
Estimation of Image Sensor Fill Factor Using a Single Arbitrary Image


Abstract
:1. Introduction
2. Image Acquisition and Processing Pipelines
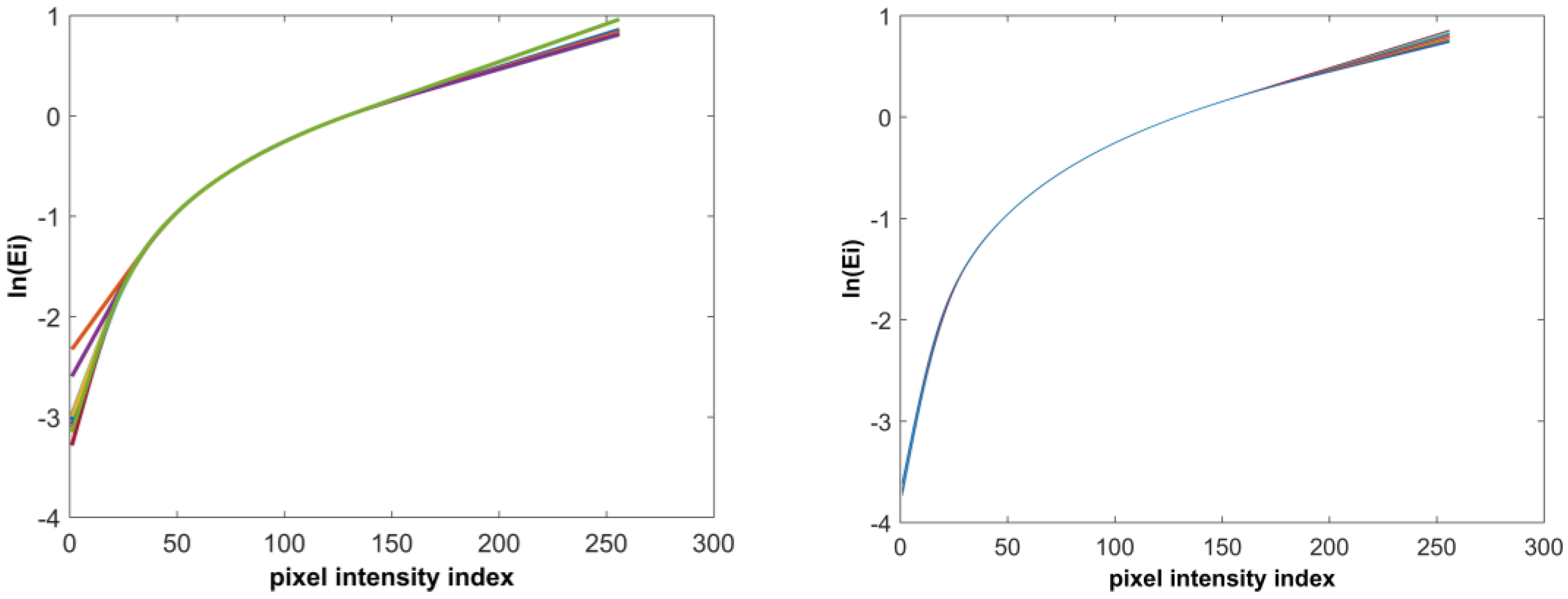
3. Camera Response Function vs. Virtual Camera Response Function
4. Relation of Fill Factor to the Virtual Camera Respond Function
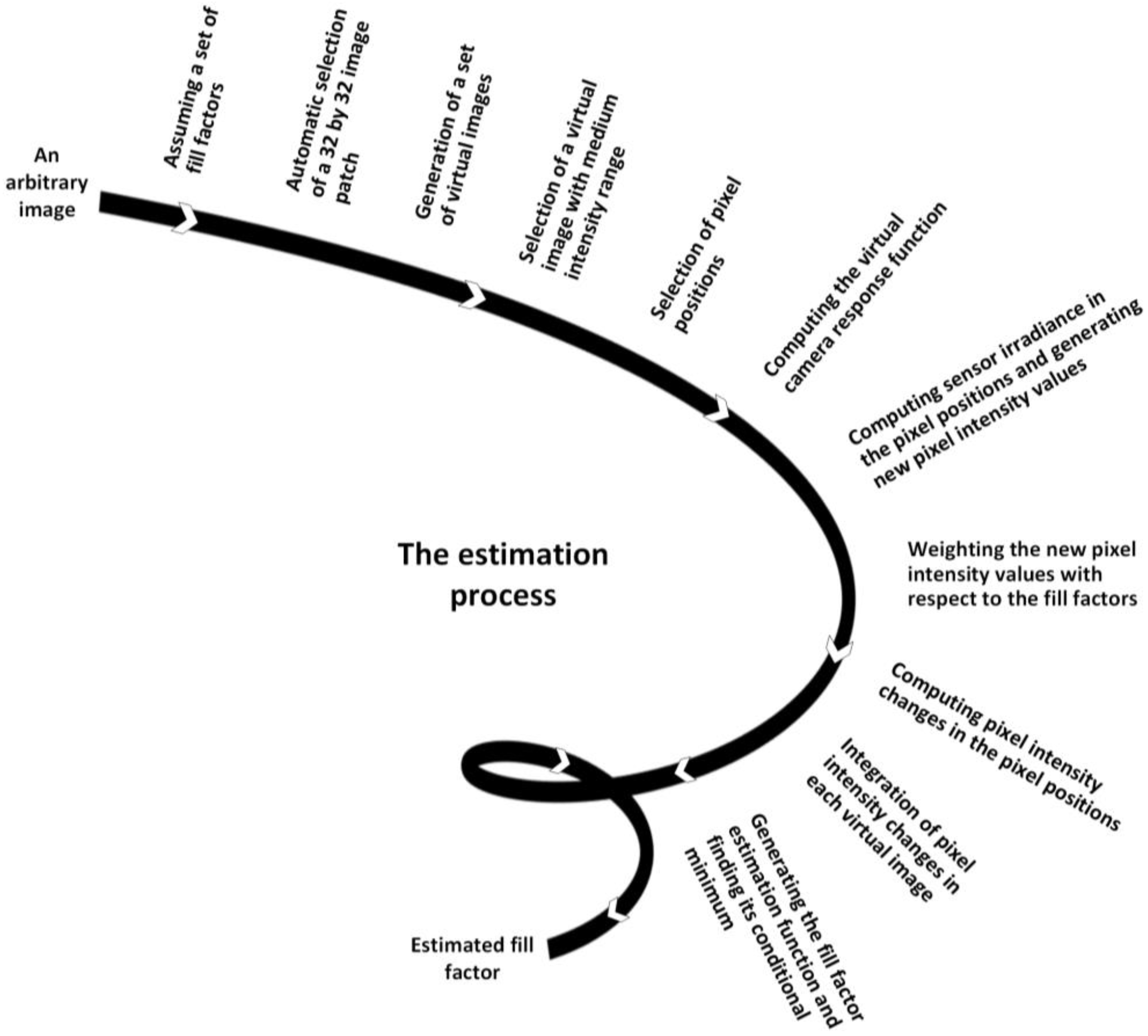
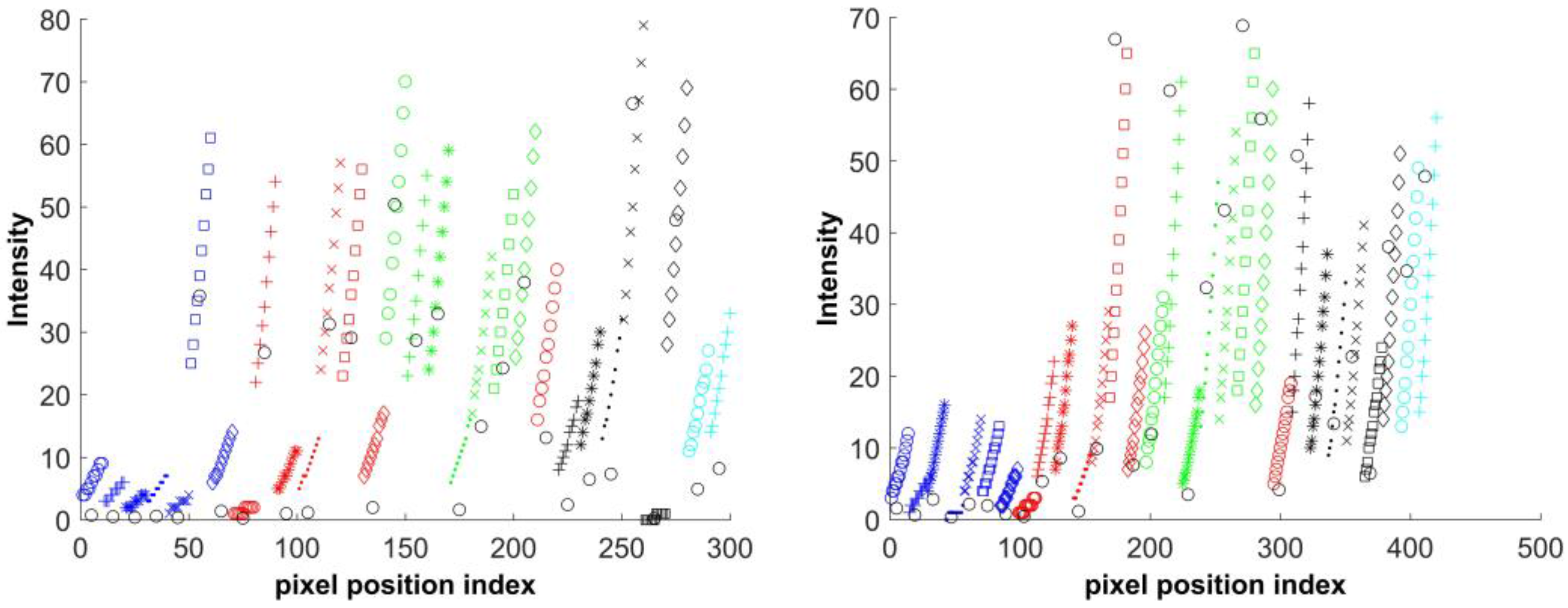
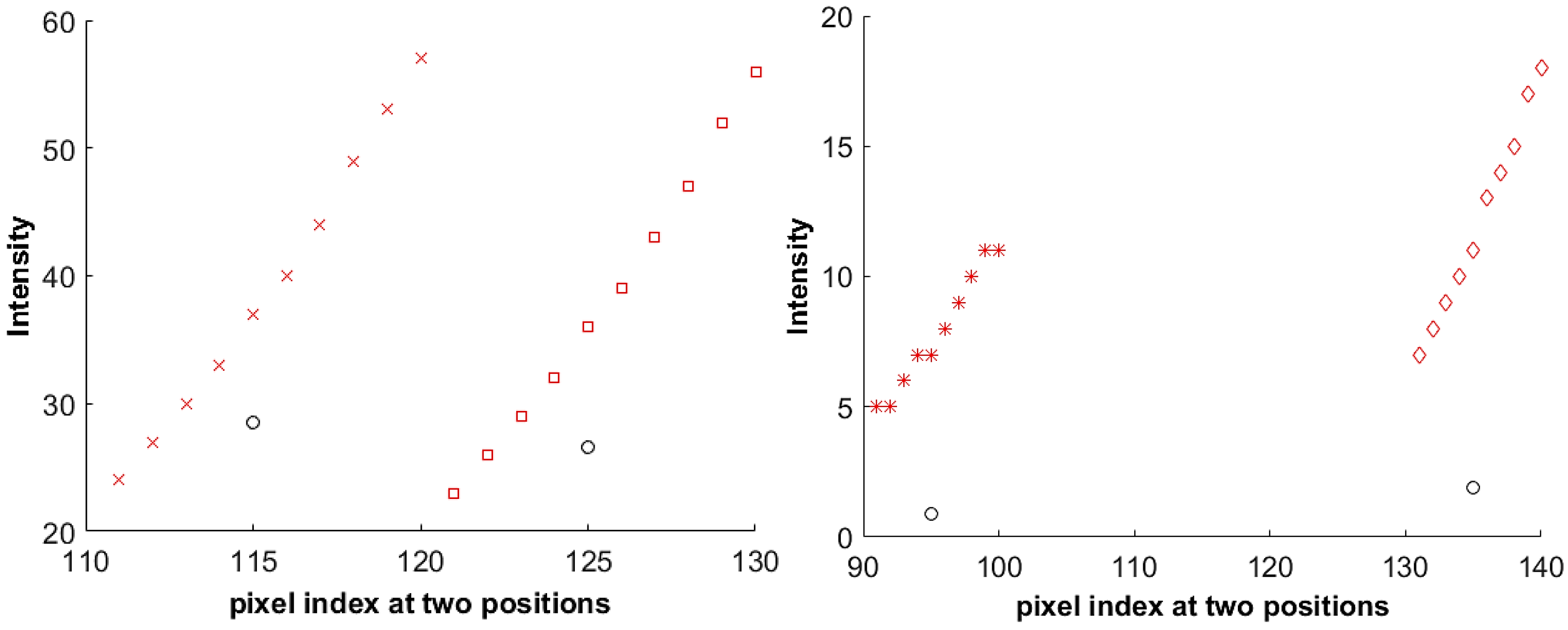
