
Easy and Fast Reconstruction of a 3D Avatar with an RGB-D Sensor

Abstract
:1. Introduction
- (1)
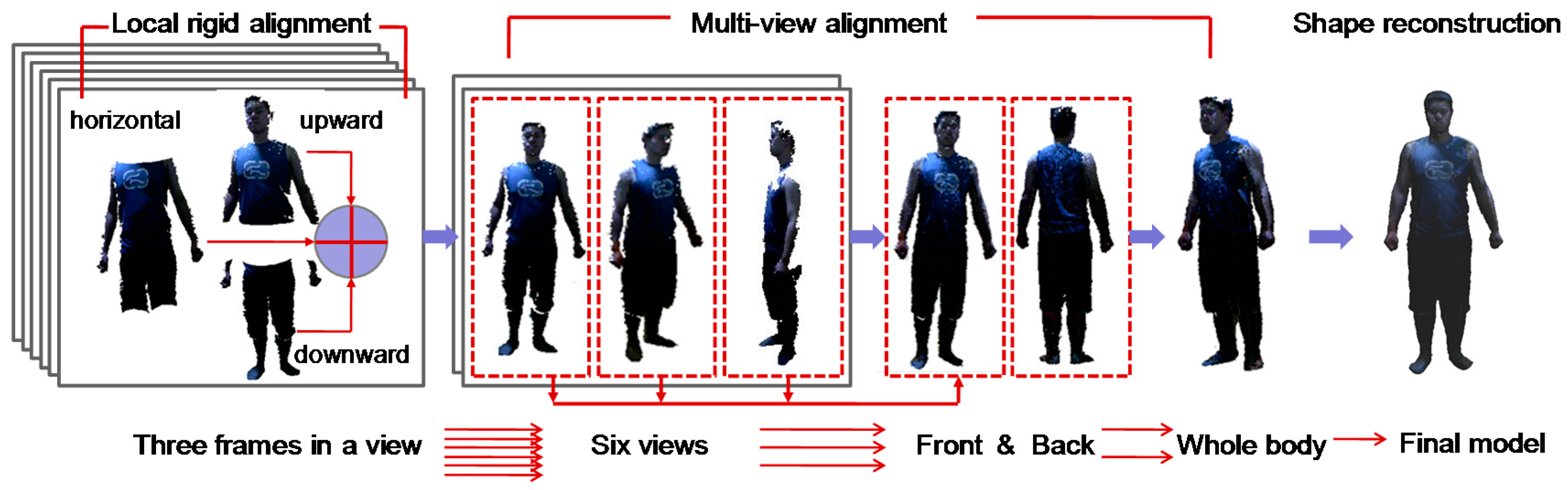
- We adopt a new data capture strategy to scan the human body. It captures data from six views by rotating the human body, and in each view only three frames are obtained in upward, horizontal and downward directions (see details in Section 4.1). Thus, there are a total of 18 frames that cover the full human body, which dramatically reduces the amount of captured frames compared to previous work. For instance, in the system by Cui et al. [6], the user is turned around every 20 to 30 s to capture 10 frames within 0.5 s intervals; in the work of Tong et al. [5], each Kinect acquired images at 15 frames per second about every 30 s; in the system of Li et al. [7], the user was scanned from eight to nine views, and in each view, roughly 150 raw frames were captured. The greatly reduced amount of captured frames in our work helps reduce the computation loads for raw data analysis and thus speeds up the modeling procedure.
- (2)
- We propose efficient alignment algorithms for aligning the point clouds in a single view and multi-views. Based on the new data capture strategy, new efforts have been made to achieve authentic aligned results quickly, including: (I) exploring the optimal combination of different correspondence pairing methods concerning alignment quality and efficiency both in the rigid and non-rigid alignment; (II) designing a three-step non-rigid alignment algorithm, which, unlike in previous works of human body modeling, introduces a pre-alignment of multi-view data frames using the model silhouettes to reduce the search space and thus improve alignment efficiency; (III) managing the point clouds throughout all the steps in alignment, which is helpful for generating more accurate results with no errors generated by the mesh operations; (IV) aligning the point clouds without the assistance of shape priors or subdivision tools, which helps to simplify the reconstruction procedure and reduce reconstruction complexity.
- (3)
- We offer an easy-to-follow platform for 3D avatar modeling, one that highlights the technique details in each step and makes it possible for readers to follow along or develop such a method. With this platform, users can quickly generate 3D avatars for human factors/ergonomics applications, virtual entertainment and business.
