
Context Relevant Prediction Model for COPD Domain Using Bayesian Belief Network



Abstract
:1. Introduction
2. Issues
Discussion
3. Related Works
3.1. Context Aware Systems
3.1.1. The Importance of Context in Healthcare
3.1.2. Context Definition
3.1.3. General Architecture of Context-Aware Systems
3.2. Context Representation Models and Comparison
3.3. Context Reasoning Algorithms
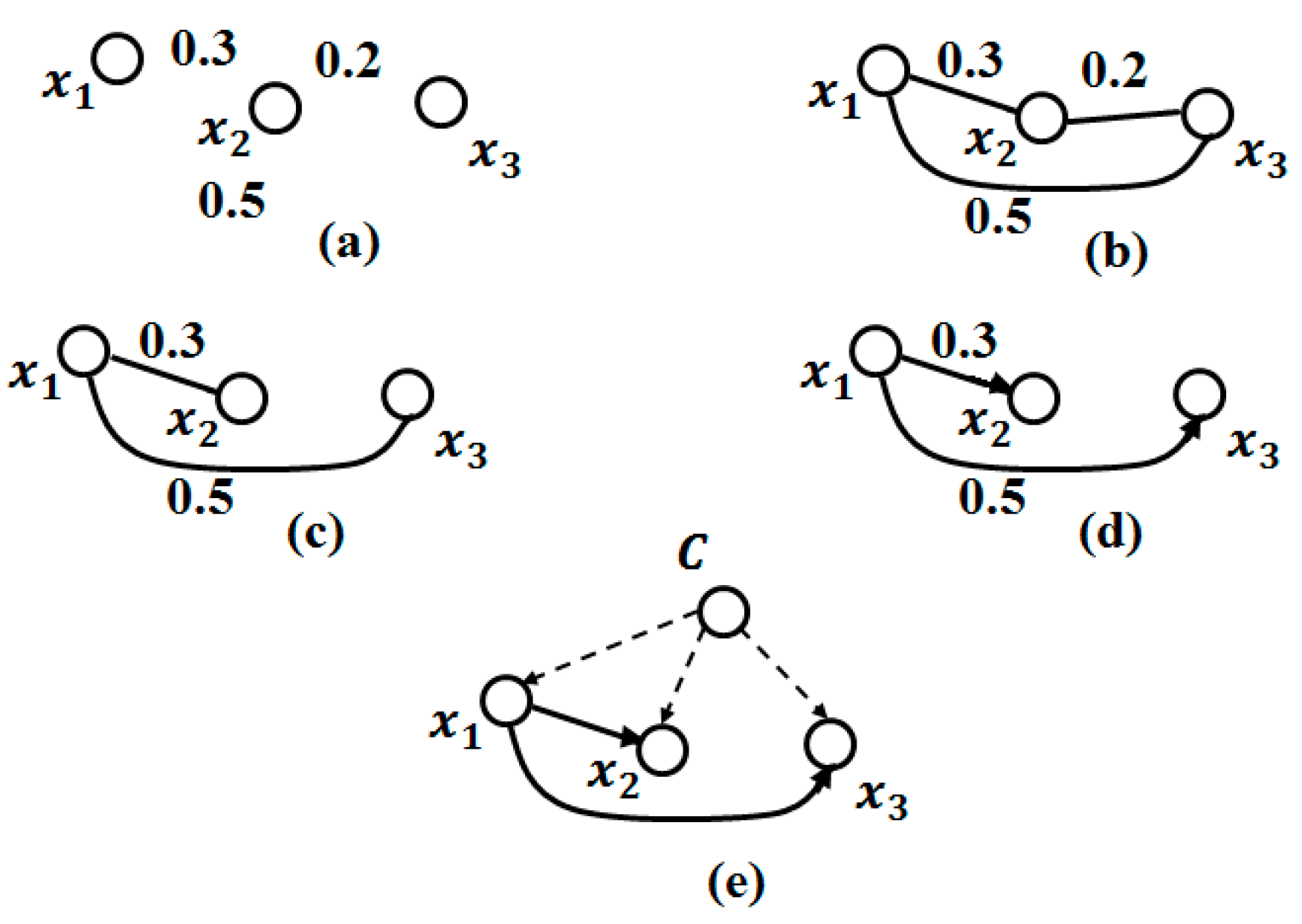
3.3.1. Bayesian Network
3.3.2. The Dependency Structure between Attributes
Algorithm K2
TAN Algorithm (Tree Augmented Naive Bayes)
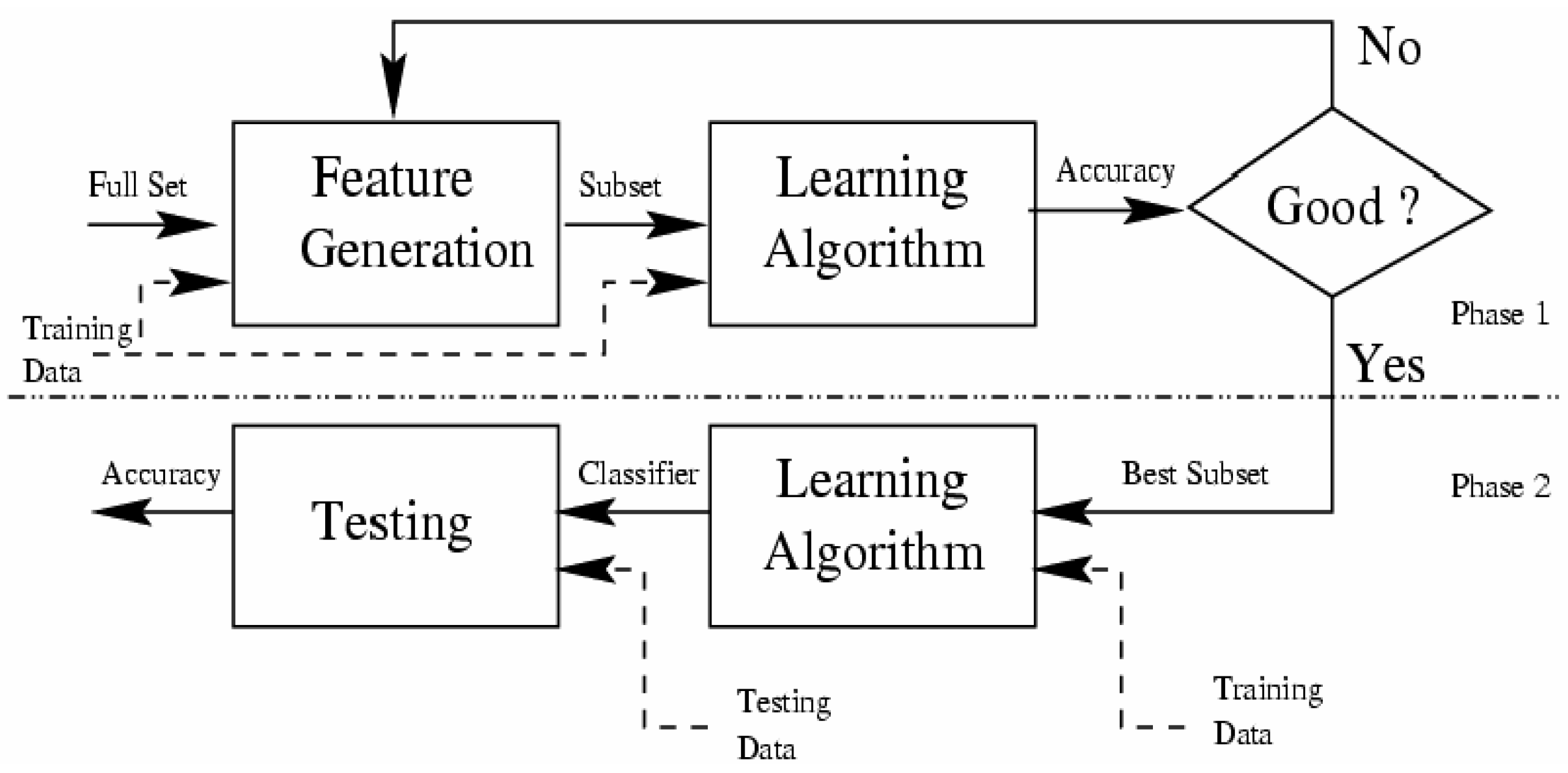
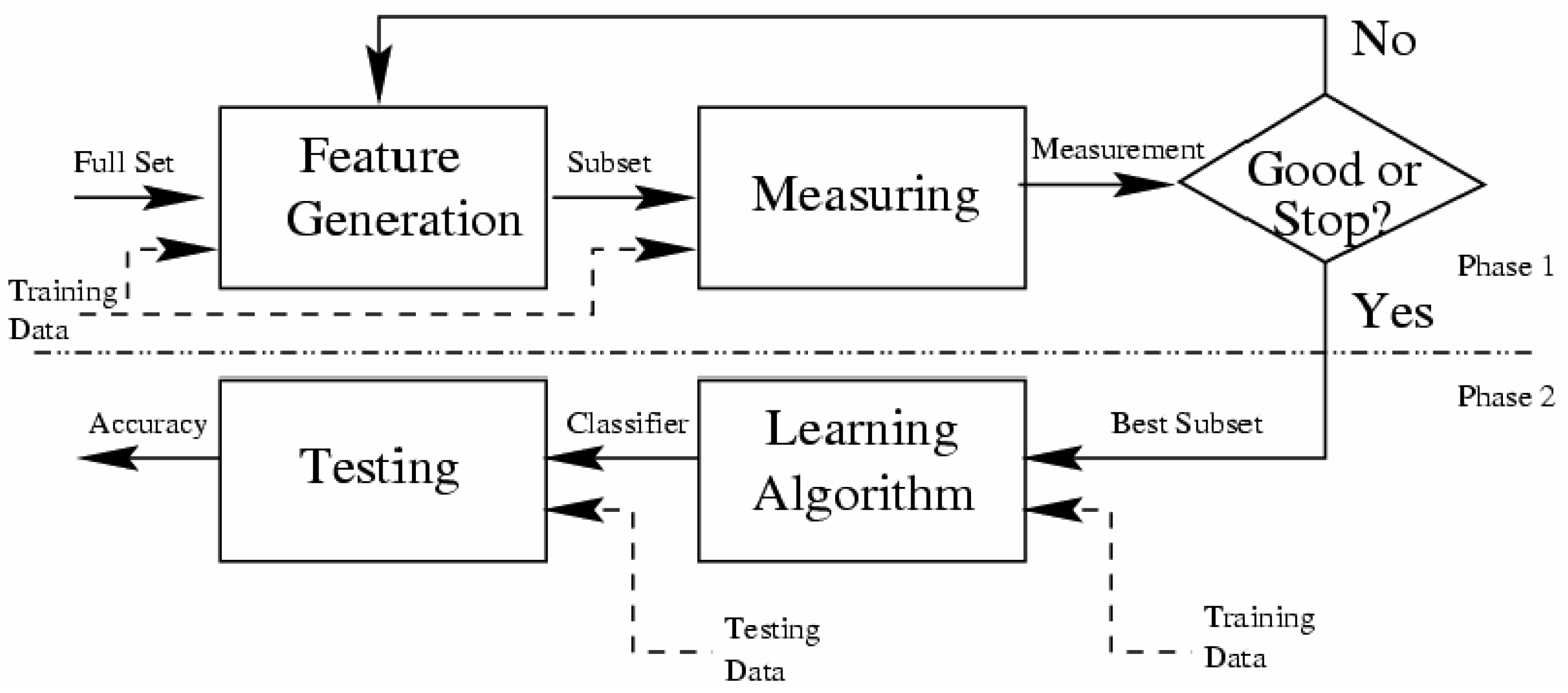
3.3.3. Technics and Algorithms to Select Relevant Attributes
- The starting point: It is a set of attributes, from which the selection process can begin to affect the direction of the search, e.g., the search can begin with all existing attributes in the database or with no attribute.
- Research organization: It is the strategy that generates a subset of attributes, which will be tested by the evaluation method. Heuristic search strategies are more feasible than exhaustive where they often yield good results [82], e.g., Best-First Heuristic Research.
- Evaluation strategy: How to evaluate the selected subsets of attributes? It can be seen as distinguishing method between the selections algorithms. The role of this function is to measure the discrimination capacity of a subset attributes in order to tell the states of the attribute class, e.g., the Gain measure.
- Stop criterion: To stop the search through the space of the attribute subset, this criterion is used. This criterion is defined according to the research procedure and the evaluation strategy.
- (1)
- Wrappers Algorithms; and
- (2)
- Filters Algorithms.
