GesID: 3D Gesture Authentication Based on Depth Camera and One-Class Classification



Abstract
:1. Introduction
1.1. Background
1.2. Goal and Approach
- Can authenticate from a single, customized gesture;
- Achieves high accuracy without an excessive number of gestures for training; and
- Continues learning the user’s gesture during use of the system.
1.3. Related Work
2. Method
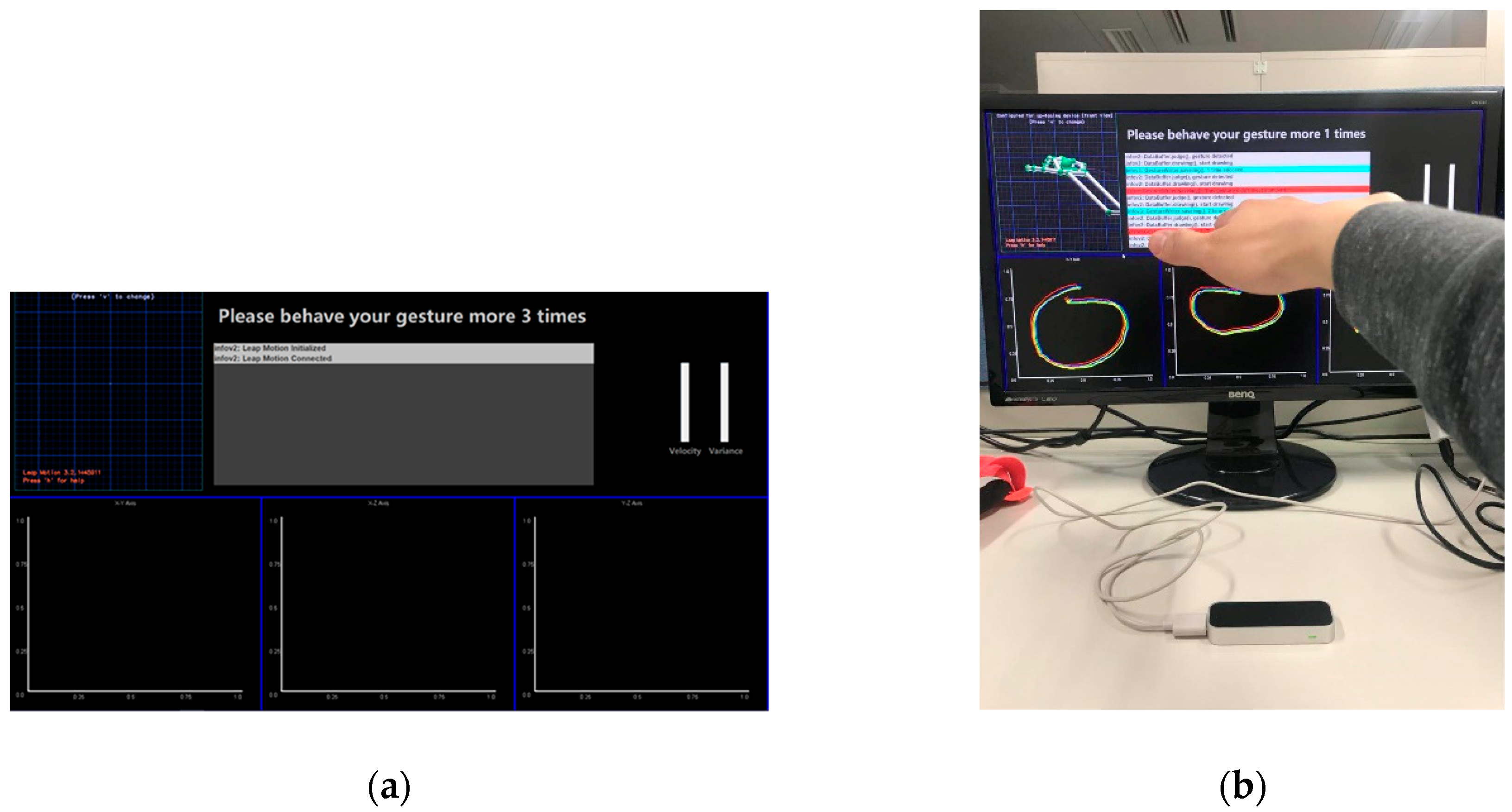
2.1. Data Collection
2.2. Preprocess
2.2.1. Filter
2.2.2. Normalization and 3D Mapping
- (1)
- Generate 676 (=26 × 26) 2D scanning windows. The start location of a window can be described as follows (here we take the mapping of the X-Y plane as an example; X-Z and Y-Z planes are handled similarly):where is the start location of scanning window, is the max value in the X dimension of the gesture, and , , and are similar. The reason we use the window size 26 × 26 instead of 28 × 28 is to prepare for the next data augmentation. Please refer to the data augmentation below for details.
