
Variable Admittance Control Based on Fuzzy Reinforcement Learning for Minimally Invasive Surgery Manipulator


Abstract
:1. Introduction
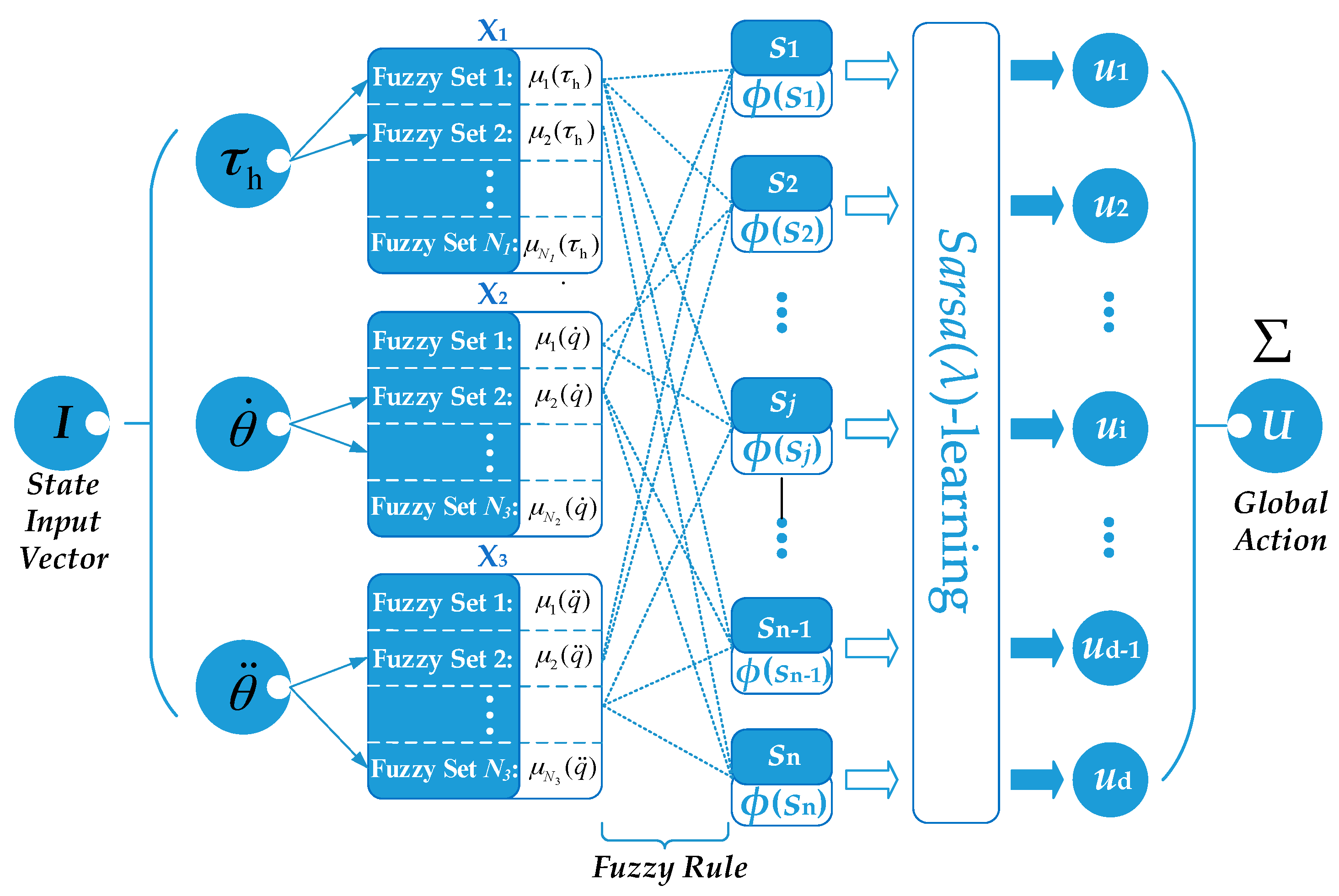
2. Sarsa(λ)-Algorithm
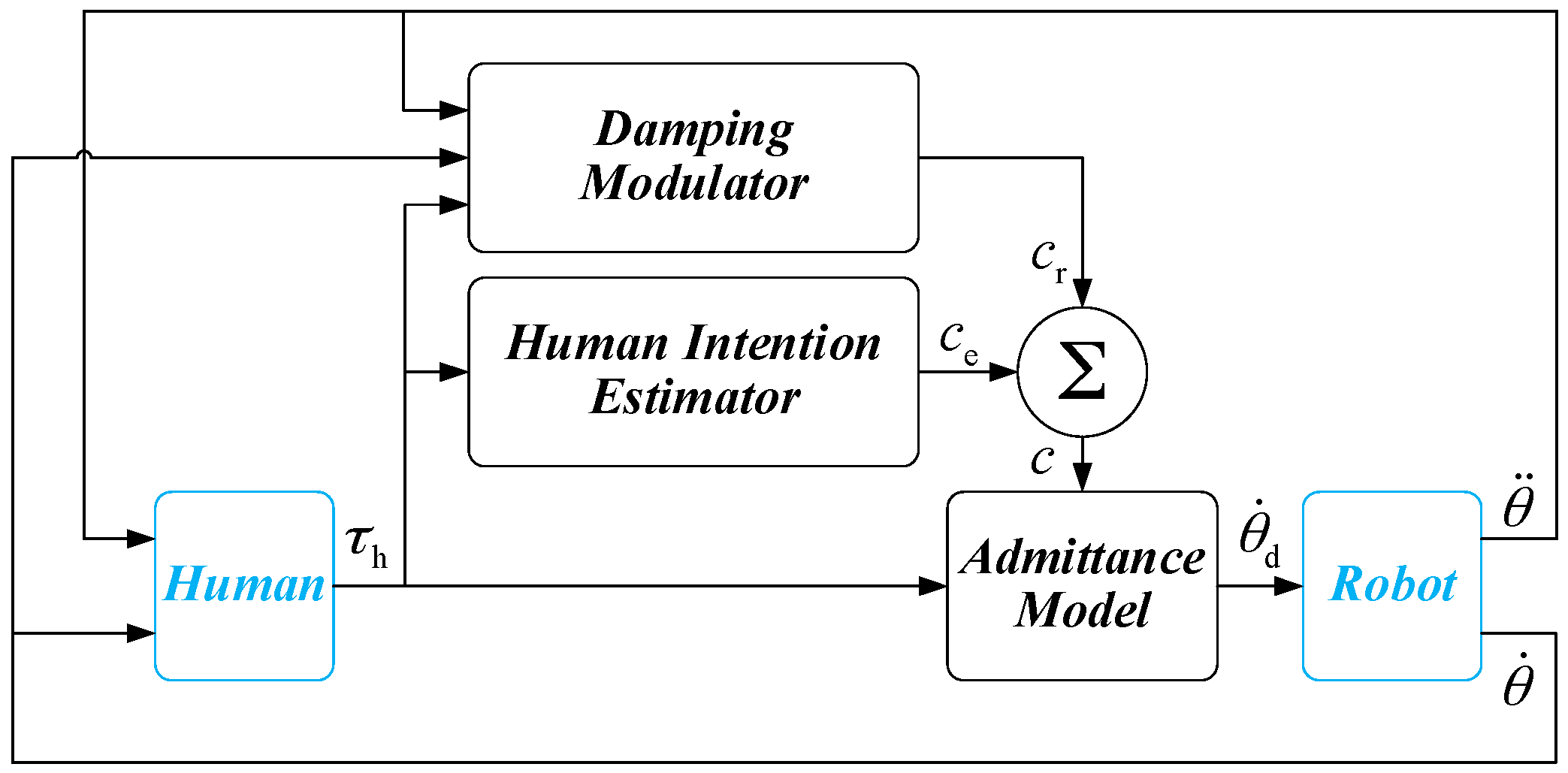
3. Variable Admittance Control Scheme
3.1. Variable Admittance Controller
3.2. Damping Modulator Based on FSL
4. Experimental Evaluation
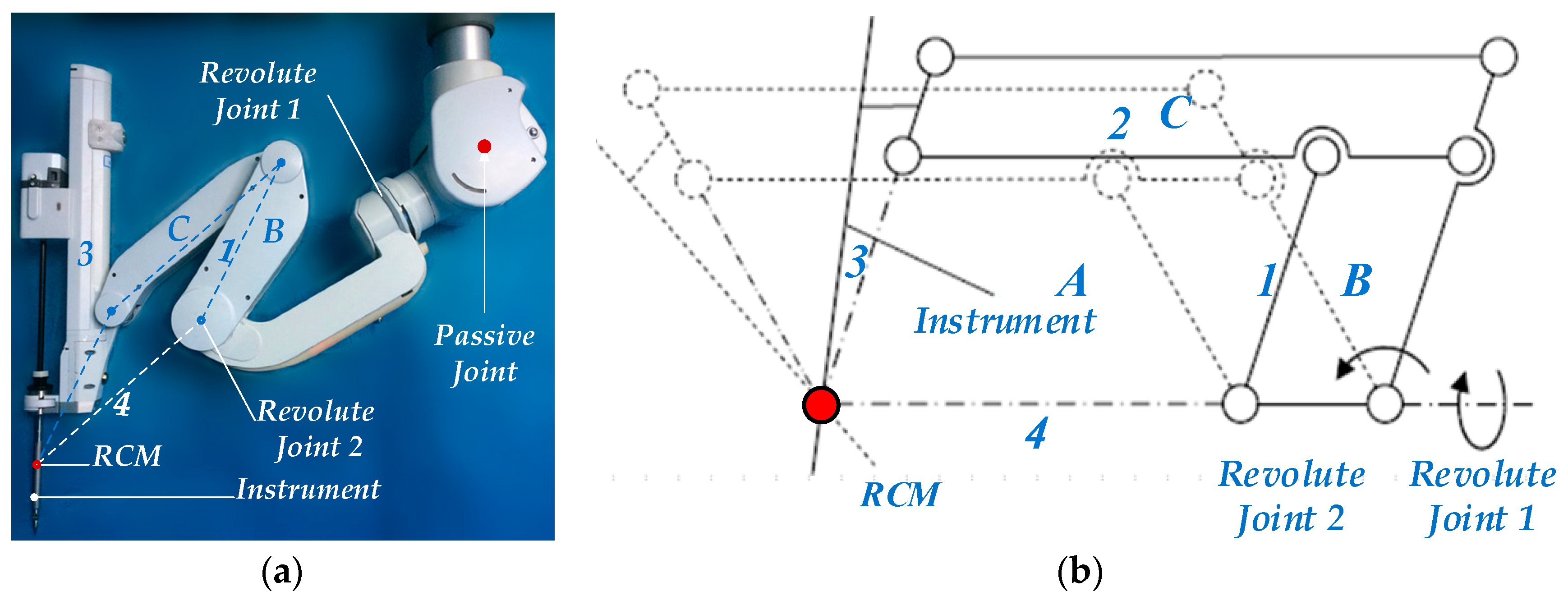
4.1. Minimally Invasive Surgical Manipulator
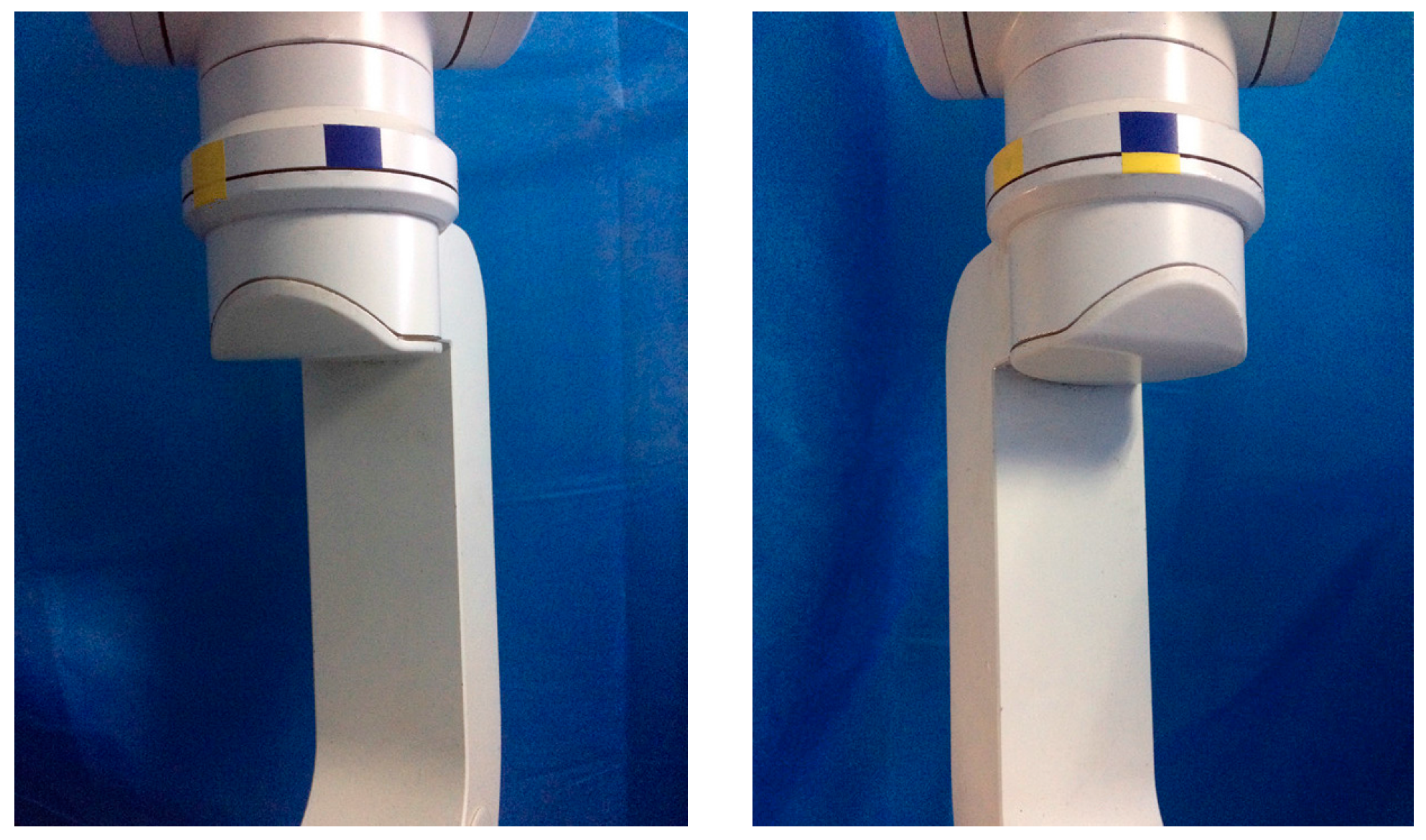
4.2. Experimental Design
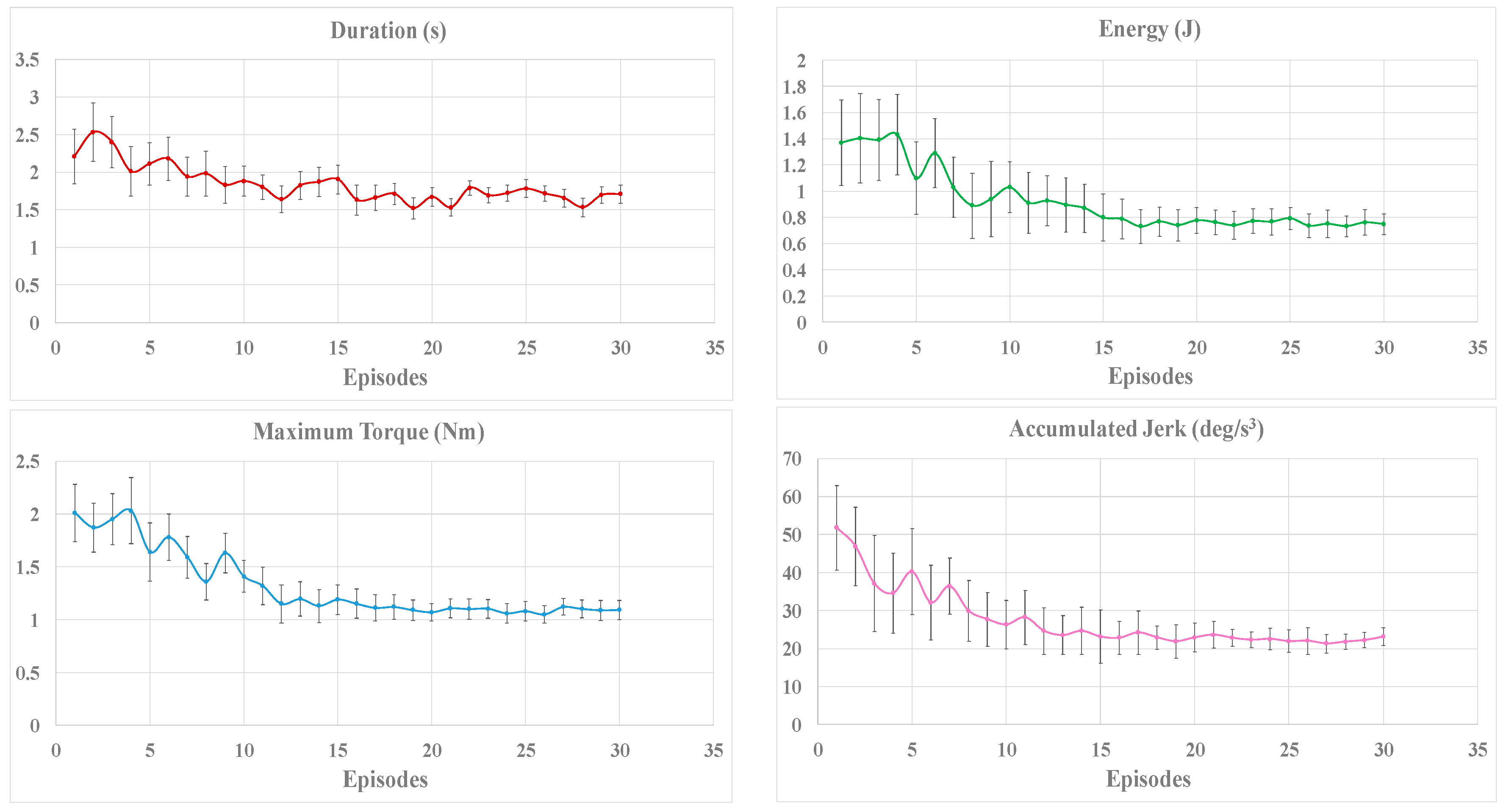
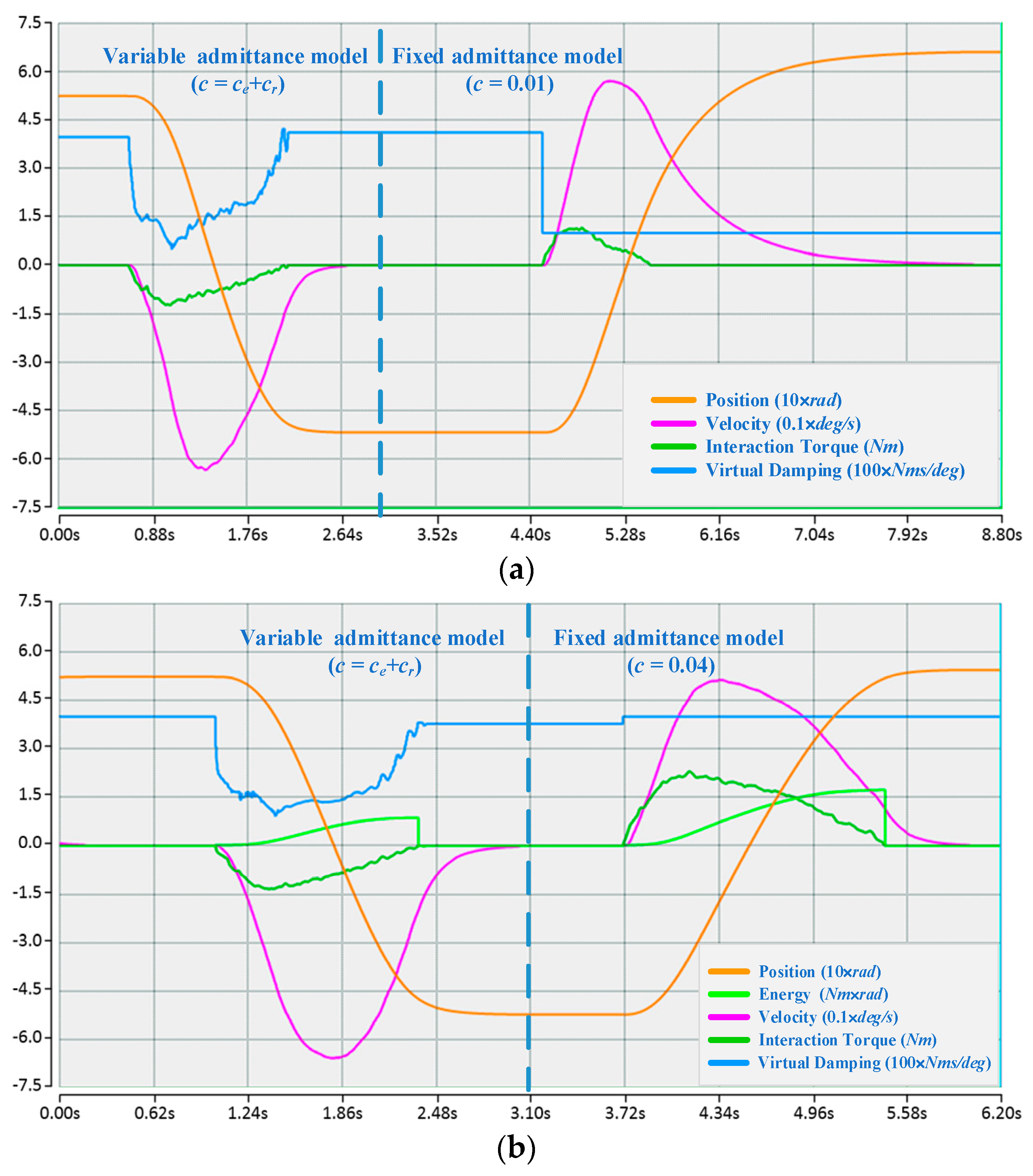
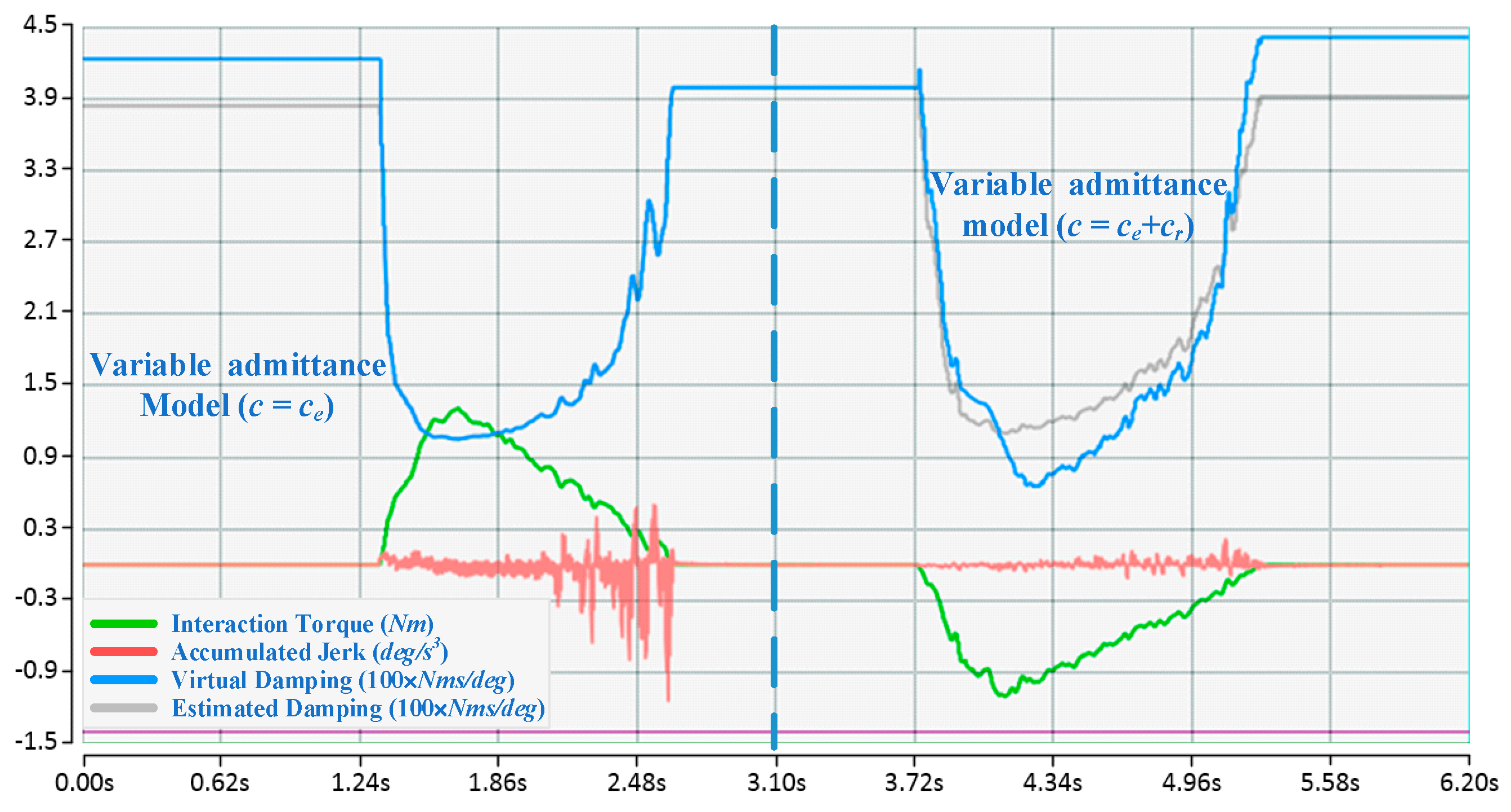
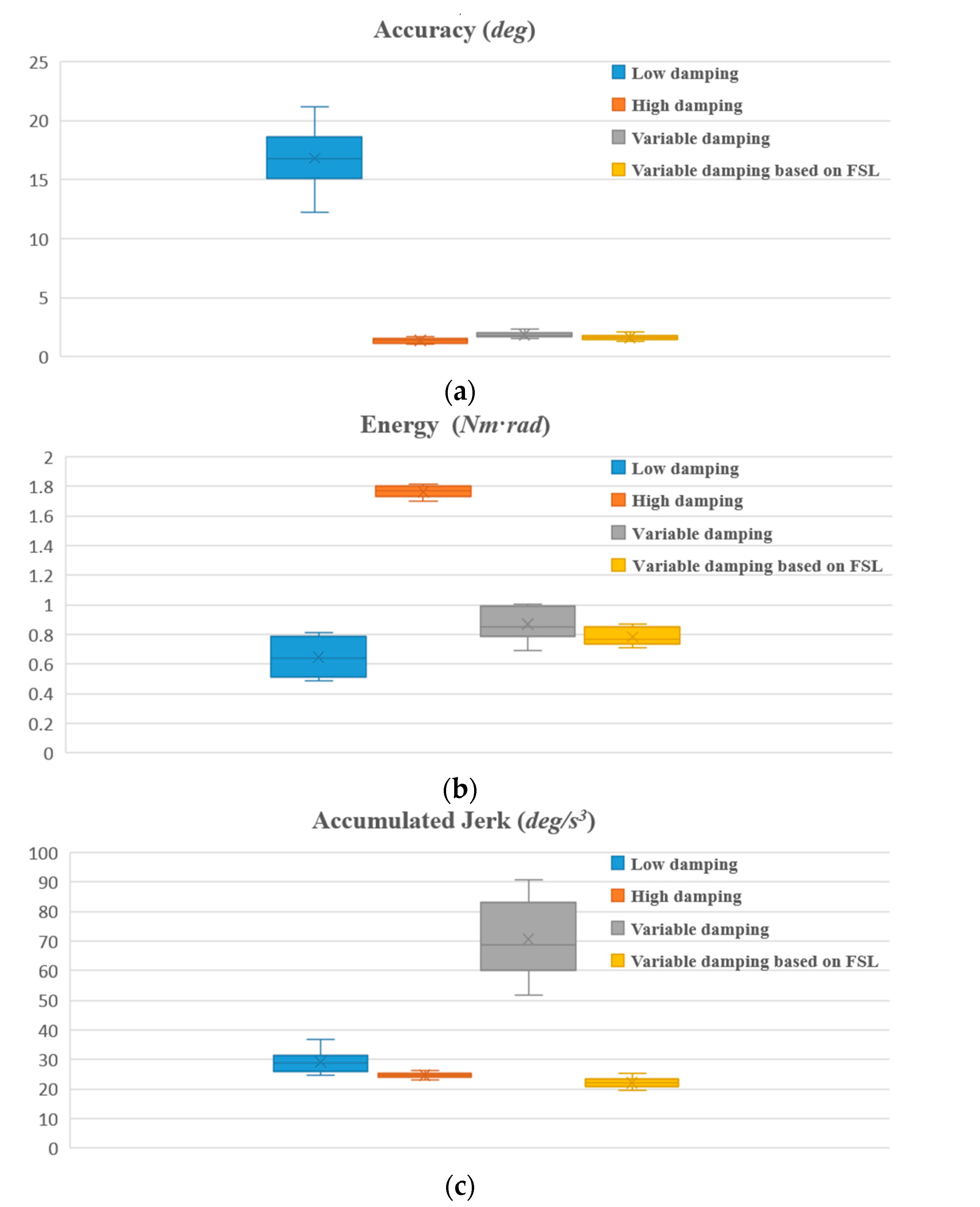
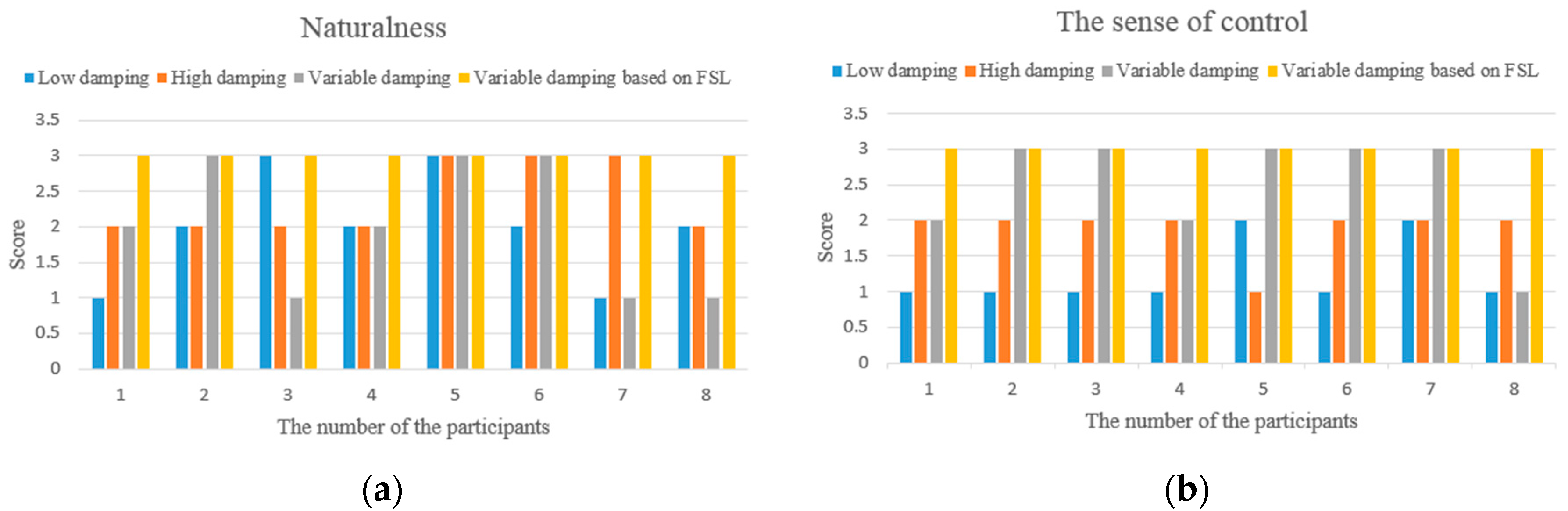
4.3. Experimental Results and Discussion
4.3.1. Contrastive Verification
4.3.2. Questionnaire for Comments
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Murphy, D.A.; Miller, J.S.; Langford, D.A. Endoscopic robotic mitral valve surgery. J. Thorac. Cardiovasc. Surg. 2007, 133, 1119–1120. [Google Scholar] [CrossRef] [PubMed]
