Streaming MASSIF: Cascading Reasoning for Efficient Processing of IoT Data Streams

 , , , and
, , , and 
Abstract
:1. Introduction
- Combine various data streams: To make meaningful analysis we need to combine streams from various sensors.
- Integrate background knowledge: Since the sensory data typically only describe the sensor readings, we need to be able to link additional data, e.g., the type of measurement linked to the sensor and the location of the sensor.
- Integrate complex domain knowledge: In order to correctly interpret the domain, domain knowledge needs to be integrated. The more accurate the domain definition, the more complex the domain knowledge and the higher the required reasoning expressivity.
- Detect temporal dependencies: Understanding the temporal domain is often necessary when processing streaming data, as many events in data streams have temporal dependencies.
- Easy subscription: To allow service to subscribe to the data of their interest, they should be able to define their information need in a straightforward and declarative manner.
2. Related Work
3. Background on Cascading Reasoning
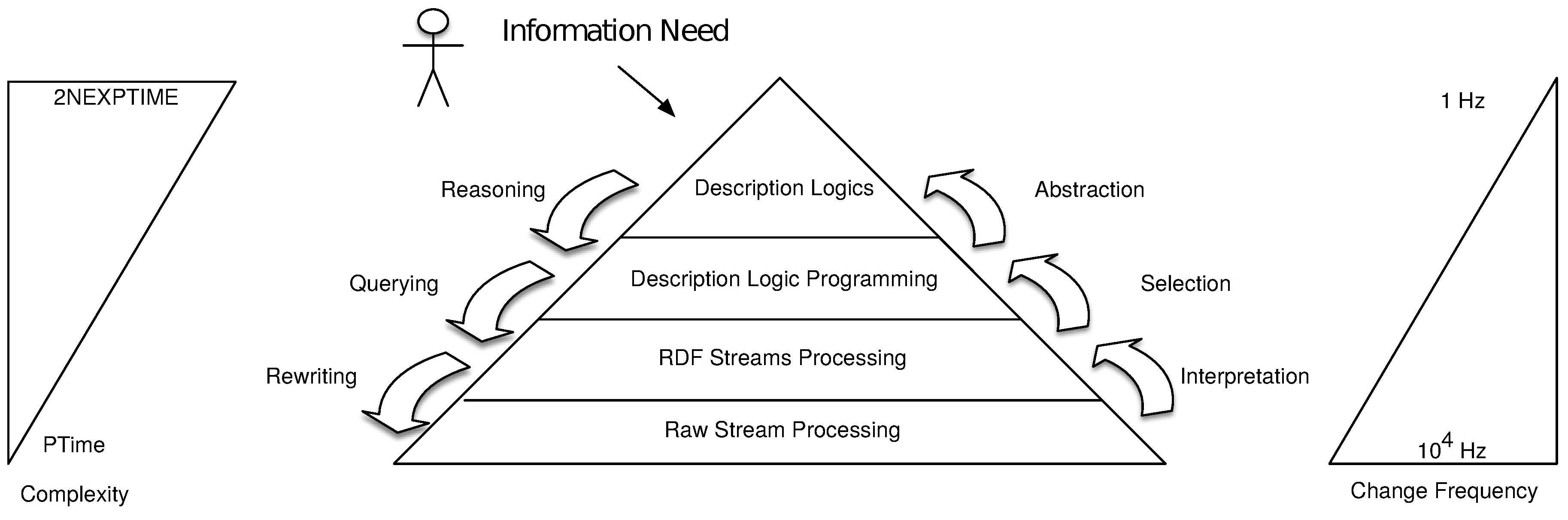
3.1. The Original Cascading Reasoning Vision
3.1.1. Raw Stream Processing
- AND is a binary operator: A AND B matches if both A and B occur in the stream and turns true when the latest of the two occurs in the stream. In Figure 2, A AND B matches at in both Stream 1 and Stream 2.
- OR is a binary operator: A OR B matches if either A or B occurs in the stream. In Figure 2, A OR B matches at in both Stream 1 and Stream 2.
- SEQ is a binary operator that takes temporal dependencies into account. A SEQ B matches when B occurs after A, in the time-domain. In Figure 2, A SEQ B matches at in Stream 1 and at in Stream 2.
- NOT is a unary operator: NOT A matches when A is not present in the stream. NOT A matches at in Stream 1 and at Stream 2.
- WITHIN is a guard that limits the scope of the pattern within the time domain. A SEQ A WITHIN 2 s matches in Figure 2 at in Stream 2 and has no match in Stream 1.
- EVERY is a modifier that forces the re-evaluation of a pattern once it has matched. EVERY A SEQ B matches at in Stream 1 and at & in Stream 2 for and .
- DecreasingTraffic = EVERY HighTraffic SEQ LowTraffic WITHIN 10 m.
- However, it is not straightforward in CEP to define what a HighTraffic or LowTraffic exactly is.
3.1.2. RDF Stream Processing
- SE is an RSP-QL algebraic expression;
- SDS is an RSP-QL dataset;
- ET is a sequence of time instants on which the evaluation of the query occurs;
- QF is the Query Form (e.g., Select or Construct)
3.1.3. Description Logic Programming
3.1.4. Description Logics
- OWL2 RL, which does not allow existential quantifiers on the right-hand side of the concept inclusion, eliminating the need to reason about individuals that are not explicitly present in the knowledge base. Furthermore, it does not allow quantified restriction, e.g., a minimum number of roles, a maximum number of roles or exactly a specific number of quantified roles. This profile is ideal to be executed on a rule-engine.
