Online Recognition of Daily Activities by Color-Depth Sensing and Knowledge Models


Abstract
:1. Introduction
2. Related Work
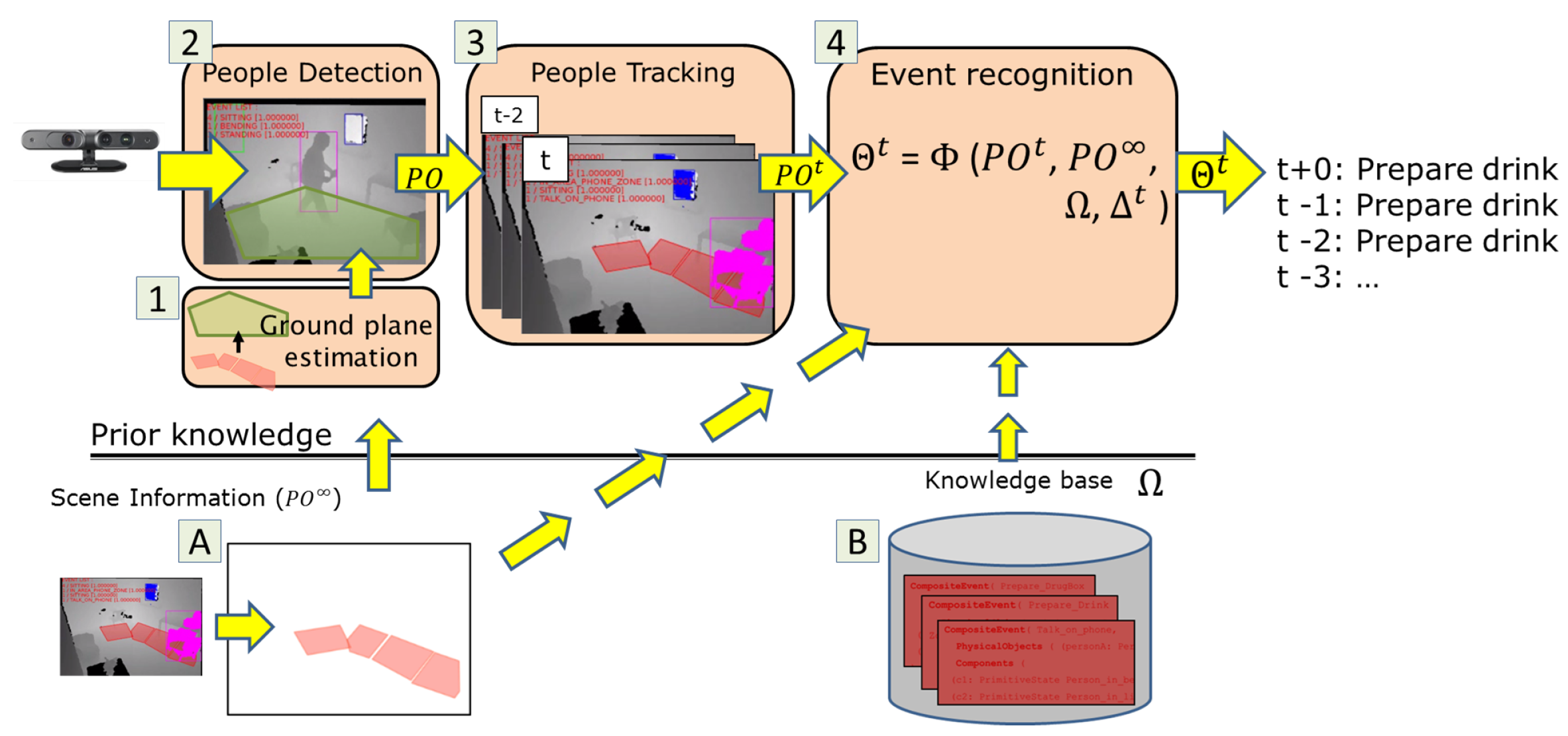
3. Knowledge-Driven Event Recognition
3.1. Ground Plane Estimation
3.2. People Detection
3.3. People Tracking
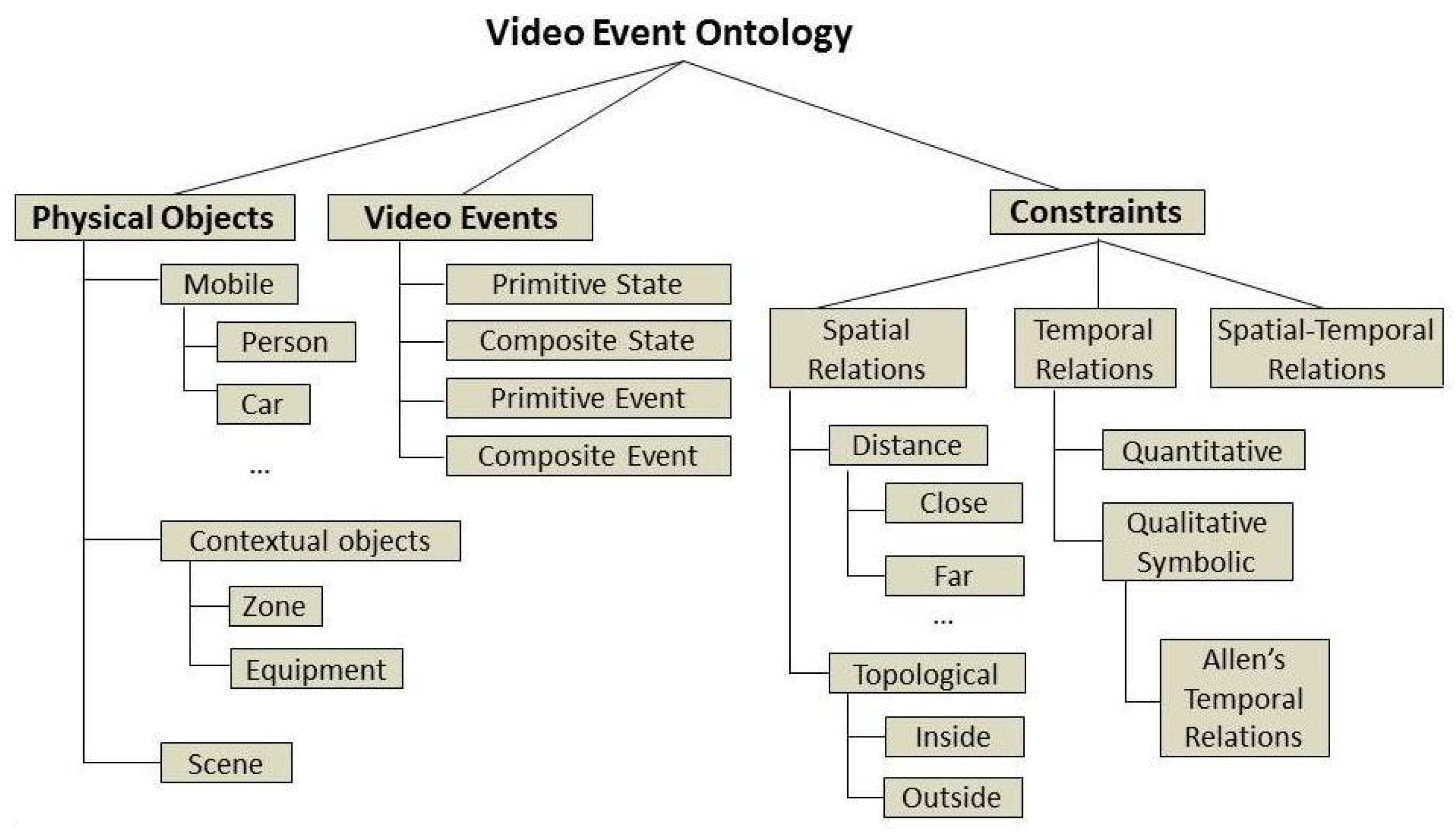
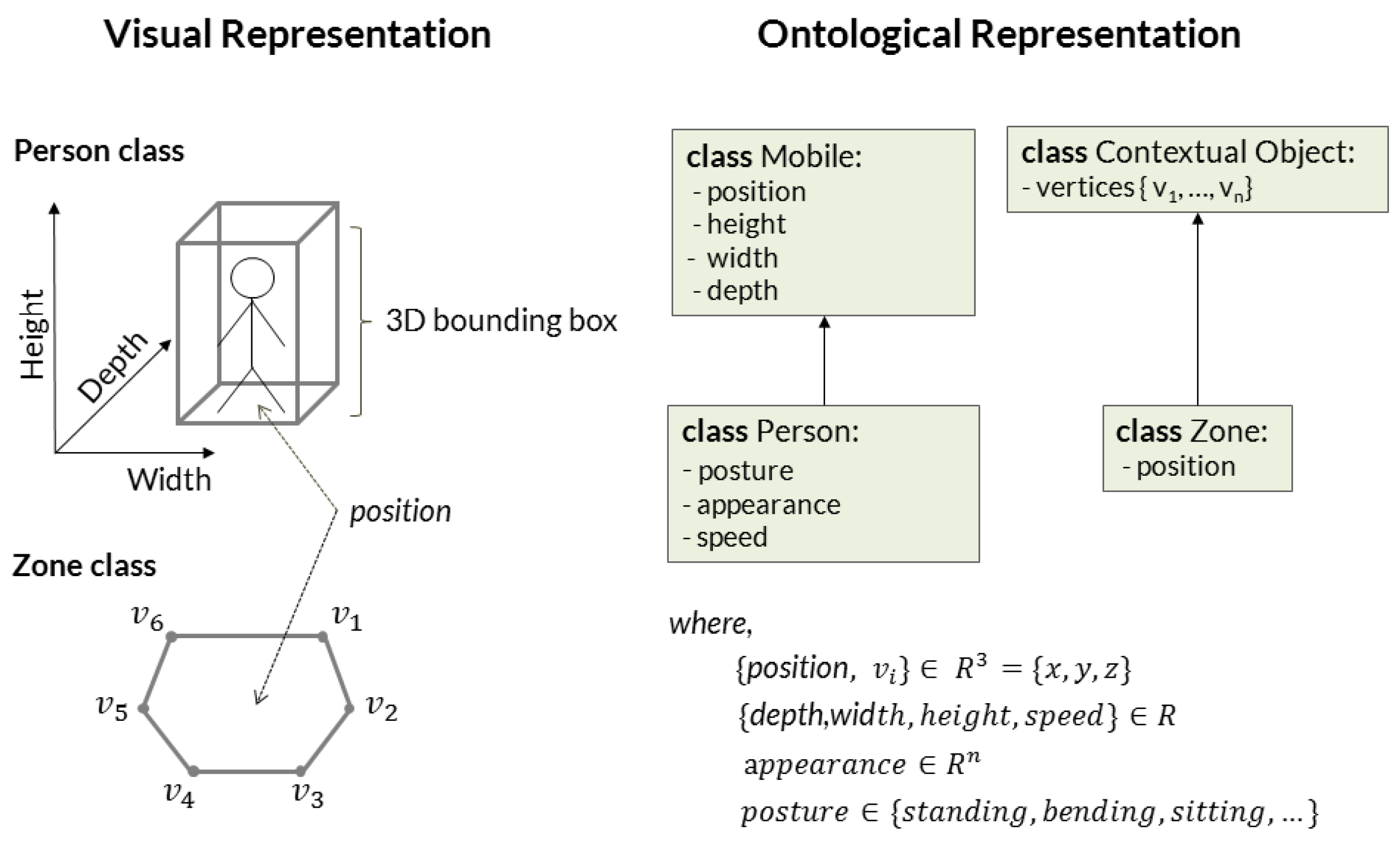
3.4. Ontology-Driven Event Recognition
- : event model j,
- : set of physical object abstractions involved in model j, with ,
- : set of components in model j, with ,
- : set of constraints in model j, with .
- Primitive State models the value of a attribute of a physical object (e.g., person posture, or person inside a semantic zone) constant over a time interval.
- Composite State refers to a composition of two or more primitive states.
- Primitive Event models a change in the value of a physical object’s attribute (e.g., person changes from sitting to standing posture).
- Composite Event refers to a composition of two events of any type and it generally defines a temporal constraint about the time ordering between event components (sub-events).
