This section presents the basic elements of the Edukas environment, showing how this work treats the link between educational governance, strategic planning and computational intelligence. The Edukas model will be focused in of of the tasks mentioned above: (1) classify students’ profiles, (2) recommendations for students and others and (3) predicting student performance. This section is finalized with the presentation and discussion of the paper hypothesis.
3.1. Edukas Environment
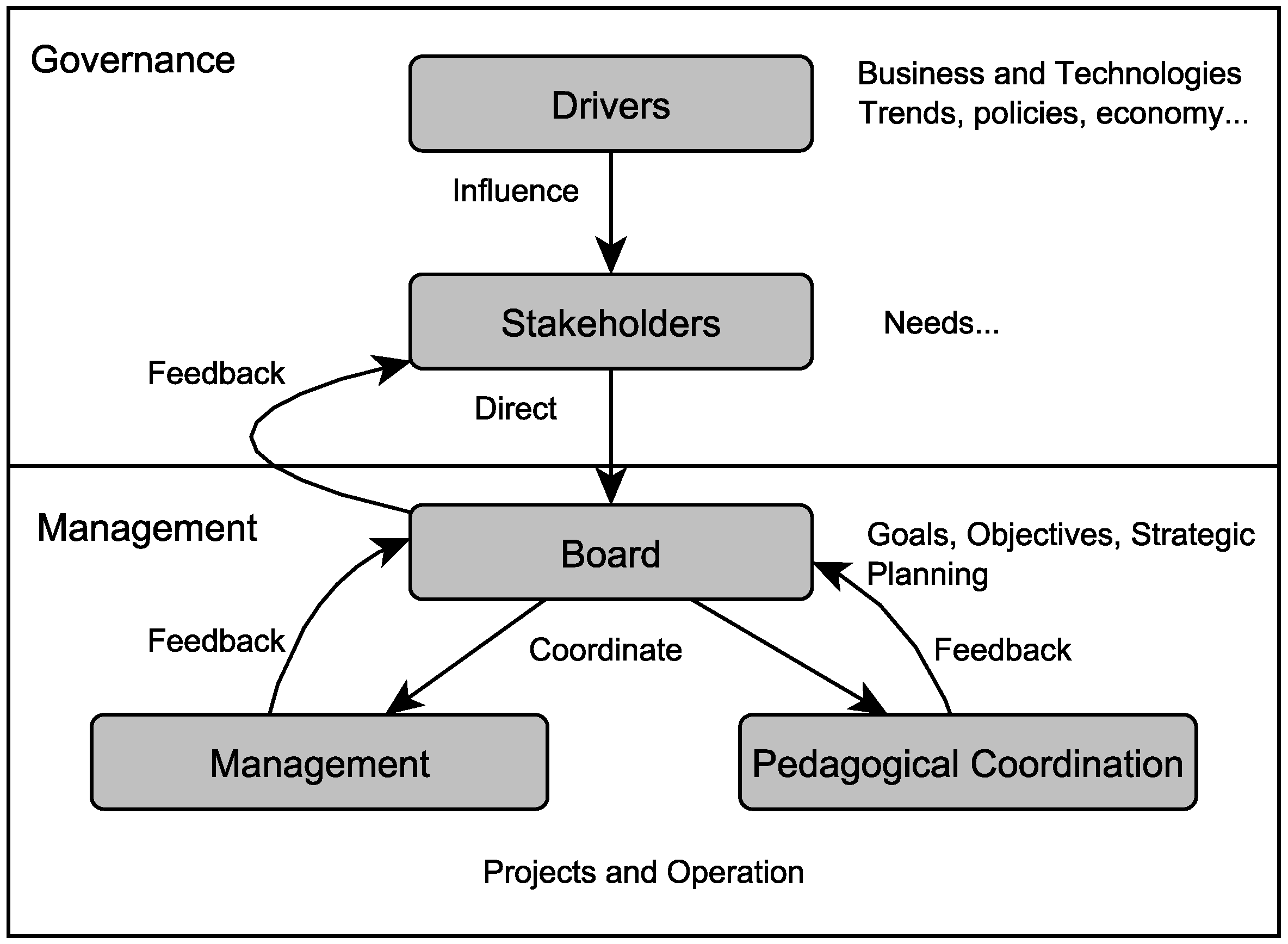
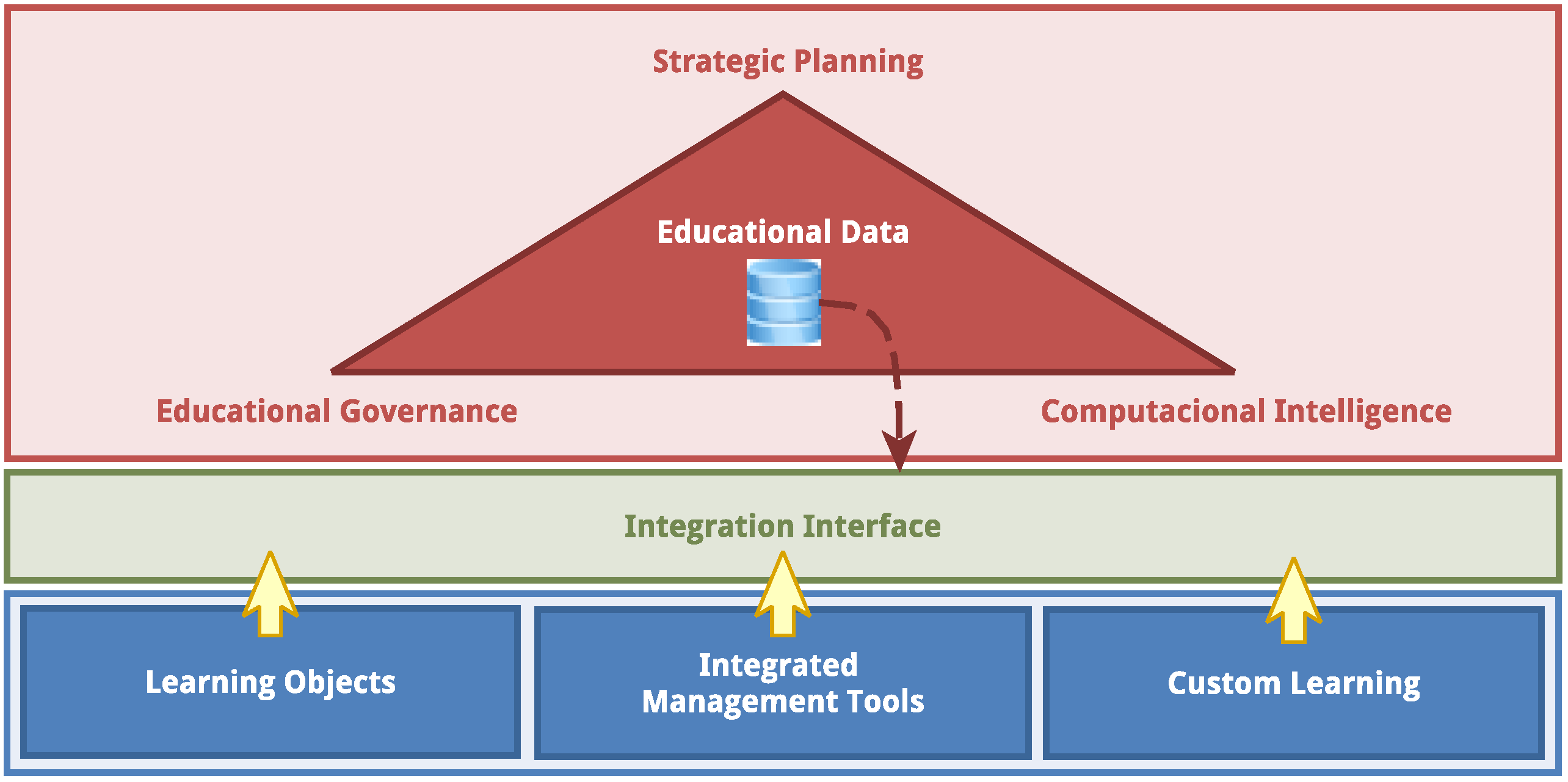
Based on the exposed background, the Edukas environment comprises three main layers, as shown in
Figure 3. The lowest layer contains the systems that can be accessed by the stakeholders. The middle layer records all data resulting from the interaction with these systems, forming a educational database. The highest layer uses the data stored in the database, transformed by the corporate governance model, by the computational intelligence algorithms and by the strategic planning tools, to generate tangible information for the stakeholders.
