Replication Strategy for Spatiotemporal Data Based on Distributed Caching System


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
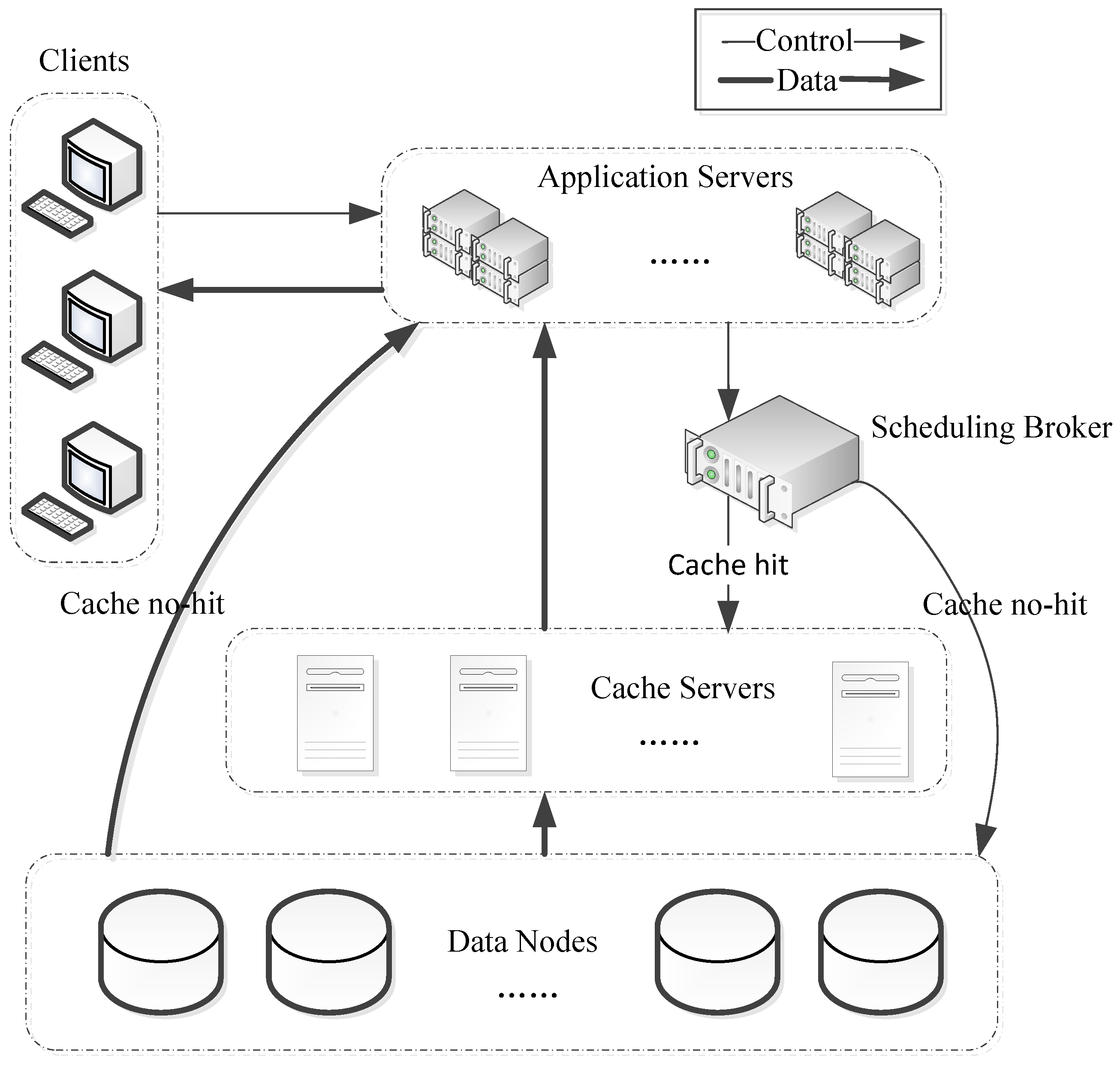
3. System Model
- Cache files selection: select the files with high popularity according to the access frequency and then place them into the cache. Thus, the cache hit rate can be improved, which insures the files to be obtained from the high-performance cache server as much as possible.
- Replica generation: generate replica according to the popularity of cache file and the capacity of cache nodes, then, distribute them into different cache nodes. Hence, the request queuing time can be reduced by balancing the system burden.
- Replica placement: place the replica of access associated file as a whole in the same cache node according to the spatiotemporal correction of user’s access request and the real-time status of the cache node so that the request cross node scheduling time can be reduced.
4. Methodology
4.1. Basic Concepts and Methods
4.1.1. Popularity of Files
4.1.2. Q-Value Scheme for Cache Replica Generation
- (1)
- Create a replica for each cache file in the cache filesets Fcache, that is, R1 = R2 =…= RM = 1; then, the remaining cache space capacity of the system is .