- Meireles, O.; Horgan, S. Applications of surgical robotics in general surgery. In Surgical Robotics: Systems, Applications, and Visions; Rosen, J., Hannaford, B., Satava, R.M., Eds.; Springer: New York, NY, USA, 2011; pp. 791–812. [Google Scholar]
- Wang, W.; Wang, W.D.; Dong, W.; Yu, H.J.; Yan, Z.Y.; Du, Z.J. Dimensional optimization of a minimally invasive surgical robot system based on NSGA-II algorithm. Adv. Mech. Eng. 2015, 7, 1687814014568541. [Google Scholar] [CrossRef]
- De Santis, A.; Siciliano, B.; De Luca, A.; Bicchi, A. An atlas of physical human–robot interaction. Mech. Mach. Theory 2008, 43, 253–270. [Google Scholar] [CrossRef]
- Mitchell, B.; Koo, J.; Iordachita, I.; Kazanzides, P.; Kapoor, A.; Handa, J.; Taylor, R. Development and application of a new steady-hand manipulator for retinal surgery. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 623–629. [Google Scholar]
- Lopez Infante, M.; Kyrki, V. Usability of force-based controllers in physical human-robot interaction. In Proceedings of the ACM 6th International Conference on Human-Robot Interaction, Lausanne, Switzerland, 6–9 March 2011; pp. 355–362. [Google Scholar]