The lower layer is responsible for the collection and structure of data. It is in this layer that the administrative, academic and content systems are deployed and used to generate the transactional information of the educational communities. The middle layer is responsible for housing data mining and data preparation tools. Finally, the upper layer is responsible for the data analytics and the decision-making, which leads to the strategic planning, to the educational governance and to the orientation tools used by educators.
Data collected in the lower layer can be classified into three groups, depending on their origin: learning objects, integrated management tools and custom learning. Data from the learning objects are generated from digital activities, mainly educational games and digital courseware, that are submitted to students to present knowledge and content and to evaluate students’ performances. The learning objects use different technologies such as artificial intelligence, virtual/augmented reality, digital assessment, adaptive learning, listening and sensing technology and robotic telepresence. Learning objects’ data allows the definition of students’ knowledge profiles, which is a history map showing the knowledge each student has built up to some point in time.
Data from integrated management gathers information from heterogeneous data provided by different education management systems. These are mainly administrative data.
Data from custom learning use the teaching-learning activities to identify attributes for each student and discover the students’ learning profiles, which are history maps that show how students work in order to acquire their knowledge. These maps can help educators to identify and solve gaps in the teaching-learning process. The creation of the learning profiles uses technologies such as adaptive learning, artificial intelligence, digital assessment, listening and sensing technology, predictive analytics and hybrid integration platforms.
In the upper layer, strategic planning provides the direction to reach the goals; educational governance establishes the goals and monitors if the organization reaches them or not; and computational intelligence provides real-time analysis of information for the decision-making. These three tools must be tightly related and integrated. They make use of the educational database that collects data of different types and from different sources.
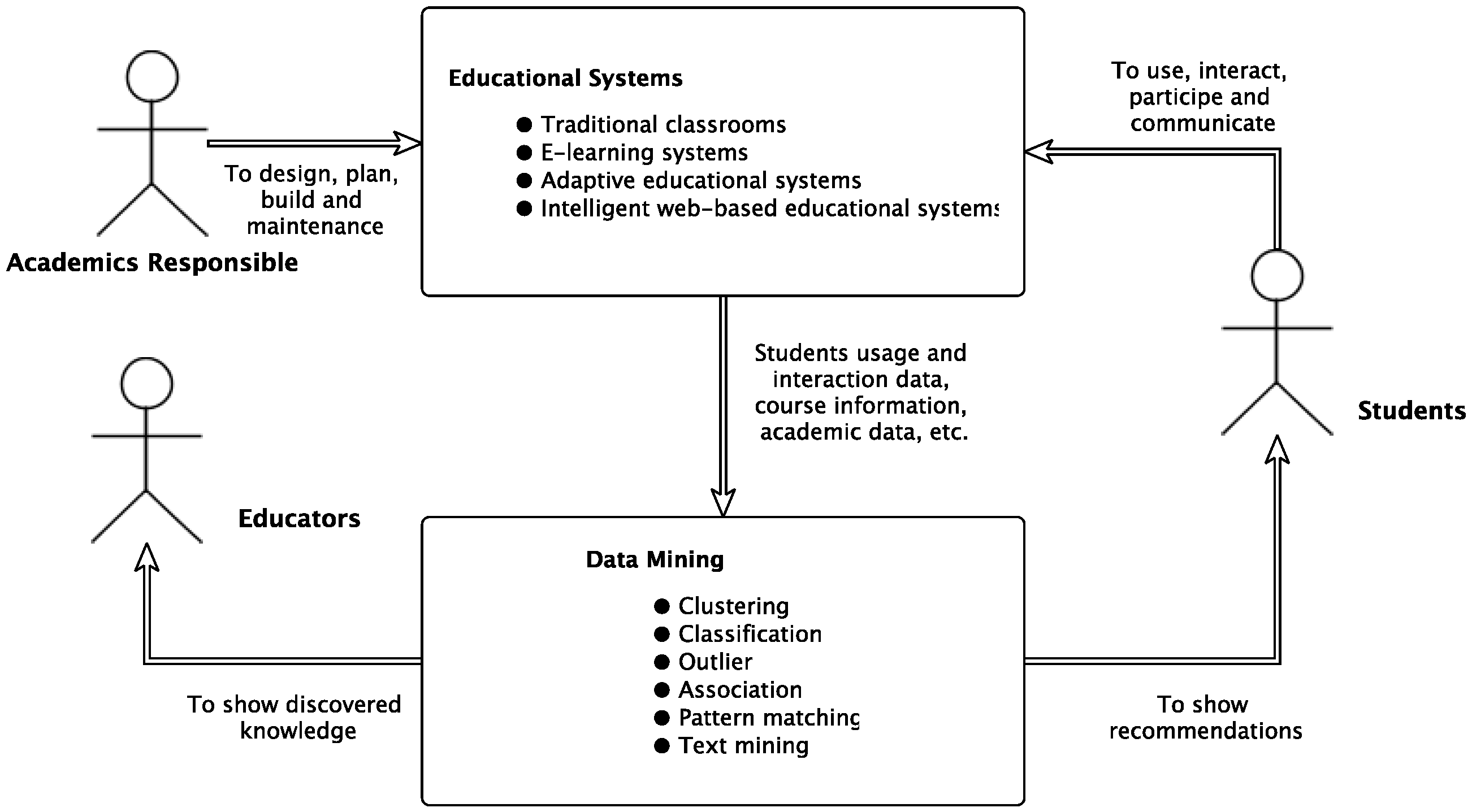
Edukas is, at the same time, a learning environment, a management system and an analytics framework, which are defined by each of the three layers discussed above. With Edukas, students receive education content from the learning environment; data scientists gather the vital information to analyze each student and improve the odds for him/her to obtain the best education the system has to offer. With the Edukas framework, educators can use assessment methods and define road maps to define actions that can lead to the best decision-making processes.
