All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
College of Electronic and Information Engineering, School of Mathematics and Statistics, Southwest University, and Key Laboratory of Nonlinear Circuits and Intelligent Information Processing, Chongqing 400715, China
2
College of Electronic and Information Engineering, Southwest University, Chongqing 400715, China
*
Author to whom correspondence should be addressed.
†
Current address: Key Laboratory of Nonlinear Circuits and Intelligent Information Processing, No.2, Tiansheng Road, Beibei District, Chongqing 400715, China
In wireless sensor networks (WSNs), each sensor node can estimate the global parameter from the local data in a distributed manner. This paper proposed a robust diffusion estimation algorithm based on a minimum error entropy criterion with a self-adjusting step-size, which are referred to as the diffusion MEE-SAS (DMEE-SAS) algorithm. The DMEE-SAS algorithm has a fast speed of convergence and is robust against non-Gaussian noise in the measurements. The detailed performance analysis of the DMEE-SAS algorithm is performed. By combining the DMEE-SAS algorithm with the diffusion minimum error entropy (DMEE) algorithm, an Improving DMEE-SAS algorithm is proposed for a non-stationary environment where tracking is very important. The Improving DMEE-SAS algorithm can avoid insensitivity of the DMEE-SAS algorithm due to the small effective step-size near the optimal estimator and obtain a fast convergence speed. Numerical simulations are given to verify the effectiveness and advantages of these proposed algorithms.
The problem of parameter estimation, which is the indirect determination of the unknown parameters from measurements of other quantities [1,2,3,4,5,6], is a key issue in the signal processing field. Distributed estimation has become very popular for parameter estimation in wireless sensor networks. The objective is to enable the nodes to estimate a vector of parameters of interest in a distributed manner from the observed data. Distributed estimation schemes over adaptive networks can be mainly classified into incremental strategies [7,8,9], consensus strategies [10,11], and diffusion strategies [12,13,14,15,16,17,18,19,20,21,22]. In the incremental strategies, data is processed in a cyclic fashion through the network. The consensus strategies rely on the fusion of intermediate estimates of multiple neighboring nodes. In the Diffusion strategies, information is processed at all nodes while the nodes communicate with all their neighbors to share their intermediate estimates. The diffusion strategies are particularly attractive because they are robust, flexible and fully-distributed, such as the diffusion least mean squares (DLMS) algorithm [12]. In this paper, we focus on the diffusion estimation strategies.
The performance of distributed estimation degrades severely when the signals are perturbed by non-Gaussian noise. Non-Gaussian noise may be natural, due to atmospheric phenomena, or man-made, due to either electric machinery present in the operation environment, or multipath telecommunications signals [23,24,25]. Recently, some researchers focus on improving robustness for non-Gaussian noise of distributed estimation methods. The efforts are mainly directed at searching for a more robust cost function to replace the MSE criterion, which is optimal only when the measurement noise is Gaussian. To address this problem, the diffusion least mean p-power (DLMP) based on p-norm error criterion was proposed to estimate the parameters of the wireless sensor networks [26]. The correntropy as a nonlinear similarity measure has been successfully used as a robust and efficient cost function for non-Gaussian signal processing [27,28,29,30]. In [27], two robust MCC based diffusion algorithms, namely the Adapt-then-Combine (ATC) and Combine-then-Adapt (CTA) diffusion maximum correntropy criterion (DMCC) algorithms, are developed to improve the performance of the distributed estimation over network in impulsive noise environments.
The error entropy criterion based on the minimum error entropy (MEE) method also has shown its ability to achieve more accurate estimates than mean-square error (MSE) under non-Gaussian noise [31,32,33,34,35,36,37]. In [31], the diffusion minimum error entropy (DMEE) was proposed. The DMEE algorithm achieved improved performance for non-Gaussian noise with the fixed step-size, but it still suffers from conflicting requirements between convergence rate and the steady-state mean square error. A large step-size leads to a fast convergence rate but a large mean-square error at the steady state. For this problem, variable step-size techniques have been widely used to improve the convergence of diffusion LMS algorithms remarkably by adjusting the step-size appropriately [38,39,40,41]. Lee et al. [38] proposed a novel variable step-size diffusion LMS algorithm which controls the step-size suboptimally to attain the minimum mean square error at each time instant. In [41], Abdolee investigated the effect of adaptation step-sizes on the tracking performance of DLMS algorithms in networks under non-stationary signal conditions. However, to the best of our knowledge, the variable step-size technique has not been extended to the field of distributed minimum error entropy estimation for non-Gaussian noise yet.
