1. Introduction
In robotic community, the topic of autonomous mobile robot navigation has been widely discussed for decades, and various navigation schemes based on different types of sensors have been proven to be effective and employed in practical applications [
1,
2,
3,
4,
5]. Among the numerous vision-based autonomous navigation solutions, visual homing has drawn extensive attention for its simple model and high navigation accuracy. Using visual homing approaches, the robot can be guided to the specified destination only by comparing its currently captured panoramic image with the pre-stored target image [
6,
7,
8,
9].
Visual homing is inspired by biological navigation, which can be considered as a kind of qualitative autonomous navigation technique [
10,
11]. In contrast to the most popular visual SLAM technology [
12,
13,
14,
15], visual homing does not require any localization or mapping. Instead, it only needs to continuously calculate the direction vector, known as the homing vector, pointing from the current location to the destination. In summary, the robot can achieve the homing task by solely repeating the following three steps: (1) relating the current panoramic image to the target panoramic image; (2) computing the homing vector; and (3) moving based on the calculated homing vector [
16,
17,
18].
Visual homing requires only one type of input called landmark. In the early stage, researchers often adopted distinctive objects (such as black or brightly colored cylinders) in the environment as artificial landmarks [
19,
20]. However, since the identification of such landmarks must be manually interfered, this would inevitably limit the application scope, and natural landmarks thus gradually became a better choice. Some homing approaches adopted pixels at fixed locations in the panoramic images as natural landmarks [
21,
22]. This solution proved to be feasible, but a problem was unsolved that the homing performance would drop sharply when illumination changed during the movement of the mobile robot. With the development of computer vision technology, image feature extraction algorithms were proposed, such as SIFT [
23] and speed-up robust features (SURF) [
24]. The SIFT and SURF features have two outstanding advantages. First, these features are highly distinctive and can be correctly matched with high probability. Second, these features can exhibit excellent invariance to affine distortion, addition of noise and change in illumination [
25]. Currently, numerous visual homing approaches use SIFT or SURF features as natural landmarks to complete navigation tasks in practical applications [
26,
27,
28].
Aiming at guiding the robot to the specific destination accurately, different types of visual homing algorithms have been proposed. Among them, warping and average landmark vector (ALV) are the two most representative homing approaches. Both warping and ALV have been verified to exhibit good homing performance and robustness. These two homing approaches are widely used in practical applications, and many advanced algorithms based on them have been presented.
The warping methods distort either of the panoramic images (usually the target image) based on the parameters describing the distance, direction and rotation of the mobile robot’s movement. Multiple parameter combinations produce different forms of the distorted images, and the warping methods will compare all the distorted images with the current image. The optimal parameters will be determined when the distorted image best fits the current image, and in what follows the homing vector can be generated [
21]. Based on the original warping method, many advanced warping algorithms have been proposed to further optimize the homing performance. Möller et al. proposed the 2D-warping and min-warping methods, and these two advanced algorithms could achieve the variation of the alignment angle estimation in the environment instead of the external compass in the original 1D-warping [
29]. Besides, a SIMD implementation was also adopted based on min-warping so that the tolerance and efficiency can be further enhanced [
30,
31]. Zhu et al. used SIFT features such as natural landmarks instead of fixed pixels in the image so that the robustness to the illumination can be improved [
27]. Recently, several actual experiments were performed to compare these advanced warping methods with other homing approaches in many aspects, such as illumination tolerance and computation speed [
32,
33,
34].
ALV is considered as one of the simplest homing approaches in concept, and it is often used as a benchmark in the field of visual homing. ALV is defined as an average bearing of all the extracted landmarks with respect to a certain location, and the homing vector can be calculated by the difference between the ALV at the current location and the ALV at the target location [
20,
26]. Thus far, ALV has also been enriched to further optimize the homing performance. Zhu et al. presented an optimal ALV model based on sparse landmarks [
35]. Yu et al. analyzed the effect of landmark vectors and proposed an improved ALV algorithm, called Distance-Estimated Landmark Vector (DELV) [
36]. Lee et al. adopted the omnidirectional depth information to further enrich DELV [
37]. All these advanced homing algorithms have been verified to be effective and feasible, and, under the guidance of these algorithms, mobile robot can move towards the target location with a better trajectory.
As a local navigation strategy, although visual homing exhibits high navigation accuracy in a small-scale environment, it is constrained by the landmark distribution. Most of the visual homing approaches should satisfy as much as possible the equal distance assumption, which describes an ideal landmark distribution state. Due to the lack of depth sensors for traditional visual homing approaches, distance information between key locations and landmarks is difficult to obtain, so the equal distance assumption provides constraint that the landmarks need to be uniformly located the same distance from the target location [
28,
29]. Although this assumption has been verified to be correct [
36], it is always violated in practical applications, and irregularly distributed landmarks will have a negative impact on the performance for visual homing.
The landmark distribution is one of the key factors affecting the homing performance. However, research on the optimization of landmark distribution is very limited. Zhu et al. presented two solutions: The first solution is to establish a task-dependent optimization procedure to distinguish the most relevant landmarks, including the spatial distribution, feature selection and updating [
38,
39]. The second solution is to optimize the landmark distribution by removing some of the landmarks and preserving only the landmarks that are uniformly distributed [
35]. In addition, since the DELV algorithm adopts the depth sensor, it is considered to be able to overcome the constraints of the equal distance assumption so that the possible effects can be reduced [
37]. The above three methods can effectively improve the homing accuracy of the robot, but these methods still have some limitations. The first two methods achieve distribution optimization at the expense of discarding landmarks; if the current location is far from the target location, the number of landmarks that can be used as input is too small, thus the probability of potential errors may be increased. Besides, although DELV can exhibit good homing performance, the use of depth sensors will inevitably increase computational complexity and experimental costs.
To avoid the above problems, this paper presents three landmark optimization strategies for mobile robot visual homing. We adopt SIFT features as natural landmarks, and the proposed strategies have two purposes. The first purpose is to eliminate mismatching landmarks (Strategy 1). The second purpose is to optimize the landmark distribution by the idea of weight assignment (Strategies 2 and 3). The proposed strategies evaluate the value of each landmark, and, for the landmarks that are judged to be of low quality, the strategies will assign them lower weights, weakening their contribution to the homing approaches. These strategies do not require any excessive landmark elimination or external sensors, and the effect of the optimal landmark distribution can be achieved by setting a reasonable weight for each landmark. In this paper, we combine our proposed strategies with the ALV model to test their effectiveness.
The paper is summarized as the following sections: In
Section 2, we introduce the ALV algorithm in detail. We then present the three landmark optimization strategies in
Section 3. In
Section 4, we perform a series of experiments on both image databases and a real mobile robot along with the related analysis. In
Section 5, we discuss the homing performance of the algorithms. In
Section 6, we draw conclusions and point out the future work.
