectory-level exclusion in multiple object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013.
- Poiesi, F.; Mazzon, R.; Cavallaro, A. Multi-target tracking on confidence maps: An application to people tracking. Comput. Vis. Image Underst. 2013, 117, 1257–1272. [Google Scholar] [CrossRef]
- Bae, S.; Yoon, K. Robust Online Multi-Object Tracking based on Tracklet Confidence and Online Discriminative Appearance Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014.
- Bak, S.; Chau, D.; Badie, J.; Corvee, E.; Bremond, F.; Thonnat, M. Multi-target tracking by Discriminative analysis on Riemannian Manifold. In Proceedings of the IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012.
- Ba, S.; Alameda-Pineda, X.; Xompero, A.; Horaud, R. An on-line variational Bayesian model for multi-person tracking from cluttered scenes. Comput. Vis. Image Underst. 2016, 153, 64–76. [Google Scholar] [CrossRef] [Green Version]
- Ukita, N.; Okada, A. High-order framewise smoothness-constrained globally-optimal tracking. Comput. Vis. Image Underst. 2016, 153, 130–142. [Google Scholar] [CrossRef]
- Milan, A.; Roth, S.; Schindler, K. Continuous energy minimization for multitarget tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 58–72. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.-K.; Stenger, B.; Kittler, J.; Cipolla, R. Incremental linear discriminant analysis using sufficient spanning sets and its applications. Int. J. Comput. Vis. 2011, 91, 216–232. [Google Scholar] [CrossRef]
- Yang, B.; Huang, C.; Nevatia, R. Learning Affinities and Dependencies for Multi-Target Tracking using a CRF Model. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 21–23 June 2011.
- Yang, M.; Lv, F.; Xu, W.; Gong, Y. Detection driven adaptive multi-cue integration for multiple human tracking. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009.
- Wu, B.; Nevatia, R. Detection and tracking of multiple, partially occluded humans by Bayesian combination of edgelet based part detectors. Int. J. Comput. Vis. 2007, 75, 247–266. [Google Scholar] [CrossRef]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503. [Google Scholar] [CrossRef]
- Kuo, C.-H.; Huang, C.; Nevatia, R. Multi-Target Tracking by On-Line Learned Discriminative Appearance Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010.
- Yang, B.; Nevatia, R. An Online Learned CRF Model for Multi-Target Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012.
- Huang, C.; Wu, B.; Nevatia, R. Robust object tracking by hierarchical association of detection responses. In Proceedings of the 10th European Conference on Computer vision, Marseille, France, 12–18 October 2008.
- Ramos, F.; Fox, D.; Durrant-Whyte, H. CRF-Matching: Conditional random fields for feature-based scan matching. In Proceedings of the Robotics Science and Systems, Atlanta, GA, USA, 27–30 June 2007.
- Sutton, C.; Mccallum, A. An Introduction to Conditional Random Fields for Relational Learning. In Introduction to Statistical Relational Learning; Getoor, L., Taskar, B., Eds.; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Besag, J. Statistical Analysis of Non-lattice Data. Statistician 1975, 24, 179. [Google Scholar] [CrossRef]
- Tuzel, O.; Porikli, F.; Meer, P. Region covariance: A fast descriptor for detection and classification. In Proceeding of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006.
- CAVIAR Test Case Scenarios. Available online: http://homepages.inf.ed.ac.uk/rbf/CAVIARDATA1/ (accessed on 15 August 2016).
- PETS 2009 Benchmark Data. Available online: http://www.cvg.rdg.ac.uk/PETS2009/a.html (accessed on 15 August 2016).
- ETH Data. Available online: https://data.vision.ee.ethz.ch/cvl/aess/dataset/ (accessed on 15 August 2016).
- Wu, B.; Nevatia, R. Tracking of multiple, partially occluded humans based on static body part detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006.
- Yang, B.; Nevatia, R. Multi-target tracking by online learning of non-linear motion patterns and robust appearance models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012.
- Kim, S.; Kwak, S.; Feyereusl, J.; Kim, B.H. Online Multi-Target Tracking by Large Margin Structured Learning. In Proceedings of the 11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012.