- (1)
- The classifier; and
- (2)
- The search algorithm
3.3.4. The Used Discretization Method
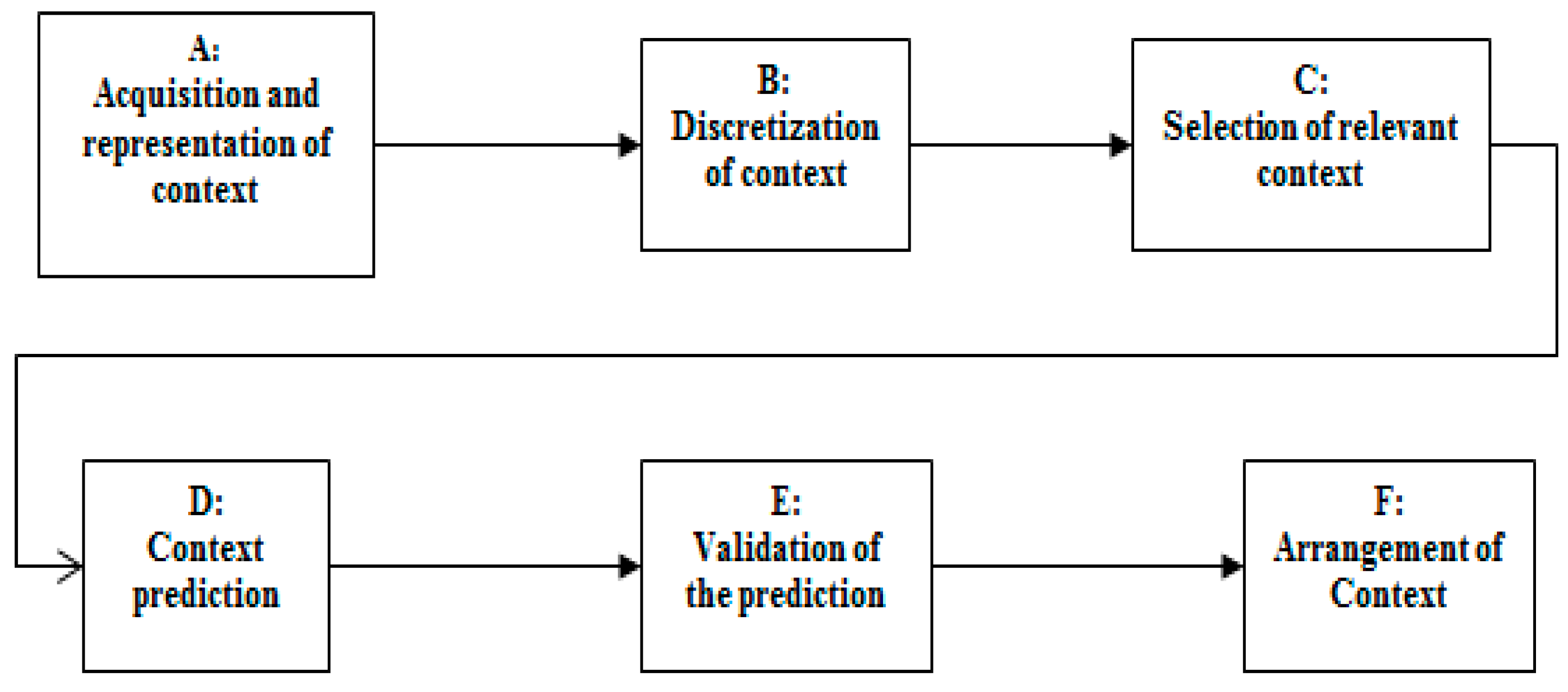
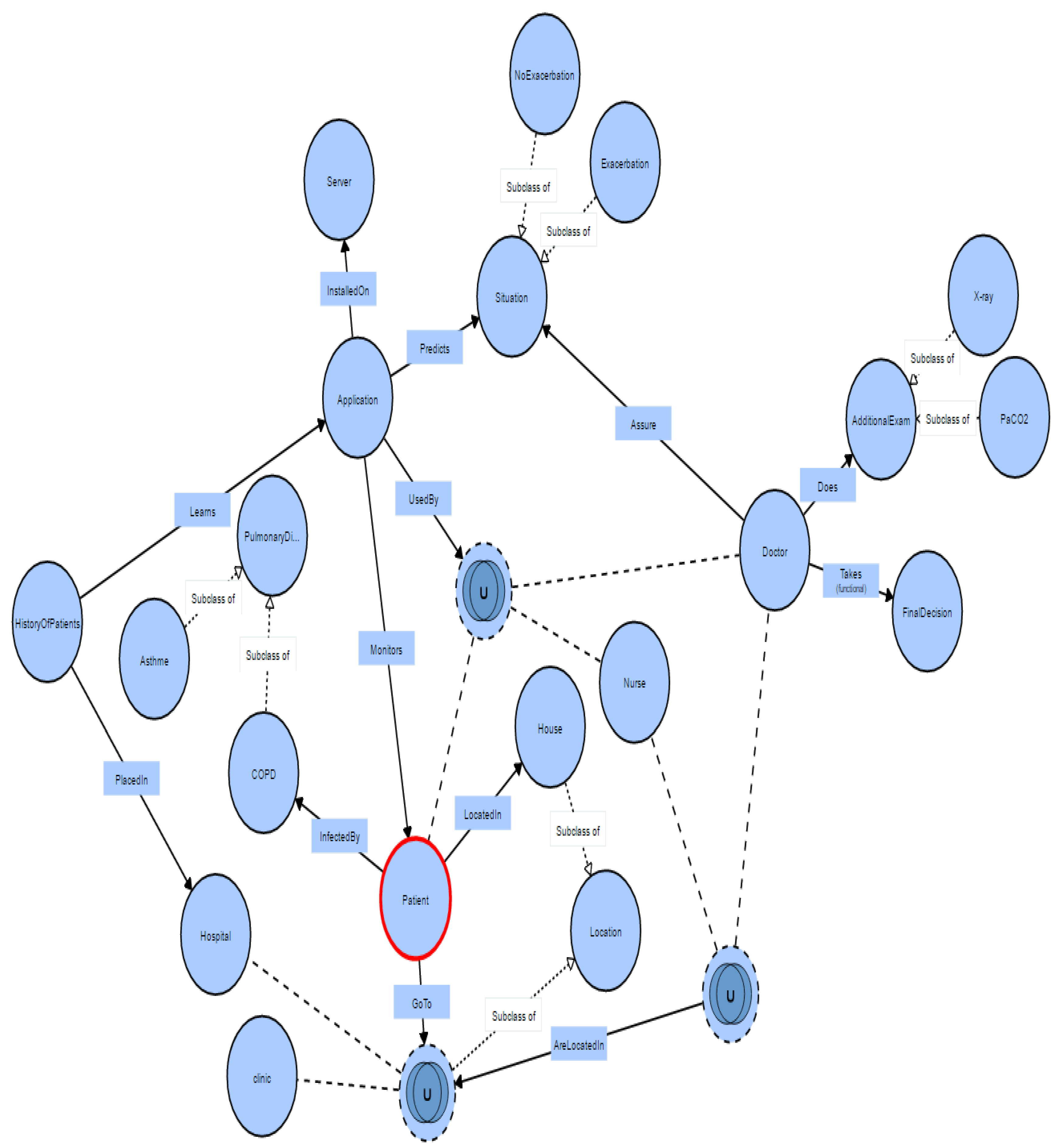
4. Helper Engine Context Model for COPD Domain
4.1. The Representation Scenario of the COPD Context Aware Application
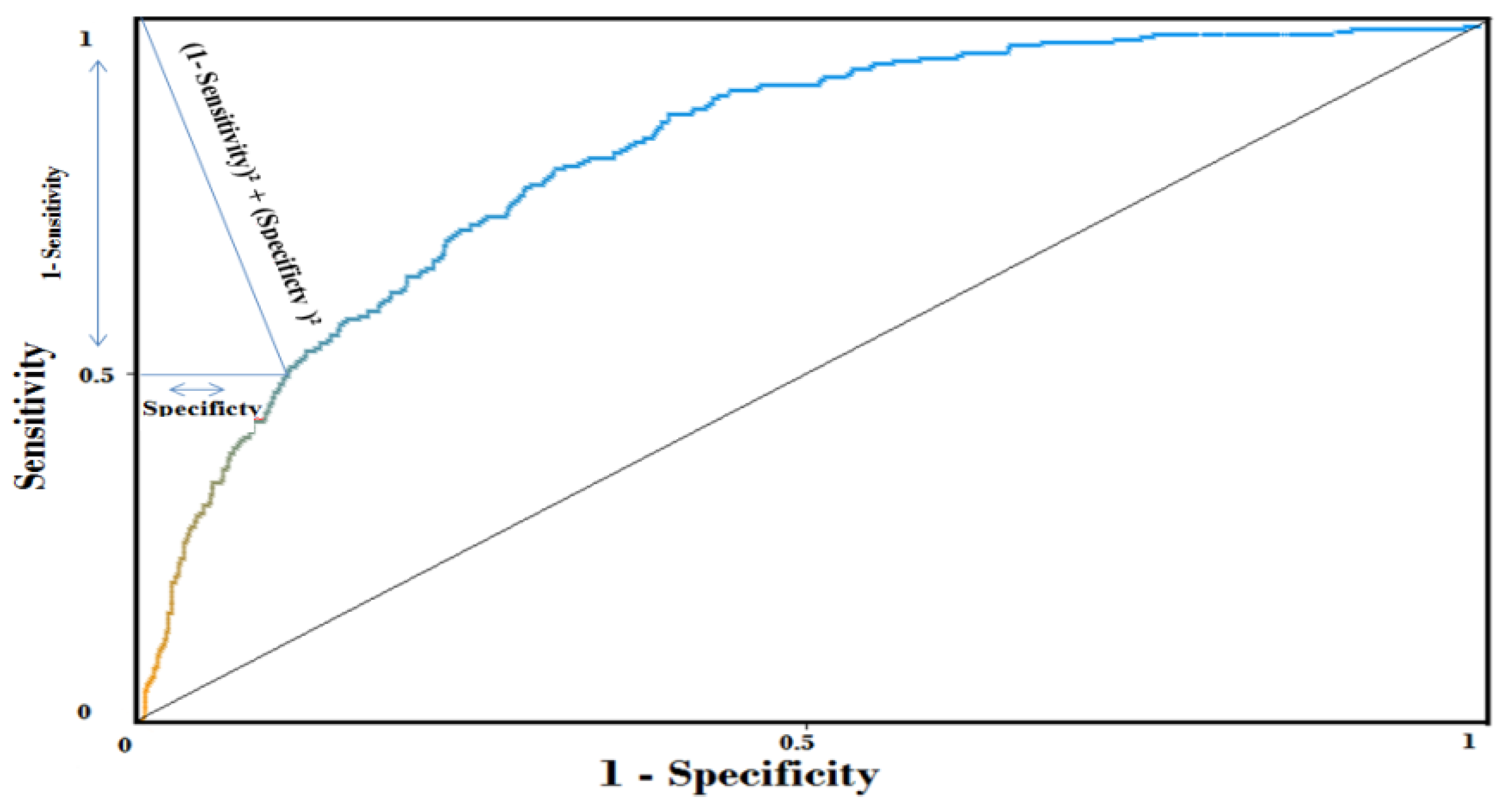
4.2. Experimentation and Results of the Selected Algorithms
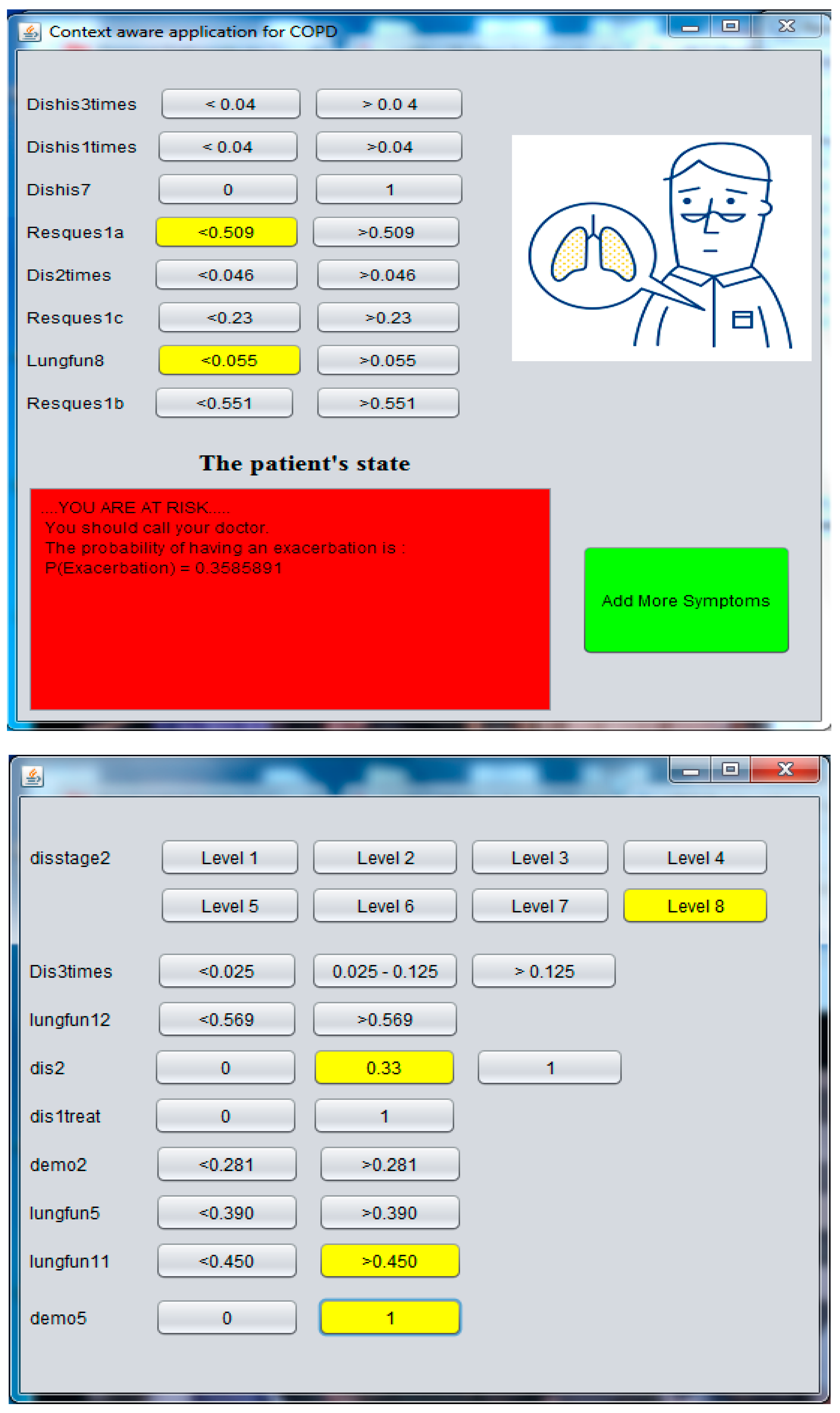
4.3. Implementation of the Context Aware Application
5. Conclusions and Future Works
Author Contributions
Conflicts of Interest
References
- Dey, A.K. Understanding and using context. Pers. Ubiquitous Comput. 2001, 5, 4–7. [Google Scholar] [CrossRef]
- Funtowicz, S.O.; Ravetz, J.R. Uncertainty and Quality in Science for Policy; Springer Science & Business Media: Dordrecht, The Netherlands, 1990; Volume 15. [Google Scholar]
- Québec, A.P.D. MPOC, Bronchite et Emphysème. Available online: http://www.pq.poumon.ca/diseases-maladies/copd-mpoc/ (accessed on 16 July 2016).
