User Characteristic Aware Participant Selection for Mobile Crowdsensing


Abstract
:1. Introduction
- (1)
- First, we evaluate the heat of different regions in the MCS service scenario based on the number of active users, their average residence time, and sensing tasks history. Then, the user state information and sensing task records are combined to calculate the willingness, reputation and activity of users, respectively. Furthermore, we analyze the influence of user characteristics on the probability of completing sensing tasks, credibility of the submitted task data and ability of participants to complete the task.
- (2)
- Second, we design a task queuing strategy and a community assistance strategy. According to users’ activity and willingness, the upper limit of queues is dynamically set. The participants complete the tasks in the queue according to their priority. When a sensing task cannot be performed by a participant due to the changes of the participants’ own conditions, it can be assisted by the community to reduces the task failure rate. In addition, our designed community assistance strategy attracts users to participate in the sensing tasks extensively and further expands the MCS coverage.
- (3)
- Finally, we propose UCPS-H and UCPS-L algorithms for high-heat and low-heat regions, respectively. In the high-heat regions, we evaluate the comprehensive data quality by leveraging user characteristics and task bidding, and then select participants for the maximum task data quality. In the low-heat regions, we divide the participant selection process into multiple stages. Within each stage, participants with reliable profits exceeding the dynamic threshold are selected to guarantee the credibility of task data.
2. Related Work
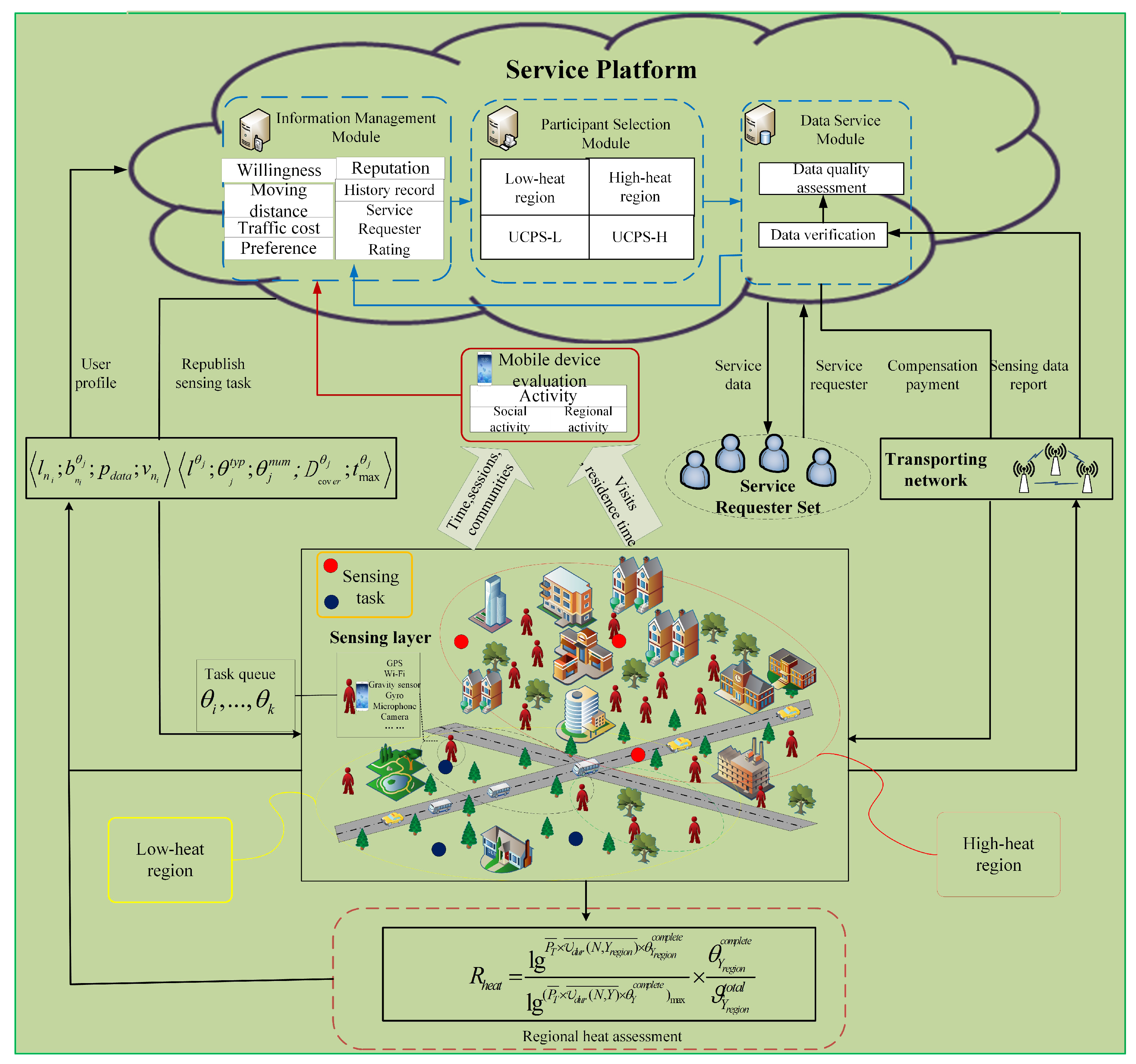
3. System Model
