Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model

Abstract
:1. Introduction
2. Related Works
3. The Method
3.1. Problem Formulation
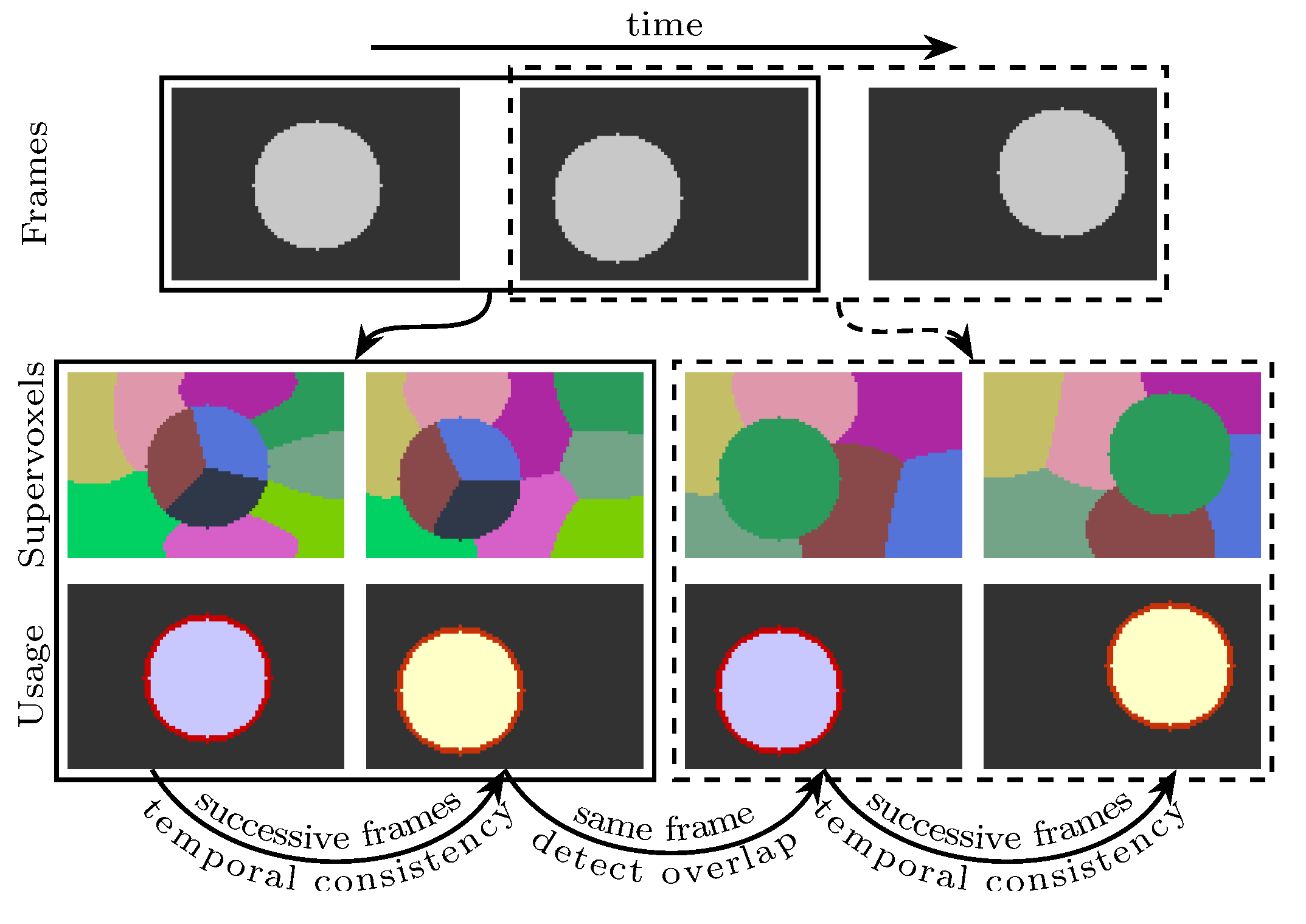
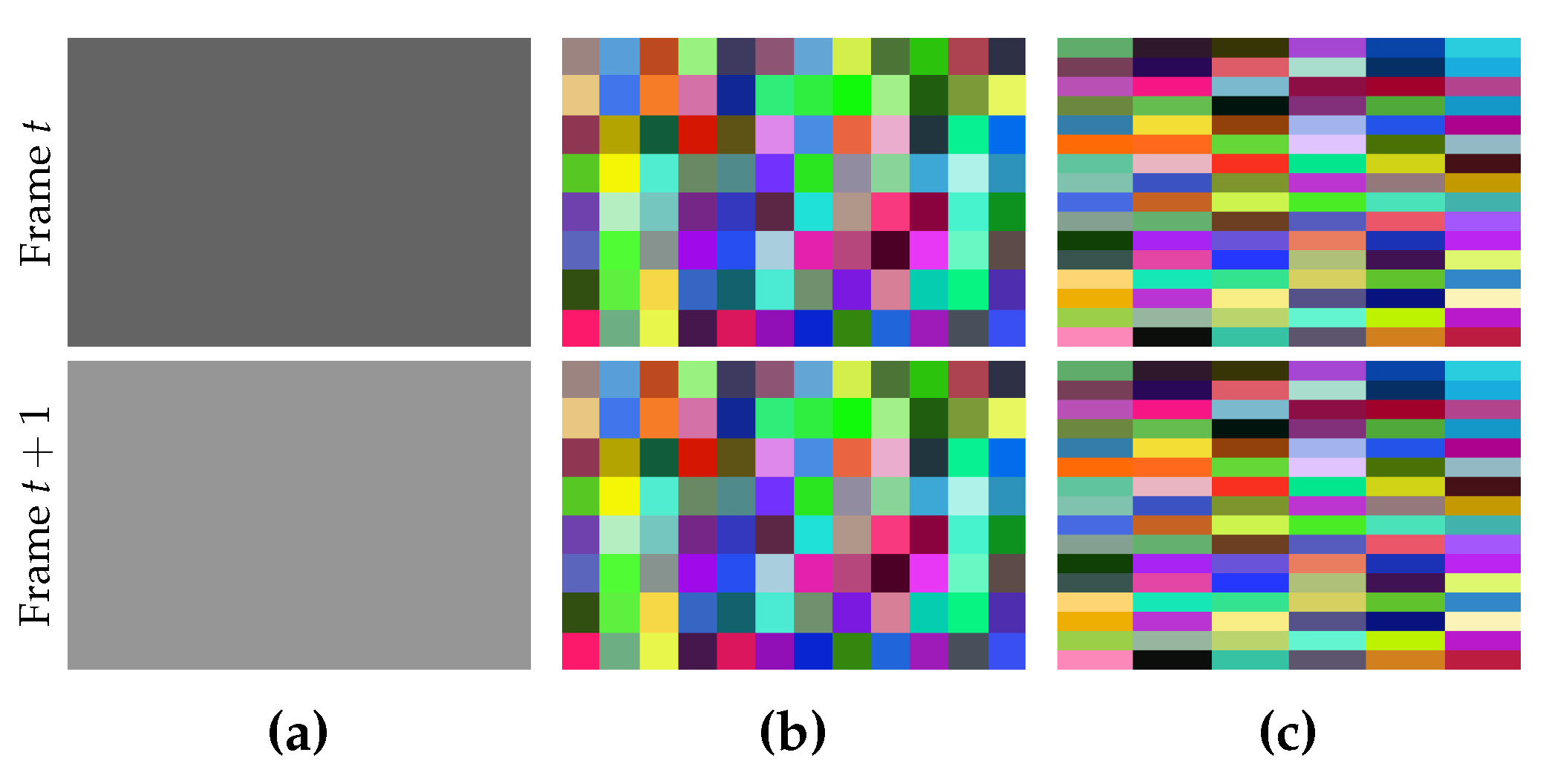
3.2. The Model
3.3. Estimating Parameters of Gaussian Distributions
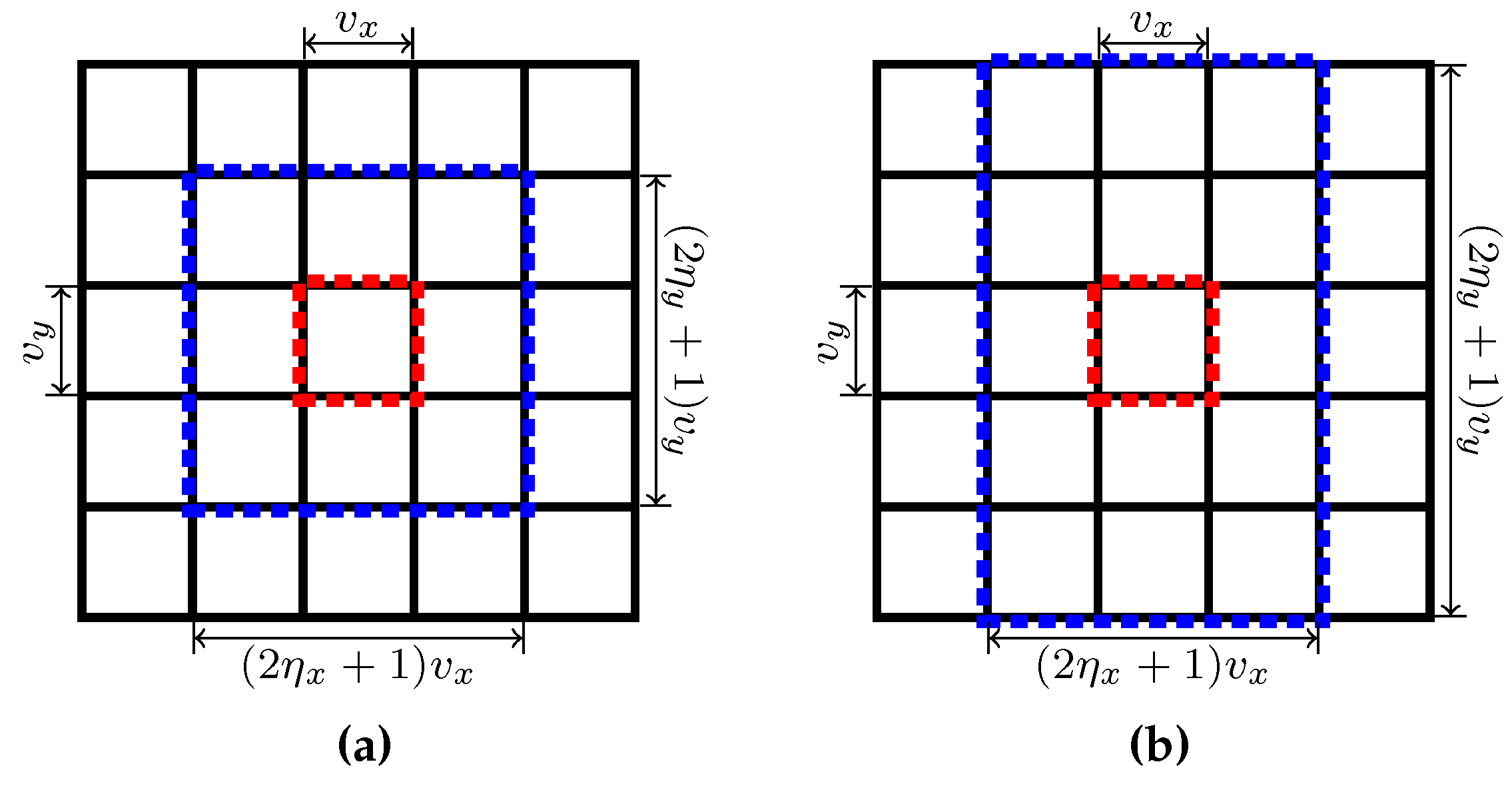
3.4. Defining and Initializing
3.5. Computational Complexity
| Algorithm 1 The proposed supervoxel algorithm. |
| Input: and , two successive frames. Output: and , . 1: for all do 2: Initialize , , , , , (refer to Section 3.4). 3: end for 4: for to M do {refer to Section 3.3 for the value of M} 5: for all do 6: for all do {refer to Section 3.4 for } 7: Update and using Equation (17). 8: end for 9: end for 10: for all do 11: Update , , and using Equations (24)–(26). 12: Update , and using Equations (24)–(27). 13: end for 14: end for 15: for all do 16: and are determined by Equation (9). 17: end for |
