1. Introduction
Geovisualization, or geographic visualization, is an efficient way to describe the real geographic world through visual means, thereby making complex geographic data and information intuitive and easy to understand. An appropriate geovisualization method can provide prompt insight and understanding to support real-world knowledge construction and decision-making [
1]. Recently, as a tool, a process and a mode of thought, geovisualization has been widely used in environmental monitoring [
2], spatial decision-making [
3], urban mobility [
4], meteorology [
5], and archaeology [
6], among other fields. However, traditional geovisualization methods suffer from several drawbacks when facing various increasingly challenging representation needs. On the one hand, traditional geovisualization usually refers to 2D/3D cartographic visualization, which, to some degree, is isolated from the real world because it involves creating another “world” (such as a map or a virtual environment) to describe the real world, and this isolation may result in improper spatial cognition or may even produce incorrect information. For example, the limitation of small screens on mobile or embedded devices adds difficulty to user’s cognitive mapping [
7]. On the other hand, interaction, as an important dimension of geovisualization [
8], is vital to the user experience. However, the outputs of traditional geovisualization are usually limited to paper maps or electronic maps, which provide limited modes of interaction for users.
Augmented Reality (AR) is a promising branch of technology that offers new modes of visualization, navigation and user interaction [
9]. In particular, outdoor AR technology provides new opportunities for visualizing geographic data and information in a more direct and intuitive way in an outdoor geographical environment. Many current AR methods and applications are based on visual fiducial markers [
10,
11,
12]. However, such methods demand a controlled environment (usually an indoor environment) and require markers to be placed in advance. In the case of outdoor geographical environments, it is usually not practical to cover such an uncontrolled environment with markers [
13]. To date, many attempts have been made to develop AR methods targeting outdoor environments, and some of them have already been applied to enhance the results of geovisualization [
14,
15,
16]. In most outdoor AR methods and applications, a Global Positioning System (GPS) receiver, inertial sensors and magnetic sensors are generally used to obtain the relative distances and orientations of users and geographic objects; however, such sensors suffer from many problems, such as deterioration in the GPS precision and drift and distortion in the output of inertial and magnetic sensors [
17], which sometimes lead to unsatisfactory results. As an essential area of AR research, vision-based natural feature detection [
17] enables the extraction of object features from uncontrolled environments for classification and localization and has been widely used in outdoor AR methods for detection and tracking [
18,
19]. Traditional vision-based natural feature detection methods, such as natural keypoint detectors (e.g., SIFT [
20], SURF [
21], HOG [
22], and Haar [
23]) or edge-based approaches [
24], can achieve high positional accuracy but are overly sensitive to motion blur, changes in lighting conditions, occlusion, and other such phenomena and have difficulty coping with multiple objects or detection at multiple scales or from multiple perspectives, which frequently results in instability and even failure. As is noted in [
9], a single technology is not always sufficient for registration and interaction in AR; therefore, it is necessary to integrate various technologies together.
The purpose of the study reported in this paper was to develop a robust, fast and markerless outdoor AR method for execution on mobile or embedded devices in uncontrolled outdoor environments to achieve registration, geovisualization and interaction that can adapt to various challenging outdoor conditions, such as motion blur, rotation, occlusion, and multiple objects, scales and perspectives. To achieve this goal, a lightweight, energy-efficient but powerful vision-based geographic object detection approach for outdoor mobile AR is needed, and the vision-based detection results for geographic objects should be combined with their corresponding spatial relationships to achieve the precise registration of virtual objects, with the help of the host device’s built-in GPS receiver, Inertial Measurement Unit (IMU) and magnetometer, to serve as the basis for subsequent AR geovisualization and interaction. Moreover, for robustness against the poor signal conditions found in many challenging outdoor environments, the method should be sufficiently flexible and independent; achieving this goal requires a small model size and eliminating any dependence on the network to the greatest possible extent. Our method can accurately detect geographic objects in near real time with sufficient robustness and can then augment them by registering and visualizing virtual objects generated based on geospatial information. Our method provides a new AR-based means of geovisualization and interaction to assist users in understanding and interacting with the geographical environment in an intuitive manner, thereby enriching the user experience, which is expected to be beneficial in many diverse applications, such as urban planning, environmental monitoring and spatial decision-making.
The remainder of this paper is organized as follows: in
Section 2, the development of outdoor AR systems is introduced, and recent deep-learning-based object detection methods are reviewed. In
Section 3, a lightweight vision-based deep learning object detection approach for outdoor AR on mobile or embedded devices is proposed and evaluated. In
Section 4, we describe our proposed method of mobile outdoor AR for registration, geovisualization and interaction, which combines vision-based detection results and spatial relationships with the help of the host device’s built-in GPS receiver, IMU and magnetometer. In
Section 5, a prototype system we developed using the proposed method is presented, which was tested on the Wuhan University campus to evaluate the method and validate its results, and a discussion of the findings is presented. Conclusions and future work are outlined in
Section 6.
3. A Lightweight SSD for Mobile Outdoor AR
We choose SSD as the visual object detection approach for our mobile outdoor AR method by virtue of its high detection accuracy and speed. However, because of its enormous computational cost, it is still too slow and computationally expensive to run the original SSD without a powerful GPU, let alone on low-power mobile or embedded devices. Moreover, the heavy and complex architecture of the original SSD requires a weight file of more than 100 MB, which is excessively large for a mobile application when the storage space is limited or a large number of models are needed. Currently, a common solution is to first implement SSD on a powerful server and then allow mobile or embedded devices to send input images to the server and receive output visual detection results from the server through the network. However, this solution will inevitably lead to dependence on the network, resulting in latency and vulnerability to poor signal conditions, which should be avoided to the greatest possible extent in outdoor AR.
In brief, a local, energy-efficient and lightweight object detection method that can run on mobile devices is more suitable than one running on a server for handling various outdoor environments under poor signal conditions. Therefore, we propose lightweight SSD, a version of SSD that has been modified by changing the original SSD architecture to make it sufficiently lightweight for mobile or embedded devices. We greatly reduce the computing cost (and also the size of the weight file) to achieve near-real-time performance on mobile or embedded devices while maintaining a high detection accuracy.