- (2)
- To calculate the Q-value {Q1, Q2, …, QM} for each cache file, if Qm = max(Q1, Q2, …, QM), then add 1 to the replica of file fm, that is Rm = Rm + 1; then, the remaining cache space capacity of the system is CSYre = CSYre − Cm.
- (3)
- Loop step (2) until the remaining cache space of system CSYre is less than the size of file fm.
- (4)
- Finally, if the number of replica of the file fm is more than the number of cached nodes, that is Rm > L, then, delete the redundant replica and set the number of replica as Rm = L. Delete the file fm from the filesets Fcache.
- (5)
- Loop steps (2–4), until the remaining cache space CSYre cannot store any cache files.
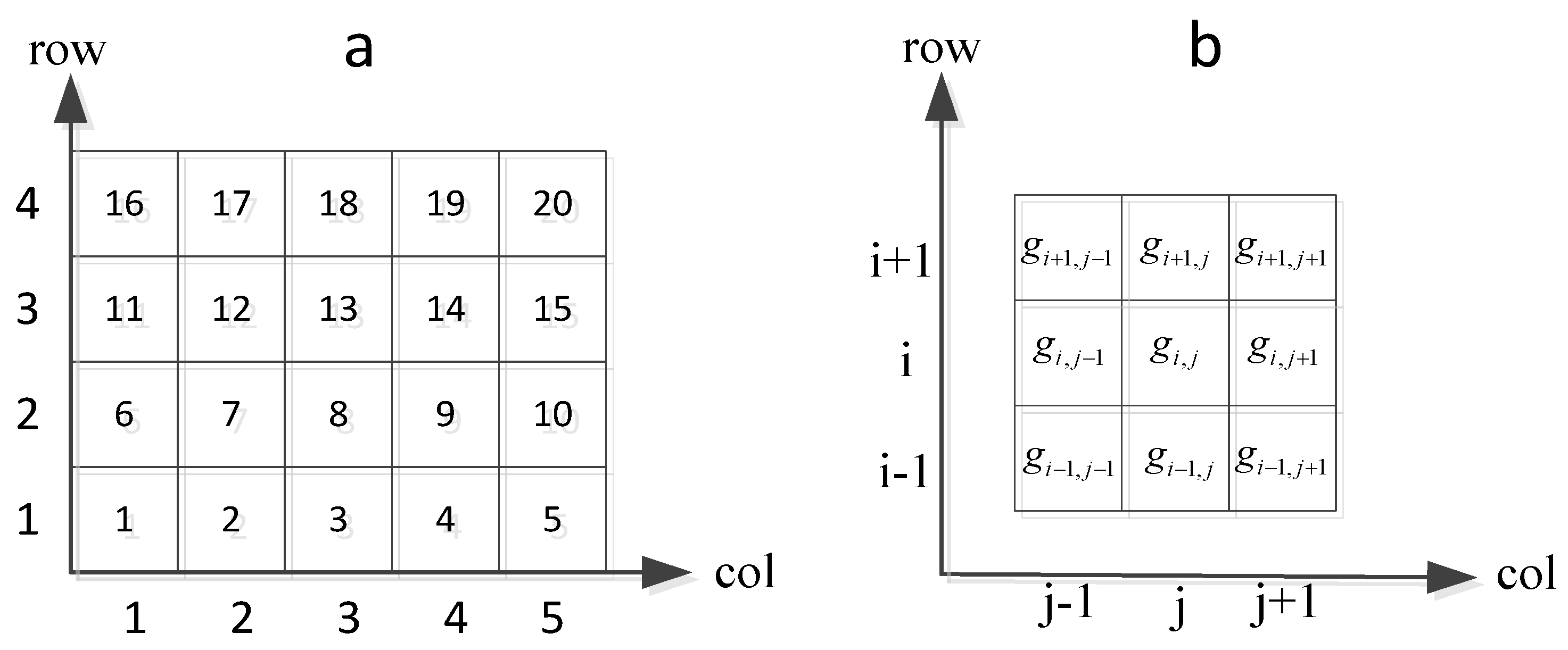
4.1.3. Mining Associated Files
- Step 1:
- Mine the user access request cache filesets that belong to the cell gij and its neighbor cells from the user access filesets Fset.
- Step 2:
- Calculate the access popularity of each file in , and find the most popular file fk, and its popularity .
- Step 3:
- The FP-growth algorithm is used to iterate through the user access filesets Fset (the file accessed in a time segment Δt corresponds to a record in the FP-growth algorithm), and the popularity between the file fk and other files in is calculated; if the popularity of access associated between them is greater than or equal to , then consider these files as access associated.
- Step 4:
- The files related to fk constitute access related filesets; place the files into the filesets , and then delete these files from .
- Step 5:
- Loop steps (2–5) until there are no access associated filesets generated, and finally the total set is formed.
- Step 6:
- Files that have low access associated popularity, but with popularity higher than the average access popularity are called non-associated files; place these files into the non-associated filesets .
