A FPGA-Based, Granularity-Variable Neuromorphic Processor and Its Application in a MIMO Real-Time Control System


Abstract
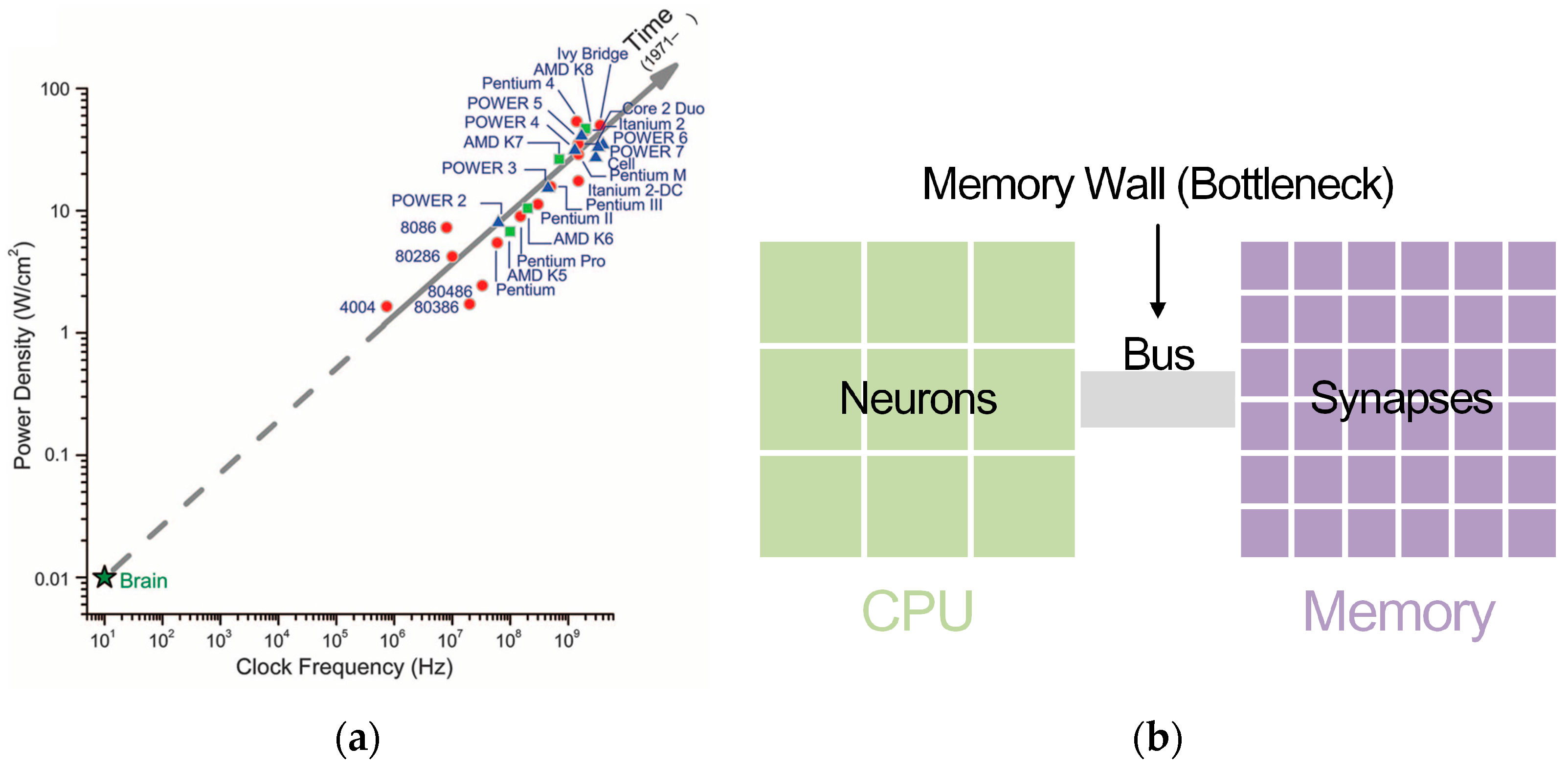
:1. Introduction
- (1)
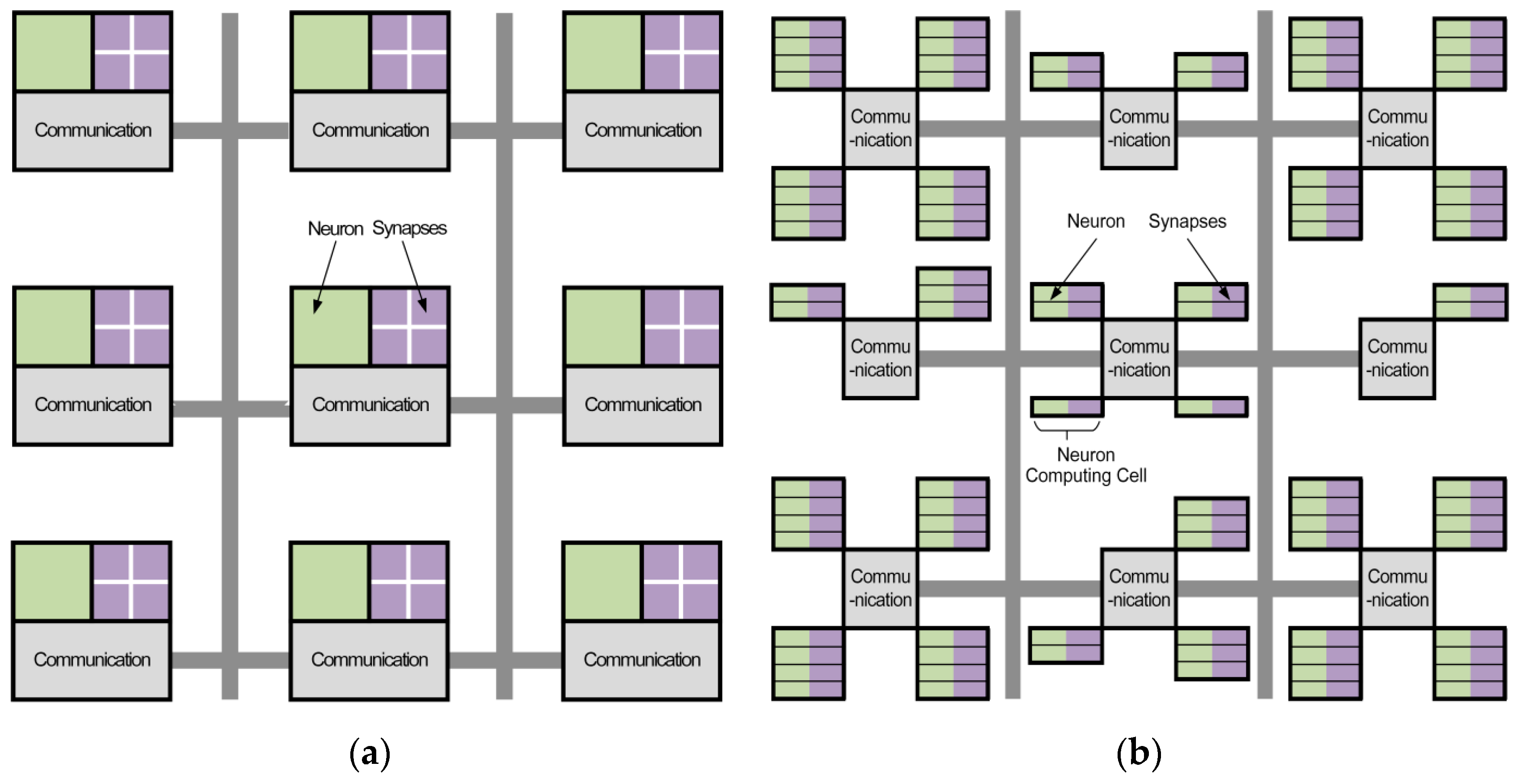
- Granularity variability: The number of the cells in one neural computing unit can vary, which will enhance the flexibility of the neuromorphic core compared with fixed architectures. The neuron computing cells perform as the basic elements in this architecture. One can expand the size of the cells as required. That will make the core better suited for different applications.
- (2)
- Scalability: The scalability is achieved by connecting different cores with routers and extending inner neural computing units. The data interaction through routers links the neuromorphic cores so they become whole. Generally, routers serve as the communication nodes in the multi-core network and the network scale can be extended as needed.
- (3)
- Integrated computing and addressing ability: The neuron computing cell combines together computing and addressing abilities. The data transmission uses the broadcast mechanism. On this