3.1. Network Architecture
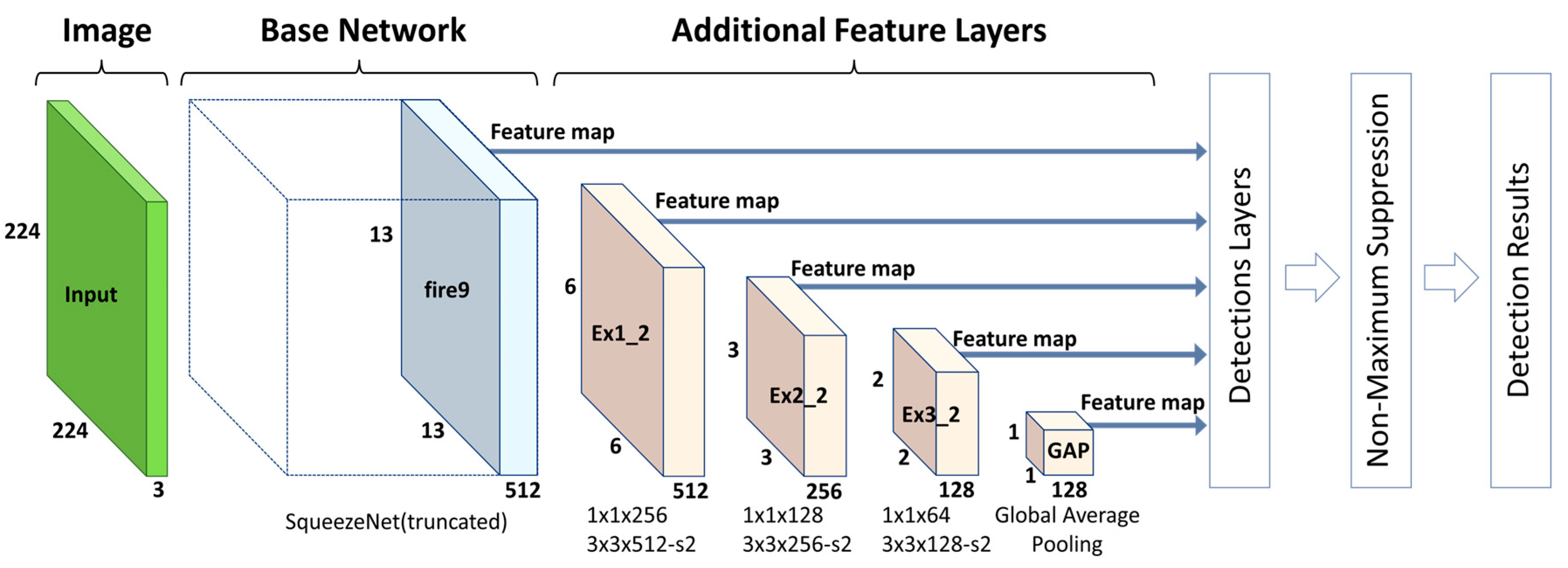
A large proportion of the computational cost of SSD is due to the base network (e.g., truncated VGG-16 in the original SSD) and additional feature layers, which are mainly used to extract multi-scale features from the input image. Thus, we replace the heavy base network with a more lightweight one and modify the subsequent additional feature layers. SqueezeNet [
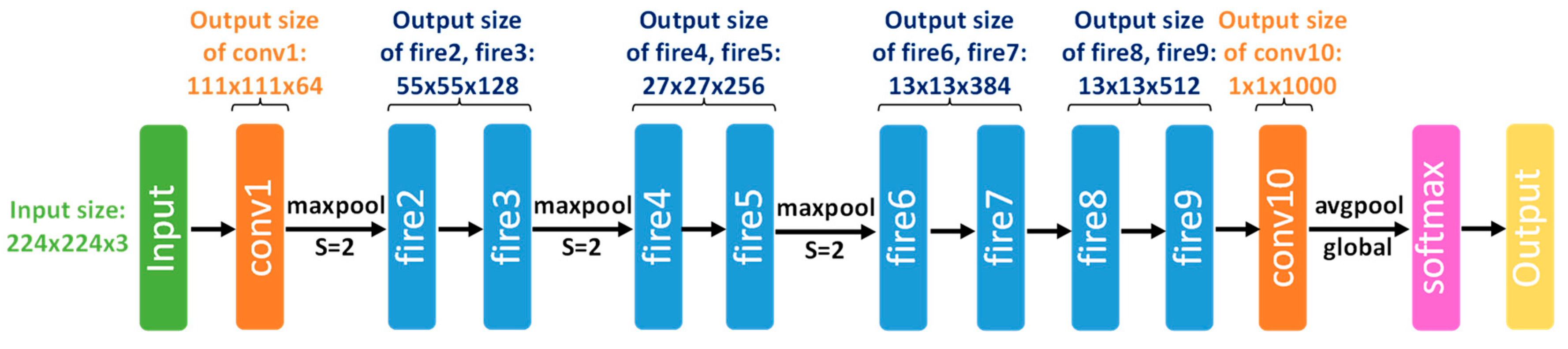
68] is a very lightweight classification CNN architecture that achieves AlexNet-level accuracy on ImageNet with 50 × fewer parameters and a weight file of only 4.8 MB in size. The latest version, SqueezeNet v1.1 (the architecture is shown in
Figure 3), requires 2.4 × fewer computations than the original, without sacrificing accuracy.
Therefore, to significantly reduce the computational cost of the proposed lightweight SSD approach, we use a truncated SqueezeNet architecture (with conv10 and the softmax classifier removed) as the base network and append several additional feature layers (at lower depths than the original) with decaying spatial resolution. Furthermore, whereas the original SSD takes input of 300 × 300 pixels in size and selects six layers from among both the base network layers and the additional feature layers to extract multi-scale features, we use only 224 × 224 pixel input and select only five layers. All of these modifications allow the method as a whole to achieve energy-efficient and near-real-time performance when running on mobile or embedded devices. The details of the architecture are shown in
Figure 4.
3.2. Network Performance
As was done for the original SSD, we trained the proposed lightweight SSD on the PASCAL VOC2007 + VOC2012 trainval datasets and then tested it on the PASCAL VOC2007 test dataset to evaluate its performance. We characterize the training stage in terms of accuracy and loss values. The accuracy is the overall accuracy, including foreground object predictions and background object predictions, and the loss is the overall objective loss function used in [
66], which is a weighted sum of the localization loss and the confidence loss and is defined in Equation (1):
where
is the number of default boxes matched to any ground-truth boxes with a Jaccard overlap higher than a specific threshold (e.g., 0.5) for training. The loss is set to 0 when N is 0.
is the confidence loss, which is the softmax loss over the confidences of multiple classes.
is the localization loss, which is a Smooth L1 [
63] loss between the predicted box parameters and the ground-truth box parameters.
is a weight term, which is set to 1 through cross validation.
and
are defined in Equations (2) and (3), respectively:
where
is an indicator for the matching of the
i-th default box to the
j-th ground-truth box for category
.
is the confidence of category
corresponding to the i-th default box.
is one of the parameters
of the
i-th predicted box, and
is one of the parameters
of the
j-th ground-truth box, where
can be one of the central coordinates
and
or the width
or the height
of the default bounding box for regression, as presented in [
64]. According to the hard negative mining strategy [
61], the ratio between the number of positive examples
and the number of negative examples
should be 1:3 to ensure fast and stable training.
