
Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors

Abstract
:1. Introduction
2. Related Works
3. Proposed Method
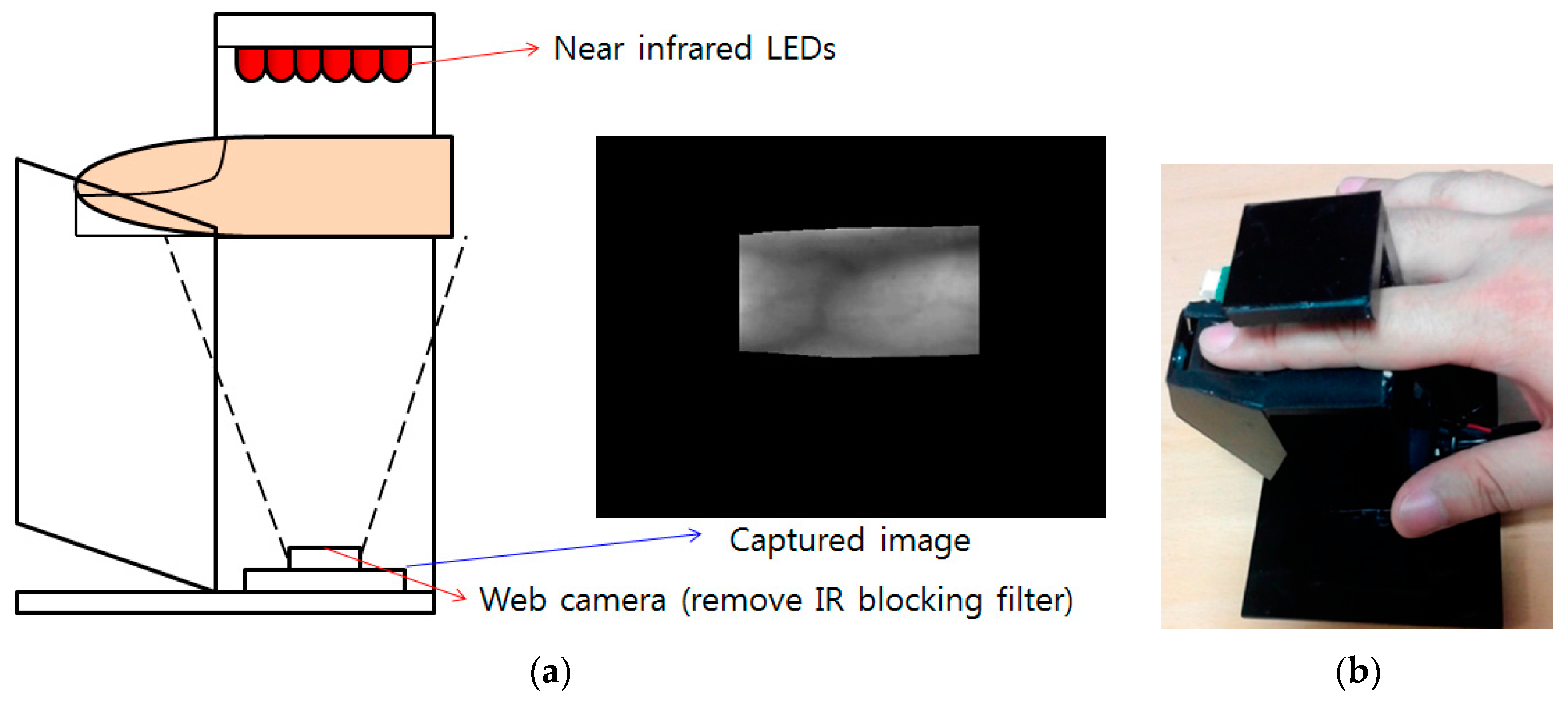
3.1. Overview of the Proposed System
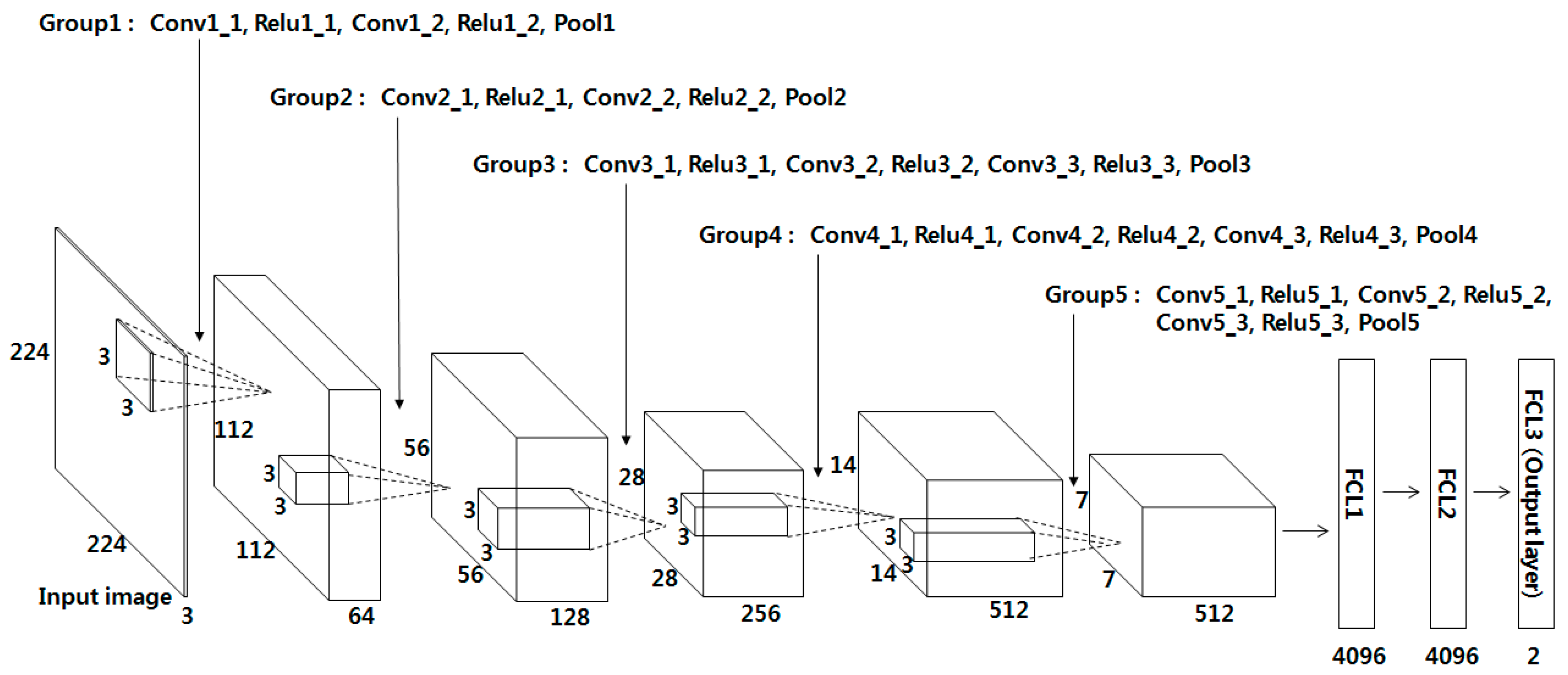
3.2. CNN-Based Finger-Vein Recognition
3.3. FCL of CNN
4. Experimental Results
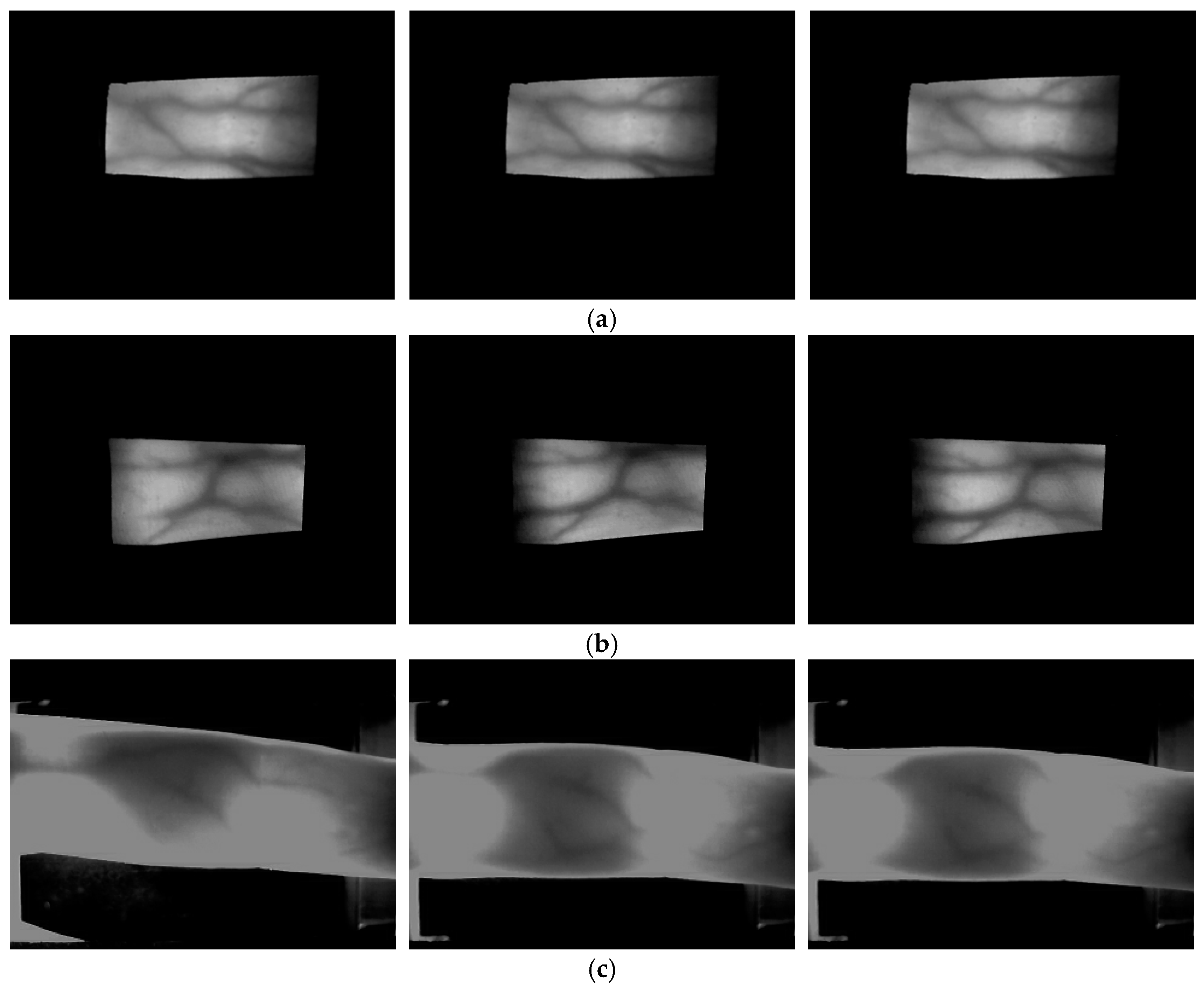
4.1. Experimental Data and Environment
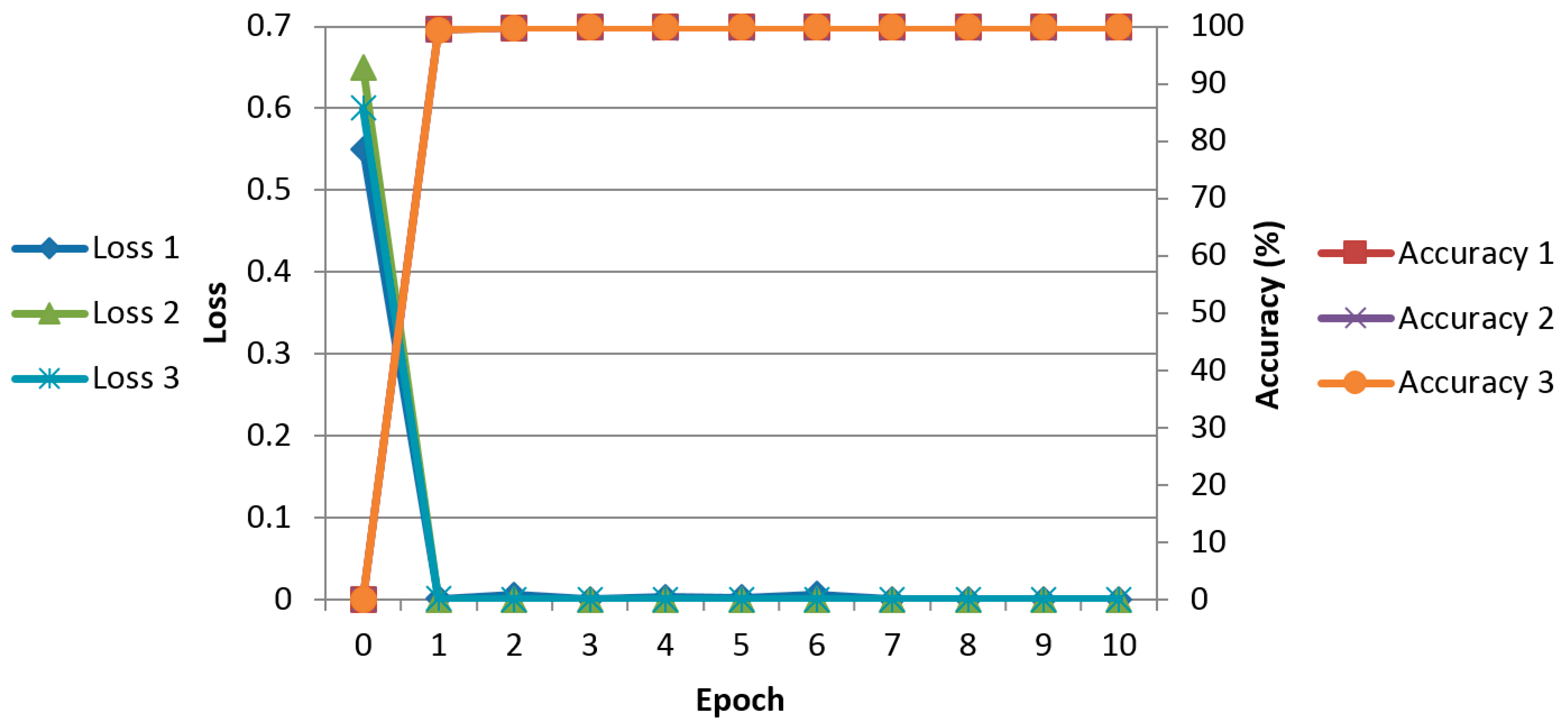
4.2. Training of CNN
4.3. Testing of the Proposed CNN-Based Finger-Vein Recognition
4.3.1. Comparative Experiments with the Original Finger-Vein Image and Gabor Filtered Image
4.3.2. Comparison of the Proposed Method with the Previous Method and Various CNN Nets
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Larrain, T.; Bernhard, J.S.; Mery, D.; Bowyer, K.W. Face Recognition Using Sparse Fingerprint Classification Algorithm. IEEE Trans. Inf. Forensic Secur. 2017, 12, 1646–1657. [Google Scholar] [CrossRef]
- Bonnen, K.; Klare, B.F.; Jain, A.K. Component-Based Representation in Automated Face Recognition. IEEE Trans. Inf. Forensic Secur. 2013, 8, 239–253. [Google Scholar] [CrossRef]
- Jain, A.K.; Arora, S.S.; Cao, K.; Best-Rowden, L.; Bhatnagar, A. Fingerprint Recognition of Young Children. IEEE Trans. Inf. Forensic Secur. 2017, 12, 1501–1514. [Google Scholar] [CrossRef]
- Ivanov, V.I.; Baras, J.S. Authentication of Swipe Fingerprint Scanners. IEEE Trans. Inf. Forensic Secur. 2017. [Google Scholar] [CrossRef]
- Daugman, J. How Iris Recognition Works. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 21–30. [Google Scholar] [CrossRef]
- Viriri, S.; Tapamo, J.R. Integrating Iris and Signature Traits for Personal Authentication Using User-specific Weighting. Sensors 2012, 12, 4324–4338. [Google Scholar] [CrossRef] [PubMed]
- Waluś, M.; Kosmala, J.; Saeed, K. Finger Vein Pattern Extraction Algorithm. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Wrocław, Poland, 23–25 May 2011; pp. 404–411. [Google Scholar]