basis, a neuron computing cell serves as a data receiving and processing terminal and the two processes are executed simultaneously, which makes the computations perform in parallel.
2. Neuromorphic Processor Architecture
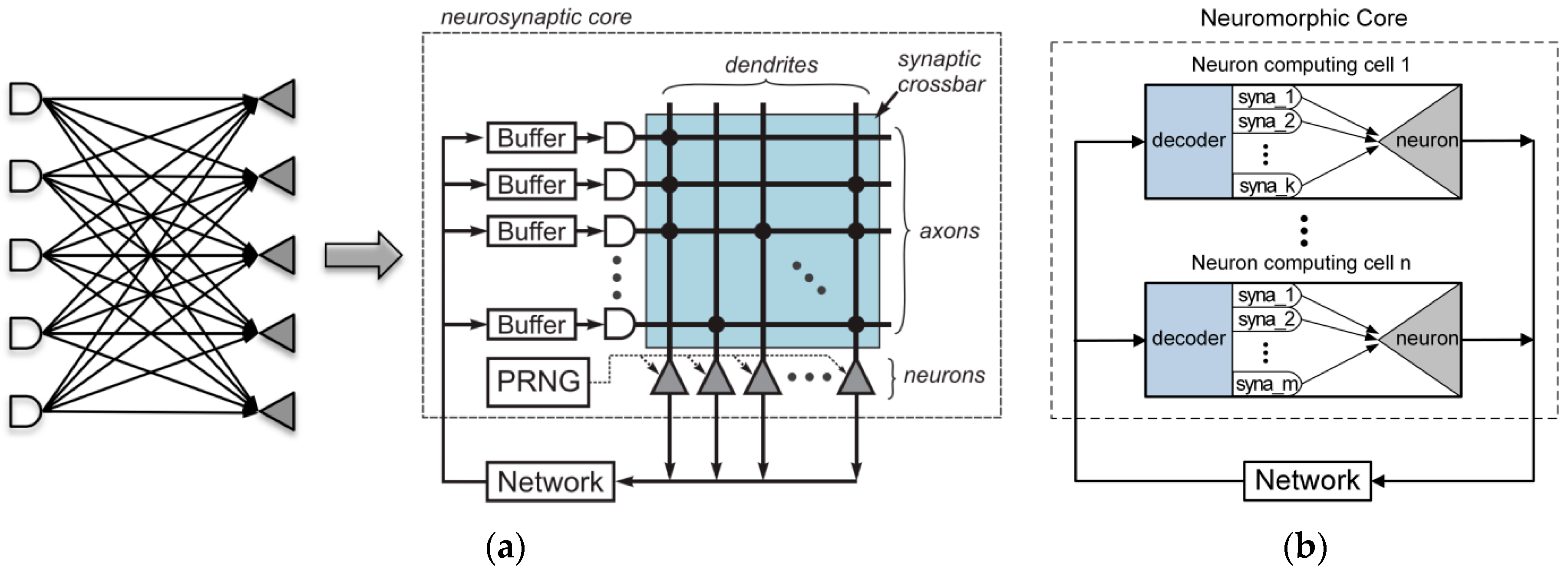
2.1. Architecture of FBGVNP
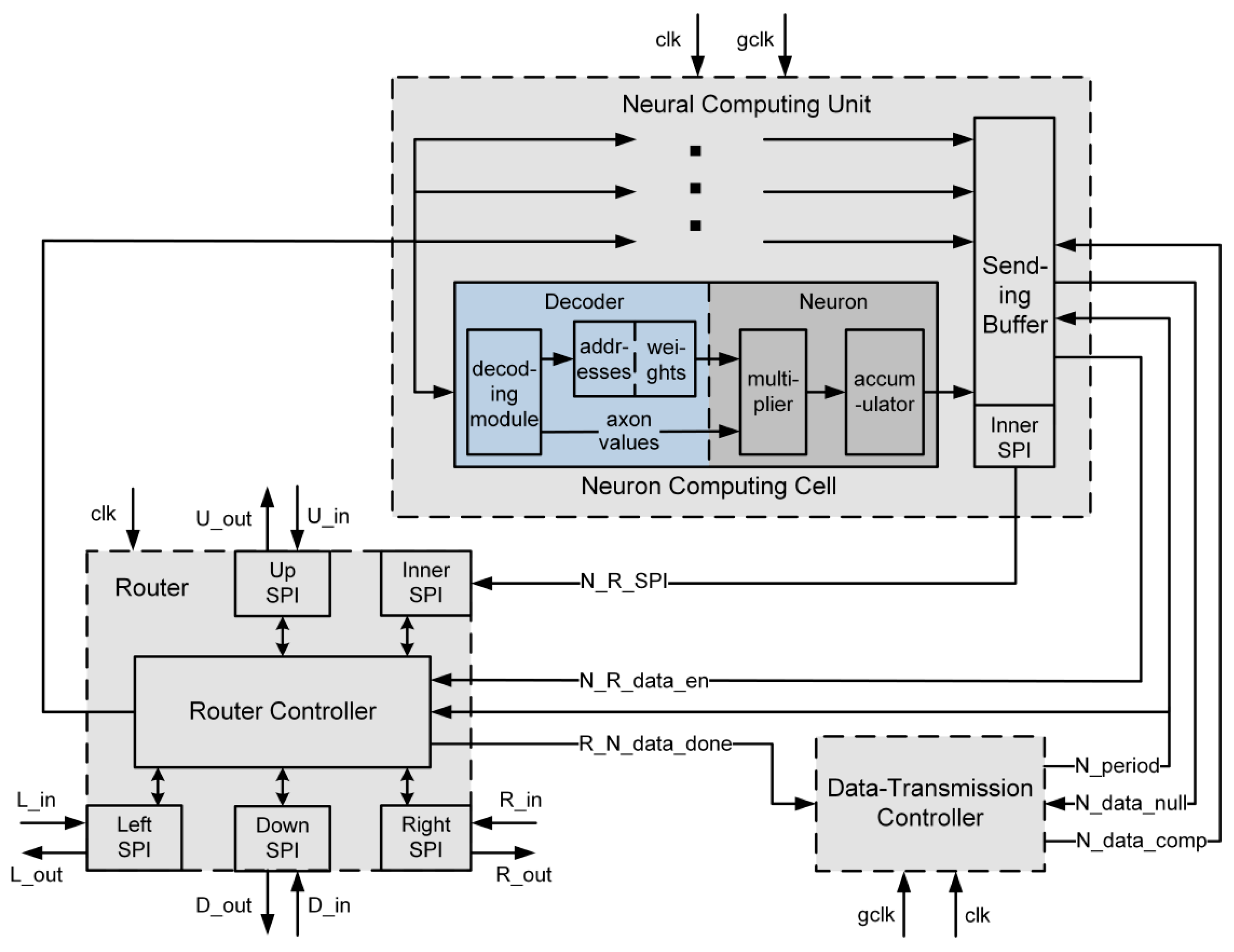
2.2. FBGVNP Internals
- (1)
- A neuromorphic core receives a packet from the network and resolves it. If not equal to zero, the dx field will be decremented or incremented and the packet will be sent to the corresponding right or left routing hop. Then, when dx becomes 0, the dy field will also be decremented or incremented in a vertical direction transmission until it turns to 0.
- (2)
- The destination unit index field will be resolved to get the target unit neural computing unit address. The dx, dy, and destination unit index field bits are stripped and the remaining 16 bits are broadcasted to the cells in the target neural computing unit. The destination cell index field bits will be compared to the address entries pre-stored in each decoder. If they match, the corresponding weight in the decoder will be sent to the neuron for computing, as well as to the neuron output field bits in the packet. If not, the cell will work only when the next packet reaches the neuron.
- (3)
- The neuron receives weight and neuron output field bits from the decoder and multiplies them. The result will be sent to an accumulator.
- (4)
- When a synchronization trigger signal called the global clock arrives, each neuron outputs the accumulator result to the sending buffer and the core steps in the data sending process.
- (5)
- After the global clock arrives, the core step is in the data transmission period. The data-transmission controller initializes the N_period signal. It is a number denoting which neuron’s computing result is selected to be transferred out. At the same time, the N_data_comp signal pulses once and drives a process verifying the validity of the selected neuron’s computing result stored in the sending buffer. If invalid, the N_data_null signal pluses once, and the core goes to another data transmission period. On the other hand, if valid, the N_R_data_en signal turns to the enabling state, until the end of this period’s data sending.