The discussion presented so far, and considering that the driver “good student performance” leads to the objective “improve the student success rate”, as shown in
Table 5, shows that modern education cannot afford being left out of the “smart” movement that is taken over most of the science and business areas of contemporary society.
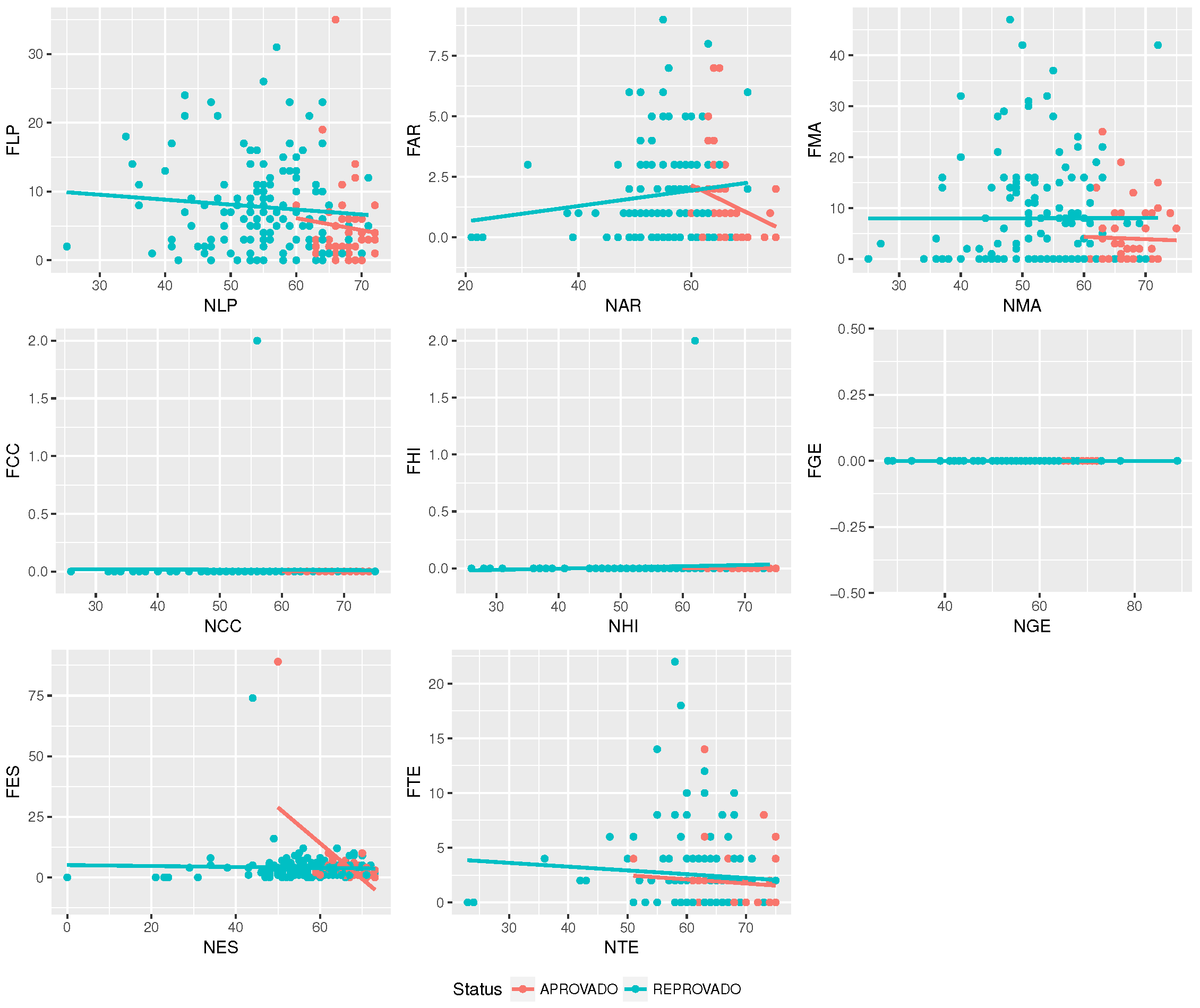
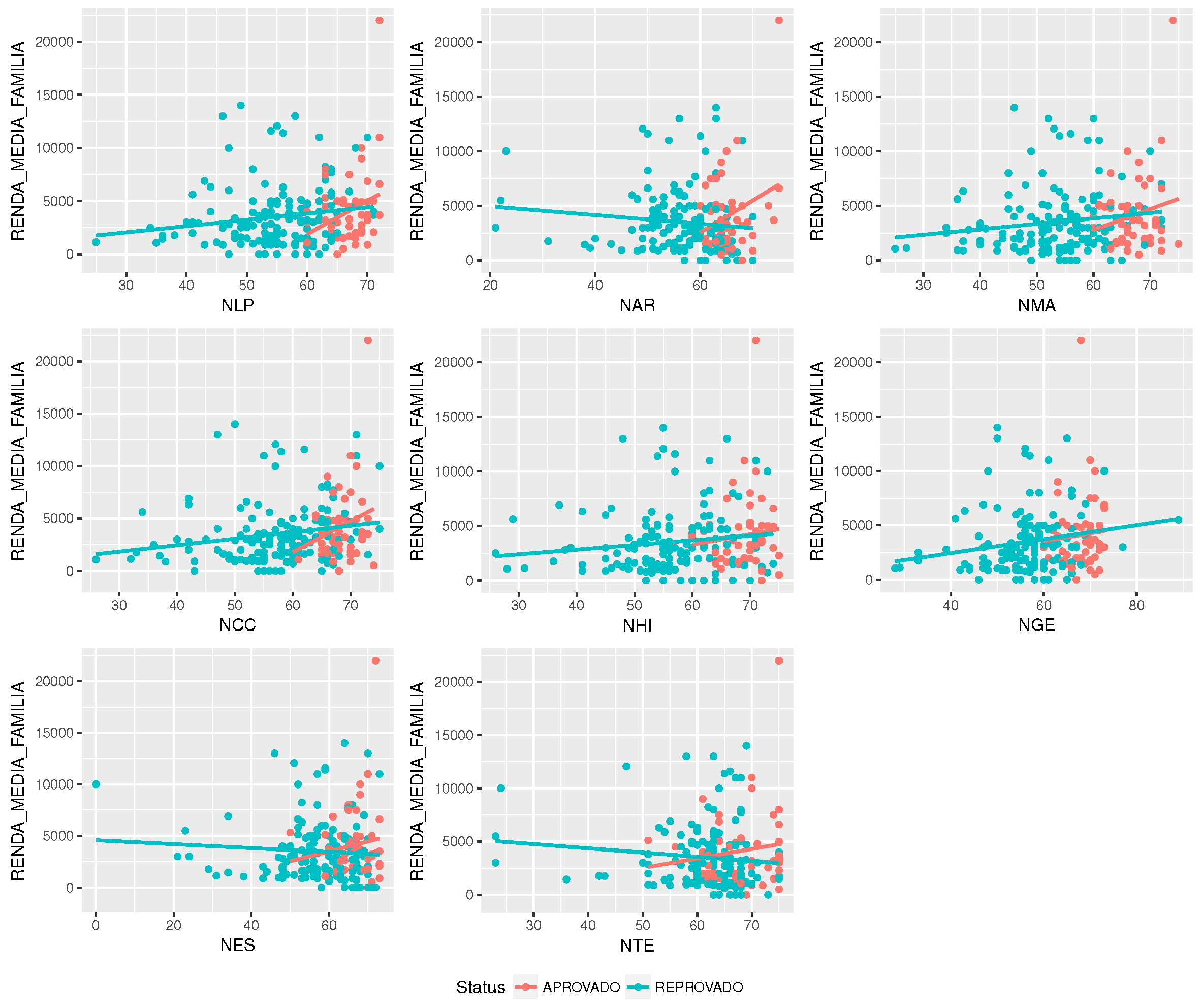
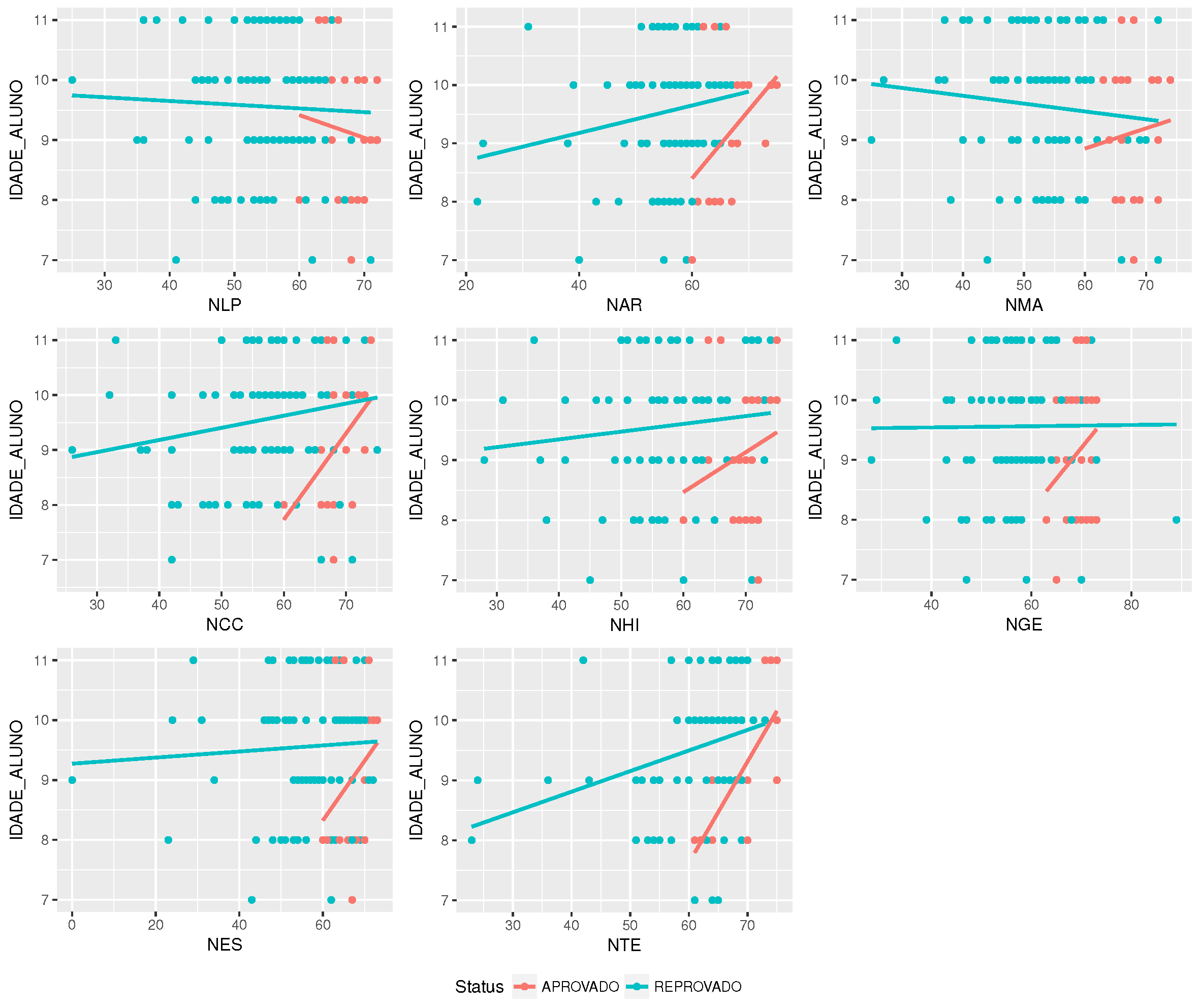
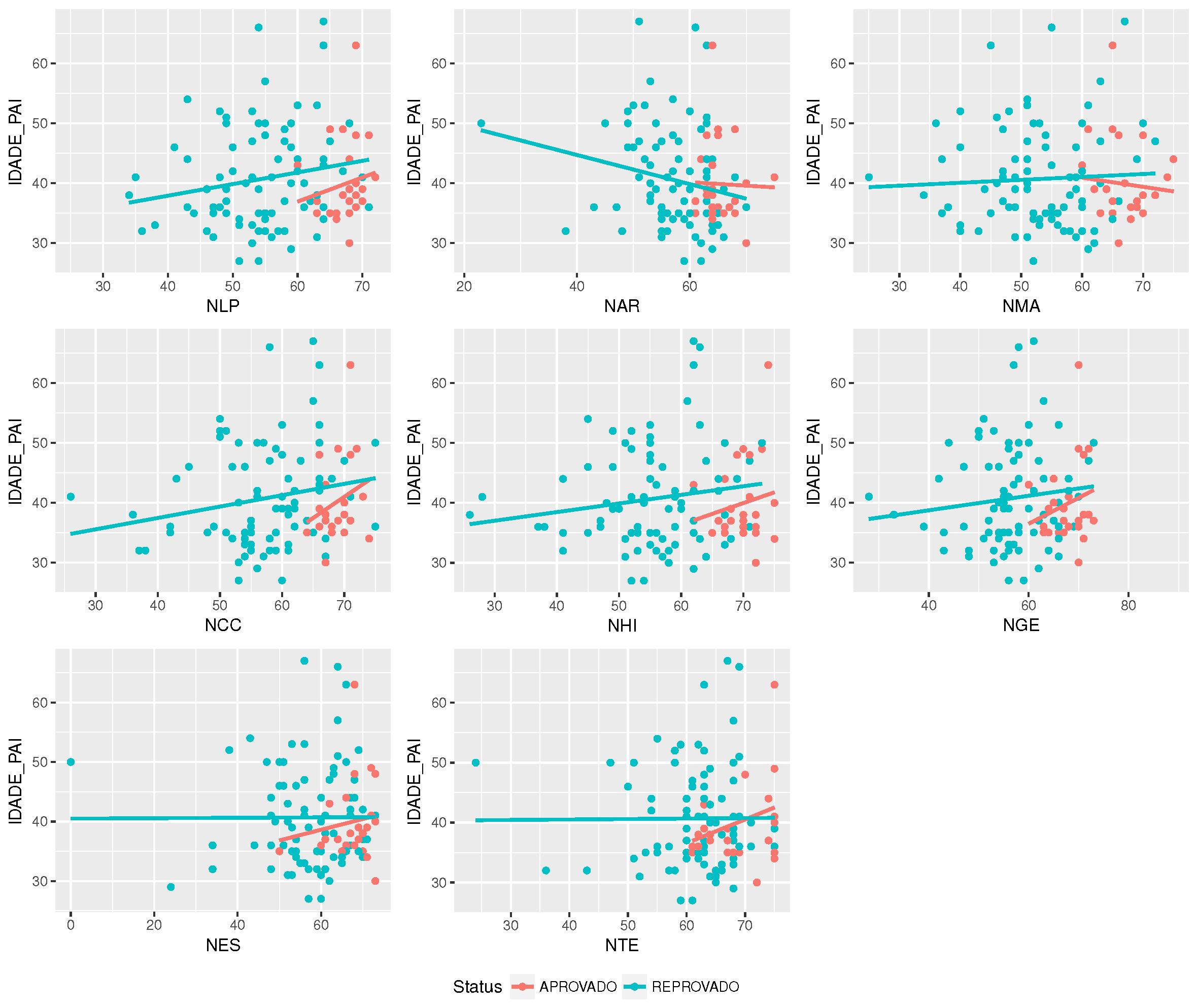