- Kosmala, J.; Saeed, K. Human Identification by Vascular Patterns Biometrics and Kansei Engineering; Springer: New York, NY, USA, 2012; pp. 67–87. [Google Scholar]
- Marcolin, F.; Vezzetti, E. Novel Descriptors for Geometrical 3D Face Analysis. Multimedia Tools Appl. 2016. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F.; Tornincasa, S.; Maroso, P. Application of Geometry to RGB Images for Facial Landmark Localisation—A Preliminary Approach. Int. J. Biometr. 2016, 8, 216–236. [Google Scholar] [CrossRef]
- Wu, J.-D.; Ye, S.-H. Driver Identification Using Finger-vein Patterns with Radon Transform and Neural Network. Expert Syst. Appl. 2009, 36, 5793–5799. [Google Scholar] [CrossRef]
- Pham, T.D.; Park, Y.H.; Nguyen, D.T.; Kwon, S.Y.; Park, K.R. Nonintrusive Finger-vein Recognition System Using NIR Image Sensor and Accuracy Analyses According to Various Factors. Sensors 2015, 15, 16866–16894. [Google Scholar] [CrossRef] [PubMed]
- Rosdi, B.A.; Shing, C.W.; Suandi, S.A. Finger Vein Recognition Using Local Line Binary Pattern. Sensors 2011, 11, 11357–11371. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Yang, J.; Shi, Y. Finger-vein Segmentation Based on Multi-channel Even-symmetric Gabor Filters. In Proceedings of the IEEE International Conference on Intelligent Computing and Intelligent Systems, Shanghai, China, 20–22 November 2009; pp. 500–503. [Google Scholar]
- Yang, J.; Shi, Y.; Yang, J. Personal Identification Based on Finger-vein Features. Comput. Hum. Behav. 2011, 27, 1565–1570. [Google Scholar] [CrossRef]
- Wang, K.; Liu, J.; Popoola, O.P.; Feng, W. Finger Vein Identification Based on 2-D Gabor Filter. In Proceedings of the 2nd International Conference on Industrial Mechatronics and Automation, Wuhan, China, 30–31 May 2010; pp. 10–13. [Google Scholar]
- Yang, J.; Shi, Y.; Yang, J.; Jiang, L. A Novel Finger-Vein Recognition Method with Feature Combination. In Proceedings of the 16th IEEE International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 2709–2712. [Google Scholar]