- (6)
- When the N_R_data_en signal is enabled, the selected neuron’s computing result will be transferred to the router, if the inner serial peripheral interface (SPI) port’s buffer is not full. After the transferring, the router controller will send the packet targeting to the destination core and return back a R_N_data-done signal to the data-transmission controller. Then, the N_period and N_data_comp signals will be updated along with the core steps in another data transmission period.
- (7)
- After the transferring of the last neuron’s computing result, the core will keep waiting for the next arrival of the global clock.
2.3. Features Comparison of FBGVNP and TrueNorth
3. Experiments and Discussion
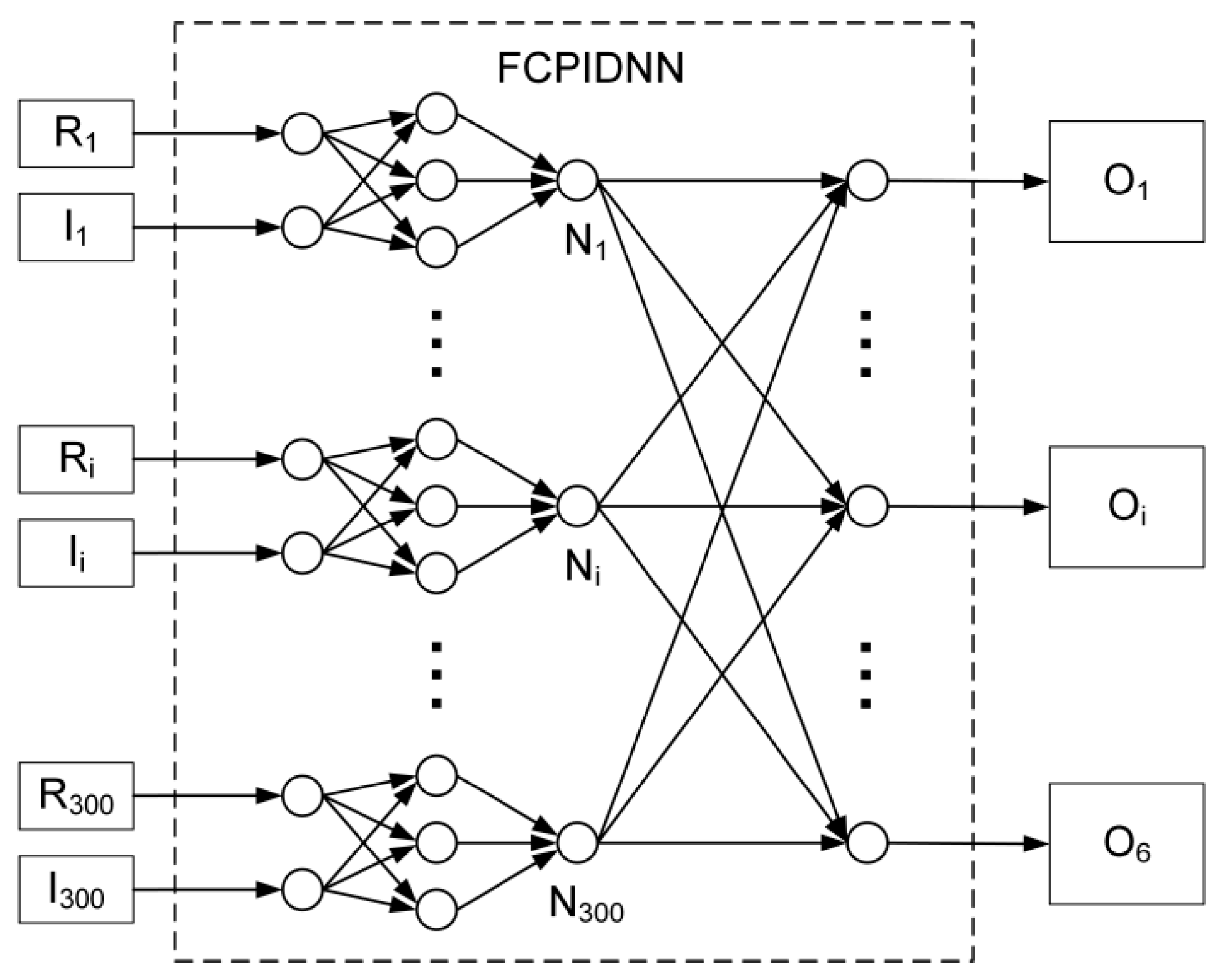
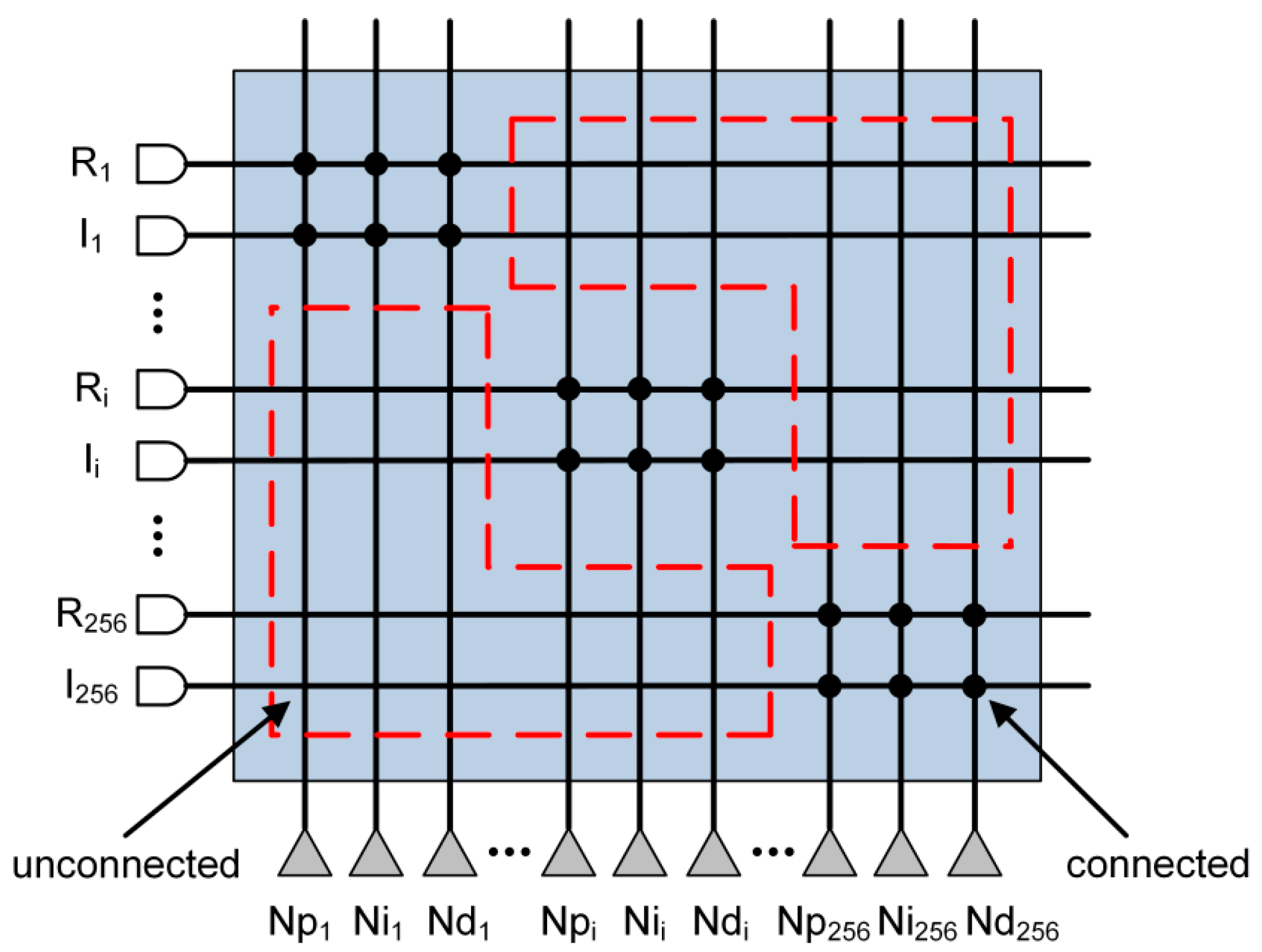
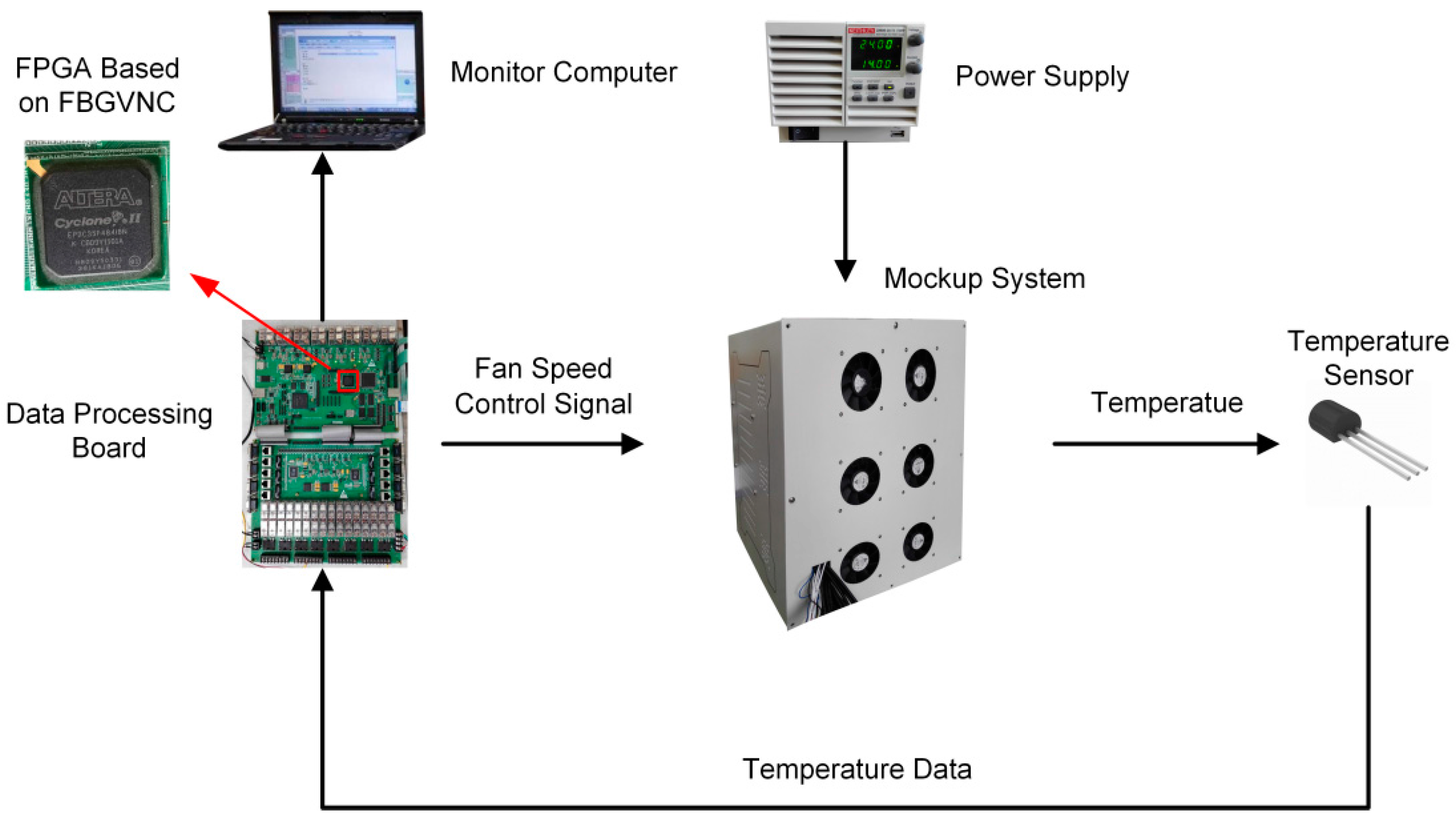
3.1. Experiment Setup
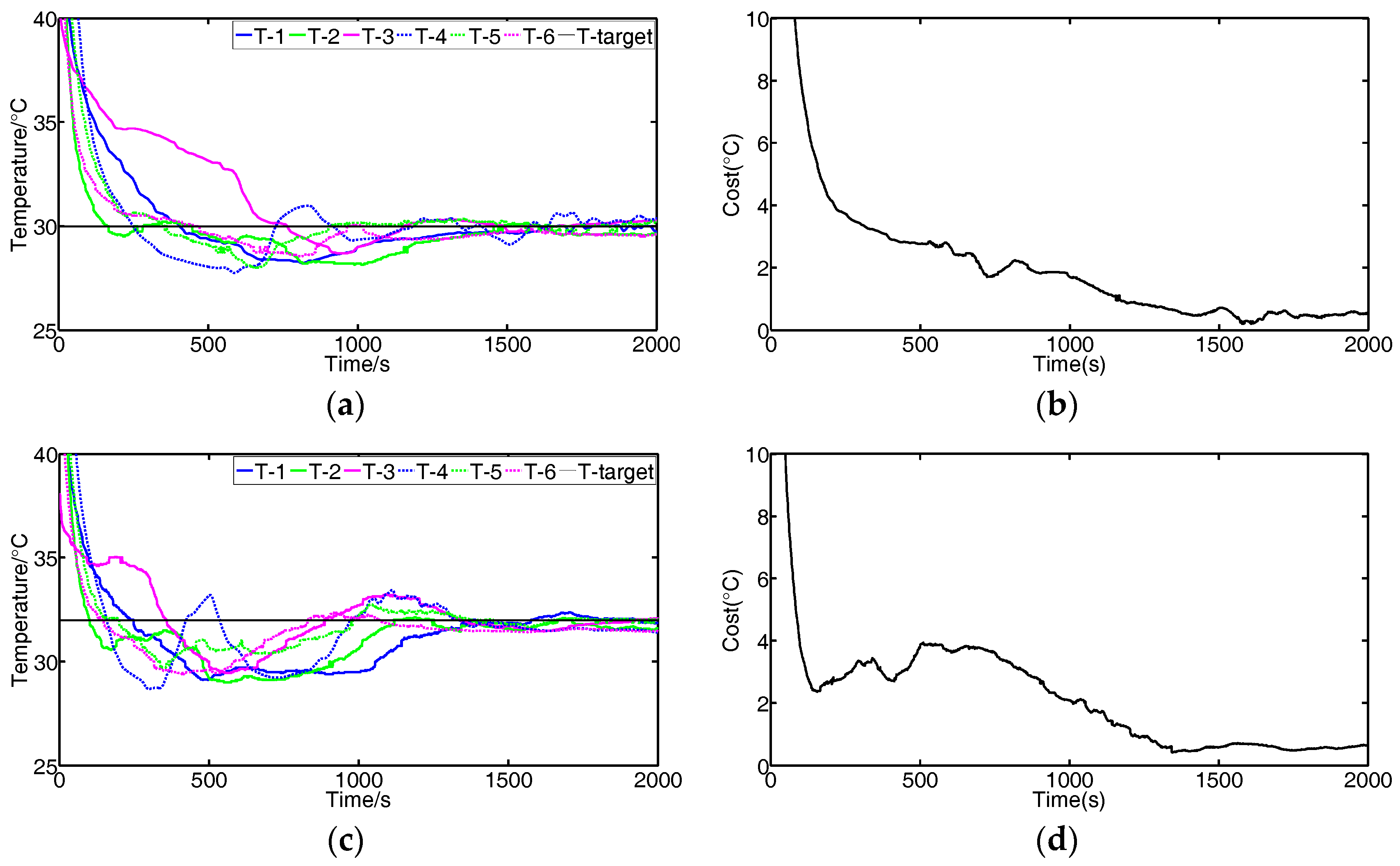
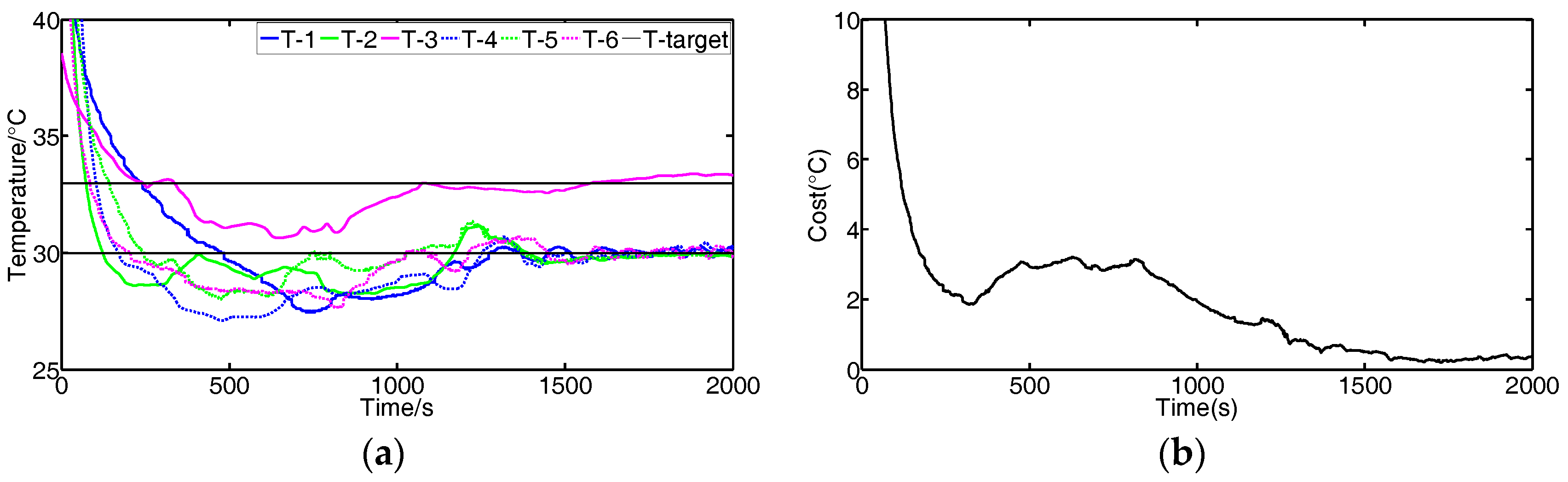
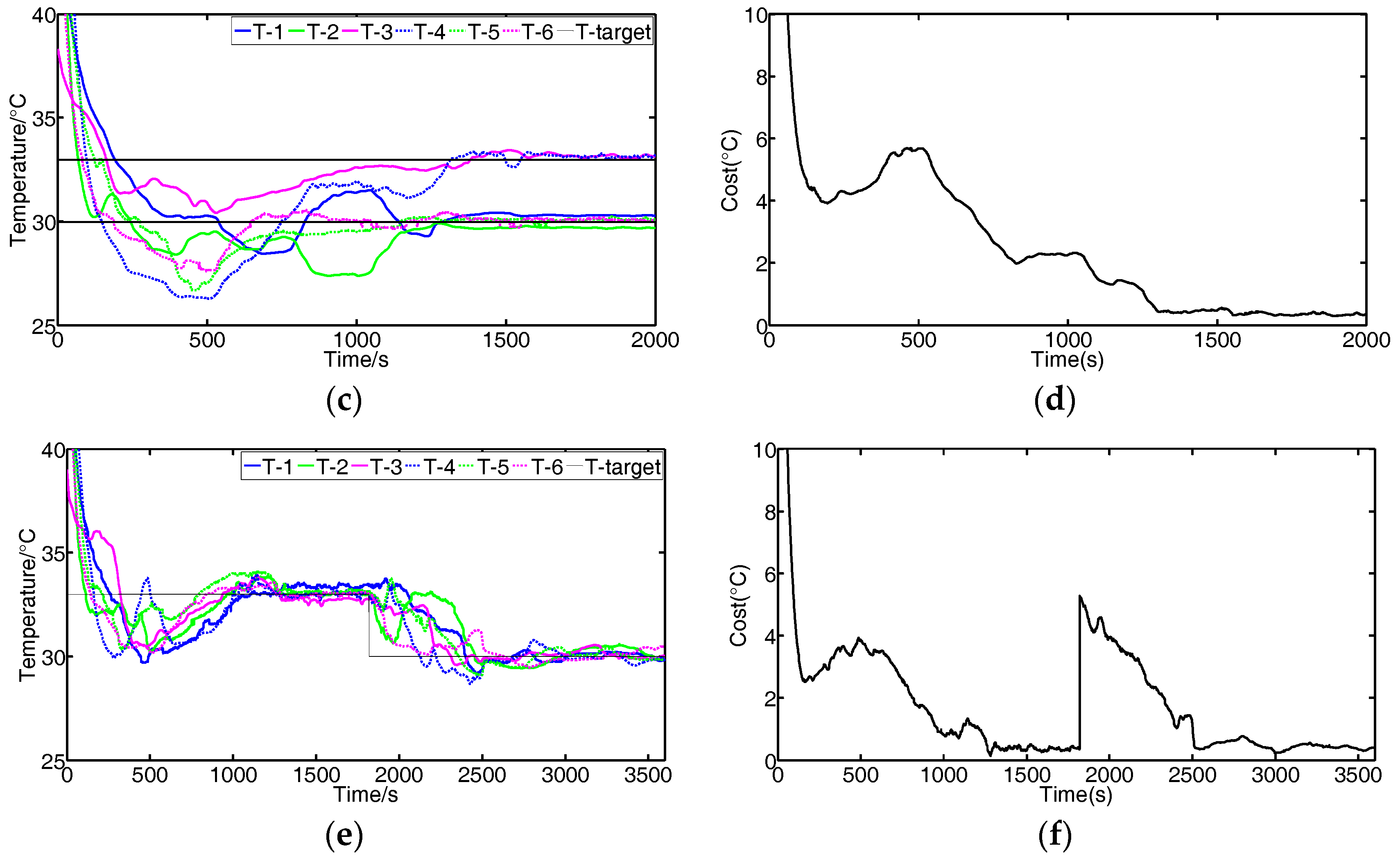
3.2. Experiment Results and Discussions
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lacey, G.; Taylor, G.W.; Areibi, S. Deep learning on FPGAs: Past, present, and future. arXiv, 2016; arXiv:arXiv:1602.04283. [Google Scholar]