- OWL2 EL, which mainly provides support for conjunctions and existential quantifiers. This profile is ideal for reasoning over large TBoxes that do not contain, among others, universal quantifiers, quantified restrictions or inverse object properties.
- OWL2 QL, which does not allow, among others, existential quantifiers to a class expression or a data range on the left-hand side of the concept inclusion. This makes the profile ideal for query rewriting techniques.
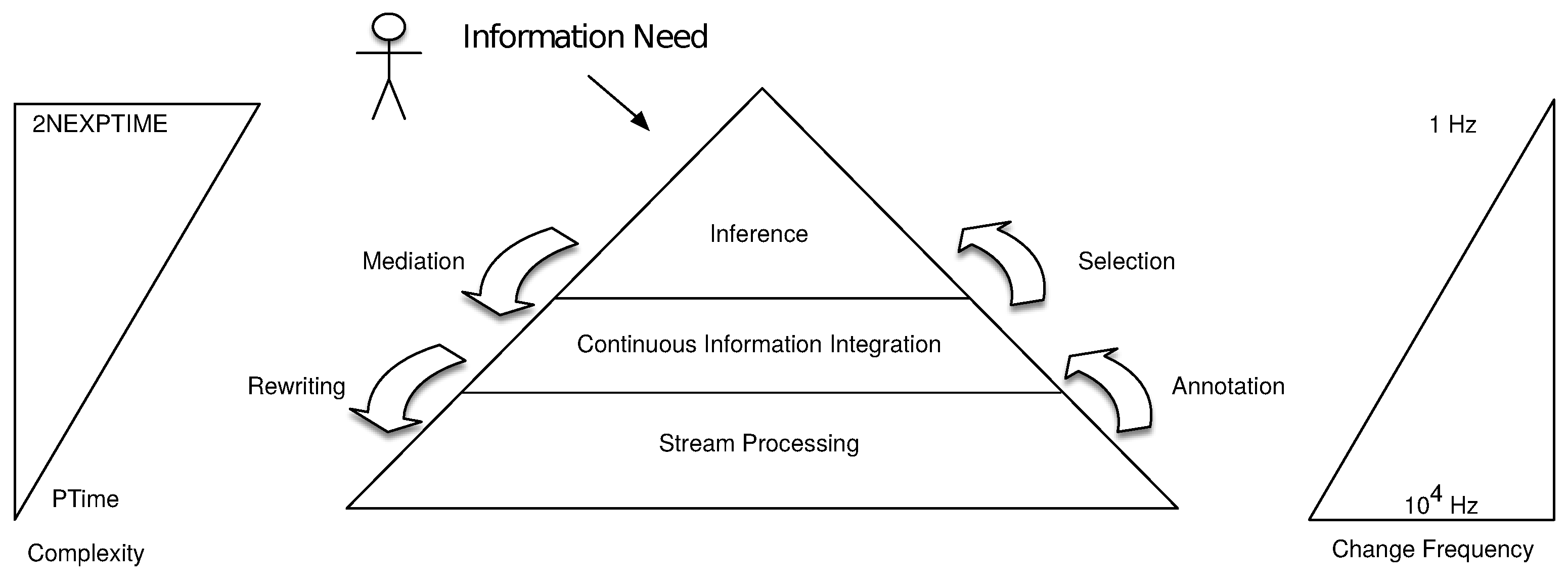
3.2. Cascading Reasoning Generalization
- Stream Processing: At the lowest level, the data streams are processed. Different processing techniques can be used accordingly to the levels above, e.g., which information integration technique is used (if any). This layer can implement stream processing techniques like DSMSs and CEPs or use RSP when dealing with semantically annotated data. Moreover, this level can also solve part of the analytic needs, since it is able to compute descriptive analysis of the streaming data.
- Continuous Information Integration: In order to achieve a high-level view on the streaming data, we need an information integration layer that offers a homogeneous view over the streams. The Continuous Information Integration layer combines data from heterogeneous streams into a common semantic space by the means of mapping assertions that populate a conceptual model. Two approaches are then possible to access the data: (i) Data Annotation (a.k.a. data materialization), i.e., data are transformed into a new format closer to the information need (ii) Query Rewriting (a.k.a. data visualization), i.e., the information need is rewritten into sub tasks that are closer to each of the original data formats.
- Inference: In a cascading approach, an information need (IN) is formulated accordingly to a high-level view of the data. To enable efficient IN resolution, we need an inference layer that mediates the IN with domain-specific knowledge to the lower layers. Computational tasks at this level have a high complexity. This reduces the volume of data this level can actually process. Therefore, it is necessary to select, from the lower layers, the relevant parts of the streams that this layer has to interpret to infer hidden data. Possible inference implementations range from expressive reasoning, such as DL, ASP, metric temporal logic (MTL), or CEP, to machine learning techniques such as Bayesian Networks (BN) or hidden Markov models (HMM).
4. Cascading Reasoning with Streaming MASSIF
4.1. Layer Design
4.2. Architecture
4.2.1. Selection Module
| Listing 1: Example of the RSP-QL Query used in the Selection Module. |
CONSTRUCT {
?obs_X a ssn:Observation.
?obs_X ssn:observedBy ?sensor_X.
?obs_X ssn:observedProperty ?property_X.
?property_X a CongestionLevel.
?obs_X hasValue ?value.
?property_X isPropertyOf ?foi.
?foi isLocationOf ?loc.
?loc hasPolicy ?pol. }
FROM NAMED WINDOW :traffic [RANGE 5m, SLIDE 1m] ON STREAM :Traffic
WHERE {
?property_X a CongestionLevel.