Model 1. Composite Event bed exit. CompositeEvent(BED_EXIT, PhysicalObjects((p1:Person),(zB:Zone),(zSB:Zone)) Components( (s1: PrimitiveState in_zone_bed (p1,zB)) (s2: PrimitiveState out_of_bed (p1,zSB))) Constraints((s1 meet s2) // c1 (duration(s2) > 1)) //c2 Alarm ((Level : URGENT)) )
4. Experiments
4.1. Activity Modeling and Knowledge Transfer
4.2. Performance Baselines
4.3. CHUN Dataset
- Prepare drink (P. Drink, e.g., prepare tea/coffee);
- Prepare drug box (organize medication);
- Talk on the telephone (calling, answering);
- Read article;
- Search bus line and;
- Water the plant.
4.4. GAADRD Dataset
- Establish account balance (M.Payment);
- Prepare drink (P. Drink, e.g., prepare tea/coffee);
- Prepare drug box (P. Pill box);
- Read article;
- Talk on the telephone (T. Telephone, e.g., calling);
- Turn radio on; and
- Water plant.
4.5. Nursing Home Dataset
5. Results
5.1. CHUN Dataset
5.2. GAADRD Dataset
5.3. Nursing Home Dataset
6. Discussion
6.1. Overall People Tracking
6.2. CHUN Dataset
6.3. GAADRD Dataset
6.4. Nursing Home Dataset
6.5. Summary
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| IADL | Instrumental Activities of Daily Living |
References
- Fleury, A.; Noury, N.; Vacher, M. Introducing knowledge in the process of supervised classification of activities of Daily Living in Health Smart Homes. In Proceedings of the 12th IEEE International Conference on e-Health Networking Applications and Services, Lyon, France, 1–3 July 2010; pp. 322–329. [Google Scholar]
- Medjahed, H.; Istrate, D.; Boudy, J.; Baldinger, J.L.; Dorizzi, B. A pervasive multi-sensor data fusion for smart home healthcare monitoring. In Proceedings of the IEEE International Conference on Fuzzy Systems, Taipei, Taiwan, 27–30 June 2011; pp. 1466–1473. [Google Scholar]
- Crispim-Junior, C.; Bathrinarayanan, V.; Fosty, B.; Konig, A.; Romdhane, R.; Thonnat, M.; Bremond, F. Evaluation of a Monitoring System for Event Recognition of Older People. In Proceedings of the the 10th IEEE International Conference on Advanced Video and Signal-Based Surveillance 2013 ( AVSS 2013), Krakow, Poland, 27–31 August 2013. [Google Scholar]
- Banerjee, T.; Keller, J.M.; Popescu, M.; Skubic, M. Recognizing Complex Instrumental Activities of Daily Living Using Scene Information and Fuzzy Logic. Comput. Vis. Image Underst. 2015, 140, 68–82. [Google Scholar] [CrossRef]
- Tasoulis, S.; Doukas, C.; Plagianakos, V.; Maglogiannis, I. Statistical data mining of streaming motion data for activity and fall recognition in assistive environments. Neurocomputing 2013, 107, 87–96. [Google Scholar] [CrossRef]
- Gonzalez-Ortega, D.; Díaz-Pernas, F.; Martínez-Zarzuela, M.; Antón-Rodríguez, M. A Kinect-based system for cognitive rehabilitation exercises monitoring. Comput. Methods Progr. Biomed. 2014, 113, 620–631. [Google Scholar] [CrossRef] [PubMed]
- Vu, T.; Bremond, F.; Thonnat, M. Automatic Video Interpretation: A Novel Algorithm for Temporal Scenario Recognition. In Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence (IJCAI’03), Acapulco, Mexico, 9–15 August 2003. [Google Scholar]
- Cao, Y.; Tao, L.; Xu, G. An event-driven context model in elderly health monitoring. In Proceedings of the Symposia and Workshops on Ubiquitous, Autonomic and Trusted Computing, Brisbane, Australia, 7–9 July 2009. [Google Scholar]