- Thoracologie, S.C.D. Le Fardeau Humain et Financier de la MPOC—Une des Principales Causes d’hospitalisation au Canada. Available online: http://www.lignesdirectricesrespiratoires.ca/sites/all/files/MPOC_report.pdf (accessed on 15 August 2016).
- Connors, A.F., Jr.; Dawson, N.V.; Thomas, C.; Harrell, F.E., Jr.; Desbiens, N.; Fulkerson, W.J.; Kussin, P.; Bellamy, P.; Goldman, L.; Knaus, W.A. Outcomes following acute exacerbation of severe chronic obstructive lung disease. The SUPPORT investigators (Study to Understand Prognoses and Preferences for Outcomes and Risks of Treatments). Am. J. Respir. Crit. Care Med. 1996, 154, 959–967. [Google Scholar] [CrossRef] [PubMed]
- Lareau, S.; Moseson, E.; Slatore, C.G. Patient information series. Am. J. Respir. Crit. Care Med. 2014, 189. [Google Scholar] [CrossRef]
- Van der Heijden, M.; Velikova, M.; Lucas, P.J. Learning Bayesian networks for clinical time series analysis. J. Biomed. Inform. 2014, 48, 94–105. [Google Scholar] [CrossRef] [PubMed]
- Simões, P.W.; Silva, G.D.d.; Moretti, G.P.; Simon, C.S.; Winnikow, E.P.; Nassar, S.M.; Medeiros, L.R.; Rosa, M.I. Metanálise do uso de redes bayesianas no diagnóstico de câncer de mama. Cadernos de Saúde Pública 2015, 31, 26–38. [Google Scholar] [CrossRef] [PubMed]
- Reynolds, G.M.; Peet, A.C.; Arvanitis, T.N. Generating prior probabilities for classifiers of brain tumours using belief networks. BMC Med. Inform. Decis. Mak. 2007, 7, 27. [Google Scholar] [CrossRef] [PubMed]
- Verduijn, M.; Rosseel, P.M.; Peek, N.; de Jonge, E.; de Mol, B.A. Prognostic bayesian networks: II: An application in the domain of cardiac surgery. J. Biomed. Inform. 2007, 40, 619–630. [Google Scholar] [CrossRef] [PubMed]
- Sanders, D.L.; Aronsky, D. Detecting asthma exacerbations in a pediatric emergency department using a Bayesian network. AMIA Annu. Symp. Proc. Arch. 2006, 2006, 684–688. [Google Scholar]
- Naïm, P.; Wuillemin, P.-H.; Leray, P.; Pourret, O.; Becker, A. Réseaux Bayésiens, 3rd ed.; Eyrolles: Paris, France, 2007. [Google Scholar]
- Himes, B.E.; Dai, Y.; Kohane, I.S.; Weiss, S.T.; Ramoni, M.F. Prediction of chronic obstructive pulmonary disease (COPD) in asthma patients using electronic medical records. J. Am. Med. Inform. Assoc. 2009, 16, 371–379. [Google Scholar] [CrossRef] [PubMed]
- Amalakuhan, B.; Kiljanek, L.; Parvathaneni, A.; Hester, M.; Cheriyath, P.; Fischman, D. A prediction model for COPD readmissions: Catching up, catching our breath, and improving a national problem. J. Commun. Hosp. Intern. Med. Perspect. 2012, 2. [Google Scholar] [CrossRef] [PubMed]
- Burt, L.; Corbridge, S. COPD exacerbations. AJN Am. J. Nurs. 2013, 113, 34–43. [Google Scholar] [CrossRef] [PubMed]
- Seemungal, T.A.; Donaldson, G.C.; Bhowmik, A.; Jeffries, D.J.; Wedzicha, J.A. Time course and recovery of exacerbations in patients with chronic obstructive pulmonary disease. Am. J. Respir. Crit. Care Med. 2000, 161, 1608–1613. [Google Scholar] [CrossRef] [PubMed]
- Seemungal, T.A.; Donaldson, G.C.; Paul, E.A.; Bestall, J.C.; Jeffries, D.J.; Wedzicha, J.A. Effect of exacerbation on quality of life in patients with chronic obstructive pulmonary disease. Am. J. Respir. Crit. Care Med. 1998, 157, 1418–1422. [Google Scholar] [CrossRef] [PubMed]
- Canada, S. Le Fardeau Humain et Financier de la MPOC; Société Canadienne de Thoracologie: Ottawa, ON, Canada, 2010. [Google Scholar]
- Wilkinson, T.M.; Donaldson, G.C.; Hurst, J.R.; Seemungal, T.A.; Wedzicha, J.A. Early therapy improves outcomes of exacerbations of chronic obstructive pulmonary disease. Am. J. Respir. Crit. Care Med. 2004, 169, 1298–1303. [Google Scholar] [CrossRef] [PubMed]
- Van der Heijden, M.; Lucas, P.J.; Lijnse, B.; Heijdra, Y.F.; Schermer, T.R. An autonomous mobile system for the management of COPD. J. Biomed. Inform. 2013, 46, 458–469. [Google Scholar] [CrossRef] [PubMed]
- Jensen, M.H.; Cichosz, S.L.; Hejlesen, O.K.; Toft, E.; Nielsen, C.; Grann, O.; Dinesen, B.I. Clinical impact of home telemonitoring on patients with chronic obstructive pulmonary disease. Telemed. e-Health 2012, 18, 674–678. [Google Scholar] [CrossRef] [PubMed]
- Trappenburg, J.C.; Niesink, A.; de Weert-van Oene, G.H.; van der Zeijden, H.; van Snippenburg, R.; Peters, A.; Lammers, J.-W.J.; Schrijvers, A.J. Effects of telemonitoring in patients with chronic obstructive pulmonary disease. Telemed. e-Health 2008, 14, 138–146. [Google Scholar] [CrossRef] [PubMed]
- Maiolo, C.; Mohamed, E.I.; Fiorani, C.M.; De Lorenzo, A. Home telemonitoring for patients with severe respiratory illness: The Italian experience. J. Telemed. Telecare 2003, 9, 67–71. [Google Scholar] [CrossRef] [PubMed]
- Vontetsianos, T.; Giovas, P.; Katsaras, T.; Rigopoulou, A.; Mpirmpa, G.; Giaboudakis, P.; Koyrelea, S.; Kontopyrgias, G.; Tsoulkas, B. Telemedicine-assisted home support for patients with advanced chronic obstructive pulmonary disease: Preliminary results after nine-month follow-up. J. Telemed. Telecare 2005, 11, 86–88. [Google Scholar] [CrossRef] [PubMed]
- McLean, S.; Nurmatov, U.; Liu, J. L.; Pagliari, C.; Car, J.; Sheikh, A. Telehealthcare for chronic obstructive pulmonary disease: Cochrane Review and meta-analysis. Br. J. Gen. Pract. 2012, 62, e739–e749. [Google Scholar] [CrossRef] [PubMed]
- Halpin, D.M.; Laing-Morton, T.; Spedding, S.; Levy, M.L.; Coyle, P.; Lewis, J.; Newbold, P.; Marno, P. A randomised controlled trial of the effect of automated interactive calling combined with a health risk forecast on frequency and severity of exacerbations of COPD assessed clinically and using EXACT PRO. Prim. Care Respir. J. 2011, 20, 324–331. [Google Scholar] [CrossRef] [PubMed]