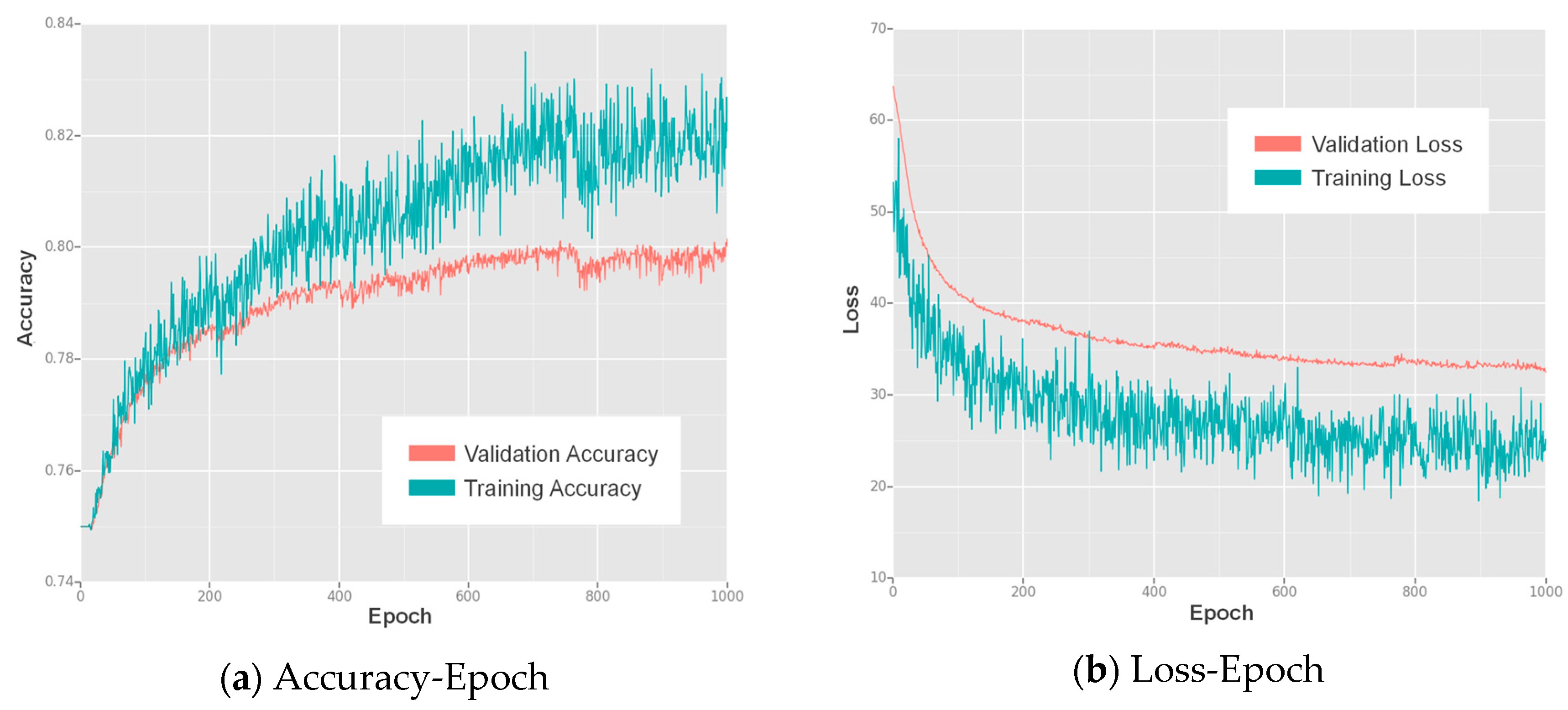
We trained our lightweight SSD for 1000 epochs, and the resulting accuracy-epoch and loss-epoch curves are shown in
Figure 5. The SSD showed increasing accuracy and decreasing loss during training and finally reached convergence at approximately the 1000th epoch, where both the accuracy and loss values became stable.
After the training stage, we obtained a trained model with a weight file of only 17.8 MB in size, which is much smaller than that of the original and very suitable for mobile or embedded devices and applications. We then evaluated the trained lightweight SSD on the PASCAL VOC2007 test dataset to determine its mAP. Finally, we compared our approach with two popular object detection approaches: the original SSD and Fast YOLO (the fast version of YOLO with a simplified architecture). The details of this comparison are shown in
Table 1.
As shown in
Table 1, our approach has a lower mAP than that of the original SSD because of its less accurate base network, fewer feature layers and smaller input size; however, its mAP value is still higher than that of the other fast object detection approach, Fast YOLO, by 1%. By virtue of its lightweight architecture, the size of its weight file is only 17.8 MB, which is approximately 17% of the size of the original SSD weight file and approximately 27% of that of the Fast YOLO weight file. Regarding speed, our approach runs at 66.7 FPS on an NVIDIA GTX 1060 GPU, almost 5 times faster than the original SSD and approximately 2 times faster than Fast YOLO. On an Intel
® Core™ i7-6700K CPU, our approach runs at 9.1 FPS, still faster than the others. On the mobile phone, we tested only our approach and the original SSD because we did not implement a mobile version of Fast YOLO. Our framework runs at approximately 2 FPS on a Qualcomm Snapdragon 821 mobile CPU, 10 times faster than the original SSD. In summary, compared with the other two object detection approaches, our approach has the fastest speed and the smallest model size while maintaining a competitive accuracy.
4. A Mobile Outdoor AR Method for Geovisualization
We propose a mobile outdoor AR method for geovisualization that integrates the vision-based detection results for geographic objects obtained using the proposed lightweight SSD with their corresponding spatial relationships with the help of a GPS receiver, an IMU and a magnetometer. Important functionalities such as registration, visualization through superimposition of virtual objects and interaction are realized.
4.1. Overview of the Method
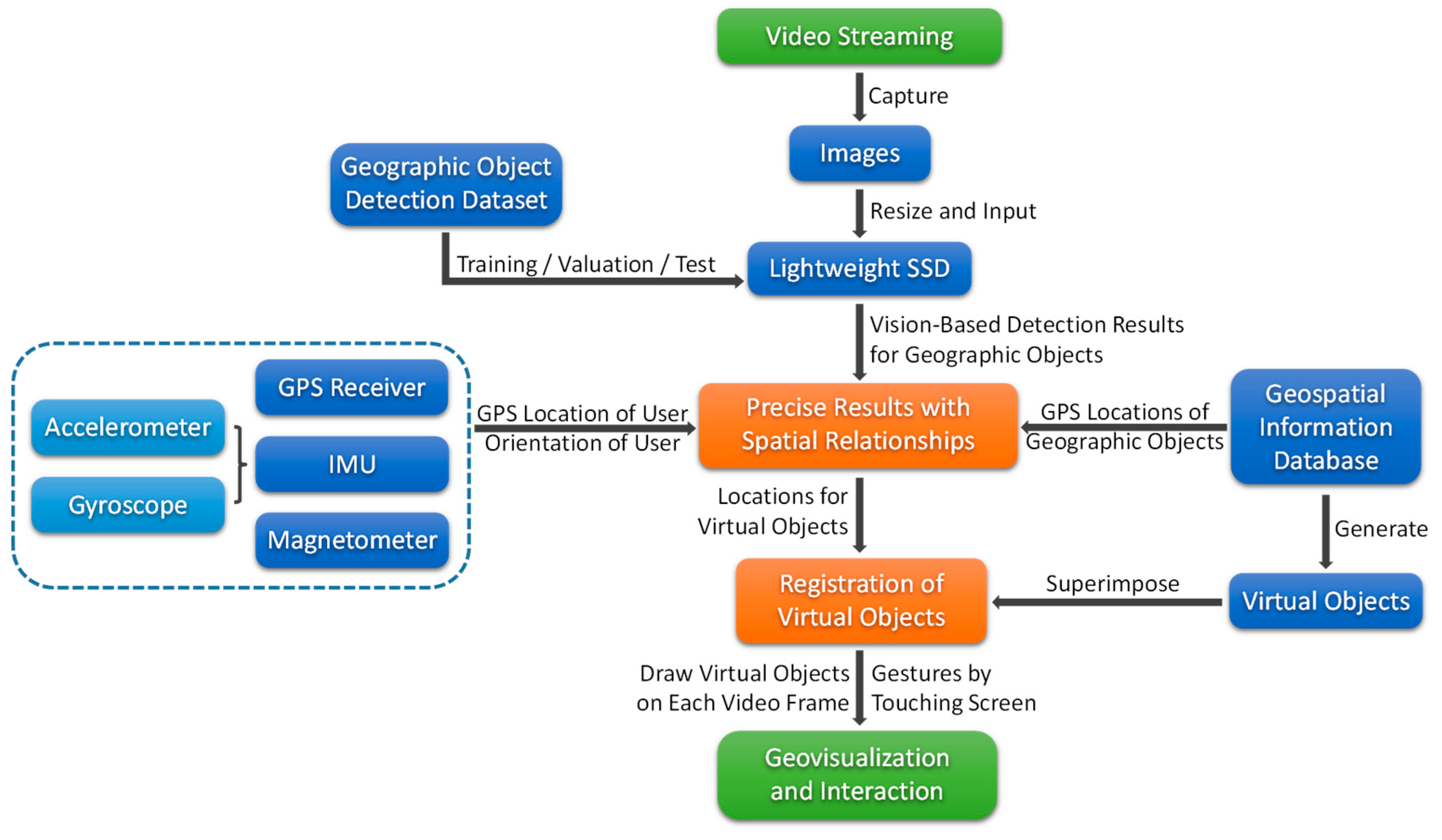
An overview of the proposed mobile outdoor AR method is shown in
Figure 6. Overall, the proposed method can be divided into three important phases:
Training and detection with the lightweight SSD.
