
Comparative Study of Neural Network Frameworks for the Next Generation of Adaptive Optics Systems

 , , , ,
, , , , 
Abstract
:1. Introduction
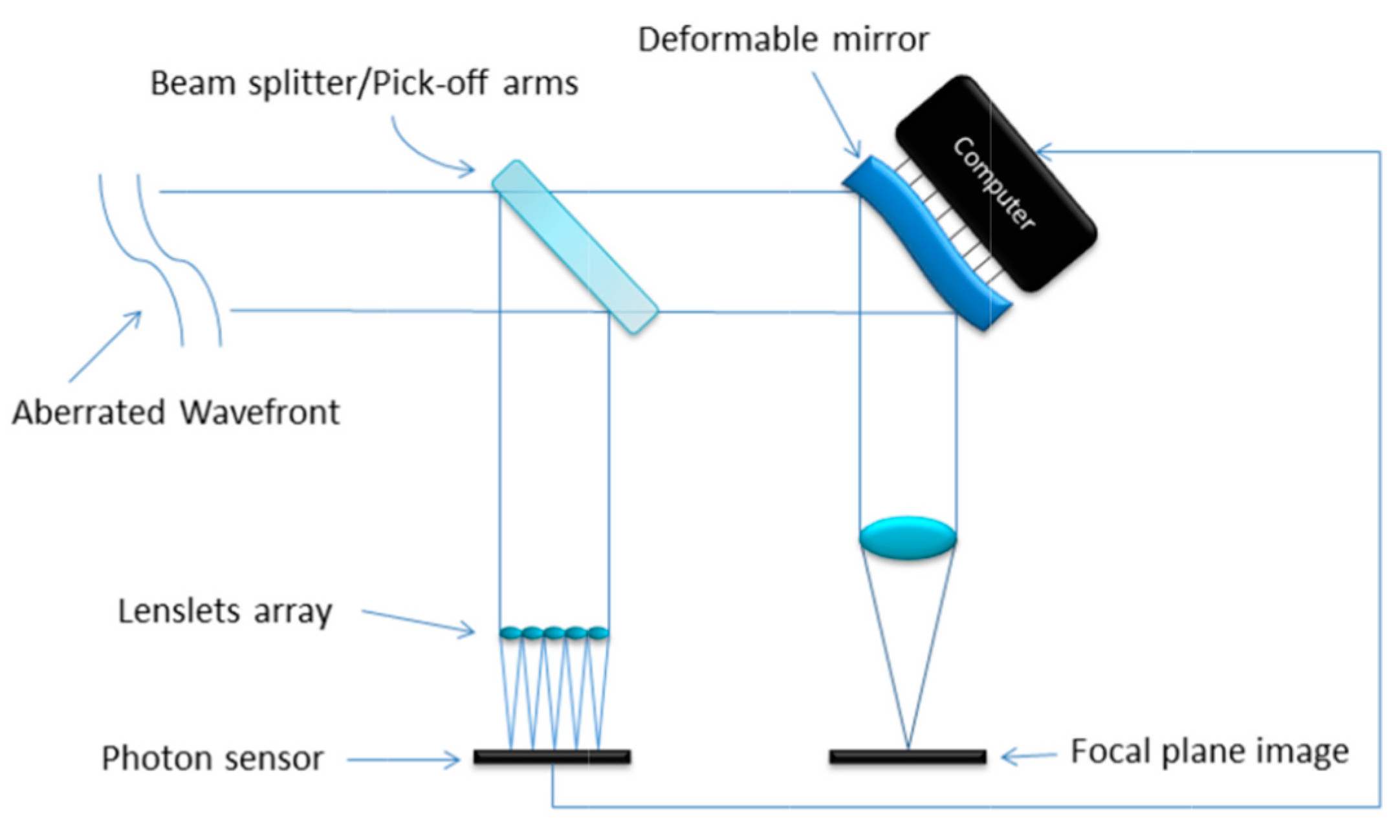
2. Adaptive Optics Systems
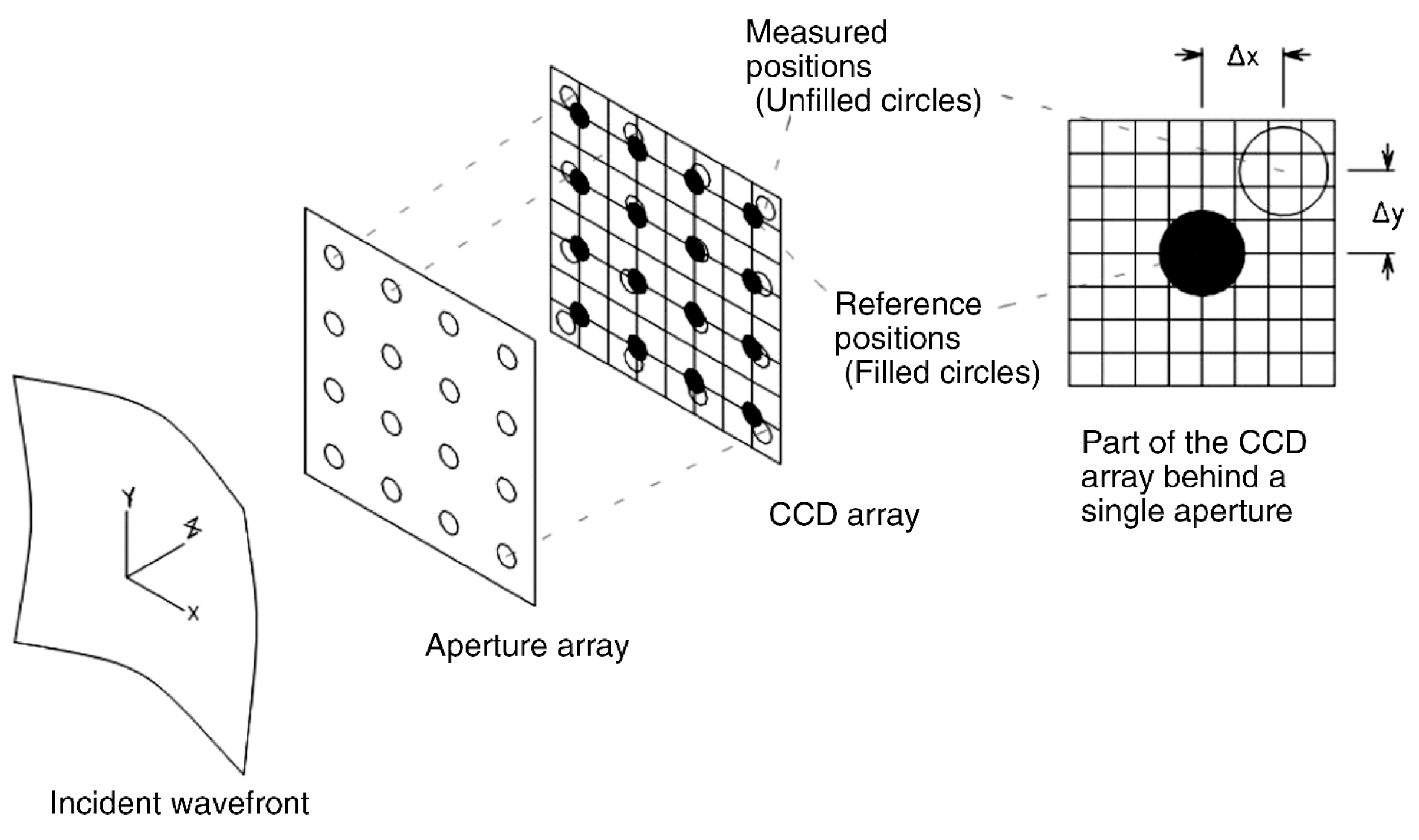
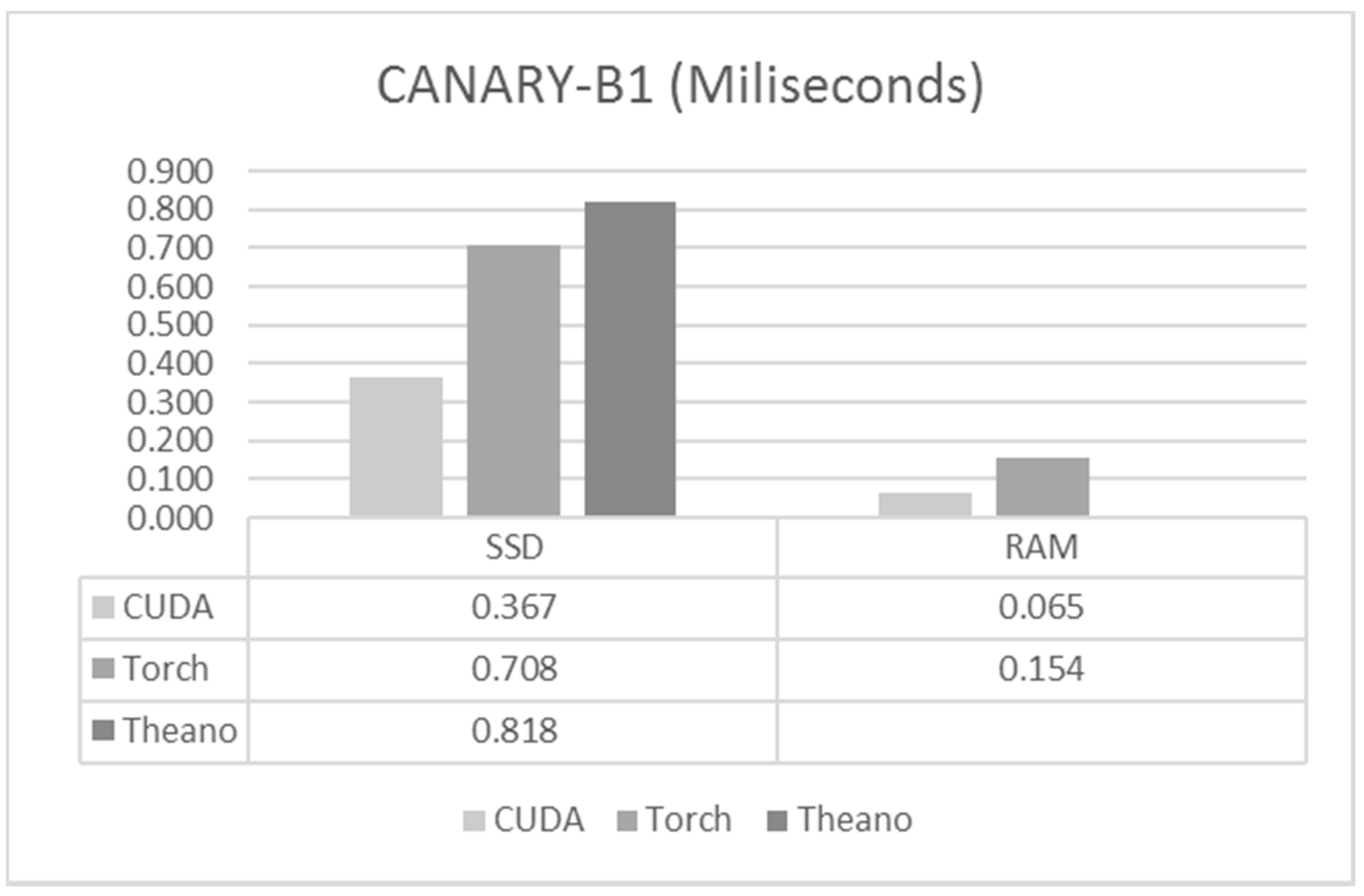
- CANARY Phase B1: is designed to perform observations with one Rayleigh Laser Guide Star (LGS), and up to four Natural Guide Stars (NGSs). It has a Shack Hartman Wavefront Sensor with 7 × 7 subapertures, although only 36 of them are activated due to the circular telescope pupil and secondary obscuration.