2. Related Work
2.1. RGB-D Sensors for 3D modeling
2.2. Multi-view Alignment
3. Overview
4. Reconstruction Approach
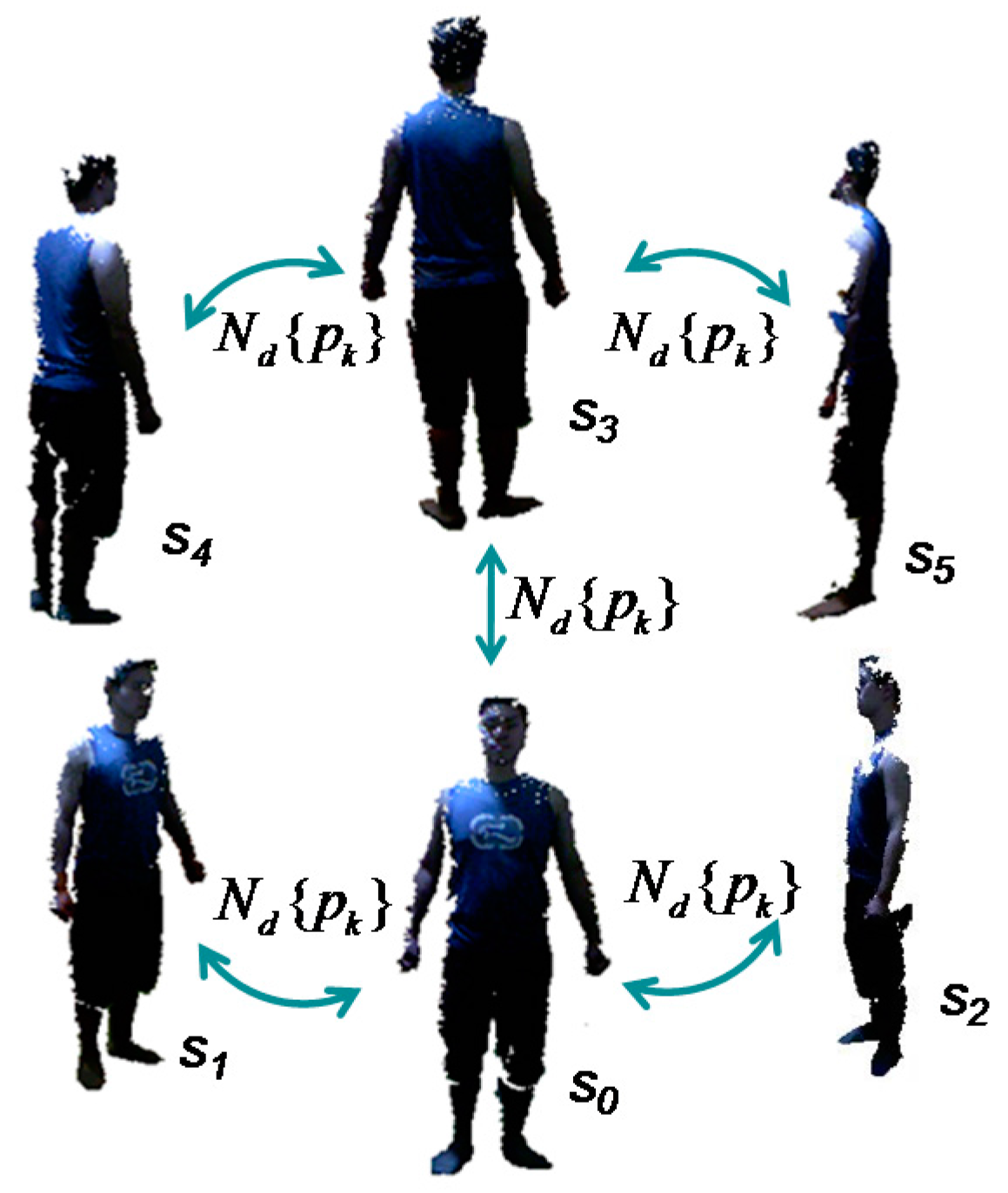
4.1. Data Capture