Combination of vision-based detection results and spatial relationships.
Registration, geovisualization and interaction.
The entire framework of the method is designed for outdoor AR on mobile or embedded devices without reliance on the network. Consequently, it takes full advantage of mobile computing capabilities and can adapt to various outdoor environments with poor signal conditions.
4.2. Training and Detection with the Lightweight SSD
To apply the lightweight SSD in the proposed AR method for geographic object detection, we first need to train it on a suitable geographic object detection dataset. A geographic object detection dataset should consist of a large number of images of geographic objects and their corresponding annotations, including classification labels and bounding box coordinates on the images. After appropriate training parameters have been set, such as the learning rate and weight decay, the lightweight SSD should reach convergence after training (e.g., after 1000 epochs), meaning that it has achieved a stable accuracy and is ready to be used for geographic object detection.
Afterwards, we can use this trained lightweight SSD to detect geographic objects. From the video stream generated by the visual sensor of a mobile or embedded device, we continuously and instantaneously capture frames to serve as input images. Before detection, all images need to be resized to 224 × 224 pixels because of the input size requirement of the lightweight SSD, which is almost the only necessary preprocessing step. Then, the lightweight SSD takes those images as inputs for visual detection and returns a set of results containing the information on the detected geographic objects, such as their classifications and their bounding box coordinates. Finally, the bounding box coordinates on the 224 × 224 pixel images are stretched to match the screen-size video frames (e.g., 1920 × 1080 pixels) for further registration usage.
4.3. Combination of Vision-Based Detection Results and Spatial Relationships
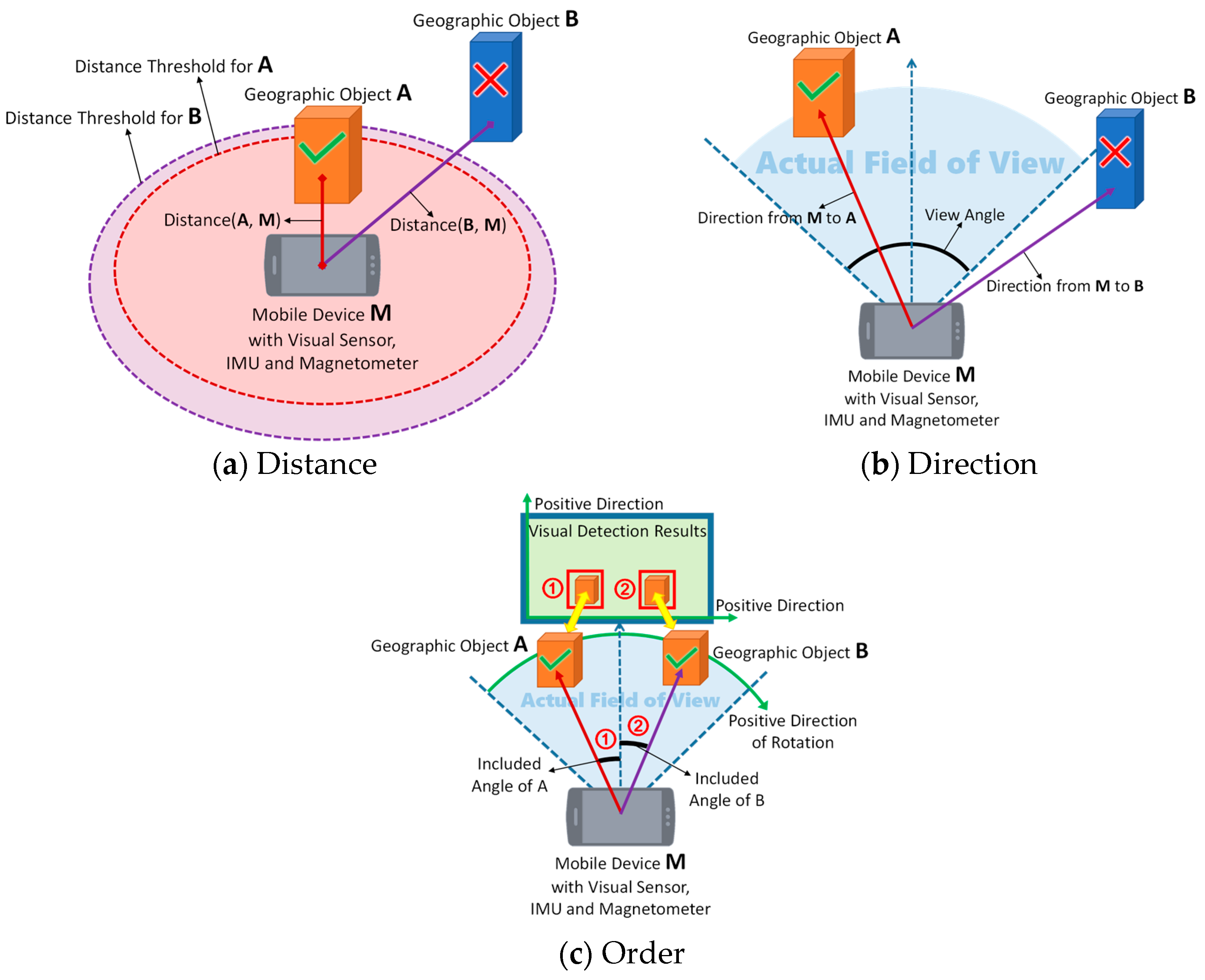
Lightweight SSD is a purely vision-based approach and therefore does not consider spatial relationships, which are vital to the validity of vision-based detection results when applied to the real geographic world. A vision-based object detection approach has no concern for the distances and directions from the visual sensor to the objects; consequently, it may commit certain errors, such as identifying some geographic objects that are either too far away or in completely incorrect directions such that they cannot actually appear in the image at all. Even when the distances and directions are appropriate, some difficulties may still arise in obtaining precise results. For example, it is common for multiple buildings in the same housing estate to share nearly identical visual properties. An efficient object detection approach can detect these buildings with state-of-the-art performance but usually fails to distinguish individual specific buildings. Thus, it is necessary to combine vision-based detection results for geographic objects with their spatial relationships with the help of a GPS receiver, an IMU and a magnetometer to achieve the subsequent precise registration of virtual objects. In our method, we consider three aspects of the problem (examples are shown in
Figure 7):
4.3.1. Distance
We consider the concept of a distance threshold, which represents the maximum valid distance between the visual sensor and a geographic object. When the vision-based detection results are generated, GPS locations are queried to calculate the distance from each object to the visual sensor. The distance calculated from a pair of GPS locations is defined in Equation (4):
where
and
are the latitude and longitude of GPS location A,
and
are the latitude and longitude of GPS location B, and
is the radius of the Earth (km). The result is the distance (km) between locations A and B. The distances thus computed are compared with their corresponding distance thresholds, and any geographic object that does not satisfy the requirement will be discarded. An example is shown in
Figure 7a.