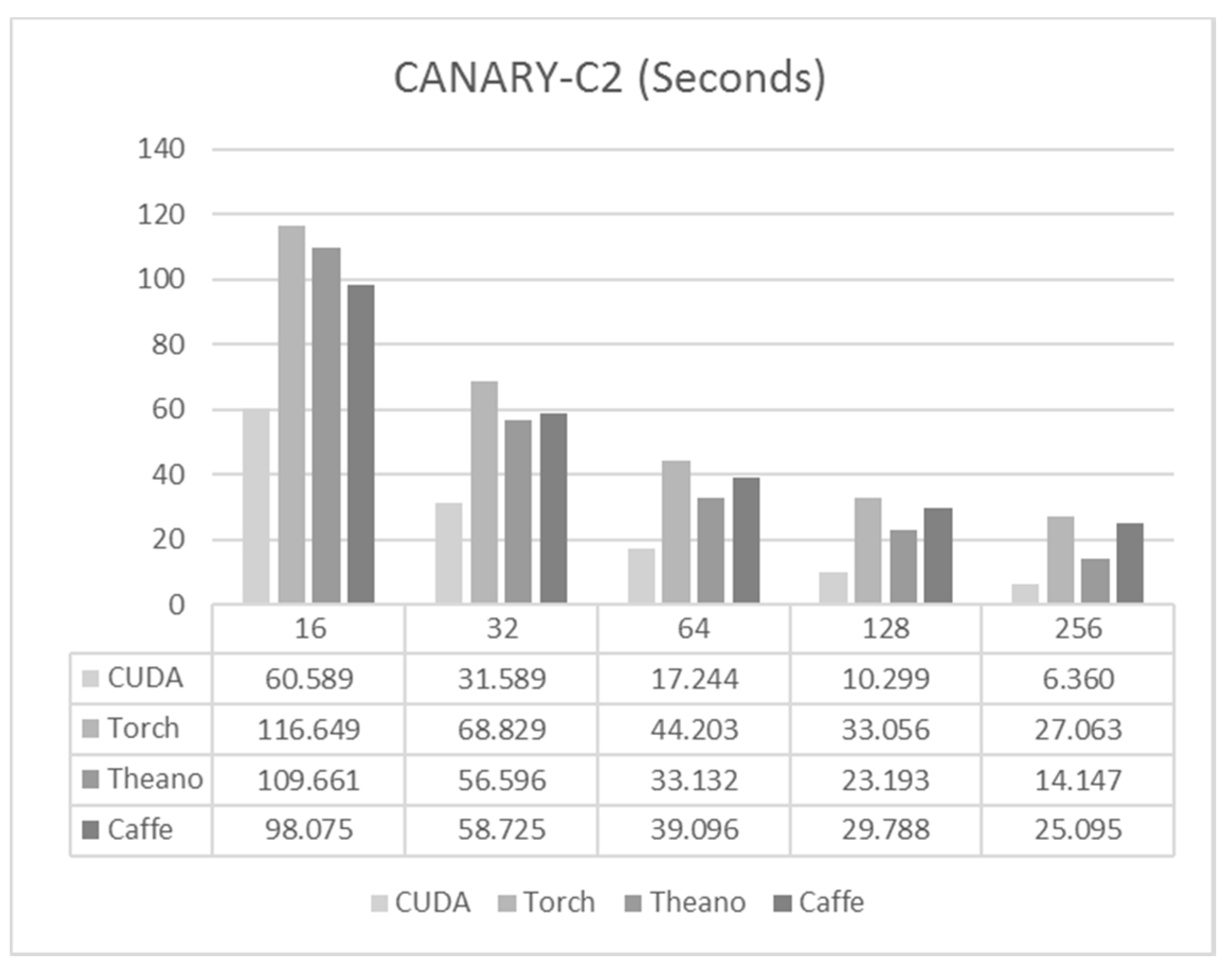
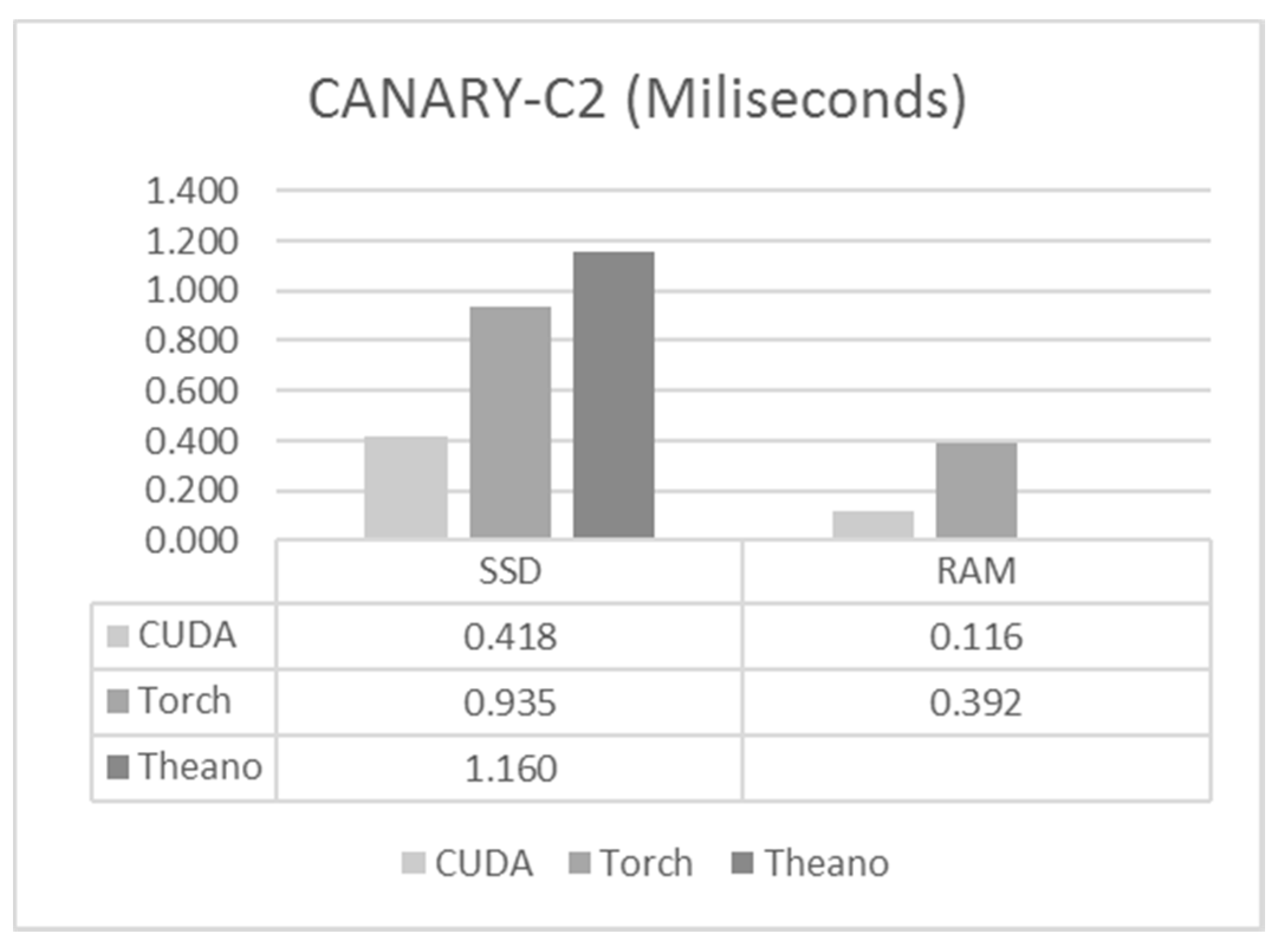
- CANARY Phase C2: is designed for the study of Laser Tomography AO (LTAO) and Multi-Object AO (MOAO). There are four Rayleigh Laser Guide Stars, and the corresponding wave-front sensors have 14 × 14 subapertures (144 active).