- Chen, L.; Hoey, J.; Nugent, C.; Cook, D.; Yu, Z. Sensor-Based Activity Recognition. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Town, C. Ontological inference for image and video analysis. Mach. Vis. Appl. 2006, 17, 94–115. [Google Scholar] [CrossRef]
- Ceusters, W.; Corso, J.J.; Fu, Y.; Petropoulos, M.; Krovi, V. Introducing Ontological Realism for Semi-Supervised Detection and Annotation of Operationally Significant Activity in Surveillance Videos. In Proceedings of the the 5th International Conference on Semantic Technologies for Intelligence, Defense and Security (STIDS), Fairfax, VA, USA, 26–29 October 2010. [Google Scholar]
- Chen, L.; Nugent, C.; Okeyo, G. An Ontology-Based Hybrid Approach to Activity Modeling for Smart Homes. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 92–105. [Google Scholar] [CrossRef]
- Rantz, M.; Banerjee, T.; Cattoor, E.; Scott, S.; Skubic, M.; Popescu, M. Automated Fall Detection With Quality Improvement “Rewind” to Reduce Falls in Hospital Rooms. J. Gerontol. Nurs. 2014, 40, 13–17. [Google Scholar] [CrossRef] [PubMed]
- Tran, S.D.; Davis, L.S. Event Modeling and Recognition Using Markov Logic Networks. In Proceedings of the the 10th European Conference on Computer Vision (ECCV 2008), Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany; pp. 610–623. [Google Scholar]
- Kitani, K.M.; Ziebart, B.D.; Bagnell, J.A.D.; Hebert, M. Activity Forecasting. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin, Germany, 2012. [Google Scholar]
- Kwak, S.; Han, B.; Han, J.H. Scenario-based video event recognition by constraint flow. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3345–3352. [Google Scholar]
- Brendel, W.; Fern, A.; Todorovic, S. Probabilistic event logic for interval-based event recognition. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3329–3336. [Google Scholar]
- Nghiem, A.T.; Bremond, F. Background subtraction in people detection framework for RGB-D cameras. In Proceedings of the 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; pp. 241–246. [Google Scholar]
- Pramerdorfer, C. Evaluation of Kinect Sensors for Fall Detection. In Proceedings of the IASTED International Conference on Signal Processing, Pattern Recognition and Applications (SPPRA 2013), Innsbruck, Austria, 12–14 February 2013. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time Human Pose Recognition in Parts from Single Depth Images. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Kuhn, H.W. The Hungarian Method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Chau, D.P.; Thonnat, M.; Bremond, F. Automatic parameter adaptation for multi-object tracking. In Proceedings of the International Conference on Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013. [Google Scholar]
- Allen, J.F. Maintaining Knowledge About Temporal Intervals. Commun. ACM 1983, 26, 832–843. [Google Scholar] [CrossRef]
- Wang, H.; Klaser, A.; Schmid, C.; Liu, C.L. Action Recognition by Dense Trajectories. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 3169–3176. [Google Scholar]
- Folstein, M.F.; Robins, L.N.; Helzer, J.E. THe mini-mental state examination. Arch. Gen. Psychiatry 1983, 40, 812. [Google Scholar] [CrossRef] [PubMed]
- Karakostas, A.; Briassouli, A.; Avgerinakis, K.; Kompatsiaris, I.; Tsolaki, M. The Dem@Care Experiments and Datasets: A Technical Report; Technical Report; Centre for Research and Technology Hellas: Thessaloniki, Greece, 2014. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event | DT-HOG | DT-HOF | DT-MBH | Proposed |