4.3.2. Direction
We also calculate the direction from the visual sensor to each geographic object using GPS locations. The direction is calculated as defined in Equation (5):
where
and
are the latitude and longitude of GPS location A,
and
are the latitude and longitude of GPS location B, and
is the ratio between the circumference of a circle and its diameter. The result is the azimuth of location B relative to location A, which represents the direction from A to B.
Then, we determine the actual horizontal field of view of the image from the horizontal view angle of the visual sensor and the information on the pose of the mobile or embedded device acquired from the IMU and magnetometer. All geographic objects whose directions lie within the actual field of view will be reserved, and the others will be eliminated from the vision-based detection results. An example is shown in
Figure 7b.
4.3.3. Order
To distinguish similar geographic objects with nearly identical visual properties, we determine the order of those similar objects based on their GPS locations. First, we determine the orientation of the visual sensor using the IMU and magnetometer in the mobile or embedded device. Then, we calculate the included angles between the directions from the visual sensor to each geographic object and the orientation of the visual sensor. Finally, we sort those similar geographic objects in ascending order of their included angles (i.e., from negative to positive, where the positive direction of rotation is considered to be clockwise) and then associate those geographic objects with their vision-based detection results in the image in order (e.g., from left to right). In this way, similar geographic objects can be correctly distinguished. An example is shown in
Figure 7c.
It is notable that there have been many works that focus on learning spatial relationships, using spatial relationships for object recognition or refining object detection results [
69,
70,
71,
72,
73]. Reference [
69] presents a probabilistic model which uses the joint statistics of local appearance and position on objects for face recognition. This method achieves high detection rate on face detection while it focuses on the spatial arrangement of the features of the objects rather than the spatial relationships between the objects. Reference [
70] introduces the 3D Geometric Phrase (3DGP) model that learns and reasons spatial relationships between the objects in the same 3D spatial configuration, thereby obtaining an accurate scene composition. Reference [
71] describes a method using the proposed face-centric geometric descriptors and an unsupervised learning algorithm for learning object-to-object spatial relationships. However, these two methods are designed for indoor scenes and are not suitable for outdoor scenes because it is not practical to annotate objects by, for example, oriented rectangular bounding volumes [
71] in an outdoor unprepared environment. Also, an additional training stage is required and a training dataset is needed in these methods. In [
72], a framework is provided using a single image to model the interdependence of objects, surface orientations and camera viewpoint simultaneously in the context of the 3D scene, while one assumption of this framework is that all objects rest on the same ground plane, which is not true in many outdoor environments. Besides, this framework requires the estimation of the viewpoint (involving the horizon position and the camera height), which means the framework may not work well when the ground plane is not visible. Reference [
73] presents a coherent framework with three modules for jointly detecting objects, estimating the scene layout and segmenting the supporting surfaces, thereby capturing the contextual geometrical relationship to refine the results. However, one necessary condition for this framework is that at least three objects coexist in the same image for estimating the layout.
Compared with the aforementioned methods, our method uses a simpler but still effective way which can be easily implemented on low-power mobile or embedded devices to refine the object detection results in unprepared outdoor environments. One of the advantages of our method is that there is no additional training stage (except for the training for object detection) required for generating spatial relationships, thereby allowing instantaneous calculation or modification for the spatial relationships just with the help of the sensors and the geospatial information database; Also, our method has few assumptions or prerequisites, making it a general solution to various outdoor conditions; Moreover, our method helps to correctly distinguish individual specific objects with nearly identical visual properties, which is rarely considered in other methods.
After this combination procedure, the vision-based detection results will be integrated with the corresponding spatial relationships and can be further distinguished by their order, and any that do not satisfy the specified distance and direction requirements will be discarded. Finally, with the help of a GPS receiver, an IMU and a magnetometer, we obtain a more authentic set of geographic object detection results that includes spatial relationships for registration, geospatial information visualization and interaction.
4.4. Registration, Geovisualization and Interaction
An authoritative definition of AR, proposed by Azuma et al. [
13], is that an AR system supplements the real world with virtual (computer-generated) objects that appear to coexist in the same space as the real world. This means that the purpose of AR is not to replace the real world but to enhance it. Thus, we use a geospatial information database prepared in advance to generate virtual objects that contain geographic data and information, and these virtual objects are registered with respect to their corresponding geographic objects in the real world in accordance with their GPS locations and detected bounding box coordinates. In fact, they are also integrated with the spatial relationships of those objects because they coexist with the geographic objects in the same locations in reality.
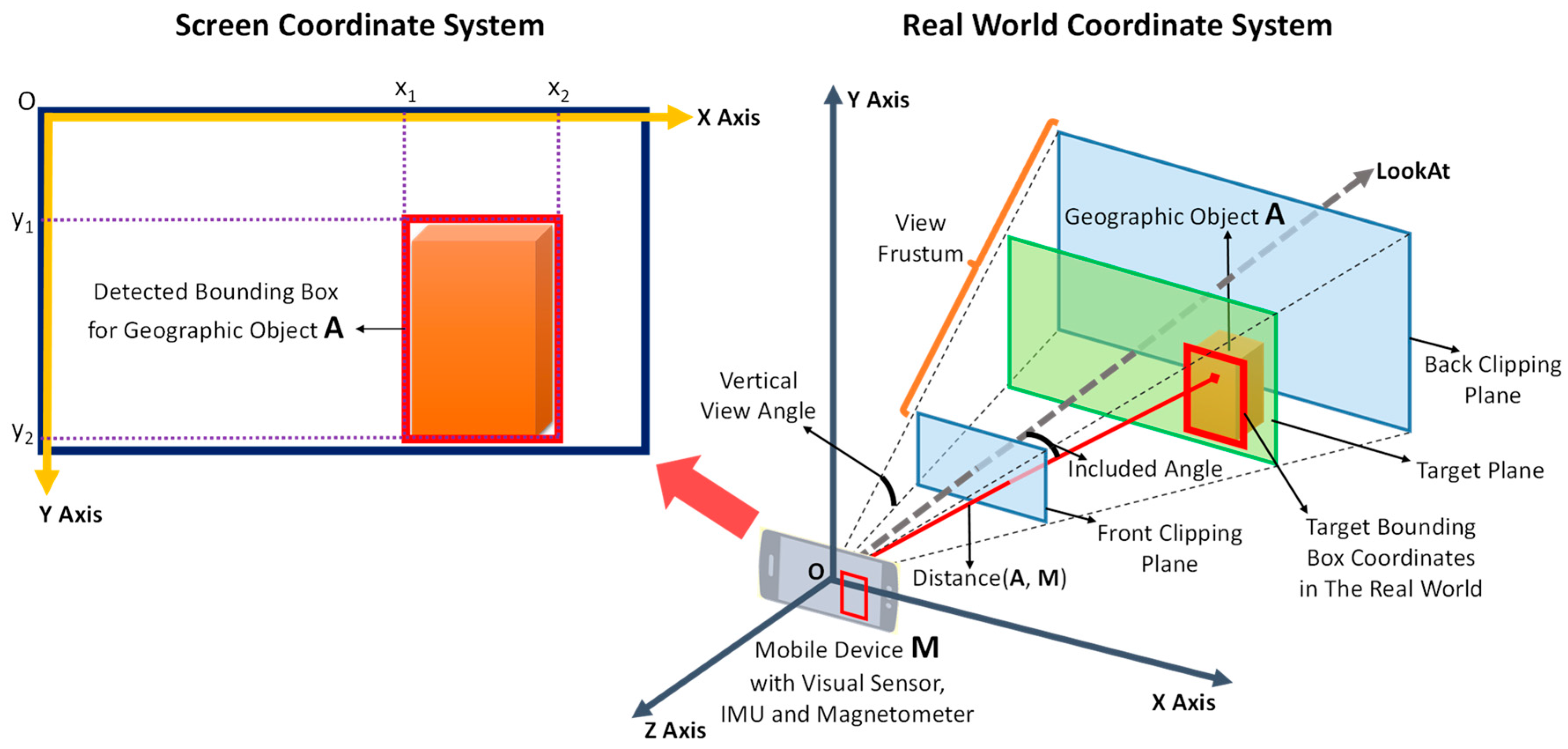
To enable the registration of virtual objects, the location of the geographic object in the 3D coordinate system of the real world must first be determined. Theoretically, if the size of the geographic object is known, we are able to determine the location of the geographic object in the 3D real world coordinate system just with the help of the GPS location and device posture information inferred by sensors. However, especially in the outdoor uncontrolled environment, the devices usually suffer from the deterioration in the GPS precision and the drift and distortion in the output of sensors, resulting in serious visual position deviation between the geographic object and registered virtual objects on the screen. Thus, the conversion of the coordinates of the detected bounding boxes from the 2D screen coordinate system into the 3D coordinate system of the real world is required to avoid the visual position deviation and achieve accurate registration. These two coordinate systems and their relationships are illustrated in
Figure 8.