- (2)
- For each window, scan the specific plane (e.g., X-Y plane’s scanning means only X and Y dimension’s data will be used) of gesture. If there exists at least one data point, the mapped result will be 1, otherwise it will be 0, represented as follows:where means the point in the result matrix;
- (3)
- Generate four edges of the result, adding a row (or column) of all 0 values to the top, bottom, left, and right.
- (4)
- Repeat steps (1) to (3) until the three planes are all scanned.
2.2.3. Data Augmentation
2.3. One-Class Classification with Sparse Autoencoder
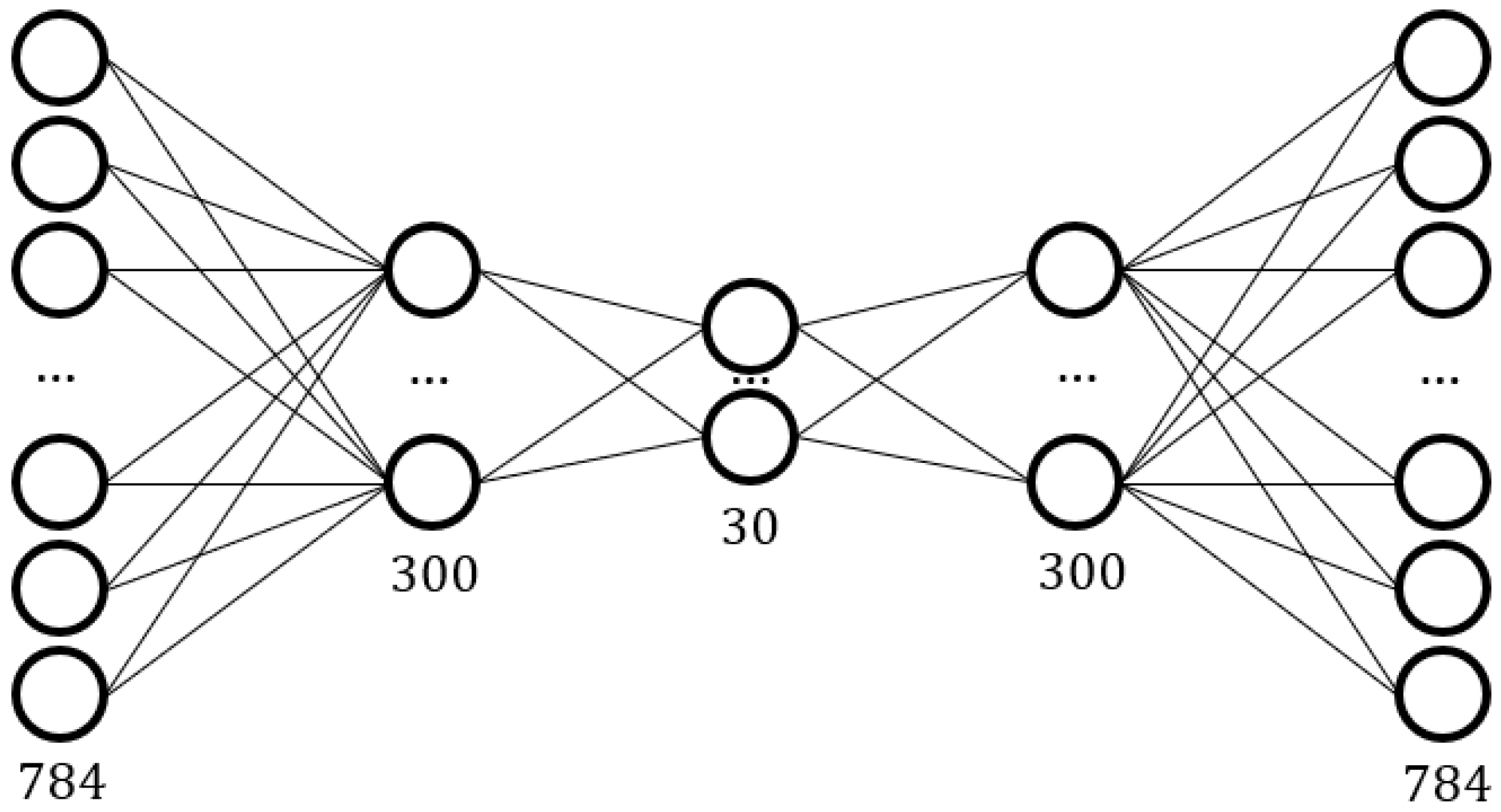