- Pallegedara, A.; Matsuda, Y.; Egashira, N.; Sugi, T.; Goto, S. Simulation and analysis of dynamics of the force-free control for industrial robot arms. In Proceedings of the 2012 12th IEEE International Conference on Control, Automation and Systems (ICCAS), Jeju Island, Korea, 17–21 October 2012; pp. 733–738. [Google Scholar]
- Goto, S.; Usui, T.; Kyura, N.; Nakamura, M. Forcefree control with independent compensation for industrial articulated robot arms. Control Eng. Pract. 2007, 15, 627–638. [Google Scholar] [CrossRef]
- Hogan, N. Impedance control: An approach to manipulation: Part I theory; Part II implementation; Part III applications. J. Dyn. Syst. Meas. Control 1985, 107, 1–24. [Google Scholar] [CrossRef]
- Erden, M.S.; Marić, B. Assisting manual welding with robot. Rob. Comput. Integr. Manuf. 2011, 27, 818–828. [Google Scholar] [CrossRef]
- Lecours, A.; Mayer-St-Onge, B.; Gosselin, C. Variable admittance control of a four-degree-of-freedom intelligent assist device. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 3903–3908. [Google Scholar]
- Ficuciello, F.; Villani, L.; Siciliano, B. Variable Impedance Control of Redundant Manipulators for Intuitive Human–Robot Physical Interaction. IEEE Trans. Robot. 2015, 31, 850–863. [Google Scholar] [CrossRef]