?property_X isPropertyOf ?foi.
?foi isLocationOf ?loc.
?loc hasPolicy ?pol.
WINDOW ?w {
?obs_X a ssn:Observation.
?obs_X ssn:observedBy ?sensor_X.
?obs_X ssn:observedProperty ?property_X.
?obs_X hasValue ?value.
FILTER(?value > 0.03 || ?value < 0.01)
}
}
|
4.2.2. The Abstraction Module
4.2.3. The Event Processing Module
4.2.4. The Remaining Modules
| Listing 2: Syntax of the Streaming MASSIF DSL. |
DSL -> NameSpace* EventDecl* RSPQL?
EventDecl -> ‘NAMED EVENT’ EventName (AbstractEvent | ComplexEvent)
AbstractEvent -> ‘AS’ DLDescription
ComplexEvent -> ‘MATCH’ (Modifier)? EventPattern (Guard)? (IFClause)?
EventPattern -> EventPattern EventOperator EventPattern|AbstractEvent|‘NOT’EventPattern
IFClause -> ‘IF’ ‘{’ (‘EVENT’ AbstractEvent ‘{’ BGP ‘}’)* ‘}’
EventOperator -> ‘AND’ | ‘OR’| ‘SEQ’
Modifier -> ‘EVERY’ | ‘FIRST’ | ‘LAST’
Guard -> ‘WHITIN’ Num ‘(’ TIMEUNIT ‘)’
TIMEUNIT -> ‘s’ | ‘m’ | ‘h’ | ‘d’
EventName -> String
Num -> [0-9]+
NameSpace -> SPARQL PREFIX SYNTAX
DLDescription -> MANCHESTER SYNTAX
BGP -> SPARQL BGP SYNTAX
RSPQL -> RSP-QL SYNTAX
|
4.3. A Domain Specific Language for Streaming MASSIF
- DLDescription: The definition of the abstract event types is based on the Manchester syntax. For more information regarding this syntax, we refer the reader to the Manchester W3C page (https://www.w3.org/TR/owl2-manchester-syntax/).
- BGP: In the definition of the complex events, one can define Basic Graph Pattern (BGP) for restricting the validity of the events. We did not incorporate the explanation of the syntax of BGP in this proposal.
- RSPQL: For targeting the RSP module, we utilize RSP-QL. The full syntax of RSP-QL has not been incorporated in our syntax proposal, more information regarding RSP-QL can be found in Dell’Aglio et al. [31].
4.3.1. DSL Fragment for the RSP Layer
4.3.2. DSL Fragment for the DL Sub-Layer
4.3.3. DSL Fragment for the CEP Sub-Layer
| Listing 3: DSL Event Restriction Clause Example. |
1 NAMED EVENT :DecreasingTrafficEvent {
2 MATCH EVERY :HighTrafficEvent
3 SEQ :LowTrafficEvent WITHIN (10 m)
4 IF {
5 EVENT :HighTrafficEvent { ?o timeStamp ?time.
6 FILTER(hours(?time) > 15) }
7 EVENT :LowTrafficEvent { ?o2 timeStamp ?time2.
8 FILTER(hours(?time)>15) } }
9 }
|
5. Streaming MASSIF’s Formalization
5.1. RDF Stream Processing Layer
5.2. Continuous Information Integration Layer
5.3. The Inference Layer
- h as the complex event type,
- p as the pattern defined using operators, modifiers, and guards, and
- R as a set of restrictions.
- as the complex event type ,
- p as the pattern describing EVERY -, and
- R as a set of restrictions of the form consisting of
- * , with1 Select * WHERE {2 ?o ssniot:hasLocation ?loc.}
- * , with1 Select * WHERE {2 ?o2 ssniot:hasLocation ?loc.}
5.4. Unified Evaluation Functions
- —a set of one or more selected physical events contained in .
- —the ontology describing the domain knowledge. with the TBox and the ABox describing .
- —an ontology TBox that bridges the domain ontology and the physical events . This describes formally the abstraction based on . Only the concepts in will be considered as abstracted events.
- —the entailment regime under which the reasoner has to extract the abstract events from .