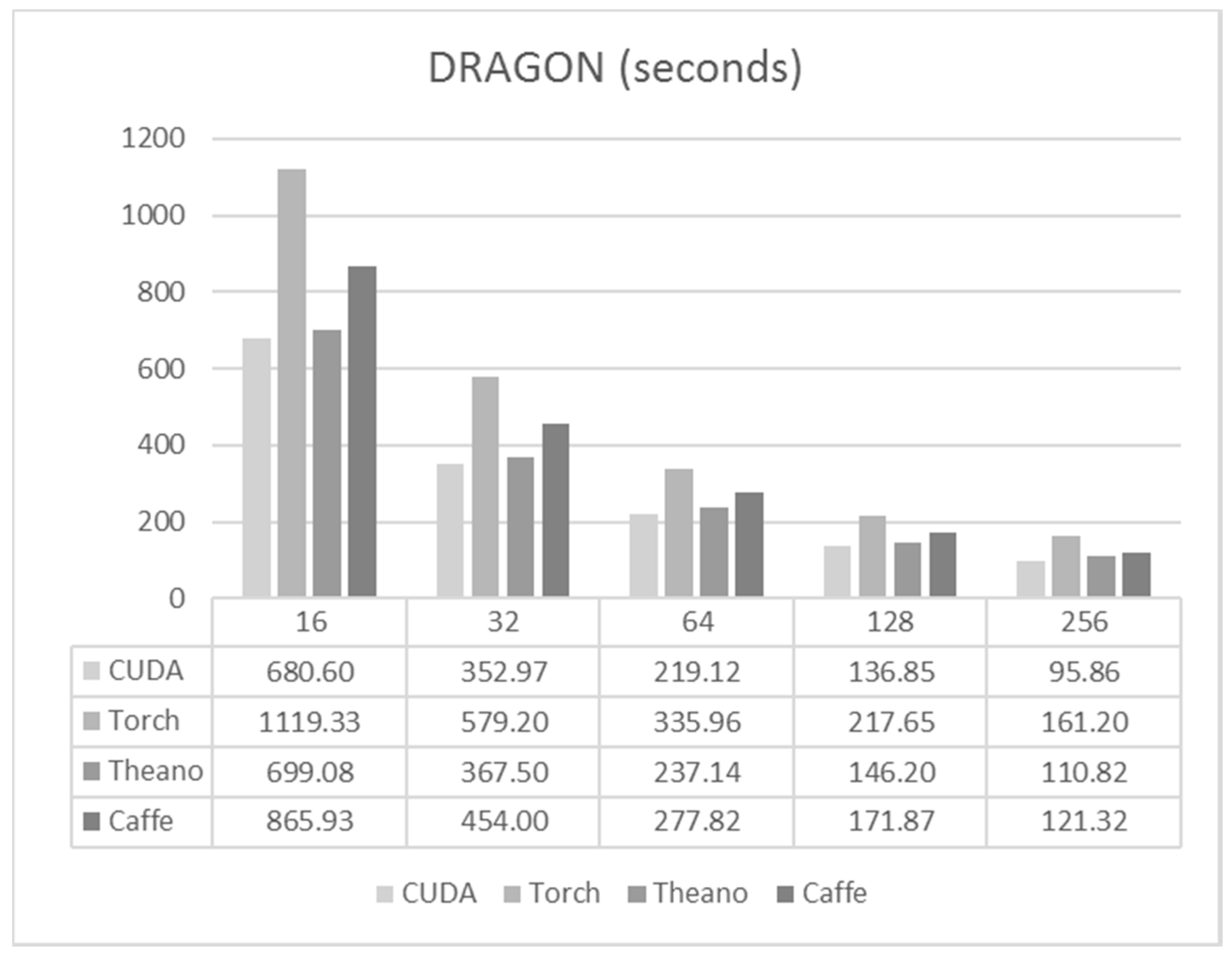
- DRAGON: DRAGON aims to replicate CANARY concepts, to provide a single channel MOAO system with a woofer-tweeter DM configuration, four NGSs and four LGSs each with 30 × 30 subapertures. In this case, DRAGON is still a prototype, so we are going to use the most challenging case scenario where all the subapertures are functional, which gives as a total of 900 subapertures per star.
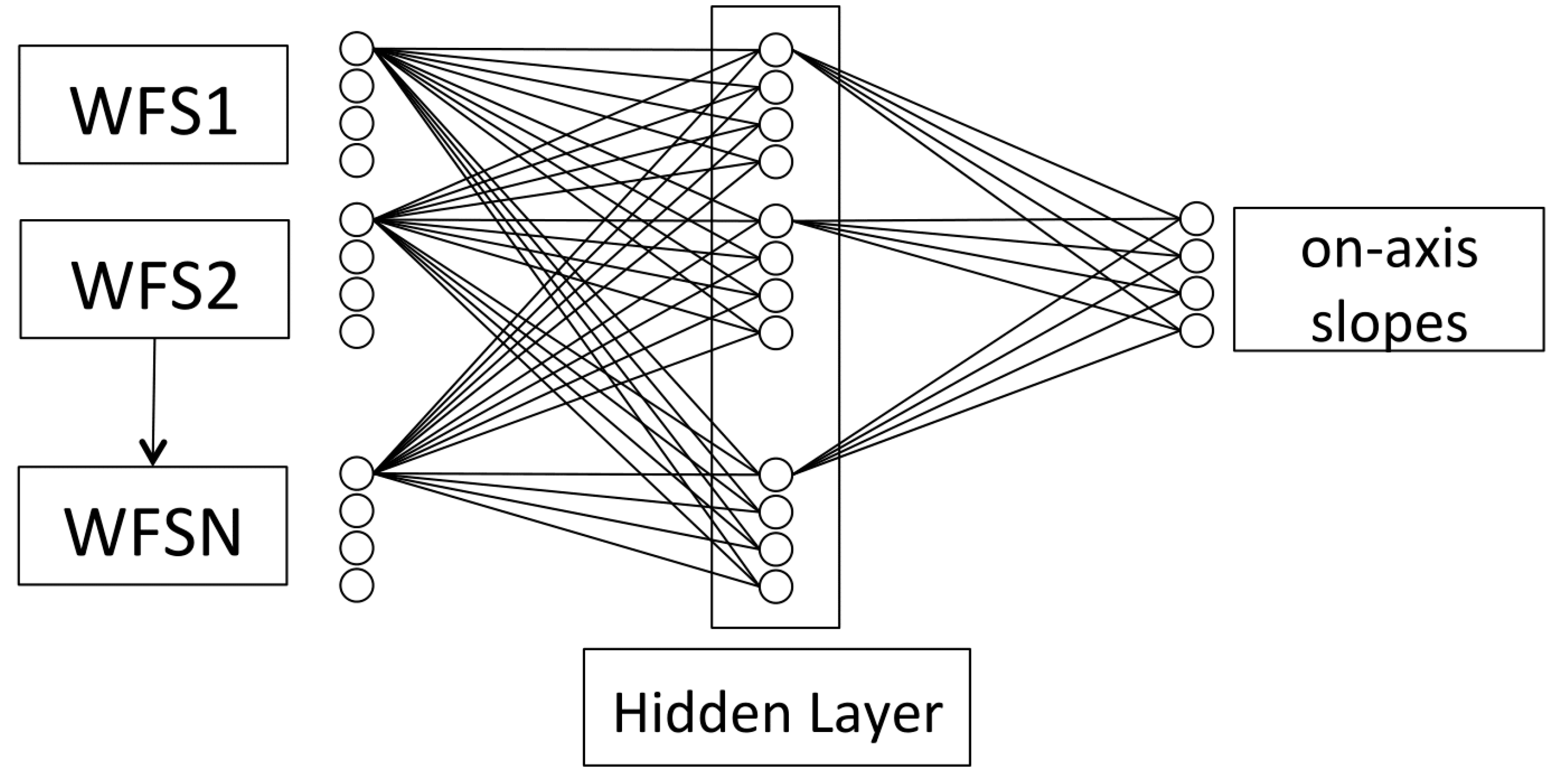
3. CARMEN Architecture
4. Overview of Neural Network Frameworks
4.1. Caffe
4.2. Torch
4.3. Theano
4.4. C/CUDA
5. Experiment Description
5.1. Training Benchmark
5.2. Execution Benchmark
5.3. Experiment Equipment
6. Results
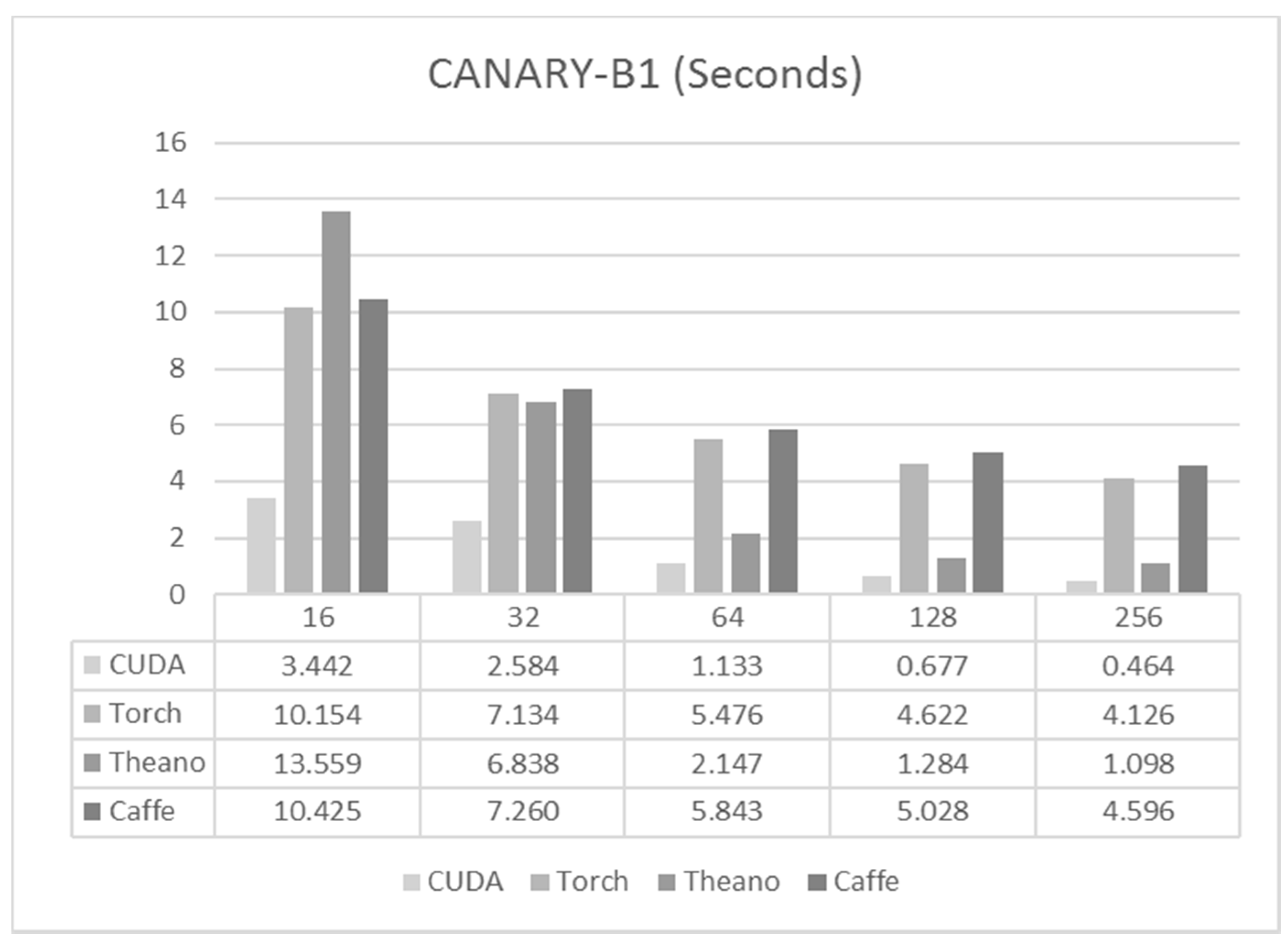
6.1. CANARY-B1
6.2. CANARY-C2
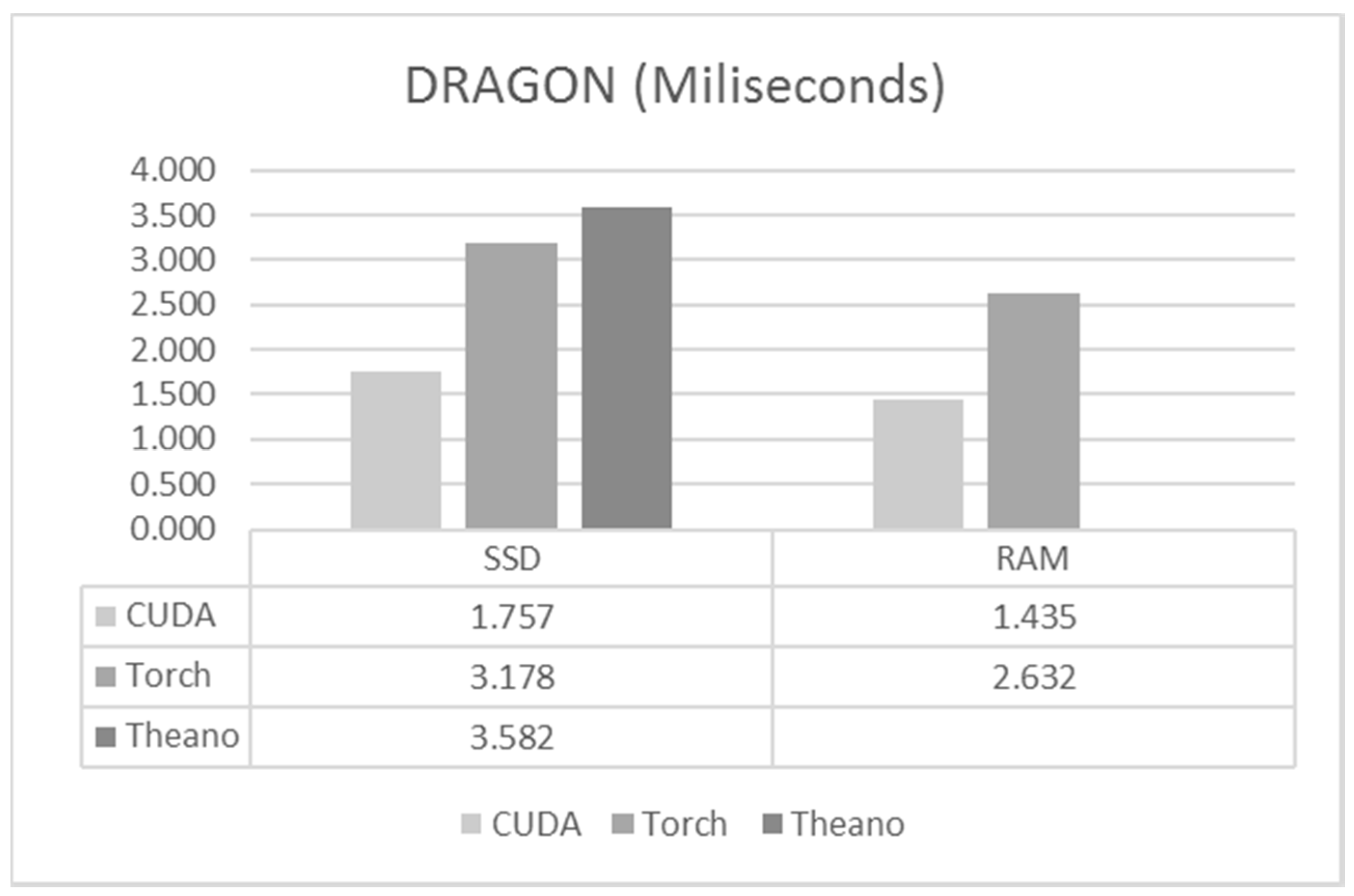
6.3. DRAGON
6.4. Discussion
7. Conclusions and Future Lines
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Guzmán, D.; Juez, F.J.D.C.; Myers, R.; Guesalaga, A.; Lasheras, F.S. Modeling a MEMS deformable mirror using non-parametric estimation techniques. Opt. Express 2010, 18, 21356–21369. [Google Scholar] [CrossRef] [PubMed]
- Basden, A.; Geng, D.; Myers, R.; Younger, E. Durham adaptive optics real-time controller. Appl. Opt. 2010, 49, 6354. [Google Scholar] [CrossRef] [PubMed]
- Guzmán, D.; de Juez, F.J.C.; Lasheras, F.S.; Myers, R.; Young, L. Deformable mirror model for open-loop adaptive optics using multivariate adaptive regression splines. Opt. Express 2010, 18, 6492–6505. [Google Scholar] [CrossRef] [PubMed]
- Ellerbroek, B.L. First-order performance evaluation of adaptive-optics systems for atmospheric-turbulence compensation in extended-field-of-view astronomical telescopes. J. Opt. Soc. Am. A 1994, 11, 783. [Google Scholar] [CrossRef]
- Fusco, T.; Conan, J.-M.; Rousset, G.; Mugnier, L.M.; Michau, V. Optimal wave-front reconstruction strategies for multiconjugate adaptive optics. J. Opt. Soc. Am. A 2001, 18, 2527. [Google Scholar] [CrossRef]
- Roggemann, M.C. Optical performance of fully and partially compensated adaptive optics systems using least-squares and minimum variance phase reconstructors. Comput. Electr. Eng. 1992, 18, 451–466. [Google Scholar] [CrossRef]