- Hasan, R.; Taha, T. A reconfigurable low power high throughput architecture for deep network training. arXiv, 2016; arXiv:arXiv:1603.07400. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Huang, T.; Wang, J.; Sun, J.; Hussain, A.; Yang, E. Dual-branch deep convolution neural network for polarimetric SAR image classification. Appl. Sci. 2017, 7, 447. [Google Scholar] [CrossRef]
- Anibal, P.; Gloria, B.; Oscar, D.; Gabriel, C.; Saúl, B.; María, B.R. Automated Diatom Classification (Part B): A Deep Learning Approach. Appl. Sci. 2017, 7, 460. [Google Scholar]
- Pastur-Romay, L.A.; Cedron, F.; Pazos, A.; Porto-Pazos, A.B. Deep Artificial Neural Networks and Neuromorphic Chips for Big Data Analysis: Pharmaceutical and Bioinformatics Applications. Int. J. Mol. Sci. 2016, 17, 1313. [Google Scholar] [CrossRef] [PubMed]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Yadan, O.; Adams, K.; Taigman, Y.; Ranzato, M. Multi-gpu training of convnets. arXiv, 2016; arXiv:arXiv:1312.5853. [Google Scholar]
- Yu, K. Large-scale deep learning at Baidu. In Proceedings of the ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2211–2212. [Google Scholar]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L.A. The SpiNNaker Project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Beyeler, M.; Carlson, K.D.; Chou, T.S.; Dutt, N. CARLsim 3: A user-friendly and highly optimized library for the creation of neurobiologically detailed spiking neural networks. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Farabet, C.; Poulet, C.; Han, J.Y.; LeCun, Y. CNP: An FPGA-based processor for Convolutional Networks. In Proceedings of the International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 32–37. [Google Scholar]