In this paper, we incorporate the minimum error entropy criterion with self-adjusting step-size (MEE-SAS) [42] into the cost function in diffusion distributed estimation. Then, we figure out the diffusion-strategy solutions, which are referred to as the diffusion MEE-SAS (DMEE-SAS) algorithm. Numerical simulation results show that the DMEE-SAS algorithm outperforms DLMS, DLMP and DMEE algorithms when the noise is modeled to be non-Gaussian noise. We also design an Improving DMEE-SAS algorithm by using a switching scheme between DMEE-SAS and DMEE algorithms for a non-stationary environment, which tracks the changing estimator very effectively. The Improving DMEE-SAS algorithm can avoid the small effective step-size of the DMEE-SAS algorithm when it is close to the optimal estimator.
We organize the paper as follows. In Section 2, we briefly revisit the minimization error entropy criterion. In Section 3, firstly, we propose the DMEE-SAS algorithm and analyze the mean, mean square and instantaneous MSD performance for the DMEE-SAS algorithm. Then, we propose the Improving DMEE-SAS algorithm for a non-stationary scenario. Simulation results are shown in Section 4. Finally, we draw conclusions in Section 5.
2. Minimization Error Entropy Criterion
Considering the limited computational capability and limited memory space for nodes in real distributed networks, this paper is based on an MEE criterion, which is simple enough and has good estimation accuracy. Important properties of MEE can be found in [32,35,37]. In many real world applications, the MEE estimator can outperform significantly the well-known MSE estimator and show strong robustness to noises, especially when data are contaminated by non-Gaussian noises. In this subsection, we introduce an MEE criterion, which could be used to derive a robust diffusion estimation algorithm with a self-adjusting step-size (DMEE-SAS) algorithm.
The aim of the adaptive signal processing problem is to minimize the difference between the desired and the system outputs, which is defined as error e. For the evaluation of the error entropy, we seek to estimate entropy directly from the error samples. Therefore, system parameters can be estimated by minimizing the Renyi’s entropy of the error e. Renyi’s entropy is given by
where is the probability density function of a continuous error e, and is a parameter. When parameter is set as 2, Equation (1) is quadratic Renyi’s entropy. Using a Gaussian kernel with kernel size , we can obtain a convenient evaluation of the integral operator in the formulation of quadratic Renyi’s entropy as follows:
where is N independent and identically distributed samples, and the Gaussian kernel is defined as
The information is quadratic information potential and is defined as the expectation of probability density function, . The quadratic information potential can be easily estimated by using a simple and effective nonparametric estimator
The maximum value of the quadratic information potential will be achieved when . The above results are obtained in the case of batch mode, where the N data points are fixed. For online training methods, in order to reduce calculation costs, the estimate of quadratic information potential can be approximated stochastically by dropping the time average in (3), leading to
where L is the latest L samples at time i.
Obviously, to minimize the error entropy is equivalent to maximizing the quadratic information potential since the log is a monotonic function. Therefore, the cost function for the MEE criterion is given by
The selection of the kernel size is an important step in estimating the information potential and is critical to the success of information theoretic criteria. In particular, increasing the kernel size leads to a stretching effect on the performance surface in the weight space, which results in increased accuracy of the quadratic approximation around the optimal point [43]. In order to ensure accuracy, in the following, a large enough kernel size can be used during the adaptation process, which is commonly used in information theoretic criteria [42,44].
3. Proposed Algorithms
As mentioned in the Introduction, the diffusion minimum error entropy algorithm achieved improved performance for non-Gaussian noise with the fixed step-size, but it still suffers from conflicting requirements between convergence rate and the steady-state mean square error. Therefore, we consider a new cost function, which can achieve fast convergence speed and strong robustness against non-Gaussian noise.
3.1. Diffusion MEE-SAS Algorithm
Consider a connected wireless sensor networks with K nodes. is the node index and i is the time index. To proceed with the analysis, we assume a liner measurement model as follows:
where is a deterministic but unknown vector, is a scalar measurement of some random process, is the regression vector at time i with zero mean, and is the random noise signal at time i with zero mean. For each node k, we have
where . The maximum value will be achieved when .