4.2. Segmentation and Denoising
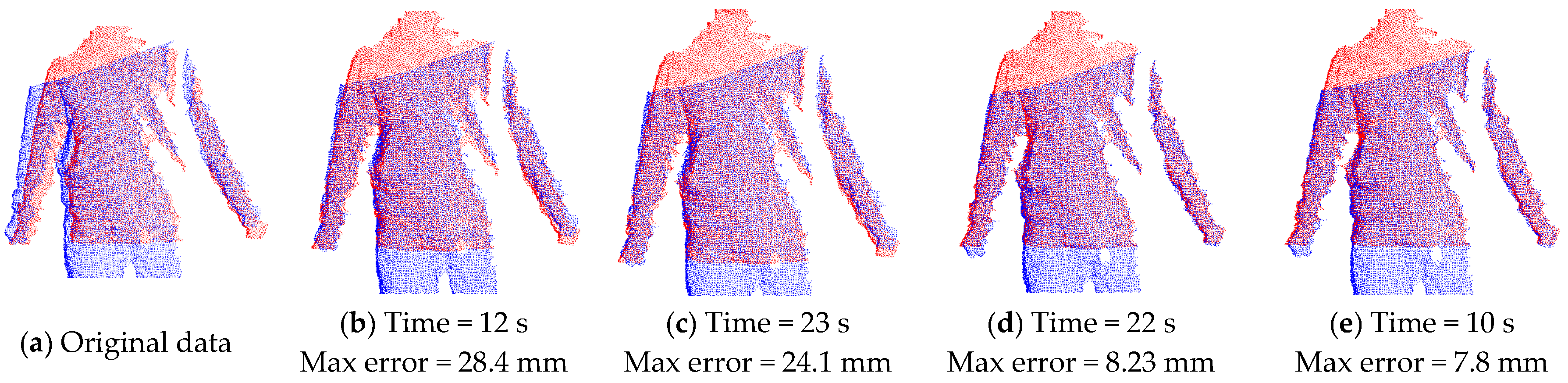
4.3. Local Rigid Alignment
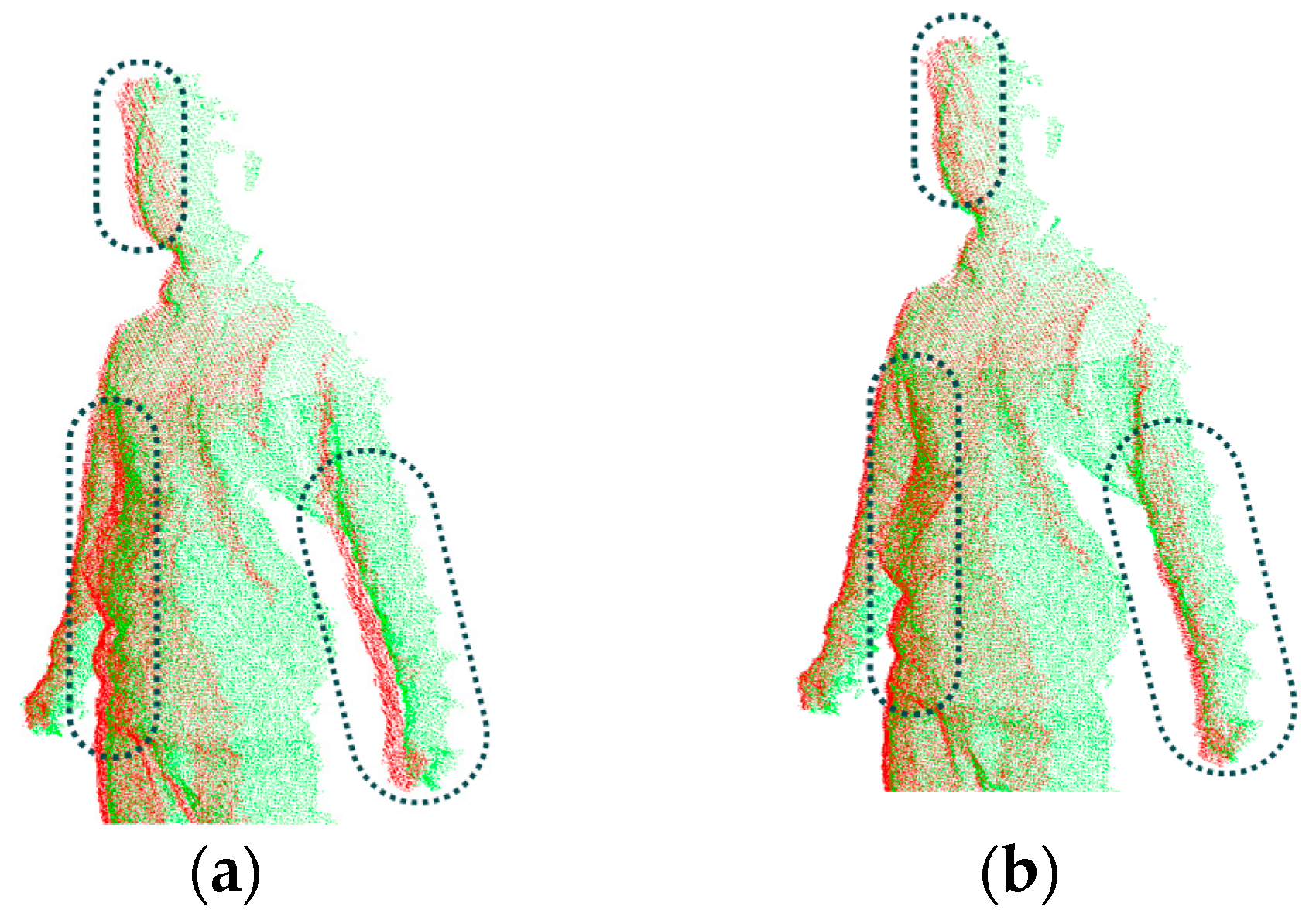
4.4. Multi-View Alignment