4. User Characteristics Awareness
4.1. Regional Heat Assessment
4.2. User Willingness
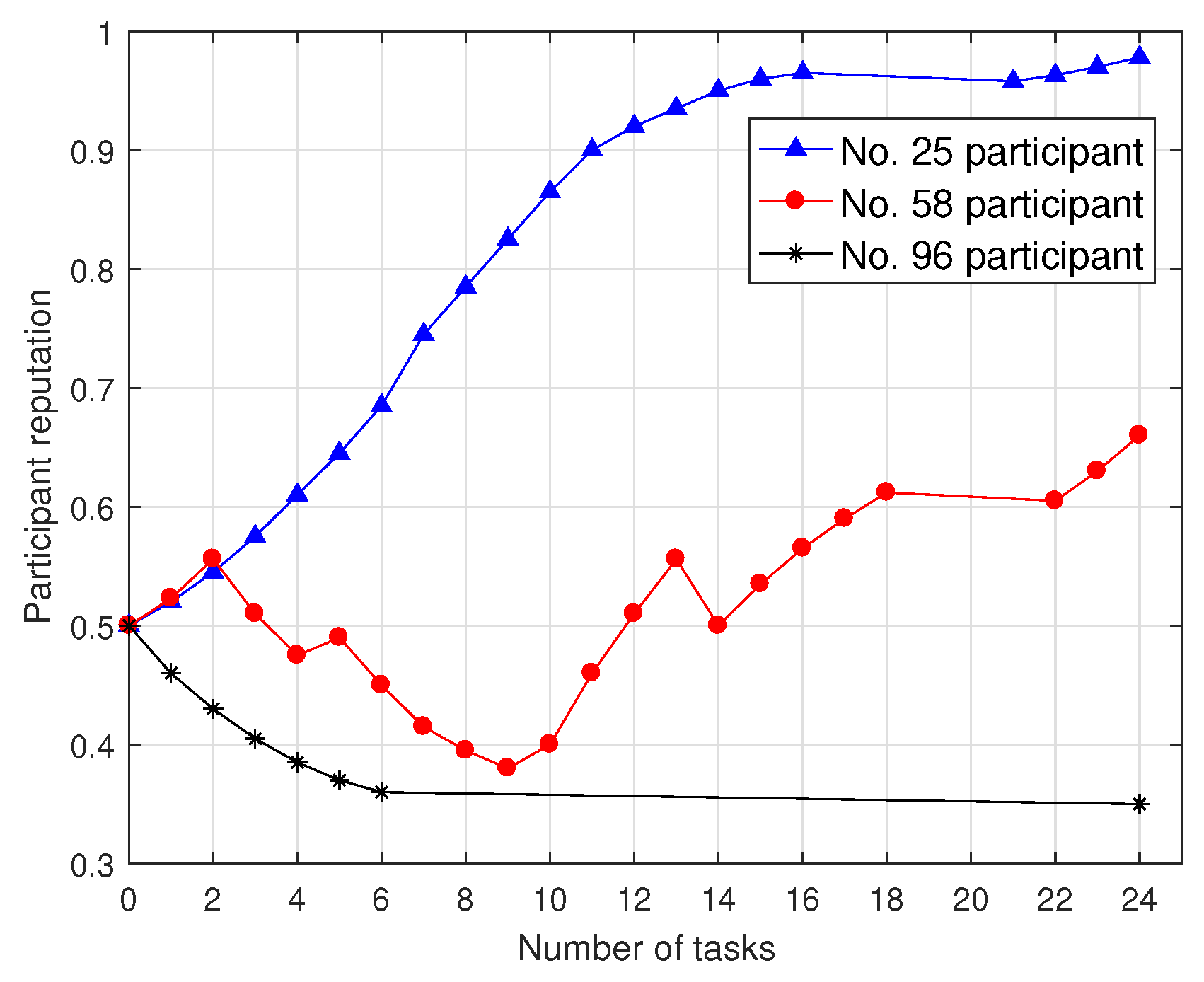
4.3. User Reputation
4.4. User Activity
4.4.1. Regional Activity
4.4.2. Social Activity
5. Participant Selection Strategy
5.1. Task Queueing Strategy and Community Assistance Strategy
5.1.1. Task Queueing Strategy
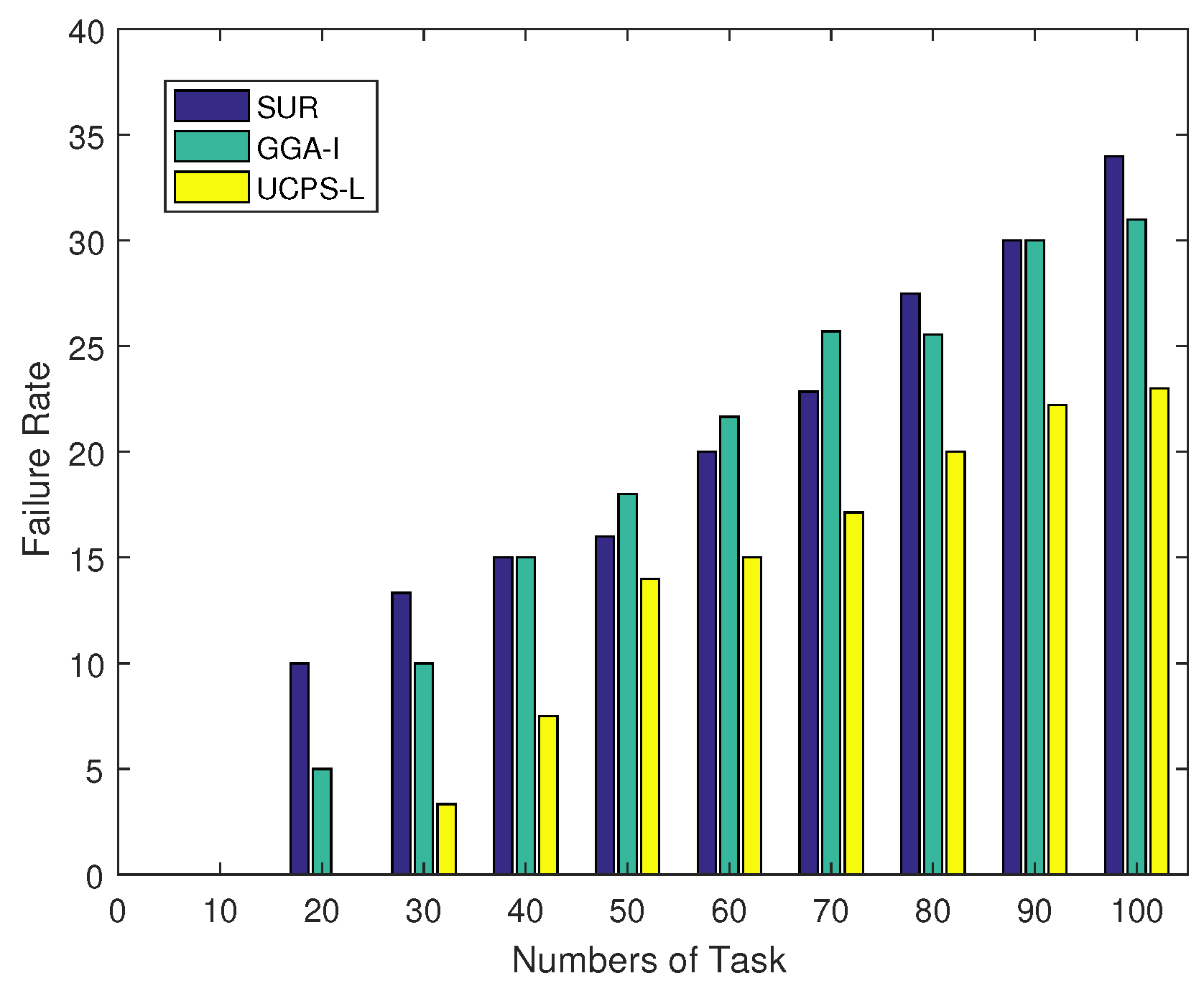
5.1.2. Community Assistance Strategy
5.2. Participant Selection Strategy for High-Heat Regions
| Algorithm 1 User Characteristic Aware Participant Selection for High-Heat Regions (UCPS-H) |
| Input: Task set , User set N; Output: 1: Participant selected for task , the payment for participants and participants set U; 2: ; 3: while do 4: Calculate the comprehensive data quality of users for task through Equation (31); and rank the comprehensive data quality of users in descending order 5: Assign task to user with the highest comprehensive data quality; 6: ; 7: ; 8: ; 9: return to 3; 10: if task achieves the desired data quality then 11: remove it from ; 12: end if 13: if all tasks are assigned or budget runs out then 14: stop the selection process; 15: end if 16: end while 17: return ; |
5.3. Participant Selection Strategy for Low-Heat Regions
| Algorithm 2 User Characteristic Aware Participant Selection for Low-Heat Regions (UCPS-L) |
| Input: 1: Task set , Budget B, Deadline T; Output: 2: The task set allocated to participant , the payment and participant set C; 3: ; 4: if then 5: add user arriving at t to online active user set N; 6: ; 7: end if 8: while do 9: Compute threshold according (34); 10: if then 11: ; 12: end if 13: if there are still remaining tasks in stage then 14: return to 10; 15: else 16: all tasks in stage are allocated, remove the allocated tasks; 17: end if 18: according (34) update threshold ; 19: end while 20: if then 21: ; 22: ; 23: end if 24: return ; |