We seek an estimate of by minimizing a linear combination of local information. As explained in Section 2, minimizing a linear combination of the local information is equivalent to maximizing a linear combination of the local quadratic information potential . To maximize the information potential is equivalent to minimizing the following cost function:
where
denotes the one-hop neighbor set of node k, and are some non-negative cooperative coefficients satisfying if , and . Here, is a matrix with individual entries and is a all-unity vector. The gradient of the individual local cost function is given by
where
We can replace the estimate of quadratic information potential by the stochastic quadratic information potential, leading to
where
where
Iterative steepest-descent solution for estimating at each node k can thus be derived as
where is a positive step size. Using the general framework for diffusion-based distributed adaptive optimization [13], an adapt-then-combine (ATC) strategy for diffusion MEE-SAS algorithm can be formulated as
According to Equation (15), the DMEE-SAS algorithm can be seen as a diffusion estimation algorithm with variable step size , where
The DMEE-SAS algorithm is described formally in Algorithm 1.
Algorithm 1: DMEE-SAS Algorithm
Initialize:
for
for each nodek:
Adaptation
Combination
end for
In the adaption step of DMEE-SAS algorithm, is close to when the algorithm starts, and it is close to 0 when the algorithm begins to converge. is always a non-negative scalar quantity, which can accelerate the rate of convergence and achieve small steady-state estimation errors. The fast convergence rate and the small steady-state estimation errors of the DMEE-SAS algorithm can be established against non-Gaussian noise in the measurements.
3.2. Performance Analysis
In this section, we analyze the mean, mean-square and instantaneous MSD performance of the DMEE-SAS algorithm. For tractability of the analysis, here we focus on the case of batch mode. To briefly present the convergence property of the proposed algorithm in terms of global quantities, the following notations are introduced: , , , , , , is the identity matrix.
In order to make the analysis tractable, the followings are assumed:
Assumption 1: The regressor is independent identically distributed (i.i.d) in time and spatially independent, and , .
Assumption 2: The input noise is super-Gaussian noise. In addition, and the regressor are independent from each other. We have and .
Assumption 3: The step-sizes, , , are small enough such that their squared values are negligible.
3.2.1. Mean Performance
Because the input signal and output noises are generated from stationary and ergodic processes, the double time average in Equation (10) can be replaced by the expectation, leading to
We consider the gradient error caused by approximating the quadratic information potential with their instantaneous values [45]. The gradient error at iteration i and each node k is defined as follows:
Using Equation (15), the update equation of the intermediate estimate can be rewritten as
According to [44], when input signal-to-noise ratio is not too low, the error should be small on the whole. Therefore, for a relative large kernal size , when , ( and . Therefore, the Hessian matrix function of is calculated as:
where is the weight error vector for node k. We assume that the estimate of each node converges to the vicinity of the unknown vector . Therefore, is small enough such that it is negligible, yielding
We can also obtain the approximation of the gradient error at the vicinity of , which is given by
Substituting Equations (22) and (23) into Equation (19), an approximation of intermediate estimate can be obtained at the vicinity of
By substituting Equation (24) into the second equation of Equation (15), we get the estimate of unknown parameter as follows:
Using global quantities defined above gives the update equation for the network estimate vector as
where H collects the Hessian matrix across the network into the global vector . Noting that , subtraction of both sides of Equation (26) from gives
In view of assumptions A1 and A2, , H and C are independent of each other. Hence, taking expectation of both sides of Equation (27) leads to
We can easily find that , and Equation (28) has therefore been reduced to this form
From Equation (29), we observe that, in order to be stable for Algorithm 1 in the mean sense, the matrix should be stable. All the entries of are non-negative and all the rows of it add up to unity. Therefore, to ensure the stability in the mean, it should hold that
We use the notion to denote the maximum eigenvalue of a Hermitian matrix A. Thus, we note that a sufficient condition for unbiasedness is
3.2.2. Mean-Square Performance
In order to make the presentation clearer, we shall introduce the following notation
Performing weighted energy balance on both sides of Equation (27) and taking expectations gives
where is an arbitrary symmetric nonnegative-definite matrix, and the notion represents a weighted vector norm for any Hermitian . By defining
where the vec(.) notation stacks the columns of its matrix argument on top of each other. We can modify Equation (32) to
Using the following relationship of the vectorization operator and the Kronecker product [47]:
We can obtain that
where
Considering Assumption 3, we can approximate Equation (35) as
Using the following relationship of the vectorization operator and the matrix trace [47]:
We find that
where
Substituting Equations (34) and (37) into Equation (33), we can then reformulate recursion as follows:
It is known that Equation (38) is stable and convergent if the matrix is stable [48], form the Equation
We know that all the entries of in Equation (37) are non-negative, and all its columns sum up to unity. Using the property , the stability of has the same conditions as the stability of . Therefore, we choose the step size in accordance with Equation (31), which can keep the DMEE-SAS stable in the mean-square sense.