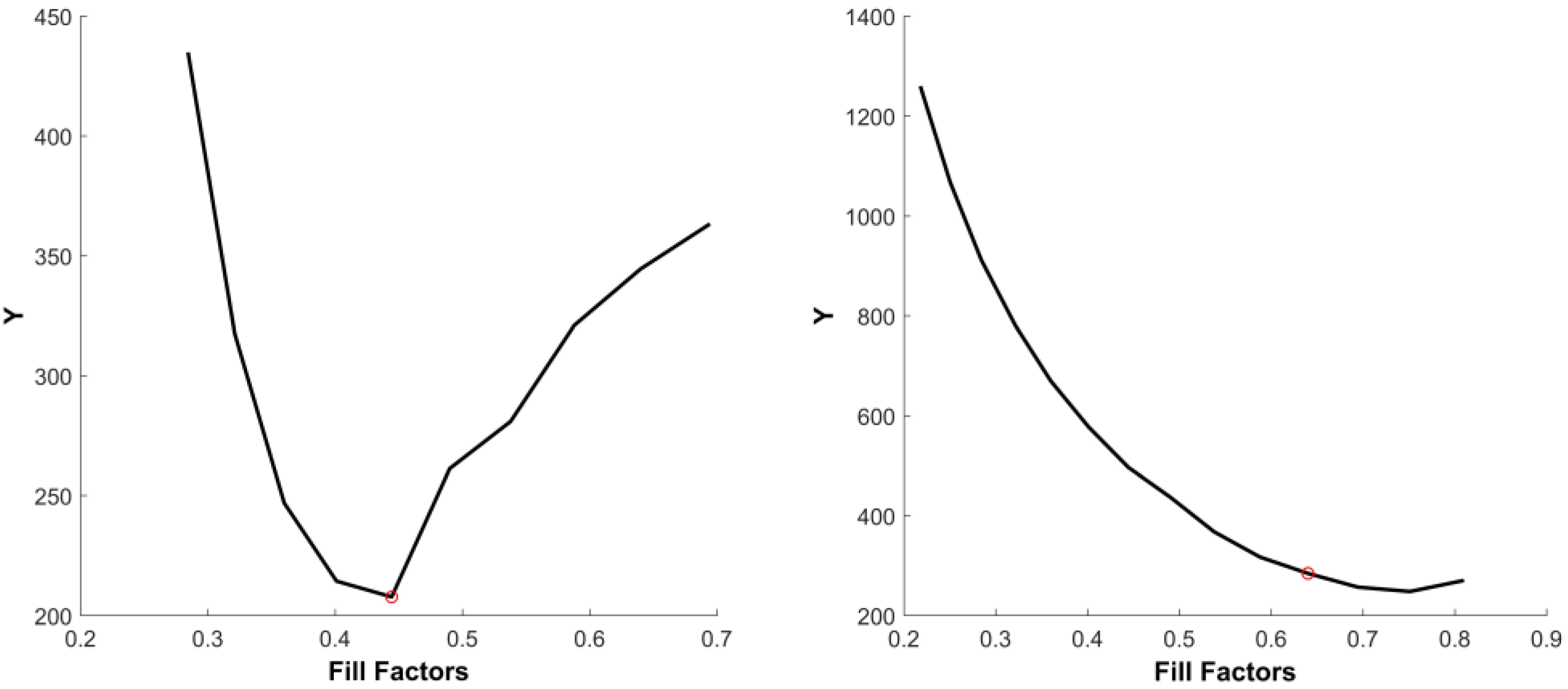
5. Fill Factor Estimation
- (a)
- A grid of virtual image sensor pixels is designed. Each pixel is divided into 30 × 30 subpixels. According to the hypothetical fill factor , the size of the active area is A by A, where . The intensity value of every pixel in the original image is assigned to the virtual active area in the new grid. The intensities of subpixels in the non-sensitive areas are assigned to be zero.
- (b)
- The second step is to estimate the values of the subpixels in the new grid of subpixels. Considering the statistical fluctuation of the incoming photons and their conversion to electrons on the sensor, a statistical model is necessary for estimating the original signal. Bayesian inference is used for estimating every subpixel intensity which is considered to be in the new position of resampling. Therefore, the more subpixels that are used to represent one pixel, the more accurate the resampling is. By introducing the Gaussian noise into a matrix of selected pixels, and estimating the intensity values of the subpixels at the non-sensitive area with different sizes of active area by local modeling, a vector of intensity values for each subpixel is created. Then each subpixel intensity is estimated by the maximum likelihood.
- (c)
- In the third step, the subpixels are projected back to the original grid. To obtain the intensity value of the pixels in the original grid, the intensity value of a pixel in the new grid is the intensity value which has the strongest contribution in the histogram of belonging subpixels. The corresponding intensity is divided by the fill factor for removing the fill factor effect to obtain the pixel intensity.