- Peng, J.; Wang, N.; Abd El-Latif, A.A.; Li, Q.; Niu, X. Finger-Vein Verification Using Gabor Filter and SIFT Feature Matching. In Proceedings of the 8th International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Piraeus-Athens, Greece, 18–20 July 2012; pp. 45–48. [Google Scholar]
- Yang, J.F.; Yang, J.L. Multi-Channel Gabor Filter Design for Finger-Vein Image Enhancement. In Proceedings of the Fifth International Conference on Image and Graphics, Xi’an, China, 20–23 September 2009; pp. 87–91. [Google Scholar]
- Shin, K.Y.; Park, Y.H.; Nguyen, D.T.; Park, K.R. Finger-vein Image Enhancement Using a Fuzzy-based Fusion Method with Gabor and Retinex Filtering. Sensors 2014, 14, 3095–3129. [Google Scholar] [CrossRef] [PubMed]
- Park, Y.H.; Park, K.R. Image Quality Enhancement Using the Direction and Thickness of Vein Lines for Finger-vein Recognition. Int. J. Adv. Robot. Syst. 2012, 9, 1–10. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, J. Finger-Vein Image Enhancement Based on Combination of Gray-Level Grouping and Circular Gabor Filter. In Proceedings of the International Conference on Information Engineering and Computer Science, Wuhan, China, 19–20 December 2009; pp. 1–4. [Google Scholar]
- Yang, J.; Zhang, X. Feature-level Fusion of Global and Local Features for Finger-Vein Recognition. In Proceedings of the IEEE 10th International Conference on Signal Processing, Beijing, China, 24–28 October 2010; pp. 1702–1705. [Google Scholar]
- Lu, Y.; Yoon, S.; Park, D.S. Finger Vein Recognition Based on Matching Score-level Fusion of Gabor features. J. Korean Inst. Commun. Inf. Sci. 2013, 38A, 174–182. [Google Scholar] [CrossRef]
- Pi, W.; Shin, J.; Park, D. An Effective Quality Improvement Approach for Low Quality Finger Vein Image. In Proceedings of the International Conference on Electronics and Information Engineering, Kyoto, Japan, 1–3 August 2010; pp. V1-424–V1-427. [Google Scholar]