2.3.1. Structure of Proposed Sparse Autoencoder
2.3.2. Network Parameters and Training Process
2.4. Boundary Making Strategy
2.5. Incremental Learning
3. Experiments and Results
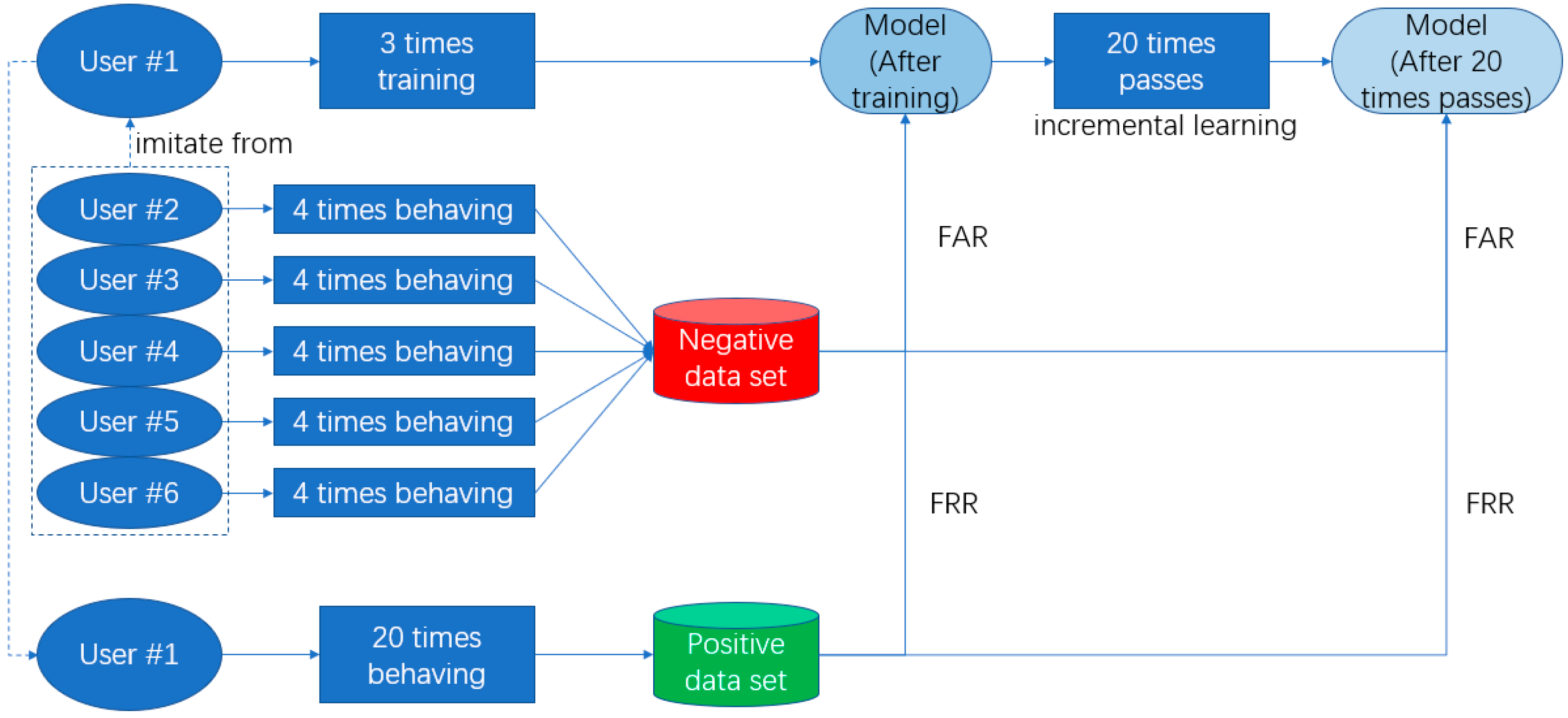
- At registering stage, two users will be asked to perform a simple gesture, two users will be asked to perform a normal complexity gesture, and two users will be asked to perform a complicated gesture. Figure 16 shows the sample of simple, normal, and complicated gestures (every user will gesture three times); Then users will prepare 20 times’ positive gestures as true class for further analysis.