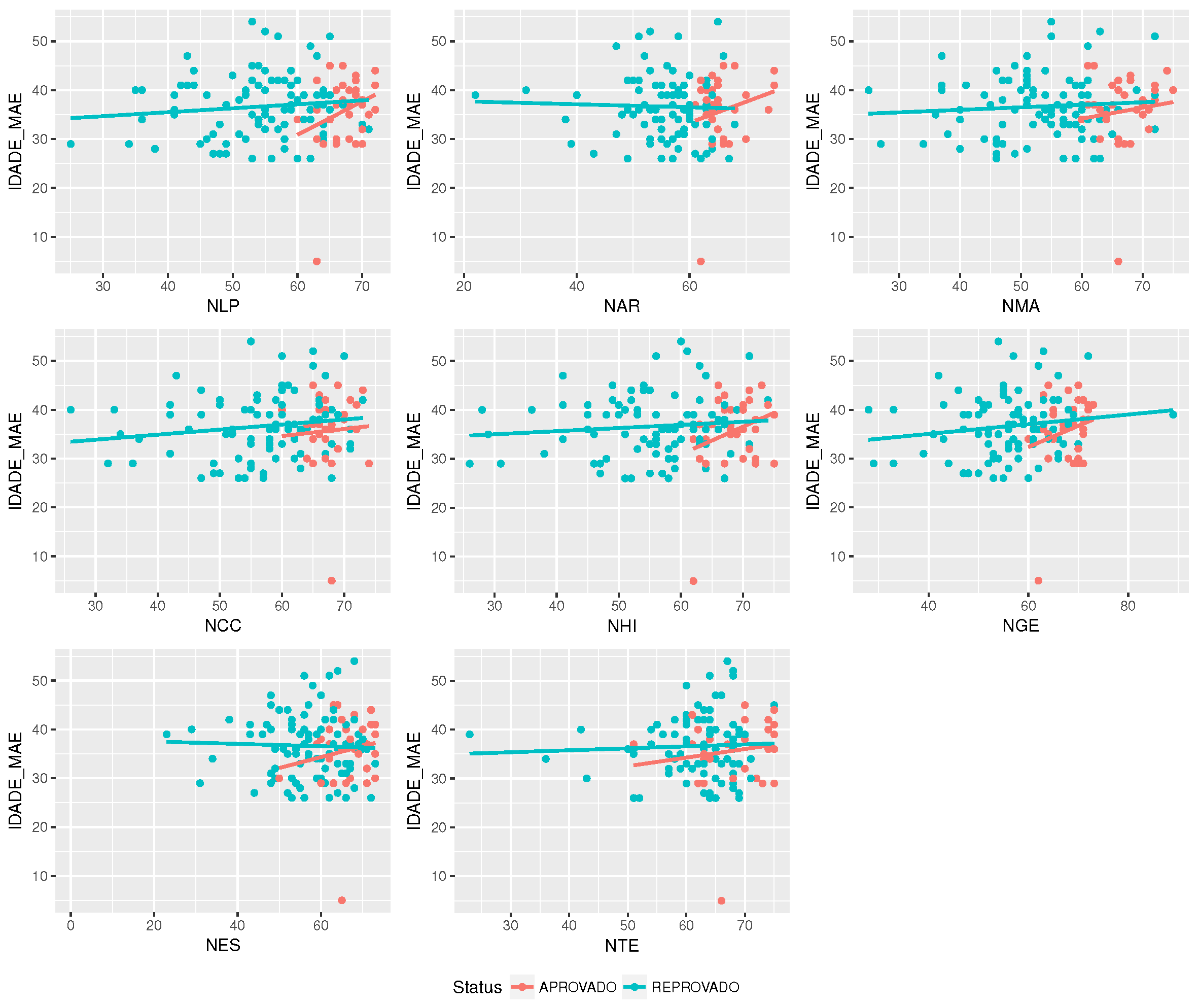
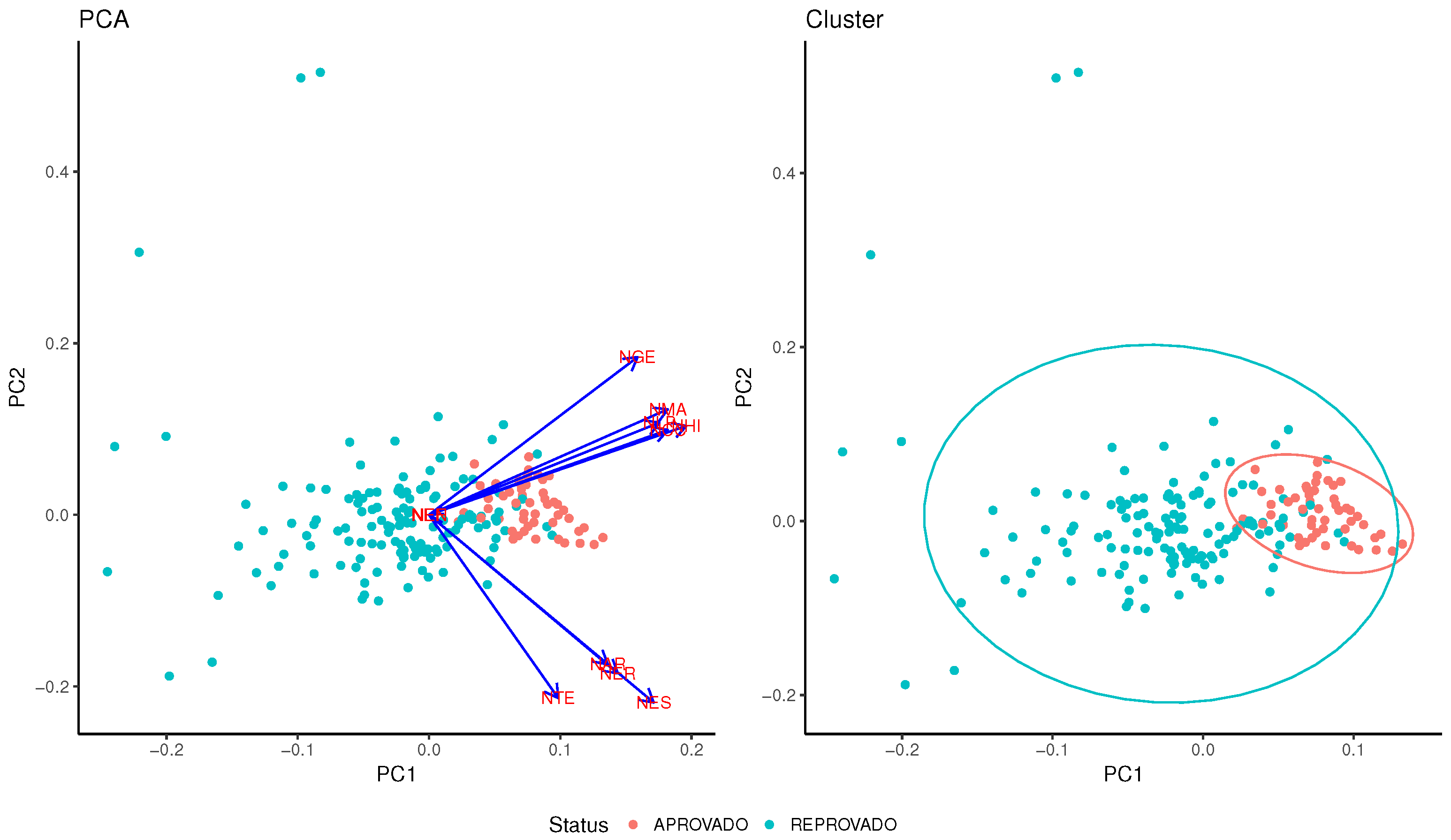
Now, it is necessary to define how to develop the analysis that can generate the indicators composing the students’ profiles discussed before. These indicators are described in
Section 5.