6. Numerical Results
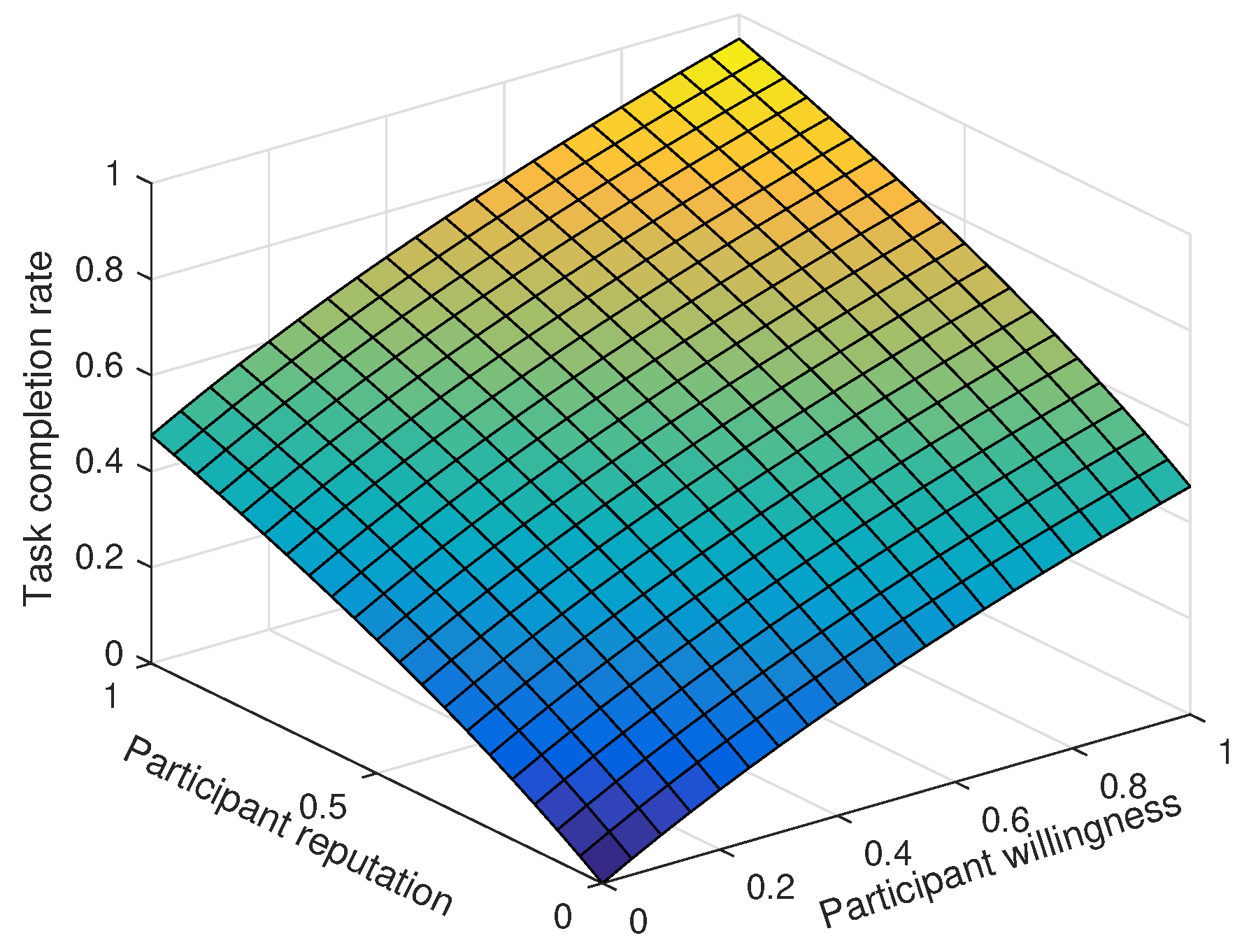
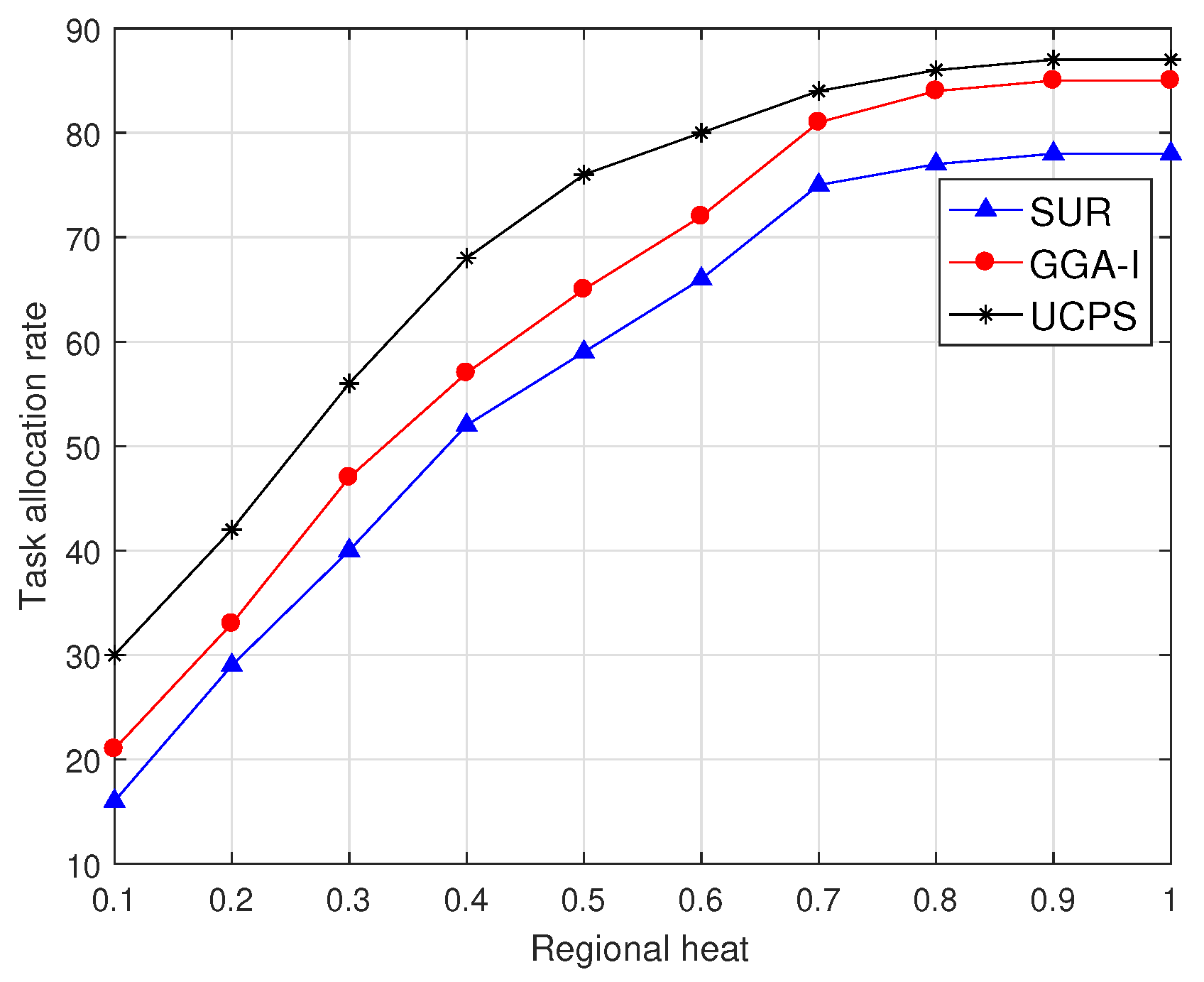
6.1. The Impact of User Characteristics on Task Allocation Rate and Task Completion Ratio
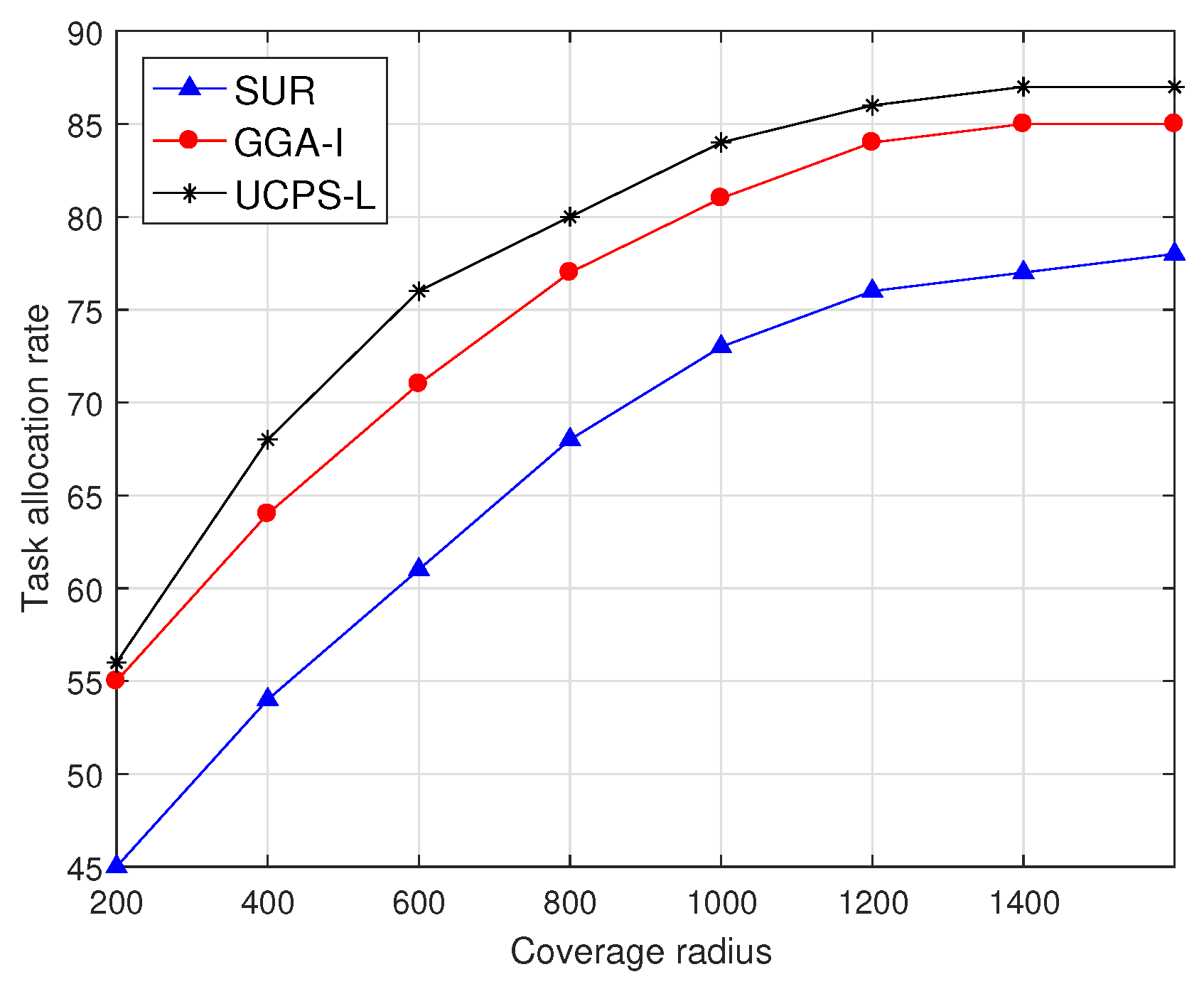
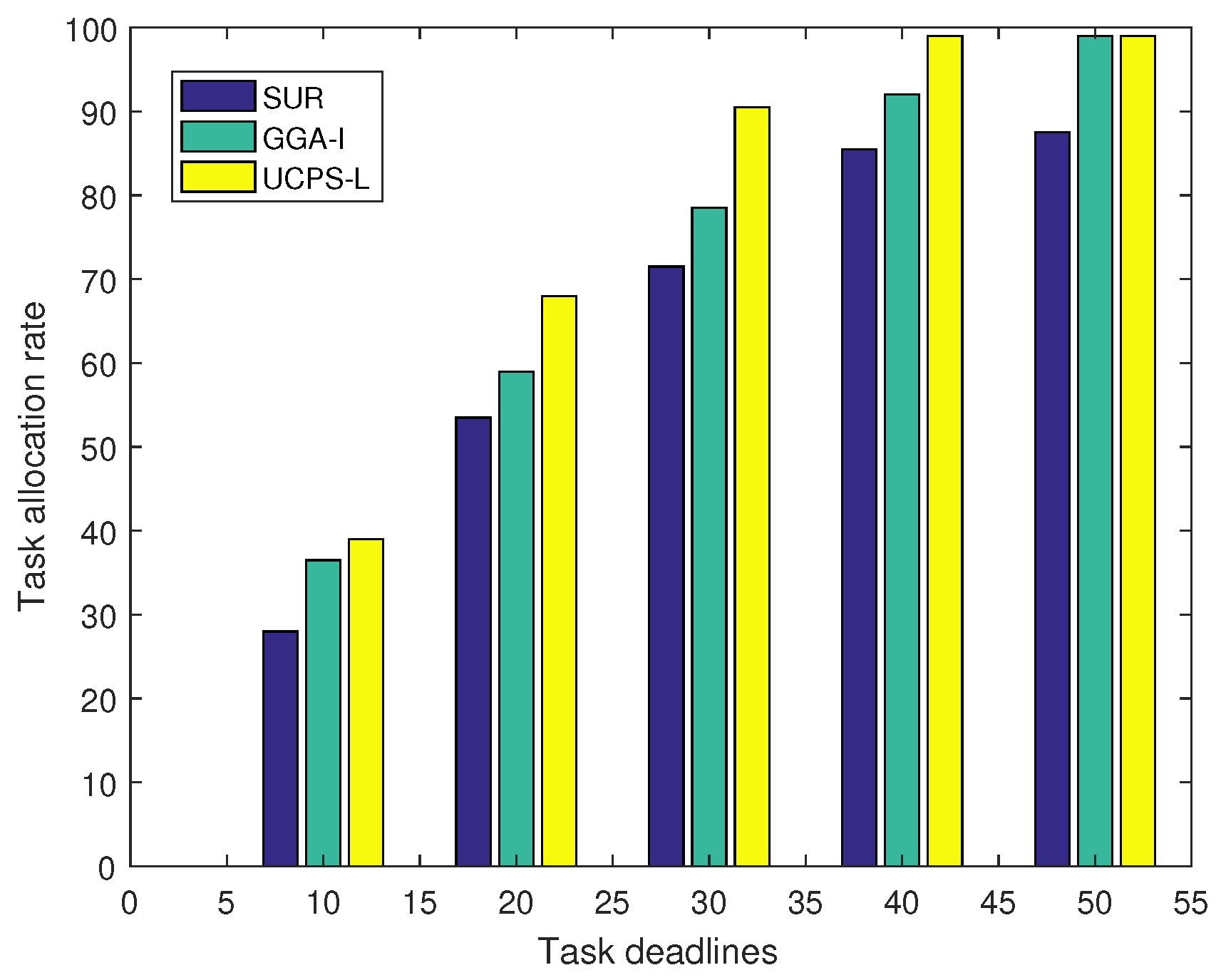
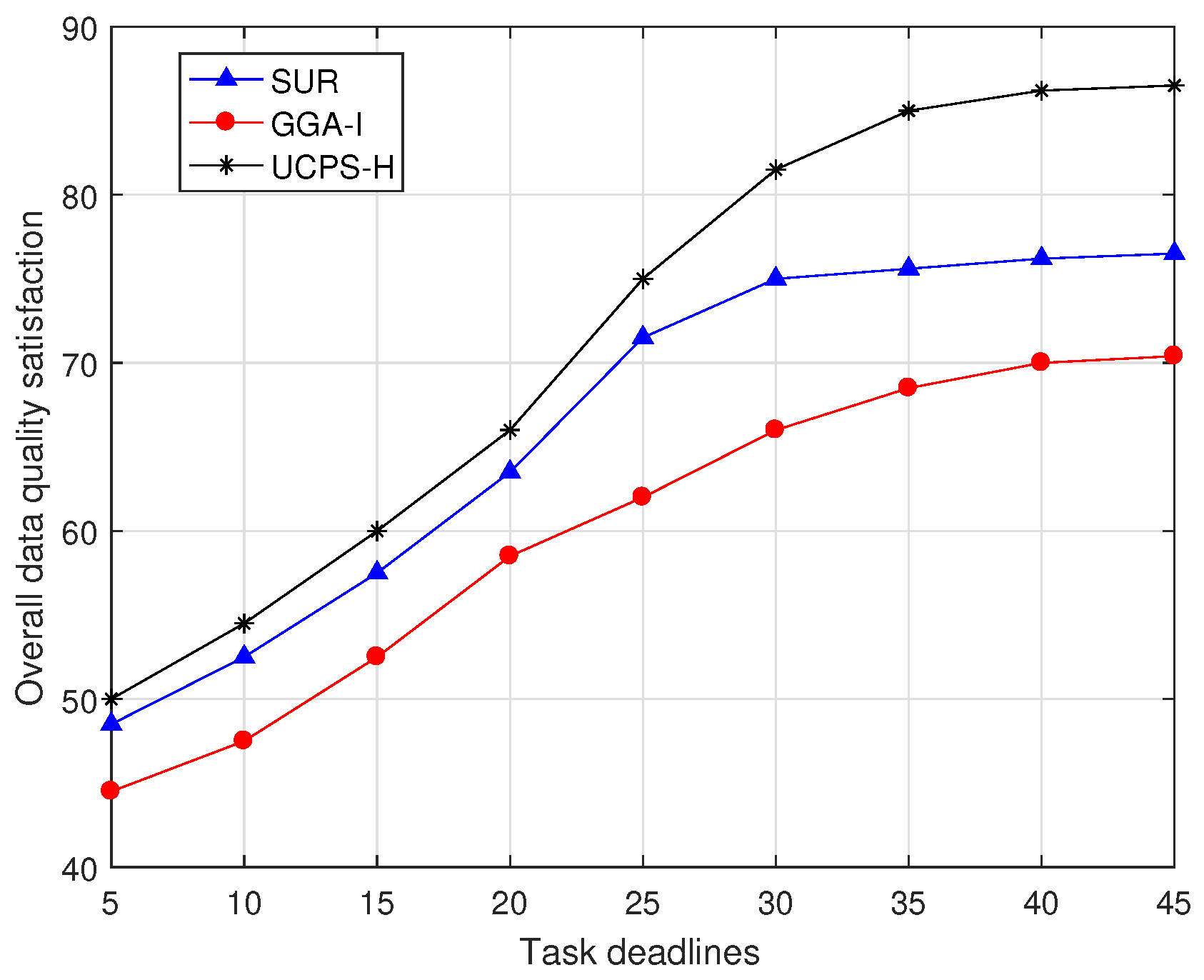
6.2. The Effect of Task Coverage Radius and Deadline on the Task Allocation Rate
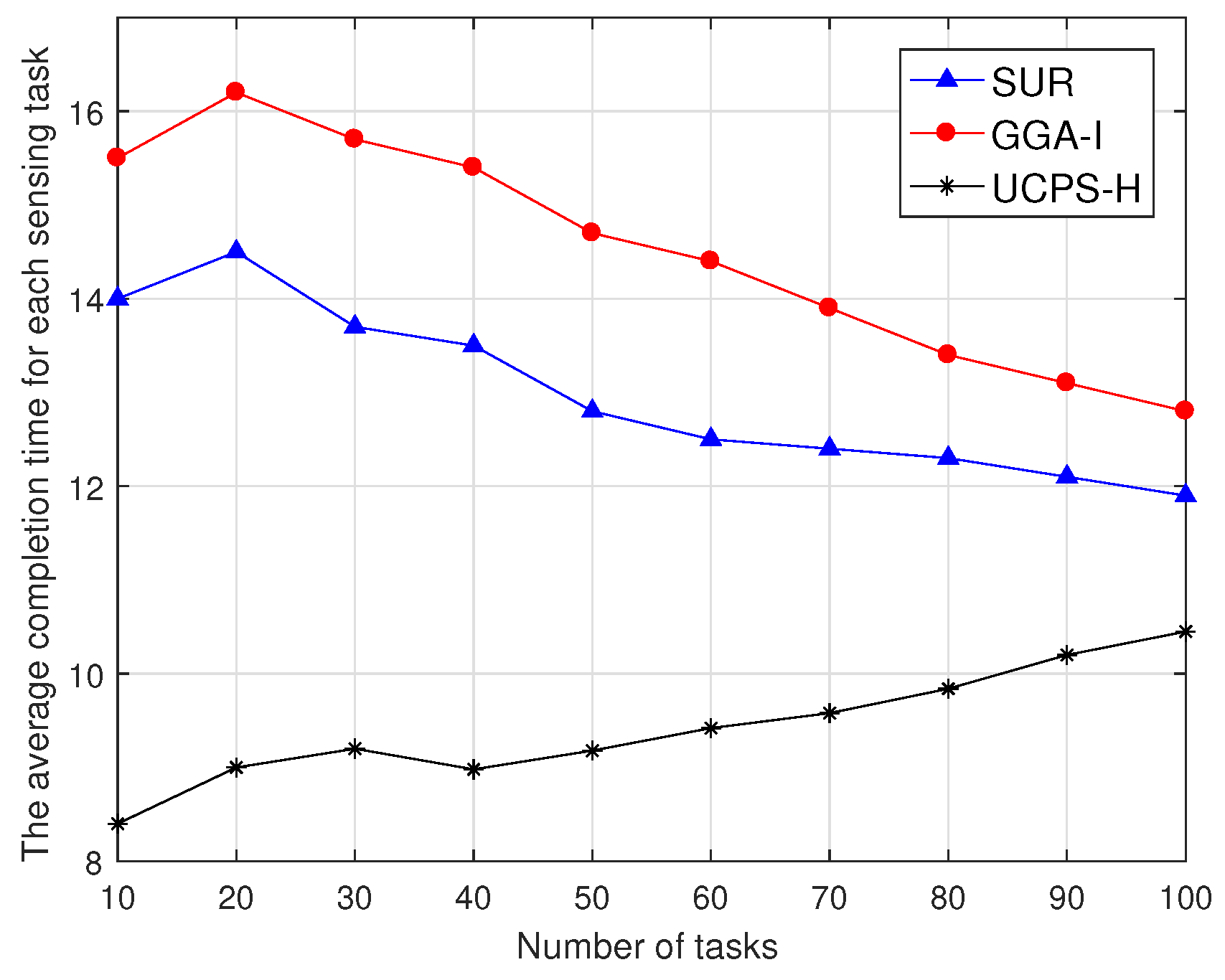
6.3. Analysis of Average Task Completion Time and Service Platform Satisfaction
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Ganti, R.; Ye, F.; Lei, H. Mobile crowdsensing: Current state and future challenges. IEEE Commun. Mag. 2011, 49, 32–39. [Google Scholar] [CrossRef]
- Liang, J.; Mao, C. Distributed compressive sensing in heterogeneous sensor network. Signal Proc. 2016, 126, 96–102. [Google Scholar] [CrossRef]
- Wu, D.; Si, S.; Wang, R. Dynamic Trust Relationships Aware Data Privacy Protection in Mobile Crowd- Sensing. IEEE Internet Things J. 2018, 5, 2958–2970. [Google Scholar] [CrossRef]
- Dardari, D.; Pasolini, G.; Zabini, F. An efficient method for physical fields mapping through crowdsensing. Pervasive Mob. Comput. 2018, 48, 69–83. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, S.; Hu, S.; Su, L.; Yao, S.; Shao, H.; Wang, H.; Abdelzaher, T. GreenDrive: A Smartphone-Based Intelligent Speed Adaptation System with Real-Time Traffic Signal Prediction. In Proceedings of the 8th International ACM/IEEE Conference on Cyber-Physical Systems (ICCPS), Pittsburgh, PA, USA, 18–20 April 2017; pp. 229–238. [Google Scholar]
- Zheng, Y.; Liu, F.; Hsieh, H. U-Air: When Urban Air Quality Inference Meets Big Data. In Proceedings of the Sixth international Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1436–1444. [Google Scholar]