- Yu, C.B.; Zhang, D.M.; Li, H.B.; Zhang, F.F. Finger-Vein Image Enhancement Based on Multi-Threshold Fuzzy Algorithm. In Proceedings of the International Congress on Image and Signal Processing, Tianjin, China, 17–19 October 2009; pp. 1–3. [Google Scholar]
- Qian, X.; Guo, S.; Li, X.; Zhong, F.; Shao, X. Finger-vein Recognition Based on the Score Level Moment Invariants Fusion. In Proceedings of the International Conference on Computational Intelligence and Software Engineering, Wuhan, China, 11–13 December 2009; pp. 1–4. [Google Scholar]
- Yang, G.; Xi, X.; Yin, Y. Finger Vein Recognition Based on a Personalized Best Bit Map. Sensors 2012, 12, 1738–1757. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Yoon, S.; Xie, S.J.; Yang, J.; Wang, Z.; Park, D.S. Finger Vein Recognition Using Generalized Local Line Binary Pattern. KSII Trans. Internet Inf. Syst. 2014, 8, 1766–1784. [Google Scholar]
- Cho, S.R.; Park, Y.H.; Nam, G.P.; Shin, K.Y.; Lee, H.C.; Park, K.R.; Kim, S.M.; Kim, H.C. Enhancement of Finger-Vein Image by Vein Line Tracking and Adaptive Gabor Filtering for Finger-Vein Recognition. Appl. Mech. Mater. 2012, 145, 219–223. [Google Scholar] [CrossRef]
- Miura, N.; Nagasaka, A.; Miyatake, T. Feature Extraction of Finger-Vein Patterns Based on Repeated Line Tracking and its Application to Personal Identification. Mach. Vis. Appl. 2004, 15, 194–203. [Google Scholar] [CrossRef]
- Yang, J.; Shi, Y. Finger-vein ROI localization and vein ridge enhancement. Pattern Recognit. Lett. 2012, 33, 1569–1579. [Google Scholar] [CrossRef]
- Yang, J.; Wang, J. Finger-Vein Image Restoration Considering Skin Layer Structure. In Proceedings of the International Conference on Hand-Based Biometrics, Hong Kong, China, 17–18 November 2011; pp. 1–5. [Google Scholar]
- Yang, J.; Zhang, B.; Shi, Y. Scattering Removal for Finger-vein Image Restoration. Sensors 2012, 12, 3627–3640. [Google Scholar] [CrossRef] [PubMed]