4.2. RSSD Algorithm
4.2.1. Cache Files Selection
4.2.2. Replica Generation
- (1)
- Use the Q-value scheme to generate replica for each file in Fcache.
- (2)
- Take any fileset from F1, and arrange them in descending order according to the number of replica of the file assuming that the sorted filesets are {fi, fj, …, fk}, where Ri ≥ Rj ≥…≥ Rk.
- (3)
- Split the filesets {fi,fj, …, fk} into subsets based on the number of replica of each file. The first subset formed after splitting is itself, that is {fi, fj, …, fk}, and the number of replica is R(i,j,…,k) = min(Ri, Rj, …, Rk) = Rk. Then, put the subset into the new associated filesets , and record the number of replica R(i,j,…,k) = Rk.
- (4)
- At this point, the remaining replica of each file in the filesets {fi, fj, …, fk} are Ri = Ri – Rk, Rj = Rj – Rk,…, Rk = Rk – Rk. Then, we delete the files with zero copy number to form a new fileset {fi, fj, …, fk} = {fi, fj, …, fk} − fk.
- (5)
- Repeat steps (2–4) until the filesets {fi, fj, …, fk} are split. To this extent, the number of files in the filesets is zero, or there is only one file fi with the largest number of replica. For the remaining file fi, we treat it as non-associated file (at least two files can be referred to as associated) and put them into the non-associated filesets , and record the number of replica Ri = Ri – Rj −…− Rk.
- (6)
- Loop steps (2–5) until every MAF is split in the filesets F1, and put the results of the split into the filesets and F2. Similarly, here are .
4.2.3. Replica Placement
- Step 1:
- Place access associated filesets
- (1)
- Calculate the size of each fileset .