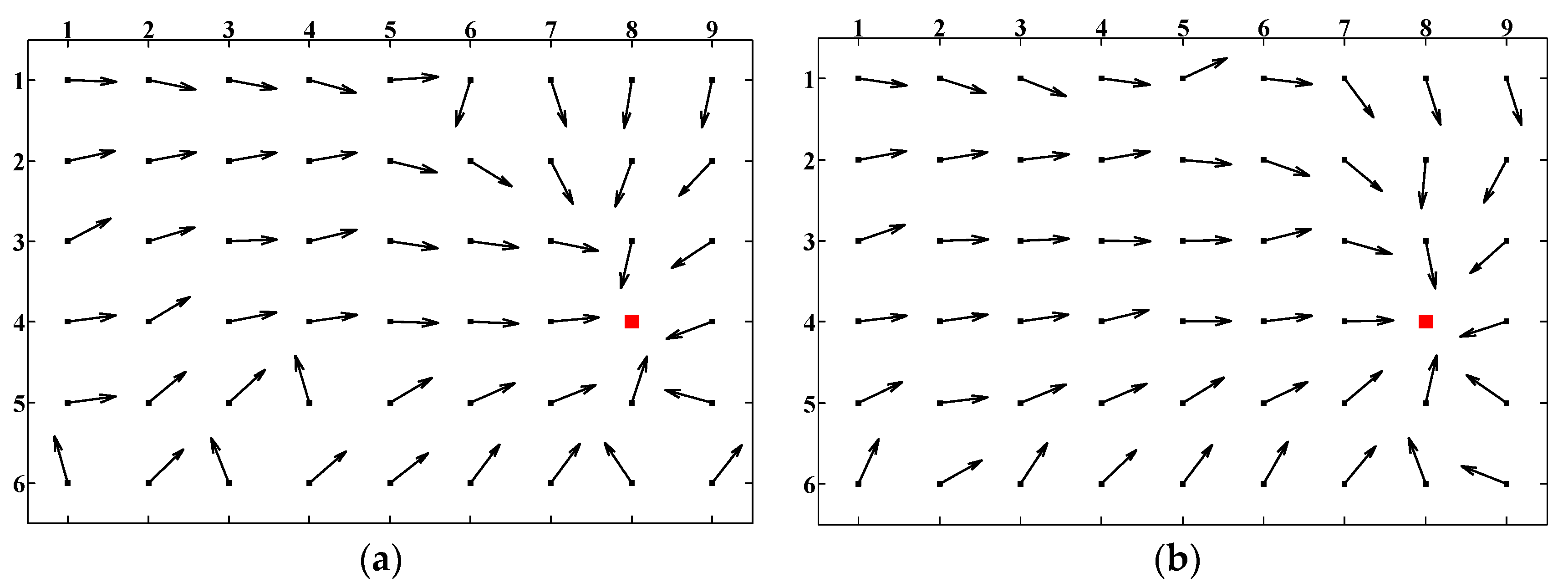
2. Average Landmark Vector
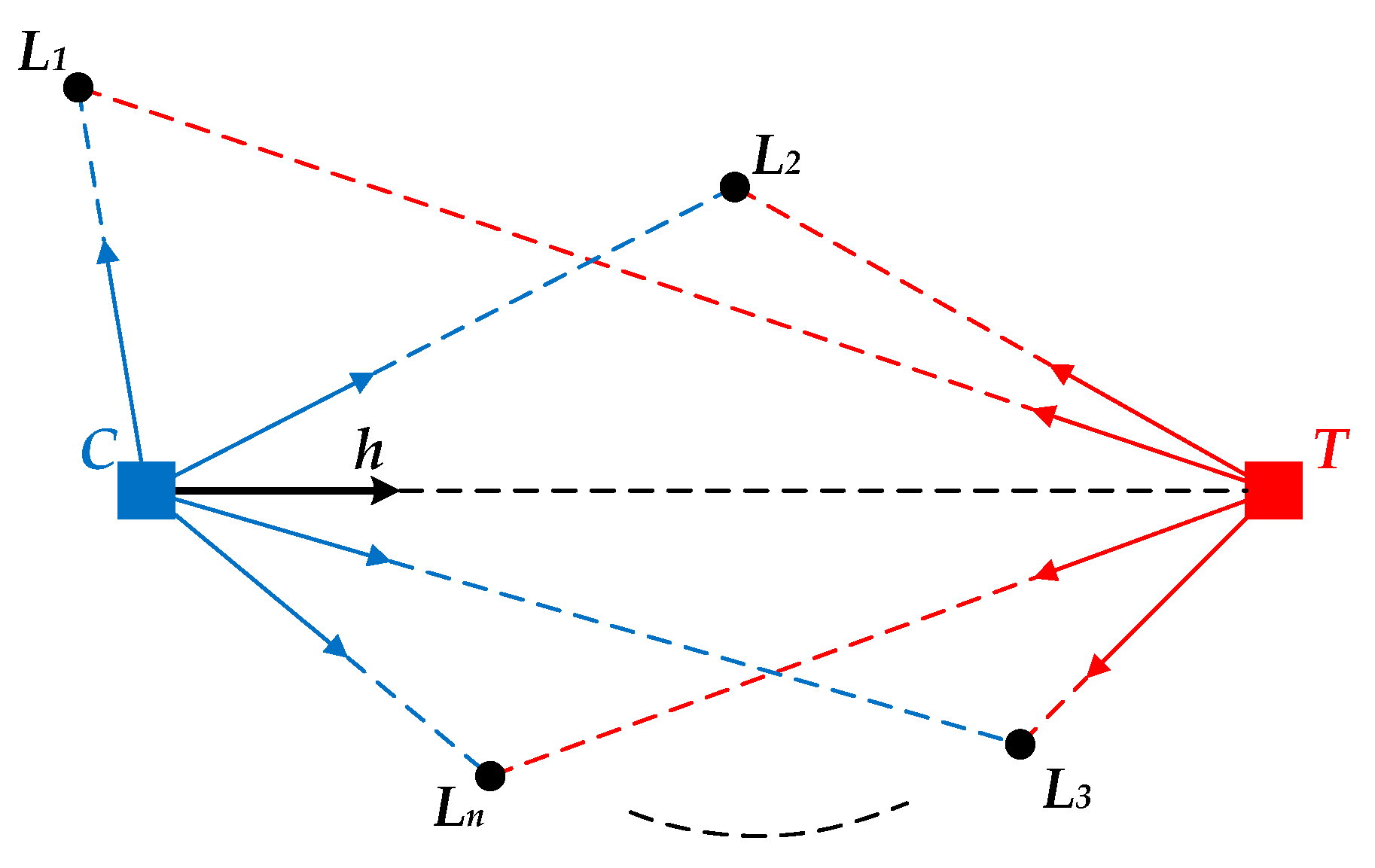
The ALV model is described in
Figure 1.
C is the current location of the robot.
T is the target location.
Li is the
ith landmark, where
i = 1, 2, …,
n.
h is the desired homing vector pointing from
C towards
T.
For the current image captured at
C, according to the imaging principle of panoramic vision, it can be indicated that the projection point of
C will be in the center of the panoramic image. We define
C as the origin and create the image coordinate system. Assuming that the image coordinate of
Li is
, the corresponding landmark vector of
Li can thus be calculated by:
where
is the image coordinate of
C. For all the landmarks observed at
C, the average landmark vector can be computed as follows:
Similarly, for the target image captured at
T, the landmark vector of
Li can be calculated by:
where
is the coordinate of
Li in the target image, and
is the coordinate of
T. For all the landmarks observed at
T, the average vector can be computed as follows:
Finally, the unit homing vector can be obtained by the subtraction of the average landmark vector at
C and
T:
ALV is a conceptually simple visual homing approach with an easy-to-understand model, and the desired homing vector can be generated only by vector calculation. However, ALV is greatly affected by the landmark distribution. Since all the landmark vectors are set to unit vectors in the original ALV algorithm, the calculated homing vector will be close to the ideal homing vector only when the distance from the target location to each landmark is approximately equal.
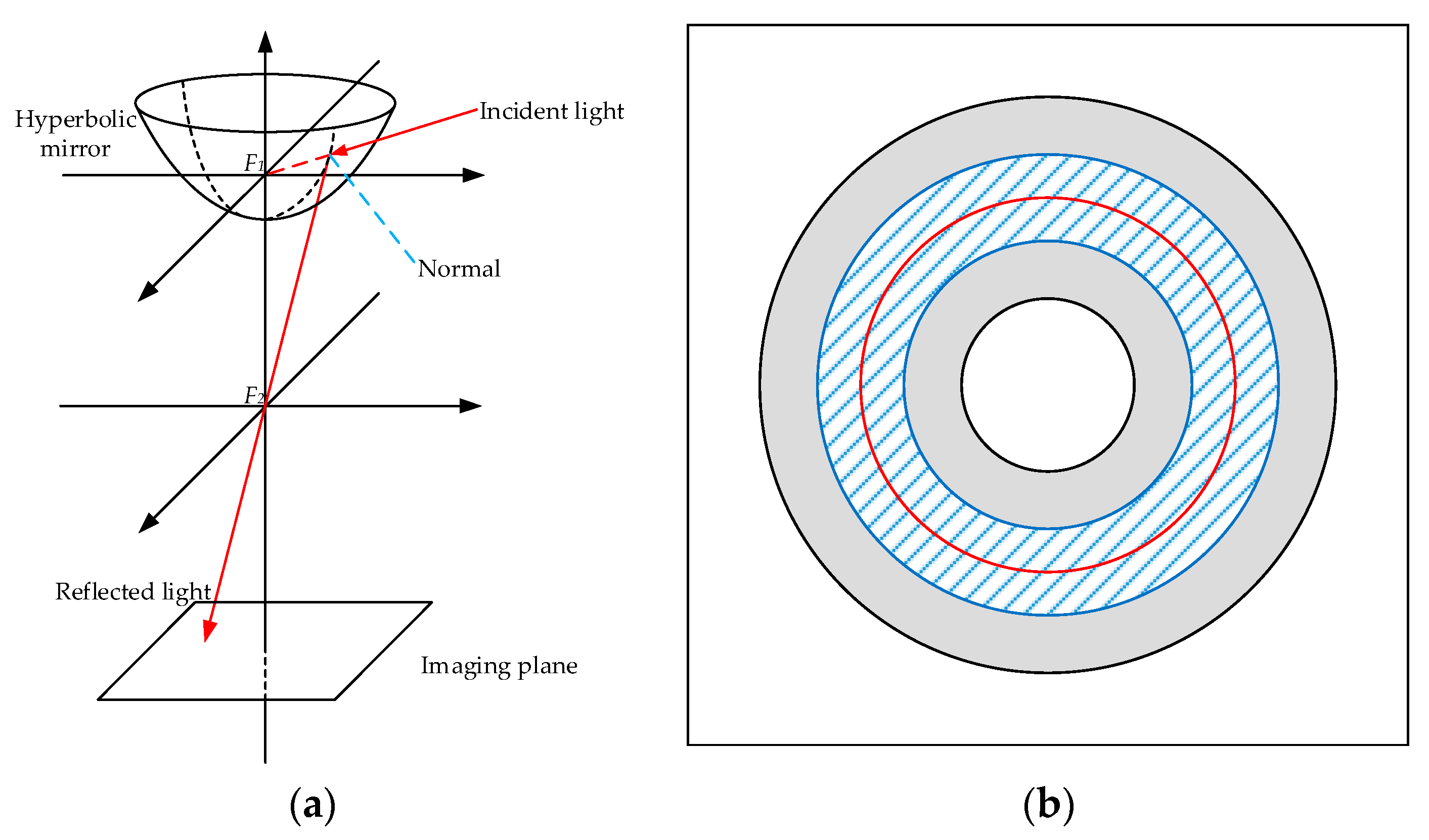
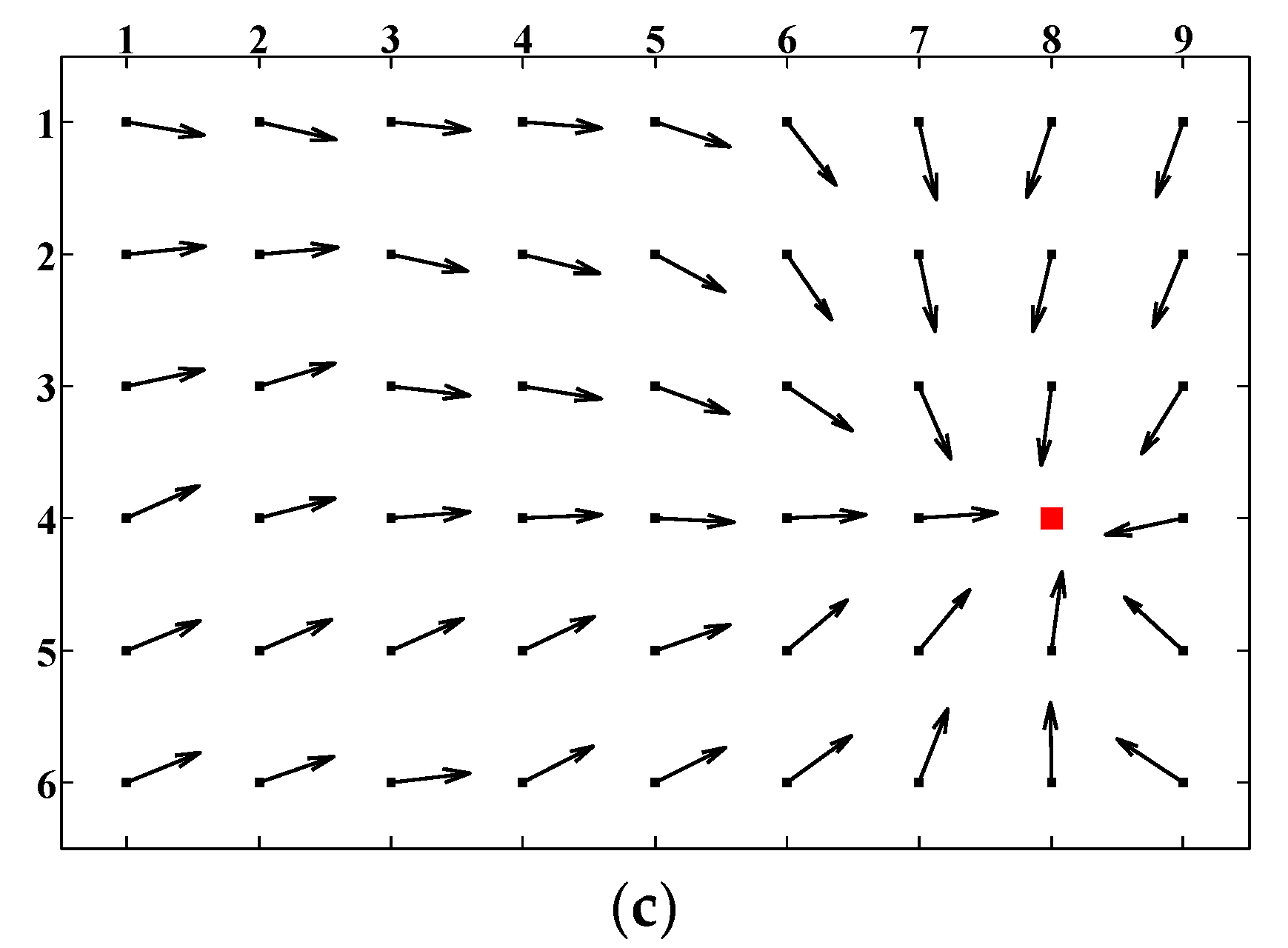
To solve the landmark distribution problem of ALV, an improved algorithm was proposed based on sparse landmarks, abbreviated as SL-ALV in this paper [
35]. We will introduce SL-ALV in detail because we use it as a comparative method with our proposed strategies. SL-ALV optimizes the landmark distribution inspired by the imaging principle of panoramic vision system, which is shown in
Figure 2. The panoramic vision system contains a hyperbolic mirror, which reflects all the incident lights onto the imaging plane.
F1 and
F2 are two foci of the system. According to the imaging principle, all extensions of the incident lights will converge on
F1, and all reflected lights will pass through
F2. A crucial phenomenon can be stated that, for landmarks with the same height as
F1 in the panoramic vision system, since the angles between all the corresponding incident lights and the hyperbolic mirror are constant, the angles between the reflected lights and the imaging plane will also remain the same. Hence, the projection pixels of these landmarks must be on a fixed circle of the image, called horizon circle. Wherever the system moves, these projection pixels will not leave the horizon circle.