- Lee, E.C.; Jung, H.; Kim, D. New Finger Biometric Method Using Near Infrared Imaging. Sensors 2011, 11, 2319–2333. [Google Scholar] [CrossRef] [PubMed]
- Cui, F.; Yang, G. Score Level Fusion of Fingerprint and Finger Vein Recognition. J. Comput. Inf. Syst. 2011, 7, 5723–5731. [Google Scholar]
- Ghazi, M.M.; Ekenel, H.K. A Comprehensive Analysis of Deep Learning Based Representation for Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 34–41. [Google Scholar]
- Wu, J.-D.; Liu, C.-T. Finger-Vein Pattern Identification Using SVM and Neural Network Technique. Expert Syst. Appl. 2011, 38, 14284–14289. [Google Scholar] [CrossRef]
- Qin, H.; Qin, L.; Xue, L.; He, X.; Yu, C.; Liang, X. Finger-Vein Verification Based on Multi-Features Fusion. Sensors 2013, 13, 15048–15067. [Google Scholar] [CrossRef] [PubMed]
- Raghavendra, R.; Busch, C. Presentation Attack Detection Algorithms for Finger Vein Biometrics: A Comprehensive Study. In Proceedings of the 11th International Conference on Signal Image Technology & Internet-Based Systems, Bangkok, Thailand, 23–27 November 2015; pp. 628–632. [Google Scholar]
- Khellat-kihel, S.; Abrishambaf, R.; Cardoso, N.; Monteiro, J.; Benyettou, M. Finger Vein Recognition Using Gabor Filter and Support Vector Machine. In Proceedings of the IEEE International Image Processing, Applications and Systems Conference, Hammamet, Tunisia, 5–7 November 2014; pp. 1–6. [Google Scholar]
- Radzi, S.A.; Khalil-Hani, M.; Bakhteri, R. Finger-Vein Biometric Identification Using Convolutional Neural Network. Turk. J. Electr. Eng. Comp. Sci. 2016, 24, 1863–1878. [Google Scholar] [CrossRef]
- Itqan, K.S.; Syafeeza, A.R.; Gong, F.G.; Mustafa, N.; Wong, Y.C.; Ibrahim, M.M. User Identification System Based on Finger-Vein Patterns Using Convolutional Neural Network. ARPN J. Eng. Appl. Sci. 2016, 11, 3316–3319. [Google Scholar]
- Melekhov, I.; Kannala, J.; Rahtu, E. Siamese Network Features for Image Matching. In Proceedings of the 23rd International Conference on Pattern Recognition, Cancún, Mexico, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Dongguk Finger-Vein Database (DFingerVein-DB1) & CNN Model. Available online: http://dm.dgu.edu/link.html (accessed on 23 May 2017).