3.2. Hypothesis
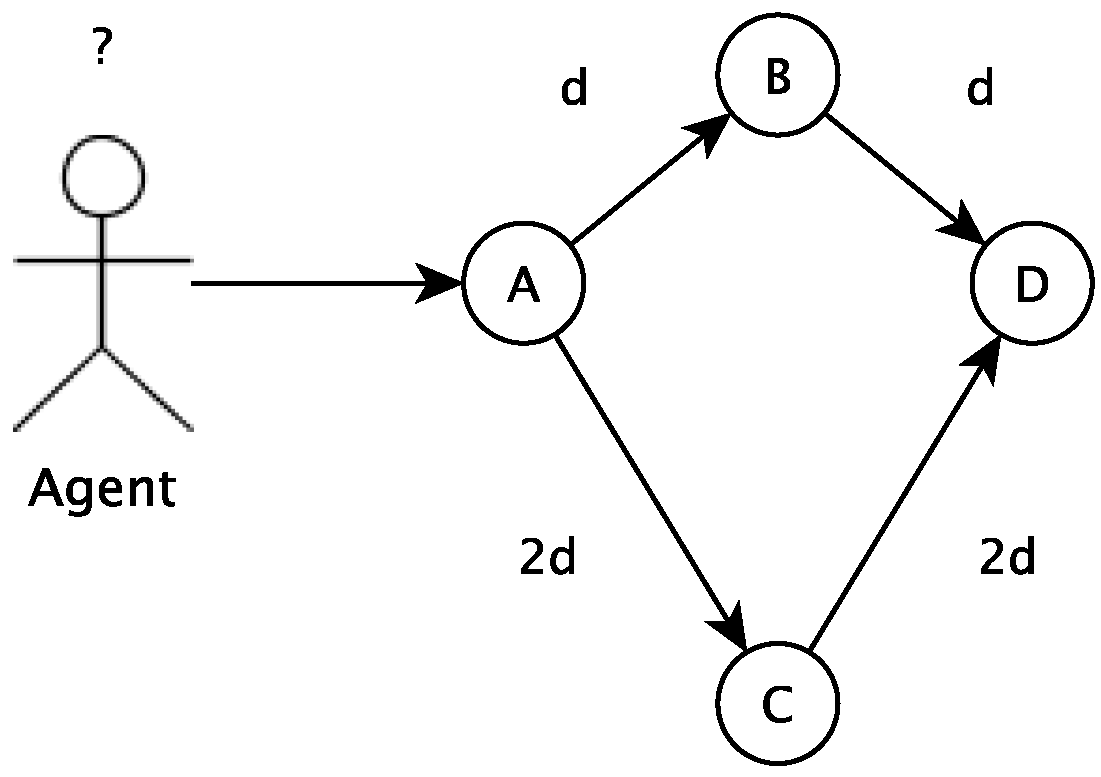
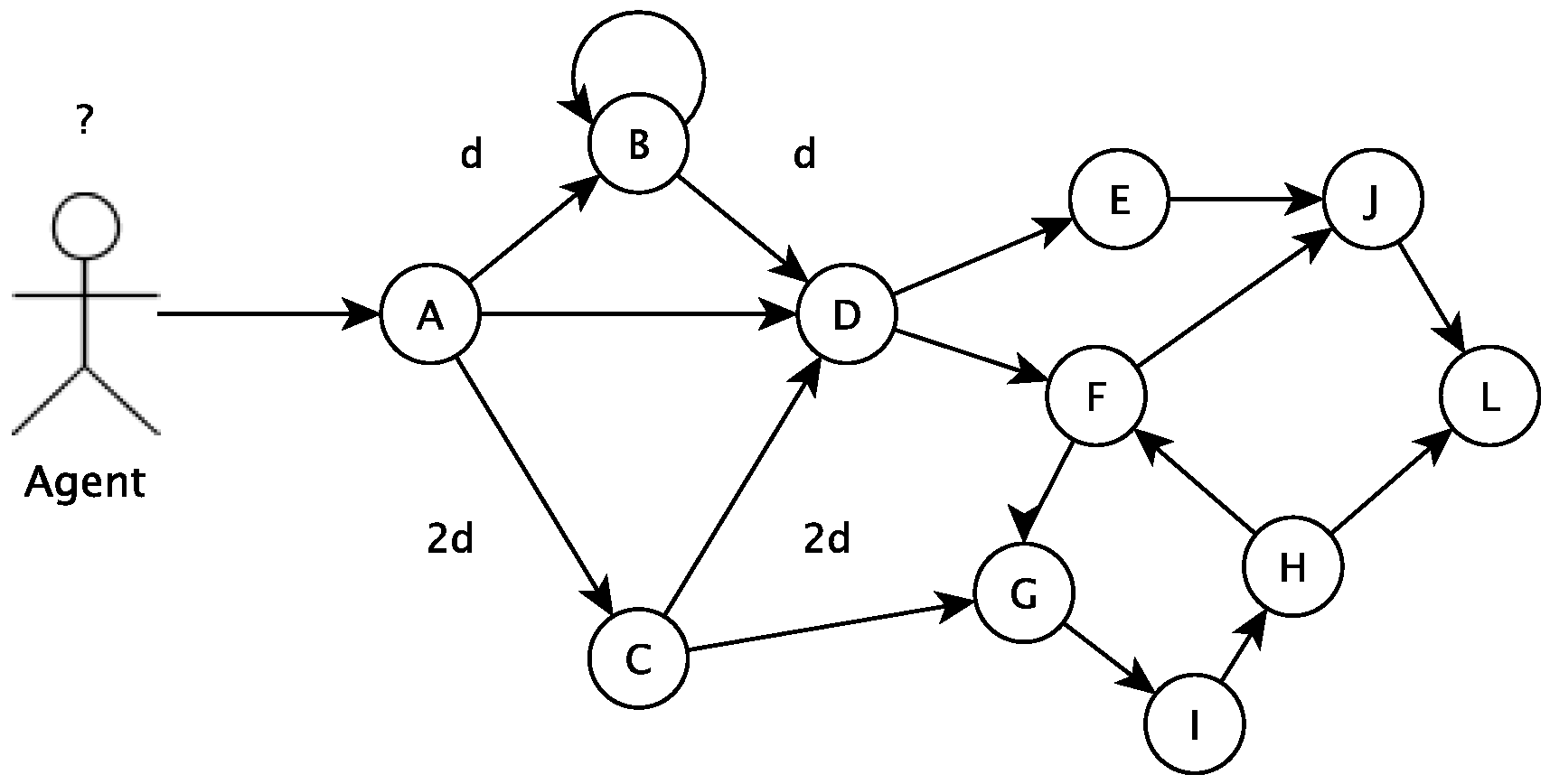
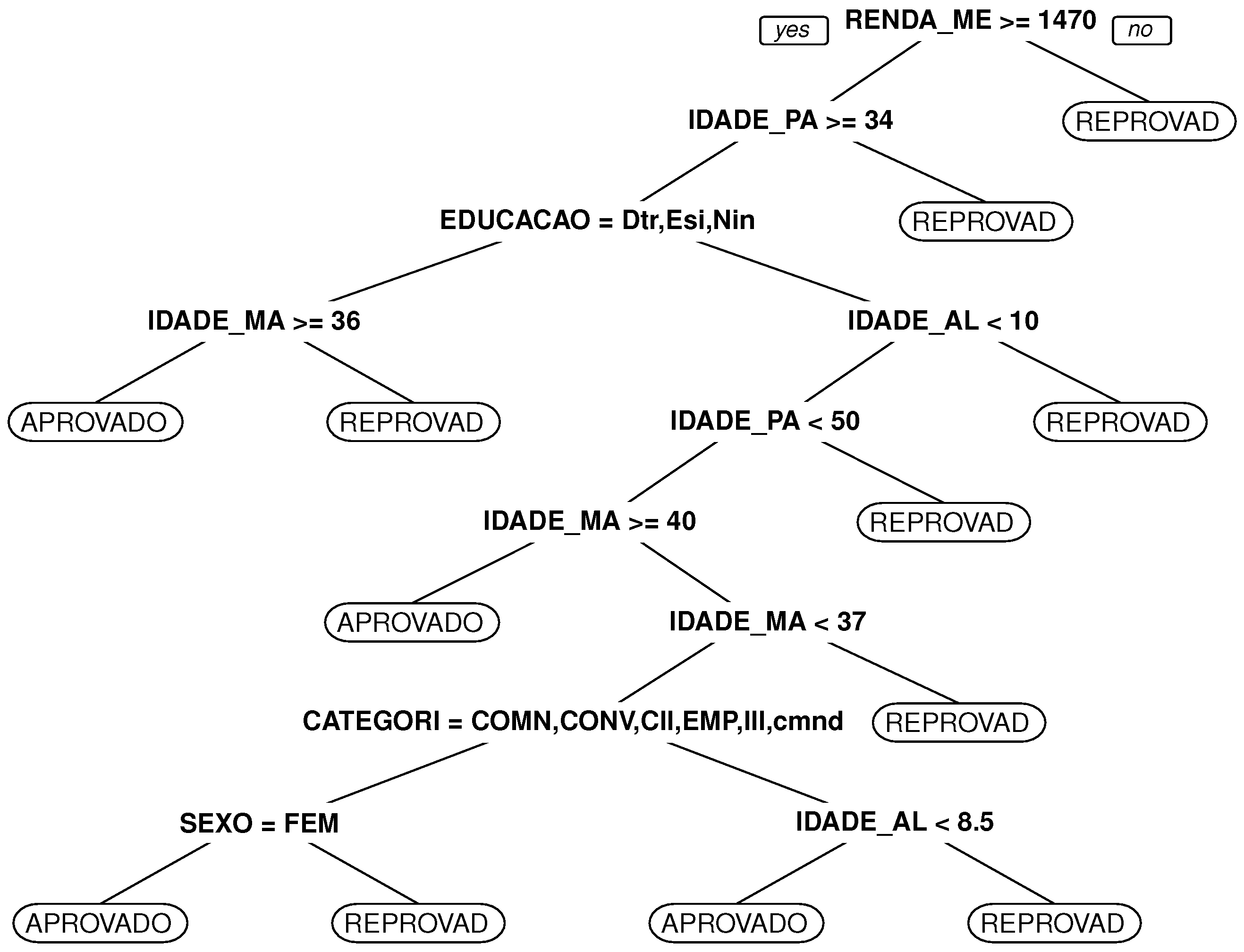
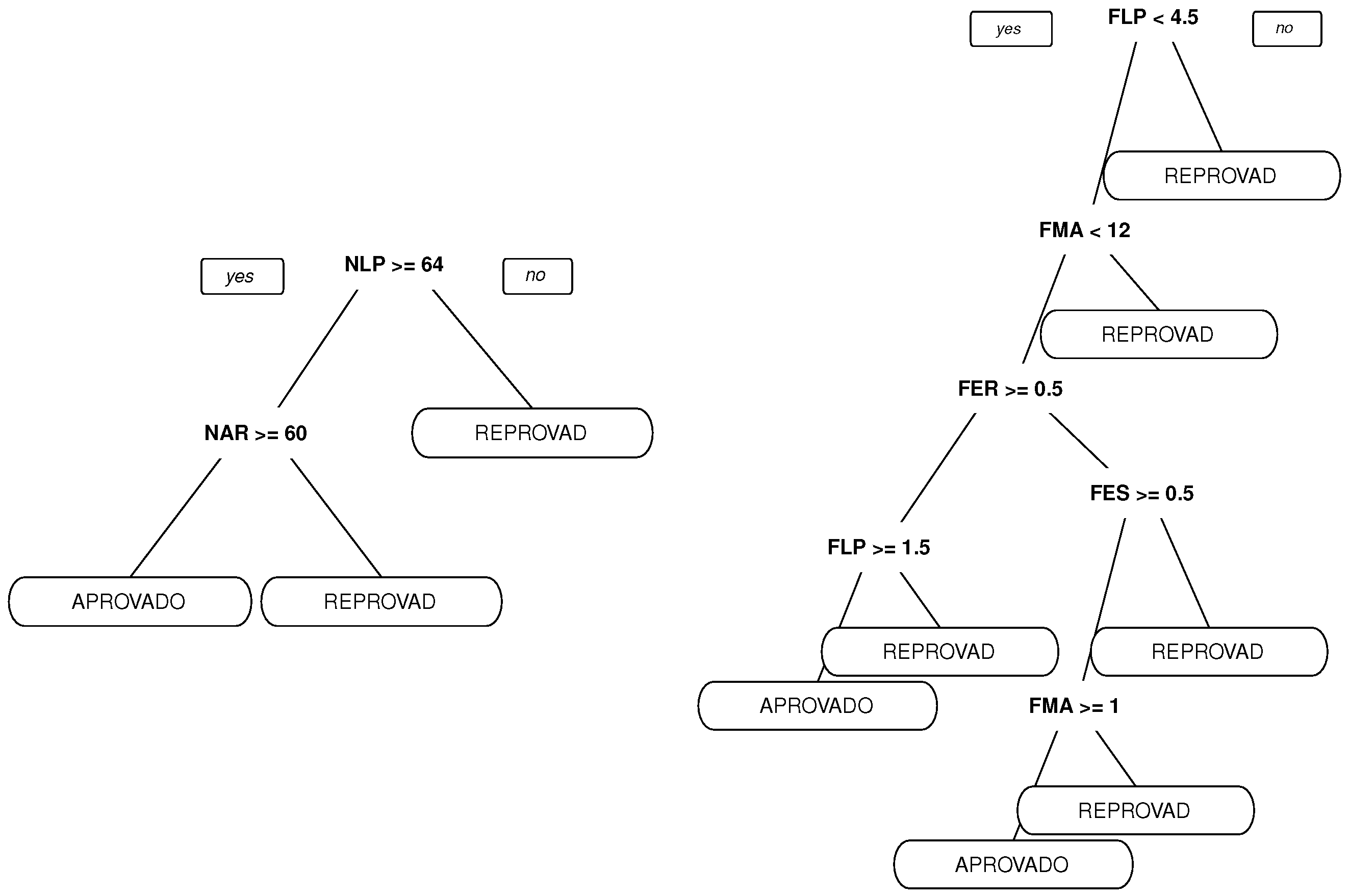
In this section, the algorithm used to choose a path, among several others, is presented. This algorithm is based on the ant colony concept. The algorithm tries to define the best path to follow based on past utilization results of all paths. In the proposed algorithm, a vertex describes a particular state of an agent (which can be a student, a group of students, an educator, etc.). To go from one state to another, the agent has to undergo a transition, defined by a path in the algorithm. A procedure (a student playing an educational game, for example) can move the agent between states. The agent movement can be modeled in a graph
where each vertex
is a possible state to where the agent can move and the edges
connecting the states are the possible paths to navigate from one vertex (a state) to another, as shown in
Figure 4.
In the beginning, an agent initial state must be defined. If this agent is a student, for example, its initial state can be defined by classification and clusterization tasks. The initial state is a vertex in the graph. The other vertices are different states the student can go to departing from the current state. There are vertices (states) that are not directly connected to the current vertices, and the student has to go to more than one change of state to get there. The recommendation tool will calculate the cost (for example, number of study hours, number of disciplines or related activities) associated with all possible paths. Based on the ant colony concept, the recommended next vertex (or state) will consider previous students’ chosen next state.
There is a cost associated with the movement from one state to another; then, paths have costs associated with them. This cost might be a function or many functions
, which represent how easy or difficult it is to follow that path. Moreover, there is a set of information that is used to decide about the next vertex. This information might be used to represent if the agent is predisposed to follow the path modeled. This predisposition or tendency can be modeled by a function