4. Experiments
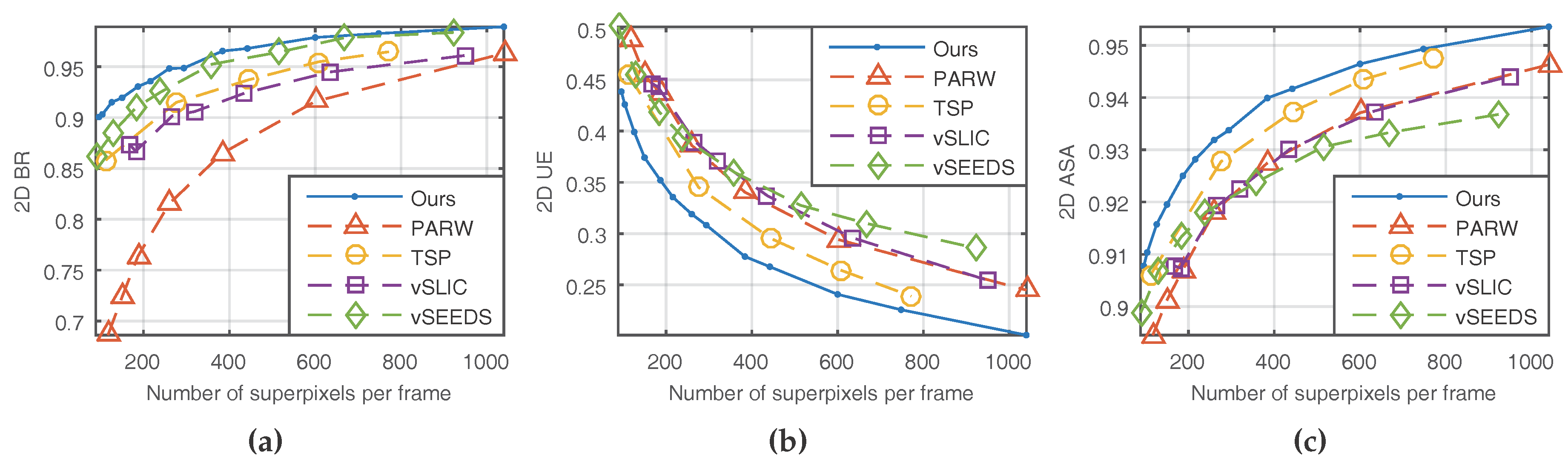
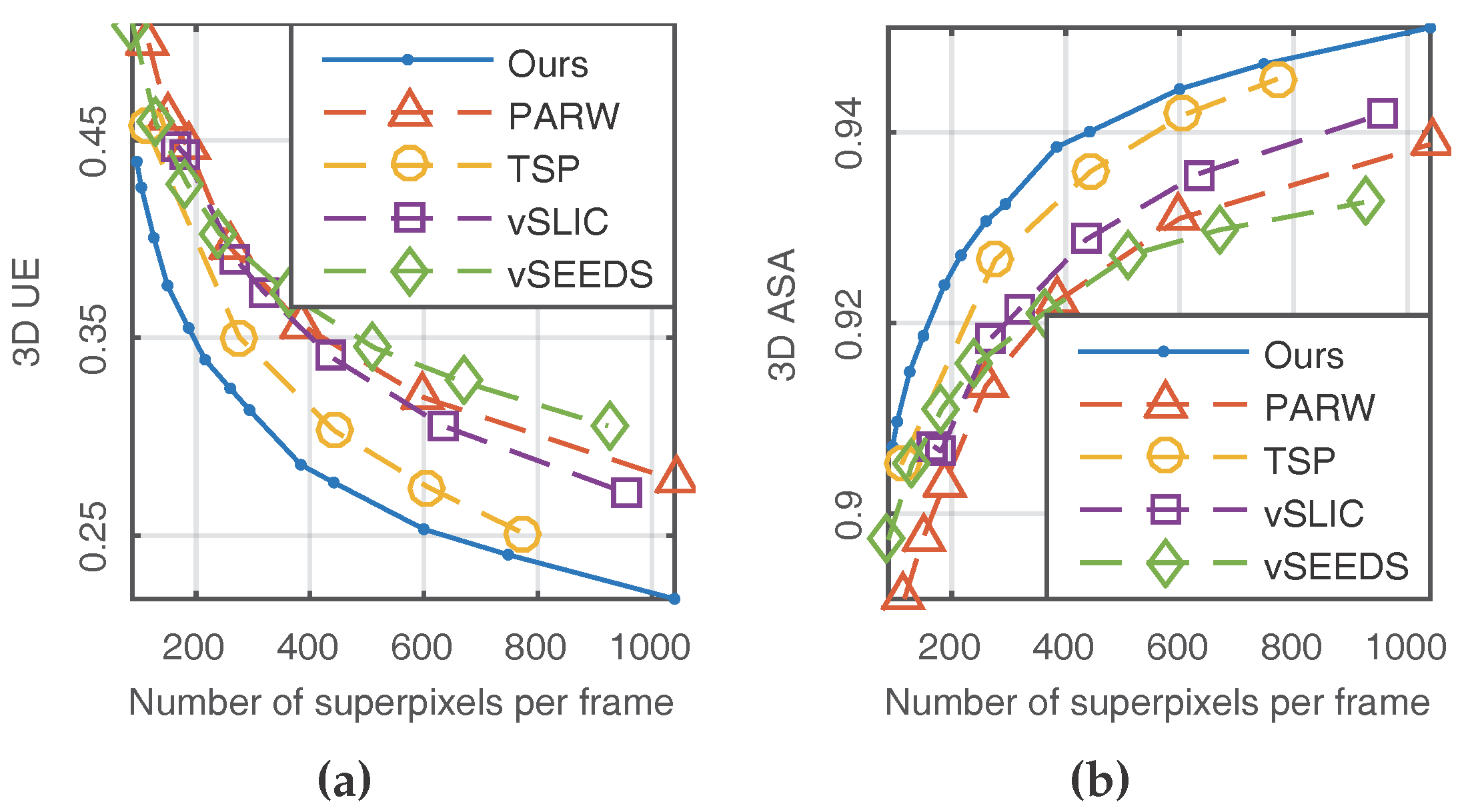
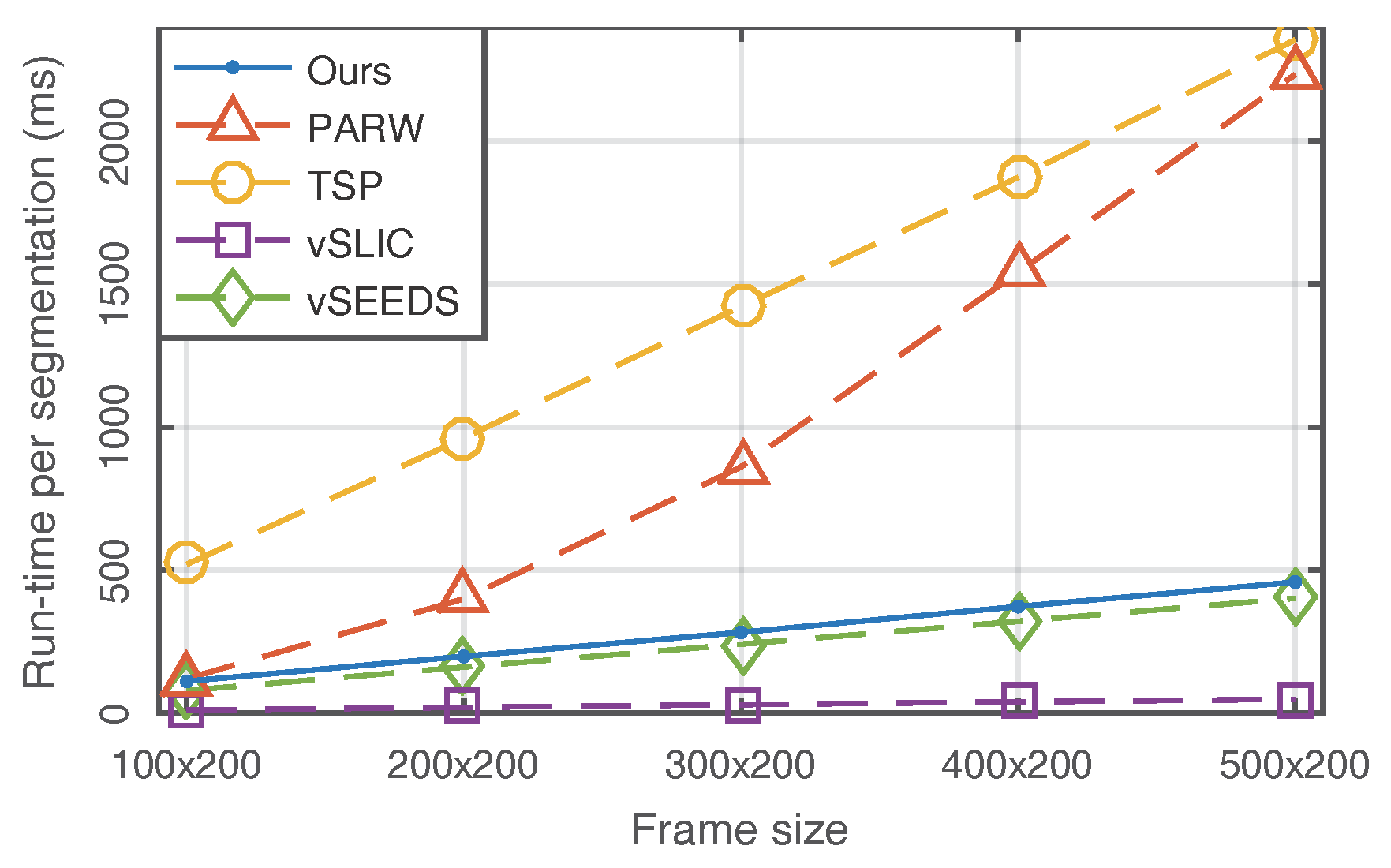
4.1. Quantitative Comparisons
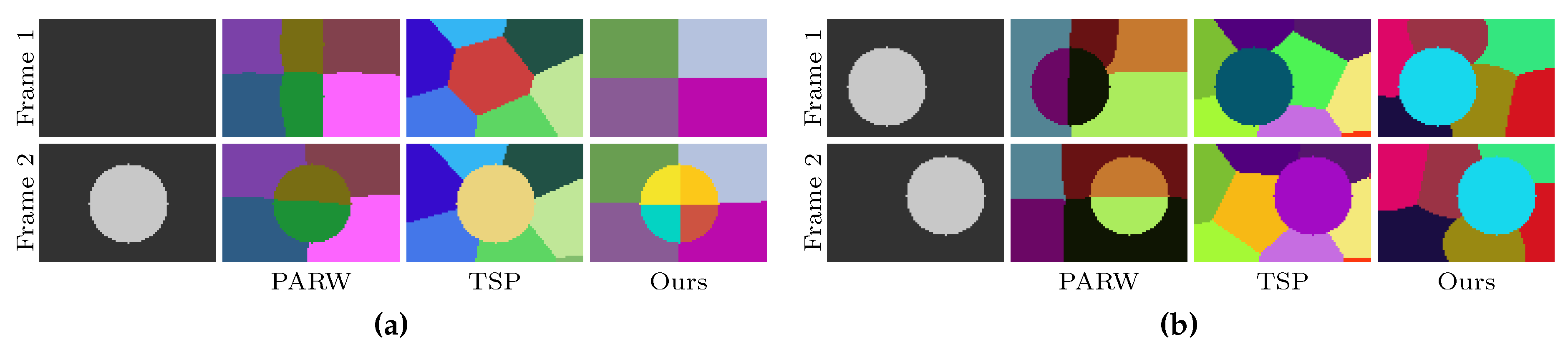
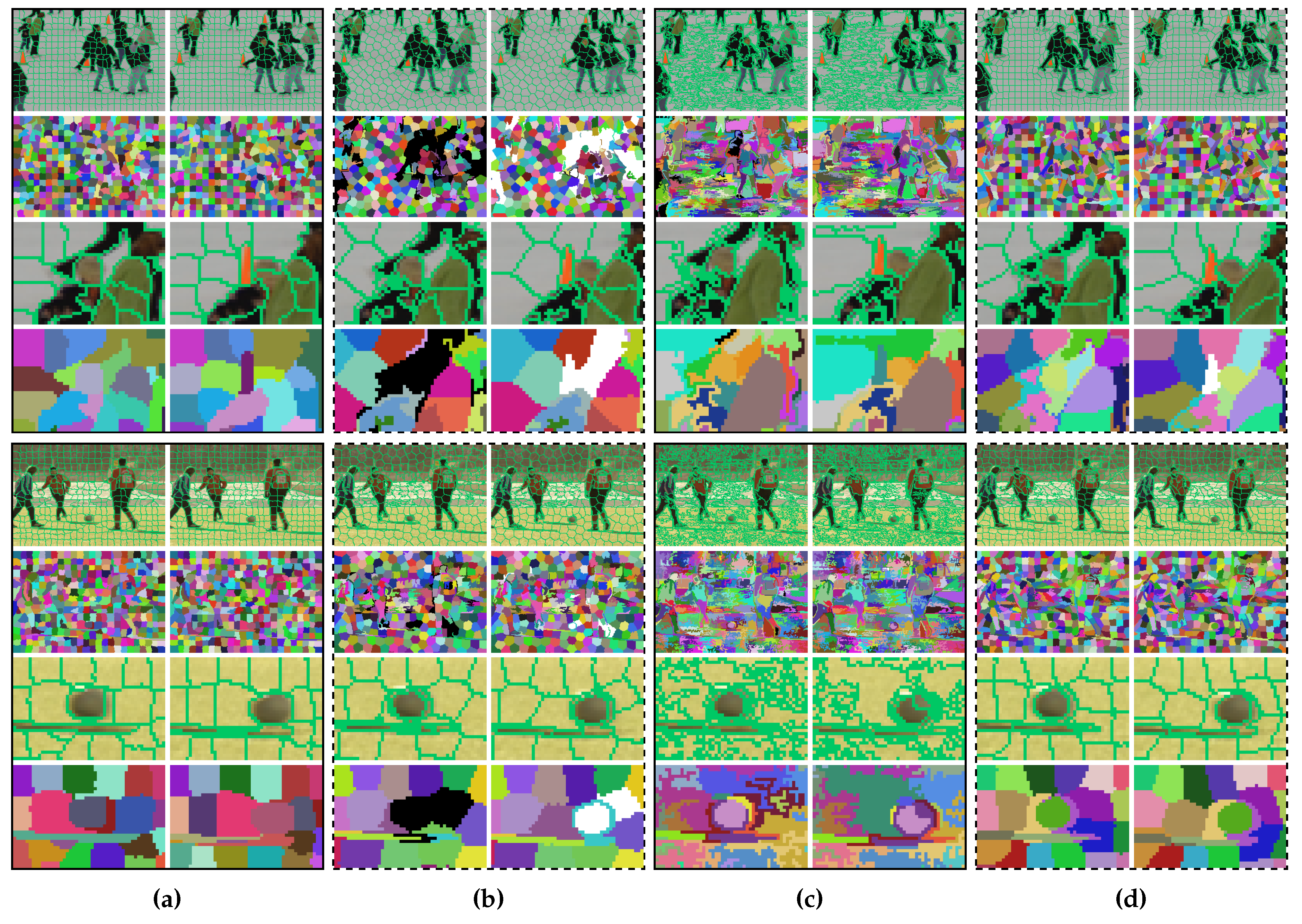
4.2. Qualitative Comparisons
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, Z.; Huang, B. Linear Spectral Clustering Superpixel. IEEE Trans. Image Process. 2017, 26, 3317–3330. [Google Scholar] [CrossRef] [PubMed]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast Superpixels Using Geometric Flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed]
- Ban, Z.; Liu, J.; Fouriaux, J. GLSC: LSC superpixels at over 130 FPS. J. Real-Time Image Process. 2016, 1–12. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, K.; Lin, J. An Automatic Localization Algorithm for Ultrasound Breast Tumors Based on Human Visual Mechanism. Sensors 2017, 17, 1101. [Google Scholar]