Inspired by the above phenomenon, SL-ALV considers the projection pixels (i.e., landmarks) located near the horizon circle to be relatively more valuable. On the one hand, the horizon circle can provide a reference for the optimal landmark distribution, and the projection pixels near the horizon circle are substantially the same image distance from the center of the image. On the other hand, when the panoramic vision system moves, the projection pixels near the horizon circle will not have a large shift in image position so that the stability of the landmark distribution can be better ensured. In the SL-ALV algorithm, the horizon circle is properly expanded to form a ring area (the width of the ring area is usually set to half the width of the valid area, shown as
Figure 2b), and all the landmarks located outside the ring area will be discarded. Therefore, the remaining landmarks can better satisfy the equal distance assumption, and SL-ALV can thus improve the homing accuracy compared to the original ALV algorithm. However, SL-ALV inevitably reduces the total number of landmarks, which may lead to a potential problem that the small sample sizes will cause unpredictable errors. This problem is particularly evident when the current location is far from the target location, because the similarity of the two panoramic images is low in this case, and this will result in a very limited number of the extracted landmarks.
3. Landmark Optimization Strategies
In this section, we introduce the three landmark optimization strategies in detail, including mismatching landmark elimination, landmark contribution evaluation and multi-level matching. We use SIFT features as natural landmarks, and the optimized landmarks have higher accuracy and more reasonable distribution.
3.1. Strategy 1: Mismatching Landmark Elimination
Strategy 1 is presented to improve the overall accuracy of the extracted landmarks. Based on the SIFT scale principle and panoramic image principle, Strategy 1 can effectively detect and eliminate the potential mismatching landmarks to further optimize the performance of the visual homing approaches.
3.1.1. SIFT Scale Principle
As mentioned in [
28], a noteworthy conclusion is drawn that the SIFT scale value is negatively related to the spatial distance from the landmark to the viewer. That is to say, if the viewer is closer to a certain landmark, the SIFT feature, which refers to this landmark, will have a larger scale value. This is because scale indicates the degree of Gaussian blurring required to reveal the distinctive characteristic of the feature. When the landmark is approached, its corresponding SIFT feature need to be detected with a higher degree of Gaussian blurring. Therefore, for the same SIFT feature matching pair, we can qualitatively estimate the distance from the landmark to the two capture positions by comparing the scale values of the two SIFT features.
We use Lowe’s SIFT implementation (available from:
http://www.cs.ubc.ca/~lowe/keypoints/) and the
ith SIFT feature can be described as follows:
where
and
are the image coordinates of
;
is the orientation;
is the scale; and
is the descriptor.