- Vidal, F.; Gendron, E.; Rousset, G. Tomography approach for multi-object adaptive optics. J. Opt. Soc. Am. A 2010, 27, A253–A264. [Google Scholar] [CrossRef] [PubMed]
- De Cos Juez, F.J.; Sánchez Lasheras, F.; Roqueñí, N.; Osborn, J. An ANN-based smart tomographic reconstructor in a dynamic environment. Sensors 2012, 12, 8895–8911. [Google Scholar] [CrossRef] [PubMed]
- Turrado, C.; López, M.; Lasheras, F.; Gómez, B.; Rollé, J.; Juez, F. Missing Data Imputation of Solar Radiation Data under Different Atmospheric Conditions. Sensors 2014, 14, 20382–20399. [Google Scholar] [CrossRef] [PubMed]
- Andersen, D.R.; Jackson, K.J.; Blain, C.; Bradley, C.; Correia, C.; Ito, M.; Lardière, O.; Véran, J.-P. Performance Modeling for the RAVEN Multi-Object Adaptive Optics Demonstrator. Publ. Astron. Soc. Pac. 2012, 124, 469–484. [Google Scholar] [CrossRef]
- Lardière, O.; Andersen, D.; Blain, C.; Bradley, C.; Gamroth, D.; Jackson, K.; Lach, P.; Nash, R.; Venn, K.; Véran, J.-P.; et al. Multi-object adaptive optics on-sky results with Raven. In Proceedings of the SPIE 9148, Adaptive Optics Systems IV, Montreal, QC, Canada, 22 June 2014; p. 91481G. [Google Scholar]
- Andrés, J.D.E.; Sánchez-lasheras, F.; Lorca, P.; de Cos Juez, F.J. A Hybrid Device of Self Organizing Maps (SOM) and Multivariate Adaptive Regression Splines (MARS) for the Forecasting of Firms’. J. Account. Manag. Inf. Syst. 2011, 10, 351–374. [Google Scholar]
- Fernández, J.R.A.; Díaz, C.; Niz, M.; Nieto, P.J.G.; De Cos Juez, F.J.; Lasheras, F.S.; Roqu Ní, M.N. Forecasting the cyanotoxins presence in fresh waters: A new model based on genetic algorithms combined with the MARS technique. Ecol. Eng. 2013, 53, 68–78. [Google Scholar] [CrossRef]
- Suárez Gómez, S.; Santos Rodríguez, J.; Iglesias Rodríguez, F.; de Cos Juez, F. Analysis of the Temporal Structure Evolution of Physical Systems with the Self-Organising Tree Algorithm (SOTA): Application for Validating Neural Network Systems on Adaptive Optics Data before On-Sky Implementation. Entropy 2017, 19, 103. [Google Scholar] [CrossRef]