- Yañez, A.M.; Guerrero, D.; de Alejo, R.P.; Garcia-Rio, F.; Alvarez-Sala, J.L.; Calle-Rubio, M.; de Molina, R.M.; Falcones, M.V.; Ussetti, P.; Sauleda, J. Monitoring breathing rate at home allows early identification of COPD exacerbations. CHEST J. 2012, 142, 1524–1529. [Google Scholar] [CrossRef] [PubMed]
- Ryynänen, O.-P.; Soini, E.J.; Lindqvist, A.; Kilpeläinen, M.; Laitinen, T. Bayesian predictors of very poor health related quality of life and mortality in patients with COPD. BMC Med. Inform. Decis. Mak. 2013, 13, 34. [Google Scholar] [CrossRef] [PubMed]
- Cooper, G.F.; Herskovits, E. A Bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef]
- Raghavan, N.; Lam, Y.M.; Webb, K.A.; Guenette, J.A.; Amornputtisathaporn, N.; Raghavan, R.; Tan, W.C.; Bourbeau, J.; O’Donnell, D.E. Components of the COPD Assessment Test (CAT) associated with a diagnosis of COPD in a random population sample. COPD J. Chron. Obstr. Pulm. Dis. 2012, 9, 175–183. [Google Scholar] [CrossRef] [PubMed]
- Mcheick, H.; Saleh, L.; Ajami, H.; Mili, H. HCES: Helper Context-Aware Engine System to Predict Relevant State of patients in COPD Domain using Naïve Bayesian. In Proceedings of International Conference on Internet of Things and Machine Learning (IML 2017); ACM Digital Library: Liverpool City, UK, 2017. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Weiser, M. Hot topics-ubiquitous computing. Computer 1993, 26, 71–72. [Google Scholar] [CrossRef]
- Blazer, D.G.; Hernandez, L.M. Genes, Behavior, and the Social Environment: Moving Beyond the Nature/Nurture Debate; National Academies Press: Washington, MD, USA, 2006. [Google Scholar]
- Sannino, G.; De Pietro, G. A mobile system for real-time context-aware monitoring of patients’ health and fainting. Int. J. Data Min. Bioinform. 2014, 10, 407–423. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.H.; Batalin, M.A.; Au, L.K.; Bui, A.A.; Kaiser, W.J. Context-aware sensing of physiological signals. In Proceedings of the 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS 2007), Lyon, France, 22–26 August 2007; pp. 5271–5275. [Google Scholar]
- Bricon-Souf, N.; Newman, C.R. Context awareness in health care: A review. Int. J. Med. Inform. 2007, 76, 2–12. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharyya, S.; Saravanagru, R.; Thangavelu, A. Context aware healthcare application. IJCA Int. J. Comput. Appl. 2011, 22. [Google Scholar] [CrossRef]
- Garcia-Valverde, T.; Muñoz, A.; Arcas, F.; Bueno-Crespo, A.; Caballero, A. Heart health risk assessment system: A nonintrusive proposal using ontologies and expert rules. BioMed Res. Int. 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, A.; Rogers, A.; Bower, P. Support for self-care for patients with chronic disease. BMJ Br. Med. J. 2007, 335, 968–970. [Google Scholar] [CrossRef] [PubMed]
- Bayliss, E.A.; Bonds, D.E.; Boyd, C.M.; Davis, M.M.; Finke, B.; Fox, M.H.; Glasgow, R.E.; Goodman, R.A.; Heurtin-Roberts, S.; Lachenmayr, S. Understanding the context of health for persons with multiple chronic conditions: Moving from what is the matter to what matters. Ann. Fam. Med. 2014, 12, 260–269. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.-H.; Chung, K. Emergency situation monitoring service using context motion tracking of chronic disease patients. Clust. Comput. 2015, 18, 747–759. [Google Scholar] [CrossRef]
- Tris, C.R. Ontology-Based Diagnosis and Personalization of Medical Knowledge; Universitat Rovira i Virgili: Tarragona, Spain, 2009. [Google Scholar]
- Kida, K.; Jinno, S.; Nomura, K.; Yamada, K.; Katsura, H.; Kudoh, S. Pulmonary rehabilitation program survey in North America, Europe, and Tokyo. J. Cardiopulm. Rehabil. Prev. 1998, 18, 301–308. [Google Scholar] [CrossRef]
- Kim, H.F.S.; Kunik, M.E.; Molinari, V.A.; Hillman, S.L.; Lalani, S.; Orengo, C.A.; Petersen, N.J.; Nahas, Z.; Goodnight-White, S. Functional impairment in COPD patients: The impact of anxiety and depression. Psychosomatics 2000, 41, 465–471. [Google Scholar] [CrossRef] [PubMed]
- Murray, C.J.; Lopez, A.D. Global Burden of Disease; Harvard University Press: Boston, UK, 1996; Volume 1. [Google Scholar]
- Murray, C.J.; Lopez, A.D. Alternative projections of mortality and disability by cause 1990–2020: Global Burden of Disease Study. Lancet 1997, 349, 1498–1504. [Google Scholar] [CrossRef]
- Roche, N.; Deslée, G.; Caillaud, D.; Brinchault, G.; Nesme-Meyer, P.; Surpas, P.; Escamilla, R.; Perez, T.; Chanez, P.; Pinet, C. Impact of gender on COPD expression in a real-life cohort. Respir. Res. 2014, 15, 20. [Google Scholar] [CrossRef] [PubMed]
- Crapo, J.D.; Broaddus, V.C.; Brody, A.R.; Malindzak, G. Workshop on lung disease and the environment. Am. J. Respir. Crit. Care Med. 2003, 168, 250–254. [Google Scholar] [PubMed]
- Kaptein, A.A.; Dekker, F.W. Psychosocial support. Eur. Respir. Monogr. 2000, 13, 58–69. [Google Scholar]
- Brézillon, P. Task-realization models in contextual graphs. In Proceedings of the International and Interdisciplinary Conference on Modeling and Using Context, Paris, France, 5–8 July 2005; pp. 55–68. [Google Scholar]
- Dey, A.K. Providing Architectural Support for Building Context-Aware Applications; Georgia Institute of Technology: Atlanta, GA, USA, 2000. [Google Scholar]
- Li, X.; Eckert, M.; Martinez, J.-F.; Rubio, G. Context Aware Middleware Architectures: Survey and Challenges. Sensors 2015, 15, 20570–20607. [Google Scholar] [CrossRef] [PubMed]
- Bettini, C.; Brdiczka, O.; Henricksen, K.; Indulska, J.; Nicklas, D.; Ranganathan, A.; Riboni, D. A survey of context modelling and reasoning techniques. Pervasive Mob. Comput. 2010, 6, 161–180. [Google Scholar] [CrossRef]