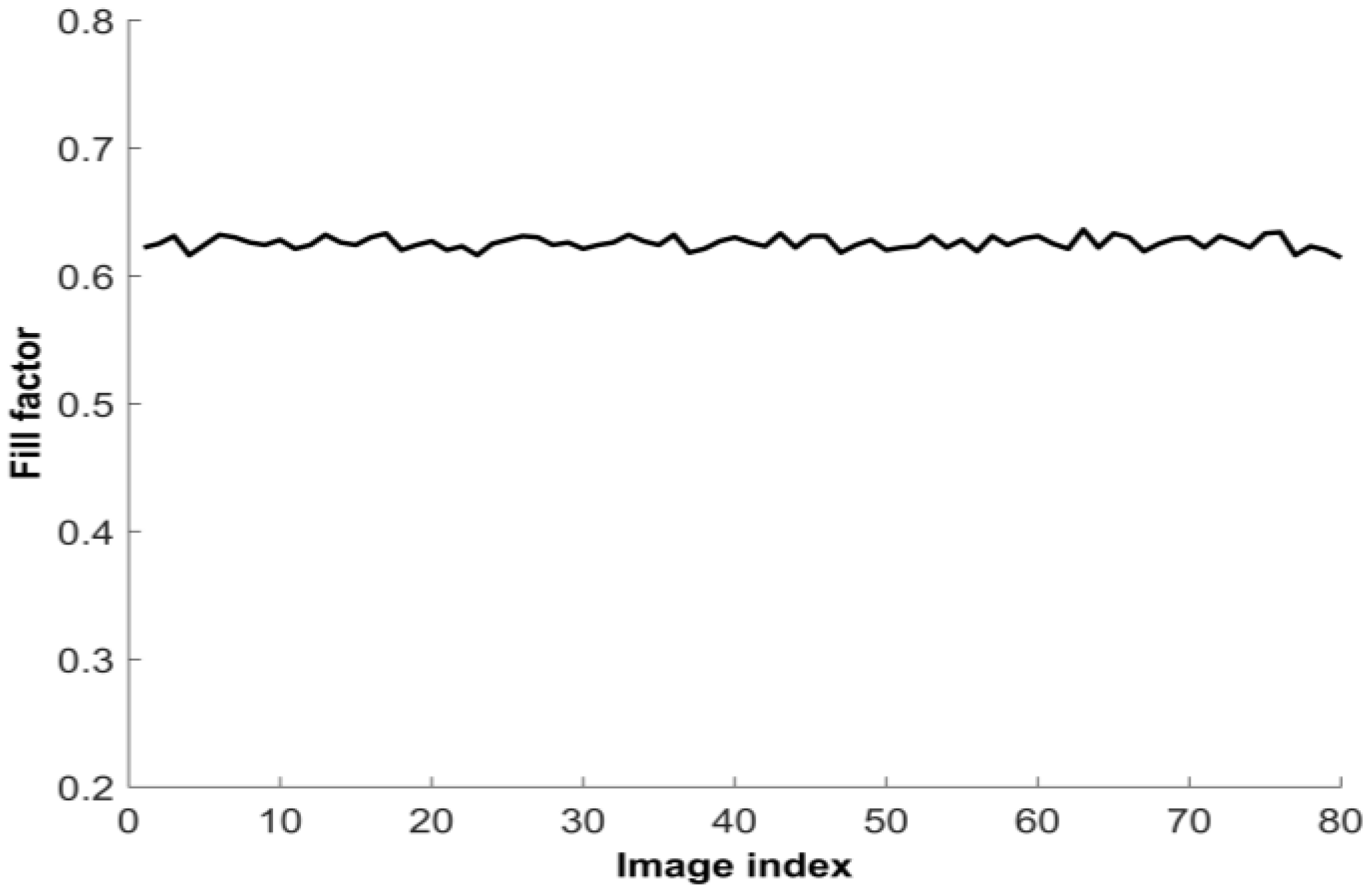
6. Experimental Setup
7. Results and Discussion
8. Conclusions
Author Contributions
Conflicts of Interest
References
- Prakel, D. The Visual Dictionary of Photography; Ava Publishing: Worthing, UK, 2009. [Google Scholar]
- Goldstein, D.B. Physical Limits in Digital Photography. Available online: http://cdn.northlight-images.co.uk/downloadable_2/Physical_Limits_2.pdf (accessed on 6 April 2016).