- SFH 4783. Available online: http://www.osram-os.com/osram_os/en/products/product-catalog/infrared-emitters,-detectors-andsensors/infrared-emitters/high-power-emitter-gt500mw/emitters-with-850nm/sfh-4783/index.jsp (accessed on 7 April 2017).
- Webcam C600. Available online: http://www.logitech.com/en-us/support/5869 (accessed on 7 April 2017).
- KODAK PROFESSIONAL High-Speed Infrared Film. Available online: http://wwwuk.kodak.com/global/en/professional/support/techPubs/f13/f13.pdf (accessed on 7 April 2017).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/#overview (accessed on 7 March 2017).
- Convolutional Neural Network. Available online: https://en.wikipedia.org/wiki/Convolutional_neural_network (accessed on 7 March 2017).
- Heaton, J. Artificial Intelligence for Humans, Volume 3: Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- SDUMLA-HMT Finger Vein Database. Available online: http://mla.sdu.edu.cn/sdumla-hmt.html (accessed on 17 February 2017).
- Caffe. Available online: http://caffe.berkeleyvision.org (accessed on 17 February 2017).
- Jiang, Z.; Wang, Y.; Davis, L.; Andrews, W.; Rozgic, V. Learning Discriminative Features via Label Consistent Neural Network. arXiv, 2016; arXiv:1602.01168. [Google Scholar]
- Li, D.; Zhang, Z.; Chen, X.; Ling, H.; Huang, K. A Richly Annotated Dataset for Pedestrian Attribute Recognition. arXiv, 2016; arXiv:1603.07054. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Bianco, S.; Buzzelli, M.; Mazzini, D.; Schettini, R. Deep Learning for Logo Recognition. Neurocomputing 2017, 245, 23–30. [Google Scholar] [CrossRef]
- Stochastic Gradient Descent. Available online: https://en.wikipedia.org/wiki/Stochastic_gradient_descent (accessed on 7 March 2017).
- Biometrics. Available online: https://en.wikipedia.org/wiki/Biometrics (accessed on 1 June 2017).