| Algorithm 1: Non-rigid alignment for two point clouds in neighboring views. |
|
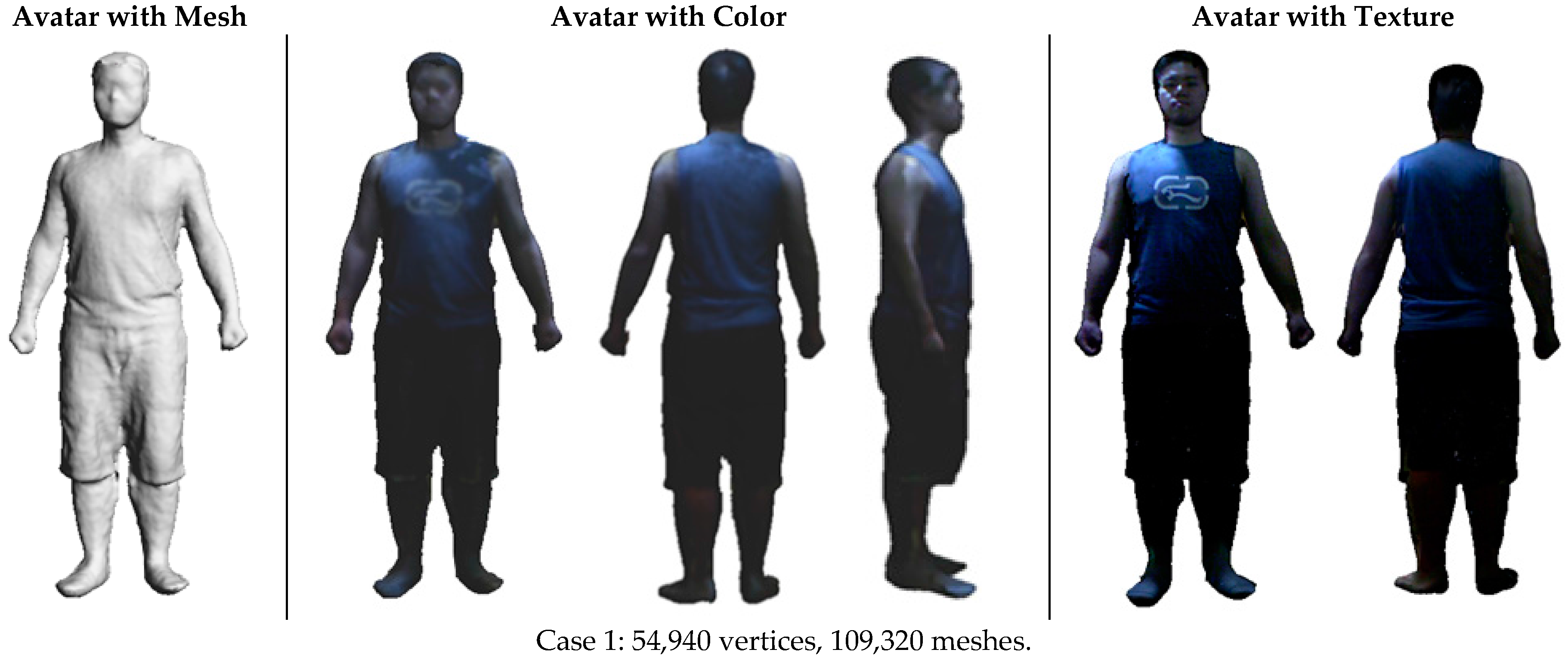
4.5. Watertight Reconstruction
4.6. Texture Mapping
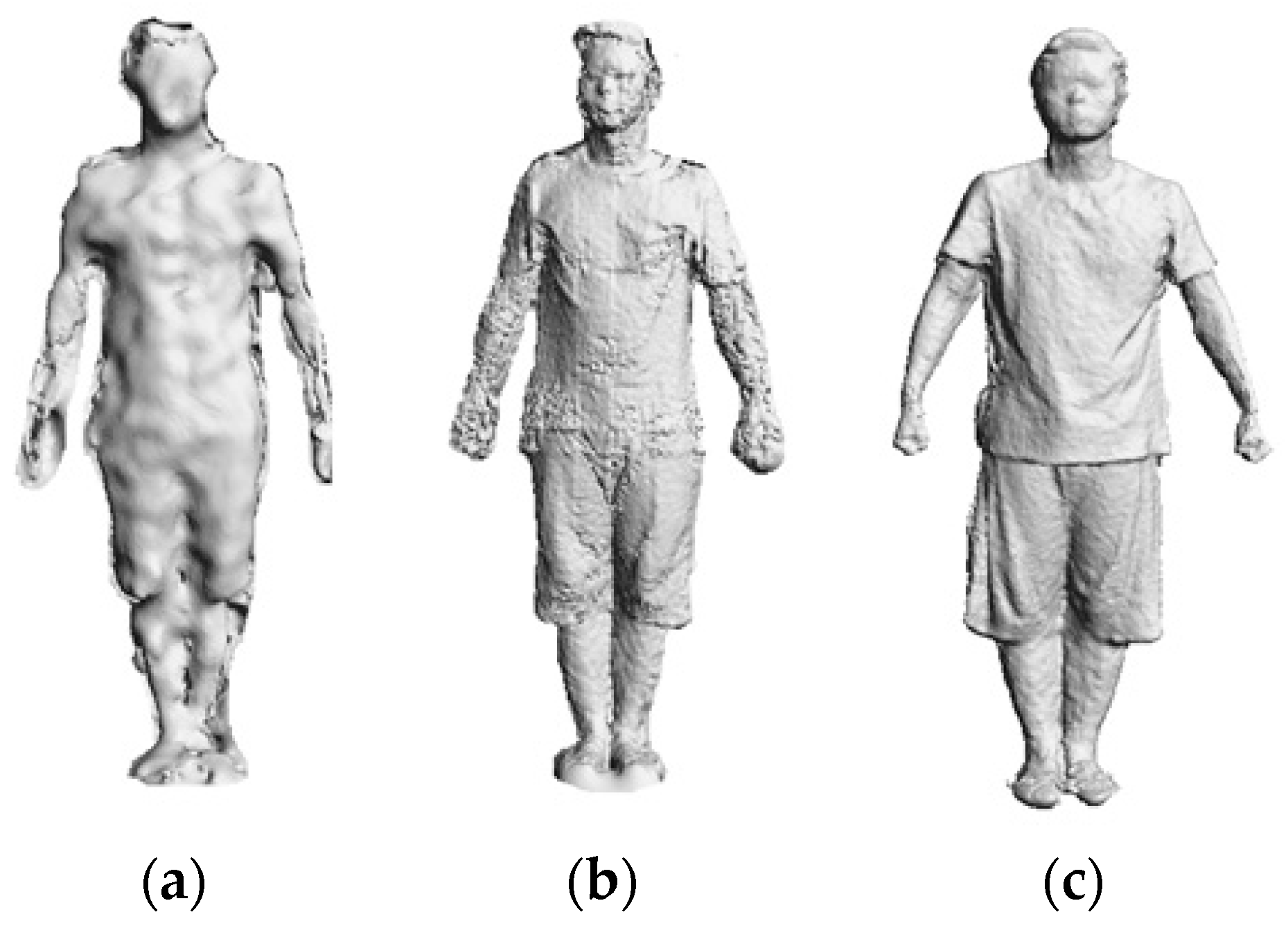
