In this section, we will introduce and evaluate the first of the two complementary approaches proposed in this work, which is based on source coding techniques. The main goal is to increase the robustness of the video streaming by properly configuring some of the features provided by the selected video encoder. So, the robust bit stream will better fight against packet losses resulting in better perceived video quality. First of all, we will evaluate the proposed techniques in the absence of data losses. This is done to measure the compression efficiency of the different alternatives (i.e., which configuration generates a lower bit rate at the same quality level). This allows us to characterize the configurations in ideal conditions or, equivalently, in soft environments where the data losses can be completely neutralized with the FEC mechanisms proposed in
Section 4. Therefore, to determine the configuration of the proposed approaches, in
Section 3.1, we will analyze the available HEVC frame partitioning schemes (slices and tiles), proposing a novel hybrid approach which we call tileslices, to better fight against video delivery errors. In
Section 3.2, we will propose the use of 9 different intra-refresh coding modes which will be in charge of stopping the error propagation effect found in video inter-prediction coding. In
Section 3.3, a simple error concealment approach will be introduced in the receiver side to hide the visual artifacts produced by data losses when rendering the video to the user. Finally, in
Section 3.4, a performance evaluation of all the above proposals is done, using a simple probabilistic error model.
In the encoding process, each frame is divided into small square regions (usually, a 64 × 64 pixels area). Let’s call them blocks. These blocks can be encoded using one of three modes: (a) without any prediction, (b) using spatial prediction, or (c) using temporal prediction. Spatial prediction exploits redundancy within a single frame. In order to encode a block, it uses previously encoded regions of the same frame to search for similar pixel information to create a prediction. This prediction is subtracted from the current block to obtain the prediction residual. This method is also called intra-frame prediction. Temporal prediction uses previously encoded frames to estimate a block prediction by means of the search of a similar block in other frames (called reference frames), which have been previously encoded, decoded, and stored in a buffer. It exploits temporal redundancy, taking advantage of the fact that nearby frames usually contain blocks that are very similar to the current block and so the residuum of the motion compensation is close to zero. This method is also called inter-frame prediction.
3.1. Tileslices, a New Frame Partition Proposal
Slices are regions of an encoded frame that can be independently decoded, regarding other slices of the same frame. Slices are not a new concept in HEVC and were used in previous standards. The purpose of slices is providing error resilience to a frame. If one slice of a frame gets lost, then the rest of the slices of the same frame can be correctly decoded and only the region covered by the missing slice is lost. Slices consist of correlative blocks (Coding Tree Units—CTUs) in raster scan order (see
Figure 1a). The main disadvantage of dividing a frame into slices is that the coding efficiency is reduced because of (a) the loss of prediction accuracy, since the information in neighbor slices is not available, and (b) the overhead introduced by slice headers in the bit stream.
One of the new features introduced in HEVC is the ability to divide a frame into rectangular regions, called tiles (see
Figure 1b). The original aim of using tiles is to take advantage of parallel computing, because they are independently decodable regions of a frame. Tiles are not useful for error resilience purposes, because if one tile of a frame is missing, the whole frame cannot be decoded. As they do not have headers, and due to their rectangular shape, tiles are more efficient than slices.
In the search for robust video streaming techniques, while attempting to keep the overhead introduced by slices low, we have devised a new element that we call tileslice. A tileslice is the combination of one tile and one slice. First, one frame is divided into tiles (
Figure 1b), and then after encoding all the CTUs of each tile, they are “inserted” into the syntax of a slice, including the slice header (as it is shown in
Figure 1c). In this way the tileslice keeps its rectangular form (which is more efficient than typical slices), and also it behaves as a slice (so missing tileslices do not prevent the correctly received tileslices from being decoded). This combination is possible in the definition of the HEVC standard, so it can be used in practice. However, although it is a very simple idea, there are no previous works, to the authors’ knowledge, that use this particular combination of slices and tiles.
As tileslices contain slice headers, overhead introduced by them is not zero. So, is it really worth using tileslices instead of typical slices for error resilience purposes? To answer this question, we have compared the overhead introduced by slices and tileslices. From this point forward we will use the term tile to refer to what we have defined as tileslice, i.e., one slice that contains one rectangular tile.