- Vilán Vilán, J.A.; Alonso Fernández, J.R.; García Nieto, P.J.; Sánchez Lasheras, F.; de Cos Juez, F.J.; Díaz Muñiz, C. Support Vector Machines and Multilayer Perceptron Networks Used to Evaluate the Cyanotoxins Presence from Experimental Cyanobacteria Concentrations in the Trasona Reservoir (Northern Spain). Water Resour. Manag. 2013, 27, 3457–3476. [Google Scholar] [CrossRef]
- Casteleiro-Roca, J.-L.; Calvo-Rolle, J.; Méndez Pérez, J.; Roqueñí Gutiérrez, N.; de Cos Juez, F. Hybrid Intelligent System to Perform Fault Detection on BIS Sensor During Surgeries. Sensors 2017, 17, 179. [Google Scholar] [CrossRef] [PubMed]
- Suárez Sánchez, A.; Iglesias-Rodríguez, F.J.; Riesgo Fernández, P.; de Cos Juez, F.J. Applying the K-nearest neighbor technique to the classification of workers according to their risk of suffering musculoskeletal disorders. Int. J. Ind. Ergon. 2016, 52, 92–99. [Google Scholar] [CrossRef]
- De Cos Juez, F.J.; Sánchez Lasheras, F.; García Nieto, P.J.; Álvarez-Arenal, A. Non-linear numerical analysis of a double-threaded titanium alloy dental implant by FEM. Appl. Math. Comput. 2008, 206, 952–967. [Google Scholar] [CrossRef]
- De Cos Juez, F.J.; Suárez-Suárez, M.A.; Sánchez Lasheras, F.; Murcia-Mazón, A. Application of neural networks to the study of the influence of diet and lifestyle on the value of bone mineral density in post-menopausal women. Math. Comput. Model. 2011, 54, 1665–1670. [Google Scholar] [CrossRef]
- Lasheras, F.S.; Javier De Cos Juez, F.; Suárez Sánchez, A.; Krzemień, A.; Fernández, P.R. Forecasting the COMEX copper spot price by means of neural networks and ARIMA models. Resour. Policy 2015, 45, 37–43. [Google Scholar] [CrossRef]
- Osborn, J.; Juez, F.J.D.C.; Guzman, D.; Butterley, T.; Myers, R.; Guesalaga, A.; Laine, J. Using artificial neural networks for open-loop tomography. Opt. Express 2012, 20, 2420–2434. [Google Scholar] [CrossRef] [PubMed]
- Osborn, J.; Guzman, D.; Juez, F.J.D.C.; Basden, A.G.; Morris, T.J.; Gendron, E.; Butterley, T.; Myers, R.M.; Guesalaga, A.; Lasheras, F.S.; et al. Open-loop tomography with artificial neural networks on CANARY: On-sky results. Mon. Not. R. Astron. Soc. 2014, 441, 2508–2514. [Google Scholar] [CrossRef]