- Oh, Y.; Woo, W. User-centric integration of contexts for a unified context-aware application model. In Proceedings of the Joint sOc-EUSAI Conference, Grenoble, France, 12–14 October 2005. [Google Scholar]
- Wood, A.D.; Stankovic, J.A.; Virone, G.; Selavo, L.; He, Z.; Cao, Q.; Doan, T.; Wu, Y.; Fang, L.; Stoleru, R. Context-aware wireless sensor networks for assisted living and residential monitoring. IEEE Netw. 2008, 22. [Google Scholar] [CrossRef]
- Sielis, G.; Mettouris, C. idSpace D3. 3–Definition and Implementation of Context Awareness v2; Open University of the Netherlands: Heerlen, The Netherlands, 2009. [Google Scholar]
- Mühlhäuser, M. Handbook of Research on Ubiquitous Computing Technology for Real Time Enterprises; IGI Global: Hershey, PA, USA, 2008. [Google Scholar]
- Tsihrintzis, G.A.; Jain, L.C. Advances in Multimedia Services in Intelligent Environments—Integrated Systems. In Multimedia Services in Intelligent Environments; Springer: Berlin, Heidelberg, 2010; pp. 1–3. [Google Scholar]
- Strang, T.; Linnhoff-Popien, C. A context modeling survey. In Workshop Proceedings. First International Workshop on Advanced Context Modelling; Reasoning and Management at UbiComp: Nottingham, UK, 2004. [Google Scholar]
- Reichle, R.; Wagner, M.; Khan, M.U.; Geihs, K.; Lorenzo, J.; Valla, M.; Fra, C.; Paspallis, N.; Papadopoulos, G.A. A comprehensive context modeling framework for pervasive computing systems. In Proceedings of the IFIP International Conference on Distributed Applications and Interoperable Systems, Oslo, Norway, 4–6 June 2008; pp. 281–295. [Google Scholar]
- Hoareau, C. A Model Checking Based Framework for Building Correct Context-Aware Systems; The Graduate University for Advanced Studie: Hayama, Japan, 2009. [Google Scholar]
- Bradley, N.A.; Dunlop, M.D. Toward a multidisciplinary model of context to support context-aware computing. Hum. Comput. Interact. 2005, 20, 403–446. [Google Scholar] [CrossRef]
- ElGammal, M.; Eltoweissy, M. Chemistry-inspired, Context-Aware, and Autonomic Management System for Networked Objects. In Proceedings of the Seventh International Conference on Future Computational Technologies and Applications, Nice, France, 22–27 March 2015. [Google Scholar]
- Paganelli, F.; Giuli, D. Context-aware information services to support tourist communities. Inform. Technol. Tour. 2008, 10, 313–327. [Google Scholar] [CrossRef]
- Khattak, A.M.; Akbar, N.; Aazam, M.; Ali, T.; Khan, A.M.; Jeon, S.; Hwang, M.; Lee, S. Context representation and fusion: Advancements and opportunities. Sensors 2014, 14, 9628–9668. [Google Scholar] [CrossRef] [PubMed]
- Strang, T.; Linnhoff-Popien, C. A context modeling survey. In Workshop Proceedings. First International Workshop on Advanced Context Modelling; Reasoning and Management at UbiComp: Nottingham, UK, 2004. [Google Scholar]
- Paganelli, F.; Giuli, D. An ontology-based system for context-aware and configurable services to support home-based continuous care. IEEE Trans. Inform. Technol. Biomed. 2011, 15, 324–333. [Google Scholar] [CrossRef] [PubMed]
- Gu, T.; Pung, H.K.; Zhang, D.Q. A service-oriented middleware for building context-aware services. J. Netw. Comput. Appl. 2005, 28, 1–18. [Google Scholar] [CrossRef]
- Brickley, D.; Guha, R.V. RDF Vocabulary Description Language 1.0: RDF Schema. Available online: https://www.w3.org/2001/sw/RDFCore/Schema/200203/ (accessed on 15 September 2016).
- Rodriguez-Roisin, R. Toward a consensus definition for COPD exacerbations. Chest 2000, 117, 398S–401S. [Google Scholar] [CrossRef] [PubMed]
- Hurst, J.R.; Donaldson, G.C.; Perera, W.R.; Wilkinson, T.M.; Bilello, J.A.; Hagan, G.W.; Vessey, R.S.; Wedzicha, J.A. Use of plasma biomarkers at exacerbation of chronic obstructive pulmonary disease. Am. J. Respir. Crit. Care Med. 2006, 174, 867–874. [Google Scholar] [CrossRef] [PubMed]
- Society, A.T. Standard for the diagnosis and care of patients with chronic obstructive pulmonary disease. Am. J. Respir. Crit. Care Med. 1995, 152, S77–S120. [Google Scholar]
- Gu, T.; Pung, H.K.; Zhang, D.Q.; Pung, H.K.; Zhang, D.Q. A Bayesian Approach for Dealing with Uncertain Contexts; Austrian Computer Society: Clementi, Singapore, 2004. [Google Scholar]
- Olivier, F. De L’identification de Structure de Réseaux Bayésiensa la Reconnaissance de Formesa Partir D’informations Completes ou Incompletes; INSA de Rouen: Rouvray, France, 2006. [Google Scholar]
- Lerner, B.; Malka, R. Investigation of the K2 algorithm in learning Bayesian network classifiers. Appl. Artif. Intell. 2011, 25, 74–96. [Google Scholar] [CrossRef]
- Robinson, R.W. Counting unlabeled acyclic digraphs. In Combinatorial Mathematics V; Springer: Berlin, Germany, 1977; pp. 28–43. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann: Financial District, SF, USA, 2011. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Chow, C.; Liu, C. Approximating discrete probability distributions with dependence trees. IEEE Trans. Inform. Theory 1968, 14, 462–467. [Google Scholar] [CrossRef]
- Gama, J.; Porto, L.-I. Bayesian Learning: An Introduction; University of Porto: Porto, Portugal, 2008. [Google Scholar]
- Hall, M.A. Correlation-based feature selection of discrete and numeric class machine learning. In Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford University, Stanford, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Goswami, S.; Chakrabarti, A. Feature selection: A practitioner view. Int. J. Inform. Technol. Comput. Sci. (IJITCS) 2014, 6, 66. [Google Scholar] [CrossRef]
- Cornuéjols, A. Sélection d’attributs. Available online: https://www.lri.fr/~antoine/Courses/DEA-I3/Tr-selection-attributs.pdf (accessed on 1 May 2016).