We have compared the compression efficiency of tiles against slices for six different layouts: 1, 2, 4, 6, 8 and 10 slices (or tiles) per frame, using fourteen video sequences, of the HEVC “common test conditions” [
17]. They are enumerated in
Table 1. Seven of them have a resolution of 832 × 480 pixels and, the other seven, have a resolution of 416 × 240 pixels. Each sequence has a frame rate of 25 or 30 frames per second (FPS). The two encoding modes used for the HEVC evaluation are All Intra (AI) and Low-delay P (LP),which are included in the HEVC reference software [
18]. In AI mode, every frame of a video sequence is encoded as an I (intra) frame, so temporal prediction is not used at all. This mode has inherent error resilience properties because errors do not propagate to other frames. The main drawback of this mode is that it produces a bit stream with a high bit rate.
In LP mode, the first frame of the sequence is encoded as an I frame, and then P (predictive) frames are generated for the rest of the sequence. P frames are mainly formed by inter-coded CTUs, i.e., CTUs that are encoded by using motion estimation and compensation using other frames as reference (temporal prediction). A P frame can also contain intra-coded CTUs (e.g., if the encoder estimates that those CTUs are more efficiently encoded in an intra way). LP mode is much more efficient than AI mode as it generates a much smaller bit stream for the same quality level, but a simple error in a frame is propagated until the end of the sequence, even if the rest of the frames are correctly received. The compression rate of both modes can be selected by means of the Quantization Parameter (QP). This parameter is used by the quantization process, which entails the loss of precision in the transformed coefficients (lossy compression). When high QP values are used, the generated bit stream has a low bit rate and, correspondingly, low visual quality. When low QP values are used, the generated bit stream has a high bit rate with a resulting high visual quality. For the analysis of HEVC, 4 values for the QP have been used (22, 27, 32 and 37) as it is specified in the common test conditions.
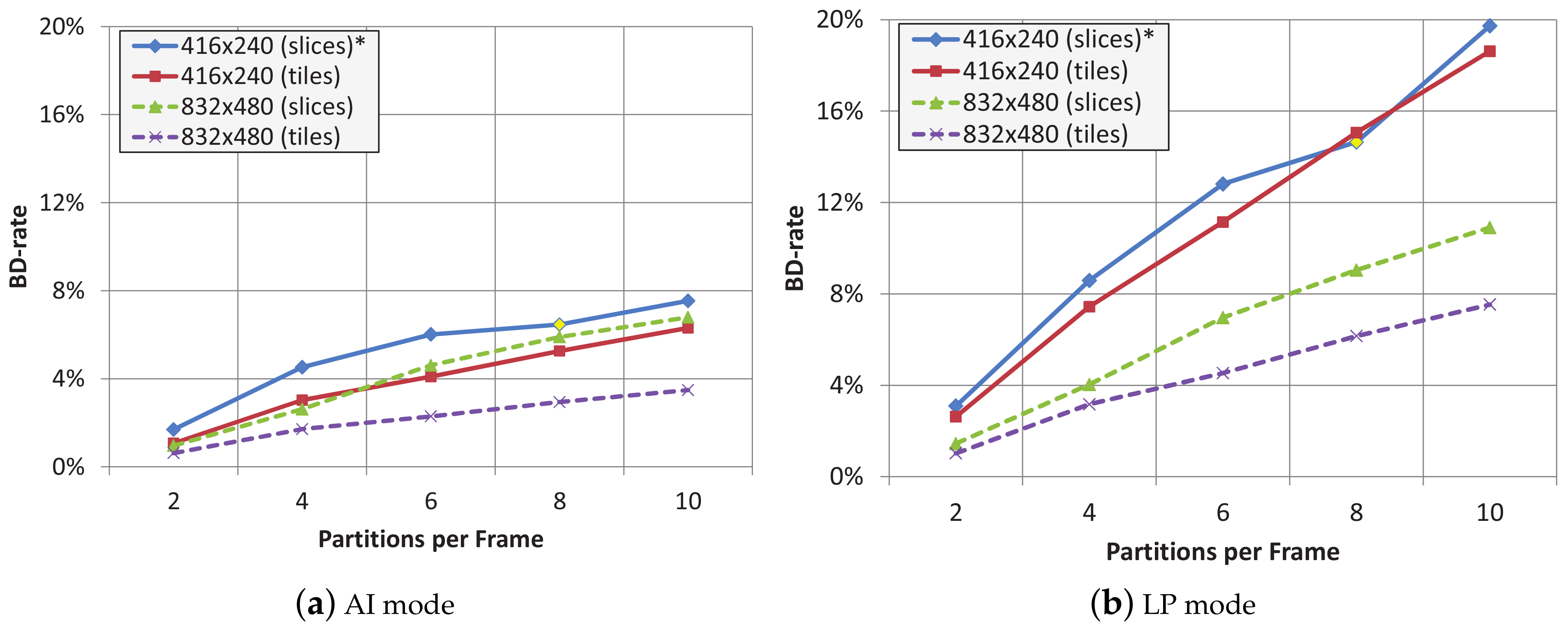
In
Figure 2, Bjørntegaard Delta Rate (BD-Rate) [
19] average values of both sets of source video sequences are shown when using 2, 4, 6, 8 and 10 tiles or slices per frame, both for AI and LP modes. BD-Rate is a measurement that shows the relative bit rate increase (or decrease) of one encoding proposal with respect to another one, chosen as reference. For the low resolution source videos (416 × 240), dividing a frame into 8 slices is not possible, so, we have decided to use 7 slices per frame instead. We have placed and asterisk (*) in the figure legend to remind this fact. Except in this specific