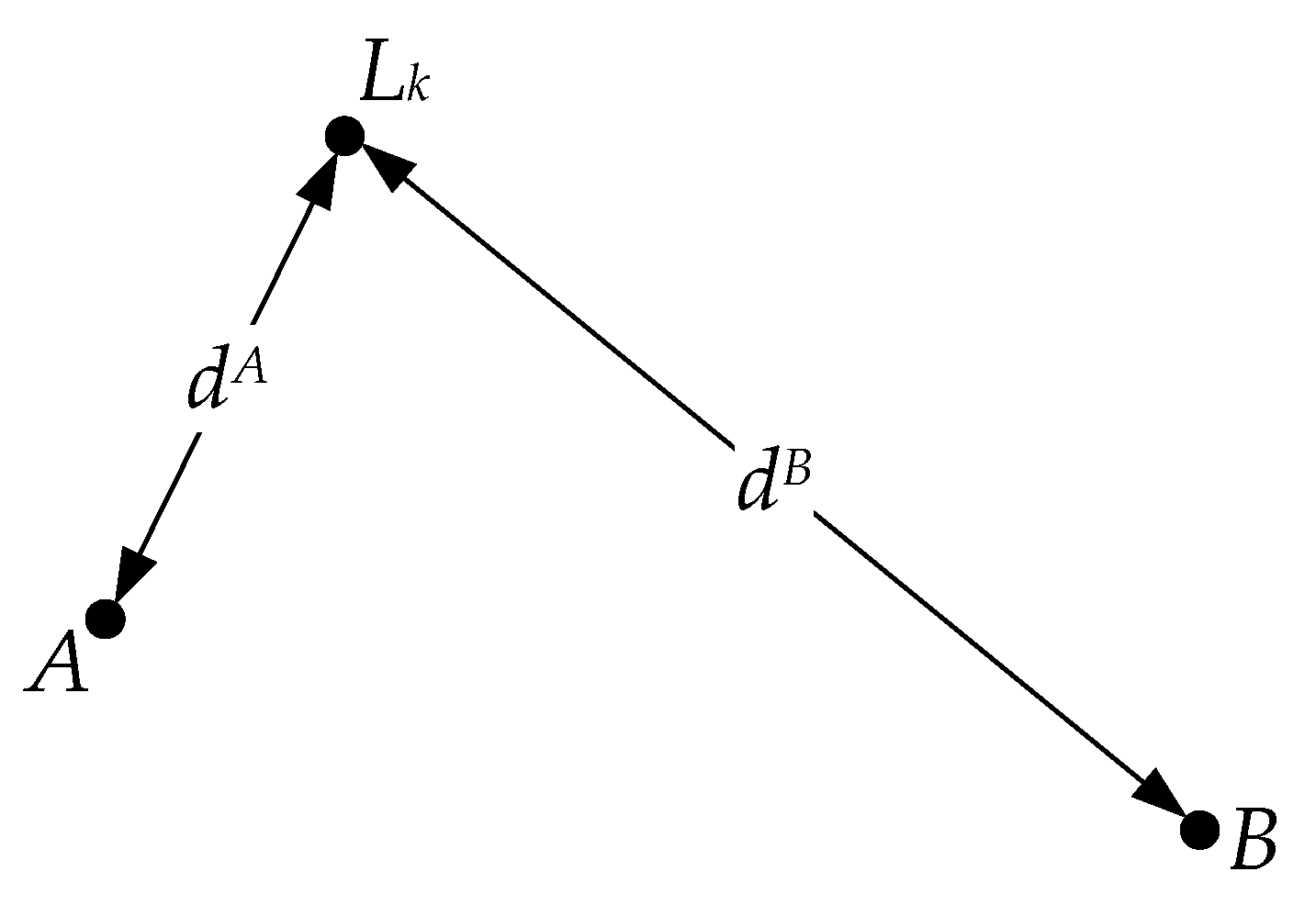
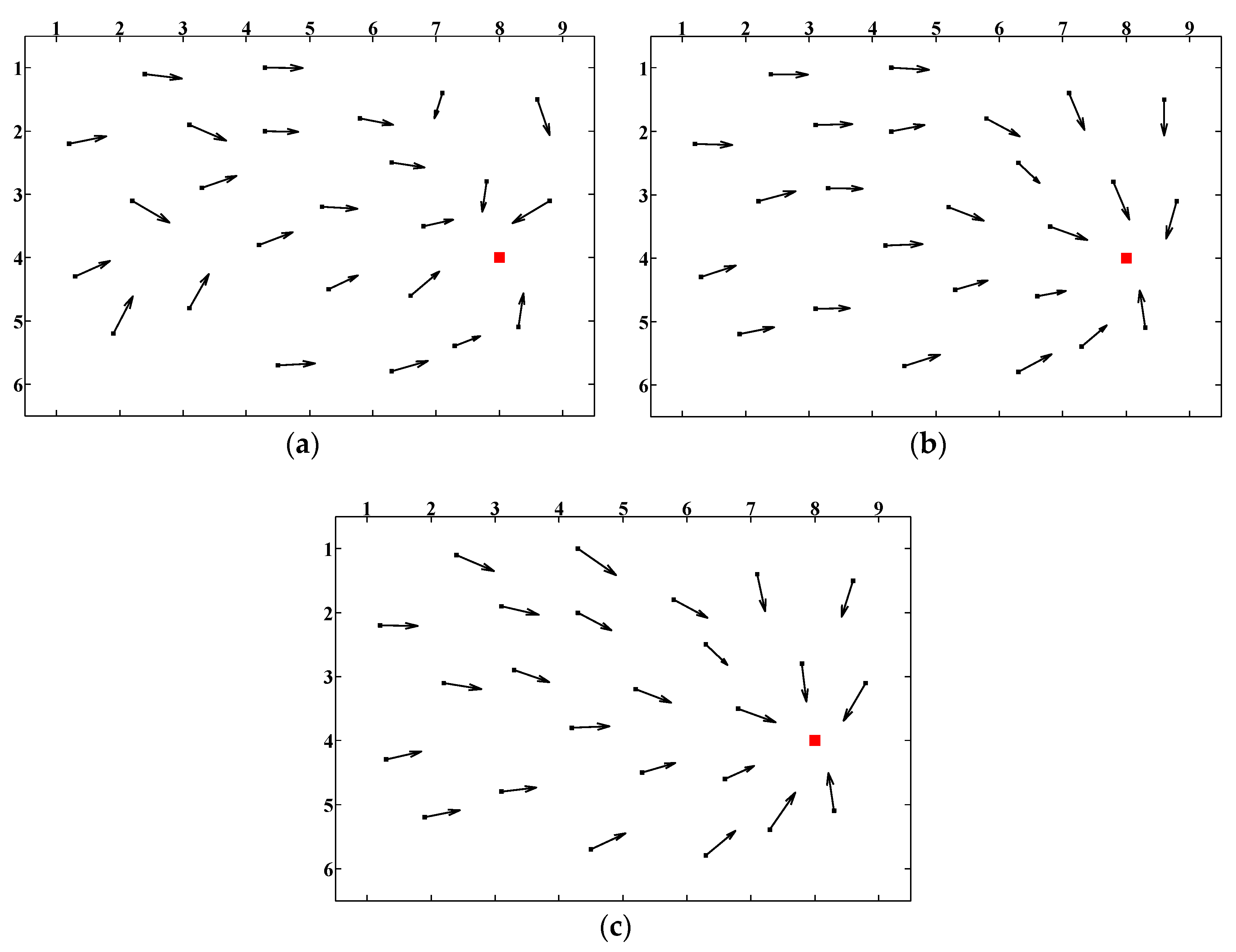
Figure 3 shows the key locations in the simulated scene. Assuming that the viewer captures the panoramic image
IA and
IB at positions
A and
B, respectively, when the two images are matched, the
kth SIFT feature matching pair can be described as follows:
where
fi is the
ith SIFT features in
IA, and
fj is the
jth SIFT feature in
IB.
We define
as the difference between the scale values of
fi and
fj:
Therefore,
dA and
dB can be qualitatively compared based on
:
3.1.2. Panoramic Imaging Principle
Generally, almost all visual homing approaches select panoramic images as input because a panoramic vision system can capture the entire 360-degree information in azimuthal direction and close to 180-degree information in unilateral vertical direction [
40]. Compared to other types of images, panoramic images always contain more environmental information in space.
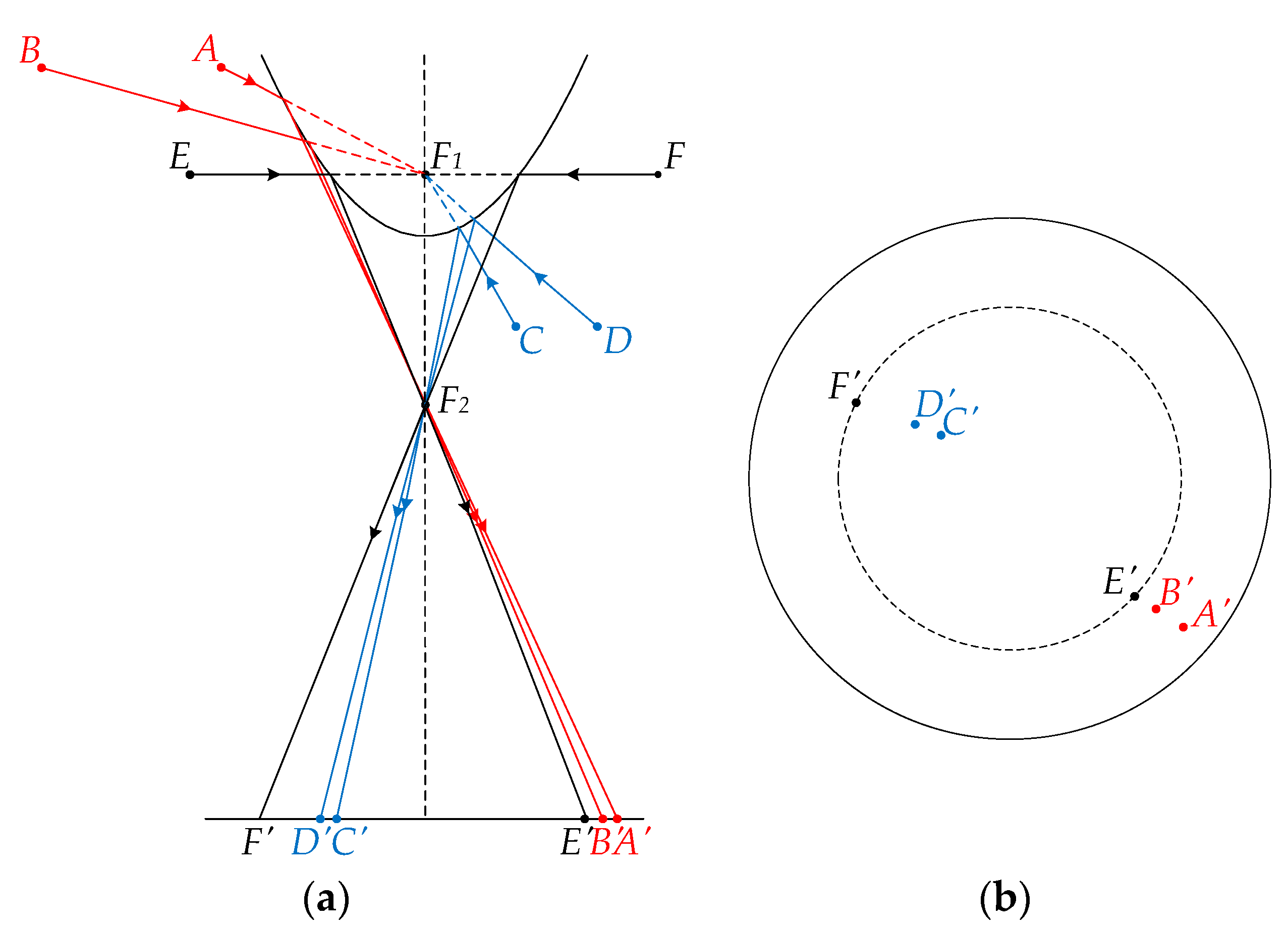
Figure 4 shows the schematic diagram of panoramic imaging principle, which can be summarized as follows:
- (1)
If the landmarks with the same vertical height are located above F1, their projection points will always lie outside the horizon circle, shown as (A, A’) and (B, B’). The distance between the projection point and the image center will decrease as the panoramic vision system moves away from the landmark.