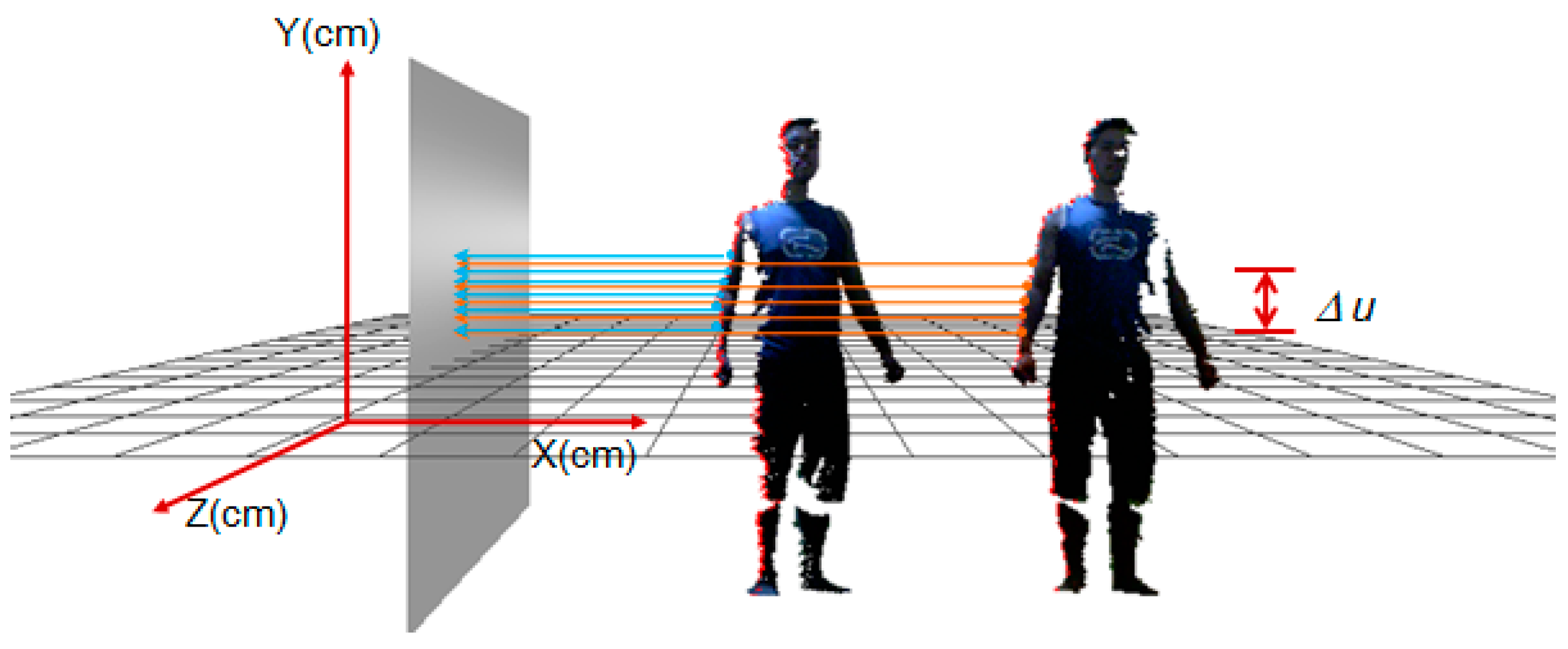
5. Results and Discussion
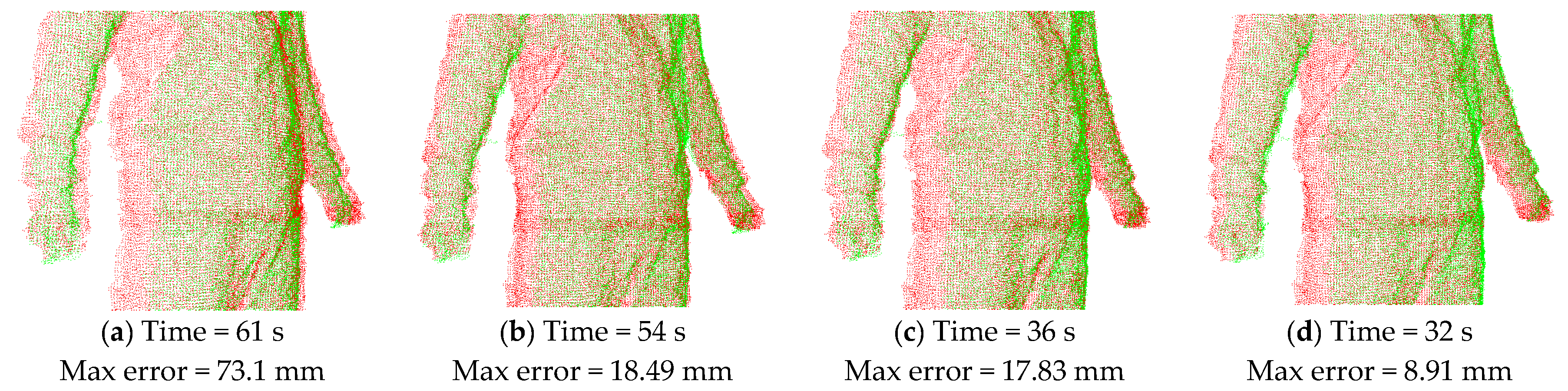
5.1. Experimental Results
5.2. Performance Comparison
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Microsoft Kinect. Available online: http://www.xbox.com/en-US/xbox-one/accessories/kinect-for-xbox-one (accessed on 10 September 2015).