- (2)
- Calculate the file placement factor for each cache node.
- (3)
- Place the first replica of the filesets with the largest size in as a whole in the cache node where the placement factor is largest. Then, if the storage capacity of the node is not enough, the cache node with the second-largest placement factor will be selected.
- (4)
- Loop steps (2–3), place the remaining replica in different cache nodes in turn.
- (5)
- Loop steps (1–4), place all access associate filesets in as a whole into the cache node.
- Step 2:
- Place access non-associated filesets.
- (1)
- Calculate the size of each file in F2.
- (2)
- Calculate the file placement factor for each cache node.
- (3)
- Place the first replica of the filesets with the largest size in F2 into the cache node whose placement factor is the largest. Then, if the storage capacity of the node is not enough, select the cache node with the second-largest placement factor.
- (4)
- Loop steps (2–3), place the remaining replica in different cache nodes in turn.
- (5)
- Loop steps (1–4), place all files in F2 into the cache node.
5. Experimental and Performance Evaluation
5.1. Evaluation Metrics
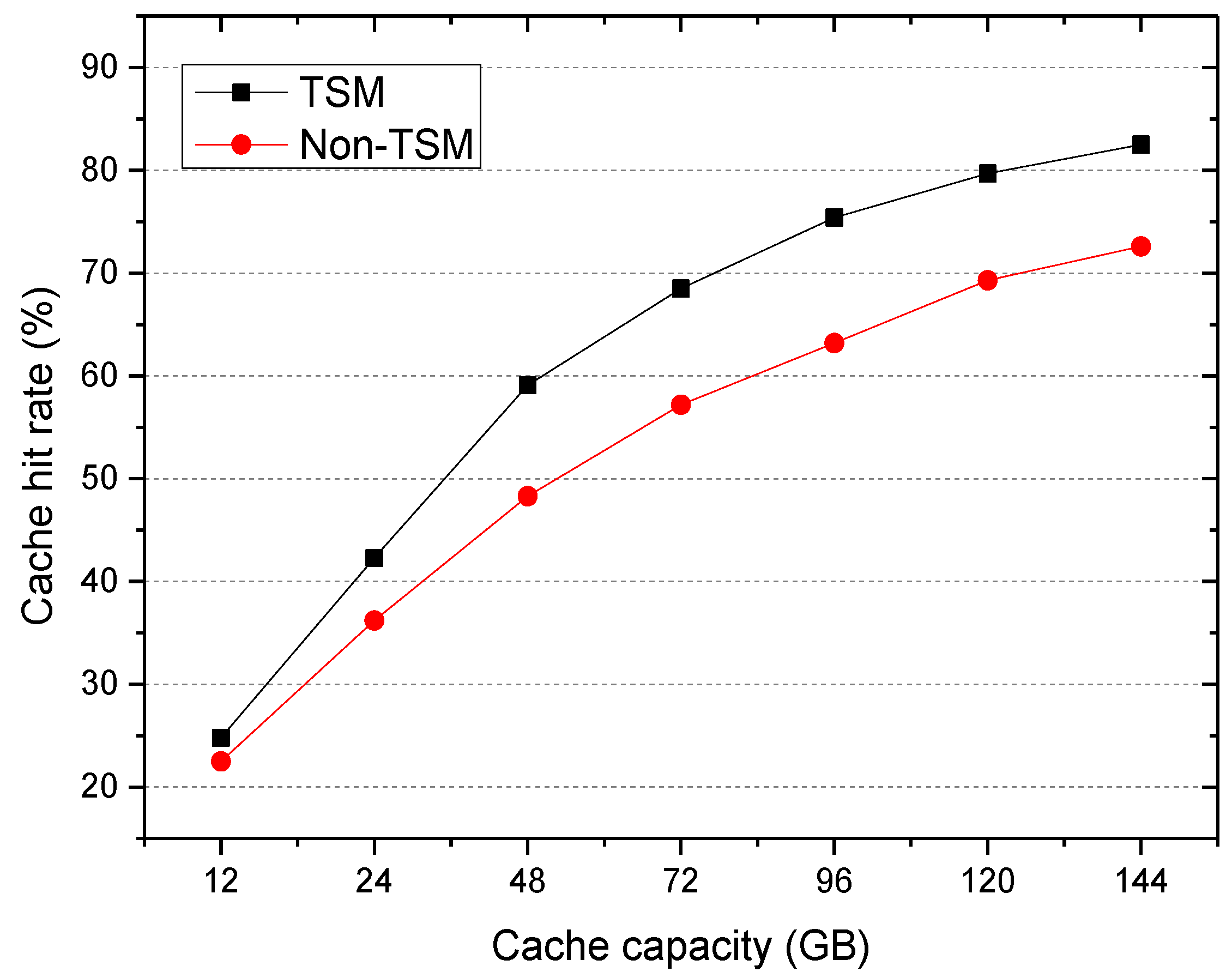
- Cache hit rates: a percentage of the total number of requests hit in a user access request, which is used to measure the performance of cache file selection mechanisms.
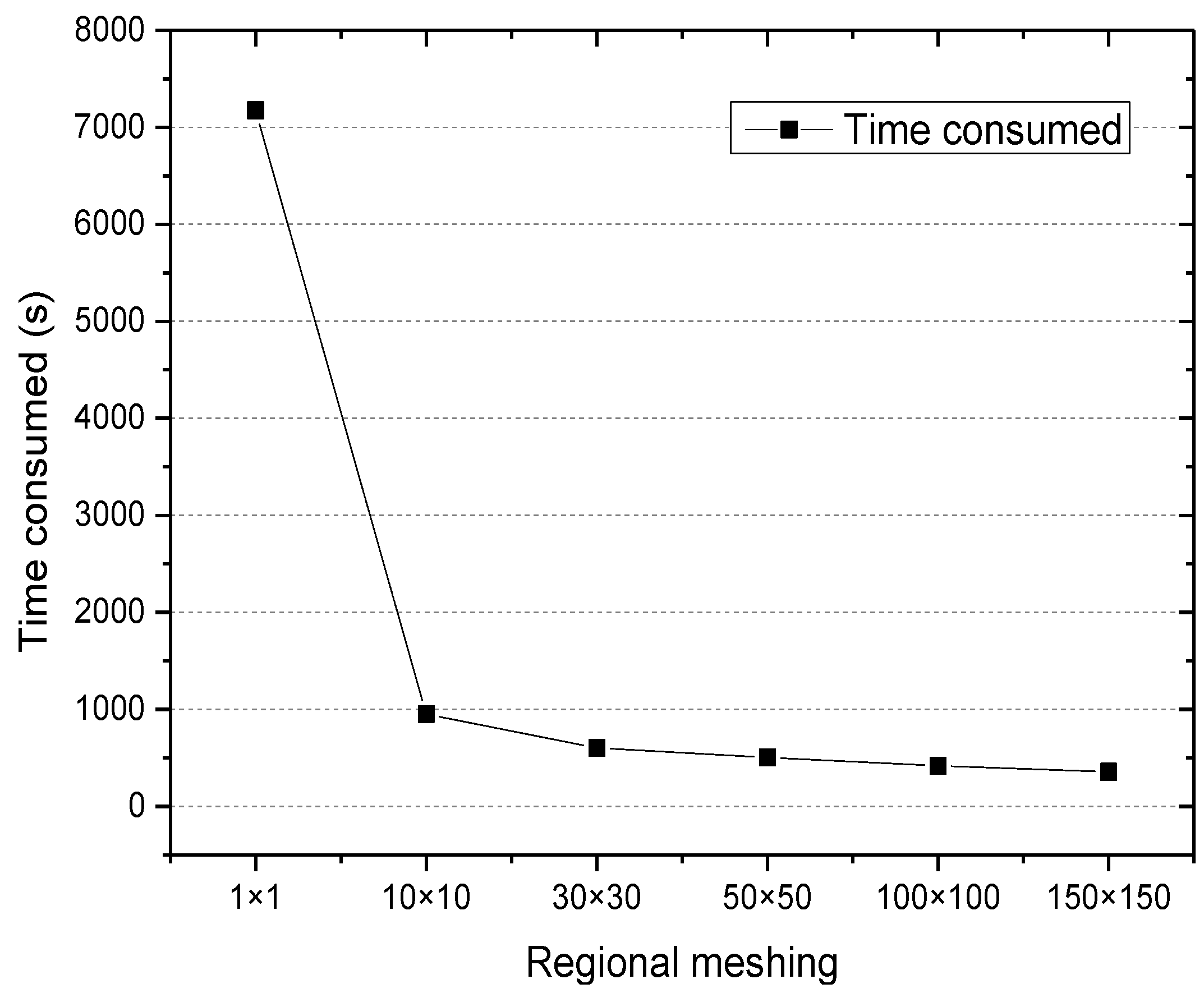
- Mining time: the time consumed for mining the access associated files from the historical user access information, which is used to measure the computational efficiency of the algorithm.