- Duchaine, V.; Gosselin, C.M. General model of human-robot cooperation using a novel velocity based variable impedance control. In Proceedings of the IEEE Second Joint EuroHaptics Conference and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems (WHC’07), Tsukuba, Japan, 22–24 March 2007; pp. 446–451. [Google Scholar]
- Duchaine, V.; Gosselin, C.M. Investigation of human-robot interaction stability using Lyapunov theory. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2008, Pasadena, CA, USA, 19–23 May 2008; pp. 2189–2194. [Google Scholar]
- Kim, Y.; Oyabu, T.; Obinata, G.; Hase, K. Operability of joystick-type steering device considering human arm impedance characteristics. IEEE Trans. Syst. Man Cybern. Part A Syst. Humans 2012, 42, 295–306. [Google Scholar] [CrossRef]
- Mitsantisuk, C.; Ohishi, K.; Katsura, S. Variable mechanical stiffness control based on human stiffness estimation. In Proceedings of the 2011 IEEE International Conference on Mechatronics (ICM), Istanbul, Turkey, 13–15 April 2011; pp. 731–736. [Google Scholar]
- Tsumugiwa, T.; Yokogawa, R.; Hara, K. Variable impedance control based on estimation of human arm stiffness for human-robot cooperative calligraphic task. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA’02, Washington, DC, USA, 11–15 May 2002; pp. 644–650. [Google Scholar]
- Gallagher, W.; Gao, D.; Ueda, J. Improved stability of haptic human–robot interfaces using measurement of human arm stiffness. Adv. Robot. 2014, 28, 869–882. [Google Scholar] [CrossRef]
- Corteville, B.; Aertbeliën, E.; Bruyninckx, H.; De Schutter, J.; Van Brussel, H. Human-inspired robot assistant for fast point-to-point movements. Proceedings 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3639–3644. [Google Scholar]
- Dimeas, F.; Aspragathos, N. Fuzzy learning variable admittance control for human-robot cooperation. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4770–4775. [Google Scholar]
- Flash, T.; Hogan, N. The coordination of arm movements: an experimentally confirmed mathematical model. J. Neurosci. 1985, 5, 1688–1703. [Google Scholar] [PubMed]
- Suzuki, S.; Furuta, K. Adaptive impedance control to enhance human skill on a haptic interface system. J. Control Sci. Eng. 2012, 1, 1–10. [Google Scholar] [CrossRef]