- Anguelov, D.; Srinivasan, P.; Koller, D.; Thrun, S.; Rodgers, J.; Davis, J. SCAPE: Shape completion and animation of people. ACM Trans. Graph. 2005, 24, 408–416. [Google Scholar] [CrossRef]
- Cruz, L.; Lucio, D.; Velho, L. Kinect and RGBD images: Challenges and applications. In Proceedings of the 25th SIBGRAPI Conference on Graphics, Patterns and Images Tutorials (SIBGRAPI-T), Ouro Preto, Brazil, 22–25 August 2012; pp. 36–49. [Google Scholar]
- Weiss, A.; Hirshberg, D.; Black, M.J. Home 3D body scans from noisy image and range data. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1951–1958. [Google Scholar]
- Tong, J.; Zhou, J.; Liu, L.G.; Pan, Z.G.; Yan, H. Scanning 3D full human bodies using Kinects. IEEE Trans. Vis. Comput. Graph. 2012, 18, 643–650. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Chang, W.; Nolly, T.; Stricker, D. Kinectavatar: Fully automatic body capture using a single Kinect. In Proceedings of the Asian Conference on Computer Vision (ACCV), Daejeon, Korea, 5–9 November 2012; pp. 133–147. [Google Scholar]
- Li, H.; Vouga, E.; Gudym, A.; Luo, L.; Barron, J.T.; Gusev, G. 3D self-portraits. ACM Trans. Graph. 2013, 32, 187. [Google Scholar] [CrossRef]
- Chen, Y.; Dang, G.; Cheng, Z.Q.; Xu, K. Fast capture of personalized avatar using two Kinects. J. Manuf. Syst. 2014, 33, 233–240. [Google Scholar] [CrossRef]
- Zhu, H.Y.; Yu, Y.; Zhou, Y.; Du, S.D. Dynamic human body modeling using a single RGB camera. Sensors 2016, 16, 402. [Google Scholar] [CrossRef] [PubMed]
- Khoshelham, K.; Elberink, S.O. Accuracy and resolution of Kinect depth data for indoor mapping applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef] [PubMed]
- Canessa, A.; Chessa, M.; Gibaldi, A.; Sabatini, S.P.; Solari, F. Calibrated depth and color cameras for accurate 3D interaction in a stereoscopic augmented reality environment. J. Vis. Commun. Image Represent. 2014, 25, 227–237. [Google Scholar] [CrossRef]
- Herrera, D.; Kannala, J.; Heikkila, J. Joint depth and color camera calibration with distortion correction. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2058–2064. [Google Scholar] [CrossRef] [PubMed]
- Point Cloud Library. Available online: http://pointclouds.org (accessed on 15 September 2015).
- OpenNI. Available online: http://openni.org/ (accessed on 15 September 2015).
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohli, P.; Shotton, J.; Hodges, S. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Dong, H.W.; Nadia, F.; Abdulmotaleb, E.S. Towards consistent reconstructions of indoor spaces based on 6D RGB-D odometry and KinectFusion. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2014), Chicago, IL, USA, 14–18 September 2014; pp. 1796–1803. [Google Scholar]
- Ren, X.F.; Fox, D.; Konolige, K. Change their perception: RGB-D for 3-D modeling and recognition. IEEE Robot. Autom. Mag. 2013, 20, 49–59. [Google Scholar] [CrossRef]
- Khoshelham, K.; Santos, D.R.D.; Vosselman, G. Generation and weighting of 3D point correspondences for improved registration of RGB-D data. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Antalya, Turkey, 11–17 November 2013; pp. 127–132. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Third International Conference on 3D Digital Imaging and Modeling (3DIM), Quebec City, QC, Canada, 28 May–1 June 2001; pp. 144–152. [Google Scholar]
- Besl, P.J.; Mckay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Zinsser, T.; Schmidt, J.; Niemann, H. A refined ICP algorithm for robust 3-D correspondence estimation. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. II695–II698. [Google Scholar]
- Jost, T.; Hugli, H. A multi-resolution scheme ICP algorithm for fast shape registration. In Proceedings of the First International Symposium on 3D Data Processing Visualization and Transmission, Padova, Italy, 19–21 June 2002; pp. 540–543. [Google Scholar]
- Liu, Z.B.; Qin, H.L.; Bu, S.H.; Meng, Y.; Huang, J.X.; Tang, X.J.; Han, J.W. 3D real human reconstruction via multiple low-cost depth cameras. Signal Proc. 2015, 112, 162–179. [Google Scholar] [CrossRef]
- Chen, Y.; Medioni, G. Object modeling by registration of multiple range images. In Proceedings of the IEEE International Conference on Robotics and Automation, Sacramento, CA, USA, 9–11 April 1991; pp. 2724–2729. [Google Scholar]
- Masuda, T.; Sakaue, K.; Yokoya, N. Registration and integration of multiple range images for 3-D model construction. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996; pp. 879–883. [Google Scholar]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.F.; Fox, D. RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Endres, F.; Hess, J.; Engelhard, N.; Sturm, J.; Cremers, D.; Burgard, W. An evaluation of the RGB-D SLAM system. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 1691–1696. [Google Scholar]