case, the overhead of tile partitions is lower than the one experienced with slice partitions. This is the reason the tile (tileslice) partition will be the favorite frame partition method to protect the video bit streams. The maximum overhead reduction, around 3% less overhead than slices, is obtained with 10 tiles per frame in the 832 × 480 video sequences for both LP and AI coding modes. As seen, by using tileslices instead of slices we obtain the same level of error resilience and a better compression performance.
3.2. Intra Refresh Coding Modes
In the previous tests, two encoding modes have been used: All Intra and Low-delay P modes. AI offers better error resilience properties than LP because an error in one tile does not propagate to other frames. On the other hand, LP mode is very sensitive to lost tiles, because P frames are “infected” by erroneous reference frames, and these infected P frames, when used as reference frames, “spread disease” until the end of the sequence. There is also an unpredictable reaction in LP mode in the presence of packet losses. For example, when an LP encoded sequence loses the last frame, then the error affects only that frame. However, if the first frame (I) gets lost, then no frame can be correctly reconstructed at all. So, the position of the missing parts is also important when dealing with errors in LP mode. These two encoding modes have been determined as our upper and lower bounds regarding error resiliency. In this work, 7 new encoding modes with different intra-refresh rates have been proposed and evaluated. Intra refresh is an error resilience technique that forces to periodically intra encode (refresh) certain frame areas in P frames, in order to stop the error propagation mentioned before. The 9 encoding methods evaluated are the following ones:
AI—Encodes every frame as an I frame. It is considered our upper bound mode.
LP—Encodes the first frame as an I frame and the rest of the frames as P frames. Four previous reference frames are available for temporal estimation and compensation for each P frame. It is considered our lower bound mode.
IPx—Similar to LP mode but every P frame uses only the previous frame as reference frame, instead of having 4 reference frames.
IPx25pctCTU—Similar to IPx mode, where 25% of the CTUs are forced to be intra refreshed.
IPx25pctTIL—Similar to IPx mode, where 25% of the tiles are forced to be intra refreshed.
IPxpattern—Similar to IPx mode, where 25% of the tiles are forced to be refreshed following a specific pattern, which covers all the tiles of a whole frame every 4 frames.
IPPP—Similar to IPx mode, with an I frame inserted every 4 frames.
LPI4—Similar to LP mode, with an I frame inserted every 4 frames.
IPIP—I and P frames are inserted alternatively. Every P frame uses the previous I frame as reference.