A bounding box in the vision-based detection results is defined by four pairs of coordinates, (
,
), (
,
), (
,
) and (
,
), in the 2D screen coordinate system, whose origin is at the top left of the screen. By contrast, the origin of the 3D real world coordinate system lies at the centre of the visual sensor, which can be assumed to coincide with the centre of the screen; therefore, the coordinates of the bounding box must first be converted into the screen-centred coordinate system, whose origin is at the centre of the screen. The conversion formula is given in Equation (6):
where
and
are the coordinates of the bounding box in the screen-centred coordinate system,
and
are the coordinates of the bounding box in the original screen coordinate system, and
and
are the width and height of the screen.
Then, these coordinates must be converted into target bounding box coordinates on the target plane in the view frustum, which is defined by two clipping planes in the 3D real world coordinate system. The target plane is perpendicular to the LookAt direction (the orientation of the visual sensor as determined by the IMU and magnetometer; also the negative direction of the
z axis); therefore, the
z coordinate value of the target plane is defined as shown in Equation (7):
where D is the distance between the geographic object and the coordinate origin as calculated from the GPS locations, θ is the included angle between the direction from the coordinate origin to the geographic object and the LookAt direction, and the result
is the Z coordinate value of both the target plane and the target bounding box.
When the height and width of the target plane and the screen are properly matched, the
x and
y coordinates of the detected bounding box can be easily converted from the screen coordinates to the target plane coordinates. The conversion ratio is defined in Equation (8):
where
is the height of the screen;
is the vertical view angle of the visual sensor; and
, obtained from Equation (7), is the Z coordinate value of the target plane in the real world and is also the distance between the origin of the coordinate system and the target plane. Therefore, the x and y coordinates of the target bounding box are defined as shown in Equation (9):
where
and
are the coordinates of the target bounding box in the 3D real world coordinate system,
and
are the coordinates of the detected bounding box in the screen-centred coordinate system, and
is the conversion ratio from the screen coordinates to the target plane coordinates.
In this way, every pair of coordinates (x, y) of the bounding box in the 2D screen coordinate system is converted into the corresponding coordinates () of the target bounding box in the 3D real world coordinate system. Then, registration can be achieved by selecting locations near the target bounding box for the placement of virtual objects, thereby allowing those virtual objects to coexist with the detected geographic object in the same place in the real world.
After registration, these virtual objects are instantaneously superimposed in accordance with their registration locations, and all virtual objects in the view frustum are projected and superposed on every image frame of the video stream. Because the information available for the virtual objects includes their spatial relationships, objects at closer distances will be automatically placed in front of farther objects on the screen, thereby avoiding potential problems with overlay order among the virtual objects.
With regard to interaction, because of the size limitations of the screens of mobile or embedded devices, it is nearly impossible to visualize all of the available geospatial information for these small virtual objects at once; doing so would be both unnecessary and overly crowded. Therefore, we have designed an interactive way to allow users to interact with their devices using our mobile outdoor AR method by touching the screen to acquire more information or even to request additional geospatial services. Initially, all of the detected geographic objects are enhanced only with virtual labels indicating their names. When the user touches a geographic object on the screen, several additional corresponding virtual objects will fade in and present some concise geospatial information. More detailed geographic data and information can be accessed and visualized by touching these virtual objects. Other extensions, such as editing, querying and spatial analysis of geographic data and information, can also be easily executed through this mode of interaction.
5. Application, Validation and Discussion
We developed a prototype system using our proposed method on the Android platform. The functional modules, the geographic object detection dataset, the geospatial information database and the virtual objects were designed and built, and a performance optimization scheme targeted at mobile or embedded devices was implemented to speed up the image capture process of the visual sensor. We tested the prototype system on the Wuhan University campus to evaluate the proposed mobile outdoor AR method and validate its results. In this section, the prototype development and experiments are reported, and then a discussion is presented.
5.1. Prototype System Development
Our AR system was developed using Android Studio v2.2 on the Ubuntu 14.04 LTS desktop OS. Our proposed lightweight SSD approach was implemented using MXNet [
74] v0.9.0, an efficient machine learning and deep learning library. We compiled the entire MXNet library into a single dynamic link library file (*.so) through the Android amalgamation method to enable its use on Android mobile or embedded devices for object detection with the help of Java Native Interface (JNI) technology. The geospatial information database for mobile or embedded devices was established using SQLite, a popular native lightweight database engine. We used OpenGL ES v2.0, a powerful graphics library, to create visual elements such as labels, virtual objects, and animation effects. The interaction functionalities were designed and implemented using Android Gestures APIs, which can recognize users’ gestures on a screen and return responses.
We optimized the image capture process for mobile or embedded devices to speed up performance. The raw data of the frames captured from the video streams produced by the visual sensors of most mobile or embedded devices are YUV data, and the default format is YCbCr_420_SP (NV21). These raw data need to be converted into 3-channel RGB data before they can be used as inputs to the lightweight SSD for detection. However, YUV-to-RGB conversion algorithms are commonly run on the CPU by default and consequently incur a high time cost (nearly 1 second for each captured image). We instead implemented this conversion on a mobile GPU by means of off-screen rendering technology, which enables rapid processing or rendering of data in an off-screen buffer with the help of the parallel computing capability of a GPU. We implemented the conversion algorithm in OpenGL Shading Language (GLSL) using OpenGL ES v2.0, and we found that our optimized method requires only approximately 15 ms to convert a YUV image into an RGB image on a mobile GPU, which represents a significant reduction in time cost.