3.2.3. Instantaneous MSD
In order to analyze instantaneous mean-square-error (MSD), we can exploit the liberty of choosing at time i. Then, Expression (38) gives:
The sum of both sides of Equation (39) for can be given by
We can also adopt a similar way to describe the time instant , given by
Subtraction of both sides of Equation (40) from Equation (41) gives
By setting
in Equation (44) and dividing both sides of it by N, the instantaneous MSD for the whole network are computed by:
where can be obtained by the following iteration:
3.3. An Improving Scheme for the DMEE-SAS Algorithm
The too small effective step size near the optimal estimator will hinder the tracking ability of the DMEE-SAS algorithm in a non-stationary environment. In a non-stationary environment, the optimal estimator has small changes. A random-walk model is commonly used in the literature to describe the non-stationarity of the weight vector [48].
Therefore, we try to combine the DMEE-SAS algorithm with the DMEE algorithm [31] in a non-stationary environment where tracking is important. The DMEE-SAS algorithm should be used due to the faster convergence when the algorithm starts, and the DMEE algorithm should be used when the algorithm begins to converge. We use the Lyapunov stability theory [49] to analyze the switching time for each node.
The Lyapunov energy function is a method for analyzing the convergence characteristics of dynamic systems. The cost function can be viewed as a Lyapunov energy function. For the DMEE-SAS algorithm, the continuous-time learning rule is
The temporal dynamics for the Lyapunov energy that describes the DMEE-SAS algorithm can be obtained as follows:
The individual local energy function for DMEE algorithm can be written as
For the DMEE algorithm, the continuous-time learning rule is
In a similar way, the temporal dynamics for the Lyapunov energy that describes the DMEE algorithm can be obtained as follows:
The switching time is determined as
When the condition of Equation (50) is met, we should switch from the DMEE-SAS algorithm to the DMEE-SAS algorithm. We introduce the following auxiliary variable:
This yields the following algorithm, which we refer to as the improving DMEE-SAS algorithm:
For the purpose of clarity, we summarize the procedure of the Improving DMEE-SAS algorithm in Algorithm 2.
Algorithm 2: Improving DMEE-SAS Algorithm
Initialize:
for
for each nodek:
Adaptation
each node calculates the switching time using Equation (50).
each node updates intermediate estimateaccording to the first equation of Equation (51).
Combination
end for
4. Simulation Results
Twenty sensors are randomly placed in a square shown in Figure 1. The communication distance is set as 50. In this paper, the performance of the steady-state network MSD [12] is adopted for performance comparison. All of the performance measures are averaged over 100 trials.
We employ the super-Gaussian distribution as the noise model in our simulations. We generate the noise from the zero-mean generalized Gaussian distribution of probability density function , where p is a positive shape parameter of probability density function [50]. We set to make the noise distribution be super-Gaussian.
(a) In Stationary Environment
Here, the proposed DMEE-SAS algorithm performance is compared with that of some existing algorithms in the literature. We assume the communication link is the ideal link. The unknown parameter vector is set to .
We set the window length and kernel size for both DMEE and DMEE-SAS algorithms. Furthermore, the p is 1.2 for the DLMP algorithm. The steady state MSD curves are plotted in Figure 2. It is found that the DMEE-SAS algorithm is robust to the non-Gaussian noises and performs better than the DLMP algorithm [26] and DLMS [12]. The DMEE-SAS algorithm achieves a better convergence performance than the DMEE [31] algorithm when the DMEE-SAS and DMEE algorithms achieve comparable performance.