The 9 encoding modes can be classified into four groups, depending on the whole-frame refreshing rate: (a) LP and IPx modes only have an I frame at the beginning of the sequence, so no refreshing is performed (0%); (b) IPPP, IPx25pctCTU, IPx25pctTIL, IPxpattern, and LPI4 modes have an average frame-refresh rate of one intra frame every four frames (25%); (c) IPIP mode has an intra frame-refresh rate of one frame out of two (50%); (d) AI mode uses a full rate of intra-refreshed frames (100%). For the following tests, we have selected the BasketballDrill sequence (832 × 480 pixels, 25 fps,
bbd_25), which exhibits an average coding performance among the 832 × 480 sequence set. In
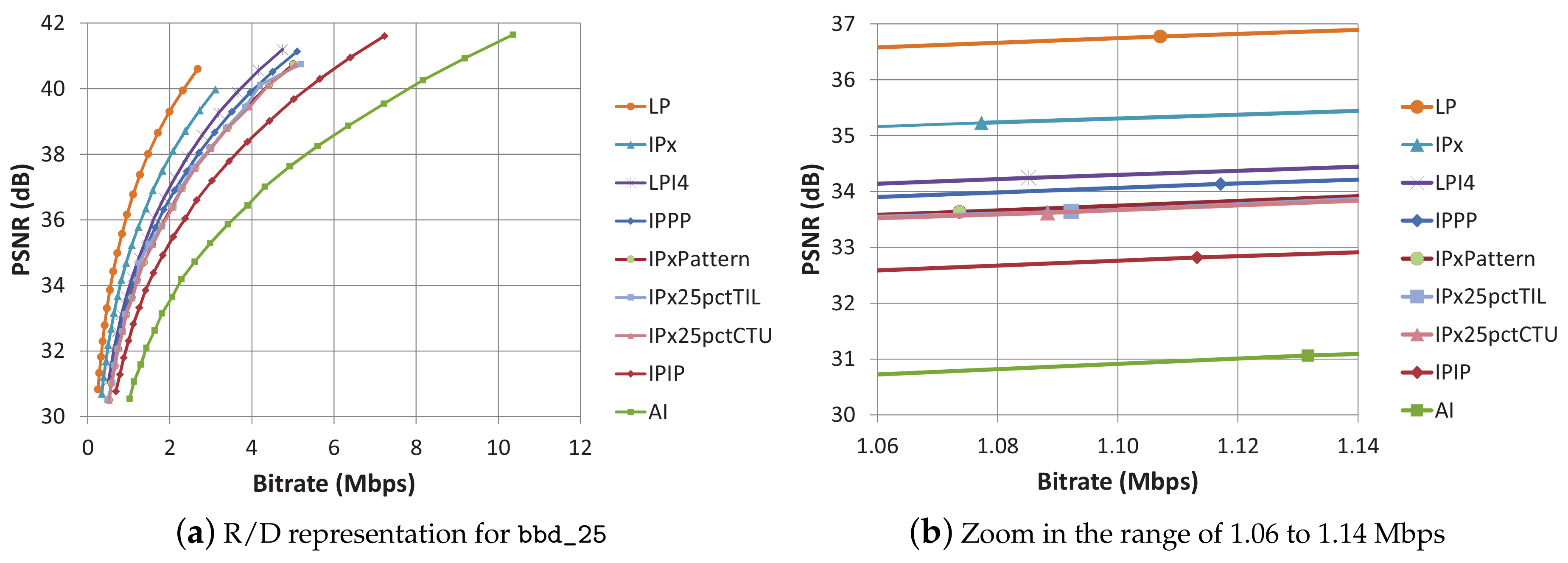
Figure 3a, the resulting rate/distortion curves for the 9 encoding modes (for a very wide range of QP values) are plotted. LP mode results the most efficient mode of all, and AI the least efficient.
For the evaluations carried out in
Section 3.4 regarding the performance of the 9 encoding modes under packet losses, we have selected an individual QP value for every mode so that they generate a bit stream with a similar bit rate (fair conditions). The QP values used for each encoding mode with the resulting bit rate and PSNR values are listed in
Table 2.
Figure 3b is a zoomed version of
Figure 3a, which shows the curves at the selected QP values. The curves corresponding to encoding modes belonging to group (b) exhibit very similar coding efficiency. On the contrary, in group (a), LP and IPx curves are not close to each other, and LP clearly outperforms IPx regarding coding efficiency, which remarks the importance of the available reference frames. The PSNR values range from 31.07 dB (AI) to 36.77 dB (LP) in a no-loss scenario. The list of the 9 encoding modes, ordered by their coding efficiency, is the same order found at plot labeling.
3.4. Evaluation of Source Coding Protection
In this section, first a video quality analysis varying the Tile Loss Ratio (TLR) is carried out, and the reconstructed video quality (PSNR) is measured. In addition, then, the average proportion of packets per tile is presented and experiments varying the Packet Loss Ratio (PLR) are carried out. In these experiments, we measure both how the different configurations produce different TLR for the fixed PLRs, and also the final video quality (by means of the PSNR) provided by each configuration. The obtained results will be analyzed to find out the most appropriate source coding architecture that fulfills our goal.