- Users are then asked to authenticate their own gesture 20 times, the autoencoder model will be saved after every time finished. (Incremental learning is used in every time of authenticating successfully, and the autoencoder will learn the new knowledge.);
- Each user’s gesture will be tested by the other five users. Each user will test four times, totaling 4 × 5 = 20 times for each user. This is an attack experiment.
3.1. Analysis on False Rate
3.2. Comparison of Simple, Normal, and Complicated Gesture
3.3. Analysis on Data Augmentation
3.4. Analysis of Incremental Learning
3.5. Comparison of Previous Work
3.6. Comparison of Other One-Class Classification Methods
3.6.1. One-Class SVM
3.6.2. Distance-Based K-Nearest Neighbor
3.6.3. Hidden Markov Model
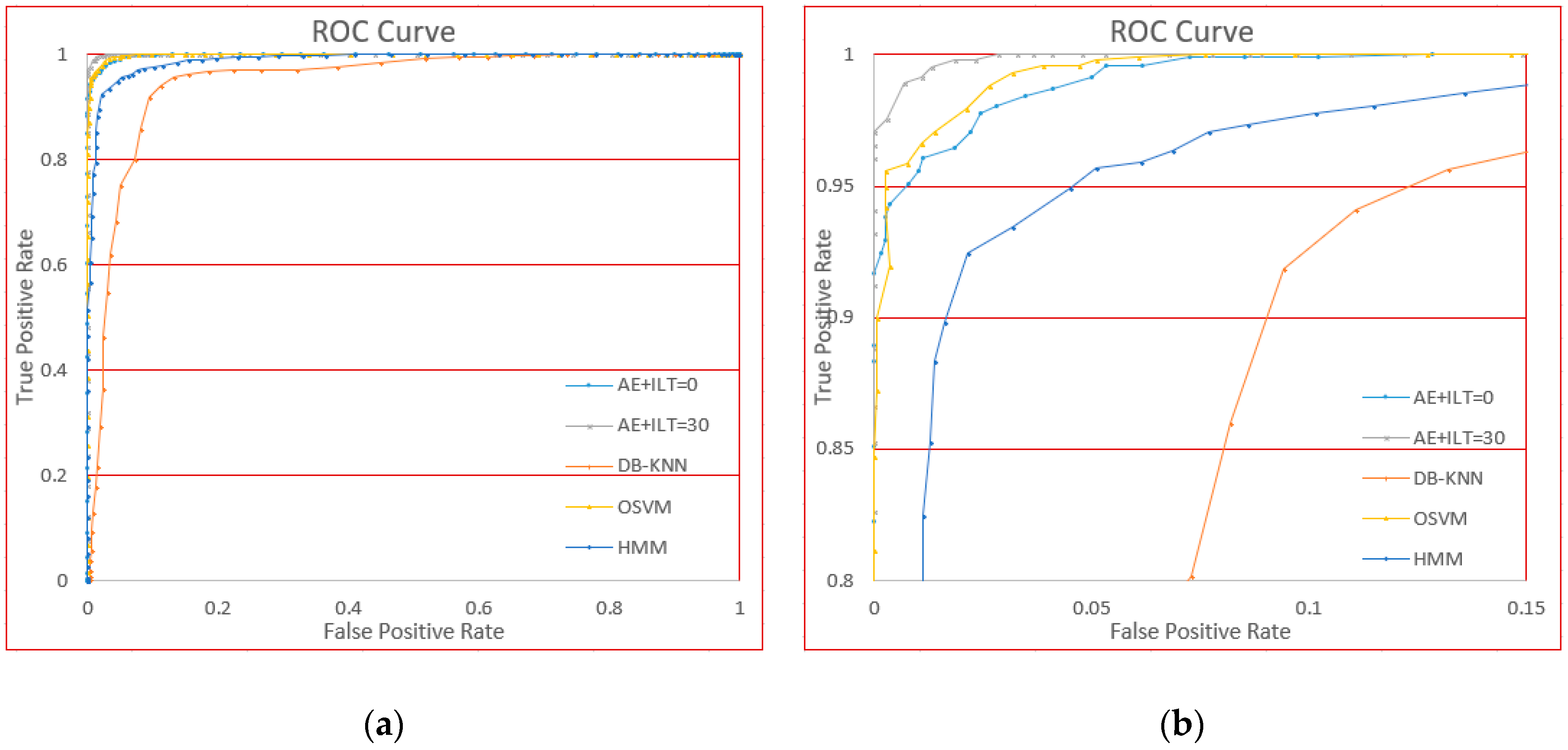
3.6.4. Comparison of Different Methods
4. Discussion
- Can authenticate from a single, customized gesture;
- Achieves high accuracy without an excessive number of gestures for training; and
- Continues learning the user’s gesture during use of the system.