- Peng, Z.; Gao, S.; Xiao, B.; Guo, S.; Yang, Y. CrowdGIS: Updating Digital Maps via Mobile Crowdsensing. IEEE Trans. Autom. Sci. Eng. 2018, 15, 369–380. [Google Scholar] [CrossRef]
- Zhou, L.; Wu, D.; Dong, Z.; Li, X. When Collaboration Hugs Intelligence: Content Delivery over Ultra-Dense Networks. IEEE Commun. Mag. 2017, 55, 91–95. [Google Scholar] [CrossRef]
- Luo, C.; Guo, S.; Yang, L.; Min, G.; Xie, X. Green Communication in Energy Renewable Wireless Mesh Networks: Routing, Rate Control, and Power Allocation. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 3211–3220. [Google Scholar] [CrossRef] [Green Version]
- Zhao, N.; Richard Yu, F.; Leung Victor, C.M. Opportunistic Communications in Interference Alignment Networks with Wireless Power Transfer. IEEE Wirel. Commun. 2015, 22, 88–95. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, F.; Wang, H.; Wang, R. Security-Oriented Opportunistic Data Forwarding in Mobile Social Networks. Future Gener. Comput. Syst. 2018, 87, 803–815. [Google Scholar] [CrossRef]
- Guo, B.; Liu, Y.; Wu, W.; Yu, Z.; Han, Q. ActiveCrowd: A Framework for Optimized Multitask Allocation in Mobile Crowdsensing Systems. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 392–403. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Zhang, B.; Su, X.; Ma, J.; Wang, W.; Leung, K. Energy-Aware Participant Selection for Smartphone-Enabled Mobile Crowd Sensing. IEEE Syst. J. 2017, 11, 1435–1446. [Google Scholar] [CrossRef] [Green Version]
- An, X.; Guo, H.; Wang, X.; Chen, X. Load Balanced Mobile User Recruitment for Mobile Crowdsensing Systems. IEEE Commun. Lett. 2017, 21, 2420–2423. [Google Scholar] [CrossRef]