5.5. Summary
6. Evaluation
6.1. The Need for Cascading Reasoning
6.1.1. Setup
6.1.2. Results
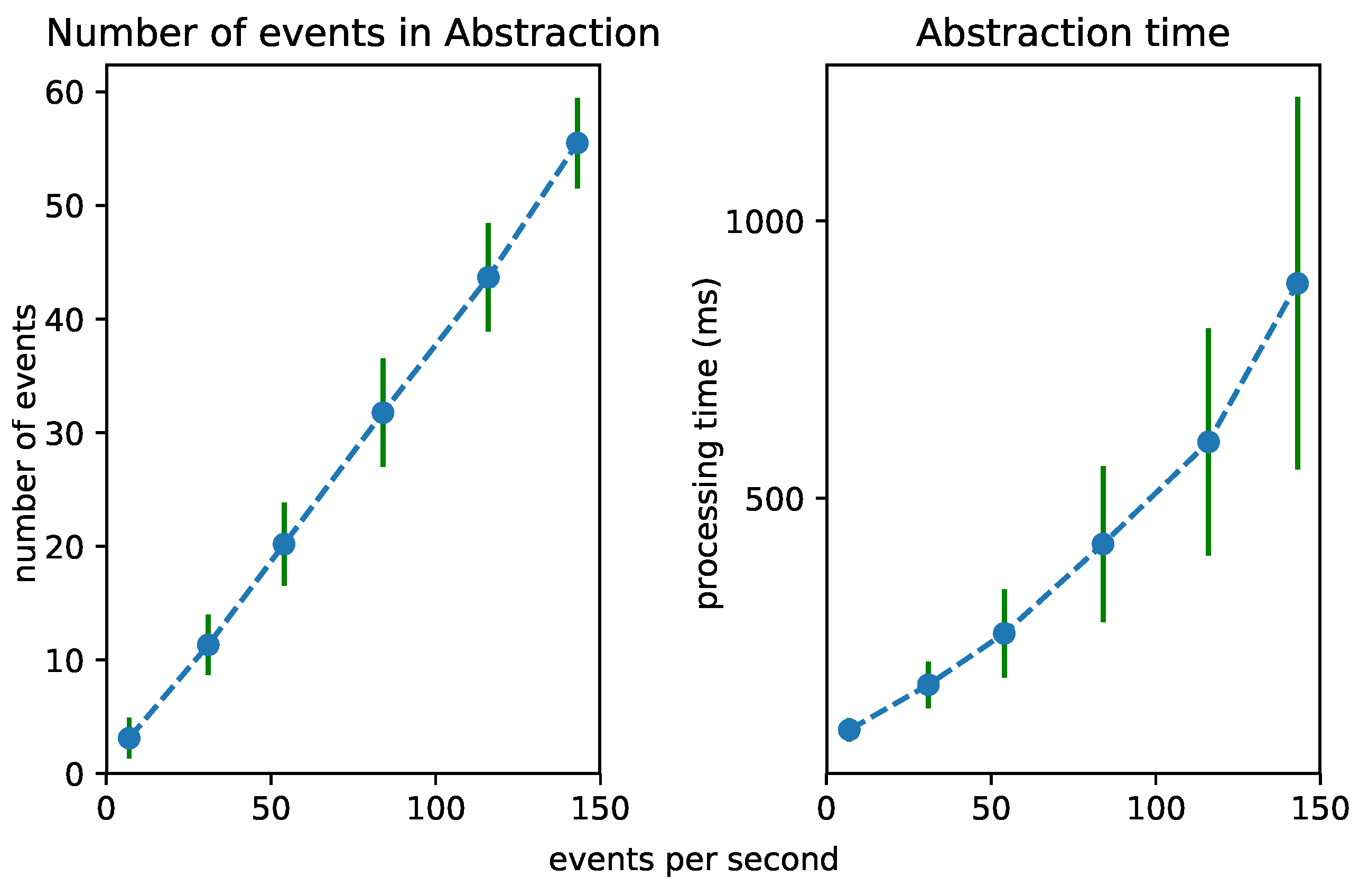
6.2. Test 1: Increasing Event Rate
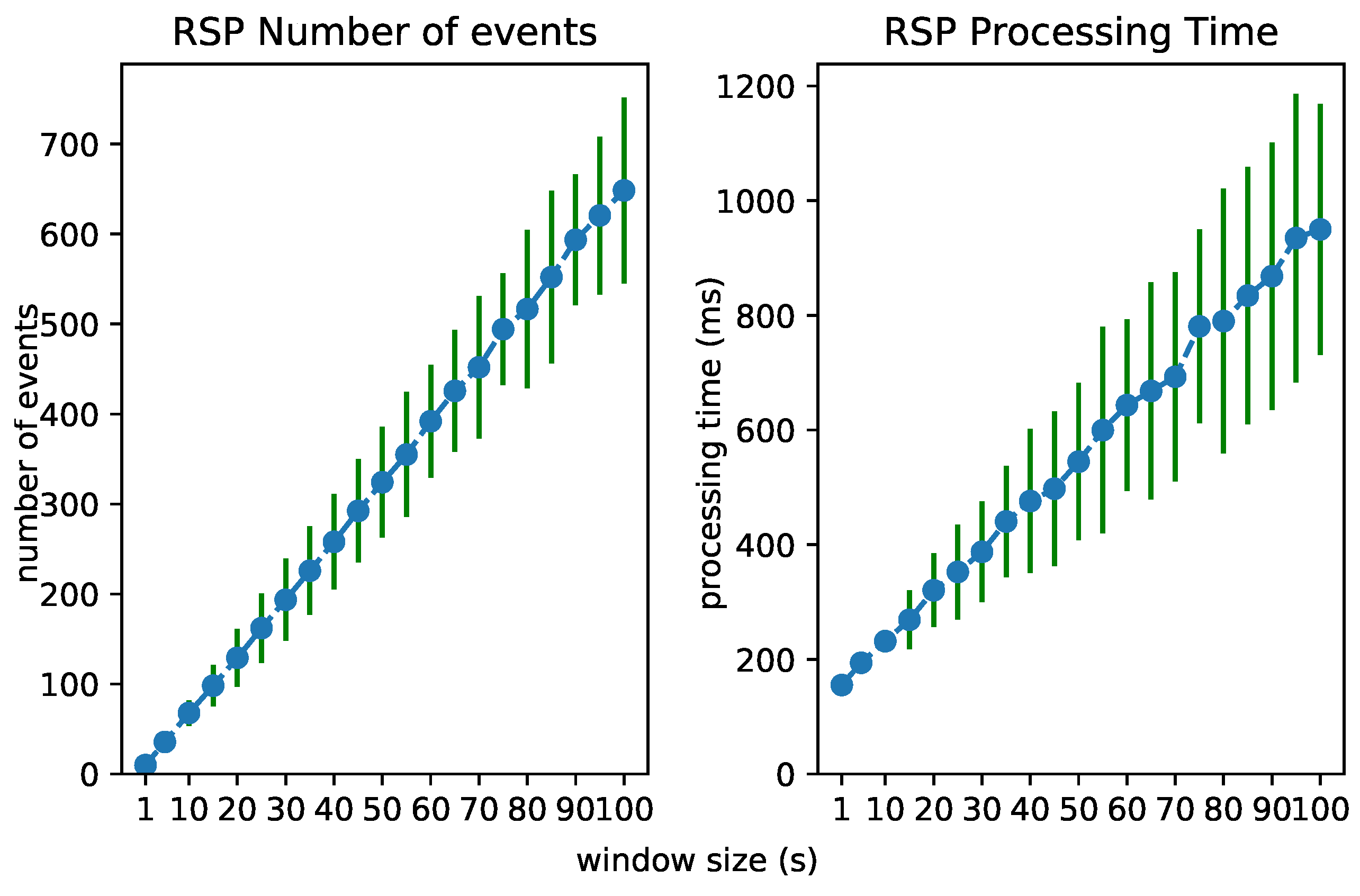
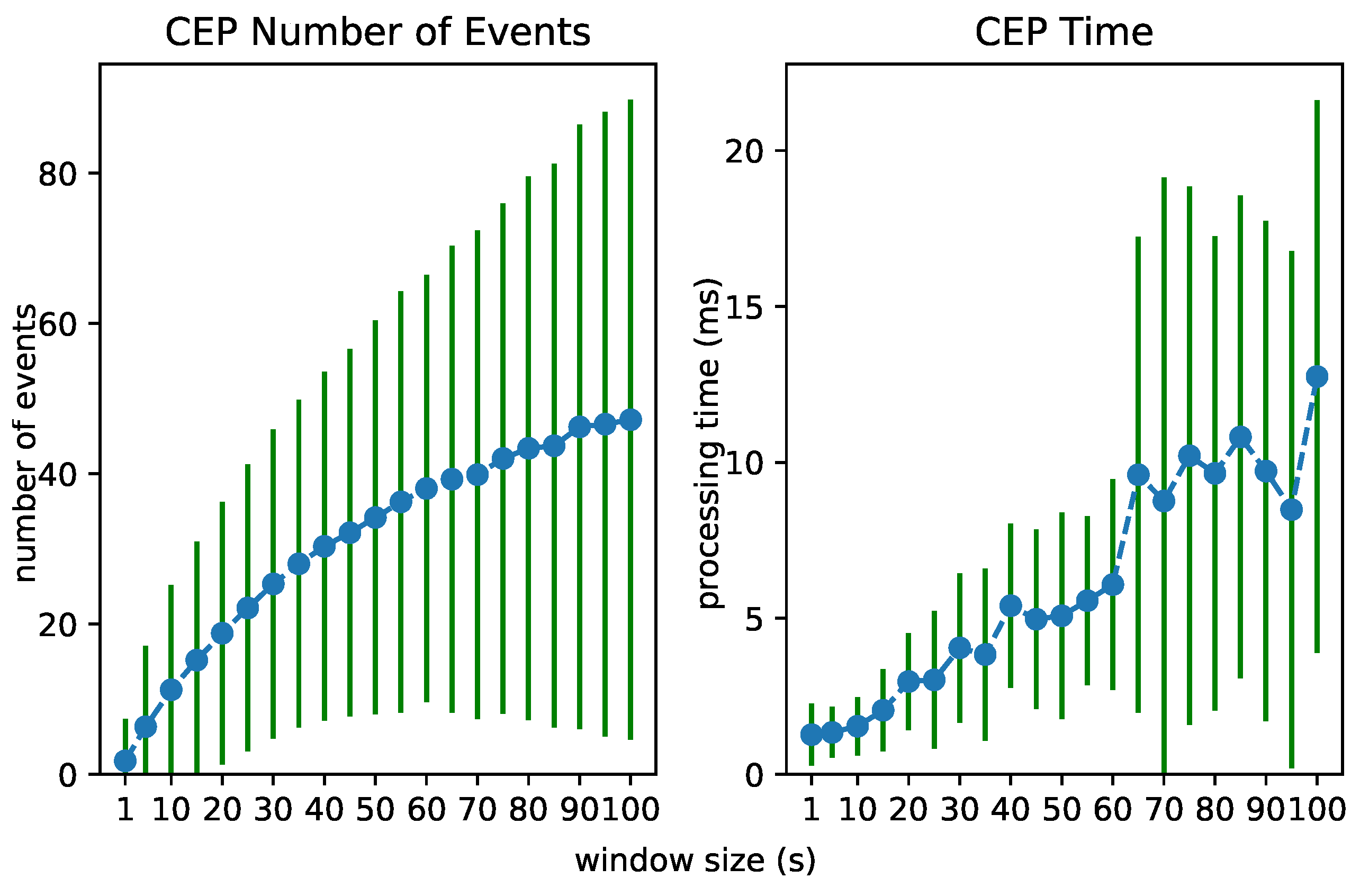
6.3. Test 2: Increasing Window Size
6.4. Test 3: The Influence of the Selection Rate
6.5. Test 4: Comparison with MASSIF
7. Discussion
7.1. Objectives Discussion
- Combine various data streams: Streaming MASSIF can combine various heterogeneous data streams by utilizing a common semantic model, i.e., an ontology, that can be understood throughout the platform. The Selection Module allows one to process multiple streams, combining them together, while keeping a common semantics. From these various streams, the Selection Module selects those parts that are relevant for further processing.