- (2)
If the landmarks with the same vertical height are located below F1, their projection points will always lie inside the horizon circle, shown as (C, C’) and (D, D’). The distance between the projection point and the image center will decrease as the panoramic vision system moves towards the landmark.
- (3)
If the landmarks are located the same height as F1, their projection points will always be on the horizon circle, shown as (E, E’) and (F, F’)
In conclusion, based on the panoramic imaging principle, we can take advantage of the pixel positions in the panoramic images to qualitatively determine the distance relation from the system to the two capture positions. Assuming that the actual distances from the system to the six landmarks mentioned in
Figure 4 are
dA,
dB,
dC,
dD,
dE and
dF, the corresponding pixel distances from the image center to the projection points are
dA’,
dB’,
dC’,
dD’,
dE’ and
dF’. The panoramic principle can thus be formulated as follows:
3.1.3. Mismatching Landmark Elimination
Inspired by the above analysis, two principles can be provided to obtain the relative distance relation between the selected landmark and the capture positions, including SIFT scale principle and panoramic imaging principle. Therefore, for each SIFT feature matching pair, if the conclusions drawn by the above two principles are conflicting, it can be inferred that at least one conclusion is mistaken. In this case, Strategy 1 considers that the currently verified SIFT feature matching pair is not reliable, which needs to be discarded. The pseudo code of Strategy 1 is shown in Algorithm 1.
| Algorithm 1. Pseudo code of Strategy 1. |
| 1: Capture the panoramic images at two different positions. |
2: Execute the SIFT detection and matching algorithm
3: for (each SIFT feature matching pair) do
4: Determine the conclusion from SIFT scale principle based on Equation (9) |
5: Determine the conclusion form panoramic imaging principle based on Equation (10)
6: Verify whether the above two conclusions are conflicting
7: if TRUE then
8: Discard the currently verified SIFT feature matching pair
9: else
10: Reserve the currently verified SIFT feature matching pair
11: end if
12: end for |
Strategy 1 is theoretically correct and feasible, but the two images are inevitably affected by some uncertainties in practice applications, such as image resolution, ground flatness, human error, etc. If the scale difference of the two SIFT features in the same matching pair is too approximated, it will be unreliable by using this strategy to determine whether such type of matches is mismatched. Hence, a scale difference threshold
can be set, and Strategy 1 will only verify the SIFT matches with . Based on our experimental results, the optimal performance can be obtained when we set . However, this value is not constant; can be modified appropriately based on the actual situation to exhibit the optimal performance of Strategy 1.
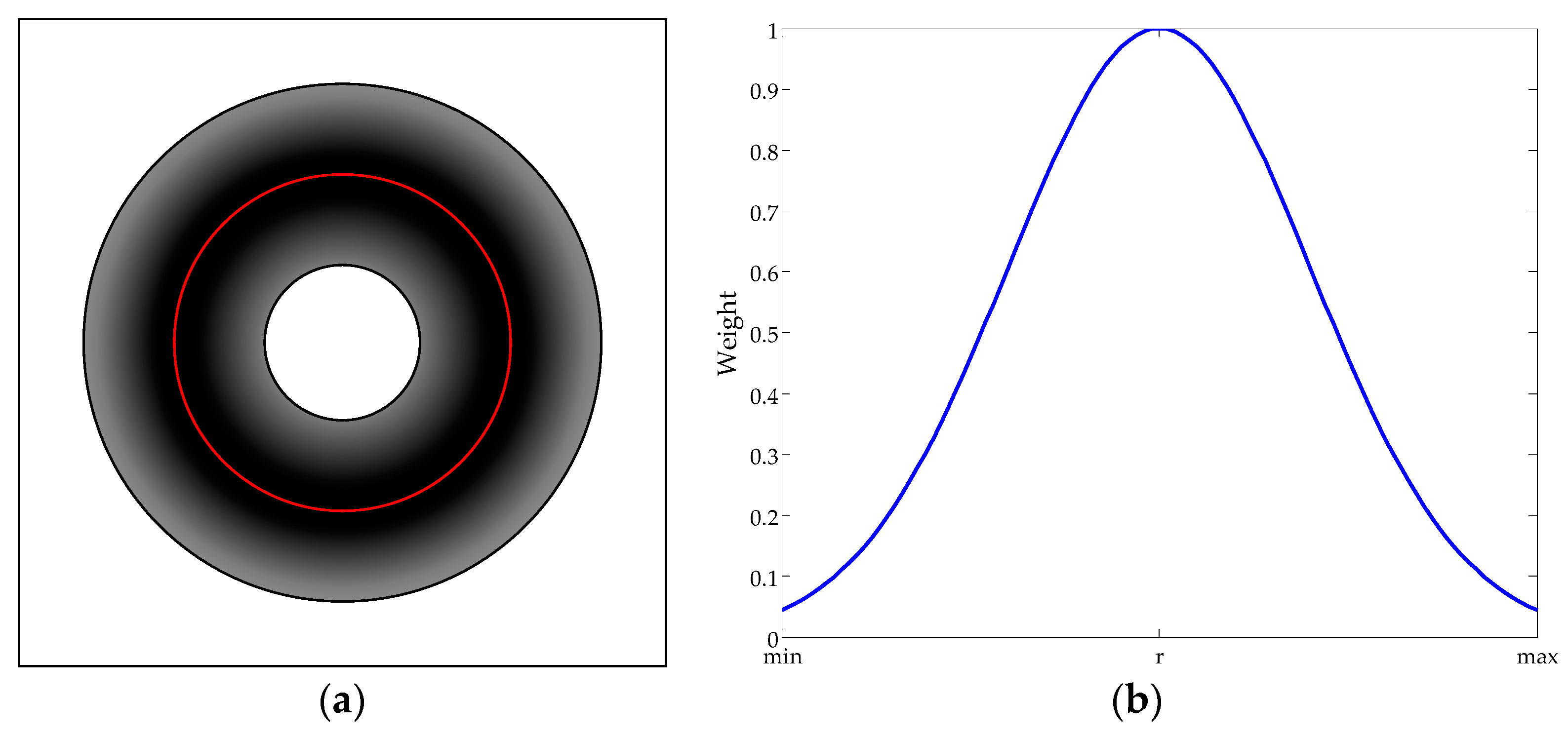
3.2. Strategy 2: Landmark Contribution Evaluation
Strategy 2 is applied to optimize the landmark distribution for visual homing. Compared to the traditional optimization algorithm, Strategy 2 does not directly discard the landmarks, but evaluates their contribution to the final result. For the landmarks with low contribution, Strategy 2 will accordingly reduce their weights, thereby optimizing the actual landmark distribution while preserving the existing landmarks.
Strategy 2 adopts the similar idea to SL-ALV. Based on the imaging principle of the panoramic images introduced in
Section 2, it can be concluded that the landmarks detected near the horizon circle are more accurate and valuable than those far from the horizon circle. Therefore, Strategy 2 is designed to assign a specific weight to each landmark based on its projected position in the panoramic image. We employ Gaussian function to evaluate the contribution of the landmarks, and the weight of the
ith landmark
wi can be calculated as follows:
where
is the standard deviation;
di is the image distance between the
ith landmark and the image center; and
r is the radius of the horizon circle. In this paper, we set
according to our own experimental conditions. Similar to the setting of
in Strategy 1, the value of
is also optional, and researchers can modify this value based on the actual situation to exhibit the optimal performance of Strategy 2.
Figure 5 shows the model of Strategy 2. Landmarks in the darker color area are assigned higher weights, and this type of landmarks will play a more important role in the subsequent homing calculations.
Strategy 2 effectively evaluates the reliability and stability of the landmarks without discarding landmarks, thus solving the potential problems that may arise due to the excessive landmark elimination. Based on Strategy 2, high-quality landmarks will play a key role in the homing approaches, while the effect of low-quality landmarks will be reduced.
3.3. Strategy 3: Multi-Level Matching
Strategy 3 is presented according to the key point matching criterion in the SIFT algorithm. By setting multi-level distance ratio thresholds, SIFT features can be extracted in stages, and the features are assigned corresponding weights in different intervals. Finally, the contribution of the features determined to be less accurate is weakened.
3.3.1. Nearest-Neighbor Distance Ratio
Nearest-neighbor distance ratio (NNDR) is a type of key point matching metric for SIFT algorithm. Since the SIFT matches determined by NNDR have extremely high matching accuracy, NNDR has become the most commonly used key point matching criterion in the fields of object recognition and image registration.
When a SIFT feature is detected, the corresponding descriptors are obtained based on the local image gradients measured at the selected scale in the region around the feature. Each descriptor contains 128-dimensional feature vectors, which describe significant levels of local shape distortion and change in illumination [
23]. NNDR is applied to find the best candidate match between two images: If the nearest neighbor is defined as the feature with minimum Euclidean distance for the descriptor vector, a possible match can be declared when the distance ratio of the nearest neighbor to the second-nearest neighbor is less than a certain threshold. According to Lowe et al. [
23], when the distance ratio threshold is set to 0.8, most of the false matches can be eliminated and only a small number of correct matches are discarded at the same time. As the threshold decreases, the total number of matches that can be obtained will decrease, but the proportion of correct matches will increase.