- Curcio, C.A.; Sloan, K.R.; Kalina, R.E.; Hendrickson, A.E. Human photoreceptor topography. J. Comp. Neurol. 1990, 292, 497–523. [Google Scholar] [CrossRef] [PubMed]
- Rossi, E.A.; Roorda, A. The relationship between visual resolution and cone spacing in the human fovea. Nat. Neurosci. 2010, 13, 156–157. [Google Scholar] [CrossRef] [PubMed]
- Farrell, J.; Xiao, F.; Kavusi, S. Resolution and light sensitivity tradeoff with pixel size. In Electronic Imaging 2006; SPIE: San Jose, CA, USA, 2006; Vol. 60690N; pp. 211–218. [Google Scholar]
- Deguchi, M.; Maruyama, T.; Yamasaki, F.; Hamamoto, T.; Izumi, A. Microlens design using simulation program for CCD image sensor. IEEE Trans. Consum. Electron. 1992, 38, 583–589. [Google Scholar] [CrossRef]
- Donati, S.; Martini, G.; Norgia, M. Microconcentrators to recover fill-factor in image photodetectors with pixel on-board processing circuits. Opt. Express 2007, 15, 18066–18075. [Google Scholar] [CrossRef] [PubMed]
- Reinhard, E.; Heidrich, W.; Debevec, P.; Pattanaik, S.; Ward, G.; Myszkowski, K. High Dynamic Range Imaging: Acquisition, Display, and Image-Based Lighting; Morgan Kaufmann: Burlington, MA, USA, 2010. [Google Scholar]
- Nakamura, J. Image Sensors and Signal Processing for Digital Still Cameras; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Zhou, J. Getting the Most out of Your Image-Processing Pipeline; White Paper; Texas Instruments: Dallas, TX, USA, 2007. [Google Scholar]
- Ramanath, R.; Snyder, W.E.; Yoo, Y.; Drew, M.S. Color image processing pipeline. IEEE Signal Process. Mag. 2005, 22, 34–43. [Google Scholar] [CrossRef]
- Kao, W.-C.; Wang, S.-H.; Chen, L.-Y.; Lin, S.-Y. Design considerations of color image processing pipeline for digital cameras. IEEE Trans. Consum. Electron. 2006, 52, 1144–1152. [Google Scholar] [CrossRef]
- Heckaman, R.L.; Fairchild, M.D. Jones and Condit redux in high dynamic range and color. In Color and Imaging Conference; Society for Imaging Science and Technology: Albuquerque, NM, USA, 2009; Volume 2009, pp. 8–14. [Google Scholar]
- Wen, W.; Khatibi, S. Novel Software-Based Method to Widen Dynamic Range of CCD Sensor Images. In Proceedings of the International Conference on Image and Graphics, Tianjin, China, 13–16 August 2015; pp. 572–583.
- Chen, M.; Fridrich, J.; Goljan, M.; Lukas, J. Determining Image Origin and Integrity Using Sensor Noise. IEEE Trans. Inf. Forensics Secur. 2008, 3, 74–90. [Google Scholar] [CrossRef]
- Yeganeh, H.; Wang, Z. High dynamic range image tone mapping by maximizing a structural fidelity measure. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 1879–1883.
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Mann, S.; Picard, R. On Being “Undigital” With Digital Cameras: Extending dynamic Range by Combining Differently Exposed Pictures. Available online: http://citeseer.ist.psu.edu/viewdoc/download;jsessionid=7326D46CCCDEC6BAE898CBA7A6849222?doi=10.1.1.21.3141&rep=rep1&type=pdf (accessed on 6 April 2016).
- Wen, W.; Khatibi, S. A software method to extend tonal levels and widen tonal range of CCD sensor images. In Proceedings of the 2015 9th International Conference on Signal Processing and Communication Systems (ICSPCS), Cairns, Australia, 14–16 December 2015; pp. 1–6.
- Feierabend, M.; Rückel, M.; Denk, W. Coherence-gated wave-front sensing in strongly scattering samples. Opt. Lett. 2004, 29, 2255–2257. [Google Scholar] [CrossRef] [PubMed]
- Horn, B. Robot Vision; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Jähne, B. EMVA 1288 Standard for Machine Vision. Opt. Photonik 2010, 5, 53–54. [Google Scholar] [CrossRef]
- Goesele, M.; Heidrich, W.; Seidel, H.-P. Entropy-Based Dark Frame Subtraction. Available online: http://ultra.sdk.free.fr/docs/Astrophotography/articles/Entropy-Based%20Dark%20Frame%20Subtraction.pdf (accessed on 6 April 2016).