- Karegowda, A.G.; Jayaram, M.; Manjunath, A. Feature subset selection problem using wrapper approach in supervised learning. Int. J. Comput. Appl. 2010, 1, 13–17. [Google Scholar] [CrossRef]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and unsupervised discretization of continuous features. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; Volume 12, pp. 194–202. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning; The University of Waikato: Hamilton, New Zealand, 1999. [Google Scholar]
- Pawlik, M. Available online: http://www.inf.unibz.it/dis/teaching/DWDM/slides2011/lesson5-Classification-2.pdf (accessed on 1 April 2016).
- Priyadarsini, R.P.; Valarmathi, M.; Sivakumari, S. Gain ratio based feature selection method for privacy preservation. ICTACT J. Soft Comput. 2011, 1. [Google Scholar] [CrossRef]
- Wang, J.; Valtorta, M. Using Relative Classification Probability to Increase Accuracy of Restricted Structure Bayesian Network Classifiers. In Proceedings of the 2012 IEEE 24th International Conference on Tools with Artificial Intelligence, Athens, Greece, 7–9 November 2012; Volume 1, pp. 105–113. [Google Scholar]
- Rakotomalala, R. TANAGRA: Un logiciel gratuit pour l'enseignement et la recherche. In Proceedings of the Extraction et Gestion des Connaissances (EGC’2005), Actes des Cinquièmes Journées Extraction et Gestion des Connaissances, Paris, France, 18–21 January 2005; Volume 2, pp. 697–702. [Google Scholar]
- Waikato Environment for Knowledge Analysis, version 3.8.0; The University of Waikato: Hamilton, New Zealand, 2016.
- Lustgarten, J.L.; Gopalakrishnan, V.; Grover, H.; Visweswaran, S. Improving classification performance with discretization on biomedical datasets. AMIA Ann. Symp. Proc. 2008, 2008, 445. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D. Discretization techniques: A recent survey. GESTS Int. Trans. Comput. Sci. Eng. 2006, 32, 47–58. [Google Scholar]
- Fayyad, U.; Irani, K. Multi-Interval Discretization of Continuous-Valued Attributes for Classification Learning; 1993. Available online: http://hdl.handle.net/2014/35171 (accessed on 22 June 2017).
- Mansoor, W.; Khedr, M.; Benslimane, D.; Maamar, Z.; Hauswirth, M.; Aberer, K.; Chaari, T.; Laforest, F.; Celentano, A. Adaptation in context-aware pervasive information systems: The SECAS project. Int. J. Pervasive Comput. Commun. 2008, 3, 400–425. [Google Scholar]
- Baldauf, M.; Dustdar, S.; Rosenberg, F. A survey on context-aware systems. Int. J. Ad Hoc Ubiquitous Comput. 2007, 2, 263–277. [Google Scholar] [CrossRef]
- Steffen, L.S.N.; Florian, H.; Thomas, E. Visualizing Ontologies with (VOWL). Available online: http://vowl.visualdataweb.org/webvowl (accessed on 15 June 2016).
- Rajasekaran, S. Database about COPD Exacerbation. Available online: https://github.com/sibrajas/data-python/blob/master/CAX_COPD_TRAIN_data.csv (accessed on 10 May 2015).
- Analytix, C. Available online: https://www.crowdanalytix.com/contests/predict-exacerbation-in-patients-with-copd (accessed on 1 May 2015).
- Van den Berge, M.; Hop, W.C.; van der Molen, T.; van Noord, J.A.; Creemers, J.P.; Schreurs, A.J.; Wouters, E.F.; Postma, D.S. Prediction and course of symptoms and lung function around an exacerbation in chronic obstructive pulmonary disease. Respir. Res. 2012, 13, 44. [Google Scholar] [CrossRef] [PubMed]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Ijcai 1995, 14, 1137–1145. [Google Scholar]
- Manual Netica.-Java Library, version 4.18; Norsys Software Corp.: Vancuver, BC, Canada, 2012.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mobility | Reasoning | Distribution | Expressiveness | Validation Tools | |
|---|---|---|---|---|---|
| Key-value | - | - | - | - | o |
| Markup | + | - | + | - | + |
| Graphical | - | o | - | + | o |
| Object-oriented | ++ | - | ++ | - | - |
| Logic | - | + | ++ | + | - |
| Multidisciplinary | - | o | o | + | - |
| Domain focused | - | + | o | + | - |
| User centric | + | + | o | + | - |
| Spatial | ++ | + | o | + | - |
| Chemistry | - | o | + | + | - |
| Ontology | + | ++ | ++ | ++ | + |
| Hybrid | + | ++ | ++ | ++ | - |
| Discretization → Selection of Attributes | Mixed Variables (Continuous and Discrete) | |||
|---|---|---|---|---|
| 1985 Patients Using weka | ||||
| 10—Cross Validation Stratified, Bayesian Network | ||||
| Algo | AUC | Number of attributes | ||
| - | - | 0.768 | 60 | |
| Fayyad and Irani’s MDL | Filters | CFS | 0.795 | 14 |
| GainRatio | 0.76 | 14 | ||
| Wrappers | BestFirst | 0.80 | 11 | |
| Genetic | 0.80 | 28 | ||
| A- The Variables Are Discrete, with Fayyad and Irani’s MDL. | ||
|---|---|---|
| B- Selection Using Wrapper with Best First Search Algorithm. | ||
| 10-Cross Validation | Area Under Roc Curve-AUC | Number of relevant attributes |
| BN (K2)—1 parent | 80% | 11 |
| BN (K2)—2 parents | 80.9% | 15 |
| BN (K2)—3 parents | 80.20% | 14 |
| BN (TAN) | 81.50% | 17 |
| Number of Attributes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |
| AUC | 78% | 78.4% | 79.6% | 79.9% | 80.4% | 80.5% | 81% | 80.9% | 81.1% | 81.5% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mcheick, H.; Saleh, L.; Ajami, H.; Mili, H. Context Relevant Prediction Model for COPD Domain Using Bayesian Belief Network. Sensors 2017, 17, 1486. https://doi.org/10.3390/s17071486
Mcheick H, Saleh L, Ajami H, Mili H. Context Relevant Prediction Model for COPD Domain Using Bayesian Belief Network. Sensors. 2017; 17(7):1486. https://doi.org/10.3390/s17071486
Chicago/Turabian StyleMcheick, Hamid, Lokman Saleh, Hicham Ajami, and Hafedh Mili. 2017. "Context Relevant Prediction Model for COPD Domain Using Bayesian Belief Network" Sensors 17, no. 7: 1486. https://doi.org/10.3390/s17071486
APA StyleMcheick, H., Saleh, L., Ajami, H., & Mili, H. (2017). Context Relevant Prediction Model for COPD Domain Using Bayesian Belief Network. Sensors, 17(7), 1486. https://doi.org/10.3390/s17071486