- Li, H.; Sumner, R.W.; Pauly, M. Global correspondence optimization for non-rigid registration of depth scans. Comput. Graph. Forum 2008, 27, 1421–1430. [Google Scholar] [CrossRef]
- Nishino, K.; Ikeuchi, K. Robust simultaneous registration of multiple range images. In Proceedings of the 5th Asian Conference on Computer Vision, Melbourne, Australia, 22–25 January 2002; pp. 1–8. [Google Scholar]
- Li, H.; Adams, B.; Leonidas, J.G.; Mark, P. Robust single view geometry and motion reconstruction. In Proceedings of the 2nd ACM SIGGRAPH Conference and Exhibition in Asia, Yokohama, Japan, 19 December 2009. [Google Scholar]
- Zhang, Q.; Fu, B.; Ye, M.; Yang, R.G. Quality dynamic human body modeling using a single low-cost depth camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’14), Columbus, OH, USA, 23–28 June 2014; pp. 676–683. [Google Scholar]
- Kazhdan, M.; Hugues, H. Screened poisson surface reconstruction. ACM Trans. Graph. 2013, 32, 29. [Google Scholar] [CrossRef]
- Barron, J.T.; Malik, J. Shape, illumination, and reflectance from shading. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1670–1687. [Google Scholar] [CrossRef] [PubMed]
- Sorkine, O.; Cohen-Or, D.; Lipman, Y.; Alexa, M.; Rossl, C.; Seidel, H.P. Laplacian surface editing. In Proceedings of the 2004 Eurographics/ACM SIGGRAPH Symposium on Geometry Processing, Nice, France, 8–10 July 2004; pp. 175–184. [Google Scholar]
- Rusu, R.B. Semantic 3D object maps for everyday manipulation in human living environments. Künstliche Intell. 2010, 24, 345–348. [Google Scholar] [CrossRef]
- Low, K.L. Linear Least-Squares Optimization for Point-to-Plane ICP Surface Registration; Technical Report TR04-004; Department of Computer Science, University of North Carolina at Chapel Hill: Chapel Hill, NC, USA, 2004. [Google Scholar]
- Wang, R.Z.; Choi, J.; Medioni, G. 3D Modeling from wide baseline range scans using contour coherence. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 4018–4025. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Height (cm) | Neck to Hip Distance (cm) | Shoulder Width (cm) | Waist Length (cm) | Hip Length (cm) | Arm Length (cm) | Leg Length (cm) | |
|---|---|---|---|---|---|---|---|
| In [8] with two Kinect | 1.0 | 2.4 | 1.9 | 6.5 | 4.0 | 3.2 | 2.2 |
| In [5] with two Kinect | 2.5 | 1.5 | 6.2 | 3.8 | 3.0 | 2.1 | |
| In [6] with one Kinect | 2.1 | 1.0 | 3.2 | 2.6 | 2.3 | 3.1 | |
| In [9] with one Kinect | 3.7 | 3.3 | 1.4 | ||||
| Ours with one Kinect | 0.5 | 2.0 | 1.2 | 3.1 | 2.2 | 1.4 | 1.4 |
| In [6] with One Kinect (CPU Intel Xeon 2.67 GHz, 12 GB RAM) | In [7] with One Kinect (CPU Intel i7-930 2.8 Ghz, 4 Cores, 12 GB RAM) | Ours (CPU Intel i5-2450 m 2.5 GHz, 4 GB RAM) | ||||
|---|---|---|---|---|---|---|
| Steps | Time (s) | Steps | Time (s) | Steps | Time (s) | Time Complexity |
| Super-resolution | 28 | Scanning with ICP registration | 113 | Data capture | 99 | |
| Rigid | 110 | Poisson fusions | 130 | Segmentation and denoising | 15 | |
| Non-Rigid | 620 | Background segmentation | 22 | Local rigid alignment | 85 | |
| Poisson | 68 | Rigid alignment | 23 | Pre-alignment of multi-view | 3 | |
| Nonrigid alignment | 126 | Rigid alignment of multi-view | 62 | |||
| Albedo extraction | 120 (in Matlab) | Non-rigid alignment of multi-view | 200 | |||
| Visual hull | 14 | Watertight reconstruction | 21 | |||
| Final watertight fusion | 119 | Texture mapping | 100 | |||
| Poisson texture blending | 180 | |||||
| Total | 826 | Total | 847 | Total | 585 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, A.; Zhang, H.; Liu, Y.; Zheng, Y.; Li, G.; Han, G. Easy and Fast Reconstruction of a 3D Avatar with an RGB-D Sensor. Sensors 2017, 17, 1113. https://doi.org/10.3390/s17051113
Mao A, Zhang H, Liu Y, Zheng Y, Li G, Han G. Easy and Fast Reconstruction of a 3D Avatar with an RGB-D Sensor. Sensors. 2017; 17(5):1113. https://doi.org/10.3390/s17051113
Chicago/Turabian StyleMao, Aihua, Hong Zhang, Yuxin Liu, Yinglong Zheng, Guiqing Li, and Guoqiang Han. 2017. "Easy and Fast Reconstruction of a 3D Avatar with an RGB-D Sensor" Sensors 17, no. 5: 1113. https://doi.org/10.3390/s17051113
APA StyleMao, A., Zhang, H., Liu, Y., Zheng, Y., Li, G., & Han, G. (2017). Easy and Fast Reconstruction of a 3D Avatar with an RGB-D Sensor. Sensors, 17(5), 1113. https://doi.org/10.3390/s17051113