- Average response time: the average response time of user access to a single file, which is used to measure the overall performance of the algorithm.
5.2. Experimental Data and Methods
5.3. Experimental Results
5.3.1. Cache Hit Rates
5.3.2. Mining Time
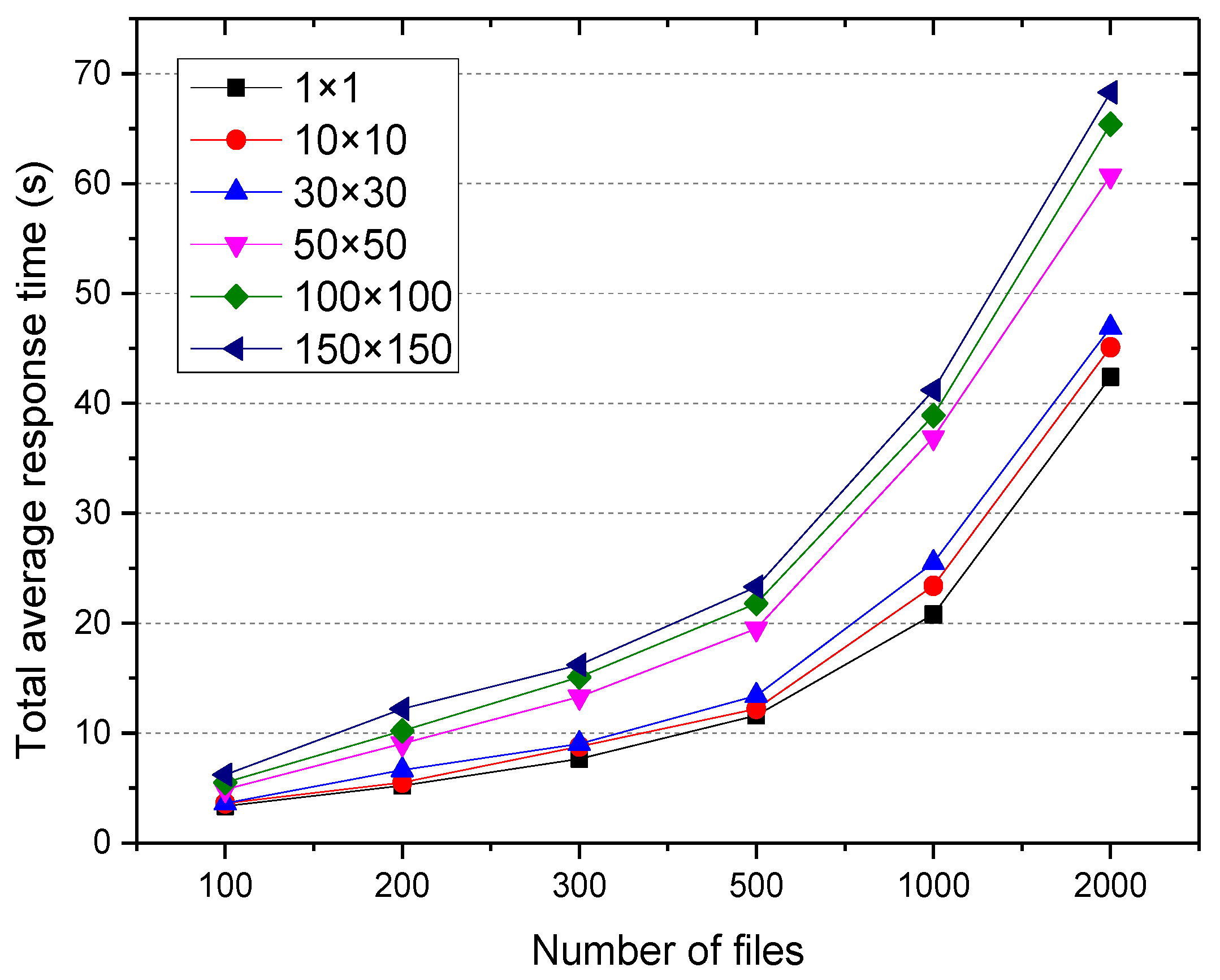
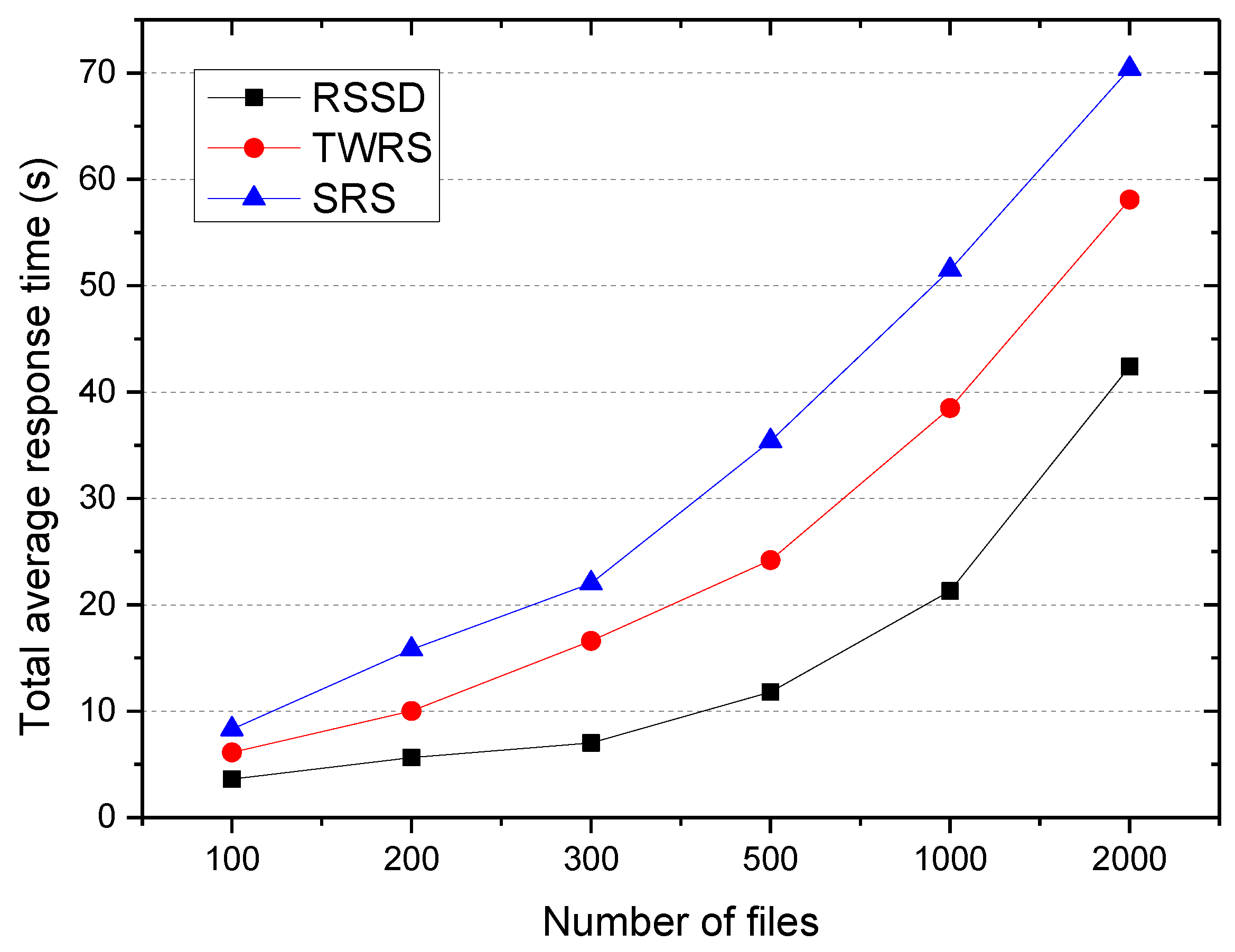
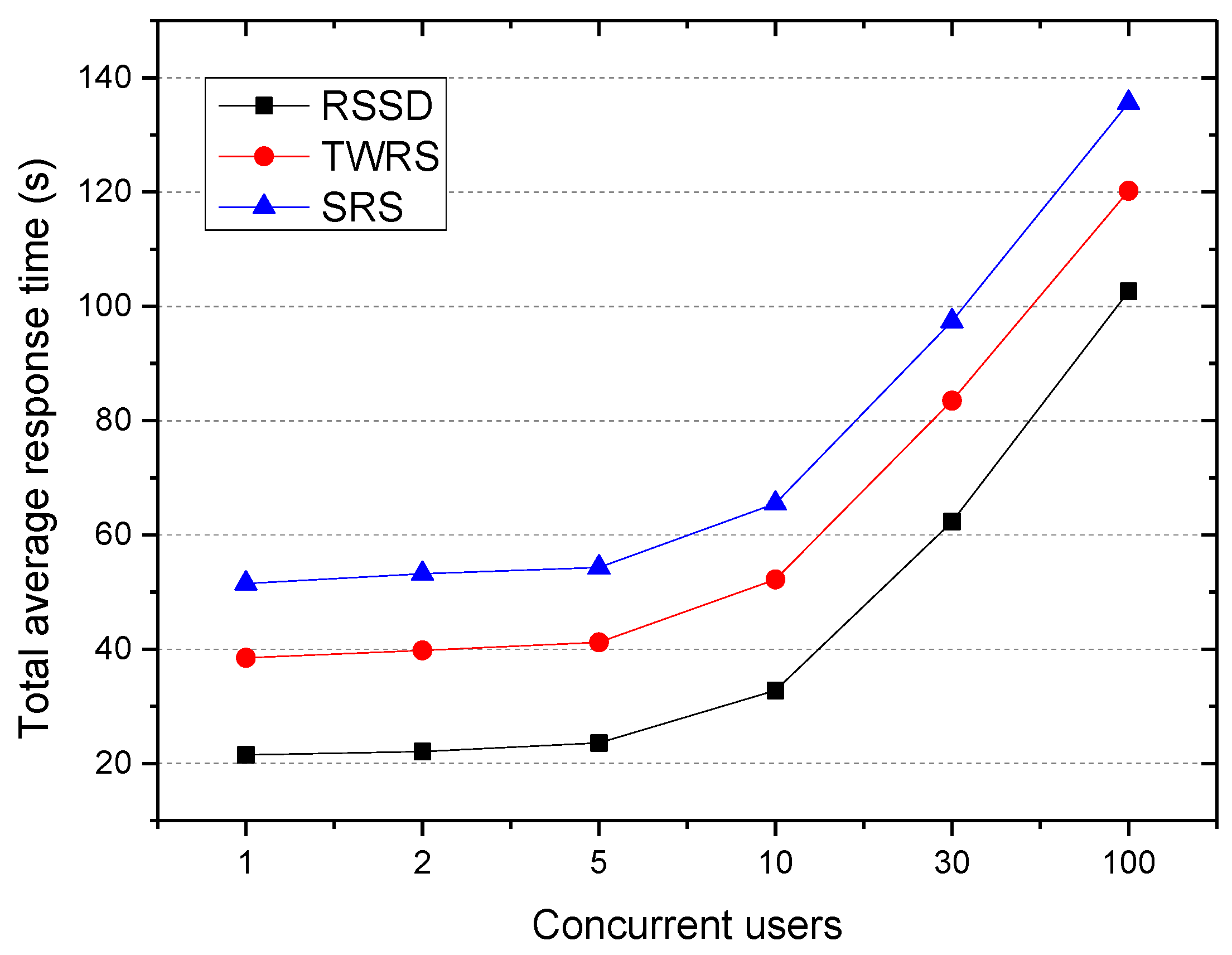
5.3.3. Average Response Time
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Li, D.R.; Cao, J.J.; Yuan, Y. Big Data in Smart Cities. Sci. China Inf. Sci. 2015, 39, 1–12. [Google Scholar] [CrossRef]
- Li, D.R.; Yao, Y.; Shao, Z.F.; Wang, L. From digital Earth to Smart Earth. Chin. Sci. Bull. 2014, 59, 722–733. [Google Scholar] [CrossRef]
- Qin, X.L.; Zhang, W.B.; Wei, J.; Wang, W.; Zhong, H.; Huang, T. Progress and Challenges of Distributed Caching Techniques in Cloud Computing. J. Softw. 2013, 24, 50–66. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, G.; Hu, X.; Wu, X. A Distributed Cache for Hadoop Distributed File System in Real-Time Cloud Services. Grid Computing (GRID). In Proceedings of the 2012 ACM/IEEE 13th International Conference on Grid Computing (GRID), Washington, DC, USA, 20–23 September 2012. [Google Scholar]
- Xiong, L.; Xu, Z.; Wang, H.; Jia, S.; Zhu, L. Prefetching scheme for massive spatiotemporal data in a smart city. Int. J. Distrib. Sens. Netw. 2016, 2016, 412735. [Google Scholar] [CrossRef]
- Tang, M.; Lee, B.S.; Yeo, C.K.; Tang, X. Dynamic Replication Algorithms for the Multi-tier Data Grid. Futur. Gener. Comput. Syst. 2005, 21, 775–790. [Google Scholar] [CrossRef]