5.2. Application and Validation
5.2.1. Data Acquisition
We tested the prototype system on the Wuhan University campus to evaluate the method and validate its results. We selected 10 representative geographic objects on the campus, including buildings, famous statues, and pavilions. Some of the selected objects are located very close to each other and often appear together in the same image, thereby allowing us to evaluate the method’s multiple-object detection performance. Some of the objects also share very similar visual properties, allowing us to evaluate the ability to further precisely distinguish them based on their spatial relationships with the help of the built-in GPS receiver, IMU and magnetometer. Moreover, most of these geographic objects are of various sizes, appearances and colours, and various outdoor environmental conditions were encountered during the test, allowing us to thoroughly test the robustness of the method. The distribution of the selected geographic objects is shown in
Figure 9.
A corresponding database was established to store geospatial information on these geographic objects. The current geospatial information database stores ID, name (assigned code), category (e.g., building), area (estimated area of the geographic object), height (maximum height of the geographic object), longitude (east longitude), latitude (north latitude) and text introduction of the geographic object. Additional types of information could easily be added by extending the table entries of the database. The structural details of the geospatial information database are shown in
Table 2.
To train the proposed lightweight SSD for vision-based detection, we acquired an enormous number of photographs of the geographic objects. Each geographic object corresponds to at least 200 images, and each image contains at least one of the geographic objects, sometimes multiple. We captured approximately 2000 photographs at multiple scales (mainly from different distances) and from multiple perspectives (from different directions) as well as under many different conditions to assist the detector in learning the essential features of the geographic objects. The objective was to allow these geographic objects to be detected in images at any possible size, from various possible view directions and under many possible conditions by a successfully trained detection algorithm.
5.2.2. Preprocessing and Training
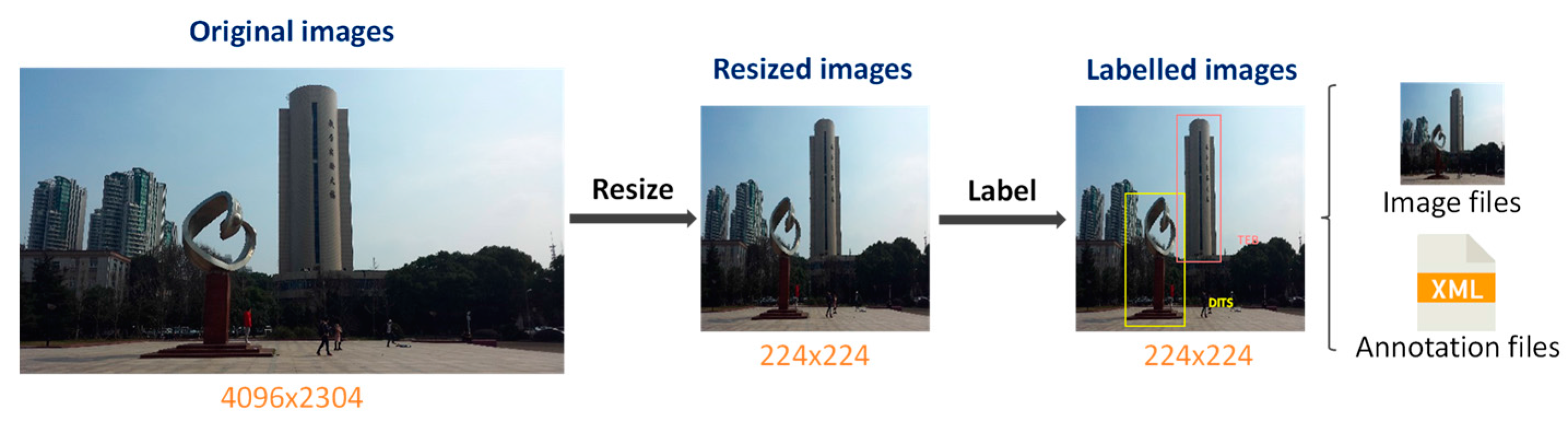
To train the proposed lightweight SSD, images alone are not sufficient. Annotations specifying classifications and bounding box coordinates for each geographic object in the images are needed. We produced a detection dataset in the VOC2007 format for the selected geographic objects (the entire process is illustrated in
Figure 10). First, we resized all images to dimensions of 224 × 224 pixels, and then, we manually created annotations by labelling classifications and bounding box coordinates for all of the geographic objects in the images. Those annotations are organized in accordance with the VOC2007 format requirements and are stored in XML files together with all of the resized images in the VOC2007 format. We designated 1000 of the annotated images as the training set, another 500 as the validation set, and the rest as the test set. The training and validation sets were both used to train the detector, and the test set was used to calculate the mAP to evaluate its performance.
We trained the lightweight SSD on a desktop PC with an NVIDIA GTX 1060 GPU (with 6 GB of video memory) and an Intel
® Core™ i7-6700K CPU @ 4.00 GHz x 8 (with 8 GB of memory). The detector was implemented and trained using MXNet v0.9.0, which supports CUDA, a parallel computing platform for General-Purpose computing on Graphical Processing Units (GPGPU). This hardware and these platforms significantly reduced the time cost for training. We trained the approach for 1000 epochs using the same training configuration that was used in the preliminary network performance evaluation, and the resulting accuracy-epoch and loss-epoch curves are presented in
Figure 11. This figure shows that convergence was reached at approximately the 800th epoch, after which the accuracy-epoch and loss-epoch curves remained stable.
5.2.3. Results and Validation
We evaluated the trained lightweight SSD on the test set of the geographic object detection dataset by calculating AP and mAP values. None of the images in the test set was used in the training stage; therefore, this evaluation provides a fair estimate of the actual performance of the proposed detection method. The results are shown in
Table 3. Our approach achieves a mAP value of 0.97, which indicates very high vision-based detection accuracy for the selected geographic objects.
Subsequently, we returned to the campus to test the prototype system using the mobile outdoor AR method. The mobile device we used was an Android mobile phone with a Qualcomm Snapdragon 821 mobile CPU, an Adreno 530 mobile GPU, 6 GB of memory, a 16-megapixel Sony IMX 298 sensor, a 5.5-inch Optic AMOLED capacitive touchscreen, a built-in GPS receiver and several inertial/magnetic sensors, including a magnetometer, an accelerometer, and a gyroscope.
We tested the overall performance under many challenging uncontrolled outdoor conditions, including motion blur, rotation, occlusion, lighting changes, multiple scales, multiple perspectives and multiple objects, and we also tested the performance in distinguishing geographic objects with similar visual properties. All of the test results are presented in
Figure 12.
The first four rows in
Figure 12 show that our method can cope with intense motion blur, rotation, occlusion and various lighting conditions. The fifth and sixth rows show that our method can precisely detect the selected geographic objects regardless of which side is facing the visual sensor or at what distance the object lies from the visual sensor, thereby confirming its robust detection performance from multiple perspectives and at multiple scales. The seventh row shows that our method is capable of detecting multiple objects. In the last row, two geographic objects, DM 3 and DM 4 (two dormitories with similar visual properties, which both belong to the “DM” class in the geographic object detection dataset but for which information is separately stored in the geospatial information database), are correctly distinguished, and the corresponding virtual objects superimposed on the screen are displayed with the proper locations and overlay order. The interaction method was also tested; several example screenshots illustrating this process are shown in
Figure 13.
In the spot tests, all of the geographic objects were correctly detected, and the system always exhibited high-accuracy registration as well as stable AR geovisualization and interaction. Finally, the average time cost of our method, divided into several basic stages, when running on a mobile phone is reported in
Table 4.