- Toh, K.-A.; Kim, J.; Lee, S. Biometric Scores Fusion Based on Total Error Rate Minimization. Pattern Recognit. 2008, 41, 1066–1082. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Strength | Weakness | ||
|---|---|---|---|---|---|
| Non-training-based | Image enhancement based on the blood vessel direction | Gabor filter [14,15,16,17,18,19,20,21,22], Edge-preserving and elliptical high-pass filters [25] | Improved finger-vein recognition accuracy based on clear quality images | Recognition performance is affected by the misalignment and shading of finger-vein images. | |
| Method considering local patterns of blood vessel | Local binary pattern (LBP) [12], personalized best bit map (PBBM) [28] | Processing speed is fast because the entire texture data of ROI is used without detecting the vein line | |||
| Method considering the vein line characteristics | LLBP [13,29] | Recognition accuracy is high because the blood vessel features are used instead of the entire texture data of ROI | |||
| Vein line tracking [30,31] | |||||
| Training-based | SVM [38,39,40,41] | Robust to various factors and environmental changes because many images with shading and misalignments are learned. | A separate process of optimal feature extraction and dimension reduction is required for the input to SVM | ||
| CNN | Reduced-complexity four-layer CNN [42,43] | A separate process of optimal feature extraction and dimension reduction is not necessary | Cannot be applied to finger-vein images of non-trained classes | ||
| Proposed method | Finger-vein images of non-trained classes can be recognized | The CNN structure is more complex than existing methods [42,43] | |||
| Layer Type | Number of Filter | Size of Feature Map | Size of Kernel | Number of Stride | Number of Padding | |
|---|---|---|---|---|---|---|
| Image input layer | 224 (height) × 224 (width) × 3 (channel) | |||||
| Group 1 | Conv1_1 (1st convolutional layer) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu1_1 | 224 × 224 × 64 | |||||
| Conv1_2 (2nd convolutional layer) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu1_2 | 224 × 224 × 64 | |||||
| Pool1 | 1 | 112 × 112 × 64 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 2 | Conv2_1 (3rd convolutional layer) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu2_1 | 112 × 112 × 128 | |||||
| Conv2_2 (4th convolutional layer) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu2_2 | 112 × 112 × 128 | |||||
| Pool2 | 1 | 56 × 56 × 128 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 3 | Conv3_1 (5th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu3_1 | 56 × 56 × 256 | |||||
| Conv3_2 (6th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1×1 | 1 × 1 | |
| Relu3_2 | 56 × 56 × 256 | |||||
| Conv3_3 (7th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu3_3 | 56 × 56 × 256 | |||||
| Pool3 | 1 | 28 × 28 × 256 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 4 | Conv4_1 (8th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu4_1 | 28 × 28 × 512 | |||||
| Conv4_2 (9th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu4_2 | 28 × 28 × 512 | |||||
| Conv4_3 (10th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu4_3 | 28 × 28 × 512 | |||||
| Pool4 | 1 | 14 × 14 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 5 | Conv5_1 (11th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| Relu5_1 | 14 × 14 × 512 | |||||
| Conv5_2 (12th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu5_2 | 14 × 14 × 512 | |||||
| Conv5_3 (13th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| Relu5_3 | 14 × 14 × 512 | |||||
| Pool5 | 1 | 7 × 7 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Fc6 (1st FCL) | 4096 × 1 | |||||
| Relu6 | 4096 × 1 | |||||
| Dropout6 | 4096 × 1 | |||||
| Fc7 (2nd FCL) | 4096 × 1 | |||||
| Relu7 | 4096 × 1 | |||||
| Dropout7 | 4096 × 1 | |||||
| Fc8 (3rd FCL) | 2 × 1 | |||||
| Softmax layer | 2 × 1 | |||||
| Output layer | 2 × 1 | |||||
| Good-Quality Database | Mid-Quality Database | Low-Quality Database | |||
|---|---|---|---|---|---|
| Original images | # of images | 1200 | 1980 | 3816 | |
| # of people | 20 | 33 | 106 | ||
| # of hands | 2 | 2 | 2 | ||
| # of fingers * | 3 | 3 | 3 | ||
| # of classes (# of images per class) | 120 (10) | 198 (10) | 636 (6) | ||