- Furuta, K.; Kado, Y.; Shiratori, S. Assisting control in Human Adaptive Mechatronics—Single ball juggling. In Proceedings of the IEEE International Conference on Control Applications, Munich, Germany, 4–6 October 2006; pp. 545–550. [Google Scholar]
- Kurihara, K.; Suzuki, S.; Harashima, F.; Furuta, K. Human adaptive mechatronics (HAM) for haptic system. In Proceedings of the 30th Annual Conference of IEEE Industrial Electronics Society, IECON 2004, Busan, Korea, 2–6 November 2004; pp. 647–652. [Google Scholar]
- Yang, C.; Ganesh, G.; Haddadin, S.; Parusel, S.; Albu-Schaeffer, A.; Burdet, E. Human-like adaptation of force and impedance in stable and unstable interactions. IEEE Trans. Robot. 2011, 27, 918–930. [Google Scholar] [CrossRef]
- Howard, M.; Braun, D.J.; Vijayakumar, S. Transferring human impedance behavior to heterogeneous variable impedance actuators. IEEE Trans. Robot. 2013, 29, 847–862. [Google Scholar] [CrossRef]
- Kronander, K.; Billard, A. Online learning of varying stiffness through physical human-robot interaction. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 1842–1849. [Google Scholar]
- Oh, S.; Woo, H.; Kong, K. Frequency-shaped impedance control for safe human–robot interaction in reference tracking application. IEEE/ASME Trans. Mech. 2014, 19, 1907–1916. [Google Scholar] [CrossRef]
- Modares, H.; Ranatunga, I.; Lewis, F.L.; Popa, D.O. Optimized assistive human–robot interaction using reinforcement learning. IEEE Trans. Cybern. 2016, 46, 655–667. [Google Scholar] [CrossRef] [PubMed]
- Busoniu, L.; Babuska, R.; De Schutter, B.; Ernst, D. Reinforcement Learning and Dynamic Programming Using Function Approximators; CRC Press: New York, NY, USA, 2010. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Dimeas, F.; Aspragathos, N. Reinforcement learning of variable admittance control for human-robot co-manipulation. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1011–1016. [Google Scholar]
- Jouffe, L. Fuzzy inference system learning by reinforcement methods. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 1998, 28, 338–355. [Google Scholar] [CrossRef]
- Derhami, V.; Majd, V.J.; Ahmadabadi, M.N. Fuzzy Sarsa learning and the proof of existence of its stationary points. Asian J. Control 2008, 10, 535–549. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| γ | α | λ | η | Δt (s) |
|---|---|---|---|---|