- Li, X.; Zhao, N.; Sun, Y.; Richard Yu, F. Interference Alignment Based on Antenna Selection with Imperfect Channel State Information in Cognitive Radio Networks. IEEE Trans. Veh. Technol. 2016, 65, 5497–5511. [Google Scholar] [CrossRef]
- Xiao, M.; Wu, J.; Huang, H.; Huang, L.; Hu, C. Deadline-sensitive User Recruitment for mobile crowdsensing with probabilistic collaboration. In Proceedings of the 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–10. [Google Scholar]
- Zhang, M.; Yang, P.; Tian, C.; Tang, S.; Gao, X.; Wang, B. Quality-aware sensing coverage in budget-constrained mobile crowdsensing networks. IEEE Trans. Veh. Technol. 2016, 65, 7698–7707. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Zhang, D.; Wang, L.; Xiong, H.; Helal, S. Fine-grained multi-task allocation for participatory sensing with a shared budget. IEEE Internet Things J. 2016, 3, 1395–1405. [Google Scholar] [CrossRef]
- Deng, N.; Zhou, W.; Haenggi, M. The Ginibre Point Process as a Model for Wireless Networks with Repulsion. IEEE Trans. Wirel. Commun. 2015, 14, 107–121. [Google Scholar] [CrossRef]
- Zabini, F.; Conti, A. Ginibre sampling and signal reconstruction. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 865–869. [Google Scholar]
- Guo, A.; Zhong, Y.; Zhang, W.; Haenggi, M. The Gauss–Poisson Process for Wireless Networks and the Benefits of Cooperation. IEEE Trans. Commun. 2016, 64, 1916–1929. [Google Scholar] [CrossRef]
- Zabini, F.; Pasolini, G.; Conti, A. On random sampling with nodes attraction: The case of Gauss-Poisson process. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2278–2282. [Google Scholar]
- Peng, D.; Wu, F.; Chen, G. Data Quality Guided Incentive Mechanism Design for Crowdsensing. IEEE Trans. Mob. Comput. 2018, 17, 307–319. [Google Scholar] [CrossRef]