- Nageswaran, J.M.; Dutt, N.; Krichmar, J.L.; Nicolau, A.; Veidenbaum, A.V. A configurable simulation environment for the efficient simulation of large-scale spiking neural networks on graphics processors. Neural Netw. 2009, 22, 791–800. [Google Scholar] [CrossRef] [PubMed]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.; et al. True North: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip. IEEE Trans. Comput Aid D Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Aydonat, U.; O’Connell, S.; Capalija, D.; Ling, A.C.; Chiu, G.R. An OpenCL(TM) Deep Learning Accelerator on Arria 10. arXiv, 2017; arXiv:arXiv:1701.03534. [Google Scholar]
- Park, J.; Sung, W. FPGA based implementation of deep neural networks using on-chip memory only. In Proceedings of the International Conference on Acoustics Speech and Signal Processing, Shanghai, China, 20–25 March 2016; pp. 1011–1015. [Google Scholar]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the Acm/sigda International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar]
- Peemen, M.; Setio, A.A.A.; Mesman, B.; Corporaal, H. Memory-Centric Accelerator Design for Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Design, Asheville, NC, USA, 6–9 October 2013; pp. 13–19. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. Acm/sigda International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- Zhan, C.; Fang, Z.; Zhou, P.; Pan, P.; Cong, J. Caffeine: Towards Uniformed Representation and Acceleration for Deep Convolutional Neural Networks. In Proceedings of the IEEE ACM International Conference on Computer-Aided Design, Austin, TX, USA, 7–10 November 2016. [Google Scholar]
- Lee, C.; Chen, R. Optimal Self-Tuning PID Controller Based on Low Power Consumption for a Server Fan Cooling System. Sensors 2015, 15, 11685–11700. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Ma, C.; Zhu, R. Self-Tuning Fully-Connected PID Neural Network System for Distributed Temperature Sensing and Control of Instrument with Multi-Modules. Sensors 2016, 16, 1709. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | General Purpose Processors (GPPs) | Neuromorphic Processors | |||
|---|---|---|---|---|---|
| multicore CPU | GPGPU | MCU | ASIC-based | FPGA-based | |
| computing process | sequential | parallel | |||
| computing structure | centralized | distributed | |||
| energy-efficiency | low | best | better | ||
| development round | short | longest | longer | ||
| cost | high | high | low | highest | moderate |
| Dx | Dy | Destination Unit Index | Destination Cell Index | Neuron Output |