The compression performance of the proposed encoding modes and the overhead introduced by tiles and slices have already been evaluated. Now, we will evaluate the robustness of tiles and encoding modes for different TLR values. The combination of the 9 intra-refresh coding modes with the different tile partition layouts (1, 2, 4, 6, 8 and 10 tiles/frm), under a simple probabilistic data loss model, will be evaluated. Six different TLR values have been fixed for the tests: 1%, 3%, 5%, 7%, 10% and 20%. For every one of these loss rates, 5 different seeds for the random number generator have been used, and the results have been averaged.
First of all, we have evaluated the EC methods implemented in the decoder. The frame copy method has been always used in order to obtain a reconstructed video sequence with the same number of frames than the original video sequence. Also, the zero-MV technique has been tested and the PSNR differences when enabling this method are always positive. This means that the EC decoder version provides better PSNR values than the version without EC. The PSNR gains range from 0.14 up to 3.02 dB. However, the LP and IPx encoding modes (no intra-refresh) obtain PSNR values below the quality bounds which are considered the minimum aceptable, even when the EC decoder is enabled. As a product of these observations, from this point forward we will always use the EC decoder version for the reconstruction of video sequences.
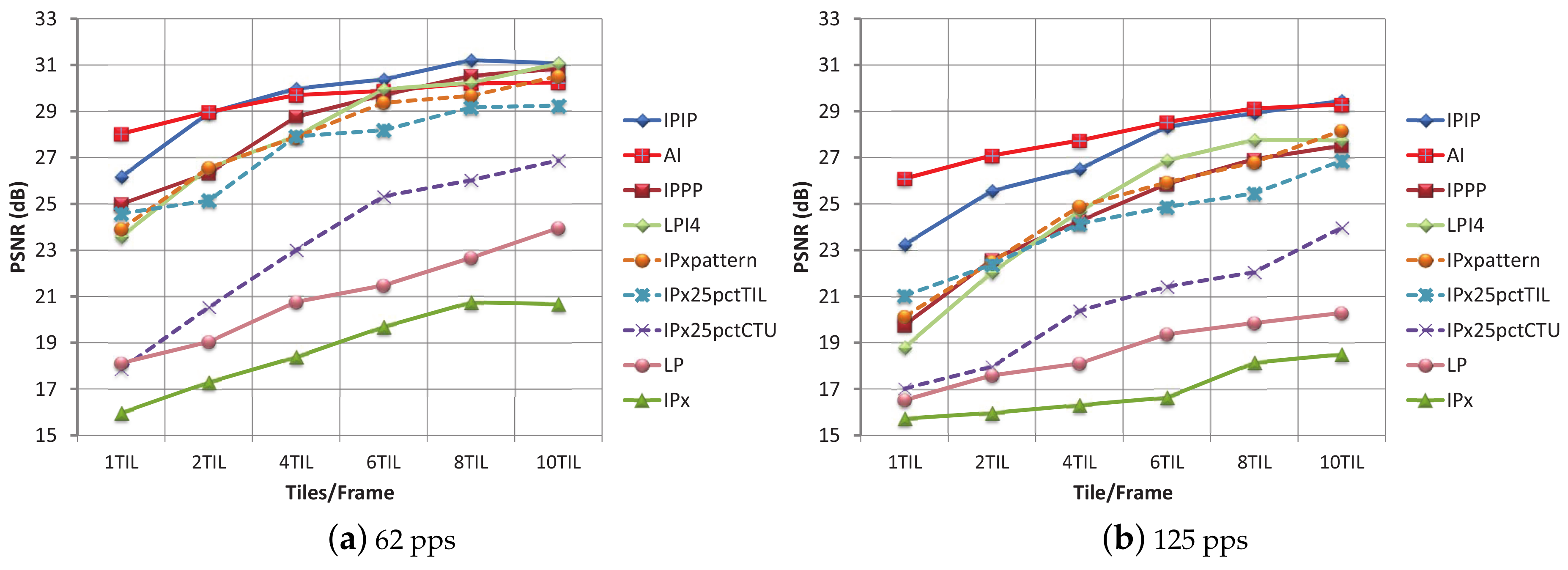
Regarding the error resilience attributes related to the encoding modes and the tile layouts, in
Figure 4 the PSNR values obtained for each encoding mode with a 3% and a 10% TLR are shown. Three of the encoding modes show a non-robust response to tile loss (PSNR values under 29 dB are considered low quality values). For LP and IPx this is the expected result, as they have no intra refreshing strategy. However, the bad performance for IPx25pctCTU was not expected, because in this mode 25% of the CTUs (one out of four) are forced to be intra-coded. Previously, this encoding mode showed the same coding efficiency as IPx25pctTIL and IPxpattern (which share the same percentage of intra refreshed areas), but it is clear that a random CTU intra refresh does not provide the expected protection against tile losses. Why intra refresh on the CTU level is not 100% effective? The reason is that intra-frame encoding uses pixel information (surrounding the CTU) to compute a prediction, which is used both in the encoding and decoding processes. If the pixels used to compute that prediction belong to inter-coded CTUs whose reference frames are corrupted, then the