| Data augmentation for training | CNN using original image as input (Case 1) | # of images | 72,600 (60 classes × 10 images × 121 times) | 119,790 (99 classes × 10 images × 121 times) | 230,868 (318 classes × 6 images × 121 times) |
| CNN using difference image as input (Case 2) | # of images | 15,480 | 25,542 | 48,972 | |
| 7740 ** ((10 images × 13 times – 1) × 60 classes) | 12,771 ** ((10 images × 13 times – 1) × 99 classes) | 24,486 ** ((6 images × 13 times – 1) × 318 classes) | |||
| 7740 *** | 12,771 *** | 24,486 *** | |||
| Input Image | Original Image as Input to CNN (Case 1 of Table 2) | Difference Image as Input to CNN (Case 2 of Table 2) | ||||
|---|---|---|---|---|---|---|
| Net configuration | VGG Face (no fine-tuning/fine-tuning) | VGG Net-16 (no fine-tuning/fine-tuning) | VGG Net-19 (no fine-tuning/fine-tuning) | Revised Alexnet-1 (whole training) | Revised Alexnet-2 (whole training) | VGG Net-16 (fine-tuning) (Proposed method) |
| Method name | A/A−1 | B/B−1 | C/C−1 | D | E | F |
| # of layers | 16 | 16 | 19 | 8 | 8 | 16 |
| Filter size (# of filters) | conv3 (64) conv3 (64) | conv3 (64) conv3 (64) | conv3 (64) conv3 (64) | Conv11 (96) | conv3 (64) | conv3 (64) conv3 (64) |
| Pooling type | MAX | MAX | MAX | MAX | MAX | MAX |
| Filter size (# of filters) | conv3 (128) conv3 (128) | conv3 (128) conv3 (128) | conv3 (128) conv3 (128) | Conv5 (128) | conv3 (128) | conv3 (128) conv3 (128) |
| Pooling type | MAX | MAX | MAX | MAX | MAX | MAX |
| Filter size (# of filters) | conv3 (256) conv3 (256) conv3 (256) | conv3 (256) conv3 (256) conv3 (256) | conv3 (256) conv3 (256) conv3 (256) conv3 (256) | conv3 (256) | conv3 (256) | conv3 (256) conv3 (256) conv3 (256) |
| Pooling type | MAX | MAX | MAX | MAX | MAX | |
| Filter size (# of filters) | conv3 (512) conv3 (512) conv3 (512) | conv3 (512) conv3 (512) conv3 (512) | conv3 (512) conv3 (512) conv3 (512) conv3 (512) | conv3 (256) | conv3 (256) | conv3 (512) conv3 (512) conv3 (512) |
| Pooling type | MAX | MAX | MAX | MAX | MAX | |
| Filter size (# of filters) | conv3 (512) conv3 (512) conv3 (512) | conv3 (512) conv3 (512) conv3 (512) | conv3 (512) conv3 (512) conv3 (512) conv3 (512) | conv3 (128) | conv3 (128) | conv3 (512) conv3 (512) conv3 (512) |
| Pooling type | MAX | MAX | MAX | MAX | MAX | MAX |
| Fc6 (1st FCL) | 4096 | 4096 | 4096 | 4096 | 2048 | 4096 |
| Fc7 (2nd FCL) | 4096 | 4096 | 4096 | 1024 | 2048 | 4096 |
| Fc8 (3rd FCL) | 2622/# of class | 1000/# of class | 1000/# of class | 2 | 2 | 2 |
| Method Name | Input Image | EER (%) | ||
|---|---|---|---|---|
| Good-Quality Database | Mid-Quality Database | Low-Quality Database | ||
| B (of Table 4) (VGG Net-16 (no fine-tuning)) | Gabor filtered image | 1.078 | 4.016 | 7.905 |
| Original image | 1.481 | 4.928 | 7.278 | |
| B-1 (of Table 4) (VGG Net-16 (fine-tuning)) | Gabor filtered image | 0.830 | 3.412 | 7.437 |
| Original image | 0.804 | 2.967 | 6.115 | |
| Method Name | Input Image | Features (or Values) Used for Recognition | EER (%) | ||
|---|---|---|---|---|---|
| Good-Quality Database | Mid-Quality Database | Low-Quality Database | |||
| Previous method [12] | Original image | - | 0.474 | 2.393 | 8.096 |
| A (VGG Face (no fine-tuning)) | Fc7 | 1.536 | 5.177 | 7.264 | |
| A-1 (VGG Face (fine-tuning)) | Fc7 | 0.858 | 3.214 | 7.044 | |
| B (VGG Net-16 (no fine-tuning)) | Fc7 | 1.481 | 4.928 | 7.278 | |
| B-1 (VGG Net-16 (fine-tuning)) | Fc7 | 0.804 | 2.967 | 6.115 | |
| C (VGG Net-19 (no fine-tuning)) | Fc7 | 4.001 | 8.216 | 6.692 | |
| C-1 (VGG Net-19 (fine-tuning)) | Fc7 | 1.061 | 6.172 | 6.443 | |
| D (Revised Alexnet-1 (whole training)) | Difference image | Fc8 | 0.901 | 8.436 | 8.727 |
| E (Revised Alexnet-2 (whole training)) | Fc8 | 0.763 | 4.767 | 6.540 | |
| F (VGG Net-16 (fine-tuning) (proposed method)) | Fc8 | 0.396 | 1.275 | 3.906 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors. Sensors 2017, 17, 1297. https://doi.org/10.3390/s17061297
Hong HG, Lee MB, Park KR. Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors. Sensors. 2017; 17(6):1297. https://doi.org/10.3390/s17061297
Chicago/Turabian StyleHong, Hyung Gil, Min Beom Lee, and Kang Ryoung Park. 2017. "Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors" Sensors 17, no. 6: 1297. https://doi.org/10.3390/s17061297
APA StyleHong, H. G., Lee, M. B., & Park, K. R. (2017). Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors. Sensors, 17(6), 1297. https://doi.org/10.3390/s17061297