- Osborn, J.; Guzman, D.; de Cos Juez, F.J.; Basden, A.G.; Morris, T.J.; Gendron, É.; Butterley, T.; Myers, R.M.; Guesalaga, A.; Sanchez Lasheras, F.; et al. First on-sky results of a neural network based tomographic reconstructor: CARMEN on CANARY. In SPIE Astronomical Telescopes + Instrumentation; Marchetti, E., Close, L.M., Véran, J.-P., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2014; p. 91484M. [Google Scholar]
- Ramsay, S.K.; Casali, M.M.; González, J.C.; Hubin, N. The E-ELT instrument roadmap: A status report. In Proceedings of the SPIE 9147, Ground-based and Airborne Instrumentation for Astronomy V, Montreal, QC, Canada, 22 June 2014; Volume 91471Z. [Google Scholar]
- Marichal-Hernández, J.G.; Rodríguez-Ramos, L.F.; Rosa, F.; Rodríguez-Ramos, J.M. Atmospheric wavefront phase recovery by use of specialized hardware: Graphical processing units and field-programmable gate arrays. Appl. Opt. 2005, 44, 7587–7594. [Google Scholar] [CrossRef] [PubMed]
- Ltaief, H.; Gratadour, D. Shooting for the Stars with GPUs. Available online: http://on-demand.gputechconf.com/gtc/2015/video/S5122.html (accessed on 14 March 2016).
- González-Gutiérrez, C.; Santos-Rodríguez, J.D.; Díaz, R.Á.F.; Rolle, J.L.C.; Gutiérrez, N.R.; de Cos Juez, F.J. Using GPUs to Speed up a Tomographic Reconstructor Based on Machine Learning. In International Joint Conference SOCO’16-CISIS’16-ICEUTE’16; Springer: San Sebastian, Spain, 2017; pp. 279–289. [Google Scholar]
- Suárez Gómez, S.L.; González-Gutiérrez, C.; Santos-Rodríguez, J.D.; Sánchez Rodríguez, M.L.; Sánchez Lasheras, F.; de Cos Juez, F.J. Analysing the performance of a tomographic reconstructor with different neural networks frameworks. In Proceedings of the International Conference on Intelligent Systems Design and Applications, Porto, Portugal, 14–16 December 2016. [Google Scholar]
- Gulcehre, C. Deep Learning—Software Links. Available online: http://deeplearning.net/software_links/ (accessed on 15 February 2017).
- Bahrampour, S.; Ramakrishnan, N.; Schott, L.; Shah, M. Comparative Study of Deep Learning Software Frameworks. arXiv 2015. [Google Scholar]
- Soumith, C. Convnet-Benchmarks. Available online: https://github.com/soumith/convnet-benchmarks (accessed on 20 May 2016).