pixels used for the intra-frame prediction are not correct, and, even if the intra CTU is correctly received, it will be incorrectly decoded. Inversely, if intra refresh is carried out on tile level, as all the CTUs that belong to a tile do not depend on CTUs from outside that tile, then every correctly received intra CTU will be correctly decoded. Intra refreshing on the CTU level does not provide enough bit stream robustness.
One of the consistent results throughout all the tile loss percentages tested is that, for a fixed TLR, when the number of tiles per frame increases (smaller tiles), the quality decreases. The reason is that the loss of small parts in many frames causes a worse effect than the loss of one big part in only one frame, even if the data loss percentage is the same. For 1% and 3% TLR, the most robust encoding modes are LPI4 and IPPP. At 5% TLR, these two modes and IPIP show very similar performance. In addition, at 7% TLR and above, IPIP is the most resilient mode. At 20% TLR, AI mode is over IPIP for 4 tiles per frame layout and above, but very low PSNR values are obtained at this point, being not effective at this TLR values.
From these experiments, it seems that the 1 tile per frame is the most robust layout. However, in the “real world”, a particular PLR may produce very different TLRs, depending on the ratio between the tile size and the network Maximum Transfer Unit (MTU). As the tile size depends on several factors such as the frame type (I, P), the number of tiles per frame, and the selected QP parameter (the compression ratio), we will now evaluate the robustness of the combination of these parameters, for different PLR values.
First of all, note that, if a tile is larger than the network MTU, that tile has to be divided into several network packets, and, if one of these packets gets lost, then the rest of the packets belonging to the same tile are completely useless because that tile cannot be decoded at all. The average number of network packets per tile in the encoded bit streams is shown in
Table 3. For the 1 tile per frame layout, the proportion is over 4 packets per tile. This means that the loss of one network packet will probably entail the effective loss of four packets. For the 10 tiles per frame layout, the proportion is near 1 packet per tile. This means that the loss of one network packet will probably entail the effective loss of only that packet.
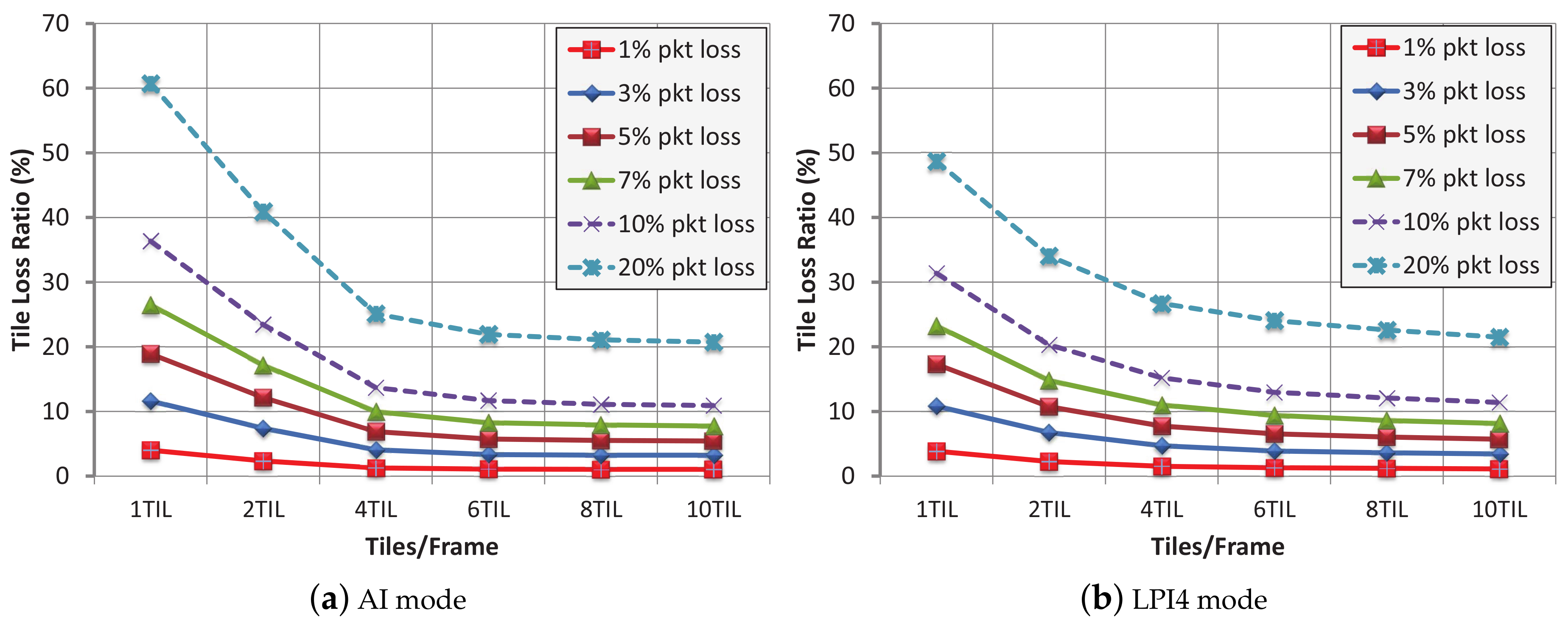