|---|---|---|---|---|
| 8 bits | 8 bits | 4 bits | 8 bits | 8 bits |
| Processors | Neuron Number | Computing and Addressing | Scalability | Power Consumption |
|---|---|---|---|---|
| FBGVNP | variable | integrated | internal & external | high |
| TrueNorth | fixed | separated | external | low |
| Processors | 1st Layer (Gclk Period) | 2nd Layer (Gclk Period) | 3rd Layer (Gclk Period) | 4th Layer (Gclk Period) |
|---|---|---|---|---|
| FBGVNP | 1 | 1 | 1 | 1 |
| TrueNorth | 1 | 1 | 1 | 2 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Ma, C.; Zhu, R. A FPGA-Based, Granularity-Variable Neuromorphic Processor and Its Application in a MIMO Real-Time Control System. Sensors 2017, 17, 1941. https://doi.org/10.3390/s17091941
Zhang Z, Ma C, Zhu R. A FPGA-Based, Granularity-Variable Neuromorphic Processor and Its Application in a MIMO Real-Time Control System. Sensors. 2017; 17(9):1941. https://doi.org/10.3390/s17091941
Chicago/Turabian StyleZhang, Zhen, Cheng Ma, and Rong Zhu. 2017. "A FPGA-Based, Granularity-Variable Neuromorphic Processor and Its Application in a MIMO Real-Time Control System" Sensors 17, no. 9: 1941. https://doi.org/10.3390/s17091941
APA StyleZhang, Z., Ma, C., & Zhu, R. (2017). A FPGA-Based, Granularity-Variable Neuromorphic Processor and Its Application in a MIMO Real-Time Control System. Sensors, 17(9), 1941. https://doi.org/10.3390/s17091941