(b) In Non-stationary Environment
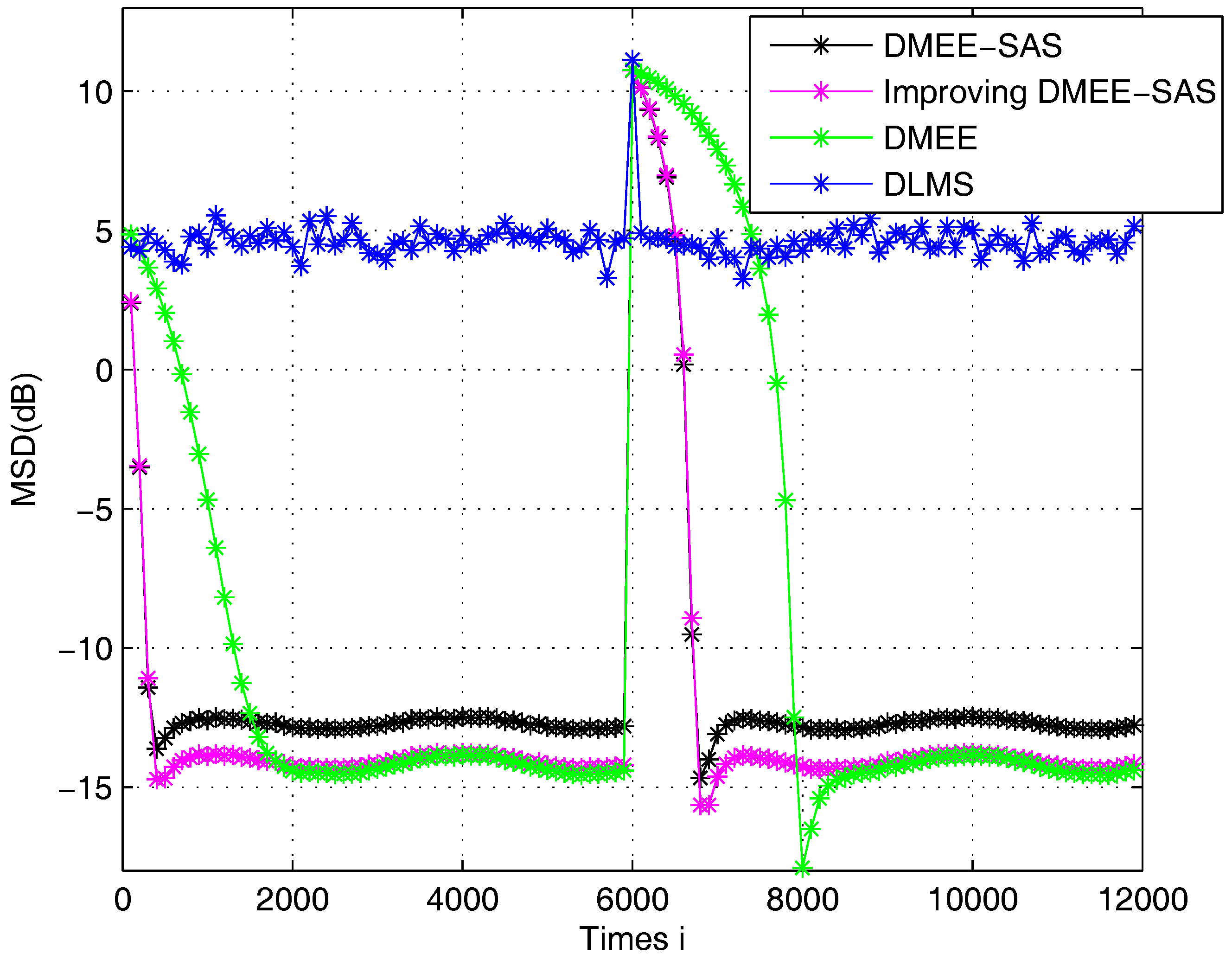
Here, the simulations are carried out in the same environments as those shown in stationary environment, except for the optimal estimator . We compare the proposed Improving DMEE-SAS algorithm with other algorithms.
Motivated by [51], we assume a time-varying of length 6 as follows:
where for and .
The unknown link is assumed to change at time 6000. In Figure 3, the Improving DMEE-SAS algorithm can detect the weight vector change and the performance of it is better than the DLMS algorithm. We observe that Improving DMEE-SAS and DMEE algorithms achieve comparable performance and Improving DMEE-SAS achieves better convergence performance than the DMEE algorithm. When compared with the DMEE-SAS algorithm, the Improving DMEE-SAS algorithm exhibits a significant improvement in performance when the estimate is close to the optimal estimator. The Improving DMEE-SAS algorithm achieves a low MSD and fast rate of convergence in the non-stationary environment.
5. Conclusions
In this paper, a robust diffusion estimation algorithm with self-adjusting step-size is developed which is called the DMEE-SAS algorithm. The mean and mean square convergence analysis of this new algorithm are carried out, and a sufficient condition for ensuring the stability is obtained. Simulation results illustrate that the DMEE-SAS algorithm can achieve better performance than the DLMS, robust DLMP, and DMEE algorithms in non-Gaussian noise scenario. In addition, we propose the Improving DMEE-SAS algorithm, using it in the non-stationary scenario where the unknown parameter is changing over time. The Improving DMEE-SAS algorithm combined the DMEE-SAS algorithm with the DMEE algorithm, and it can avoid the small effective step-size of the DMEE-SAS algorithm when close to the optimal estimator.