- Goto, Y.; Yamauchi, Y.; Fujiyoshi, H. CS-HOG: Color similarity-based hog. In Proceedings of the Korea–Japan Joint Workshop on Frontiers of Computer Vision, Incheon, Korea, 30 January–1 February 2013.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Idx | Description |
|---|---|
| 1: | Length of T1 (or T2) |
| 2: | Number of detection responses in T1 (or T2) |
| 3: | Number of detection response in T1 (or T2) divided by length of T1 (or T2) |
| 4: | distance between color histograms of the tail part of T1 and the head part of T2 |
| 5: | Appearance(color, texture) consistency of the object in the interpolated trajectory between T1 and T2 |
| 6: | Number of miss detected frames in the gap between T1 and T2 |
| 7: | Number of frames occluded by other tracklets in the frame gap between T1 and T2 |
| 8: | Number of miss detected frames in the gap divided by the frame gap between T1 and T2 |
| 9: | Number of frames occluded in the gap divided by the frame gap between T1 and T2 |
| 10: | Estimated time from T1’s head to the nearest entry point. |
| 11: | Estimated time from T2’s tail to the nearest exit point. |
| 12: | Motion smoothness in image plane if T1 and T2 are linked |
| 13: | Motion smoothness in ground plane if T1 and T2 are linked |
| Metric | Description |
|---|---|
| Ground Truth (GT) | Number of trajectories in the ground truth. |
| Recall (RC) | Number of correctly matched detections divided by the total number of detections in GT. |
| Mostly tracked trajectories (MT) | Percentage of trajectories that are successfully tracked for more than 80% divided by GT. |
| Partially tracked trajectories (PT) | Percentage of trajectories that are tracked between 20% and 80% divided by GT. |
| False alarm per frame (FAF) | Number of false alarms per frame |
| Mostly lost trajectories (ML) | Percentage of trajectories that are tracked for less than 20% divided by GT. |
| Fragments (FRG) | Total number of times that a trajectory in ground truth is interrupted by the tracking results. |
| ID switches (IDS) | Total number of times that a tracked trajectory changes its matched GT identity. |
| Method | RC | PRCS | FAF | GT | MT | PT | ML | FRG | IDS |
|---|---|---|---|---|---|---|---|---|---|
| Wu and Nevatia [47] | 75.2% | 0.281 | 140 | 75.7% | 17.9% | 6.4% | 35 | 17 | |
| Zhang et al. [7] | 76.4% | 0.105 | 140 | 85.7% | 10.7% | 3.6% | 20 | 15 | |
| Huang et al. [39] | 86.3% | 0.186 | 143 | 78.3% | 14.7% | 7.0% | 54 | 12 | |
| Li et al. [24] | 89.0% | 0.157 | 143 | 84.6% | 14.0% | 1.4% | 17 | 11 | |
| Kuo et al. [37] | 89.4% | 96.9% | 0.085 | 143 | 84.6% | 14.7% | 0.7% | 18 | 11 |
| Bak et al. [28] | - | - | - | 84.6% | 9.5% | 5.9% | - | - | |
| Yang et al. [48] | 90.2% | 96.1% | 0.095 | 143 | 89.1% | 10.2% | 0.7% | 11 | 5 |
| CRF-Boosting MOT | 93.1% | 98.5% | 0.099 | 143 | 86.7% | 12.1% | 1.2% | 17 | 10 |
| Method | RC | PRCS | FAF | GT | MT | PT | ML | FRG | IDS |
|---|---|---|---|---|---|---|---|---|---|
| Kuo et al. [22] | 89.5% | 99.6% | 0.020 | 19 | 78.9% | 21.1% | 0.0% | 23 | 1 |
| Yang et al. [48] | 91.8% | 99.0% | 0.053 | 19 | 89.5% | 10.5% | 0.0% | 9 | 0 |