Future Work
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Jain, A.K.; Bolle, R.; Pankanti, S. (Eds.) Biometrics: Personal Identification in Networked Society; Springer Science & Business Media: New York, NY, USA, 2006; Volume 479. [Google Scholar]
- Maltoni, D.; Maio, D.; Jain, A.; Prabhakar, S. Handbook of Fingerprint Recognition; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Friedman, J. Muscle memory: Performing embodied knowledge. In Text and Image; Routledge: London, UK, 2017; pp. 156–180. [Google Scholar]
- Fong, S.; Zhuang, Y.; Fister, I. A biometric authentication model using hand gesture images. Biomed. Eng. 2013, 12, 111. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Agrawal, S.; Agrawal, J. Survey on anomaly detection using data mining techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef]
- Clark, G.; Lindqvist, J. Engineering gesture-based authentication systems. arXiv, 2014; arXiv:1408.6010. [Google Scholar] [CrossRef]
- Chong, M.K.; Marsden, G. Exploring the use of discrete gestures for authentication. In Lecture Notes in Computer Science, Proceedings of the IFIP Conference on Human-Computer Interaction, Uppsala, Sweden, 24–28 August 2009; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Sae-Bae, N.; Memon, N.; Isbister, K.; Ahmed, K. Multitouch gesture-based authentication. IEEE Trans. Infor. Forensics Secur. 2014, 9, 568–582. [Google Scholar] [CrossRef]
- Mohd Shukran, M.A.; Ariffin, M.S.B. Kinect-based gesture password recognition. Aust. J. Basic Appl. Sci. 2012, 6, 492–499. [Google Scholar]
- Chahar, A.; Yadav, S.; Nigam, I.; Singh, R.; Vatsa, M. A leap password based verification system. In Proceedings of the 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), Arlington, VA, USA, 8–11 September 2015. [Google Scholar]
- Van Dyk, D.A.; Meng, X.-L. The art of data augmentation. J. Comput. Graph. Stat. 2001, 10, 1–50. [Google Scholar] [CrossRef]
- Ross, D.A.; Lim, J.; Lin, R.; Yang, M.-H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Z.; Zhong, L.; Wickramasuriya, J.; Vasudeva, V. uWave: Accelerometer-based personalized gesture recognition and its applications. Pervasive Mob. Comput. 2009, 5, 657–675. [Google Scholar] [CrossRef] [Green Version]
- Aumi, M.T.I.; Kratz, S.G. AirAuth: Evaluating in-air hand gestures for authentication. In Proceedings of the ACM 16th International Conference on Human-Computer Interaction with Mobile Devices & Services, Toronto, ON, Canada, 23–26 September 2014. [Google Scholar]
- Kamaishi, S.; Uda, R. Biometric authentication by handwriting using leap motion. In Proceedings of the ACM 10th International Conference on Ubiquitous Information Management and Communication, Danang, Vietnam, 4–6 January 2016. [Google Scholar]
- Zhao, J.; Tanaka, J. Hand Gesture Authentication using Depth Camera. In Proceedings of the Future of Information and Communication Conference, Singapore, 5–6 April 2018. [Google Scholar]
- Leap Motion. Available online: https://www.leapmotion.com/ (accessed on 6 August 2018).