- Viggiano, J.S. Comparison of the accuracy of different white-balancing options as quantified by their color constancy. In Electronic Imaging 2004; SPIE: San Jose, CA, USA, 2004; pp. 323–333. [Google Scholar]
- Reinhard, E.; Stark, M.; Shirley, P.; Ferwerda, J. Photographic tone reproduction for digital images. ACM Trans. Graph. 2002, 21, 267–276. [Google Scholar] [CrossRef]
- Maini, R.; Aggarwal, H. A comprehensive review of image enhancement techniques. J. Comput. 2010, 2, 8–13. [Google Scholar]
- HTTP Archive–Interesting Stats. Available online: httparchive.org/interesting.php#imageformats (accessed on 6 April 2016).
- Chang, Y.-C.; Reid, J.F. RGB calibration for color image analysis in machine vision. IEEE Trans. Image Process. 1996, 5, 1414–1422. [Google Scholar] [CrossRef] [PubMed]
- Mitsunaga, T.; Nayar, S.K. Radiometric self calibration. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999.
- Grossberg, M.D.; Nayar, S.K. Determining the camera response from images: What is knowable? IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1455–1467. [Google Scholar] [CrossRef]
- Lin, S.; Gu, J.; Yamazaki, S.; Shum, H.-Y. Radiometric calibration from a single image. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. 938–945.
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In ACM SIGGRAPH 2008 Classes; ACM Inc.: Los Angeles, CA, USA, 2008; p. 31. [Google Scholar]
- Nene, S.A.; Nayar, S.K.; Murase, H. Columbia Object Image Library (COIL-20). Available online: https://pdfs.semanticscholar.org/ca68/91667e2cf6c950c3c8f8ea93e55320173505.pdf (accessed on 6 April 2016).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | No. 1 | No. 2 | No. 3 | No. 4 | No. 5 | No. 6 | No. 7 | No. 8 | No. 9 | No. 10 | Total | Percent |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FF 40% | 5 | 8 | 10 | 9 | 12 | 11 | 7 | 8 | 15 | 4 | 88 | 29% |
| FF 44% | 25 | 22 | 20 | 21 | 18 | 19 | 23 | 22 | 15 | 26 | 212 | 71% |
| Final | 43% | 43% | 43% | 43% | 42% | 42% | 43% | 43% | 42% | 43% | 43% |
| Images | No. 1 | No. 2 | No. 3 | No. 4 | No. 5 | No. 6 | No. 7 | No. 8 | No. 9 | No. 10 | Total | Percent |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FF 59% | 13 | 11 | 8 | 15 | 10 | 5 | 6 | 18 | 11 | 13 | 110 | 37% |
| FF 64% | 17 | 19 | 22 | 15 | 20 | 25 | 24 | 12 | 19 | 17 | 190 | 63% |
| Final | 62% | 62% | 63% | 62% | 62% | 63% | 63% | 61% | 62% | 62% | 62% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, W.; Khatibi, S. Estimation of Image Sensor Fill Factor Using a Single Arbitrary Image. Sensors 2017, 17, 620. https://doi.org/10.3390/s17030620
Wen W, Khatibi S. Estimation of Image Sensor Fill Factor Using a Single Arbitrary Image. Sensors. 2017; 17(3):620. https://doi.org/10.3390/s17030620
Chicago/Turabian StyleWen, Wei, and Siamak Khatibi. 2017. "Estimation of Image Sensor Fill Factor Using a Single Arbitrary Image" Sensors 17, no. 3: 620. https://doi.org/10.3390/s17030620
APA StyleWen, W., & Khatibi, S. (2017). Estimation of Image Sensor Fill Factor Using a Single Arbitrary Image. Sensors, 17(3), 620. https://doi.org/10.3390/s17030620