Acknowledgments
This work was supported in part by the Doctoral Fund of Southwest University (No. SWU113067), the National Natural Science Foundation of China (Grant Nos. 61672436, 61571372, 61372139, 61101233, 60972155), Fundamental Research Funds for the Central Universities (Grant Nos. XDJK2014A009, XDJK2016A001, XDJK2014C018) and Program for New Century Excellent Talents in University (Grant Nos. 201347).
Author Contributions
Xiaodan Shao conceived and designed the study and wrote the paper; Feng Chen did the simulations and gave the data analysis of the proposed algorithms. Qing Ye and Xiaodan Shao revised the paper; Shukai Duan checked the algorithms mentioned in this paper and helped to polish the English; all authors approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
Wang, G.; Li, C.; Dong, L. Noise estimation using mean square cross prediction error for speech enhancement. IEEE Trans. Circuits Syst. I Regul. Pap.2010, 57, 1489–1499. [Google Scholar] [CrossRef]
Xia, Y.; Douglas, S.C.; Mandic, D.P. Adaptive frequency estimation in smart grid applications: Exploiting noncircularity and widely linear adaptive estimators. IEEE Signal Process. Mag.2012, 29, 44–54. [Google Scholar] [CrossRef]
Liu, Y.; Li, C. Complex-valued Bayesian parameter estimation via Markov chain Monte Carlo. Inf. Sci.2016, 326, 334–349. [Google Scholar] [CrossRef]
Xia, Y.; Mandic, D.P. Widely linear adaptive frequency estimation of unbalanced three-phase power systems. IEEE Trans. Instrum. Meas.2012, 61, 74–83. [Google Scholar] [CrossRef]
Xia, Y.; Blazic, Z.; Mandic, D.P. Complex-valued least squares frequency estimation for unbalanced power systems. IEEE Trans. Instrum. Meas.2015, 64, 638–648. [Google Scholar] [CrossRef]
Lopes, C.G.; Sayed, A.H. Incremental Adaptive Strategies over Distributed Networks. IEEE Trans. Signal Process.2007, 55, 4064–4077. [Google Scholar] [CrossRef]
Rabbat, M.G.; Nowak, R.D. Quantized incremental algorithms for distributed optimization. IEEE J. Sel. Areas Commun.2006, 23, 798–808. [Google Scholar] [CrossRef]
Nedic, A.; Bertsekas, D.P. Incremental subgradient methods for nondifferentiable optimization. SIAM J. Optim.2001, 12, 109–138. [Google Scholar] [CrossRef]
Kar, S.; Moura, J.M.F. Distributed Consensus Algorithms in Sensor Networks With Imperfect Communication: Link Failures and Channel Noise. IEEE Trans. Signal Process.2009, 57, 355–369. [Google Scholar] [CrossRef]
Carli, R.; Chiuso, A.; Schenato, L. Distributed Kalman filtering based on consensus strategies. IEEE J. Sel. Areas Commun.2008, 26, 622–633. [Google Scholar] [CrossRef]
Cattivelli, F.S.; Sayed, A.H. Diffusion LMS Strategies for Distributed Estimation. IEEE Trans. Signal Process.2010, 58, 1035–1048. [Google Scholar] [CrossRef]
Chen, J.; Sayed, A.H. Diffusion adaptation strategies for distributed optimization and learning over networks. IEEE Trans. Signal Process.2012, 60, 4289–4305. [Google Scholar] [CrossRef]
Chen, F.; Shao, X. Broken-motifs Diffusion LMS Algorithm for Reducing Communication Load. Signal Process.2017, 133, 213–218. [Google Scholar] [CrossRef]
Xia, Y.; Mandic, D.P.; Sayed, A.H. An Adaptive Diffusion Augmented CLMS Algorithm for Distributed Filtering of Noncircular Complex Signals. IEEE Signal Process. Lett.2011, 18, 659–662. [Google Scholar]
Kanna, S.; Mandic, D.P. Steady-State Behavior of General Complex-Valued Diffusion LMS Strategies. IEEE Signal Process. Lett.2016, 23, 722–726. [Google Scholar] [CrossRef]
Kanna, S.; Talebi, S.P.; Mandic, D.P. Diffusion widely linear adaptive estimation of system frequency in distributed power grids. In Proceedings of the IEEE International Energy Conference, Leuven, Belgium, 8 April 2014; pp. 772–778. [Google Scholar]