- Integrate background knowledge: Streaming MASSIF allows the integration with background knowledge both in the Selection Module and in the Abstraction Module. The integration in the Selection Module allows one to combine the data streams with more static data, in order to retrieve more information about the observations in the streams, which typically do not describe the full context they observe. The integration in the Abstraction Module allows one to take more context into account to perform the expressive reasoning. The tight coupling between these two modules also allows parts of the static background to be selected in the Selection Module, such that it can be used in the Abstraction Module.
- Integrate complex domain knowledge: The integration of complex domain knowledge is achieved by allowing expressive reasoning in the Abstraction Module in order to correctly interpret the domain. The domain knowledge itself is modeled in the ontology.
- Detect temporal dependencies: Streaming MASSIF can detect temporal dependencies between abstracted events. This is achieved by first abstracting selected observations in the data streams and performing CEP over these abstractions. This allows one to efficiently introduce a temporal aspect in ontology reasoning and integrate complex domain knowledge in CEP. This is more efficient as the direct integration of the temporal domain in DL, i.e., temporal DLs, as they easily become undecidable [18] and CEP is unable to model complex domains [17].
- Easy subscription: Streaming MASSIF allows services to easily subscribe to the data streams, enabling filtering, abstraction, and temporal reasoning, through the use of its unifying query language. This allows services to define their information need in a declarative way, without the need for writing code.
7.2. Related Work Comparison
7.3. Evaluation Discussion
7.4. Streaming MASSIF Limitations & Future Work Directions
7.5. Applicability for Real-World Use-Cases
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Su, X.; Riekki, J.; Nurminen, J.K.; Nieminen, J.; Koskimies, M. Adding semantics to internet of things. Concurr. Comput. Pract. Exp. 2015, 27, 1844–1860. [Google Scholar] [CrossRef]
- Della Valle, E.; Dell’Aglio, D.; Margara, A. Taming velocity and variety simultaneously in big data with stream reasoning: Tutorial. In Proceedings of the 10th ACM International Conference on Distributed and Event-Based Systems, Irvine, CA, USA, 20–24 June 2016; ACM: New York, NY, USA, 2016. [Google Scholar]
- Ali, M.I.; Gao, F.; Mileo, A. Citybench: A configurable benchmark to evaluate rsp engines using smart city datasets. In Proceedings of the International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 374–389. [Google Scholar]
- Barnaghi, P.; Wang, W.; Henson, C.; Taylor, K. Semantics for the Internet of Things: early progress and back to the future. Int. J. Semant. Web Inf. Syst. 2012, 8, 1–21. [Google Scholar] [CrossRef]
- Margara, A.; Urbani, J.; Van Harmelen, F.; Bal, H. Streaming the web: Reasoning over dynamic data. Web Semant. Sci. Serv. Agents World Wide Web 2014, 25, 24–44. [Google Scholar] [CrossRef] [Green Version]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Context aware computing for the internet of things: A survey. IEEE Commun. Surv. Tutor. 2014, 16, 414–454. [Google Scholar] [CrossRef]
- Della Valle, E.; Schlobach, S.; Krötzsch, M.; Bozzon, A.; Ceri, S.; Horrocks, I. Order matters! harnessing a world of orderings for reasoning over massive data. Semant. Web 2013, 4, 219–231. [Google Scholar]
- Stuckenschmidt, H.; Ceri, S.; Della Valle, E.; Van Harmelen, F. Towards Expressive Stream Reasoning. In Semantic Challenges in Sensor Networks; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2010. [Google Scholar]
- Teymourian, K. A Framework for Knowledge-Based Complex Event Processing. Ph.D. Thesis, Free University of Berlin, Berlin, Germany, 2014. [Google Scholar]
- Kontchakov, R.; Zakharyaschev, M. An introduction to description logics and query rewriting. In Reasoning Web International Summer School; Springer: Berlin/Heidelberg, Germany, 2014; pp. 195–244. [Google Scholar]
- Barbieri, D.F.; Braga, D.; Ceri, S.; Valle, E.D.; Grossniklaus, M. Querying RDF streams with C-SPARQL. SIGMOD Rec. 2010, 39, 20–26. [Google Scholar] [CrossRef]
- Anicic, D.; Fodor, P.; Rudolph, S.; Stojanovic, N. EP-SPARQL: A unified language for event processing and stream reasoning. In Proceedings of the 20th International Conference on World Wide, Hyderabad, India, 28 March–1 April 2011; pp. 635–644. [Google Scholar]
- Le-Phuoc, D.; Dao-Tran, M.; Xavier Parreira, J.; Hauswirth, M. A Native and Adaptive Approach for Unified Processing of Linked Streams and Linked Data. In Semantic Web—ISWC 2011, Proceedings of the 10th International Semantic Web Conference, Bonn, Germany, 23–27 October 2011; Aroyo, L., Welty, C., Alani, H., Taylor, J., Bernstein, A., Kagal, L., Noy, N., Blomqvist, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 370–388. [Google Scholar] [CrossRef]