. Therefore, the total cost is defined as
. The two main hypotheses of this work are:
Hypothesis 1. The agent (or decision-maker) uses cost and predisposed information to decide which is the next path to choose. Predisposed information might be defined as a pheromone.
Hypothesis 2. The agent behavior (or decisions) might be predicted using the current state, paths, cost functions and pheromone functions.
Some assumptions were considered to improve the model quality:
Humans are social agents; thus, they exchange messages based on the pheromone (information)
When an agent decides and acts, a trace of the pheromone is created for each path used by this agent
Each agent tends to choose a path with the greater concentration of pheromone
The vertex A represents initial context, and vertex D represents final context (or goal)
The graph is considered a Markov chain
To find each agent’s real state, agents can initially be put on randomly chosen vertices. At each construction step, agent
k applies a probabilistic action choice rule, called the random proportional rule, to decide which vertex to visit next. In particular, the probability with which agent
k, currently at vertex
i, chooses to go to vertex
j is [
31]:
where
is a heuristic value that is available a priori,
a and
b are two parameters that determine the relative influence of the pheromone trail and the heuristic information and
is the feasible neighborhood of agent
k when being at vertex
i, that is the set of vertices that agent
k has not visited yet (the probability of choosing a vertex outside
is zero).
By this probabilistic rule, the probability of choosing a particular arc increases with the value of the associated pheromone trail and of the heuristic information value .
The role of the parameters
and
is the following. If
, the closest vertex is more likely to be selected. This corresponds to a classic stochastic greedy algorithm with multiple starting points since ants are initially randomly distributed over the cities. If
, only pheromone amplification is at work, that is only the pheromone is used, without any heuristic bias. This generally leads to rather poor results, and in particular, for values of