- Sola, J.; Sevilla, J. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans. Nucl. Sci. 1997, 44, 1464–1468. [Google Scholar] [CrossRef]
- Khan, S.S.; Madden, M.G. A survey of recent trends in one class classification. In Proceedings of the Irish Conference on Artificial Intelligence and Cognitive Science, Dublin, Ireland, 19–21 August 2009; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Japkowicz, N.; Myers, C.; Gluck, M. A novelty detection approach to classification. In Proceedings of the IJCAI’95 14th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Volume 1. [Google Scholar]
- Makhzani, A.; Frey, B. K-sparse autoencoders. arXiv, 2013; arXiv:1312.5663. [Google Scholar]
- Manevitz, L.; Yousef, M. One-class document classification via neural networks. Neurocomputing 2007, 70, 1466–1481. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, J.; Zhang, R.; Zhang, Y. Your song your way: Rhythm-based two-factor authentication for multi-touch mobile devices. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015. [Google Scholar]
- Yang, Y.; Clark, G.D.; Lindgvist, J.; Oulasvirta, A. Free-form gesture authentication in the wild. In Proceedings of the 2016 ACM CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016. [Google Scholar]
- Sun, Z.; Wang, Y.; Qu, G.; Zhou, Z. A 3-D hand gesture signature based biometric authentication system for smartphones. Secur. Commun. Netw. 2016, 9, 1359–1373. [Google Scholar] [CrossRef]
- Schölkopf, B.; Williamson, R.C.; Smola, A.J.; Shawe-Taylor, J. Support vector method for novelty detection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Chen, Y.; Zhou, X.S.; Huang, T.S. One-class SVM for learning in image retrieval. In Proceedings of the 2001 IEEE International Conference on Image Processing, Thessaloniki, Greece, 7–10 October 2001; Volume 1. [Google Scholar]
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient algorithms for mining outliers from large data sets. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data, Dallas, TX, USA, 15–18 May 2000; Volume 29. No. 2. [Google Scholar]
- Meng, W.; Wong, D.S.; Furnell, S.; Zhou, J. Surveying the development of biometric user authentication on mobile phones. IEEE Commun. Surv. Tutor. 2015, 17, 1268–1293. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User ID | After Training | After 20 Passes | ||
|---|---|---|---|---|
| FAR | FRR | FAR | FRR | |
| 1 | 0.90% | 4.70% | 0.54% | 0.74% |
| 2 | 1.24% | 4.09% | 0.69% | 1.08% |
| 3 | 1.82% | 3.46% | 0.67% | 1.18% |
| 4 | 1.53% | 3.66% | 0.62% | 1.02% |
| 5 | 2.31% | 2.73% | 0.82% | 1.06% |
| 6 | 2.26% | 2.82% | 0.79% | 1.22% |
| Avg. | 1.68% | 3.58% | 0.69% | 1.05% |
| Type | FAR | FRR |
|---|---|---|
| DA & 3 times | 1.24% | 4.09% |
| Shift Only & 15 times | 1.67% | 4.21% |
| None & 60 times | 0.97% | 4.80% |
| Type | FAR | FRR |
|---|---|---|
| ILT = 0 | 1.24% | 4.09% |
| ILT = 5 | 1.10% | 1.45% |
| ILT = 20 | 0.69% | 1.08% |
| Reference | Sensor | Algorithm | FAR | FRR | ERR 1 | Accuracy |
|---|---|---|---|---|---|---|
| [17] | Leap Motion | HMM 2 | 1.65% | 4.82% | - | 95.21% |
| [15] | Intel Senze3D | DTW 3 | - | - | 2.9% | 96.6% |
| [14] | Accelerometer | DTW | - | - | - | 98.4% |
| [24] | Tablet | SVM 4 | 1.2% | 2.6% | - | Over 98% |
| [25] | Tablet | ESM 5 | - | - | - | 98.90% |
| [11] | Leap Motion | CMIM 6 | 1% | 18.83% | - | - |
| [26] | Smartphone | DTW | 0.27% | 4.65% | 1.86% | - |
| Ours (ILT = 0) | Leap Motion | AE 7 | 1.68% | 3.58% | - | - |
| Ours (ILT = 20) | Leap Motion | AE | 0.69% | 1.05% | - | - |
| Method | FAR | FRR |
|---|---|---|
| OSVM | 1.37% | 2.96% |
| DB-KNN | 7.27% | 19.80% |
| HMM | 1.65% | 4.82% |
| AE + ILT = 0 | 1.68% | 3.58% |
| AE + ILT = 20 | 0.69% | 1.05% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Tanaka, J. GesID: 3D Gesture Authentication Based on Depth Camera and One-Class Classification. Sensors 2018, 18, 3265. https://doi.org/10.3390/s18103265
Wang X, Tanaka J. GesID: 3D Gesture Authentication Based on Depth Camera and One-Class Classification. Sensors. 2018; 18(10):3265. https://doi.org/10.3390/s18103265
Chicago/Turabian StyleWang, Xuan, and Jiro Tanaka. 2018. "GesID: 3D Gesture Authentication Based on Depth Camera and One-Class Classification" Sensors 18, no. 10: 3265. https://doi.org/10.3390/s18103265
APA StyleWang, X., & Tanaka, J. (2018). GesID: 3D Gesture Authentication Based on Depth Camera and One-Class Classification. Sensors, 18(10), 3265. https://doi.org/10.3390/s18103265