- Tang, M.; Lee, B.S.; Tang, X.; Yeo, C.K. The Impact of Data Replication on Job Scheduling Performance in the Data Grid. Futur. Gener. Comput. Syst. 2006, 22, 254–268. [Google Scholar] [CrossRef]
- Sun, X.; Li, Q.Z.; Zhao, P.; Wang, K.X.; Pan, F. An Optimized Replica Distribution Method for Peer-to-Peer Network. Chin. J. Comput. 2014, 37, 1424–1433. [Google Scholar]
- Li, R.; Feng, W.; Wu, H.; Huang, Q. A Replication Strategy For a Distributed High-speed Caching System Based on Spatiotemporal Access Patterns of Geospatial Data. Comput. Environ. Urban Syst. 2014. [Google Scholar] [CrossRef]
- Chang, R.S.; Chang, H.P. A dynamic data replication strategy using access-weights in data grids. J. Supercomput. 2008, 45, 277–295. [Google Scholar] [CrossRef]
- Sun, D.W.; Chang, G.R.; Gao, S.; Jin, L.; Wang, X. Modeling a Dynamic Data Replication Strategy to Increase System Availability in Cloud Computing Environments. J. Comput. Sci. Technol. 2012, 27, 256–272. [Google Scholar] [CrossRef]
- Xu, X.; Yang, C.; Shao, J. Data Replica Placement Mechanism for Open Heterogeneous Storage Systems. Procedia Comput. Sci. 2017, 109, 18–25. [Google Scholar] [CrossRef]
- Pan, S.; Xiong, L.; Xu, Z.; Meng, Q. A dynamic replication management strategy in distributed GIS. Comput. Geosci. 2017, 112, 1–8. [Google Scholar] [CrossRef]
- Wei, Q.; Veeravalli, B.; Gong, B.; Zeng, L.; Feng, D. CDRM: A Cost-Effective Replication Management Scheme for Cloud Storage Cluster. In Proceedings of the 2010 IEEE International Conference on Cluster Computing (CLUSTER), Heraklion, Greece, 20–24 September 2010. [Google Scholar]