Figure 5 shows the TLRs obtained for different PLRs, for both AI and LPI4 modes. It can be seen that the 1 tile per frame layout suffers from vulnerability in both modes, so this layout which apparently showed to be the most robust in the previous tests, now provides higher TLRs than the rest of the layouts, for a fixed PLR, which is a drawback. The obtained TLRs are strongly correlated with the values from
Table 3, so when the number of packets per tile tends to one, the TLR obtains its minimum value. Dividing a frame into 6, 8 or 10 tiles per frame produces similar TLRs, because the proportions of packets per tile for these three modes are very close.
Now, we will show the video quality performance of the different tiles per frame layouts, at a fixed PLR. In
Figure 6, the PSNR values for each number of tiles per frame layout at 3% and 10% PLR, is shown. Again, LP, IPx, and IPx25pctCTU obtain very low PSNR values, showing little resilience against errors. The other six modes have increasing PSNR values when the number of tiles per frame increases. This result is consistent throughout all the PLRs tested, therefore, in all the experiments, we have observed that when a high number of tiles per frame is selected, the recovered video sequence obtains a better PSNR value. For low packet loss (1%), IPPP and LPI4 are still the best encoding methods; for a medium packet loss percentage (3%), IPPP and IPIP are the best methods; and, for the rest of PLRs (5%, 7%, 10% and 20%), the best methods are AI and IPIP, although for values of 7% and higher, the PSNR values are very low.
From these results, some conclusions can be drawn. Of the 9 encoding modes evaluated, there are three that do not have good error resilience properties. Two of them (LP, IPx) have shown the expected performance as they do not use any intra refreshing at all. However, the third one (IPx25pctCTU), which refreshes one of every four CTUs, does not have the expected intra-refresh effect in the bit stream. For the rest of the modes, two of them (LPI4 and IPPP) stand out with respect to the others when the percentage of loss remains low, and another method (IPIP) has a good performance when the percentage of loss increases. With respect to the effect of frame partitioning, we have confirmed in all experiments that the higher the number of tiles per frame, the higher the final video quality. However, it is recommended to use no more than 6 tiles per frame, since the benefits in video quality are negligible for higher values. Although some of the methods exhibit good error resilience properties, this is not enough to guarantee robust video streaming. In the next section, we will evaluate RaptorQ codes, and will search for the best setup to provide the desirable protection to the video packet stream.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}