- Shi, S.; Wang, Q.; Xu, P.; Chu, X. Benchmarking State-of-the-Art Deep Learning Software Tools. arXiv 2016. [Google Scholar]
- Platt, B.C.; Shack, R. History and Principles of Shack-Hartmann Wavefront Sensing. J. Refract. Surg. 2001, 17, S573–S577. [Google Scholar] [PubMed]
- Southwell, W.H. Wave-front estimation from wave-front slope measurements. J. Opt. Soc. Am. 1980, 70, 998–1006. [Google Scholar] [CrossRef]
- Basden, A.G.; Atkinson, D.; Bharmal, N.A.; Bitenc, U.; Brangier, M.; Buey, T.; Butterley, T.; Cano, D.; Chemla, F.; Clark, P.; et al. Experience with wavefront sensor and deformable mirror interfaces for wide-field adaptive optics systems. Mon. Not. R. Astron. Soc 2016, 459, 1350–1359. [Google Scholar] [CrossRef]
- Morris, T.; Gendron, E.; Basden, A.; Martin, O.; Osborn, J.; Henry, D.; Hubert, Z.; Sivo, G.; Gratadour, D.; Chemla, F.; et al. Multiple Object Adaptive Optics: Mixed NGS/LGS tomography. In Proceedings of the Third AO4ELT Conference, Firenze, Italy, 26–31 May 2013. [Google Scholar]
- Chanan, G. Principles of Wavefront Sensing and Reconstruction. In Proceedings: Summer School on Adaptive Optics; Center for Adaptive Optics (CfAO): Santa Cruz, CA, USA, 2000; pp. 5–40. [Google Scholar]
- Xiao, X.; Zhang, Y.; Liu, X. Single exposure compressed imaging system with Hartmann-Shack wavefront sensor. Opt. Eng. 2014, 53, 53101. [Google Scholar] [CrossRef]
- Myers, R.M.; Hubert, Z.; Morris, T.J.; Gendron, E.; Dipper, N.A.; Kellerer, A.; Goodsell, S.J.; Rousset, G.; Younger, E.; Marteaud, M.; et al. CANARY: The on-sky NGS/LGS MOAO demonstrator for EAGLE. In SPIE Astronomical Telescopes+ Instrumentation; International Society for Optics and Photonics: Bellingham, WA, USA, 2008; p. 70150E. [Google Scholar]
- Reeves, A.P.; Myers, R.M.; Morris, T.J.; Basden, A.G.; Bharmal, N.A.; Rolt, S.; Bramall, D.G.; Dipper, N.A.; Younger, E.J. DRAGON, the Durham real-time, tomographic adaptive optics test bench: Progress and results. In SPIE Astronomical Telescopes+ Instrumentation; Marchetti, E., Close, L.M., Véran, J.-P., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2014; p. 91485U. [Google Scholar]
- Dipper, N.A.; Basden, A.; Bitenc, U.; Myers, R.M.; Richards, A.; Younger, E.J. Adaptive Optics for Extremely Large Telescopes III ADAPTIVE OPTICS REAL-TIME CONTROL SYSTEMS FOR THE E-ELT. In Proceedings of the Adaptive Optics for Extremely Large Telescopes III, Florence, Italy, 26–31 May 2013. [Google Scholar]
- Osborn, J.; De Cos Juez, F.J.; Guzman, D.; Butterley, T.; Myers, R.; Guesalaga, A.; Laine, J. Open-loop tomography using artificial nueral networks. In Proceedings of the Adaptive Optics for Extremely Large Telescopes II, Victoria, BC, Canada, 25–30 september 2011. [Google Scholar]
- Gómez Victoria, M. Research of the Tomographic Reconstruction Problem by Means of Data Mining and Artificial Intelligence Technologies. Ph.D. Thesis, Universidad de Oviedo, Asturias, Spain, 2014. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the ACM International Conference on Multimedia—MM ’14; ACM Press: New York, NY, USA, 2014; pp. 675–678. [Google Scholar]
- Al-Rfou, R.; Alain, G.; Almahairi, A.; Angermueller, C.; Bahdanau, D.; Ballas, N.; Bastien, F.; Bayer, J.; Belikov, A.; Belopolsky, A.; et al. Theano: A Python framework for fast computation of mathematical expressions. arXiv 2016. [Google Scholar]
- The HDF Group Introduction to HDF5. Available online: https://www.hdfgroup.org/HDF5/doc/H5.intro.html#Intro-WhatIs (accessed on 20 June 2016).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Funahashi, K.; Nakamura, Y. Approximation of dynamical systems by continuous time recurrent neural networks. Neural Netw. 1993, 6, 801–806. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Network Size | Training Data (Number of Samples) |
|---|---|---|
| CANARY-B1 | 216-216-72 | 350,000 |
| CANARY-C2 | 1152-1152-288 | 1,500,000 |
| DRAGON | 7200-7200-1800 | 1,000,000 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
González-Gutiérrez, C.; Santos, J.D.; Martínez-Zarzuela, M.; Basden, A.G.; Osborn, J.; Díaz-Pernas, F.J.; De Cos Juez, F.J. Comparative Study of Neural Network Frameworks for the Next Generation of Adaptive Optics Systems. Sensors 2017, 17, 1263. https://doi.org/10.3390/s17061263
González-Gutiérrez C, Santos JD, Martínez-Zarzuela M, Basden AG, Osborn J, Díaz-Pernas FJ, De Cos Juez FJ. Comparative Study of Neural Network Frameworks for the Next Generation of Adaptive Optics Systems. Sensors. 2017; 17(6):1263. https://doi.org/10.3390/s17061263
Chicago/Turabian StyleGonzález-Gutiérrez, Carlos, Jesús Daniel Santos, Mario Martínez-Zarzuela, Alistair G. Basden, James Osborn, Francisco Javier Díaz-Pernas, and Francisco Javier De Cos Juez. 2017. "Comparative Study of Neural Network Frameworks for the Next Generation of Adaptive Optics Systems" Sensors 17, no. 6: 1263. https://doi.org/10.3390/s17061263
APA StyleGonzález-Gutiérrez, C., Santos, J. D., Martínez-Zarzuela, M., Basden, A. G., Osborn, J., Díaz-Pernas, F. J., & De Cos Juez, F. J. (2017). Comparative Study of Neural Network Frameworks for the Next Generation of Adaptive Optics Systems. Sensors, 17(6), 1263. https://doi.org/10.3390/s17061263