5.3. Discussion
The experimental results show that our mobile outdoor AR method achieves excellent performance in detecting and enhancing geographic objects in uncontrolled outdoor environments and enriches the user experience. Our method achieves a high detection success rate and accuracy for several reasons. On the one hand, the detection approach we use, the proposed lightweight SSD, is a vision-based deep learning approach, which can learn essential and robust features from image data to achieve highly accurate detection performance that is superior to that of many traditional approaches based on manually crafted features. On the other hand, when constructing the geographic object detection dataset, we used images that captured the selected geographic objects from all perspectives and scales and under many conditions to the greatest possible extent. Doing so facilitated the ability of the lightweight SSD to learn essential and robust features, thereby improving the detection success rate and accuracy. Moreover, the integration of the vision-based detection results with the corresponding spatial relationships with the help of the mobile or embedded device’s built-in GPS receiver, IMU and magnetometer significantly reduces detection errors and enables precise distinction between geographic objects with similar visual properties, which is quite difficult for a purely vision-based detection algorithm to achieve.
Notably, although the lightweight SSD approach achieves a mAP value of 97% on our geographic object detection dataset, its mAP value on the standard VOC2007 test dataset is only 53.7%. The key reason for this enormous difference is that the types of objects in the VOC2007 dataset are abstract, such as “car” and “bottle”, and the purpose of the VOC2007 dataset is to train an algorithm that can detect, for example, all kinds of cars and all kinds of bottles; consequently, it is generally a difficult task to achieve a very high mAP on this dataset. By contrast, the objects included in our geographic object detection dataset are quite specific, and specific objects are much easier to train a detector to detect; consequently, our trained detector can achieve state-of-the-art detection performance and a high mAP.
In addition, the detection and AR geovisualization results of our system are stable. This is because the two essential components of the detection task—classification and localization—are both vision-based and are therefore less susceptible to interference from various outdoor variables, such as electromagnetic fluctuations, and thus more stable than methods based purely on inertial/magnetic sensors, which suffer from drift and distortion. Our AR geovisualization is based on stable detection results combined with spatial relationships, and consequently, the final visualization results satisfy visual expectations.
Furthermore, the weight file of the trained lightweight SSD is much smaller (17.8 MB for one model) than those of most detection frameworks and is thus compatible with the limited storage space of various mobile or embedded devices. With the application of compression technologies, such as deep compression [
75], the model size could be further reduced. In addition, the entire AR method is independent of the network; all computing tasks are performed offline by the user’s mobile or embedded device, thereby eliminating the effects of network latency and making the method very flexible and robust for application in challenging uncontrolled outdoor environments with poor signal conditions.
The method also has several limitations. First, the detection approach we adopt in this method is a vision-based approach; consequently, it cannot handle very poor lighting conditions (e.g., night). Second, although our method can detect geographic objects at multiple scales from different distances, it still may fail when the distance between the visual sensor and a geographic object is excessively long or short. When the object is too near, the appearance of the geographic object may be too large to be completely captured by the visual sensor, and thus, the incomplete object in the image may fail to be detected. When the object is too far, the appearance of the geographic object in the image may be too small for successful detection. Therefore, although our lightweight SSD framework is able to detect geographic objects at multiple scales in most cases, it is still necessary to avoid extreme distances between the visual sensor and the geographic objects of interest when using this method. Third, the overall method does not run very fast on a mobile CPU. We simplified the detection approach and optimized the image capture process, and as a result, we achieved near-real-time performance with a rate of approximately 2 FPS; this is faster than many server-based methods, which all suffer from network latency, but it is still not very fast. The most time-consuming step of the method is the lightweight SSD detection; further simplifying the lightweight SSD architecture would reduce the time cost but might also decrease the detection accuracy, leading to a trade-off between speed and accuracy. However, it should be noted that the mobile CPU we used in the test was not the most up-to-date model available; therefore, it is expected that with a higher-performance CPU, the time cost will be further reduced, allowing the method to run at a higher speed. Fourth, the spatial relationships we use such as distances, directions, and orders are effective but still not sufficient for the refinement. For example, our method lacks the application of scene segmentation and the understanding of the spatial layout of outdoor environments, thus it may fail to eliminate some unreasonable results (e.g., it may think that a building floating in the air is reasonable); Also, the spatial relationships we infer rely heavily on the GPS receiver and other sensors, making them vulnerable to the deterioration in the GPS precision and drift and distortion in the output of sensors; Besides, the location of a geographic object is represented only by a pair of GPS coordinate in our method, therefore it will be very challenging to construct correct spatial relationships when the geographic objects with complex structures entangles together.
6. Conclusions and Future Work
Traditional forms of geovisualization, such as paper maps and digital maps, are limited by their insufficiently intuitive use and generally provide limited modes of interaction. Outdoor AR is, in principle, a suitable way to visualize geographic data and information by supplementing the real world with virtual objects that users can easily understand and interact with. However, many traditional AR methods have several drawbacks when applied in various outdoor environments: fiducial-marker-based methods are inappropriate for use in uncontrolled environments, whereas sensor-based methods can be overly sensitive to certain variables in outdoor environments, such as magnetic fields, which can easily cause errors and even failures.
In this paper, we proposed a robust, markerless and near-real-time mobile outdoor AR method for geovisualization. We adopted SSD, a vision-based deep learning object detection approach, for the detection of geographic objects based on their natural features under various outdoor conditions. To reduce the computational burden and weight of this approach for mobile outdoor AR, we modified its original structure to obtain lightweight SSD, a energy-efficient, less computationally expensive but still powerful approach. To facilitate registration, we combined the vision-based detection results of the proposed lightweight SSD with the corresponding spatial relationships between objects in the real world with the help of the host device’s built-in GPS receiver, IMU and magnetometer, thereby significantly reducing detection errors and achieving the ability to correctly distinguish between similar geographic objects. Then, we designed and implemented methods of AR geovisualization and interaction based on virtual objects generated from geospatial information and the recognition of touch gestures on mobile or embedded devices. Because of the poor signal conditions found in many challenging outdoor environments, we chose to take full advantage of mobile computing capabilities by means of a performance optimization scheme that allows all computational tasks to be executed on the user’s mobile or embedded device, thereby eliminating any dependence on the network and eradicating latency. Finally, we developed a prototype system on the Android platform and tested it on the Wuhan University campus using several representative geographic objects to evaluate the method and validate its results.
The findings demonstrate that our method has a high detection success rate and accuracy, produces stable AR geovisualization results, and is lightweight and flexible by virtue of its small model size and network independence. All of these features make it very suitable for use in uncontrolled outdoor environments. The system benefits from the combination of geovisualization with mobile outdoor visual-IMU-magnetometer AR, and it also reflects the potential, high accuracy and robustness of deep-learning-based approaches for geographic object detection. Furthermore, this work offers a new way to visualize geographic data and information and to interact with such information in the real world through mobile outdoor AR, which enriches the user experience and is expected to be beneficial for various applications related to geospatial information.
Our future research will focus on modifying the architecture of the detection approach to make it lighter, faster and more accurate; Using layout estimation and scene segmentation to generate more robust and powerful spatial relationships for understanding the outdoor environment and refining detection results; integrating a high-speed object tracking algorithm into the system to further reduce the time cost; and incorporating a pose estimation algorithm to precisely estimate the orientations of geographic objects.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}