- Fiandrino, C.; Anjomshoa, G.; Kantarci, B.; Kliazovich, D.; Bouvry, P.; Matthews, J. Sociability-Driven Framework for Data Acquisition in Mobile Crowdsensing Over Fog Computing Platforms for Smart Cities. IEEE Trans. Sustain. Comput. 2018, 2, 345–358. [Google Scholar] [CrossRef]
- Pouryazdan, M.; Kantarci, B.; Soyata, T.; Foschini, L.; Song, H. Quantifying User Reputation Scores, Data Trustworthiness, and User Incentives in Mobile Crowd-Sensing. IEEE Access 2017, 5, 1382–1397. [Google Scholar] [CrossRef]
- Xiong, J.; Ren, J.; Chen, L.; Yao, Z.; Lin, M.; Wu, D.; Niu, B. Enhancing privacy and availability for data clustering in intelligent electrical service of IoT. IEEE Internet Things J. 2018. [Google Scholar] [CrossRef]
- Yu, H.; Miao, C.; Shen, Z.; Leung, C.; Chen, Y.; Yang, Q. Efficient task sub-delegation for crowdsourcing. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 1305–1311. [Google Scholar]
- An, J.; Gui, X.; Wang, Z.; Yang, J.; He, X. A Crowdsourcing Assignment Model Based on Mobile Crowd Sensing in the Internet of Things. IEEE Internet Things J. 2015, 2, 358–369. [Google Scholar] [CrossRef]
- Wu, D.; Yan, J.; Wang, H.; Wu, D.; Wang, R. Social Attribute Aware Incentive Mechanism for Device-to-Device Video Distribution. IEEE Trans. Multimed. 2017, 19, 1908–1920. [Google Scholar] [CrossRef]
- Karaliopoulos, M.; Telelis, Q.; Koutsopoulos, I. User recruitment for mobile crowdsensing over opportunistic networks. In Proceedings of the 2015 IEEE Conference on Computer Communications, Kowloon, Hong Kong, 26 April–1 May 2015; pp. 2254–2262. [Google Scholar]
- Zhou, T.; Cai, Z.; Xu, M.; Chen, Y. Leveraging Crowd to improve data credibility for mobile crowdsensing. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 561–568. [Google Scholar]