|---|---|---|---|---|
| Prepare drink | 58.61 | 47.33 | 63.09 | 74.07 |
| Prepare drug box | 60.14 | 70.97 | 27.59 | 90.91 |
| Read | 51.75 | 56.26 | 65.87 | 83.33 |
| Search bus line | 66.67 | 63.95 | 42.52 | 60.00 |
| Talk on telephone | 92.47 | 46.62 | 72.61 | 95.00 |
| Water plant | 42.58 | 13.08 | 24.83 | 72.22 |
| Average ± SD | 62.0 ± 17.0 | 49.7 ± 20.3 | 49.4 ± 20.6 | 79.3 ± 13.0 |
| IADL | Recall (%) | Precision (%) | -Score (%) |
|---|---|---|---|
| Walking 8 m | 90.75 | 93.10 | 91.91 |
| IADL | Recall (%) | Precision (%) | -Score (%) |
|---|---|---|---|
| Prepare drink | 89.4 | 71.9 | 79.7 |
| Prepare drug box | 95.4 | 95.4 | 95.4 |
| Talk on telephone | 89.6 | 86.7 | 88.1 |
| Water plant | 74.1 | 69.0 | 71.5 |
| Average | 87.1 | 81.0 | 85.3 |
| Event | DT-HOG | DT-HOF | DT-MBH | Proposed |
|---|---|---|---|---|
| Account Balance | 44.96 | 34.71 | 42.98 | 66.67 |
| Prepare Drink | 81.66 | 44.87 | 52.00 | 100.00 |
| Prepare Drug Box | 14.19 | 0.00 | 0.00 | 57.14 |
| Read Article | 52.10 | 42.86 | 33.91 | 63.64 |
| Talk on telephone | 82.35 | 0.00 | 33.76 | 100.00 |
| Turn on radio | 85.71 | 42.52 | 58.16 | 94.74 |
| Water Plant | 0.00 | 0.00 | 0.00 | 52.63 |
| Average ± SD | 51.8 ± 34.4 | 23.6 ± 22.3 | 31.5 ± 23.3 | 76.4 ± 21.0 |
| Day | D1 | D2 | D3 | |||
|---|---|---|---|---|---|---|
| Index | Recall | Precision | Recall | Precision | Recall | Precision |
| Camera at living area | ||||||
| Enter restroom | 100.0 | 100.0 | 100.0 | 84.2 | 61.7 | 100.0 |
| Exit restroom | 100.0 | 34.8 | 100.0 | 41.0 | 100.0 | 81.4 |
| Leave room | 91.1 | 100.0 | 63.0 | 100.0 | 96.7 | 100.0 |
| Enter room | 79.7 | 100.0 | 61.1 | 100.0 | 98.3 | 100.0 |
| Sit in armchair | 100.0 | 100.0 | 87.5 | 100.0 | 100.0 | 45.4 |
| Average | 94.2 | 87.0 | 82.3 | 85.0 | 91.3 | 85.4 |
| Camera at bed area | ||||||
| Enter bed | 100.0 | 100.0 | 100.0 | 62.5 | 100.0 | 77.8 |
| Bed exit | 50.0 | 100.0 | 100.0 | 100.0 | 100.0 | 77.8 |
| Average | 75.0 | 100.0 | 100.0 | 81.2 | 100.0 | 77.8 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crispim-Junior, C.F.; Gómez Uría, A.; Strumia, C.; Koperski, M.; König, A.; Negin, F.; Cosar, S.; Nghiem, A.T.; Chau, D.P.; Charpiat, G.; et al. Online Recognition of Daily Activities by Color-Depth Sensing and Knowledge Models. Sensors 2017, 17, 1528. https://doi.org/10.3390/s17071528
Crispim-Junior CF, Gómez Uría A, Strumia C, Koperski M, König A, Negin F, Cosar S, Nghiem AT, Chau DP, Charpiat G, et al. Online Recognition of Daily Activities by Color-Depth Sensing and Knowledge Models. Sensors. 2017; 17(7):1528. https://doi.org/10.3390/s17071528
Chicago/Turabian StyleCrispim-Junior, Carlos Fernando, Alvaro Gómez Uría, Carola Strumia, Michal Koperski, Alexandra König, Farhood Negin, Serhan Cosar, Anh Tuan Nghiem, Duc Phu Chau, Guillaume Charpiat, and et al. 2017. "Online Recognition of Daily Activities by Color-Depth Sensing and Knowledge Models" Sensors 17, no. 7: 1528. https://doi.org/10.3390/s17071528
APA StyleCrispim-Junior, C. F., Gómez Uría, A., Strumia, C., Koperski, M., König, A., Negin, F., Cosar, S., Nghiem, A. T., Chau, D. P., Charpiat, G., & Bremond, F. (2017). Online Recognition of Daily Activities by Color-Depth Sensing and Knowledge Models. Sensors, 17(7), 1528. https://doi.org/10.3390/s17071528