Jahanchahi, C.; Mandic, D.P. An adaptive diffusion quaternion LMS algorithm for distributed networks of 3D and 4D vector sensors. In Proceedings of the IEEE Signal Processing Conference, Napa, CA, USA, 11 August 2013; pp. 1–5. [Google Scholar]
Abdolee, R.; Champagne, B.; Sayed, A.H. A diffusion LMS strategy for parameter estimation in noisy regressor applications. In Proceedings of the Signal Processing Conference, Ann Arbor, MI, USA, 5 August 2012; pp. 749–753. [Google Scholar]
Abdolee, R.; Champagne, B. Diffusion LMS Strategies in Sensor Networks With Noisy Input Data. IEEE/ACM Trans. Netw.2016, 24, 3–14. [Google Scholar] [CrossRef]
Abdolee, R.; Champagne, B.; Sayed, A. Diffusion Adaptation over Multi-Agent Networks with Wireless Link Impairments. IEEE Trans. Mob. Comput.2016, 15, 1362–1376. [Google Scholar] [CrossRef]
Kanna, S.; Dini, D.H.; Xia, Y. Distributed Widely Linear Kalman Filtering for Frequency Estimation in Power Networks. IEEE Trans. Signal Inf. Process. Netw.2015, 1, 45–57. [Google Scholar] [CrossRef]
Middleton, D. Non-Gaussian noise models in signal processing for telecommunications: New methods an results for class A and class B noise models. IEEE Trans. Inf. Theory1999, 45, 1129–1149. [Google Scholar] [CrossRef]
Zoubir, A.M.; Koivunen, V.; Chakhchoukh, Y.; Muma, M. Robust estimation in signal processing: A tutorial-style treatment of fundamental concepts. IEEE Signal Process. Mag.2012, 29, 61–80. [Google Scholar] [CrossRef]
Zoubir, A.M.; Brcich, R.F. Multiuser detection in heavy tailed noise. Digit. Signal Process.2002, 12, 262–273. [Google Scholar] [CrossRef]
Wen, F. Diffusion least-mean P-power algorithms for distributed estimation in alpha-stable noise environments. Electron. Lett.2013, 49, 1355–1356. [Google Scholar] [CrossRef]
Ma, W.; Chen, B.; Duan, J.; Zhao, H. Diffusion maximum correntropy criterion algorithms for robust distributed estimation. Digit. Signal Process.2016, 58, 10–19. [Google Scholar] [CrossRef]
Ma, W.; Qu, H.; Gui, G.; Xu, L.; Zhao, J.; Chen, B. Maximum correntropy criterion based sparse adaptive filtering algorithms for robust channel estimation under non-Gaussian environments. J. Frankl. Inst.2015, 352, 2708–2727. [Google Scholar] [CrossRef]
Chen, B.; Xing, L.; Liang, J.; Zheng, N.; Principe, J.C. Steady-state Mean-square Error Analysis for Adaptive Filtering under the Maximum Correntropy Criterion. IEEE Signal Process. Lett.2014, 21, 880–884. [Google Scholar]
Li, C.; Shen, P.; Liu, Y.; Zhang, Z. Diffusion information theoretic learning for distributed estimation over network. IEEE Trans. Signal Process.2013, 61, 4011–4024. [Google Scholar] [CrossRef]
Chen, B.; Zhu, Y.; Hu, J. Mean-Square Convergence Analysis of ADALINE Training with Minimum Error Entropy Criterion. IEEE Trans. Neural Netw.2010, 21, 1168–1179. [Google Scholar] [CrossRef] [PubMed]
Chen, B.; Hu, H.; Pu, L.; Sun, Z. Stochastic gradient algorithm under (h, phi)-entropy criterion. Circuits Syst. Signal Process.2007, 26, 941–960. [Google Scholar] [CrossRef]
Chen, B.; Zhu, P.; Principe, J.C. Survival information potential: A new criterion for adaptive system training. IEEE Trans. Signal Process.2012, 60, 1184–1194. [Google Scholar] [CrossRef]
Chen, B.; Principe, J.C. Some further results on the minimum error entropy estimation. Entropy2012, 14, 966–977. [Google Scholar] [CrossRef]
Chen, B.; Xing, L.; Xu, B.; Zhao, H.; Principe, J.C. Insights into the Robustness of Minimum Error Entropy Estimation. IEEE Trans. Neural Netw. Learn. Syst.2016, 1–7. [Google Scholar] [CrossRef] [PubMed]
Lee, H.S.; Kim, S.E.; Lee, J.W. A Variable Step-Size Diffusion LMS Algorithm for Distributed Estimation. IEEE Trans. Signal Process.2015, 63, 1808–1820. [Google Scholar] [CrossRef]