In this section, we propose an extended NNDR matching criterion, called multi-level matching. The proposed criterion can be specifically used in the field of visual homing. By setting multi-level distance ratio thresholds, the matches declared in different intervals will be given corresponding weights, thus further optimizing the accuracy of the landmarks.
3.3.2. Multi-Level Matching
Strategy 3 selects five distance ratio thresholds to declare matches in stages. Since the number of matches that can be obtained is limited when the threshold is less than 0.4, the candidate thresholds we select are 0.4, 0.5, 0.6, 0.7 and 0.8 in order. The reason we set the thresholds in this way is mainly to provide an easy-to-operate scheme. To avoid excessive computation complexity while ensuring optimization effects, we consider that dividing the intervals evenly is a straightforward and effective solution.
The core idea of multi-level matching can be described as follows: When the first threshold 0.4 is set, the obtained matches are considered to be almost error-free, so the landmarks represented by these matches are assigned a weight of 1. When the second threshold 0.5 is set, new matches can be declared. Since these new matches are obtained with the threshold increases, the landmarks represented by these new matches are assigned a weight slightly less than 1. Repeated steps are performed until the maximum threshold 0.8 is set, and then the weighted SIFT matches can be generated. The parameter settings we select for multi-level matching are shown in
Table 1, where τ represents the weight for multi-level matching.
Similar to Strategy 2, multi-level matching is also a strategy for weight evaluation, which is appropriate and effective for visual homing. Under the premise that the total number of landmarks is limited, multi-level matching further highlights the value of the high-quality landmarks.
Based on Strategies 2 and 3, the optimized landmarks will carry two types of weight information, namely
w and
τ. Therefore, for the
ith landmark
vi, the landmark vector it forms is no longer the traditional unit vector, the modulus of the vector becomes the product of
wi and
τi:
After the moduli of all landmark vectors are calculated, the optimal ALV computed in the proposed method becomes in fact a weighted average of landmark vectors, and the final homing vector can be similarly generated based on Equation (5).
3.4. Overview of the Proposed Strategies
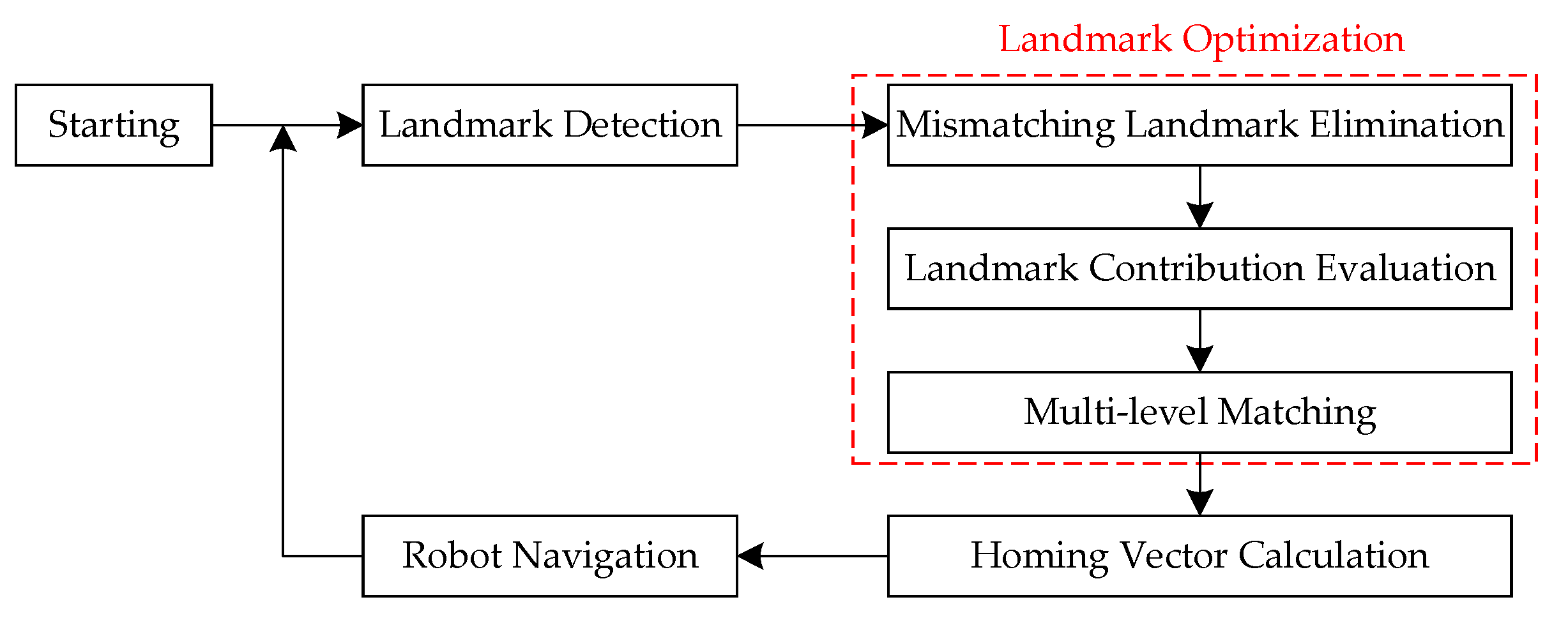
Figure 6 shows the complete procedure of the mobile robot’s visual homing process based on the proposed strategies. The details are characterized as follows:
Landmark Detection: SIFT features are detected and matched from the currently captured image and pre-stored target image, all SIFT matches are considered as the original landmarks.
Landmark Optimization: Based on the proposed three strategies, the original landmarks are optimized in terms of precision and distribution.
Homing Vector Calculation: A certain visual homing approach is adopted to calculate the homing vector based on the optimized landmarks. It should be noted that, although we only use ALV in this paper, the proposed strategies can also apply to other landmark-based visual homing approaches.
Robot Navigation: The mobile robot is guided by the calculated homing vector to move a preset step, and then re-performs the process of Landmark Detection until the target location is reached.
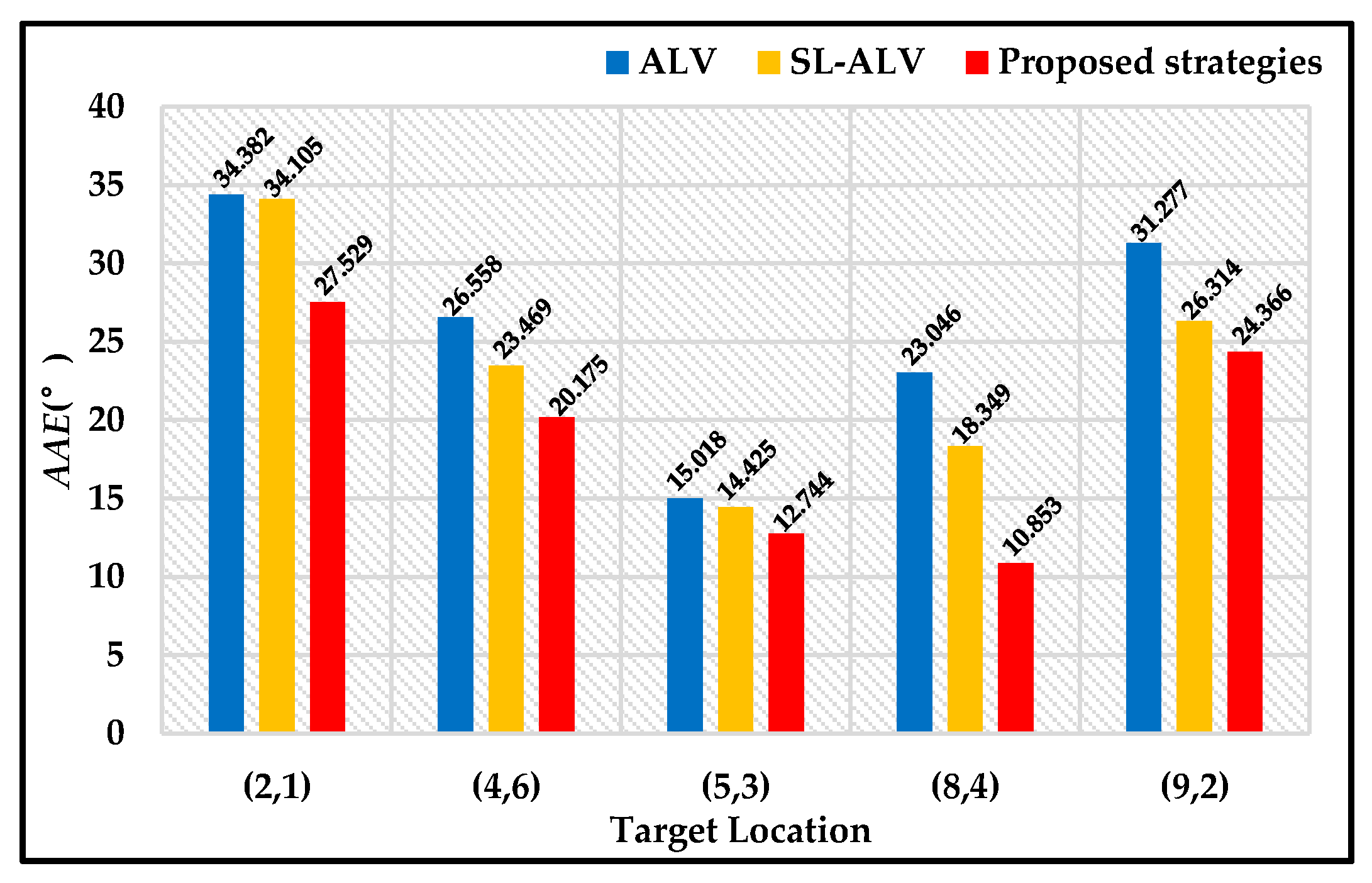
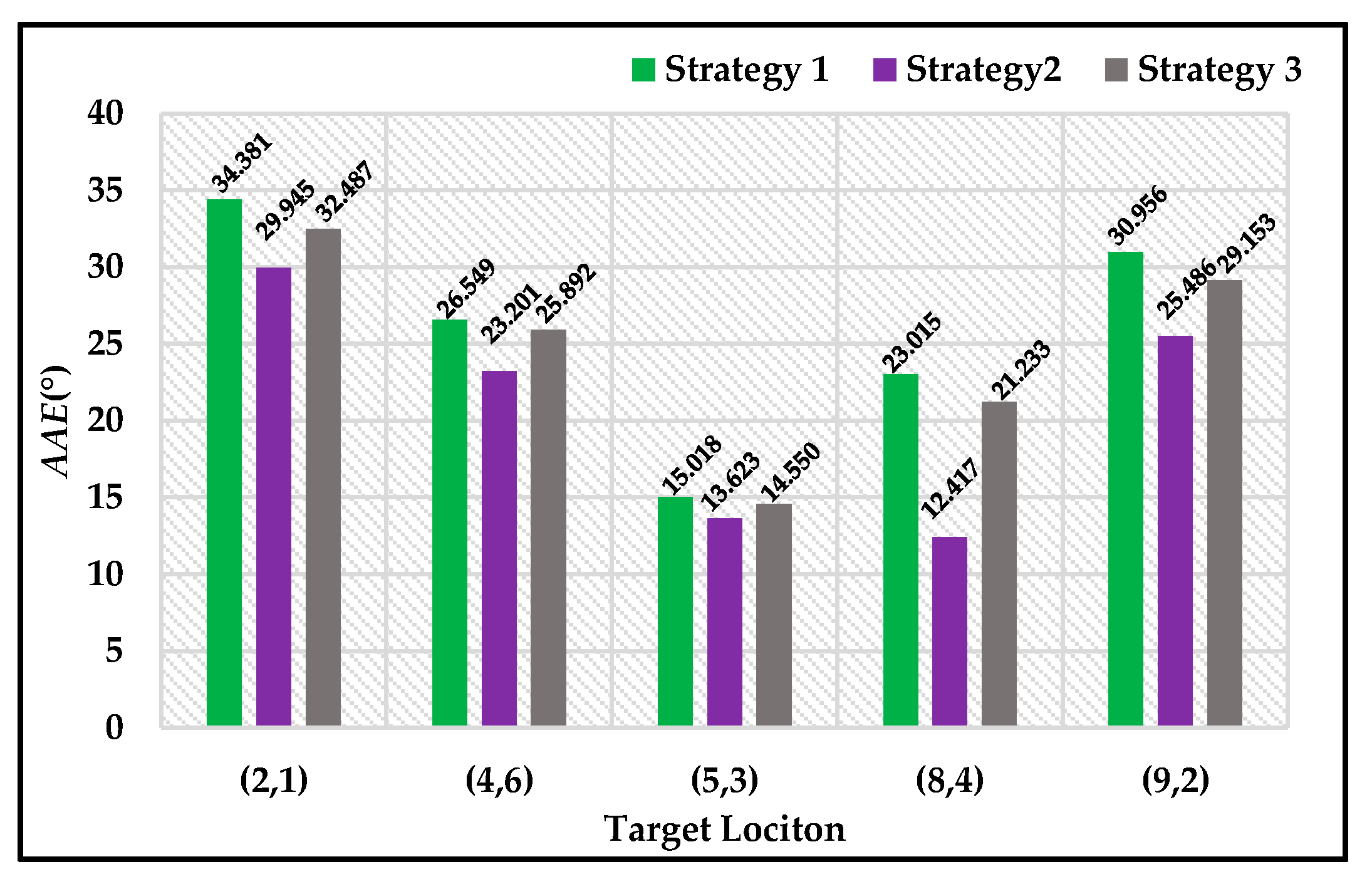
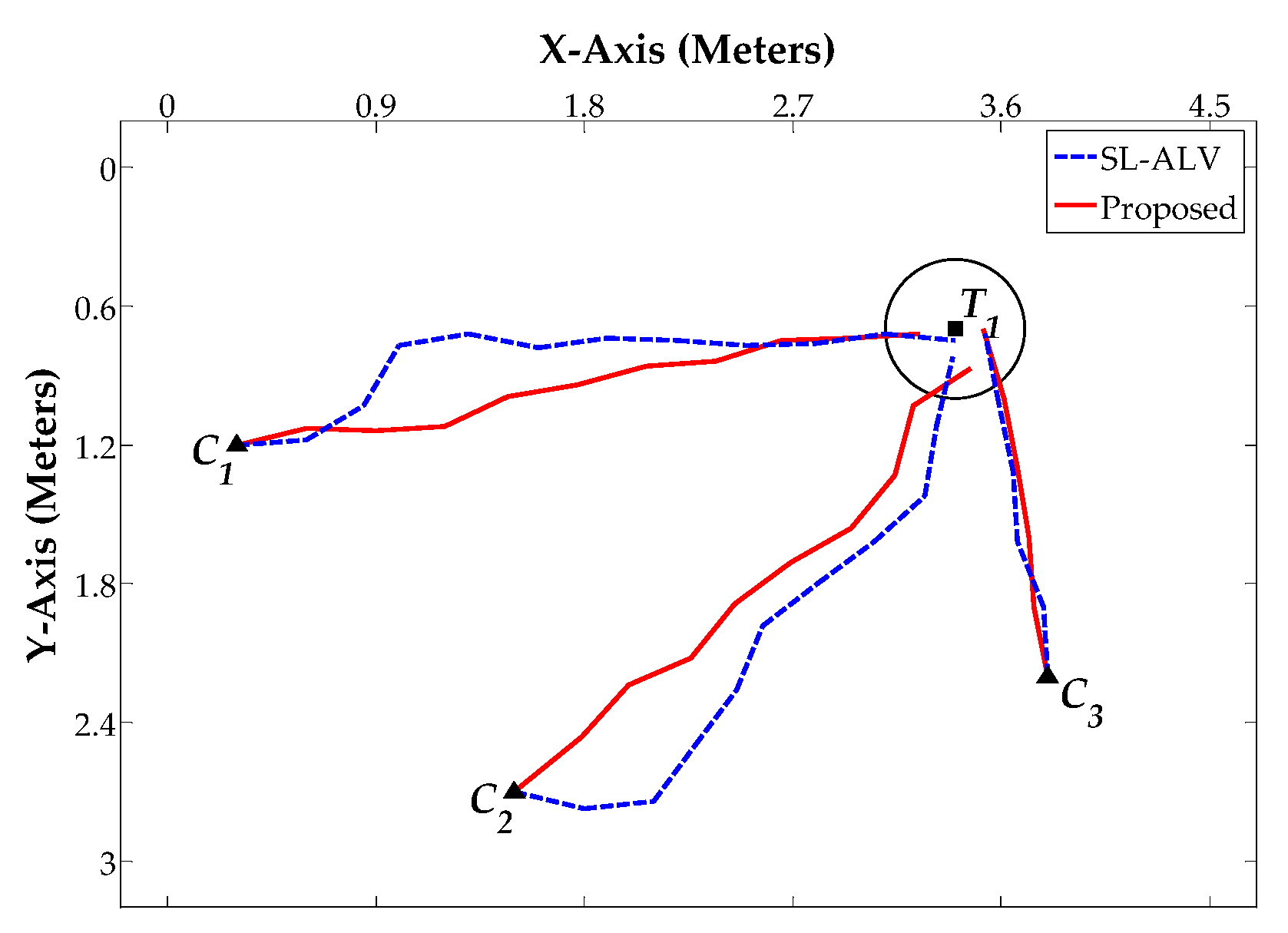
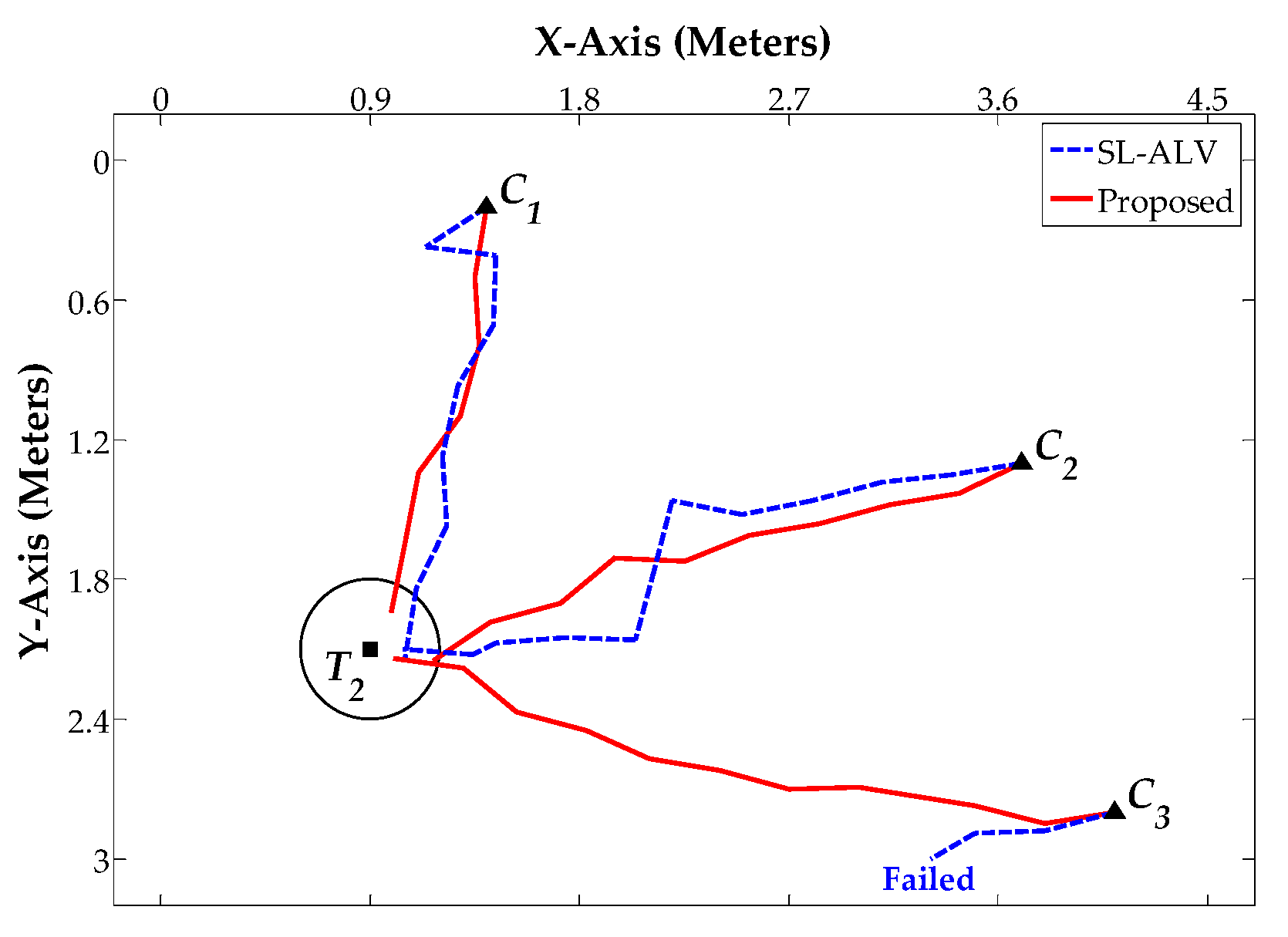
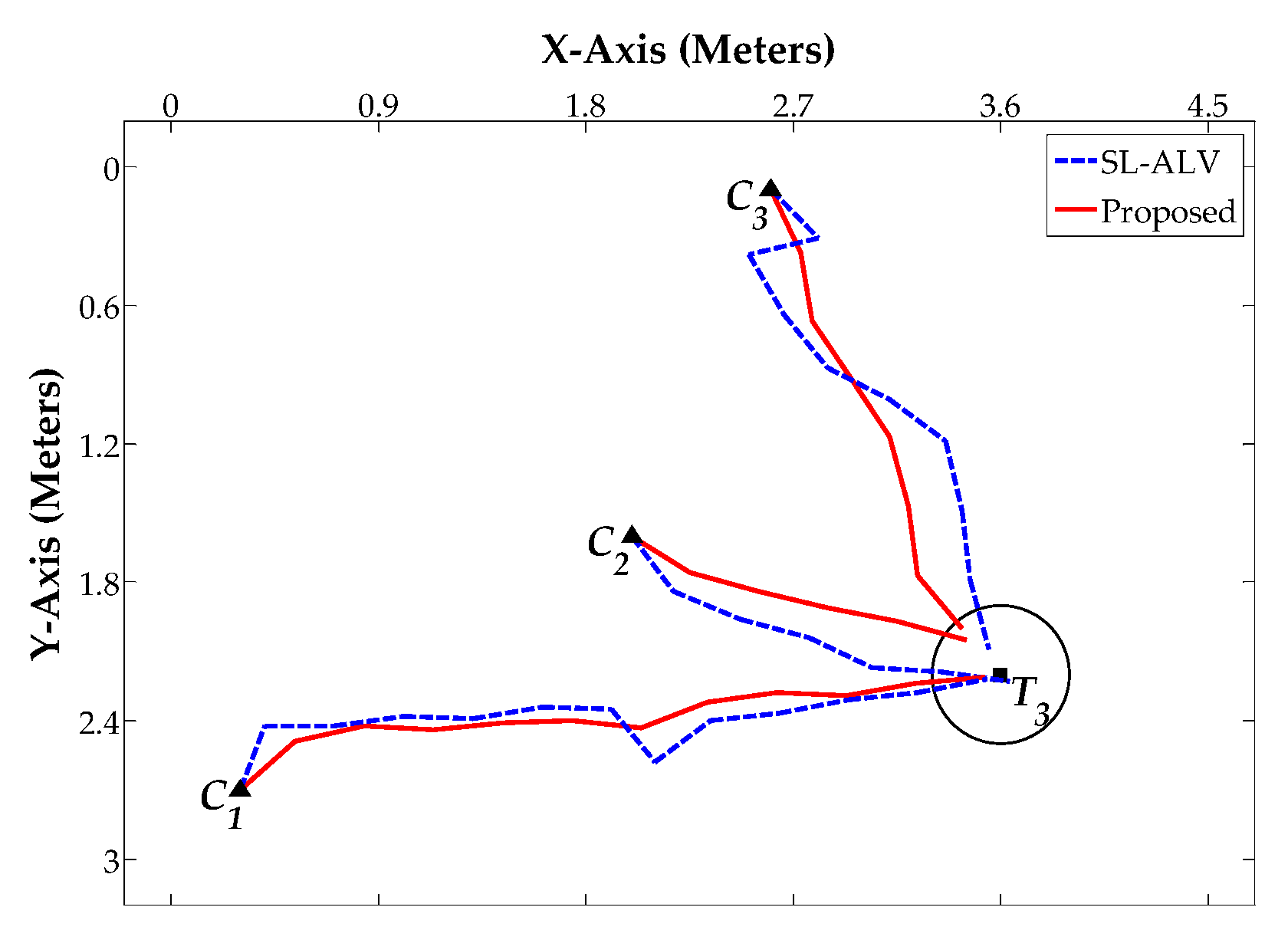
5. Discussion
In
Section 4, we performed the related experiments to evaluate the homing performance of ALV, SL-ALV and our proposed strategies. The experiments consist of two aspects, one based on the image databases and the other based on the real mobile robot. For the experiments on image databases, the homing performance of the algorithms was evaluated under ideal conditions, the experimental environment was always static and the robot’s orientation was almost guaranteed to be constant. For the experiments on mobile robot, the homing performance of the algorithms was evaluated under actual conditions, the robot’s orientation might be slightly offset during the movement. According to the experimental results, our proposed strategies were verified to exhibit good performance both in theory and in practice. The simulation results of our proposed strategies had low
AAE values and high
RR values, while the robot’s trajectories generated by our proposed strategies had low
TDE values and low
ATS values.
However, in the process of the experiments, we also found two problems that cannot be solved at present. On the one hand, the environment should always be static. If dynamic situations occurred (for example, during the movement of the robot, the researchers were randomly moving and the positions of some objects were arbitrarily changed), the optimization effect would be reduced. On the other hand, the mobile robot should always be subject to holonomic constraints. The performance of all the mentioned homing algorithms would significantly drop under nonholonomic constraints, such as randomly changing the robot’s orientation and vertical height.