- Wang, X.; Zhang, J.; Tian, X.; Gan, X.; Guan, Y.; Wang, X. Crowdsensing-Based Consensus Incident Report for Road Traffic Acquisition. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2536–2547. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, Z.; Liu, Y.; Li, Y.; Ming, Z. Toward Efficient Mechanisms for Mobile Crowdsensing. IEEE Trans. Veh. Technol. 2017, 66, 1760–1771. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Liu, J.; Li, W. Social Collaborative Filtering by Trust. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1633–1647. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Pei, Y.; Hou, F.; Ma, S. Reputation-aware incentive mechanism for participatory sensing. IET Commun. 2017, 11, 1985–1991. [Google Scholar] [CrossRef]
- Giannotti, F.; Nanni, M.; Pedreschi, D.; Renso, C.; Trasarti, R. Mining Mobility Behavior from Trajectory Data. In Proceedings of the 2009 International Conference on Computational Science and Engineering, Vancouver, BC, Canada, 29–31 August 2009; pp. 948–951. [Google Scholar]
- Anjomshoa, F.; Aloqaily, M.; Kantarci, B.; Erol-Kantarci, M.; Schuckers, S. Social Behaviometrics for Personalized Devices in the Internet of Things Era. IEEE Access 2017, 5, 12199–12213. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, P.; Liu, D.; Sun, S. SRSM-based Adaptive Relay Selection for D2D Communications. IEEE Internet Things J. 2018, 5, 2323–2332. [Google Scholar] [CrossRef]
- Wu, D.; Liu, Q.; Wang, H.; Wu, D.; Wang, R. Socially Aware Energy-Efficient Mobile Edge Collaboration for Video Distribution. IEEE Trans. Multimed. 2017, 19, 2197–2209. [Google Scholar] [CrossRef]
- Luo, T.; Kanhere, S.S.; Das, S.K.; Tan, H. Incentive Mechanism Design for Heterogeneous Crowdsourcing Using All-Pay Contests. IEEE Trans. Mob. Comput. 2016, 15, 2234–2246. [Google Scholar] [CrossRef]
- Wang, R.; Yan, J.; Wu, D.; Wang, H.; Yang, Q. Knowledge-Centric Edge Computing based on Virtualized D2D Communication Systems. IEEE Commun. Mag. 2018, 56, 32–38. [Google Scholar] [CrossRef]