- Shearer, R.; Motik, B.; Horrocks, I. HermiT: A Highly-Efficient OWL Reasoner. In Proceedings of the OWLED 2008, Karlsruhe, Germany, 26–27 October 2008; Volume 432, p. 91. [Google Scholar]
- Nenov, Y.; Piro, R.; Motik, B.; Horrocks, I.; Wu, Z.; Banerjee, J. RDFox: A Highly-Scalable RDF Store. In Proceedings of the ISWC, Osaka, Japan, 9–11 September 2015; Springer: Cham, Switzerland, 2015; pp. 3–20. [Google Scholar]
- Dell’Aglio, D.; Della Valle, E.; van Harmelen, F.; Bernstein, A. Stream reasoning: A survey and outlook. Data Sci. 2017, 1–24. [Google Scholar]
- Batsakis, S.; Petrakis, E.G.; Tachmazidis, I.; Antoniou, G. Temporal representation and reasoning in OWL 2. Semant. Web. 2017, 8, 981–1000. [Google Scholar] [CrossRef]
- Mileo, A.; Abdelrahman, A.; Policarpio, S.; Hauswirth, M. Streamrule: a nonmonotonic stream reasoning system for the semantic web. In Proceedings of the International Conference on Web Reasoning and Rule Systems, Mannheim, Germany, 27–29 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 247–252. [Google Scholar]
- Gebser, M.; Leone, N.; Maratea, M.; Perri, S.; Ricca, F.; Schaub, T. Evaluation Techniques and Systems for Answer Set Programming: A Survey. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 5450–5456. [Google Scholar]
- Ali, M.I.; Ono, N.; Kaysar, M.; Griffin, K.; Mileo, A. A Semantic Processing Framework for IoT-Enabled Communication Systems. In The Semantic Web—ISWC, Proceedings of the International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; Springer: Cham, Switzerland; pp. 241–258. [CrossRef]
- Puiu, D.; Barnaghi, P.; Tonjes, R.; Kumper, D.; Ali, M.I.; Mileo, A.; Xavier Parreira, J.; Fischer, M.; Kolozali, S.; Farajidavar, N.; et al. CityPulse: Large Scale Data Analytics Framework for Smart Cities. IEEE Access 2016, 4, 1086–1108. [Google Scholar] [CrossRef]
- Taylor, K.; Leidinger, L. Ontology-Driven Complex Event Processing in Heterogeneous Sensor Networks. In The Semanic Web: Research and Applications—ESWC 2011, Proceedings of the Extended Semantic Web Conference, Heraklion, Greece, 29 May–2 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 285–299. [Google Scholar]
- Gillani, S.; Zimmermann, A.; Picard, G.; Laforest, F. A query language for semantic complex event processing: Syntax, semantics and implementation. Semant. Web. 2017, 1–41. [Google Scholar] [CrossRef]
- Tommasini, R.; Bonte, P.; Della Valle, E.; Mannens, E.; De Turck, F.; Ongenae, F. Towards Ontology-Based Event Processing. In OWL: Experiences and Directions–Reasoner Evaluation; Springer: Berlin/Heidelberg, Germany, 2016; pp. 115–127. [Google Scholar]
- Margara, A.; Cugola, G.; Collavini, D.; Dell’Aglio, D. Efficient Temporal Reasoning on Streams of Events with DOTR. In The Semantic Web, Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 384–399. [Google Scholar]
- Bonte, P.; Ongenae, F.; De Backere, F.; Schaballie, J.; Arndt, D.; Verstichel, S.; Mannens, E.; Van de Walle, R.; De Turck, F. The MASSIF platform: A modular and semantic platform for the development of flexible IoT services. Knowl. Inf. Syst. 2017, 51, 89–126. [Google Scholar] [CrossRef]
- Cugola, G.; Margara, A. Processing flows of information: From data stream to complex event processing. ACM Comput. Surv. 2012, 44, 15. [Google Scholar] [CrossRef]
- Luckham, D. The Power of Events: An Introduction to Complex Event Processing in Distributed Enterprise Systems. In International Workshop on Rules and Rule Markup Languages for the Semantic Web; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Allen, J.F. Maintaining knowledge about temporal intervals. Commun. ACM 1983, 26, 832–843. [Google Scholar] [CrossRef] [Green Version]
- Dell’Aglio, D.; Della Valle, E.; Calbimonte, J.; Corcho, Ó. RSP-QL Semantics: A Unifying Query Model to Explain Heterogeneity of RDF Stream Processing Systems. Int. J. Semant. Web Inf. Syst. 2014, 10, 17–44. [Google Scholar] [CrossRef]
- Grosof, B.N.; Horrocks, I.; Volz, R.; Decker, S. Description logic programs: combining logic programs with description logic. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; ACM: New York, NY, USA, 2003; pp. 48–57. [Google Scholar]
- Horrocks, I.; Kutz, O.; Sattler, U. The Even More Irresistible SROIQ. Kr 2006, 6, 57–67. [Google Scholar]
- Compton, M.; Barnaghi, P.; Bermudez, L.; GarcíA-Castro, R.; Corcho, O.; Cox, S.; Graybeal, J.; Hauswirth, M.; Henson, C.; Herzog, A.; et al. The SSN ontology of the W3C semantic sensor network incubator group. Web Semant. Sci. Serv. Agents World Wide Web. 2012, 17, 25–32. [Google Scholar] [CrossRef] [Green Version]