| 0.9 | 0.03 | 0.95 | 85 | 0.004 |
| X1 (Nm) | X2 (deg/s) | X3 (deg/s2) | ke | cmin (Nms/deg) | cmax (Nms/deg) |
|---|---|---|---|---|---|
| −2.5 ~ 0.0 | −8.5 ~ 0.0 | −4.5 ~ 4.5 | 3.06 | 0.01 | 0.04 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Z.; Wang, W.; Yan, Z.; Dong, W.; Wang, W. Variable Admittance Control Based on Fuzzy Reinforcement Learning for Minimally Invasive Surgery Manipulator. Sensors 2017, 17, 844. https://doi.org/10.3390/s17040844
Du Z, Wang W, Yan Z, Dong W, Wang W. Variable Admittance Control Based on Fuzzy Reinforcement Learning for Minimally Invasive Surgery Manipulator. Sensors. 2017; 17(4):844. https://doi.org/10.3390/s17040844
Chicago/Turabian StyleDu, Zhijiang, Wei Wang, Zhiyuan Yan, Wei Dong, and Weidong Wang. 2017. "Variable Admittance Control Based on Fuzzy Reinforcement Learning for Minimally Invasive Surgery Manipulator" Sensors 17, no. 4: 844. https://doi.org/10.3390/s17040844
APA StyleDu, Z., Wang, W., Yan, Z., Dong, W., & Wang, W. (2017). Variable Admittance Control Based on Fuzzy Reinforcement Learning for Minimally Invasive Surgery Manipulator. Sensors, 17(4), 844. https://doi.org/10.3390/s17040844