- Zhao, D.; Li, X.; Ma, H. Budget-Feasible Online Incentive Mechanisms for Crowdsourcing Tasks Truthfully. IEEE/ACM Trans. Netw. 2016, 24, 647–661. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, Y. Layered Admission Control Algorithms with QoE in Heterogeneous Network. Ad Hoc Netw. 2017, 58, 179–190. [Google Scholar] [CrossRef]
- Xiao, M.; Wu, J.; Zhang, S.; Yu, J. Secret-sharing-based secure user recruitment protocol for mobile crowdsensing. In Proceedings of the 2017 IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Value |
|---|---|
| Region size | 1–2 km |
| Regional heat | 0–1 |
| Task deadline | 5–45 min |
| Number of participants required for single task | 1–5 |
| Number of tasks accepted by each participant | 0–8 |
| Number of tasks published by the service platform | 1–100 |
| Task coverage radius | 200 m–1600 m |
| Participant reputation | 0–1 |
| Participant activity | 0–1 |
| Participant speed | 10–50 km/h |
| Task types | 5 |
| The maximum budget for each sensing task | 50 |
| The maximum price per sensing task | 10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Li, H.; Wang, R. User Characteristic Aware Participant Selection for Mobile Crowdsensing. Sensors 2018, 18, 3959. https://doi.org/10.3390/s18113959
Wu D, Li H, Wang R. User Characteristic Aware Participant Selection for Mobile Crowdsensing. Sensors. 2018; 18(11):3959. https://doi.org/10.3390/s18113959
Chicago/Turabian StyleWu, Dapeng, Haopeng Li, and Ruyan Wang. 2018. "User Characteristic Aware Participant Selection for Mobile Crowdsensing" Sensors 18, no. 11: 3959. https://doi.org/10.3390/s18113959
APA StyleWu, D., Li, H., & Wang, R. (2018). User Characteristic Aware Participant Selection for Mobile Crowdsensing. Sensors, 18(11), 3959. https://doi.org/10.3390/s18113959