- Zhang, Q.; Liu, Y.; Zhu, S.; Han, J. Salient object detection based on super-pixel clustering and unified low-rank representation. Comput. Vis. Image Underst. 2017, 161, 51–64. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, J.; Tao, Y.; Li, W.; Shi, Y. Salient object detection via color and texture cues. Neurocomputing 2017, 243, 35–48. [Google Scholar] [CrossRef]
- Van De Sande, K.E.A.; Uijlings, J.R.R.; Gevers, T.; Smeulders, A.W.M. Segmentation as selective search for object recognition. In Proceedings of the 2011 International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1879–1886. [Google Scholar]
- Zhong, Z.; Lei, M.; Cao, D.; Fan, J.; Li, S. Class-specific object proposals re-ranking for object detection in automatic driving. Neurocomputing 2017, 242, 187–194. [Google Scholar] [CrossRef]
- Liu, J.; Tang, Z.; Cui, Y.; Wu, G. Local Competition-Based Superpixel Segmentation Algorithm in Remote Sensing. Sensors 2017, 17, 1364. [Google Scholar] [CrossRef] [PubMed]
- Qiu, W.; Gao, X.; Han, B. A superpixel-based CRF saliency detection approach. Neurocomputing 2017, 244, 19–32. [Google Scholar] [CrossRef]
- Fu, P.; Li, C.; Cai, W.; Sun, Q. A spatially cohesive superpixel model for image noise level estimation. Neurocomputing 2017, 266, 420–432. [Google Scholar] [CrossRef]
- Reso, M.; Jachalsky, J.; Rosenhahn, B.; Ostermann, J. Temporally Consistent Superpixels. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 385–392. [Google Scholar]
- Liang, Y.; Dong, X.; Shen, J. Supervoxel using random walks. In Proceedings of the 2014 7th International Congress on Image and Signal Processing, Dalian, China, 14–16 October 2014; pp. 120–124. [Google Scholar]
- Xu, C.; Corso, J.J. Evaluation of super-voxel methods for early video processing. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1202–1209. [Google Scholar]