, it leads to the rapid emergence of a stagnation situation, a situation in which all the agents follow the same path and construct the same tour, which, in general, is strongly sub-optimal.
Figure 5 below shows an example of this tour.
After all the agents have constructed their tours, the pheromone trails are updated. This is done by first lowering the pheromone value on all arcs by a constant factor and then adding pheromone on the arcs the ants have crossed in their tours. Pheromone evaporation is implemented by:
where
is the pheromone evaporation rate. The parameter r is used to avoid unlimited accumulation of the pheromone trails, and it enables the algorithm to “forget” bad decisions previously made. In fact, if an arc is not chosen by the agents, its associated pheromone value decreases exponentially in the number of iterations. After evaporation, all agents deposit pheromone on the arcs they have crossed in their tour, which is calculated by:
where
is the amount of pheromone ant
k deposits on the arcs it has visited, which is defined as:
In this last equation
, the length of the tour
built by the
k-th agent is computed as the sum of the lengths of the arcs belonging to
. By means of Equation (
4), the better an agent’s tour is, the more the amount of pheromone the arcs belonging to that tour receive. In general, arcs that are used by many agents and which are part of short tours receive more pheromone and are, consequently, more likely to be chosen by ants in future iterations of the algorithm.
According to Dorigo [
31], there are some aspects that should be considered when building an ant colony optimization model:
Construction of the graph, to express the paths along the time that can be used;
Constraints, to limit the path options in the graph;
Pheromone trails, to define the strategy of pheromone deposit;
Heuristic information, the functions that should be optimized;
Solution construction, issues about software engineering;
Pheromone update, the strategy to eliminate unused paths;
Local search, the strategy to avoid premature optimization;
Particularities, some specific point to be considered;
Results, results in a simple means of expression;
Remarks, points to express much information;

 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}