Ghazanfari-Rad, S.; Labeau, F. Optimal variable step-size diffusion LMS algorithms. IEEE Stat. Signal Process. Workshop2014, 464–467. [Google Scholar] [CrossRef]
Ni, J.; Yang, J. Variable step-size diffusion least mean fourth algorithm for distributed estimation. Signal Process.2016, 122, 93–97. [Google Scholar] [CrossRef]
Abdolee, R.; Vakilian, V.; Champagne, B. Tracking Performance and Optimal Adaptation Step-Sizes of Diffusion-LMS Networks. IEEE Trans. Control Netw. Syst.2016. [Google Scholar] [CrossRef]
Han, S.; Rao, S.; Erdogmus, D.; Jeong, K.H.; Principe, J. A minimum-error entropy criterion with self-adjusting step-size (MEE-SAS). Signal Process.2007, 87, 2733–2745. [Google Scholar] [CrossRef]
Erdogmus, D.; Principe, J.C. Convergence properties and data efficiency of the minimum error entropy criterion in ADALINE training. IEEE Trans. Signal Process.2003, 51, 1966–1978. [Google Scholar] [CrossRef]
Shen, P.; Li, C. Minimum Total Error Entropy Method for Parameter Estimation. IEEE Trans. Signal Process.2015, 63, 4079–4090. [Google Scholar] [CrossRef]
Arablouei, R.; Werner, S. Analysis of the gradient-descent total least-squares adaptive filtering algorithm. IEEE Trans. Signal Process.2014, 62, 1256–1264. [Google Scholar] [CrossRef]
Kelley, C.T. Iterative Methods for Optimization; SIAM: Philadelphia, PA, USA, 1999; Volume 9, p. 878. [Google Scholar]
Sayed, A.H. Adaptive Filters; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
Khalil, H.K. Nonlinear Systems; Macmillan: New York, NY, USA, 1992. [Google Scholar]
Li, H.; Li, X.; Anderson, M. A class of adaptive algorithms based on entropy estimation achieving CRLB for linear non-Gaussian filtering. IEEE Trans. Signal Process.2012, 60, 2049–2055. [Google Scholar] [CrossRef]
Zhao, X.; Tu, S.; Sayed, A.H. Diffusion adaptation over networks under imperfect information exchange and non-stationary data. IEEE Trans. Signal Process.2012, 60, 3460–3475. [Google Scholar] [CrossRef]
Shao, X.; Chen, F.; Ye, Q.; Duan, S.
A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs. Sensors2017, 17, 824.
https://doi.org/10.3390/s17040824
AMA Style
Shao X, Chen F, Ye Q, Duan S.
A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs. Sensors. 2017; 17(4):824.
https://doi.org/10.3390/s17040824
Chicago/Turabian Style
Shao, Xiaodan, Feng Chen, Qing Ye, and Shukai Duan.
2017. "A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs" Sensors 17, no. 4: 824.
https://doi.org/10.3390/s17040824
APA Style
Shao, X., Chen, F., Ye, Q., & Duan, S.
(2017). A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs. Sensors, 17(4), 824.
https://doi.org/10.3390/s17040824
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.
Article Metrics
No
No
Article Access Statistics
For more information on the journal statistics, click here.
Multiple requests from the same IP address are counted as one view.
Shao, X.; Chen, F.; Ye, Q.; Duan, S.
A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs. Sensors2017, 17, 824.
https://doi.org/10.3390/s17040824
AMA Style
Shao X, Chen F, Ye Q, Duan S.
A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs. Sensors. 2017; 17(4):824.
https://doi.org/10.3390/s17040824
Chicago/Turabian Style
Shao, Xiaodan, Feng Chen, Qing Ye, and Shukai Duan.
2017. "A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs" Sensors 17, no. 4: 824.
https://doi.org/10.3390/s17040824
APA Style
Shao, X., Chen, F., Ye, Q., & Duan, S.
(2017). A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs. Sensors, 17(4), 824.
https://doi.org/10.3390/s17040824
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.


{kind=link}
{kind=link}
{kind=link}