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and Supervoxels in an Energy Optimization Framework. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 211–224. [Google Scholar]
- Liang, Y.; Shen, J.; Dong, X.; Sun, H.; Li, X. Video Supervoxels Using Partially Absorbing Random Walks. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 928–938. [Google Scholar] [CrossRef]
- Levinshtein, A.; Sminchisescu, C.; Dickinson, S. Spatiotemporal Closure. In Proceedings of the 10th Asian Conference on Computer Vision (ACCV), Queenstown, New Zealand, 8–12 November 2011; pp. 369–382. [Google Scholar]
- Bergh, M.V.D.; Roig, G.; Boix, X.; Manen, S.; Gool, L.V. Online Video SEEDS for Temporal Window Objectness. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 377–384. [Google Scholar]
- Chang, J.; Wei, D.; Fisher, J.W., III. A Video Representation Using Temporal Superpixels. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2051–2058. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Reynolds, D. Gaussian mixture models. In Encyclopedia of Biometrics; Li, S.Z., Jain, A.K., Eds.; Springer: Boston, MA, USA, 2015; pp. 827–832. [Google Scholar]
- Ma, J.; Zhao, J.; Ma, Y.; Tian, J. Non-rigid visible and infrared face registration via regularized Gaussian fields criterion. Pattern Recognit. 2015, 48, 772–784. [Google Scholar] [CrossRef]
- Ban, Z.; Liu, J.; Cao, L. Superpixel Segmentation Using Gaussian Mixture Model. arXiv, 2016; arXiv:1612.08792. [Google Scholar]
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; pp. 10–17. [Google Scholar]
- Grundmann, M.; Kwatra, V.; Han, M.; Essa, I. Efficient hierarchical graph-based video segmentation. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2141–2148. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Xu, C.; Xiong, C.; Corso, J.J. Streaming Hierarchical Video Segmentation. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 626–639. [Google Scholar]
- Van den Bergh, M.; Boix, X.; Roig, G.; de Capitani, B.; Van Gool, L. SEEDS: Superpixels Extracted via Energy-Driven Sampling. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 13–26. [Google Scholar]
- Van den Bergh, M.; Boix, X.; Roig, G.; Van Gool, L. SEEDS: Superpixels Extracted via Energy-Driven Sampling. Int. J. Comput. Vis. 2015, 111, 298–314. [Google Scholar] [CrossRef]
- Chen, A.Y.C.; Corso, J.J. Propagating multi-class pixel labels throughout video frames. In Proceedings of the 2010 Western New York Image Processing Workshop, Rochester, NY, USA, 5 November 2010; pp. 14–17. [Google Scholar]
- Ochs, P.; Malik, J.; Brox, T. Segmentation of Moving Objects by Long Term Video Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1187–1200. [Google Scholar] [CrossRef] [PubMed]
- Brox, T.; Malik, J. Object Segmentation by Long Term Analysis of Point Trajectories. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 282–295. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ban, Z.; Chen, Z.; Liu, J. Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model. Sensors 2018, 18, 128. https://doi.org/10.3390/s18010128
Ban Z, Chen Z, Liu J. Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model. Sensors. 2018; 18(1):128. https://doi.org/10.3390/s18010128
Chicago/Turabian StyleBan, Zhihua, Zhong Chen, and Jianguo Liu. 2018. "Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model" Sensors 18, no. 1: 128. https://doi.org/10.3390/s18010128
APA StyleBan, Z., Chen, Z., & Liu, J. (2018). Supervoxel Segmentation with Voxel-Related Gaussian Mixture Model. Sensors, 18(1), 128. https://doi.org/10.3390/s18010128