- Barbieri, D.F.; Braga, D.; Ceri, S.; Valle, E.D.; Huang, Y.; Tresp, V.; Rettinger, A.; Wermser, H. Deductive and Inductive Stream Reasoning for Semantic Social Media Analytics. IEEE Intell. Syst. 2010, 25, 32–41. [Google Scholar] [CrossRef]
- Balduini, M.; Celino, I.; Dell’Aglio, D.; Valle, E.D.; Huang, Y.; Lee, T.K.; Kim, S.; Tresp, V. Reality mining on micropost streams—Deductive and inductive reasoning for personalized and location-based recommendations. Semant. Web. 2014, 5, 341–356. [Google Scholar]
- Tommasini, R.; Della Valle, E. Challenges & Opportunities of RSP-QL Implementations. In Proceedings of the WSP/WOMoCoE@ ISWC 2017, Vienna, Austria, 21–25 October 2017. [Google Scholar]
- Mauri, A.; Calbimonte, J.P.; Dell’Aglio, D.; Balduini, M.; Brambilla, M.; Della Valle, E.; Aberer, K. Triplewave: Spreading RDF streams on the web. In Proceedings of the International Semantic Web Conference, Kobe, Japan, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 140–149. [Google Scholar]
- Dimou, A.; Vander Sande, M.; Colpaert, P.; Verborgh, R.; Mannens, E.; Van de Walle, R. RML: A Generic Language for Integrated RDF Mappings of Heterogeneous Data. In Proceedings of the 7th Workshop on Linked Data on the Web, Seoul, Korea, 8 April 2014. [Google Scholar]
- Pan, J.Z.; Ren, Y.; Jekjantuk, N.; Garcia, J. Reasoning the FMA ontologies with TrOWL. In Proceedings of the 2nd International Workshop on OWL Reasoner Evaluation (ORE-2013), Ulm, Germany, 23–26 July 2013. [Google Scholar]
- Beck, H.; Dao-Tran, M.; Eiter, T. LARS: A Logic-based framework for Analytic Reasoning over Streams. Artif. Intell. 2018, 261, 16–70. [Google Scholar] [CrossRef]
- Xiao, G.; Calvanese, D.; Kontchakov, R.; Lembo, D.; Poggi, A.; Rosati, R.; Zakharyaschev, M. Ontology-based data access: A survey. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of things for smart cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Engine/#Events | 1 | 10 | 100 | 1000 | 10,000 | 25,000 | 50,000 | 80,000 |
| RSP | 15 | 15.1 | 23.1 | 127.3 | 398.3 | 973.5 | 2011.4 | 3291.3 |
| RDFox | 21.2 | 21.6 | 27.7 | 130.7 | 500.15 | 1230.7 | 2453.3 | 4405.5 |
| TrOWL | 440.3 | 455.9 | 415.7 | 702.8 | 1292.45 | 3205.6 | 7083.3 | 14,153.0 |
| Hermit | 12,895.0 | 12,972.0 | 13,440.0 | 27,885.0 | 170,532.5 | |||
| Cascading | 74.2 | 76.9 | 74.4 | 147.5 | 443.3 | 1040.0 | 2303.9 | 3754.4 |
| Data Streams | Background Knowledge | Complex Domains | Temporal Dependencies | Unifying QL | Service Subscription | |
|---|---|---|---|---|---|---|
| EP-SPARQL [13] | X | / | RDFS | Allen Algebra | X | / |
| StreamRule [19] | X | / | ASP | / | / | / |
| Ali et al. [21] | X | / | / | ASP | / | / |
| CityPulse [22] | X | / | ASP | CEP | / | X |
| HermiT [15] | / | X | OWL2 DL | / | / | / |
| RDFox [16] | / | X | OWL2 RL | / | / | / |
| TrOWL [40] | / | X | OWL2 DL | / | / | / |
| MASSIF [27] | / | X | OWL2 DL | / | / | X |
| Streaming MASSIF | X | X | OWL2 DL | CEP | X | X |
| Name | Stream Processing | Continuous Information | Inference Entailment | Unifying QL | |
|---|---|---|---|---|---|
| Integration | |||||
| EP-SPARQL | Etalis | RSP | Rewriting | RDFS & Allen Algebra | ✓ |
| StreamRule | CQELS | RSP | Annotation | ASP | None |
| Ali et al. | CQELS | RSP | Annotation | Action-Rules in ASP | None |
| CityPulse | CQELS | RSP | Annotation | ASP & CEP | None |
| Frequency | Single Sensor Events/s | # Sensors | Total Events/s | |
|---|---|---|---|---|
| Antwerp | ||||
| Air Quality | 1 per 30 s | 0.034 | 22 | 0.667 |
| Temperature | 100 per day | 0.001 | 2 | 0.002 |
| Rain | 250 per day | 0.003 | 4 | 0.012 |
| Traffic Count | ±800 per day | ±0.01 | ±115 | ±1.15 |
| Traffic Lights | 5 per second | 5 | 8 | 40 |
| Aarhus | ||||
| Air Quality | 1 per 5 min | 0.0034 | 449 | 1.5 |
| Weather | 1 per 5 min | 0.0034 | 9 | 0.03 |
| Parking | 1 per 5 min | 0.0034 | 449 | 1.5 |
| Traffic Count | 3 per hour | 0.0008 | 1 | 0.008 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonte, P.; Tommasini, R.; Della Valle, E.; De Turck, F.; Ongenae, F. Streaming MASSIF: Cascading Reasoning for Efficient Processing of IoT Data Streams. Sensors 2018, 18, 3832. https://doi.org/10.3390/s18113832
Bonte P, Tommasini R, Della Valle E, De Turck F, Ongenae F. Streaming MASSIF: Cascading Reasoning for Efficient Processing of IoT Data Streams. Sensors. 2018; 18(11):3832. https://doi.org/10.3390/s18113832
Chicago/Turabian StyleBonte, Pieter, Riccardo Tommasini, Emanuele Della Valle, Filip De Turck, and Femke Ongenae. 2018. "Streaming MASSIF: Cascading Reasoning for Efficient Processing of IoT Data Streams" Sensors 18, no. 11: 3832. https://doi.org/10.3390/s18113832
APA StyleBonte, P., Tommasini, R., Della Valle, E., De Turck, F., & Ongenae, F. (2018). Streaming MASSIF: Cascading Reasoning for Efficient Processing of IoT Data Streams. Sensors, 18(11), 3832. https://doi.org/10.3390/s18113832