- Li, W.Z.; Chen, D.X.; Lu, L.S. Graph-Based Optimal Cache Deployment Algorithm for Distributed Caching Systems. J. Softw. 2010, 21, 1524–1535. [Google Scholar]
- Tu, M.; Yen, I.L. Distributed replica placement algorithms for correlated data. J. Supercomput. 2014, 68, 245–273. [Google Scholar] [CrossRef]
- Zaman, S.; Grosu, D. A Distributed Algorithm for the Replica Placement Problem. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 1455–1468. [Google Scholar] [CrossRef]
- Nagarajan, V.; Mohamed, M.A.M. A prediction-based replication strategy for data-intensive applications. Comput. Electr. Eng. 2017, 57, 281–293. [Google Scholar] [CrossRef]
- Lin, J.W.; Chen, C.H.; Chang, J.M. QoS-Aware Data Replication for Data-Intensive Applications in Cloud Computing Systems. IEEE Trans. Cloud Comput. 2013, 1, 101–115. [Google Scholar]
- Shorfuzzaman, M.; Graham, P.; Eskicioglu, R. Distributed Placement of Replica in Hierarchical Data Grids with User and System QoS Constraints. In Proceedings of the 2011 International Conference on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), Barcelona, Spain, 26–28 October 2011. [Google Scholar]
- Cheng, C.W.; Wu, J.J.; Liu, P. QoS-aware, access-efficient, and storage-efficient replica placement in grid environments. J. Supercomput. 2009, 49, 42–63. [Google Scholar] [CrossRef]
- You, K.; Tang, B.; Qian, Z.; Lu, S.; Chen, D. QoS-aware placement of stream processing service. J. Supercomput. 2013, 64, 919–941. [Google Scholar] [CrossRef]