| Chari et al. [13] | 92.4% | 94.3% | - | 19 | 94.7% | 5.3% | 0.0% | 74 | 56 |
| Ba et al. [29] | 90.2% | 87.6% | - | - | - | - | - | - | - |
| Milan et al. [31] | 92.4% | 98.4% | 23 | 91.3% | 4.3% | 4.4% | 6 | 11 | |
| Milan et al. [25] | 96.8% | 94.1% | - | 19 | 94.7% | 5.3% | 0.0% | 15 | 22 |
| Wen et al. [20] | 93.3% | 98.7% | 23 | 95.7% | 4.3% | 0.0% | 10 | 5 | |
| CRF-Boosting MOT | 91.1% | 99.2% | 0.031 | 19 | 89.9% | 10.1% | 0.0% | 10 | 0 |
| Method | RC | PRCS | FAF | GT | MT | PT | ML | FRG | IDS |
|---|---|---|---|---|---|---|---|---|---|
| Kuo et al. [22] | 76.8% | 86.6% | 0.891 | 125 | 58.4% | 33.6% | 8.0 % | 23 | 11 |
| Kim et al. [49] | 78.4% | 84.1% | 0.977 | 124 | 62.7% | 29.6% | 7.7% | 72 | 5 |
| Bo and Nevatia [38] | 79.0% | 90.4% | 0.637 | 125 | 68.0% | 24.8% | 7.2% | 19 | 11 |
| Milan et al. [25] | 77.3% | 87.2% | - | - | 66.4% | 25.4% | 8.2% | 69 | 57 |
| Poiesi et al. [26] | 78.7% | 85.5% | - | 125 | 62.4% | 29.6% | 8.0% | 69 | 45 |
| Bae and Yoon [27] | - | - | 126 | 73.81% | 23.81 | 2.38% | 38 | 18 | |
| Ukita and Okada [30] | - | - | - | 70.0% | 25.2% | 4.8% | 30 | 17 | |
| CRF-Boosting MOT | 79.1% | 92.8% | 0.805 | 125 | 81.3% | 17.2% | 1.5% | 11 | 2 |
| Method | RC | PRCS | FAF | GT | MT | PT | ML | FRG | IDS |
|---|---|---|---|---|---|---|---|---|---|
| CRF-Boosting MOT w/o Boosting | 87.3% | 94.6% | 0.203 | 143 | 80.3% | 14.7% | 5.0% | 45 | 14 |
| CRF-Boosting MOT w/o CRF-Matching | 88.0% | 95.0% | 0.157 | 143 | 84.2% | 13.6% | 2.2% | 17 | 11 |
| CRF-Boosting MOT | 93.1% | 98.5% | 0.099 | 143 | 86.7% | 12.1% | 1.2% | 17 | 10 |
| Method | Evaluation Speed | Conditions |
|---|---|---|
| Online Boosting-MOT [37] | Approx. 4 FPS | − Tested on CAVIAR dataset − Codes were implemented using Matlab |
| Online CRF-MOT [38] | Approx. 10 FPS | − Tested on ETH dataset − Codes were implemented using C++ |
| CRF-Boosting MOT w/o Boosting | 20.9 FPS | − Tested on CAVIAR dataset − Codes were implemented using C++ |
| CRF-Boosting MOT w/o CRF-Matching | 18.3 FPS | − Tested on CAVIAR dataset − Codes were implemented using C++ |
| CRF-Boosting MOT | 17.4 FPS | − Tested on CAVIAR dataset − Codes were implemented using C++ |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, E.; Gwak, J.; Jeon, M. Conditional Random Field (CRF)-Boosting: Constructing a Robust Online Hybrid Boosting Multiple Object Tracker Facilitated by CRF Learning. Sensors 2017, 17, 617. https://doi.org/10.3390/s17030617
Yang E, Gwak J, Jeon M. Conditional Random Field (CRF)-Boosting: Constructing a Robust Online Hybrid Boosting Multiple Object Tracker Facilitated by CRF Learning. Sensors. 2017; 17(3):617. https://doi.org/10.3390/s17030617
Chicago/Turabian StyleYang, Ehwa, Jeonghwan Gwak, and Moongu Jeon. 2017. "Conditional Random Field (CRF)-Boosting: Constructing a Robust Online Hybrid Boosting Multiple Object Tracker Facilitated by CRF Learning" Sensors 17, no. 3: 617. https://doi.org/10.3390/s17030617
APA StyleYang, E., Gwak, J., & Jeon, M. (2017). Conditional Random Field (CRF)-Boosting: Constructing a Robust Online Hybrid Boosting Multiple Object Tracker Facilitated by CRF Learning. Sensors, 17(3), 617. https://doi.org/10.3390/s17030617