For the emergence of the above problems, we believe that it is related to the basic concept of visual homing. Since traditional visual homing relies on only a panoramic vision sensor to complete the navigation task, the application scope of this technique will be relatively limited. Although our proposed strategies can effectively improve the homing performance, it is an algorithm-level optimization after all. As far as we know, most existing visual homing approaches require control variables, such as static environments, illumination changes, holonomic constraints, etc. Some papers have proposed improvements to solve these problems, and visual homing can now cope with the problem of illumination changes well by adopting scale-invariant features. However, in terms of dealing with dynamic environments and nonholonomic constraints, although relevant solutions have made progress, some defects still exist, such as poor performance and excessive calculation [
17,
28,
41]. Therefore, it will be valuable to further improve the performance of visual homing in these aspects.
6. Conclusions
In this paper, we propose three landmark optimization strategies for mobile robot visual homing. Two outstanding advantages of our strategies can be summarized. On the one hand, to avoid potential problems that may arise due to the excessive landmark elimination, our strategies adopt the method of weight assignment, and the landmark distribution can thus be optimized by adjusting the contribution of each landmark. On the other hand, our strategies have almost no influence on the calculation speed, and the robot can still reach the target location with high efficiency.
Homing experiments were carried out on both image databases and a real mobile robot. The results reveal that our proposed strategies can better improve the homing performance of ALV. By using our proposed strategies, the AAE values can be further reduced and the RR values can be further increased. In practical applications, the robot can reach the target location with a more ideal trajectory, and the TDE and ATS values can also be further reduced.
In the future, we will conduct research from the following three aspects: First, we will be more concerned with improving the effect of the visual homing methods in more complex (such as the presence of obstacles or dynamic objects) or larger environments. Second, instead of artificially setting too many key parameters (such as Strategy 3), we will explore more intelligent solutions to adaptively determine parameters by sensing environments. Third, we will consider the homing performance for more general mobile robots, and solve the problem that the effect will decrease under nonholonomic constraints.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}