- Tos, U.; Mokadem, R.; Hameurlain, A.; Ayav, T.; Bora, S. Dynamic Replication Strategies in Data Grid Systems: A Survey. J. Supercomput. 2015, 71, 4116–4140. [Google Scholar] [CrossRef]
- Suciu, G.; Butca, C.; Dobre, C.; Popescu, C. Smart City Mobility Simulation and Monitoring Platform. In Proceedings of the 2017 21st International Conference on Control Systems and Computer Science, Bucharest, Romania, 29–31 May 2017. [Google Scholar]
- Srikant, R.; Agrawal, R. Mining Sequential Patterns: Generalizations and Performance Improvement. In Proceedings of the 5th International Conference on Extending Database Technology: Advances in Database Technology, London, UK, 25–29 March 1996. [Google Scholar]
- Han, J.W.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data (SIGMOD'00), Dallas, TX, USA, 16–18 May 2000. [Google Scholar]







© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, L.; Yang, L.; Tao, Y.; Xu, J.; Zhao, L. Replication Strategy for Spatiotemporal Data Based on Distributed Caching System. Sensors 2018, 18, 222. https://doi.org/10.3390/s18010222
Xiong L, Yang L, Tao Y, Xu J, Zhao L. Replication Strategy for Spatiotemporal Data Based on Distributed Caching System. Sensors. 2018; 18(1):222. https://doi.org/10.3390/s18010222
Chicago/Turabian StyleXiong, Lian, Liu Yang, Yang Tao, Juan Xu, and Lun Zhao. 2018. "Replication Strategy for Spatiotemporal Data Based on Distributed Caching System" Sensors 18, no. 1: 222. https://doi.org/10.3390/s18010222
APA StyleXiong, L., Yang, L., Tao, Y., Xu, J., & Zhao, L. (2018). Replication Strategy for Spatiotemporal Data Based on Distributed Caching System. Sensors, 18(1), 222. https://doi.org/10.3390/s18010222